
Energy Consumption Forecasting for the Digital-Twin Model of the Building



Abstract
:1. Introduction
1.1. Research Background
1.2. Aim of the Paper
1.3. Related Work
1.4. Contribution
- We propose an approach for forecasting the energy consumption for the next day that is based on data obtained from the digital-twin model of a building. Thanks to this, we can use data describing the energy consumption of the devices used in the building together with data describing the whole energy consumption of the location and the weather data. As far as we know, this approach is unique in comparison with other work.
- In our approach, we focus mostly on residential buildings. In the paper [37], it was highlighted that this direction of research is very important because of the high energy consumption share of this sector. The paper also points out that accurate energy demand predictions in residential houses could be highly beneficial if the forecasts were used to implement successful energy reducing strategies.
- The proposed models give satisfactory results, and for three models from four locations, we obtained the expected effectiveness of the forecasts (the goal was to obtain less than 25% error).
- In the paper, we also propose our methodology for explaining the model in the interpretable way. As it was mentioned in [37], a lot of data-driven prediction models are black-box models, so they provide limited understanding of the situations, when the model makes a mistake. In our research, we address this problem.
- We use our explanatory methodology in order to limit the number of monitored devices.
2. Materials and Methods
- Location A—flat in a block of flats, 3 people (family 2 + 1).
- Location B—flat in a block of flats, 2 adults.
- Location C—modern detached house, approximately 120 m with electric heating, 3 people (family 2 + 1).
- Location D—detached house, approximately 140 m, 4 people (family 2 + 2).
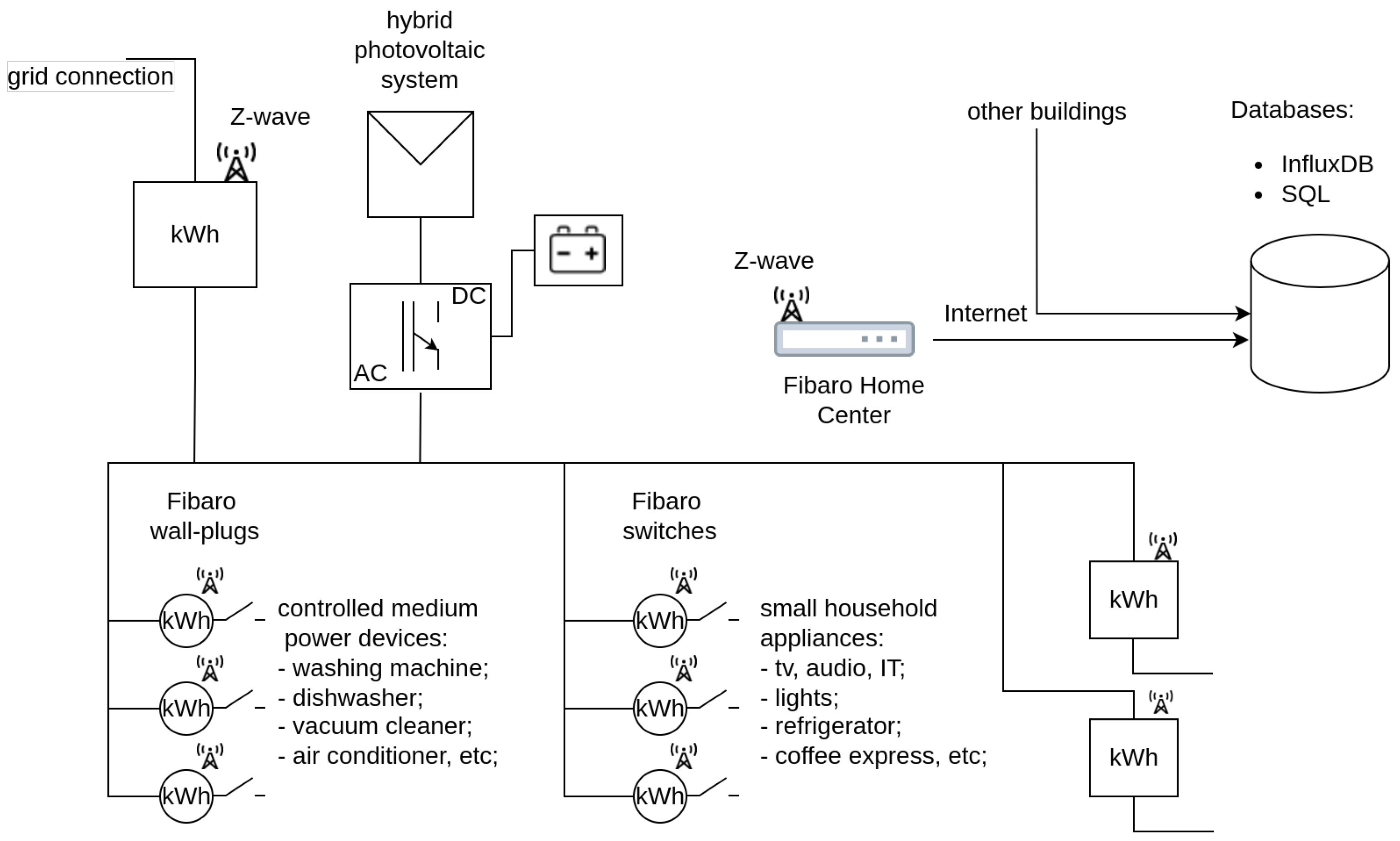
2.1. Data Preparation
- In location A—computer, shower light, recess lighting, outdoor lighting, dinner room lighting, washing machine, Wi-Fi socket, socket under desk, bedroom lamp, hood.
- Location B—fridge, socket for RTV, dishwasher, socket no. 1, socket no. 2, microwave, socket no. 3, air conditioner, socket no. 4, socket no. 5.
- Location C—socket for hot water tank, heater in the bathroom, radiator heater, fridge, socket for the desk, dishwasher, induction stove, fridge in the pantry, socket under TV, socket in the office.
- Location D—fridge, TV-Audio, dishwasher, fridge no. 2, dryer, boiler, TV in kitchen, kettle, socket near the desk, alarm power supply.
2.2. Experiments
2.2.1. Baseline and Linear Regression Models
2.2.2. LSTM and Prophet
- Using information only about the total energy consumption.
- Using information about the total energy consumption and the weather.
- Using information about the total energy consumption and the energy consumption of the top 10 energy-consuming devices.
- Using information about the total energy consumption, the weather and the energy consumption of the top 10 energy-consuming devices.
3. Results
- val_week_before—Naive model. It predicted the value that was observed in the location a week before.
- lr_30day—Linear regression calculated on 30 days of data.
- lr_2weeks—Linear regression calculated on 2 weeks of data.
- lr_1week—Linear regression calculated on 1 week of data.
- lr_4days—Linear regression calculated on 4 days of data.
- simple_prophet—Prophet model that used only information about the total energy consumption.
- weather_prophet—Prophet model that used information about the total energy consumption and the weather.
- devices_prophet—Prophet model that used information about the total energy consumption and the energy consumption of the top 10 energy-consuming devices.
- devices_weather_prophet—Prophet model that used information about the total energy consumption, the weather and the energy consumption of the top 10 energy-consuming devices.
- simple_telemony—LSTM model that used only information about the total energy consumption.
- weather_telemony—LSTM model that used information about the total energy consumption and the weather.
- devices_telemony—LSTM model that used information about the total energy consumption and the energy consumption of the top 10 energy-consuming devices.
- devices_weather_telemony—LSTM model that used information about the total energy consumption, the weather and the energy consumption of the top 10 energy-consuming devices.
3.1. Analysis of Made Mistakes
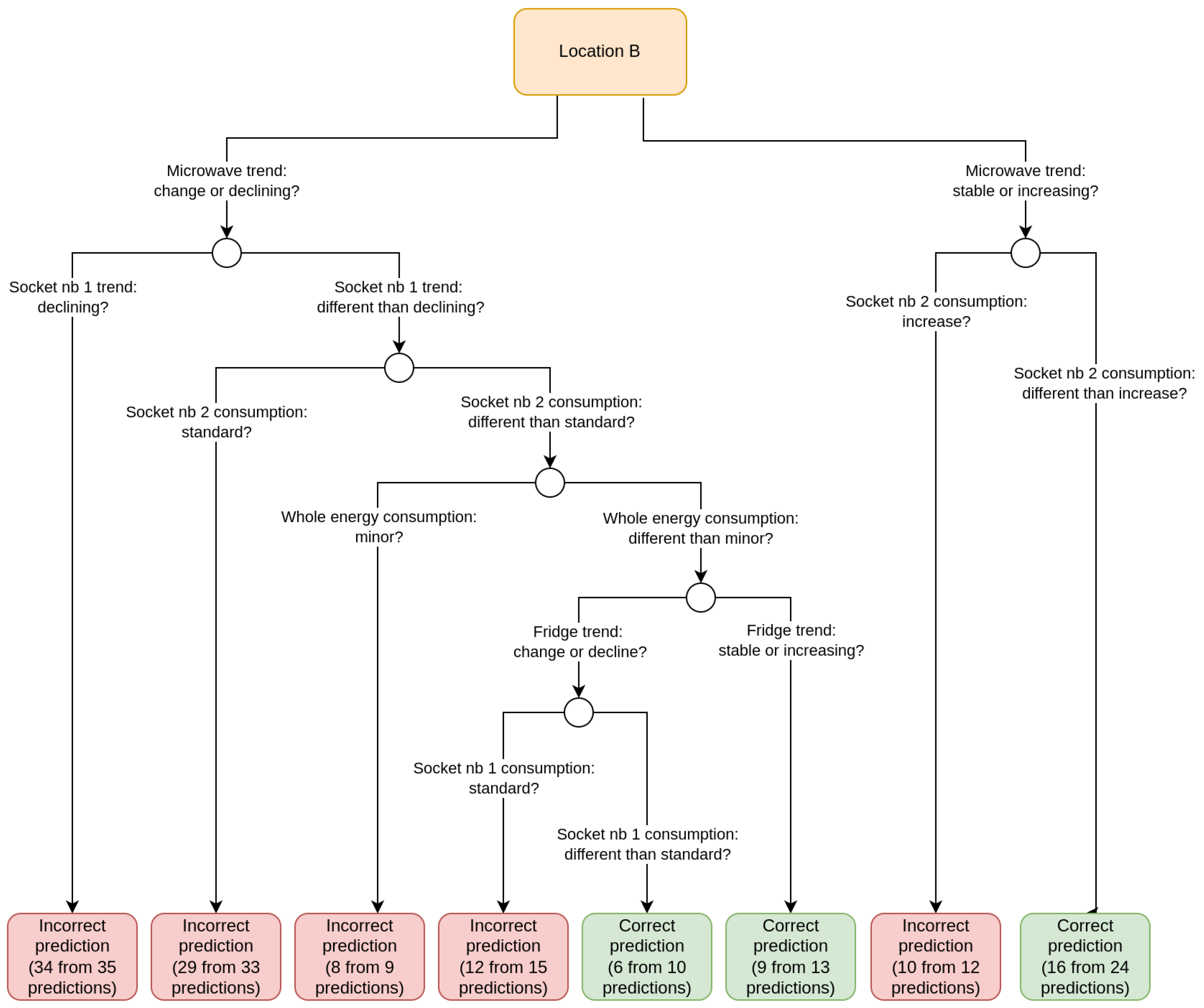
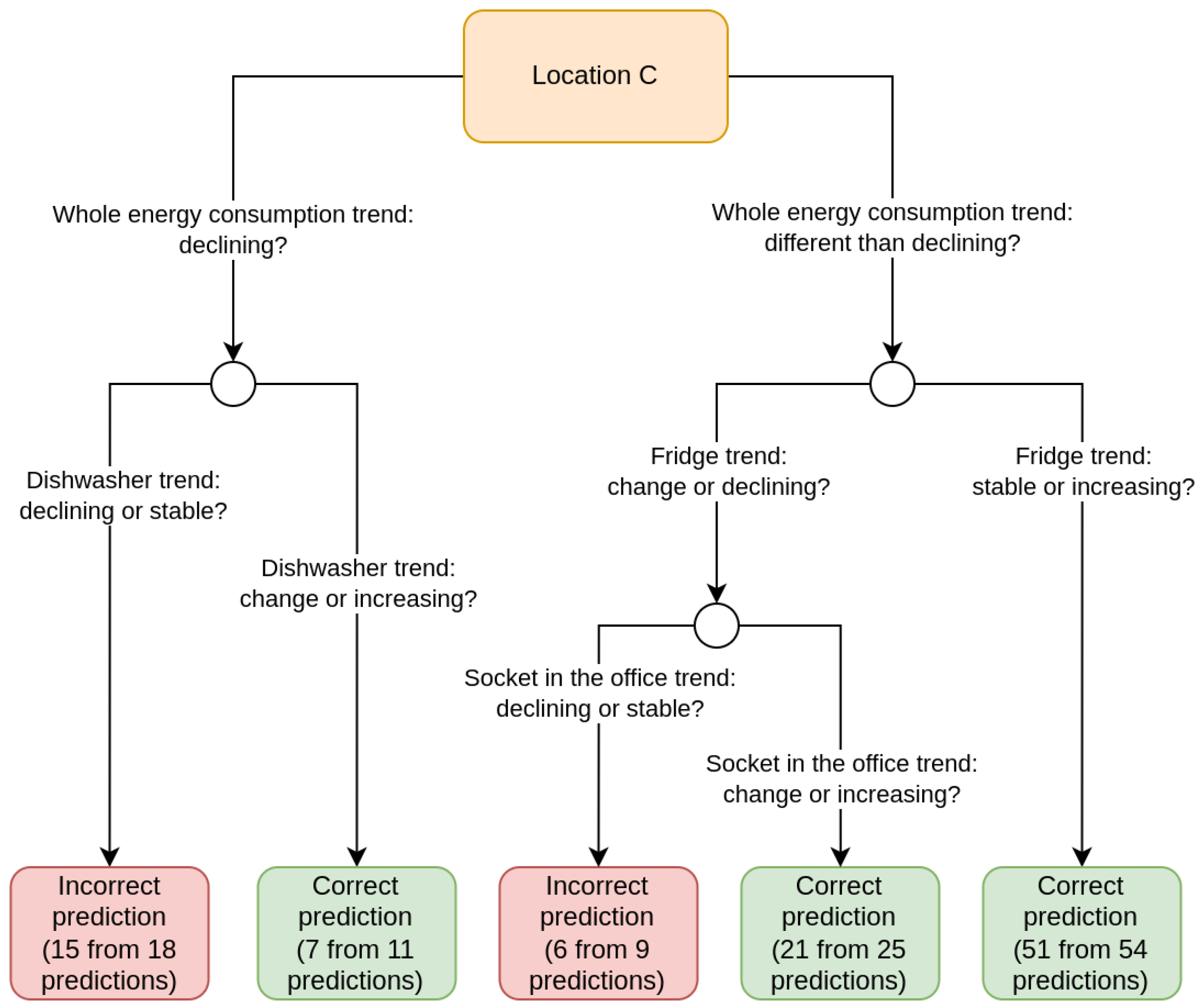
- Consumption was minor—the consumption was in the range , where is the mean value of the time series x and is the standard deviation of the time series x. Time series x is the time series describing 14 days before the day for which the attribute value was determined.
- There was a decrease in consumption—the consumption was in the range.
- The consumption was standard—the consumption was in the range.
- There was an increase in consumption—the consumption was in the range.
- The consumption was intense—the consumption was in the range.
- The trend was stable—the current consumption and the consumption for the day before were described as “standard”.
- The trend was declining—the current consumption and the consumption for the day before were described as “minor” or “decrease”.
- The trend was increasing—the current consumption and the consumption for the day before were described as “increase” or “intense”.
- There was a change in the trend—the current consumption was described differently than the consumption for the day before.
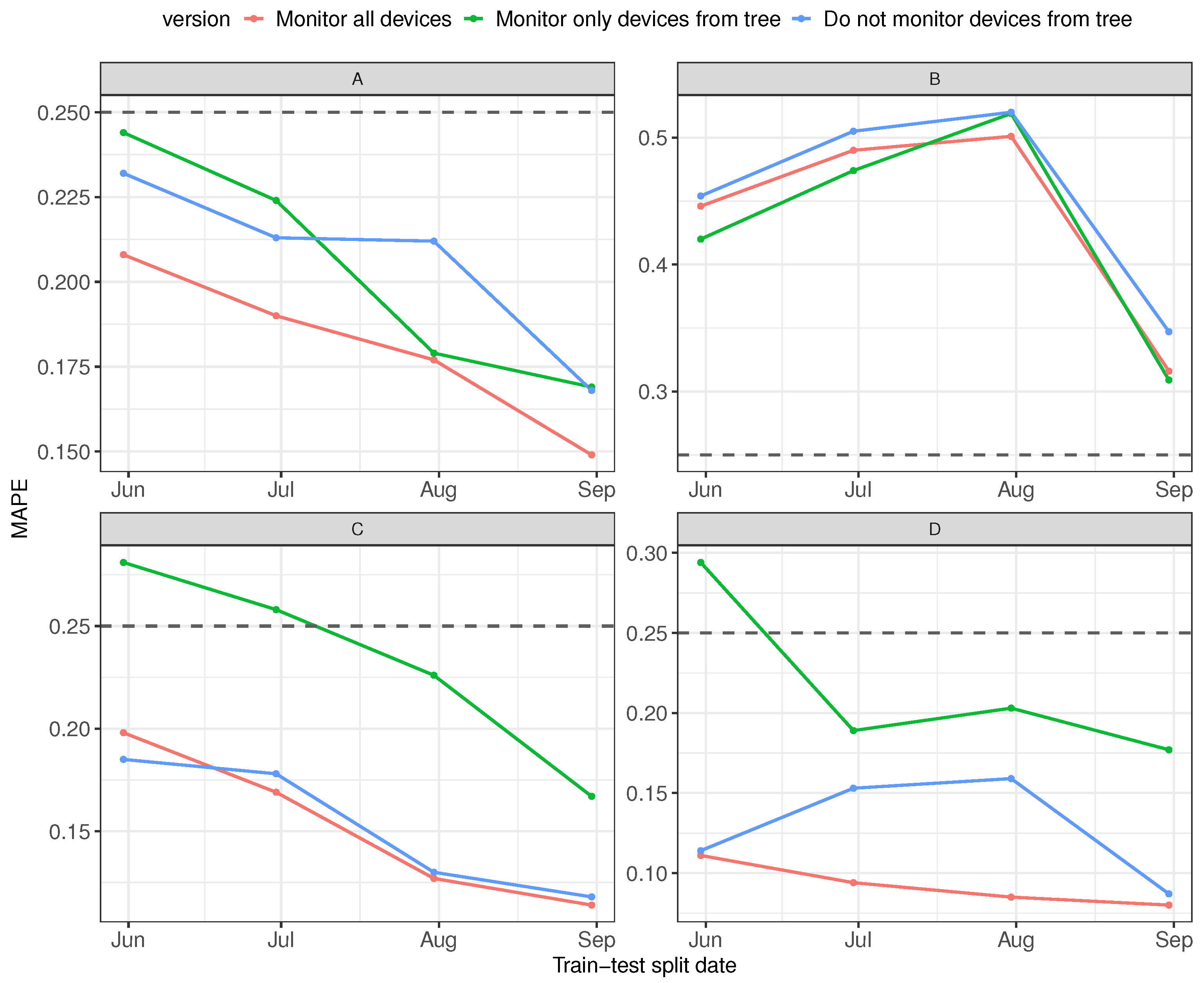
3.2. Limiting Number of Monitored Devices Based on Tree Decision Models
- How will the Prophet model perform on the test part when we use only the time series of the appliances whose features appeared in the decision tree and the time series describing the total energy consumption of the location to build a new model?
- How will the Prophet model perform on the test part when we do not use the time series of appliances whose features appeared in the decision tree?
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zielińska-Sitkiewicz, M.; Chrzanowska, M.; Furmańczyk, K.; Paczutkowski, K. Analysis of Electricity Consumption in Poland Using Prediction Models and Neural Networks. Energies 2021, 14, 6619. [Google Scholar] [CrossRef]
- Czosnyka, M.; Wnukowska, B.; Karbowa, K. Electrical energy consumption and the energy market in Poland during the COVID-19 pandemic. In Proceedings of the 2020 Progress in Applied Electrical Engineering (PAEE), Koscielisko, Poland, 21–26 June 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Jadwiszczak, P.; Jurasz, J.; Kaźmierczak, B.; Niemierka, E.; Zheng, W. Factors Shaping A/W Heat Pumps CO2 Emissions—Evidence from Poland. Energies 2021, 14, 1576. [Google Scholar] [CrossRef]
- Alkhraijah, M.; Alowaifeer, M.; Alsaleh, M.; Alfaris, A.; Molzahn, D.K. The Effects of Social Distancing on Electricity Demand Considering Temperature Dependency. Energies 2021, 14, 473. [Google Scholar] [CrossRef]
- Ozcanli, A.K.; Yaprakdal, F.; Baysal, M. Deep learning methods and applications for electrical power systems: A comprehensive review. Int. J. Energy Res. 2020, 44, 7136–7157. [Google Scholar] [CrossRef]
- O’Dwyer, E.; Pan, I.; Charlesworth, R.; Butler, S.; Shah, N. Integration of an energy management tool and digital twin for coordination and control of multi-vector smart energy systems. Sustain. Cities Soc. 2020, 62, 102412. [Google Scholar] [CrossRef]
- Walther, J.; Weigold, M. A Systematic Review on Predicting and Forecasting the Electrical Energy Consumption in the Manufacturing Industry. Energies 2021, 14, 968. [Google Scholar] [CrossRef]
- Nowy System Rozliczania, Tzw. Net-Billing. Available online: https://www.gov.pl/web/klimat/nowy-system-rozliczania-tzw-net-billing (accessed on 30 May 2022).
- Markakis, E.K.; Nikoloudakis, Y.; Lapidaki, K.; Fiorentzis, K.; Karapidakis, E. Unification of Edge Energy Grids for Empowering Small Energy Producers. Sustainability 2021, 13, 8487. [Google Scholar] [CrossRef]
- Khajavi, S.H.; Motlagh, N.H.; Jaribion, A.; Werner, L.C.; Holmström, J. Digital Twin: Vision, Benefits, Boundaries, and Creation for Buildings. IEEE Access 2019, 7, 147406–147419. [Google Scholar] [CrossRef]
- Reinhardt, H.; Bergmann, J.P.; Münnich, M.; Rein, D.; Putz, M. A survey on modeling and forecasting the energy consumption in discrete manufacturing. Procedia CIRP 2020, 90, 443–448. [Google Scholar] [CrossRef]
- Erdogdu, E. Electricity demand analysis using cointegration and ARIMA modelling: A case study of Turkey. Energy Policy 2007, 35, 1129–1146. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Wang, J.; Zhao, G.; Dong, Y. Application of residual modification approach in seasonal ARIMA for electricity demand forecasting: A case study of China. Energy Policy 2012, 48, 284–294. [Google Scholar] [CrossRef]
- Tso, G.K.; Yau, K.K. Predicting electricity energy consumption: A comparison of regression analysis, decision tree and neural networks. Energy 2007, 32, 1761–1768. [Google Scholar] [CrossRef]
- Bianco, V.; Manca, O.; Nardini, S. Linear Regression Models to Forecast Electricity Consumption in Italy. Energy Sources Part B Econ. Plan. Policy 2013, 8, 86–93. [Google Scholar] [CrossRef]
- Ciulla, G.; D’Amico, A. Building energy performance forecasting: A multiple linear regression approach. Appl. Energy 2019, 253, 113500. [Google Scholar] [CrossRef]
- Hong, T.; Gui, M.; Baran, M.E.; Willis, H.L. Modeling and forecasting hourly electric load by multiple linear regression with interactions. In Proceedings of the IEEE PES General Meeting, Minneapolis, MN, USA, 25–29 July 2010; pp. 1–8. [Google Scholar] [CrossRef]
- Amber, K.P.; Aslam, M.W.; Mahmood, A.; Kousar, A.; Younis, M.Y.; Akbar, B.; Chaudhary, G.Q.; Hussain, S.K. Energy Consumption Forecasting for University Sector Buildings. Energies 2017, 10, 1579. [Google Scholar] [CrossRef] [Green Version]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using Deep Neural Networks. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 7046–7051. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.Y.; Cho, S.B. Electric Energy Consumption Prediction by Deep Learning with State Explainable Autoencoder. Energies 2019, 12, 739. [Google Scholar] [CrossRef] [Green Version]
- Borghini, E.; Giannetti, C.; Flynn, J.; Todeschini, G. Data-Driven Energy Storage Scheduling to Minimise Peak Demand on Distribution Systems with PV Generation. Energies 2021, 14, 3453. [Google Scholar] [CrossRef]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM Model for Short-Term Individual Household Load Forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Multi-Sequence LSTM-RNN Deep Learning and Metaheuristics for Electric Load Forecasting. Energies 2020, 13, 391. [Google Scholar] [CrossRef] [Green Version]
- Yan, K.; Li, W.; Ji, Z.; Qi, M.; Du, Y. A Hybrid LSTM Neural Network for Energy Consumption Forecasting of Individual Households. IEEE Access 2019, 7, 157633–157642. [Google Scholar] [CrossRef]
- Koltsaklis, N.; Panapakidis, I.P.; Pozo, D.; Christoforidis, G.C. A prosumer model based on smart home energy management and forecasting techniques. Energies 2021, 14, 1724. [Google Scholar] [CrossRef]
- Bu, S.J.; Cho, S.B. Time series forecasting with multi-headed attention-based deep learning for residential energy consumption. Energies 2020, 13, 4722. [Google Scholar] [CrossRef]
- Braulio-Gonzalo, M.; Bovea, M.D.; Jorge-Ortiz, A.; Juan, P. Contribution of households’ occupant profile in predictions of energy consumption in residential buildings: A statistical approach from Mediterranean survey data. Energy Build. 2021, 241, 110939. [Google Scholar] [CrossRef]
- Song, S.Y.; Leng, H. Modeling the household electricity usage behavior and energy-saving management in severely cold regions. Energies 2020, 13, 5581. [Google Scholar] [CrossRef]
- Sepehr, M.; Eghtedaei, R.; Toolabimoghadam, A.; Noorollahi, Y.; Mohammadi, M. Modeling the electrical energy consumption profile for residential buildings in Iran. Sustain. Cities Soc. 2018, 41, 481–489. [Google Scholar] [CrossRef]
- Beaudin, M.; Zareipour, H. Home energy management systems: A review of modelling and complexity. Renew. Sustain. Energy Rev. 2015, 45, 318–335. [Google Scholar] [CrossRef]
- Sharma, V.; Cortes, A.; Cali, U. Use of Forecasting in Energy Storage Applications: A Review. IEEE Access 2021, 9, 114690–114704. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yang, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Almazrouee, A.I.; Almeshal, A.M.; Almutairi, A.S.; Alenezi, M.R.; Alhajeri, S.N. Long-Term Forecasting of Electrical Loads in Kuwait Using Prophet and Holt–Winters Models. Appl. Sci. 2020, 10, 5627. [Google Scholar] [CrossRef]
- Bashir, T.; Haoyong, C.; Tahir, M.F.; Liqiang, Z. Short term electricity load forecasting using hybrid prophet-LSTM model optimized by BPNN. Energy Rep. 2022, 8, 1678–1686. [Google Scholar] [CrossRef]
- Vartholomaios, A.; Karlos, S.; Kouloumpris, E.; Tsoumakas, G. Short-Term Renewable Energy Forecasting in Greece Using Prophet Decomposition and Tree-Based Ensembles. In Database and Expert Systems Applications—DEXA 2021 Workshops; Springer: Cham, Switzerland, 2021; pp. 227–238. [Google Scholar] [CrossRef]
- Hasan Shawon, M.M.; Akter, S.; Islam, M.K.; Ahmed, S.; Rahman, M.M. Forecasting PV Panel Output Using Prophet Time Series Machine Learning Model. In Proceedings of the 2020 IEEE REGION 10 CONFERENCE (TENCON), Osaka, Japan, 16–19 November 2020; pp. 1141–1144. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Prophet. Prophet, Forecasting at Scale. Available online: https://facebook.github.io/prophet/ (accessed on 3 May 2022).
- Punia, S.; Nikolopoulos, K.; Singh, S.P.; Madaan, J.K.; Litsiou, K. Deep learning with long short-term memory networks and random forests for demand forecasting in multi-channel retail. Int. J. Prod. Res. 2020, 58, 4964–4979. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; Association for Computing Machinery: New York, NY, USA, 2018. KDD ’18. pp. 387–395. [Google Scholar] [CrossRef] [Green Version]
- Taylor, S.J.; Letham, B. Forecasting at Scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Jetcheva, J.G.; Majidpour, M.; Chen, W.P. Neural network model ensembles for building-level electricity load forecasts. Energy Build. 2014, 84, 214–223. [Google Scholar] [CrossRef]
- Jovanović, R.Ž.; Sretenović, A.A.; Živković, B.D. Ensemble of various neural networks for prediction of heating energy consumption. Energy Build. 2015, 94, 189–199. [Google Scholar] [CrossRef]
- Jain, R.K.; Smith, K.M.; Culligan, P.J.; Taylor, J.E. Forecasting energy consumption of multi-family residential buildings using support vector regression: Investigating the impact of temporal and spatial monitoring granularity on performance accuracy. Appl. Energy 2014, 123, 168–178. [Google Scholar] [CrossRef]
- Iwafune, Y.; Yagita, Y.; Ikegami, T.; Ogimoto, K. Short-term forecasting of residential building load for distributed energy management. In Proceedings of the 2014 IEEE International Energy Conference (ENERGYCON), Cavtat, Croatia, 13–16 May 2014; pp. 1197–1204. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Type | Min. Energy [kWh] | Mean Energy [kWh] | Median Energy [kWh] | Max. Energy [kWh] |
|---|---|---|---|---|---|
| A | Flat | 2.14 | 6.64 | 6.52 | 13.89 |
| B | Flat | 1.34 | 3.66 | 3.30 | 10.44 |
| C | House | 3.92 | 17.19 | 17.68 | 29.68 |
| D | House | 6.68 | 14.65 | 14.63 | 34.62 |
| Experiment | MAPE A | MAPE B | MAPE C | MAPE D |
|---|---|---|---|---|
| val_week_before | 43.4 | 47.66 | 51.58 | 31.93 |
| lr_30days | 33.58 | 38.93 | 40.1 | 29.6 |
| lr_2weeks | 40.86 | 40.85 | 41.78 | 29 |
| lr_1week | 43.91 | 52.25 | 35.71 | 32.32 |
| lr_4days | 47.58 | 62.01 | 32.27 | 35.75 |
| simple_prophet | 34.71 | 40.69 | 31.32 | 27.32 |
| weather_prophet | 34.51 | 40.80 | 38.93 | 27.23 |
| devices_prophet | 19.9 | 43.90 | 18.17 | 11.1 |
| devices_weather_prophet | 20.81 | 44.57 | 19.34 | 12.07 |
| simple_telemony | 52.02 | 49.02 | 60.54 | 40.24 |
| weather_telemony | 41.54 | 49.55 | 51.28 | 41.13 |
| devices_telemony | 39.69 | 37.44 | 70.31 | 41.53 |
| devices_weather_telemony | 56.15 | 39.14 | 50.19 | 37.23 |
| Experiment | % Days A | % Days B | % Days C | % Days D |
|---|---|---|---|---|
| val_week_before | 47.37 | 40.4 | 48.72 | 58.17 |
| lr_30days | 51.97 | 41.06 | 47.86 | 55.56 |
| lr_2weeks | 50.66 | 34.44 | 45.3 | 56.21 |
| lr_1week | 40.13 | 29.8 | 49.57 | 47.06 |
| lr_4days | 37.09 | 27.15 | 48.72 | 45.75 |
| simple_prophet | 55.73 | 42.98 | 60.71 | 61.44 |
| weather_prophet | 55.56 | 44 | 53.33 | 62.75 |
| devices_prophet | 71.71 | 38.18 | 77.98 | 91.5 |
| devices_weather_prophet | 68.21 | 38.89 | 76.85 | 88.24 |
| simple_telemony | 37.5 | 36.42 | 40.17 | 52.29 |
| weather_telemony | 44.08 | 39.74 | 35.9 | 39.22 |
| devices_telemony | 46.71 | 49.67 | 43.48 | 54.25 |
| devices_weather_telemony | 41.45 | 45.03 | 35.65 | 50.33 |
| Experiment | % Missing Days A | % Missing Days B | % Missing Days C | % Missing Days D |
|---|---|---|---|---|
| val_week_before | 0.00 | 0.00 | 0.00 | 0.00 |
| lr_30days | 0.00 | 0.00 | 0.00 | 0.00 |
| lr_2weeks | 0.00 | 0.00 | 0.00 | 0.00 |
| lr_1week | 0.00 | 0.00 | 0.00 | 0.00 |
| lr_4days | 0.00 | 0.00 | 0.00 | 0.00 |
| simple_prophet | 13.82 | 24.50 | 28.21 | 0.00 |
| weather_prophet | 17.11 | 33.77 | 23.08 | 0.00 |
| devices_prophet | 0.00 | 27.15 | 6.84 | 0.00 |
| devices_weather_prophet | 0.66 | 28.48 | 7.69 | 0.00 |
| simple_telemony | 0.00 | 0.00 | 0.00 | 0.00 |
| weather_telemony | 0.00 | 0.00 | 0.00 | 0.00 |
| devices_telemony | 0.00 | 0.00 | 1.71 | 0.00 |
| devices_weather_telemony | 0.00 | 0.00 | 1.71 | 0.00 |
| Location A | Location B | Location C | Location D | |
|---|---|---|---|---|
| 31 May 2021 | 4 | 1 | 2 | 3 |
| 30 June 2021 | 5 | 3 | 3 | 4 |
| 31 July 2021 | 4 | 3 | 4 | 4 |
| 31 August 2021 | 4 | 6 | 5 | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henzel, J.; Wróbel, Ł.; Fice, M.; Sikora, M. Energy Consumption Forecasting for the Digital-Twin Model of the Building. Energies 2022, 15, 4318. https://doi.org/10.3390/en15124318
Henzel J, Wróbel Ł, Fice M, Sikora M. Energy Consumption Forecasting for the Digital-Twin Model of the Building. Energies. 2022; 15(12):4318. https://doi.org/10.3390/en15124318
Chicago/Turabian StyleHenzel, Joanna, Łukasz Wróbel, Marcin Fice, and Marek Sikora. 2022. "Energy Consumption Forecasting for the Digital-Twin Model of the Building" Energies 15, no. 12: 4318. https://doi.org/10.3390/en15124318
APA StyleHenzel, J., Wróbel, Ł., Fice, M., & Sikora, M. (2022). Energy Consumption Forecasting for the Digital-Twin Model of the Building. Energies, 15(12), 4318. https://doi.org/10.3390/en15124318