The case study on which the method was validated includes a set of motors of various natures and different working conditions.
5.1. Measurement Setup
To assess the performance of the methods, a proper measurement station based on an embedded platform has been designed and implemented. In particular, the current sensor chosen for the acquisition is the MCR1101-20-5 (
Figure 5). The main sensor specifications are reported in
Table 1.
It was decided to adopt this sensor due to its full-scale, passband and limited magnetic hysteresis characteristics. The sensor performance has been assessed in laboratory tests using the Fluke 5720A [
23] calibrator and 5725A amplifier [
24] as reference current sources. The evaluation of the magnetic hysteresis was performed by stimulating the sensor with increasing and decreasing current flows and acquiring ten thousand samples for each current step.
Obtained results are presented in
Table 2; for each value of nominal current
, the averages of 10,000 samples for increasing (
) and decreasing (
) current flows as well as the respective standard deviation (
and
) are reported.
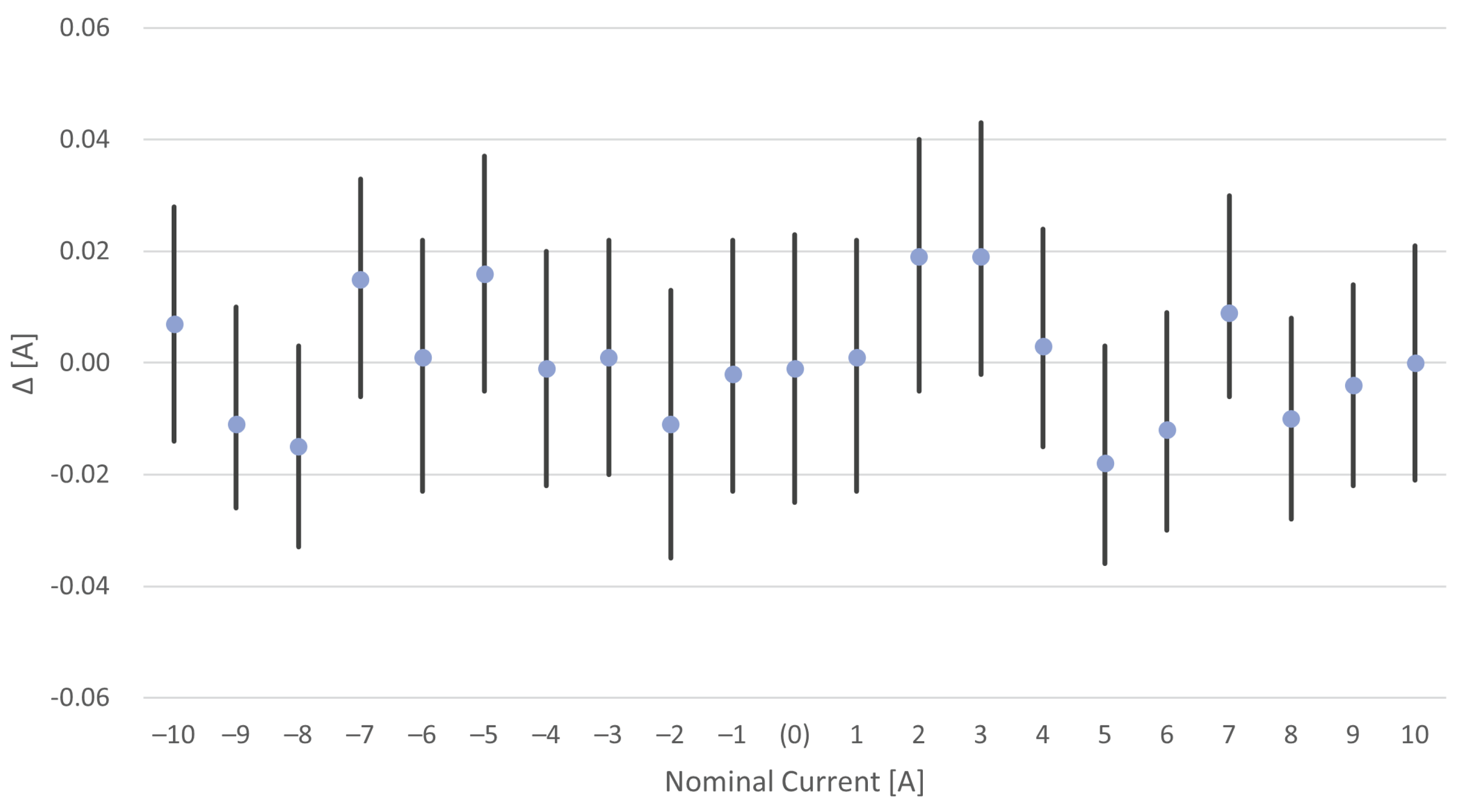
To better appreciate the sensor performance, the difference between increasing and decreasing currents has been provided.
Results are also summarized in
Figure 6, where the evaluation of the differences
versus the nominal currents is shown. Intervals centered in the difference
, whose half-amplitude is equal to three times the associated standard deviation, are also reported. As can be noticed, all the intervals are metrologically compatible with 0, thus ensuring a negligible contribution of the magnetic hysteresis in the considered application.
Gain and offset error, equal to and 0.290 A, respectively, were also evaluated and compensated in the successive processing step.
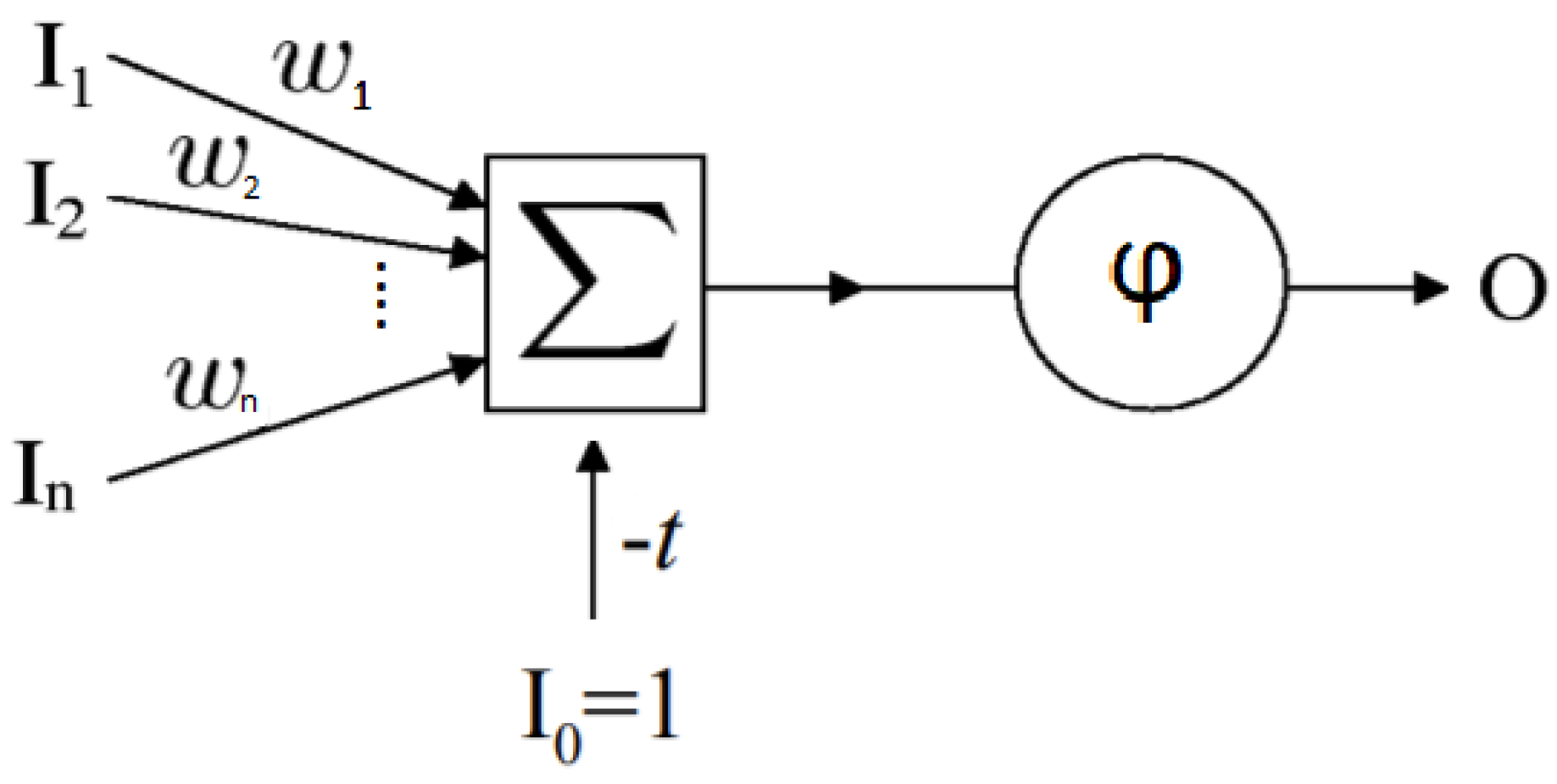
The microcontroller (MCU) chosen for the measurement setup is the STM32F4V11VET. The MCU’s characteristics are written below and, for the sake of brevity, just information relevant for the case study are reported.
Arm® 32-bit Cortex®-M4 CPU with FPU;
512 Kbytes of flash memory;
128 Kbytes of SRAM;
general-purpose DMA;
up to 11 timers;
a 12-bit A/D converter 2.4 MSPS with 16 channels;
up to 3 USARTs.
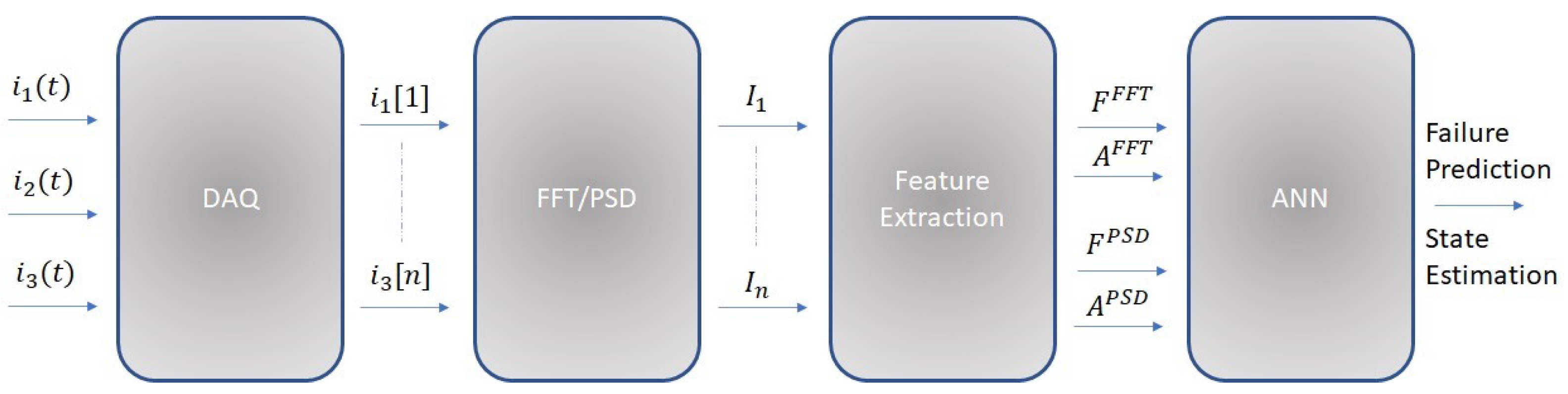
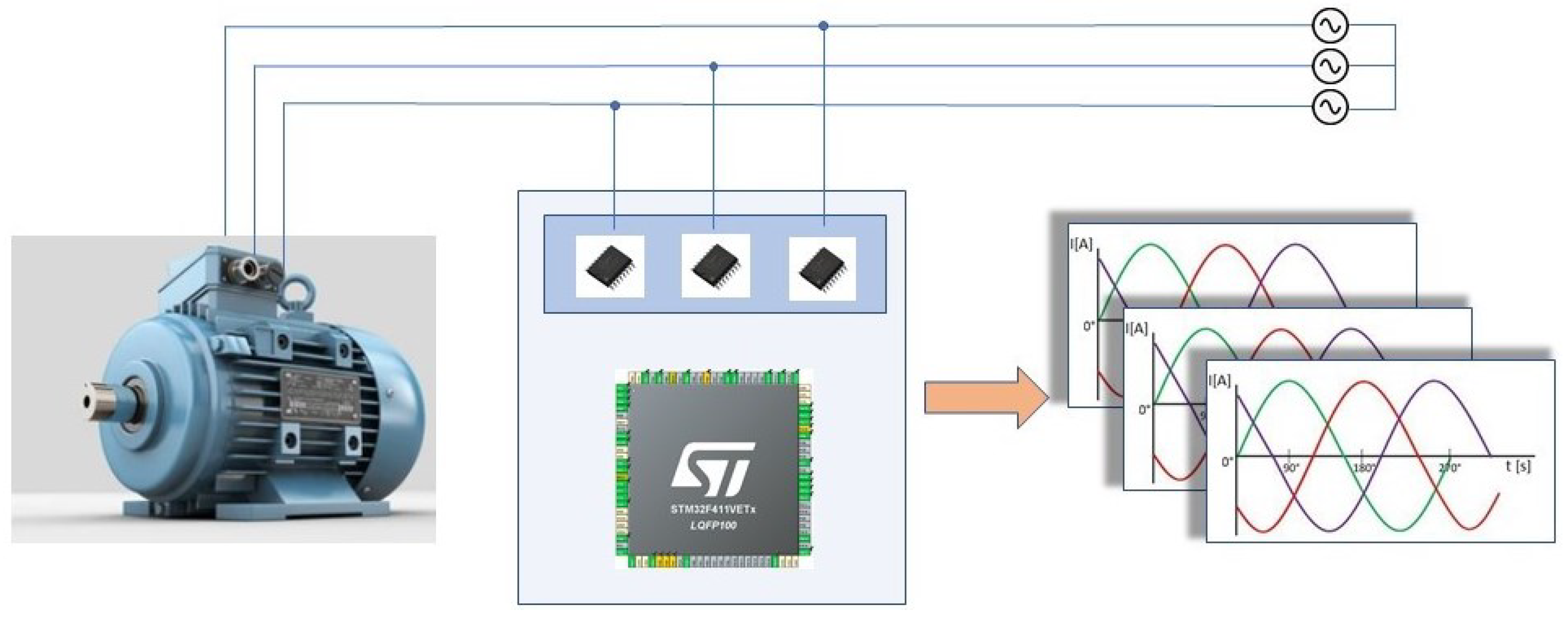
The current sensors output a voltage proportional to the measured current. Since it is necessary to acquire samples coming from 3 motor phases, 3 ADC channels have been used into which the voltage signals coming from the MCR1101-20-5 sensors are input (
Figure 7).
It is necessary to reach a sampling rate in order to collect from the three channels measurements at 10,000 samples per second. This is possible by using the DMA and setting it so that as soon as the ADC produces a valid value, the DMA takes it to a buffer in RAM. Of course, it is necessary to reach a trade-off between sample size and available RAM resources.
In this case study, it was possible to acquire 20 whole periods with 20,000 samples for each phase, for a total buffer of 60,000 samples.
The device including sensors and wiring to operate the acquisitions is shown in
Figure 8.
5.2. Feature Extraction and Modeling
To operate the measurement campaign, it was necessary to acquire samples from a large number of motors in different health conditions. Samples from the 3 power supply streams were collected for each motor. The dataset used for the case study is shown in
Table 3.
A large number of spectral components would allow having a complete description of the acquired signal but it would increase the consumption of computing and memory resources for the following steps. A trade-off between the dataset quality and the consumed hardware resources is required.
For each sample, the 10 largest frequency components of the fast Fourier transform (FFT) and the 10 largest components of the power spectral density (PSD) were selected.
The dataset is then created by taking the frequencies and amplitudes of the largest 10 components of the FFT and PSD.
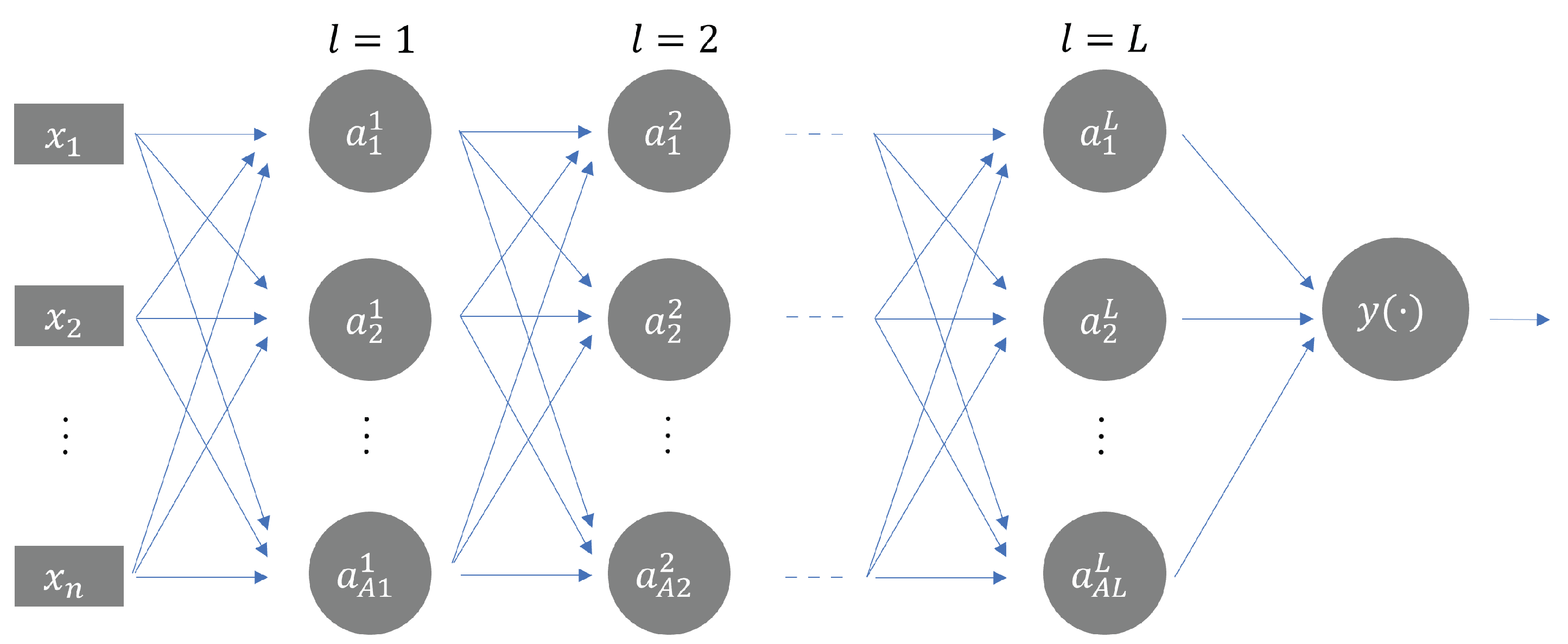
The dataset is therefore composed of 40 features that describe, in a synthetic way and with a good approximation, the nature of the acquired signal. For the training and testing of the model, the k-fold technique was adopted. In this case, 5 folds were selected.
It is necessary to make a choice of hyperparameters before starting the training. As illustrated above, the random search technique can lead to satisfactory results by reducing development times.
Table 4 shows the ranges of all the hyperparameters, it is natural that the number of all the possible configurations is very high, and this entails a great deal of difficulty in operating a grid search technique (exhaustive evaluation of all configurations).
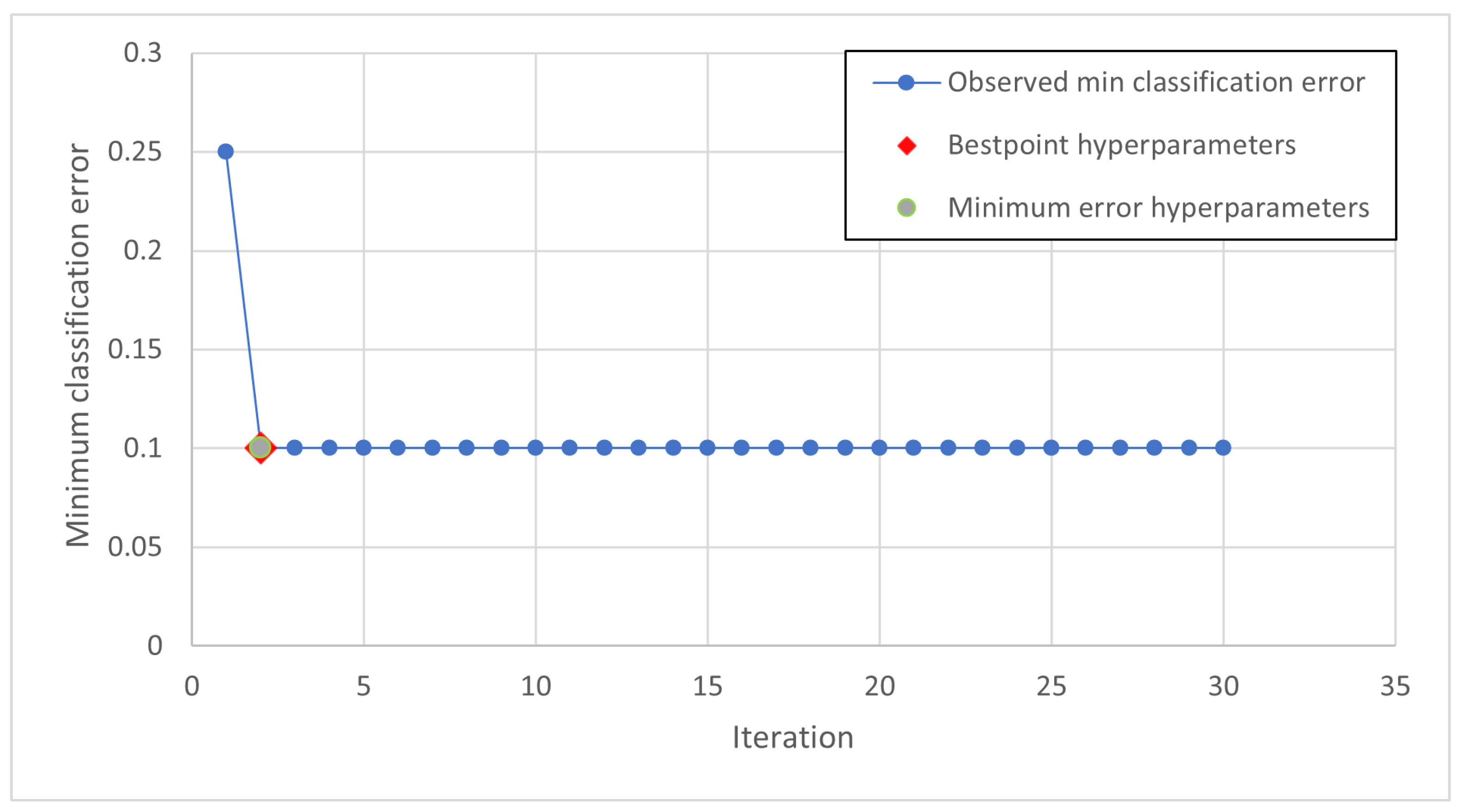
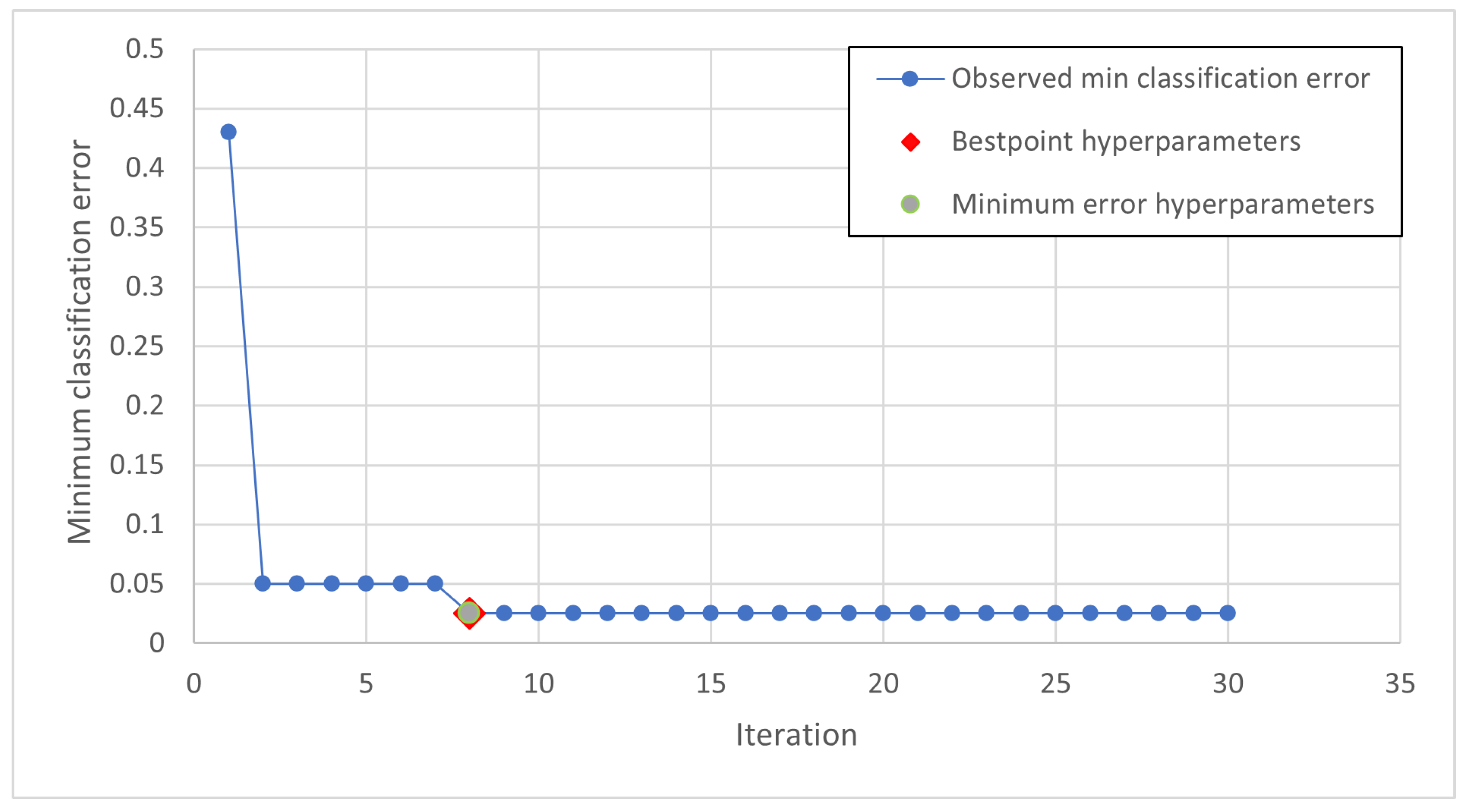
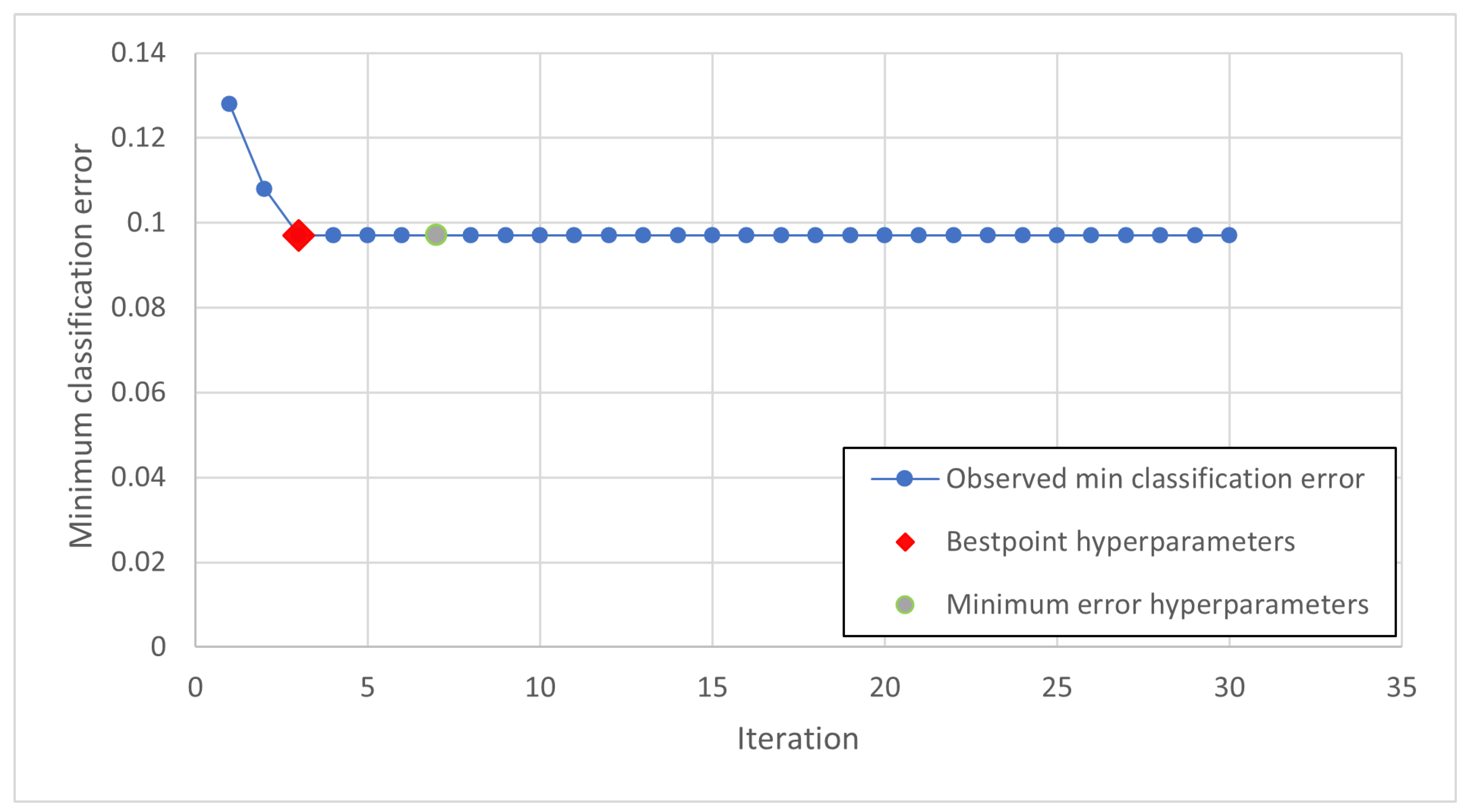
The training phase is therefore carried out iteratively and it is necessary to introduce criteria with which to terminate it. The iterations can be limited in number, in time or on the basis of an index and the achievement of its threshold value.
The graph in the plot represents the estimate of the minimum classification error (MCE). The MCE is calculated considering the sets of hyperparameter values for each iteration (blue points). The yellow dot and the red square represent the minimum error hyperparameters and the bestpoint hyperparameters, respectively. In
Figure 9, the minimum error Hyperparameters and the bestpoint hyperparameters coincide.
The optimized hyperparamete configuration obtained in the case study is reported in
Table 5.
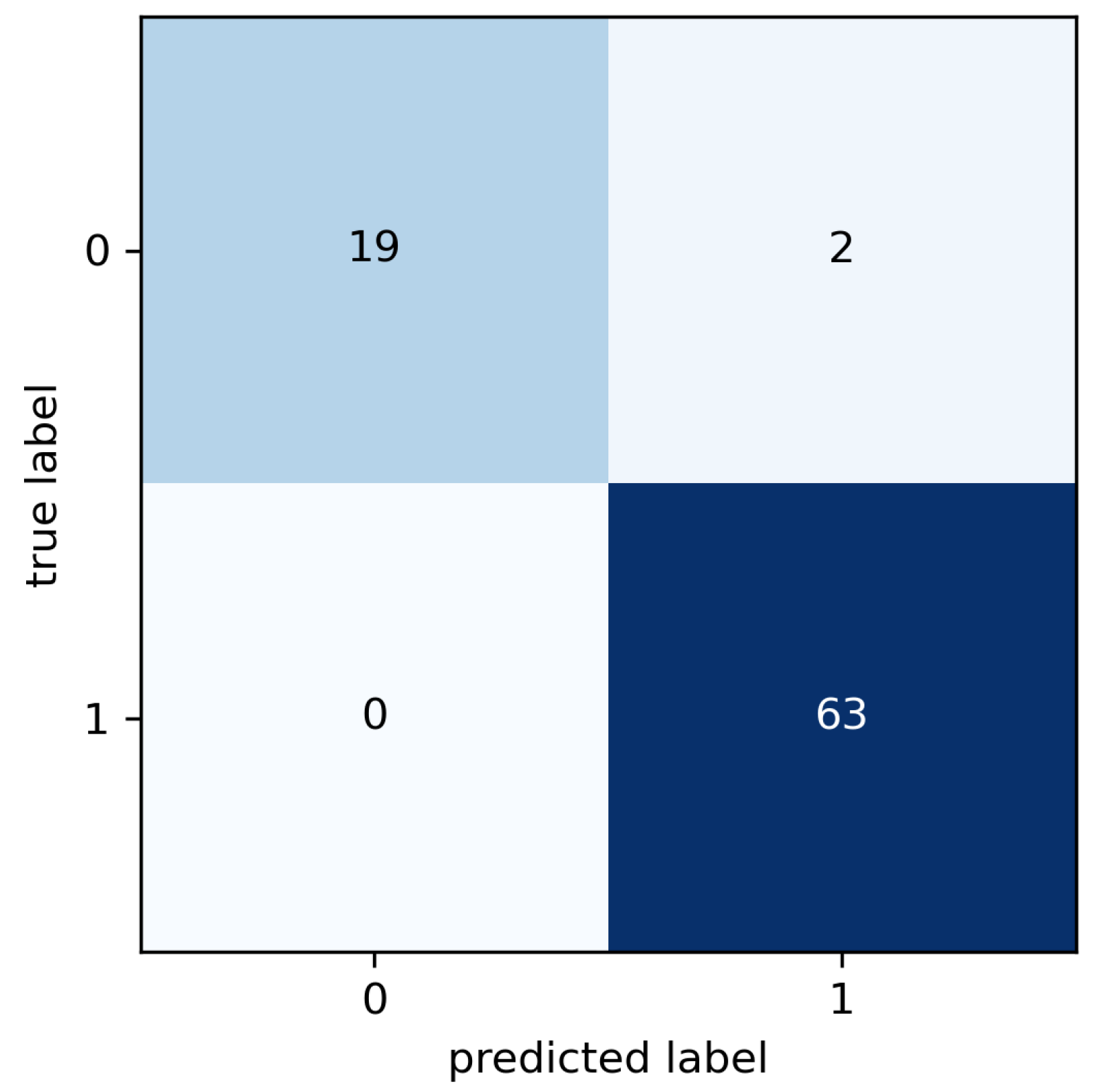
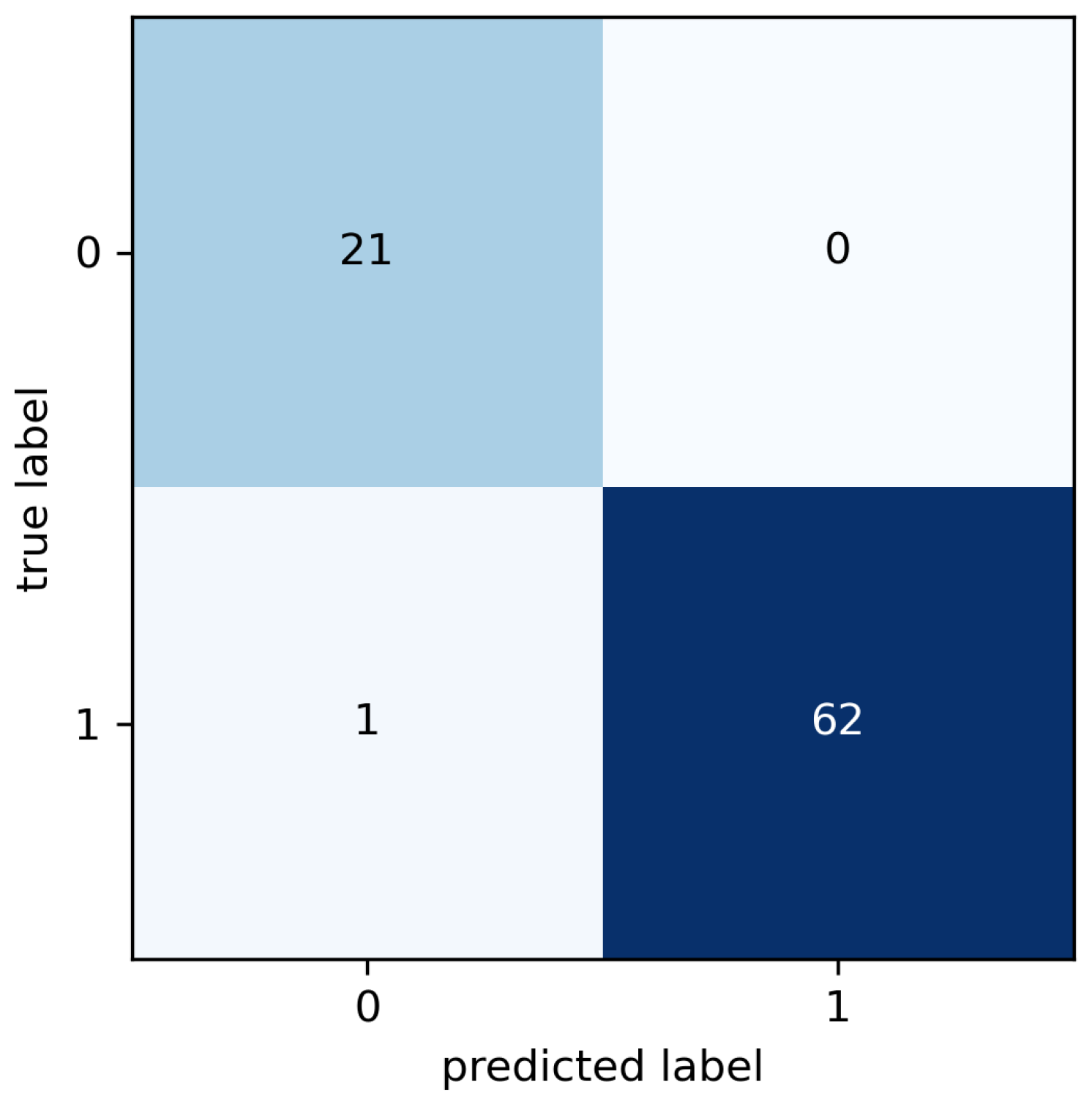
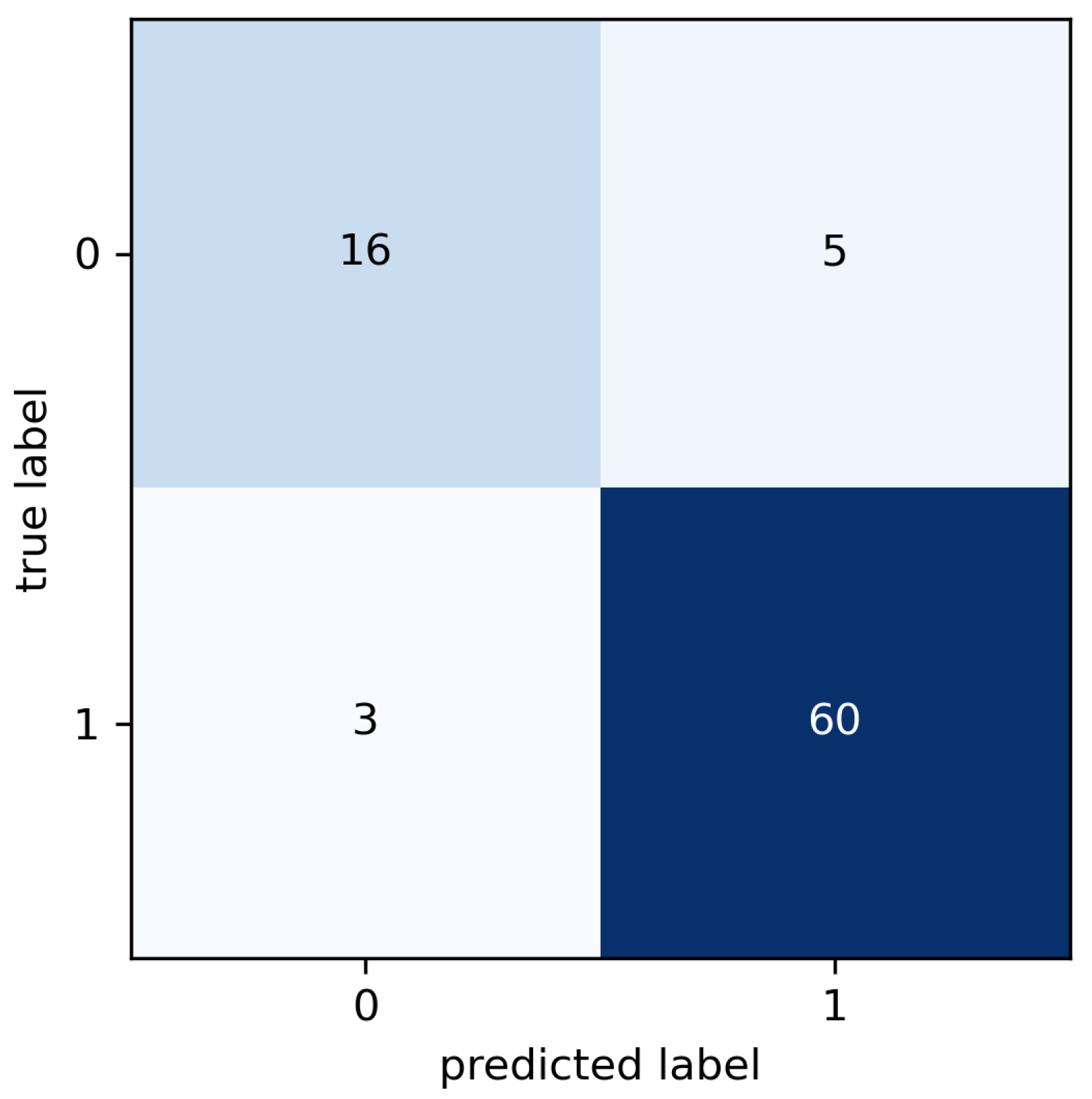
The results of the cross validation are summarized in the confusion matrix (
Figure 10) where known and predicted classes are reported. The false classes (labeled as 0) correspond to observations labeled as healthy, that is, observations collected from the motors in good condition. The true classes are the classes labeled as faulty, i.e., observations corresponding to motors in anomalous conditions (broken bearings, misalignments, etc.).
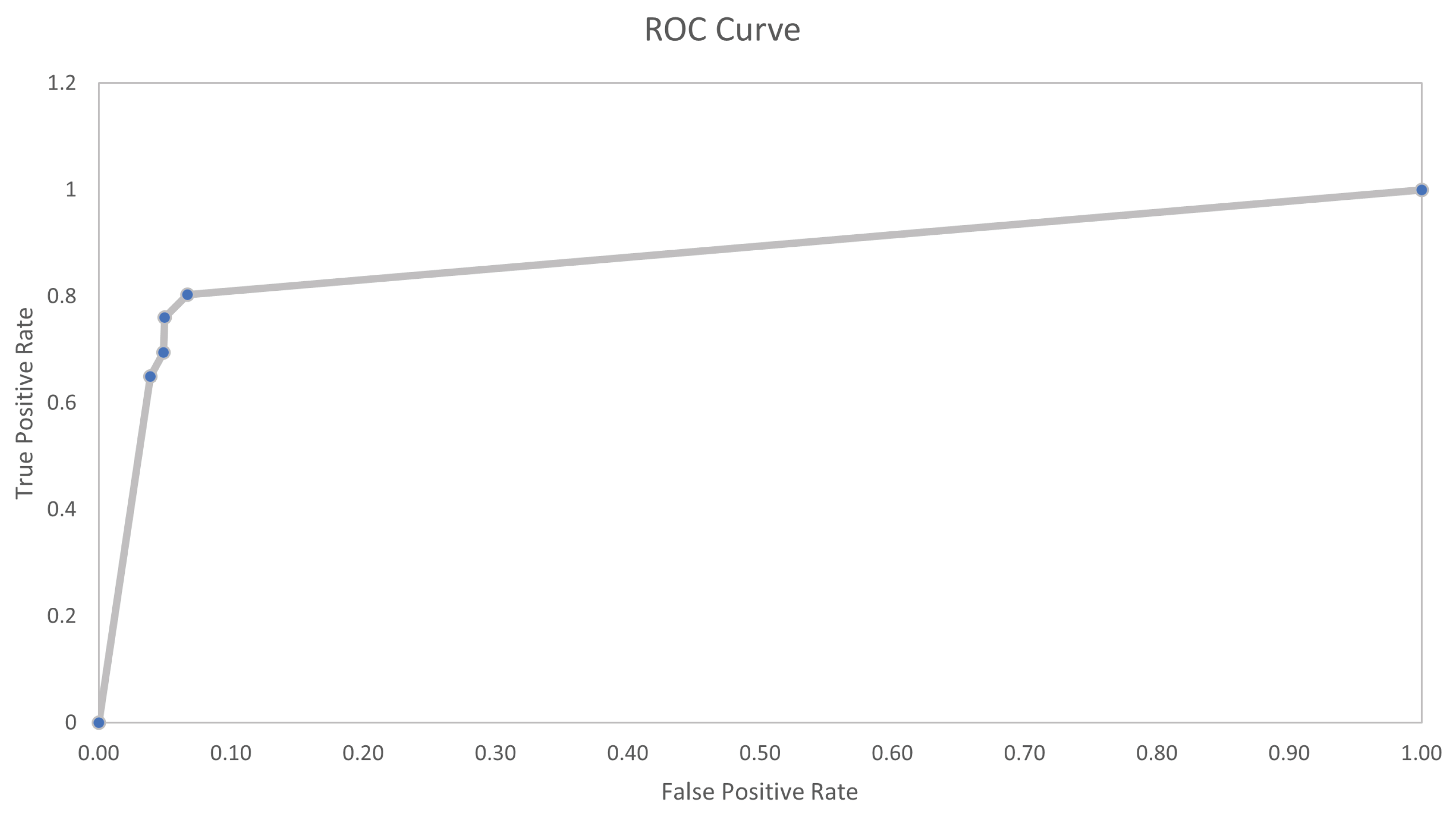
Figure 11 shows the receiver operating characteristic (ROC) curve which represents the relationship between sensitivity (true positive rate) and specificity (true negative rate).
The sensitivity is calculated by taking the ratio between the cases belonging to the class of fault signals correctly classified as positive (the true positives) divided by the sum of true positives and the faulty cases erroneously classified as negative (the false negatives) (
5) [
25]. This index represents the probability with which a classifier correctly identifies a faulty case as positive.
The specificity is calculated by taking the ratio between the cases belonging to the class of nominal device signals correctly classified as negative (the true negatives) divided by the sum of true negatives and the healthy cases erroneously classified as positive (the false positives). This index represents the likelihood with which a classifier correctly identifies a healthy case as negative.
Both sensitivity and specificity indices are calculated from the results presented in the confusion matrix in
Figure 10.
5.3. Performance Comparison
A comparative analysis was carried out between the results provided by the proposed method and those obtained by replacing the machine learning core with two common classifiers. The selected algorithms for this comparison were chosen for their characteristic of being widely used in diagnostic applications based on the machine learning approach. In particular, the solution based on a feed-forward neural network has been compared with the support vector machine (SVM) and decision tree (DT).
The support vector machine is a binary classifier trained on a set of labeled patterns [
26]. A training set can be defined as:
where
is the input dataset and
is the target. The goal of the support vector machine is to divide the samples by a hyperplane so that the division coincides with the targets
.
The classification function is defined as:
The function is the bipolar sign function, the vector w is the vector of coefficient and b stands for the bias of the hyperplane.
The classifier hyperplane must be identified in order to satisfy the condition that
is greater than or equal to one:
Equation (
9) can be modified as reported in Equation (
10), in order to introduce a slack variable to identify a hyperplane that does not fully satisfy Equation (
9) but maximizes the result.
The goal of the algorithm is to minimize the following:
As performed in the case of the neural networks described above, in this case, for comparative purposes, we proceeded with the evaluation of the performances with the cross validation technique. The random search technique was also applied to the support vector machine for the configuration of the hyperparameters. The possible values that the hyperparameters can assume are shown in
Table 6.
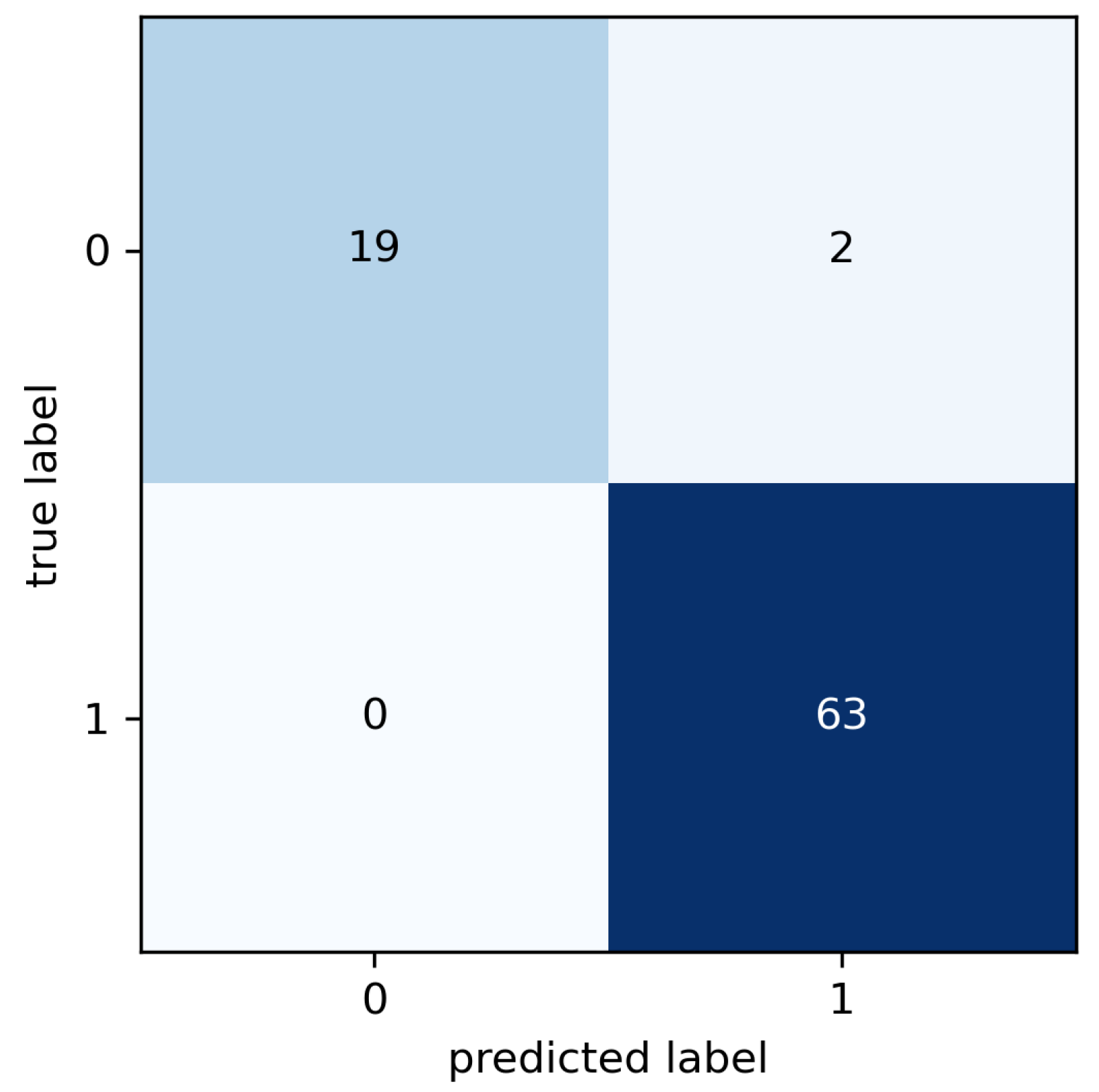
Following the application of the random search, the optimal configuration obtained consists of a kernel function such as the Gaussian, a kernel scale of 12.6062, a box constraint level of 167.007 and standardize data as true (
Figure 12). This optimal configuration allowed for reaching an accuracy of 97.6%, true positive rate of 100% and true negative rate of 90.4% (
Figure 13).
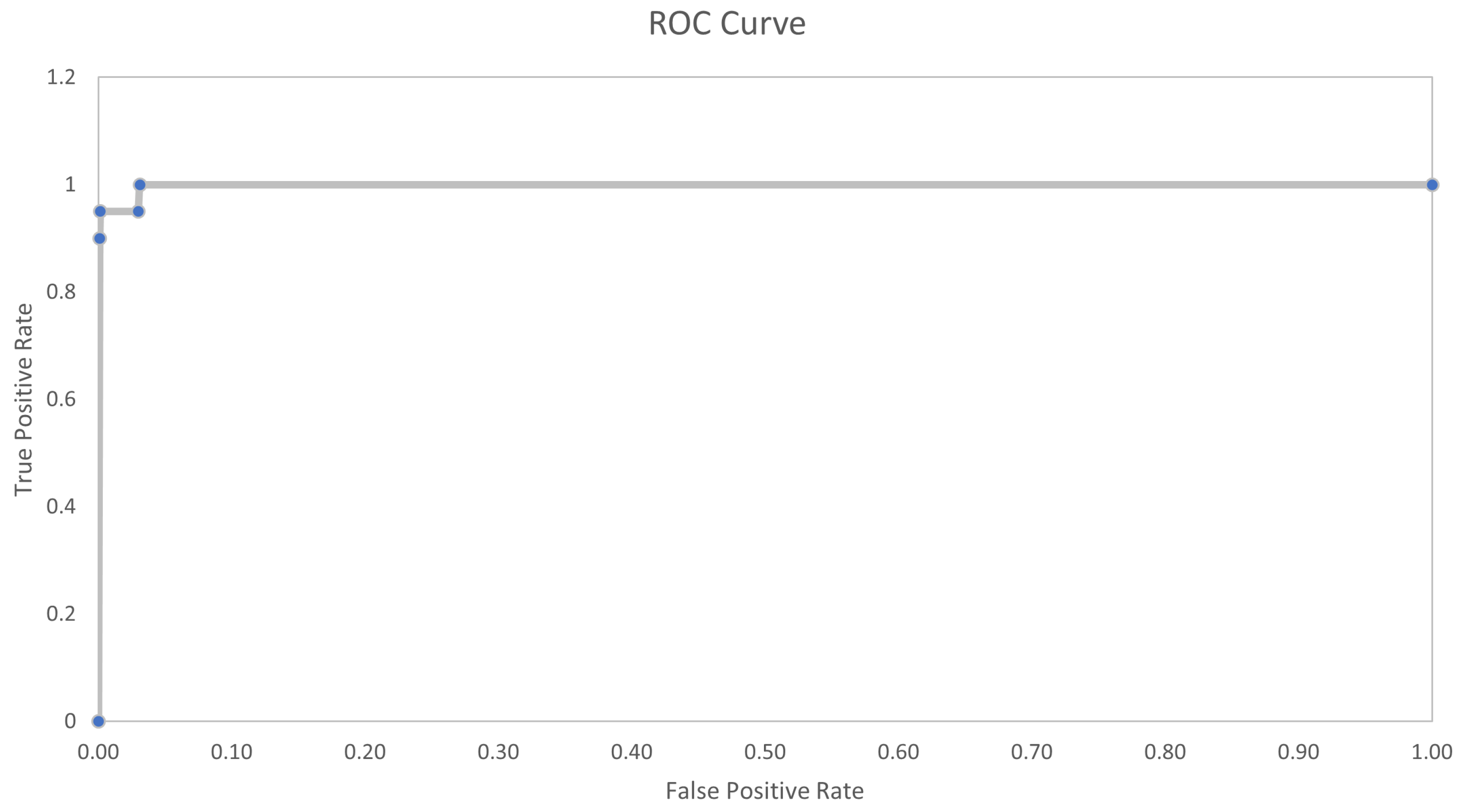
The support vector machine ROC curve is shown in
Figure 14. The curve is quite similar to that obtained with the feed-forward neural network proposed in the method, in fact, the accuracy level achieved is not much lower. This does not mean that the feed-forward neural network is the best choice for predictive maintenance purposes in asynchronous three-phase electric motors.
Decision trees are machine learning algorithms that can be used for both regression and classification problems. A decision tree is a tree-like model of decisions and it is usually built upside down with its leaves at the bottom.
In decision trees, decisions are represented by the path taken from the root to the leaf node. Tree construction occurs iteratively through leaf splitting or pruning. The random search and cross validation techniques have also been applied in the case of decision trees [
27]. The possible values that the hyperparameters can assume are shown in
Table 7. It is necessary to establish the optimal split criterion for this case. This choice will also be made by means of the random search technique. Two split criteria are considered: Gini diversity index and maximum deviance reduction function. The Gini index (
G) is defined according to Formula (
12):
where the percentage inside a group of elements is defined as
and the group of elements must belong to class
k [
28]. The value
G represents the purity and it is equal to 0 if all the elements (inside the group) are part of the same class. Thus, from the branches the node returns an output observation of just one class and, if all the elements belong to that specific class, the classification error is null.
The other split criterion is the maximum deviance reduction (
) function (sometimes called cross entropy). The function is defined as:
In the maximum deviance reduction function, the elements that are part of the class
k are represented by the variable
which stands for the percentage inside a group [
29]. The procedure of splitting keeps going if the conditions are still valid. Of course, a too complex decision tree is not advisable and must be avoided, otherwise there could be risks of overfitting, poor interpretability and unreliability of predictions.
Following the application of the random search in the decision tree algorithm, the optimal configuration obtained consists of six splits and the Gini diversity index as the split criterion (
Figure 15). This optimal configuration allowed for reaching an accuracy of 90.5%, true positive rate (sensitivity) of 95.2% and true negative rate (specificity) of 76.2% (
Figure 16).
Figure 17 shows the ROC curves of the decision tree model. It is possible to note that the area under the curve is considerably smaller than that of the curves in the two previous models. This suggests that the performances cannot be superior or equal to those of the other two algorithms previously explored. Perfomance comparison is summarized in
Table 8.
5.4. Further Comparisons with State-of-the-Art Solutions
Additional comparisons, in terms of performance, were carried out by comparing the results published in the literature. An exhaustive comparison is not easy to make as the methods proposed as the state of the art generally have more than one characteristic different from those that make up the method proposed in this work. In order to carry out a suboptimal comparison, all selected works are based on samples coming from the supply current signals.
The authors of [
30] have proposed a multi-stage approach based on an MLP-ANN machine learning algorithm capable of detecting fault causes in induction motors.
The authors of [
31] have proposed a method based on a frequency plot-based convolutional neural network (FOP-CNN) for detecting motor faults. The study was performed under different workloads.
The authors of [
32] have proposed a method based on an unsupervised technique whose advantage is learning from the dataset without an external intervention for data labeling. The machine learning algorithm is based on a CNN. The work is focused on bearing faults and no information was provided regarding other kinds of faults.
The authors of [
33] have proposed an empirical wavelet transform convolutional neural network (EWT-CNN). The method proposed in the work achieves 97.3% accuracy.
All the methods reported in this comparative subsection have been validated on case studies limited to a few units of faulty motors. Moreover, papers considered in
Table 9 do not provide a complete description of the adopted sensors and sample acquisition technologies. Therefore, it is not possible to hypothesize the absence of overfitting of the trained models.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}