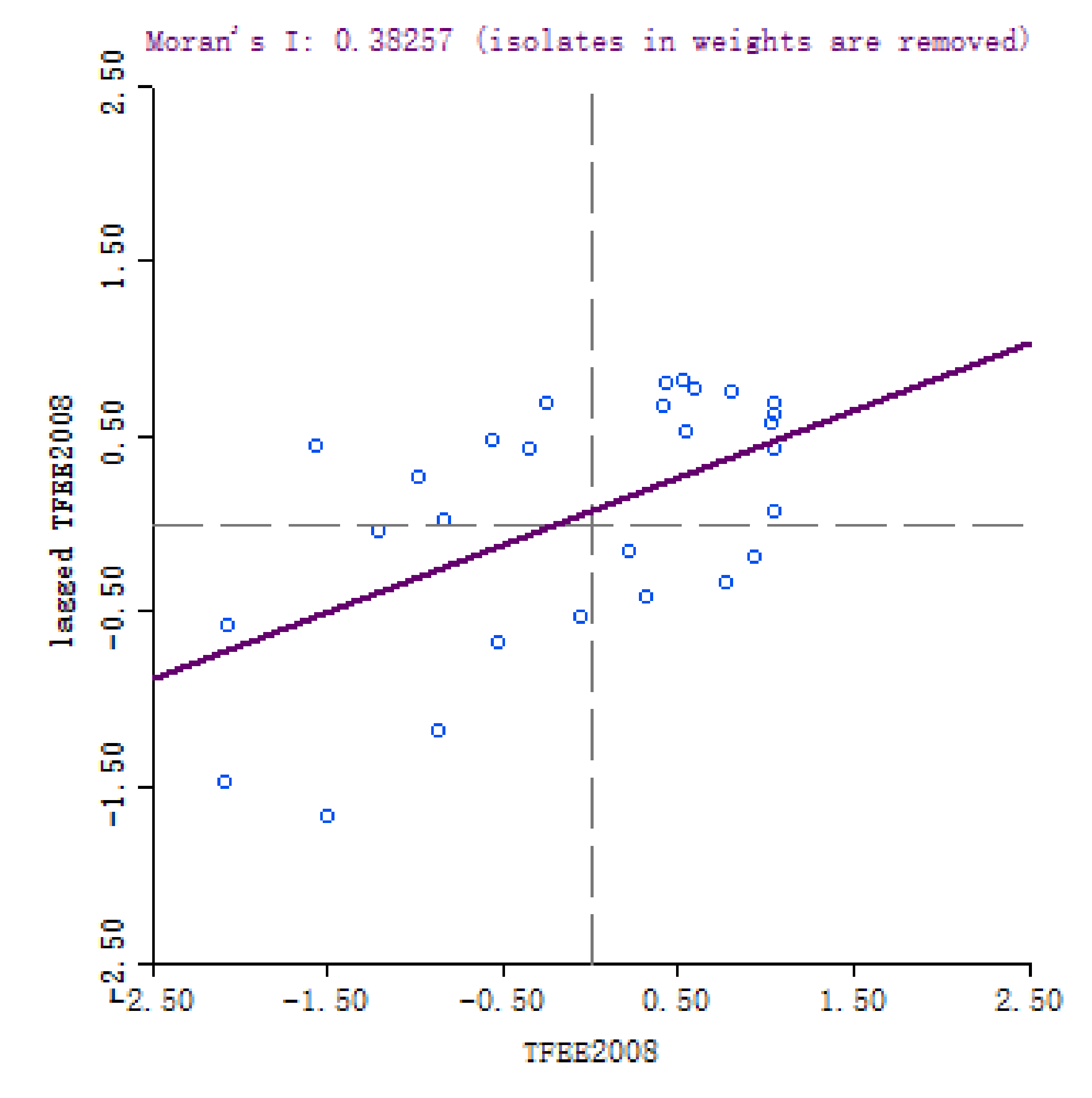
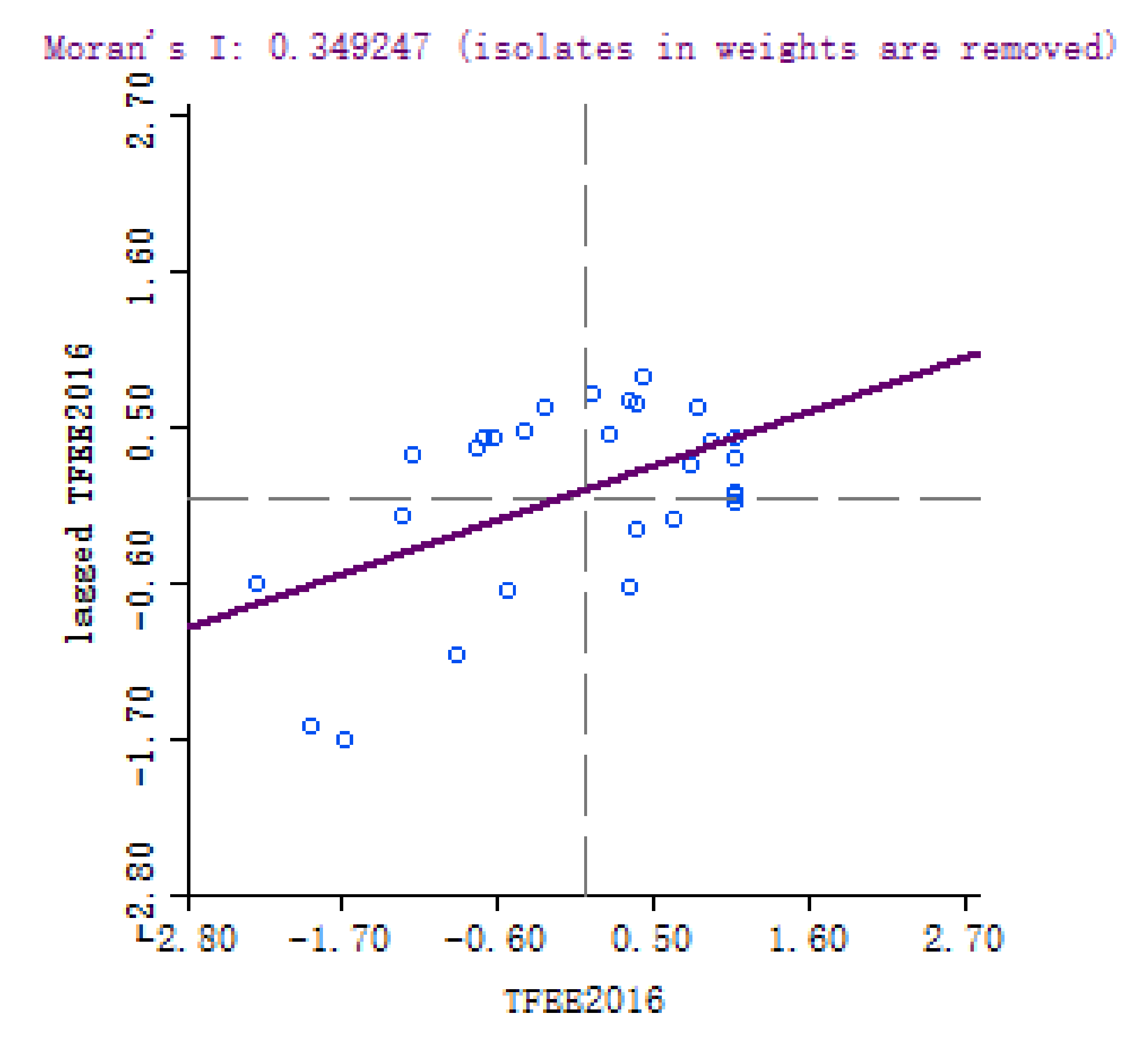
2.1. Spatial Auto-Correlation Test Based on Index
In this subsection, we introduce the measurement of energy efficiency, and LISA which are employed to test the spatial autocorrelation of energy efficiency.
For the measurement of energy efficiency, we use the data envelopment analysis (DEA) by taking the so-called low-carbon GDP [
19] as the output variable. For convenience, we briefly describe the method of data envelopment analysis here. Assume there are
n regions or called decision making units (DMU) in some references. Each region has
m input variables and
k output variables. For a year in the
j-th region,
and
represent input and output vectors respectively, whose corresponding weight vectors are denoted by
and
respectively. The CRS-DEA model [
21] of the
j-th region can be expressed as follows:
The dual problem of model (
1) can be expressed as:
where
is a scalar, the efficiency value of the
j-th region. It embodies the region’s ability to effectively allocate resources and sustainable development capability. If
, it means that the
j-th region is located at the production frontier, that is, the
j-th region that obtains the maximum output under certain input is effective.
is an
vector of constants. It serves to form a convex combination of observed inputs and outputs.
The global
describes the global spatial autocorrelation of all data, which is defined as follows [
20]:
where
,
n the number of areas (spatial units),
the energy efficiency value of the
i-th region,
the element of the spatial weight matrix, which represents the adjacent relationship between the
i-th region and the
j-th region. It is defined as follows:
The design of the spatial weight matrix in this paper follows the rook adjacency method. That is, if there is a common boundary between the two regions, they are considered to be adjacent. Using this method, a spatial weight matrix can be constructed.
The range of is . A positive means that there is a positive spatial correlation between the economic behaviors of various regions. The negative indicates that there is a spatial negative correlation between economic behaviors in various regions. If , there is no spatial correlation, and the economic behavior of each region is independent of each other. The closer the absolute value of is to 1, the greater the spatial correlation between regions.
By standardizing statistic
, a significance test can be performed. Let
Under the null hypothesis
:
, that is, the null hypothesis of no spatial autocorrelation, we have:
where
;
;
;
,
. When the null hypothesis holds,
follows a normal distribution.
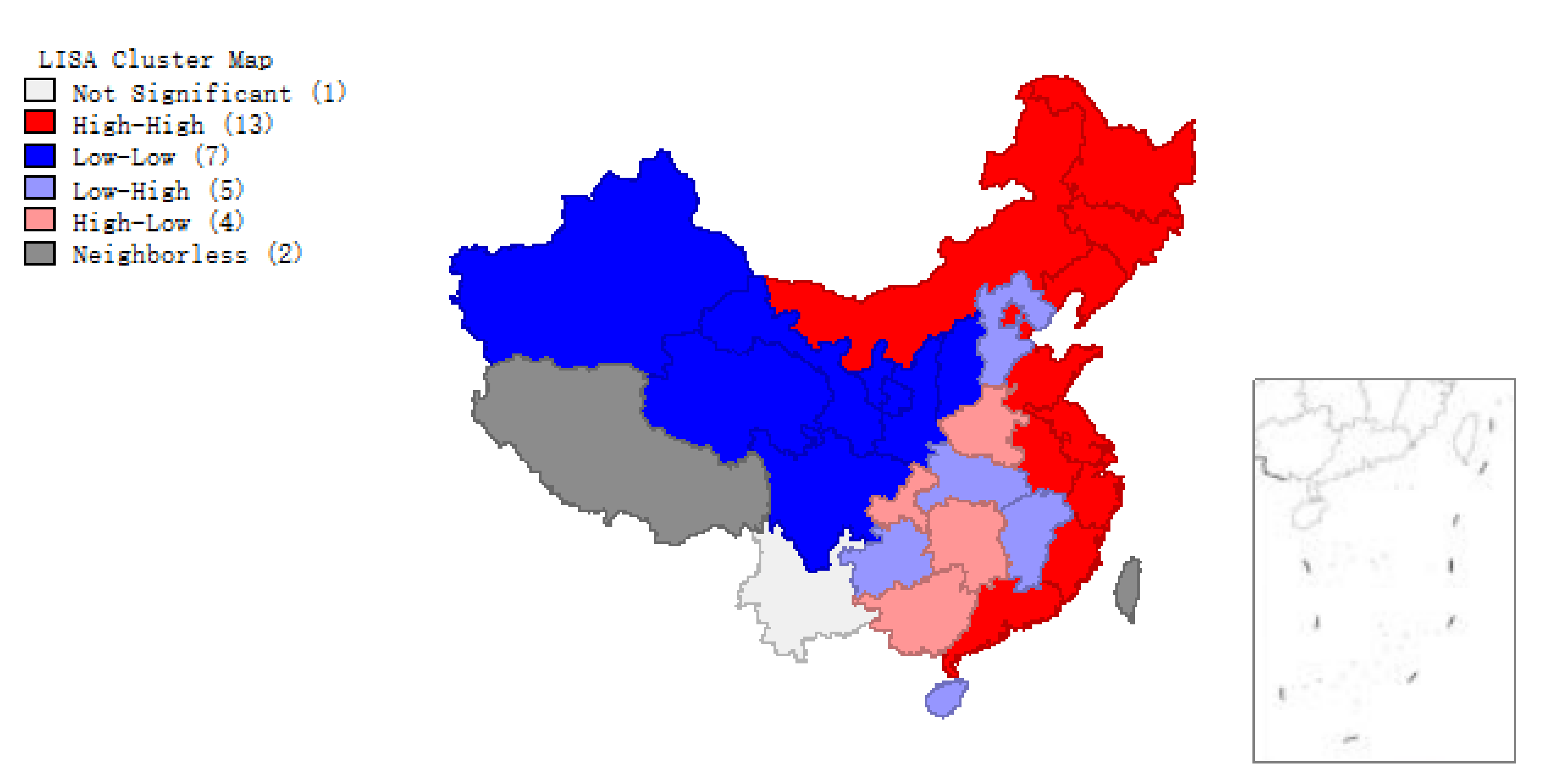
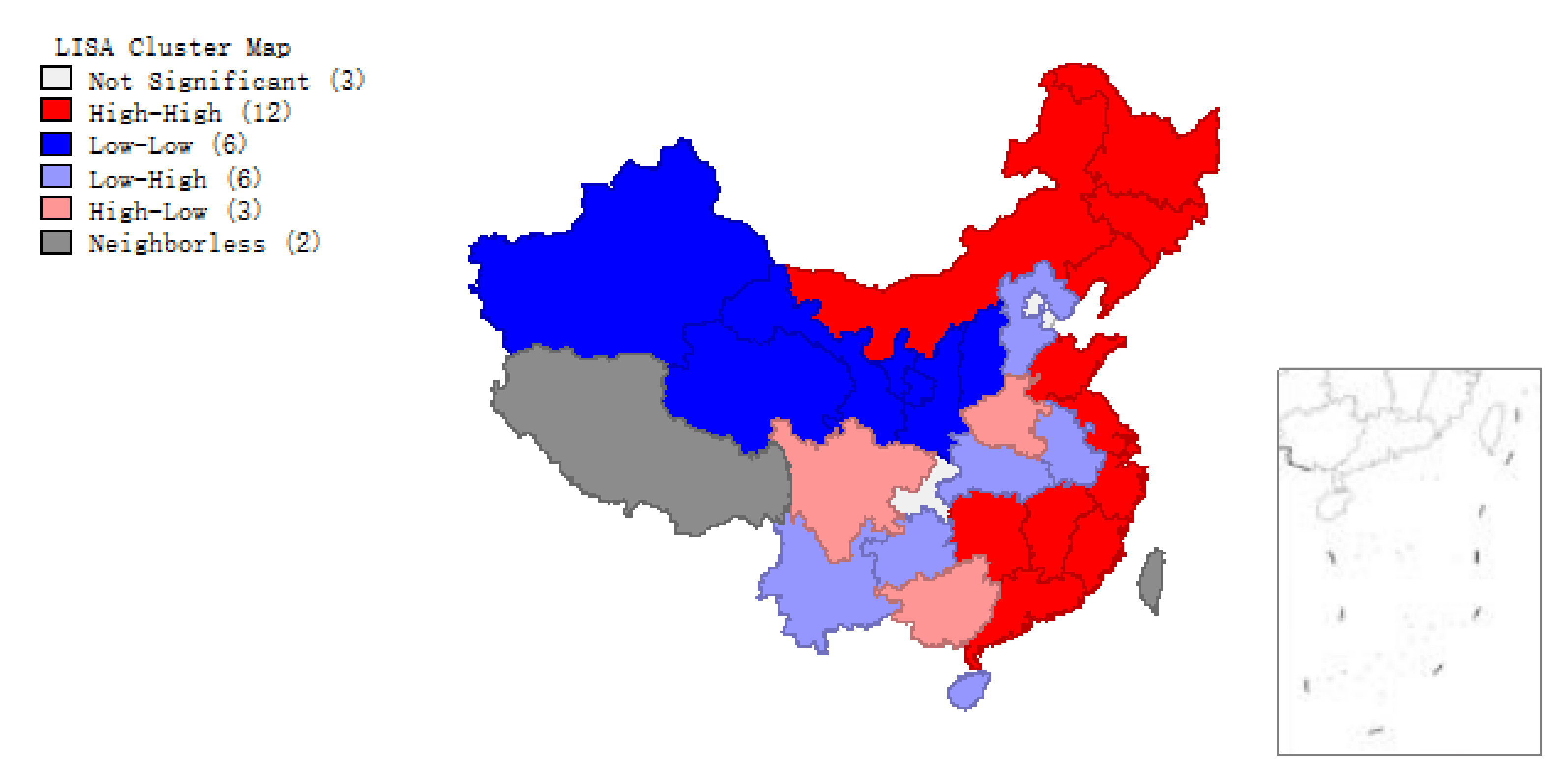
Global spatial autocorrelation analysis yields only one statistic to summarize the whole study area. One statistic is not enough to describe the details of individual regions. One way is to study the local spatial autocorrelation of local regions. The local indicators of spatial association (LISA) to evaluate the clustering in those individual units by calculating Local
for each spatial unit and evaluating the statistical significance for the
i-th region:
2.2. Spatial Quantile Autoregressive Model
Based on Su and Yang’s research [
22] on the spatial quantile autoregressive model under cross-section data, we extend it to the panel data case. Combining the spatial autoregressive model with quantile regression method, we need to deal with endogenous issues. We use the instrumental variable method proposed by Chernozhukov and Hansen [
23,
24] to solve the variable endogenous problem, and give the process of parameter estimation of the spatial quantile autoregressive model.
In 1978, Koenker and Bassett [
16] proposed the idea of quantile regression and extended the mean regression model to the quantile one.
Let be a probability space, Y a random variable defined in . For any real number y, the distribution function of the random variable Y is defined by . For any , is called the -th quantile of Y. is abbreviated as . can be seen as a function of , called the quantile function of Y. Particularly, is the median of Y.
The multivariate quantile regression model is defined as follows:
where
with dependent components.
is a non-random explanatory matrix, where the transpose ’′‘ follows the transpose rules of the block matrix. For each
,
.
is the parameter vector to be estimated.
is the error term. Assume each error component
satisfying the condition
the formulas (
9) mean that the conditional
-quantile of each error term is 0.
In 1973, Cliff and Ord [
25] proposed a spatial autoregressive model. For the cross-sectional data, the spatial autoregressive model is expressed as:
where the subscript
i is the cross section unit.
is the explained variable of the
i-th cross section unit, and
is the explanatory vector.
is the weight, reflecting the relation between the
i-th region and the
j-th region. Denote
,
,
,
.
is the random error vector of independent and identically distributed with zero mean. The model (
10) can be written in matrix form as follows:
By applying the first-order moment constraint
to Equation (
10), then the conditional mean
, where
. Similarly, applying quantile constraint
to Equation (
10), the following Equation (
12) can be obtained:
Combining formula in (
10) and (
12), we have the spatial quantile autoregressive model for the cross-sectional data as follows:
We extend model (
13) to the spatial quantile autoregressive model for panel data:
where
is an
m-dimensional column vector.
Note: t can also be continuous time. Here we only consider the discrete case. We assume the time is divided into T periods. For each i and t, ( is the set of all real numbers, is the m-dimensional Euclidean space). , is the coefficient of the spatial lagged factor. is an vector of regression coefficients, is the error term with zero quantile, .
Endogenous variables are important in economic modeling, which are determined by their relationship with other variables within the model and show whether a variable causes a particular effect. The spatial lagged factor in the spatial autoregressive model can be regarded as an endogenous variable. The spatial econometric model combined with quantile regression needs to deal with endogenous issues. Otherwise, it will affect the accuracy of parameter estimation. Therefore, in the next subsection, we will discuss the instrumental variable method to deal with endogenous problems and parameter estimation.
2.3. Instrument Variable Method for Endogenous Problem and Parameter Estimation
Instrumental variables are variables that do not belong to the original model and are related to endogenous variables (Pearl, 2000 [
26]). Concerning instrumental variable(IV) method, we refer to the literatures of Chernozhukov and Hansen [
23,
24], Matthew and Carlos (2009) [
27].
Let
be a matrix of instrument variables, where
.
is related to
but unrelated to
and satisfies
Let
, where
is the
identity matrix and ‘⊗’ represents the Kronecker product.
Take
, where
,
for
, which implies the spatial weights are invariable in different periods. Then
is strictly exogenous and related to endogenous variables. The IV method will be simpler if
are independently and identically distributed. Then (
15) is equivalent to find
such that zero is a solution to the ordinary quantile regression:
where
.
is the indicator function.
G is a class of measurable functions of
. Let
, there is
. Here we assume
G is defined as follows:
where
is a column vector and
. In order to solve the problem (
17), we construct the weighted quantile regressive objective function as follows:
By the results in [
23], the principle to solve problem (
17) is to find
such that the instrument variable coefficient
is driven as close to zero as possible. Here we use the two-stage least squares on the objective function (
18).
Assumptions:
- (1)
.
- (2)
For any t, .
- (3)
Given a value of , the conditional distribution function has a bounded continuous conditional probability density function . Where , is the element of G.
- (4)
X is non-random. Its absolute value is uniformly bounded and contains the intercept term.
- (5)
The instrument variable Z is non-random with full column rank.
Let . The algorithm of solving parameter estimation of the SQAR model are summarized as follows:
Step 1: for a given
, to perform a ordinary quantile regression on
based on
as follows:
Step 2: minimize the value of
, and then get the estimator of
:
where
,
,
, A is a symmetric positive definite matrix. In fact, in order to find the estimator of
, the coefficient
of the instrument variable should be driven as close to zero as possible. For simplicity, referring to the study of Chernozhukov and Hansen [
23,
24], here we take
to be an identity matrix.
Step 3: performing weighted quantile regression on
based on
we can get an estimator of
:





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}