Advances in the Definition of Needs and Specifications for a Climate Service Tool Aimed at Small Hydropower Plants’ Operation and Management †

 , ,
, ,  and
and 
Abstract
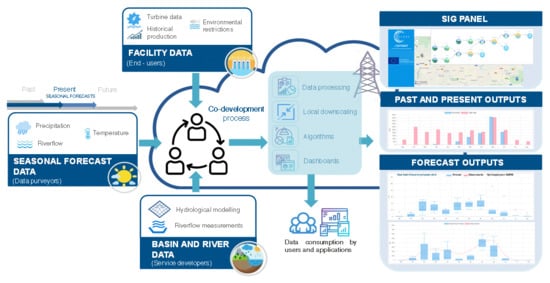
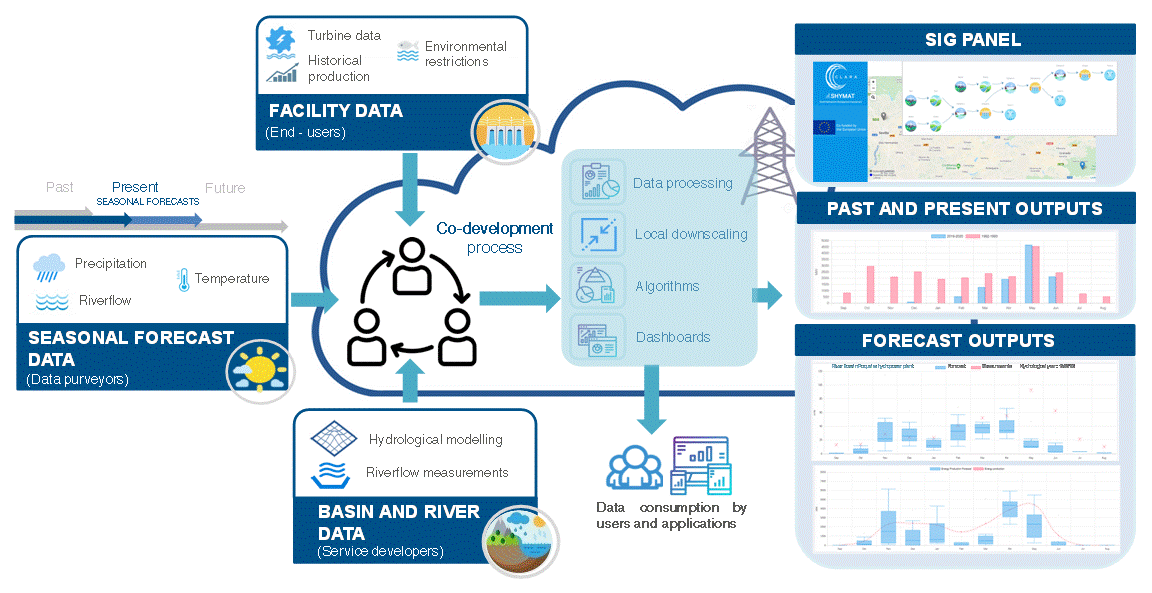
1. Introduction
2. Materials and Methods
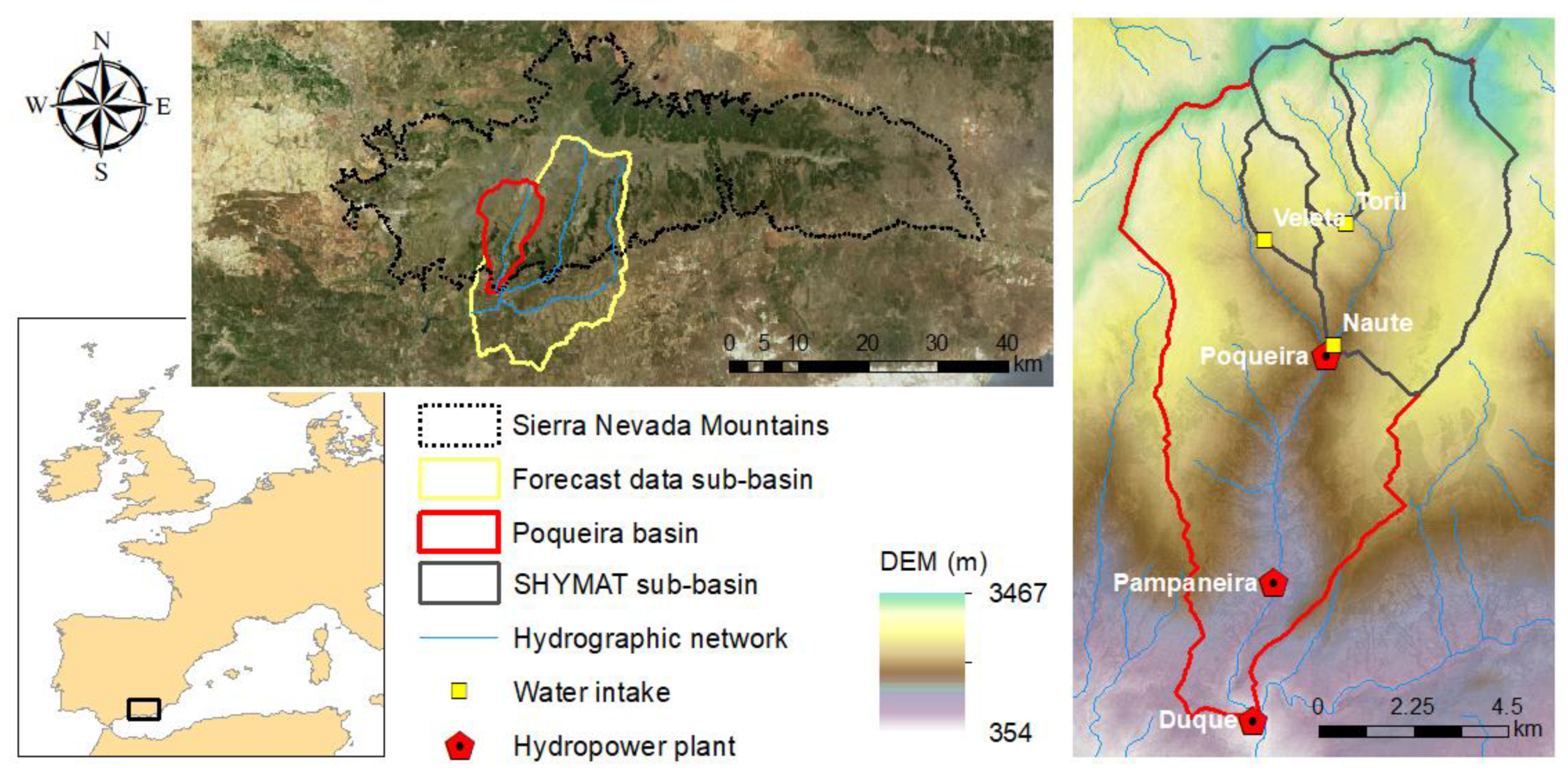
2.1. The Pilot Area in Southern Spain
2.2. Data and Models
- Seasonal (which go up to a seven-month prediction lead time) forecast of daily river flow data issued monthly by the Swedish Meteorological and Hydrological Institute (SMHI). SMHI produces these data by forcing the E-HYPE (European Hydrological Predictions for the Environment) model with the ECMWF SEAS5 seasonal forecast. SEAS5 is based on a global climate model, which, since the oceanic circulation is a major source of predictability in the seasonal scale, is based on coupled ocean-atmosphere integrations [17]. E-HYPE is the European setup of the HYPE model, which calculates hydrological variables on a daily time step at an average sub-basin resolution of 120 km2 over the entire continent [17,18,19]. Figure 1 shows the location of the sub-basin where seasonal forecast data are produced, which has a size of 527 km2. Probabilistic forecasts are produced as an ensemble of scenarios that present the range of future river flow possibilities. In the service testing stage, we used the SEAS5 hindcast period 1981–2015 for each calendar month and up to seven months ahead, considering an ensemble of 51 members. In this work, the raw seasonal forecast data were presented at a monthly scale and downscaled to the intake points of the three RoR systems to match the temporal and spatial scale suitable for this particular application. This was done by using a quantile mapping methodology [20,21], usually adopted as a bias correction method, which leads to a good performance [21,22].
- Interpolation of the meteorological real-time data and current state of the hydrological variables were extracted from GMS-Snowmed service [23], which makes use of WiMMed (Water Integrated Management in MEDiterranean Environments) [24,25,26], a physically based and fully distributed hydrological model. This service makes use of past and quasi-real-time observations of daily hydro-meteorological data (precipitation, temperature, river flow), from different meteo-hydrological networks in the area (Red Guadalfeo, SAIH Guadalquivir, RIA-JA, Red Hidrosur). The outputs of GMS-Snowmed directly offer distributed information about the antecedent weather and current water availability in the basin upstream from the RoR plants at daily and monthly scales.
- Past observations of daily streamflow measurements provided by the managers of the hydropower system and available for the period 1969–2018. These data provide a very adequate overview of the historical river inflow to the RoR system.
- Some records related to the specific consumption of the turbines that are also provided by the managers of the hydropower system. This information is mainly used to compute the production of the hydropower plants.
- Threshold value of the target indicators in the service, according to the turbine’s minimum and maximum discharge, provided by the managers of the hydropower system.
- Minimum environmental flow restrictions, as defined in the Hydrological Plan of the Mediterranean River Basin, the water authority in the study site.
2.3. Climate Service Approach
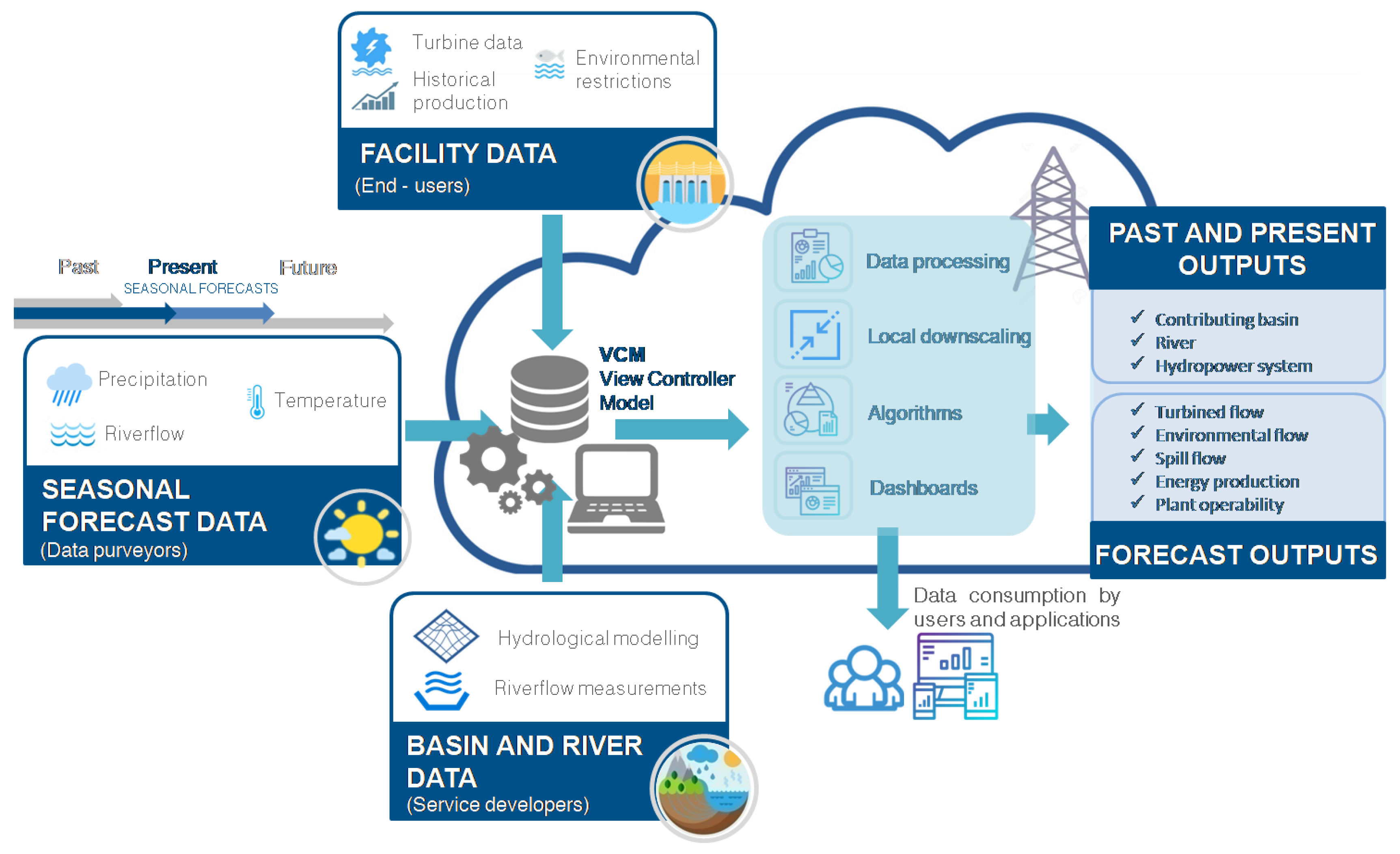
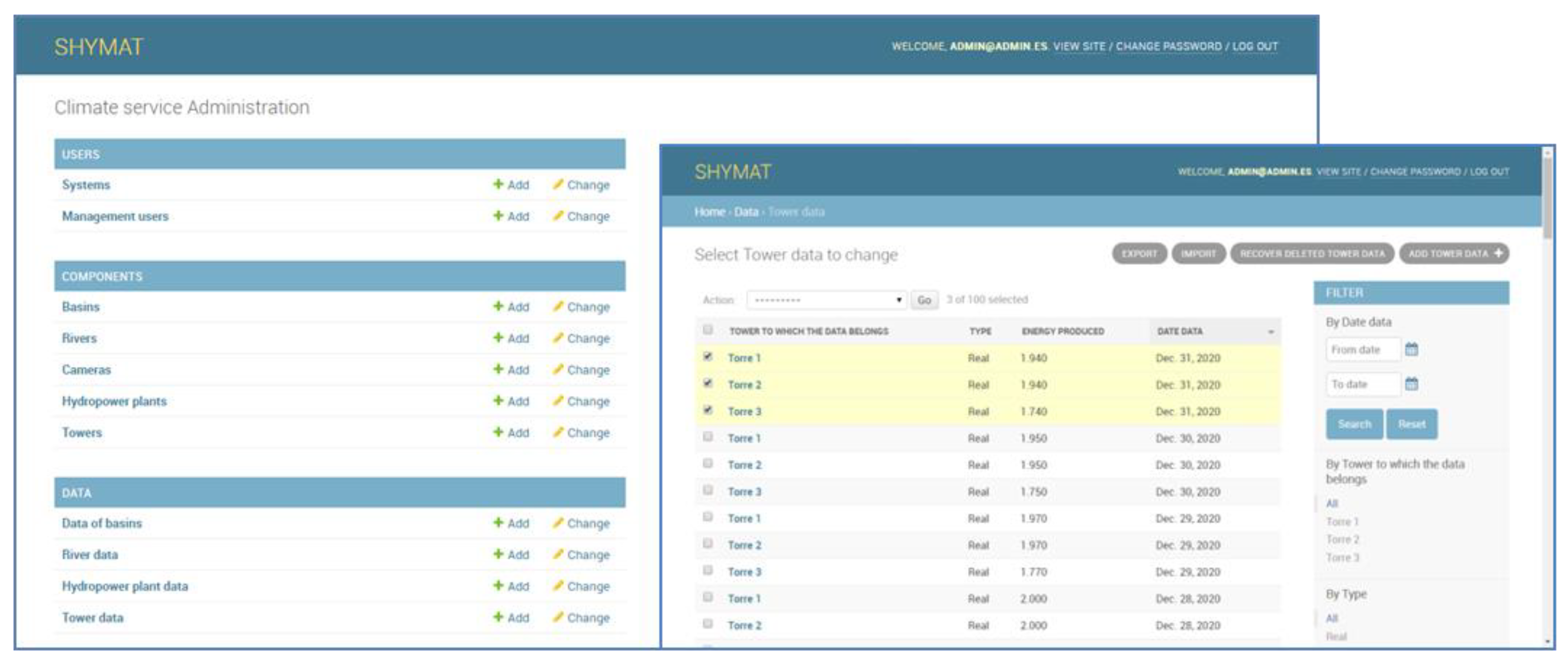
- A web administration panel: A CS administrator (or also a CS developer) accesses a panel in order to define, store, and manage the information to be included in SHYMAT. Through this administration panel, a CS administrator is able to create users, hydropower systems, the elements that compose the hydropower systems (rivers, load chambers, hydropower plants, basins, power grid), and also import the available data (related to climate, hydrology, energy production, and local facility data).
- A web-user interface: A CS user accesses a graphical application, which allows fast and intuitive access to all the information included in SHYMAT. This user interface has capacities for SIG geolocalization, user registration, data processing and acquisition, and graphical monitoring and supervision of the hydropower systems. It includes two different modes: One for “historical information” and another one for “forecast information”. The historical mode is devoted to showing weather and hydrological past and real-time data. The forecast mode includes hydro-meteorological forecast information and offers the user seasonal forecast information together with a prediction of the operability of the plant and the energy production expected for the next seven months (because, as it was already said before, seasonal forecast data go up to a seven-month prediction lead time).
3. Results
3.1. Outcomes of the Co-Development Process
- The user needs and the specifications and requirements to be implemented in the CS were set according to the operation in RoR plants. SHYMAT should cover the end-user’s needs, providing an answer to these questions: (1) Will my RoR plant be operative during the coming months? (2) What is the best date to plan maintenance tasks for the next coming months? (3) Will the minimum environmental flow restrictions be met for the next months? (4) What is the energy production expected for the coming months? and (5) When should I tune up the machines to increase the capacity of my plant to take advantage of the water excess discharges coming from snowmelt?
- Hydropower managers traditionally use historical inflows in order to predict the water availability and energy production; different past data-based scenarios (last year, driest year, wettest year) are compared to the current situation on a monthly basis, as a simple forecast approach. The difficulty in using forecast information is mainly that the data do not provide reliable and concise information to be used in the decision support process.
- The main data required for the CS implementation provided by the end-users were identified: Specific consumption of the machines, turbine minimum and maximum discharge, ecological flow to be considered, historical daily production, and turbined flow data.
- Regarding the analysis of how the CS could improve the management of the plants, the definition of payoff should be considered in terms of the amount of produced energy. However, the value of the energy production forecast is also related to market issues and to the schedule of the operation for investment or maintenance tasks.
- The web-user interface and graphical outputs were defined. One of the main lessons learnt was that users prefer graphs that are not too technical and do not contain too much information in the same graph, as well as clear information about the forecast skill and comparison between the past forecast and observed data. Moreover, users were also interested in the hydrological state of the basin upstream (defined by variables, such as the current amount of snow) and short-term forecast data, as managers also need to plan for the short term (which will be taken into account in the updated version of the service).
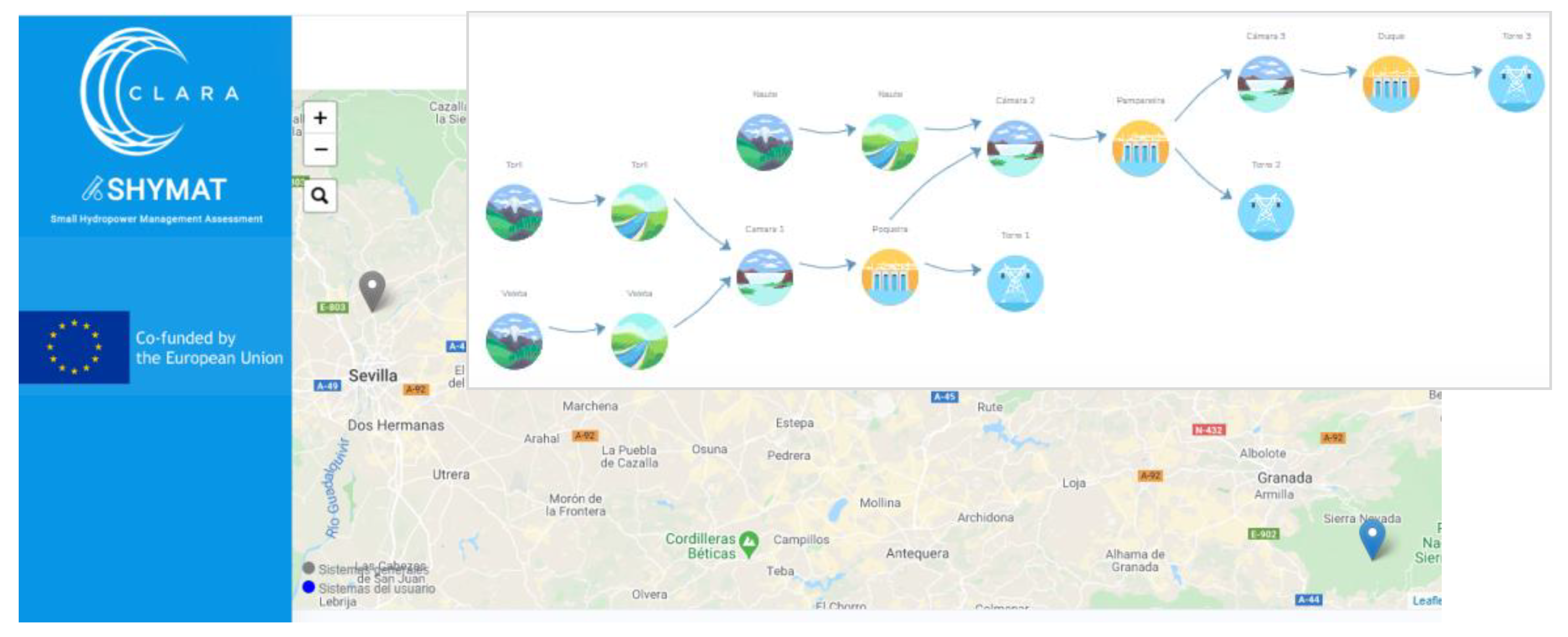
- The CS tool should be easily scalable to other small hydropower plants. For this reason, SHYMAT is presented as a cloud web application based on a scalable database, allowing implementation in other systems with similar characteristics to the pilot area. This database is managed through an administration panel, which includes the users and typical component and data of the hydropower systems (Figure 3). From the information included in this database, a topological panel is dynamically generated showing the different components and relations (Figure 4).
- Uncertainty information is one of the key issues when providing trustworthy forecast information to end-users, especially in the case of seasonal forecast information due to its higher uncertainty when compared to short-term forecasts, which they are usually familiar with. For this, the interaction with the end-users in the cogeneration process of the service was crucial for them not only to understand what uncertainty means in this framework but also to efficiently advise on how to incorporate this metadata in a displayable and rigorous way. As will be shown in Section 3.2, forecast information is included in the service as probabilistic data by using boxplot graphs, which graphically show the data through their quartiles. This provides a range of potentially likely values and how probable each interval is.
- A login screen for each customer to access its personalized web page service. After on-line registration, access is given to certain RoR systems (payed access) or only to public information (open access). Both types of access login need to be previously accepted by the service developers’ team.
- A GIS (Geographic Information System) panel: A geolocation map presents the user all the RoR systems included in SHYMAT, showing in a different color those over which the user has control (the rest will not be selectable, since they would belong to other users). Then, the user can select a system to launch an information queries process through a topological panel.
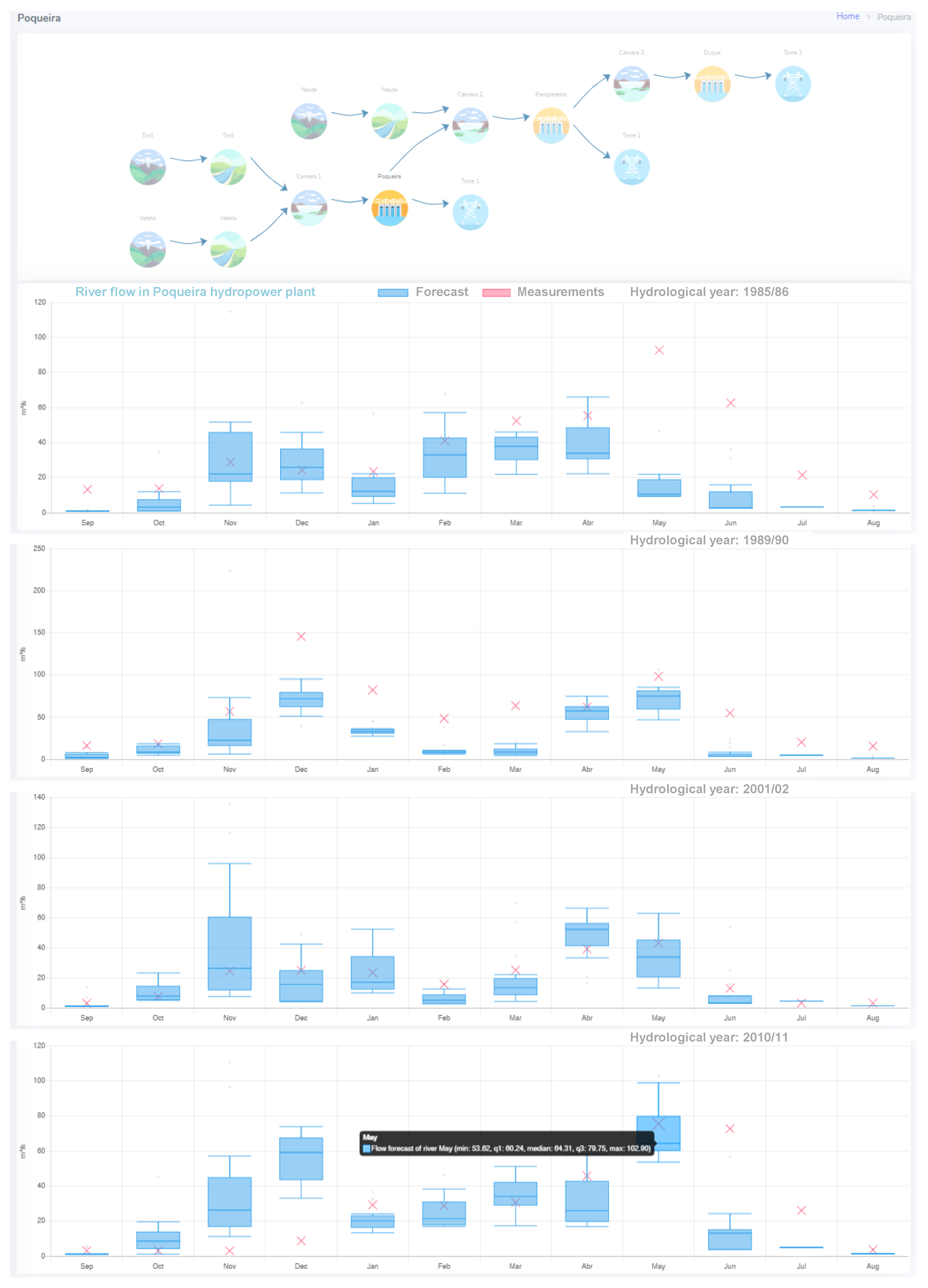
- A topological panel module: All the elements that comprise the small hydropower system and their interactions need to be defined during the setup phase of the CS; after, the topological panel of the system is dynamically generated. The sequence of icons in the topology panel means the path which river flow follows from the sub-basin outlet, passing through a river stretch, load chamber, and hydropower plant, and ending in the conversion to energy.
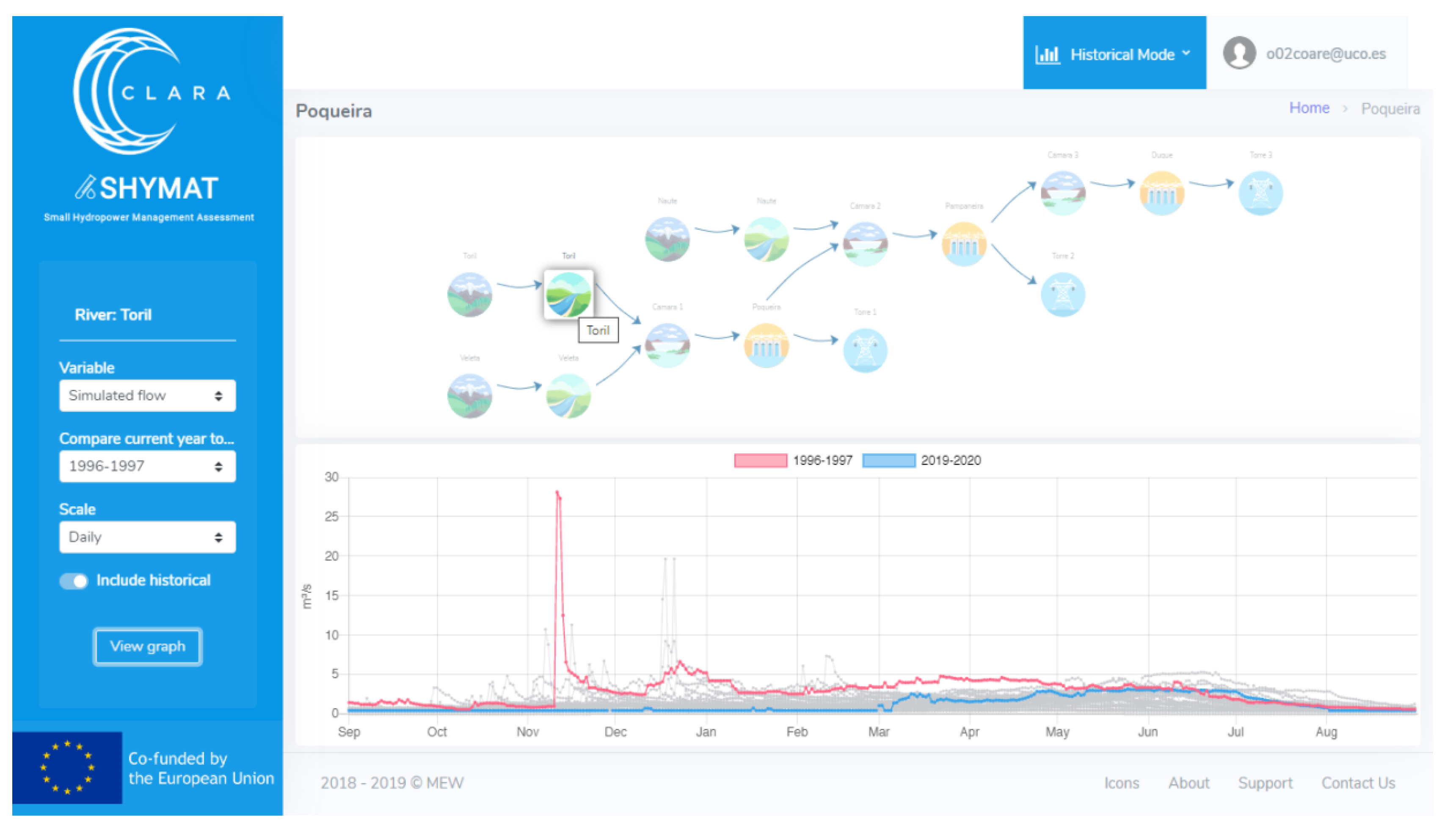
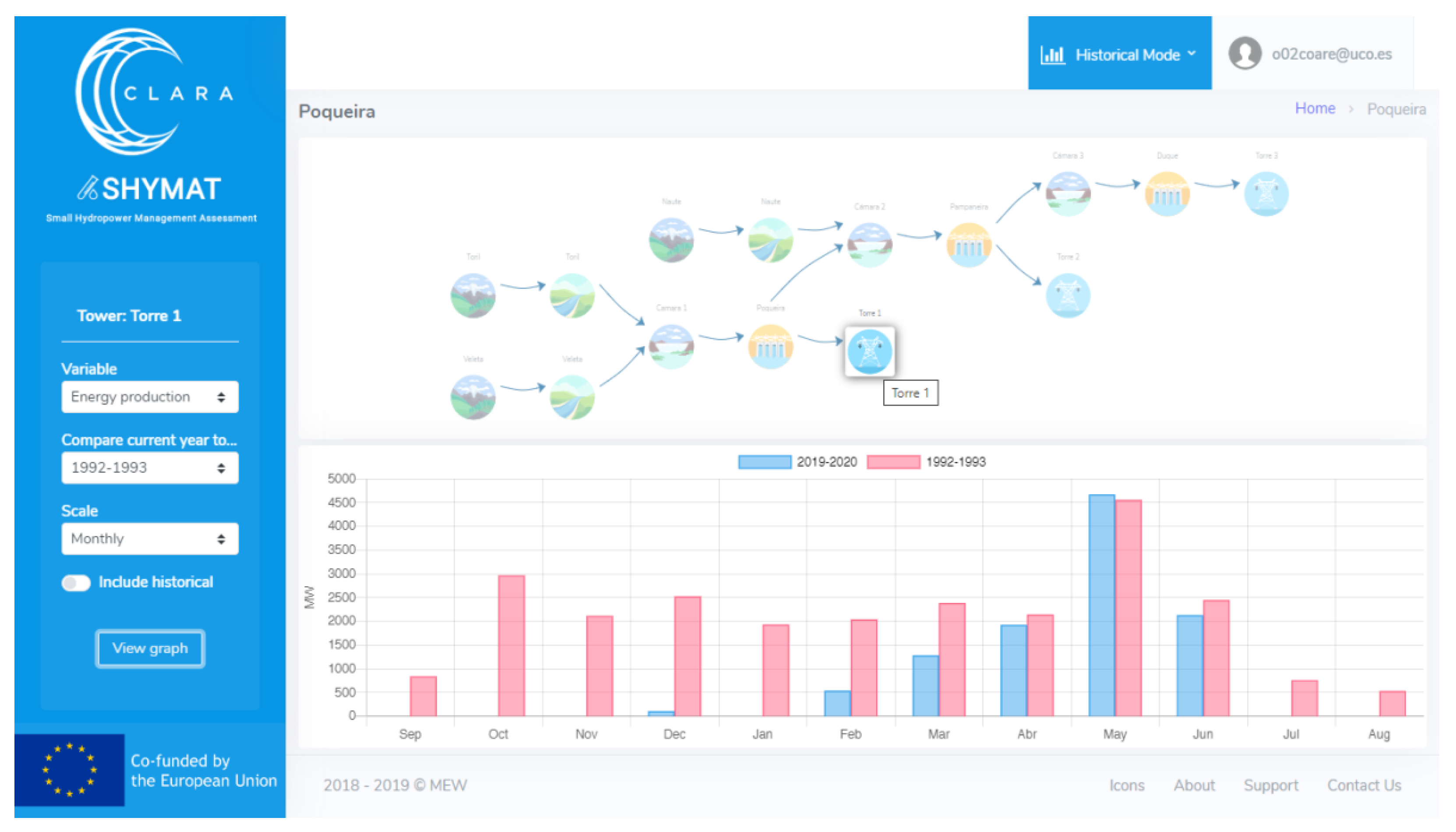
- A water availability and operation module: Here, a set of weather data (rainfall, snow, and temperature), hydrological data (river flow), and operation data (number of days with operation and energy production) is computed and stored. This provides users with information about the past, present, and future climate and water availability in the basin and in the uptake point of the plant. This module includes both a historical and a forecast information mode. In the historical mode, hydro-meteorological and operational data related to the RoR system are displayed and compared for different years at a daily and monthly scale. The module for forecast purposes covers some operation aspects, such as the inflow, operability, and energy production, expected for the next seven months according to the provided seasonal climate forecast.
- A tool for exporting the raw data to different formats required by the user and sending queries for certain periods. This facilitates the integration of the CS outputs into the individual operational and managerial systems of the end-users.
3.2. Service Outputs
- Hydro-meteorological forecast: The user can check how the temperature, precipitation, or river flow forecasts compare with past years. Information about both periods, the previous past five months and the next seven months, is shown in the same graph. Moreover, this option allows the user to compare the past forecast data with past observed data so that the end-user can check the level of the skill of the seasonal forecast information.
- Inflow forecast: Forecast of the water availability is provided for the next seven months. Moreover, this information is split into the turbine discharge and spill but also into a minimum environmental flow, the minimum flow that must be released from a plant in order to meet environmental water requirements. These water volumes are computed according to the turbine’s minimum and maximum discharge values and the environmental requirements defined in the hydrological plan. An example of the presentation of inflow forecast data, for the hydrological years 1985/86, 1989/90, 2001/02, and 2010/11 (with annual precipitation around 450, 840, 510, and 700 mm, respectively), is presented in Figure 7. Once a hydropower plant element is selected in the topology panel, a graph showing forecast and real or measured data of monthly river flow data is displayed on the screen. Here, real data are represented as points; however, as forecasts are produced as an ensemble of scenarios that present the range of future river flow possibilities, this variable is represented as boxplots, giving the user a range of values with an associated probability. In most of the cases, the forecasted values are close to real values, which is expected because forecast data show a wide range of possibilities. However, as shown in Figure 7, it seems that snow precipitation is underestimated by the forecast model. On the other hand, the melting of snow causes an increase in flow at times of melting (winter and spring) and the flow remains constant during the maintenance of flow in the first months of the summer, even though this fact is not captured by the forecast data either. Thus, after comparing monthly forecast data with monthly real data and considering the maximum, mean, and minimum values of the forecast, the river flow predictions are true in 54% of the cases for the hindcast period 1981–2015.
- Operability forecast: The operability of the plant is predicted according to the production and non-production periods for the next seven months. In this sense, the number of days of the month in which the inflow forecast reaches or drops below the turbine’s minimum discharge is computed, which means the periods when the water availability in the plant is enough for the system to remain operational or stop, respectively.
- Energy production forecast: An estimation of the energy production is given taking into account the prediction of water available to be discharged and the specific consumption of the turbines. Figure 8 shows how well the energy production forecast data fits the real data.
4. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yildiz, V.; Vrugt, J.A. A toolbox for the optimal design of run-of-river hydropower plants. Environ. Model. Softw. 2019, 111, 34–152. [Google Scholar] [CrossRef]
- Berga, L. The Role of Hydropower in Climate Change Mitigation and Adaptation: A Review. Eng. Lond. 2016, 2, 313–318. [Google Scholar] [CrossRef]
- Paish, O. Small hydro power: Technology and current status. Renew. Sustain. Energy Rev. 2020, 6, 537–556. [Google Scholar] [CrossRef]
- IRENA. Renewable Energy Technologies: Cost Analysis Series-Hydropower; IRENA Secretariat: Abu Dhabi, United Arab Emirates, 2012; Volume 1, Available online: www.irena.org/Publications (accessed on 23 January 2020).
- Manzano-Agugliaro, F.; Tahera, M.; Zapata-Sierra, A.; Del Juaidi, A.; Montoya, F.G. An overview of research and energy evolution for small hydropower in Europe. Renew. Sustain. Energy Rev. 2017, 75, 476–489. [Google Scholar] [CrossRef]
- Li, G.; Sun, Y.; He, Y.; Li, X.; Tu, Q. Short-Term Power Generation Energy Forecasting Model for Small Hydropower Stations Using GA-SVM. Math. Probl. Eng. 2014, 2014, 381387. [Google Scholar] [CrossRef]
- Monteiro, C.; Ramirez-Rosado, I.J.; Fernández-Jimenez, L.A. Short-term forecasting model for aggregated regional hydropower generation. Energy Convers. Manag. 2014, 88, 231–238. [Google Scholar] [CrossRef]
- Anugrah, P.; Setiawan, A.A.; Budiarto, R.; Sihana, F. Evaluating Micro Hydro Power Generation System under Climate Change Scenario in BayangCatchment, KabupatenPesisir Selatan, West Sumatra. Energy Procedia 2015, 65, 257–263. [Google Scholar] [CrossRef]
- MainardiFana, F.; Schwanenberg, D.; Collischonna, W.; Weerts, A. Verification of inflow into hydropower reservoirs using ensemble forecasts of the TIGGE database for large scale basins in Brazil. J. Hydrol. Reg. Stud. 2015, 4, 196–277. [Google Scholar]
- Contreras, E.; Herrero, J.; Aguilar, C.; Polo, M.J. Management and Operation of Small Hydropower Plants through a Climate Service Targeted at End-Users. In Proceedings of the2019 IEEE International Conference on Environment and Electrical Engineering and 2019 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Genova, Italy, 11–14 June 2019; pp. 1–6. [Google Scholar]
- ECMWF. ECMWF Ensemble Weather Forecasting. Available online: https://www.ecmwf.int/en/about/media-centre/fact-sheet-ensemble-weather-forecasting (accessed on 15 December 2019).
- Climate change |Copernicus. Available online: https://www.copernicus.eu/en/services/climate-change (accessed on 1 April 2019).
- Johnson, S.J.; Stockdale, T.N.; Ferranti, L.; Balmaseda, M.A.; Molteni, F.; Magnusson, L.; Tietsche, S.; Decremer, D.; Weisheimer, A.; Balsamo, G.; et al. SEAS5: The new ECMWF seasonal forecast system. Geosci.Model Dev. 2019, 12, 1087–1117. [Google Scholar] [CrossRef]
- Pérez-Palazón, M.J.; Pimentel, R.; Herrero, J.; Aguilar, C.; Perales, J.M.; Polo, M.J. Extreme values of snow-related variables in Mediterranean regions: Trends and long-term forecasting in Sierra Nevada (Spain). Proc. Int. Assoc. Hydrol. Sci. 2015, 369, 157–162. [Google Scholar] [CrossRef]
- Herrero, J.; Polo, M.J.; Moñino, A.; Losada, M.A. An energy balance snowmelt model in a Mediterranean site. J. Hydrol. 2009, 371, 98–107. [Google Scholar] [CrossRef]
- Pimentel, R.; Herrero, J.; Polo, M.J. Subgrid parameterization of snow distribution at a Mediterranean site using terrestrial photography. Hydrol. Earth Syst. Sci. 2017, 21, 805–820. [Google Scholar] [CrossRef]
- Molteni, F.; Stockdale, T.; Balmaseda, M.; Balsamo, G.; Buizza, R.; Ferranti, L.; Magnusson, L.; Mogensen, K.; Palmer, T.; Vitart, F. The New ECMWF Seasonal Forecast System (System 4); ECMWF: Reading, UK, 2011; Volume 49. [Google Scholar]
- Hundecha, Y.; Arheimer, B.; Donnelly, C.; Pechlivanidis, I. A regional parameter estimation scheme for a pan-European multi-basin model. J.Hydrol. Reg. Stud. 2016, 6, 90–111. [Google Scholar] [CrossRef]
- Crochemore, L.; Ramos, M.-H.; Pechlivanidis, I.G. Can Continental Models Convey Useful Seasonal Hydrologic Information at the Catchment Scale? Water Resour.Res. 2020, 56, e2019WR025700. [Google Scholar] [CrossRef]
- Herrero, J.; Contreras, E.; Pimentel, R.; Aguilar, C.; Polo, M.J. Challenges for the Use of Seasonal Forecasts in Mediterranean Mountain Areas in 2020. In Proceedings of the SnowHydro 2020/International Conference on Snow Hydrology, Challenges in Mountain Areas, Bolzano, Italy, 28–31 January 2020. [Google Scholar]
- Heo, J.-H.; Ahn, H.; Shin, J.-Y.; Rodding Kjeldsen, T.; Jeong, C. Probability Distributions for a Quantile Mapping Technique for a Bias Correction of Precipitation Data: A Case Study to Precipitation Data Under Climate Change. Water 2019, 11, 1475. [Google Scholar] [CrossRef]
- Crochemore, L.; Ramos, M.-H.; Pappenberger, F. Bias correcting precipitation forecasts to improve the skill of seasonal streamflow forecasts. Hydrol. Earth Syst. Sci. 2016, 20, 3601–3618. [Google Scholar] [CrossRef]
- Polo, M.J.; Herrero, J.; Pimentel, R.; Pérez-Palazón, M.J. The Guadalfeo Monitoring Network (Sierra Nevada, Spain): 14 years of measurements to understand the complexity of snow dynamics in semiarid regions. Earth Syst. Sci. Data 2019, 11, 393–407. [Google Scholar] [CrossRef]
- Herrero, J.; Aguilar, C.; Millares, A.; Polo, M.J. WiMMed Manual de Usuario v1.1. Grupo de Dinámica Fluvial e Hidrología; Universidad de Córdoba: Andalusia, Spain, 2011. [Google Scholar]
- Polo, M.J.; Herrero, J.; Aguilar, C.; Millares, A.; Moñino, A.; Nieto, S.; Losada, M.A. WiMMed, a Distributed Physically-Based Watershed Model (I): Description and Validation. In Theorical, Experimental and Computational Solutions, Proceedings of the International Workshop on Environmental Hydraulics 09, Valencia, Spain, 28–29 October 2009; Taylor & Francis: Valencia, Spain, 2009; pp. 225–228. [Google Scholar]
- Herrero, J.; Millares, A.; Aguilar, C.; Egüen, M.; Losada, M.A.; Polo, M.J. Coupling Spatial And Time Scales in the Hydrological Modelling of Mediterranean Regions: WiMMed. CUNY Academic Works. 2014. Available online: https://academicworks.cuny.edu/cc_conf_hic/315/ (accessed on 18 November 2019).
- Polo, M.J.; Jurado, A.; Contreras, E.; Herrera, E.; Herrero, J.; Mysiak, J.; Calliari, E.; Del Piazzo, E.; Tornato, A.; Mazzoli, P.; et al. Climate Forecast Enabled Knowledge Services. D2.1. Forum Activity Report I. 2018. Available online: https://drive.google.com/file/d/1a1Hu2EC7dHDkx3hQGmuznReFh7SJCLYi/view (accessed on 12 February 2019).
- Lee, H.-Y.; Wanga, N.-J. Cloud-based enterprise resource planning with elastic model–view–controller architecture for Internet realization. Comp. Stand. Interf. 2019, 64, 11–23. [Google Scholar] [CrossRef]
- Buizer, J.; Jacobs, K.; Cash, D. Making short-term climate forecasts useful: Linking science and action. Proc. Natl. Acad. Sci. USA 2016, 113, 4597–4602. [Google Scholar] [CrossRef]
- Bruno, M.; Dessai, S. Exploring the use of seasonal climate forecast in Europe through expert elicitation. Clim. Risk Manag. 2015, 10, 8–16. [Google Scholar] [CrossRef]
- Maraun, D. Nonstationarities of regional climate model biases in European seasonal mean temperature and precipitation sums. Geophys. Res. Lett. 2012, 39, L06706. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Naute | Veleta | Toril |
|---|---|---|---|
| Size (km2) | 27.3 | 6.7 | 4.4 |
| Mean slope (degrees) | 21.3 | 26.0 | 21.9 |
| Mean elevation (m a.s.l.) [range] | 2508 [1530–3479] | 2775 [2106–3386] | 2479 [2000–2992] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Contreras, E.; Herrero, J.; Crochemore, L.; Pechlivanidis, I.; Photiadou, C.; Aguilar, C.; Polo, M.J. Advances in the Definition of Needs and Specifications for a Climate Service Tool Aimed at Small Hydropower Plants’ Operation and Management. Energies 2020, 13, 1827. https://doi.org/10.3390/en13071827
Contreras E, Herrero J, Crochemore L, Pechlivanidis I, Photiadou C, Aguilar C, Polo MJ. Advances in the Definition of Needs and Specifications for a Climate Service Tool Aimed at Small Hydropower Plants’ Operation and Management. Energies. 2020; 13(7):1827. https://doi.org/10.3390/en13071827
Chicago/Turabian StyleContreras, Eva, Javier Herrero, Louise Crochemore, Ilias Pechlivanidis, Christiana Photiadou, Cristina Aguilar, and María José Polo. 2020. "Advances in the Definition of Needs and Specifications for a Climate Service Tool Aimed at Small Hydropower Plants’ Operation and Management" Energies 13, no. 7: 1827. https://doi.org/10.3390/en13071827
APA StyleContreras, E., Herrero, J., Crochemore, L., Pechlivanidis, I., Photiadou, C., Aguilar, C., & Polo, M. J. (2020). Advances in the Definition of Needs and Specifications for a Climate Service Tool Aimed at Small Hydropower Plants’ Operation and Management. Energies, 13(7), 1827. https://doi.org/10.3390/en13071827