
Transition Modeling for Low Pressure Turbines Using Computational Fluid Dynamics Driven Machine Learning

 , ,
, , 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Transition Modeling
2.1. Laminar Kinetic Energy Model
2.2. Proposed Model Formulation
2.2.1. Scientific Ideology
2.2.2. Non-Dimensional Pi Groups
3. Machine Learning Framework
3.1. Advantages
3.2. Methodology
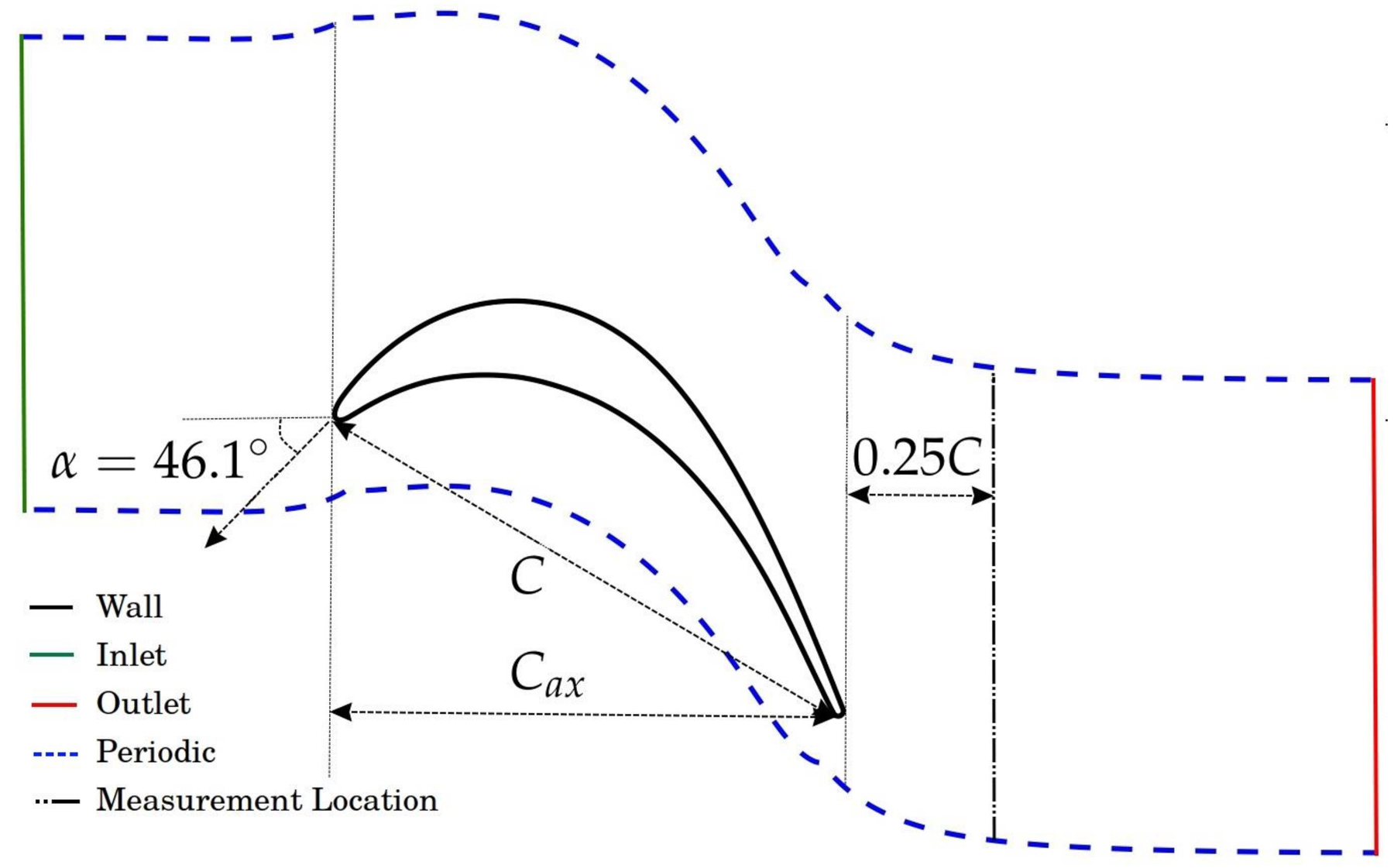
4. Numerical Setup and Configuration
5. Results and Discussions
5.1. Single-Objective Optimization
5.1.1. Baseline RANS Calculation
5.1.2. Cost Function
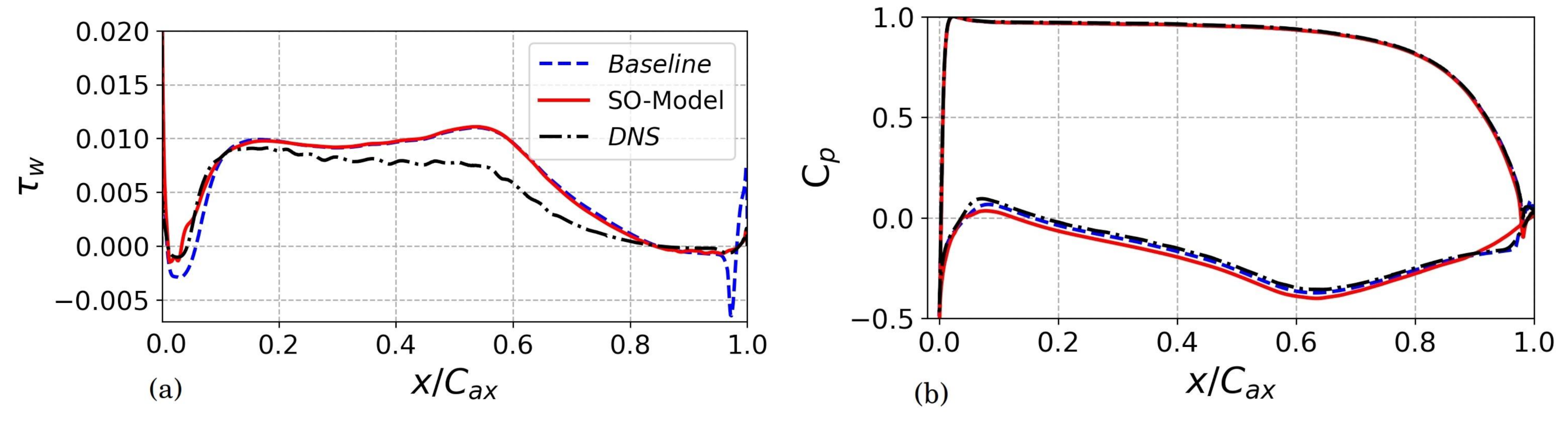
5.1.3. Analysis of the SO-Model
5.2. Multi-Objective Optimization
5.2.1. Cost Functions
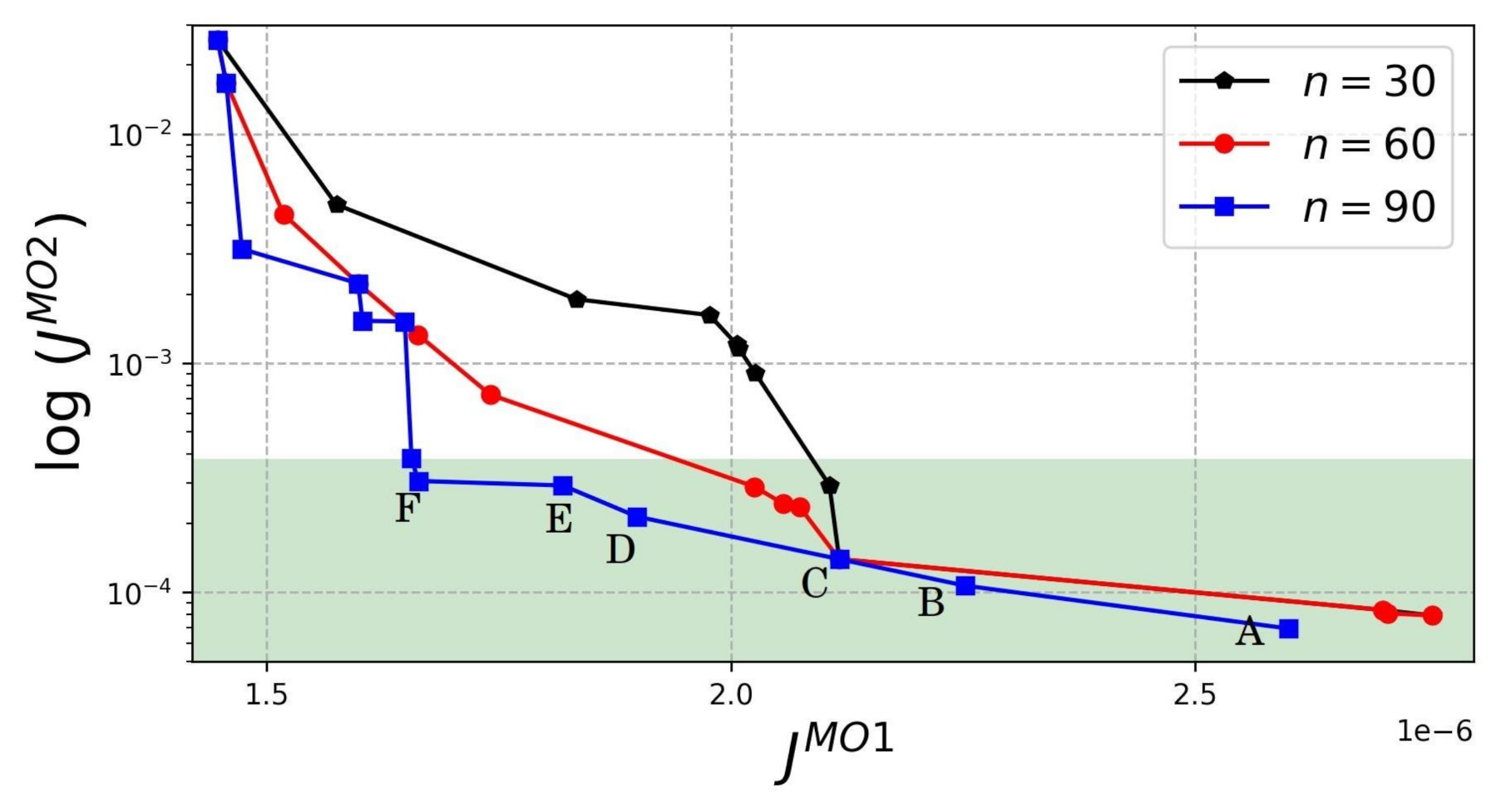
5.2.2. Pareto Analysis
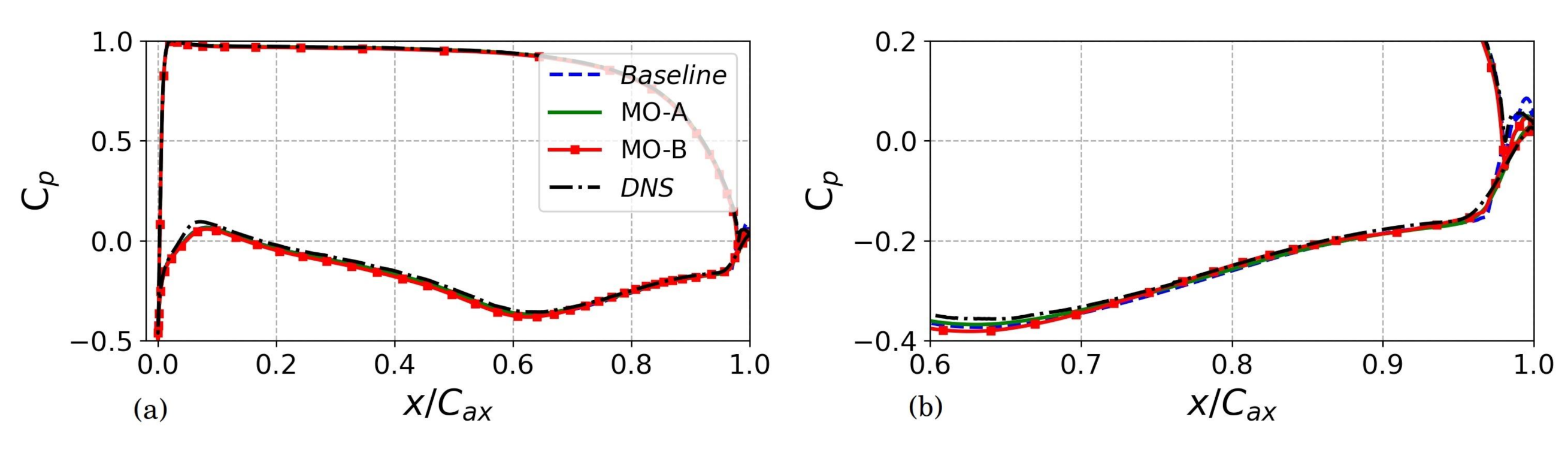
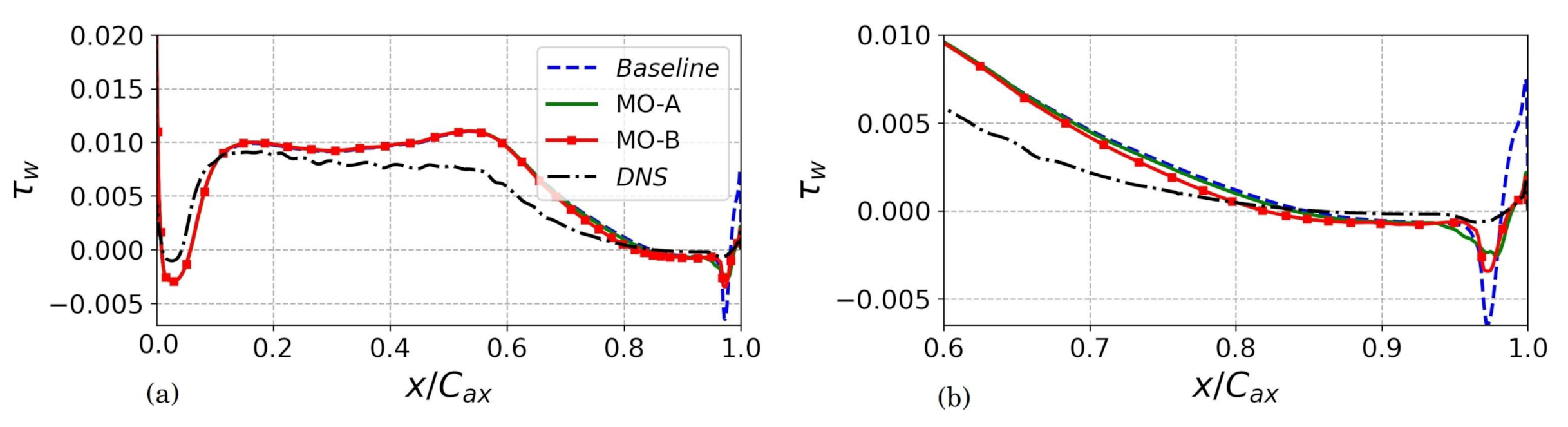
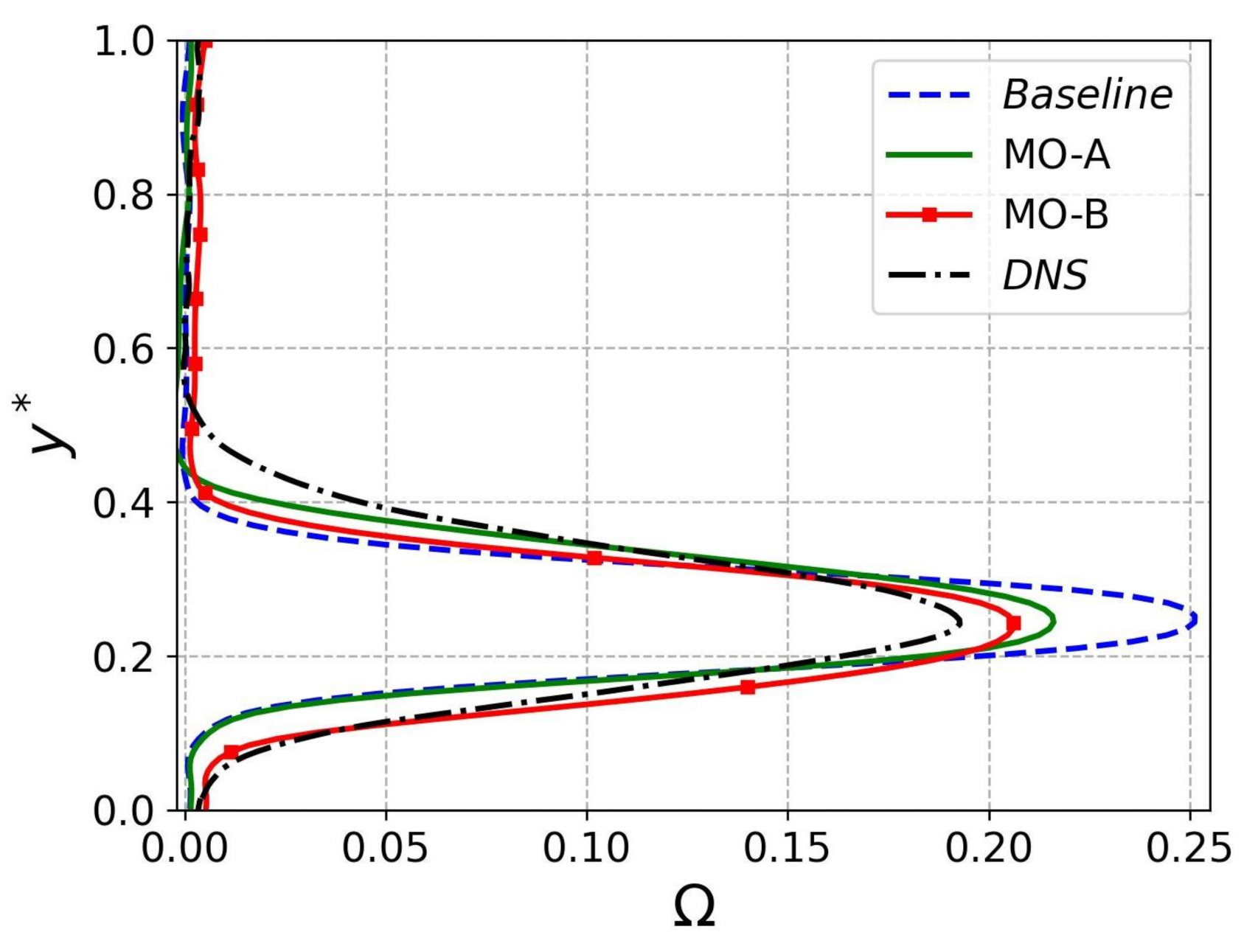
5.2.3. Analysis of Solutions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CFD | Computational fluid dynamics |
| DNS | Direct numerical simulation |
| EARSM | Explicit algebraic Reynolds stress model |
| GEP | Gene expression programming |
| LES | Large eddy simulation |
| LKE | Laminar kinetic energy |
| LPT | Low pressure turbine |
| MO | Multi-objective |
| RANS | Reynolds averaged Navier–Stokes |
| SO | Single-objective |
| TE | Trailing edge |
| TKE | Turbulent kinetic energy |
References
- Michelassi, V.; Chen, L.W.; Pichler, R.; Sandberg, R.D. Compressible Direct Numerical Simulation of Low Pressure Turbine—Part II: Effect of Inflow Disturbances. J. Turbomach. 2015, 137, 71005. [Google Scholar] [CrossRef]
- Hodson, H.P.; Howell, R.J. Bladerow Interactions, Transition, and High-Lift Aerofoils in Low-Pressure Turbines. Annu. Rev. Fluid Mech. 2005, 37, 71–98. [Google Scholar] [CrossRef]
- Mayle, R.E. The Role of Laminar-Turbulent Transition in Gas Turbine Engines. J. Turbomach. 1991, 113, 509–537. [Google Scholar] [CrossRef]
- Schlichting, H.; Gersten, K. Boundary Layer Theory; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Stieger, R.D.; Hodson, H.P. The Transition Mechanism of Highly-Loaded LP Turbine Blades. J. Turbomach. 2004, 126, 536–543. [Google Scholar] [CrossRef]
- Denton, J.D. The 1993 IGTI Scholar Lecture: Loss Mechanisms in Turbomachines. J. Turbomach. 1993, 115, 621. [Google Scholar] [CrossRef]
- Michelassi, V.; Chen, L.; Pichler, R.; Sandberg, R.; Bhaskaran, R. High-Fidelity Simulations of Low-Pressure Turbines: Effect of Flow Coefficient and Reduced Frequency on Losses. J. Turbomach. 2016, 138, 111006. [Google Scholar] [CrossRef]
- Dick, E.; Kubacki, S. Transition Models for Turbomachinery Boundary Layer Flows: A Review. Int. J. Turbomach. Propuls. Power 2017, 2, 4. [Google Scholar] [CrossRef] [Green Version]
- Menter, F.R.; Langtry, R.B.; Likki, S.R.; Suzen, Y.B.; Huang, P.G. A Correlation-Based Transition Model Using Local Variables—Part I: Model Formulation. J. Turbomach. 2006, 128, 413–422. [Google Scholar] [CrossRef]
- Walters, D.K.; Cokljat, D. A Three-Equation Eddy-Viscosity Model for Reynolds-Averaged Navier-Stokes Simulations of Transitional Flow. J. Fluids Eng. 2008, 130, 121401. [Google Scholar] [CrossRef]
- Pacciani, R.; Marconcini, M. Calculation of High-Lift Cascades in Low Pressure Turbine Conditions Using a Three-Equation Model. J. Turbomach. 2011, 133, 1–9. [Google Scholar] [CrossRef]
- Brunton, S.L.; Noack, B.R.; Koumoutsakos, P. Machine Learning for Fluid Mechanics. Annu. Rev. Fluid Mech. 2020, 52, 477–508. [Google Scholar] [CrossRef] [Green Version]
- Duraisamy, K.; Spalart, P.R.; Rumsey, C.L. Status, Emerging Ideas and Future Directions of Turbulence Modeling Research in Aeronautics; Technical Report November; NASA: Hampton, VA, USA, 2017.
- Medic, G. Impact of Vision 2030 on CFD Practices in Propulsion Industry. In Proceedings of the AIAA Aviation 2019 Forum, Dallas, TX, USA, 17–21 June 2019. [Google Scholar]
- Runchal, A.K.; Rao, M.M. CFD of the Future: Year 2025 and Beyond. In 50 Years of CFD in Engineering Sciences; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Ling, J.; Jones, R.; Templeton, J. Machine learning strategies for systems with invariance properties. J. Comput. Phys. 2016, 318, 22–35. [Google Scholar] [CrossRef] [Green Version]
- Milani, P.M.; Ling, J.; Eaton, J.K. Turbulent Scalar Flux in Inclined Jets in Crossflow: Counter Gradient Transport and Deep Learning Modelling. J. Fluid Mech. 2021, 906. [Google Scholar] [CrossRef]
- Milani, P.M.; Ling, J.; Saez-Mischlich, G.; Bodart, J.; Eaton, J.K. A Machine Learning Approach for Determining the Turbulent Diffusivity in Film Cooling Flows. J. Turbomach. 2018, 140, 021006. [Google Scholar] [CrossRef] [Green Version]
- Milani, P.M.; Ling, J.; Eaton, J.K. Physical Interpretation of Machine Learning Models Applied to Film Cooling Flows. J. Turbomach. 2019, 141, 011004. [Google Scholar] [CrossRef]
- Duraisamy, K.; Iaccarino, G.; Xiao, H. Turbulence Modeling in the Age of Data. Annu. Rev. Fluid Mech. 2019, 53, 357–377. [Google Scholar] [CrossRef] [Green Version]
- Duraisamy, K. Machine Learning Augmented Reynolds-Averaged & Large eddy Simulation Models of Turbulence. arXiv 2021, arXiv:2009.10675v3. [Google Scholar]
- Ferreira, C. Gene Expression Programming: A New Adaptive Algorithm for Solving Problems. Complex Syst. 2001, 13, 87–129. [Google Scholar]
- Weatheritt, J.; Sandberg, R.D. A Novel Evolutionary Algorithm Applied to Algebraic Modifications of the RANS Stress-Strain Relationship. J. Comput. Phys. 2016, 325, 22–37. [Google Scholar] [CrossRef]
- Akolekar, H.D.; Sandberg, R.D.; Hutchins, N.; Michelassi, V.; Laskowski, G. Machine-Learnt Turbulence Closures for Low Pressure Turbines with Unsteady Inflow Conditions. J. Turbomach. 2019, 141, 101009. [Google Scholar] [CrossRef]
- Akolekar, H.D.; Weatheritt, J.; Hutchins, N.; Sandberg, R.D.; Laskowski, G.; Michelassi, V. Development and Use of Machine-Learnt Algebraic Reynolds Stress Models for Enhanced Prediction of Wake Mixing in Low-Pressure Turbines. J. Turbomach. 2019, 141, 041010. [Google Scholar] [CrossRef]
- Parneix, S.; Laurence, D.; Durbin, P.A. A Procedure for Using DNS Databases. J. Fluids Eng. 1998, 120, 40–46. [Google Scholar] [CrossRef]
- Akolekar, H.D.; Zhao, Y.; Sandberg, R.D.; Hutchins, N.; Michelassi, V. Turbulence Model Development for Low & High Pressure Turbines Using a Machine Learning Approach. In Proceedings of the 24th International Society of Air Breathing Engines, Canberra, Australia, 22–27 September 2019. [Google Scholar]
- Weatheritt, J.; Pichler, R.; Sandberg, R.D.; Laskowski, G.; Michelassi, V. Machine Learning for Turbulence Model Development Using a High Fidelity HPT Cascade Simulation. In Proceedings of the Turbo Expo: Power for Land, Sea, and Air, Charlotte, NC, USA, 26–30 June 2017. [Google Scholar]
- Zhao, Y.; Akolekar, H.D.; Weatheritt, J.; Michelassi, V.; Sandberg, R.D. RANS Turbulence Model Development Using CFD-Driven Machine Learning. J. Comput. Phys. 2020, 411, 109413. [Google Scholar] [CrossRef] [Green Version]
- Akolekar, H.D.; Zhao, Y.; Sandberg, R.D.; Pacciani, R. Integration of Machine Learning and Computational Fluid Dynamics to Develop Turbulence Models for Improved Low Pressure Turbine Wake Mixing Predictions. J. Turbomach. 2021, 143, 121001. [Google Scholar] [CrossRef]
- Waschkowski, F.; Zhao, Y.; Sandberg, R.; Klewicki, J. Multi-Objective CFD-Driven Development of Coupled Turbulence Closure Models. arXiv 2021, arXiv:2105.06225. [Google Scholar]
- Zafar, M.I.; Xiao, H.; Choudhari, M.M.; Li, F.; Chang, C.L.; Paredes, P.; Venkatachari, B. Convolutional Neural Network for Transition Modeling Based on Linear Stability Theory. Phys. Rev. Fluids 2020, 5, 1–15. [Google Scholar] [CrossRef]
- Yang, M.; Xiao, Z. Improving the k-ω-γ-Ar Transition Model by the Field Inversion and Machine Learning Framework. Phys. Fluids 2020, 32, 064101. [Google Scholar]
- White, F.M. Fluid Mechanics; McGraw Hill: New York, NY, USA, 2017. [Google Scholar]
- Mayle, R.; Schulz, A. The Path to Predicting Bypass Transition. J. Turbomach. 1997, 119, 405–411. [Google Scholar] [CrossRef]
- Lardeau, S.; Leschziner, M.A.; Li, N. Modelling Bypass Transition with Low-Reynolds-Number Nonlinear Eddy-Viscosity Closure. Flow Turbul. Combust. 2004, 73, 49–76. [Google Scholar] [CrossRef]
- Schmitt, G. About Boussinesq’s Turbulent Viscosity Hypothesis: Historical Remarks and a Direct Evaluation of its Validity. Comptes Rendus Mec. Elsevier Masson 2007, 335, 617–627. [Google Scholar] [CrossRef] [Green Version]
- Pacciani, R.; Marconcini, M.; Arnone, A.; Bertini, F. An Assessment of the Laminar Kinetic Energy Concept for the Prediction of High-Lift, Low-Reynolds Number Cascade Flows. Proc. Inst. Mech. Eng. Part A J. Power Energy 2011, 225, 995–1003. [Google Scholar] [CrossRef]
- Pacciani, R.; Marconcini, M.; Arnone, A.; Bertini, F. Predicting High-Lift Low-Pressure Turbine Cascades Flow Using Transition-Sensitive Turbulence Closures. J. Turbomach. 2014, 136, 051007. [Google Scholar] [CrossRef]
- Akolekar, H.D. Turbulence Model Development and Implementation For Low Pressure Turbines Using a Machine Learning Approach. Ph.D. Thesis, University of Melbourne, Melbourne, Australia, 2019. [Google Scholar]
- Arnone, A.; Liou, M.S.; Povinelli, L.A. Navier-Stokes Solution of Transonic Cascade Flows Using Non-Periodic C-Type Grids. J. Propuls. Power 1992, 8, 410–417. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akolekar, H.D.; Waschkowski, F.; Zhao, Y.; Pacciani, R.; Sandberg, R.D. Transition Modeling for Low Pressure Turbines Using Computational Fluid Dynamics Driven Machine Learning. Energies 2021, 14, 4680. https://doi.org/10.3390/en14154680
Akolekar HD, Waschkowski F, Zhao Y, Pacciani R, Sandberg RD. Transition Modeling for Low Pressure Turbines Using Computational Fluid Dynamics Driven Machine Learning. Energies. 2021; 14(15):4680. https://doi.org/10.3390/en14154680
Chicago/Turabian StyleAkolekar, Harshal D., Fabian Waschkowski, Yaomin Zhao, Roberto Pacciani, and Richard D. Sandberg. 2021. "Transition Modeling for Low Pressure Turbines Using Computational Fluid Dynamics Driven Machine Learning" Energies 14, no. 15: 4680. https://doi.org/10.3390/en14154680
APA StyleAkolekar, H. D., Waschkowski, F., Zhao, Y., Pacciani, R., & Sandberg, R. D. (2021). Transition Modeling for Low Pressure Turbines Using Computational Fluid Dynamics Driven Machine Learning. Energies, 14(15), 4680. https://doi.org/10.3390/en14154680