
Physics-Based Method for Generating Fully Synthetic IV Curve Training Datasets for Machine Learning Classification of PV Failures


Abstract
:1. Introduction
2. Methodology
2.1. Simulation Using the Diode Model
| Algorithm 1: String-level IV simulation pipeline [40] |
 |
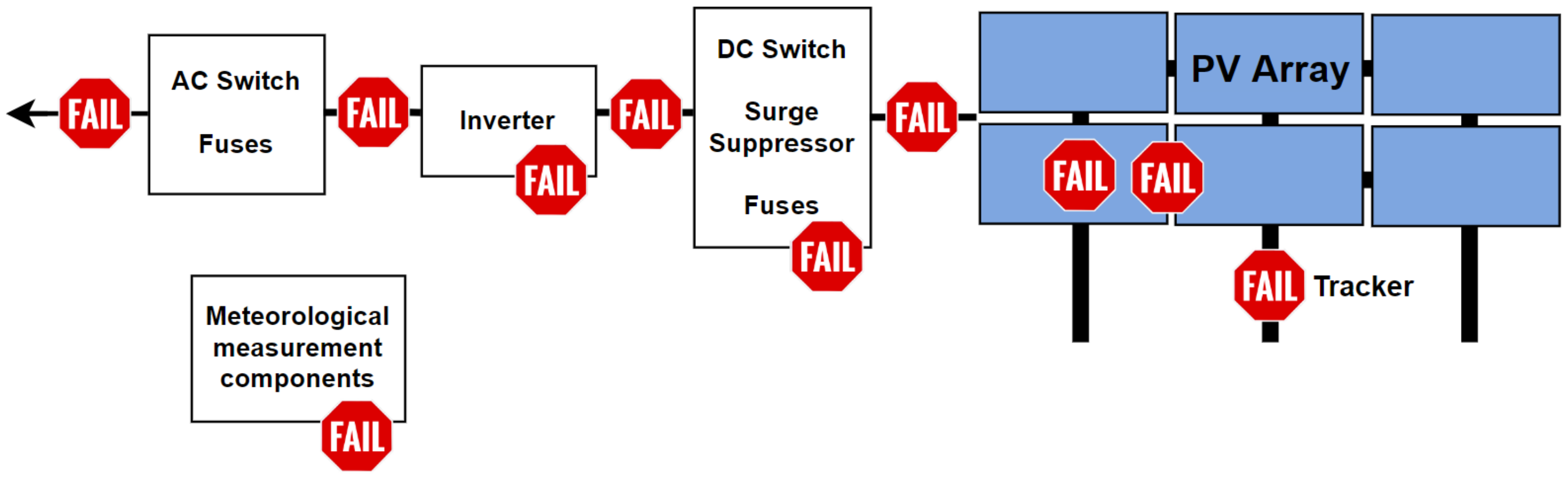
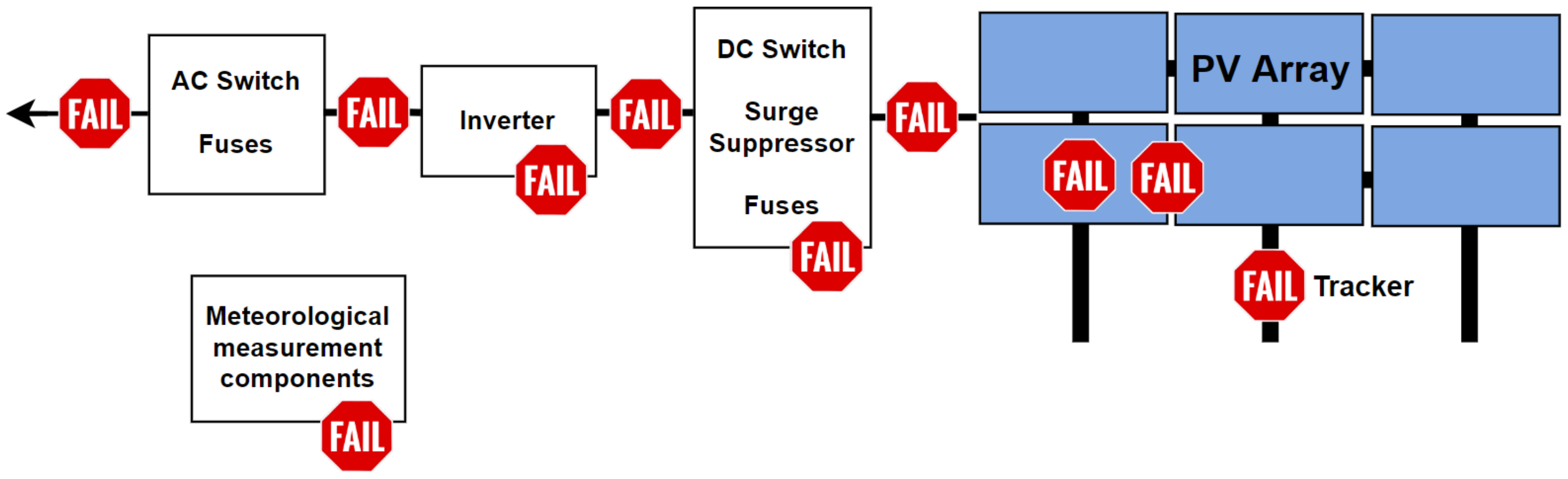
2.2. Failure Definitions
2.3. Data
2.3.1. Indoor Data
2.3.2. Outdoor Data
2.4. Data Filtering, Processing and Feature Generation
2.5. Machine Learning
3. Results
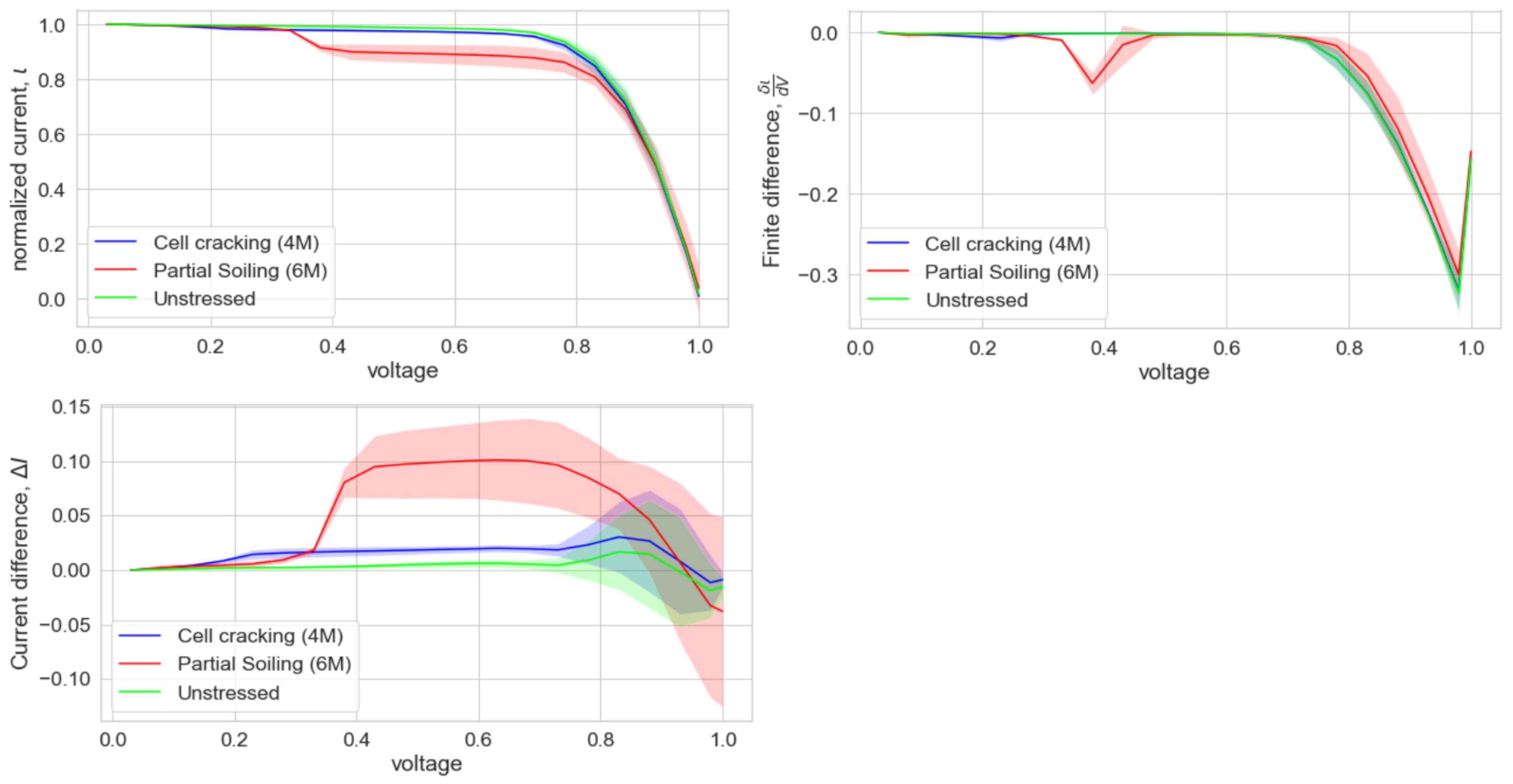
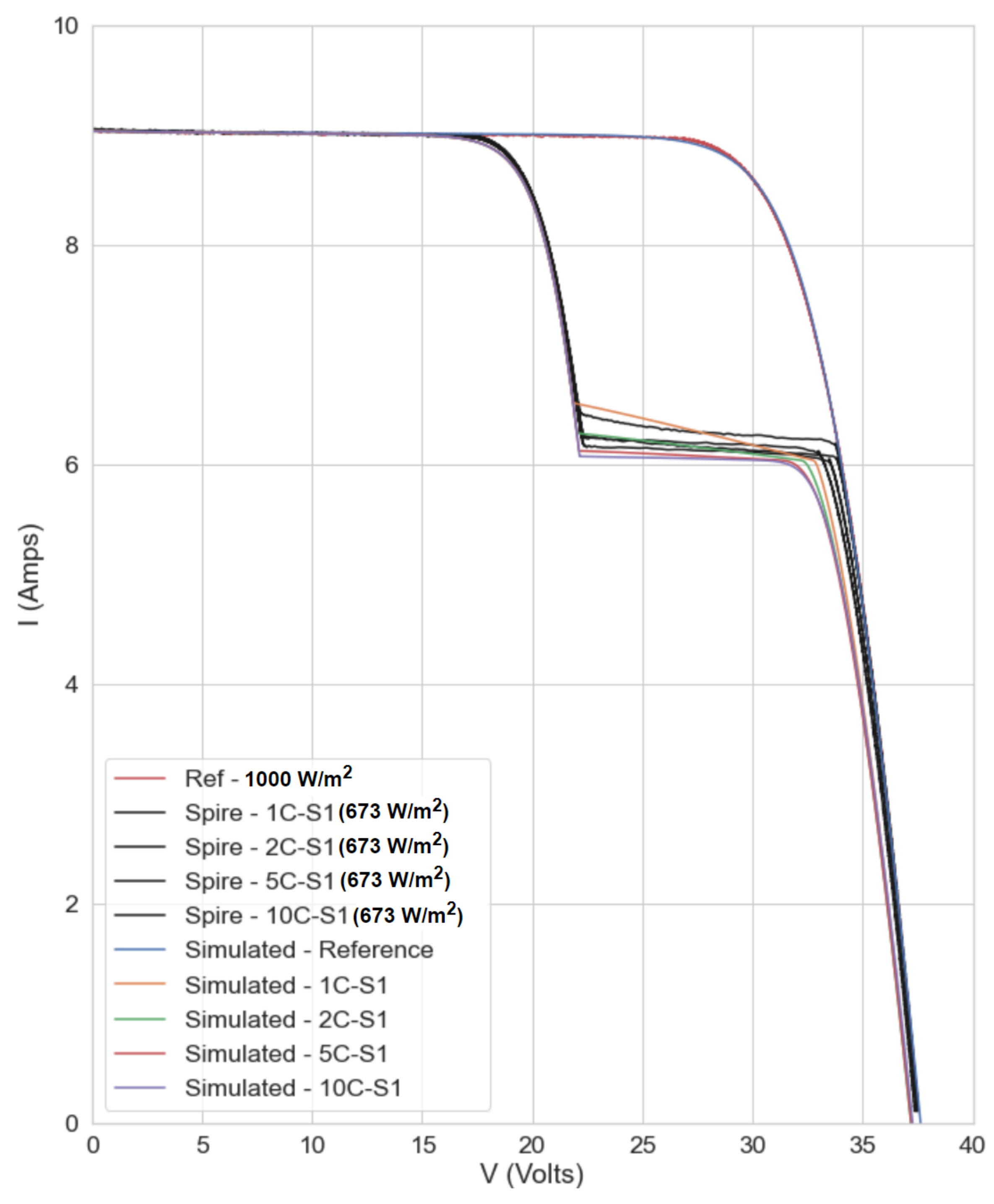
3.1. Simulation Verification
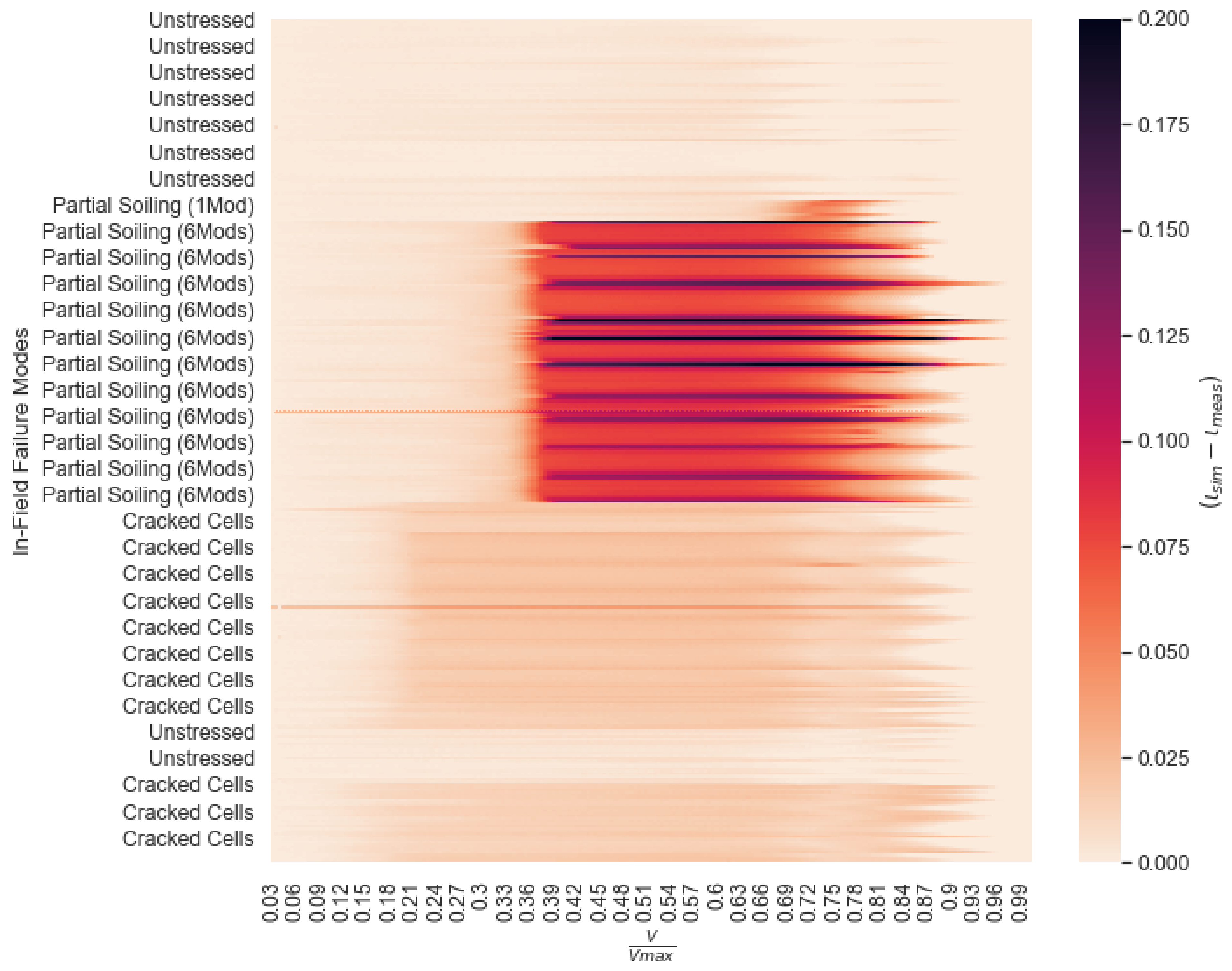
3.2. Simulation Validation
3.3. IV Curve Classification
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Seigneur, H.; Mohajeri, N.; Brooker, R.P.; Davis, K.O.; Schneller, E.J.; Dhere, N.G.; Rodgers, M.P.; Wohlgemuth, J.; Shiradkar, N.S.; Scardera, G.; et al. Manufacturing metrology for c-Si photovoltaic module reliability and durability, Part I: Feedstock, crystallization and wafering. Renew. Sustain. Energy Rev. 2016, 59, 84–106. [Google Scholar] [CrossRef] [Green Version]
- Köntges, M.; Kurtz, S.; Packard, C.; Jahn, U.; Berger, K.; Kato, K.; Kazuhilo, F.; Thomas, F.; Liu, H.; van Iseghem, M. IEA-PVPS Task 13: Review of Failures of Photovoltaic Modules; SUPSI: Manno, Switzerland, 2014. [Google Scholar]
- Haque, A.; Bharath, K.V.S.; Khan, M.A.; Khan, I.; Jaffery, Z.A. Fault diagnosis of photovoltaic modules. Energy Sci. Eng. 2019, 7, 622–644. [Google Scholar] [CrossRef] [Green Version]
- Lillo-Bravo, I.; González-Martínez, P.; Larrañeta, M.; Guasumba-Codena, J. Impact of Energy Losses Due to Failures on Photovoltaic Plant Energy Balance. Energies 2018, 11, 363. [Google Scholar] [CrossRef] [Green Version]
- Moser, D.; Buono, M.D.; Jahn, U.; Herz, M.; Richter, M.; Brabandere, K.D. Identification of technical risks in the photovoltaic value chain and quantification of the economic impact. Prog. Photovolt. Res. Appl. 2017, 25, 592–604. [Google Scholar] [CrossRef]
- Jordan, D.C.; Marion, B.; Deline, C.; Barnes, T.; Bolinger, M. PV field reliability status—Analysis of 100 000 solar systems. Prog. Photovolt. Res. Appl. 2020, 28, 739–754. [Google Scholar] [CrossRef]
- Madeti, S.R.; Singh, S. A comprehensive study on different types of faults and detection techniques for solar photovoltaic system. Sol. Energy 2017, 158, 161–185. [Google Scholar] [CrossRef]
- Li, B.; Delpha, C.; Diallo, D.; Migan-Dubois, A. Application of Artificial Neural Networks to photovoltaic fault detection and diagnosis: A review. Renew. Sustain. Energy Rev. 2021, 138, 110512. [Google Scholar] [CrossRef]
- Pillai, D.S.; Rajasekar, N. A comprehensive review on protection challenges and fault diagnosis in PV systems. Renew. Sustain. Energy Rev. 2018, 91, 18–40. [Google Scholar] [CrossRef]
- Gabor, A.M.; Schneller, E.J.; Seigneur, H.; Rowell, M.W.; Colvin, D.; Hopwood, M.; Davis, K.O. The impact of cracked solar cells on solar panel energy delivery. In Proceedings of the 2020 47th IEEE Photovoltaic Specialists Conference (PVSC), Calgary, ON, Canada, 15 June–21 August 2020; pp. 0810–0813. [Google Scholar]
- Zhao, Y. Fault Detection, Classification and Protection in Solar Photovoltaic Arrays; Northeastern University: Boston, MA, USA, 2015. [Google Scholar]
- Akram, M.N.; Lotfifard, S. Modeling and health monitoring of DC side of photovoltaic array. IEEE Trans. Sustain. Energy 2015, 6, 1245–1253. [Google Scholar] [CrossRef]
- Appiah, A.Y.; Zhang, X.; Ayawli, B.B.K.; Kyeremeh, F. Review and performance evaluation of photovoltaic array fault detection and diagnosis techniques. Int. J. Photoenergy 2019, 2019, 6953530. [Google Scholar] [CrossRef]
- Livera, A.; Theristis, M.; Makrides, G.; Georghiou, G.E. Recent advances in failure diagnosis techniques based on performance data analysis for grid-connected photovoltaic systems. Renew. Energy 2019, 133, 126–143. [Google Scholar] [CrossRef]
- Rodrigues, S.; Ramos, H.G.; Morgado-Dias, F. Machine Learning in PV Fault Detection, Diagnostics and Prognostics: A Review. In Proceedings of the 2017 IEEE 44th Photovoltaic Specialist Conference (PVSC), Washington, DC, USA, 25–30 June 2017; pp. 3178–3183. [Google Scholar] [CrossRef]
- Lu, X.; Lin, P.; Cheng, S.; Lin, Y.; Chen, Z.; Wu, L.; Zheng, Q. Fault diagnosis for photovoltaic array based on convolutional neural network and electrical time series graph. Energy Convers. Manag. 2019, 196, 950–965. [Google Scholar] [CrossRef]
- Ma, M.; Zhang, Z.; Yun, P.; Xie, Z.; Wang, H.; Ma, W. Photovoltaic Module Current Mismatch Fault Diagnosis Based on I-V Data. IEEE J. Photovolt. 2021, 11, 779–788. [Google Scholar] [CrossRef]
- Huang, J.M.; Wai, R.J.; Gao, W. Newly-Designed Fault Diagnostic Method for Solar Photovoltaic Generation System Based on IV-Curve Measurement. IEEE Access 2019, 7, 70919–70932. [Google Scholar] [CrossRef]
- Chine, W.; Mellit, A.; Lughi, V.; Malek, A.; Sulligoi, G.; Massi Pavan, A. A novel fault diagnosis technique for photovoltaic systems based on artificial neural networks. Renew. Energy 2016, 90, 501–512. [Google Scholar] [CrossRef]
- Aziz, F.; Ul Haq, A.; Ahmad, S.; Mahmoud, Y.; Jalal, M.; Ali, U. A Novel Convolutional Neural Network-Based Approach for Fault Classification in Photovoltaic Arrays. IEEE Access 2020, 8, 41889–41904. [Google Scholar] [CrossRef]
- Li, X.; Yang, Q.; Lou, Z.; Yan, W. Deep Learning Based Module Defect Analysis for Large-Scale Photovoltaic Farms. IEEE Trans. Energy Convers. 2019, 34, 520–529. [Google Scholar] [CrossRef]
- Tang, W.; Yang, Q.; Xiong, K.; Yan, W. Deep learning based automatic defect identification of photovoltaic module using electroluminescence images. Sol. Energy 2020, 201, 453–460. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhan, K.; Wang, Z.; Shen, W. Deep learning-based automatic detection of multitype defects in photovoltaic modules and application in real production line. Prog. Photovolt. Res. Appl. 2021, 29, 471–484. [Google Scholar] [CrossRef]
- Hoffmann, M.; Buerhop-Lutz, C.; Reeb, L.; Pickel, T.; Winkler, T.; Doll, B.; Würfl, T.; Marius Peters, I.; Brabec, C.; Maier, A.; et al. Deep-learning-based pipeline for module power prediction from electroluminescense measurements. Prog. Photovolt. Res. Appl. 2021, 28, 920–935. [Google Scholar] [CrossRef]
- Pierce, B.G.; Karimi, A.M.; Liu, J.; French, R.H.; Braid, J.L. Identifying Degradation Modes of Photovoltaic Modules Using Unsupervised Machine Learning on Electroluminescense Images. In Proceedings of the 2020 47th IEEE Photovoltaic Specialists Conference (PVSC), Calgary, ON, Canada, 15 June–21 August 2020; pp. 1850–1855. [Google Scholar]
- Karimi, A.M.; Fada, J.S.; Parrilla, N.A.; Pierce, B.G.; Koyutürk, M.; French, R.H.; Braid, J.L. Generalized and mechanistic PV module performance prediction from computer vision and machine learning on electroluminescence images. IEEE J. Photovolt. 2020, 10, 878–887. [Google Scholar] [CrossRef]
- Bommes, L.; Pickel, T.; Buerhop-Lutz, C.; Hauch, J.; Brabec, C.; Peters, I.M. Computer vision tool for detection, mapping, and fault classification of photovoltaics modules in aerial IR videos. Prog. Photovolt. Res. Appl. 2021, 29, 1236–1251. [Google Scholar] [CrossRef]
- Dunderdale, C.; Brettenny, W.; Clohessy, C.; van Dyk, E.E. Photovoltaic defect classification through thermal infrared imaging using a machine learning approach. Prog. Photovolt. Res. Appl. 2020, 28, 177–188. [Google Scholar] [CrossRef]
- Hopwood, M.W.; Gunda, T.; Seigneur, H.; Walters, J. Neural network-based classification of string-level IV curves from physically-induced failures of photovoltaic modules. IEEE Access 2020, 8, 161480–161487. [Google Scholar] [CrossRef]
- Gao, W.; Wai, R.J. A Novel Fault Identification Method for Photovoltaic Array via Convolutional Neural Network and Residual Gated Recurrent Unit. IEEE Access 2020, 8, 159493–159510. [Google Scholar] [CrossRef]
- Guo, S.; Schneller, E.; Walters, J.; Davis, K.O.; Schoenfeld, W.V. Detecting loss mechanisms of c-Si PV modules in-situ I-V measurement. In Proceedings of the Reliability of Photovoltaic Cells, Modules, Components, and Systems IX, International Society for Optics and Photonics, San Diego, CA, USA, 6–7 August 2016; Volume 9938, p. 99380N. [Google Scholar] [CrossRef]
- Ma, X.; Huang, W.H.; Schnabel, E.; Köhl, M.; Brynjarsdóttir, J.; Braid, J.L.; French, R.H. Data-Driven I–V Feature Extraction for Photovoltaic Modules. IEEE J. Photovolt. 2019, 9, 1405–1412. [Google Scholar] [CrossRef] [Green Version]
- Hopwood, M.; Gunda, T.; Seigneur, H.; Walters, J. An assessment of the value of principal component analysis for photovoltaic IV trace classification of physically-induced failures. In Proceedings of the 2020 47th IEEE Photovoltaic Specialists Conference (PVSC), Calgary, ON, Canada, 15 June–21 August 2020; pp. 0798–0802. [Google Scholar] [CrossRef]
- Wang, M.; Liu, J.; Burleyson, T.J.; Schneller, E.J.; Davis, K.O.; French, R.H.; Braid, J.L. Analytic Method and Power Loss Modes From Outdoor Time-Series I–V Curves. IEEE J. Photovolt. 2020, 10, 1379–1388. [Google Scholar] [CrossRef]
- Teodorescu, R.; Kerekes, T.; Sera, D.; Spataru, S. Monitoring and Fault Detection in Photovoltaic Systems Based On Inverter Measured String I-V Curves. In Proceedings of the 31st European Photovoltaic Solar Energy Conference and Exhibition, Hamburg, Germany, 14–18 September 2015; pp. 1667–1674, ISBN 9783936338393. [Google Scholar] [CrossRef]
- Cáceres, M.; Firman, A.; Montes-Romero, J.; González Mayans, A.R.; Vera, L.H.; F Fernández, E.; de la Casa Higueras, J. Low-Cost I–V Tracer for PV Modules under Real Operating Conditions. Energies 2020, 13, 4320. [Google Scholar] [CrossRef]
- Pordis, LLC. String-Level I-V Curve Tracer Specification Sheet. Available online: http://www.pordis.com/ (accessed on 17 March 2021).
- Walters, J.; Seigneur, H.; Schneller, E.; Matam, M.; Hopwood, M. Experimental Methods to Replicate Power Loss of PV Modules in the Field for the Purpose of Fault Detection Algorithm Development. In Proceedings of the 2019 IEEE 46th Photovoltaic Specialists Conference (PVSC), Chicago, IL, USA, 16–21 June 2019; pp. 1410–1413. [Google Scholar] [CrossRef]
- Buerhop-Lutz, C.; Pickel, T.; Denz, J.; Doll, B.; Hauch, J.; Brabec, C. Analysis of Digitized PV-Module/System Data for Failure Diagnosis. In Proceedings of the EU PVSEC 2019 Conference, Marseille, France, 9–13 September 2019; pp. 1336–1341. [Google Scholar]
- Bishop, J. Computer simulation of the effects of electrical mismatches in photovoltaic cell interconnection circuits. Sol. Cells 1988, 25, 73–89. [Google Scholar] [CrossRef]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving rubik’s cube with a robot hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Grzeszczuk, R.; Terzopoulos, D.; Hinton, G.E. Fast neural network emulation of dynamical systems for computer animation. Adv. Neural Inf. Process. Syst. 1998, 11, 882–888. [Google Scholar]
- Tompson, J.; Schlachter, K.; Sprechmann, P.; Perlin, K. Accelerating eulerian fluid simulation with convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 3424–3433. [Google Scholar]
- Chunlai, L.; Xianshuang, Z. A survey of online fault diagnosis for PV module based on BP neural network. In Proceedings of the 2016 International Conference on Smart City and Systems Engineering (ICSCSE), Hunan, China, 25–26 November 2016; pp. 483–486. [Google Scholar]
- Garoudja, E.; Chouder, A.; Kara, K.; Silvestre, S. An enhanced machine learning based approach for failures detection and diagnosis of PV systems. Energy Convers. Manag. 2017, 151, 496–513. [Google Scholar] [CrossRef] [Green Version]
- Mendoza, H.; Hopwood, M.; Gunda, T. pvOps: Improving operational assessments through data fusion. In Proceedings of the 2021 IEEE 48th Photovoltaic Specialists Conference (PVSC), Virtual, 20–25 June 2021; pp. 0112–0119. [Google Scholar]
- Holmgren, W.F.; Hansen, C.W.; Mikofski, M.A. pvlib python: A python package for modeling solar energy systems. J. Open Source Softw. 2018, 3, 884. [Google Scholar] [CrossRef] [Green Version]
- Mikofski, M.; Meyers, B.; Chaudhari, C. PVMismatch Project; SunPower Corporation: Richmond, CA, USA, 2018. [Google Scholar]
- CEC DB PVLib. Module-Level CEC Database Hosted on PVLib. Available online: https://github.com/pvlib/pvlib-python (accessed on 17 March 2021).
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 2000, 42, 55–61. [Google Scholar] [CrossRef]
- ISO/IEC TR 29110-1:2016; Photovoltaic System Performance—Part 1: Monitoring. International Electrotechnical Commission: Geneva, Switzerland, 2017.
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Parameter | Value |
|---|---|---|
| Maximum Power | 270 W | |
| Maximum Power Voltage | 31.7 V | |
| Maximum Power Current | 8.52 A | |
| Open Circuit Voltage | 38.8 V | |
| Short Circuit Current | 9.09 A | |
| temperature coefficient | −0.3%/C | |
| temperature coefficient | 0.06%/C | |
| Tilt Angle of system | ||
| Azimuth Angle of system (angle from North) | ||
| N | Number of cells connected in series | 60 |
| Module Area | 1.64 m2 |
| Training Set | Evaluation Set | Accuracy (%) | Train Support | Test Support |
|---|---|---|---|---|
| Measured | Measured (test split) | 100 | 288 | 33 |
| Simulated | Simulated | 100 | 2457 | 273 |
| Simulated | Measured (test split) | 100 | 2457 | 33 |
| Simulated | Measured (all) | 95.9 | 2457 | 321 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hopwood, M.W.; Stein, J.S.; Braid, J.L.; Seigneur, H.P. Physics-Based Method for Generating Fully Synthetic IV Curve Training Datasets for Machine Learning Classification of PV Failures. Energies 2022, 15, 5085. https://doi.org/10.3390/en15145085
Hopwood MW, Stein JS, Braid JL, Seigneur HP. Physics-Based Method for Generating Fully Synthetic IV Curve Training Datasets for Machine Learning Classification of PV Failures. Energies. 2022; 15(14):5085. https://doi.org/10.3390/en15145085
Chicago/Turabian StyleHopwood, Michael W., Joshua S. Stein, Jennifer L. Braid, and Hubert P. Seigneur. 2022. "Physics-Based Method for Generating Fully Synthetic IV Curve Training Datasets for Machine Learning Classification of PV Failures" Energies 15, no. 14: 5085. https://doi.org/10.3390/en15145085
APA StyleHopwood, M. W., Stein, J. S., Braid, J. L., & Seigneur, H. P. (2022). Physics-Based Method for Generating Fully Synthetic IV Curve Training Datasets for Machine Learning Classification of PV Failures. Energies, 15(14), 5085. https://doi.org/10.3390/en15145085