
Trend- and Periodicity-Trait-Driven Gasoline Demand Forecasting

Abstract
:1. Introduction
2. Testing Methods of Trend and Periodicity Traits
2.1. Trend Test Method
- (a)
- Given a time series , the statistic of the MK test can be expressed in Equation (1):where the symbolic function is shown in Equation (2):
- (b)
- The Mann-Kendall proved that roughly follows a normal distribution with a mean of 0 and a variance of where the number of the ith data points, when . Accordingly, the MK normalized statistic is shown in Equation (3).
- (c)
- The null hypothesis in the MK test is that there is no monotonic trend in the time series . When , the null hypothesis is rejected, where the standard normal variance is , and is the significance level. In particular, Z is positive for “uptrend” and Z is negative for “downtrend”. If values of are greater than or equal to the critical values of 1.645, 1.96, and 2.576, the significance tests at the confidence levels of 90%, 95%, and 99% are passed, respectively.
2.2. Periodicity Test Method
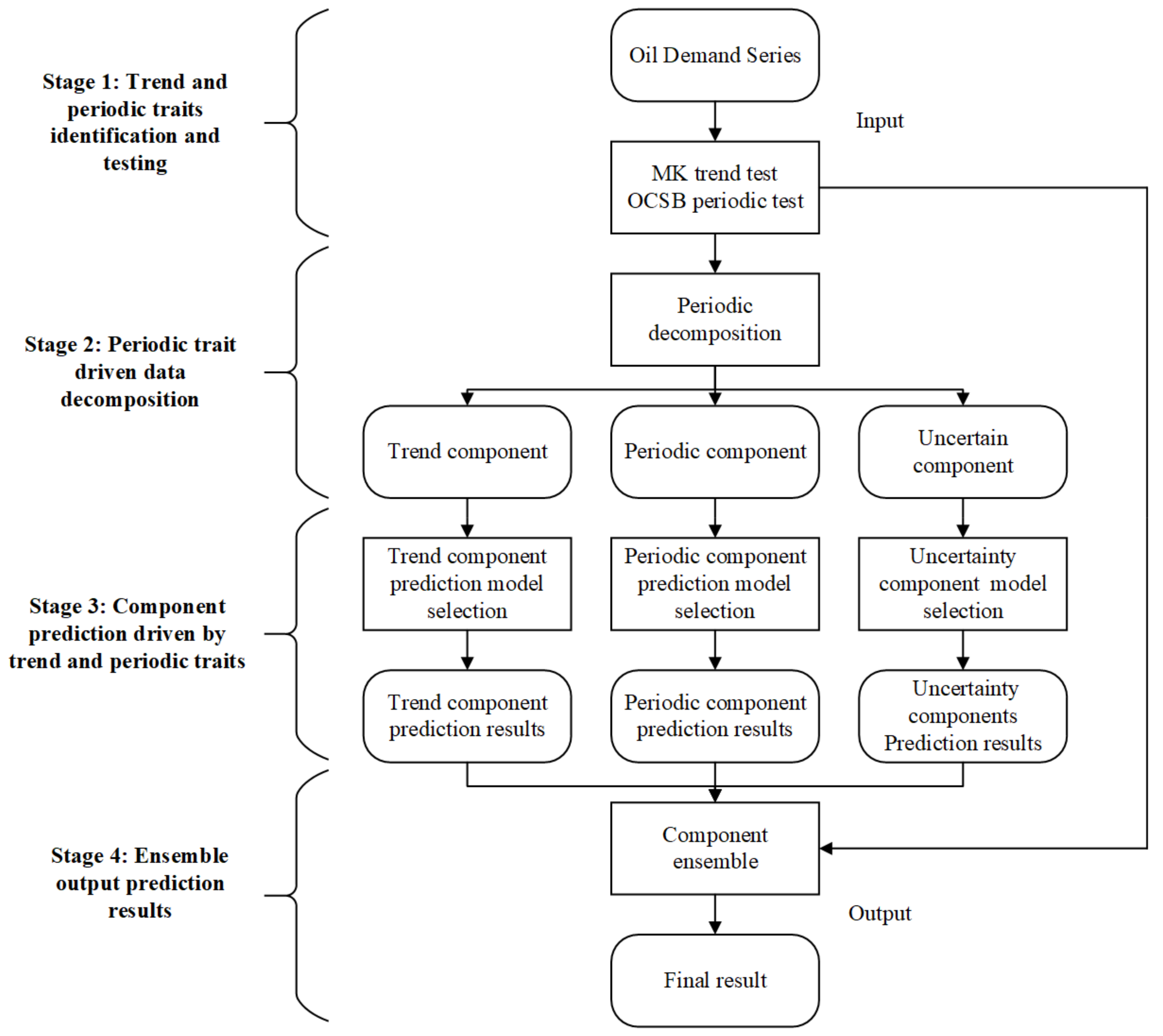
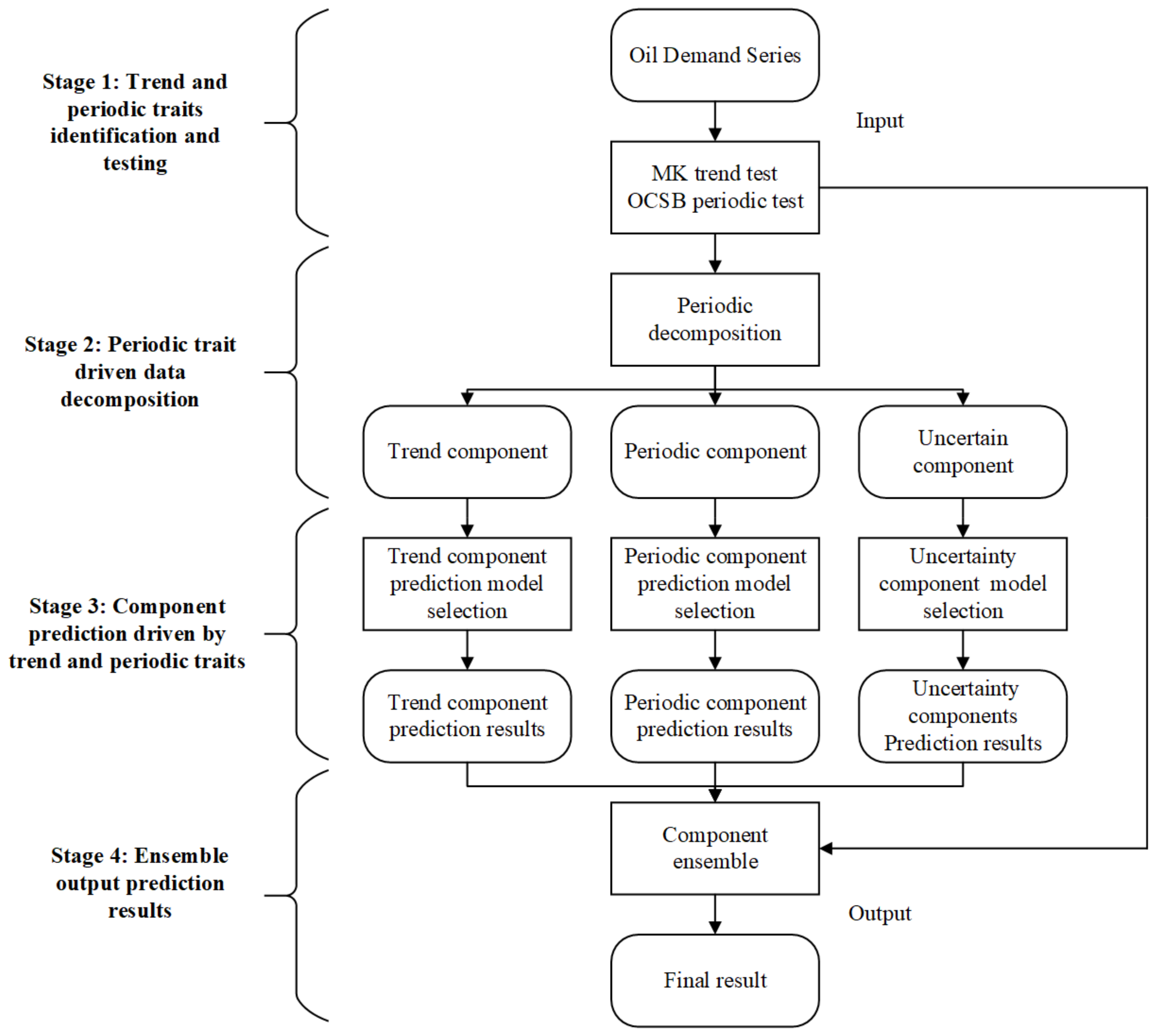
3. Trend- and Periodicity-Trait-Driven Decomposition-Ensemble Forecasting Model
4. Experimental Results
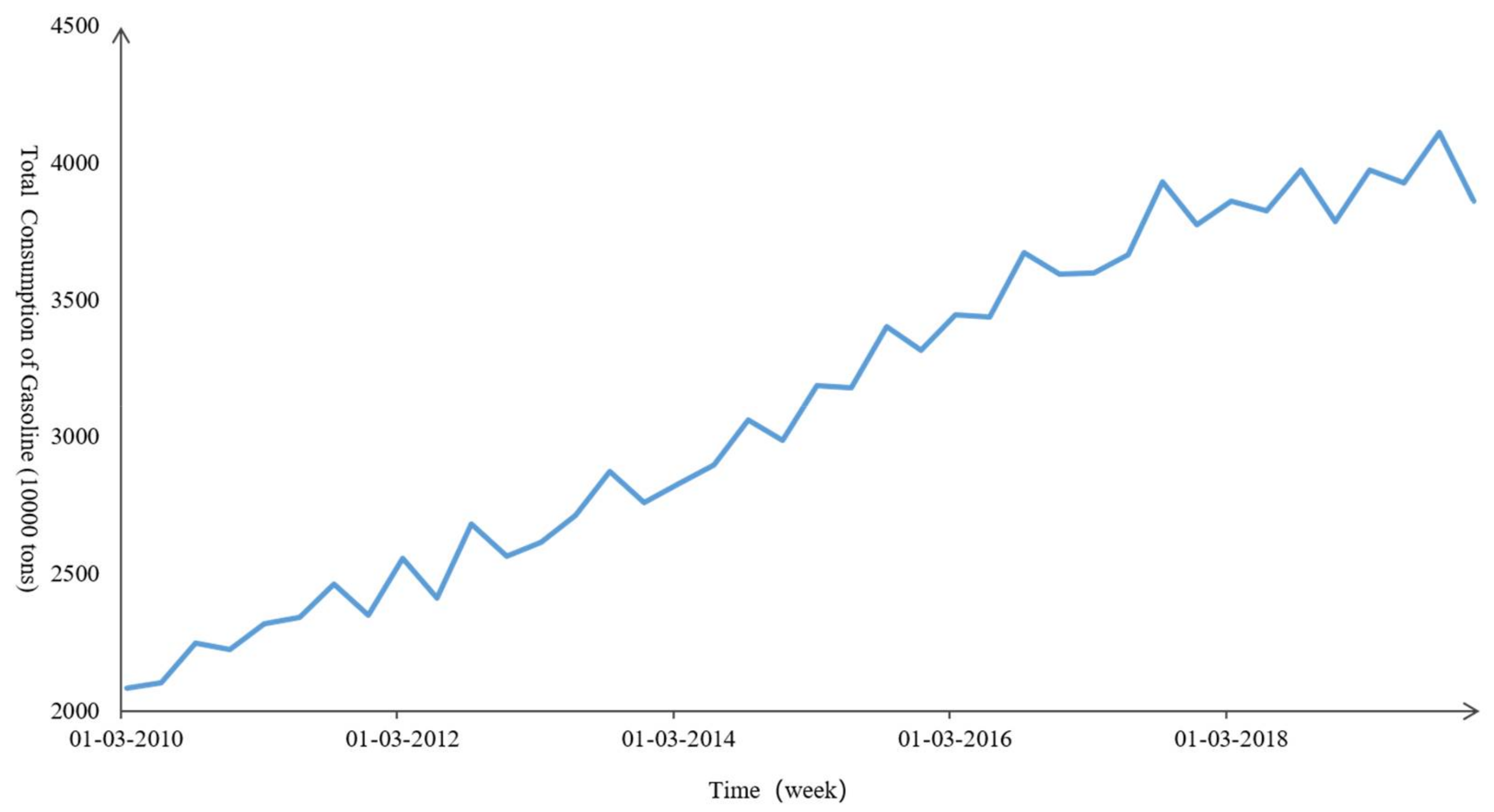
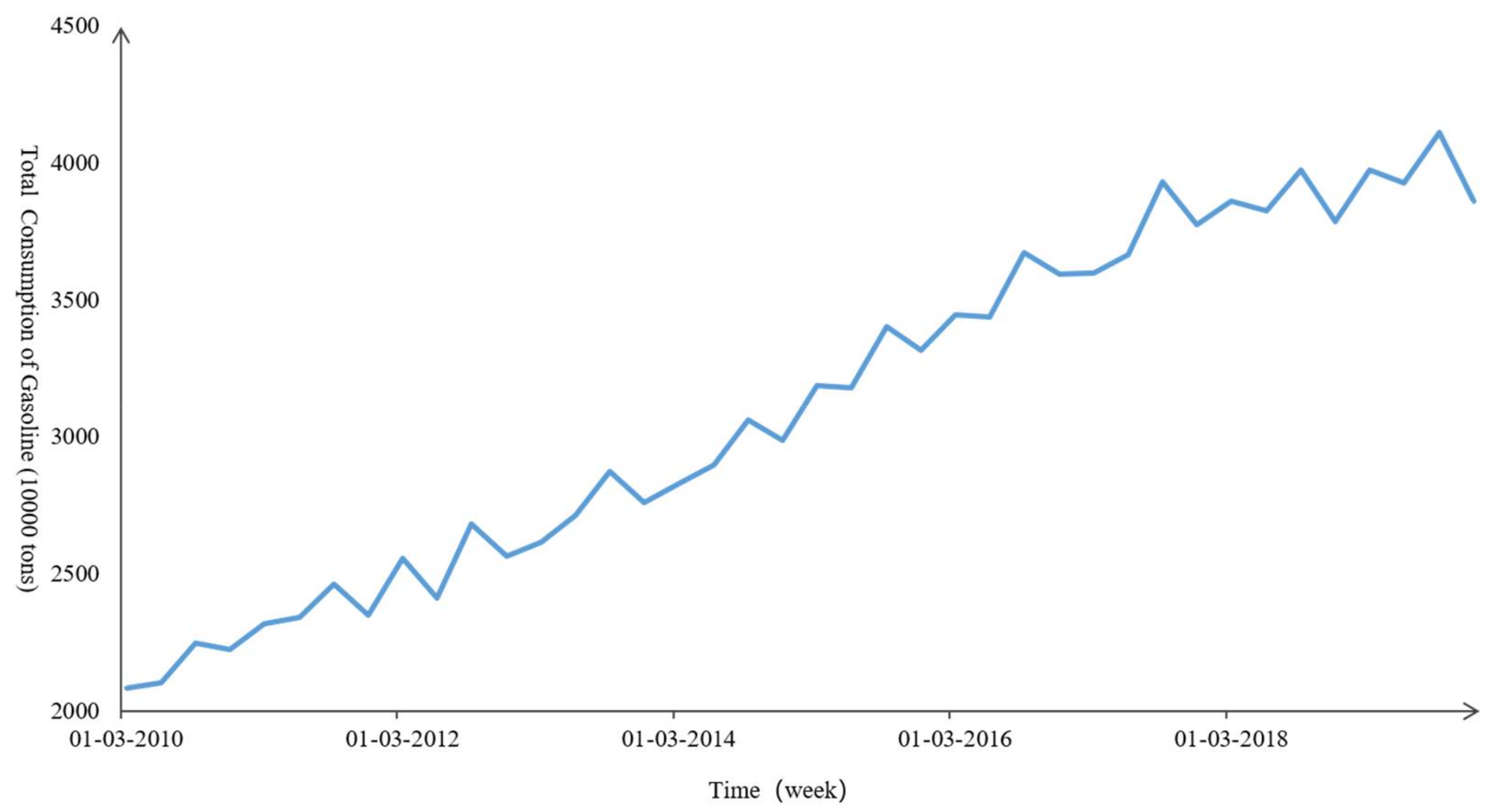
4.1. Data Description and Experimental Design
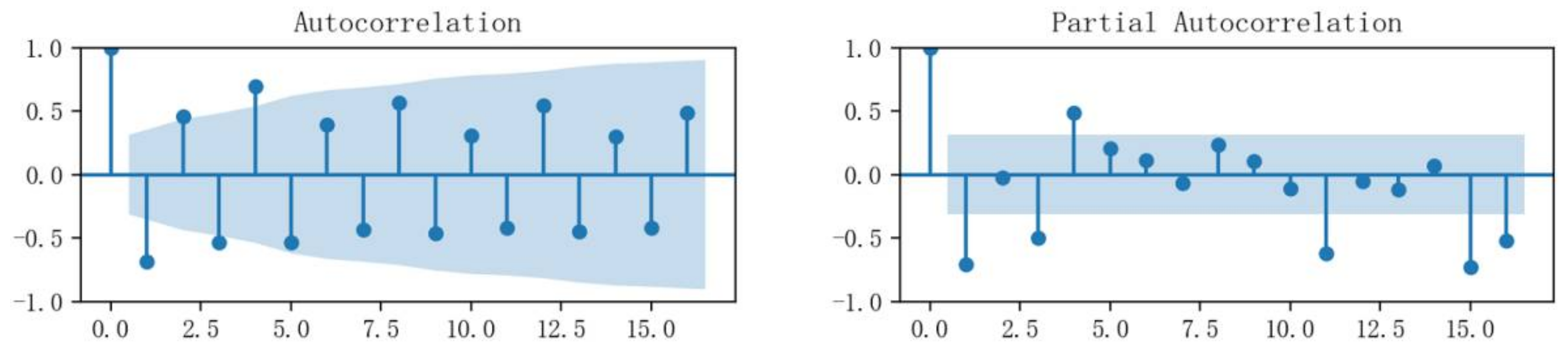
4.2. Data Trait Testing
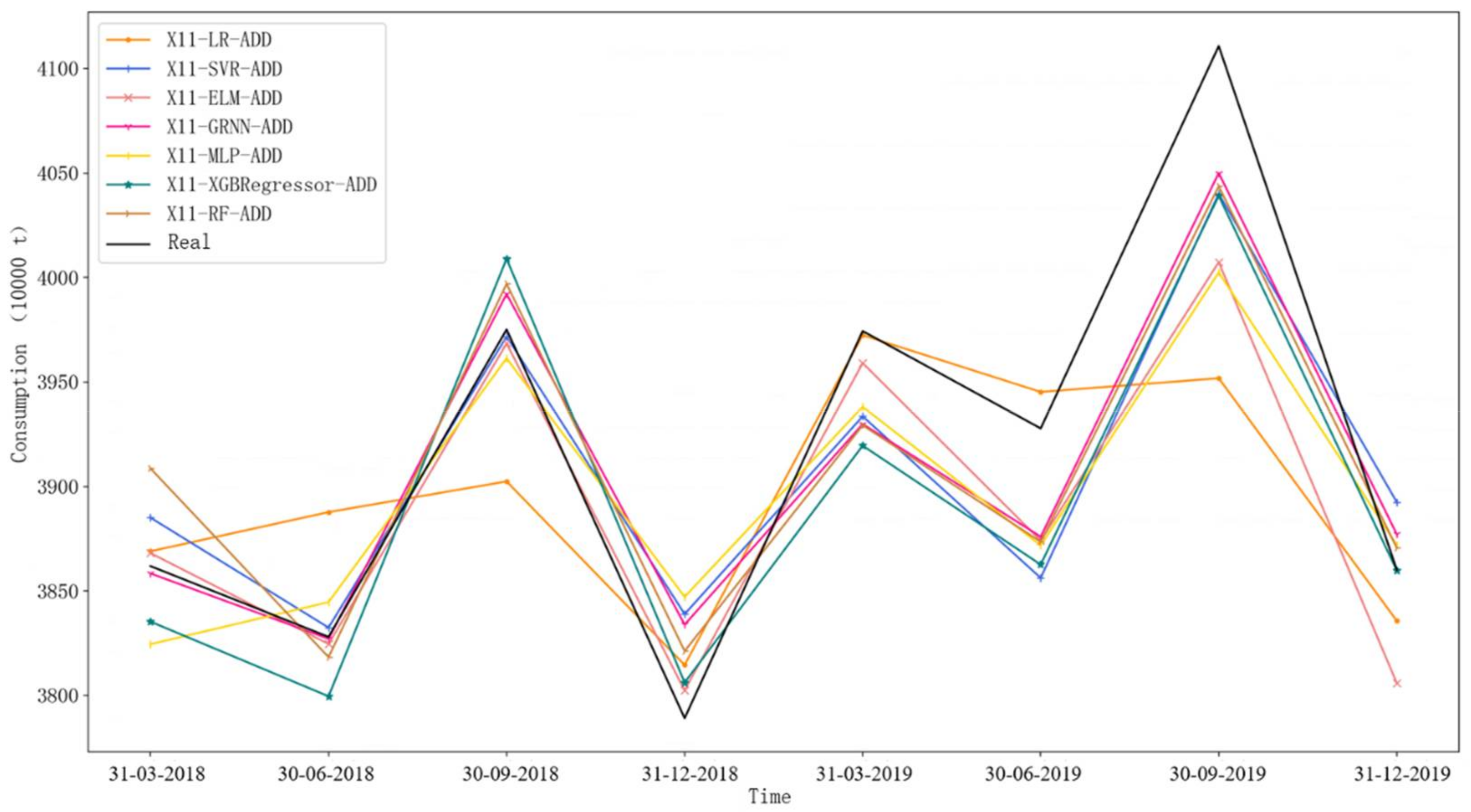
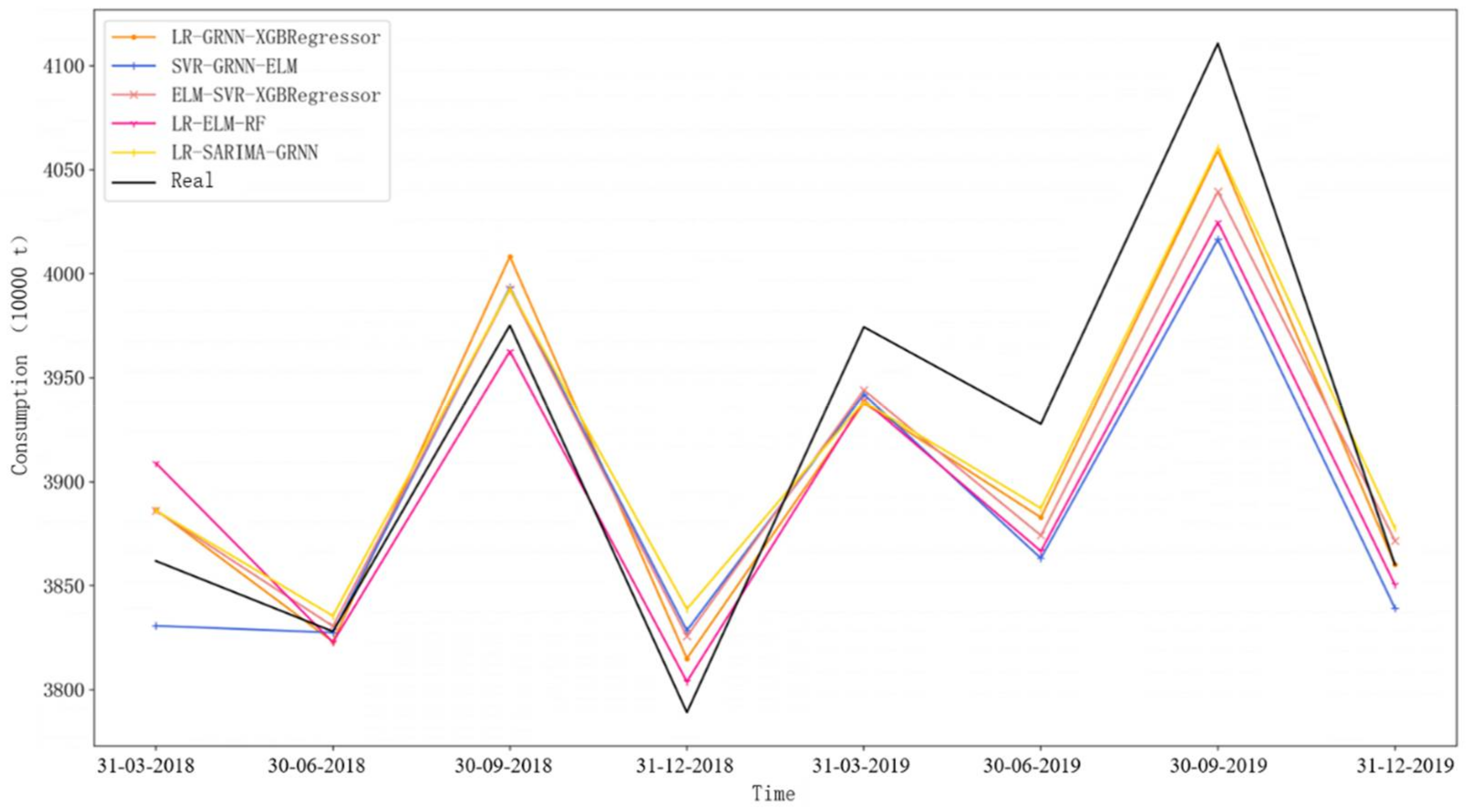
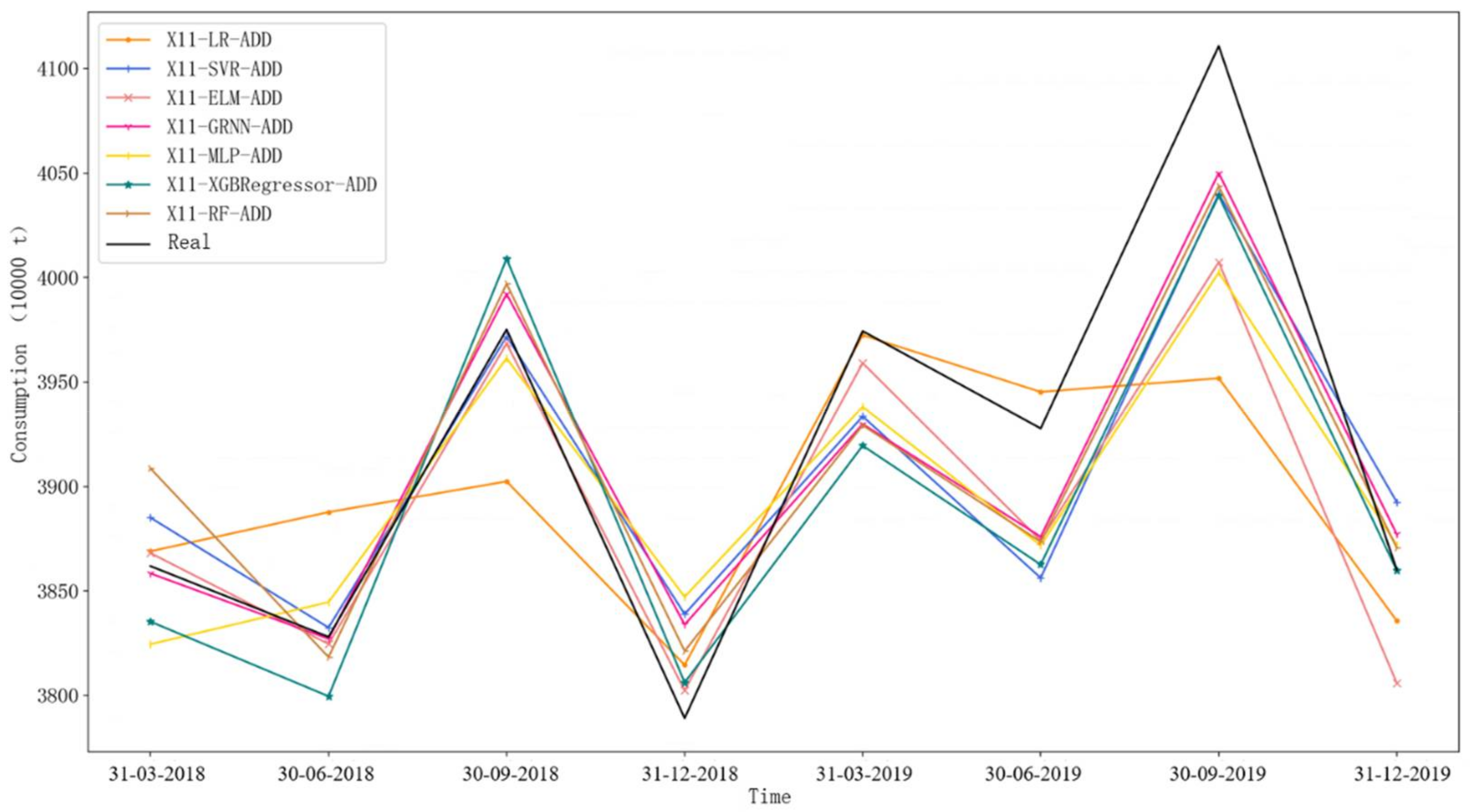
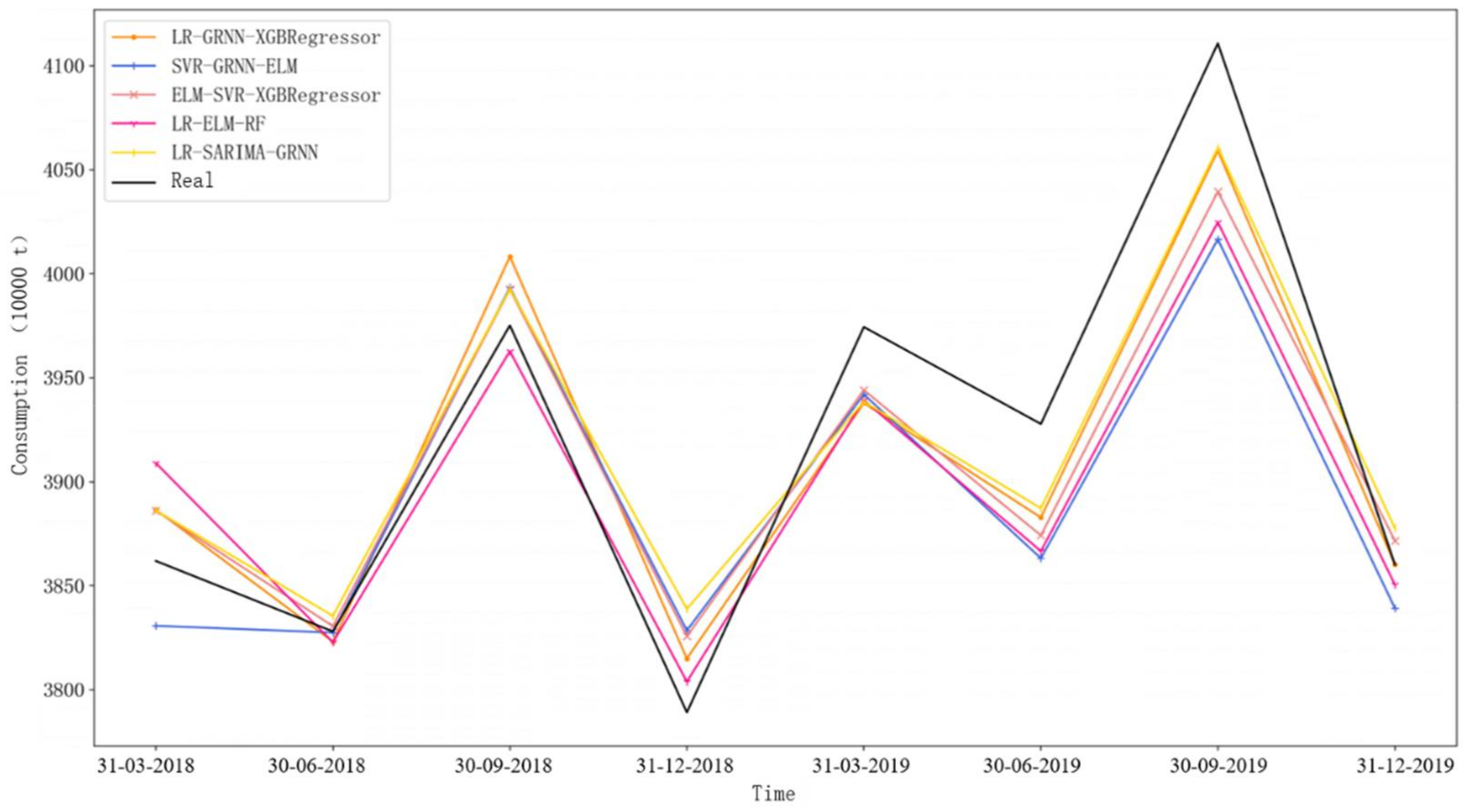
4.3. Experimental Results Analysis
- (1)
- Comparing the decomposition-ensemble prediction model with the single model, it can be found that at 90% confidence degree, the prediction performance of two different decomposition-ensemble models at each step is significantly better than the single models. The main reason for this is that the decomposition-ensemble framework can significantly reduce the complexity of modeling, thereby improving the prediction performance.
- (2)
- By comparing the ordinary decomposition-ensemble model without considering the component data traits with the component data-trait-driven decomposition-ensemble model, it can be found that the latter can significantly improve the prediction accuracy in short-term prediction. For example, in the first-step-ahead prediction, the X11-LR-SARIMA-GRNN-ADD model exhibits a better prediction performance than the other decomposition-ensemble models. This is because this model selects different prediction techniques in terms of the specific data traits of different components in turn, which effectively improves the results of component prediction. This also shows that data-trait-driven modeling plays a key role in gasoline demand forecasting.
- (3)
- Comparing the test results of the single models, the advantages and disadvantages of each model cannot be strictly determined from the statistical perspective when predicting shorter steps (one-step- and two-step-ahead), but for the longer steps (three-step- and four-step-ahead), significant differences are shown between the models. This is due to the fact that short-term predictions tend to achieve more accurate results than long-term predictions, and their difference in prediction performance is not significant. However, in long-term predictions, the predictive power of different forecasting models tends to vary greatly.
5. Discussion and Future Directions
- (1)
- The proposed decomposition-ensemble forecasting model is more suitable for time series data with the traits of trend and periodicity. However, if there are some other data traits such as long-memory, chaos, and fractality in the time series data, the proposed model may not be suitable for such time series data. Therefore, we will continue to explore the time series forecasting methods with other data traits.
- (2)
- Because gasoline demand is affected by multiple factors, it usually shows the coexistence of multiple data traits. This paper only considered two data traits; more data traits should be taken into account, which is also the direction to be studied in the future.
- (3)
- The proposed trend- and periodicity-trait-driven decomposition-ensemble forecasting model can also be applied to other markets, such as precious metal markets, chemical products markets, and other energy markets. Therefore, these new markets will be investigated in the future.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Azadeh, A.; Ghaderi, S.; Sohrabkhani, S. Annual electricity consumption forecasting by neural network in high energy consuming industrial sectors. Energy Convers. Manag. 2008, 49, 2272–2278. [Google Scholar] [CrossRef]
- Bianco, V.; Manca, O.; Nardini, S. Electricity consumption forecasting in Italy using linear regression models. Energy 2009, 34, 1413–1421. [Google Scholar] [CrossRef]
- Kucukali, S.; Baris, K. Turkey’s short-term gross annual electricity demand forecast by fuzzy logic approach. Energy Policy 2010, 38, 2438–2445. [Google Scholar] [CrossRef]
- Wang, S.; Yu, L.; Tang, L.; Wang, S.Y. A novel seasonal decomposition based least squares support vector regression ensemble learning approach for hydropower consumption forecasting in China. Energy 2011, 36, 6542–6554. [Google Scholar] [CrossRef]
- Tang, L.; Yu, L.; Wang, S.; Li, J.P.; Wang, S.Y. A novel hybrid ensemble learning paradigm for nuclear energy consumption forecasting. Appl. Energy 2012, 93, 432–443. [Google Scholar] [CrossRef]
- Tang, L.; Yu, L.; He, K.J. A novel data-characteristic-driven modeling methodology for nuclear energy consumption forecasting. Appl. Energy 2014, 128, 1–14. [Google Scholar] [CrossRef]
- Ahmad, A.S.; Hassan, M.Y.; Abdullah, M.P.; Rahman, H.A.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Tang, L.; Wang, Z.S.; Li, X.X.; Yu, L.; Zhang, G.X. A novel hybrid FA-based LSSVR learning paradigm for hydropower con-sumption forecasting. J. Syst. Sci. Complex. 2015, 28, 1080–1101. [Google Scholar] [CrossRef]
- Akpinar, M.; Yumusak, N. Year Ahead Demand Forecast of City Natural Gas Using Seasonal Time Series Methods. Energies 2016, 9, 727. [Google Scholar] [CrossRef]
- Ruiz, L.G.B.; Rueda, R.; Cuéllar, M.P.; Pegalajar, M.C. Energy consumption forecasting based on Elman neural networks with evolutive optimization. Expert Syst. Appl. 2018, 92, 380–389. [Google Scholar] [CrossRef]
- Yu, L.; Zhao, Y.Q.; Tang, L.; Yang, Z.B. Online big data-driven oil consumption forecasting with Google trends. Int. J. Forecast. 2019, 35, 213–223. [Google Scholar] [CrossRef]
- Yan, K.; Li, W.; Ji, Z.; Qi, M.; Du, Y. A Hybrid LSTM Neural Network for Energy Consumption Forecasting of Individual Households. IEEE Access 2019, 7, 157633–157642. [Google Scholar] [CrossRef]
- Bedi, J.; Toshniwal, D. Deep learning framework to forecast electricity demand. Appl. Energy 2019, 238, 1312–1326. [Google Scholar] [CrossRef]
- Liu, T.; Tan, Z.; Xu, C.; Chen, H.; Li, Z. Study on deep reinforcement learning techniques for building energy consumption forecasting. Energy Build. 2019, 208, 109675. [Google Scholar] [CrossRef]
- Yu, L.; Ma, Y.; Ma, M. An effective rolling decomposition-ensemble model for gasoline consumption forecasting. Energy 2021, 222, 119869. [Google Scholar] [CrossRef]
- Yu, L.; Ma, Y. A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting. Energies 2021, 14, 4604. [Google Scholar] [CrossRef]
- Yue, S.; Pilon, P.; Cavadias, G. Power of the Mann–Kendall and Spearman’s rho tests for detecting monotonic trends in hy-drological series. J. Hydrol. 2002, 259, 254–271. [Google Scholar] [CrossRef]
- Osborn, D.R.; Chui, A.; Smith, J.P.; Birchenhall, C.R. Seasonality and the order of integration for consumption. Oxf. Bull. Econ. Stat. 2010, 50, 361–377. [Google Scholar] [CrossRef]
- Ladiray, D.; Quenneville, B. Seasonal Adjustment with the X-11 Method; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econ. Stat. 1995, 13, 134–144. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Lag Order | Critic Value | t Statistic |
| Gasoline demand | 2 | −1.9520 | −1.2621 |
| 3 | −1.9176 | −2.800 | |
| 4 | −1.8927 | −1.2130 | |
| 5 | −1.8735 | −5.3354 |
| Step Size | Metric | LR | SVR | ELM | GRNN | MLP | XGB | RF |
| One step | Dstat | 0.6250 | 0.1250 | 0.7500 | 0.5000 | 0.2500 | 0.6250 | 0.6250 |
| MAPE | 0.0240 | 0.0324 | 0.0222 | 0.0305 | 0.0264 | 0.0311 | 0.0244 | |
| RMSE | 112.6617 | 155.6208 | 94.9666 | 130.8414 | 117.6011 | 135.2791 | 112.6359 | |
| Two steps | Dstat | 0.5000 | 0.7500 | 0.5000 | 0.5000 | 0.2500 | 0.7500 | 0.6250 |
| MAPE | 0.0262 | 0.0415 | 0.0264 | 0.0295 | 0.0285 | 0.0300 | 0.0263 | |
| RMSE | 120.4158 | 196.1568 | 118.4198 | 138.8445 | 125.4783 | 139.5928 | 121.6565 | |
| Three steps | Dstat | 0.5000 | 0.2500 | 0.5000 | 0.3750 | 0.3750 | 0.3750 | 0.3750 |
| MAPE | 0.0361 | 0.0553 | 0.0330 | 0.0262 | 0.0251 | 0.0310 | 0.0300 | |
| RMSE | 146.9760 | 270.0291 | 136.0105 | 142.7566 | 122.1430 | 167.1368 | 156.0496 | |
| Four steps | Dstat | 0.6250 | 0.6250 | 0.6250 | 0.5000 | 0.2500 | 0.5000 | 0.3750 |
| MAPE | 0.0322 | 0.0767 | 0.0264 | 0.0322 | 0.0347 | 0.0336 | 0.0365 | |
| RMSE | 149.0826 | 332.0082 | 133.9106 | 143.4993 | 146.9649 | 149.6941 | 160.8493 |
| Step Size | Metric | X11-LR-ADD | X11-SVR-ADD | X11-ELM-ADD | X11-GRNN-ADD | X11-MLP-ADD | X11-XGB-ADD | X11-RF-ADD |
| One step | Dstat | 0.6250 | 0.7500 | 0.7500 | 0.7500 | 0.6250 | 0.7500 | 0.7500 |
| MAPE | 0.0115 | 0.0094 | 0.0134 | 0.0076 | 0.0107 | 0.0094 | 0.0088 | |
| RMSE | 66.8267 | 44.5502 | 72.2153 | 36.9964 | 51.9117 | 43.7886 | 39.2769 | |
| Two steps | Dstat | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0174 | 0.0091 | 0.0087 | 0.0087 | 0.0125 | 0.0103 | 0.0099 | |
| RMSE | 87.1333 | 41.8056 | 47.4198 | 40.2201 | 57.0031 | 45.2247 | 42.1567 | |
| Three steps | Dstat | 0.7500 | 0.7500 | 0.6250 | 0.7500 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0156 | 0.0097 | 0.0134 | 0.0096 | 0.0132 | 0.0089 | 0.0121 | |
| RMSE | 79.8560 | 44.9304 | 64.0893 | 45.3510 | 61.2052 | 43.0854 | 50.6549 | |
| Four steps | Dstat | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0109 | 0.0087 | 0.0078 | 0.0078 | 0.0092 | 0.0089 | 0.0099 | |
| RMSE | 51.8899 | 43.1658 | 39.3814 | 40.1956 | 43.9967 | 40.4888 | 44.4135 |
| Step Size | Metric | X11-LR-GRNN-XGB-ADD | X11-SVR-GRNN-ELM-ADD | X11-ELM-SVR-XGB-ADD | X11-LR-ELM-RF-ADD | X11-LR-SARIMA-GRNN-ADD |
| One step | Dstat | 0.7500 | 0.7500 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0077 | 0.0096 | 0.0080 | 0.0092 | 0.0070 | |
| RMSE | 33. 8595 | 46.1372 | 38.1287 | 48.9500 | 32. 4460 | |
| Two steps | Dstat | 0.7500 | 0.6250 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0083 | 0.0107 | 0.0079 | 0.0080 | 0.0100 | |
| RMSE | 33.9634 | 50.4139 | 34.4110 | 34.1056 | 41.2624 | |
| Three steps | Dstat | 0.7500 | 0.6250 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0099 | 0.0123 | 0.0092 | 0.0102 | 0.0128 | |
| RMSE | 42.4172 | 54.3939 | 39.2703 | 45.5302 | 52.1904 | |
| Four steps | Dstat | 0.7500 | 0.6250 | 0.7500 | 0.7500 | 0.7500 |
| MAPE | 0.0099 | 0.0082 | 0.0096 | 0.0100 | 0.0116 | |
| RMSE | 47.2062 | 41.2325 | 48.8391 | 45.3290 | 49.0334 |
| Model | X11-SVR-GRNN-ELM-ADD | X11-ELM-ADD | X11-GRNN-ADD | ELM | SVR | MLP | LR |
| X11-LR-SARIMA-GRNN-ADD | −1.38 (0.17) | −2.31 (0.02) | −0.14 (0.89) | −4.50 (0.00) | −3.20 (0.00) | −4.09 (0.00) | −2.68 (0.01) |
| X11-SVR-GRNN-ELM-ADD | −2.23 (0.03) | 1.45 (0.15) | −4.31 (0.00) | −3.12 (0.00) | −3.90 (0.00) | −2.29 (0.02) | |
| X11-ELM-ADD | 2.58 (0.01) | −1.62 (0.11) | −2.17 (0.03) | −1.96 (0.05) | −1.04 (0.30) | ||
| X11-GRNN-ADD | −3.82 (0.00) | −3.07 (0.00) | −4.19 (0.00) | −2.44 (0.01) | |||
| ELM | −1.37 (0.17) | −0.64 (0.52) | −0.29 (0.77) | ||||
| SVR | 0.91 (0.36) | 0.81 (0.42) | |||||
| MLP | 0.30 (0.76) |
| Model | X11-SVR-GRNN-ELM-ADD | X11-ELM-ADD | X11-GRNN-ADD | ELM | SVR | MLP | LR |
| X11-LR-SARIMA-GRNN-ADD | −0.26 (0.80) | −1.01 (0.31) | 0.97 (0.33) | −4.05 (0.00) | −2.94 (0.00) | −3.54 (0.00) | −2.83 (0.00) |
| X11-SVR-GRNN-ELM-ADD | −1.53 (0.13) | 1.13 (0.26) | −3.21 (0.00) | −2.92 (0.00) | −3.80 (0.00) | −2.16 (0.03) | |
| X11-ELM-ADD | 1.87 (0.06) | −2.96 (0.00) | −2.63 (0.01) | −3.31 (0.00) | −1.88 (0.06) | ||
| X11-GRNN-ADD | −3.60 (0.00) | −2.91 (0.00) | −4.17 (0.00) | −2.55 (0.01) | |||
| ELM | −1.18 (0.24) | −0.06 (0.95) | 0.72 (0.47) | ||||
| SVR | 1.27 (0.20) | 1.30 (0.19) | |||||
| MLP | 0.25 (0.80) |
| Model | X11-SVR-GRNN-ELM-ADD | X11-ELM-ADD | X11-GRNN-ADD | ELM | SVR | MLP | LR |
| X11-LR-SARIMA-GRNN-ADD | 0.10 (0.92) | 1.54 (0.12) | −1.97 (0.05) | −4.35 (0.00) | −2.73 (0.01) | −1.83 (0.07) | −5.96 (0.00) |
| X11-SVR-GRNN-ELM-ADD | −2.37 (0.02) | 1.58 (0.11) | −3.31 (0.00) | −2.79 (0.01) | −2.06 (0.04) | −3.94 (0.00) | |
| X11-ELM-ADD | −0.34 (0.74) | −4.15 (0.00) | −2.84 (0.00) | −2.48 (0.01) | −4.91 (0.00) | ||
| X11-GRNN-ADD | −3.86 (0.00) | −2.82 (0.00) | −2.23 (0.03) | −5.06 (0.00) | |||
| ELM | −1.65 (0.10) | 1.04 (0.30) | −1.33 (0.18) | ||||
| SVR | 2.51 (0.01) | 1.18 (0.24) | |||||
| MLP | −1.25 (0.21) |
| Model | X11-SVR-GRNN-ELM-ADD | X11-ELM-ADD | X11-GRNN-ADD | ELM | SVR | MLP | LR |
| X11-LR-SARIMA-GRNN-ADD | 1.03 (0.30) | 0.67 (0.50) | 1.29 (0.20) | −2.40 (0.02) | −4.65 (0.00) | −4.37 (0.00) | −3.09 (0.00) |
| X11-SVR-GRNN-ELM-ADD | −0.36 (0.72) | 0.74 (0.46) | −2.16 (0.03) | −5.00 (0.00) | −5.54 (0.00) | −2.60 (0.01) | |
| X11-ELM-ADD | 0.61 (0.54) | −2.61 (0.01) | −4.76 (0.00) | −3.96 (0.00) | −3.20 (0.00) | ||
| X11-GRNN-ADD | −2.14 (0.03) | −4.89 (0.00) | −6.10 (0.00) | −2.57 (0.01) | |||
| ELM | −3.30 (0.00) | −0.40 (0.69) | −1.13 (0.26) | ||||
| SVR | 3.44 (0.00) | 3.08 (0.00) | |||||
| MLP | 0.25 (0.81) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Zhao, J. Trend- and Periodicity-Trait-Driven Gasoline Demand Forecasting. Energies 2022, 15, 3553. https://doi.org/10.3390/en15103553
Zhang J, Zhao J. Trend- and Periodicity-Trait-Driven Gasoline Demand Forecasting. Energies. 2022; 15(10):3553. https://doi.org/10.3390/en15103553
Chicago/Turabian StyleZhang, Jindai, and Jinlou Zhao. 2022. "Trend- and Periodicity-Trait-Driven Gasoline Demand Forecasting" Energies 15, no. 10: 3553. https://doi.org/10.3390/en15103553
APA StyleZhang, J., & Zhao, J. (2022). Trend- and Periodicity-Trait-Driven Gasoline Demand Forecasting. Energies, 15(10), 3553. https://doi.org/10.3390/en15103553