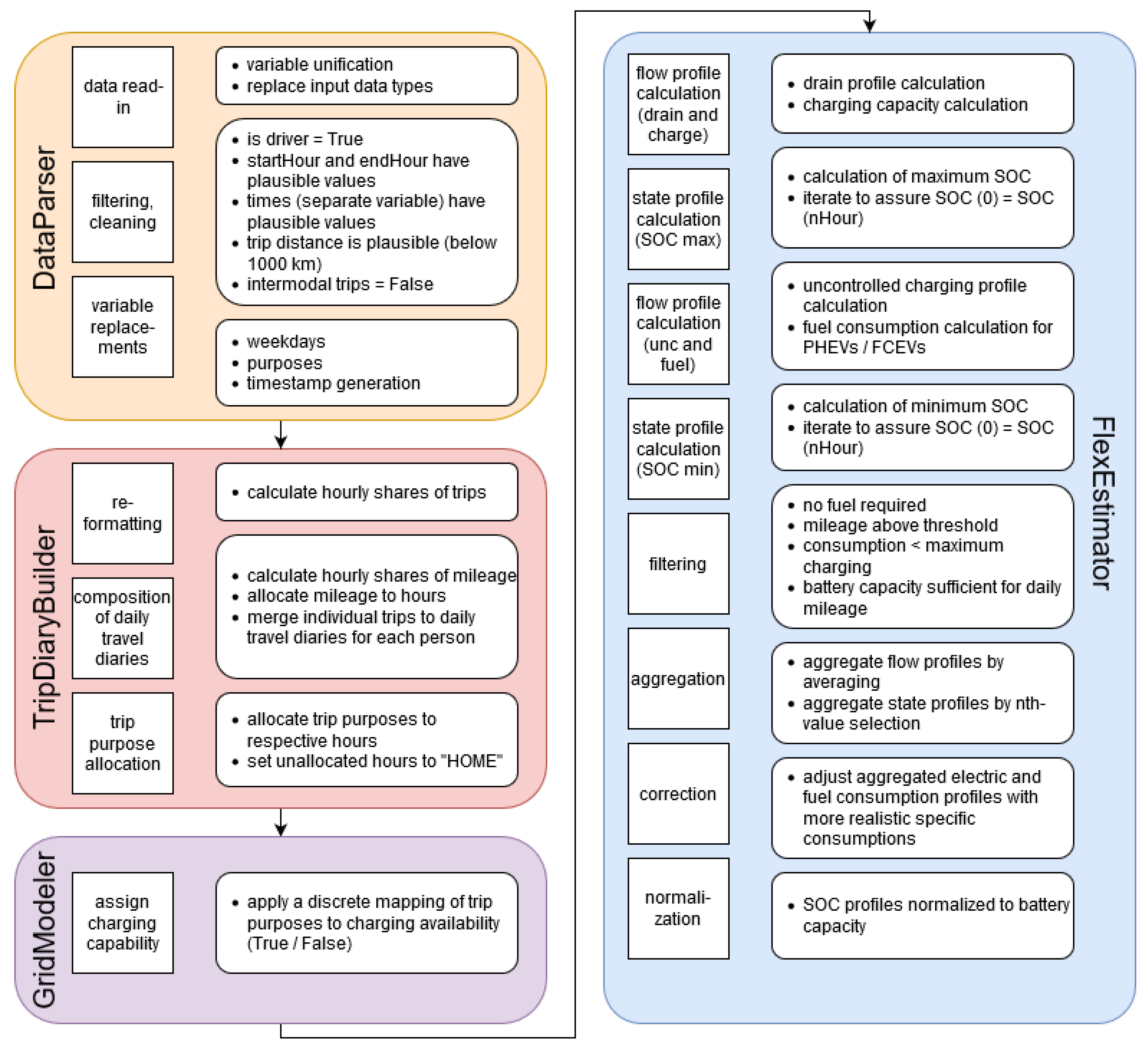
Appendix B. Detailed Description of Trip Diary Composition
In both MiD data sets, no explicit timestamp information for the survey time May 2016 to October 2017 is available, so we synthesize timestamps from the variables ST_JAHR, ST_WOCHE, ST_WOTAG, W_SZS and W_SZM. We use calendaric weeks to determine the month of the survey day. Timestamp for start and end are written to two separate columns. Afterwards, the end timestamp is updated to account for overnight trips where the arrival day is different from departure day. We then transform the data set, allocating trip distances to hours and potentially splitting the trip distances of reported trips to multiple hours. This follows the steps
The trip duration is calculated using the timestamp information
It is determined if the trip ends in the same hour as it starts
For 1-h trips the share of the start hour is set to one, for multi-hour trips the remaining minutes of the first trip hour are divided by the trip duration to determine the share of the first hour
For 1-h-trips, the end hour share is set to 0. For multi-hour trips, the end hour share is calculated by dividing the minute attribute of the end timestamp by the duration.
The number of full travel hours between start and end hours is calculated. Currently end-timestamps at exactly the full hour are allocated to fullHour trips if the trip duration exceeds 60 min. Thus, a trip starting at 11:30 and ending at 13:00 has a start hour share of 33%, an end hour share of 0%, one full hour of travel and a full hour share of 67%.
Table A2.
Exemplary trip timestamps and respective conversions to shares of end and starting hours as well as number and trip length of full hours in the trip. The first row shows a single-hour trip, the second row a single-hour trip starting in a different hour than ending and the third row a multiple-hour trip.
Table A2.
Exemplary trip timestamps and respective conversions to shares of end and starting hours as well as number and trip length of full hours in the trip. The first row shows a single-hour trip, the second row a single-hour trip starting in a different hour than ending and the third row a multiple-hour trip.
| Timestamp Start | Timestamp End | Start Hour Share | End Hour Share | No. of Full Hours | Full Hour Trip Length |
|---|
| 2017-04-25 11:10:00 | 2017-04-25 11:35:00 | 1 | 0 | 0 | 0 |
| 2017-02-08 10:30:00 | 2017-02-08 11:05:00 | 0.86 | 0.14 | 0 | 0 |
| 2017-06-16 11:15:00 | 2017-06-16 13:50:00 | 0.29 | 0.32 | 2 | 110 |
After this procedure we created six additional variables for the same number of observations. However, due to formatting of input data, some inconsistencies still occur after this trip length allocation that have to be filtered out. Specifically, there are trips where the share of the start hour is not 1 but the share of end hour and the number of full hour trips are both equal to 0. This occurs for three trips due to a trip duration being 0 () resulting in a start hour share of NA or because of one overnight trip where the variable W_FOLGETAG was falsely set to 1. These three trips are filtered out. The clean base trip data set now consists of 414,683 trip entries.
Table A3.
Exemplary output (first 9 observations) of daily travel diaries as input for VencoPy.
Table A3.
Exemplary output (first 9 observations) of daily travel diaries as input for VencoPy.
| hhPersonID | tripStartWeekday | tripWeight | ...7 | 8 | 9 | 10 | 11... | ...17 | 18 | 19... |
|---|
| 10001952 | TUE | 0.49 | 0.00 | 0.00 | 0.00 | 0.00 | 9.50 | 0.00 | 9.50 | 0.00 |
| 10002161 | WED | 0.24 | 0.00 | 9.50 | 0.00 | 8.14 | 1.36 | 0.00 | 0.00 | 0.00 |
| 10002341 | SAT | 0.11 | 0.00 | 6.18 | 1.43 | 0.00 | 0.00 | 0.00 | 0.00 | 6.18 |
| 10002422 | THU | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | 2.38 | 0.00 | 36.27 | 20.73 |
| 10003121 | SAT | 2.02 | 0.00 | 0.00 | 0.00 | 0.00 | 34.83 | 0.00 | 0.00 | 0.00 |
| 10003122 | SAT | 1.26 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 28.50 | 0.00 | 0.00 |
| 10003123 | SAT | 2.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 28.50 | 0.00 | 0.00 |
| 10003124 | SAT | 2.24 | 0.00 | 0.00 | 0.00 | 0.00 | 34.83 | 34.83 | 69.67 | 0.00 |
| 10003852 | TUE | 0.35 | 4.75 | 1.90 | 2.85 | 0.00 | 1.90 | 0.00 | 0.00 | 0.00 |
Since at the end of the parsing a data set is needed with explicit information of distance travelled in each hour, a new dataframe is created with one column for each hour and with the same ID column (Household-person ID) as the base data set. From a software-design point of view, this is performance intensive since the operation has to be applied to each row but to various columns. In the current version, this is solved by a callable class FillHourValues() and a function applying that class to each row of the empty dataframe. The callable class obtains all required attributes from the clean base trip data set.
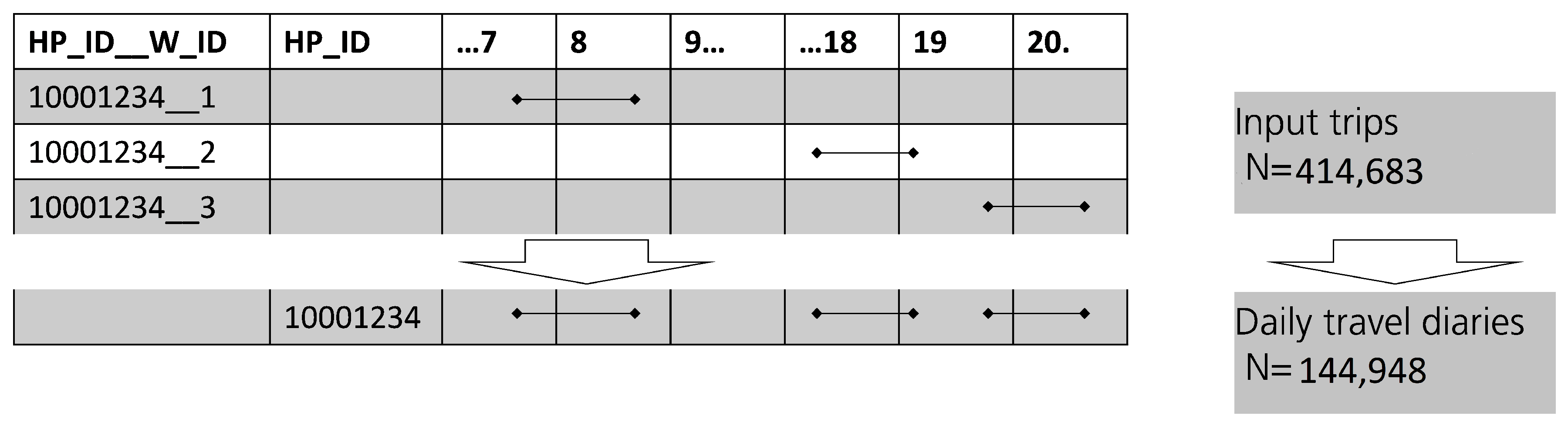
Merging individual trips to daily travel diaries In the next step, the dataset is merged as shown in
Figure A1. Thereby, individual trips of the same household and person are merged together to one travel diary with its respective unique ID.
Figure A1.
Merging of individual trips to travel diaries.
Figure A1.
Merging of individual trips to travel diaries.
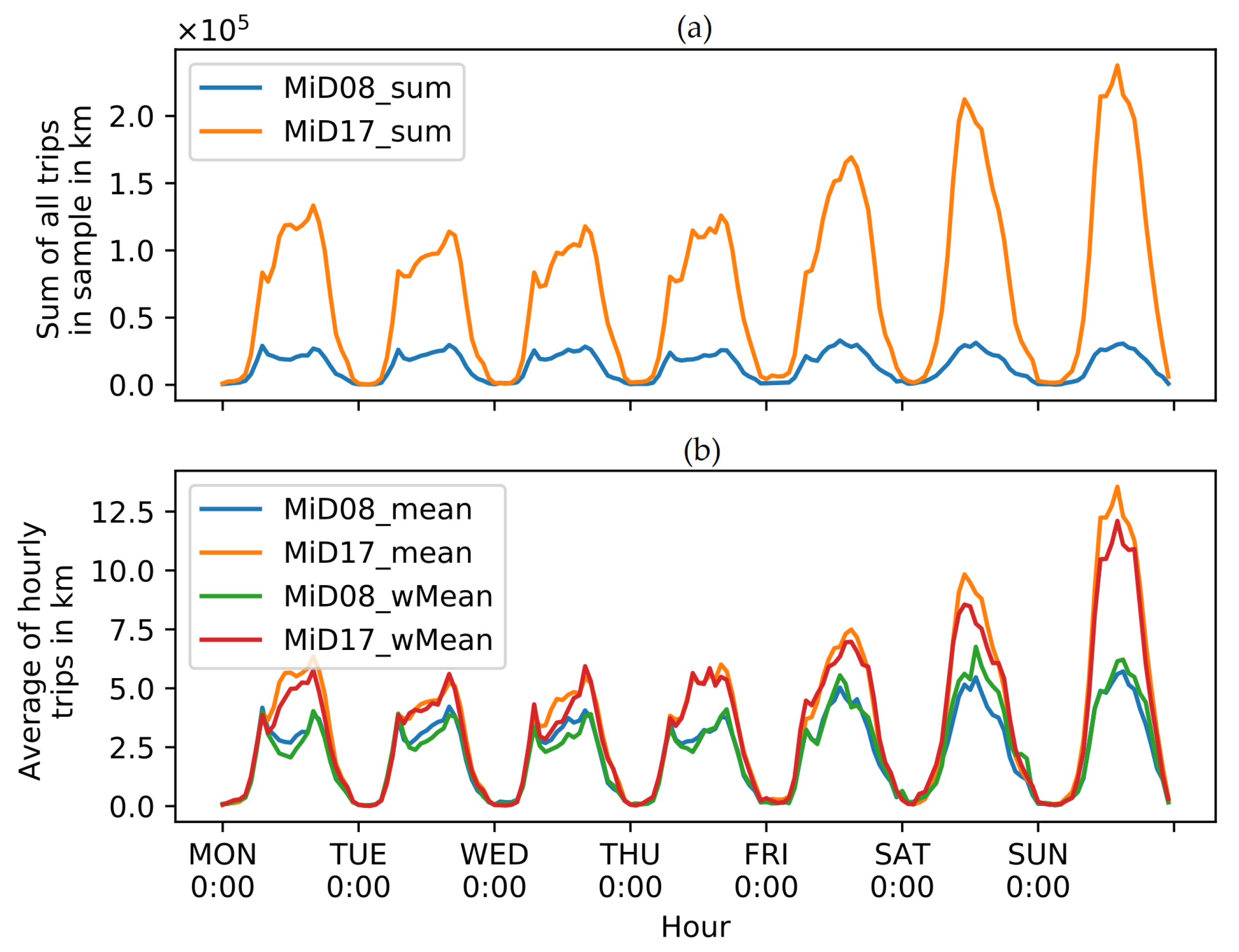
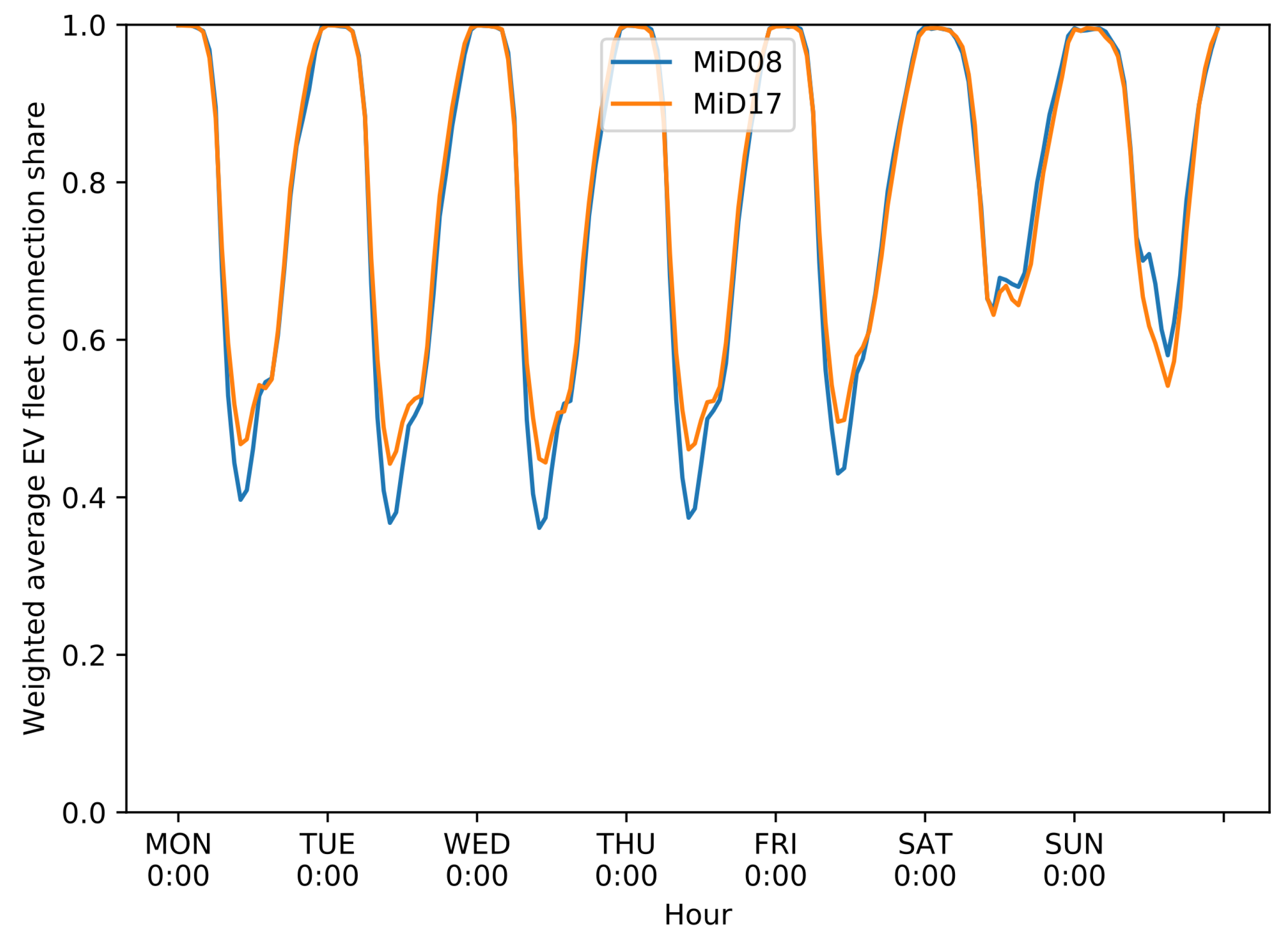
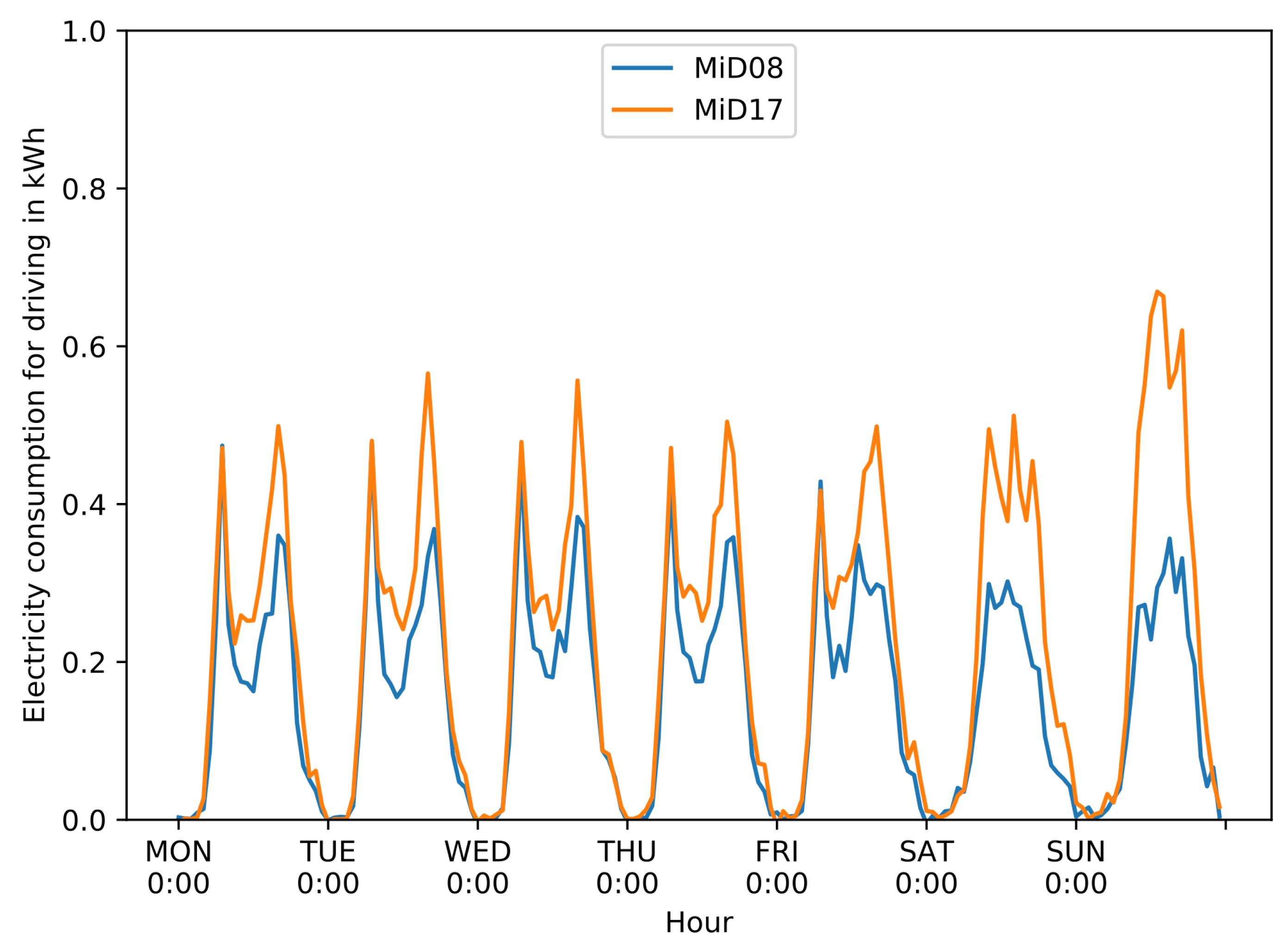
The daily trip diary now has 105,453 observations with the access to all geographical, temporal, technical and socio-economic information from the person and household data set through merging by the identifier. For the weekday and the weights, this is done by default in the flexibility estimation for further analysis and scaling. The data set is then written in a .csv-file as an input into VencoPy:
The MiD2017 B2 trip data set contains a variable
zweck, German for ‘purpose’, that differentiates the following trip purposes as shown in
Table A4.
Table A4.
Trip purpose descriptions in the data set MiD2017 and respective mappings to VencoPy internal trip categories.
Table A4.
Trip purpose descriptions in the data set MiD2017 and respective mappings to VencoPy internal trip categories.
| Variable Value | German Description | English Description | Aggregated Identifier |
|---|
| 1 | Erreichen des Arbeitsplatzes | Reaching work | WORK |
| 2 | dienstlich/geschäftlich | Work trip | WORK |
| 3 | Erreichen dAusbildungsstätte/Schule | Reaching educational facility | SCHOOL |
| 4 | Einkauf | Shopping | SHOPPING |
| 5 | private Erledigung | Private errand | SHOPPING |
| 6 | Bringen/Holen/Begleiten von Personen | Bringing, fetching and accompanying persons | LEISURE |
| 7 | Freizeitaktivität | Leisure | LEISURE |
| 8 | nach Hause | Trip home | HOME |
| 9 | Rückweg vom vorherigen Weg | Trip back from trip before | HOME |
| 10 | anderer Zweck | Other purpose | OTHER |
| 99 | keine Angabe | Not available | NA |
From the trip purposes we are able to learn the location category of a vehicle during the course of the day. This information can, together with assumptions of location-specific charging infrastructure distribution, yield the information whether a charging station is available or not at a respective location category e.g., HOME. We introduce an additional purpose ‘DRIVING’ to account for hours where vehicle holders are mainly driving and thus cannot charge. The filling of trip purposes follows these steps
Take the trip distance diary data set and replace all non-zero entries with ‘DRIVING’.
We are foremost interested in setting inter-trip hours to specific purposes, and thus we have to go through each diary ID but also through each trip of the diary in its original data set (W_ID) in order to extract and correctly allocate the purpose.
All trips are assumed to start at HOME; thus, for the first trip, the hours from beginning to the hour of the trip are filled with ‘HOME’. If the trip starts in the first half of an hour, that hour is not filled with ‘HOME’; if it starts in the second half, it is. If it starts exactly at HH:30, this hour is set to ‘DRIVING’.
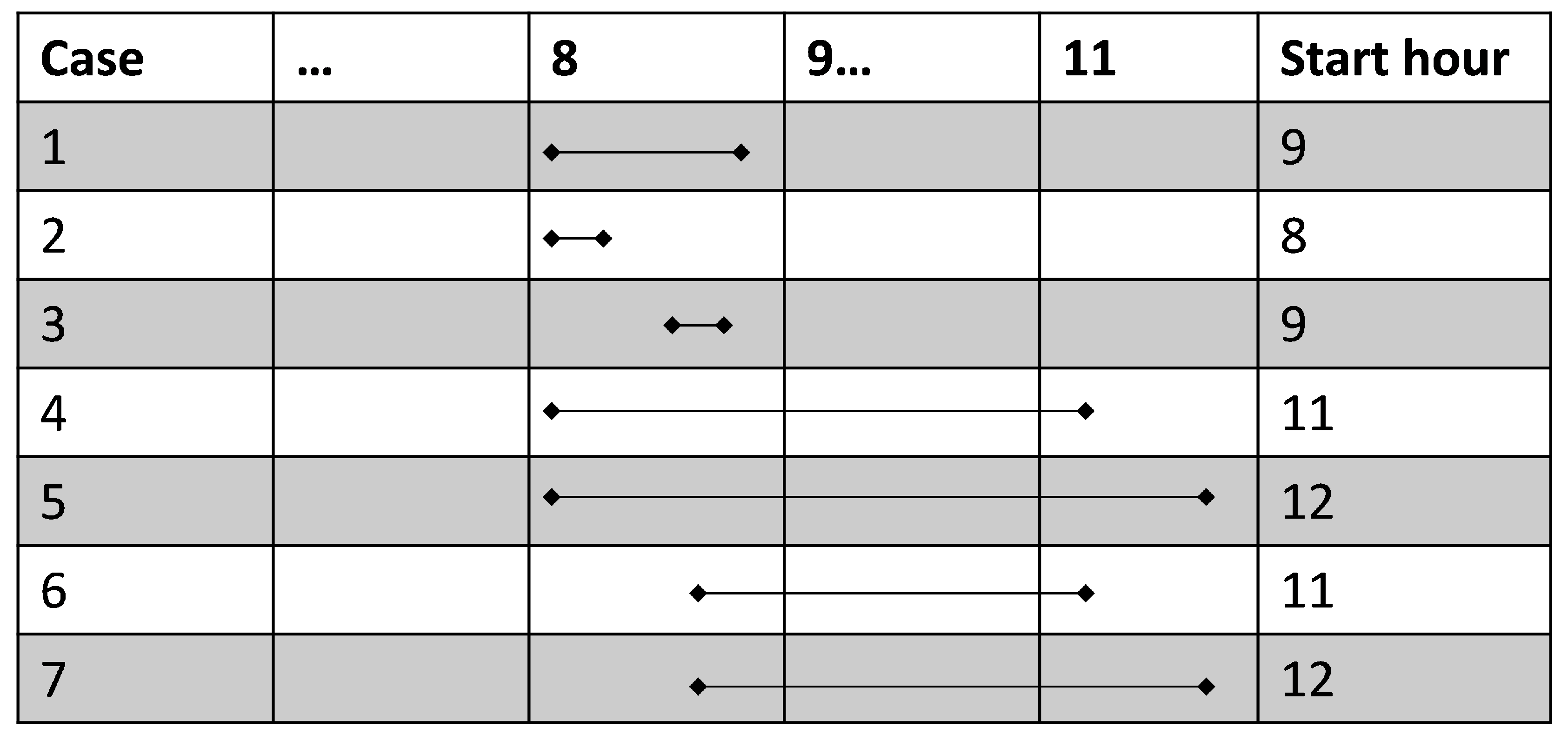
For all other trips, the first hour, in which the purpose is not ‘DRIVING’ (or the previous purpose in case of <30 min trips) is identified based on a logical case differentiation schematically shown in the following
Figure A2.
Figure A2.
Differentiation of cases for the allocation of location purposes based on the trip purpose.
Figure A2.
Differentiation of cases for the allocation of location purposes based on the trip purpose.
Ending hours are currently not differentiated in detail. Thus, the starting hour of the next trip is always determined by the duration of the next trip and the purpose between the two trips ends in the hours before the next trip starts regardless of the start being in the first or second half of the hour, e.g., someone drives to work from 7:30 to 8:20 and then home from 17:20 to 18:10, and thus hour 7 will be determined as ‘DRIVING’; the hours 8–16 will be determined as ‘WORK’, hour 17 as ‘DRIVING’ and the hours from 18 onward will be determined ‘HOME’.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







