A Data-Driven and Data-Based Framework for Online Voltage Stability Assessment Using Partial Mutual Information and Iterated Random Forest

 , ,
, , 
Abstract
1. Introduction
- (1)
- In this paper, a feature preprocessing approach and a feature selection procedure are designed. The approach can remove redundant and irrelevant features from the collected PMU data and aims to improve computational efficiency. The procedure can significantly reduce the dimension of the sample set in preparation for the subsequent prediction. Specifically, PMI is applied in the feature selection procedure to select key variables by detecting connotative correlations, which can overcome the problems of underestimation and overestimation in conventional feature selection methods.
- (2)
- In view of large-scale operation data, the partially missing PMU data, and the real-time requirement of VSA in power systems, a VSA model based on IRF is presented. IRF has the following advantages: accommodating large-scale data sets, dealing with partially missing data, and reducing the computational burden. In addition, a model update mechanism is designed for VSA models, which can adapt to unforeseen changes of practical power system conditions.
- (3)
- Some impact factors in the practical operation of systems are taken into consideration in this paper, including topology change, variation of peak/minimum load, and variation of generator/load power distribution. A desirable assessment performance and the robustness of the VSA model are verified.
2. Problem Statement and Methodology Description
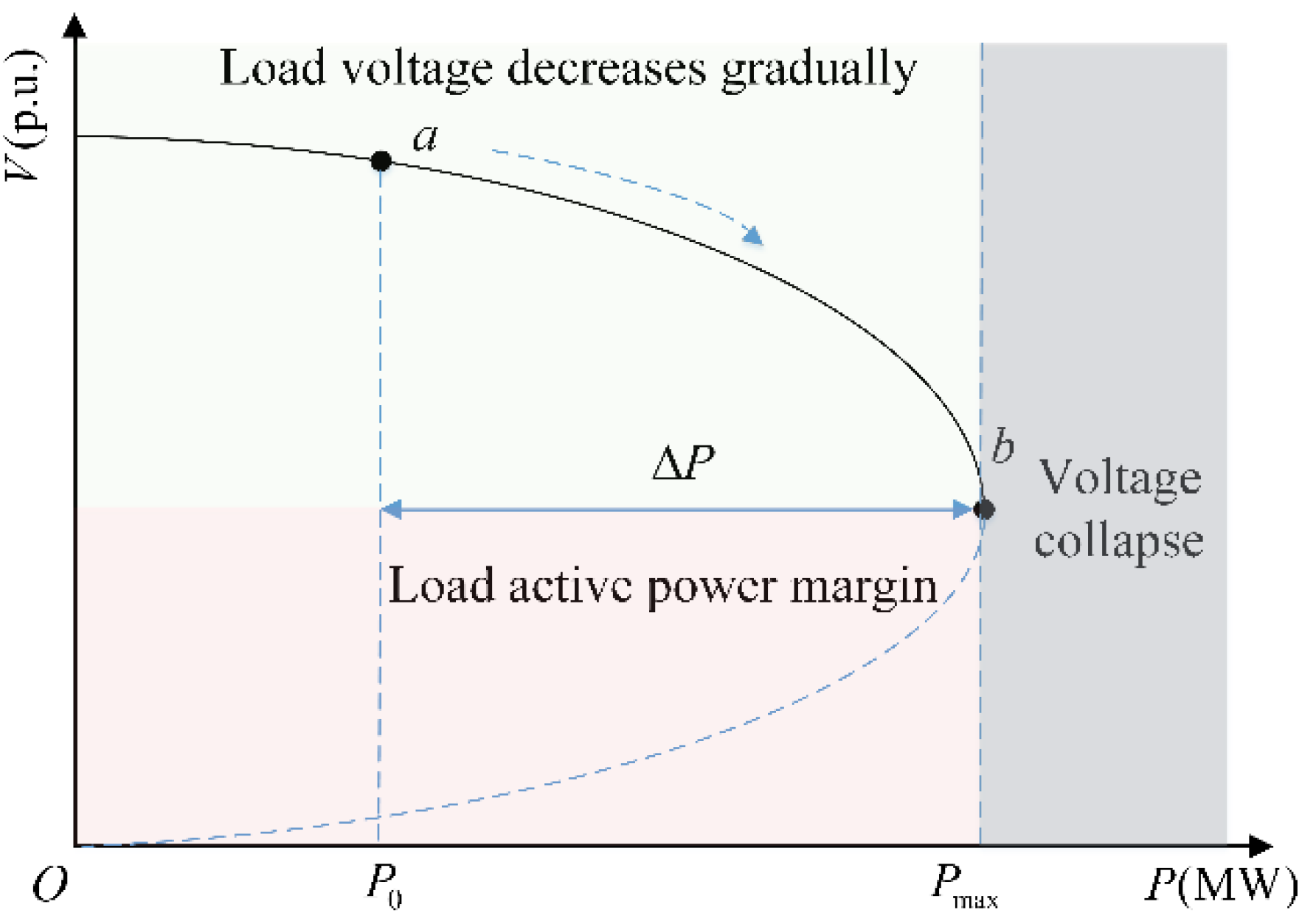
2.1. VSM
2.2. PMI
- (1)
- A larger value of means that a stronger association exists between x and y.
- (2)
- means that there is a statistically independent association between x and y.
- (3)
- A value of that is close to 1 means that there is a close association between x and y.
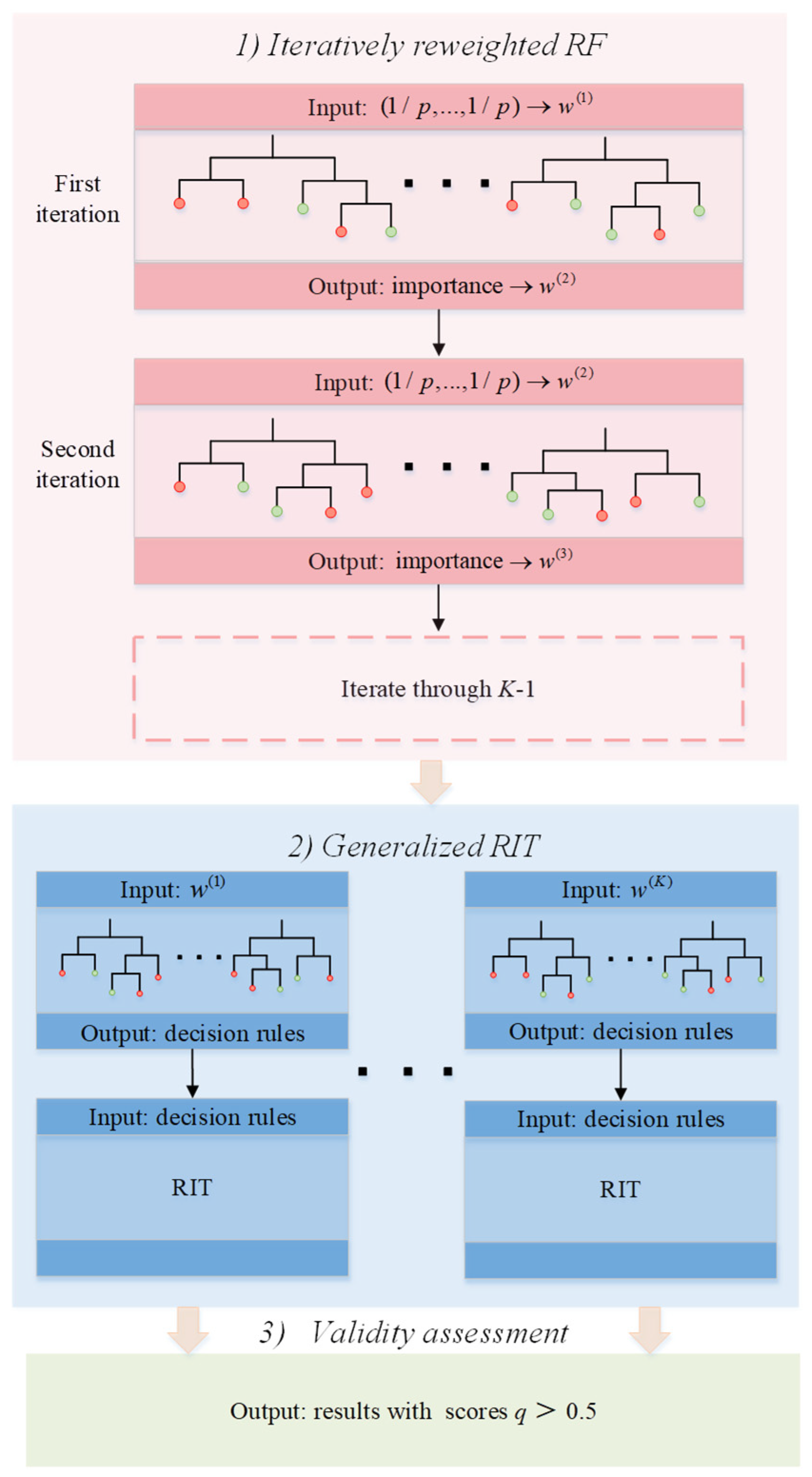
2.3. IRF
2.3.1. Iteratively Reweighted RF
2.3.2. Generalized RIT
2.3.3. Validity Assessment
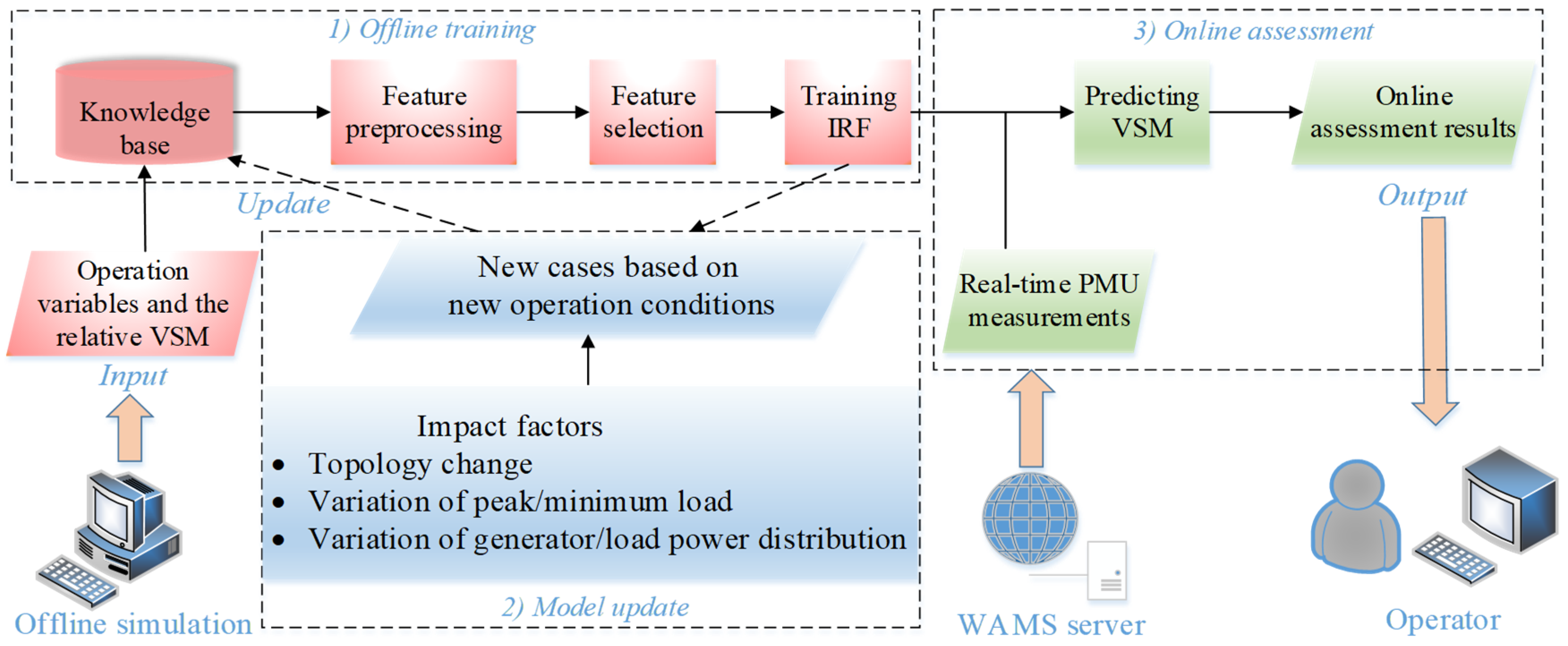
3. Proposed Framework for Online VSM Assessment
3.1. Offline Training
3.1.1. Knowledge Base Construction
3.1.2. Feature Preprocessing
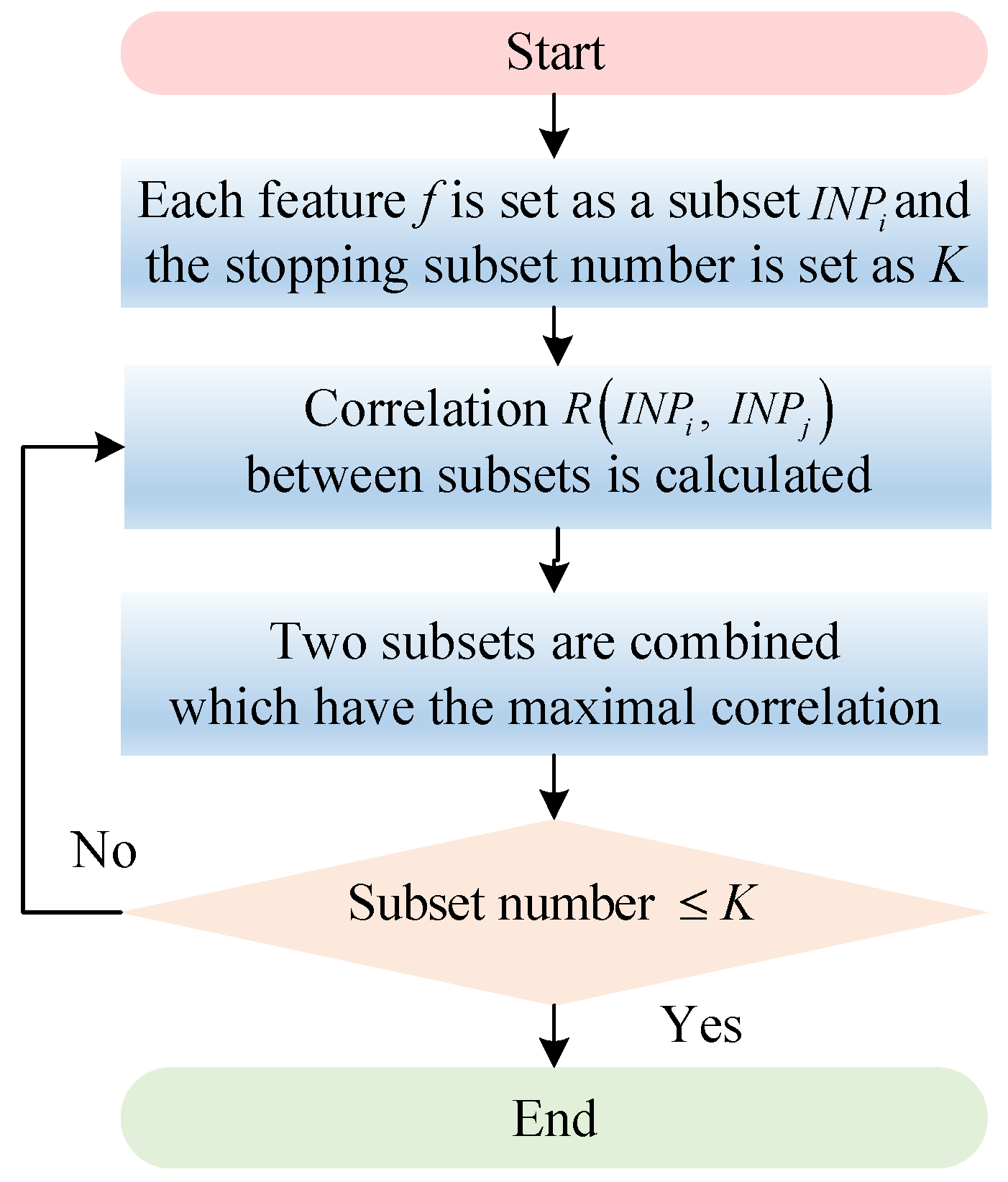
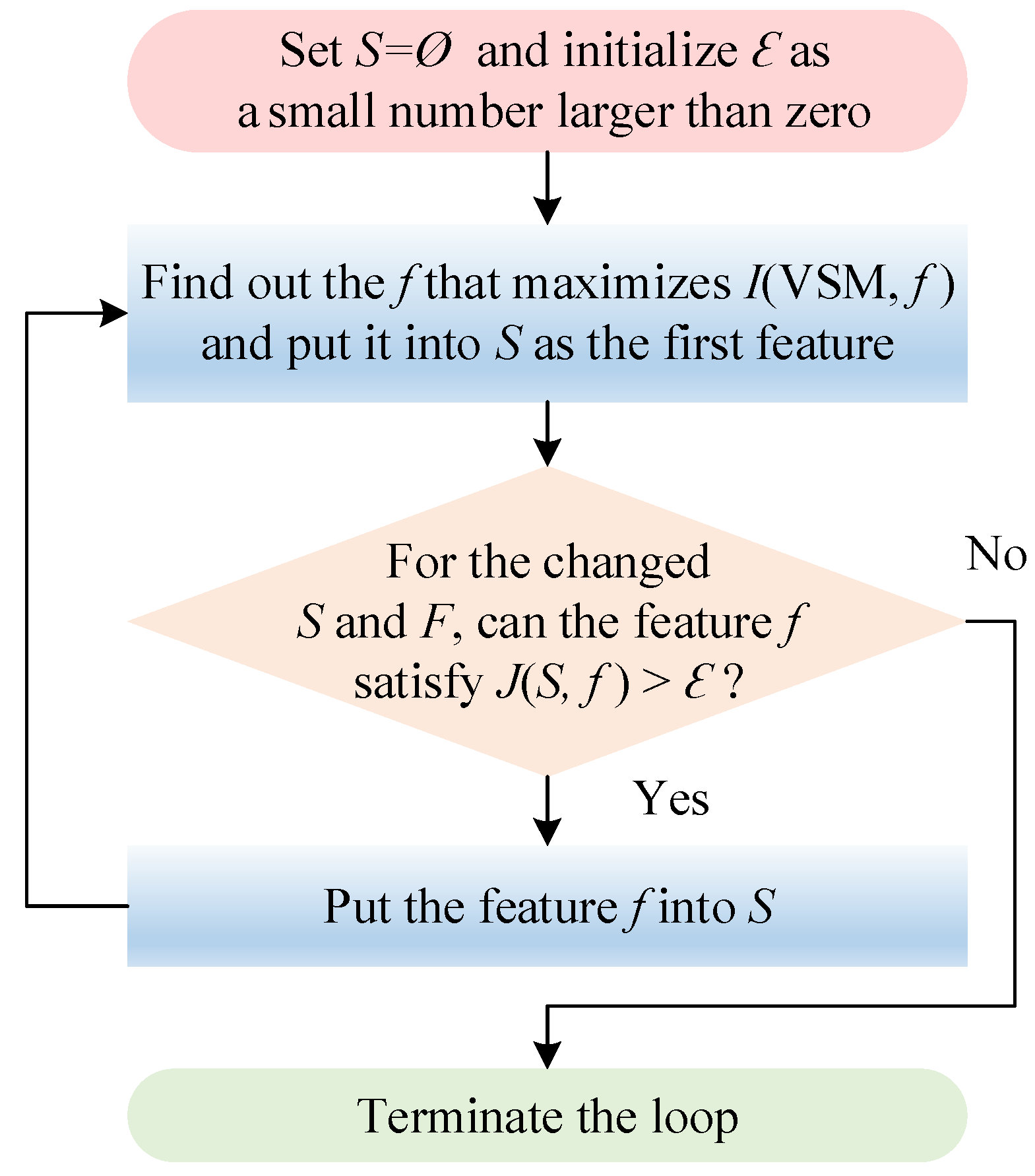
3.1.3. Feature Selection Procedure
3.2. Model Update
- (1)
- If the changed operation condition has been recorded in the knowledge base, the corresponding VSA model will be immediately selected out to replace the original one.
- (2)
- If the match cannot be found, the assessment accuracies of readily available trained models will be checked based on the changed operation condition. (1) If some models can provide acceptable accuracies, the model with the highest accuracy of such candidates will be used to accomplish VSA for the system with the changed operation condition. (2) If the existing models cannot provide acceptable accuracies for the changed operation condition, the construction process of a new VSA model will be activated. Then, the changed operation condition will be recorded, and the corresponding new model will be absorbed in the knowledge base. By continuously executing the model update, fewer unseen operation conditions will be encountered and seamless online VSA can be gradually achieved.
3.3. Online Assessment
4. Performance Examination
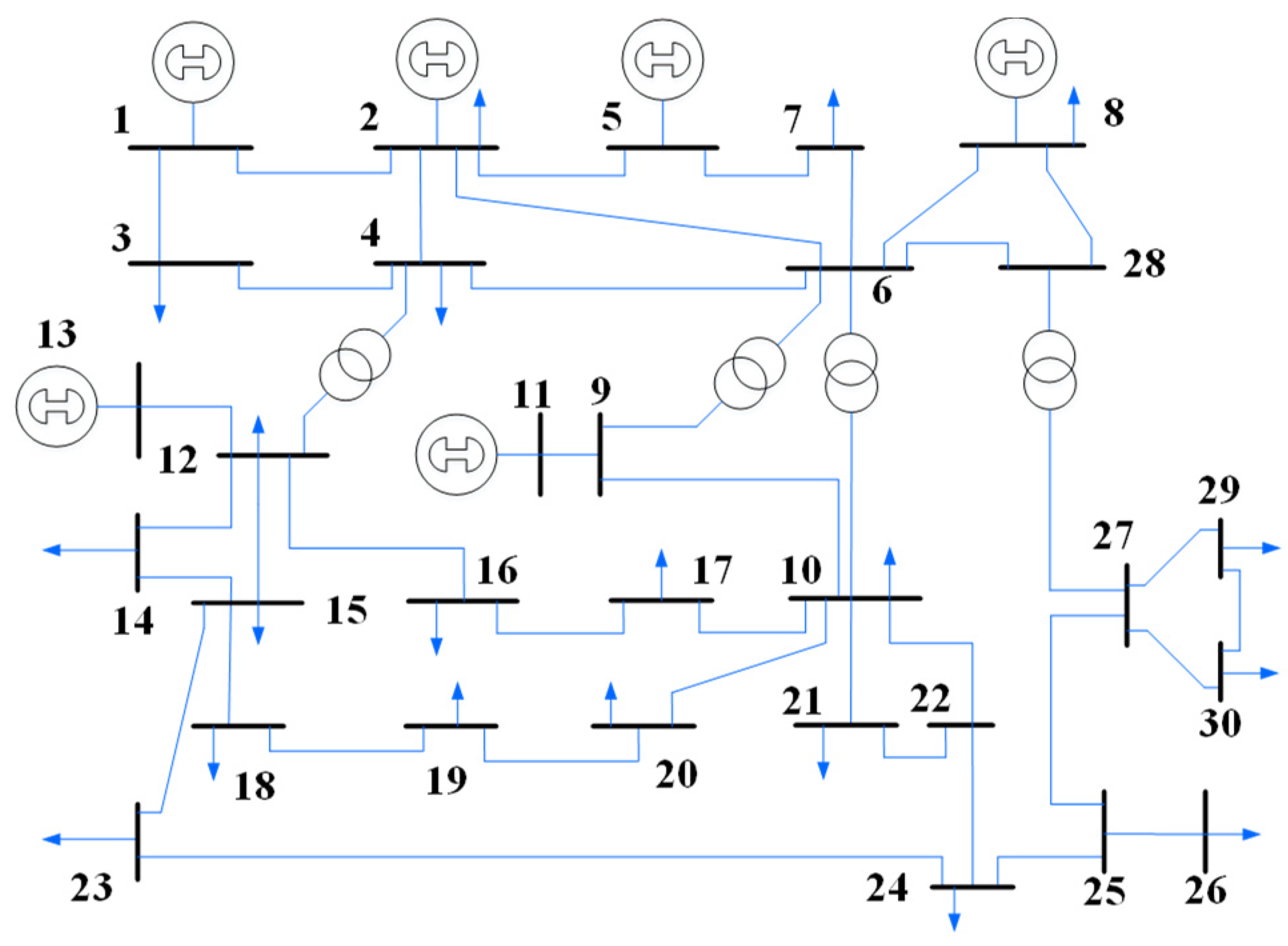
4.1. Test System and Data Generation
4.2. Feature Selection
4.3. VSA Test
5. Application to a Larger System
5.1. Comparison with Different Regression Tools
- (1)
- For LR and SVM, it is an arduous task to train a massive number of samples. In particular, the accuracy may not be acceptable when LR is applied to a large-scale feature space [29]. Due to the attribute of IRF for accommodating large-scale data and the feature selection procedure, the VSA model is able to train massive samples efficiently.
- (2)
- For RT, missing data situations cannot be effectively handled. In addition, overly complex rules may be established when the depth of a tree is large [30]. Compared with RT, IRF has a parallel data processing structure with multiple trees, which can provide sufficient alternative choice of feature sets to overcome data missing.
- (3)
- For ANN and ELM, the high calculation cost is an obvious problem for the implementation of online VSA. The iterative tuning and slow learning speed may lead to a large consumption of computational resources when ANNs and ELMs are trained for prediction with large-scale data. Because of the rapid calculation of the IRF regressor and screening of the key variables in advance, the computational burden can be significantly reduced.
5.2. Robustness Assessment
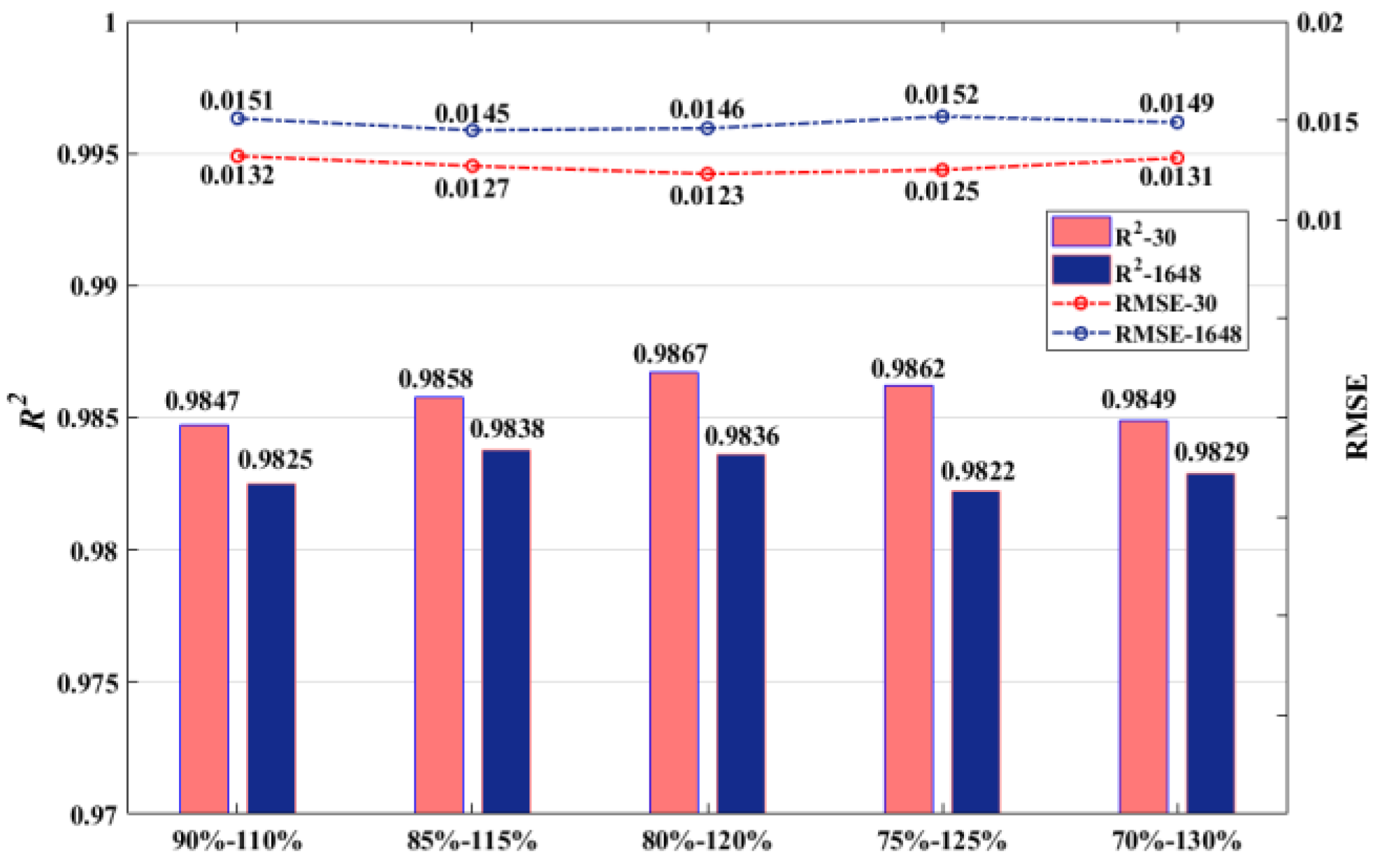
- (1)
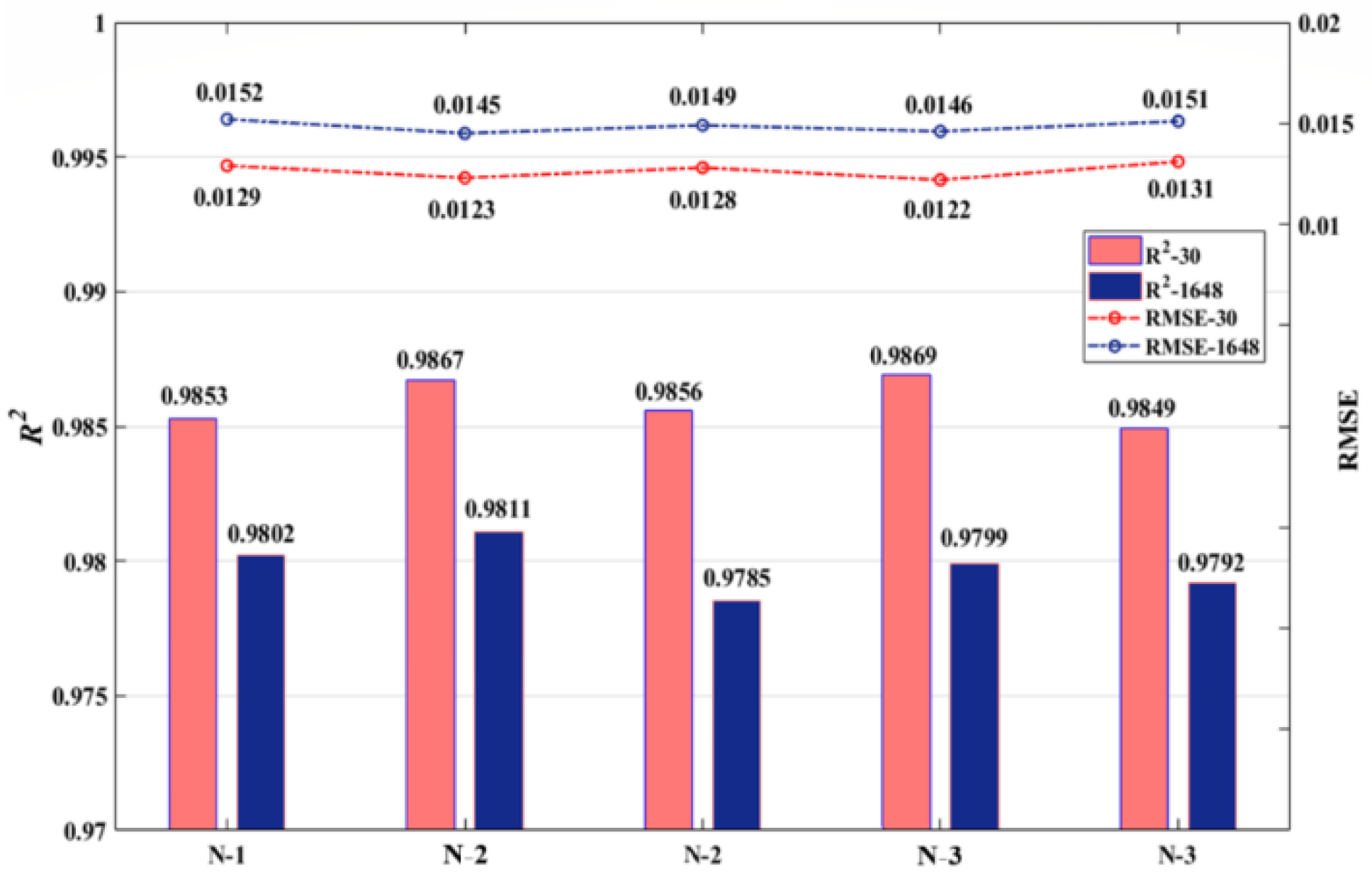
- Topology Change: Different network topologies were tested in this study and a part of them is shown in Table 3. The corresponding test results are shown in Figure 7, where R2-30 and RMSE-30 represent the accuracies of the tests for the IEEE 30-bus system. Similarly, R2-1648 and RMSE-1648 represent the accuracies of tests for the 1648-bus system.
- (2)
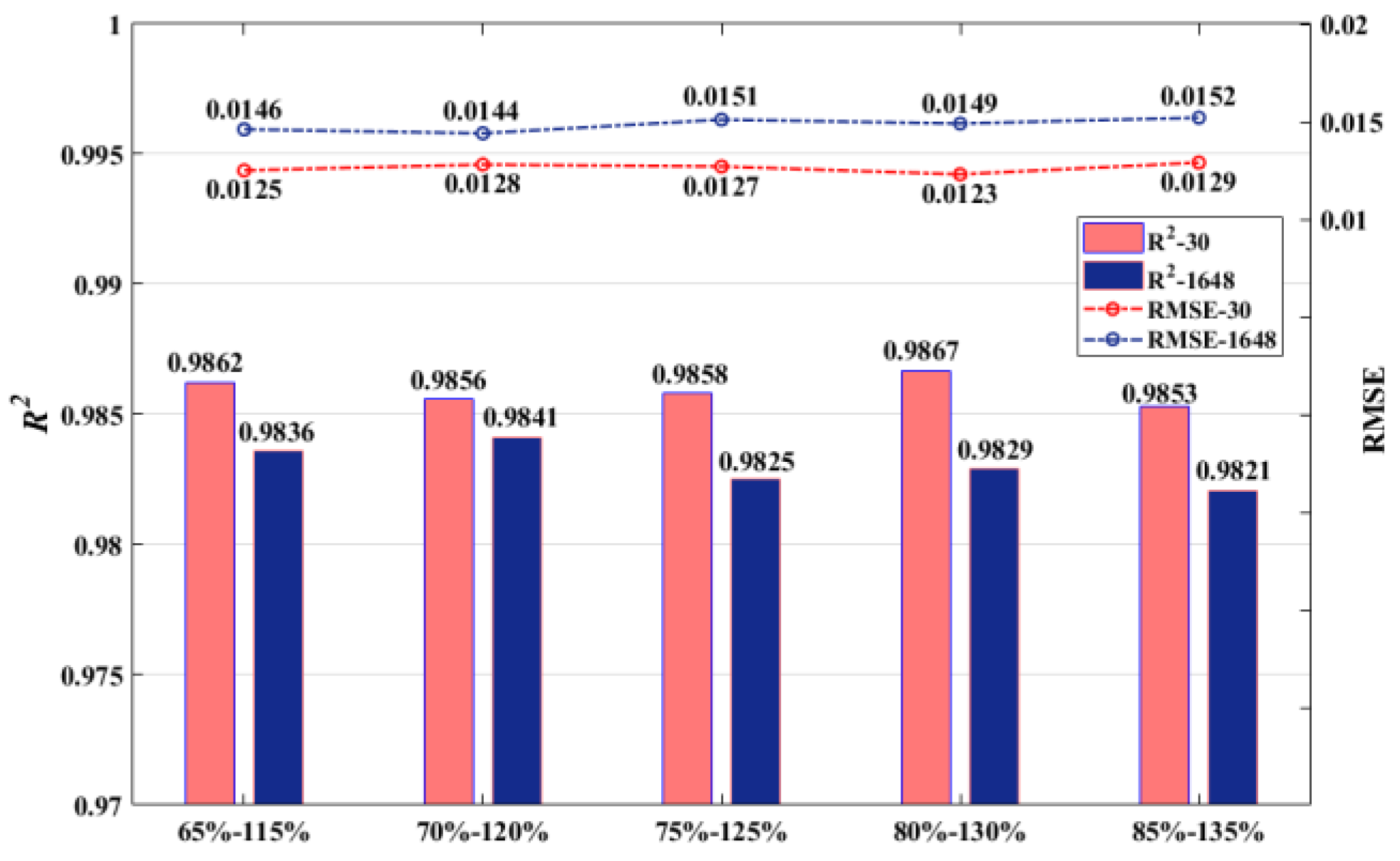
- Variation of Peak/Minimum Load: The impact of different peak/minimum load ranges on the assessment accuracy was examined, and the test results are shown in Figure 8. Although fluctuation occurs in the prediction accuracy, the accuracy can still be maintained in an acceptable range () for the two systems.
- (3)
- Variation of Generator/Load Power Distribution: Different generator/load power distributions were taken into account for testing, and the corresponding results are shown in Figure 9.
5.3. Impact of PMU Measurement Errors
- (1)
- Noise was added only to the test set.
- (2)
- Noise was added to both the training set and test set.
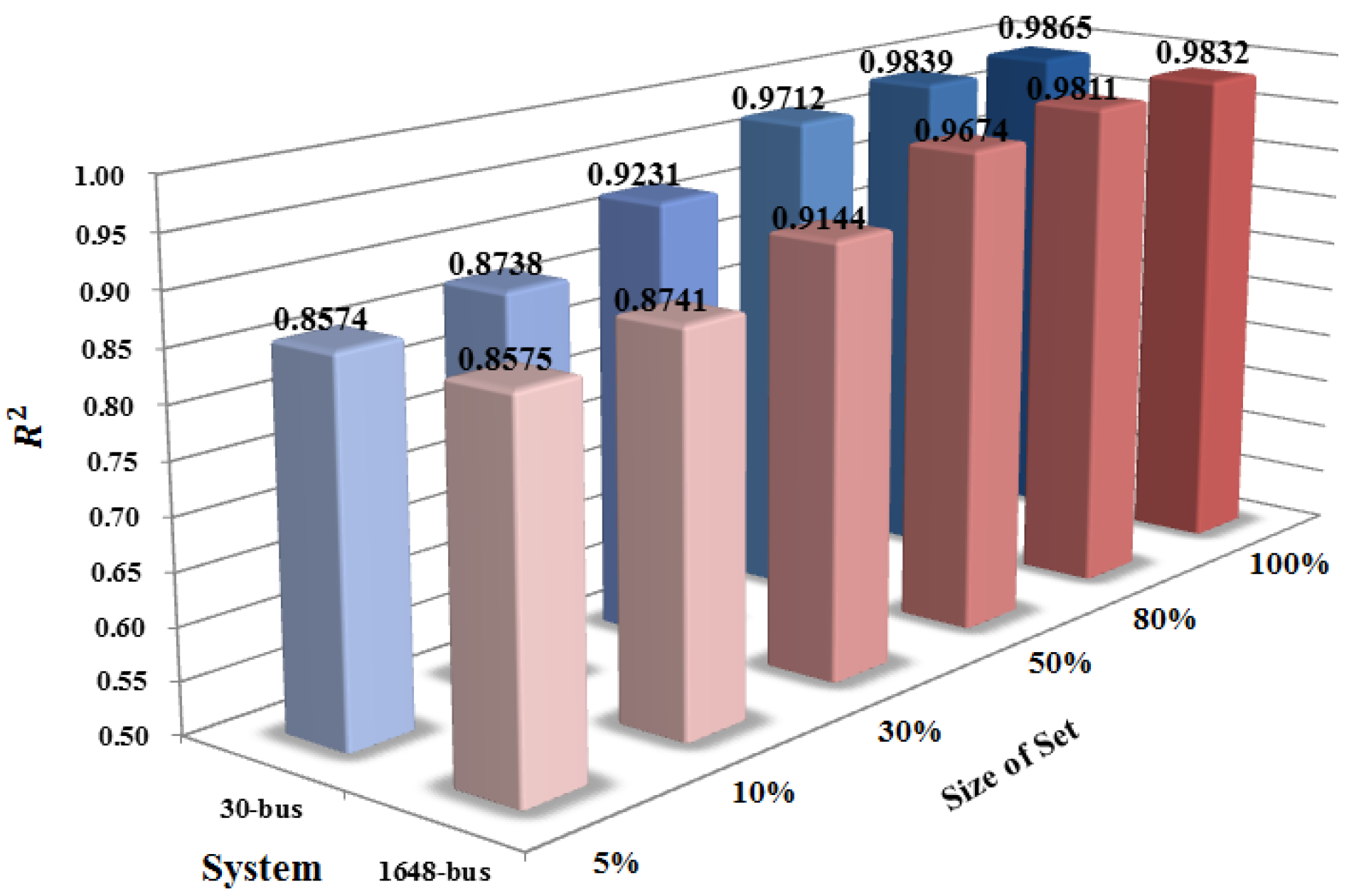
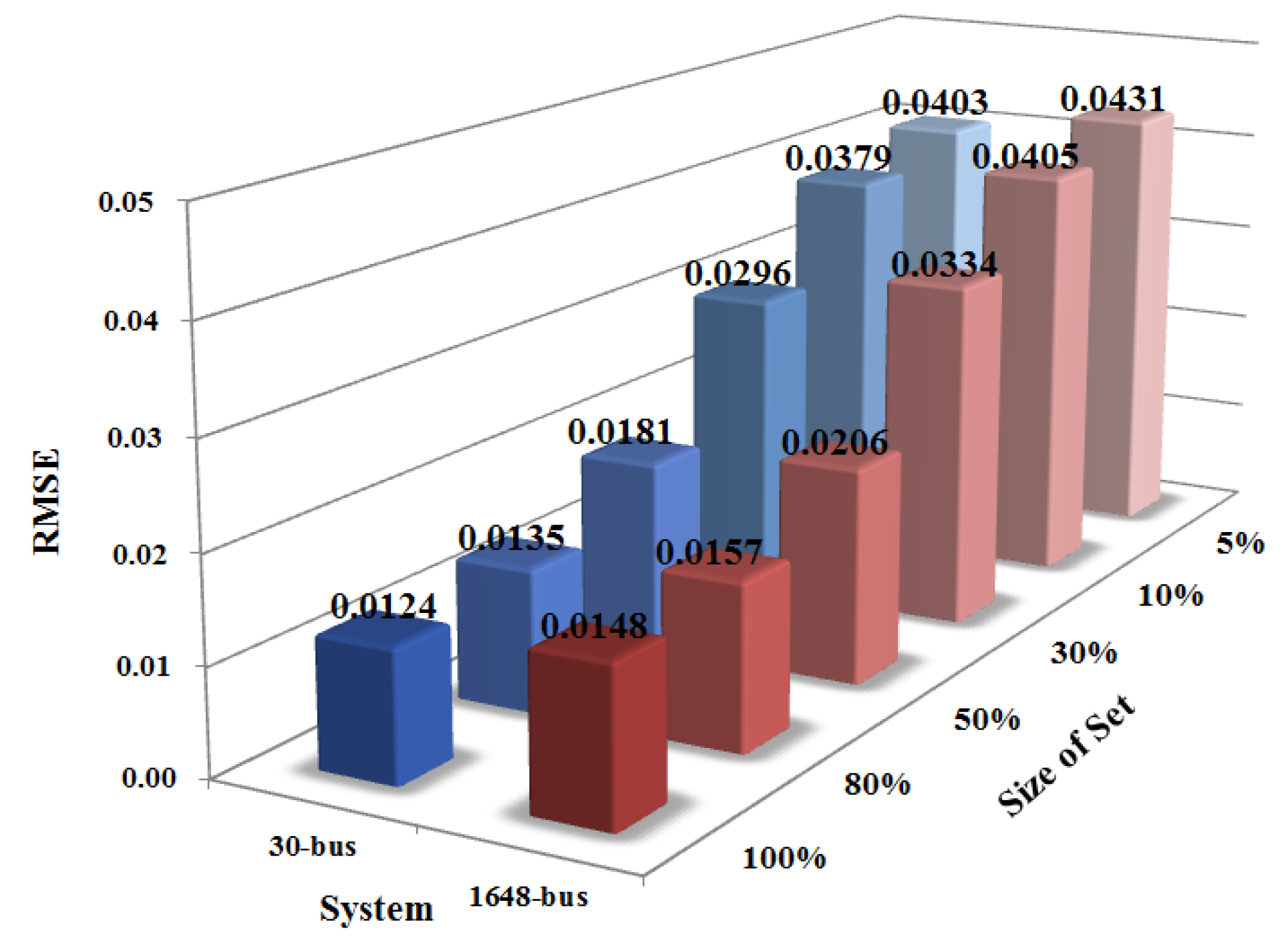
5.4. Impact of Training Set Size
5.5. Data Processing Speed
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, X.; Gui, D.; Zhao, Z.F.; Li, X.Y.; Wu, X.; Hua, Y.W.; Guo, P.F.; Zhong, H. Operation Optimization of Electrical-Heating Integrated Energy System Based on concentrating solar power plant hybridized with combined heat and power plant. J. Clean. Prod. 2021, 289, 125712. [Google Scholar] [CrossRef]
- Qiu, L.; Li, Y.; Yu, Y.; Xiao, Y.; Su, P.; Xiong, Q.; Jiang, J.; Li, L. Numerical and experimental investigation in electromagnetic tube expansion with axial compression. Int. J. Adv. Manuf. Technol. 2019, 104, 3045–3051. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, N.; Dong, B.; Wu, L.; Yan, J.; Shen, X.; Xing, C.; Liu, S.; Huang, Y. Multi-Lateral participants decision-making: A distribution system planning approach with incomplete information game. IEEE Access 2020, 8, 88933–88950. [Google Scholar] [CrossRef]
- Cutsem, T.V.; Vournas, C. Voltage stability of electric power systems. Springer Int. 2007, 18, 32. [Google Scholar]
- Leonardi, B.; Ajjarapu, V. Development of multilinear regression models for online voltage stability margin estimation. IEEE Trans. Power Syst. 2011, 26, 374–383. [Google Scholar] [CrossRef]
- Zhang, X.P.; Ju, P.; Handschin, E. Continuation three-phase power flow: A tool for voltage stability analysis of unbalanced three-phase power systems. IEEE Trans. Power Syst. 2005, 20, 1320–1329. [Google Scholar] [CrossRef]
- Su, H.Y.; Liu, C.W. Estimating the voltage stability margin using PMU measurements. IEEE Trans. Power Syst. 2016, 31, 3221–3229. [Google Scholar] [CrossRef]
- Lee, D.H.A. Voltage stability assessment using equivalent nodal analysis. IEEE Trans. Power Syst. 2016, 31, 454–463. [Google Scholar] [CrossRef]
- Youssef, K.H. A new method for online sensitivity-based distributed voltage control and short circuit analysis of unbalanced distribution feeders. IEEE Trans. Smart Grid 2015, 6, 1253–1260. [Google Scholar] [CrossRef]
- Hashiesh, F.; Mostafa, H.E.; Khatib, A.R.; Helal, I.; Mansour, M.M. An intelligent wide area synchrophasor based system for predicting and mitigating transient instabilities. IEEE Trans. Smart Grid 2012, 3, 645–652. [Google Scholar] [CrossRef]
- Liu, S.K.; Liu, L.H.; Fan, Y.P.; Zhang, L.; Huang, Y.H.; Zhang, T.; Cheng, J.Z.; Wang, L.Y.; Zhang, M.L.; Shi, R.Y.; et al. An integrated scheme for online dynamic security assessment based on partial mutual information and iterated random forest. IEEE Trans. Smart Grid 2020, 11, 3606–3619. [Google Scholar] [CrossRef]
- Liu, S.K.; Liu, L.H.; Yang, N.; Mao, D.; Zhang, L.; Cheng, J.Z.; Xue, T.L.; Liu, L.; Yan, G.H.; Qiu, L.; et al. A data-driven approach for online dynamic security assessment with spatial-temporal dynamic visualization using random bits forest. Int. J. Electr. Power Energy Syst. 2021, 124, 106316. [Google Scholar] [CrossRef]
- Wang, B.; Fang, B.; Wang, Y.J.; Liu, H.S.; Liu, Y.L. Power system transient stability assessment based on big data and the core vector machine. IEEE Trans. Smart Grid 2016, 7, 2561–2570. [Google Scholar] [CrossRef]
- Achlerkar, P.D.; Samantaray, S.R.; Manikandan, M.S. Variational mode decomposition and decision tree based detection and classification of power quality disturbances in grid-connected distributed generation system. IEEE Trans. Smart Grid 2018, 9, 3122–3132. [Google Scholar] [CrossRef]
- Zhou, D.Q.; Annakkage, U.D.; Rajapakse, A.D. Online monitoring of voltage stability margin using an artificial neural network. IEEE Trans. Power Syst. 2010, 25, 1566–1574. [Google Scholar] [CrossRef]
- Xu, Y.; Dong, Z.Y.; Zhao, J.H.; Zhang, P.; Wong, K.P. A reliable intelligent system for real-time dynamic security assessment of power systems. IEEE Trans. Power Syst. 2012, 27, 1253–1263. [Google Scholar] [CrossRef]
- Zhao, J.; Zhou, Y.W.; Zhang, X.J.; Chen, L.N. Part mutual information for quantifying direct associations in networks. Proc. Natl. Acad. Sci. USA 2016, 113, 5130–5135. [Google Scholar] [CrossRef]
- Basu, S.; Kumbier, K.; Brown, J.B.; Yu, B. Iterative random forests to discover predictive and stable high-order interactions. Proc. Natl. Acad. Sci. USA 2018, 115, 1943–1948. [Google Scholar] [CrossRef]
- Ajjarapu, V.; Christy, C. The continuation power flow: A tool for steady state voltage stability analysis. IEEE Trans. Power Syst. 1992, 7, 416–423. [Google Scholar] [CrossRef]
- Zheng, C.; Malbasa, V.; Kezunovic, M. Regression tree for stability margin prediction using synchrophasor measurements. IEEE Trans. Power Syst. 2013, 28, 1978–1987. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; Hao, J.; Zhao, X.; Chen, L. Conditional mutual inclusive information enables accurate quantification of associations in gene regulatory networks. Nucleic Acids Res. 2014, 43, 31–41. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhao, X.-M.; He, K.; Lu, L.; Cao, Y.; Liu, J.; Hao, J.-K.; Liu, Z.-P.; Chen, L. Inferring gene regulatory networks from gene expression data by path consistency algorithm based on conditional mutual information. Bioinformatics 2012, 28, 98–104. [Google Scholar] [CrossRef] [PubMed]
- Janzing, D.; Balduzzi, D.; Grosse-Wentrup, M.; Schölkopf, B. Quantifying causal influences. Ann Stat. 2013, 41, 2324–2358. [Google Scholar] [CrossRef]
- Anaissi, A.; Kennedy, P.J.; Goyal, M.; Catchpoole, D.R. A balanced iterative random forest for gene selection from microarray data. Bioinformatics 2013, 14, 261. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Voumvoulakis, E.M.; Hatziargyriou, N.D. A particle swarm optimization method for power system dynamic security control. IEEE Trans. Power Syst. 2010, 25, 1032–1041. [Google Scholar] [CrossRef]
- He, M.; Vittal, V.; Zhang, J. Online dynamic security assessment with missing PMU measurements: A data mining approach. IEEE Trans. Power Syst. 2013, 28, 1969–1977. [Google Scholar] [CrossRef]
- Nau, R.F. Forecasting. February 2005. Available online: http://www.duke.edu/~rnau/rsquared.htm (accessed on 1 June 2020).
- Zhao, B.B.; Cao, J.W.; Zhu, Z.Y.; Zhang, H.Y. A new transient voltage stability prediction model using big data analysis. In Proceedings of the 2016 IEEE Innovative Smart Grid Technologies—Asia (ISGT-Asia), Melbourne, Australia, 28 November–1 December 2016; Volume 25, pp. 2378–8542. [Google Scholar]
- Diao, R.S.; Vittal, V.J.; Logic, N. Design of a real-time security assessment tool for situational awareness enhancement in modern power systems. IEEE Trans. Power Syst. 2010, 25, 957–965. [Google Scholar] [CrossRef]
- IEEE Standard for Synchrophasors for Power Systems; IEEE Std. C37.118-2005; IEEE: New York, NY, USA, 2005.
- Su, H.Y.; Liu, T.Y. Enhanced-online-random-forest model for static voltage stability assessment using wide area measurements. IEEE Trans. Power Syst. 2018, 33, 6696–6704. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | 30-Bus System | 1648-Bus System |
|---|---|---|
| 0.9865 | 0.9832 | |
| RMSE | 0.0124 | 0.0148 |
| Tool | 30-Bus System | 1648-Bus System | ||
|---|---|---|---|---|
| RMSE | RMSE | |||
| LR | 0.9759 | 0.0165 | 0.9736 | 0.0185 |
| SVM | 0.9687 | 0.0189 | 0.9608 | 0.0226 |
| RT | 0.9716 | 0.0179 | 0.9694 | 0.0199 |
| ANN | 0.9746 | 0.0171 | 0.9707 | 0.0195 |
| ELM | 0.9713 | 0.0181 | 0.9658 | 0.0211 |
| IRF | 0.9865 | 0.0124 | 0.9832 | 0.0148 |
| Type | Out of Service (30-Bus System) | Out of Service (1648-Bus System) |
|---|---|---|
| N-1 | Lines 4–14 | Lines 303–310 |
| N-2 | G 3 and Lines 15–17 | G 42 and Lines 6–10 |
| N-2 | Lines 5–18 and Lines 12–13 | Lines 55–76 and Lines 344–385 |
| N-3 | G 2, Lines 4–6, and Lines 55–76 | G 128, Lines 9–21, and Lines 1262–1035 |
| N-3 | Lines 1–9, Lines 12–13, and Lines 21–22 | G 540, Lines 89–92, and Shunt 171 |
| Scenario | 30-Bus System | 1648-Bus System | ||
|---|---|---|---|---|
| RMSE | RMSE | |||
| Scenario 1 | 0.9608 | 0.0230 | 0.9589 | 0.0252 |
| Scenario 2 | 0.9742 | 0.0187 | 0.9684 | 0.0221 |
| System | Training Time | Test Time |
|---|---|---|
| 30-bus | 23.64 s (3331 records) | 2.79 s (1428 records) |
| 1648-bus | 239.82 s (11,605 records) | 9.25 s (4947 records) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Shi, R.; Huang, Y.; Li, X.; Li, Z.; Wang, L.; Mao, D.; Liu, L.; Liao, S.; Zhang, M.; et al. A Data-Driven and Data-Based Framework for Online Voltage Stability Assessment Using Partial Mutual Information and Iterated Random Forest. Energies 2021, 14, 715. https://doi.org/10.3390/en14030715
Liu S, Shi R, Huang Y, Li X, Li Z, Wang L, Mao D, Liu L, Liao S, Zhang M, et al. A Data-Driven and Data-Based Framework for Online Voltage Stability Assessment Using Partial Mutual Information and Iterated Random Forest. Energies. 2021; 14(3):715. https://doi.org/10.3390/en14030715
Chicago/Turabian StyleLiu, Songkai, Ruoyuan Shi, Yuehua Huang, Xin Li, Zhenhua Li, Lingyun Wang, Dan Mao, Lihuang Liu, Siyang Liao, Menglin Zhang, and et al. 2021. "A Data-Driven and Data-Based Framework for Online Voltage Stability Assessment Using Partial Mutual Information and Iterated Random Forest" Energies 14, no. 3: 715. https://doi.org/10.3390/en14030715
APA StyleLiu, S., Shi, R., Huang, Y., Li, X., Li, Z., Wang, L., Mao, D., Liu, L., Liao, S., Zhang, M., Yan, G., & Liu, L. (2021). A Data-Driven and Data-Based Framework for Online Voltage Stability Assessment Using Partial Mutual Information and Iterated Random Forest. Energies, 14(3), 715. https://doi.org/10.3390/en14030715