A Novel Risk-Based Prioritization Approach for Wireless Sensor Network Deployment in Pipeline Networks



Abstract
1. Introduction
- Sorting—identifying the critical regions by ranking different deployment regions in terms of risk;
- Optimizing—determining the deployment strategy in order to achieve the maximum utility of a wireless sensor network.
- Our approach combines risk-based prioritization with spatial statistics, which quantitatively estimates risk of any geographic region where the pipeline network located with the consideration of the area of the region. It is very useful for the second step to be executed when the deployment/placement scheme is required to be assessed based on coverage ratio;
- Statistical tests are applied before modelling, which provide a strong credible basis for the estimation of risk uncertainty. It is valuable for engineers to determine the deployed region with consideration of the effect of condition monitoring, in particular, detecting the failure events.
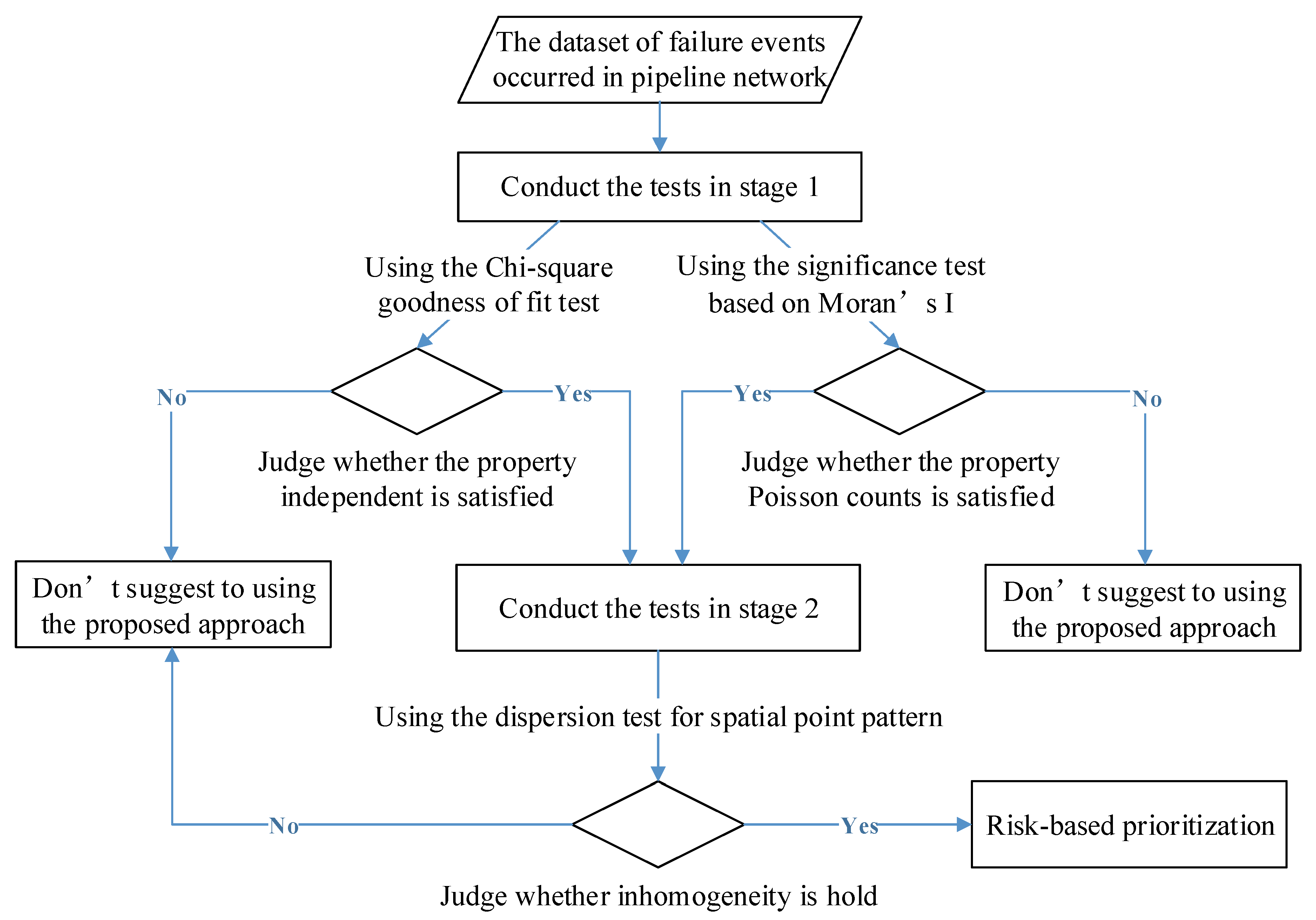
2. Method
2.1. Inhomogeneous Poisson Point Process
- Poisson Counts—the number of failure events, , has a Poisson distribution;
- Independent—if parts of Region are , ,…, , which do not overlap, the counts ,…, are independent random variables.
2.2. Statistical Tests for Inhomogeneous Poisson Point Process
2.2.1. First Test in Stage One: Chi-Square Goodness of Fit Test
- H0: the number of pipeline failure events in Region and a given period, , follows a Poisson distribution;
- H1: the number of pipeline failure events in Region and a given period, , does not follow a Poisson distribution.
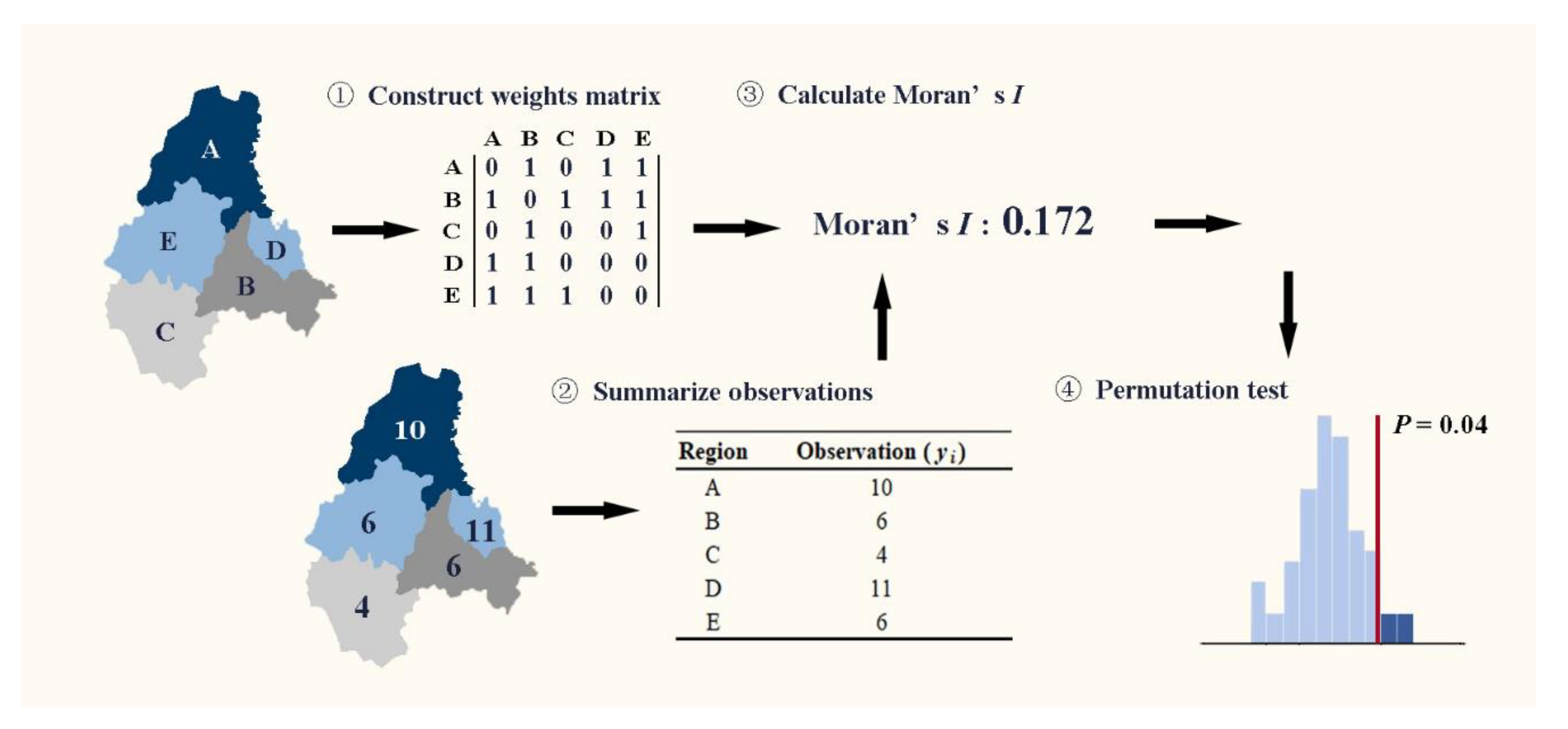
2.2.2. Second Test in Stage One: The Significance Test Based on Moran’s I
- H0: the number of pipeline failure events in different regions are spatially independent;
- H1: the number of pipeline failure events in different regions are spatially dependent.
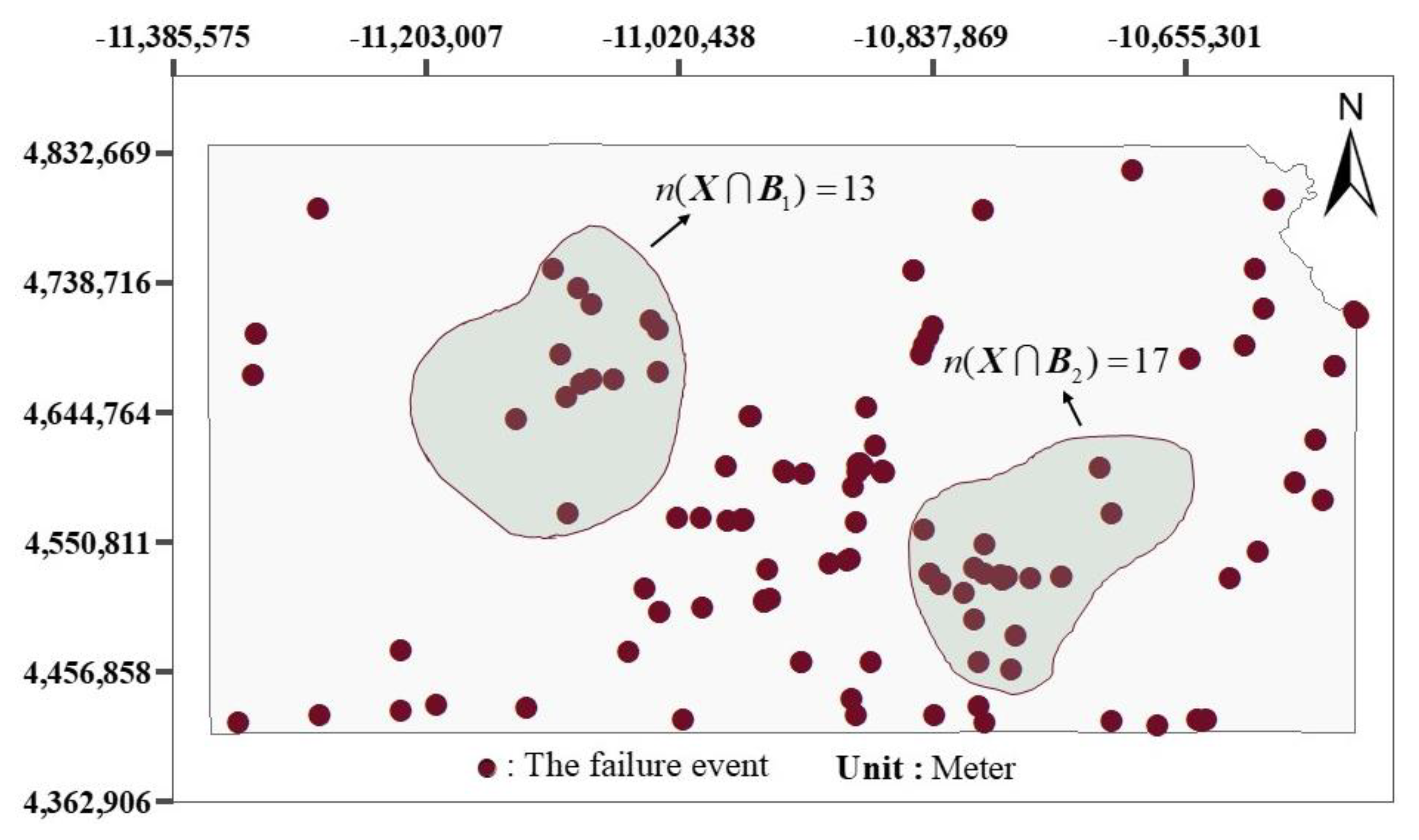
2.2.3. Test in Stage Two: The Dispersion Test for Spatial Point Pattern Based on Quadrat Counts
- H0: the intensity is homogeneous in the Poisson point process based on the dataset of pipeline failure events;
- H1: the intensity is inhomogeneous in the Poisson point process based on the dataset of pipeline failure events.
2.3. Risk-Based Prioritization
3. Case Study
3.1. Statistical Tests for Inhomogeneous Poisson Point Process
3.2. Risk-Based Prioritization
3.3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheklat, L.; Amad, M.; Boukerram, A. Wireless Sensor Networks, State of Art and Recent Challenges: A Survey. Sens. Lett. 2017, 15, 697–719. [Google Scholar] [CrossRef]
- Modieginyane, K.M.; Letswamotse, B.B.; Malekian, R.; Abu-Mahfouz, A.M. Software defined wireless sensor networks application opportunities for efficient network management: A survey. Comput. Electr. Eng. 2018, 66, 274–287. [Google Scholar] [CrossRef]
- Martini, A.; Rivola, A.; Troncossi, M. Autocorrelation Analysis of Vibro-Acoustic Signals Measured in a Test Field for Water Leak Detection. Appl. Sci. 2018, 8, 2450. [Google Scholar] [CrossRef]
- Yazdekhasti, S.; Piratla, K.R.; Atamturktur, S.; Khan, A. Experimental evaluation of a vibration-based leak detection technique for water pipelines. Struct. Infrastruct. Eng. 2017, 14, 46–55. [Google Scholar] [CrossRef]
- Martini, A.; Troncossi, M.; Rivola, A. Vibroacoustic Measurements for Detecting Water Leaks in Buried Small-Diameter Plastic Pipes. J. Pipeline Syst. Eng. Pr. 2017, 8, 04017022. [Google Scholar] [CrossRef]
- Ali, A.; Mihaylova, L.; Adebisi, B.; Ikpehai, A. Location prediction optimisation in WSNs using Kriging interpolation. IET Wirel. Sens. Syst. 2016, 6, 74–81. [Google Scholar] [CrossRef]
- Aguiar, E.F.K.; Roig, H.L.; Mancini, L.H.; De Carvalho, E.N.C.B. Low-Cost Sensors Calibration for Monitoring Air Quality in the Federal District—Brazil. J. Environ. Prot. 2015, 6, 173–189. [Google Scholar] [CrossRef]
- Sivaraman, V.; Carrapetta, J.; Hu, K.; Luxan, B.G. HazeWatch: A participatory sensor system for monitoring air pollution in Sydney. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks—Workshops, Sydney, NSW, Australia, 21–24 October 2013; pp. 56–64. [Google Scholar]
- Carrapetta, J. Haze Watch: Design of a Wireless Sensor Board for Measuring Air Pollution. Ph.D. Thesis, School of Electrical Engineering and Telecommunications, Sydney, NSW, Australia, 2010. [Google Scholar]
- Marlow, D.; Beale, D.J.; Burn, S. A pathway to a more sustainable water sector: Sustainability-based asset management. Water Sci. Technol. 2010, 61, 1245–1255. [Google Scholar] [CrossRef]
- Aznoli, F.; Navimipour, N.J. Deployment Strategies in the Wireless Sensor Networks: Systematic Literature Review, Classification, and Current Trends. Wirel. Pers. Commun. 2016, 95, 819–846. [Google Scholar] [CrossRef]
- Rashid, B.; Rehmani, M.H. Applications of wireless sensor networks for urban areas: A survey. J. Netw. Comput. Appl. 2016, 60, 192–219. [Google Scholar] [CrossRef]
- Stoianov, I.; Nachman, L.; Madden, S.; Tokmouline, T. PIPENETa wireless sensor network for pipeline monitoring. In Proceedings of the 6th International Conference on Multimodal Interfaces—ICMI ’04, Porto, Portugal, 9–13 September 2007; p. 264. [Google Scholar]
- Wang, C.; Wang, B.; Liu, W. Movement strategies for improving barrier coverage in wireless sensor networks: A survey. In Proceedings of the 2011 IEEE 13th International Conference on Communication Technology, Jinan, China, 25–28 September 2011; pp. 938–943. [Google Scholar]
- Liu, Y.; Ma, X.; Li, Y.; Tie, Y.; Zhang, Y.; Gao, J. Water Pipeline Leakage Detection Based on Machine Learning and Wireless Sensor Networks. Sensors 2019, 19, 5086. [Google Scholar] [CrossRef] [PubMed]
- Wang, B. Coverage problems in sensor networks. ACM Comput. Surv. 2011, 43, 1–53. [Google Scholar] [CrossRef]
- Mini, S.; Udgata, S.; Sabat, S. Sensor Deployment and Scheduling for Target Coverage Problem in Wireless Sensor Networks. IEEE Sens. J. 2013, 14, 636–644. [Google Scholar] [CrossRef]
- Chaudhary, M.; Pujari, A.K. Q-Coverage Problem in Wireless Sensor Networks. Comput. Vis. 2008, 5408, 325–330. [Google Scholar]
- Gu, Y.; Liu, H.; Zhao, B. Target Coverage With QoS Requirements in Wireless Sensor Networks. In Proceedings of the The 2007 International Conference on Intelligent Pervasive Computing (IPC 2007), Jeju Island, Korea, 11–13 October 2007; pp. 35–38. [Google Scholar]
- Cardei, M.; Thai, M.T.; Li, Y.; Wu, W. Energy-efficient target coverage in wireless sensor networks. In Proceedings of the IEEE 24th Annual Joint Conference of the IEEE Computer and Communications Societies, Miami, FL, USA, 13–17 March 2005; Volume 3, pp. 1976–1984. [Google Scholar]
- A Papadakis, G.; Porter, S.; Wettig, J. EU initiative on the control of major accident hazards arising from pipelines. J. Loss Prev. Process. Ind. 1999, 12, 85–90. [Google Scholar] [CrossRef]
- Huang, C. Integration degree of risk in terms of scene and application. Stoch. Environ. Res. Risk Assess. 2008, 23, 473–484. [Google Scholar] [CrossRef]
- Calixto, E. Integrated Asset integrity management: Risk management, human factor, reliability and maintenance integrated methodology applied to subsea case. In Proceedings of the Safety and Reliability of Complex Engineered Systems; Informa UK Limited: London, UK, 2015; pp. 3425–3432. [Google Scholar]
- Hassan, J.; Khan, F. Risk-based asset integrity indicators. J. Loss Prev. Process. Ind. 2012, 25, 544–554. [Google Scholar] [CrossRef]
- Vinod, G.; Sharma, P.K.; Santosh, T.; Prasad, M.H.; Vaze, K. New approach for risk based inspection of H2S based Process Plants. Ann. Nucl. Energy 2014, 66, 13–19. [Google Scholar] [CrossRef]
- Arunraj, N.; Maiti, J. Risk-based maintenance—Techniques and applications. J. Hazard. Mater. 2007, 142, 653–661. [Google Scholar] [CrossRef]
- Vinod, G.; Bidhar, S.; Kushwaha, H.; Verma, A.; Srividya, A. A comprehensive framework for evaluation of piping reliability due to erosion–corrosion for risk-informed inservice inspection. Reliab. Eng. Syst. Saf. 2003, 82, 187–193. [Google Scholar] [CrossRef]
- Tchórzewska-Cieślak, B.; Pietrucha-Urbanik, K. Approaches to Methods of Risk Analysis and Assessment Regarding the Gas Supply to a City. Energies 2018, 11, 3304. [Google Scholar] [CrossRef]
- Fleming, K.N. Markov models for evaluating risk-informed in-service inspection strategies for nuclear power plant piping systems. Reliab. Eng. Syst. Saf. 2004, 83, 27–45. [Google Scholar] [CrossRef]
- Vesely, W.; Belhadj, M.; Rezos, J. PRA importance measures for maintenance prioritization applications. Reliab. Eng. Syst. Saf. 1994, 43, 307–318. [Google Scholar] [CrossRef]
- Luque, J.; Straub, D. Risk-based optimal inspection strategies for structural systems using dynamic Bayesian networks. Struct. Saf. 2019, 76, 68–80. [Google Scholar] [CrossRef]
- Cagno, E.; Caron, F.; Mancini, M.; Ruggeri, F. Using AHP in determining the prior distributions on gas pipeline failures in a robust Bayesian approach. Reliab. Eng. Syst. Saf. 2000, 67, 275–284. [Google Scholar] [CrossRef]
- Marlow, D.R.; Beale, D.J.; Mashford, J. Risk-based prioritization and its application to inspection of valves in the water sector. Reliab. Eng. Syst. Saf. 2012, 100, 67–74. [Google Scholar] [CrossRef]
- Case Studies in Spatial Point Process Modeling. Case Stud. Spat. Point Process Modeling 2006, 101, 17–35.
- Geyer, C.J.; Møller, J. Simulation procedures and likelihood inference for spatial point processes. Scand. J. Stat. 1994, 21, 359–373; [Google Scholar] [CrossRef]
- Schoenberg, F.P.; Brillinger, D.R.; Guttorp, P. Point Processes, Spatial-Temporal. Encycl. Environ. 2006. [Google Scholar]
- Penttinen, A.; Stoyan, D. statistics. Stat. Sci. 2000, 15, 61–78. [Google Scholar] [CrossRef]
- Rowlingson, B. A Conditional Approach to Point Process Modelling of Elevated Risk. J. R. Stat. Soc. Ser. A Stat. Soc. 1994, 157, 433. [Google Scholar]
- Velázquez, E.; Martinez, I.; Getzin, S.; Moloney, K.A.; Wiegand, T. An evaluation of the state of spatial point pattern analysis in ecology. Ecography 2016, 39, 1042–1055. [Google Scholar] [CrossRef]
- Sprent, P. An Introduction to Categorical Data Analysis. J. R. Stat. Soc. Ser. A Stat. Soc. 2007, 170, 1178. [Google Scholar] [CrossRef]
- Singhal, R.; Rana, R. Chi-square test and its application in hypothesis testing. J. Pr. Cardiovasc. Sci. 2015, 1, 69. [Google Scholar] [CrossRef]
- Preacher, K.J. Calculation for the Chi-Square Test: An Interactive Calculation Tool for Chi-Square Tests of Goodness of Fit and Independence [Computer Software]. 2001. Available online: http://quantpsy.org (accessed on 17 July 2018).
- Li, H.; Calder, C.; Cressie, N. Beyond Moran’s I: Testing for Spatial Dependence Based on the Spatial Autoregressive Model. Geogr. Anal. 2007, 39, 357–375. [Google Scholar] [CrossRef]
- Getis, A. A History of the Concept of Spatial Autocorrelation: A Geographer’s Perspective. Geogr. Anal. 2008, 40, 297–309. [Google Scholar] [CrossRef]
- Drapeau, P.; Legendre, P. Spatial autocorrelation and sampling design in plant ecology. Plant Ecol. 1989, 83, 209–222. [Google Scholar]
- Rosenbaum, P.R. The Consquences of Adjustment for a Concomitant Variable That Has Been Affected by the Treatment. J. R. Stat. Soc. Ser. A Gen. 1984, 147, 656. [Google Scholar] [CrossRef]
- Willis, H. Guiding Resource Allocations Based on Terrorism Risk. Risk Anal. 2007, 27, 597–606. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Failure Events Per Month () | Observed Frequency ( |
|---|---|
| 0 | 18 |
| 1 | 28 |
| 2 | 17 |
| 3 | 11 |
| 4 | 6 |
| 5 | 3 |
| 6 | 0 |
| 7 | 1 |
| No. | Cost |
|---|---|
| 1 | Property Damage Costs |
| 2 | Lost Commodity Costs |
| 3 | Public/Private Property Damage Costs |
| 4 | Emergency Response Costs |
| 5 | Environmental Remediation Costs |
| 6 | Other Costs |
| Attribution | Description |
|---|---|
| Failure location | The location of the failure occurrence of pipeline network, which is represented in terms of latitude and longitude. |
| Failure time | The time of the failure occurrence in the pipeline network |
| Failure cause | The cause of failure |
| Total cost | The total cost caused by the consequence of each pipeline failure |
| Statistic | Result |
|---|---|
| Moran’s Index | 0.055905 |
| Expected Moran’s Index | −0.066667 |
| Z-score | 1.153184 |
| P-value | 0.248577 |
| Region ID | Area (km2) | Region ID | Area (km2) | Region ID | Area (km2) | Region ID | Area (km2) |
|---|---|---|---|---|---|---|---|
| 1 | 21810.48 | 5 | 22064.53 | 9 | 22095.08 | 13 | 22034.45 |
| 2 | 21906.91 | 6 | 22136.67 | 10 | 22136.67 | 14 | 22046.50 |
| 3 | 21847.71 | 7 | 22136.67 | 11 | 22136.67 | 15 | 21962.08 |
| 4 | 21612.80 | 8 | 21936.47 | 12 | 21720.03 | 16 | 17064.15 |
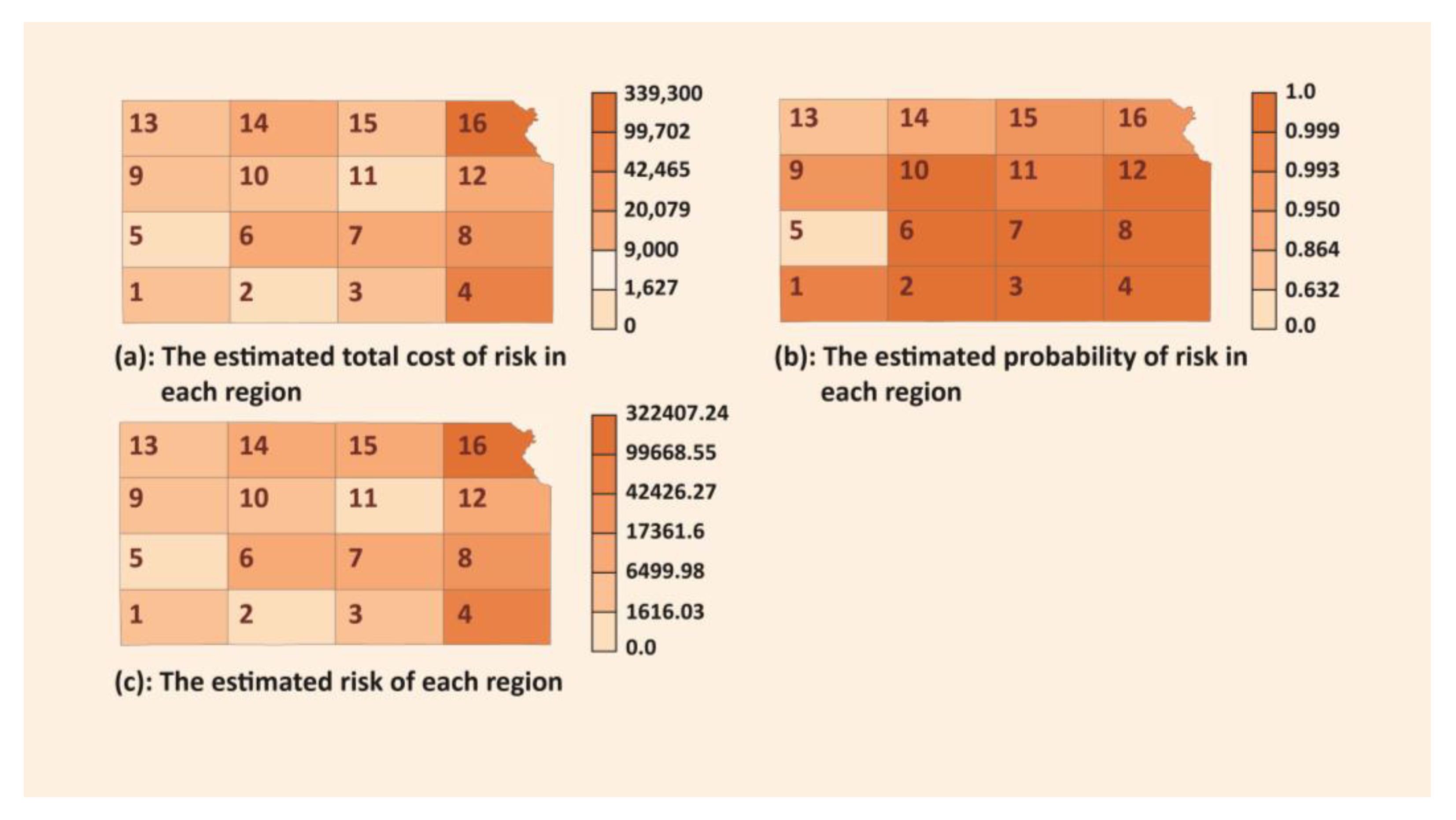
| Region ID | Cost ($) | Rank | Probability | Rank | Risk | Rank |
|---|---|---|---|---|---|---|
| 16 | 339300 | 1 | 0.950213 | 12 | 322407 | 1 |
| 4 | 99702 | 2 | 0.999665 | 7 | 99668.6 | 2 |
| 8 | 42465 | 3 | 0.999088 | 8 | 42426.3 | 3 |
| 14 | 20079 | 4 | 0.864665 | 14 | 17361.6 | 4 |
| 12 | 13110 | 5 | 0.999983 | 5 | 13109.8 | 5 |
| 7 | 12150 | 6 | 1 | 1 | 12150 | 6 |
| 6 | 11012 | 7 | 0.999877 | 6 | 11010.6 | 7 |
| 15 | 9000 | 8 | 0.950213 | 11 | 8551.92 | 8 |
| 3 | 6500 | 9 | 0.999998 | 2 | 6499.99 | 9 |
| 9 | 4750 | 10 | 0.950213 | 13 | 4513.51 | 10 |
| 10 | 3880 | 12 | 0.999994 | 3 | 3879.98 | 11 |
| 1 | 3510 | 13 | 0.993262 | 10 | 3486.35 | 12 |
| 13 | 3888 | 11 | 0.632121 | 15 | 2457.68 | 13 |
| 11 | 1627 | 14 | 0.993262 | 9 | 1616.04 | 14 |
| 2 | 300 | 15 | 0.999994 | 4 | 299.998 | 15 |
| 5 | 0 | 16 | 0 | 16 | 0 | 16 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yi, X.; Hou, P.; Dong, H. A Novel Risk-Based Prioritization Approach for Wireless Sensor Network Deployment in Pipeline Networks. Energies 2020, 13, 1512. https://doi.org/10.3390/en13061512
Yi X, Hou P, Dong H. A Novel Risk-Based Prioritization Approach for Wireless Sensor Network Deployment in Pipeline Networks. Energies. 2020; 13(6):1512. https://doi.org/10.3390/en13061512
Chicago/Turabian StyleYi, Xiaojian, Peng Hou, and Haiping Dong. 2020. "A Novel Risk-Based Prioritization Approach for Wireless Sensor Network Deployment in Pipeline Networks" Energies 13, no. 6: 1512. https://doi.org/10.3390/en13061512
APA StyleYi, X., Hou, P., & Dong, H. (2020). A Novel Risk-Based Prioritization Approach for Wireless Sensor Network Deployment in Pipeline Networks. Energies, 13(6), 1512. https://doi.org/10.3390/en13061512