1. Introduction
The share of renewable energies for gross power consumption in Germany rose to 45.4% in 2020 [
1]. To achieve the climate targets defined in international and national agreements, the government plans to increase this share up to 65% in 2030 [
2]. The associated decentralization of the power grid architecture with fluctuating feed-in leads to new requirements regarding a reliable power grid operation [
3]. Due to the different characteristics of distributed energy resources (DERs) in comparison to conventional generators, a new way of providing ancillary services is necessary, especially in local voltage control [
4]. Additionally, the number of loads and generating plants connected to the lower voltage level increased in the last couple of years and an ongoing increase in future can be expected [
5]. For example, the government’s goal is a number of seven to ten million registered electric vehicles (EVs) in Germany in 2030 [
2]. This expectation increases the challenge of grid voltage stabilization even more because every active grid participant affects the voltage and the variety of different grid scenarios caused by parallel activation of different loads and generators increases. The overarching goal of voltage control is to remain inside a tolerance band of
% of the nominal voltage [
6]. To guarantee a stable voltage in the long term despite these developments on both sides of a grid connection point, there is a need for further development on using the abilities of power electronics and the inverters, which are the interfacing devices to the power grid for most of the DERs. Current approaches to achieve voltage stability were reviewed by Mahmud and Zahadi [
7]. Some advanced methods for voltage control enable inverters to contribute to decentralized voltage control. Especially, there are different voltage control strategies with a fixed
, or
[
8]. Another approach is the usage of machine learning for reactive power control of inverters. For this, both centralized and decentralized approaches based on reinforcement learning were developed [
9,
10,
11,
12,
13].
Moreover, the implementation of energy management systems and the scheduling and monitoring of active devices is another research field contributing to an increase in energy efficiency and grid stabilization. In this research field, the so called non-intrusive load monitoring (NILM) is a growing topic. It deals with the recognition of loads in households or industrial buildings by disaggregation of aggregated data acquired from a single point of measurement like smart meters and was founded by Hart [
14]. The general idea of NILM is to exploit the repeated appliance of particular loads in a building profile and their associated, repeated patterns in the measurement data. An overview of different NILM approaches was given by Aladesanmi and Folly [
15]. They listed techniques based on active and reactive power as well as voltage and current. Faustine et al. described event-based and state-based NILM algorithms, and they mentioned two different signatures to rely on: transient signatures, which were used by Ghosh et al. [
16] and Athanasiadis et al. [
17], and steady-state signatures [
18]. In addition, as state-of-the-art algorithms regarding NILM, they described for example hidden Markov models and deep learning approaches using recurrent neural networks and convolutional neural networks [
17,
18]. Huber et al. reviewed the current status in Low-Frequency-NILM using deep learning and discussed aspects like neural network architectures, data input shape, and windowing the time series data [
19]. Next to a variety of distinct electrical features for NILM, Bernard differentiated NILM tasks with deep learning in supervised and unsupervised learning, before he decided to develop an unsupervised learning technique to disaggregate the measured load profile of a household [
20]. Furthermore, Brucke et al. proposed an unsupervised approach connecting to a forecast of load state changes [
21]. Besides, Parson et al. combined a supervised approach for development of probabilistic models of appliances and an unsupervised approach to fine-tune these models by aggregated household data with the goal to overcome the challenge of unlabeled appliances [
22]. However, Zufferey et al. successfully demonstrated a supervised learning approach using power, voltage, and current signatures of distinct loads to recognize electric loads based on their consumption profiles [
23]. They developed stochastic models for appliance classes and used k-Nearest Neighbor algorithm and Gaussian mixture models. By de Souza et al., a supervised learning approach based on a detection machine was proposed to figure out when a load is turned on or off [
24]. Another example for modeling the NILM task as a supervised learning setting was given by Basu et al., who presented a temporal multi-label classification using sliding windows, binary label vectors and different machine learning algorithms [
25]. Also, Singh and Majumbdar formulated a multi-label classification task with a sparse representation approach based on the assumption that for every test sample there is a representation as a linear combination of training samples [
26]. Furthermore, Ruzzelli et al. developed a concept for profiling appliances, building a training dataset, and learning a neural network to recognize the active appliances in real time [
27].
Generally, in NILM the data are often acquired directly at the grid connection point of a building, so that the observing direction is from the grid connection point to the consumer or prosumer side to investigate the load behavior inside the building. In this paper, the idea is to invert this observing direction to analyze load behavior at surrounding grid connection points additionally. This means, the challenge for the proposed method is the online recognition of loads based on their characteristic voltage profiles, while their influence on the grid voltage measured at a particular grid connection point is affected by the size of the load, its grid position, the local grid topology, and also the total number of active loads. So, in a sense, the appearance of a load in the grid voltage depends on more grid properties than in NILM scenarios.
The author’s future vision is to develop a self-learning inverter, which independently analyzes the measured voltage data at the inverter’s grid connection point, recognizes patterns in the data, and derives the optimal control strategy for active and reactive power management to stabilize the power grid without additional information. The first step of this development is the analysis of the conditions inside the local grid environment experienced by an inverter. This leads to the following idea of this study, which provides a setting similar to NILM tasks, demonstrated with an example of two EVs. As mentioned above, the field of e-mobility will be expanded in the upcoming years, so that the number of EVs will increase [
2]. The corresponding charging stations are usually installed in the low voltage level and the EVs have a significant impact on the voltage behavior in local grid environments as investigated by Dharmakeerthi et al. [
28]. The intelligent inverter will measure the grid voltage. Because of the possible high demand in power during the charging process of EVs, the inverter will observe significant changes in the voltage signal. Over the course of time, an EV with a characteristic charging profile, which depends on the EV type, the charging status, the temperature, and the maximum charging power, will be charged at different times of the day, and it might even change the location for charging in the grid. Nevertheless, it can be assumed that every time it is charged, it will cause a similar voltage pattern. The inverter will learn and recognize this repeated pattern. Consequently, it will be able to adapt the feed-in of active and reactive power for its specific local grid environment. Thus, it will be able to derive the optimal control strategy to stabilize the grid based on the learned voltage patterns.
Therefore, in this paper, a method to classify particular load types in a local grid based on the voltage level observed at the inverter’s grid connection point is presented. The main contributions of this paper can be listed as follows:
- (1)
The proposed method can be used in an online manner to recognize large loads in the local grid environment within a time range of a few hundreds of seconds while only using the measured voltage level. Instead of observing households, the surrounding grid environment can be analyzed and grid participants from other grid connection points can be recognized.
- (2)
A concept how to generate a dataset to train a recognition algorithm without a need for extensive simulation effort is provided.
- (3)
For demonstration, the developed method is applied to simplified grid situations with only two EVs charging in a test grid structure, which represents a proof of concept for this method.
- (4)
It is shown that in low voltage distribution grids the relative location of the active loads, the transformer, and the inverter influences the load recognition accuracy in a significant manner.
- (5)
The results of the investigations in this study indicate that in comparison to multi-layer perceptrons the convolutional neural networks are the better choice to use for load recognition in time series data.
This paper is organized as follows. In
Section 2, the overall recognition approach is described in detail and it is presented how the recognition is optimized. This is followed by
Section 3, where the recognition results of the example demonstration on two EVs are shown. In the second part of this section, the influence of different line lengths between transformer, inverter, and a load in a test grid is investigated. The results are discussed in
Section 4, and this paper is concluded in
Section 5.
2. Materials and Methods
2.1. General Concept
The overall goal of the methodology presented in this paper is the recognition of repeated voltage patterns. To achieve this, the recognition was considered as a (multi-dimensional) time series classification task. This means that based on the voltage data the states of selected load classes were identified.
On the one hand, a class could be defined as a single load, that is, the corresponding load profile should be detected in the voltage signal. On the other hand, a class could be seen as the load type, so that a couple of load profiles could be categorized in the same way.
Mathematically expressed, the task can be formulated as following:
2.1.1. General Task Formulation
Let be the m-dimensional feature space. This means, there are m different variables measured or computed. The input of the classification algorithm would be a continuously provided time series with and representing a 1 s-resolution for data acquisition.
To train the classification algorithm, the multi-dimensional time series is cut with a sliding window approach as used by Krystalakos et al. [
29]. In this approach, a window length
n is defined. This window is shifted along the time series using a step-size of 1 s, and each of the shifted windows with the last
n data points is used as one sample. Then, a window
w at time
has the form
.
The output of the algorithm is desired as a binary status of every class. This means, the output vector’s dimension is defined as the number of trained classes, which is denoted by c. The entries of this vector are equal to 1, if the corresponding class is active, or equal to 0, if not. The corresponding binary vectors representing the class states are used as labels to formulate the whole task as a supervised learning problem.
Therefore, the desired classification mapping is
This type of formulation of a classification task refers to so called multi-label classification. It was also used in other applications like image classification [
30,
31,
32] and in the field of NILM by Basu et al. [
25], Singh and Majumbdar [
26], and by Massidda et al. [
33].
Because of the vision of a standalone inverter, which should be able to adjust the active and reactive power management in terms of repetitive load profiles of electrical loads in its grid environment, the recognition concept was based only on data measured at the grid connection point. In detail, the voltage values from the three phases of the power grid were used as root-mean-squared values in 1 s-resolution, related to the nominal voltage (per unit specification). This setting was chosen under the assumption that loads do not change their status (active or inactive) within one second more often than once. Additionally, the voltage harmonics caused by activation of a load at other grid connection points than the measurement point are not recognizable over that distance. If only symmetric loads are active, the voltage is very similar for each grid phase. Nevertheless, it was useful to include all three phases in the input data generated in this concept because there are asymmetric loads. The classification algorithm received not only the raw measured voltage values as an input, but also computed data as kind of a derivative. In detail, it was the difference of the current value () to the value one time-step before (). The idea for this additional feature was to avoid a recognition only based on absolute values, which could easily lead to an incorrect classification of voltage patterns with slightly different magnitudes.
In total, this led to the special case of
in Equation (
1) as follows.
2.1.2. Example Task Formulation
Let be the six-dimensional feature space and S be a multi-dimensional time series, while is the number of trained classes and n is the window length. The variable denotes the voltage at time t from grid phase and represents the difference between the voltage values from time t and on grid phase i. Furthermore, let be the data point at time t with . Then, one sample at time has the form .
Finally, the classification task is to find a mapping
For the classification machine learning was applied. This was reasoned by the repeated voltage patterns and the many complex pattern recognition problems machine learning could already solve successfully, e.g., in fields of image classification [
34,
35,
36], face recognition [
37], speech recognition [
38,
39], games [
40], and various time series classification applications [
41].
In this use case, the algorithm had to learn the underlying relation of voltage drops in power lines and the activation of particular loads causing power flow through the lines. The corresponding formula for voltage drop calculation in a power grid is
with voltage
V, line length
L, current
I, power factor
, specific conductance
and conductor cross-section
q [
42].
Because the overall goal is to achieve a stable power grid, some knowledge about loads which are active in the local grid environment around an inverter would be helpful to be able to derive an optimal control of active and reactive power feed-in. Therefore, in the recognition phase it is necessary to have a clear assignment to a class of loads. By this requirement, unsupervised learning approaches like mentioned in the introduction regarding the field of NILM were excluded (e.g., [
20]).
2.2. Algorithm Selection
If this concept would be applied in a real power grid, there would be a huge number of active loads, load types, and trainable classes, so that the classification task would be very complex. Furthermore, a situation would be conceivable in which the trained algorithm should be extended to a new load class, so the output vector’s length would be increased. From these future challenges regarding a high complexity and a possible extensibility, it can be concluded that artificial neural networks are assessed as a good choice to use for the underlying problem.
In this paper, two popular architectures of neural networks were investigated.
2.2.1. Multi-Layer Perceptron Neural Network (MLP)
A multi-layer perceptron network consists of an input layer, some hidden fully connected layers, and an output layer. In a classification setting, the input layer gets an input vector of a previously specified length and processes the input. The results are passed to the next hidden layer. Here, in each unit (neuron) of the layer a weighted sum is computed. This sum is used as an input for a (non-linear) activation function and the returned value is given to the neurons of the next layer. At the end, a single output layer returns the overall output of the neural network. Depending on the structure of the task to be solved, this layer consists of as many neurons as classes considered in training. Furthermore, depending on the kind of implementation, e.g., the output is a vector containing values between zero and one. These can be interpreted as the confidence of the MLP to classify the input into the corresponding class. For example, these values can be rounded to get the desired binary output vector.
The MLP architecture was tested in the course of this paper because it is the simplest neural network architecture.
2.2.2. Convolutional Neural Network (CNN)
A convolutional neural network generally consists of an input layer, a sequence of convolutional and pooling layers, a sequence of fully-connected layers, and an output layer. Applied to the time series classification setting, the input layer gets a matrix representing a section of the multi-dimensional time series. In a convolutional layer a specified number of filters with predefined sizes (kernel size) is shifted over the layer’s input and discrete convolutions are computed. The results are forwarded to a pooling layer, in which a down-sampling method for dimensionality reduction is applied. At the end of the architecture, a variable number of fully-connected layers as in MLPs is used and the output is returned as a vector of values between 0 and 1 as the output layer of an MLP provides it. As for MLPs, a rounding step can be implemented to get the desired binary output vector.
This type of a neural network is often used in image applications because it is very powerful in pattern recognition, e.g., [
34,
37]. In Keras API, there is also an adapted version of convolutional layers called
available [
43]. This version is offered especially for usage of convolutional layers in time series applications and uses filters shifted only in the time direction instead of two directions as in image applications.
2.3. Training Environment
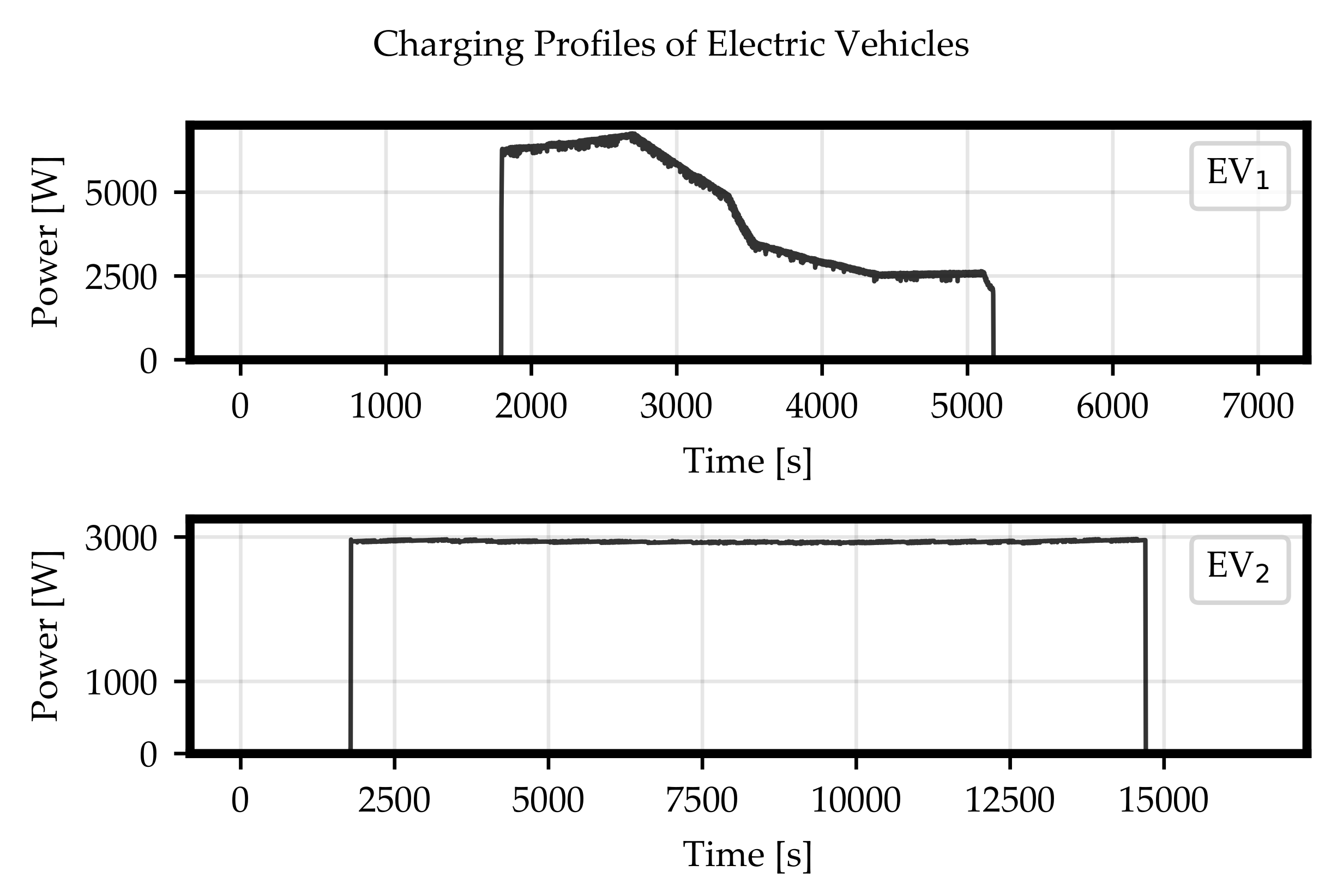
To solve the described multi-label time series classification task with neural networks, the weights had to be trained, and therefore a training dataset was needed. This dataset had to represent the possible scenarios a classification algorithm could face in the real application. In this paper, the task was simplified to just two EVs (see
Figure 1) symmetrically charging in a reference grid (see
Figure 2), such that the considered classes were represented by these EVs (
).
The procedure to generate a suitable training dataset is described in the following paragraphs.
2.3.1. Phase 1—Power Profiles
The first step of dataset generation is the power profile collection of the load classes to be recognized. For this, data sheets or laboratory measurements can be considered. This step is optional because the algorithm is trained on voltage data, not power values. This means, Phase 1 can be skipped if appropriate voltage data are already available.
For this paper, two active power profiles measured in 1 s-resolution located at two charging stations at the DLR were used (see
Figure 1). The corresponding measurement devices offered a resolution of around
V. Because of this, the entire simulated data used in this paper were rounded to this resolution [
44].
2.3.2. Phase 2—Voltage Profiles
The second step dealt with the simulation of the corresponding voltage profiles belonging to the desired load classes. So, a grid structure was needed to simulate the grid behavior during active periods of these classes.
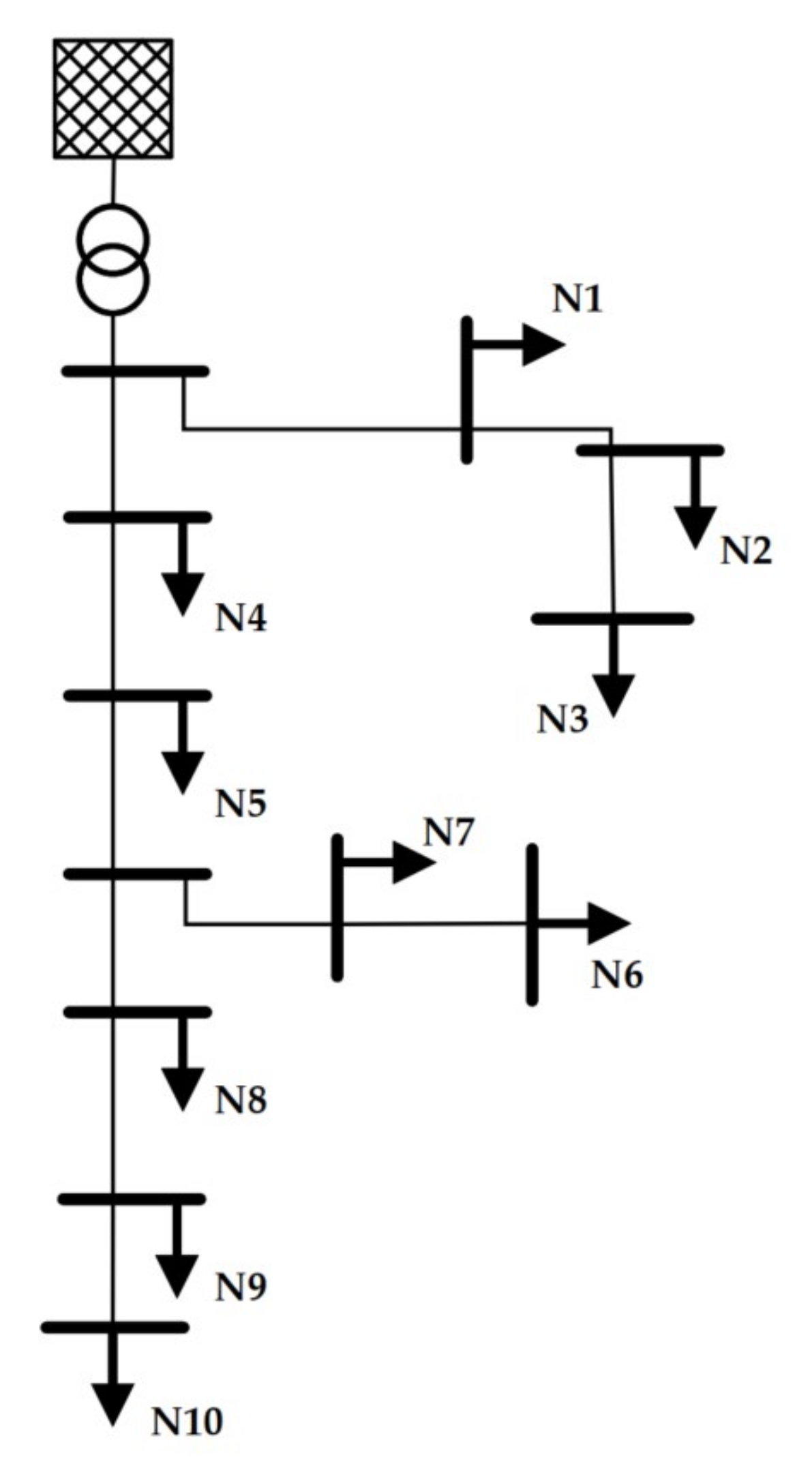
For this, a power grid model was built in MATLAB/Simulink (Release 2020b), presented in
Figure 2. As the model was a three-phase–21-bus system developed in the
Merit Order Netzausbau 2030 (MONA) project, it represented a European low voltage distribution grid with ten possible grid connection points operating at nominal grid frequency of 50 Hz and 400 V as nominal voltage [
45]. At each grid connection point one
Three-Phase Dynamic Load block from the MATLAB toolbox
Simscape (add-on
Simscape Electrical) was connected [
46,
47]. This block allows the external control by an array of active and reactive power values. The power grid lines were represented by
Three-Phase PI section line-blocks, in which parameters for line length, resistance, inductance, and capacitance can be defined. The simulation data consisted of three-phase root-mean-square-values scaled by the nominal voltage (per unit, in short pu) in 1 s-resolution. This data were measured at one grid node (
) representing the grid connection point of an inverter. The data were stored in a SQL-database and exported to csv-files.
Figure 2.
Scheme of reference grid number 8 from [
45] with labeled grid nodes.
Figure 2.
Scheme of reference grid number 8 from [
45] with labeled grid nodes.
This model built in MATLAB Simscape can be perfectly used as a validated environment for the machine learning algorithm because the simulation software is commercially provided, the implemented grid topology was developed in a scientific project, and the overall functionality was continuously tested during implementation.
2.3.3. Phase 3—Training Data Generation for Different Grid Connection Points
It is necessary to include the activation of each considered load type at different grid connection points because different locations affect the size of the voltage drops in the profiles. At first, the voltage profiles corresponding to both classes without influence of other grid participants were simulated through external control of one load block at grid node
in the grid model. After this, these profiles were scaled between the allowed voltage limits of 0.9 pu and 1.0 pu with scaling factors equally distributed between 0 and 1 to cover the tolerance band and thus the possible occurring voltage values. In the example of two EVs only five different scaling factors were used to generate five scaled voltage profiles (see
Figure 1) but this number could be adapted to the higher complexity of further investigations. This phase ended with the computation of the corresponding difference feature.
2.3.4. Phase 4—Training Data Generation for Overlapping Periods
It is possible that the trained classes have overlapping active periods. If one profile is shifted along the other, every 1 s-shift means a new activation scenario because the resulting voltage pattern can look significantly different. Therefore, the simulation effort would be immense. So, the huge number of different combinations for this scenario could not be simulated. However, the challenge of limited computer capacities can be solved by the training of neural networks with a reduced number of different overlapping combinations to get a model which is able to generalize the behavior of both classes. For this, one profile was held, while the other one was shifted along it in regular steps, and vice versa. This phase was completed by the computation of the difference feature.
Besides, the neural network has to learn the undisturbed look of the power grid. If the dataset would only consist of samples with labels including an entry equal to 1, the neural network would not be able to learn that the vector is a possible output. Because of this, there were periods with no activation of loads included. All the described single datasets were appended to create a large dataset representing the expected different grid scenarios.
2.3.5. Phase 5—Training Phase
Before training, the corresponding data were preprocessed. More precisely, both features were scaled by
whereas
represents the particular feature value
or
, respectively, (see
Section 2.1, Equation (
2)). The interval
represents the range in which the respective feature values are expected.
The presented load recognition method was applied to two different EVs, which are charged at different grid connection points in the reference grid. This implies that the case of generation plants was not considered. Therefore, the grid voltage was limited upwards to . The lower limit for voltage scaling should be due to the voltage tolerance band on low voltage level of %. The difference values were scaled based on and .
The neural networks in this paper were implemented with Keras API [
43], based on Tensorflow (Version 2.4.0) [
48]. These models were trained by the fit method from Keras in an offline supervised learning setting. This means, the whole training data were collected and labeled before training.
As mentioned in
Section 2.2, the neural networks return vectors from
. For this reason, a rounding step was executed to evaluate the final training results. Within the fit method of Keras a binary cross-entropy function was used to calculate the losses during training and a maximum number of 100 epochs was set. This number might be not completely utilized because the training could be stopped earlier by an Early-stopping-callback function provided by Keras.
Following the described procedure, a final multi-dimensional time series of 239,948 s was obtained. With two classes (
) to train, there were
possible combinations which had to be included in the dataset. These are presented in detail in
Table 1.
The dataset is balanced in that both EVs are activated five times while the other one was inactive. The different shares of the samples were caused by the different lengths of the load profiles. However, despite these differences the neural networks could be successfully trained, as shown in the results section.
2.4. Validation
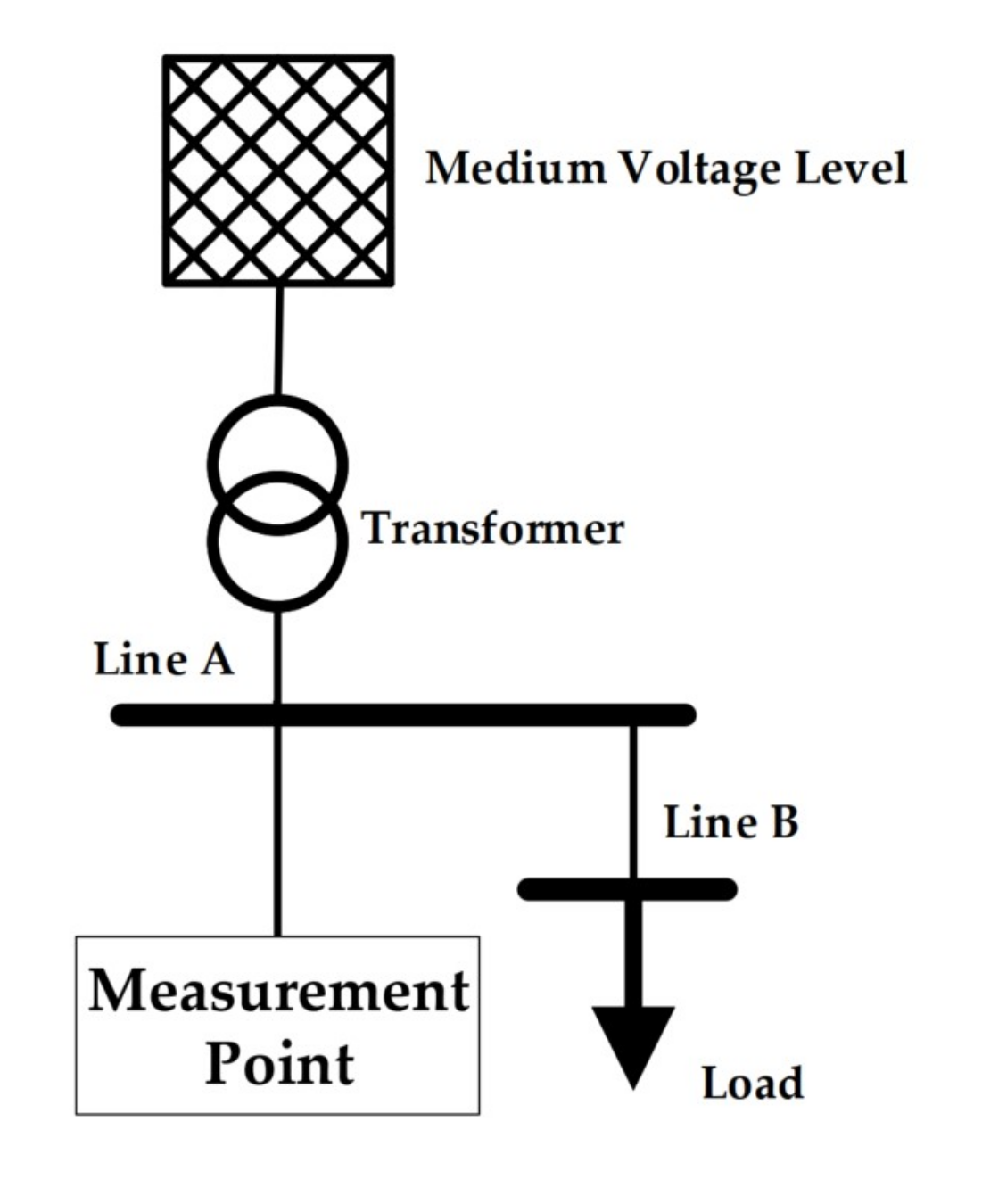
In the validation phase, it was tested whether a trained neural network was able to recognize the status of both EVs correctly, during activation of a single EV and also in parallel activation. The corresponding activation scenarios were simulated in the grid model described in
Section 2.3, whereby the possibility of charging at different grid connection point and overlapping scenarios was taken into account (Phases 3 and 4). For these, the voltage was measured at node
because it is the grid connection point which is farthest away from the transformer. This point was chosen because the voltage fluctuations from all previous nodes have a direct influence on
in particular. How strong these fluctuations at
are depends on the cable lengths between the load and the transformer. The greater the line length, the greater the fluctuation. For this reason, nodes which are far away from the transformer are particularly exposed to strong voltage fluctuations and load recognition is essential to compensate voltage band violations.
For Phase 3, the activation of each type of load was simulated at nodes –. The remaining nodes – are the nearest to the transformer and the farthest to the measurement point. From a real application perspective, it is more desirable to have an accurate performance in the near environment of an inverter’s grid connection point than far away from that node because the closer loads have higher impact to the voltage at the specific node. So, it has to be avoided that a neural network is optimized such that the classification accuracy is increased at grid nodes –, while the accuracy might drop for the other grid nodes. This was achieved by omission of scenarios at nodes –.
Each considered node yielded a single time series for each trained class: In the first half no load was active and in the second one the specific load was activated. By this, it was possible to validate the steps 1, 2, and 4 from
Table 1.
Besides for Phase 4, some datasets were needed to investigate the ability of the neural network to recognize the class states during overlapping scenarios (
Table 1, step 3). With this goal, one scenario for a charging process of EV
at node
and one of EV
at node
was simulated. Another dataset contained the measured values from a simulation with EV
charged at node
and EV
active at node
. The shifts were randomly computed as 7453 s and 2335 s, respectively. These two overlapping scenarios were chosen under consideration of the grid section used in validation. The first one represents the activation of EV
close to the measurement point while EV
was located at the farthest node considered in validation. By this setting, it could be tested whether a neural network is able to separate a pattern from a far node and a pattern caused at a close node. In contrary, the second scenario consists of an EV
closer to the measurement point than EV
. With this scenario, it could also be validated whether two patterns generated close to each other can be separated by the trained classifier. Because of the specific form of the EV
’s pattern similar to a rectangle, it has been decided to use just a single shift per location setting of both EVs.
This procedure led to 7 + 7 + 2 = 16 scenarios for validation. After simulation, the entire data were preprocessed in the same way as described in
Section 2.3, Phase 5. Then, the trained neural network was used to run a classification for each single dataset
k.
2.5. Evaluation
When a neural network is used to classify the validation data, a metric is necessary to evaluate the classification performance and to be able to compare the results of different neural networks.
This metric had to include a recognition accuracy of all classes. Besides, it should be considered that the neural network was required to have correct classifications for active, inactive and overlapping times for all classes. Because of this, the accuracies based on all correctly classified samples were used in Equation (
5). By the product term, a neural network was penalized if it focused on just learning one class, while others were ignored. The maximum value was only reachable if a neural network was able to classify both classes in a right way.
With
in the focused case of this paper, the formula for the accuracy corresponding to a single dataset
k was
with
, where
was the total number of samples of dataset
k. Further,
denoted the number of true negatives for class
i, which is the number of samples correctly classified as inactive, and
was the number of true positives for class
i, which is analogously the number of samples correctly classified as active.
The final score for the total validation had to be balanced for the two cases where just one EV is activated and the overlapping case. This was achieved by computation of a weighted sum with equal sums of weights for these three categories and equal weights within the categories:
with weights
satisfying
and
,
. While the datasets for overlapping cases were associated with
, it was required that
Obviously, it was
. Therefore, the highest achievable score for the neural network in validation phase is
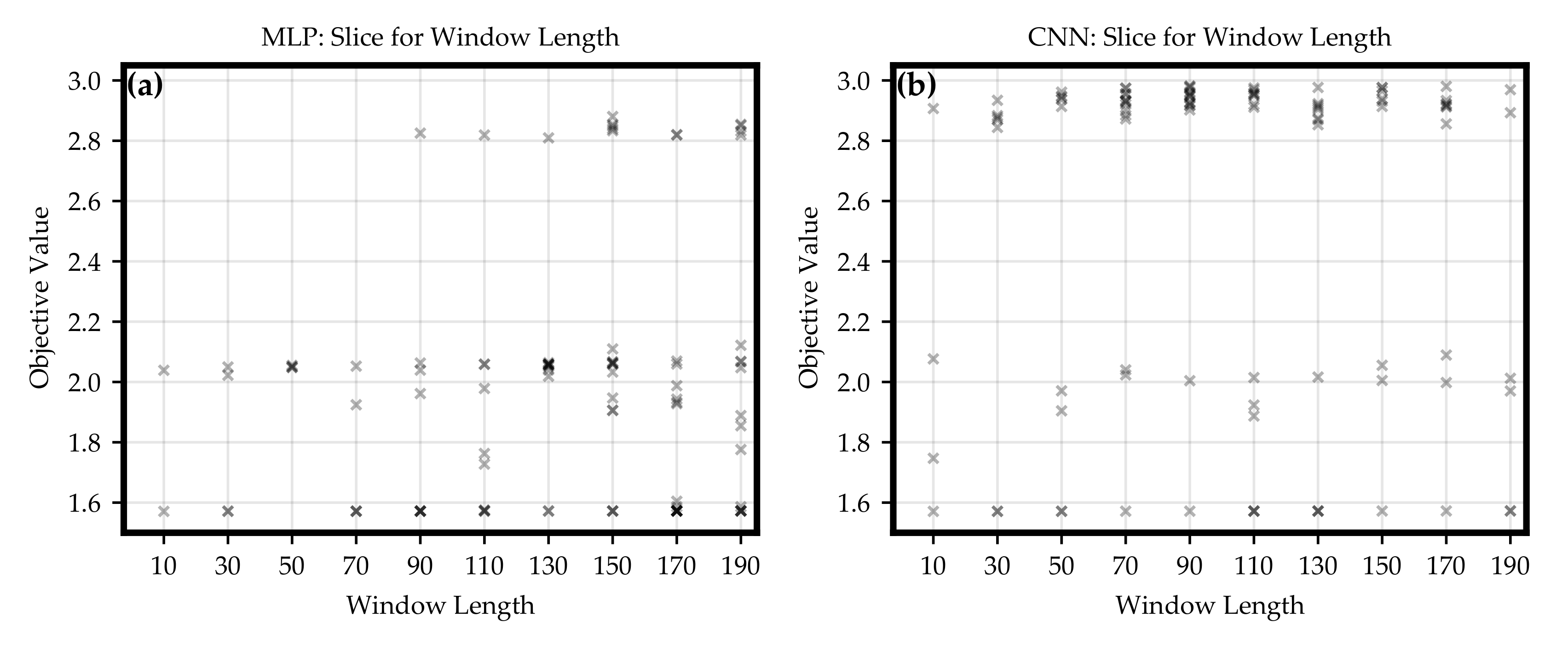
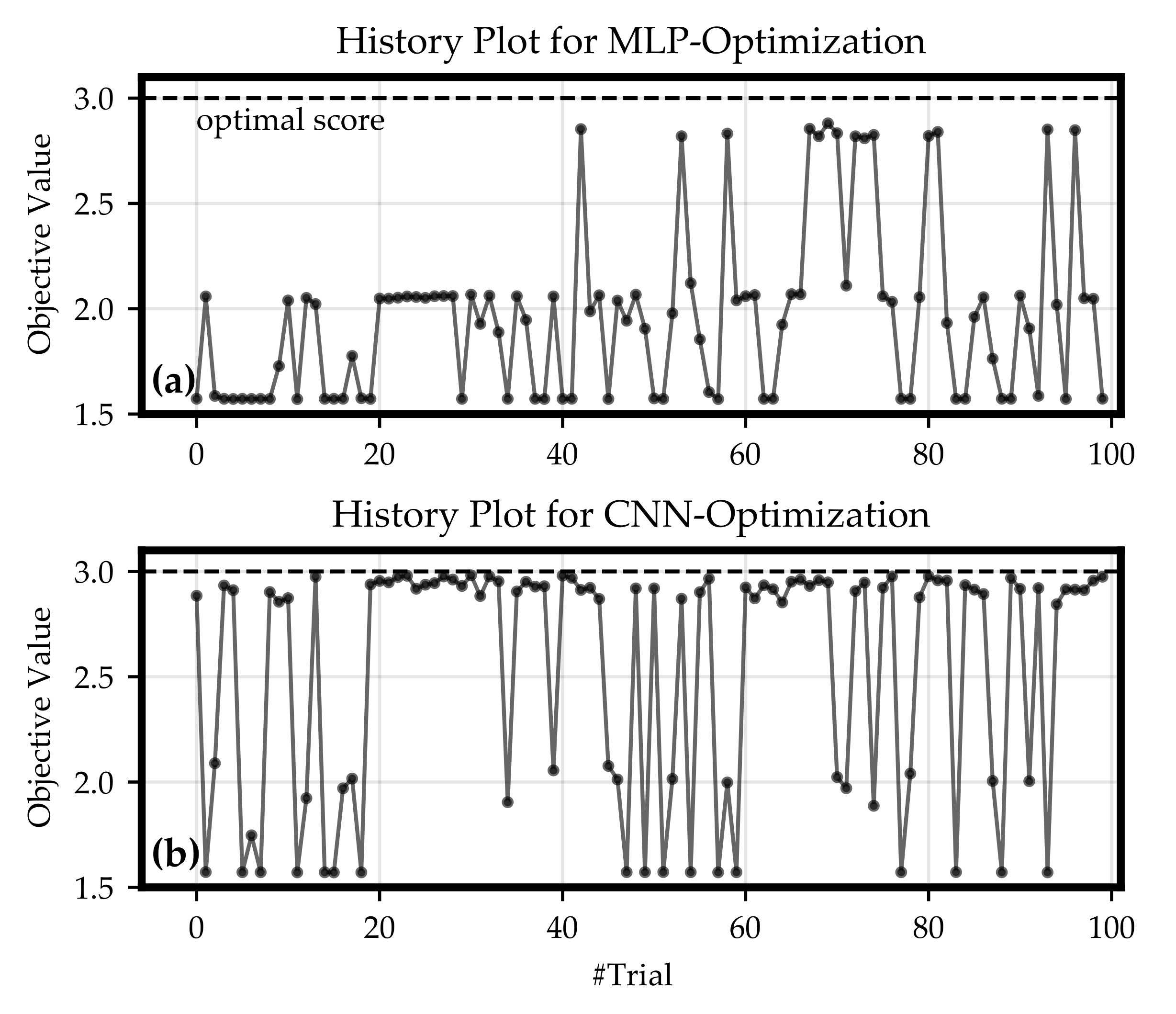
2.6. Hyper-Parameter Optimization
The pattern recognition is significantly influenced by the configuration of the neural networks, the preparation of load profiles and simulated data from grid models, and by the design of the training process. The improvement of the related, non-trainable parameters refers to
hyper-parameter optimization. For this investigation, the Optuna version 2.4.0 was used, which offers a framework to optimize the user-defined hyper-parameters [
49].
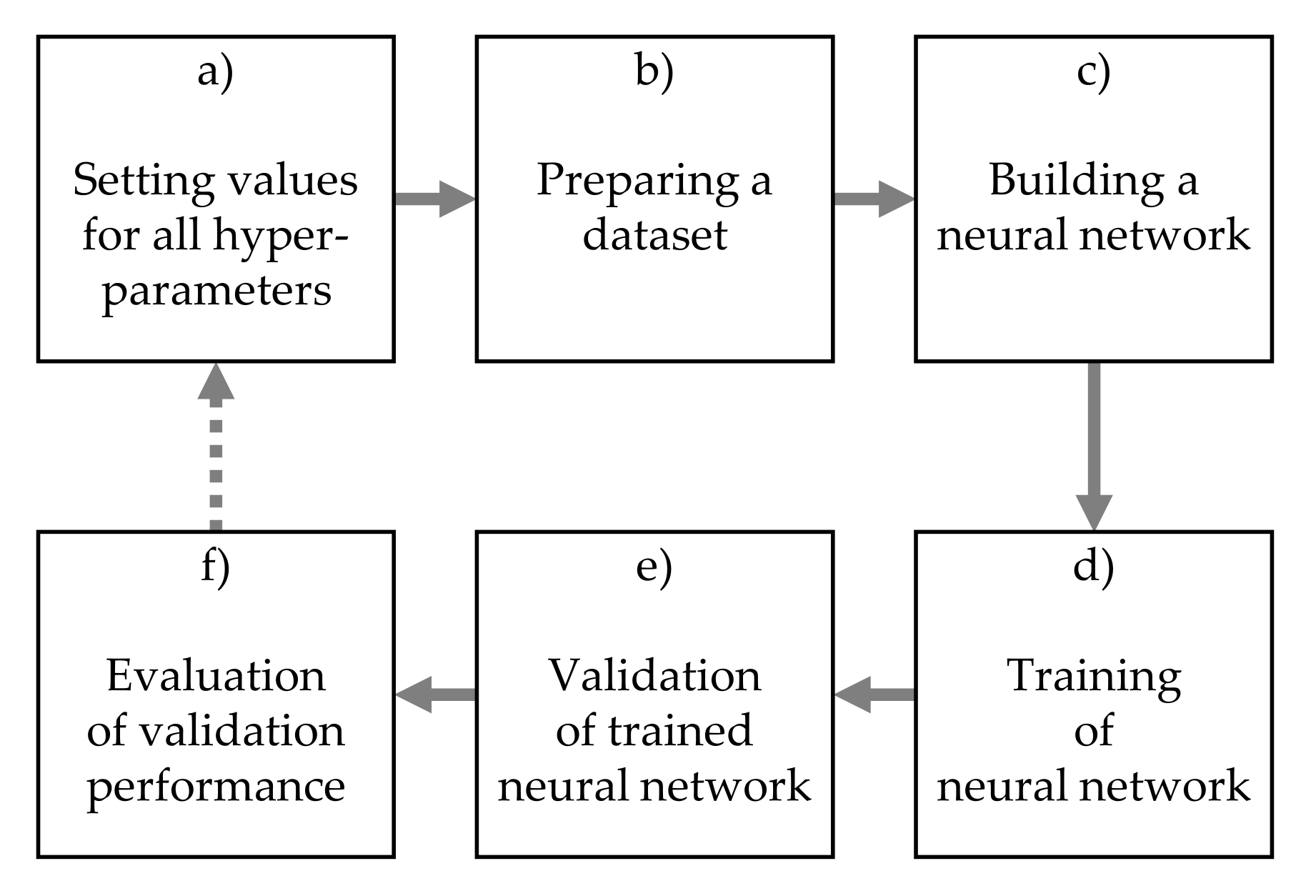
Each hyper-parameter optimization step from the proposed concept consisted of the sub-steps shown in
Figure 3:
At the end of such a step an objective value was calculated by a custom objective function. In this paper, the objective value was chosen as the score in Equation (
6). Based on this objective value, a tree-structured parzen estimator (TPE) algorithm was used to find the best configuration in the defined hyper-parameter space. The TPE is a sequential model-based optimization approach. For each optimization step, a trial is defined by setting a value for each hyper-parameter. To calculate these values for each single parameter, the TPE fits one Gaussian mixture model (GMM) to the set of parameter values associated with the best objective values. Next to it, another GMM is fitted to the remaining parameter values. Finally, the parameter value is selected such that the ratio of both GMMs is maximized [
49].
The hyper-parameters considered for the optimization (
Figure 3) are listed in
Table 2.
As mentioned before, the Keras API was used to implement the neural networks as follows. For
Figure 3c, the MLPs were built with an alternating series of dense layers using Rectifier Linear Unit (ReLU) activation function and drop-out layers with drop-out rate 0.2. The output was calculated inside a dense layer with Sigmoid activation function. The CNNs were implemented with equal number of filters in each convolutional layer. Convolutional layers with ReLU activation functions were followed by MaxPooling layers to reduce dimensionality. The output of all CNNs was computed by Global Average Pooling and a dense output-layer with Sigmoid activation function.
4. Discussion
In
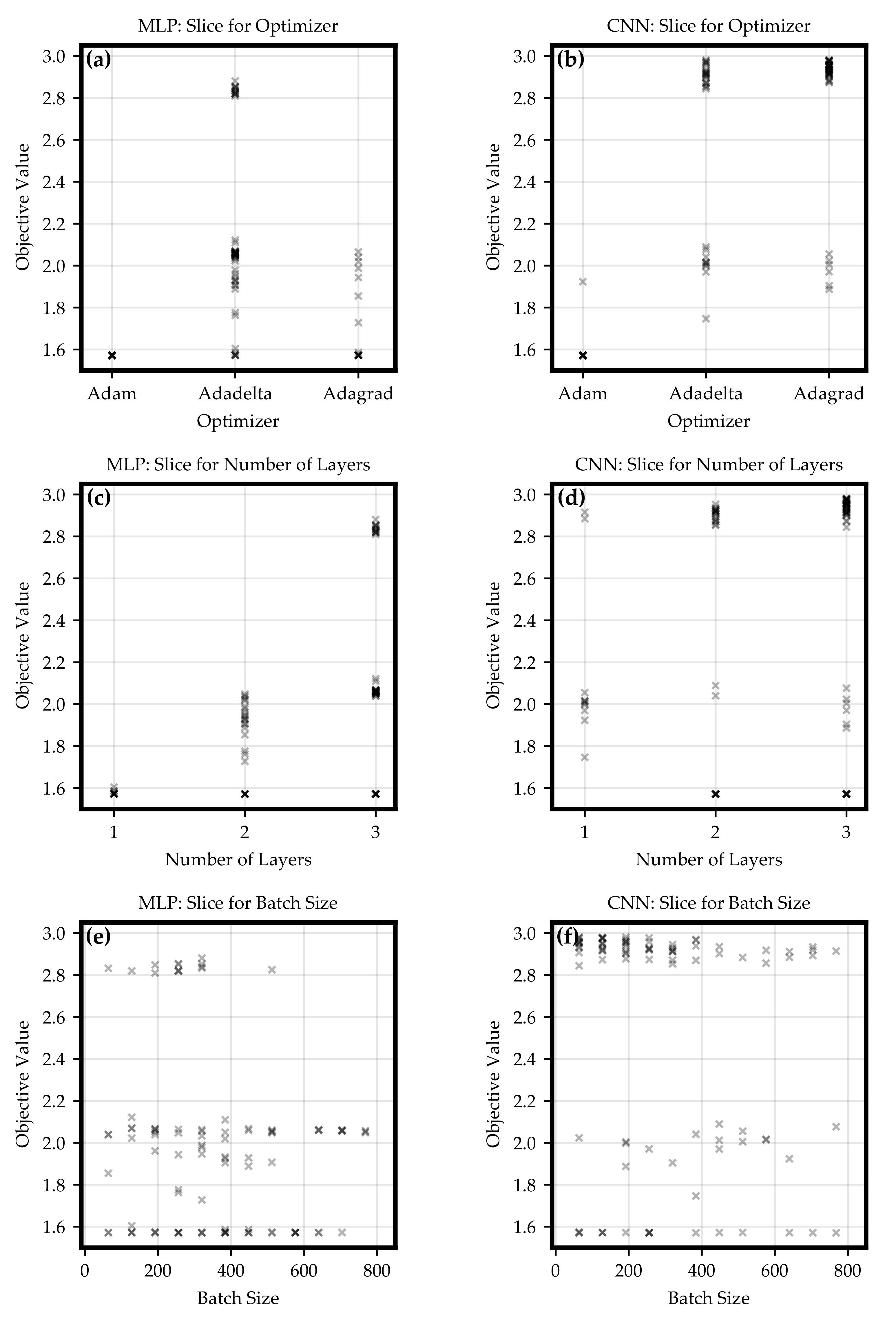
Section 3.1, hyper-parameter optimizations for MLP and CNN classifiers were executed. The results led to the conclusion that both architectures can be configured such that a trained network is able to solve the classification task formulated in this paper. Nevertheless, the CNN optimization obtained a higher number of classifiers which were able to achieve satisfying objective values. For most of the regions of the hyper-parameter space, there were choices returning objective values close to the maximum of 3. For example, even CNN models with only one convolutional layers were able to get a relatively high objective value. Because of theses reasons, it can be suspected that for a classification task with more trainable loads and more active participants in the grid the CNN architecture would rather lead to an accurate recognition and a clear separation of the trained classes than an MLP.
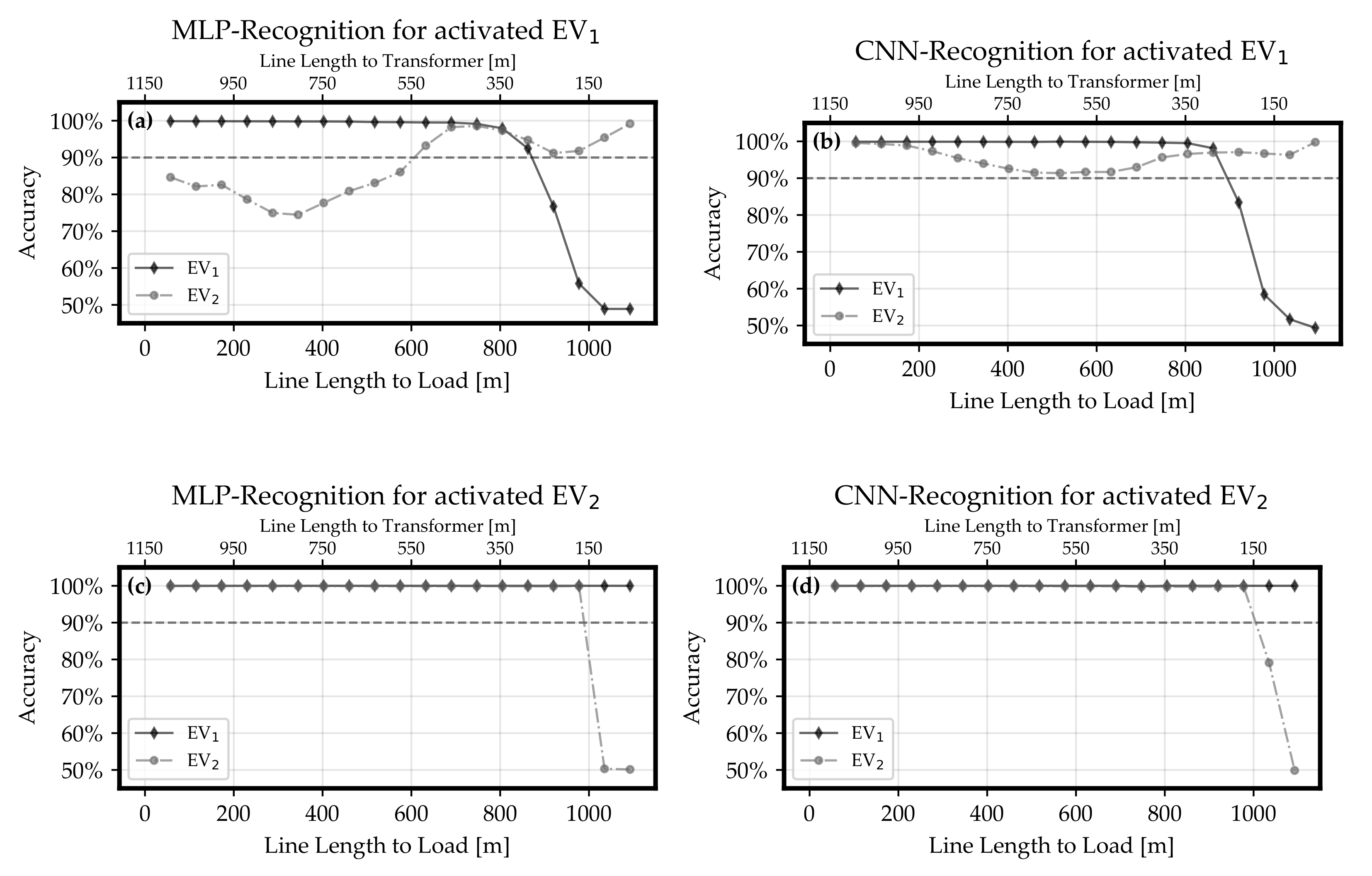
After hyper-parameter optimizations, a best MLP and a best CNN was determined. Even if the CNN classification in the validation scenarios yielded the overall best objective value, this value dropped significantly at node of the MONA reference grid.
The recognition ability of these best neural networks was investigated more precisely to examine the mentioned accuracy drop.
In
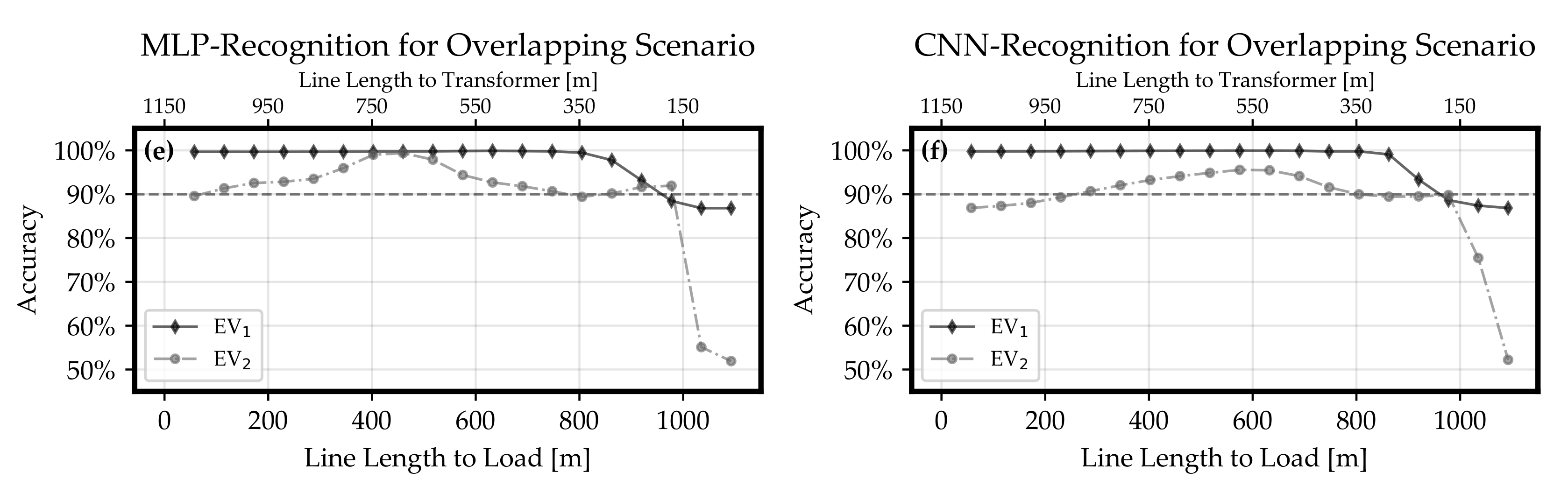
Section 3.2.1, load and inverter were assumed at the same grid node and the line distance between this node and the transformer was varied. This test case proved that larger distances between the transformer and the measurement point or inverter, respectively, improves the recognition. Furthermore, the CNN was able to achieve the threshold of 90% at less distance than the MLP, and it can be concluded that inactive classes are more accurately classified by the CNN.
Section 3.2.2 answered the question what happens if load and inverter are not located at the same grid node. It could be shown that an increasing line length between inverter and load decreases the accuracy of recognition. Regarding this relation, the CNN was able to remain the accuracy for active loads above the 90%-threshold with higher line length between inverter and load than the MLP. Similarly to
Section 3.2.1, the recognition results for the CNN classifier were more accurate regarding inactive classes. In this study, an increasing line length between inverter and load meant a larger area inside the power grid which was observed. Therefore, the CNN can be seen as the preferable classifier because more information from the grid can be gathered in a reliable manner.
From both parts of
Section 3.2, it can be concluded that classifiers trained by the proposed concept are able to provide a reliable load recognition inside typical power grid structures if they are located around hundreds of meters away from the transformer and also the distance between measurement point and active load is in the range of hundreds of meters. Thereby, the more accurate performance of the classifier in scenarios with activated EV
compared to cases when EV
is active indicates that less fluctuating profiles can be recognized with higher accuracy. The highly accurate results in the test cases of this study are very promising. Especially the CNN’s potential did not have to be fully exploited in the test conditions as there were many configurations with high objective values.
In this framework, the recognition is based only on the voltage changes caused by active loads. On the one hand, this approach does not need an extensive amount of data. In further development of this concept, it is an interesting research question to integrate more different load types into this recognition task. Here, one line of investigation could be the approach of incremental learning [
53,
54,
55]. New classes can be included in the training data without a huge simulation effort. If one characteristic profile for a new class is available, it can be trained and the corresponding recognition results can be analyzed afterwards.
On the other hand, this approach is limited because it depends on the magnitude of the voltage changes. If these changes at the point of voltage measurement are very small, it is not possible to recognize a particular profile. In this case, it is possible to train the neural network classifier inside the proposed simulation environment with differently scaled training data such that it is more sensitive to smaller changes. This adaption would not be appropriate in real world application because of the background noise in the power grid and other external effects to consider. Additionally, in the use case of voltage control it is intended to recognize not every single small or distant load but the loads with large impact to the grid voltage to determine an optimal control strategy for grid-stabilization. The particular voltage behavior at a single grid connection point is affected by the overall grid topology, the size of active loads and their position in the grid, and also the activity of other loads. This means, the limitation depends on many factors for the load recognition and is still under research.
Despite the limitations not yet explored, the quite simple demonstration example of two EVs presented in this paper is sufficient to conclude that the proof of the proposed concept was successful. The detailed potential in real world applications will be part of future work. For example, to enable the classification algorithm for load recognition under consideration of uncertain and fluctuating feed-in of renewable energies, the particular training dataset should be extended. This means, the neural network could be trained by voltage profiles which are modified by statistical noise in addition to scaled and overlapped profiles. Additionally, due to the increasing complexity it might be necessary to add more layers to the neural network.
5. Conclusions
In this study, a new concept to recognize active load classes in the local grid environment of an inverter’s grid connection point based on the locally measured voltage was presented. The proposed concept formulates the recognition task as a multi-label classification of time series windows and uses neural networks as a classifier. For demonstration and a proof of concept, the methodology was applied in an example of two electric vehicles in a simulated test environment. This approach was tested in
Section 3 regarding the influence of the inverter’s distance to the transformer and the particular active loads. It turned out that a classifier trained by the proposed concept is able to recognize different load types in the voltage signal. A usage of CNNs for recognition instead of MLPs yields higher accuracies in general. Hereby, the recognition accuracy is increased by an increasing distance between transformer and measurement point, and decreased by an increasing distance between load and measurement point.
In summary, a concept for a load recognition in low voltage distribution grids based on deep learning was developed and validated in a simulation environment. Future work can investigate the concept with an increased number of active loads in the grid and more trainable classes. Additionally, the recognition approach will be transferred into a real hardware environment. By this, the measurement will include background noise and measurement errors, for example, such that the input data for the algorithm is partially disturbed. This will challenge the algorithm to be robust to those disturbances and to decide whether a slightly changed voltage pattern still belongs to a trained class, or not.
In future, this concept can be used to gain knowledge about the local grid environment of an inverter’s grid connection point. Therefore, it can be implemented in a voltage control algorithm to set active and reactive power adapted to the grid node specific conditions. Consequently, it can contribute to a future stabilization of the grid voltage in a significant manner.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}