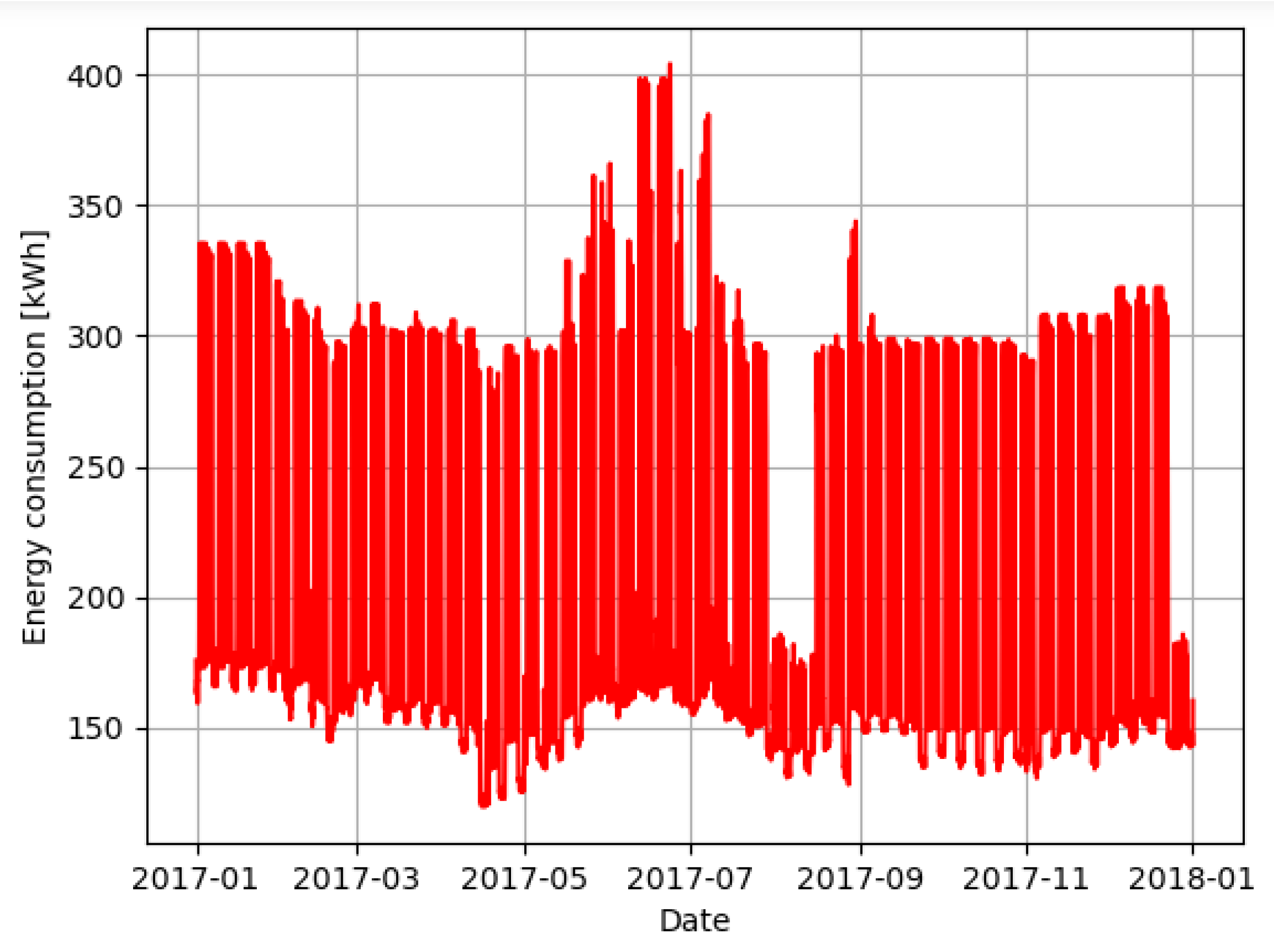
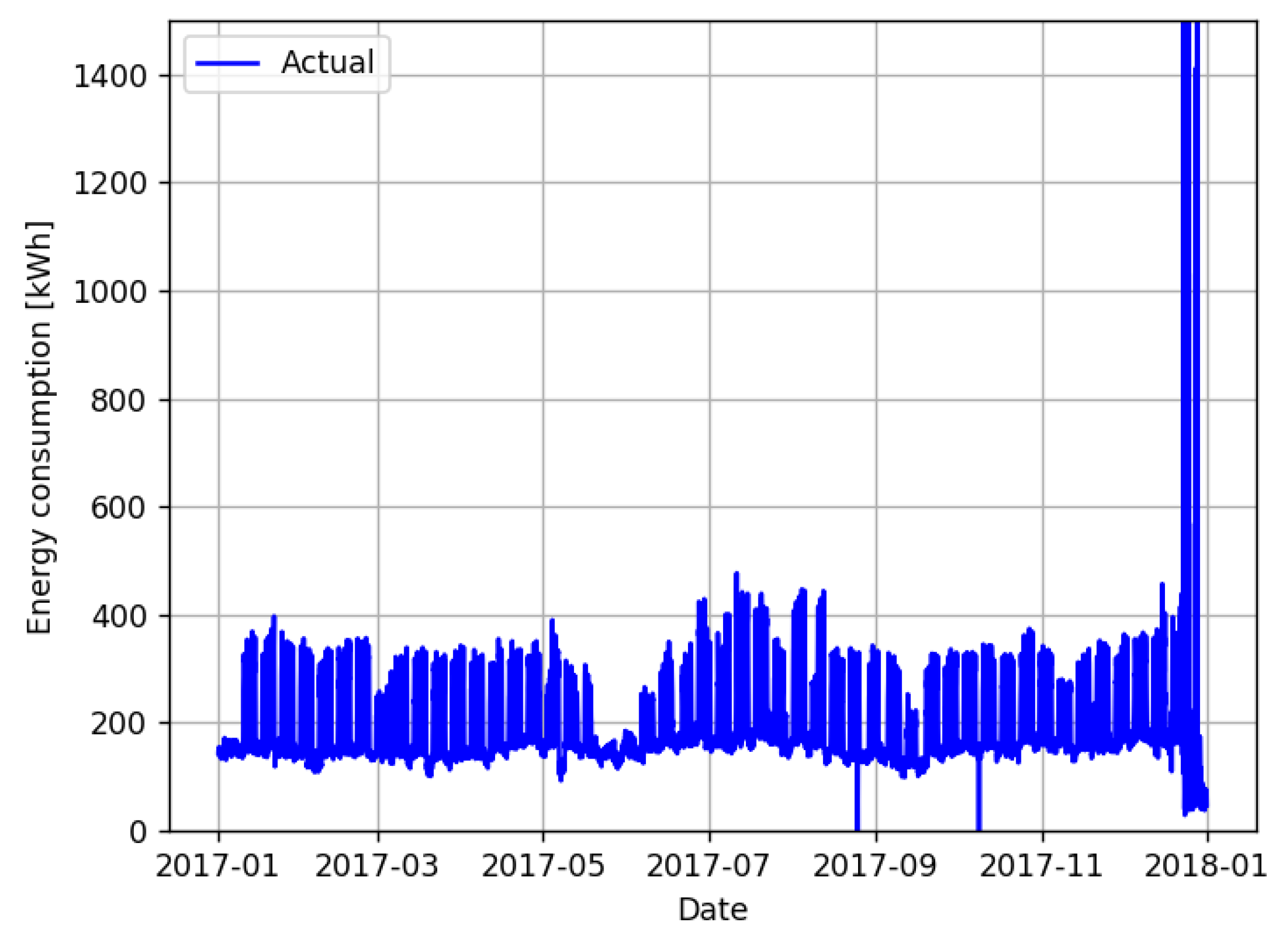
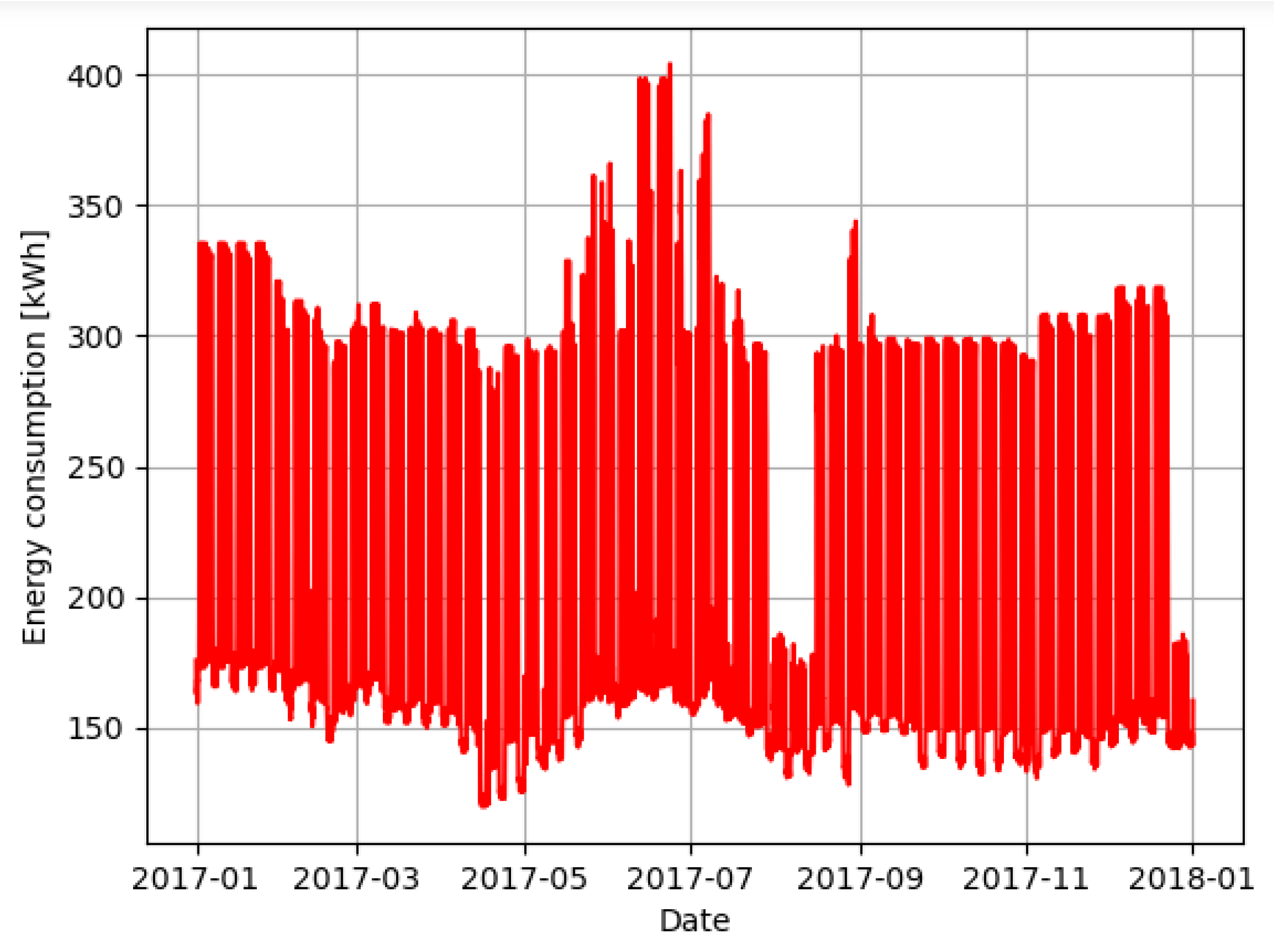
The synthetic data, free of data quality problems, are illustrated in
Figure 3. This dataset was created to simulate the behavior of the GreEn-ER building, and it was based on its own electricity consumption.
From the data exposed in the previous figure, it is possible to notice different consumption patterns for different periods. It can be seen that the periods of higher consumption match with those of higher occupation, during daytime on the weekdays. Outside these periods, during nighttime on the weekdays, weekends, holidays and vacations, the consumption reduces drastically. In addition, it is possible to notice a relation with the temperature since the highest consumption occurs during summer.
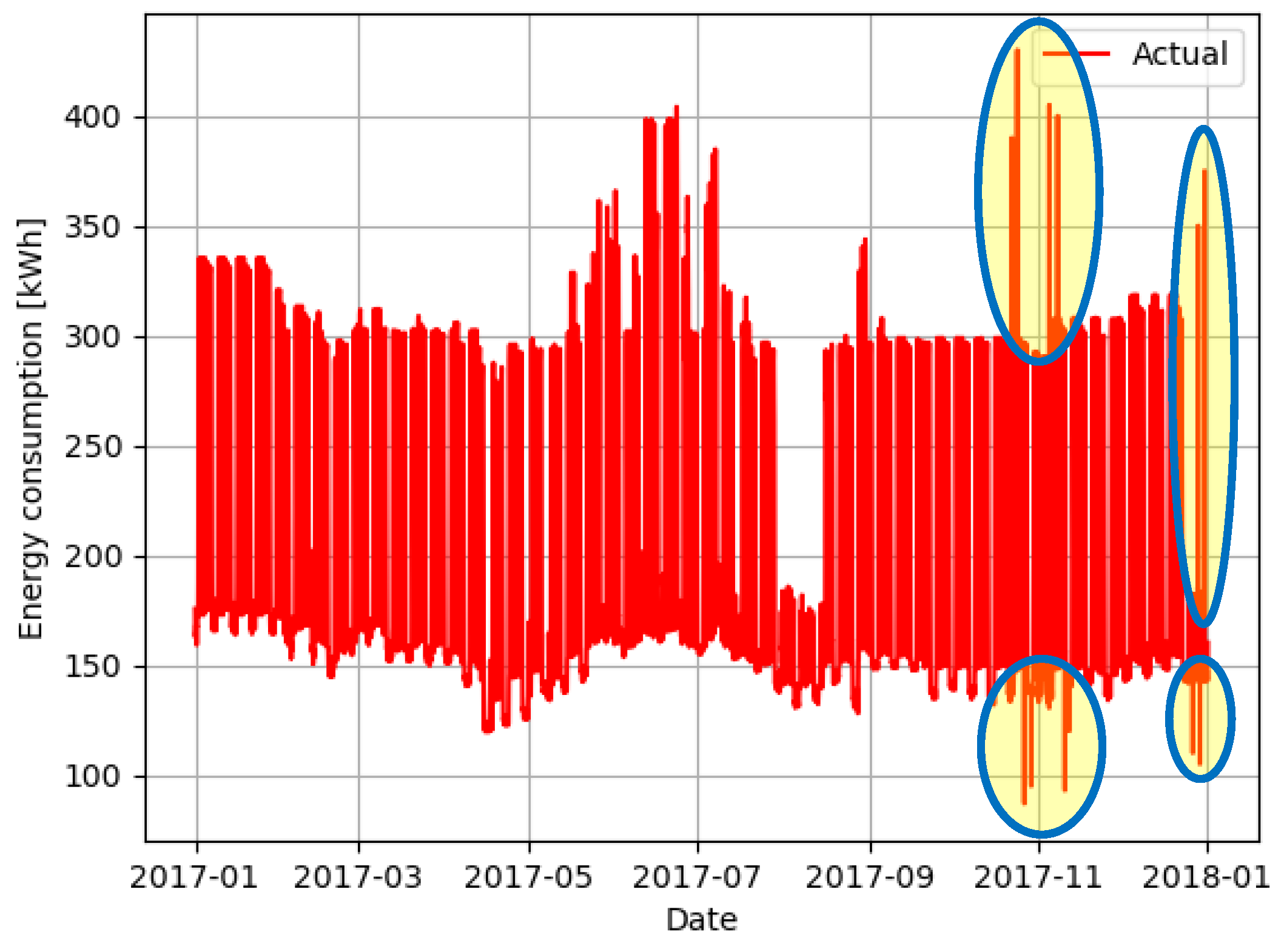
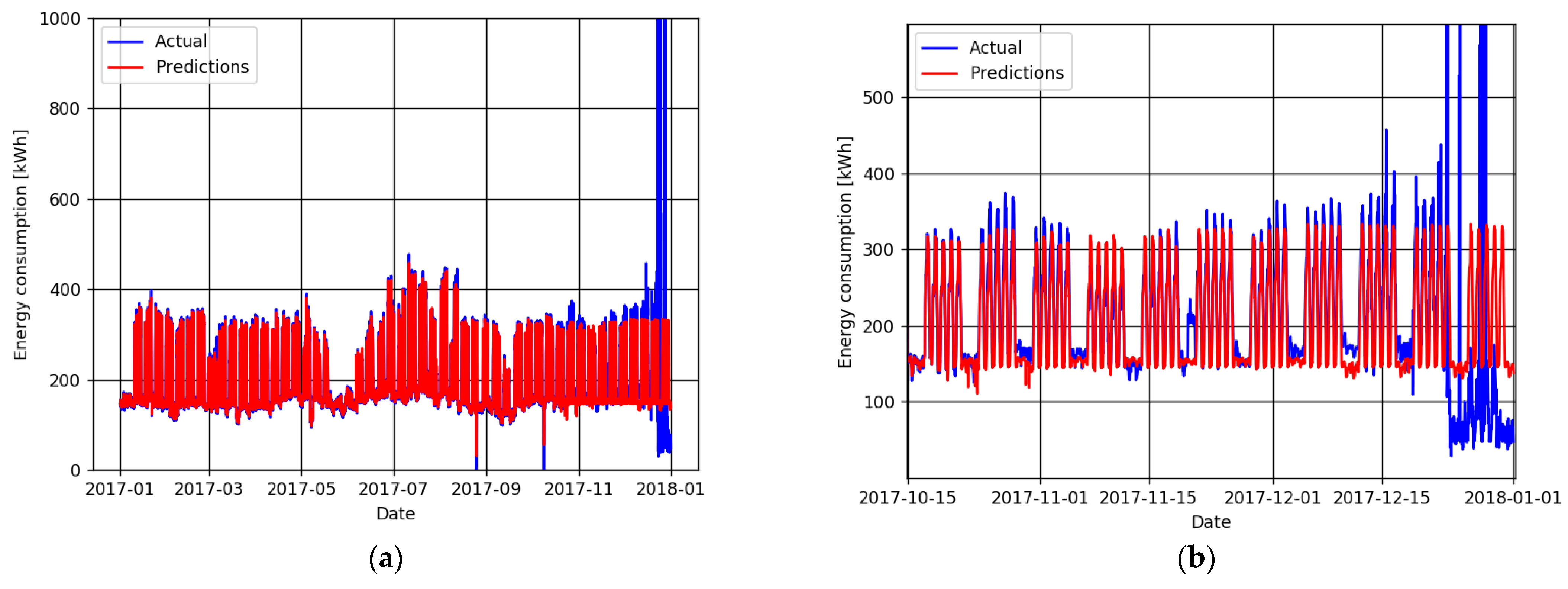
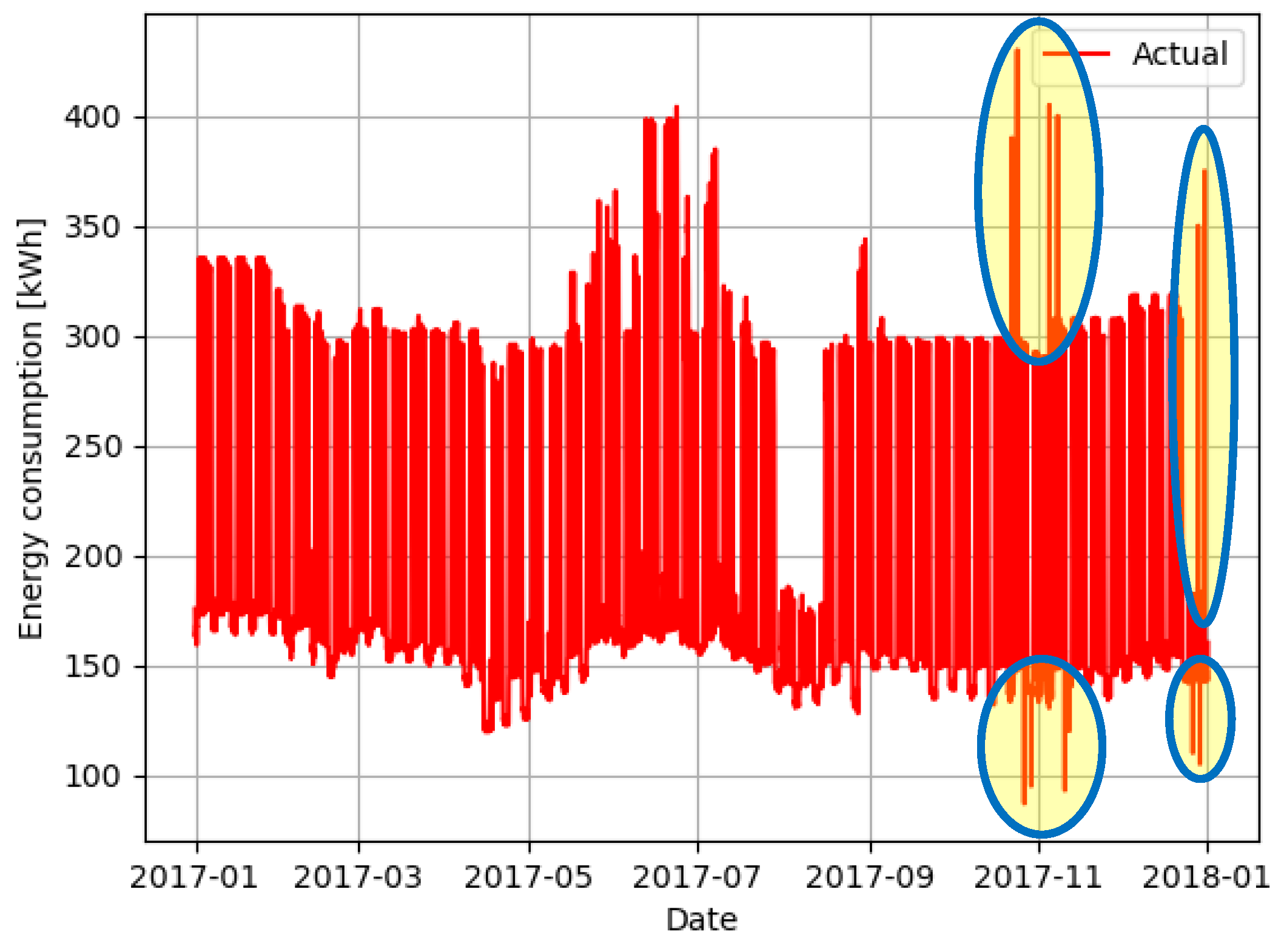
In order to test the outlier detection techniques, twelve outliers, both upper and lower, were manually introduced in the series presented in
Figure 3, resulting in the dataset presented graphically in
Figure 4. The information of these samples is shown in
Table 1, and some of these outliers are highlighted in
Figure 4 too. This information is then used as ground truth and compared with the results obtained to assess the classification of each sample in true positive, false positive and false negative.
4.1.1. Regression Methods Results
In order to find a model for the GreEn-ER energy consumption, the random forest method was applied using the data exposed in the previous section as the regression technique. For training of the algorithm, the following data features were used:
The training dataset was defined as 80% of the data, from the beginning of the year until mid-October. All the outliers inserted in this dataset are concentrated beyond this period. These data quality problems make it difficult to assess the performance of the regressor only in test time interval because of their effect in the statistical variables (mean, median, standard deviation) used also to detect these abnormal samples. Because of that, the regressor performance was evaluated in two conditions. The first one considers the whole year, including the weeks with data quality problems and the training phase. The second one considers the period of the year complementary to the training phase.
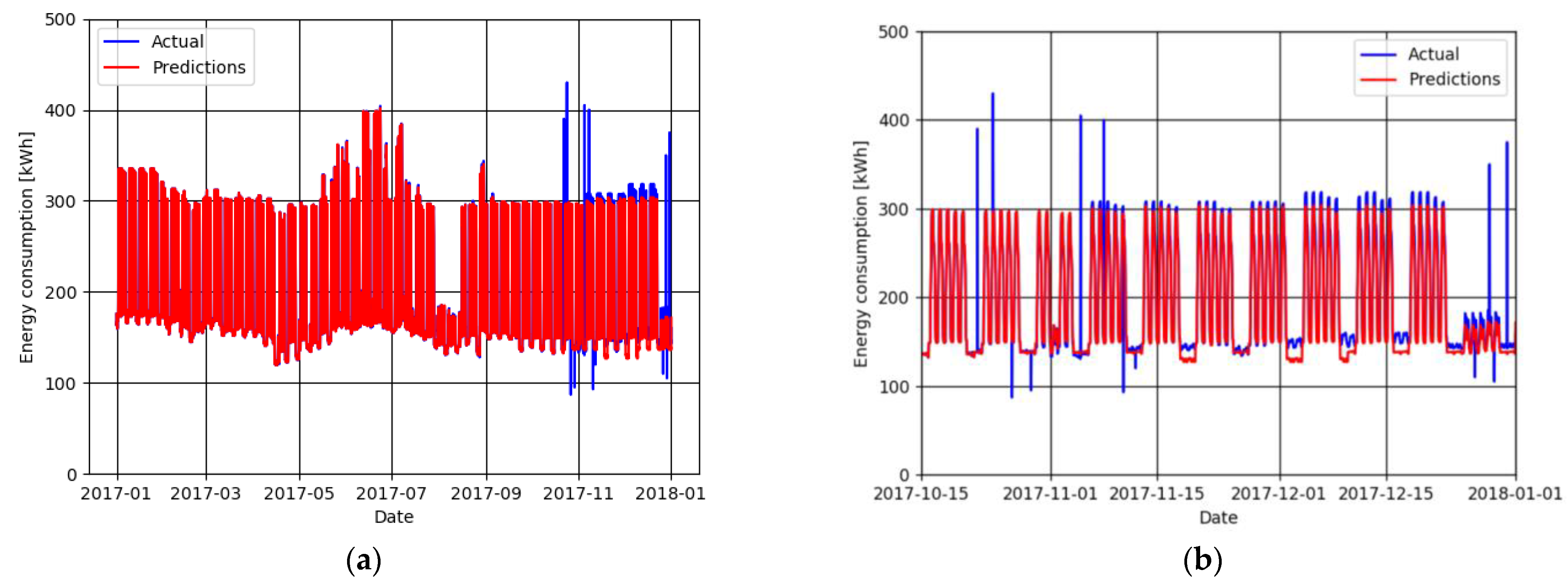
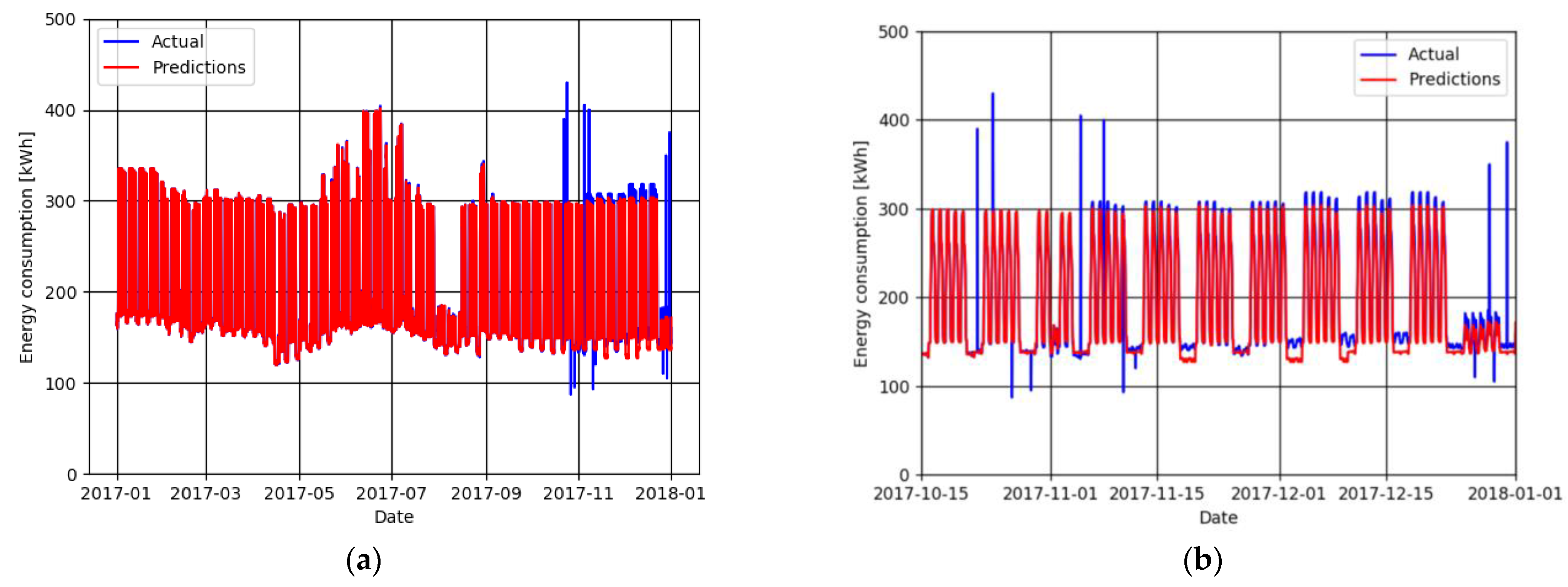
Figure 5 details, as an example, the results obtained with the application of the random forest method, using five hundred estimators as parameter. At the same time,
Table 2 quantifies the performance of these regressions with the two conditions cited above.
Observing
Figure 5b, only in the complementary period that was not used in the training phase are the results are satisfactory. Although the predictor underestimated the power on the weekends, it was able to detect the daily and weekly patterns and even during the holidays, resulting, on average, in less than a 5% error.
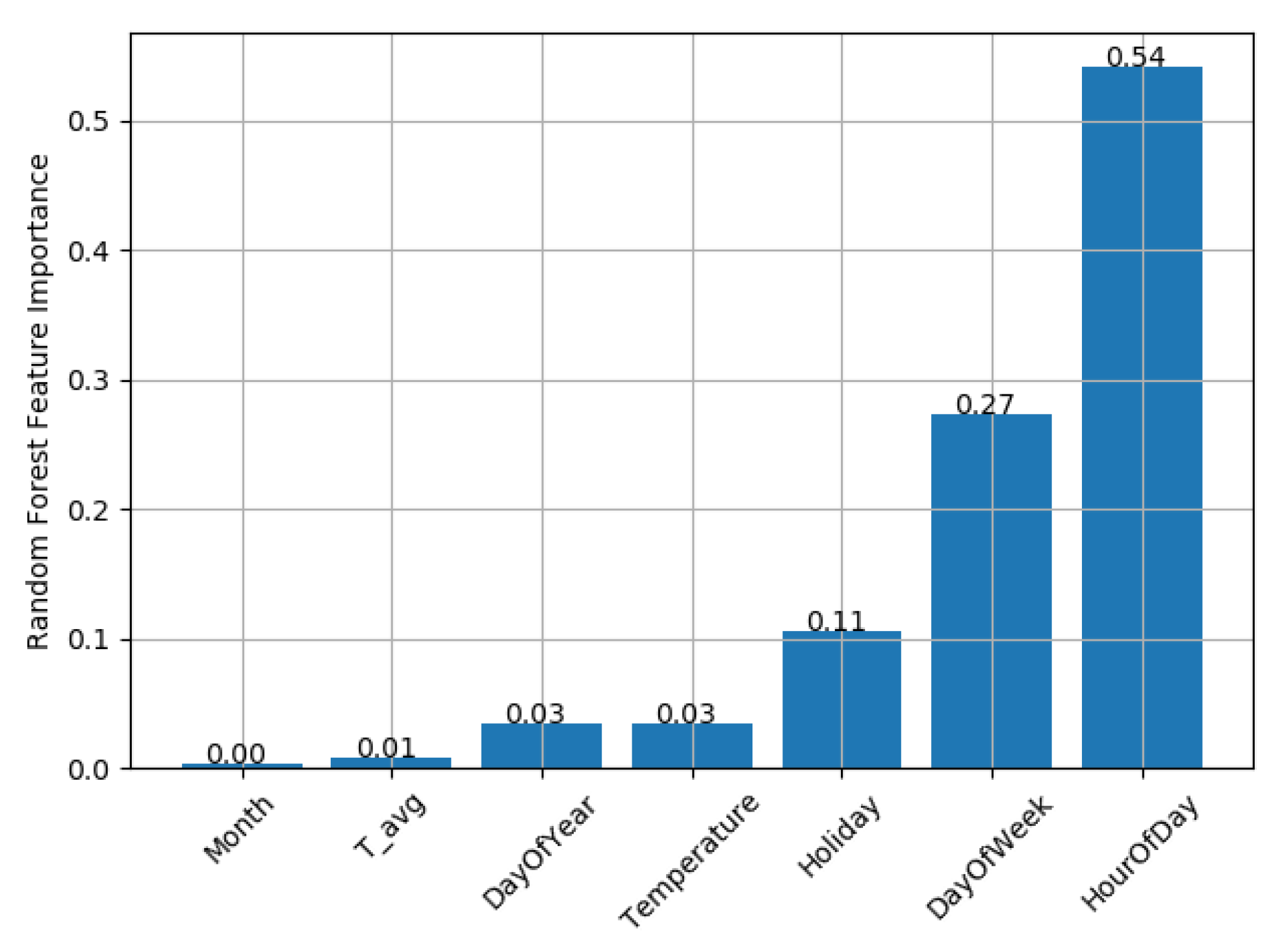
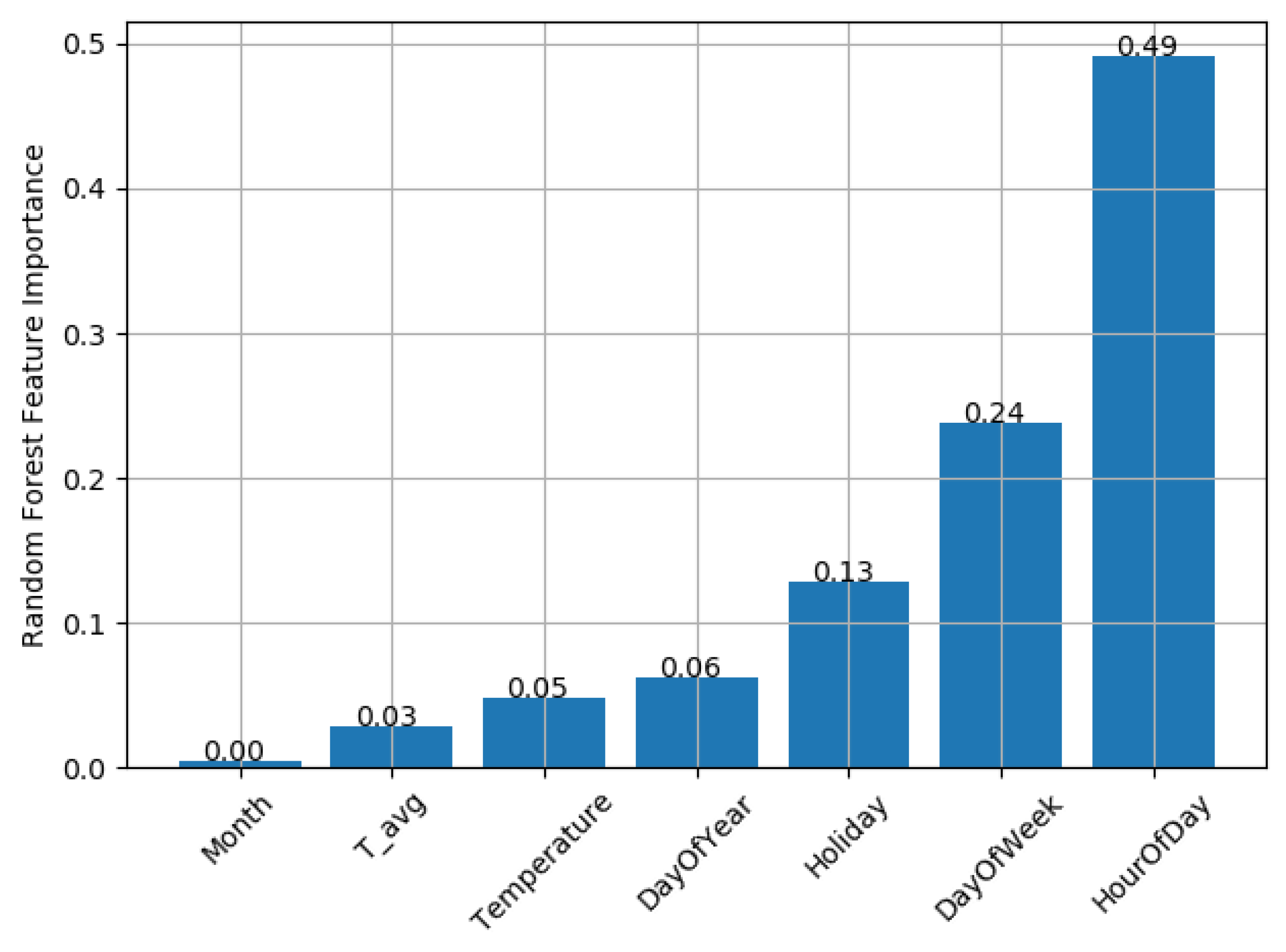
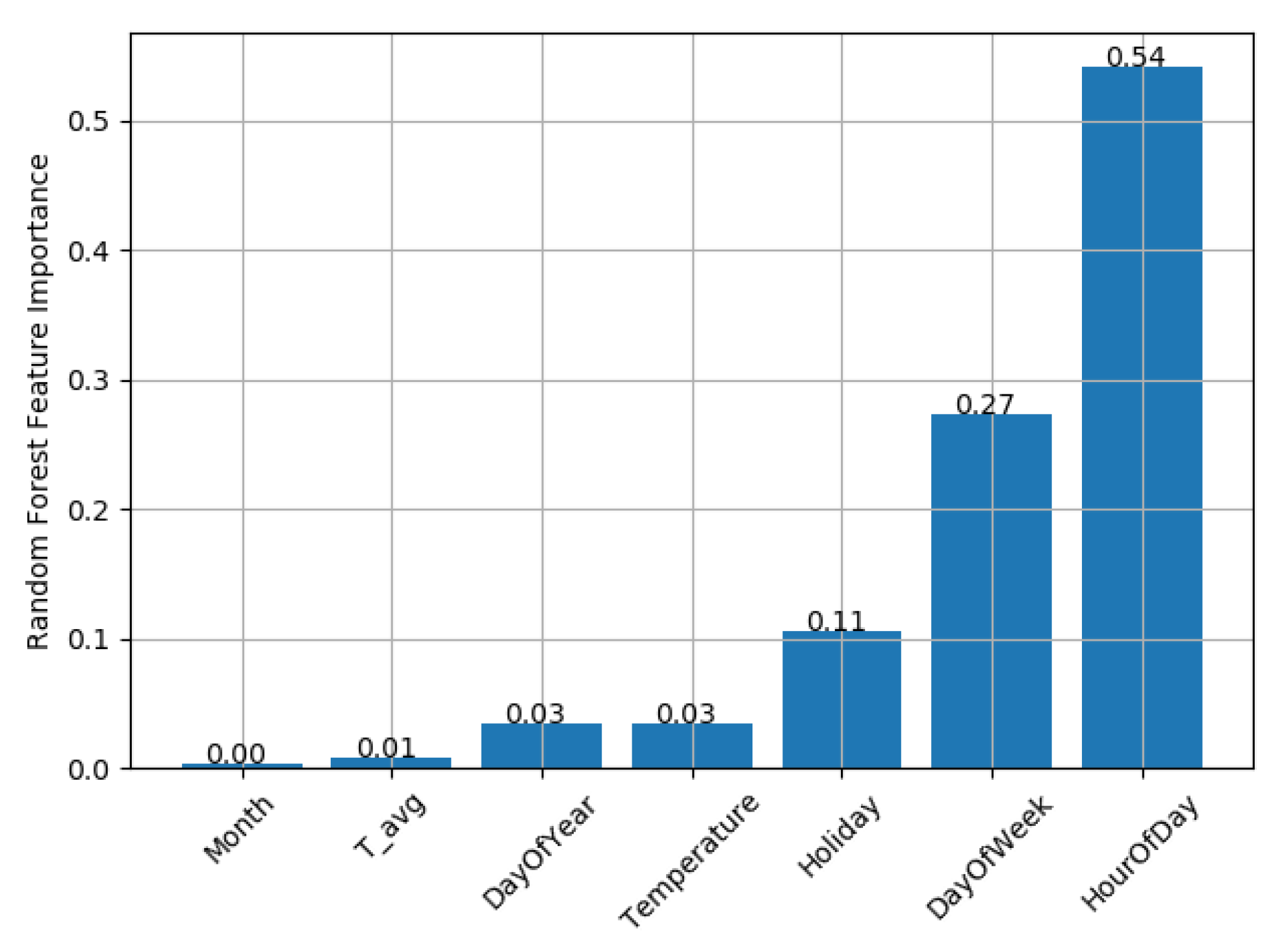
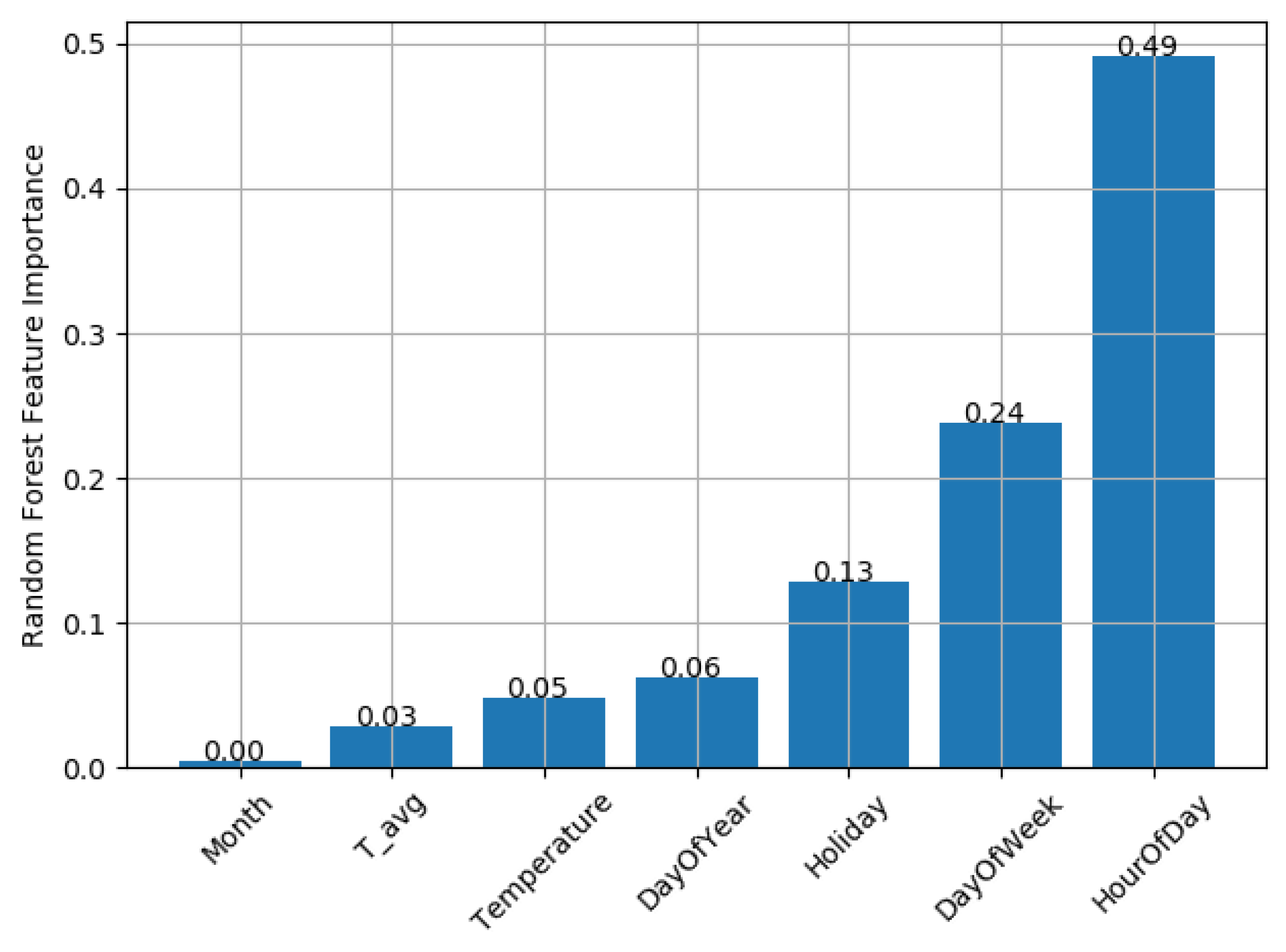
Regarding the regression, the most important features are the hour of the day, reproducing the daily pattern of the consumption, and the day of the week, reproducing the weekly shape of the load curve. The holiday feature also plays an important role in the performance of the regressor. The other features would be more important if more than a year’s worth of data were available. For instance, the external temperature would improve the regression inserting the season component, such as the difference between the days from summer and winter. However, with one year’s worth of data, and the choice of taking 80% of the series as training, this component is not important. These features were maintained in the model with the objective to improve the model in a future real time application, when more than a year would be available.
Figure 6 shows the feature importance of the regression made for the adapted data.
4.1.2. Outlier Detection
In order to detect the outliers inserted in the data series, two strategies were applied. Primarily, a global search employing the statistical methods on the power consumption data was performed. Afterward, they were used to search outliers via the forecast error. Twelve outliers were manually inserted, six of them were upper outliers and the other six, lower, as shown in the previous section.
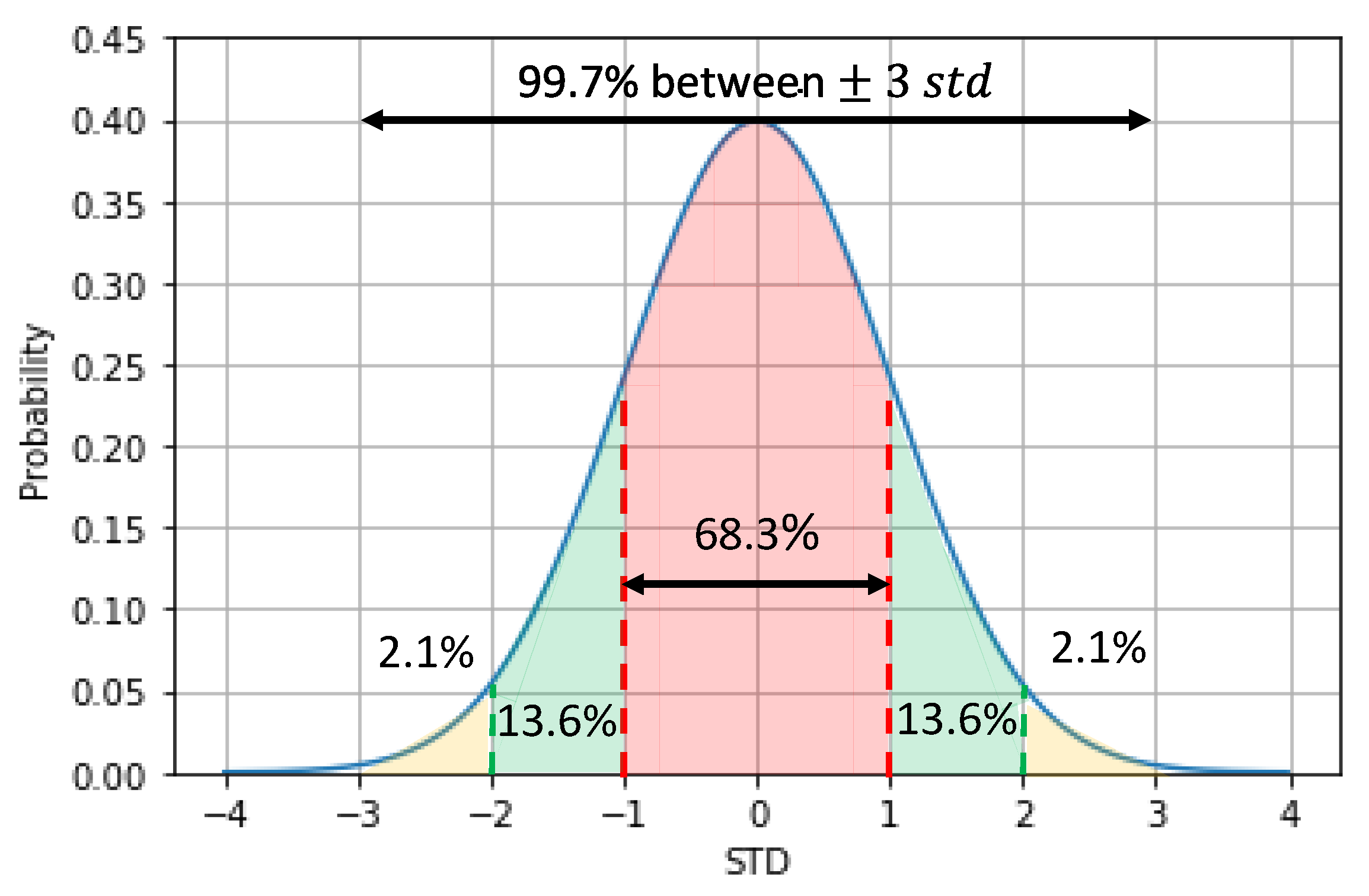
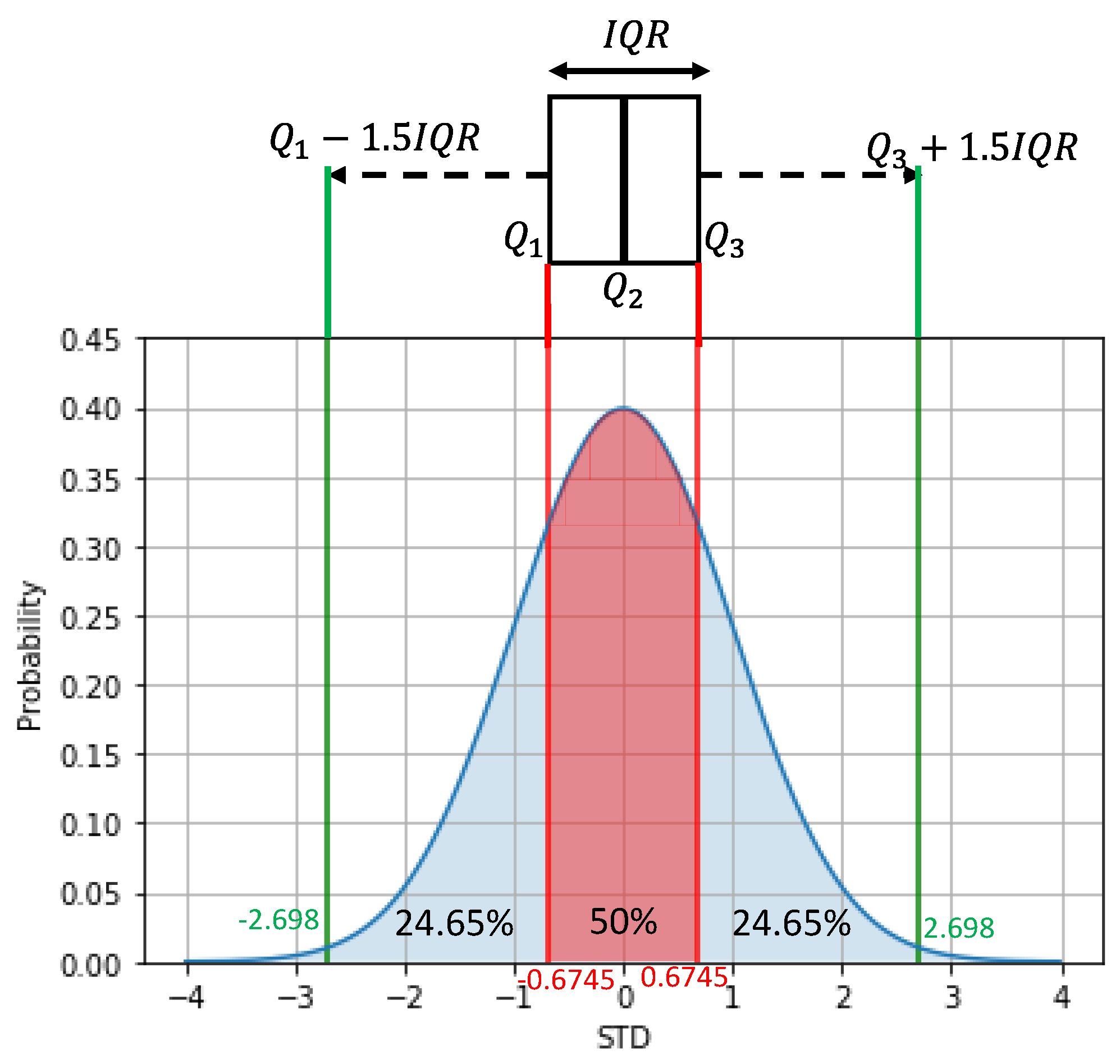
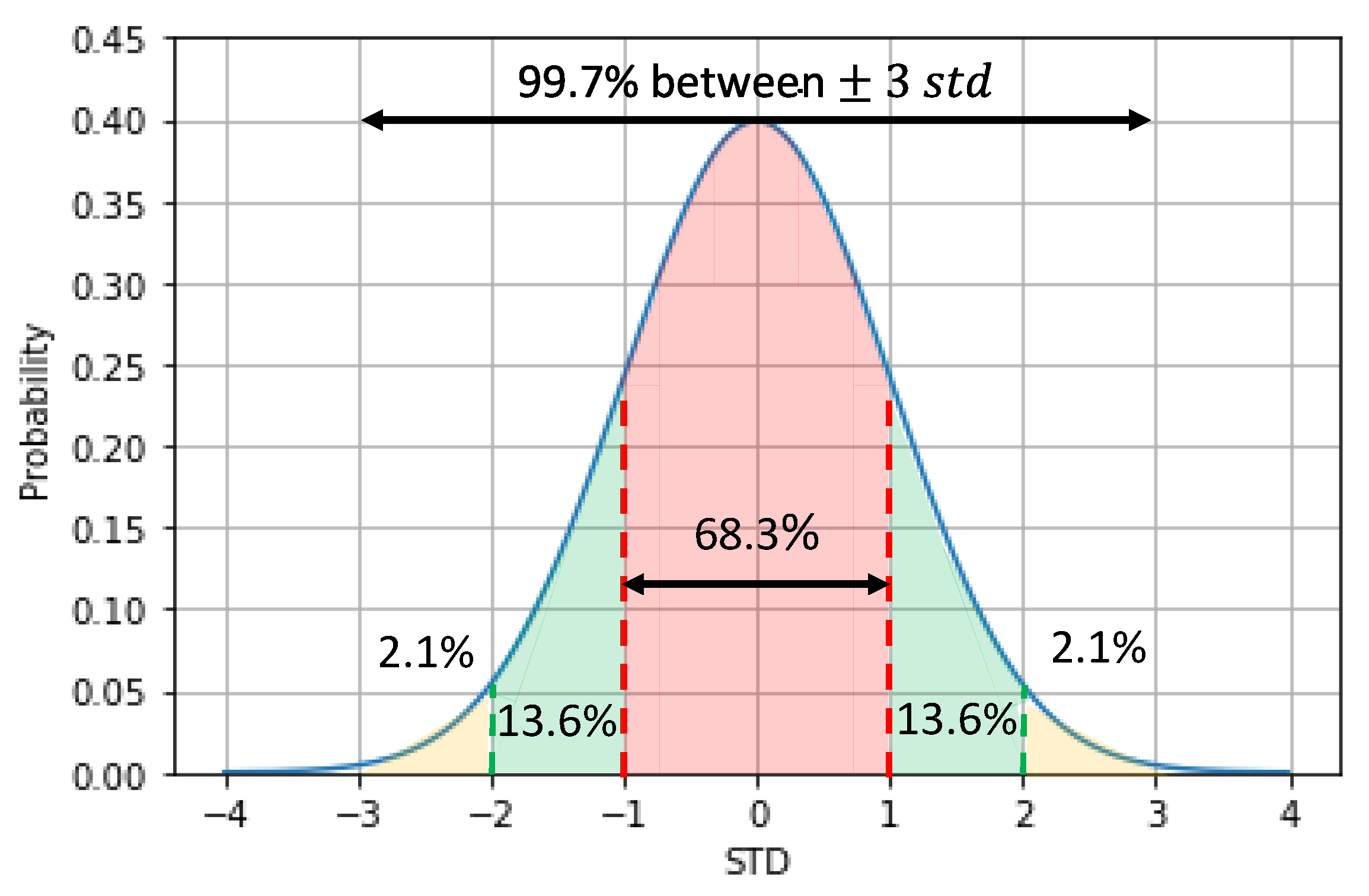
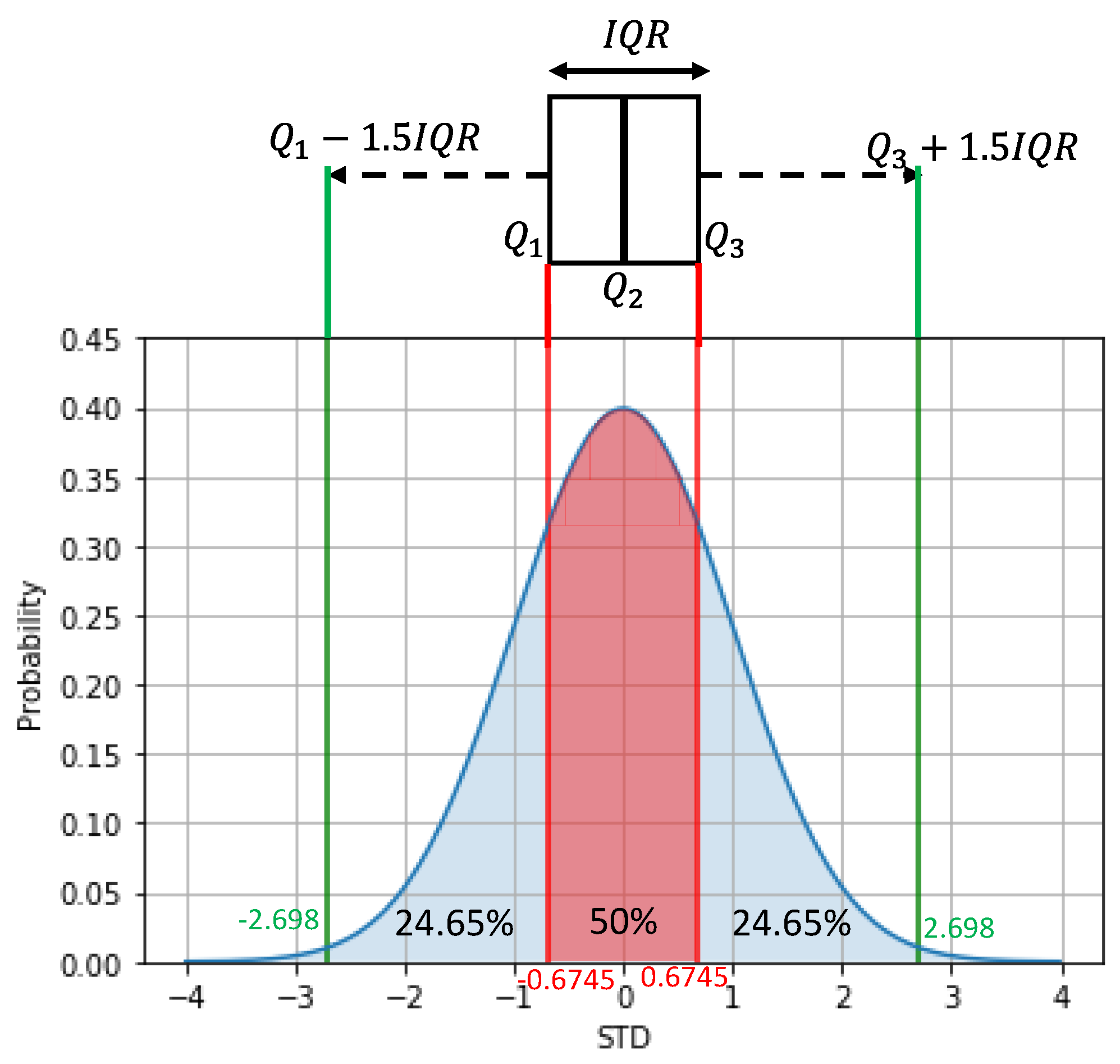
In the global search strategy, the search for outliers was performed only once. In this way, all information available is used, and the outliers are assumed to have any, or low, influence on the average value, the standard deviation, or even on the quartile values. Therefore, the global search was performed using the three-sigma rule, the boxplot, the skewed boxplot and the adjusted boxplot methods. The results are shown in
Table 3. In this table, the column Potential Outliers Detected indicates the number of samples flagged out as outliers by each method. In the True Positives column, there are the number of actual outliers detected, while in the False Negatives column, the number of undetected outliers are presented. Furthermore, in the False Positives column, the number of normal samples misclassified as outliers are shown. Therefore, the sum of the true positives and the false negatives should be equal to the number of outliers present in the dataset, in this case, twelve. The sum of the true positives and false positives is equal to the potential outliers detected and the sum of both false positives and negatives gives the total of samples misclassified by each method.
The results indicate that the MAD and the adjusted boxplot were the most successful methods in detecting outliers, having found half of them; however, they still misclassified several other samples, reducing their precision. Thus, even detecting some outliers, their poor recall, with several false positive samples classified as outliers, show that these methods alone are not the best suitable to detect outliers, especially local ones, such as those inserted in this dataset.
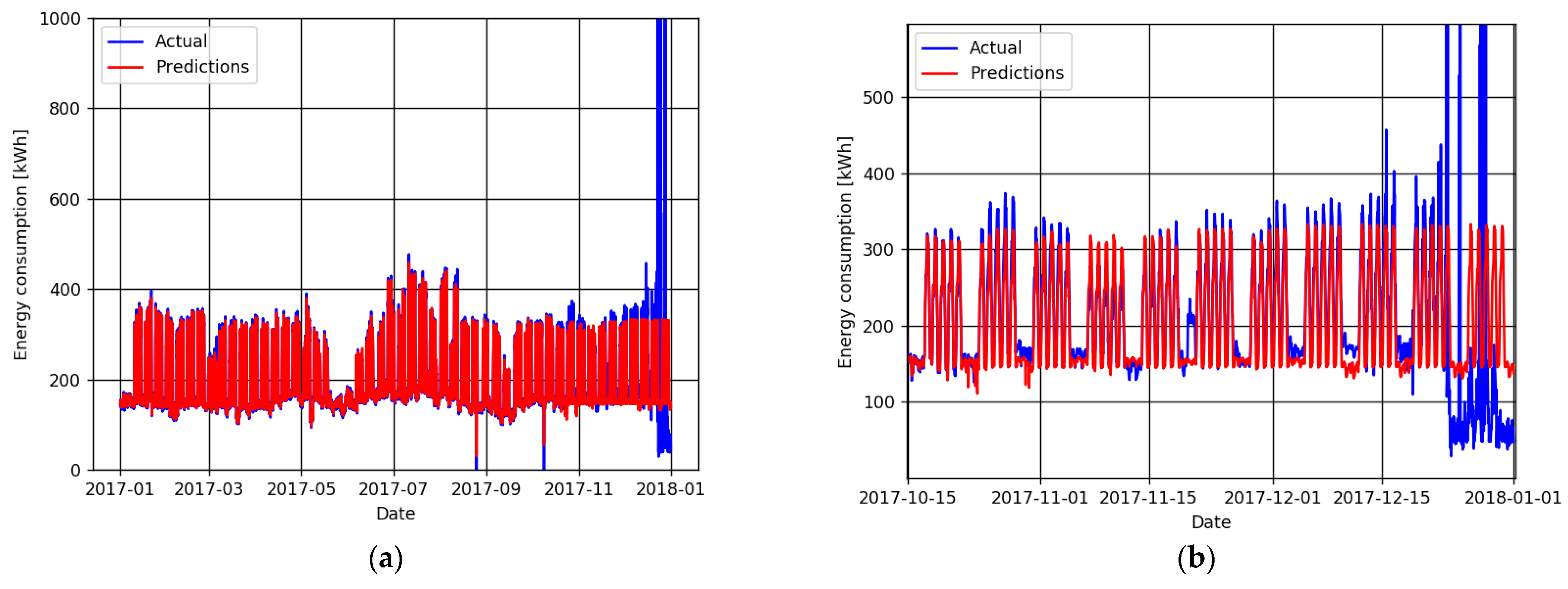
As the classical statistical methods failed to detect several outliers in the study dataset, the forecast error method, which compares the results of previous regression models with measurements was employed. The statistical methods for outlier detection are then applied on the resulting error.
Table 4 shows the number of outliers detected by each method considering the deviation between the actual values and the predictions.
The results presented in
Table 4 indicate that the all the methods were able to detect most of the outliers inserted in the dataset, using the forecast error. However, the poor precision of the MAD, the boxplot, and the skewed boxplot misclassifying several samples indicates that they are not well suitable for this task in this dataset. The other two, three-sigma rule and adjusted boxplot, perform better and similarly, with a small advantage for the adjusted boxplot.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}