
Increasing the Safety of Adaptive Cruise Control Using Physics-Guided Reinforcement Learning

 ,
,
Abstract
:1. Introduction
2. Related Work
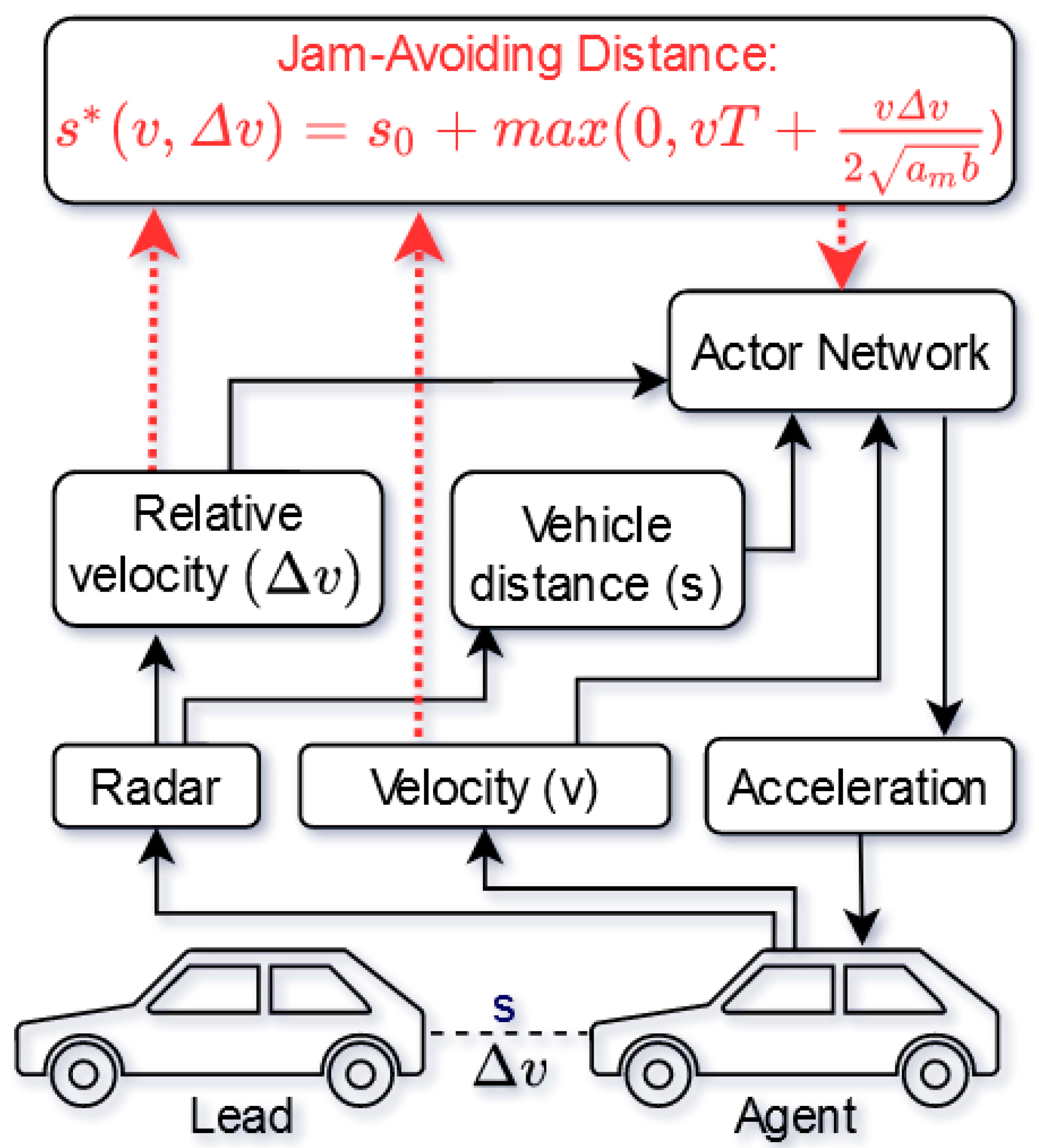
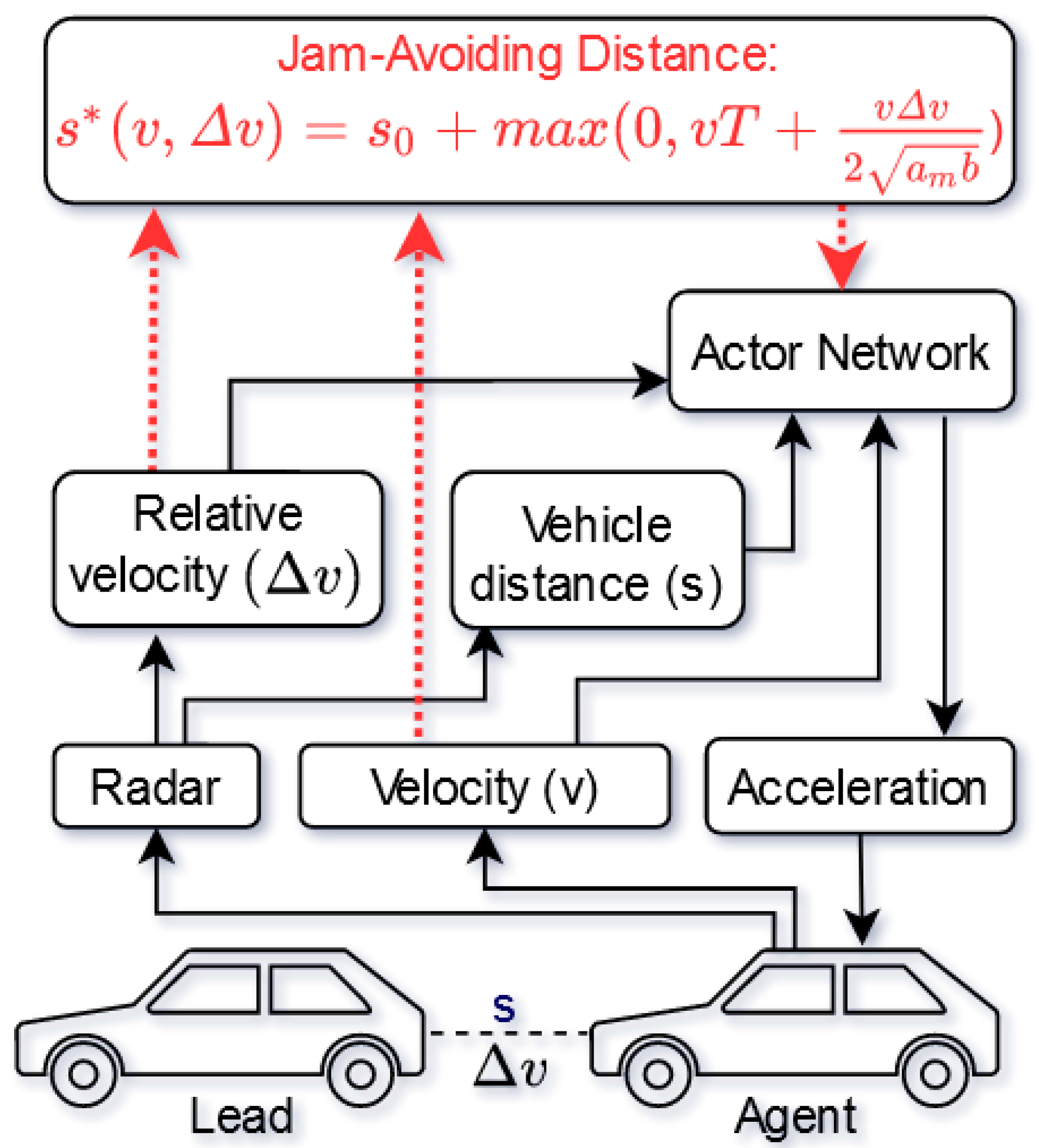
3. Physics-Guided Reinforcement Learning for Adaptive Cruise Control
3.1. Soft Actor-Critic Algorithm
3.2. Prior Knowledge
3.3. Integration of Prior Knowledge
4. Simulation
4.1. Leading Agent Acceleration
- Random acceleration at each time step (randomAcc),
- Constant acceleration with random full stops (setting lead velocity with ) (randomStops9 accelerates by 90% of its capacity and randomStops10 accelerates full throttle)
- Predetermined acceleration for each time step (predAcc).
4.2. States
4.3. Penalization
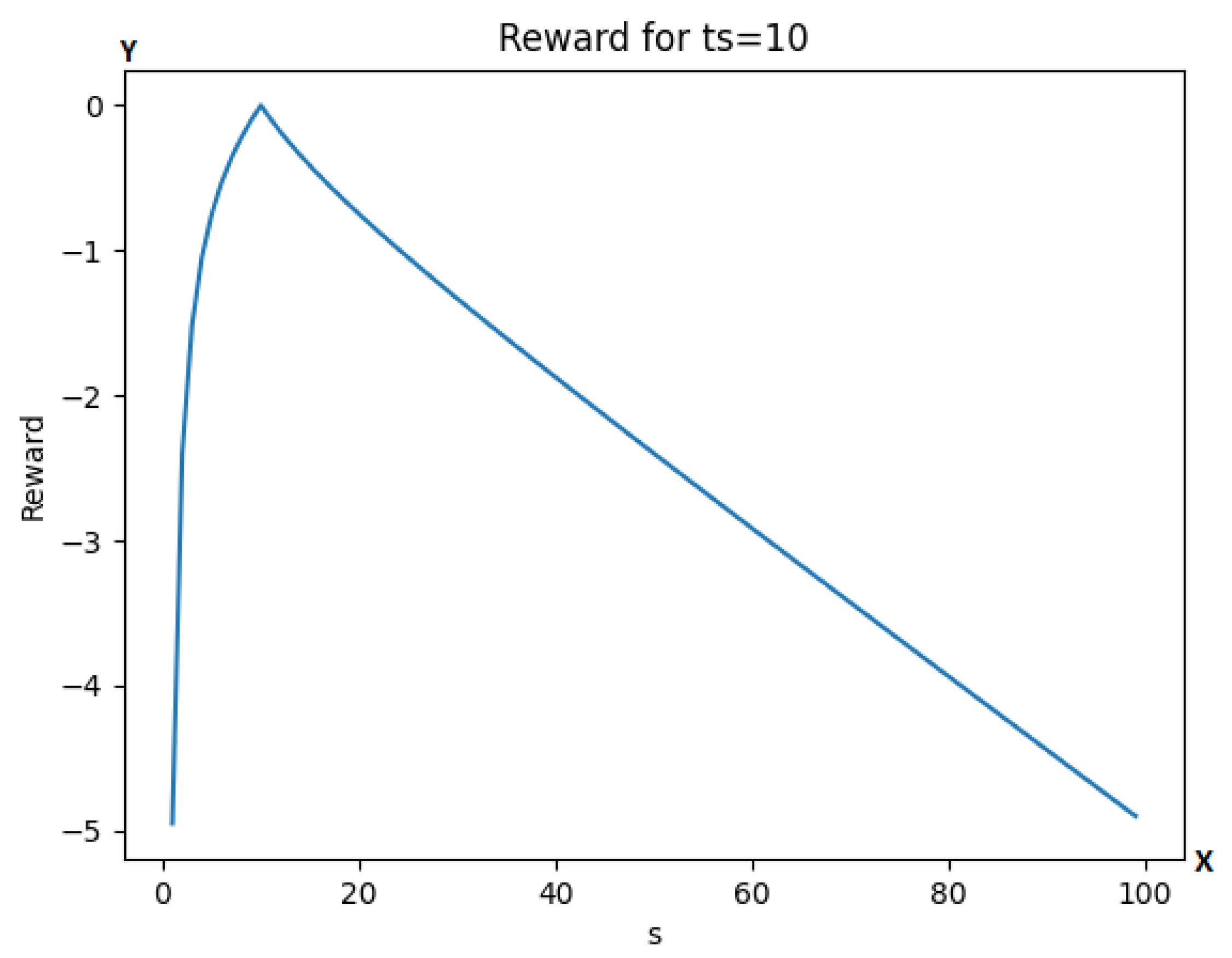
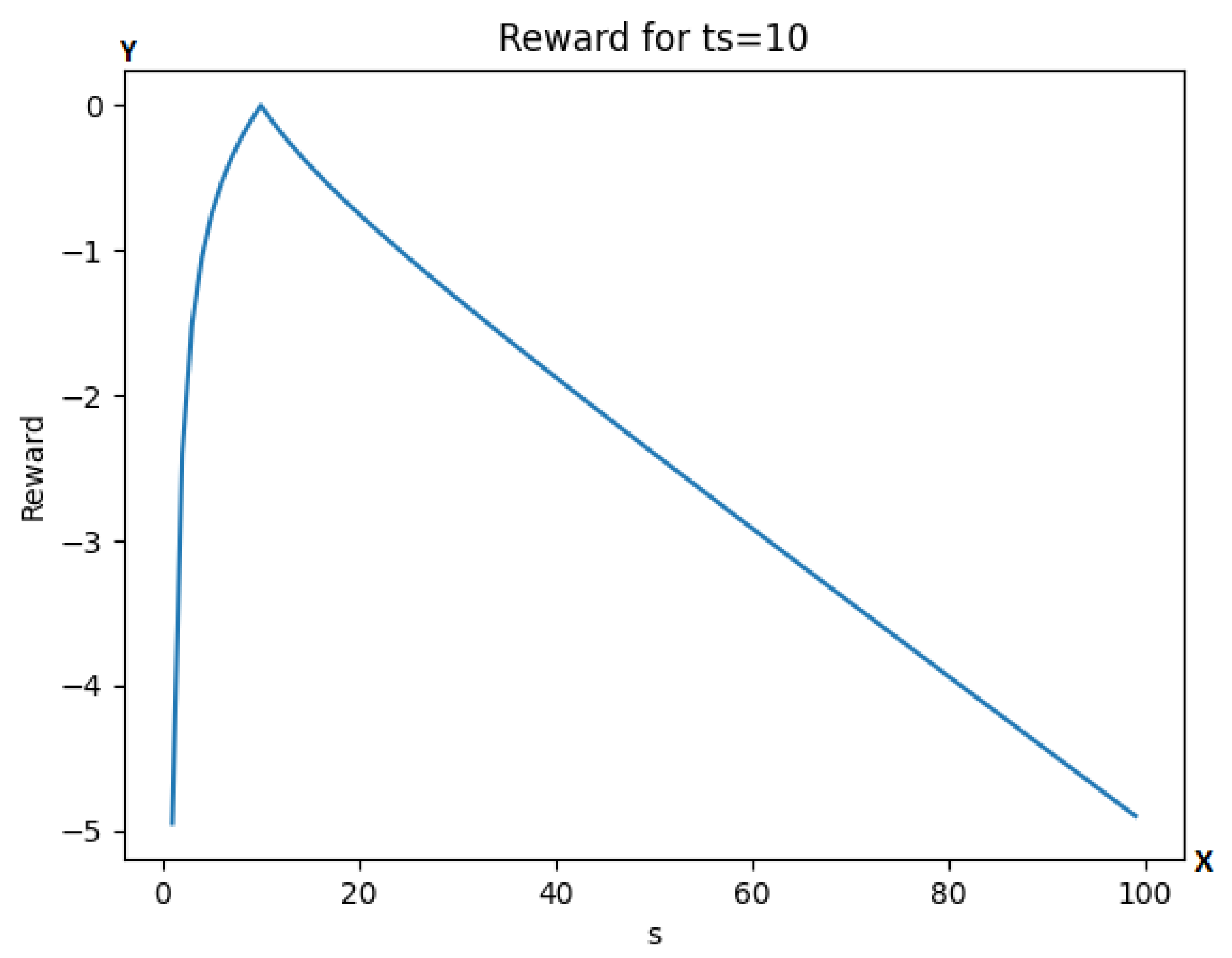
4.4. Reward
4.5. Termination Conditions
4.6. Parameter Search Test
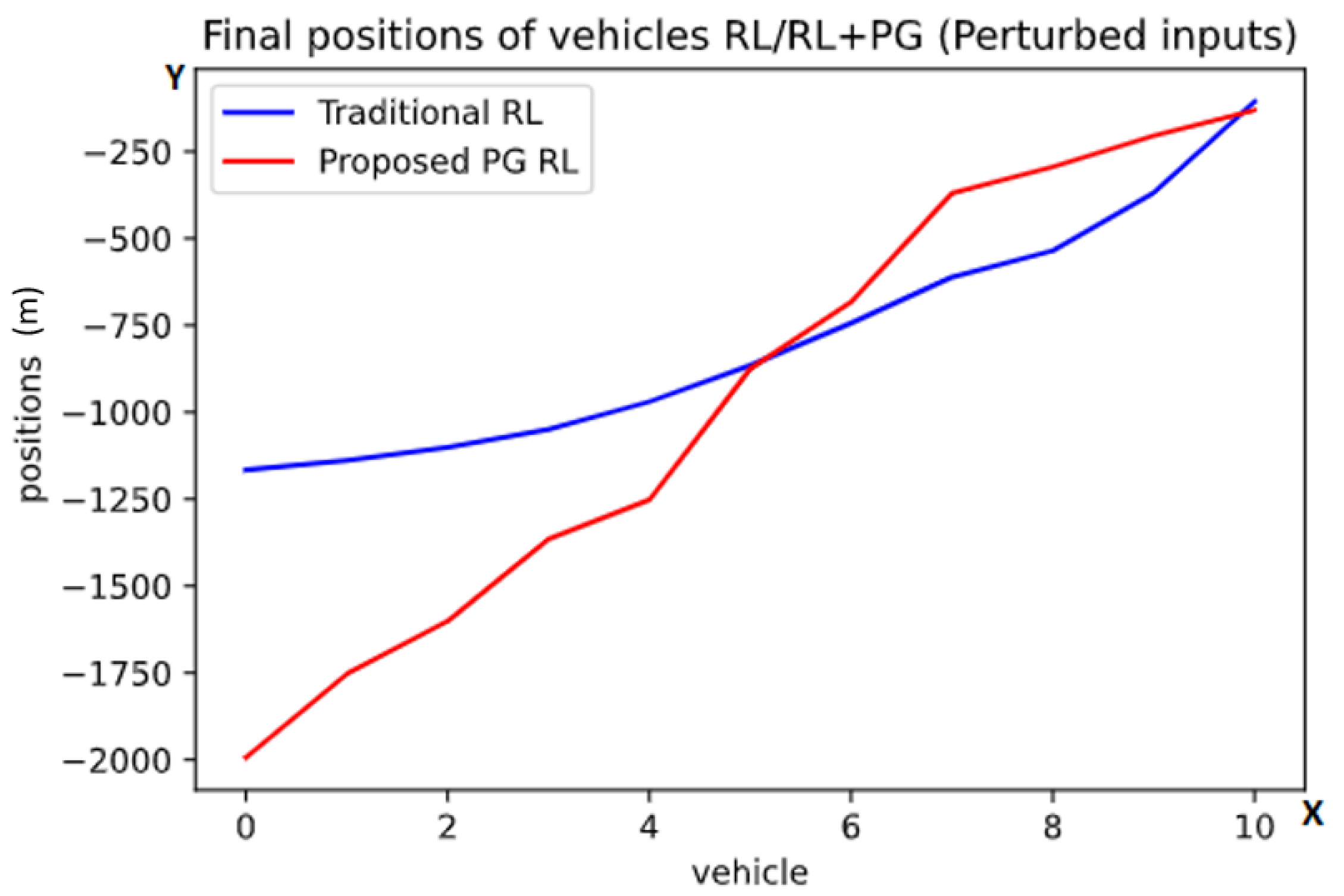
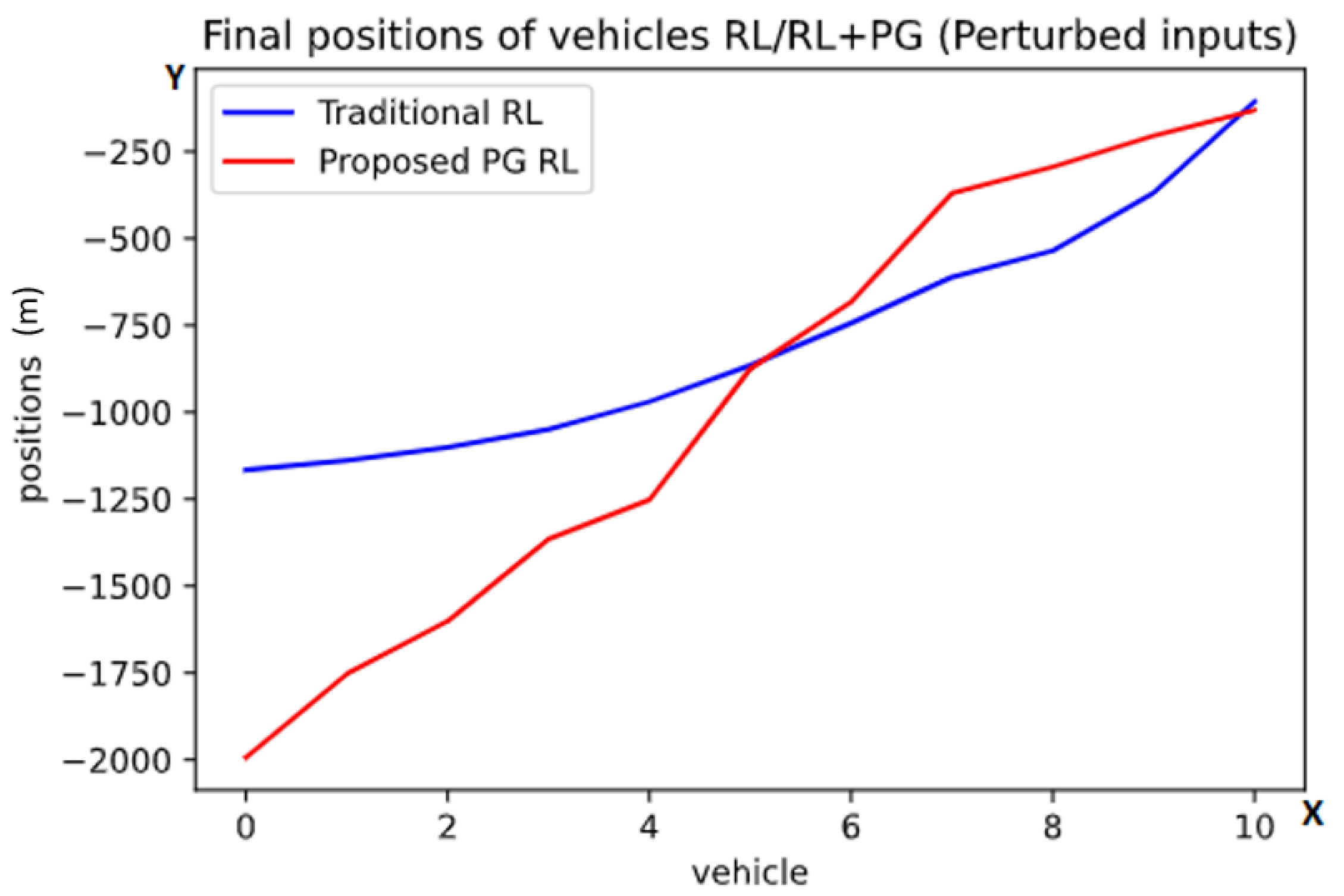
4.7. Perturbed Inputs
4.8. Training Setup
5. Evaluation
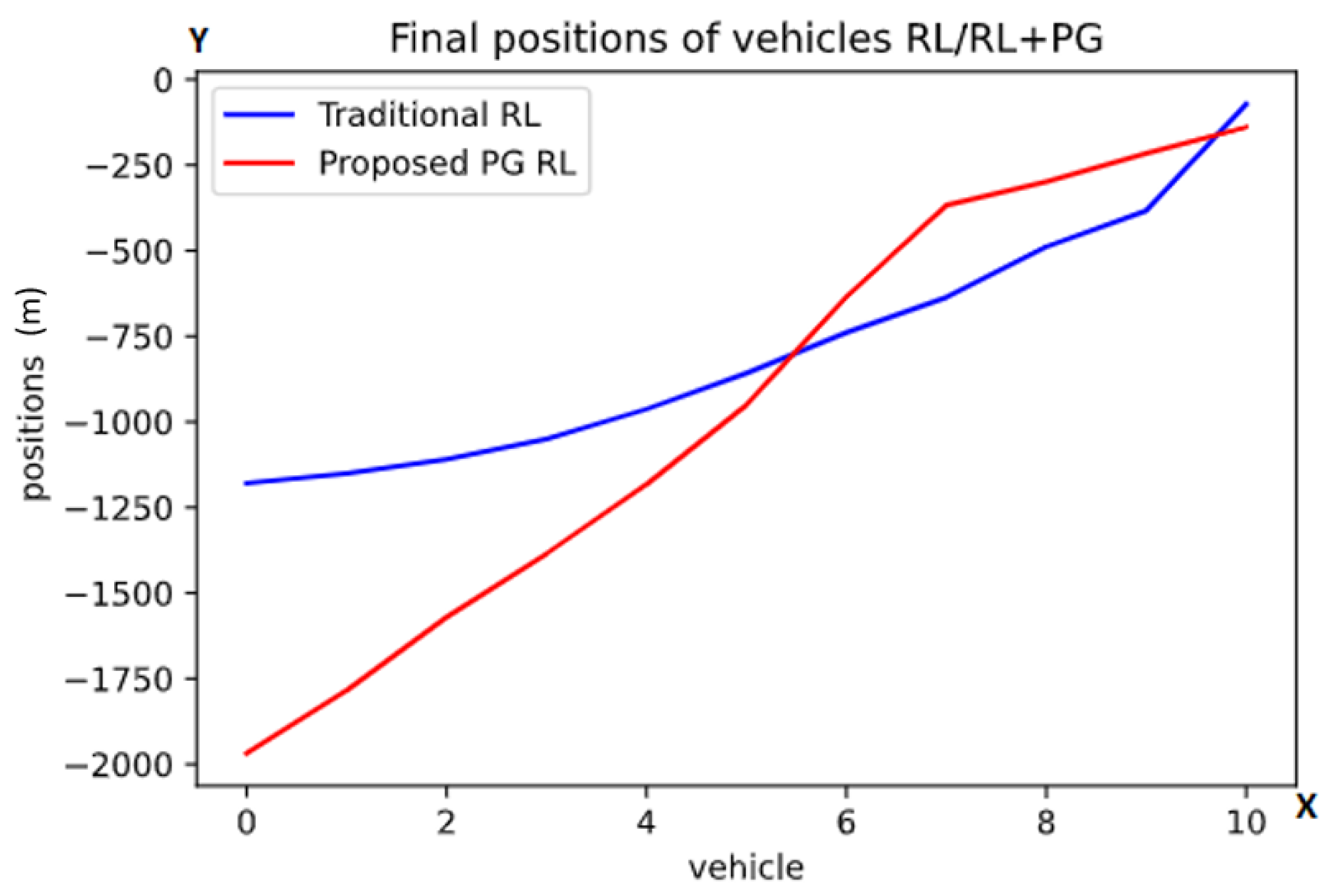
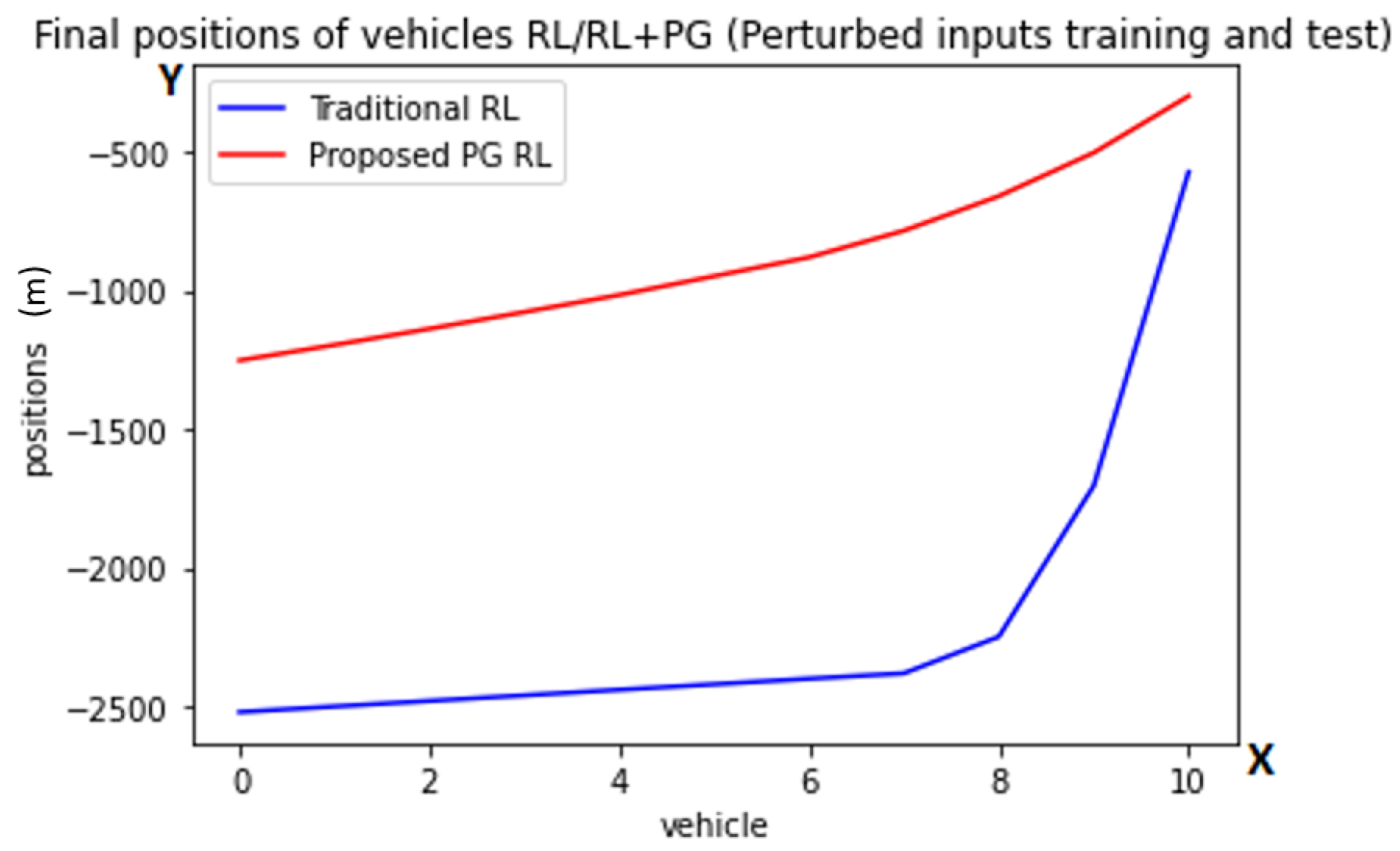
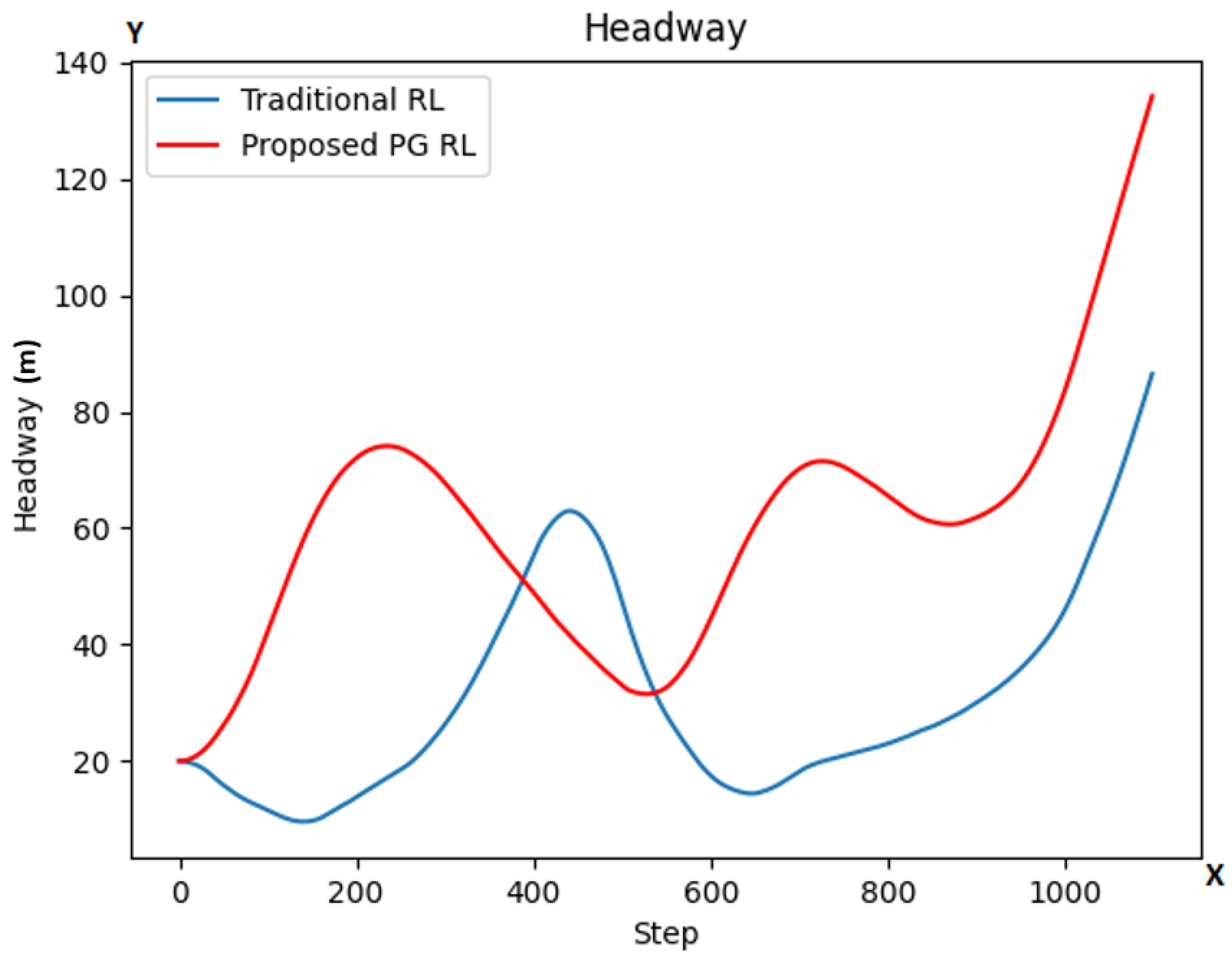
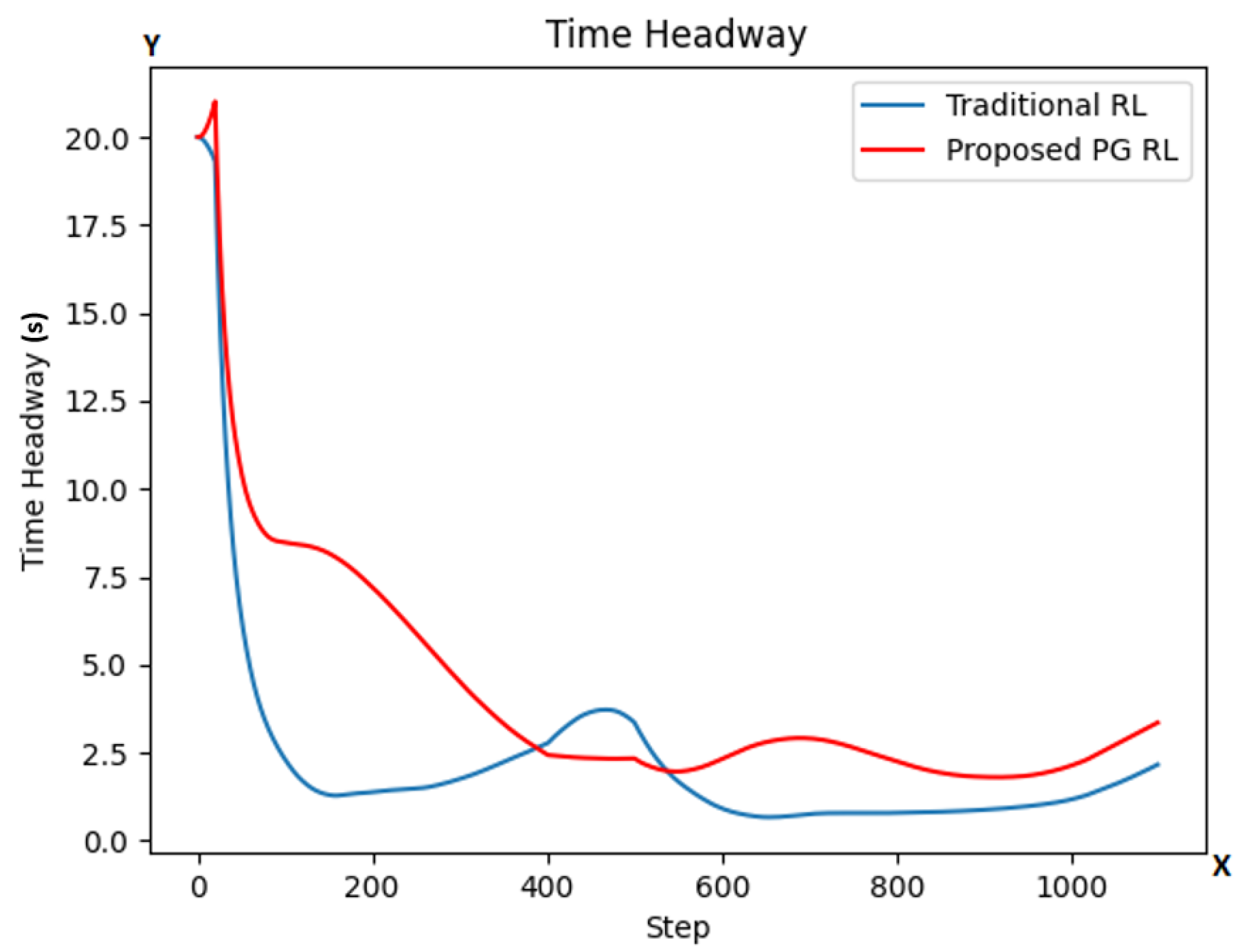
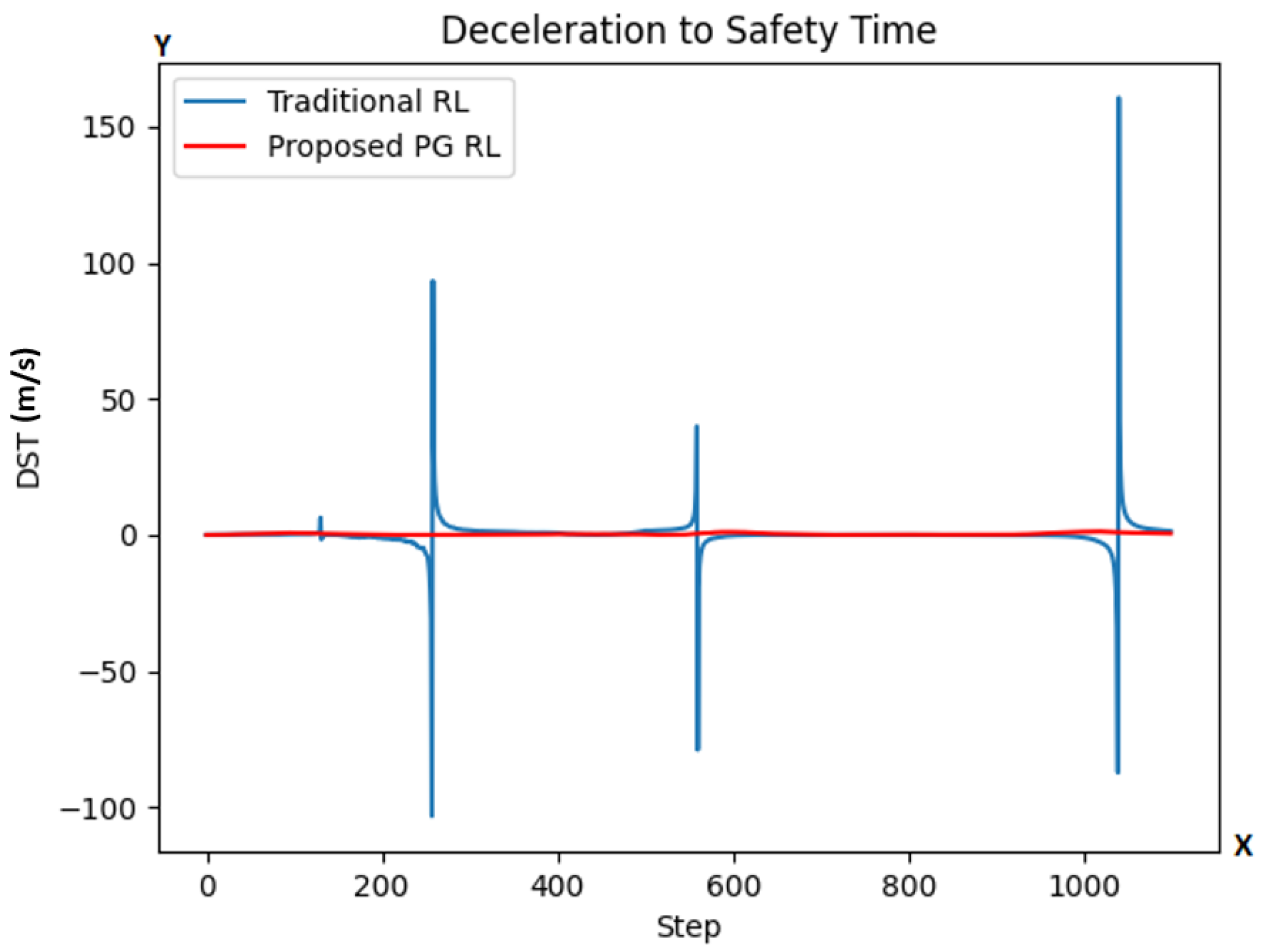
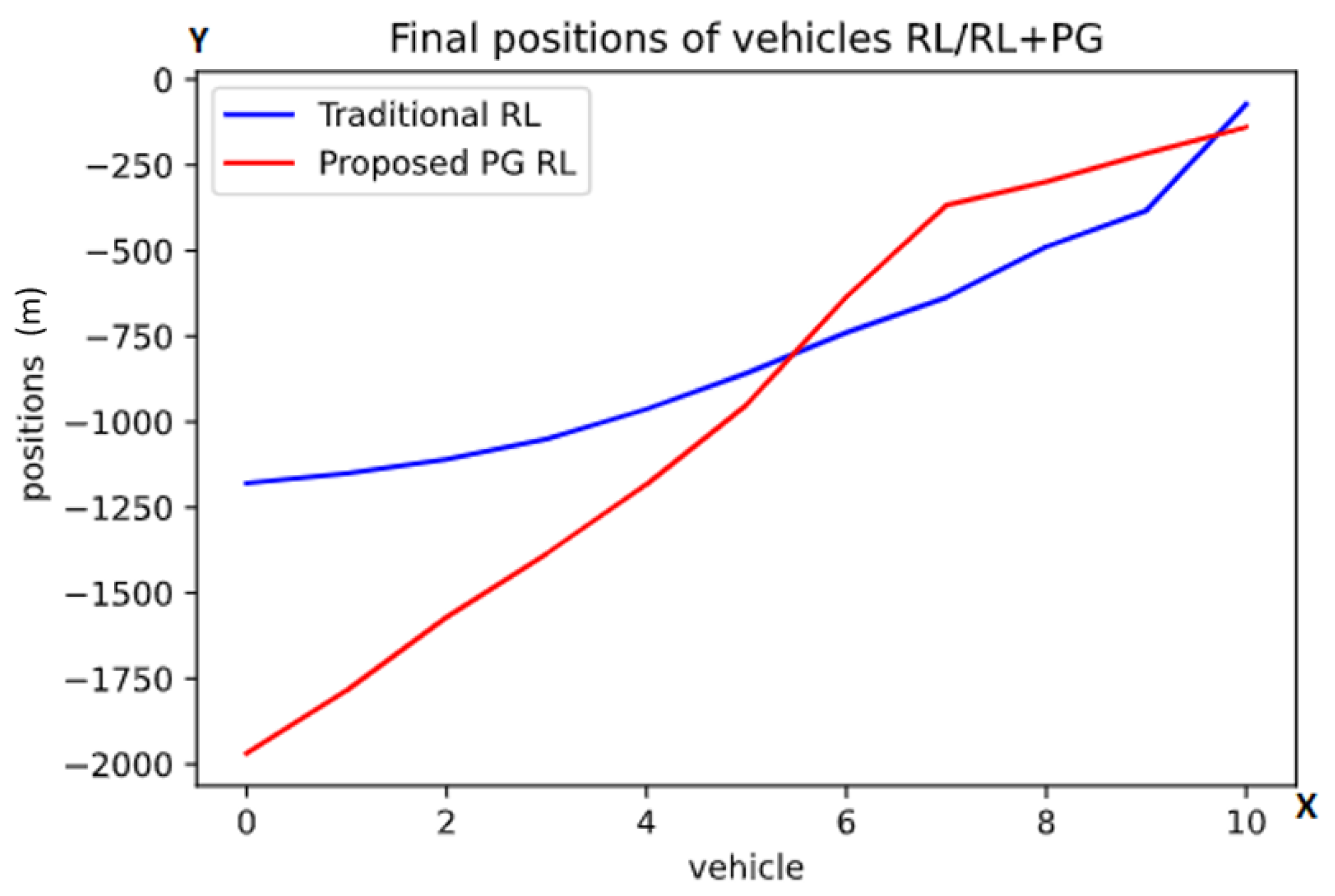
5.1. Task 1
5.2. Task 2
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations and Nomenclature
| ACC | Adaptive Cruise Control |
| ML | Machine Learning |
| SAC | Soft Actor-Critic Algorithm |
| RL | Reinforcement Learning |
| PG | Physics-guided |
| AI | Artificial Intelligence |
| AV | Autonomous vehicle |
| MRI | Magnetic Resonance Imaging |
| LIDAR | Light detection and ranging |
| IDM | Intelligent Driver Model |
| MDP | Markov decision process |
| HW | Headway |
| THW | Time Headway |
| DST | Deceleration to Safety Time |
| Soft Q-function | |
| State at time point t | |
| Action at time point t | |
| Soft Q-function parameter | |
| Policy with state-action pair | |
| Policy parameter | |
| Desired velocity | |
| T | Save time headway |
| Maximum acceleration | |
| b | Desired deceleration |
| Jam distance | |
| s | Distance to the leading vehicle |
| Minimum jam-avoiding distance | |
| v | Current agent velocity |
| Velocity difference to the leading vehicle | |
| t | Time point t |
| Velocity at time point t | |
| Acceleration at time point t | |
| Position at time point t | |
| h | Step size |
| State Space in MDP | |
| Action Space in MDP | |
| T | Deterministic transition model in MDP |
| r | Reward |
| Deterministic parametric policy | |
| Target seperation | |
| Deceleration to Safety Time | |
| Vehicle 1 | |
| Vehicle 2 |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Collisions | HW (m) | THW (s) | Separation (m) | |
|---|---|---|---|---|---|
| 0 | 0/predAcc/symmetric | 2 | 21.986616 | 4.746649 | 17.932934 |
| 1 | 0/predAcc/symmetric | 20 | 21.523313 | 4.598207 | 17.974341 |
| 2 | 0/predAcc/velocity | 20 | 12.238809 | 6.684551 | 17.714547 |
| 3 | 0/predAcc/absoluteDiff | 20 | 13.512952 | 7.932466 | 18.123747 |
| 4 | 0/predAcc/None | 10 | 552.604185 | 22.768953 | 21.750825 |
| 5 | 0/randomAcc/symmetric | 0 | 120.883542 | 5.407901 | 147.354975 |
| 6 | 0/randomAcc/velocity | 20 | 12.467875 | 7.977922 | 17.749884 |
| 7 | 0/randomAcc/absoluteDiff | 0 | 185.853298 | 8.008320 | 171.210850 |
| 8 | 0/randomAcc/None | 20 | 30.555453 | 4.365431 | 49.872451 |
| 9 | 0/randomStops9/symmetric | 10 | 111.509197 | 5.244257 | 17.899641 |
| 10 | 0/randomStops9/velocity | 20 | 17.324510 | 3.036292 | 13.902887 |
| 11 | 0/randomStops9/absoluteDiff | 20 | 13.116112 | 7.374774 | 17.958673 |
| 12 | 0/randomStops9/None | 0 | 818.533661 | 32.071159 | 229.345633 |
| 13 | 0/randomStops10/symmetric | 20 | 11.578542 | 2.877303 | 19.522080 |
| 14 | 0/randomStops10/velocity | 0 | 96.373722 | 4.650809 | 103.114341 |
| 15 | 0/randomStops10/absoluteDiff | 20 | 13.114346 | 7.399617 | 17.963344 |
| 16 | 0/randomStops10/None | 0 | 818.434954 | 32.064495 | 229.345483 |
| 17 | 100/predAcc/symmetric | 20 | 64.280247 | 7.214039 | 73.357278 |
| 18 | 100/predAcc/velocity | 20 | 12.276690 | 4.083880 | 13.097846 |
| 19 | 100/predAcc/absoluteDiff | 20 | 13.453637 | 7.653036 | 18.272531 |
| 20 | 100/predAcc/None | 10 | 795.550077 | 30.799090 | 22.119458 |
| 21 | 100/randomAcc/symmetric | 9 | 38.420217 | 2.480810 | 54.983419 |
| 22 | 100/randomAcc/velocity | 4 | 201.610520 | 7.274791 | 91.056809 |
| 23 | 100/randomAcc/absoluteDiff | 10 | 85.191944 | 4.217098 | 62.292352 |
| 24 | 100/randomAcc/None | 0 | 229.362628 | 10.193637 | 213.209962 |
| 25 | 100/randomStops9/symmetric | 0 | 88.737306 | 3.578192 | 89.672347 |
| 26 | 100/randomStops9/velocity | 20 | 9.988424 | 2.657730 | 13.041972 |
| 27 | 100/randomStops9/absoluteDiff | 20 | 12.637536 | 7.668094 | 17.778202 |
| 28 | 100/randomStops9/None | 0 | 794.717912 | 31.126503 | 229.345636 |
| 29 | 100/randomStops10/symmetric | 2 | 119.310468 | 5.001601 | 95.460083 |
| 30 | 100/randomStops10/velocity | 20 | 26.619944 | 4.218386 | 53.601016 |
| 31 | 100/randomStops10/absoluteDiff | 20 | 40.782619 | 4.782894 | 21.429448 |
| 32 | 100/randomStops10/None | 0 | 815.799968 | 31.938171 | 229.311862 |
| 33 | 3,000/predAcc/symmetric | 0 | 30.806897 | 2.256980 | 104.479287 |
| 34 | 3,000/predAcc/velocity | 18 | 16.539250 | 2.489905 | 10.804999 |
| 35 | 3,000/predAcc/absoluteDiff | 20 | 13.571941 | 4.840553 | 18.439911 |
| 36 | 3,000/predAcc/None | 0 | 800.393554 | 31.542861 | 229.345636 |
| 37 | 3,000/randomAcc/symmetric | 0 | 557.436259 | 21.370929 | 189.098820 |
| 38 | 3,000/randomAcc/velocity | 1 | 314.244283 | 11.907776 | 174.433635 |
| 39 | 3,000/randomAcc/absoluteDiff | 0 | 519.028676 | 19.635769 | 198.585035 |
| 40 | 3,000/randomAcc/None | 0 | 487.673884 | 18.984621 | 227.800876 |
| 41 | 3,000/randomStops9/symmetric | 0 | 121.610496 | 5.503739 | 145.529442 |
| 42 | 3,000/randomStops9/velocity | 0 | 71.099924 | 3.601645 | 96.712122 |
| 43 | 3,000/randomStops9/absoluteDiff | 20 | 12.240173 | 2.740492 | 16.209725 |
| 44 | 3,000/randomStops9/None | 0 | 736.721510 | 29.327481 | 229.345636 |
| 45 | 3,000/randomStops10/symmetric | 0 | 95.886739 | 4.443669 | 103.119817 |
| 46 | 3,000/randomStops10/velocity | 14 | 9.988159 | 4.999919 | 33.352000 |
| 47 | 3,000/randomStops10/absoluteDiff | 20 | 13.616155 | 6.805060 | 18.093497 |
| 48 | 3,000/randomStops10/None | 0 | 160.721774 | 7.162411 | 154.905059 |
| 49 | 100,000/predAcc/symmetric | 16 | 76.071190 | 3.418030 | 16.016787 |
| 50 | 100,000/predAcc/velocity | 1 | 134.614581 | 6.869882 | 149.200815 |
| 51 | 100,000/predAcc/absoluteDiff | 0 | 818.685845 | 32.077105 | 229.344549 |
| 52 | 100,000/predAcc/None | 0 | 761.794150 | 29.485078 | 229.345636 |
| 53 | 100,000/randomAcc/symmetric | 0 | 160.713442 | 8.460585 | 225.571123 |
| 54 | 100,000/randomAcc/velocity | 0 | 817.021321 | 31.972462 | 229.345213 |
| 55 | 100,000/randomAcc/absoluteDiff | 0 | 576.845622 | 23.913704 | 229.345636 |
| 56 | 100,000/randomAcc/None | 0 | 509.216830 | 21.192002 | 229.345242 |
| 57 | 100,000/randomStops9/symmetric | 0 | 90.975791 | 4.659583 | 135.021949 |
| 58 | 100,000/randomStops9/velocity | 0 | 76.346305 | 4.586848 | 130.914674 |
| 59 | 100,000/randomStops9/absoluteDiff | 0 | 292.012632 | 14.117718 | 229.345634 |
| 60 | 100,000/randomStops9/None | 0 | 816.244478 | 31.961323 | 229.345221 |
| 61 | 100,000/randomStops10/symmetric | 0 | 174.359445 | 7.620220 | 144.156391 |
| 62 | 100,000/randomStops10/velocity | 0 | 430.033252 | 18.551971 | 229.345570 |
| 63 | 100,000/randomStops10/absoluteDiff | 0 | 379.953210 | 16.932130 | 229.340859 |
| 64 | 100,000/randomStops10/None | 10 | 688.564158 | 26.086424 | 54.548802 |
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey 2015. Available online: https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/812115 (accessed on 24 October 2021).
- Ni, J.; Chen, Y.; Chen, Y.; Zhu, J.; Ali, D.; Cao, W. A Survey on Theories and Applications for Self-Driving Cars Based on Deep Learning Methods. Appl. Sci. 2020, 10, 2749. [Google Scholar] [CrossRef]
- Clements, L.M.; Kockelman, K.M. Economic Effects of Automated Vehicles. Transp. Res. Rec. 2017, 2606, 106–114. [Google Scholar] [CrossRef]
- Karpatne, A.; Watkins, W.; Read, J.S.; Kumar, V. Physics-guided Neural Networks (PGNN): An Application in Lake Temperature Modeling. arXiv 2017, arXiv:1710.11431. [Google Scholar]
- von Rueden, L.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Walczak, M.; Pfrommer, J.; Pick, A.; et al. Informed Machine Learning—A Taxonomy and Survey of Integrating Prior Knowledge into Learning Systems. IEEE Trans. Knowl. Data Eng. 2021, 1. [Google Scholar] [CrossRef]
- Yaman, B.; Hosseini, S.A.H.; Moeller, S.; Ellermann, J.; Uğurbil, K.; Akçakaya, M. Self-supervised learning of physics-guided reconstruction neural networks without fully sampled reference data. Magn. Reson. Med. 2020, 84, 3172–3191. [Google Scholar] [CrossRef]
- Gumiere, S.J.; Camporese, M.; Botto, A.; Lafond, J.A.; Paniconi, C.; Gallichand, J.; Rousseau, A.N. Machine Learning vs. Physics-Based Modeling for Real-Time Irrigation Management. Front. Water 2020, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Sun, C. Structural damage identification via physics-guided machine learning: A methodology integrating pattern recognition with finite element model updating. Struct. Health Monit. 2020, 20, 1675–1688. [Google Scholar] [CrossRef]
- Piccione, A.; Berkery, J.; Sabbagh, S.; Andreopoulos, Y. Physics-guided machine learning approaches to predict the ideal stability properties of fusion plasmas. Nucl. Fusion 2020, 60, 046033. [Google Scholar] [CrossRef]
- Muralidhar, N.; Bu, J.; Cao, Z.; He, L.; Ramakrishnan, N.; Tafti, D.; Karpatne, A. Physics-Guided Deep Learning for Drag Force Prediction in Dense Fluid-Particulate Systems. Big Data 2020, 8, 431–449. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Li, Y.; Zhao, R.; Gao, R.X. Physics guided neural network for machining tool wear prediction. J. Manuf. Syst. 2020, 57, 298–310. [Google Scholar] [CrossRef]
- AI Knowledge Consortium. AI Knowledge Project. 2021. Available online: https://www.kiwissen.de/ (accessed on 24 October 2021).
- Wei, Z.; Jiang, Y.; Liao, X.; Qi, X.; Wang, Z.; Wu, G.; Hao, P.; Barth, M. End-to-End Vision-Based Adaptive Cruise Control (ACC) Using Deep Reinforcement Learning. arXiv 2020, arXiv:2001.09181. [Google Scholar]
- Kesting, A.; Treiber, M.; Schönhof, M.; Kranke, F.; Helbing, D. Jam-Avoiding Adaptive Cruise Control (ACC) and its Impact on Traffic Dynamics. In Traffic and Granular Flow’05; Schadschneider, A., Pöschel, T., Kühne, R., Schreckenberg, M., Wolf, D.E., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 633–643. [Google Scholar]
- Kral, W.; Dalpez, S. Modular Sensor Cleaning System for Autonomous Driving. ATZ Worldw. 2018, 120, 56–59. [Google Scholar] [CrossRef]
- Knoop, V.L.; Wang, M.; Wilmink, I.; Hoedemaeker, D.M.; Maaskant, M.; der Meer, E.J.V. Platoon of SAE Level-2 Automated Vehicles on Public Roads: Setup, Traffic Interactions, and Stability. Transp. Res. Rec. 2019, 2673, 311–322. [Google Scholar] [CrossRef]
- Pathak, S.; Bag, S.; Nadkarni, V. A Generalised Method for Adaptive Longitudinal Control Using Reinforcement Learning. In International Conference on Intelligent Autonomous Systems; Springer: Cham, Switzerland, 2019; pp. 464–479. [Google Scholar]
- Farag, A.; AbdelAziz, O.M.; Hussein, A.; Shehata, O.M. Reinforcement Learning Based Approach for Multi-Vehicle Platooning Problem with Nonlinear Dynamic Behavior 2020. Available online: https://www.researchgate.net/publication/349313418_Reinforcement_Learning_Based_Approach_for_Multi-Vehicle_Platooning_Problem_with_Nonlinear_Dynamic_Behavior (accessed on 24 October 2021).
- Chen, C.; Jiang, J.; Lv, N.; Li, S. An intelligent path planning scheme of autonomous vehicles platoon using deep reinforcement learning on network edge. IEEE Access 2020, 8, 99059–99069. [Google Scholar] [CrossRef]
- Forbes, J.R.N. Reinforcement Learning for Autonomous Vehicles; University of California: Berkeley, CA, USA, 2002. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep Reinforcement Learning framework for Autonomous Driving. arXiv 2017, arXiv:1704.02532. [Google Scholar] [CrossRef] [Green Version]
- Kiran, B.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.; Yogamani, S.; Perez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2021, 1–18. [Google Scholar] [CrossRef]
- Di, X.; Shi, R. A survey on autonomous vehicle control in the era of mixed-autonomy: From physics-based to AI-guided driving policy learning. Transp. Res. Part Emerg. Technol. 2021, 125, 103008. [Google Scholar] [CrossRef]
- Desjardins, C.; Chaib-draa, B. Cooperative Adaptive Cruise Control: A Reinforcement Learning Approach. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1248–1260. [Google Scholar] [CrossRef]
- Curiel-Ramirez, L.; Ramirez-Mendoza, R.A.; Bautista, R.; Bustamante-Bello, R.; Gonzalez-Hernandez, H.; Reyes-Avendaño, J.; Gallardo-Medina, E. End-to-End Automated Guided Modular Vehicle. Appl. Sci. 2020, 10, 4400. [Google Scholar] [CrossRef]
- Li, Y.; Li, Z.; Wang, H.; Wang, W.; Xing, L. Evaluating the safety impact of adaptive cruise control in traffic oscillations on freeways. Accid. Anal. Prev. 2017, 104, 137–145. [Google Scholar] [CrossRef]
- Niedoba, M.; Cui, H.; Luo, K.; Hegde, D.; Chou, F.C.; Djuric, N. Improving movement prediction of traffic actors using off-road loss and bias mitigation. In Workshop on ’Machine Learning for Autonomous Driving’ at Conference on Neural Information Processing Systems. 2019. Available online: https://djurikom.github.io/pdfs/niedoba2019ml4ad.pdf (accessed on 24 October 2021).
- Phan-Minh, T.; Grigore, E.C.; Boulton, F.A.; Beijbom, O.; Wolff, E.M. Covernet: Multimodal behavior prediction using trajectory sets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14074–14083. [Google Scholar]
- Boulton, F.A.; Grigore, E.C.; Wolff, E.M. Motion Prediction using Trajectory Sets and Self-Driving Domain Knowledge. arXiv 2020, arXiv:2006.04767. [Google Scholar]
- Cui, H.; Nguyen, T.; Chou, F.C.; Lin, T.H.; Schneider, J.; Bradley, D.; Djuric, N. Deep kinematic models for physically realistic prediction of vehicle trajectories. arXiv 2019, arXiv:1908.0021. [Google Scholar]
- Bahari, M.; Nejjar, I.; Alahi, A. Injecting Knowledge in Data-driven Vehicle Trajectory Predictors. arXiv 2021, arXiv:2103.04854. [Google Scholar] [CrossRef]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-stgcnn: A social spatio-temporal graph convolutional neural network for human trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14424–14432. [Google Scholar]
- Ju, C.; Wang, Z.; Long, C.; Zhang, X.; Chang, D.E. Interaction-aware kalman neural networks for trajectory prediction. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; IEEE: Piscataway, NJ, USA, 2019; pp. 1793–1800. [Google Scholar]
- Chen, B.; Li, L. Adversarial Evaluation of Autonomous Vehicles in Lane-Change Scenarios. arXiv 2020, arXiv:2004.06531. [Google Scholar] [CrossRef]
- Ding, W.; Xu, M.; Zhao, D. Learning to Collide: An Adaptive Safety-Critical Scenarios Generating Method. arXiv 2020, arXiv:2003.01197. [Google Scholar]
- Qiao, Z.; Tyree, Z.; Mudalige, P.; Schneider, J.; Dolan, J.M. Hierarchical reinforcement learning method for autonomous vehicle behavior planning. arXiv 2019, arXiv:1911.03799. [Google Scholar]
- Li, X.; Qiu, X.; Wang, J.; Shen, Y. A Deep Reinforcement Learning Based Approach for Autonomous Overtaking. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Wu, Y.; Tan, H.; Peng, J.; Ran, B. A Deep Reinforcement Learning Based Car Following Model for Electric Vehicle. Smart City Appl. 2019, 2, 1–8. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft Actor-Critic Algorithms and Applications. arXiv 2019, arXiv:1812.05905. [Google Scholar]
- Hermand, E.; Nguyen, T.W.; Hosseinzadeh, M.; Garone, E. Constrained control of UAVs in geofencing applications. In Proceedings of the 2018 26th Mediterranean Conference on Control and Automation (MED), Zadar, Croatia, 19–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 217–222. [Google Scholar]
- Wang, P.; Gao, S.; Li, L.; Sun, B.; Cheng, S. Obstacle avoidance path planning design for autonomous driving vehicles based on an improved artificial potential field algorithm. Energies 2019, 12, 2342. [Google Scholar] [CrossRef] [Green Version]
- Westhofen, L.; Neurohr, C.; Koopmann, T.; Butz, M.; Schütt, B.; Utesch, F.; Kramer, B.; Gutenkunst, C.; Böde, E. Criticality Metrics for Automated Driving: A Review and Suitability Analysis of the State of the Art. arXiv 2021, arXiv:2108.02403. [Google Scholar]
- Cassirer, A.; Barth-Maron, G.; Brevdo, E.; Ramos, S.; Boyd, T.; Sottiaux, T.; Kroiss, M. Reverb: A Framework For Experience Replay. arXiv 2021, arXiv:2102.04736. [Google Scholar]
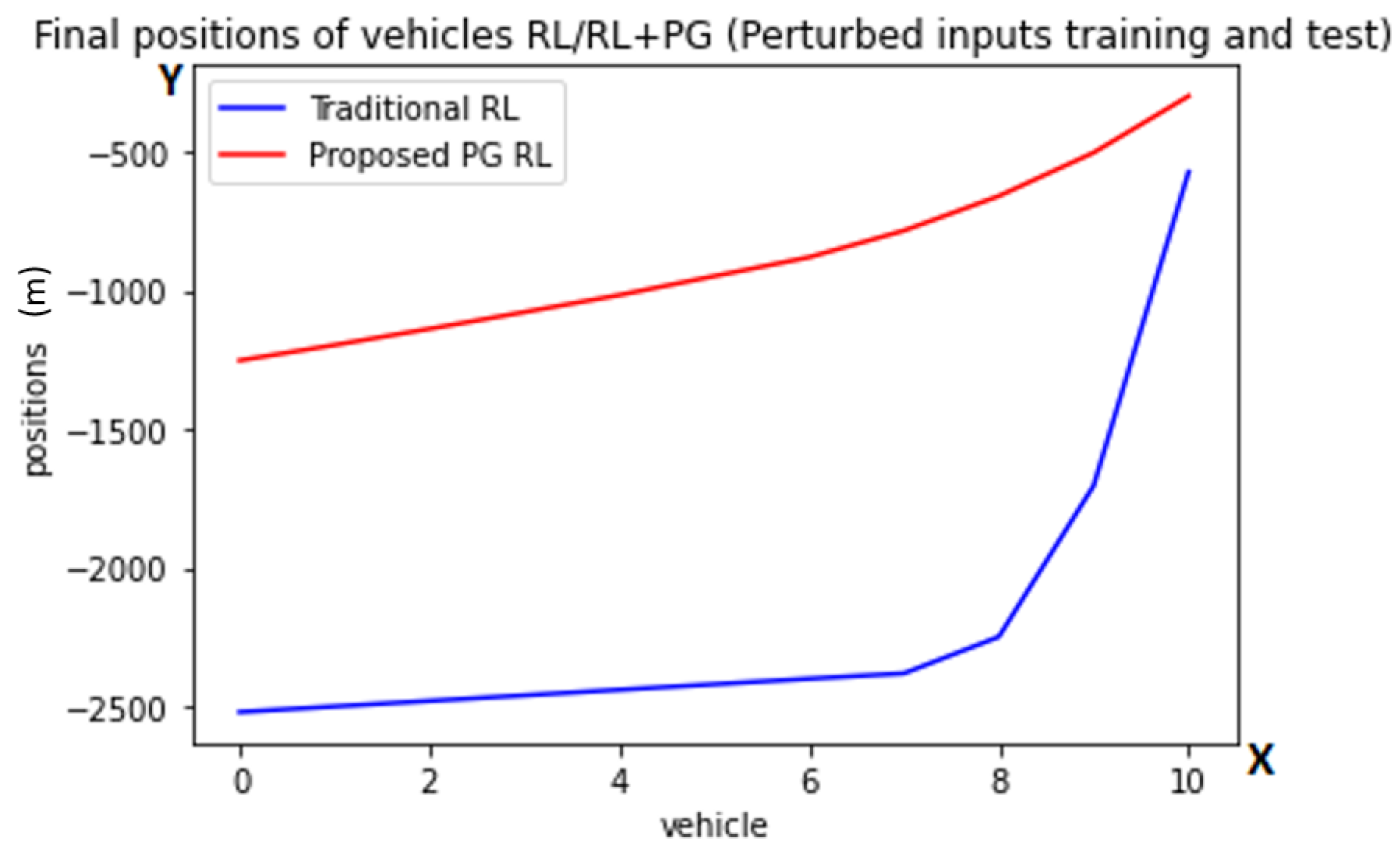

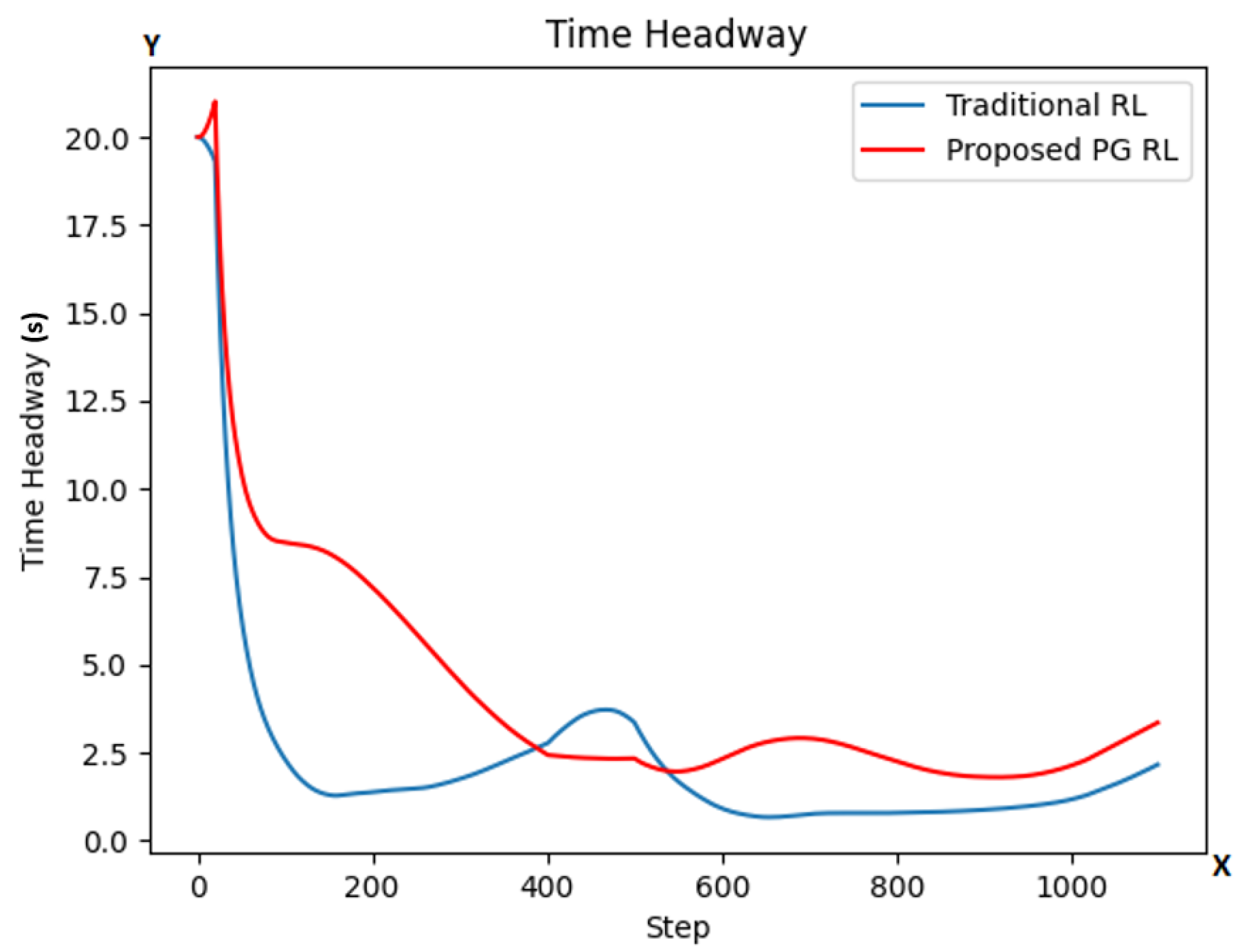
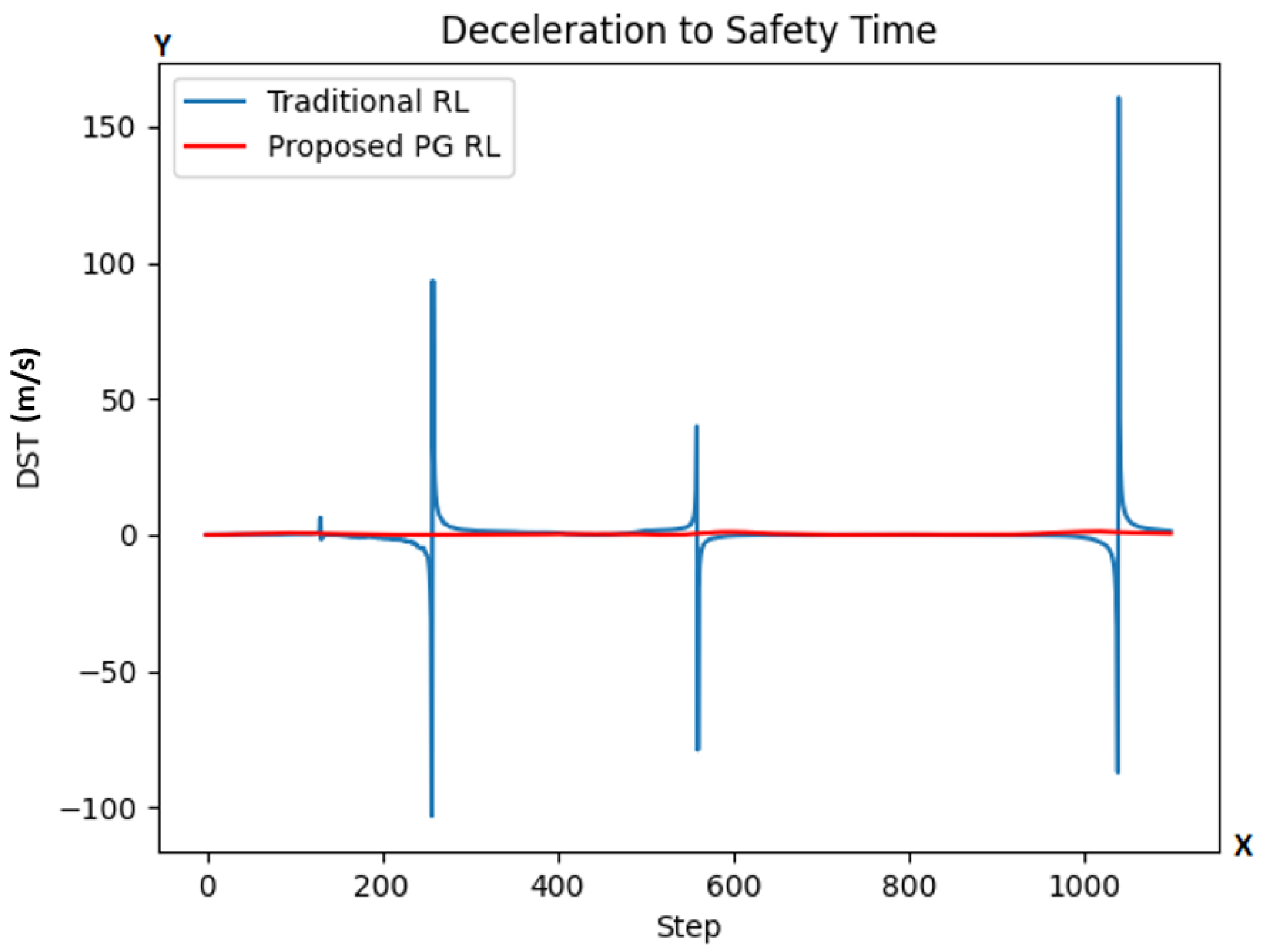
| Static Model Parameter | Symbol | Value |
|---|---|---|
| Desired velocity | 120 / | |
| Save time headway | T | |
| Maximum acceleration | / | |
| Desired deceleration | b | / |
| Jam distance | 2 |
| Lead Deceleration | Collision Vehicle PG RL | Collision Vehicle RL |
|---|---|---|
| 1.0 | 10th | 1st |
| 0.75 | No collisions | 1st |
| 0.71 | No collisions | 6th |
| 0.7 | No collisions | No collisions |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jurj, S.L.; Grundt, D.; Werner, T.; Borchers, P.; Rothemann, K.; Möhlmann, E. Increasing the Safety of Adaptive Cruise Control Using Physics-Guided Reinforcement Learning. Energies 2021, 14, 7572. https://doi.org/10.3390/en14227572
Jurj SL, Grundt D, Werner T, Borchers P, Rothemann K, Möhlmann E. Increasing the Safety of Adaptive Cruise Control Using Physics-Guided Reinforcement Learning. Energies. 2021; 14(22):7572. https://doi.org/10.3390/en14227572
Chicago/Turabian StyleJurj, Sorin Liviu, Dominik Grundt, Tino Werner, Philipp Borchers, Karina Rothemann, and Eike Möhlmann. 2021. "Increasing the Safety of Adaptive Cruise Control Using Physics-Guided Reinforcement Learning" Energies 14, no. 22: 7572. https://doi.org/10.3390/en14227572
APA StyleJurj, S. L., Grundt, D., Werner, T., Borchers, P., Rothemann, K., & Möhlmann, E. (2021). Increasing the Safety of Adaptive Cruise Control Using Physics-Guided Reinforcement Learning. Energies, 14(22), 7572. https://doi.org/10.3390/en14227572