Real-Time Autonomous Residential Demand Response Management Based on Twin Delayed Deep Deterministic Policy Gradient Learning


Abstract
1. Introduction
1.1. Background and Motivation
1.2. Literature Review
1.3. Contributions
- -
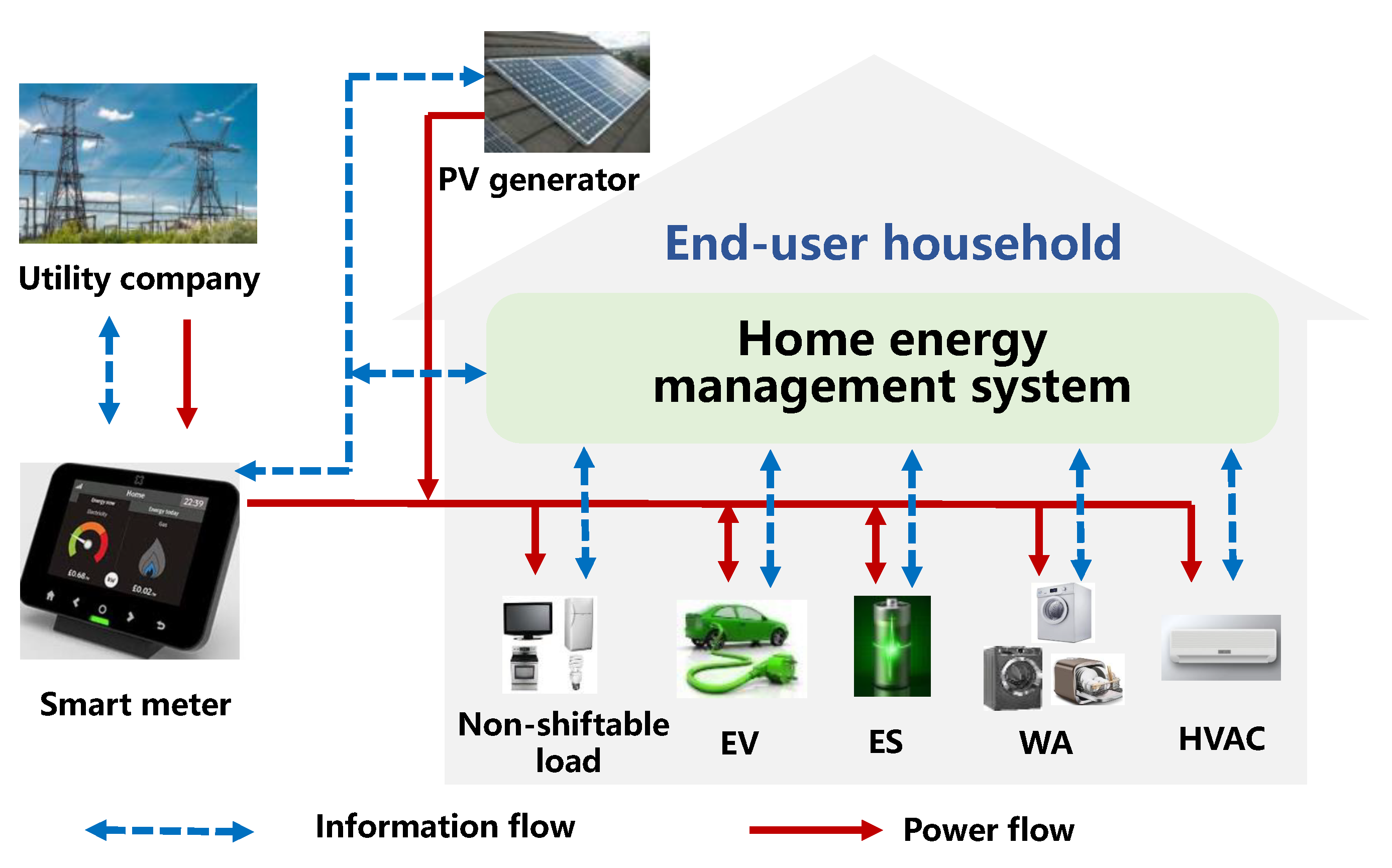
- A Markov decision process (MDP) is constructed to formulate the optimal DR management problem for a residential household operating with multiple and diverse DERs, including PV generators, ES units, and three types of FD technologies, namely an EV with flexible charging and vehicle-to-grid (V2G)/vehicle-to-home (V2H) capabilities, wet appliances (WAs) with deferrable cycles, and HVAC with certain comfortable temperature margins.
- -
- A model-free and data-driven approach based on TD3, which does not rely on any knowledge of the DERs’ operational models and parameters, is proposed to optimize the real-time DR management strategy. In contrast to previous works where the DR management problem was addressed by employing discrete control RL methods, the TD3 method allows learning of neural-network-based, fine-grained DR management policies in a multi-dimensional action space by harnessing high-dimensional sensory data that also encapsulate the system uncertainties.
- -
- Case studies on a real-world scenario substantiate the superior performance of the proposed method in being more computationally efficient, as well as in achieving a significantly lower daily energy cost than the state-of-the-art DRL methods, while coping with the uncertainties stemming from both the electricity prices and the supply and demand sides of an end-user’s DERs.
1.4. Paper Organization
2. System Model and Problem Formulation
2.1. Electric Vehicle (EV) and Energy Storage (ES)
2.2. Wet Appliances (WAs)
2.3. Heating, Ventilation, and Air Conditioning (HVAC)
2.4. Daily Energy Cost Minimization
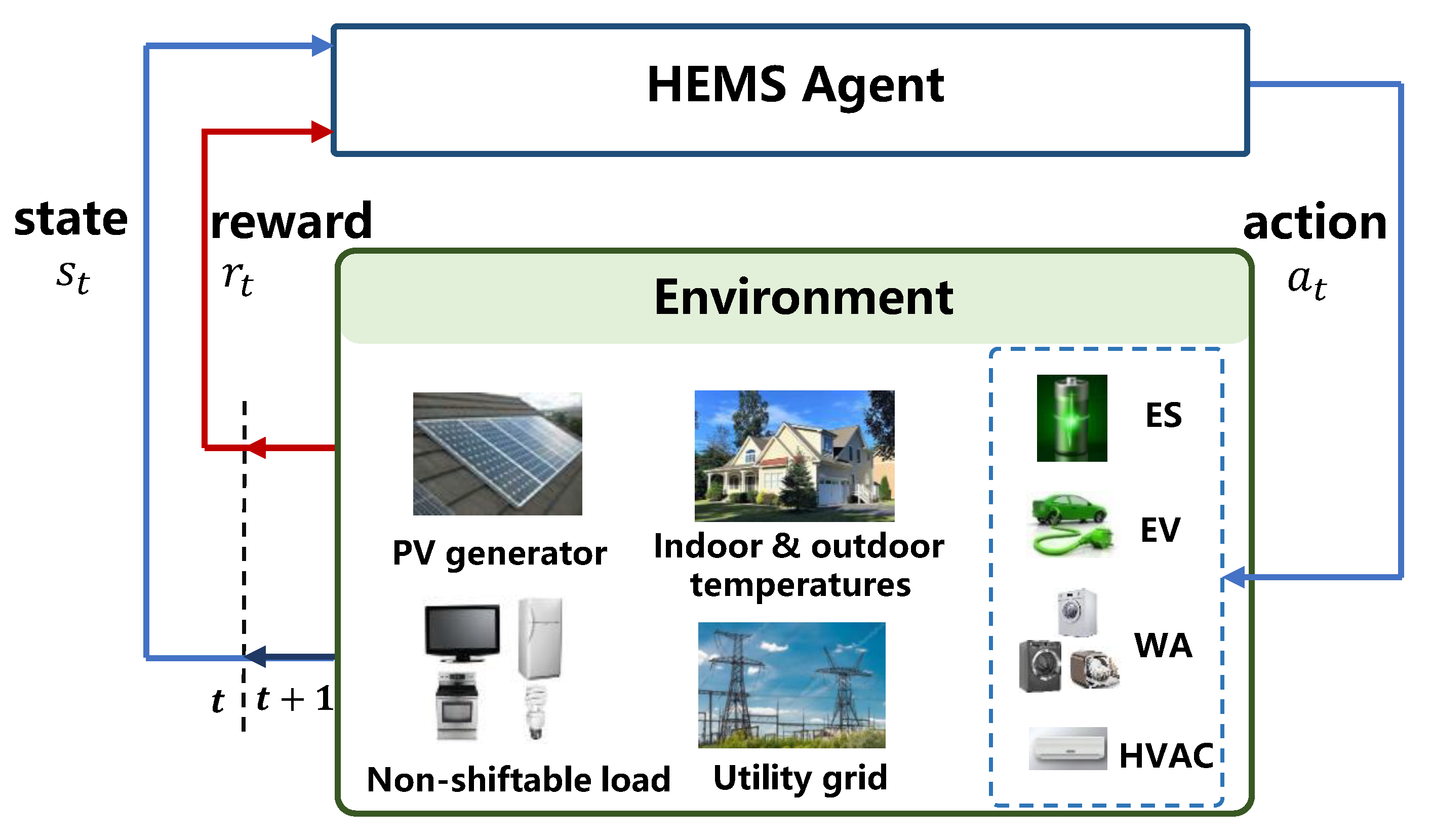
3. DR Management as an MDP
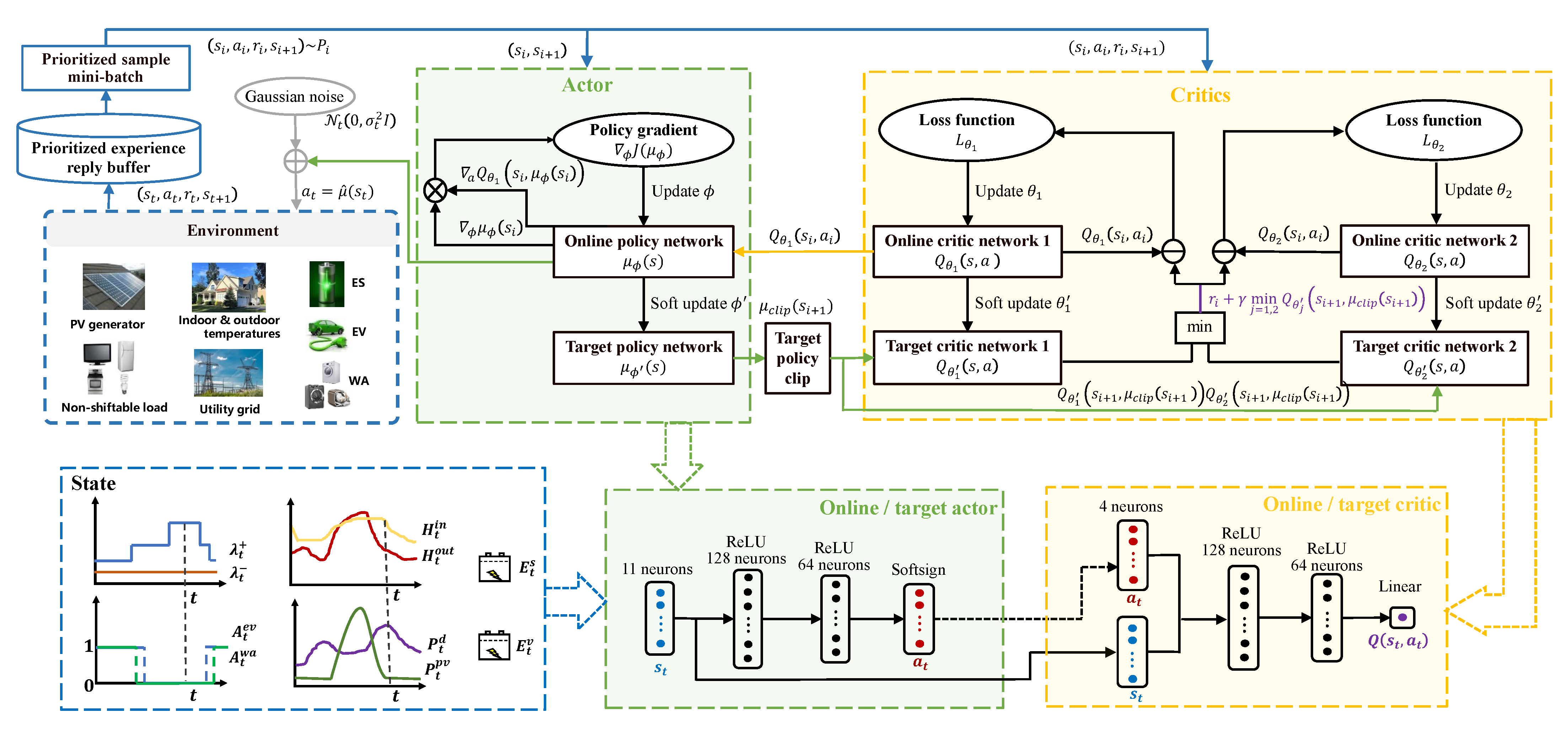
4. Proposed TD3-Based DR Management Strategy
| Algorithm 1 Training procedure of TD3 |
|
| Algorithm 2 TD3-based DR management strategy |
|
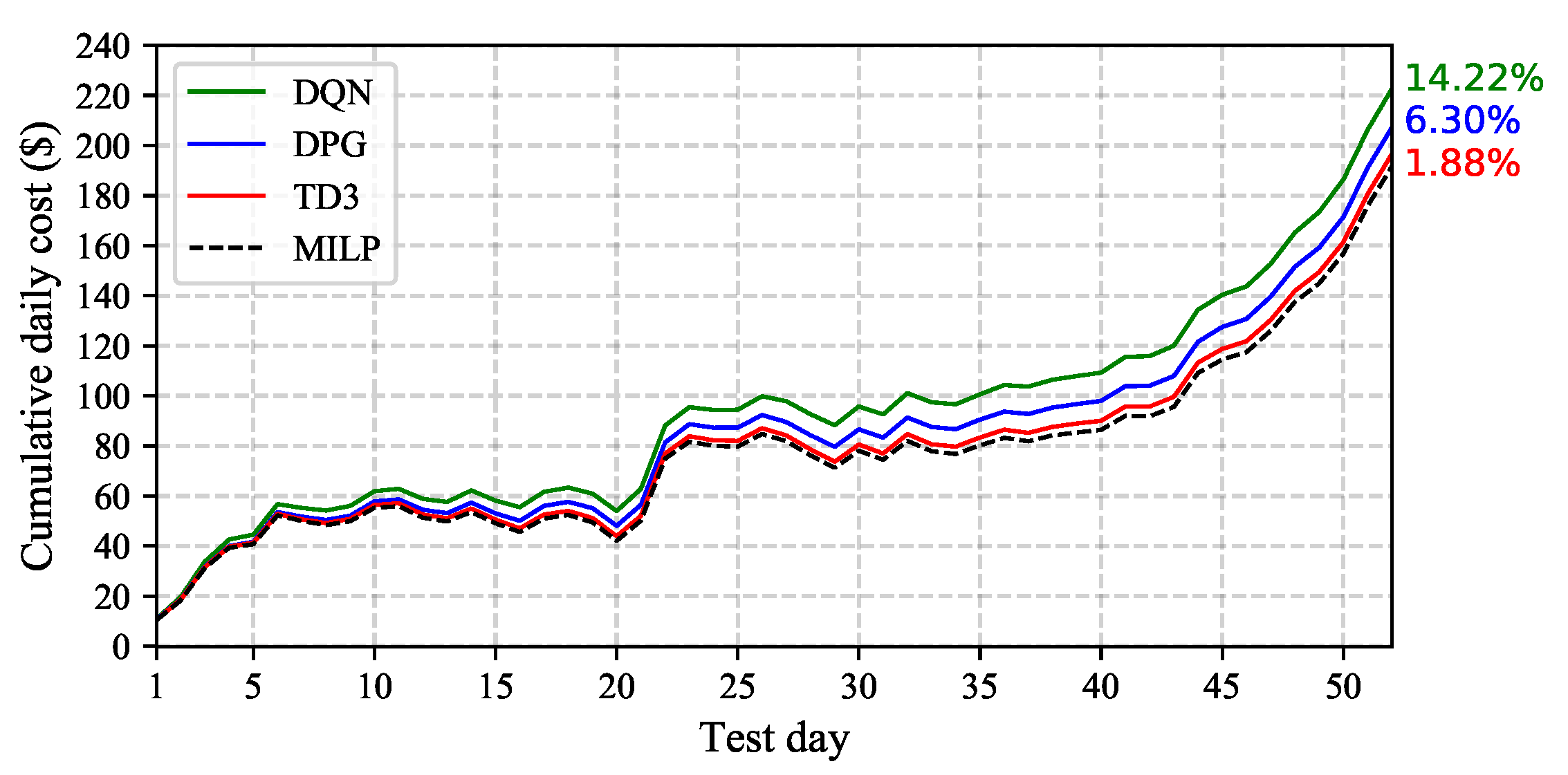
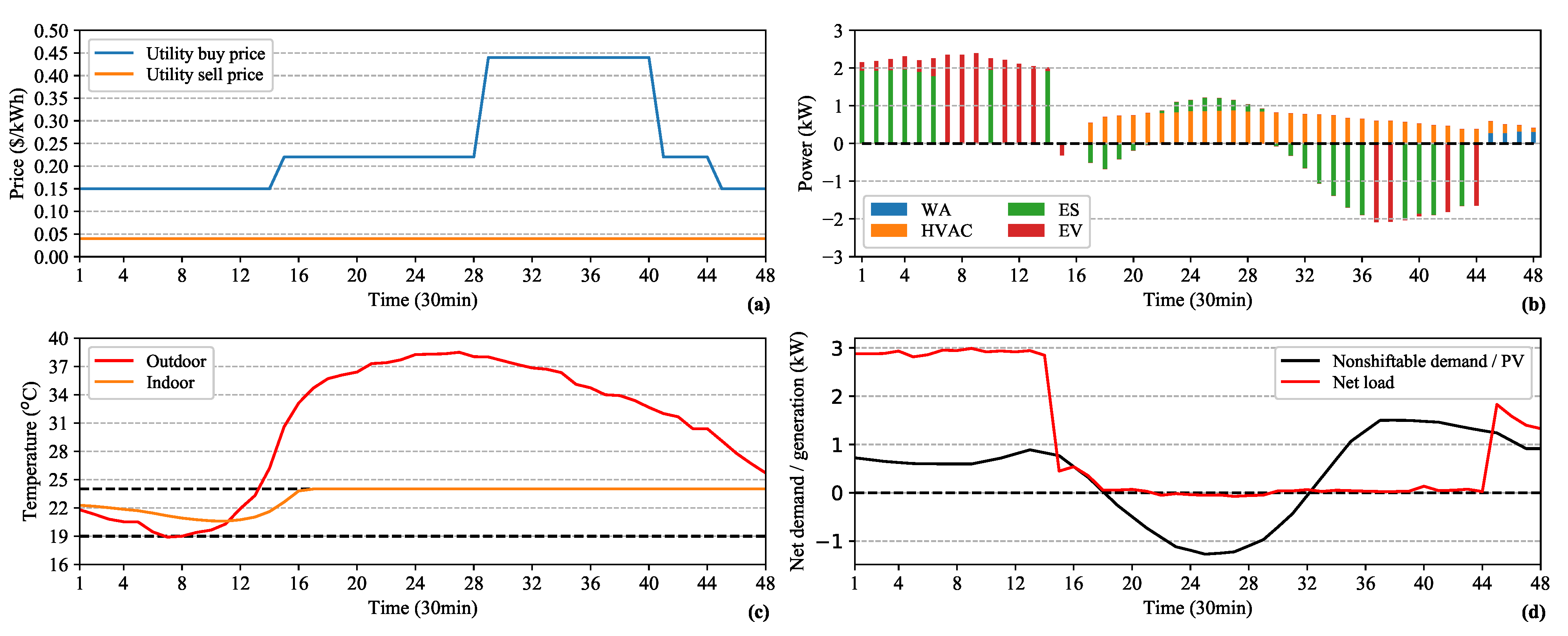
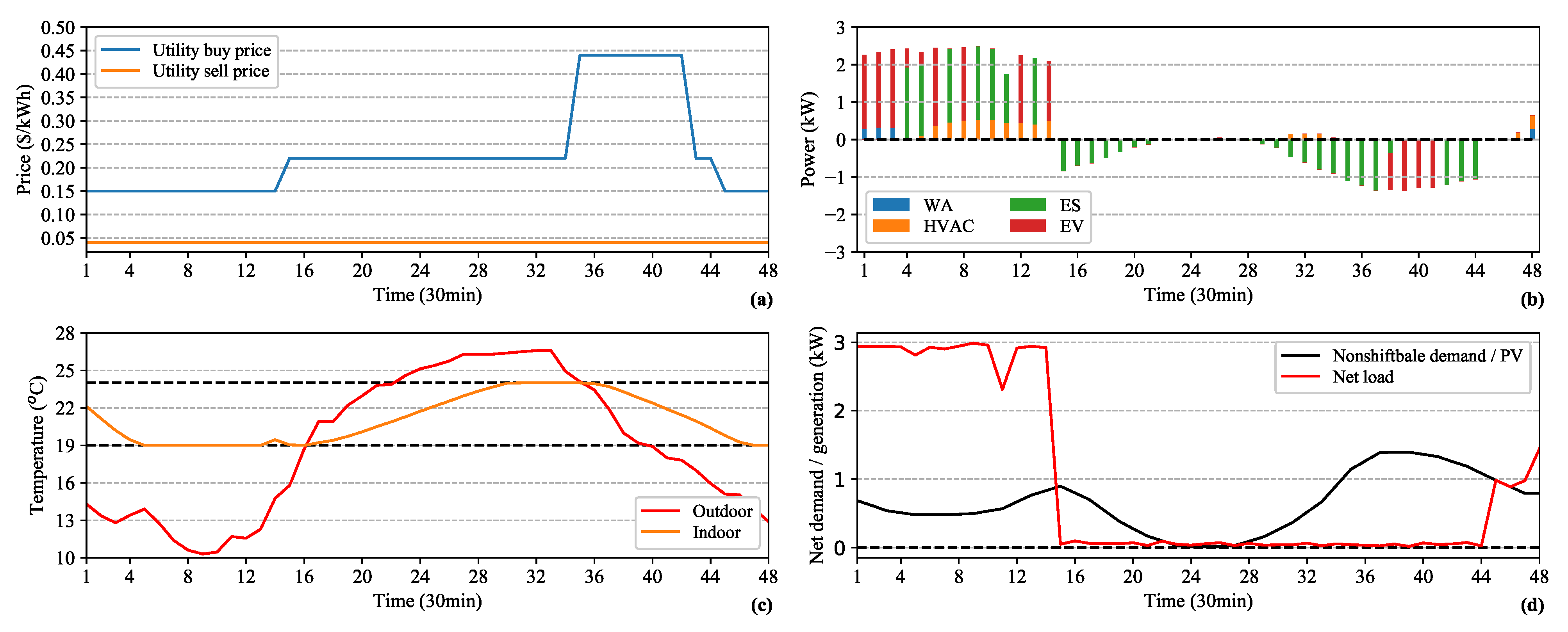
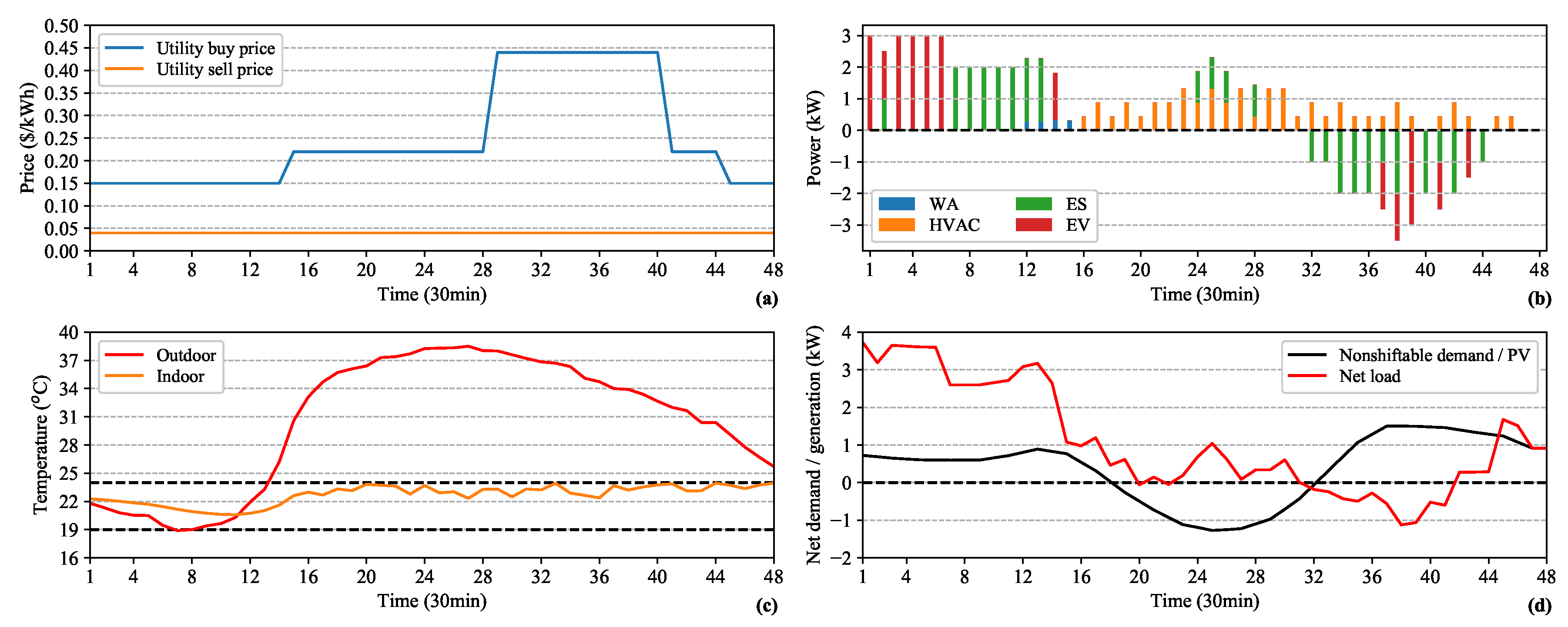
5. Results and Discussion
5.1. Simulation Setup and Implementation
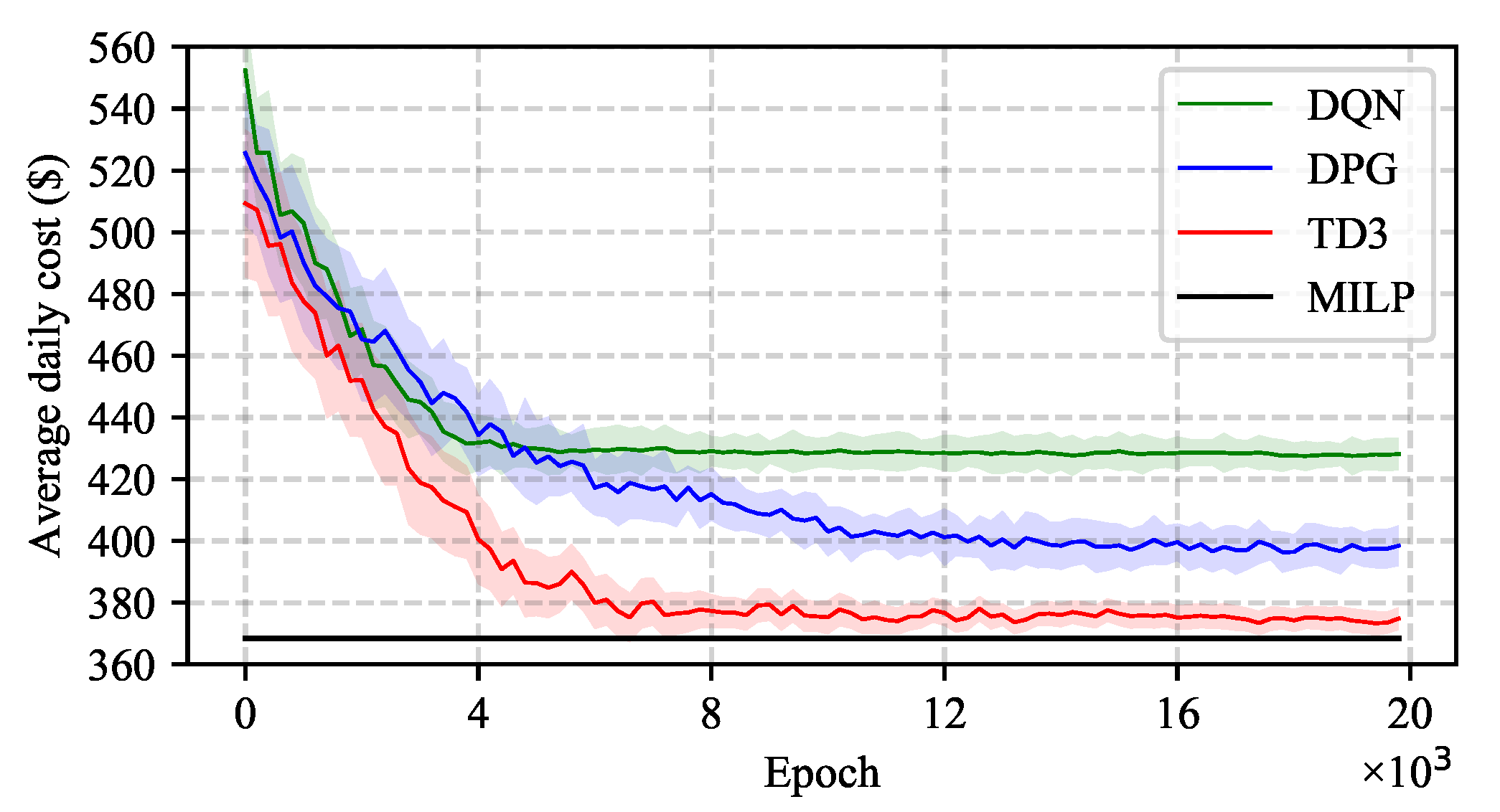
5.2. Performance Evaluation
5.3. Benefits of Continuous DR Management
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| t | Index of time steps |
| Horizon and resolution of DR management problem | |
| , | Utility buy and sell prices at t (AUD/kWh) |
| Power demand of non-shiftable loads at t (kW) | |
| Power generation of PV at t (kW) | |
| Binary indicator of whether EV charges () or discharges () at t | |
| Charging and discharging power of EV at t (kW) | |
| Maximum charging/discharging rate of EV (kW) | |
| Energy level of EV at t (kWh) | |
| Maximum and minimum energy limits of EV (kWh) | |
| Energy requirement for traveling purposes of EV at t (kWh) | |
| Charging and discharging efficiencies of EV | |
| Departure and arrival times of EV | |
| Binary indicator on EV scheduling availability at t (set as for the EV scheduling step and otherwise) | |
| Index of sub-processes of the WA cycle | |
| Power demand at sub-process of the WA cycle (kW) | |
| Power demand of WAs at t (kW) | |
| Duration of WA cycle | |
| Earliest initiation and latest termination times of WA cycle | |
| Binary indicator of WA scheduling availability at t (set as for the WA scheduling and otherwise) | |
| Binary indicator on whether the WA cycle is initiated at t ( if it is initiated, otherwise) | |
| Indoor temperature at t (°C) | |
| Outdoor temperature at t (°C) | |
| Maximum and minimum indoor temperature levels (°C) | |
| Power demand of HVAC at t (kW) | |
| Maximum power input of HVAC (kW) | |
| Coefficient of performance of HVAC | |
| Thermal capacity of the heated/cooled space (kWh/°F) | |
| Thermal resistance of the heated/cooled space (°F/kW) | |
| Binary indicator of whether ES charges () or discharges () at t | |
| Charging and discharging power of ES at t (kW) | |
| Power capacity of ES (kW) | |
| Energy in ES at t (kWh) | |
| Maximum and minimum energy limits of ES (kWh) | |
| Charging and discharging efficiencies of ES |
References
- Shakoor, A.; Davies, G.; Strbac, G. Roadmap for Flexibility Services to 2030; A report to the Committee on Climate Change; Pöyry: London, UK, 2017. [Google Scholar]
- O’Connell, A.; Taylor, J.; Smith, J.; Rogers, L. Distributed Energy Resources Takes Center Stage: A Renewed Spotlight on the Distribution Planning Process. IEEE Power Energy Mag. 2018, 16, 42–51. [Google Scholar] [CrossRef]
- Pedrasa, M.A.A.; Spooner, T.D.; MacGill, I.F. Coordinated scheduling of residential distributed energy resources to optimize smart home energy services. IEEE Trans. Smart Grid 2010, 1, 134–143. [Google Scholar] [CrossRef]
- Bozchalui, M.C.; Hashmi, S.A.; Hassen, H.; Canizares, C.A.; Bhattacharya, K. Optimal operation of residential energy hubs in smart grids. IEEE Trans. Smart Grid 2012, 3, 1755–1766. [Google Scholar] [CrossRef]
- Rastegar, M.; Fotuhi-Firuzabad, M. Load management in a residential energy hub with renewable distributed energy resources. Energ. Build. 2015, 107, 234–242. [Google Scholar] [CrossRef]
- Moghaddam, I.G.; Saniei, M.; Mashhour, E. A comprehensive model for self-scheduling an energy hub to supply cooling, heating and electrical demands of a building. Energy 2016, 94, 157–170. [Google Scholar] [CrossRef]
- Basit, A.; Sidhu, G.A.S.; Mahmood, A.; Gao, F. Efficient and autonomous energy management techniques for the future smart homes. IEEE Trans. Smart Grid 2017, 8, 917–926. [Google Scholar] [CrossRef]
- Chen, Z.; Wu, L.; Fu, Y. Real-time price-based demand response management for residential appliances via stochastic optimization and robust optimization. IEEE Trans. Smart Grid 2012, 3, 1822–1831. [Google Scholar] [CrossRef]
- Shafie-Khah, M.; Siano, P. A stochastic home energy management system considering satisfaction cost and response fatigue. IEEE Trans. Ind. Inform. 2017, 14, 629–638. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, L.; Guo, W.; Kang, Q.; Wu, Q. Chance constrained optimization in a home energy management system. IEEE Trans. Smart Grid 2016, 9, 252–260. [Google Scholar] [CrossRef]
- Yu, L.; Jiang, T.; Zou, Y. Online energy management for a sustainable smart home with an HVAC load and random occupancy. IEEE Trans. Smart Grid 2017, 10, 1646–1659. [Google Scholar] [CrossRef]
- Du, Y.F.; Jiang, L.; Li, Y.; Wu, Q. A robust optimization approach for demand side scheduling considering uncertainty of manually operated appliances. IEEE Trans. Smart Grid 2016, 9, 743–755. [Google Scholar] [CrossRef]
- Birge, J.R.; Louveaux, F. Introduction to Stochastic Programming, 2nd ed.; Springer: New York, NY, USA, 2011. [Google Scholar]
- Bertsimas, D.; Brown, D.B.; Caramanis, C. Theory and applications of robust optimization. SIAM Rev. 2011, 53, 464–501. [Google Scholar] [CrossRef]
- Liang, Y.; He, L.; Cao, X.; Shen, Z.J. Stochastic control for smart grid users with flexible demand. IEEE Trans. Smart Grid 2013, 4, 2296–2308. [Google Scholar] [CrossRef]
- Wen, Z.; O’Neill, D.; Maei, H. Optimal demand response using device-based reinforcement learning. IEEE Trans. Smart Grid 2015, 6, 2312–2324. [Google Scholar] [CrossRef]
- Remani, T.; Jasmin, E.; Ahamed, T.I. Residential load scheduling with renewable generation in the smart grid: A reinforcement learning approach. IEEE Syst. J. 2019, 12, 3283–3294. [Google Scholar] [CrossRef]
- Berlink, H.; Kagan, N.; Costa, A.H.R. Intelligent decision-making for smart home energy management. J. Intell. Robot. Syst. 2015, 80, 331–354. [Google Scholar] [CrossRef]
- Guan, C.; Wang, Y.; Lin, X.; Nazarian, S.; Pedram, M. Reinforcement learning-based control of residential energy storage systems for electric bill minimization. In Proceedings of the 12th Annual IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2015; pp. 637–642. [Google Scholar]
- Kim, S.; Lim, H. Reinforcement learning based energy management algorithm for smart energy buildings. Energies 2018, 11, 2010. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, B. Energy storage arbitrage in real-time markets via reinforcement learning. In Proceedings of the 2018 IEEE Power & Energy Society General Meeting (PESGM), Portland, OR, USA, 5–10 August 2018; pp. 1–5. [Google Scholar]
- Ruelens, F.; Claessens, B.J.; Vandael, S.; De Schutter, B.; Babuška, R.; Belmans, R. Residential demand response of thermostatically controlled loads using batch reinforcement learning. IEEE Trans. Smart Grid 2017, 8, 2149–2159. [Google Scholar] [CrossRef]
- Claessens, B.J.; Vrancx, P.; Ruelens, F. Convolutional neural networks for automatic state-time feature extraction in reinforcement learning applied to residential load control. IEEE Trans. Smart Grid 2018, 9, 3259–3269. [Google Scholar] [CrossRef]
- Ruelens, F.; Claessens, B.J.; Quaiyum, S.; De Schutter, B.; Babuška, R.; Belmans, R. Reinforcement learning applied to an electric water heater: From theory to practice. IEEE Trans. Smart Grid 2018, 9, 3792–3800. [Google Scholar] [CrossRef]
- Wu, D.; Rabusseau, G.; François-lavet, V.; Precup, D.; Boulet, B. Optimizing Home Energy Management and Electric Vehicle Charging with Reinforcement Learning. In Proceedings of the 16th Adaptive Learning Agents (ALA), Stockholm, Sweden, 10–15 July 2018; pp. 1–8. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-line building energy optimization using deep reinforcement learning. IEEE Trans. Smart Grid 2019, 10, 3698–3708. [Google Scholar] [CrossRef]
- Tsang, N.; Cao, C.; Wu, S.; Yan, Z.; Yousefi, A.; Fred-Ojala, A.; Sidhu, I. Autonomous Household Energy Management Using Deep Reinforcement Learning. In Proceedings of the 25th IEEE International Conference on Engineering, Technology and Innovation (ICE/ITMC), Valbonne Sophia-Antipolis, France, 17–19 June 2019; pp. 1–7. [Google Scholar]
- Wan, Z.; Li, H.; He, H.; Prokhorov, D. Model-Free Real-Time EV Charging Scheduling Based on Deep Reinforcement Learning. IEEE Trans. Smart Grid 2019, 10, 5246–5257. [Google Scholar] [CrossRef]
- François-Lavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In Proceedings of the European Workshop on Reinforcement Learning (EWRL 2016), Barcelona, Spain, 3–4 December 2016; pp. 1–7. [Google Scholar]
- Chen, T.; Su, W. Local Energy Trading Behavior Modeling With Deep Reinforcement Learning. IEEE Access 2018, 6, 62806–62814. [Google Scholar] [CrossRef]
- Ji, Y.; Wang, J.; Xu, J.; Fang, X.; Zhang, H. Real-Time Energy Management of a Microgrid Using Deep Reinforcement Learning. Energies 2019, 12, 2291. [Google Scholar] [CrossRef]
- Wei, T.; Wang, Y.; Zhu, Q. Deep reinforcement learning for building hvac control. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; pp. 1–7. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference Learning Represent (ICLR), San Juan, Puerto Rico, 2–4 May 2016; pp. 1–14. [Google Scholar]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 3–8 December 2000; pp. 1008–1014. [Google Scholar]
- Wan, Z.; Li, H.; He, H. Residential energy management with deep reinforcement learning. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Ye, Y.; Qiu, D.; Wu, X.; Strbac, G.; Ward, J. Model-Free Real-Time Autonomous Control for A Residential Multi-Energy System Using Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 3068–3082. [Google Scholar] [CrossRef]
- Fujimoto, S.; Van Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the Machine Learning Research, New York, NY, USA, 23–24 February 2018. [Google Scholar]
- Ye, Y.; Papadaskalopoulos, D.; Moreira, R.; Strbac, G. Investigating the impacts of price-taking and price-making energy storage in electricity markets through an equilibrium programming model. IET Gener. Transm. Distrib. 2018, 13, 305–315. [Google Scholar] [CrossRef]
- Ye, Y.; Papadaskalopoulos, D.; Strbac, G. Factoring flexible demand non-convexities in electricity markets. IEEE Trans. Power Syst. 2014, 30, 2090–2099. [Google Scholar] [CrossRef]
- Du, Y.; Jiang, L.; Duan, C.; Li, Y.; Smith, J. Energy consumption scheduling of HVAC considering weather forecast error through the distributionally robust approach. IEEE Trans. Ind. Inf. 2017, 14, 846–857. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 1–9. [Google Scholar]
- Hasselt, H.V. Double Q-learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 2613–2621. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Ratnam, E.L.; Weller, S.R.; Kellett, C.M.; Murray, A.T. Residential load and rooftop PV generation: An Australian distribution network dataset. Int. J. Sustain. Energy 2017, 36, 787–806. [Google Scholar] [CrossRef]
- Papadaskalopoulos, D.; Strbac, G. Nonlinear and randomized pricing for distributed management of flexible loads. IEEE Trans. Smart Grid 2016, 7, 1137–1146. [Google Scholar] [CrossRef]
- EnergyAustralia. Solar Rebates and Feed-in Tariffs; EnergyAustralia: Melbourne, VIC, Australia, 2020. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference Learning Represent (ICLR), Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th Conference Artificial Intelligence and Statistics (AISTATS), Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Bergstra, J.; Desjardins, G.; Lamblin, P.; Bengio, Y. Quadratic Polynomials Learn Better Image Features; Technical Report 1337; Dept. IRO, Université de Montréal: Montréal, QC, Canada, 2009. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Key Features | Modeling Method | Advantages or Limitations |
|---|---|---|---|
| Model-based |
| Deterministic |
|
| SP |
| ||
| RO |
| ||
| Model-free |
| RL |
|
| DRL |
|
| EV | ES | WA | HVAC | ||||
|---|---|---|---|---|---|---|---|
| Parameter | Value | Parameter | Value | Parameter | Value | Parameter | Value |
| (h) | 2 | (°C) * | 19, 24 | (kWh) | 10 | (kWh) | 15 |
| (kW) | 0.56 | (kWh/°F) | 0.33 | (kWh) | 2 | (kWh) | 3 |
| (kW) | 0.56 | (°F/kW) | 13.5 | (kWh) | 10 | (kWh) | 15 |
| (kW) | 0.63 | 2.2 | 0.95 | 0.93 | |||
| (kW) | 0.63 | (kW) | 1.75 | (kW) | 4 | (kW) | 6 |
| Parameter | Distribution |
|---|---|
| (kWh) | |
| (kWh) | |
| (kWh) | |
| (°C) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Y.; Qiu, D.; Wang, H.; Tang, Y.; Strbac, G. Real-Time Autonomous Residential Demand Response Management Based on Twin Delayed Deep Deterministic Policy Gradient Learning. Energies 2021, 14, 531. https://doi.org/10.3390/en14030531
Ye Y, Qiu D, Wang H, Tang Y, Strbac G. Real-Time Autonomous Residential Demand Response Management Based on Twin Delayed Deep Deterministic Policy Gradient Learning. Energies. 2021; 14(3):531. https://doi.org/10.3390/en14030531
Chicago/Turabian StyleYe, Yujian, Dawei Qiu, Huiyu Wang, Yi Tang, and Goran Strbac. 2021. "Real-Time Autonomous Residential Demand Response Management Based on Twin Delayed Deep Deterministic Policy Gradient Learning" Energies 14, no. 3: 531. https://doi.org/10.3390/en14030531
APA StyleYe, Y., Qiu, D., Wang, H., Tang, Y., & Strbac, G. (2021). Real-Time Autonomous Residential Demand Response Management Based on Twin Delayed Deep Deterministic Policy Gradient Learning. Energies, 14(3), 531. https://doi.org/10.3390/en14030531