
The Method of Rolling Bearing Fault Diagnosis Based on Multi-Domain Supervised Learning of Convolution Neural Network


Abstract
:1. Introduction
2. Theoretical Background
2.1. The Characteristic Frequency of Bearing Faults
2.2. The Short-Time Fourier Transform
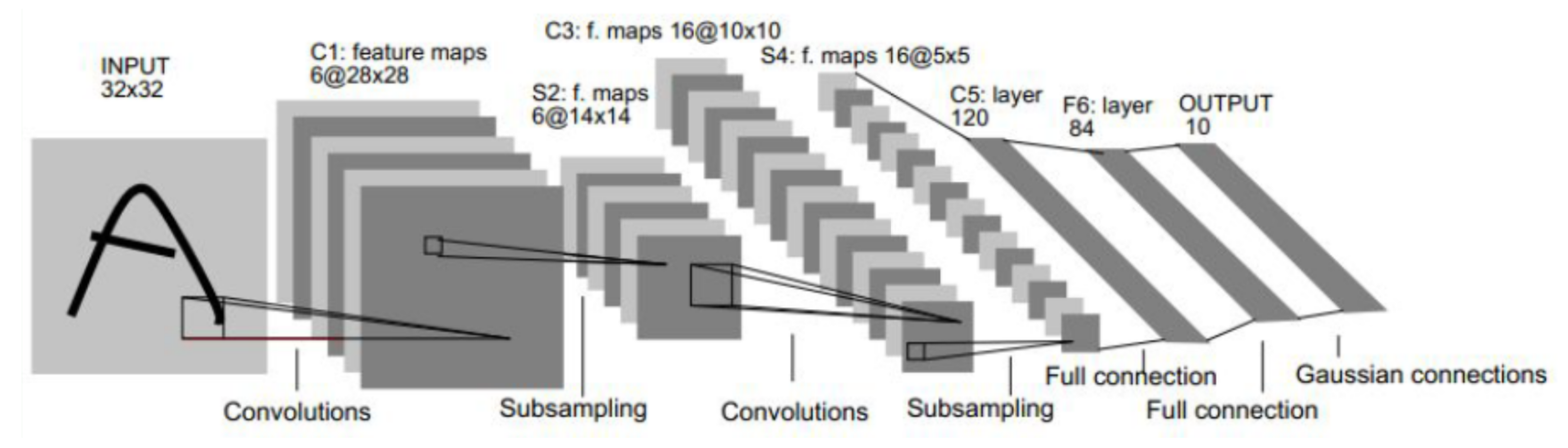
2.3. Convolutional Neural Network
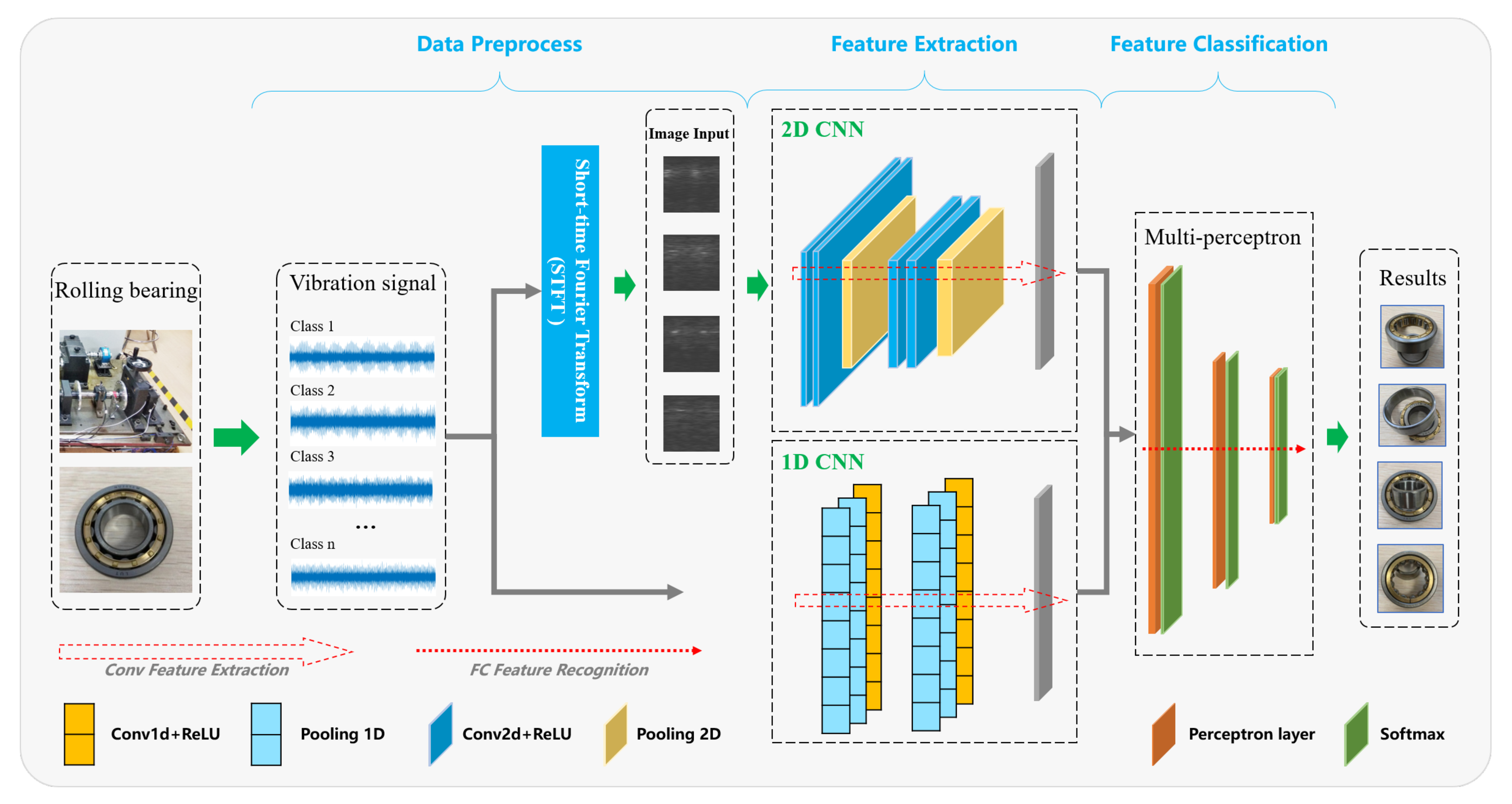
3. Methodology
3.1. Proposed Model Structure
3.2. The Design of Hyper-Parameters
4. Experimental Validation
4.1. Case 1: CWRU Dataset Fault Diagnosis
4.1.1. Data Introduction
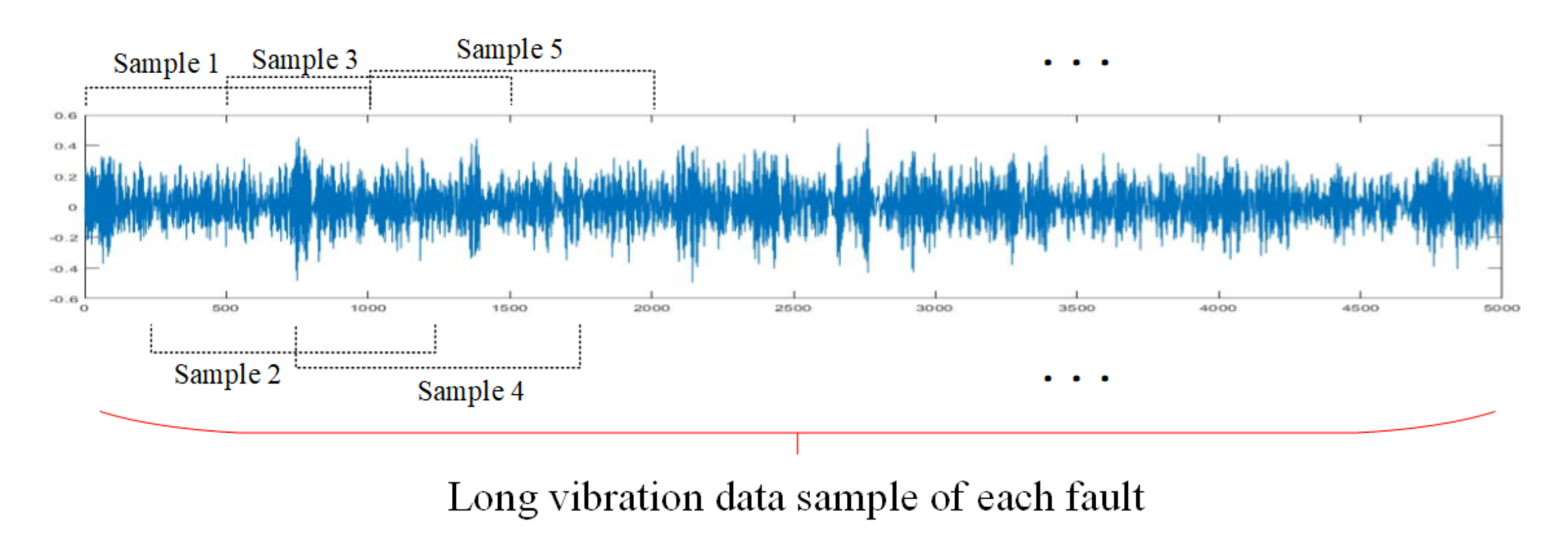
4.1.2. Data Pre-Processing
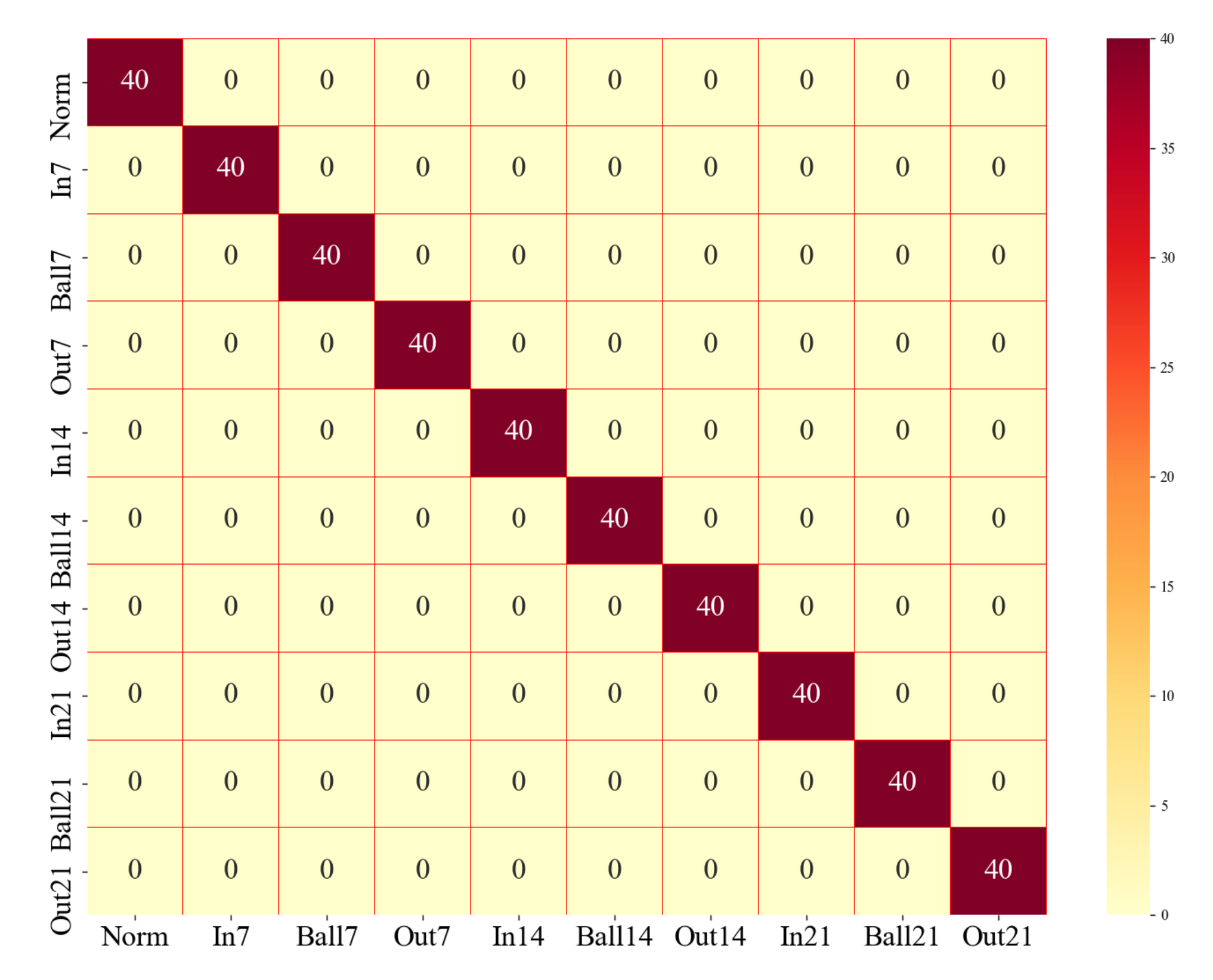
4.1.3. Model Training and Results
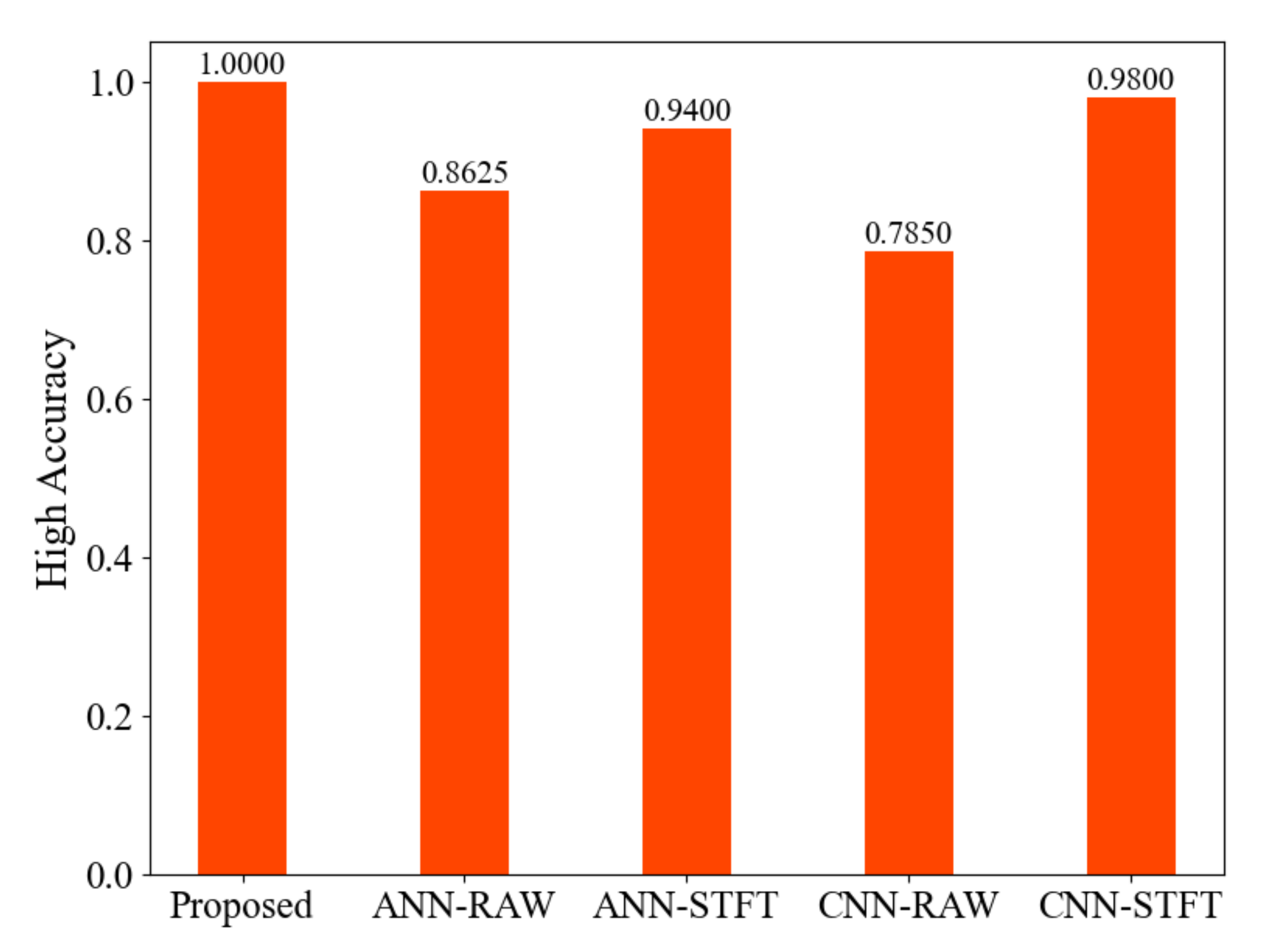
4.1.4. Comparative Analysis
4.2. Case 2: DUT Lab Dataset Fault Diagnosis
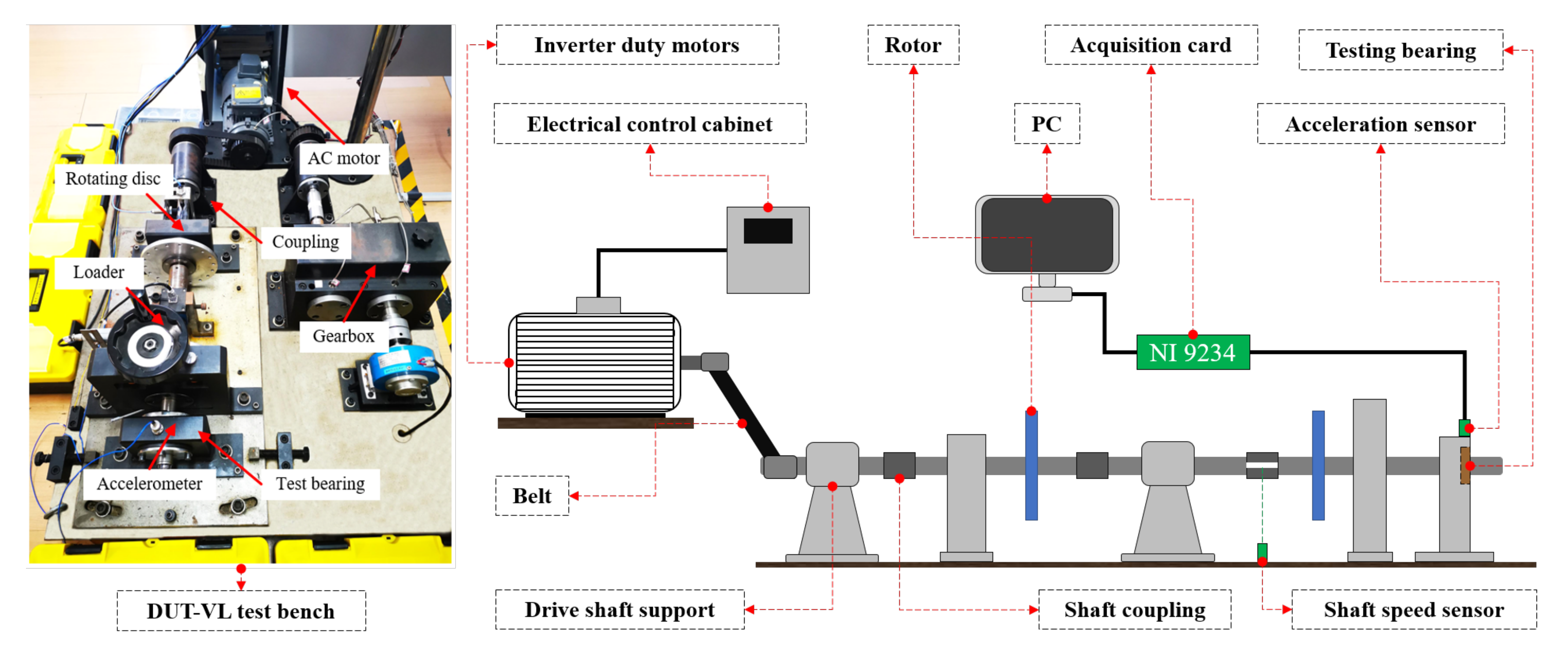
4.2.1. Data Introduction
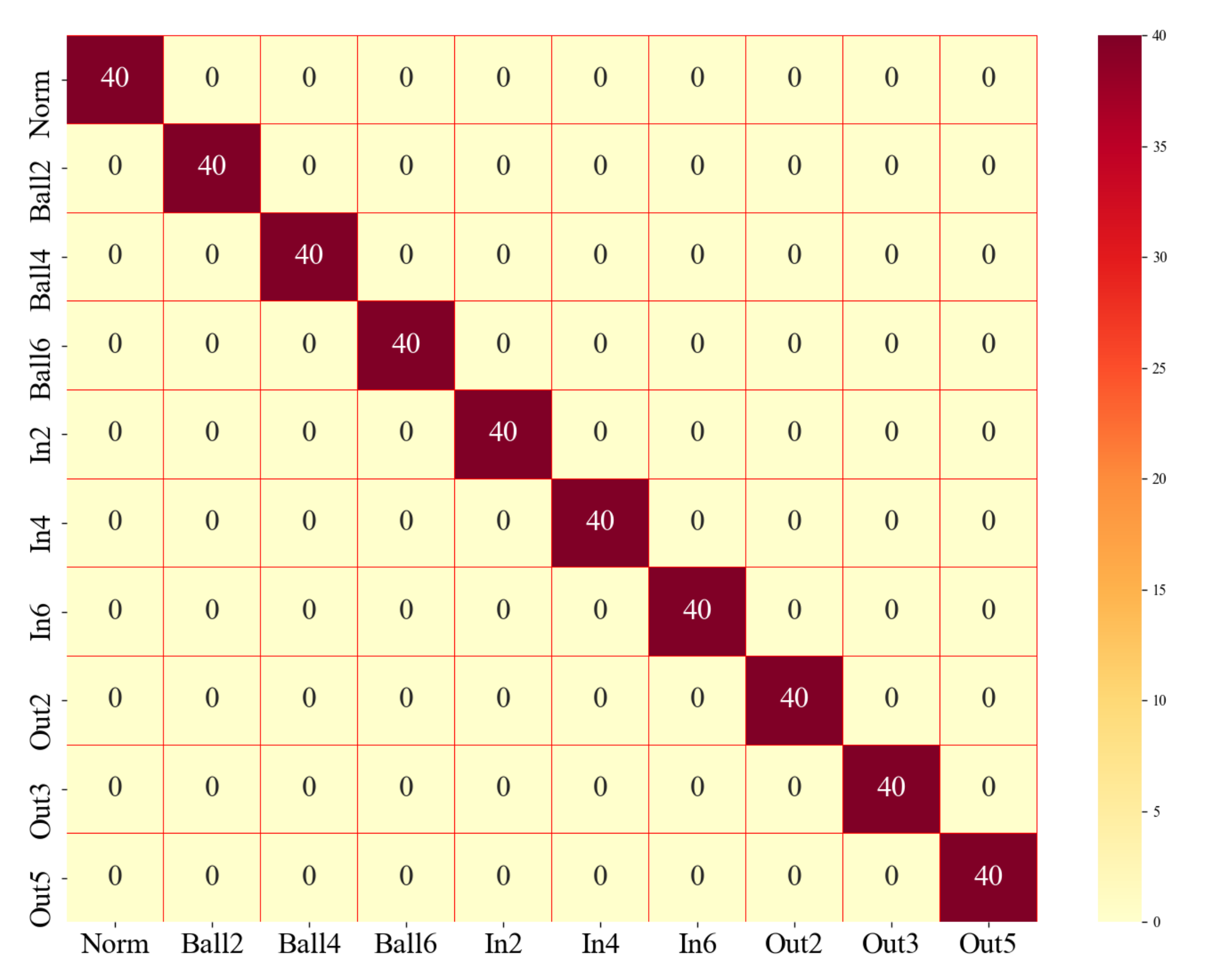
4.2.2. Model Training and Results
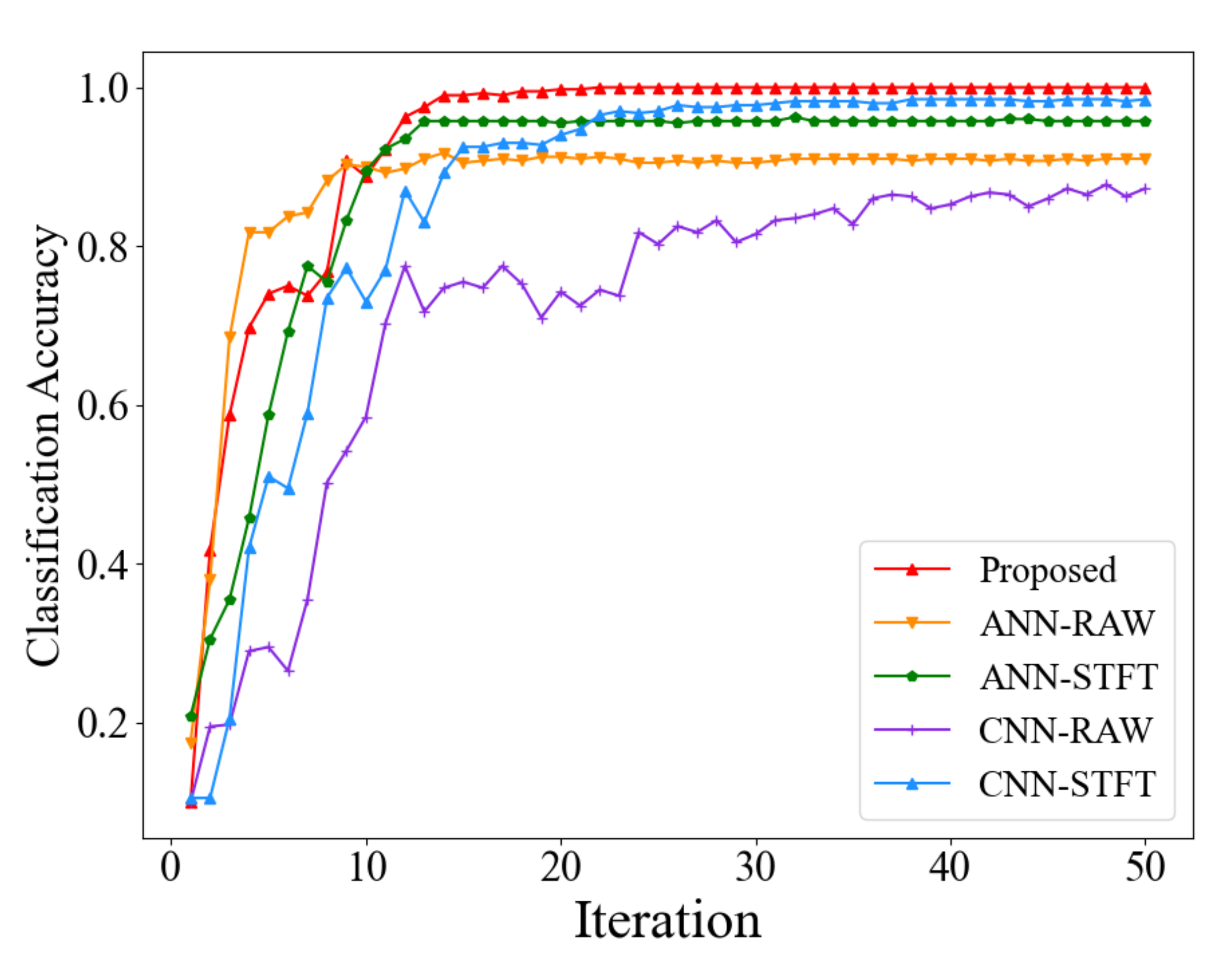
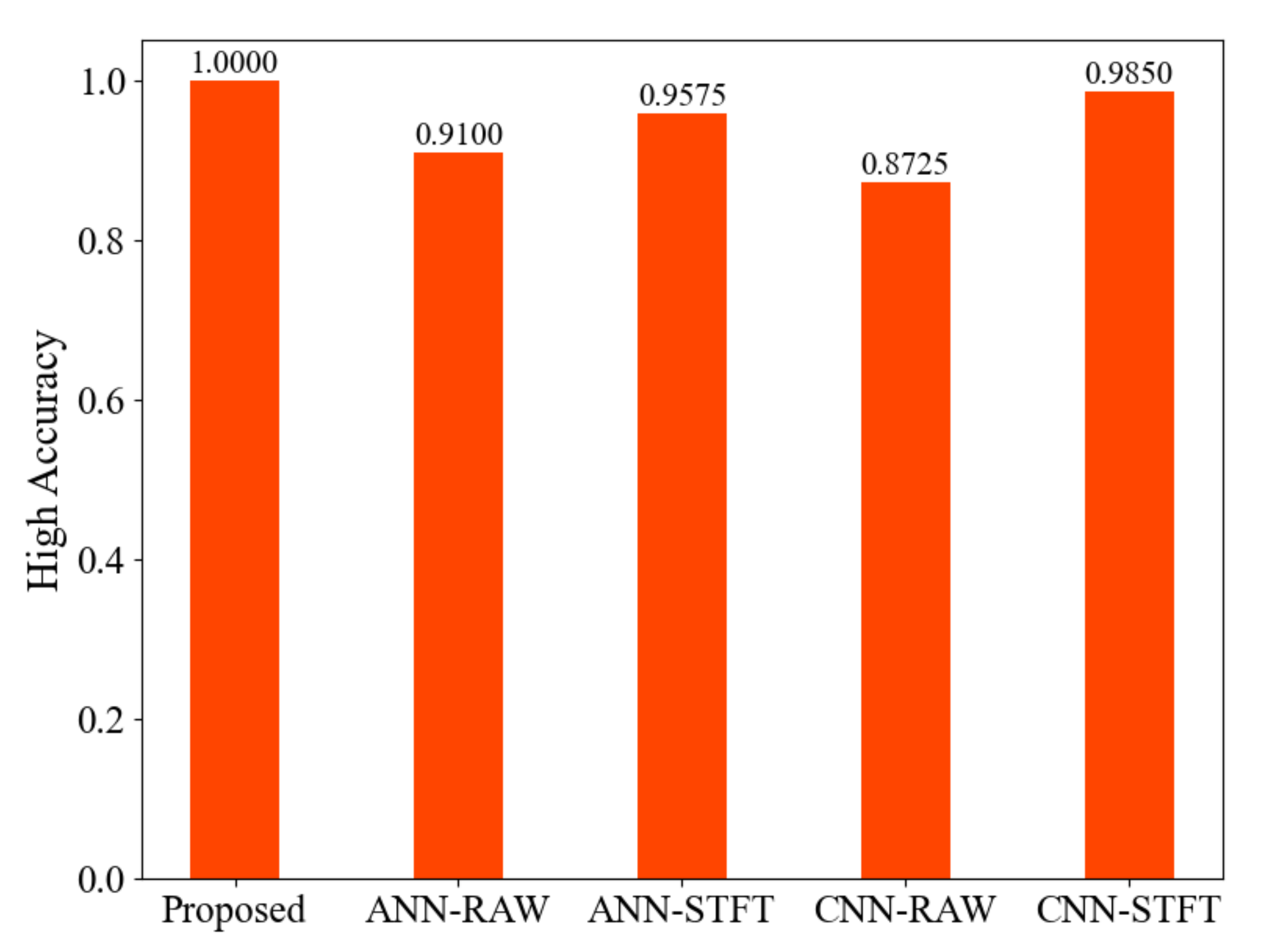
4.2.3. Comparative Analysis
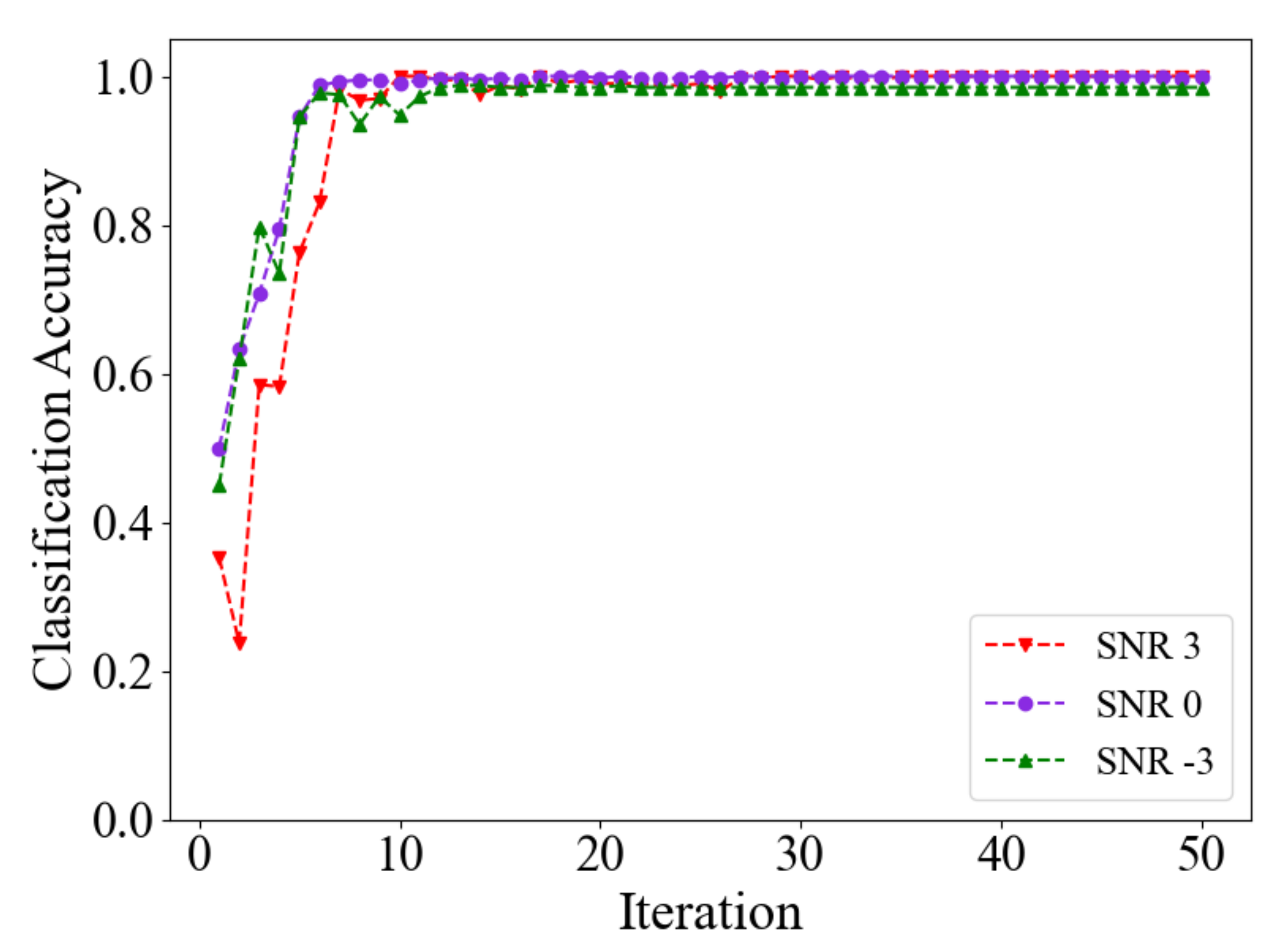
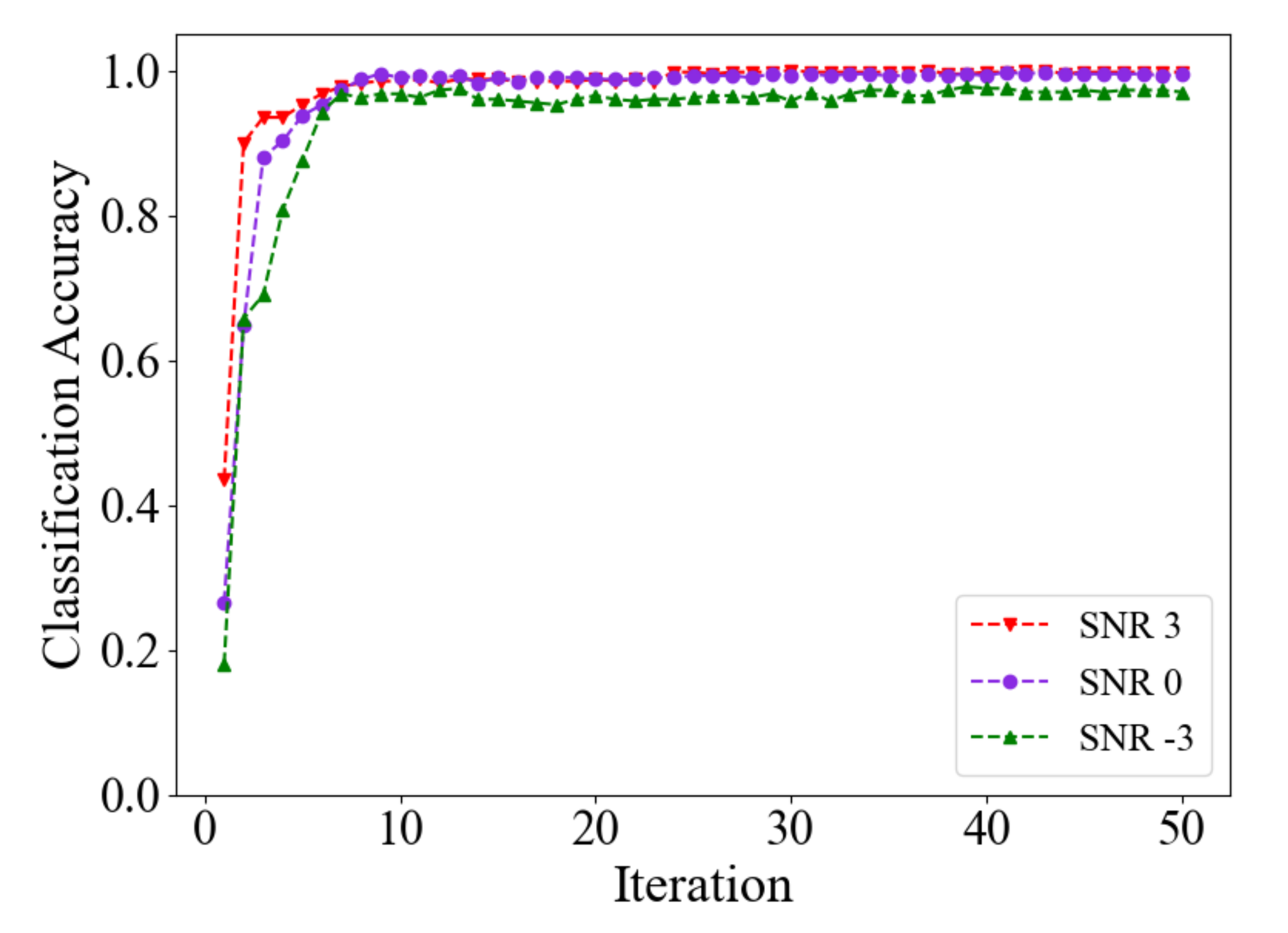
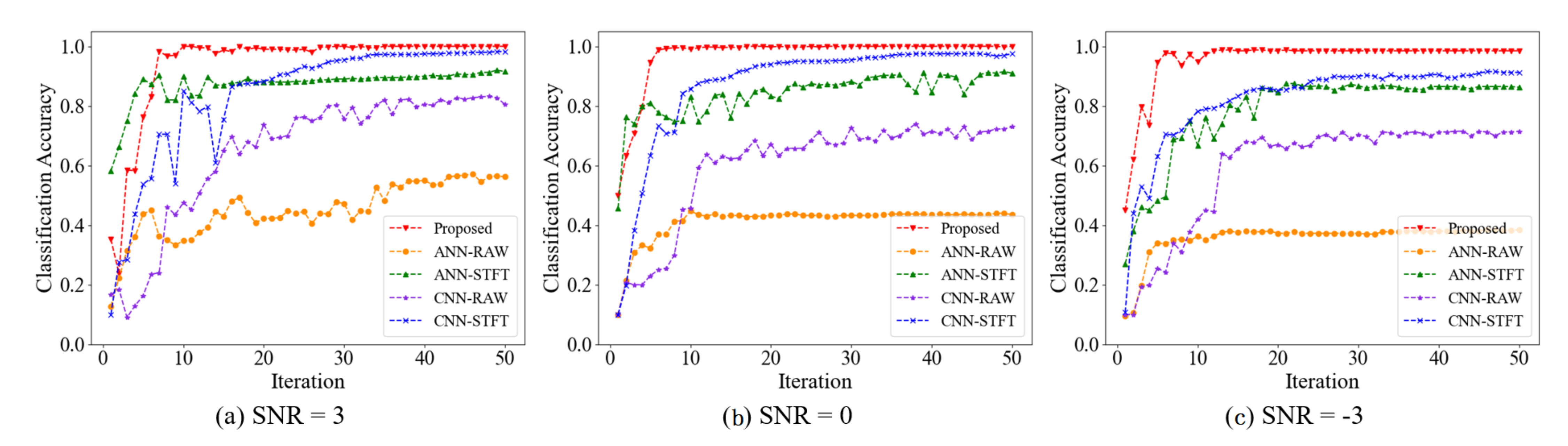
4.3. Noise: SNR3, SNR0, SNR-3
4.4. Comparison with Other Research and Efficiency Evaluation of Algorithm
4.5. Discussion
- (1)
- In this section, the effectiveness of the proposed approach was verified on two datasets: the CWRU and DUT datasets. The proposed fault diagnosis model performs well both in the training and testing steps. The prediction accuracy of fault states is more than 99.9% and is superior to the contrasting methods. Due the advantage of multi-domain learning, our proposed method extracts the fault features adaptively and realizes state prediction from the raw rolling bearing data in an end-to-end manner. Compared to the traditional fault diagnosis methods, there is no complicated feature extraction and no prior knowledge required.
- (2)
- To simulate the complicated operation conditions, different SNR noise was added to the raw samples for testing the anti-noise ability of the proposed method. The results show that the raw signal was disturbed by strong noise, but our method still achieves high classification accuracy of the fault state. The prediction accuracy of the proposed approach is slightly lower than in the test on raw data but higher than the contrasting methods, and this demonstrates the generalization ability and robustness of our methods. Moreover, the experimental results of calculation time show that our proposed algorithm is simple and effective and achieves high prediction within a short time.
5. Conclusions and Prospects
- (1)
- It constructs a new fault diagnosis model that combines the one-dimensional and two-dimensional convolution layers for learning multi-domain information of bearing faults; this model fully extracted the bearing fault features from time–frequency and raw time-domain data of bearing vibration signals.
- (2)
- The constructed multilayer perceptron establishes the mapping between feature matrix and fault state. The dropout technology is introduced to prevent the model over-fitting, and the diagnostic model performs well both in training and testing.
- (3)
- To validate the effectiveness of the proposed method, two experiments are performed on the CWRU and DUT datasets. Some different SNR noise is also added to the raw signals, and the results prove that the method proposed is effective. It also shows a generalization ability that can identify the fault state from the raw signal accurately in the strong noise condition.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, Y.; Ding, E.J.; Du, J.; Chen, G.C.; Zheng, Y. Safety detection approach in industrial equipment based on RSSD with adaptive parameter optimization algorithm. Saf. Sci. 2020, 125, 104605. [Google Scholar] [CrossRef]
- Shen, C.; Qi, Y.; Wang, J.; Cai, G.; Zhu, Z. An automatic and robust features learning method for rotating machinery fault diagnosis based on contractive autoencoder. Eng. Appl. Artif. Intell. 2018, 76, 170–184. [Google Scholar] [CrossRef]
- Hui, K.H.; Lim, M.H.; Leong, M.S.; Al-Obaidi, S.M. Dempster-Shafer evidence theory for multi-bearing faults diagnosis. Eng. Appl. Artif. Intell. 2017, 57, 160–170. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, H.; Li, S.; An, Z. Unsupervised domain adaptation via enhanced transfer joint matching for bearing fault diagnosis. Measurement 2020, 165, 108071. [Google Scholar] [CrossRef]
- Xu, X.L.; Yu, Z.W. Failure analysis of tapered roller bearing inner rings used in heavy truck. Eng. Fail. Anal. 2020, 111, 104474. [Google Scholar] [CrossRef]
- Chegini, S.N.; Bagheri, A.; Najafi, F. Application of a new EWT-based denoising technique in bearing fault diagnosis. Measurement 2019, 144, 275–297. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Z.; Wang, L.; Zhang, J.; Han, W. Bearing fault diagnosis based on sparse representations using an improved OMP with adaptive Gabor sub-dictionaries. ISA Trans. 2020, 106, 355–366. [Google Scholar] [CrossRef]
- Kim, Y.; Park, J.; Na, K.; Yuan, H.; Youn, B.D.; Kang, C.S. Phase-based time domain averaging (PTDA) for fault detection of a gearbox in an industrial robot using vibration signals. Mech. Syst. Signal Process. 2020, 138, 106544. [Google Scholar] [CrossRef]
- Li, H.; Liu, T.; Wu, X.; Chen, Q. An optimized VMD method and its applications in bearing fault diagnosis. Measurement 2020, 166, 108185. [Google Scholar] [CrossRef]
- Ma, J.; Wu, J.; Wang, X. Incipient fault feature extraction of rolling bearings based on the MVMD and Teager energy operator. ISA Trans. 2018, 80, 297–311. [Google Scholar] [CrossRef]
- He, C.; Niu, P.; Yang, R.; Wang, C.; Li, Z.; Li, H. Incipient rolling element bearing weak fault feature extraction based on adaptive second-order stochastic resonance incorporated by mode decomposition. Measurement 2019, 145, 687–701. [Google Scholar] [CrossRef]
- Shao, K.; Fu, W.; Tan, J.; Wang, K. Coordinated approach fusing time-shift multiscale dispersion entropy and vibrational Harris hawks optimization-based SVM for fault diagnosis of rolling bearing. Measurement 2021, 173, 108580. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Chen, M.; Sun, Y.; Qin, X.; Li, H. A two-stage feature selection and intelligent fault diagnosis method for rotating machinery using hybrid filter and wrapper method. Neurocomputing 2018, 275, 2426–2439. [Google Scholar] [CrossRef]
- Jiang, F.; Zhu, Z.; Li, W.; Ren, Y.; Zhou, G.; Chang, Y. A fusion feature extraction method using EEMD and correlation coefficient analysis for bearing fault diagnosis. Appl. Sci. 2018, 8, 1621. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Yu, H.; Yang, L.T.; Zhang, Q.; Armstrong, D.; Deen, M.J. Convolutional neural networks for medical image analysis: State-of-the-art, comparisons, improvement and perspectives. Neurocomputing 2021, 444, 92–110. [Google Scholar] [CrossRef]
- Banik, P.P.; Saha, R.; Kim, K.D. An automatic nucleus segmentation and CNN model based classification method of white blood cell. Expert Syst. Appl. 2020, 149, 113211. [Google Scholar] [CrossRef]
- Ban, J.E.; Rho, B.H.; Kim, K.W. A study on the sound of roller bearings operating under radial load. Tribol. Int. 2007, 40, 21–28. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, X.; Wang, X.; Mugica, J.E.; Zhang, L. Wind turbine blade bearing fault diagnosis under fluctuating speed operations via Bayesian augmented Lagrangian analysis. IEEE Trans. Ind. Inform. 2020, 17, 4613–4623. [Google Scholar] [CrossRef]
- Chen, J.; Pan, J.; Li, Z.; Zi, Y.; Chen, X. Generator bearing fault diagnosis for wind turbine via empirical wavelet transform using measured vibration signals. Renew. Energy 2016, 89, 80–92. [Google Scholar] [CrossRef]
- Tagawa, Y.; Maskeliūnas, R.; Damaševičius, R. Acoustic Anomaly Detection of Mechanical Failures in Noisy Real-Life Factory Environments. Electronics 2021, 10, 2329. [Google Scholar] [CrossRef]
- Abdelkader, R.; Kaddour, A.; Derouiche, Z. Enhancement of rolling bearing fault diagnosis based on improvement of empirical mode decomposition denoising method. Int. J. Adv. Manuf. Technol. 2018, 97, 3099–3117. [Google Scholar] [CrossRef]
- Guo, X.; Shen, C.; Chen, L. Deep fault recognizer: An integrated model to denoise and extract features for fault diagnosis in rotating machinery. Appl. Sci. 2016, 7, 41. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
- Mohanty, S.; Gupta, K.K.; Raju, K.S. Hurst based vibro-acoustic feature extraction of bearing using EMD and VMD. Measurement 2018, 117, 200–220. [Google Scholar] [CrossRef]
- Manhertz, G.; Bereczky, A. STFT spectrogram based hybrid evaluation method for rotating machine transient vibration analysis. Mech. Syst. Signal Process. 2021, 154, 107583. [Google Scholar] [CrossRef]
- Marquezino, F.L.; Portugal, R.; Sasse, F. Obtaining the Quantum Fourier Transform from the classical FFT with QR decomposition. J. Comput. Appl. Math. 2010, 235, 74–81. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Cai, H.; Han, H.; Jiang, Q.; Ji, H. Adaptive short-time Fourier transform and synchrosqueezing transform for non-stationary signal separation. Signal Process. 2020, 166, 107231. [Google Scholar] [CrossRef]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Singh, P.; Raj, P.; Namboodiri, V.P. EDS pooling layer. Image Vis. Comput. 2020, 98, 103923. [Google Scholar] [CrossRef]
- Li, C.; Li, S.; Zhang, A.; He, Q.; Liao, Z.; Hu, J. Meta-learning for few-shot bearing fault diagnosis under complex working conditions. Neurocomputing 2021, 439, 197–211. [Google Scholar] [CrossRef]
- Bosman, A.S.; Engelbrecht, A.; Helbig, M. Visualising basins of attraction for the cross-entropy and the squared error neural network loss functions. Neurocomputing 2020, 400, 113–136. [Google Scholar] [CrossRef] [Green Version]
- Loparo, K.A. Case Western Reserve University Bearing Data Center. In Bearings Vibration Data Sets; Case Western Reserve University: Cleveland, OH, USA, 2012. [Google Scholar]
- Pandhare, V.; Singh, J.; Lee, J. Convolutional neural network based rolling-element bearing fault diagnosis for naturally occurring and progressing defects using time-frequency domain features. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Paris), Paris, France, 2–5 May 2019; pp. 320–326. [Google Scholar]
- Beale, C.; Niezrecki, C.; Inalpolat, M. An adaptive wavelet packet denoising algorithm for enhanced active acoustic damage detection from wind turbine blades. Mech. Syst. Signal Process. 2020, 142, 106754. [Google Scholar] [CrossRef]
- Piltan, F.; Kim, J.M. Bearing anomaly recognition using an intelligent digital twin integrated with machine learning. Appl. Sci. 2021, 11, 4602. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | Output |
|---|---|---|---|---|---|---|
| 1024 | 63 × 3 | 163 × 3 | 17,728 | 2048 | 512 | 10 |
| 129 × 129 | 65 × 5 | 165 × 5 |
| Index | Mark | Speed/RPM | Fault Degree | Fault Location |
|---|---|---|---|---|
| 1 | In7 | 1797 | 0.007 | Inner race |
| 2 | Ball7 | 1797 | 0.007 | Ball |
| 3 | Out7 | 1797 | 0.007 | Outer race |
| 4 | In14 | 1772 | 0.014 | Inner race |
| 5 | Ball14 | 1772 | 0.014 | Ball |
| 6 | Out14 | 1772 | 0.014 | Outer race |
| 7 | In21 | 1750 | 0.021 | Inner race |
| 8 | Ball21 | 1750 | 0.021 | Ball |
| 9 | Out21 | 1750 | 0.021 | Outer race |
| 10 | Norm | 1797 | - | Normal |
| Inner Ring | Outer Ring | Cage Train | Rolling Element |
|---|---|---|---|
| 5.4152 | 3.5848 | 0.39828 | 4.7135 |
| Type of Bearing | Inner Diameter | Outer Diameter | Width | Number of Ball |
|---|---|---|---|---|
| NU205 | 20 | 47 | 14 | 9 |
| NU205EM | 20 | 47 | 14 | 9 |
| Index | Mark | Fault Location | Fault Degree (mm) | Speed (rpm) |
|---|---|---|---|---|
| 1 | Norm | - | Normal | 1200 |
| 2 | Ball2 | Ball | 0.2 | 1200 |
| 3 | Ball2 | Ball | 0.4 | 1200 |
| 4 | Ball2 | Ball | 0.6 | 1200 |
| 5 | In2 | Inner race | 0.2 | 1200 |
| 6 | In2 | Inner race | 0.4 | 1200 |
| 7 | In6 | Inner race | 0.6 | 1200 |
| 8 | Out2 | Outer race | 0.2 | 1200 |
| 9 | Out3 | Outer race | 0.36 | 1200 |
| 10 | Out5 | Outer race | 0.54 | 1200 |
| Operation Time | Proposed Method | ANN-RAW | ANN-STFT | CNN-RAW | CNN-STFT |
|---|---|---|---|---|---|
| Training time/s | 383.78 | 29.137 | 363.298 | 39.153 | 361.604 |
| Diagnosis time/s | 0.758 | 0.129 | 0.703 | 0.142 | 0.642 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Sun, W.; Li, H.; Hussain, Z.; Liu, A. The Method of Rolling Bearing Fault Diagnosis Based on Multi-Domain Supervised Learning of Convolution Neural Network. Energies 2022, 15, 4614. https://doi.org/10.3390/en15134614
Liu X, Sun W, Li H, Hussain Z, Liu A. The Method of Rolling Bearing Fault Diagnosis Based on Multi-Domain Supervised Learning of Convolution Neural Network. Energies. 2022; 15(13):4614. https://doi.org/10.3390/en15134614
Chicago/Turabian StyleLiu, Xuejun, Wei Sun, Hongkun Li, Zeeshan Hussain, and Aiqiang Liu. 2022. "The Method of Rolling Bearing Fault Diagnosis Based on Multi-Domain Supervised Learning of Convolution Neural Network" Energies 15, no. 13: 4614. https://doi.org/10.3390/en15134614
APA StyleLiu, X., Sun, W., Li, H., Hussain, Z., & Liu, A. (2022). The Method of Rolling Bearing Fault Diagnosis Based on Multi-Domain Supervised Learning of Convolution Neural Network. Energies, 15(13), 4614. https://doi.org/10.3390/en15134614