
Research on a Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN

Abstract
1. Introduction
2. Materials and Methods
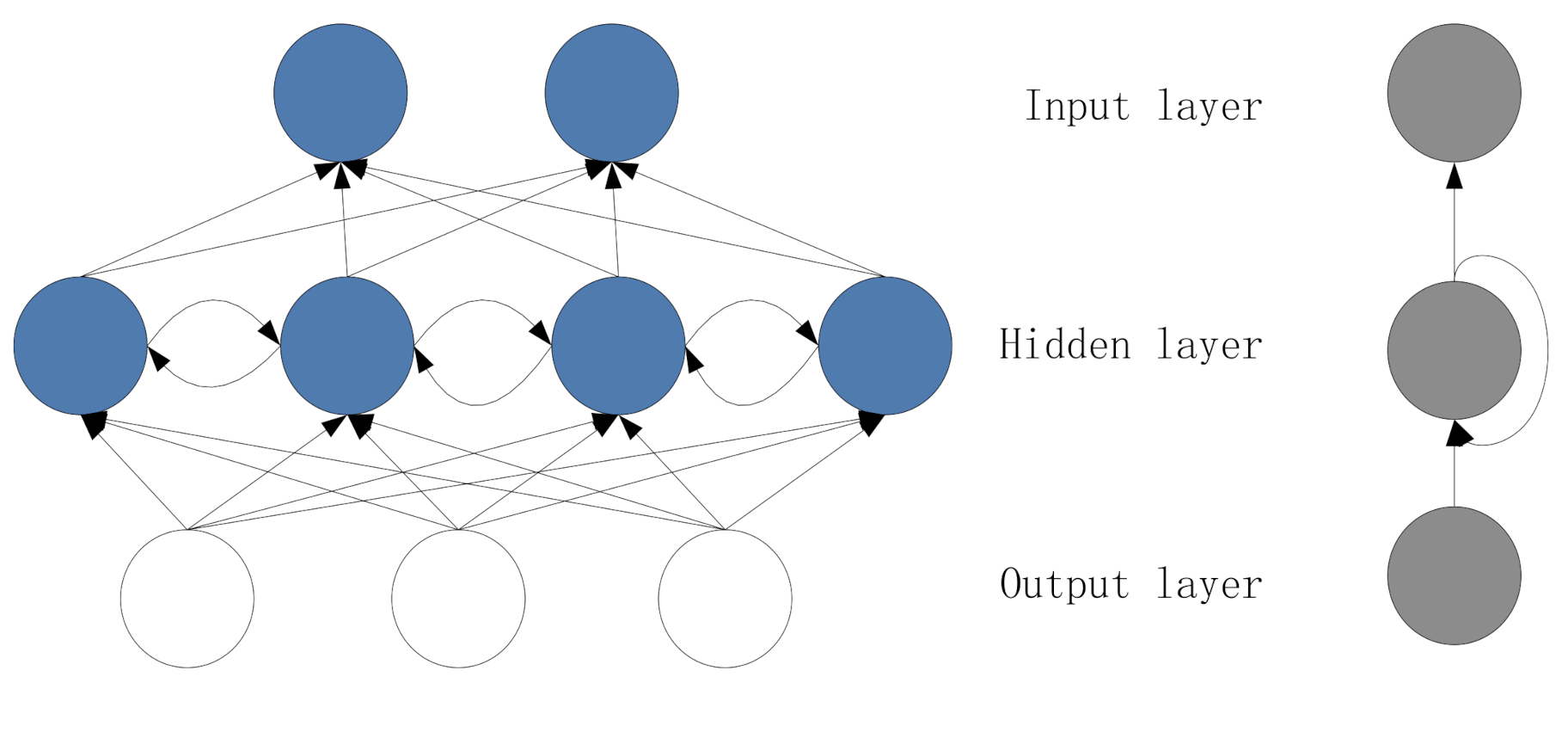
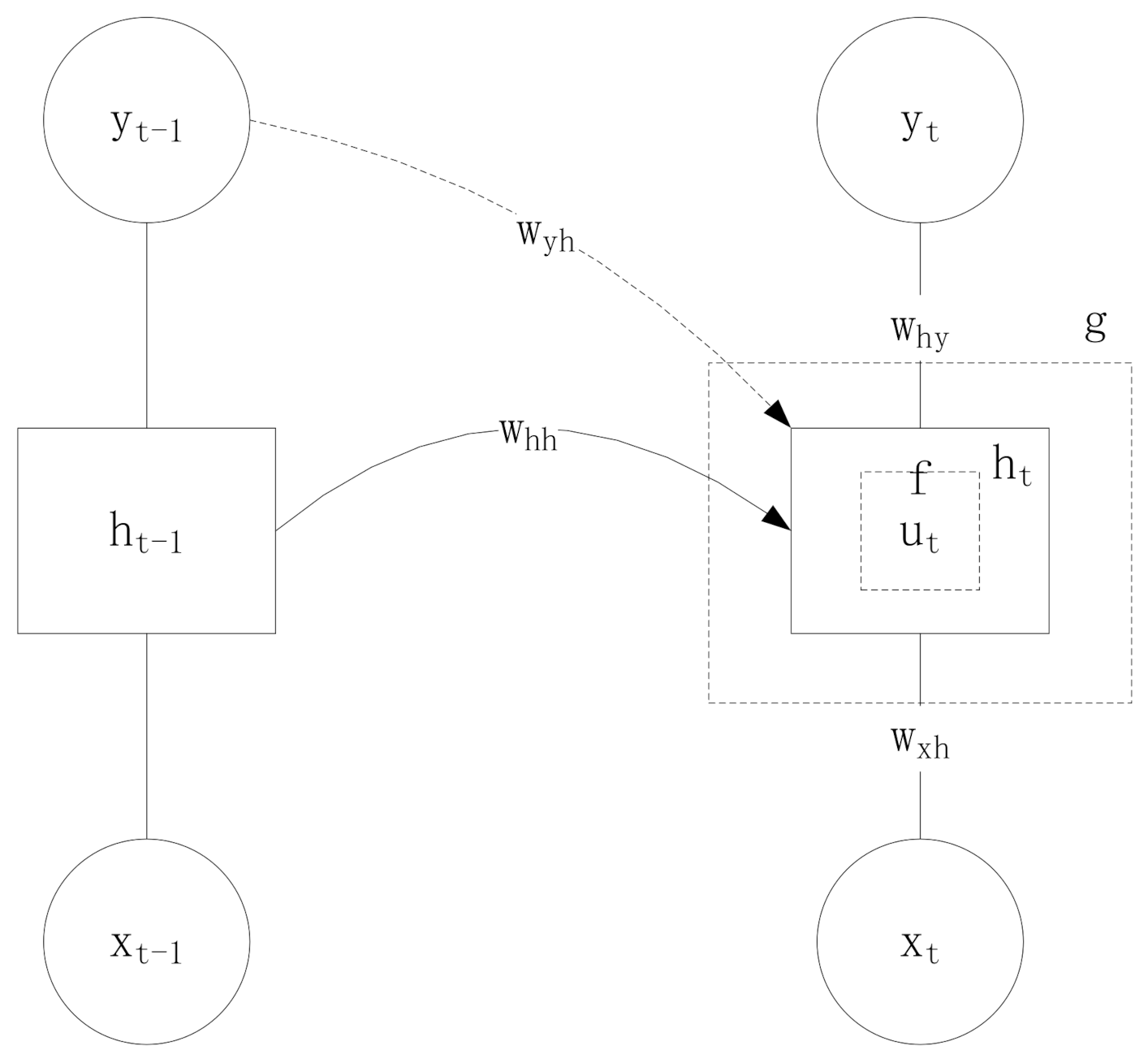
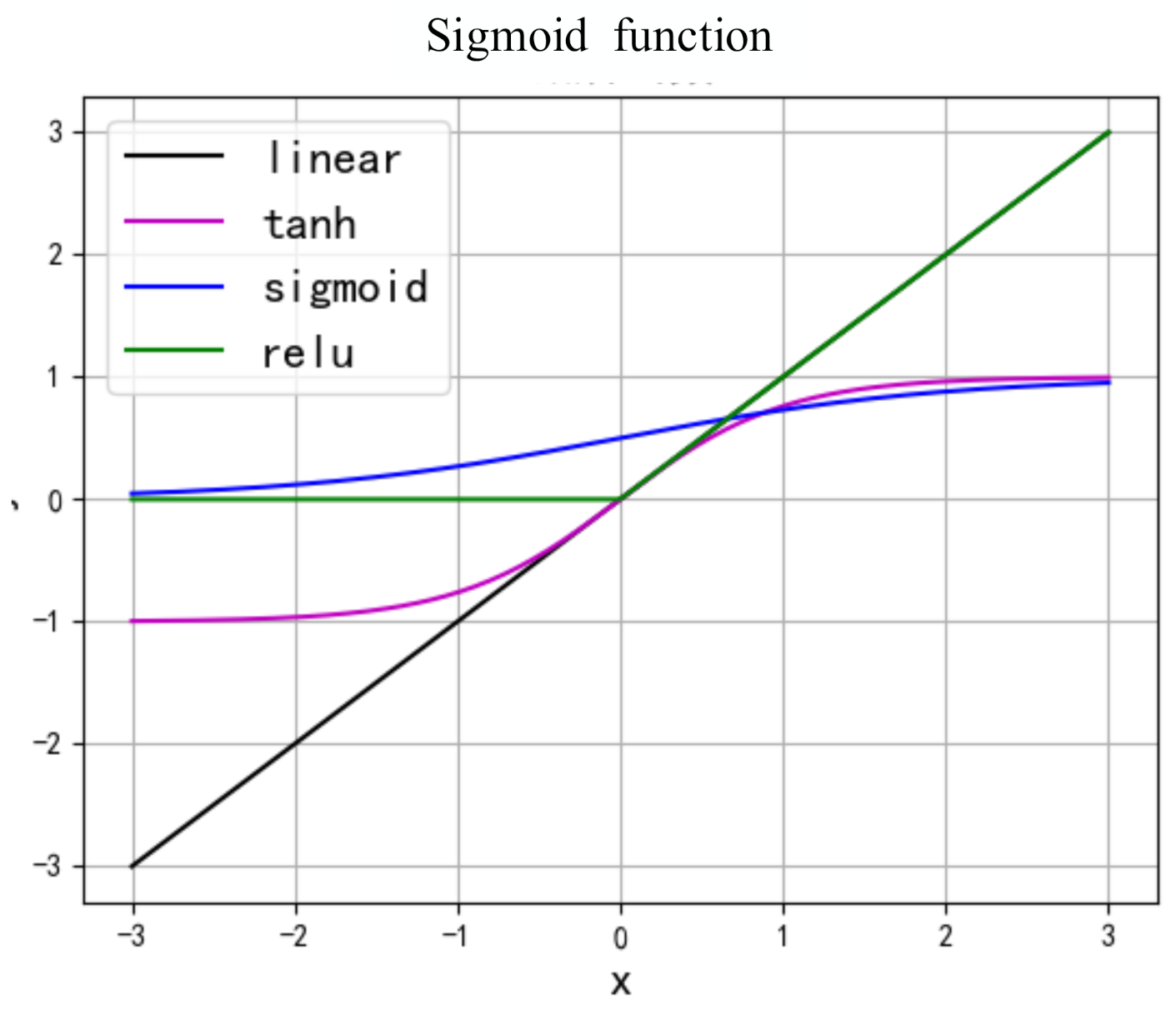
2.1. The Information of the Hidden Layer of the Recurrent Neural Network
2.2. Calculation of The information of the Output Layer of the Recurrent Neural Network
2.3. The Backpropagation of Circulating Nerves over Time
2.4. Weight Updating for Reverse Broadcasting over Time
| Algorithm 1. The time back propagation algorithm of a single-layer RNN with a square sum error function |
| 1: procedure BPTT({xt, It} ) |
| 2: do |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: end for |
| 8: |
| 9: |
| 10: do |
| 11: |
| 12: |
| 13: end for |
| 14: |
| 15: |
| 16: end procedure |
3. Experiment and Results
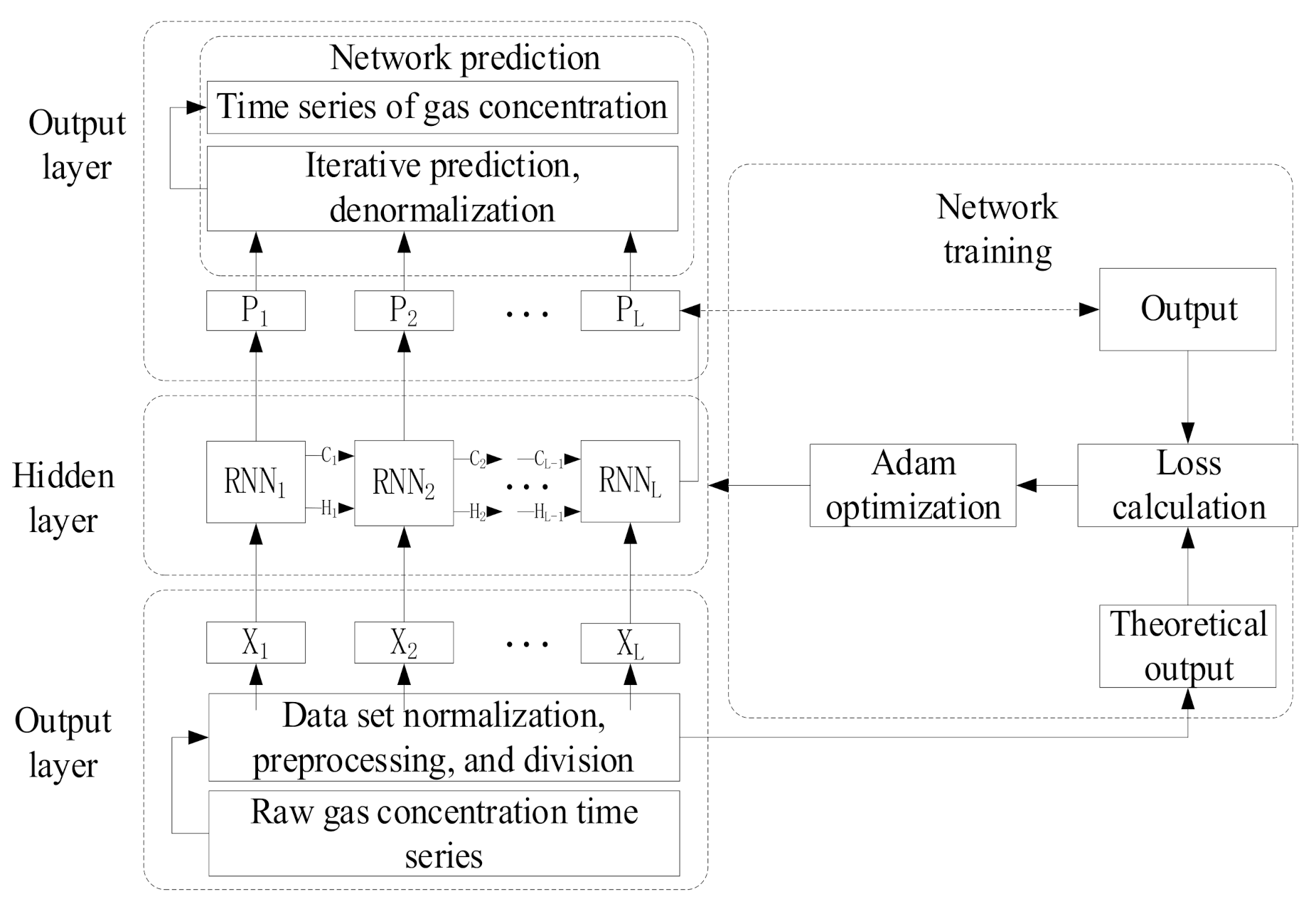
3.1. Construction of a Predictive Model
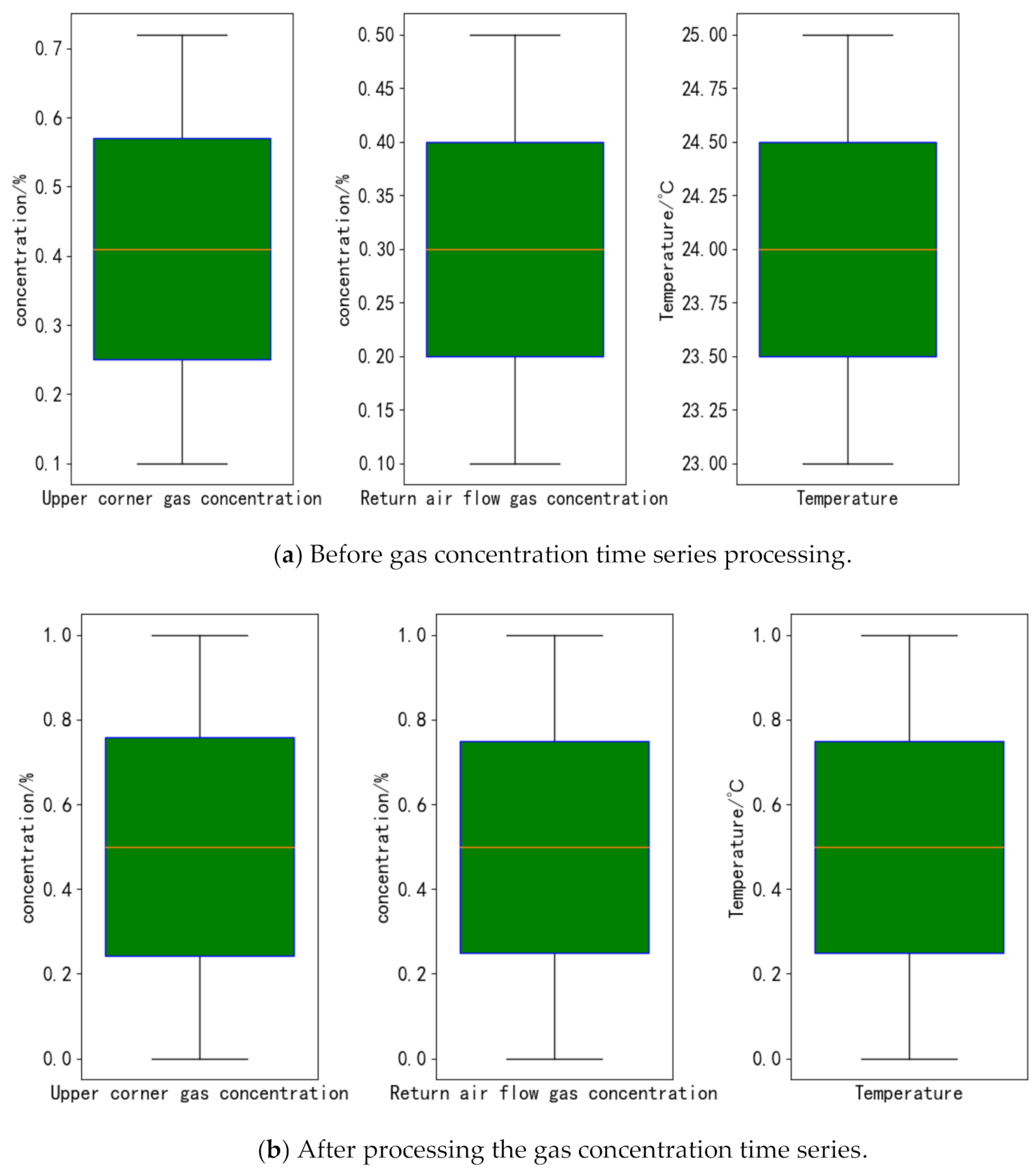
3.2. Experimental Verification of Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN
4. Discussion
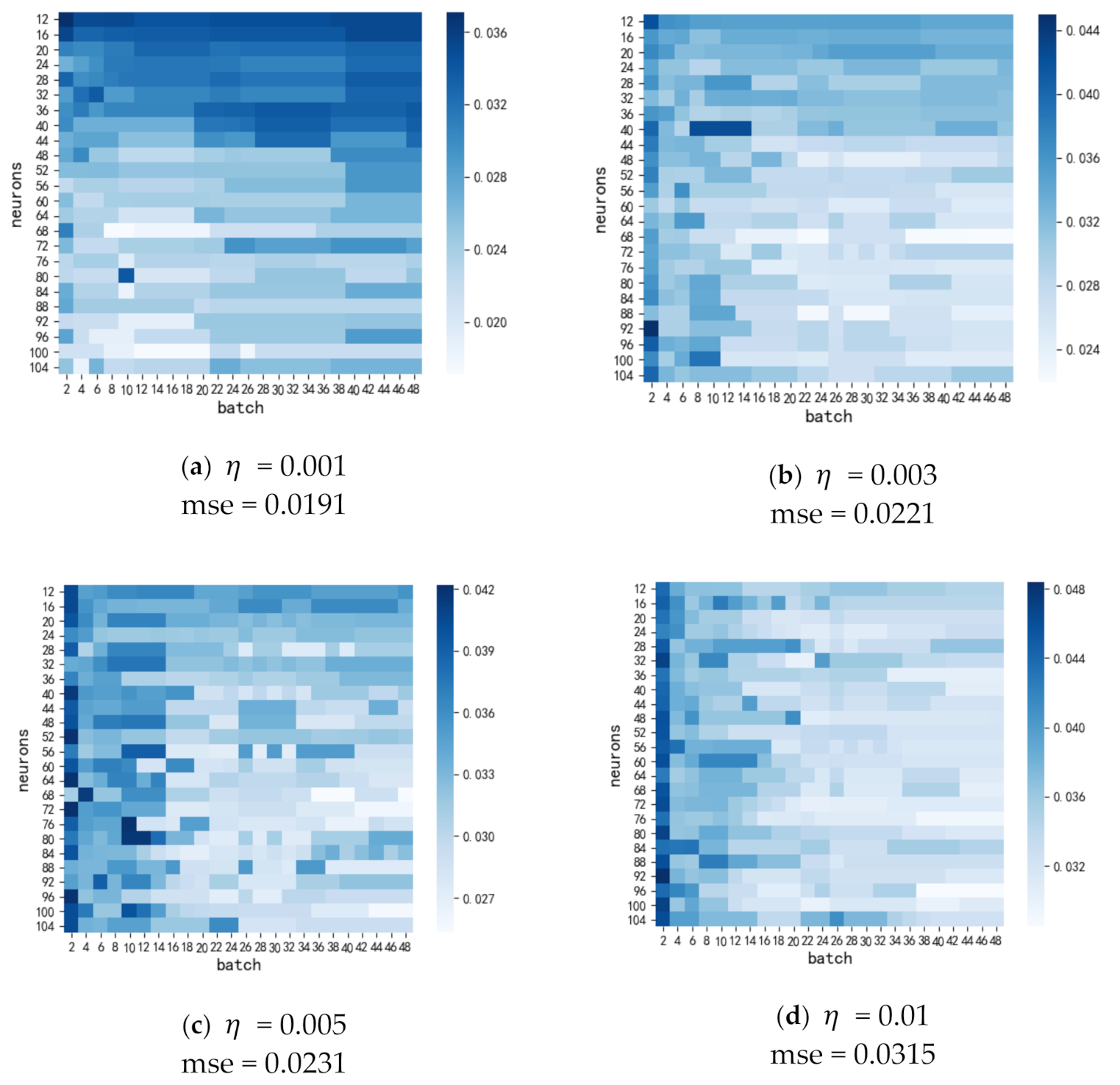
4.1. Comparison of the Hyperparameter Tuning of Learning Rate, Batch Size, and Neuron
| Algorithm 2. the training and prediction of a gas concentration prediction model for a working face based on the RNN. |
| Input: |
| 1. get , from by m |
| 2. = min-max() |
| 3. get , from by L |
| 4. create by |
| 5. connect by and L |
| 6. connect by seed |
| 7. for each step in 1: steps |
| 8. = |
| 9. |
| 10. update by Adam with loss and |
| 11. get |
| 12. for each j in 0: (n-m-1) |
| 13. |
| 14. append with [−1] |
| 15. |
| 16. error measure , |
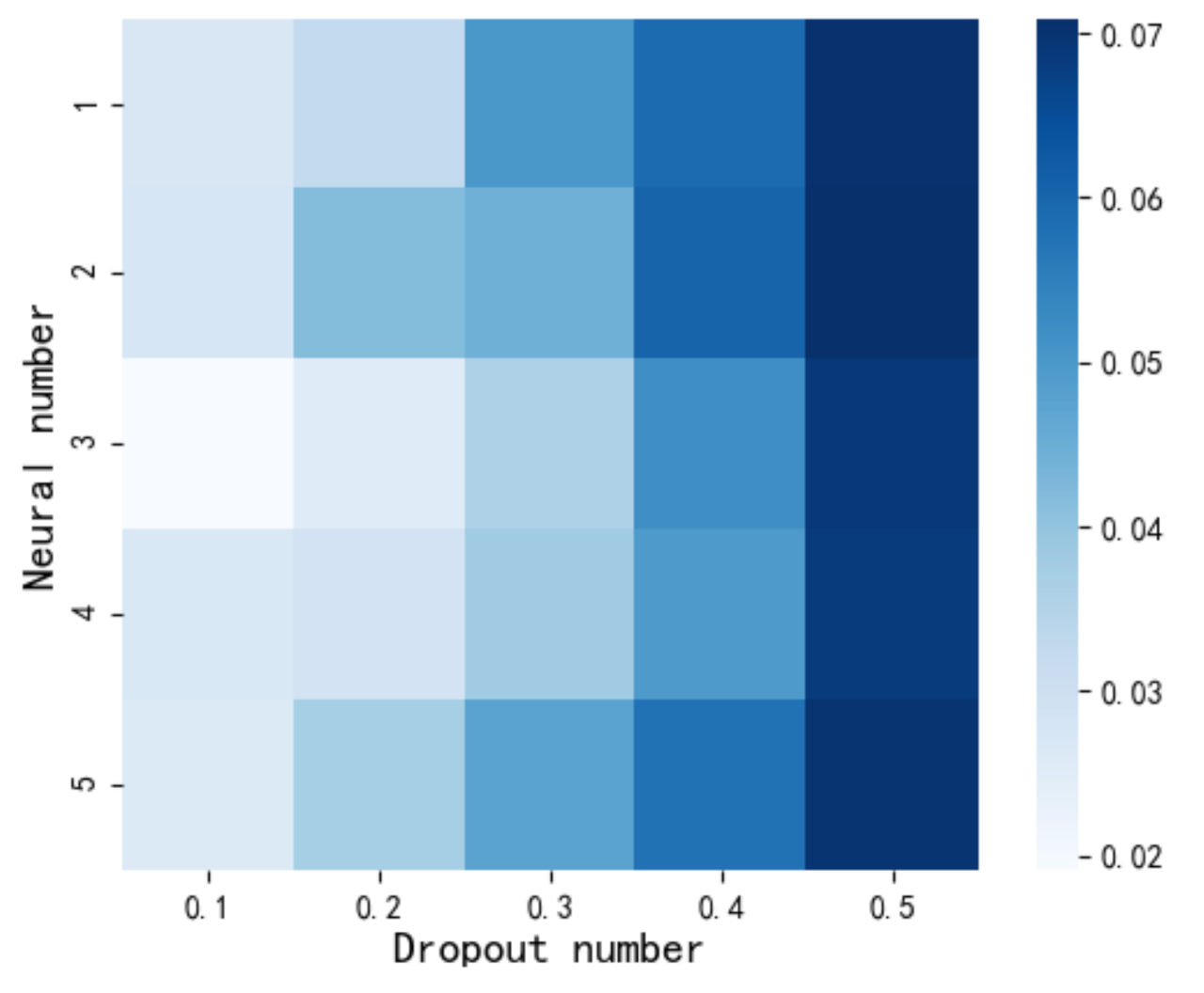
4.2. Hyperparameter Tuning Comparison of Network Depth and Discard Ratio
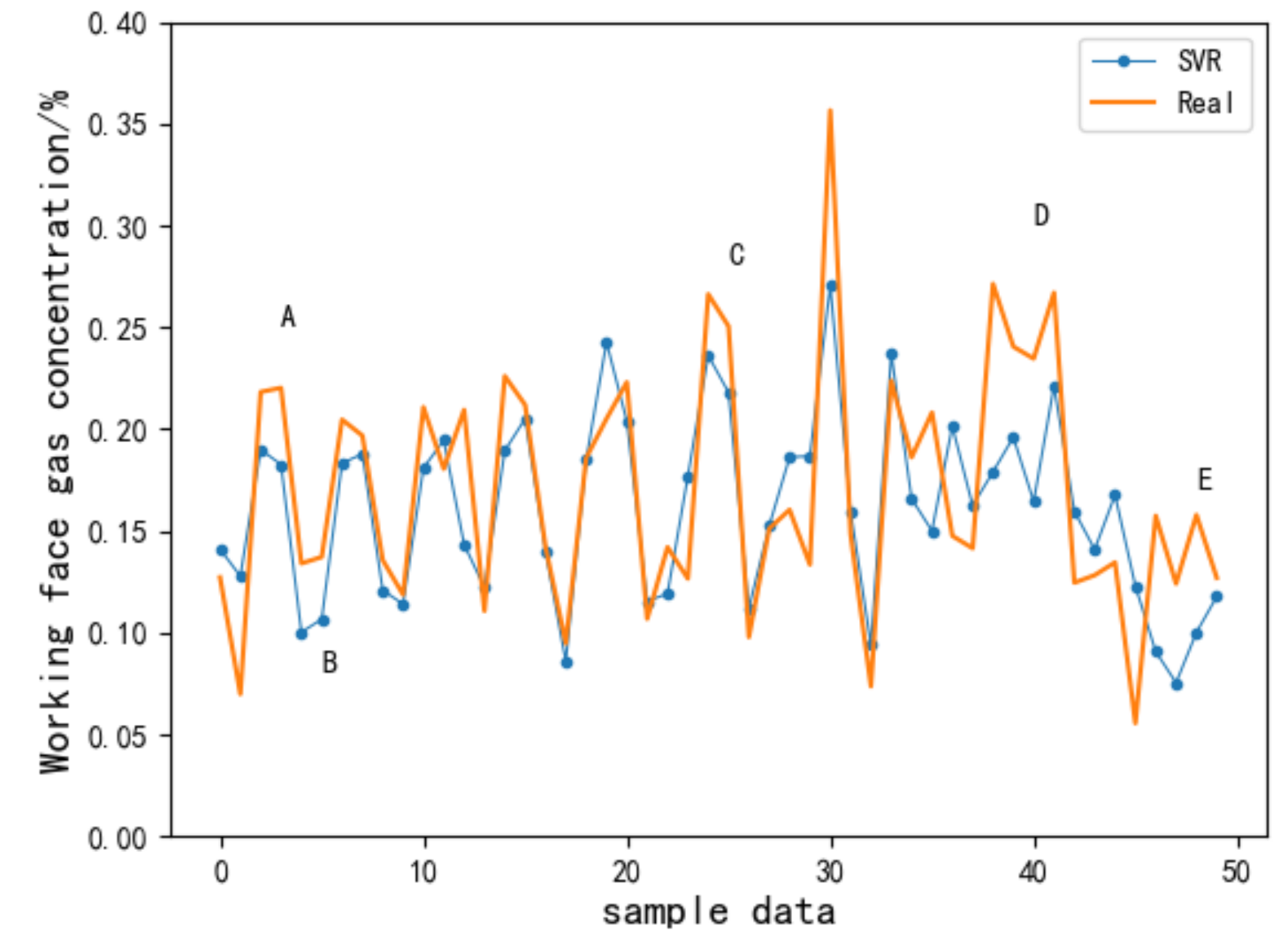
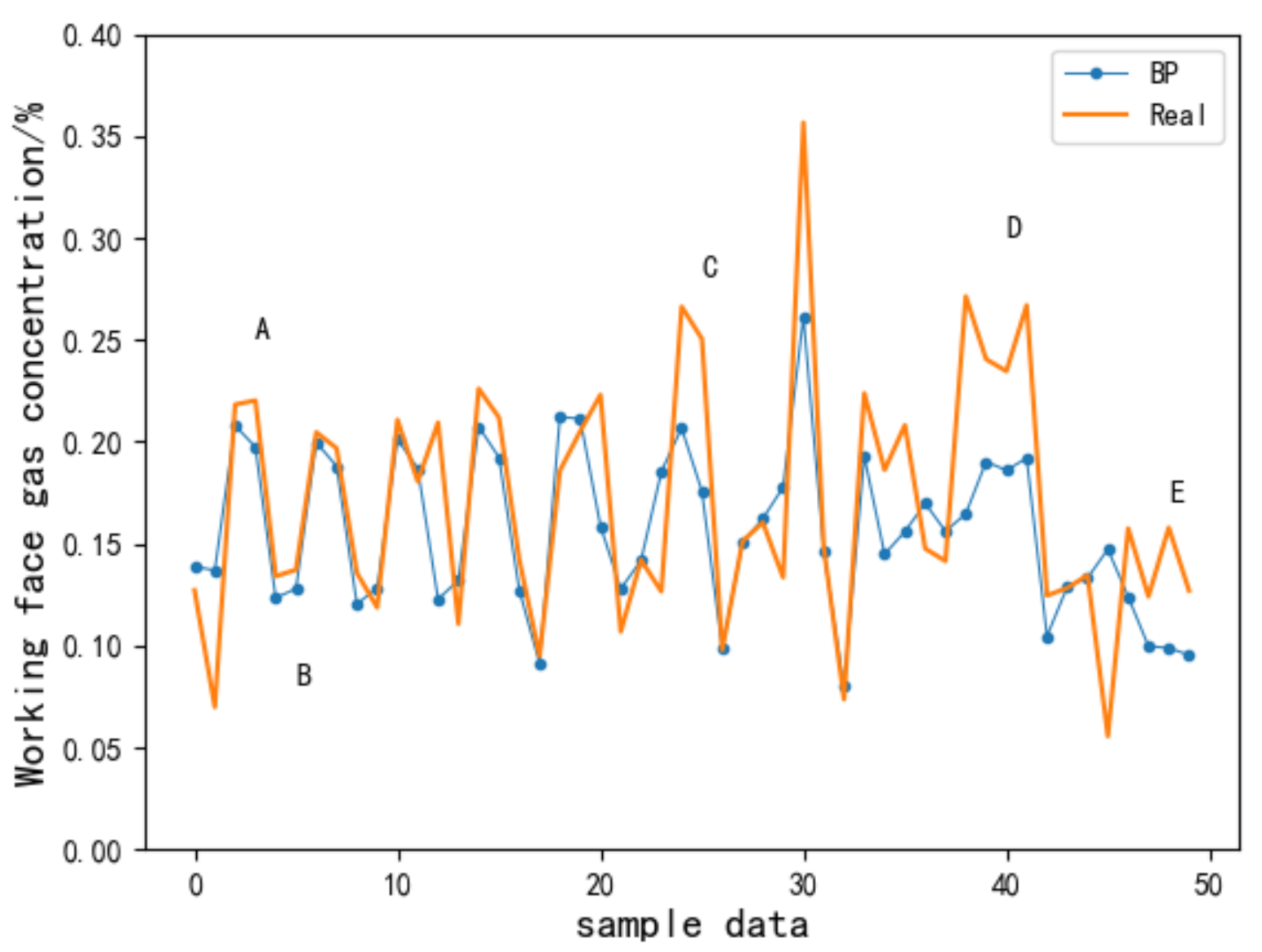
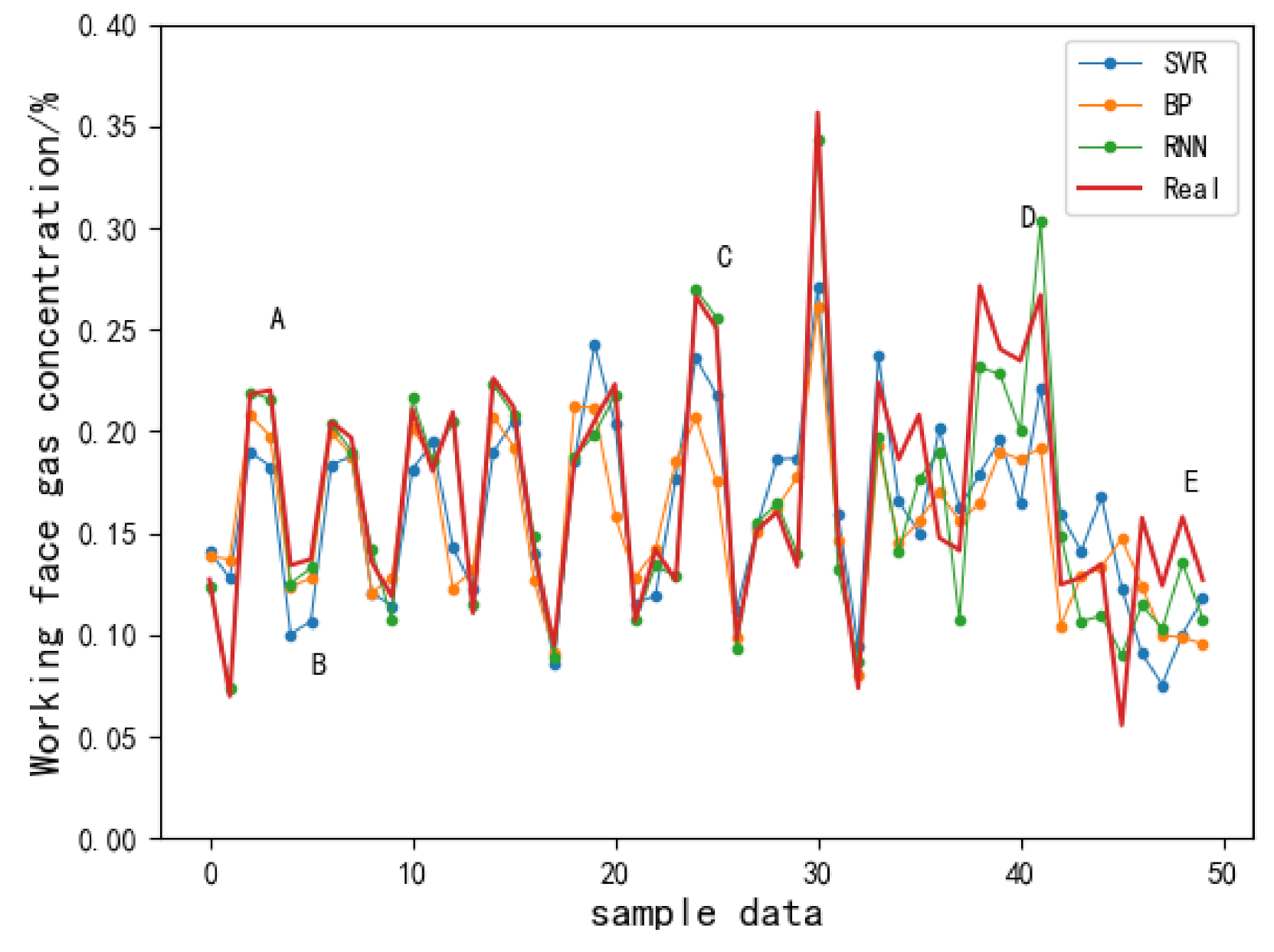
4.3. Comparison of Prediction Performances of Different Models
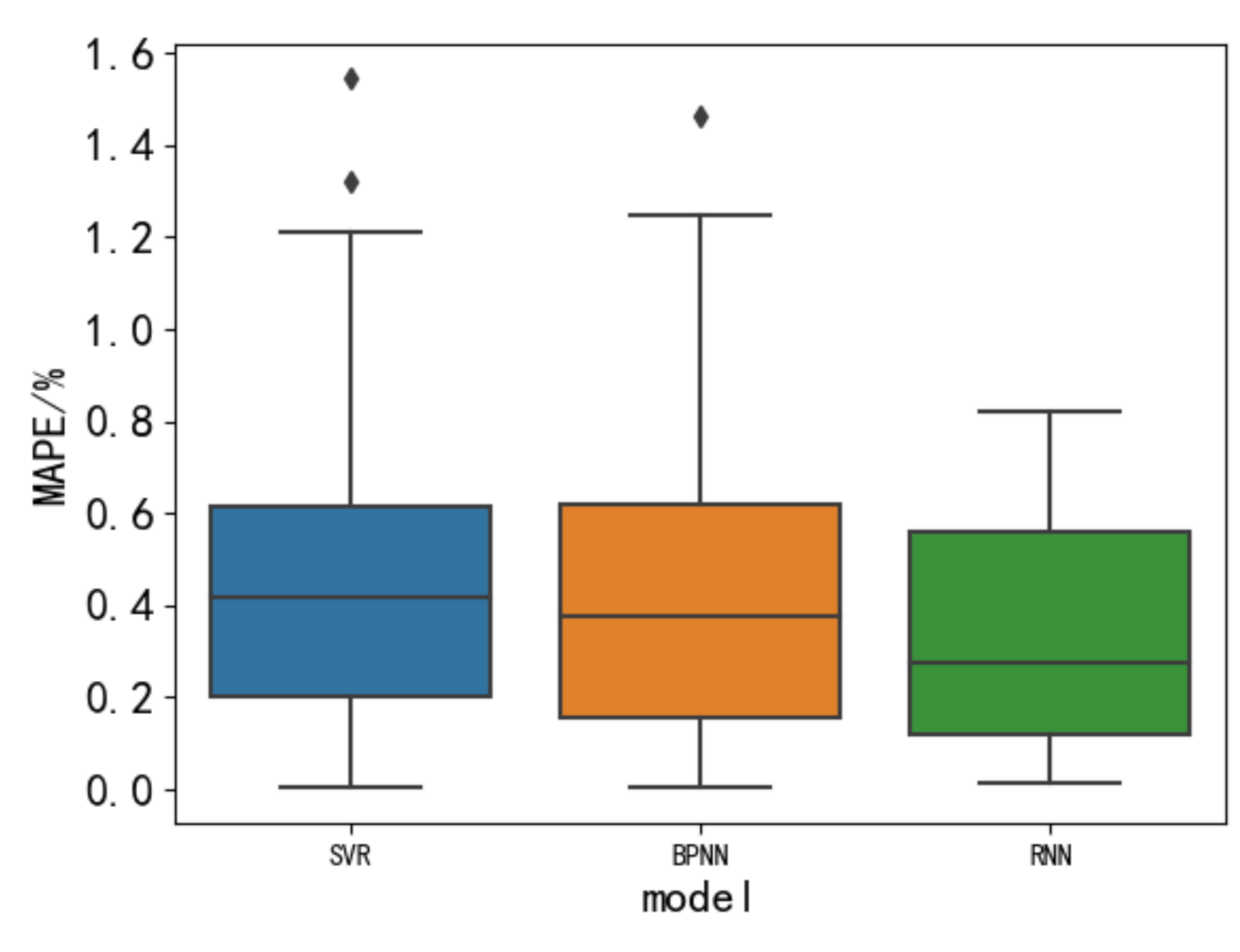
4.4. Comparative Analysis of Gas Concentration Prediction Errors Based on the SVR, BP, and RNN
5. Conclusions
- (1)
- Adam’s optimized RNN model had higher accuracy and stability than the BP neural network and SVR. During training, MAE can be reduced to 0.0573 and RMSE can be reduced to 0.0167, while MAPE can be reduced to 0.3384% during prediction.
- (2)
- Compared with the RNN gas concentration prediction model, SVR was more suitable for processing data samples with small data volumes and weak feature correlation. For gas concentration time series problems with large data samples and strong feature correlation, the prediction accuracy cannot meet the requirements; a BP neural network can be applied to large samples and high-dimensional samples; however, the ability to deal with data before and after the correlation is weak; compared to the BP neural network and SVR, RNN was more suitable for processing data related to time series due to its memory cell structure.
- (3)
- The recurrent neural network has the advantages of memory function, reasonable weight distribution, gradient descent, and backpropagation. It can memorize the current input information. When it comes to continuous, context-related tasks, it has more advantages than traditional artificial neural networks.
- (4)
- Compared with the RNN, although SVR and BP neural network methods could learn the transformation trend of a gas concentration time series, when it involved the inflection point of a gas concentration change associated with the front and back, the prediction performance was poor.
- (5)
- The RNN gas concentration prediction method and parameter optimization method based on Adam optimization can effectively predict gas concentration. Compared with the traditional BP neural network and the SVR method, the RNN method had higher accuracy and, at the same time had better robustness and applicability in terms of prediction stability. Therefore, this method has higher accuracy and could provide guidance for mine gas management.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BP | back propagation |
| BPTT | back propagation through time |
| GRU | gate recurrent unit |
| MAE | mean absolute error |
| MAPE | mean absolute percentage error |
| MSE | mean square error |
| PSO-Adam | particle swarm optimization-Adam |
| PSO-SVR | particle swarm optimization-support vector regression |
| RNN | recurrent neural network |
| RMS | root mean square |
| RMSE | root mean squared |
| SVM | support vector machine |
| Symbols | |
| f | the hidden layer activation function |
| g | the output layer activation function |
| h | the hidden layer |
| x | the input layer information |
| y | the output layer information |
| γ | the learning efficiency |
| the output neuron’s error | |
| the hidden neuron’s error | |
| the error term | |
| Wxh | weight matrix from the input layer to the hidden layer |
| Whh | weight matrix from the hidden layer to the hidden layer |
| Why | weight matrix from the hidden layer to the output layer |
References
- Fu, H.; Dai, W. Dynamic Prediction Method of Gas Concentration in PSR-MK-LSSVM Based on ACPSO. J. Transduct. Technol. 2016, 29, 903–908. [Google Scholar]
- Fu, H.; Yu, H.; Meng, X.Y.; Sun, L. A New Method of Mine Gas Dynamic Prediction Based on EKF-WLS-SVR and Chaotic Time Series Analysis. Chin. J. Sens. Actuators 2015, 28, 126–131. [Google Scholar]
- Fu, H.; Feng, S.C.; Liu, J.; Tang, B. The Modeling and Simulation of Gas Concentration Prediction Based on De-Eda-Svm. Chin. J. Sens. Actuators 2016, 29, 285–289. [Google Scholar]
- Liu, J.E.; Yang, X.F.; Guo, Z.L. Prediction of Coal Mine Gas Concentration Based on FIG-SVM. China Saf. Sci. J. 2013, 23, 80–84. [Google Scholar]
- Wang, Q.J.; Cheng, J.L. Forecast of coalmine gas concentration based on the immune neural network model. J. China Coal Soc. 2008, 33, 665–669. [Google Scholar]
- Liu, Y.J.; Zhao, Q.; Hao, W.L. Study of Gas Concentration Prediction Based on Genetic Algorithm and Optimizing BP Neural Network. Min. Saf. Environ. Prot. 2015, 42, 56–60. [Google Scholar]
- Fu, H.; Li, W.J.; Meng, X.Y.; Wang, G.H.; Wang, C.X. Application of IGA-DFNN for Predicting Coal Mine Gas Concentration. Chin. J. Sens. Actuators 2014, 27, 262–266. [Google Scholar]
- Yang, L.; Liu, H.; Mao, S.J.; Shi, C. Dynamic prediction of gas concentration based on multivariate distribution lag model. J. China Univ. Min. Technol. 2016, 45, 455–461. [Google Scholar]
- Wang, X.L.; Liu, J.; Lu, J.J. Gas Concentration Forecasting Approach Based on Wavelet Transform and Optimized Predictor. J. Basic Sci. Eng. 2011, 19, 499–508. [Google Scholar]
- Xiang, W.; Qian, J.S.; Huang, C.H.; Zhang, L. Short-term coalmine gas concentration prediction based on wavelet transform and extreme learning machine. Math. Probl. Eng. 2014. [Google Scholar] [CrossRef]
- Ma, X.L.; Hua, H. Gas concentration prediction based on the measured data of a coal mine rescue robot. J. Robot. 2016. [Google Scholar] [CrossRef]
- Yang, S.; Fan, B.; Xie, L.; Wang, L.J.; Song, G.P. Speech-driven video-realistic talking head synthesis using BLSTM-RNN. J. Tsinghua Univ. (Sci. Technol.) 2017, 57, 250–256. [Google Scholar]
- Li, Y.X.; Zhang, J.Q.; Pan, D.; Hu, D. A Study of Speech Recognition Based on RNN-RBM Language Model. J. Comput. Res. Dev. 2014, 51, 1936–1944. [Google Scholar]
- Xiao, A.L.; Liu, J.; Li, Y.Z.; Song, Q.W.; Ge, N. Two-Phase Rate Adaptation Strategy for Improving Real-Time Video QoE in Mobile Networks. China Commun. 2018, 15, 12–24. [Google Scholar] [CrossRef]
- Lee, D.; Lim, M.; Park, H.; Kang, Y.; Park, J.S.; Jang, G.J.; Kim, J.H. Long Short-Term Memory Recurrent Neural Network-Based Acoustic Model Using Connectionist Temporal Classification on a Large-Scale Training Corpus. Chin. Commun. 2017, 14, 23–31. [Google Scholar] [CrossRef]
- Shi, L.; Du, J.P.; Liang, M.Y. Social Network Bursty Topic Discovery Based on RNN and Topic Model. J. Commun. 2018, 39, 189–198. [Google Scholar]
- Gou, C.C.; Qin, Y.J.; Tian, T.; Wu, D.Y.; Liu, Y.; Cheng, X.Q. Social messages outbreak prediction model based on recurrent neural network. J. Softw. 2017, 28, 3030–3042. [Google Scholar]
- Li, J.; Lin, Y.F. Prediction of time series data based on multi-time scale run. Comput. Appl. Softw. 2018, 35, 33–37. [Google Scholar]
- Zhang, X.G.; Li, Y.D.; Zhang, L.; Fan, Q.F.; Li, X. Taxi travel destination prediction based on SDZ-RNN. Comput. Eng. Appl. 2018, 54, 143–149. [Google Scholar]
- Wang, X.X.; Xu, L.H. Short-term Traffic Flow Prediction Based on Deep Learning. J. Transp. Syst. Eng. Inf. Technol. 2018, 18, 81–88. [Google Scholar]
- Mehdi, P.; Arezoo, K. Optimising cure cycle of unsaturated polyester nanocomposites using directed grid search method. Polym. Polym. Compos. 2019, 27, 1–9. [Google Scholar]
- Fayed, H.A.; Atiya, A.F. Speed up grid-search for parameter selection of support vector machines. Appl. Soft Comput. 2019, 80, 80–92. [Google Scholar] [CrossRef]
- Sun, J.L.; Wu, Q.T.; Shen, D.F.; Wen, Y.J.; Liu, F.R.; Gao, Y.; Ding, J.; Zhang, J. TSLRF: Two-Stage Algorithm Based on Least Angle Regression and Random Forest in genome-wide association studies. Sci. Rep. 2019, 9, 15–26. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.J.; Song, S.; Li, S.G.; Ma, L.; Pan, S.B.; Han, L.Y. Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series J. Energies. 2019, 12, 1–15. [Google Scholar] [CrossRef]
- Zhao, X.G.; Song, Z.W. ADAM optimized CNN super-resolution reconstruction. Comput. Sci. Explor. 2019, 13, 858–865. [Google Scholar]
- Yang, G.C.; Yang, J.; Li, S.B.; Hu, J.J. Modified CNN algorithm based on Dropout and ADAM optimizer. J. Huazhong Univ. Sci. Technol. (Nat. Sci. Ed.) 2018, 46, 122–127. [Google Scholar]
- Wei, Y.; Mei, J.L.; Xin, P.; Guo, R.W.; Li, P.L. Application of support vector regression cooperated with modified artificial fish swarm algorithm for wind tunnel performance prediction of automotive radiators. Appl. Therm. Eng. 2020, 3, 164–188. [Google Scholar]
- Boukhalfa, G.; Belkacem, S.; Chikhi, A.; Benaggoune, S. Application of Fuzzy PID Controller Based on Genetic Algorithm and Particle Swarm Optimization in Direct Torque Control of Double Star Induction Motor. J. Cent. South Univ. 2019, 26, 1886–1896. [Google Scholar] [CrossRef]
- Wang, P.; Wu, Y.P.; Wang, S.P.; Song, C.; Wu, X.M. Study on Lagrange-ARIMA real-time prediction model of mine gas concentration. Coal Sci. Technol. 2019, 47, 141–146. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rank | Model Parameters | MSE | Time/s | ||
|---|---|---|---|---|---|
| Batch | Neurons | ||||
| 1 | 10 | 68 | 0.001 | 0.0191 | 421 |
| 2 | 12 | 100 | 0.001 | 0.0192 | 601 |
| 3 | 34 | 68 | 0.003 | 0.0219 | 312 |
| 4 | 20 | 68 | 0.003 | 0.0221 | 352 |
| 5 | 10 | 104 | 0.001 | 0.0222 | 782 |
| Rank | Model Parameters | Performance | ||
|---|---|---|---|---|
| Dropout Ratio | Layers | MSE | Time/s | |
| 1 | 0.1 | 3 | 0.0191 | 600 |
| 2 | 0.2 | 3 | 0.0255 | 631 |
| 3 | 0.1 | 4 | 0.0261 | 871 |
| 4 | 0.1 | 2 | 0.0271 | 125 |
| 5 | 0.1 | 1 | 0.0277 | 57 |
| Models | SVR | BP Neural Network | RNN |
|---|---|---|---|
| Average MAPE /% | 0.4872 | 0.4458 | 0.3384 |
| Median MAPE /% | 0.4134 | 0.3842 | 0.2825 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, S.; Li, S.; Zhang, T.; Ma, L.; Pan, S.; Gao, L. Research on a Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN. Energies 2021, 14, 1384. https://doi.org/10.3390/en14051384
Song S, Li S, Zhang T, Ma L, Pan S, Gao L. Research on a Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN. Energies. 2021; 14(5):1384. https://doi.org/10.3390/en14051384
Chicago/Turabian StyleSong, Shuang, Shugang Li, Tianjun Zhang, Li Ma, Shaobo Pan, and Lu Gao. 2021. "Research on a Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN" Energies 14, no. 5: 1384. https://doi.org/10.3390/en14051384
APA StyleSong, S., Li, S., Zhang, T., Ma, L., Pan, S., & Gao, L. (2021). Research on a Multi-Parameter Fusion Prediction Model of Pressure Relief Gas Concentration Based on RNN. Energies, 14(5), 1384. https://doi.org/10.3390/en14051384