
A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting



Abstract
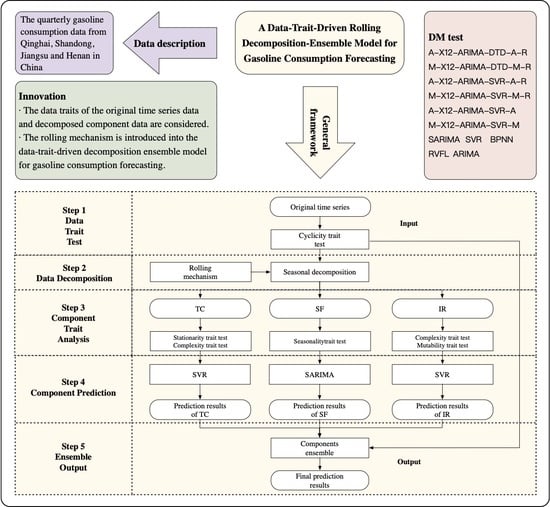
1. Introduction
2. Methodology Formulation
2.1. General Frameworks of the Proposed Methodology
2.2. Data-Trait-Driven Data Decomposition
2.2.1. Cyclicity Trait Test
2.2.2. Seasonal Decomposition (SD)
2.3. Data-Trait-Driven Component Prediction
2.4. Data-Trait-Driven Ensemble Output
2.5. Rolling Decomposition and Forecasting Mechanism
3. Empirical Analysis
3.1. Experimental Design
3.2. Experimental Results Analysis
3.2.1. Data Trait Test
3.2.2. Data Decomposition Analysis
3.2.3. Component Trait Analysis
3.2.4. Prediction Performance Analysis
3.3. Further Discussions
3.4. Summary
4. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, W.; He, T.T.; Cho, S. Government involvement in banking systems and economic growth: A comparison across countries. Econ. Political Stud. 2019, 7, 35–65. [Google Scholar] [CrossRef]
- Matas, A.; Raymond, J.L. Economic development and changes in car ownership patterns. In Proceedings of the European Transport Conference, Strasbourg, France, 18–20 September 2006. [Google Scholar] [CrossRef]
- Melikoglu, M. Demand forecast for road transportation fuels including gasoline, diesel, LPG, bioethanol and biodiesel for Turkey between 2013 and 2023. Renew. Energy 2014, 64, 164–171. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, B. Forecasting crude oil price with an autoregressive integrated moving average (ARIMA) model. Adv. Intell. Syst. Comput. 2014, 211, 275–286. [Google Scholar] [CrossRef]
- Akpinar, M.; Yumusak, N. Forecasting household natural gas consumption with ARIMA model: A case study of removing cycle. In Proceedings of the 2013 7th International Conference on Application of Information and Communication Technologies (AICT), Allahabad, India, 24–16 October 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Kaboudan, M.A. Short-term compumetric forecast of crude oil prices. IFAC Proc. Vol. 2001, 34, 365–370. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, N.; Zhao, J. Combined forecast model of refined oil demand based on grey theory. Intell. Inf. Process. Trust. Comput. Int. Symp. 2010, 60, 145–148. [Google Scholar] [CrossRef]
- Liang, T.; Chai, J.; Zhang, Y.; Zhang, Z. Refined analysis and prediction of natural gas consumption in China. J. Manag. Sci. Eng. 2019, 4, 91–104. [Google Scholar] [CrossRef]
- Iqbal, B.A.; Sami, S.; Turay, A. Determinants of China’s outward foreign direct investment in Asia: A dynamic panel data analysis. Econ. Political Stud. 2019, 7, 66–86. [Google Scholar] [CrossRef]
- Bhutto, A.W.; Bazmi, A.A.; Qureshi, K.; Harijan, K.; Karim, S.; Ahmad, M.S. Forecasting the consumption of gasoline in transport sector in Pakistan based on ARIMA model. Environ. Prog. Sustain. Energy 2017, 36, 1490–1497. [Google Scholar] [CrossRef]
- Chen, Y.; Zou, Y.; Zhou, Y.; Zhang, C. Multi-step-ahead crude oil price forecasting based on grey wave forecasting method. Procedia Comput. Sci. 2016, 91, 1050–1056. [Google Scholar] [CrossRef]
- Kapoguzov, E.A.; Chupin, R.I.; Kharlamova, M.S. Scenarios for Russian petrochemical industry development under sanctions: Forecast of automobile gasoline market based on the Bayesian approach. Becmнuк Пepмcкoгo yнuвepcumema Cepuя Экoнoмuкa 2017, 12, 421–436. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, C. An online-learning-based evolutionary many-objective algorithm. Inf. Sci. 2020, 509, 1–21. [Google Scholar] [CrossRef]
- Dulebenets, M. A novel memetic algorithm with a deterministic parameter control for efficient berth scheduling at marine container terminals. Marit. Bus. Rev. 2017, 2, 302–330. [Google Scholar] [CrossRef]
- D’Angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A proposal for distinguishing between bacterial and viral meningitis using genetic programming and decision trees. Soft Comput. 2019, 23, 11775–11791. [Google Scholar] [CrossRef]
- Villada, F.; Arroyave, D.; Villada, M. Oil price forecast using artificial neural networks. Inf. Tecnológica 2014, 25, 145–154. [Google Scholar] [CrossRef]
- Wanto, A.; Hayadi, B.; Subekti, P.; Sudrajat, D. Forecasting the export and import volume of crude oil, oil products and gas using ANN. J. Phys. Conf. Ser. 2019, 1255, 12–16. [Google Scholar] [CrossRef]
- Tang, L.; Wu, Y.; Yu, L. A non-iterative decomposition-ensemble learning paradigm using RVFL network for crude oil price forecasting. Appl. Soft Comput. 2017, 70, 1097–1108. [Google Scholar] [CrossRef]
- Xin, J.H. Crude oil prices forecasting: Time series vs. SVR models. J. Int. Technol. Inf. Manag. 2018, 27, 25–42. [Google Scholar]
- Zohrevand, N.; Sadeghifar, M.; Hassan, S.; Younes, B. Comparison of SVR and GARCH models in forecasting oil price volatility. J. Neurocytol. 2012, 19, 807–819. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Pang, Y.; Xu, W.; Yu, L.; Ma, J.; Lai, K.K.; Wang, S.; Xu, S. Forecasting the crude oil spot price by wavelet neural networks using OECD petroleum inventory levels. New Math. Nat. Comput. 2011, 07, 281–297. [Google Scholar] [CrossRef]
- Kazemi, A.; Ganjavi, H.S.; Menhaj, M.; Taghizadeh, M. A multi-level artificial neural network for gasoline demand forecasting of Iran. In Proceedings of the 2009 Second International Conference on Computer and Electrical Engineering, Dubai, United Arab Emirates, 28–30 December 2009; pp. 61–64. [Google Scholar] [CrossRef]
- Xie, W.; Yu, L.; Xu, S.; Wang, S. A new method for crude oil price forecasting based on support vector machines. In Notes in Computer Science. ICCS 2006: Computational Science—ICCS 2006; Alexandrov, V.N., van Albada, G.D., Sloot, P.M.A., Dongarra, J., Eds.; Springer: Heidelberg/Berlin, Germany, 2006; pp. 444–451. [Google Scholar] [CrossRef]
- Kulkarni, S.; Haidar, I. Forecasting model for crude oil price using artificial neural networks and commodity futures prices. Int. J. Comput. Sci. Inf. Secur. 2009, 2, 6–13. [Google Scholar]
- Yu, L.; Zhao, Y.; Tang, L.; Yang, Z. Online big data-driven oil consumption forecasting with Google trends. Int. J. Forecast. 2019, 35, 213–223. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Ahmed, A. Forecasting crude oil price volatility in India using a hybrid ANN-GARCH model. Int. J. Bus. Forecast. Mark. Intell. 2018, 4, 446–457. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Day ahead price forecasting of electricity markets by a mixed data model and hybrid forecast method. Int. J. Electr. Power Energy Syst. 2008, 30, 533–546. [Google Scholar] [CrossRef]
- Wang, M.; Zhao, L.; Du, R.; Wang, C.; Chen, L.; Tian, L.; Stanley, H. A novel hybrid method of forecasting crude oil prices using complex network science and artificial intelligence algorithms. Appl. Energy 2018, 220, 480–495. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L.; Wu, J. A hybrid grid-GA-based LSSVR learning paradigm for crude oil price forecasting. Neural Comput. Appl. 2016, 27, 2193–2215. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, Y.; Cheng, C.; Xu, W. A neural network-based ensemble prediction using PMRS and ECM. In Proceedings of the 2014 47th Hawaii International Conference on System Science, Waikoloa, HI, USA, 6–9 January 2004; pp. 1335–1343. [Google Scholar] [CrossRef]
- Babazadeh, R.; Abbasi, M. A hybrid ARIMA-ANN approach for optimum estimation and forecasting of gasoline consumption. RAIRO Oper. Res. 2017, 51, 719–728. [Google Scholar] [CrossRef]
- Li, X.; Yu, L.; Tang, L.; Dai, W. Coupling firefly algorithm and least squares support vector regression for crude oil price forecasting. In Proceedings of the 2013 Sixth International Conference on Business Intelligence and Financial Engineering (BIFE), HangZhou China, 14–16 November 2013; pp. 80–83. [Google Scholar] [CrossRef]
- Hacer, Y.; Aykut, E.; Halil, E.; Hamit, E. Optimizing the monthly crude oil price forecasting accuracy via bagging ensemble models. J. Econ. Int. Financ. 2015, 7, 127–136. [Google Scholar] [CrossRef]
- Gabralla, L.; Abraham, A. Prediction of oil prices using bagging and random subspace. Adv. Intell. Syst. Comput. 2014, 303, 342–354. [Google Scholar] [CrossRef]
- Assaad, M.; Bone, R.; Cardot, H. A new Boosting algorithm for improved time-series forecasting with recurrent neural networks. Inf. Fusion 2008, 9, 41–55. [Google Scholar] [CrossRef]
- Barrow, D.; Crone, S. A comparison of AdaBoost algorithms for time series forecast combination. Int. J. Forecast. 2016, 32, 1103–1119. [Google Scholar] [CrossRef]
- Gumus, M.; Kiran, M.S. Crude oil price forecasting using XGBoost. In Proceedings of the 2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–7 October 2017; pp. 1100–1103. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, T.; Shi, J.; Qian, Z. A CEEMDAN and XGBoost-based approach to crude oil prices. Complexity 2019, 2019, 1–15. [Google Scholar] [CrossRef]
- Zhukov, A.; Tomin, N.; Kurbatsky, V.; Sidoro, Y.D.; Panasetsky, D.; Foley, A. Ensemble methods of classification for power systems security assessment. Appl. Comput. Inform. 2019, 15, 45–53. [Google Scholar] [CrossRef]
- Zhukov, A.V.; Sidorov, D.N.; Foley, A.M. Random forest based approach for concept drift handling. In Communications in Computer and Information Science; Ignatov, D., Ed.; Springer: Berlin, Germany, 2016; p. 661. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Qu, H.; Tang, G.; Lao, Q. Oil price forecasting based on EMD and BP_AdaBoost neural network. Open, J. Stat. 2018, 8, 660–669. [Google Scholar] [CrossRef][Green Version]
- Su, M.; Zhang, Z.; Zhu, Y.; Zha, D. Data-driven natural gas spot price forecasting with least squares regression Boosting algorithm. Energies 2019, 12, 1094–1106. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Lai, K.K. Forecasting crude oil price with an EMD-based neural network ensemble learning paradigm. Energy Economics 2008, 30, 2623–2635. [Google Scholar] [CrossRef]
- Wei, Y.; Sun, S.; Ma, J.; Wang, S.; Lai, K.K. A decomposition clustering ensemble learning approach for forecasting foreign exchange rates. J. Manag. Sci. Eng. 2019, 4, 45–54. [Google Scholar] [CrossRef]
- He, K.; Yu, L.; Lai, K.K. Crude oil price analysis and forecasting using wavelet decomposed ensemble model. Energy 2012, 46, 564–574. [Google Scholar] [CrossRef]
- Tang, L.; Dai, W.; Yu, L. A novel CEEMD-based EELM ensemble learning paradigm for crude oil price forecasting. Int. J. Inf. Technol. Decis. Mak. 2015, 14, 141–149. [Google Scholar] [CrossRef]
- Tang, L.; Wu, Y.; Yu, L. A randomized-algorithm-based decomposition-ensemble learning methodology for energy price forecasting. Energy 2018, 15, 526–538. [Google Scholar] [CrossRef]
- Tang, L.; Yu, L.; He, K. A novel data-characteristic-driven modeling methodology for nuclear energy consumption forecasting. Appl. Energy 2014, 128, 1–14. [Google Scholar] [CrossRef]
- Wang, S.; Yu, L.; Tang, L.; Wang, S. A novel seasonal decomposition based least squares support vector regression ensemble learning approach for hydropower consumption forecasting in China. Energy 2011, 36, 6542–6554. [Google Scholar] [CrossRef]
- Tang, L.; Wang, S.; He, K.J.; Wang, S.Y. A novel mode-characteristic-based decomposition ensemble model for nuclear energy consumption forecasting. Ann. Oper. Res. 2015, 234, 111–132. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Z.; Tang, L. A decomposition–ensemble model with data-characteristic-driven reconstruction for crude oil price forecasting. Appl. Energy 2015, 156, 251–267. [Google Scholar] [CrossRef]
- Xie, G.; Zhang, N.; Wang, S. Data characteristic analysis and model selection for container throughput forecasting within a decomposition-ensemble methodology. Transp. Res. Part E Logist. Transp. Rev. 2017, 108, 160–178. [Google Scholar] [CrossRef]
- Tang, L.; Yu, L.; Liu, F.; Xu, W.X. An integrated data characteristic testing scheme for complex time series data exploration. Int. J. Inf. Technol. Decis. Mak. 2013, 12, 491–521. [Google Scholar] [CrossRef]
- Hart, T.; Coulson, T.; Trathan, P.N. Time series analysis of biologging data: Autocorrelation reveals periodicity of diving behavior in macaroni penguins. Anim. Behav. 2010, 79, 845–855. [Google Scholar] [CrossRef]
- Bruce, A.G.; Jurke, S.R. Non-Gaussian seasonal adjustment: X-12-ARIMA versus robust structural models. J. Forecast. 1996, 15, 305–328. [Google Scholar] [CrossRef]
- Zheng, J.; Cheng, J.; Yang, Y. Partly ensemble empirical mode decomposition: An improved noise-assisted method for eliminating mode mixing. Signal Process. 2014, 96, 362–374. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Inclan, C.; Tiao, G.C. Use of cumulative sums of squares for retrospective detection of changes of variance. Publ. Am. Stat. Assoc. 1994, 89, 913–923. [Google Scholar] [CrossRef]
- Chow, G.C. Tests of equality between sets of coefficients in two linear regressions. Economics 1960, 28, 591–605. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control, 2nd ed.; Holden Day: San Francisco, CA, USA, 1990. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory, 1st ed.; Springer: New York, NY, USA, 1995. [Google Scholar] [CrossRef]
- Vapnik, V.; Chervonenkis, A. The uniform convergence of frequencies of the appearance of events to their probabilitie. Dokl. Akad. Nauk SSSR 1968, 181, 781–783. [Google Scholar]
- Yu, L.; Ma, Y.; Ma, M. An effective rolling decomposition-ensemble model for gasoline consumption forecasting. Energy 2021, 222, 119869. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Series | Lag Period | Correlation Coefficient | Statistics | Prob. | Time Series |
|---|---|---|---|---|---|
| Qinghai | 4 | 0.738 | 70.728 | 0.000 | Qinghai |
| Henan | 4 | 0.812 | 39.229 | 0.000 | Henan |
| Shandong | 4 | 0.735 | 68.684 | 0.000 | Shandong |
| Jiangsu | 4 | 0.736 | 61.159 | 0.000 | Jiangsu |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| A-X12-ARIMA-SVR-A | 0.23269 | 5.48188 | 0.42857 |
| M-X12-ARIMA-SVR-M | 0.30811 | 6.72903 | 0.42857 |
| A-X12-ARIMA-SVR-A-R | 0.05063 | 1.20584 | 1.00000 |
| M-X12-ARIMA-SVR-M-R | 0.05323 | 1.30603 | 1.00000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| A-X12-ARIMA-SVR-A | 0.01350 | 4.32930 | 0.57143 |
| M-X12-ARIMA-SVR-M | 0.01393 | 4.40868 | 0.42857 |
| A-X12-ARIMA-SVR-A-R | 0.00832 | 2.64259 | 1.00000 |
| M-X12-ARIMA-SVR-M-R | 0.00873 | 2.73930 | 1.00000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| A-X12-ARIMA-SVR-A | 0.48476 | 138.39043 | 0.71429 |
| M-X12-ARIMA-SVR-M | 0.48202 | 150.08664 | 0.57143 |
| A-X12-ARIMA-SVR-A-R | 0.17552 | 34.80237 | 1.00000 |
| M-X12-ARIMA-SVR-M-R | 0.07182 | 21.38547 | 1.00000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| A-X12-ARIMA-SVR-A | 0.15223 | 44.59431 | 0.42857 |
| M-X12-ARIMA-SVR-M | 0.15893 | 47.27334 | 0.42857 |
| A-X12-ARIMA-SVR-A-R | 0.08419 | 22.41964 | 0.85714 |
| M-X12-ARIMA-SVR-M-R | 0.07750 | 20.53079 | 1.00000 |
| Qinghai | Shandong | Henan | Jiangsu | |
|---|---|---|---|---|
| Prob. | 0.2277 | 0.2597 | 0.9995 | 0.9217 |
| Qinghai | Shandong | Henan | Jiangsu | |
|---|---|---|---|---|
| PE values | 0.0720 | 0.3694 | 0.0000 | 0.3636 |
| Time Series | Lag Period | Correlation Coefficient | Statistics | Prob. |
|---|---|---|---|---|
| Qinghai | 2 | −0.871 | 24.590 | 0.000 |
| Henan | 4 | 0.859 | 49.274 | 0.000 |
| Shandong | 4 | 0.803 | 32.427 | 0.000 |
| Jiangsu | 2 | −0.929 | 27.877 | 0.000 |
| Qinghai | Shandong | Henan | Jiangsu | |
|---|---|---|---|---|
| PE values | 0.6035 | 0.5823 | 0.6276 | 0.6156 |
| Province | Suspect Points | ICSS Test | Chow Test | Mutability |
|---|---|---|---|---|
| Qinghai | 2015Q2 | 2.546 (0.005) | 2.788 (0.003) | √ |
| Shandong | 2012Q3 | 1.803 (0.036) | 2.527 (0.006) | √ |
| Henan | - | - | - | × |
| Jiangsu | - | - | - | × |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| ARIMA | 0.0931 | 1.9145 | 0.8571 |
| BPNN | 0.0538 | 1.2299 | 0.8571 |
| SVR | 0.1321 | 3.5025 | 0.5714 |
| RVFL | 0.2249 | 4.8609 | 0.8571 |
| SARIMA | 0.0714 | 1.8084 | 1.0000 |
| A-X12-ARIMA-SVR-A | 0.2327 | 5.4819 | 0.4286 |
| M-X12-ARIMA-SVR-M | 0.3081 | 6.7290 | 0.4286 |
| A-X12-ARIMA-SVR-A-R | 0.0506 | 1.2058 | 1.0000 |
| M-X12-ARIMA-SVR-M-R | 0.0532 | 1.3060 | 1.0000 |
| A-X12-ARIMA-DTD-A-R | 0.0461 | 1.1035 | 1.0000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| ARIMA | 0.0118 | 3.7188 | 0.5714 |
| BPNN | 0.0087 | 2.9310 | 0.7143 |
| SVR | 0.0083 | 3.0276 | 1.0000 |
| RVFL | 0.0260 | 9.6263 | 0.7143 |
| SARIMA | 0.0220 | 7.2544 | 0.5714 |
| A-X12-ARIMA-SVR-A | 0.0135 | 4.3293 | 0.5714 |
| M-X12-ARIMA-SVR-M | 0.0139 | 4.4087 | 0.4286 |
| A-X12-ARIMA-SVR-A-R | 0.0083 | 2.6426 | 1.0000 |
| M-X12-ARIMA-SVR-M-R | 0.0087 | 2.7393 | 1.0000 |
| A-X12-ARIMA-DTD-A-R | 0.0078 | 2.6302 | 1.0000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| ARIMA | 0.1827 | 32.6324 | 1.0000 |
| BPNN | 0.1239 | 25.6547 | 1.0000 |
| SVR | 0.2470 | 60.3990 | 0.8571 |
| RVFL | 0.4914 | 125.4011 | 0.8571 |
| SARIMA | 0.1916 | 43.4215 | 1.0000 |
| A-X12-ARIMA-SVR-A | 0.4848 | 138.3904 | 0.7143 |
| M-X12-ARIMA-SVR-M | 0.4820 | 150.0866 | 0.5714 |
| A-X12-ARIMA-SVR-A-R | 0.1755 | 34.8024 | 1.0000 |
| M-X12-ARIMA-SVR-M-R | 0.0718 | 21.3855 | 1.0000 |
| M-X12-ARIMA-DTD-M-R | 0.0601 | 15.2771 | 1.0000 |
| Forecasting Models | MAPE | RMSE | Dstat |
|---|---|---|---|
| ARIMA | 0.1602 | 46.3598 | 0.8571 |
| BPNN | 0.0969 | 32.4150 | 1.0000 |
| SVR | 0.1136 | 32.7750 | 0.4286 |
| RVFL | 0.4933 | 167.9224 | 0.7143 |
| SARIMA | 0.1109 | 32.5558 | 0.8571 |
| A-X12-ARIMA-SVR-A | 0.1522 | 44.5943 | 0.4286 |
| M-X12-ARIMA-SVR-M | 0.1589 | 47.2733 | 0.4286 |
| A-X12-ARIMA-SVR-A-R | 0.0842 | 22.4196 | 0.8571 |
| M-X12-ARIMA-SVR-M-R | 0.0775 | 20.5308 | 1.0000 |
| M-X12-ARIMA-DTD-M-R | 0.0621 | 16.9129 | 1.0000 |
| Tested Models | Benchmark Models | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A-X12-ARIMA-SVR-A-R | M-X12-ARIMA-SVR-M-R | A-X12-ARIMA-SVR-A | M-X12-ARIMA-SVR-M | SARIMA | SVR | BPNN | RVFL | ARIMA | |
| A-X12-ARIMA-DTD-A-R | −0.795 (0.212) | −0.554 (0.291) | −2.723 (0.003) | −3.587 (0.000) | −1.142 (0.127) | −2.232 (0.013) | −0.296 (0.382) | −2.636 (0.004) | −1.643 (0.051) |
| A-X12-ARIMA-SVR-A-R | −0.234 (0.409) | −2.763 (0.003) | −3.641 (0.000) | −0.956 (0.169) | −2.304 (0.011) | −0.053 (0.480) | −2.571 (0.005) | −1.390 (0.082) | |
| M-X12-ARIMA-SVR-M-R | −2.571 (0.005) | −3.412 (0.000) | −0.696 (0.242) | −1.955 (0.025) | 0.133 (0.448) | −2.699 (0.004) | −1.077 (0.140) | ||
| A-X12-ARIMA-SVR-A | −6.743 (0.000) | 2.403 (0.008) | 2.528 (0.006) | 2.579 (0.005) | 0.397 (0.345) | 2.312 (0.010) | |||
| M-X12-ARIMA-SVR-M | 3.264 (0.001) | 3.948 (0.000) | 3.426 (0.000) | 1.204 (0.115) | 3.168 (0.000) | ||||
| SARIMA | −1.513 (0.066) | 1.044 (0.149) | −2.392 (0.008) | −0.259 (0.397) | |||||
| SVR | 1.948 (0.026) | −1.068 (0.142) | 1.451 (0.074) | ||||||
| BPNN | −2.617 (0.004) | −3.018 (0.001) | |||||||
| RVFL | 2.414 (0.008) | ||||||||
| Tested Models | Benchmark Models | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A-X12-ARIMA-SVR-A-R | M-X12-ARIMA-SVR-M-R | A-X12-ARIMA-SVR-A | M-X12-ARIMA-SVR-M | SARIMA | SVR | BPNN | RVFL | ARIMA | |
| A-X12-ARIMA-DTD-A-R | −0.046 (0.480) | −0.474 (0.319) | −3.074 (0.001) | −3.022 (0.001) | −2.337 (0.010) | −0.386 (0.348) | −0.265 (0.394) | −1.749 (0.040) | −1.295 (0.097) |
| A-X12-ARIMA-SVR-A-R | −2.131 (0.017) | −2.751 (0.003) | −2.660 (0.004) | −2.395 (0.008) | −0.481 (0.316) | −0.277 (0.390) | −1.747 (0.040) | −1.282 (0.100) | |
| M-X12-ARIMA-SVR-M-R | −2.647 (0.004) | −2.572 (0.005) | −2.366 (0.009) | −0.352 (0.363) | −0.185 (0.425) | −1.738 (0.041) | −1.161 (0.123) | ||
| A-X12-ARIMA-SVR-A | −0.929 (0.176) | −1.780 (0.038) | 1.283 (0.100) | 1.252 (0.106) | −1.462 (0.072) | 0.805 (0.209) | |||
| M-X12-ARIMA-SVR-M | −1.729 (0.042) | 1.285 (0.099) | 1.315 (0.093) | −1.449 (0.074) | 0.919 (0.179) | ||||
| SARIMA | 2.358 (0.009) | 2.286 (0.011) | −0.690 (0.245) | 1.826 (0.034) | |||||
| SVR | 0.101 (0.156) | −1.731 (0.042) | −0.651 (0.258) | ||||||
| BPNN | −1.853 (0.032) | −0.991 (0.161) | |||||||
| RVFL | 1.618 (0.053) | ||||||||
| Tested Models | Benchmark Models | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A-X12-ARIMA-SVR-A-R | M-X12-ARIMA-SVR-M-R | A-X12-ARIMA-SVR-A | M-X12-ARIMA-SVR-M | SARIMA | SVR | BPNN | RVFL | ARIMA | |
| M-X12-ARIMA-DTD-M-R | −3.174 (0.001) | −2.079 (0.017) | −2.471 (0.006) | −2.606 (0.005) | −2.396 (0.008) | −2.235 (0.009) | −1.286 (0.096) | −1.454 (0.061) | −4.010 (0.000) |
| A-X12-ARIMA-SVR-A-R | 3.475 (0.000) | −2.400 (0.008) | −2.549 (0.004) | −1.273 (0.092) | −1.918 (0.019) | 1.134 (0.129) | −1.366 (0.076) | 0.344 (0.367) | |
| M-X12-ARIMA-SVR-M-R | −2.470 (0.006) | −2.607 (0.003) | −2.347 (0.007) | −2.214 (0.008) | −0.592 (0.271) | −1.436 (0.059) | −2.531 (0.004) | ||
| A-X12-ARIMA-SVR-A | −2.689 (0.003) | 2.466 (0.007) | 2.358 (0.009) | 2.449 (0.007) | 0.244 (0.405) | 2.372 (0.009) | |||
| M-X12-ARIMA-SVR-M | 2.612 (0.005) | 2.558 (0.005) | 2.578 (0.005) | 0.473 (0.319) | 2.515 (0.006) | ||||
| SARIMA | −1.733 (0.031) | 1.789 (0.037) | −1.274 (0.092) | 1.135 (0.127) | |||||
| SVR | 1.811 (0.035) | −1.124 (0.100) | 1.594 (0.056) | ||||||
| BPNN | −1.396 (0.081) | −1.669 (0.042) | |||||||
| RVFL | 1.366 (0.085) | ||||||||
| Tested Models | Benchmark Models | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| A-X12-ARIMA-SVR-A-R | M-X12-ARIMA-SVR-M-R | A-X12-ARIMA-SVR-A | M-X12-ARIMA-SVR-M | SARIMA | SVR | BPNN | RVFL | ARIMA | |
| M-X12-ARIMA-DTD-M-R | −1.976 (0.022) | −1.939 (0.020) | −3.079 (0.001) | −3.002 (0.001) | −1.590 (0.054) | −2.452 (0.005) | −1.775 (0.034) | −1.393 (0.079) | −1.637 (0.039) |
| A-X12-ARIMA-SVR-A-R | 1.701 (0.045) | −2.534 (0.004) | −2.512 (0.004) | −1.420 (0.057) | −1.629 (0.038) | −1.287 (0.095) | −1.388 (0.079) | −1.561 (0.051) | |
| M-X12-ARIMA-SVR-M-R | −2.761 (0.002) | −2.712 (0.002) | −1.494 (0.066) | −1.907 (0.029) | −1.448 (0.061) | −1.390 (0.079) | −1.596 (0.055) | ||
| A-X12-ARIMA-SVR-A | −2.010 (0.014) | 1.041 (0.149) | 1.988 (0.023) | 1.747 (0.040) | −1.298 (0.097) | −0.105 (0.386) | |||
| M-X12-ARIMA-SVR-M | 1.173 (0.121) | 2.189 (0.014) | 1.970 (0.024) | −1.281 (0.093) | 0.053 (0.480) | ||||
| SARIMA | −0.021 (0.429) | 0.013 (0.496) | −1.373 (0.076) | −1.603 (0.055) | |||||
| SVR | 0.113 (0.456) | −1.351 (0.073) | −0.801 (0.212) | ||||||
| BPNN | −1.358 (0.075) | −0.824 (0.164) | |||||||
| RVFL | 1.331 (0.092) | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, L.; Ma, Y. A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting. Energies 2021, 14, 4604. https://doi.org/10.3390/en14154604
Yu L, Ma Y. A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting. Energies. 2021; 14(15):4604. https://doi.org/10.3390/en14154604
Chicago/Turabian StyleYu, Lean, and Yueming Ma. 2021. "A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting" Energies 14, no. 15: 4604. https://doi.org/10.3390/en14154604
APA StyleYu, L., & Ma, Y. (2021). A Data-Trait-Driven Rolling Decomposition-Ensemble Model for Gasoline Consumption Forecasting. Energies, 14(15), 4604. https://doi.org/10.3390/en14154604