
Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer


 , ,
, ,
Abstract
:1. Introduction
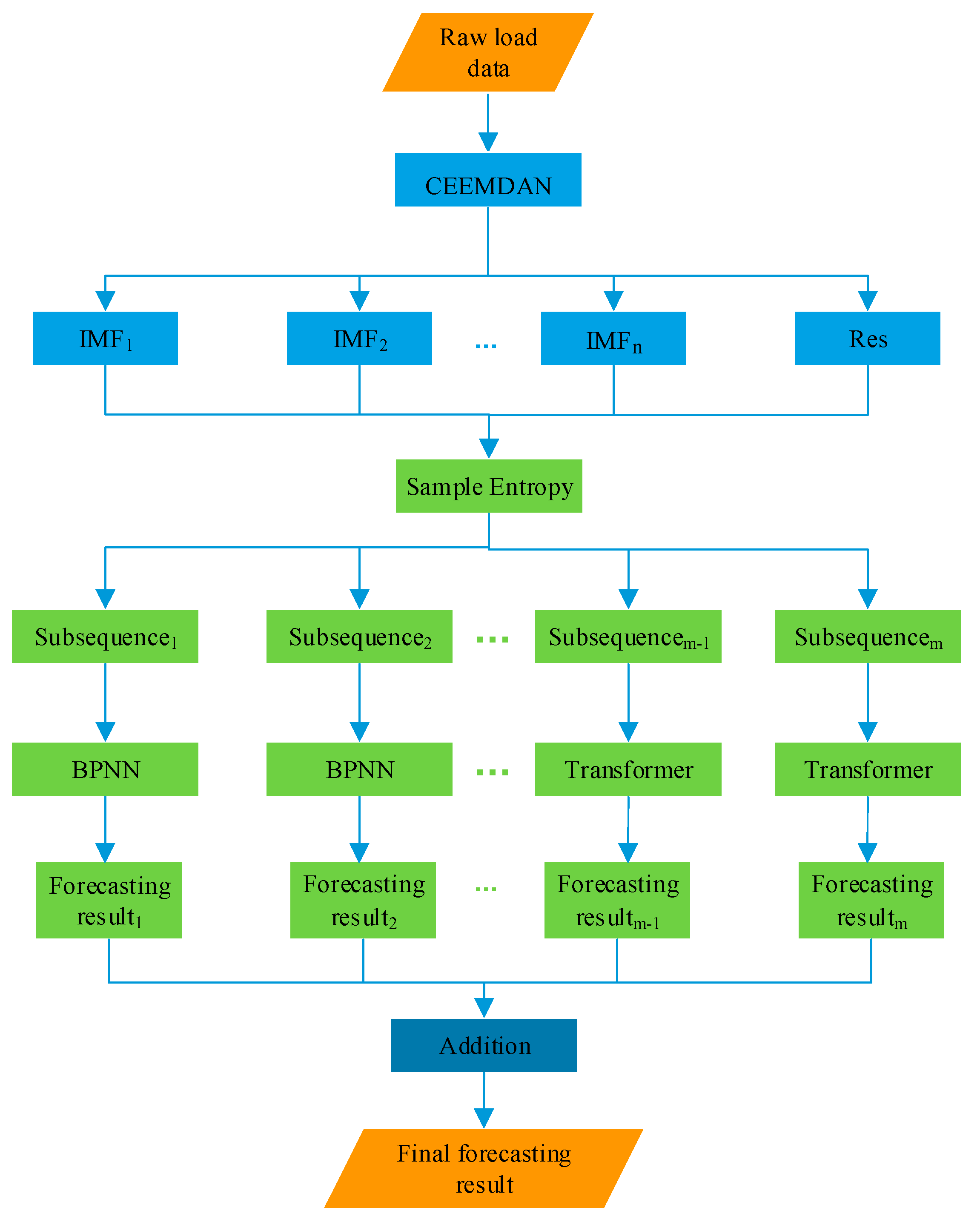
2. Combined Forecasting Model Based on the CEEMDAN-SE-SE-BPNN-Transformer
3. Methods
3.1. Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (CEEMDAN)
3.2. Sample Entropy (SE)
3.3. Back Propagation Neural Network (BPNN)
3.4. Transformer Model
4. Experiments and Discussion
4.1. Data Standardization
4.2. Power Load Data Decomposition and Complexity Analysis
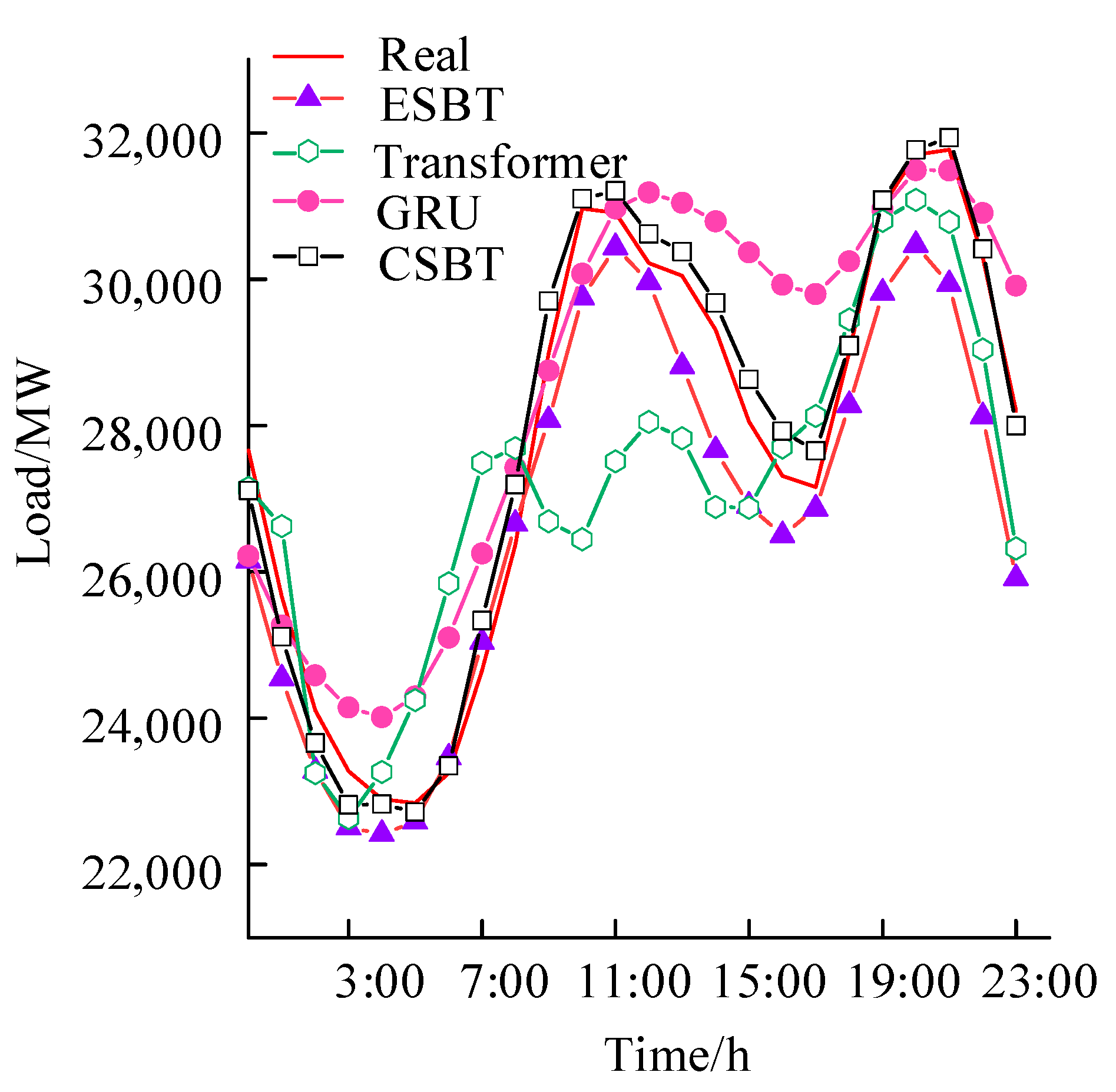
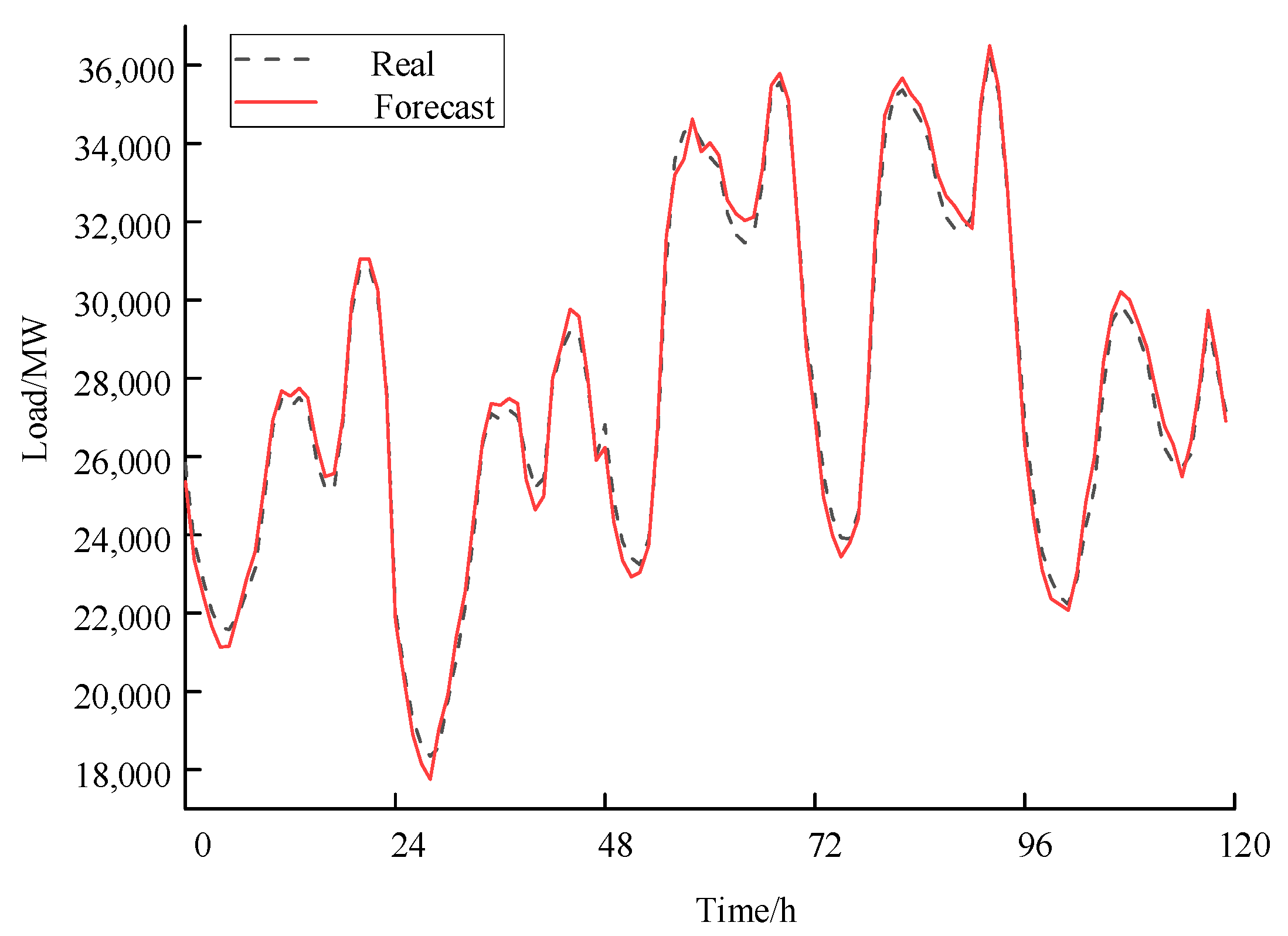
4.3. Comparative Analysis of Forecasting Results
- (1)
- Load forecasting using the Transformer model.
- (2)
- Load forecasting using GRU model.
- (3)
- Use the EEMD algorithm to decompose the original load, and then use the sample entropy to analyze the complexity and recombine the components, and then use the BPNN and the Transformer model to forecast the subsequences with low complexity and the subsequences with high complexity, respectively, abbreviated as ESBT.
- (4)
- Use the EEMD algorithm to decompose the original load, and use the zero-crossing rate proposed in [13], as the basis for dividing high-frequency components and low-frequency components, and divide the decomposed sequence into high-frequency parts and low-frequency parts, then MLR and GRU are used to forecast the low-frequency parts and the high-frequency parts, respectively, abbreviated as EGM.
- (5)
- Use the CEEMDAN algorithm to decompose the original load, and then use the sample entropy to analyze the complexity and recombine the components, and then use the BPNN and the GRU model to forecast the subsequences with low complexity and the subsequences with high complexity, abbreviated as CSBG.
- (6)
- Use the CEEMDAN algorithm to decompose the power load data, and then use the sample entropy to analyze the complexity, and divide the components into subsequences with low complexity and high complexity, and then the BPNN and Transformer model are used to forecast the low complexity subsequences and high complexity subsequences, respectively, abbreviated as CSBT (unrecombined).
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADF | Augmented Dickey-Fuller |
| ARIMA | Autoregressive Integrated Moving Average |
| BPNN | Back Propagation Neural Network |
| CEEMDAN | Complete Ensemble Empirical Mode Decomposition with Adaptive Noise |
| EEMD | Ensemble Empirical Mode Decomposition |
| EMD | Empirical Mode Decomposition |
| GRU | Gated Recurrent Unit Neural Network |
| IMF | Intrinsic Mode Functions |
| LSSVM | Least Squares Support Vector Machine |
| LSTM | Long Short-Term Memory |
| MAPE | Mean Absolute Percentage Error |
| MLR | Multiple Linear Regression |
| NLP | Natural Language Processing |
| RMSE | Root Mean Square Error |
| SE | Sample Entropy |
References
- Tan, Z.; Zhang, J.; He, Y.; Zhang, Y.; Xiong, G.; Liu, Y. Short-term load forecasting based on integration of SVR and stacking. IEEE Access 2020, 8, 227719–227728. [Google Scholar] [CrossRef]
- Mishra, M.; Nayak, J.; Naik, B.; Abraham, A. Deep learning in electrical utility industry: A comprehensive review of a decade of research. Eng. Appl. Artif. Intell. 2020, 96, 104000. [Google Scholar] [CrossRef]
- Li, B.; Lu, M. Short-term load forecasting modeling of regional power grid considering real-time meteorological coupling effect. Autom. Electr. Power Syst. 2020, 44, 60–68. [Google Scholar]
- Lu, J.; Zhang, Q.; Yang, Z.; Tu, M.; Lu, J.; Peng, H. Short-term load forecasting method based on hybrid CNN-LSTM neural network model. Autom. Electr. Power Syst. 2019, 43, 131–137. [Google Scholar]
- Wu, F.; Cattani, C.; Song, W.; Zio, E. Fractional ARIMA with an improved cuckoo search optimization for the efficient Short-term power load forecasting. Alex. Eng. 2020, 59, 3111–3118. [Google Scholar] [CrossRef]
- Hermias, J.P.; Teknomo, K.; Monje, J.C.N. Short-term stochastic load forecasting using autoregressive integrated moving average models and hidden Markov model. In Proceedings of the International Conference on Information and Communication Technologies, Karachi, Pakistan, 26–28 September 2018; pp. 131–137. [Google Scholar]
- Hong, W.-C.; Fan, G.-F. Hybrid Empirical Mode Decomposition with Support Vector Regression Model for Short Term Load Forecasting. Energies 2019, 12, 1093. [Google Scholar] [CrossRef] [Green Version]
- Rendon-Sanchez, J.F.; de Menezes, L.M. Structural combination of seasonal exponential smoothing forecasts applied to load forecasting. Eur. J. Oper. Res. 2019, 275, 916–924. [Google Scholar] [CrossRef]
- Fan, G.-F.; Yu, M.; Dong, S.-Q.; Yeh, Y.-H.; Hong, W.-C. Forecasting short-term electricity load using hybrid support vector regression with grey catastrophe and random forest modeling. Util. Policy 2021, 73, 101294. [Google Scholar] [CrossRef]
- Zhang, Y.; Ai, Q.; Lin, L.; Yuan, S.; Li, S. A very short-term load forecasting method based on deep LSTM at zone level. Power Syst. Technol. 2019, 43, 1884–1892. [Google Scholar]
- Jin, Y.; Guo, H.; Wang, J.; Song, A. A Hybrid System Based on LSTM for Short-Term Power Load Forecasting. Energies 2020, 13, 6241. [Google Scholar] [CrossRef]
- Jin, Y.; Guo, H.; Wang, J.; Song, A. Deep learning methods and applications for electrical power systems: A comprehensive review. Int. J. Energy Res. 2020, 44, 7136–7157. [Google Scholar]
- Deng, D.; Li, J.; Zhang, Z. Short-term electric load forecasting based on EEMD-GRU-MLR. Power Syst. Technol. 2020, 44, 593–602. [Google Scholar]
- Chen, Z.; Liu, J.; Li, C. Ultra short-term power load forecasting based on combined LSTM-XGBoost model. Power Syst. Technol. 2020, 44, 614–620. [Google Scholar]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Zhang, J.; He, Y.; Wang, Y. Short-term Load forecasting method vased on wavelet decomposition with second-order gray neural network model combined with ADF test. IEEE Access 2017, 05, 16324–16331. [Google Scholar] [CrossRef]
- Peng, P.; Liu, M. Short-term load forecasting method based on Prophet-LSTM combined model. Proc. CSU-EPSA 2021, 33, 15–20. [Google Scholar]
- Li, J.; Zhou, S.; Li, H. Short-term electricity forecasting method based on GRU and STL decomposition. J. Shanghai Univ. Electr. Power 2020, 36, 415–420. [Google Scholar]
- Lei, B.; Wang, Z. Research on short-term load forecasting method based on EEMD-CS-LSSVM. Proc. CSU-EPSA 2019, 33, 117–122. [Google Scholar]
- Chen, J.; Hu, Z.; Chen, W. Load prediction of integrated energy system based on combination of quadratic modal decomposition and deep bidirectional long short-term memory and multiple linear regression. Autom. Electr. Syst. 2021, 45, 85–94. [Google Scholar]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol. Heart Circ. Physiol. 2000, 278, 2039–2049. [Google Scholar] [CrossRef] [Green Version]
- Jia, S.; Ma, B.; Guo, W.; Li, Z.S. A sample entropy based prognostics method for lithium-ion batteries using relevance vector machine. J. Manuf. Syst. 2021, 61, 773–781. [Google Scholar] [CrossRef]
- Hu, Y.; Li, J.; Hong, M.; Ren, J. Short term electric load forecasting model and its verification for process industrial enterprises based on hybrid GA-PSO-BPNN algorithm—A case study of papermaking process. Energy 2019, 170, 1215–1227. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep TransformerModels for Times Series Forecasting: The Influenza Prevealence Case. arXiv 2020, arXiv:2001.08317v1. [Google Scholar]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]


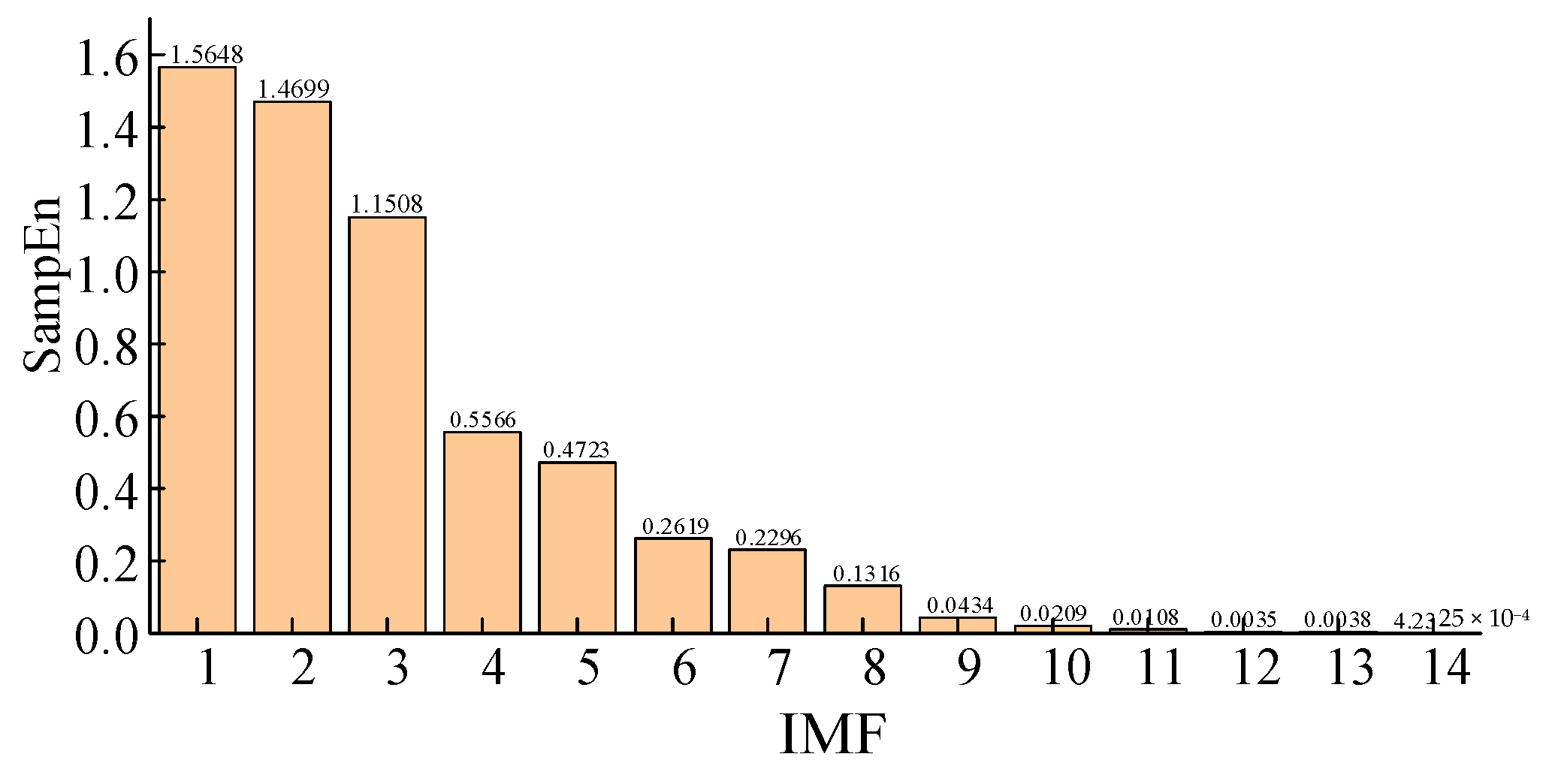


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | BPNN | SVR | ARIMA |
|---|---|---|---|
| RMSE/MW | 10.3618 | 24.3162 | 34.9004 |
| MAPE/% | 0.0305 | 0.0757 | 0.1225 |
| IMF | NEW IMF | Forecasting Model |
|---|---|---|
| 1, 2 | 1 | Transformer |
| 3 | 2 | Transformer |
| 4, 5 | 3 | Transformer |
| 6, 7, 8 | 4 | Transformer |
| 9, 10 | 5 | BPNN |
| 11, 12, 13, 14 | 6 | BPNN |
| Tuning Parameters | Values |
|---|---|
| Number of layers | 4 |
| Number of hidden layers | 2 |
| Activation function | Sigmoid |
| Learning Rate | 0.0001 |
| Tuning Parameters | Values |
|---|---|
| Learning rate | 0.0001 |
| Dropout | 0.1 |
| Batch size | 24 |
| dmodel | 256 |
| Number of encoder layers | 6 |
| Number of decoder layers | 6 |
| Number of multi-head attention | 8 |
| Model | RMSE/MW | MAPE (%) |
|---|---|---|
| GRU | 1857.99 | 5.4547 |
| Transformer | 1334.25 | 4.1312 |
| EGM | 1137.11 | 3.4130 |
| ESBT | 936.66 | 2.9513 |
| CSBG | 803.68 | 2.3840 |
| CSBT (unrecombined) | 412.60 | 1.2958 |
| CSBT | 304.40 | 1.1317 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Zhang, J.; He, Y.; Fu, X.; Fan, L.; Yao, G.; Wen, Y. Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer. Energies 2022, 15, 3659. https://doi.org/10.3390/en15103659
Huang S, Zhang J, He Y, Fu X, Fan L, Yao G, Wen Y. Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer. Energies. 2022; 15(10):3659. https://doi.org/10.3390/en15103659
Chicago/Turabian StyleHuang, Shichao, Jing Zhang, Yu He, Xiaofan Fu, Luqin Fan, Gang Yao, and Yongjun Wen. 2022. "Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer" Energies 15, no. 10: 3659. https://doi.org/10.3390/en15103659
APA StyleHuang, S., Zhang, J., He, Y., Fu, X., Fan, L., Yao, G., & Wen, Y. (2022). Short-Term Load Forecasting Based on the CEEMDAN-Sample Entropy-BPNN-Transformer. Energies, 15(10), 3659. https://doi.org/10.3390/en15103659