
Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type

 ,
,  ,
, 

Abstract
1. Introduction
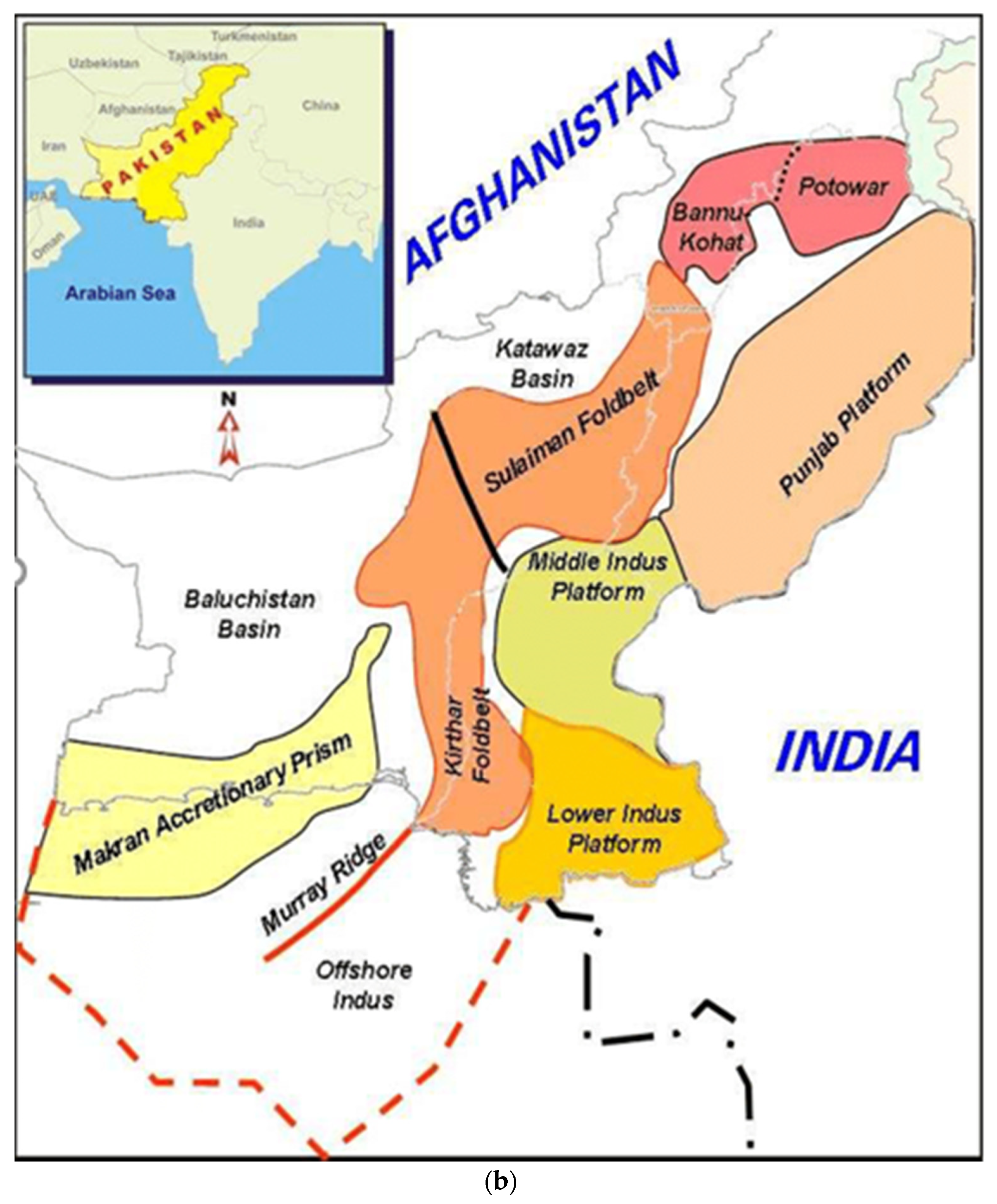
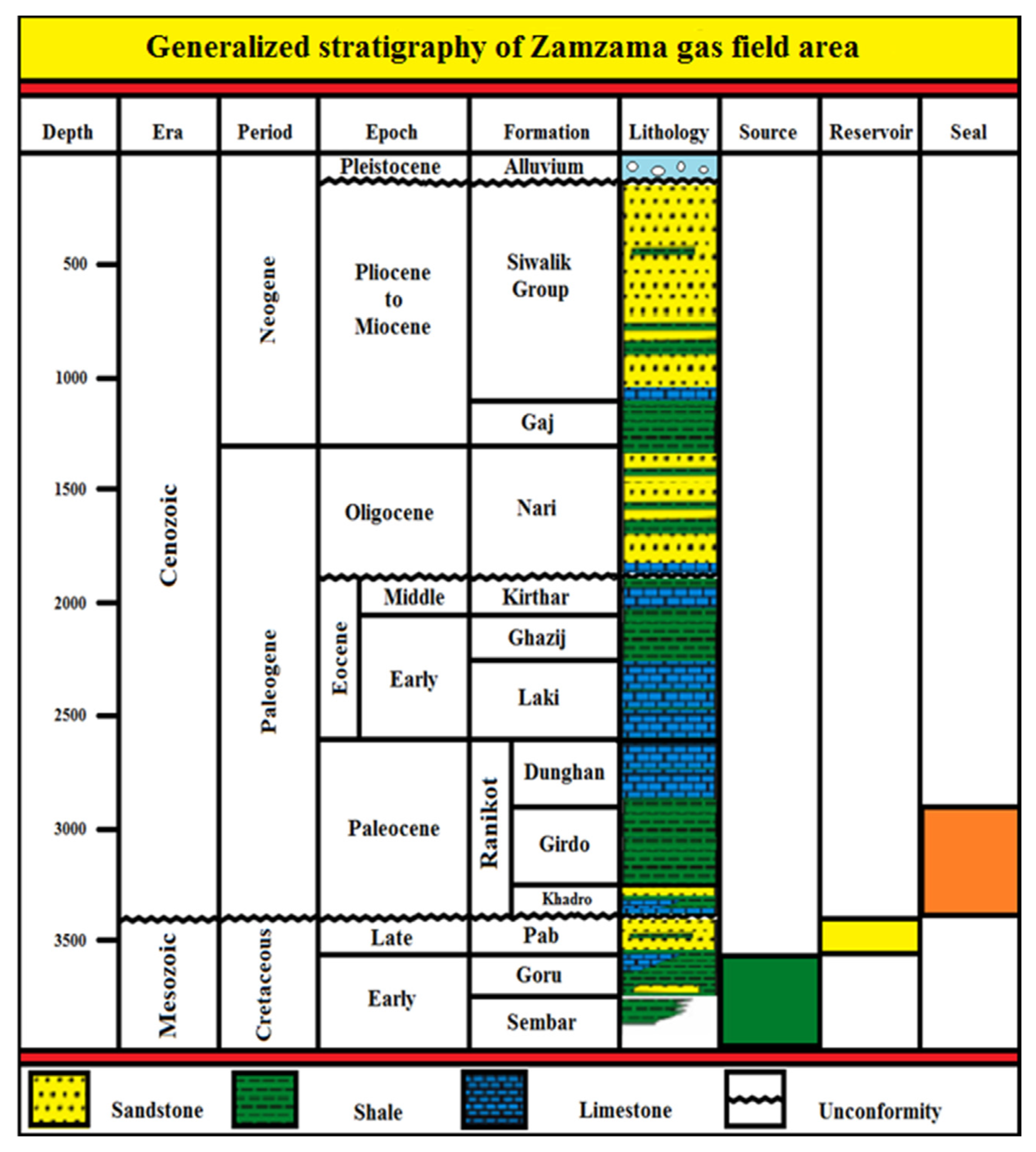
General Geology and Stratigraphy of the Study Area
2. Data and Methods
2.1. Dataset
2.2. Methods
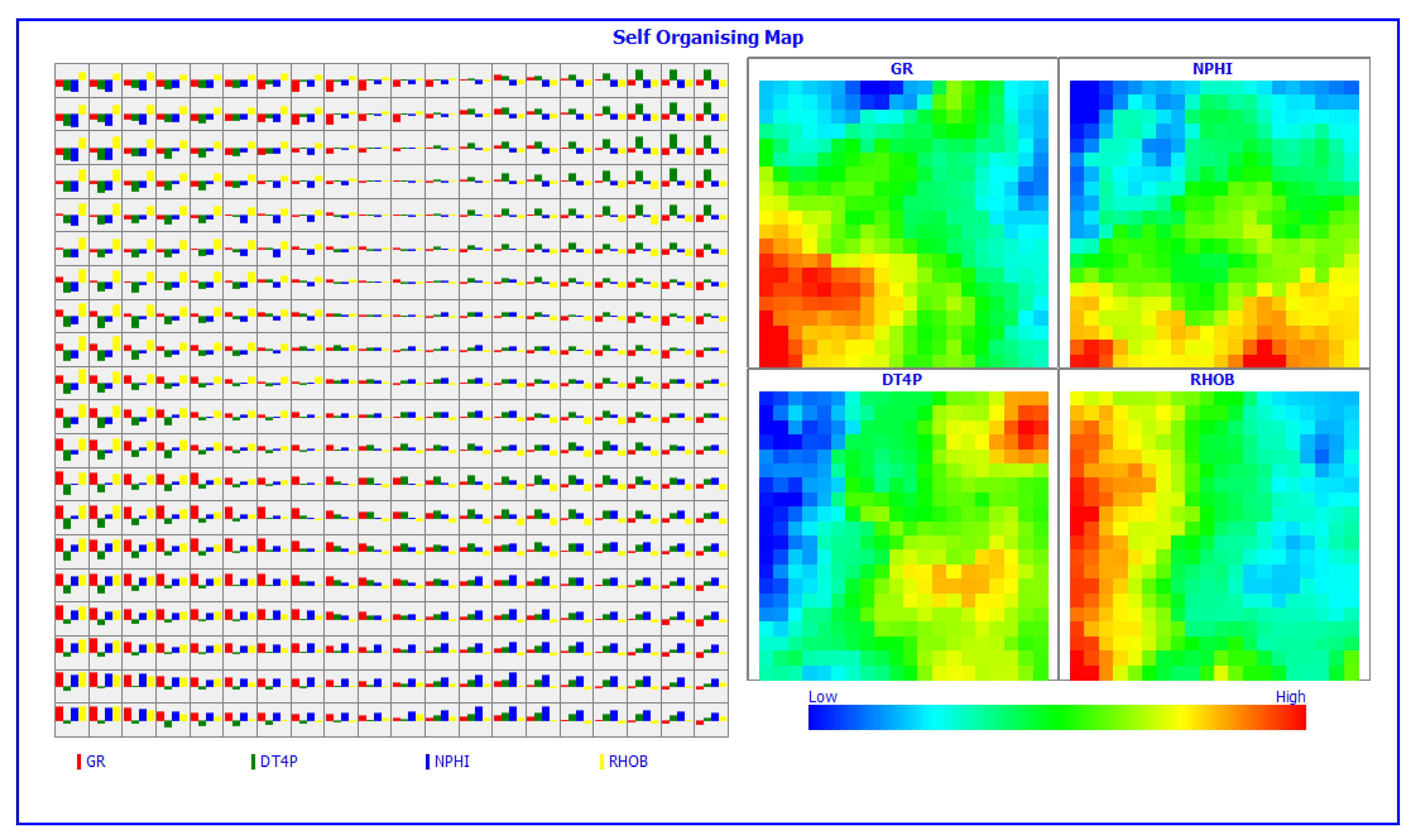
2.2.1. SOM
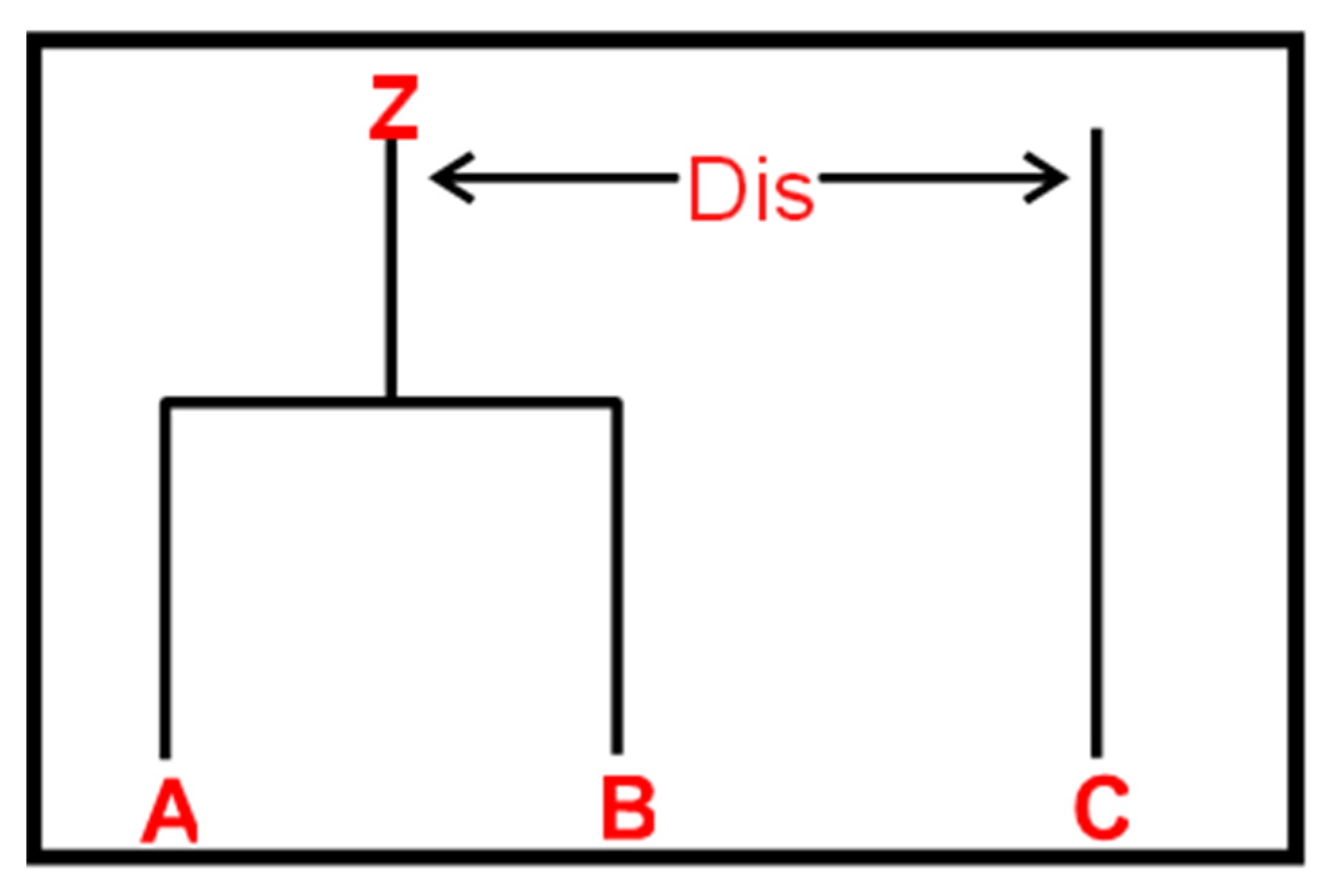
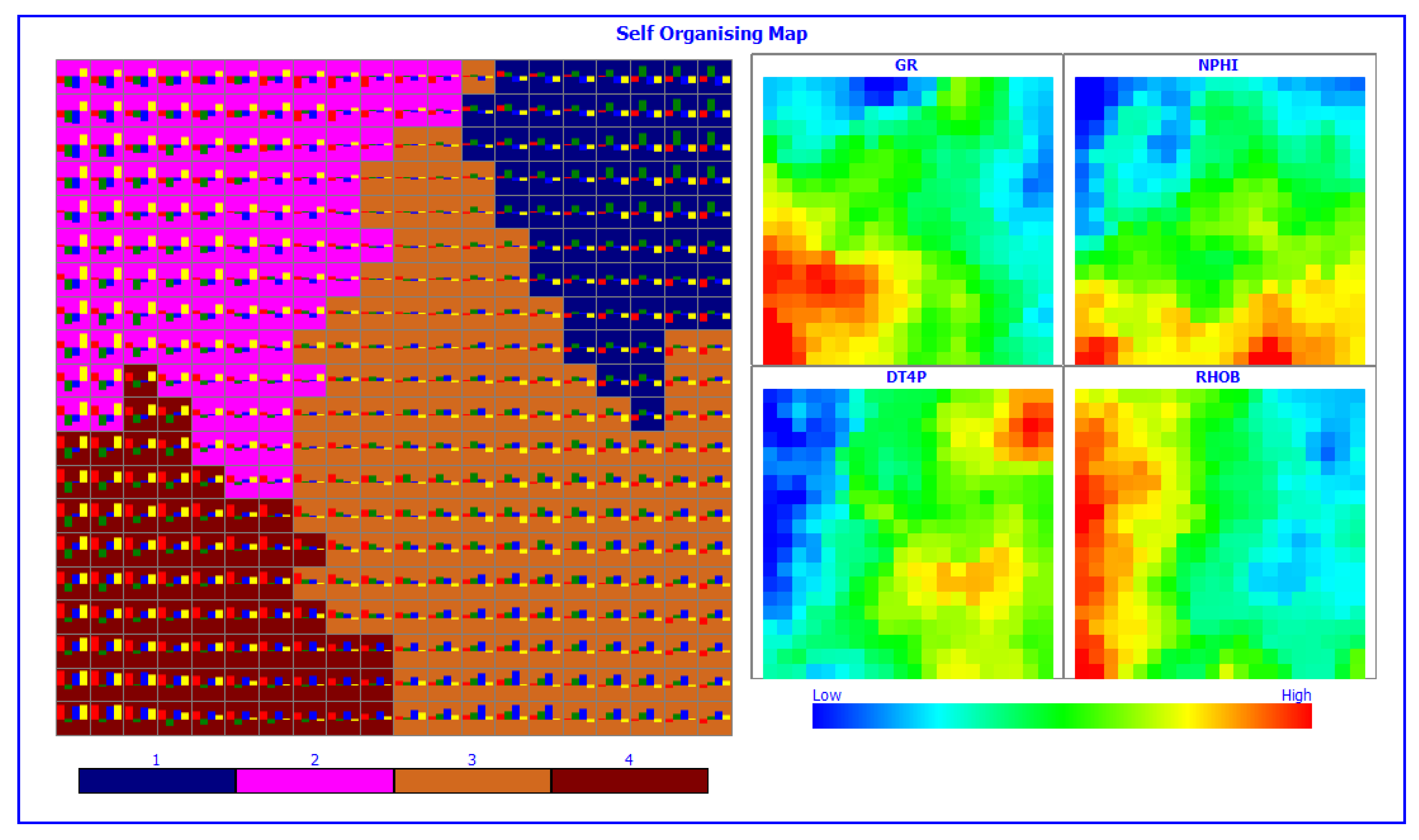
2.2.2. Clustering Procedure
Stage-2 Cluster Consolidation
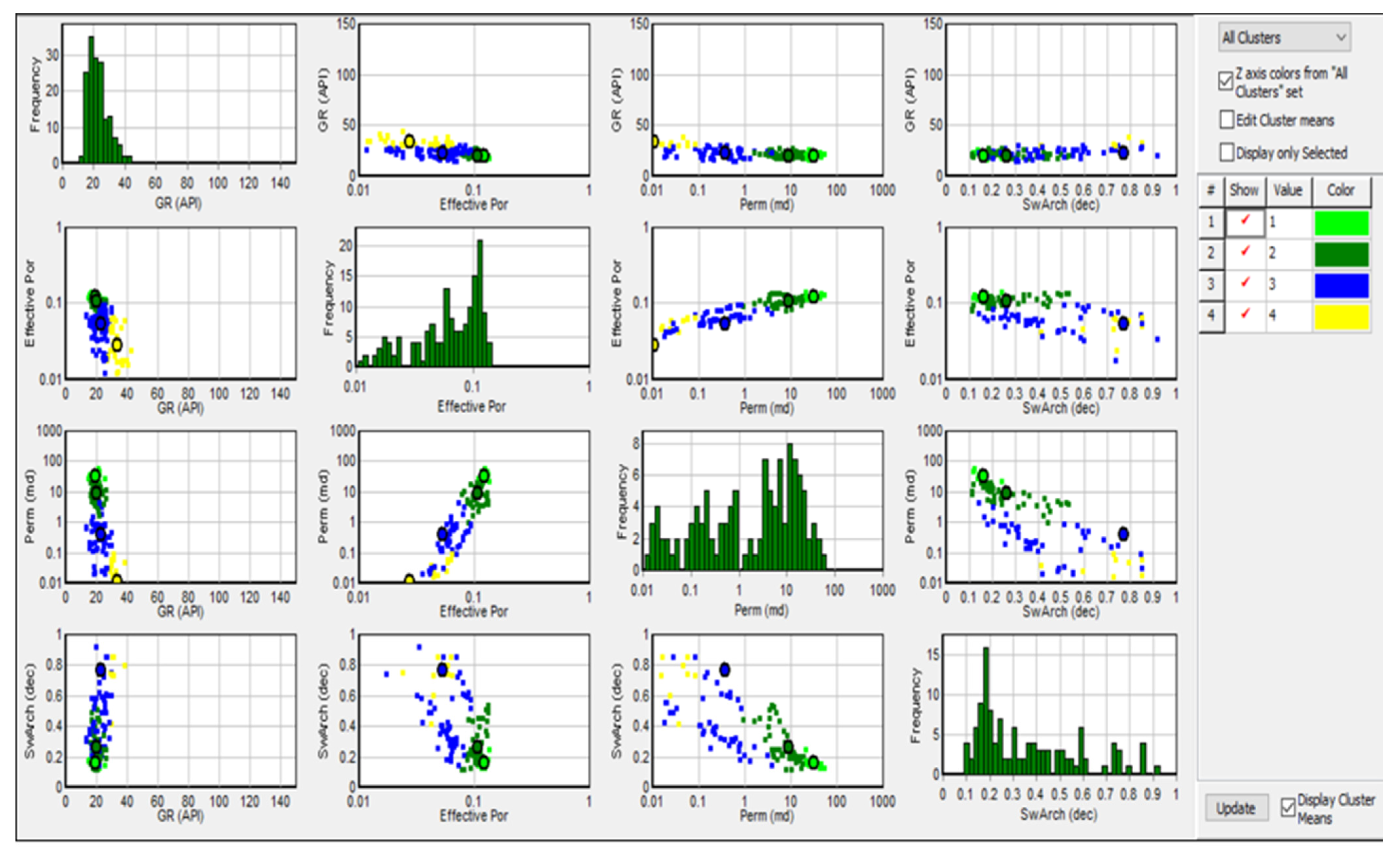
2.2.3. Non-Hierarchical or K-means Clustering Methods
3. Results and Discussion
3.1. Self-Organizing Feature Map (SOFM) Approach for Lithofacies Identification
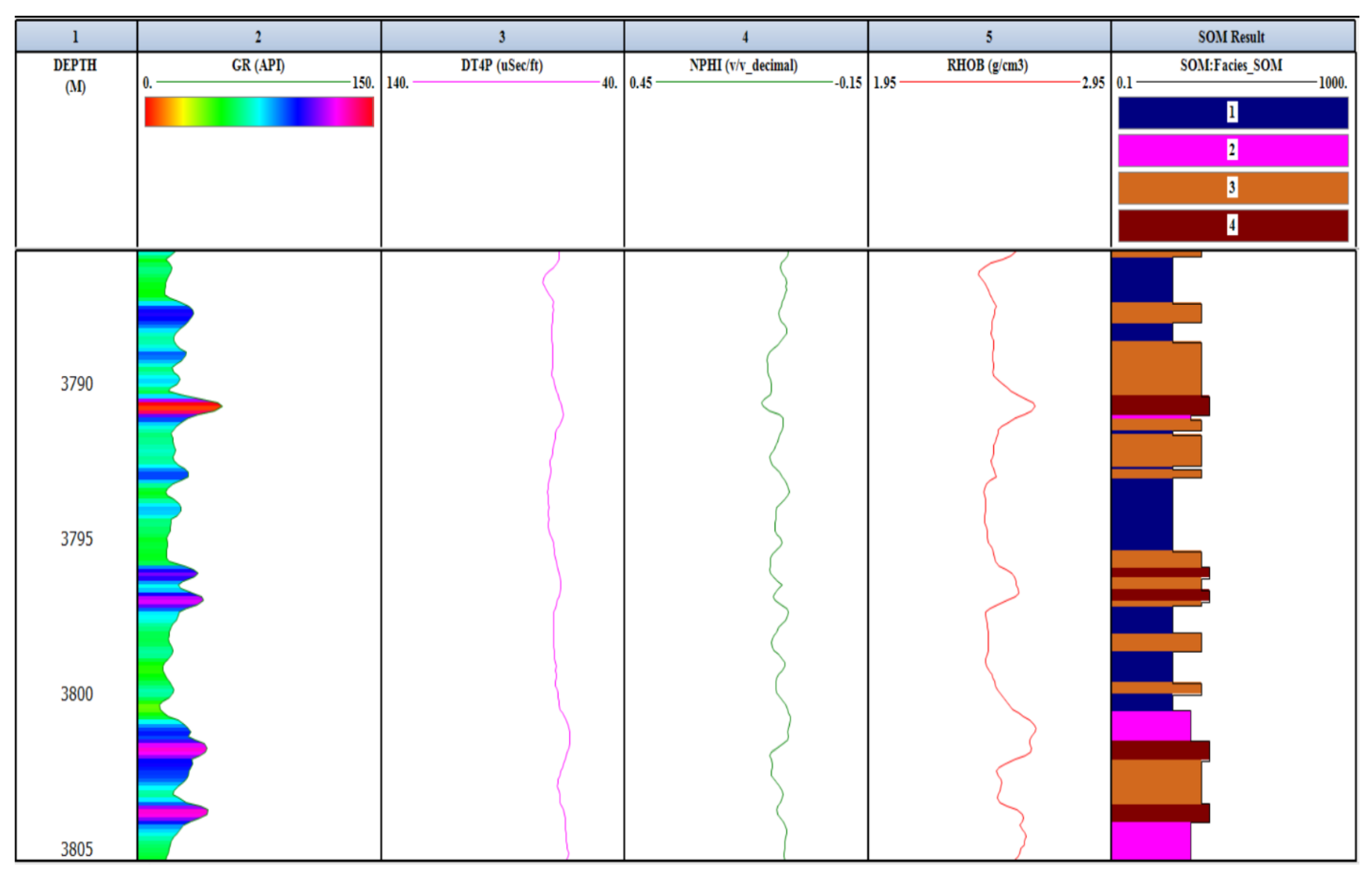
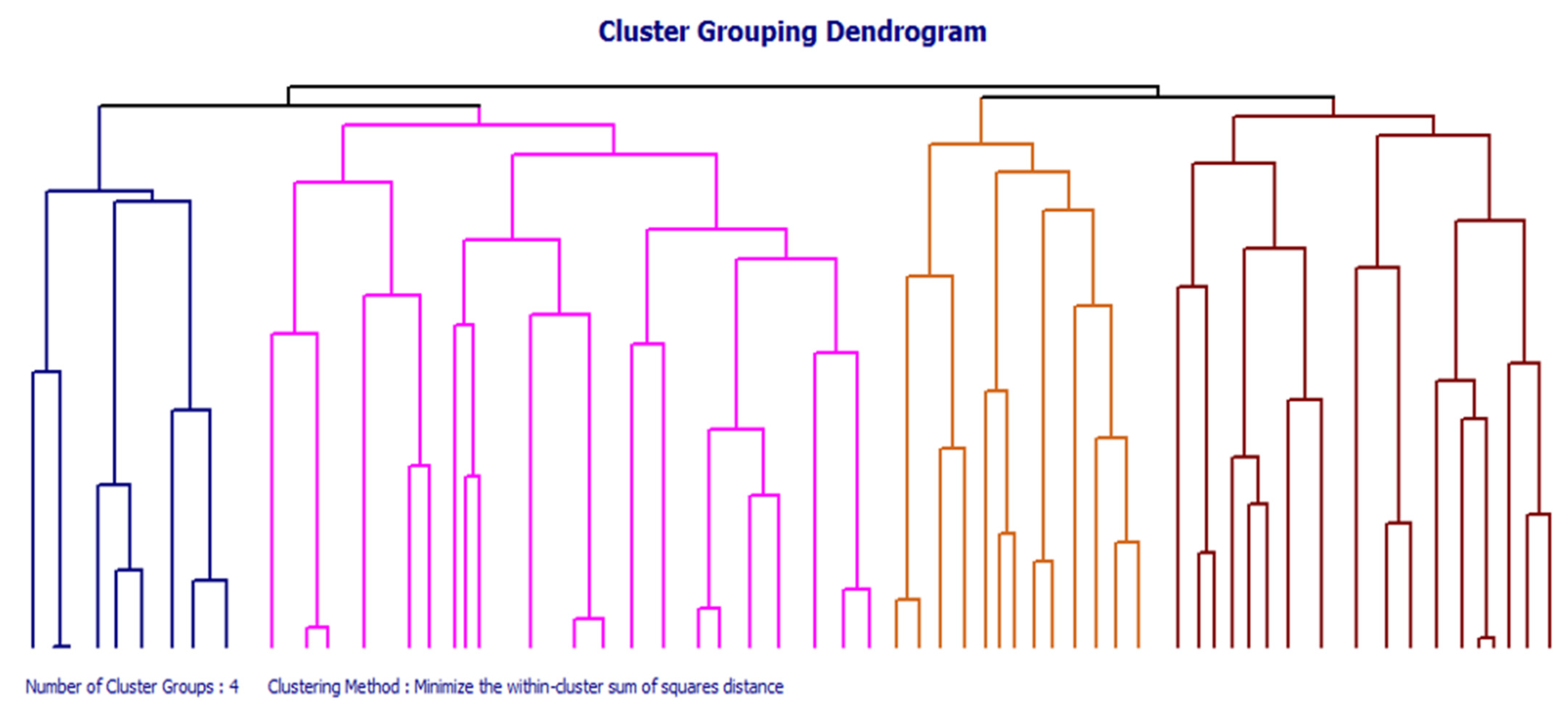
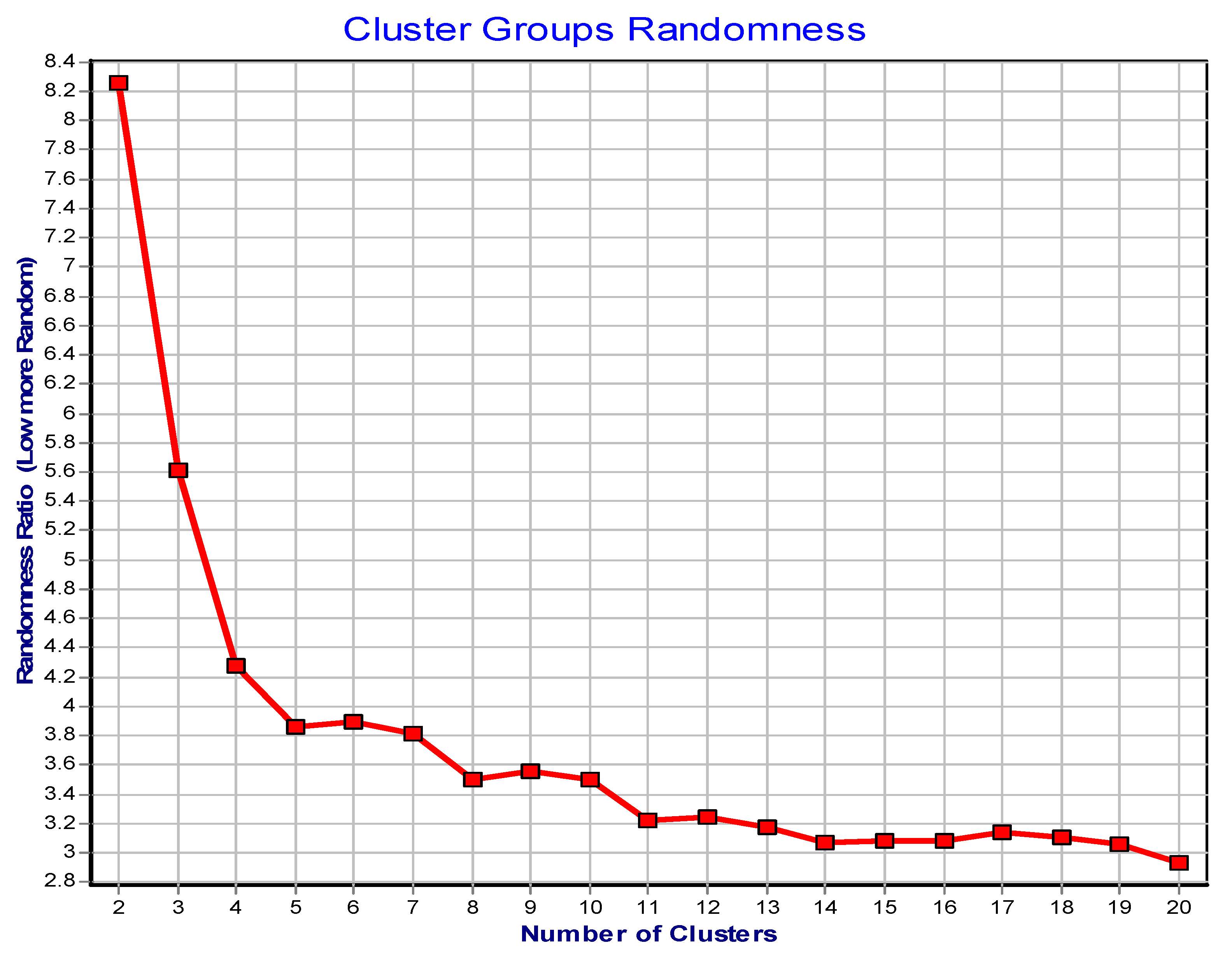
3.2. Cluster Analysis for Lithofacies Identification
3.3. Hierarchical and Non-Hierarchical
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| SOM | Self-Organizing Map |
| SOFM | Self-Organizing Feature Map |
| PCA | Principal Component Analysis |
| LGF | Lower Goru Formation |
| UGF | Upper Goru Formation |
| BMU | Best Matching Unit |
References
- Ashraf, U.; Zhang, H.; Anees, A.; Mangi, H.N.; Ali, M.; Zhang, X.; Imraz, M.; Abbasi, S.S.; Abbas, A.; Ullah, Z. A Core Logging, Machine Learning and Geostatistical Modeling Interactive Approach for Subsurface Imaging of Lenticular Geobodies in a Clastic Depositional System, SE Pakistan. Nat. Resour. Res. 2021, 30, 2807–2830. [Google Scholar] [CrossRef]
- Ali, M.; Jiang, R.; Huolin, M.; Pan, H.; Abbas, K.; Ashraf, U.; Ullah, J. Machine Learning-A Novel Approach of Well Logs Similarity Based on Synchronization Measures to Predict Shear Sonic Logs. J. Pet. Sci. Eng. 2021, 203, 108602. [Google Scholar] [CrossRef]
- Bressan, T.S.; Kehl de Souza, M.; Girelli, T.J.; Junior, F.C. Evaluation of Machine Learning Methods for Lithology Classification Using Geophysical Data. Comput. Geosci. 2020, 139, 104475. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhang, H.; Anees, A.; Mangi, H.N.; Ali, M.; Ullah, Z.; Zhang, X. Application of Unconventional Seismic Attributes and Unsupervised Machine Learning for the Identification of Fault and Fracture Network. Appl. Sci. 2020, 10, 3864. [Google Scholar] [CrossRef]
- Safaei-Farouji, M.; Vo Thanh, H.; Sheini Dashtgoli, D.; Yasin, Q.; Radwan, A.E.; Ashraf, U.; Lee, K.K. Application of Robust Intelligent Schemes for Accurate Modelling Interfacial Tension of CO2 Brine Systems: Implications for Structural CO2 Trapping. Fuel 2022, 319, 123821. [Google Scholar] [CrossRef]
- Vo-Thanh, H.; Amar, M.N.; Lee, K.K. Robust Machine Learning Models of Carbon Dioxide Trapping Indexes at Geological Storage Sites. Fuel 2022, 316, 123391. [Google Scholar] [CrossRef]
- Vo Thanh, H.; Lee, K.K. Application of Machine Learning to Predict CO2 Trapping Performance in Deep Saline Aquifers. Energy 2022, 239, 122457. [Google Scholar] [CrossRef]
- Thanh, H.V.; Van Binh, D.; Kantoush, S.A.; Nourani, V.; Saber, M.; Lee, K.; Sumi, T.; Sciences, E.; Korea, S.; Resources, W.; et al. Reconstructing Daily Discharge in a Megadelta Using Machine Learning Techniques. Water Resour. Res. 2022, 58. [Google Scholar] [CrossRef]
- Klose, C.D. Self-Organizing Maps for Geoscientific Data Analysis: Geological Interpretation of Multidimensional Geophysical Data. Comput. Geosci. 2006, 10, 265–277. [Google Scholar] [CrossRef]
- Al-Baldawi, B.A. Applying the Cluster Analysis Technique in Logfacies Determination for Mishrif Formation, Amara Oil Field, South Eastern Iraq. Arab. J. Geosci. 2015, 8, 3767–3776. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Kawamura, A.; Tong, T.N.; Nakagawa, N.; Amaguchi, H.; Gilbuena, R. Clustering Spatio-Seasonal Hydrogeochemical Data Using Self-Organizing Maps for Groundwater Quality Assessment in the Red River Delta, Vietnam. J. Hydrol. 2015, 522, 661–673. [Google Scholar] [CrossRef]
- Sfidari, E.; Kadkhodaie-Ilkhchi, A.; Rahimpour-Bbonab, H.; Soltani, B. A Hybrid Approach for Litho-Facies Characterization in the Framework of Sequence Stratigraphy: A Case Study from the South Pars Gas Field, the Persian Gulf Basin. J. Pet. Sci. Eng. 2014, 121, 87–102. [Google Scholar] [CrossRef]
- Garća, H.L.; González, I.M. Self-Organizing Map and Clustering for Wastewater Treatment Monitoring. Eng. Appl. Artif. Intell. 2004, 17, 215–225. [Google Scholar] [CrossRef]
- Unglert, K.; Radić, V.; Jellinek, A.M. Principal Component Analysis vs. Self-Organizing Maps Combined with Hierarchical Clustering for Pattern Recognition in Volcano Seismic Spectra. J. Volcanol. Geotherm. Res. 2016, 320, 58–74. [Google Scholar] [CrossRef]
- Hsieh, B.Z.; Lewis, C.; Lin, Z.S. Lithology Identification of Aquifers from Geophysical Well Logs and Fuzzy Logic Analysis: Shui-Lin Area, Taiwan. Comput. Geosci. 2005, 31, 263–275. [Google Scholar] [CrossRef]
- Al-Anazi, A.; Gates, I.D. A Support Vector Machine Algorithm to Classify Lithofacies and Model Permeability in Heterogeneous Reservoirs. Eng. Geol. 2010, 114, 267–277. [Google Scholar] [CrossRef]
- Imamverdiyev, Y.; Sukhostat, L. Lithological Facies Classification Using Deep Convolutional Neural Network. J. Pet. Sci. Eng. 2019, 174, 216–228. [Google Scholar] [CrossRef]
- Male, F.; Duncan, I.J. Lessons for Machine Learning from the Analysis of Porosity-Permeability Transforms for Carbonate Reservoirs. J. Pet. Sci. Eng. 2020, 187, 106825. [Google Scholar] [CrossRef]
- Deng, Z.; Zhu, X.; Cheng, D.; Zong, M.; Zhang, S. Efficient KNN Classification Algorithm for Big Data. Neurocomputing 2016, 195, 143–148. [Google Scholar] [CrossRef]
- Vo Thanh, H.; Sugai, Y.; Nguele, R.; Sasaki, K. A New Petrophysical Modeling Workflow for Fractured Granite Basement Reservoir in Cuu Long Basin, Offshore Vietnam. In Proceedings of the 81st EAGE Conference and Exhibition, London, UK, 3–6 June 2019; European Association of Geoscientists & Engineers: London, UK, 2019; pp. 1–5. [Google Scholar]
- Anees, A.; Zhang, H.; Ashraf, U.; Wang, R.; Liu, K.; Abbas, A.; Ullah, Z.; Zhang, X.; Duan, L.; Liu, F.; et al. Sedimentary Facies Controls for Reservoir Quality Prediction of Lower Shihezi Member-1 of the Hangjinqi Area, Ordos Basin. Minerals 2022, 12, 126. [Google Scholar] [CrossRef]
- Anees, A.; Zhang, H.; Ashraf, U.; Wang, R.; Liu, K.; Mangi, H.N.; Jiang, R.; Zhang, X.; Liu, Q.; Tan, S.; et al. Identification of Favorable Zones of Gas Accumulation via Fault Distribution and Sedimentary Facies: Insights from Hangjinqi Area, Northern Ordos Basin. Front. Earth Sci. 2022, 9, 822670. [Google Scholar] [CrossRef]
- Jiang, R.; Zhao, L.; Xu, A.; Ashraf, U.; Yin, J.; Song, H.; Su, N.; Du, B.; Anees, A. Sweet Spots Prediction through Fracture Genesis Using Multi-Scale Geological and Geophysical Data in the Karst Reservoirs of Cambrian Longwangmiao Carbonate Formation, Moxi-Gaoshiti Area in Sichuan Basin, South China. J. Pet. Explor. Prod. Technol. 2021, 12, 1313–1328. [Google Scholar] [CrossRef]
- Ullah, J.; Luo, M.; Ashraf, U.; Pan, H.; Anees, A.; Li, D.; Ali, M.; Ali, J. Evaluation of the Geothermal Parameters to Decipher the Thermal Structure of the Upper Crust of the Longmenshan Fault Zone Derived from Borehole Data. Geothermics 2022, 98, 102268. [Google Scholar] [CrossRef]
- Abbas, A.; Zhu, H.; Anees, A.; Ashraf, U.; Akhtar, N. Integrated Seismic Interpretation, 2d Modeling along with Petrophysical and Seismic Atribute Analysis to Decipher the Hydrocarbon Potential of Missakeswal Area. Pakistan. J. Geol. Geophys. 2019, 7, 1–12. [Google Scholar]
- Anees, A.; Zhong, S.W.; Ashraf, U.; Abbas, A. Development of a Computer Program for Zoeppritz Energy Partition Equations and Their Various Approximations to Affirm Presence of Hydrocarbon in Missakeswal Area. Geosciences 2017, 7, 55–67. [Google Scholar] [CrossRef]
- Shehata, A.A.; Osman, O.A.; Nabawy, B.S. Journal of Natural Gas Science and Engineering Neural Network Application to Petrophysical and Lithofacies Analysis Based on Multi-Scale Data: An Integrated Study Using Conventional Well Log, Core and Borehole Image Data. J. Nat. Gas Sci. Eng. 2021, 93, 104015. [Google Scholar] [CrossRef]
- Wang, G.; Carr, T.R.; Ju, Y.; Li, C. Identifying Organic-Rich Marcellus Shale Lithofacies by Support Vector Machine Classifier in the Appalachian Basin. Comput. Geosci. 2014, 64, 52–60. [Google Scholar] [CrossRef]
- Freund, Y. Boosting a Weak Learning Algorithm by Majority. Inf. Comput. 1995, 121, 256–285. [Google Scholar] [CrossRef]
- Al Kattan, W.; Jawad, S.N.A.L.; Jomaah, H.A. Cluster Analysis Approach to Identify Rock Type in Tertiary Reservoir of Khabaz Oil Field Case Study. Iraqi J. Chem. Pet. Eng. 2018, 19, 9–13. [Google Scholar]
- Mandal, P.P.; Rezaee, R. Facies Classification with Different Machine Learning Algorithm–An Efficient Artificial Intelligence Technique for Improved Classification. ASEG Ext. Abstr. 2019, 2019, 1–6. [Google Scholar] [CrossRef]
- Shahid, A.R.; Khan, S.; Yan, H. Human Expression Recognition Using Facial Shape Based Fourier Descriptors Fusion. In Proceedings of the Twelfth International Conference on Machine Vision (ICMV 2019), Amsterdam, The Netherlands, 16–18 November 2019; Volume 11433, p. 48. [Google Scholar] [CrossRef]
- Qureshi, M.A.; Ghazi, S.; Riaz, M.; Ahmad, S. Geo-Seismic Model for Petroleum Plays an Assessment of the Zamzama Area, Southern Indus Basin, Pakistan. J. Pet. Explor. Prod. Technol. 2020, 1–12. [Google Scholar] [CrossRef]
- Ahmed Abbasi, S.; Asim, S.; Solangi, S.H.; Khan, F. Study of Fault Configuration Related Mysteries through Multi Seismic Attribute Analysis Technique in Zamzama Gas Field Area, Southern Indus Basin, Pakistan. Geod. Geodyn. 2016, 7, 132–142. [Google Scholar] [CrossRef]
- Mangi, H.N.; Chi, R.; DeTian, Y.; Sindhu, L.; Lijin; He, D.; Ashraf, U.; Fu, H.; Zixuan, L.; Zhou, W.; et al. The Ungrind and Grinded Effects on the Pore Geometry and Adsorption Mechanism of the Coal Particles. J. Nat. Gas Sci. Eng. 2022, 100, 104463. [Google Scholar] [CrossRef]
- Mangi, H.N.; Detian, Y.; Hameed, N.; Ashraf, U.; Rajper, R.H. Pore Structure Characteristics and Fractal Dimension Analysis of Low Rank Coal in the Lower Indus Basin, SE Pakistan. J. Nat. Gas Sci. Eng. 2020, 77, 103231. [Google Scholar] [CrossRef]
- Ehsan, M.; Gu, H.; Akhtar, M.M.; Abbasi, S.S.; Ehsan, U. A Geological Study of Reservoir Formations and Exploratory Well Depths Statistical Analysis in Sindh Province, Southern Lower Indus Basin, Pakistan. Kuwait J. Sci. 2018, 45, 84–93. [Google Scholar]
- Foredeep, K. A radical seismic interpretation re-think resolves the structural complexities of the zamzama field, kirthar foredeep, pakistan. In Proceedings of the SPE Annual Technical Conference, Islamabad, Pakistan, 10–12 December 2018; pp. 1–17. [Google Scholar]
- Asim, S.; Qureshi, S.N.; Asif, S.K.; Abbasi, S.A.; Solangi, S.; Mirza, M.Q. Structural and Stratigraphical Correlation of Seismic Profiles between Drigri Anticline and Bahawalpur High in Central Indus Basin of Pakistan. Int. J. Geosci. 2014, 5, 1231–1240. [Google Scholar] [CrossRef][Green Version]
- Sirimangkhala, K.; Pimpunchat, B.; Amornsamankul, S.; Triampo, W. Modelling Greenhouse Gas Generation for Landfill. Int. J. Simul. Syst. Sci. Technol. 2018, 19, 16.1–16.7. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhu, P.; Yasin, Q.; Anees, A.; Imraz, M.; Mangi, H.N.; Shakeel, S. Classification of Reservoir Facies Using Well Log and 3D Seismic Attributes for Prospect Evaluation and Field Development: A Case Study of Sawan Gas Field, Pakistan. J. Pet. Sci. Eng. 2019, 175, 338–351. [Google Scholar] [CrossRef]
- Ashraf, U.; Zhang, H.; Anees, A.; Ali, M.; Zhang, X.; Shakeel Abbasi, S.; Nasir Mangi, H. Controls on Reservoir Heterogeneity of a Shallow-Marine Reservoir in Sawan Gas Field, SE Pakistan: Implications for Reservoir Quality Prediction Using Acoustic Impedance Inversion. Water 2020, 12, 2972. [Google Scholar] [CrossRef]
- Ali, M.; Ma, H.; Pan, H.; Ashraf, U.; Jiang, R. Building a Rock Physics Model for the Formation Evaluation of the Lower Goru Sand Reservoir of the Southern Indus Basin in Pakistan. J. Pet. Sci. Eng. 2020, 194, 107461. [Google Scholar] [CrossRef]
- Dar, Q.U.Z.; Pu, R.; Baiyegunhi, C.; Shabeer, G.; Ali, R.I.; Ashraf, U.; Sajid, Z.; Mehmood, M. The Impact of Diagenesis on the Reservoir Quality of the Early Cretaceous Lower Goru Sandstones in the Lower Indus Basin, Pakistan. J. Pet. Explor. Prod. Technol. 2021, 12, 1437–1452. [Google Scholar] [CrossRef]
- Ali, N.; Chen, J.; Fu, X.; Hussain, W.; Ali, M.; Hussain, M.; Anees, A.; Rashid, M.; Thanh, H.V. Prediction of Cretaceous Reservoir Zone through Petrophysical Modeling: Insights from Kadanwari Gas Field, Middle Indus Basin. Geosystems Geoenviron. 2022, 1, 100058. [Google Scholar] [CrossRef]
- Chon, T.S. Self-Organizing Maps Applied to Ecological Sciences. Ecol. Inform. 2011, 6, 50–61. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| K-Mean Cluster Results | ||||||
|---|---|---|---|---|---|---|
| GR | eff | Perm | Sw | |||
| Facies | Points | Rock Typing | Mean | Mean | Mean | Mean |
| 1 | 13 | Excellent-quality rock type | 19.44 | 0.12 | 32.49 | 0.16 |
| 2 | 50 | Good-quality rock type | 20.32 | 0.10 | 8.94 | 0.26 |
| 3 | 62 | Moderate-quality rock type | 22.59 | 0.05 | 0.37 | 0.77 |
| 4 | 35 | Poor-quality rock type | 33.34 | 0.02 | 0.01 | 34.69 |
| S. No | Rock Typing | GR | eff | Perm | Sw |
|---|---|---|---|---|---|
| Facies-01 | Excellent-quality rock type | Very low | Good to excellent | Good to excellent | Very low |
| Facies-02 | Good-quality rock type | low | Good | Good | low |
| Facies-03 | Moderate-quality rock type | Medium | Fair to Good | Fair to Good | Medium |
| Facies-04 | Poor-quality rock type | High | Low | Low | Very high |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hussain, M.; Liu, S.; Ashraf, U.; Ali, M.; Hussain, W.; Ali, N.; Anees, A. Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type. Energies 2022, 15, 4501. https://doi.org/10.3390/en15124501
Hussain M, Liu S, Ashraf U, Ali M, Hussain W, Ali N, Anees A. Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type. Energies. 2022; 15(12):4501. https://doi.org/10.3390/en15124501
Chicago/Turabian StyleHussain, Mazahir, Shuang Liu, Umar Ashraf, Muhammad Ali, Wakeel Hussain, Nafees Ali, and Aqsa Anees. 2022. "Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type" Energies 15, no. 12: 4501. https://doi.org/10.3390/en15124501
APA StyleHussain, M., Liu, S., Ashraf, U., Ali, M., Hussain, W., Ali, N., & Anees, A. (2022). Application of Machine Learning for Lithofacies Prediction and Cluster Analysis Approach to Identify Rock Type. Energies, 15(12), 4501. https://doi.org/10.3390/en15124501