2.1. Dynamic of Support Deformations
The dynamic behavior of support is induced by the rock stress surrounding the gate road. Deformation dynamics is the study of time varying response of support under dynamic loads. These loads are primarily considered a change of rock stress intensity induced by mining activities. As a stope approaches the gate road, the rock stress intensity increases.
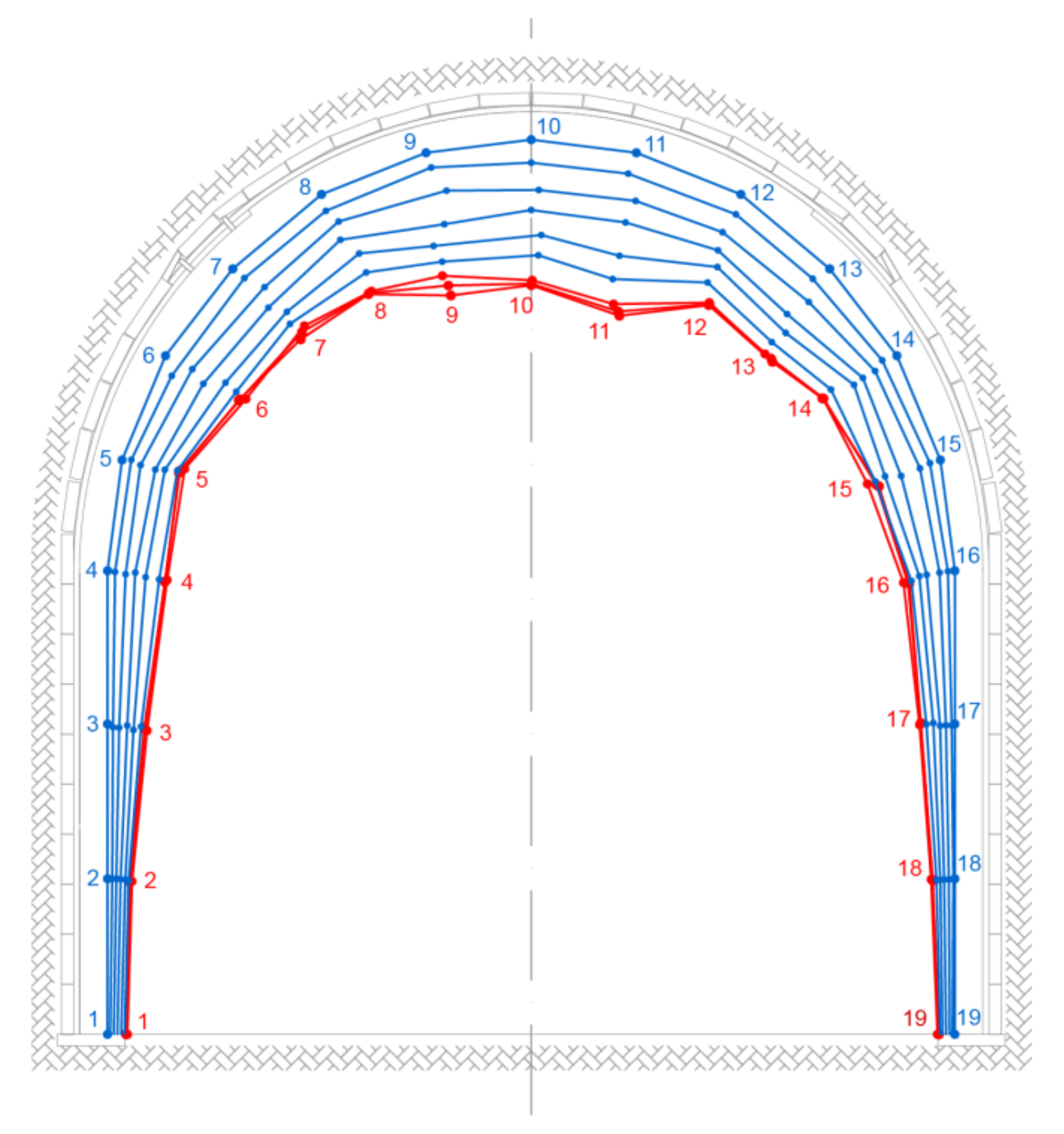
In order to describe deformations of a gate road support, we consider the time dependent displacements only in the vertical cross-section (planar problem). Let
be a surface of the support bounded by
at the current time
t, where
represents the lower edge and
represents the upper edge of the support. Without loss of generality, we equal the upper edge with the lower and transform the surface of the support into one line, i.e., we reduce a real two-dimensional support to an artificial one-dimensional support;
, (
Figure 1).
The initial configuration of is undeformed and known (recorded by laser scanning). The motion of each point on , from the initial to the current configuration, is completely defined by a time dependent mapping function. Since the equation of this function is unknown and it is necessary to make monitoring of support deformations at equal or nonequal time intervals. Monitoring at equal intervals is much more applicable for forecasting deformations of a gate road. It is very important to use the same coordinate system to describe deformations over the time of monitoring.
The position of the marker
, induced by rock stress, changes according to the following vector equation (
Figure 2):
where
—the position vector of the marker m in the current support configuration.
—the position vector of the marker m in the previous support configuration.
—the vector of displacement.
N—time of monitoring.
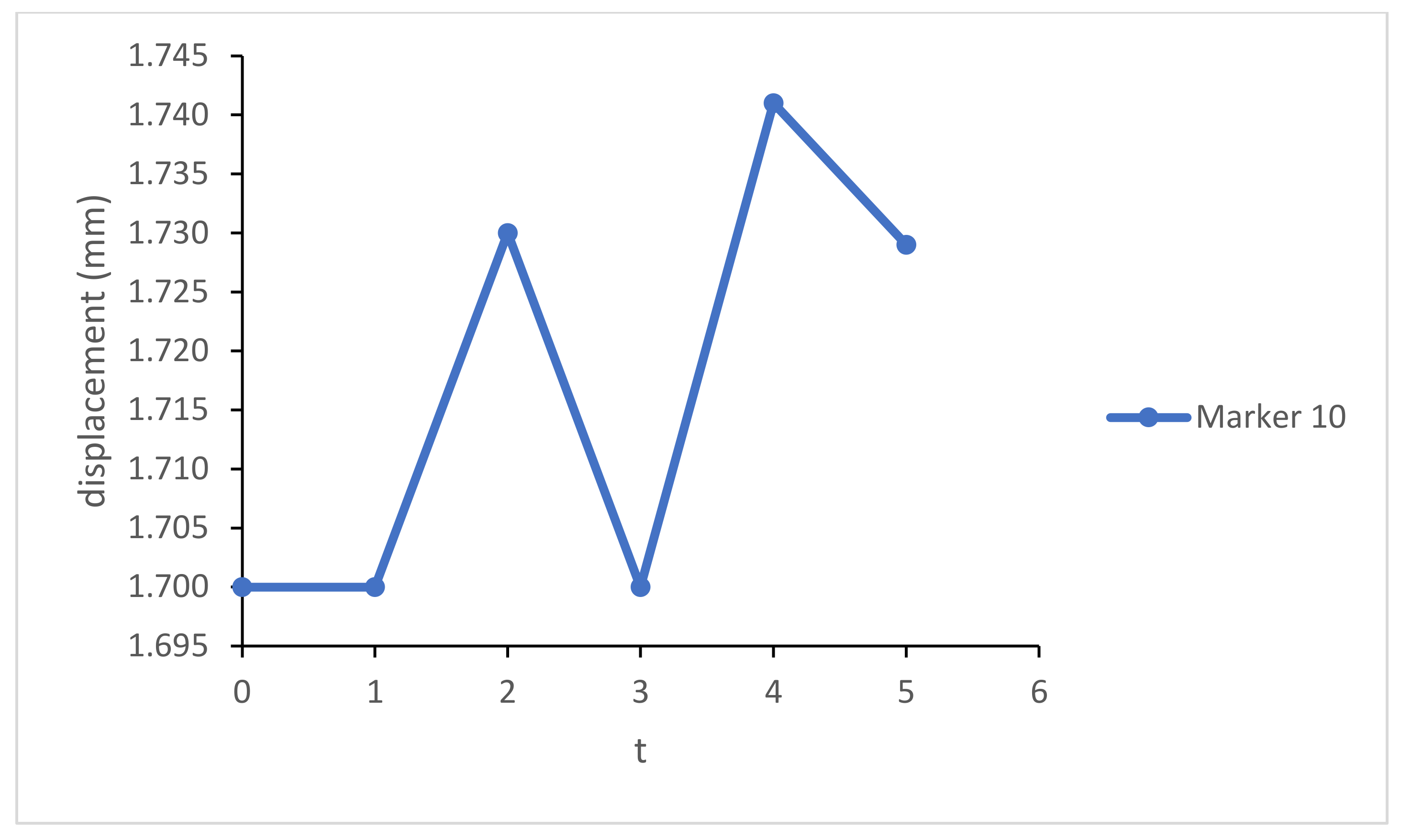
Figure 2.
Change of the marker position over time.
Figure 2.
Change of the marker position over time.
In the
xz-coordinate plane, the position of the marker
is defined as follows:
The gate road support domain
is divided into a finite number of segments “connected” at the marker’s position. Support configuration at current time
t is defined by the set
, where
M is the total number of markers. Let us define a section of the initial support configuration by the set
. At time
, the section of initial support configuration will be transformed and defined by the set
. At time
, the topology of the section is defined by the set
. The time-dependent path of the section topology transformation for
is defined as follows:
(
Figure 3).
In conventional matrix form, the data of position of all markers obtained by scanning for
can be expressed by the time-dependent position vectors as follows:
The position of each marker is represented by each row of the previous matrix, while each column represents the configuration of the gate road support over time. According to Equation (2),
x and
z coordinates of observed markers are defined as follows:
As can be seen, the obtained data can be treated as a multichannel time series. Multivariate singular spectrum analysis is a very useful tool to process such datasets.
2.2. Gateroad Support Deformation Forecasting Algorithm
Our forecasting algorithm is based on the methodology of the multivariate singular spectrum analysis (MSSA). In the paper by Harris and Yuan [
12], the basic SSA (singular spectrum analysis) algorithm was presented. Hassani and Zhigljavsky [
13] showed that SSA is a powerful method for time-series analysis and forecasting. Hassani and Mahmoudvand [
14] pointed out that this method can be applied both to single series and jointly for several series (MSSA). When it is a case of a two or more series, we are talking about MSSA. The application of the SSA technique was found to be very useful for time series analysis in many different fields, such as medicine, biology, genetics, finance, engineering and many others [
15]. The basic concept of the singular spectrum analysis is well presented in the paper by Hassani et al. [
16].
According to Equation (2), x and z coordinates of the marker m over time correspond to one channel time series. If we take into consideration the total number of markers is M, then we are faced with an M-channel time series.
Consider an M-channel time series with a series length of Ni; , where N is the time of monitoring. Here, we provide the procedure for the x coordinates of the markers. The procedure for the z coordinates is completely the same.
At the first stage of the algorithm, the decomposition, includes the following two steps: embedding and singular value decomposition (SVD) [
14,
16].
Embedding is a mapping that transfers a one dimensional time series of coordinates
into a multidimensional matrix
with vectors
, where
is the window length for each series with length
Ni and
. The result of this step is the trajectory matrix
. The trajectory matrix
is known as a Hankel matrix. Thus, the above procedure for each series separately provides
M different
trajectory matrices
. To form a new block Hankel matrix in a vertical form, we need to have
. The result of this step is the following block Hankel trajectory matrix:
where
YV indicates that the output of the first step is a block Hankel trajectory matrix formed in a vertical form; index
V means vertical.
In the second step, we perform the SVD of
YV. Denote
as the eigenvalues of
, arranged in decreasing order
and
, the corresponding eigenvectors, where
. Note also that the structure of the matrix
, is as follows:
The structure of the matrix is similar to the variance-covariance matrix in the classical multivariate statistical analysis literature. The matrix , which is used in the univariate SSA, for the series appears along the main diagonal, and the products of two Hankel matrices that are related to the series and appear in the off-diagonal. The SVD of can be written as , where and . are called factor empirical orthogonal functions and are the left and right eigenvectors of the trajectory matrix, often called principal components.
The second stage of the algorithm, called reconstruction, includes the following two steps: grouping and diagonal averaging or Hankelization [
14,
16].
The grouping step corresponds to splitting the matrices into several disjointed groups and summing the matrices within each group. The split of the set of indices into disjointed subsets corresponds to the representation of . The procedure of choosing the sets is called grouping. For a given group I, the contribution of the component is measured by the share of the corresponding eigenvalues: , where dV is the rank of and . In a simple case where we have only signal and noise components, we use two groups of indices, and and associate the group I1 with the signal component and the group I2 with the noise.
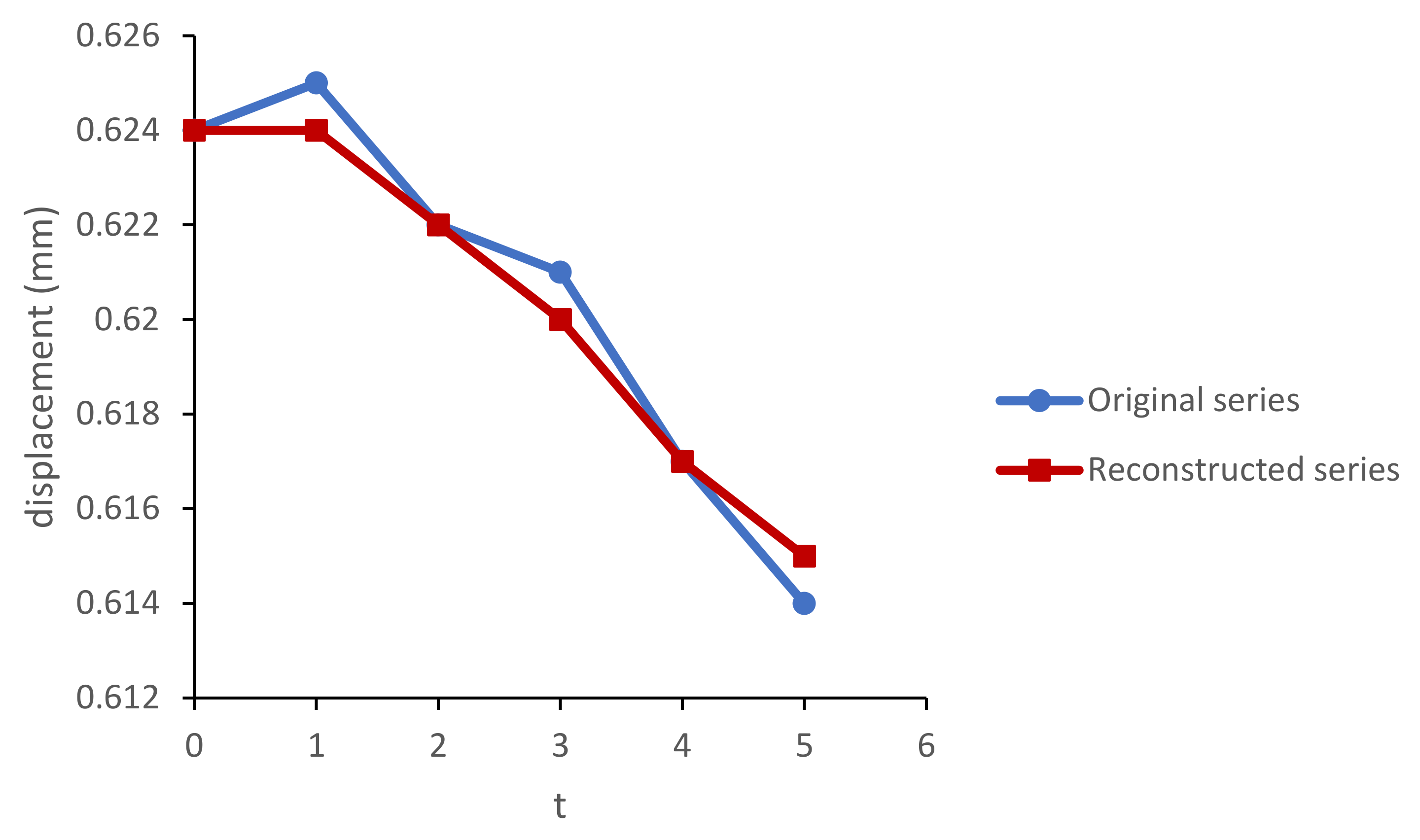
The purpose of diagonal averaging is to transform the reconstructed matrix into a Hankel matrix, which can subsequently be converted into a time series. Let be the approximation of obtained from the diagonal averaging step. If stands for an element of a matrix , then the jth term of the reconstructed series is achieved by arithmetic averaging over all (m, n) such that .
The third stage of the algorithm concerns the future positions of the markers and is based on the vertical multivariate singular spectrum analysis recurrent procedure (VMSSA-R).
Let us have
M-channel series
and corresponding window length
Li,
. Optimal values of the window length are discussed in chapter 4 of the paper by Hassani and Mahmoudvand [
14].
The VMSSA-R forecasting algorithm for the h-step ahead forecast is as follows:
For a fixed value of
K, construct the trajectory matrix
for each single series separately; construct the block trajectory matrix
as follows:
let
be the
jth eigenvector of the
, where
with length
Li corresponds to the series
; consider
the reconstructed matrix achieved from
r eigentriples:
consider matrix
as the result of the Hankelization procedure of the matrix
obtained from the previous step, where
is a Hankel operator; assume
denotes the vector of the first
components of the vector
and
is the last component of the vector
; select the number of
r eigentriples for the reconstruction stage that can also be used for forecasting purposes; define matrix
, where
is as follows:
define matrix
W as follows:
if the matrix
exists and
, then the
h-step ahead VMSSA forecasts exist and is achieved by the following formula:
where
and
. It should be noted that Equation (12) indicates that the
h-step ahead forecasts of the refined series are obtained by a multi-dimensional linear recurrent formula (LRF).
2.3. Displacement Time Series Clustering
The time displacement intensity vector of marker
m is defined as follows:
The universe of displacement (clustering) is defined as the union of the two following sets:
where
is related to the observed displacement series and
to the the
h-step ahead forecasts of the refined displacement series. Note that clustering is performed for each set separately.
To create the clusters within a defined universe of clustering, we apply the concept of fuzzy time series. Such series, which were first proposed by Song and Chissom, ref. [
17] are based on fuzzy set theory proposed by Zadeh [
18,
19]. The most important advantage of fuzzy time series approaches is to be able to work with a very small set of data and not to require the linearity assumption. In the process of measuring the cross-section of the underground roadways, certain measurement errors can occur (conditioned by the error of the measurement method, instrumental error, personal error by the operator of the instrument, or the error due to the working environment itself), the nature of fuzzy time series is a good choice for a credible presentation of displacements of the markers and its clustering.
Let
be the universe of observed displacement. Data obtained by monitoring can be clustered in different ways, for example, a cluster composed of marker displacement over time separately
, a cluster composed of each row or column data of the matrix
ΔV. We focus on each column data in order to see how displacement intensity of configuration of the gate road support changes over time. For that purpose, we apply the concept of fuzzy time series with multiple observations [
20,
21,
22].
A fuzzy set
A of
is defined as follows:
where
fA is the membership function of
A, and
. The symbol “+” denotes the union operator. Membership function represents the degree of membership of
Δvi in
A, where
. Let Δ
V (
t) be the universe of displacement on which fuzzy sets
are defined and
F(
t) is a collection of
that is referred to as a fuzzy time series of Δ
V (
t). Here,
F(
t) is viewed as a linguistic variable and
represents possible linguistic values of
F(
t). If
F(
t) is caused by
F(
t – 1
) only, the relationship can be expressed as [
23]. If the maximum degree of membership of
F(
t) belongs to
Ai then
F(
t) is considered to be
Ai. Hence,
becomes
.
The algorithm of a fuzzy time series model for multiple observations is composed of the following steps [
23]:
Step 1: define the fuzzy sets for the fuzzy time series. We set the beginning and the end of the universe of displacement as
and
, respectively. The observed data are sorted in ascending order. The distance of any two consecutive values of displacement is calculated as follows:
Now it is necessary to compute the corresponding average value
and standard deviation
. The intention is to eliminate the outliers from the sorted data and obtain an average distance value free of distortion. Outliers are values that are either abnormally high or abnormally low in the sorted dataset. The process of elimination of outliers is performed as follows:
Since the process of elimination is completed, a revised average distance value
is calculated for the remaining values in the sorted data set. Accordingly, the universe of displacement is also revised and defined as follows:
The number of equal intervals
n is given by the user and each interval is characterized by an adequate linguistic variable. The variable whose values are words or sentences in a natural or artificial language is called a linguistic variable. We use five linguistic variables
to describe displacement intensity of configuration of the gate road support;
(very small),
(small),
(medium),
(high), and
(very high). The length of interval can be calculated by the equation:
Each interval is obtained as:
. Linguistic variable
can now be defined according to defined intervals as follows:
The triangular fuzzy number is used to quantify the linguistic variable. It can be defined as a triplet (
a,
b,
c). The corresponding membership function is defined as [
24]:
Step 2: determine a fuzzy observation of displacement. Triangular fuzzy number
is also used to represent displacement of all markers at time point
t, where
a(
t), b(
t), c(
t) are the left, middle and right values of the triangular fuzzy number, respectively. These values are defined in the following way:
In other words, for every observation (column of matrix), it is necessary to separate minimum, maximum, and average values of displacement for all markers.
Step 3: calculate the fuzzy relationship,
Y(
t), between each fuzzified observation and defined fuzzy time series as in Step 1.
Fuzzified observation of displacement at time point t belongs to cluster Ai if and only if their intersection has the highest value of membership function; .
Each
is calculated according to
Figure 4, representing the intersection between a fuzzy observation of displacement
O(
t) and fuzzy time series consisting of
.
The calculation of the membership function value of intersection is based on the following approach:
From Equations (24) and (25), we can calculate the value of
as follows:


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}