
Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier

 , ,
, ,  and
and 
Abstract
:1. Introduction
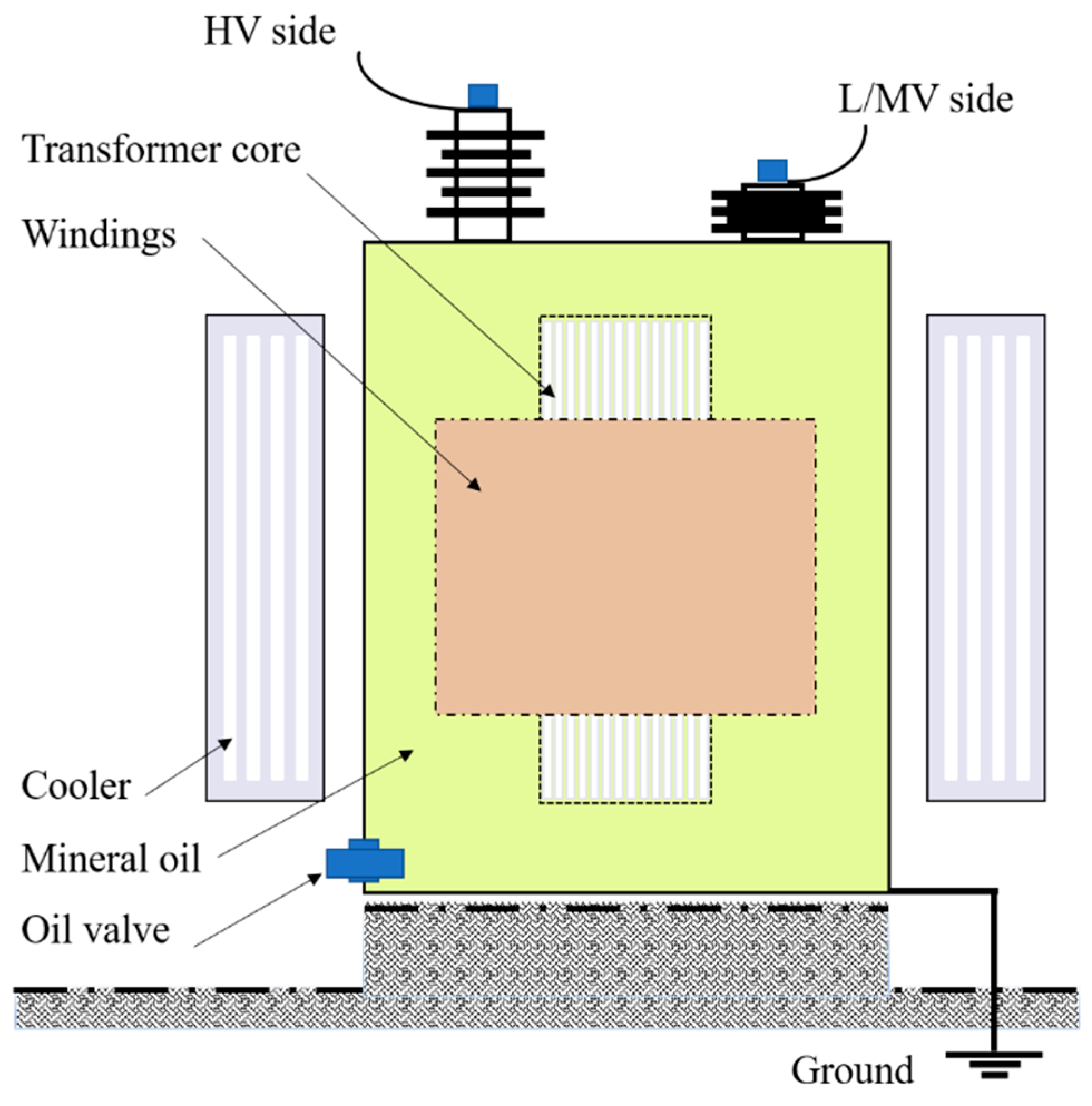
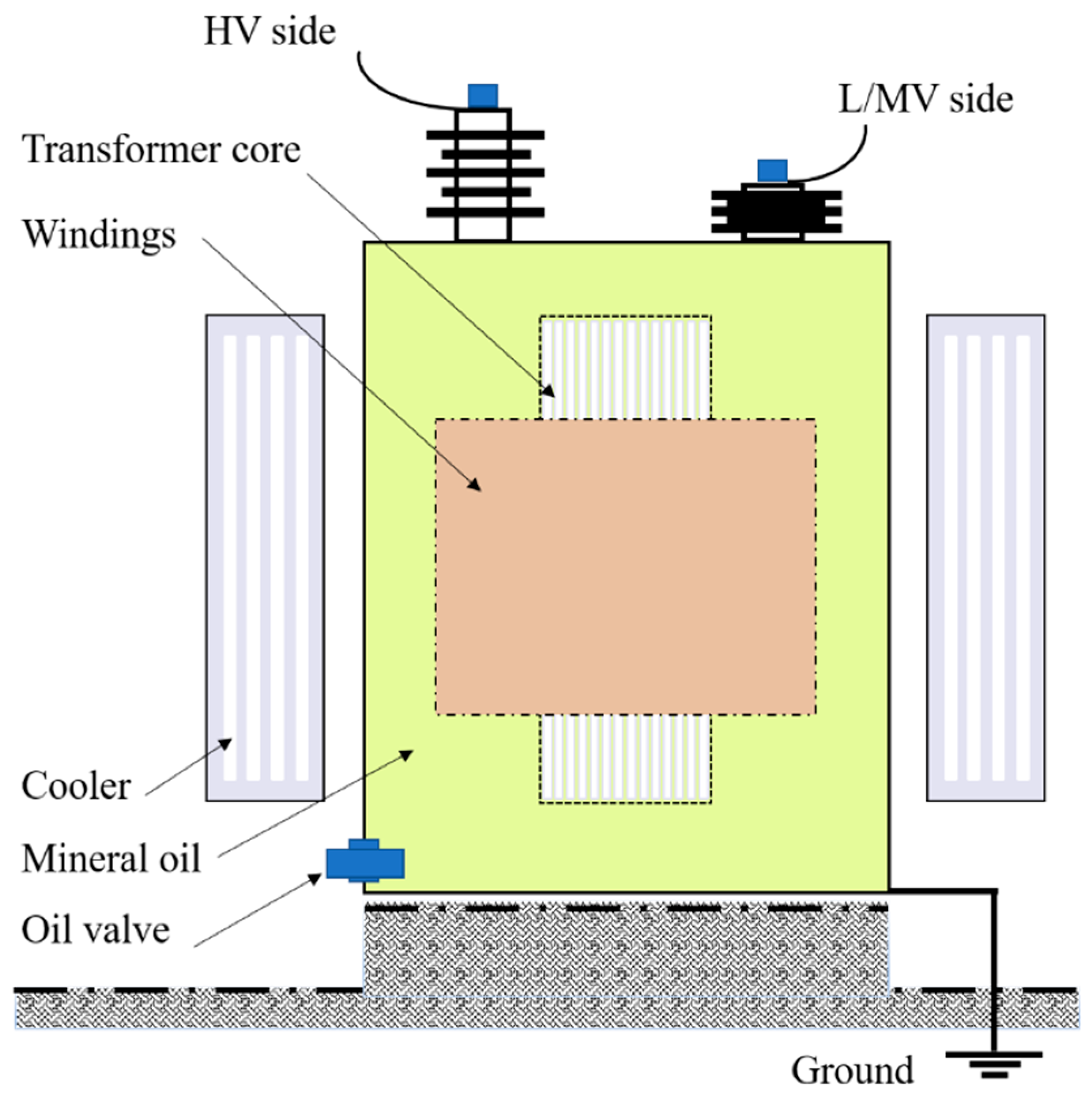
2. Problem Formulation
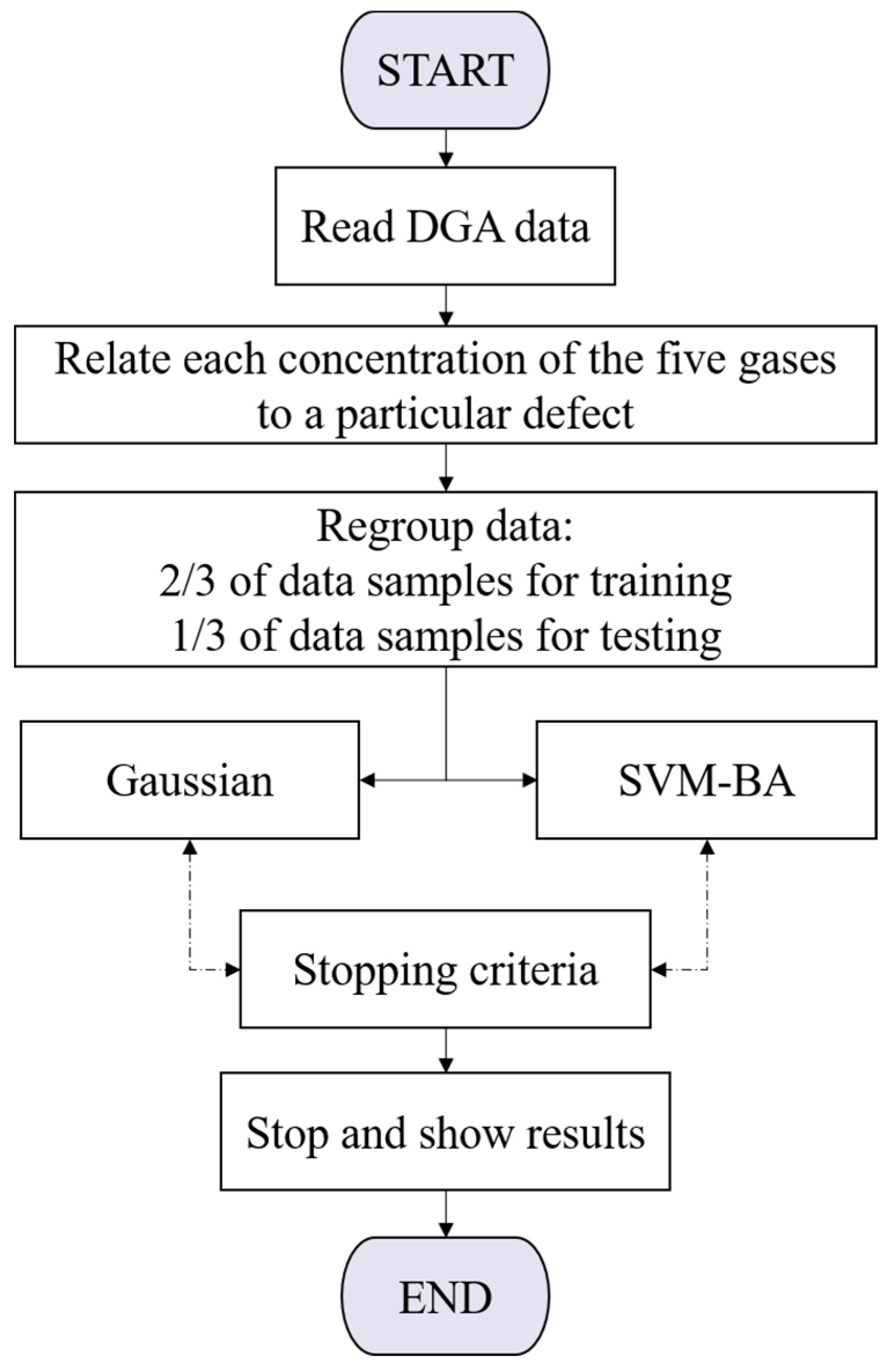
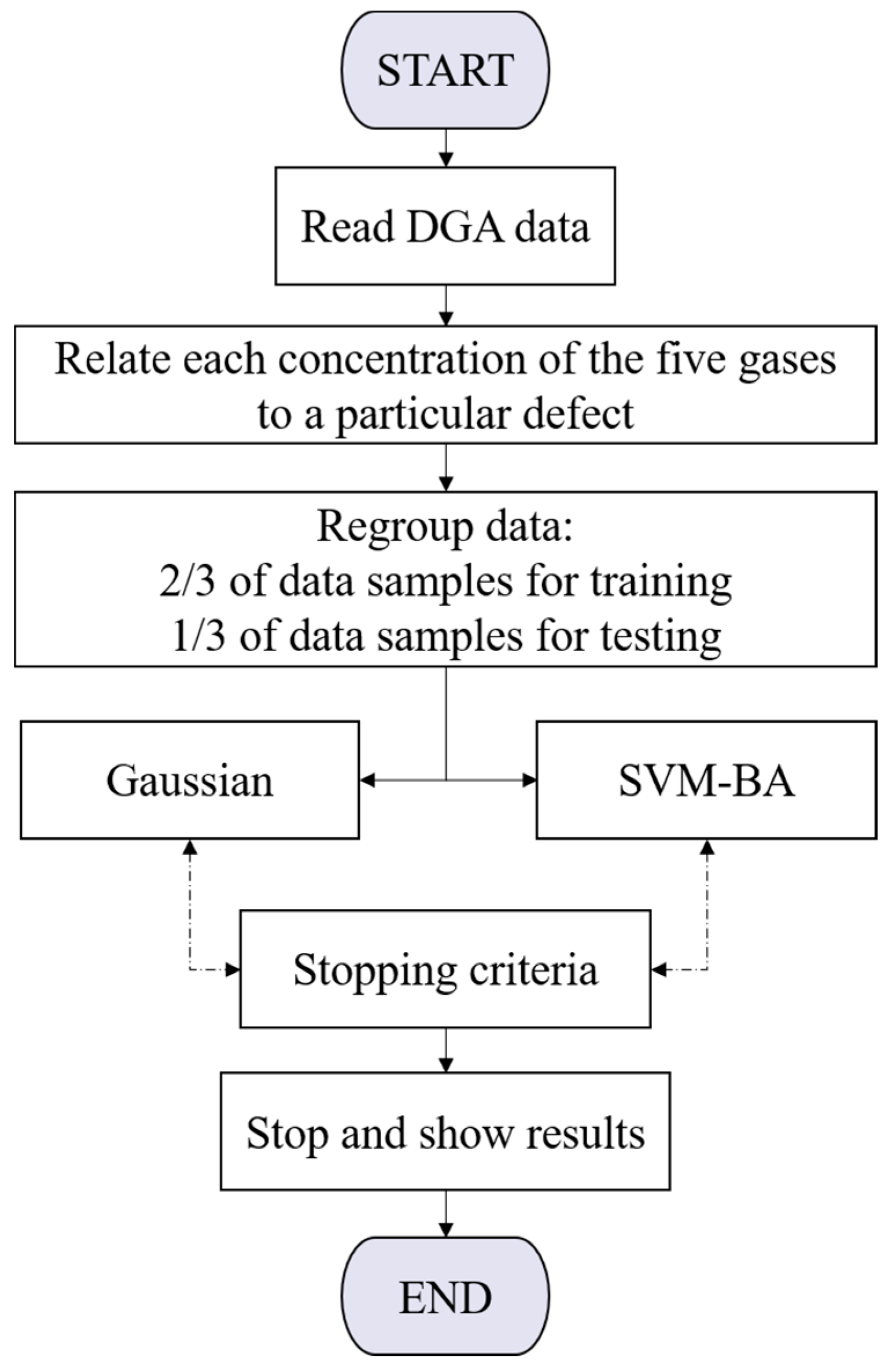
3. Classification Approach
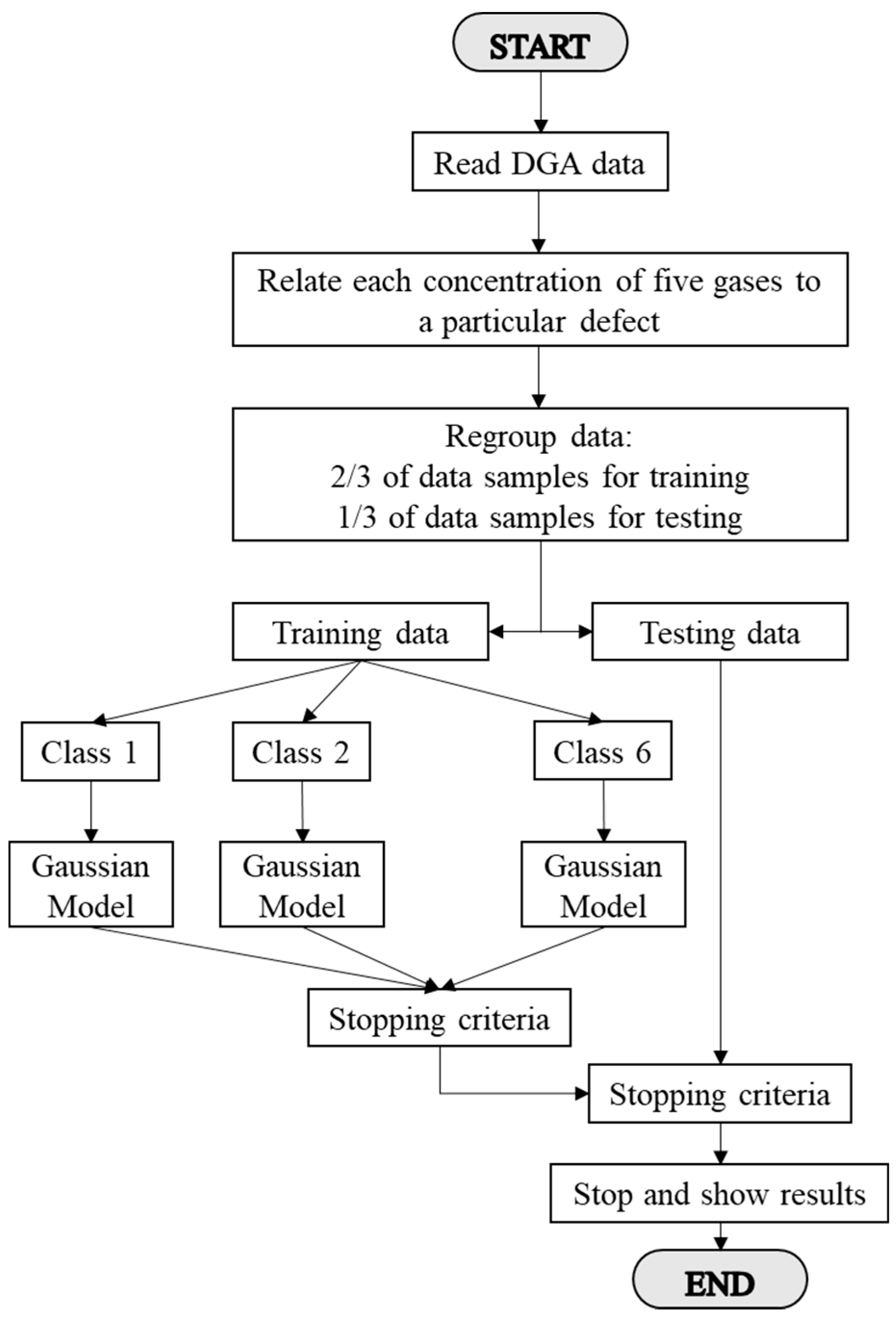
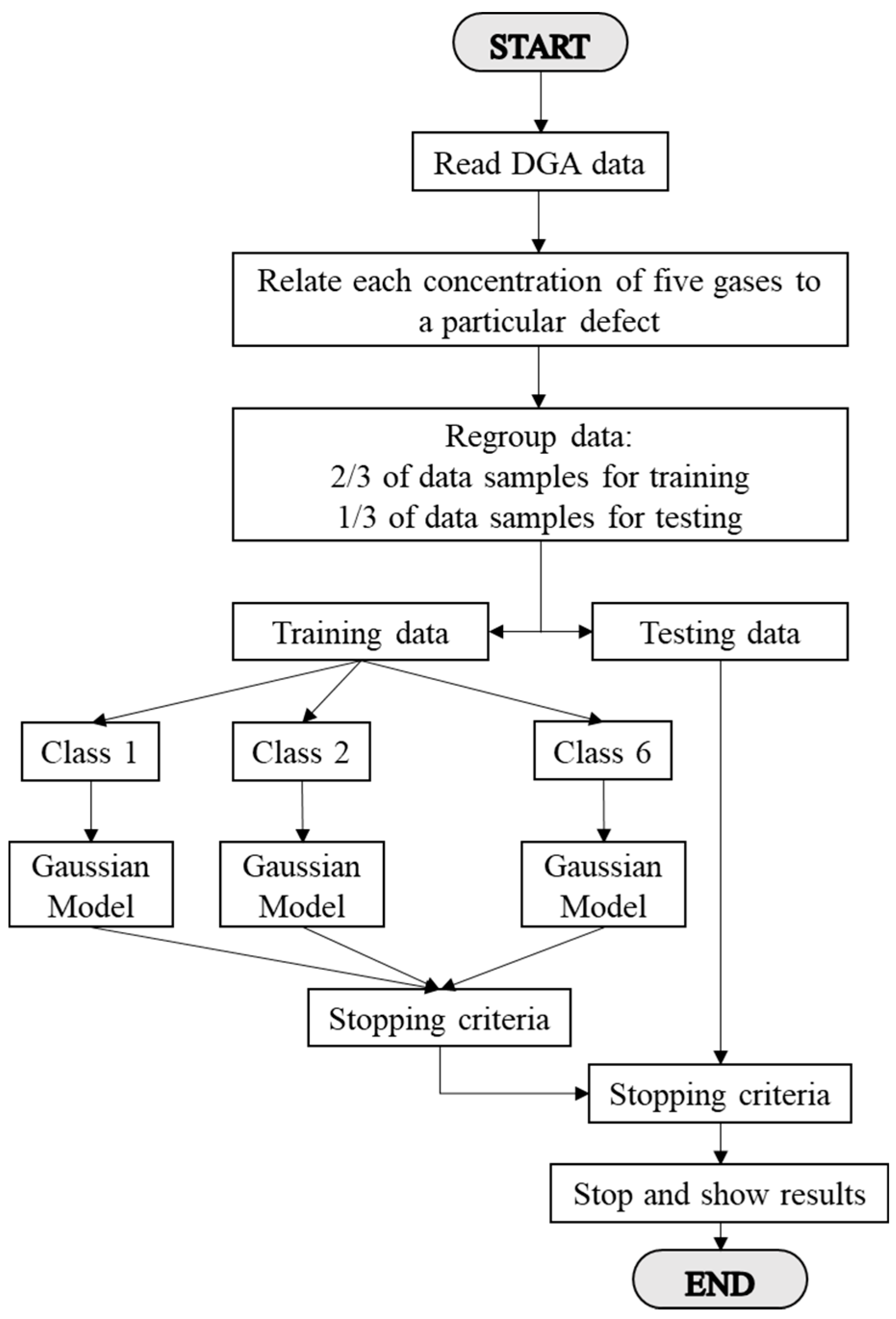
3.1. Gaussian Classifier
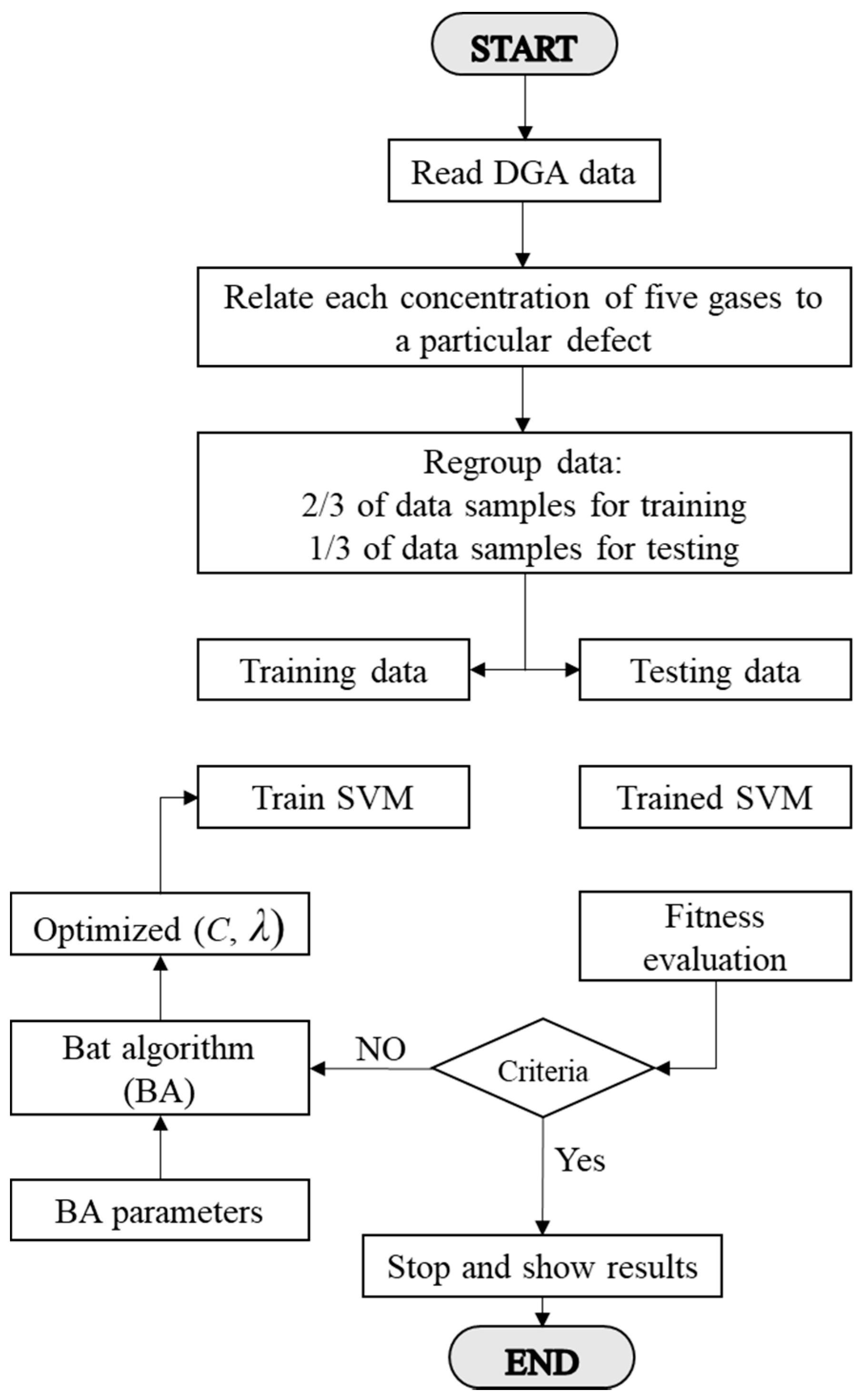
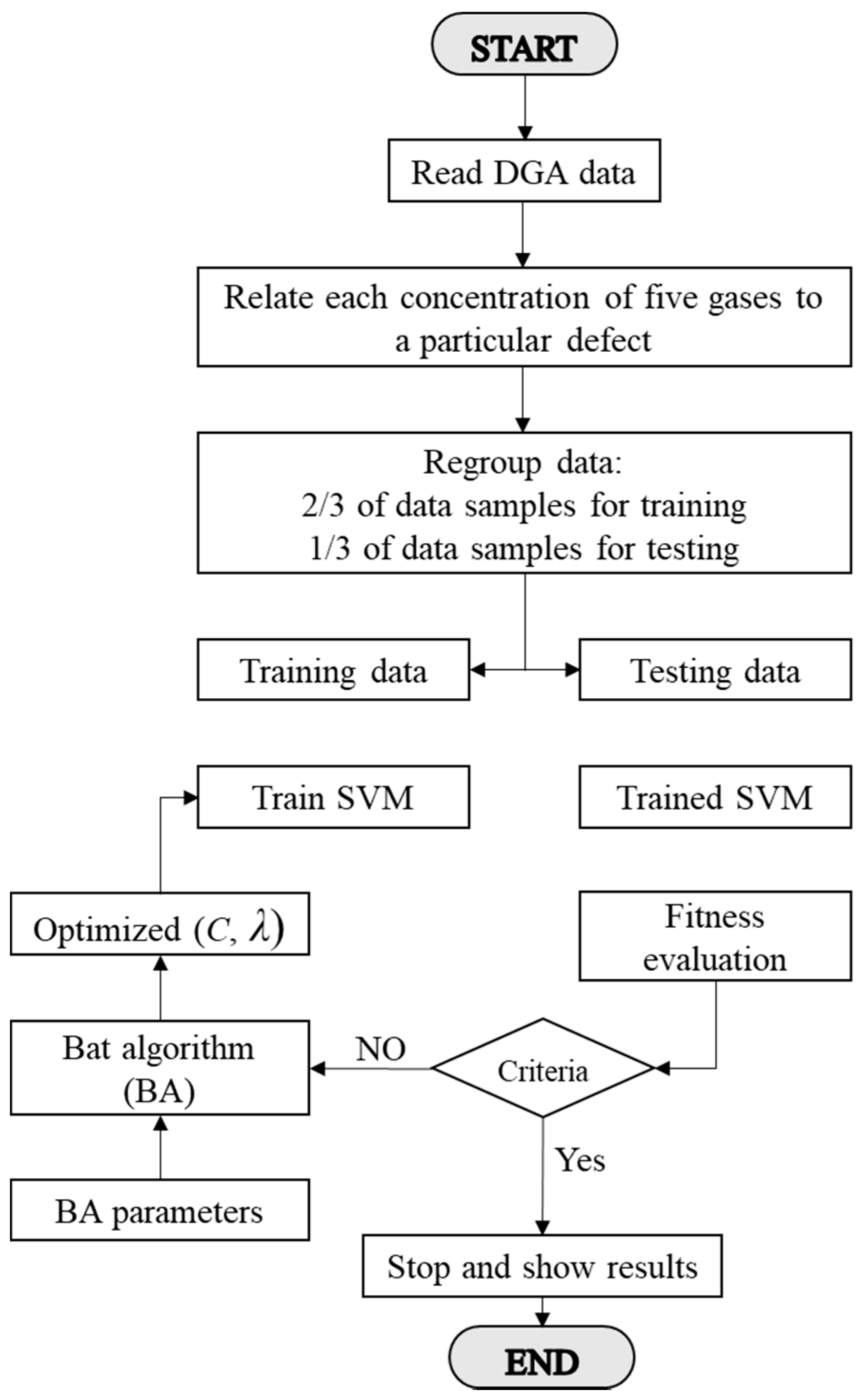
3.2. SVM Classifier Coupled with BA
- Kernel parameter λ (conditioning parameter equivalent σ in RBF kernel [24]);
- penalty parameter C (margin parameter); and
- degree d of the Kernel polynomial.
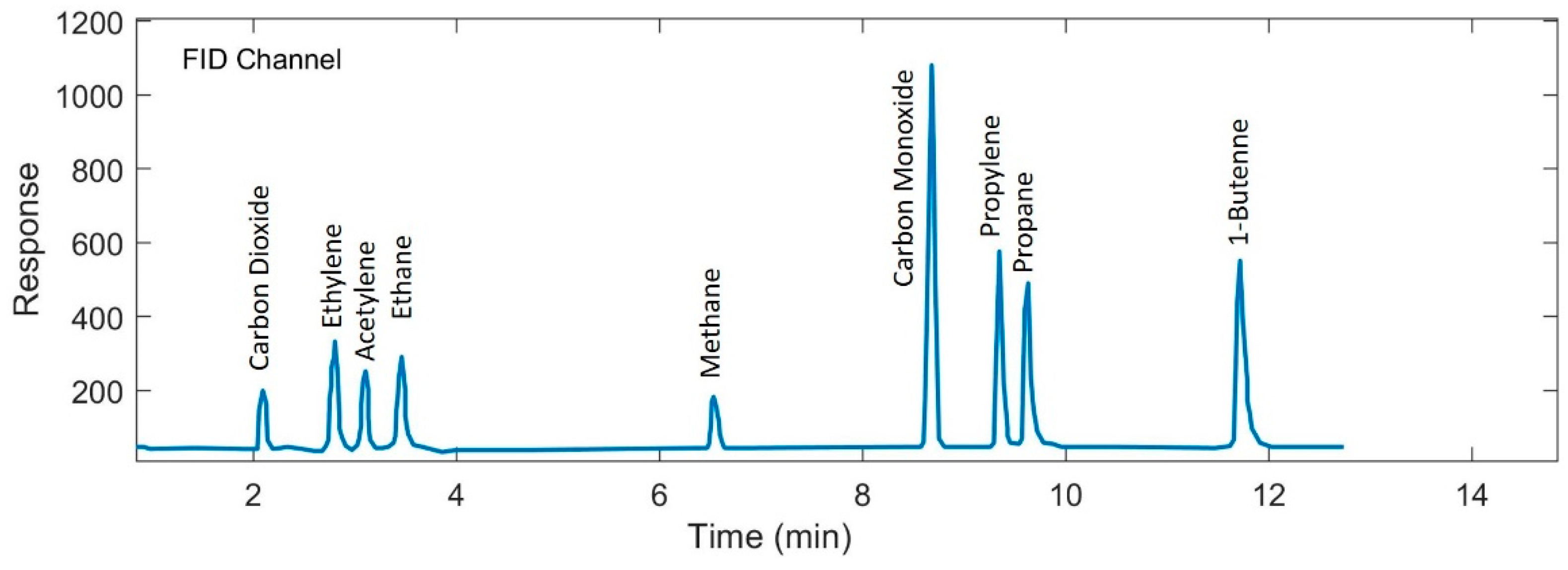
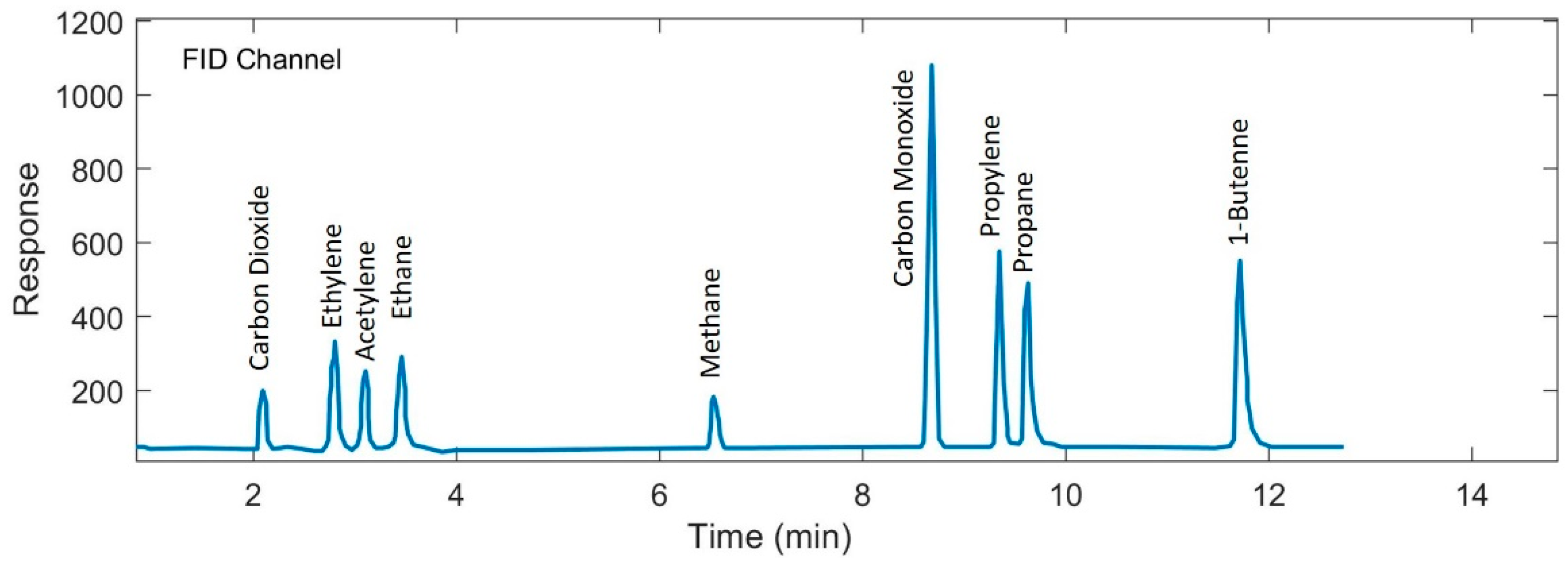
4. Experimental Work
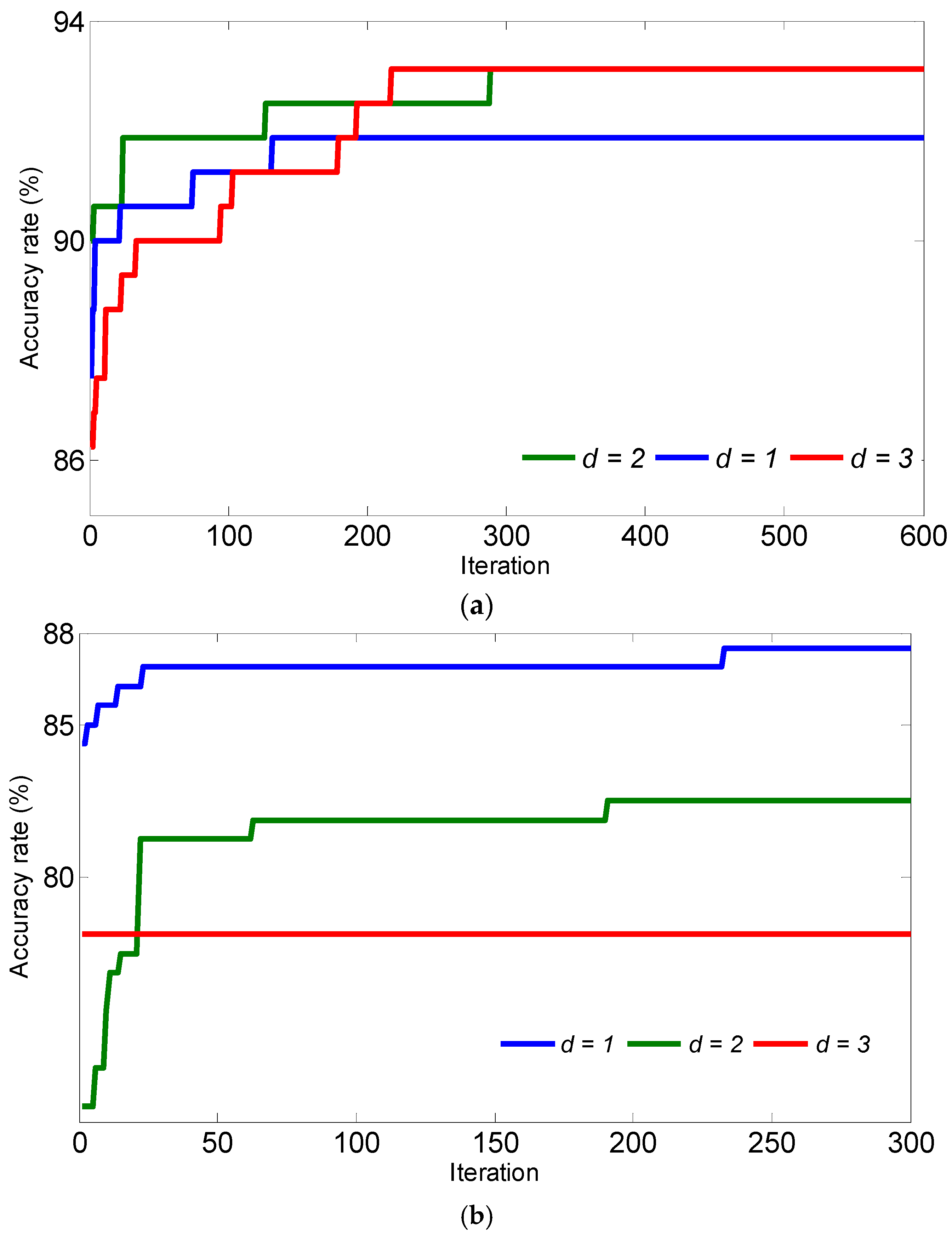
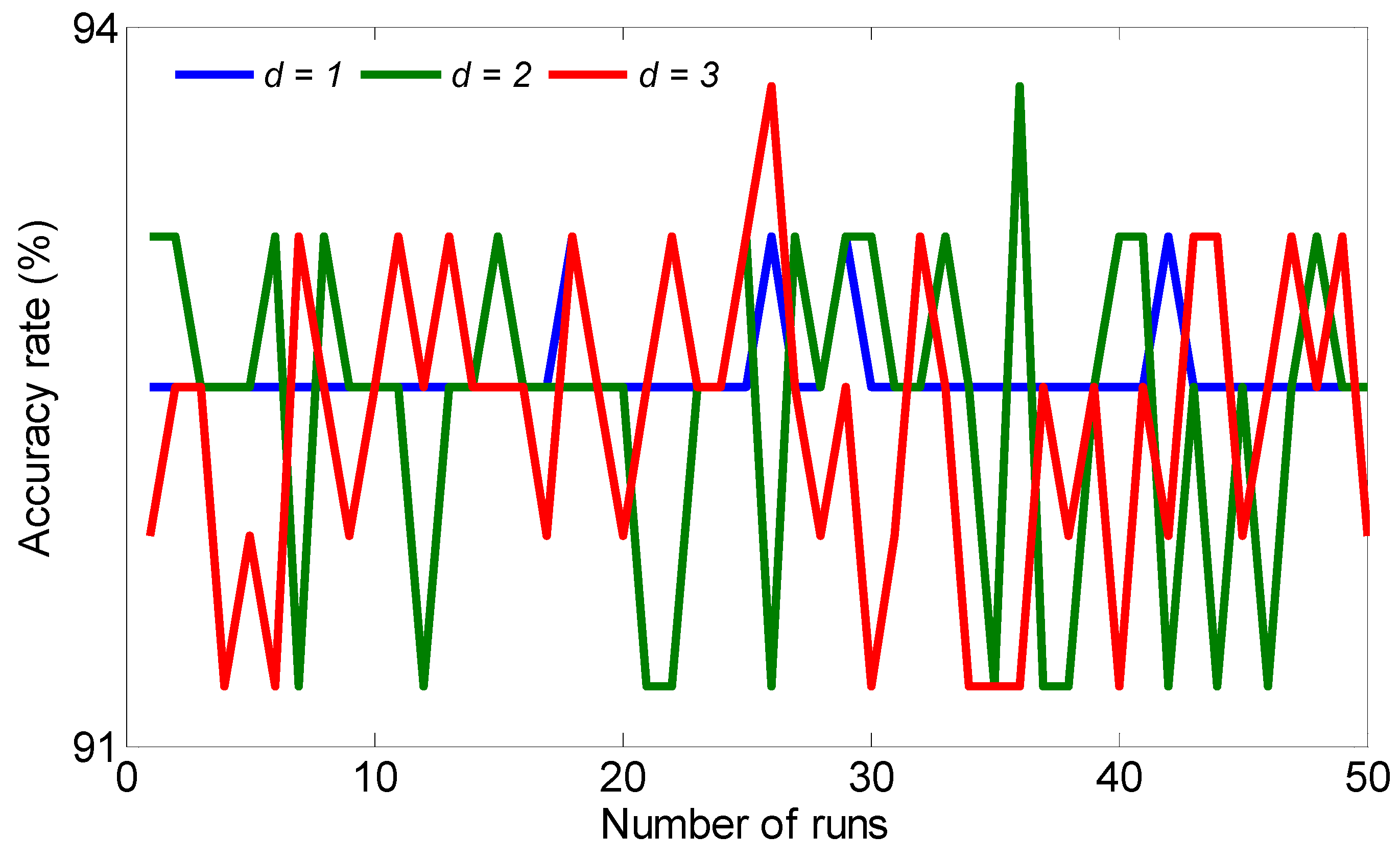
5. Results and Discussions
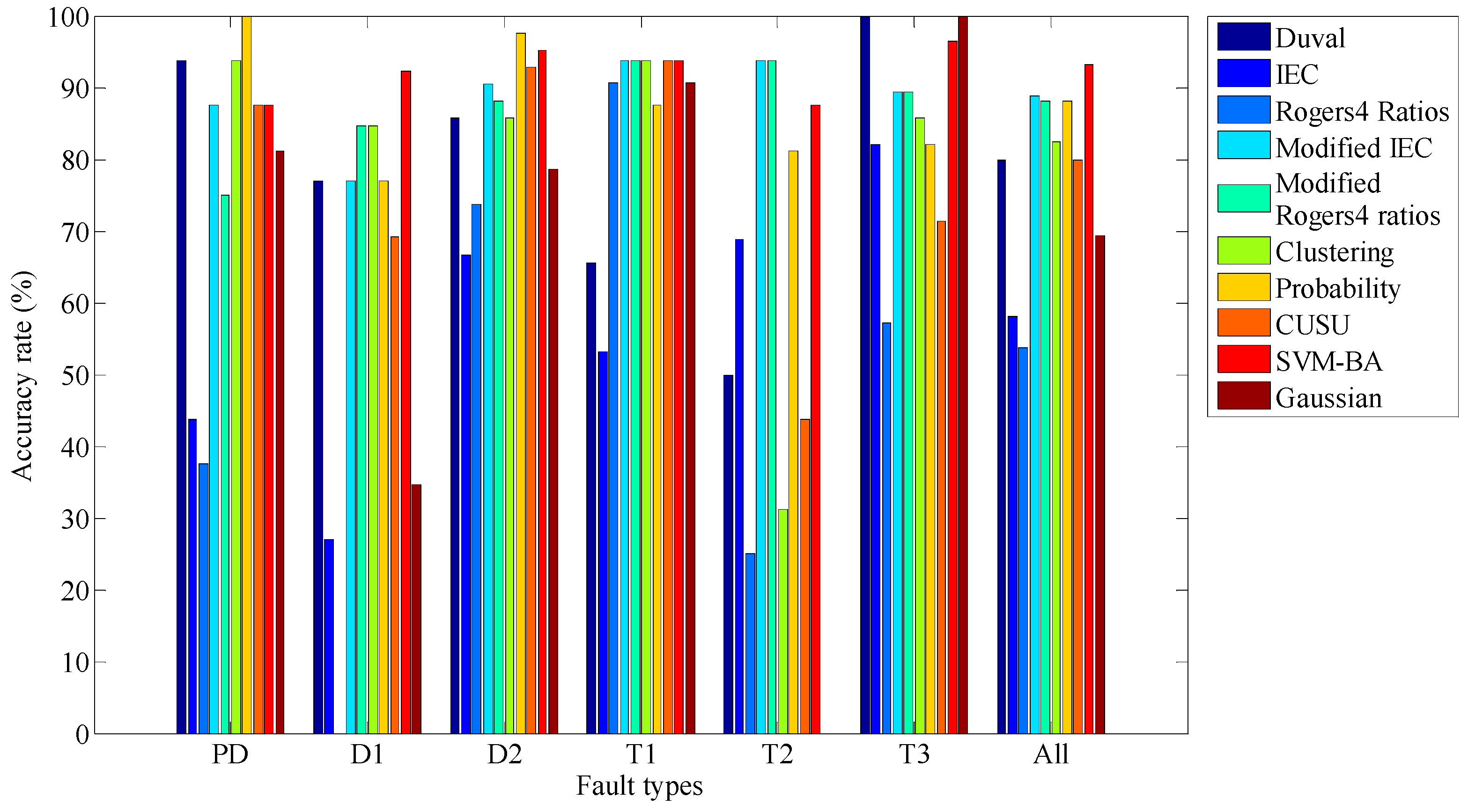
6. Validation and Overall Accuracy of the Proposed SVM-BA Classifier
7. Conclusions
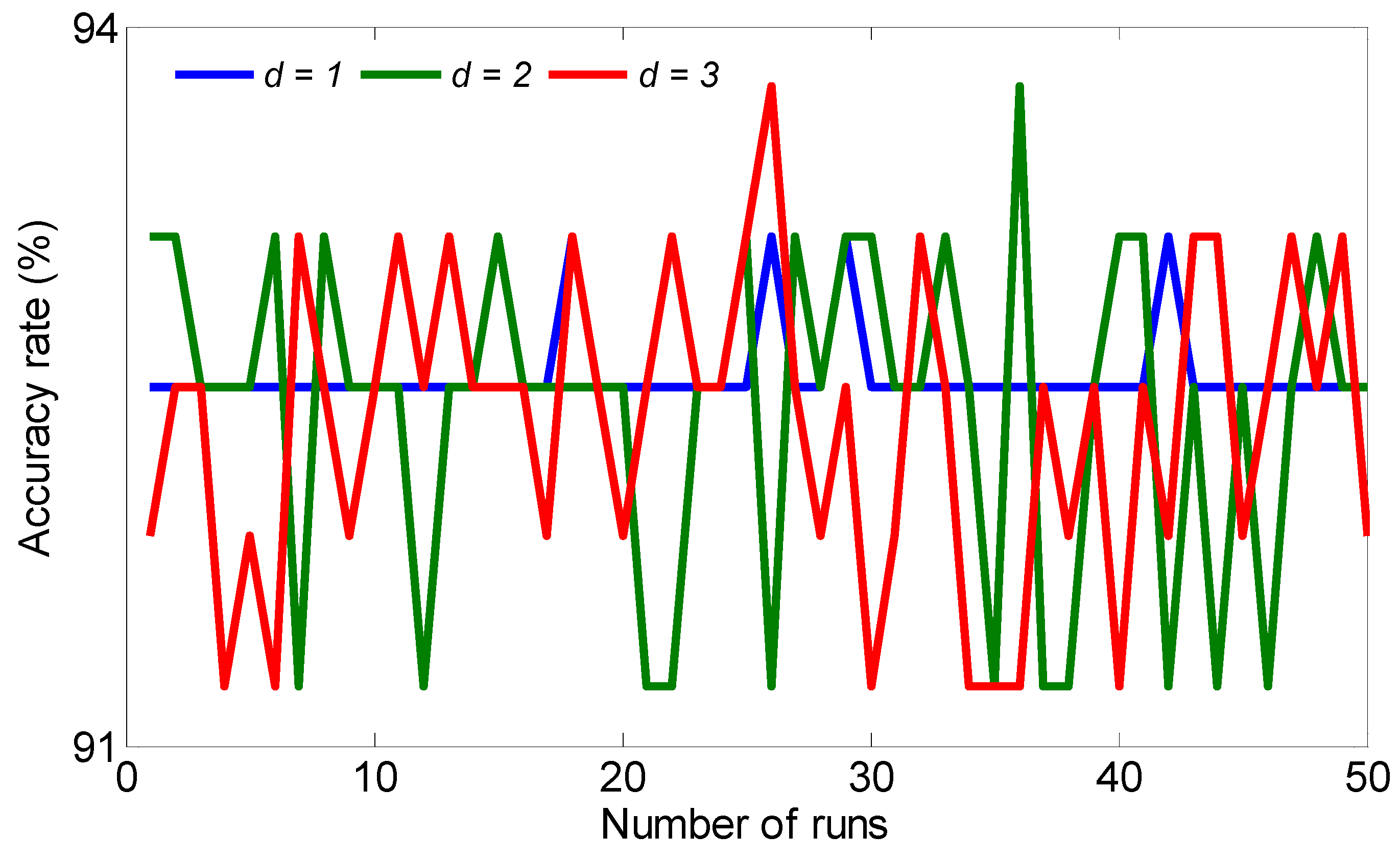
- An accuracy rate of 93.75% has been achieved when the input vector in percentage with d = 2 and 3 degrees.
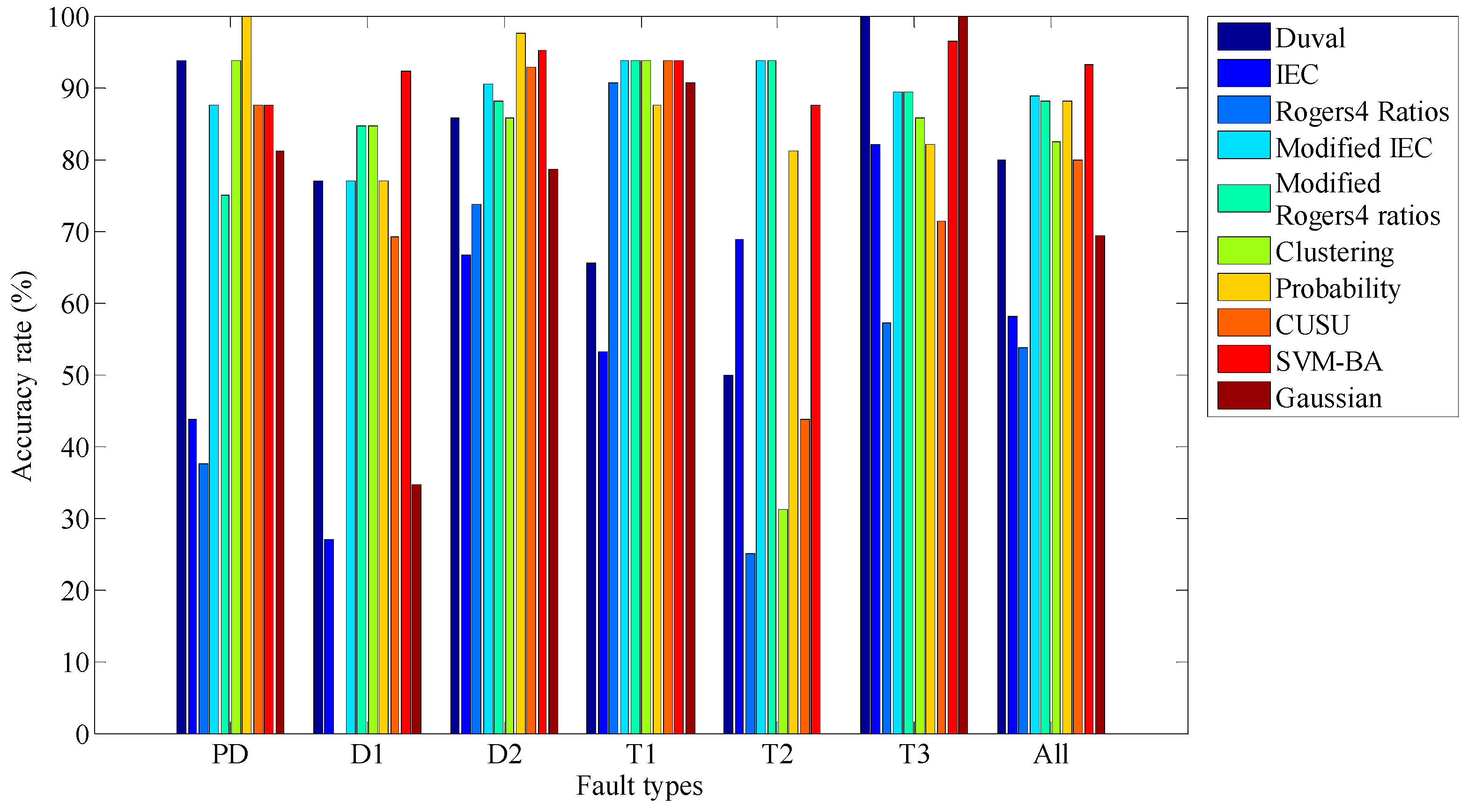
- The coupled SVM-BA classifier’s test results revealed the classifier’s ability to enhance the transformer faults’ diagnostic accuracy rather than the other DGA techniques in the literature.
- The overall accuracy of SVM-BA was 93.75%, which is higher than that of the modified IEC code (88.75%).
- It recommended determining the expected remaining life of the transformer based on the state of the insulation system.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Benmahamed, Y.; Teguar, M.; Boubakeur, A. Application of SVM and KNN to Duval Pentagon 1 Transformer Oil Diagnosis. IEEE Trans. Dielect. Electr. Inst. 2017, 24, 3443–3451. [Google Scholar] [CrossRef]
- Ji, X.; Zhang, Y.; Liu, Q. Insulation Condition Assessment of Power Transformers Employing Fused Information in Time and Space Dimensions. Electr. Power Comp. Syst. 2020, 48, 213–223. [Google Scholar] [CrossRef]
- Malik, H.; Mishra, S. Selection of Most Relevant Input Parameters Using Principal Component Analysis for Extreme Learning Machine Based Power Transformer Fault Diagnosis Model. Electr. Power Compon. Syst. 2017, 45, 1339–1352. [Google Scholar] [CrossRef]
- IEEE Standard C57-104. Guide for the Interpretation of Gases Generated in Oil-Immersed Transformers; IEEE: New York, NY, USA, 2008; p. 104. [Google Scholar]
- Jiang, J.; Chen, R.; Zhang, C.; Chen, M.; Li, X.; Ma, G. Dynamic Fault Prediction of Power Transformers Based on Lasso Regression and Change Point Detection by Dissolved Gas Analysis. IEEE Trans. Dielect. Electr. Inst. 2020, 27, 2130–2137. [Google Scholar] [CrossRef]
- Taha, I.B.M.; Hoballah, A.; Ghoneim, S.S.M. Optimal ratio limits of Rogers’ four-ratios and IEC 60599 code methods using particle swarm optimization fuzzy-logic approach. IEEE Trans. Dielect. Electr. Inst. 2020, 27, 222–230. [Google Scholar] [CrossRef]
- Gouda, O.E.; El-Hoshy, S.H.; ELTamaly, H.H. Condition assessment of power transformers based on dissolved gas analysis. IET Gener. Trans. Distrib. 2019, 13, 2299–2310. [Google Scholar] [CrossRef]
- Code, P.; Prix, C. Mineral Oil-Impregnated Electrical Equipment in Service–Guide to the Interpretation of Dissolved and Free Gases Analysis; IEC Publication 60599; British Standards Institution: London, UK, 2007. [Google Scholar]
- Duval, M.; Lamarre, L. The Duval Pentagon—A new Complementary Tool for the Interpretation of Dissolved Gas Analysis in Transformers. IEEE Electr. Insul. Mag. 2014, 30, 9–12. [Google Scholar]
- Cheim, L.; Duval, M.; and Haider, S. Combined Duval Pentagons: A Simplified Approach. Energies 2020, 13, 2859. [Google Scholar] [CrossRef]
- Mansour, D.A. Development of a new graphical technique for dissolved gas analysis in power transformers based on the five combustible gases. IEEE Trans. Dielect. Electr. Inst. 2015, 22, 2507–2512. [Google Scholar] [CrossRef]
- Benmahamed, Y.; Kemari, Y.; Teguar, M.; Boubakeur, A. Diagnosis of Power Transformer Oil Using KNN and Nave Bayes Classifiers. In Proceedings of the 2018 IEEE 2nd International Conference on Dielectrics (ICD), Budapest, Hungary, 1–5 July 2018. [Google Scholar]
- Poonnoy, N.; Suwanasri, C.; Suwanasri, T. ‘Fuzzy Logic Approach to Dissolved Gas Analysis for Power Transformer Failure Index and Fault Identification. Energies 2021, 14, 36. [Google Scholar] [CrossRef]
- Benmahamed, Y.; Teguar, M.; Boubakeur, A. Diagnosis of Power Transformer Oil Using PSO-SVM and KNN Classifiers. In Proceedings of the 2018 International Conference on Electrical Sciences and Technologies in Maghreb (CISTEM), Algiers, Algeria, 28–31 October 2018. [Google Scholar]
- Ghoneim, S.S.M.; Taha, I.B.M. A new approach of DGA interpretation technique for transformer fault diagnosis. Int. J. Electr. Power Energy Syst. 2016, 81, 265–274. [Google Scholar] [CrossRef]
- Taha, I.B.M.; Mansour, D.A.; Ghoneim, S.S.M.; Elkalashy, N. Conditional probability-based interpretation of dissolved gas analysis for transformer incipient faults. IET Gener. Transm. Distrib. 2017, 11, 943–951. [Google Scholar] [CrossRef]
- Ibrahim, S.; Ghoneim, S.S.M.; Taha, I.B.M. DGALab: An extensible software implementation for DGA. IET Gener. Transm. Distrib. 2018, 18, 4117–4124. [Google Scholar] [CrossRef]
- Ibrahim, S.; Taha, I.B.M.; Ghoneim, S.S.M. DGA Tool GitHub Repository. 2018. Available online: https://github.com/Saleh860/DGA (accessed on 19 May 2021).
- IEEE Std C57-104. IEEE Guide for the Reclamation of Mineral Insulating Oil and Criteria for Its Use; British Standards Institution: London, UK, 2015; p. 637. [Google Scholar]
- Wani, S.A.; Khan, S.A.; Prashal, G.; Gupta, D. Smart Diagnosis of Incipient Faults Using Dissolved Gas Analysis-Based Fault Interpretation Matrix (FIM). Arab. J. Sci. Eng. 2019, 44, 6977–6985. [Google Scholar] [CrossRef]
- Yazdani-Asrami, M.; Taghipour-Gorjikolaie, M.; Song, M.; Zhang, W.; Yuan, W. Prediction of Nonsinusoidal AC Loss of Superconducting Tapes Using Artificial Intelligence-Based Models. IEEE Access 2020, 8, 207287–207297. [Google Scholar] [CrossRef]
- Wei, H.; Wang, Y.; Yang, L.; Yan, C.; Zhang, Y.; and Liao, R. A new support vector machine model based on improved imperialist competitive algorithm for fault diagnosis of oil-immersed transformers. J. Elect. Eng. Technol. 2017, 12, 830–839. [Google Scholar]
- Tharwat, A.; Hassanien, A.E.; Elnaghi, B. A BA-based algorithm for parameter optimization of Support Vector Machine. Pattern Recognit. Lett. 2017, 93, 13–22. [Google Scholar] [CrossRef]
- Liu, T.; Zhu, X.; Pedrycz, W.; Li, Z. A design of information granule-based under-sampling method in imbalanced data classification. Soft Comput. 2020, 24, 17333–17347. [Google Scholar] [CrossRef]
- ASTM. Standard Test Method for Analysis of Gases Dissolved in Electrical Insulating Oil by Gas Chromatography; D3612-2; ASTM: West Conshohocken, PA, USA, 2017. [Google Scholar]
- Available online: https://www.agilent.com/cs/library/usermanuals/public/G1176-90000_034327.pdf (accessed on 19 May 2021).
- Foysal, K.H.; Chang, H.J.; Bruess, F.; Chong, J.W. SmartFit. Smartphone Application for Garment Fit Detection. Electronics 2021, 10, 97. [Google Scholar] [CrossRef]
- Ali, S.; Smith, K.A. Automatic parameter selection for polynomial kernel. In Proceedings of the Fifth IEEE Workshop on Mobile Computing Systems and Applications, Las Vegas, NV, USA, 27–29 October 2003; pp. 243–249. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect | Interpretation | Number of Samples |
|---|---|---|
| PD | Partial discharge | 48 |
| D1 | Low energy discharges | 79 |
| D2 | High energy discharges | 126 |
| T1 | Thermal faults of <300 °C | 95 |
| T2 | Thermal faults of 300 °C to 700 °C | 48 |
| T3 | Thermal faults of >700 °C | 85 |
| All | 481 |
| Parameter | Value |
|---|---|
| Population size | 50 |
| Loudness | 0.5 |
| Frequency (fmin and fmax) | 0 and 20 |
| Number of iterations | 600 |
| Pulse rate | 0.5 |
| H2 | CH4 | C2H2 | C2H4 | C2H6 | Inspection | SVM-BA (Input Vector in ppm) | Gaussian (Input Vector in ppm) | SVM-BA (Input Vector in Percentage) | Gaussian (Input Vector in Percentage) |
|---|---|---|---|---|---|---|---|---|---|
| 2587.2 | 112.25 | 0 | 1.4 | 4.704 | PD | PD | D2 * | PD | PD |
| 6870 | 1028 | 5500 | 900 | 79 | D1 | D1 | D1 | D1 | D2 * |
| 84 | 6 | 86 | 14 | 1 | D2 | D2 | T3 * | D1 * | D1 * |
| 92 | 27 | 0 | 7 | 67 | T1 | T1 | T3 * | T1 | T1 |
| 960 | 4000 | 6 | 1560 | 1290 | T2 | T3* | T3 * | T2 | T3 * |
| 1374 | 2648 | 298 | 5376 | 628 | T3 | T3 | T3 | T3 | T3 |
| Classifier | Gaussian | SVM-BA | ||
|---|---|---|---|---|
| d = 1 | d = 2 | d = 3 | ||
| DGA in percentages | 69.37 % | 93.13% | 93.75% | 93.75% |
| DGA in ppm | 32.75 % | 87.50% | 82.50% | 78.13% |
| ACT | Duval Triangle | IEC Code-60599 | Rogers’ 4 Ratios | Modified IEC Code | Modified Rogers’ 4 Ratios | Clustering | Conditional Probability | CSUS ANN | SVM-BA | Gaussian | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PD | 16 | 93.75 | 43.75 | 37.5 | 8.5 | 75 | 93.75 | 100 | 8.5 | 87.5 | 81.25 |
| D1 | 26 | 76.92 | 26.92 | 0 | 76.92 | 84.61 | 84.61 | 76.92 | 69.23 | 92.31 | 34.61 |
| D2 | 42 | 85.71 | 66.66 | 73.80 | 90.47 | 88.09 | 85.71 | 97.61 | 92.85 | 95.24 | 78.57 |
| T1 | 32 | 65.62 | 53.125 | 90.62 | 93.75 | 93.75 | 93.75 | 87.5 | 93.75 | 93.75 | 90.62 |
| T2 | 16 | 50 | 68.75 | 25 | 93.75 | 93.75 | 31.25 | 81.25 | 43.75 | 87.5 | 0 |
| T3 | 28 | 100 | 82.14 | 57.14 | 89.28 | 89.28 | 85.7 | 82.14 | 71.42 | 96.48 | 100 |
| All | 160 | 80 | 58.12 | 53.75 | 88.75 | 88.12 | 82.5 | 88.12 | 80 | 93.75 | 69.37 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benmahamed, Y.; Kherif, O.; Teguar, M.; Boubakeur, A.; Ghoneim, S.S.M. Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier. Energies 2021, 14, 2970. https://doi.org/10.3390/en14102970
Benmahamed Y, Kherif O, Teguar M, Boubakeur A, Ghoneim SSM. Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier. Energies. 2021; 14(10):2970. https://doi.org/10.3390/en14102970
Chicago/Turabian StyleBenmahamed, Youcef, Omar Kherif, Madjid Teguar, Ahmed Boubakeur, and Sherif S. M. Ghoneim. 2021. "Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier" Energies 14, no. 10: 2970. https://doi.org/10.3390/en14102970
APA StyleBenmahamed, Y., Kherif, O., Teguar, M., Boubakeur, A., & Ghoneim, S. S. M. (2021). Accuracy Improvement of Transformer Faults Diagnostic Based on DGA Data Using SVM-BA Classifier. Energies, 14(10), 2970. https://doi.org/10.3390/en14102970