
Towards Cooperative Perception Services for ITS: Digital Twin in the Automotive Edge Cloud


 , , , , , , , and
, , , , , , , and
Abstract
:1. Introduction
1.1. Scope and Significance
1.2. Prior Work
1.3. Primary Contribution
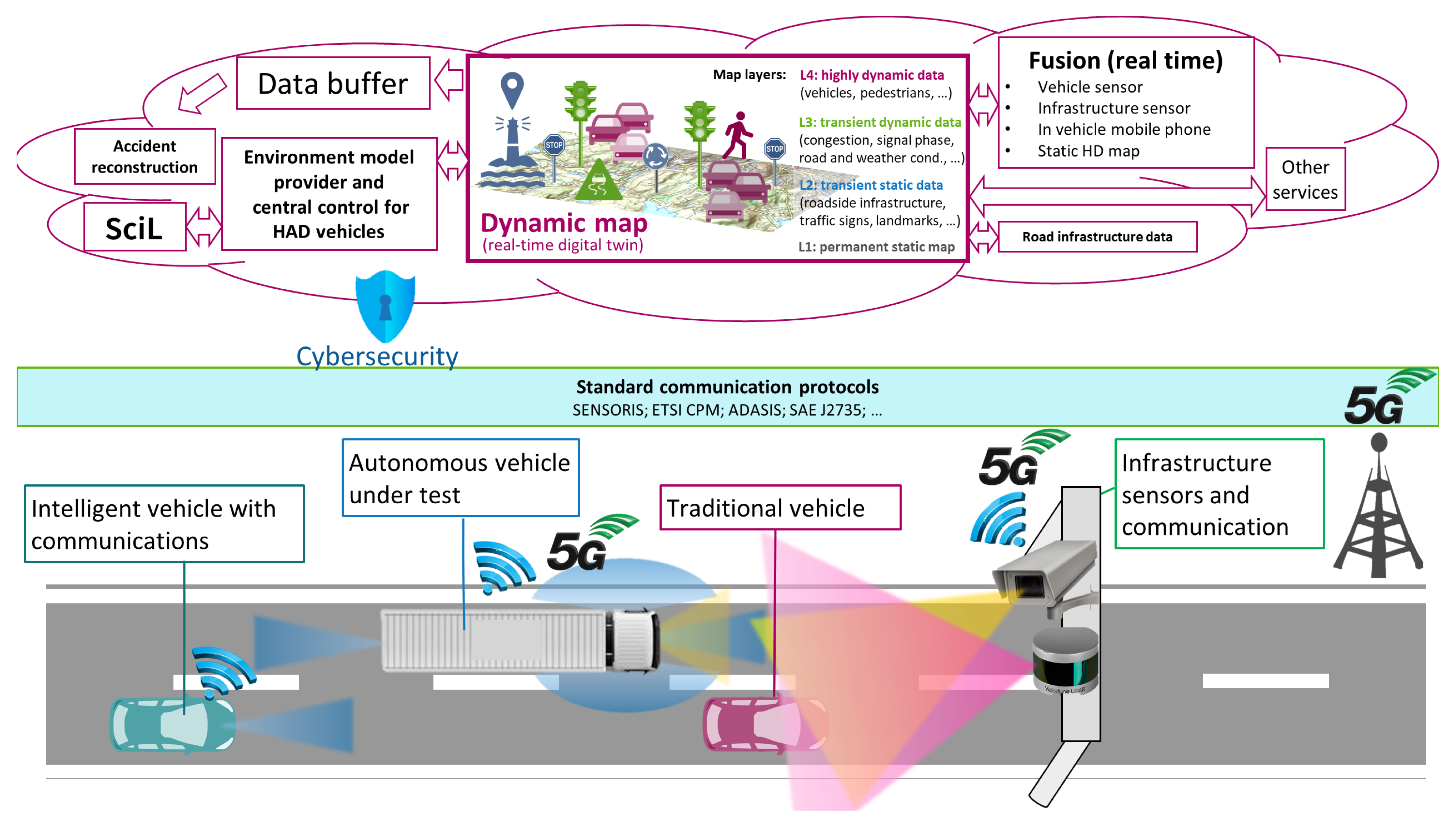
- Digital twin: a logically centralized, dynamic digital model of the traffic environment that integrates data from heterogeneous sources including both intelligent infrastructure and traffic participants in the cloud real-time.
- Derivative services: novel services that are expected to become available via a digital twin. These services fall into following major categories:
- −
- Cooperative perception services: more reliable centralized perception via sensor fusion in the cloud (Central Perception).
- −
- Dataset generation services: more reliable perception enables more sophisticated scenario extraction and data referencing on multi-sensor datasets, as well as cross-validation of perception algorithms.
- −
- Accident reconstruction related services
- −
- Cloud Control: certain control functionalities (e.g., emergency braking) could be performed centrally based on cooperative perception inputs assuming sufficiently low latencies (a technological possibility in the near future).
- −
- Proving ground and logistical yard management: some of the first potential areas of Central Perception and/or Cloud Control deployment.
- −
- Analytic services: miscellaneous real-time datastream and historical data analytics.
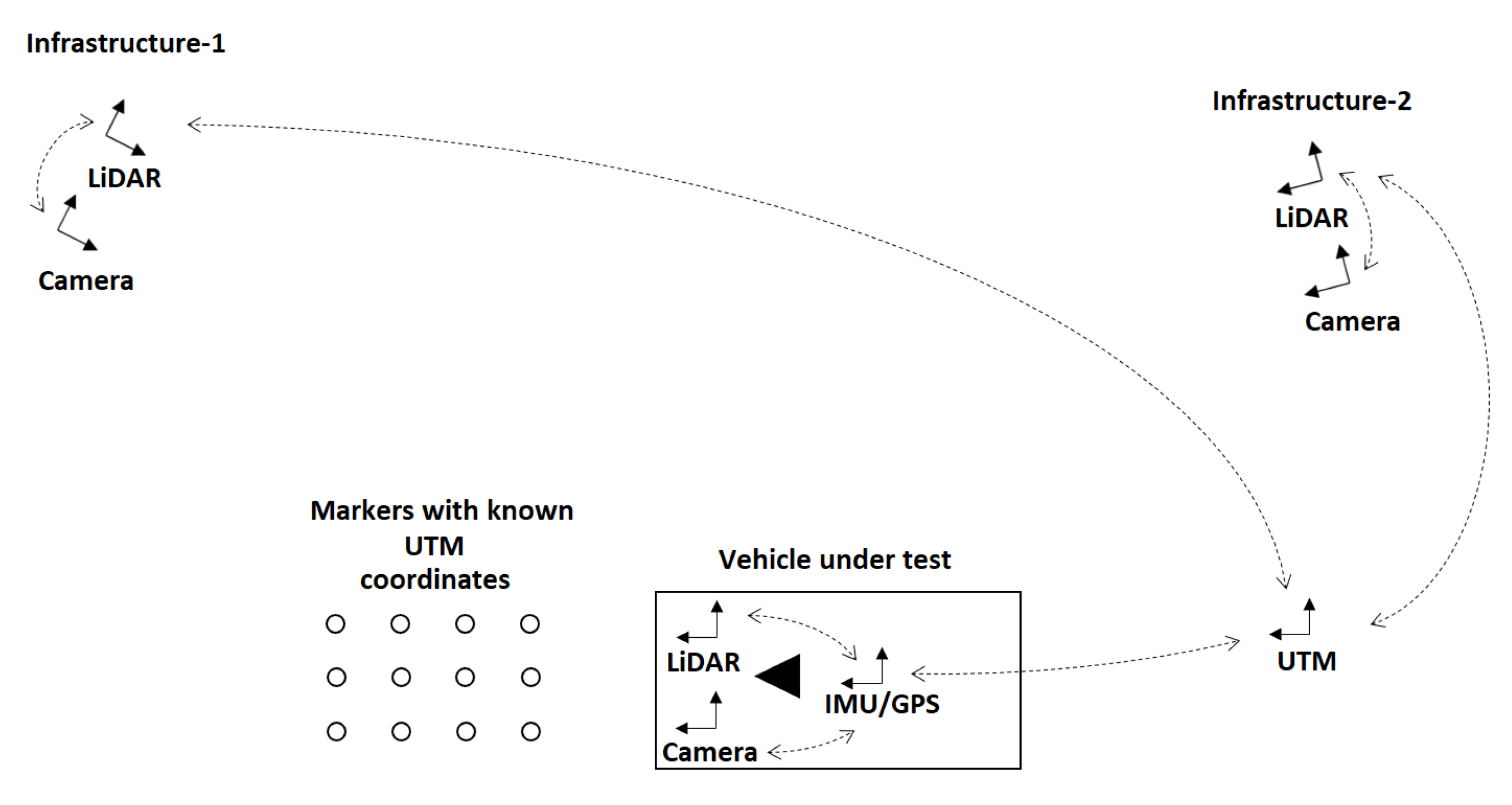
2. Problem Definition
- A single central server (edge node);
- Covering a spatially localized region of overlapping sensor field of views;
- Fusing data from three multi-sensor camera-LiDAR platforms, one of them mobile;
- Detecting (currently only) pedestrians;
- Visualizing the digital twin in a realistic 3D simulation;
- In real-time (with less than 100 ms latency).
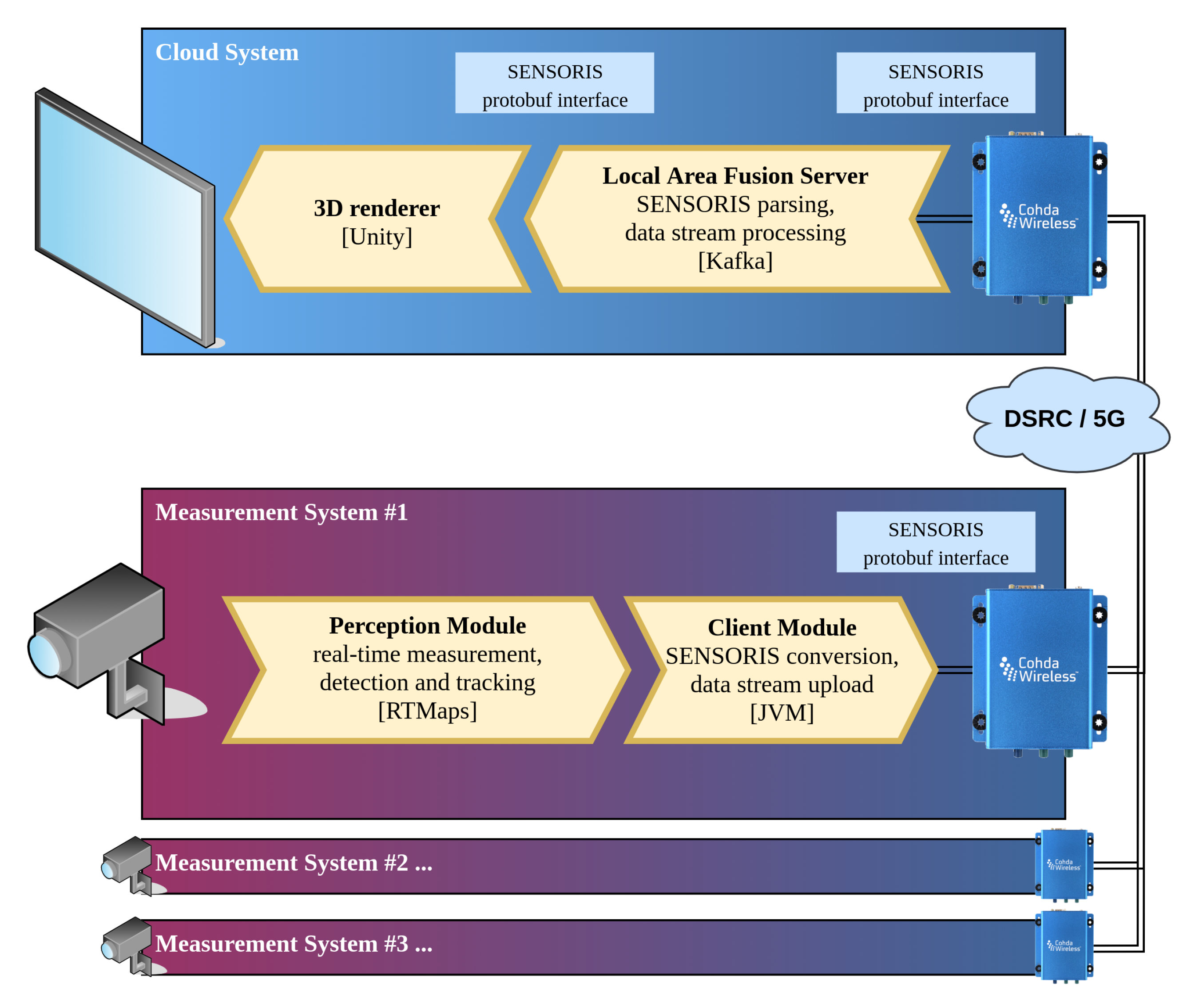
3. Overview of the Central Perception System Architecture
4. Perception Module
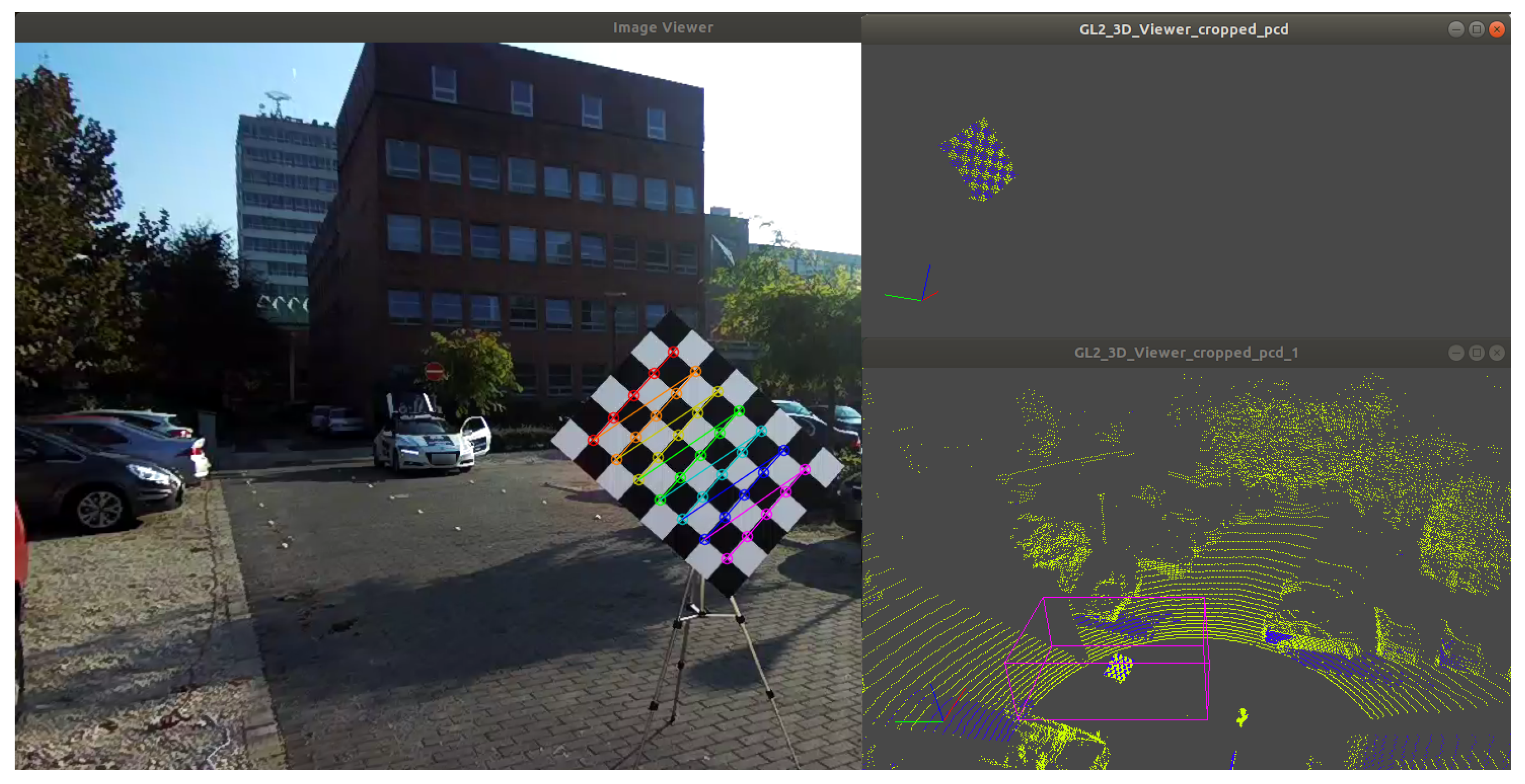
4.1. System Calibration
4.1.1. Chessboard Based Camera-LiDAR Calibration
4.1.2. Box Based Calibration
4.2. Data Synchronization
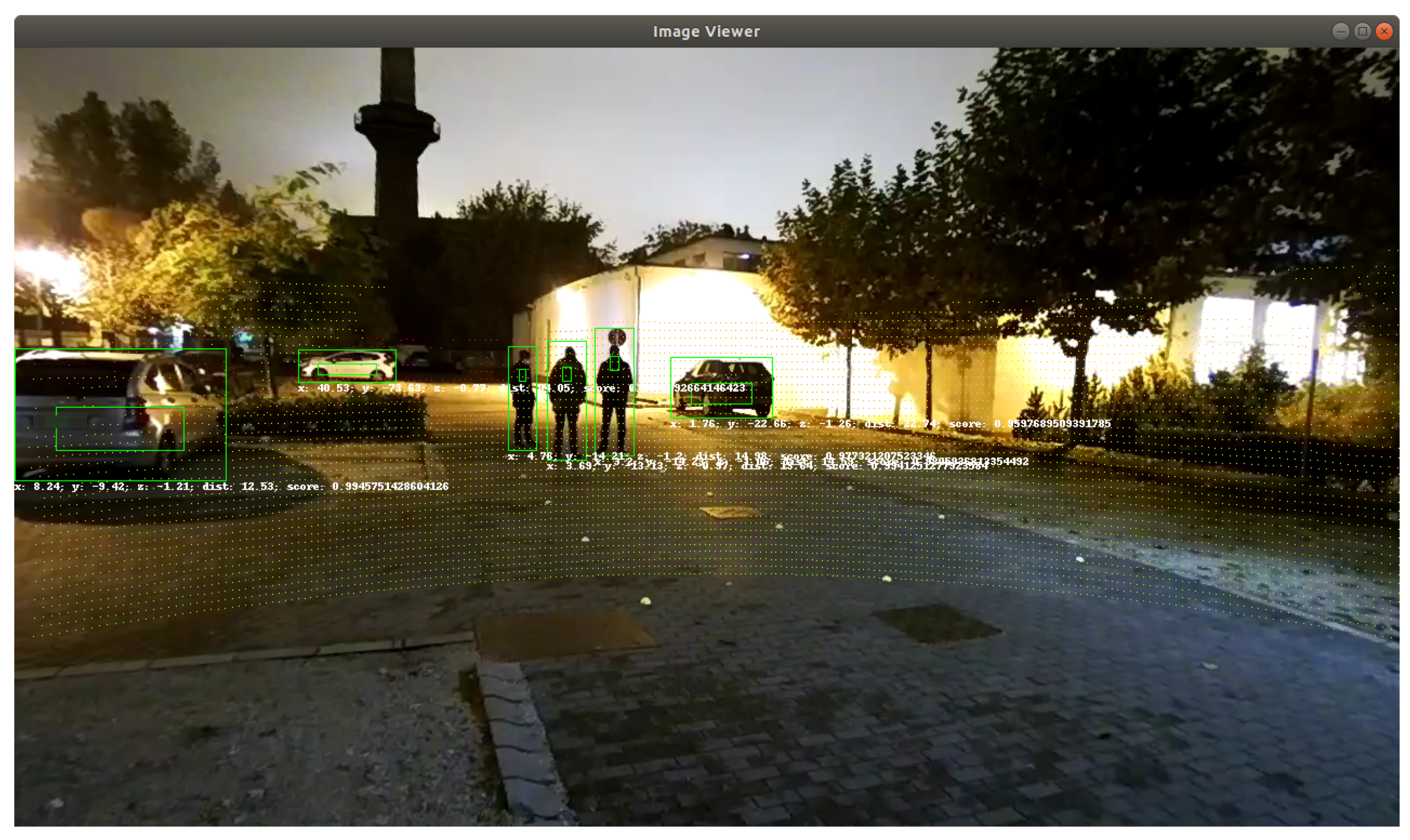
4.3. 3D Object Detection
- Camera-lidar based approach benefits from the high resolution of cameras and the high position accuracy of 3D LiDAR points.
- A single camera based detection where the YOLO 2D detection [16] algorithm and the homography between the road plane and the image plane was considered. This approach is cost efficient (due to the camera only requirement) and is preferred to be applied in such scenarios where the camera is static.
4.3.1. Yolo and Point Cloud Based Approach
4.3.2. Yolo and Homography Based Approach
4.4. Object Tracking
4.4.1. Overview
4.4.2. Implementation

5. Local Area Fusion Server
5.1. Stream Setup
- Converts system origin coordinates from WGS84 to UTM. Position uncertainty remains the same since the SENSORIS input was in (square) meters already. Rotation and its uncertainty do not change because WGS84 and UTM frames point in the same directions.
- Recalculates all object coordinates from system-relative to absolute UTM.
- (a)
- Position: The transformation matrix is straightforward to derive from the relative frame (e.g., vehicle IMU): we just calculate the rotation matrix from the platform’s current orientation and append its current position as a translation vector.
- (b)
- Orientation: The global heading is obtained by adding the relative (IMU-based) object yaw to the system yaw. Calculating global pitch and roll is more involved and was skipped since this data is not represented in our current environment model. The pitch and roll values are set to zero.
- (c)
- Position covariance: the object position covariance matrix has to be backrotated and added to system position covariance, assuming no cross-covariance between system and object positions since they are independent.denotes the IMU-to-UTM rotation matrix, while denote the resulting object position covariance, the platform position covariance and the IMU-based relative object position covariance, respectively.
- (d)
- Orientation covariance: the object heading variance is added to the system heading variance, the pitch and roll uncertainties are disregarded (set to identity).
- Here, the fusion algorithm itself is performed on the objects-utm stream. Exact details will be given in the next subsection. For convenient further utilization a very specific rule for populating the output fusion-utm stream is applied: the chosen fusion input messages and the fused output message are written sequentially to the out-stream. So later reading the messages in offset order will yield an alternating sequence of fusion inputs followed by the corresponding fusion output. Note that not every objects-utm message becomes a fusion input.
- Converts all objects from UTM coordinates into WGS84 coordinates.
- Optionally filters certain objects according to position in relation to demonstration area.
5.2. Fusion Algorithm
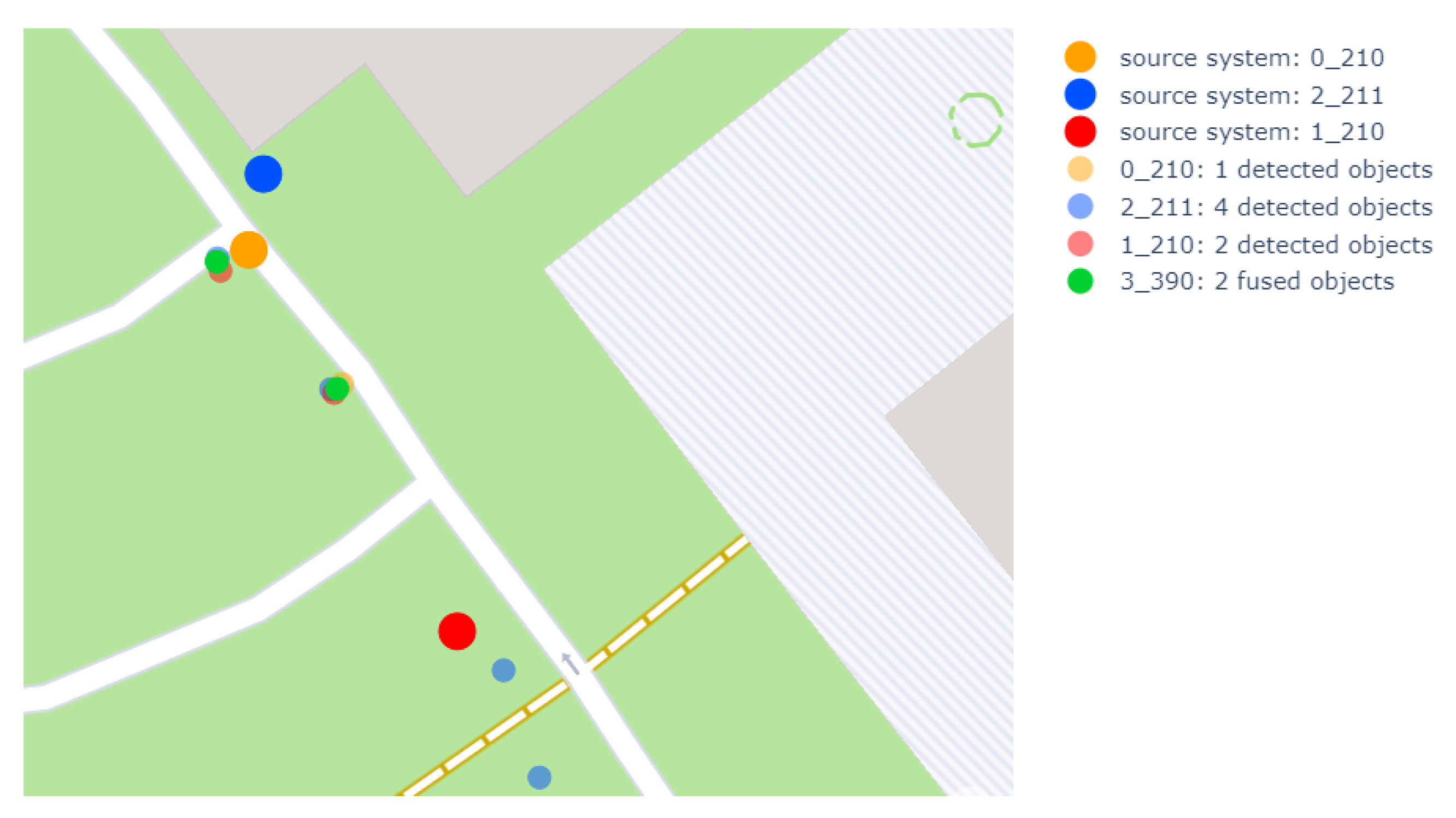
5.2.1. Central Tracking

5.2.2. Integration
- C code generation and compilation from Matlab,
- Generation of a Java wrapper using the SWIG (http://swig.org/ (accessed on 14 September 2021)) framework for integration with Kafka Streams API,
- Devising and implementing an appropriate input buffering scheme within the stream processor, and finally
- Making sure both real-time and playback fusion options are supported.
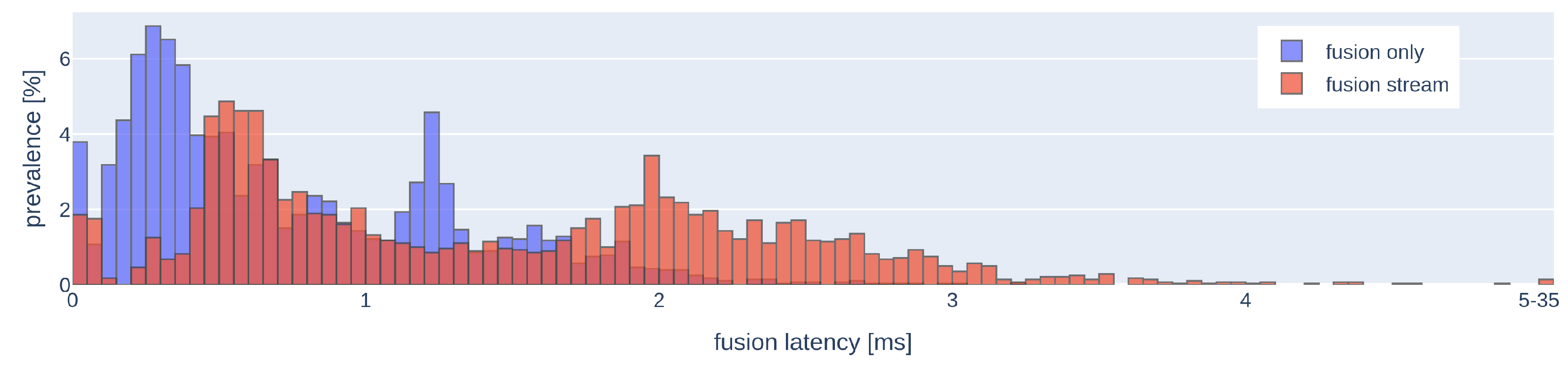
5.2.3. Buffering
- Tries to collect and buffer all available data immediately and continues to collect as long as the stream is accessible;
- Discards messages with past timestamps that precede the most recent fusion step;
- Preserves far-future data points without running out of memory;
- Collects data falling—according to timestamp—into each inter-fusion time window into separate sets;
- When the time for the next fusion step comes, the cluster of messages that falls into the preceding time-window is regarded: a collection of one latest message per sensor is retained as fusion input, the rest discarded.
5.2.4. Real-Time vs. Playback Mode
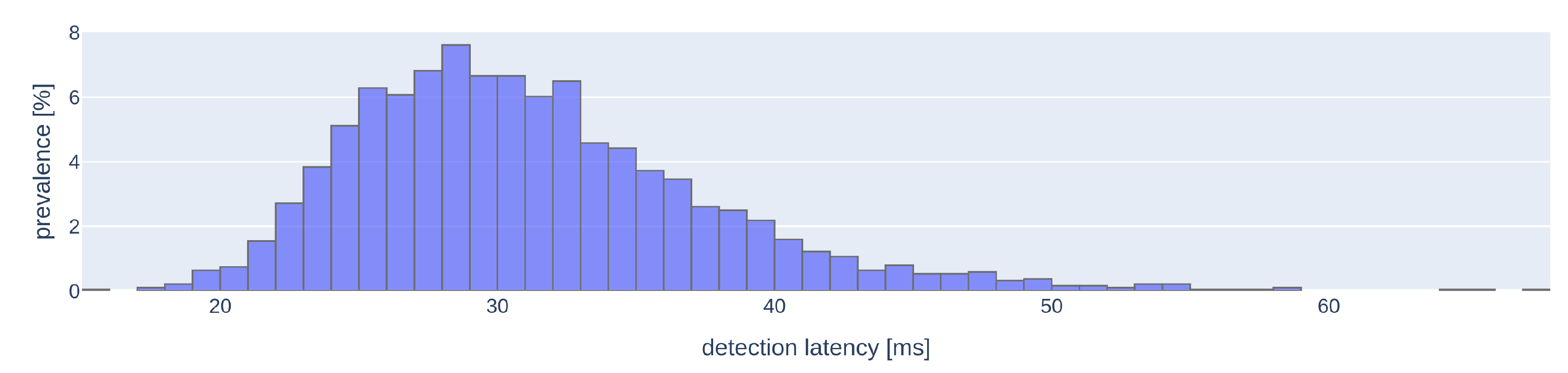
5.2.5. TrackerGNN Parametrization

5.2.6. Results
6. Client Module
6.1. DSRC Communication
- No additional infrastructure requirement: 802.11p does not require any additional infrastructure part, just the receiver and the transceiver units. This is because an ad-hoc network is formed, as soon as two DSRC units come in each other’s radio range.
- Low latency: Road experiments have shown the latency at MAC layer to be around 2 ms or less in an optimal setup. The latency value depends on several different factors, such as payload size, vehicle speed (if the unit is mounted in a vehicle), radio interference, line of sight, etc.
- Range: The range is dependent on other variable factors like data rate and environmental factors. According to documentation it offers data exchange among vehicles and roadside infrastructure within a range of 1000 m, with a transmission rate of up to 27 Mbps and a vehicle speed up to 260 km/h.
6.2. Kafka Streaming Platform
6.3. SENSORIS Message Standard
- Message identification
- Source system information
- −
- Identification (platform UUID, sensor UUID, sensor SUID) (UUID stands for universally unique identifier; SUID stands for system-wide unique identifier)
- −
- GPS PPS synchronized timestamp of originating measurement (event time)
- −
- Localization (position, orientation) and its uncertainty
- Detected objects (i.e., detections or tracks) information [given for each object]
- −
- Object SUID
- −
- Object existence uncertainty
- −
- Object type and type uncertainty
- −
- Object position and orientation in relative coordinate system and its uncertainty
- −
- Object size and uncertainty
7. 3D Renderer
7.1. Virtual Environment
7.2. Sensor Detection Visualization
8. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| 4G/5G | Fourth/fifth generation technology standard for broadband cellular networks |
| ADAS | Advanced Driver-Assistance Systems |
| API | Application Programming Interface |
| CAV | Connected and Autonomous Vehicle |
| CPU | Central Processing Unit |
| dGPS | Differential Global Positioning System |
| DSRC | Dedicated Short-Range Communications |
| FoV | Field of View |
| GNN | Global Nearest Neighbor |
| GNSS | Global Navigation Satellite System |
| GPS | Global Positioning System |
| GPU | Graphics Processing Unit |
| HAD | Highly Automated Driving |
| HD map | High Definition map |
| I2V | Infrastructure to Vehicle |
| IMM filter | Interacting Multiple Model filter |
| IMU | Inertial Measurement Unit |
| ITS | Intelligent Transportation System |
| JVM | Java Virtual Machine |
| LiDAR | Light Detection and Ranging (sensor) |
| MAC | Medium Access Control (sublayer of the data link layer in the OSI networking model) |
| NTP | Network Time Protocol |
| PPS | Pulse Per Second (synchronization signal) |
| PTP | Precision Time Protocol |
| R&D | Research and Development |
| RAID | Redundant Array of Independent Disks |
| S2T | Central tracking, aka. sensor-to-track fusion or source-to-track fusion |
| SciL | Scenario in the Loop |
| SUID | System-wide Unique Identifier |
| T2T | Track-to-track fusion |
| TCP | Transmission Control Protocol |
| UTM | Universal Transverse Mercator |
| UUID | Universally Unique Identifier |
| V2V | Vehicle to Vehicle |
| WGS84 | World Geodetic System 1984 |
| WiFi | Wireless Fidelity (network protocol family) |
| YOLO | You Only Look Once (object detection system) |
References
- Krämmer, A.; Schöller, C.; Gulati, D.; Knoll, A. Providentia—A large scale sensing system for the assistance of autonomous vehicles. arXiv 2019, arXiv:1906.06789. [Google Scholar]
- Gabb, M.; Digel, H.; Muller, T.; Henn, R.W. Infrastructure-supported perception and track-level fusion using edge computing. In Proceedings of the IEEE Intelligent Vehicles Symposium, Paris, France, 9–12 June 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 1739–1745. [Google Scholar] [CrossRef]
- Tsukada, M.; Oi, T.; Kitazawa, M.; Esaki, H. Networked roadside perception units for autonomous driving. Sensors 2020, 20, 5320. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Liao, X.; Zhao, X.; Han, K.; Tiwari, P.; Barth, M.J.; Wu, G. A Digital Twin Paradigm: Vehicle-to-Cloud Based Advanced Driver Assistance Systems. In Proceedings of the IEEE Vehicular Technology Conference, Antwerp, Belgium, 25–28 May 2020. [Google Scholar] [CrossRef]
- Kobayashi, H.; Han, K.; Kim, B. Vehicle-to-Vehicle Message Sender Identification for Co-Operative Driver Assistance Systems. In Proceedings of the 2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Han, K.; Shou, Z.; Tiwari, P.; Hansen, J.H. Sensor Fusion of Camera and Cloud Digital Twin Information for Intelligent Vehicles. arXiv 2020, arXiv:2007.04350. [Google Scholar]
- Shan, M.; Narula, K.; Wong, R.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of cooperative perception: Safety and robustness in connected and automated vehicle operations. Sensors 2020, 21, 200. [Google Scholar] [CrossRef] [PubMed]
- Tihanyi, V.; Tettamanti, T.; Csonthó, M.; Eichberger, A.; Ficzere, D.; Gangel, K.; Hörmann, L.B.; Klaffenböck, M.A.; Knauder, C.; Luley, P.; et al. Motorway Measurement Campaign to Support R&D Activities in the Field of Automated Driving Technologies. Sensors 2021, 21, 2169. [Google Scholar] [CrossRef] [PubMed]
- Szalay, Z.; Szalai, M.; Tóth, B.; Tettamanti, T.; Tihanyi, V. Proof of concept for Scenario-in-the-Loop (SciL) testing for autonomous vehicle technology. In Proceedings of the 2019 IEEE International Conference on Connected Vehicles and Expo (ICCVE), Graz, Austria, 4–8 November 2019; pp. 1–5. [Google Scholar]
- Szalay, Z.; Hamar, Z.; Simon, P. A multi-layer autonomous vehicle and simulation validation ecosystem axis: Zalazone. In International Conference on Intelligent Autonomous Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 954–963. [Google Scholar]
- Zhao, M.; Mammeri, A.; Boukerche, A. Distance measurement system for smart vehicles. In Proceedings of the 2015 7th International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 27–29 July 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Sakurada, K.; Kawaguchi, N. Reflectance Intensity Assisted Automatic and Accurate Extrinsic Calibration of 3D LiDAR and Panoramic Camera Using a Printed Chessboard. Remote Sens. 2017, 9, 851. [Google Scholar] [CrossRef] [Green Version]
- Daniilidis, K. Hand-Eye Calibration Using Dual Quaternions. Int. J. Robot. Res. 1999, 18, 286–298. [Google Scholar] [CrossRef]
- Vyacheslav, I.V.; Illya, E.K.; Irina, P.C. Accurate Time Synchronization for Digital Communication Network. In Proceedings of the 2007 17th International Crimean Conference—Microwave Telecommunication Technology, Sevastopol, Ukraine, 10–14 September 2007; pp. 259–260. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef] [Green Version]
- Yilmaz, A.; Javed, O.; Shah, M. Object tracking: A survey’ACM computing surveys (CSUR). ACM Comput. Surv. 2006, 38, 13. [Google Scholar] [CrossRef]
- Labbe, R. Kalman and bayesian filters in python. Chap 2014, 7, 246. [Google Scholar]
- Chong, C.Y. Tracking and data fusion: A handbook of algorithms (bar-shalom, y. et al; 2011) [bookshelf]. IEEE Control. Syst. Mag. 2012, 32, 114–116. [Google Scholar]
- Blom, H.; Bar-Shalom, Y. The interacting multiple model algorithm for systems with Markovian switching coefficients. IEEE Trans. Autom. Control 1988, 33, 780–783. [Google Scholar] [CrossRef]
- Blackman, S.S.; Popoli, R. Design and Analysis of Modern Tracking Systems; Artech House Radar Library: Boston, MA, USA; London, UK, 1999. [Google Scholar]
- Munkres, J. Algorithms for the assignment and transportation problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- Abd El-Gawad, M.A.; Elsharief, M.; Kim, H. A comparative experimental analysis of channel access protocols in vehicular networks. IEEE Access 2019, 7, 149433–149443. [Google Scholar] [CrossRef]
- Dinar, A.E.; Merabet, B.; Ghouali, S. NTP Server Clock Adjustment with Chrony. In Applications of Internet of Things; Springer: Berlin/Heidelberg, Germany, 2021; pp. 177–185. [Google Scholar]
- Szalai, M.; Varga, B.; Tettamanti, T.; Tihanyi, V. Mixed reality test environment for autonomous cars using Unity 3D and SUMO. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; pp. 73–78. [Google Scholar] [CrossRef]
- Xu, K.; Zhang, G.; Liu, S.; Fan, Q.; Sun, M.; Chen, H.; Chen, P.Y.; Wang, Y.; Lin, X. Adversarial T-shirt! Evading Person Detectors in A Physical World. arXiv 2020, arXiv:1910.11099. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chessboard Pose Index | RMSE [px] | Chessboard Size |
|---|---|---|
| 1 | 1.66 | The chessboard pattern is 6 × 8 with a cell size of 140 × 140 mm |
| 2 | 1.30 | |
| 3 | 1.49 | |
| 4 | 0.87 | |
| 5 | 0.87 | |
| The whole image set | 1.28 |
| Real-Time | Playback |
|---|---|
| Pace: always jump forward to the most recent available timestep. | Pace: always read input data with a natural pace: for every second passed in consumed timesteps, a second should pass in reality. |
| Missing data: our requirement for fused tracks is to disappear when no data is received from any of the sensors, i.e., to artificially advance fusion in time and “wind down” within a dozen simulated steps. | Missing data: when no data is received from any of the sensors, we want to freeze everything as it is and to not step the time forward. Empty (0-detection) data can clear the scene, but no-data should freeze it. |
| Fusion restart: not required, since real time can flow only forward. | Fusion restart: required when rewinding. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tihanyi, V.; Rövid, A.; Remeli, V.; Vincze, Z.; Csonthó, M.; Pethő, Z.; Szalai, M.; Varga, B.; Khalil, A.; Szalay, Z. Towards Cooperative Perception Services for ITS: Digital Twin in the Automotive Edge Cloud. Energies 2021, 14, 5930. https://doi.org/10.3390/en14185930
Tihanyi V, Rövid A, Remeli V, Vincze Z, Csonthó M, Pethő Z, Szalai M, Varga B, Khalil A, Szalay Z. Towards Cooperative Perception Services for ITS: Digital Twin in the Automotive Edge Cloud. Energies. 2021; 14(18):5930. https://doi.org/10.3390/en14185930
Chicago/Turabian StyleTihanyi, Viktor, András Rövid, Viktor Remeli, Zsolt Vincze, Mihály Csonthó, Zsombor Pethő, Mátyás Szalai, Balázs Varga, Aws Khalil, and Zsolt Szalay. 2021. "Towards Cooperative Perception Services for ITS: Digital Twin in the Automotive Edge Cloud" Energies 14, no. 18: 5930. https://doi.org/10.3390/en14185930
APA StyleTihanyi, V., Rövid, A., Remeli, V., Vincze, Z., Csonthó, M., Pethő, Z., Szalai, M., Varga, B., Khalil, A., & Szalay, Z. (2021). Towards Cooperative Perception Services for ITS: Digital Twin in the Automotive Edge Cloud. Energies, 14(18), 5930. https://doi.org/10.3390/en14185930