Abstract
In this paper, a new object in the form of a theoretical network is presented, which is useful as a benchmark for particle filtering algorithms designed for multivariable nonlinear systems (potentially linear, nonlinear, and even semi-Markovian jump system). The main goal of the paper is to propose an object that potentially can have similar to the power system grid properties, but with the number of state variables reduced twice (only one state variable for each node, while there are two in the case of power systems). Transition and measurement functions are proposed in the paper, and two types of transition functions are considered: dependent on one or many state variables. In addition, 10 types of measurements are proposed both for branch and nodal cases. The experiments are performed for 14 different, four-dimensional systems. Plants are both linear and highly nonlinear. The results include information about the state estimation quality (based on the mean squared error indicator) and the values of the effective sample size. It is observed how the higher effective sample size resulted in the better estimation quality in subsequent cases. It is also concluded that the very low number of significant particles is the main problem in particle filtering of multivariable systems, and this should be countered. A few potential solutions for the latter are also presented.
1. Introduction
The particle filter (PF) is potentially a very good estimation method because it is based on the optimal solution resulting from Bayesian filtering rules. On the contrary, the biggest disadvantage of PFs is their need for computational power as the number of calculations grows exponentially with the number of system variables [1]. This is the reason why PF methods are usually used only for state estimation with plants of small order.
Some solutions to this problem are hybrid filters, e.g., Rao-Blackwellized PF (RBPF) [2,3] or marginalized PF [4], in which state variables are divided into two groups (one group is estimated using the PF method and the second group using Kalman Filter (KF) methods (linear, extended or unscented)).
Another solution was proposed in [5], where all state variables were divided into groups in which estimation processes were performed; however, the disadvantage of this method was a loss of information contained in measurements, which were based on state variables from two or more groups.
The Dispersed Particle Filter (DPF) was proposed by the authors in one of the previous works [6]; this method assumed that dependencies between state variables and measurements were relatively sparse (transition and measurement functions depended on a relatively small number of different state variables). These research works were performed with the power system grid as an object. Unfortunately, the number of state variables was twice higher than the number of its nodes. Therefore, the performed calculations lasted relatively long, even for small systems.
The Power System State Estimation (PSSE) issue dates back to the 1970s, when Fred Schweppe in his three papers [7,8,9] proposed the PSSE approach using the Weighted Least Squares (WLS) method. This static estimation algorithm is still used in many applications, even after fifty years.
The literature about the PSSE topic is very rich. One can find studies relying not only on the WLS algorithm, but also Kalman filters (extended EKF [10] and unscented UKF [11]), as well as artificial neural networks [12,13]. In [14], the Mixed Kalman Particle Filter (MKPF) method was proposed, which combined elements of the EKF, UKF, and PF algorithms.
Regardless of the estimation method used, a frequent solution is a division of the whole power system grid into subareas [15,16,17,18]. A similar solution was proposed by the authors for the DPF algorithm [6], where the number of subareas was equal to the node number. However, the studies were problematic due to the calculation time. Based on studies from [19], the reasonable number of particles should be about:
where is the particle number and is the number of state variables.
The main purpose of the current article is to propose a new network-type system with the number of state variables equal to the number of nodes. Thanks to this, it will be possible to conduct studies even on quite large plants in a relatively short time. The final task will be to propose a particle filter method that will operate satisfactorily (in terms of calculation time and estimation quality) even with large networks. Based on the proposed plant, the subsequent algorithm propositions will be able to be checked quickly, and calculations in power system grids will be performed for results’ confirmation only.
However, the proposed network is much more general. It enables fast preparation of even very complex objects. Hence, it can also be used by researchers who are mainly interested in nonlinear estimation issues. Therefore, we provide a very elaborate description of the proposed system in the next section. There are many specification possibilities for both transition and measurement functions. It is also planned to share the source code, which may be used to perform calculations for a given network, without the need for code modification.
In the second section, one can find the description of the particle filter algorithm and the presentation of the proposed network. The simulations performed to evaluate the approach and the results are shown in the third section. The last section contains the conclusions and future plans in this research direction.
This paper is a greatly extended version of the article presented during the 13th Federated Conference on Computer Science and Information Systems (FedCSIS 2018) [20].
For a better understanding of the content presented herein, the authors describe the most important symbols in Table 1.

Table 1.
Explanations of the most important symbols used in the article.
2. Materials and Methods
2.1. Particle Filter
A plant can be expressed by the following state-space equations:
where is a state vector, is an input vector, is an output vector, and vectors and are internal and measurement noises, respectively; all at the time step. The main task of the considered particle filter is to estimate the state vector (2) based on the measurements and input signals.
The particle filters’ operation principle is based on recursive Bayesian filtering [21]:
where is a set of measurement vectors from the first to the time step, is a posterior Probability Density Function (PDF), is a prior PDF, is a likelihood, and is evidence (normalization factor).
The key idea in the considered PF is to implement the posterior PDF as a set of particles. The particle is represented by a pair composed of the state value and the weight. The higher the weight, the higher the probability that the value is close to the real state vector. If the number of particles, , is high enough, the information about the posterior PDF contained in the particle set is the same as in the continuous PDF function.
The first particle filter was proposed in 1993 by Gordon, Salmond, and Smith [22] and was called the bootstrap filter. The operation principle of this PF is presented in Algorithm 1.
| Algorithm 1: bootstrap filter |
|
The considered PF can be used for both non-Gaussian distributions and complex transition models. An example of such a complex system model can be a semi-Markovian jump system [23], in which the whole system model can switch to a different structure (with some probability) described by other equations and also can go back to the previous “system equations”.
Resampling
Resampling is a very important step of the algorithm. Its main task is to prevent particles from degeneration. The Sequential Importance Sampling (SIS) is an example of the algorithm without resampling and is a direct predecessor of the PF. The above-mentioned problem relates to the effect when all but one particles have their weights equal to or near zero (and the weight of that one particle tends to 1).
The particle filter is inherently connected to resampling; hence, the first usage of resampling was presented in the same article in which the particle filter was proposed [22]. During the resampling stage, particles must be drawn from the PDF obtained in previous steps. At every draw stage, the probability that the specific particle will be drawn is equal to its normalized weight.
The first resampling algorithm that was proposed in the literature is an algorithm called later “multinomial resampling”, which requires random numbers from uniform PDF . The particle is duplicated (one can also say that it is reproduced) if the condition:
holds. However, this approach has a computational complexity of order at least .
The linear complexity provided later resulted in resampling being proposed, e.g., “systematic resampling”, which was used by the authors in all experiments presented here. In this resampling, only one random value is needed, and each of the other “drawn” values is higher by from the previous one. The systematic resampling is presented in Algorithm 2 (it is assumed that rand() means a random value drawn from uniform distribution ).
| Algorithm 2: systematic resampling [24] |
1. j=1; sumQ=q(j); 2. u=rand()/N_p; 3. for i=1..N_p 4. while sumQ<u 5. j=j+1; 6. sumQ=sumQ+q(j); 7. end 8. xx(i)=x(j); 9. qq(i)=1/N_p; 10. u=u+(1/N_p); 11. end |
This particular resampling, as well as many other schemes can be found in [24], in which over 20 different algorithms, which can be used in PFs, were presented and compared.
However, even a linearly-executed resampling is the “bottleneck” of the whole PF algorithm, because all other steps can be performed in parallel. This is the reason why in some solutions, the resampling is not executed in every iteration, but only if the Effective Sample Size (ESS) (marked by ) is lower than a specified threshold (usually taken as a half of the particle number [25,26]). This parameter can be calculated by:
between Steps 4 and 5 of Algorithm 1 (after weight normalization). However, based on [27], (5) is not the only estimator of ESS, and quite good properties are also given by the measure , because the range of the practical threshold influence is wider.
The ESS parameter can be treated as the information of how many particles give significant information about the current PDF. It can take any value in the range between 1 and . For example, if all the particles have weights equal to , then:
For the case with particle weights , , , , the ESS is equal to 3.33, and if only one particle has a non-zero weight, then .
The works in [28,29,30,31] are recommended for more information about particle filters.
2.2. Proposed Network
The authors proposed a grid, which on the one hand could be easily adapted for particular requirements, and on the other hand provided wide possibilities in the new plants creation. This explained why there are many complex and maybe even incomprehensible options presented below; however, the most common networks will be presented in a very simple way. Objects created in this way will not make any physical sense, but will be an appropriate and demanding benchmark for any proposed algorithm. Moreover, if one needs to add any dependence, which is not specified, there still is a possibility to present this on the scheme.
The proposed network is composed of nodes and lines (branches). Two different nodes can be connected by a line. Exactly one state variable is associated with the node (, where is the number of state variables). Nodes can be represented in two ways: by circles or by squares. Transition function depends on the shape of the node.
In the first transition function type (circles on the scheme), a state variable depends only on itself (value from the previous time step). In the second type (squares), a state value depends on all state variables, which are connected (by branches) to the calculated state variable. Expressions for transition functions of the first type (circles) are presented below, and their connections with scheme designations are described in Table 2.
Table 2.
Explanation of designations: nodes, Part 1; for transition functions, which are based only on the state variable.
It should be noted that more than one of these expressions can be used for a specific node. For example, one can obtain transition function (11) (wide equation) by the graphical notation presented in Figure 1. In such cases, an internal noise is of course added only once.
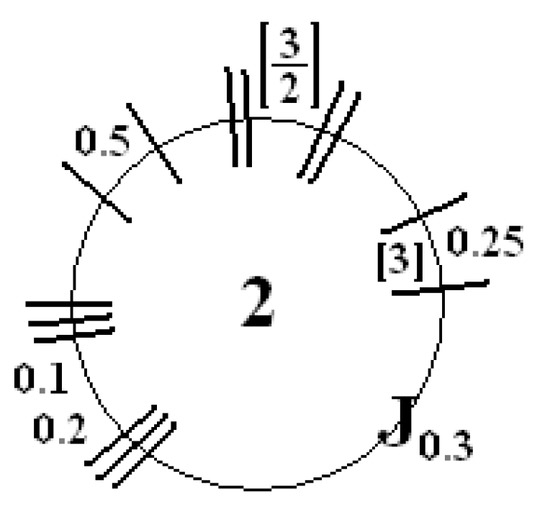
Figure 1.
Exemplary designations to obtain the transition function described by Equation (11).
For the second type of transition functions, connections between nodes play a vital role. The branch between the and nodes has a value and order ; whereas, if there is no connection between the and nodes, the branch has a value (line order does not matter in such a case). It is also assumed that and .
The types of lines are specified, which differ in line functions (where i is the number of nodes, from which line function “was called”). These functions are defined in the remaining part of the paper, and their connections with scheme designations are described in Table 3. Line functions will be used in both transition and measurement functions. If anywhere, occurs (e.g., in Equation (17)), it is assumed that the first type of line function should be used, and all line parameters are the default.
Table 3.
Explanation of designations: lines.
The second type of transition functions (squares), which depend also on other state variables, are presented below, i.e., in Equations (15)–(18), and their designations are presented and described in Table 4.
Table 4.
Explanation of designations: nodes, Part 2; for transition functions, which are based also on other state variables.
It is also possible to combine both transition function types (circles and squares). An example is presented in Figure 2, and the appropriate transition function of the first state variable is written in Equation (19). To obtain the jump function (Equation (18)) for both types of transition function, the “J” mark and value should be given in the place where the square and circle are connected.
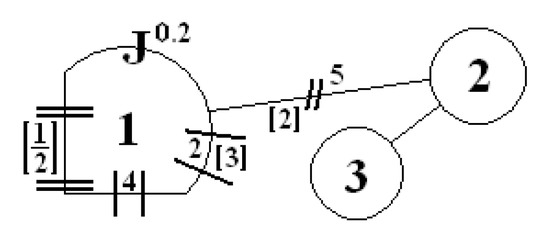
Figure 2.
Exemplary designations to combine both types of transition functions; described by Equation (19).
Inputs should be presented by the element shown in Figure 3. The specific input signal should be presented inside the element, and as long as it is possible, all needed parameters for simulation should be described inside the input figure (see Figure 3).
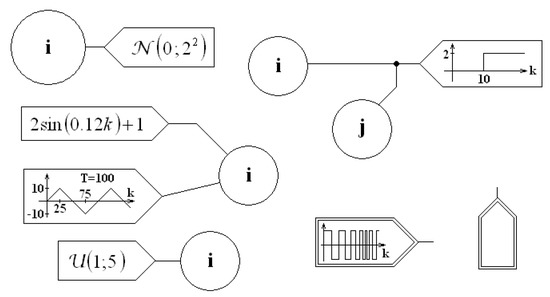
Figure 3.
Exemplary input signal notation; the input signal should be presented as an arrow-shaped pentagon. As long as it is possible, the input signal should be integrally described inside the shape. If it is not possible, the pentagon should be doubled, and an explanation should be given in the text.
One state variable can have more than one input signal. If it is not obvious that the signal is periodic, one should insert information about the period length (in time steps), e.g., “”. If all information about the input signal cannot be presented on the scheme, a double “input figure” should be used (examples are presented in Figure 3 on the right side).
The type of internal noise also should be presented on the scheme, or optionally, it should be described in the text. The PDF type with parameters should be connected to a specific node by a dashed line. Examples are presented in Figure 4.
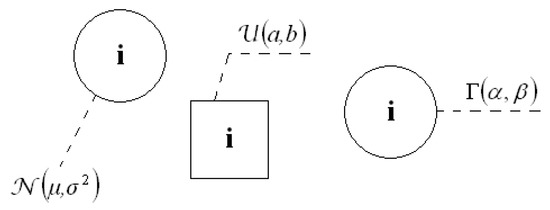
Figure 4.
Internal noises should be marked on schemes using dashed lines that connect the distributions and nodes of state variables. Probability distributions should have specified parameters.
Measurements are presented on the scheme by filled marks. There are two types of measurements: nodal (associated with a specific node) and branch (associated with a specific line). The nodal measurement can depend on a state variable of this node and also on all state variables of the nodes that are connected with this node by lines. The branch measurement depends only on the two state variables of the two nodes that are connected by the line where the measurement is placed. In the case of branch measurements, one should keep in mind that the first index informs about near to which node a specific branch measurement is placed (branch measurements are not symmetric in general).
All nodal measurements proposed in the new network (, , , , ) are described by (20)–(24), and examples of the designations on the scheme are presented in Table 5; whereas all proposed branch measurements are written by (25)–(29), and the exemplary designations are presented in Table 6.
Table 5.
Explanation of designations: measurements, Part 1; for nodal measurements at the node.
Table 6.
Explanation of designations: measurements, Part 2; for branch measurements between the and nodes, but at the node.
The measurement noise should be marked in the same way as the internal noise: by a description in the text or using a dashed line on the scheme. Examples of measurement noise designations are presented in Table 5 and Table 6.
To use another measurement function, one can simply use a new filled mark on the scheme (such a function should be explained in the text).
2.2.1. Application for Power Systems
As was mentioned in the Introduction, the network described above can be created like the power system grid. Mainly, the S-type measurements were proposed based on the power flows and power injections, which occur in power systems. Below, 4 measurements from power grids with a description are presented; however, one should take into account that the notation presented in these equations absolutely cannot be associated with any markings of the rest of the paper (the notation is typical for the power system subject). The first two are power injections (active and reactive, respectively):
and the two subsequent are power flows (active and reactive, respectively; in power flows, the first index informs about near to which bus (node) the measurement is placed):
In the above equations, B is the number of buses in a system. , and are system parameters.
The state vector in power system grids is composed of voltage magnitudes and phase angles . One phasor (voltage magnitude and phase angle) is associated with every bus (node). Hence, it is visible that the length of the state vector is two times higher than the number of nodes (actually, the number of state variables is given by the expression, because one node must be a reference node, in which the phase angle is constant, usually taken as 0).
The system composed only of S-type measurements (nodal and branch) and P-type measurements (nodal only) should successfully simulate the power system grid properties. Therefore, one can use a system created in such a way to speed up studies (due to the lower number of state variables), and after finding a promising method or algorithm, it can be checked on power systems.
The reader is directed to [32,33] for more information about power systems.
2.2.2. Exemplary Objects from the Literature
There are a few plants, which were used in literature, presented below. The first object is usually used in research associated with particle filters. It was proposed in 1978 by Netto, Gimeno, and Mendes (according to [34]). The object is a one-variable plant, the state space model of which is described by Equations (34)–(36). This model can be presented using the designations proposed in this paper, which one can see in Figure 5.
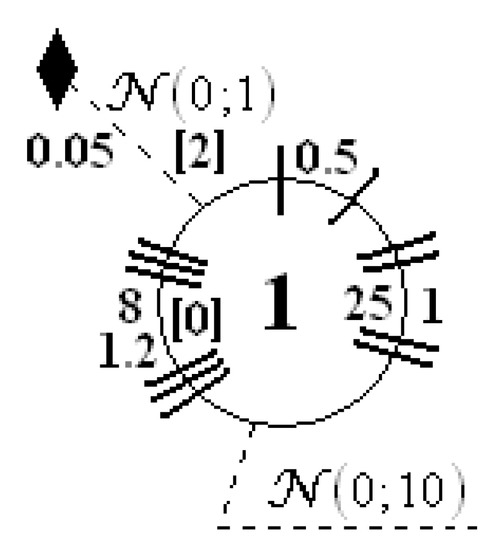
The second plant, described by Equations (37)–(39), was proposed in [35]. It can also be presented using the proposed designations, which is shown in Figure 6. This object was created based on the state Equation (34), but both (transition and measurement) functions were simplified.

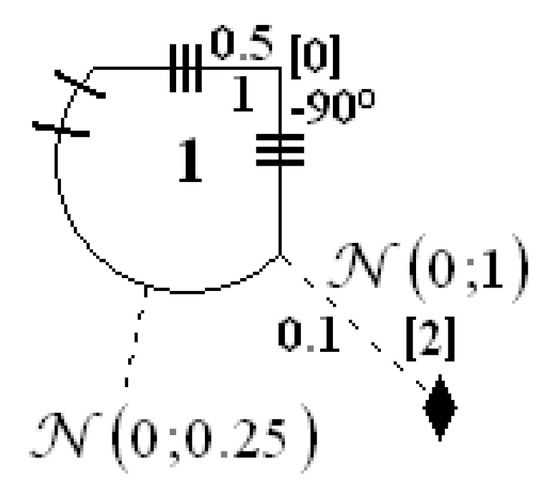
The subsequent object was used in [36] and is described by Equations (40)–(42). The description, using the proposed designations, is presented in Figure 7. As one can see, parameter was used on the scheme to obtain “sin” instead of “cos” from Equation (17).
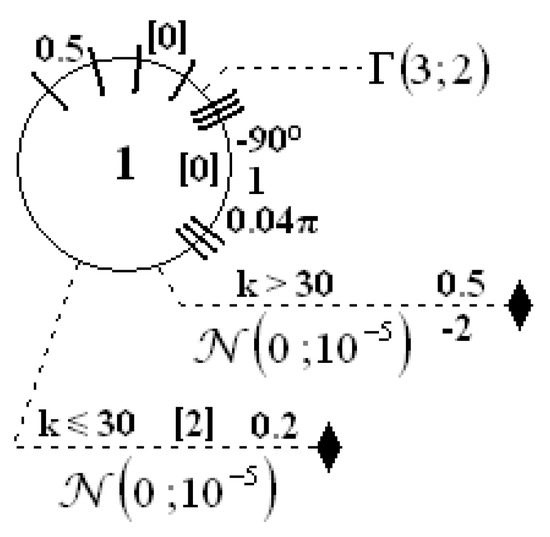
The plant described by Equations (43)–(45) differs from other objects in such a way that its measurement function is switched after 30 time steps. It is marked in Figure 8 by two measurements, but with additional information, for the range of time steps for which it should be used. Moreover, the gamma PDF was used as internal noise.
The last object, which is mentioned below, was used in [38]. It is a tracking system, and its state-space model is given by Equation (46). The first two variables (, ) are coordinates; the other two (, ) are velocities; and the system scheme is presented in Figure 9. In the referenced article, the authors did not provide information about internal and measurement noises (it is only known that they were Gaussian). State variables and do not have internal noise, and this is why on the scheme, one can find “PDF” .
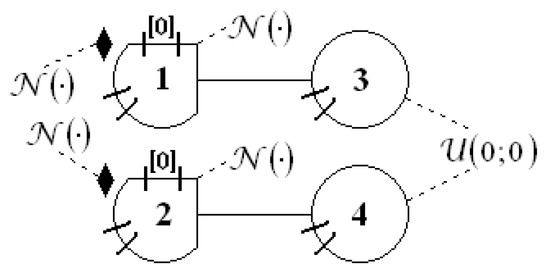
Figure 9.
Scheme of the object, which was presented in [38] and described by Equation (46).
As was presented above, it is possible to model systems presented in the literature using the network proposed in this paper; however, one should keep in mind that the main goal was the easy creation of complex, multivariable, nonlinear systems, and not modeling the existing ones. Thanks to this, research on the plants with a network-type structure is possible with a relatively short state vector (number of state variables equal to the number of nodes).
2.2.3. Plants Used in the Experiments
The experiments were performed for the networks presented in Figure 10, Figure 11 and Figure 12. On all these schemes, there are no measurements; this is because they were considered in 5 different cases: P, Q, R, S, and T. In each case, the measurements were located in every possible place, but without repetitions (10 branch measurements and 4 nodal measurements). One can see an example in Figure 13: it is a S-type case for the object.
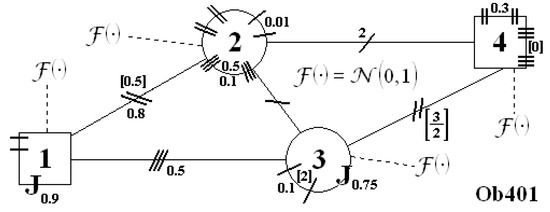
Figure 10.
Scheme of the system .
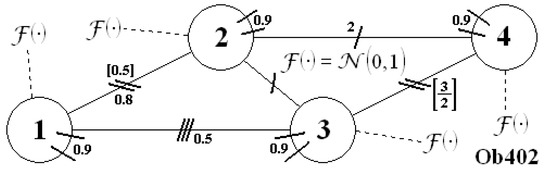
Figure 11.
Scheme of the system .
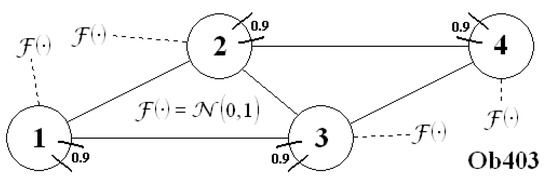
Figure 12.
Scheme of the system .
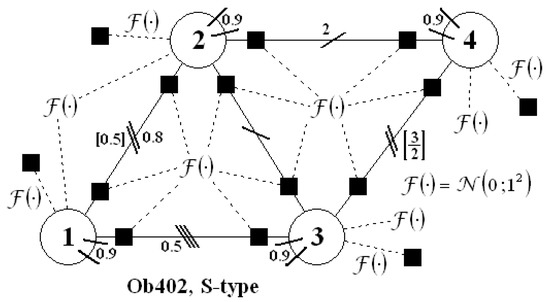
Figure 13.
Scheme of the system for the case with S-type measurements.
Finally, one should obtain 15 different systems; however, objects and had the same transition functions, and the difference was only in line functions and in line parameters, which impacted the measurements; however, P-type measurements were identical for and . Hence, the case with P-type measurements for was omitted.
The transition function of these three systems is presented below: is described by (47) and (48), and both objects, and are described by (49) and (50). All the measurement functions (for any case) one may find in the appendices: for system in Appendix A, for system in Appendix B (but the equations are the same as for ) and for plant in Appendix C (all measurements had default parameters: , , , ).
3. Results
The experiments were performed to check the dependence of the estimation quality on ESS and also on the complexity level of the transition and measurement functions.
The estimation quality was evaluated using the average root mean squared error, which is defined as:
where is the number of state variables, and:
where x with a hat is the estimated state variable, x with a plus is the real value of state variable, and M is the simulation length (set on the 1000 time steps in all experiments). The aRMSE index can be used only for comparison; it does not make any physical sense. The lower the value of this index, the better the estimation quality.
Every experiment was different, values of the initial state vector (at zero time step) were drawn from uniform distribution . It was also assumed that initial values of particles were the same as the initial state vector.
All simulations were repeated until the standard deviation of the aRMSE mean value was less than 0.0025 (the variance of the mean value was s times smaller than the variance of s samples [39]), but at least 100 times. It was not achieved only for a few cases, which are mentioned in Table 7. Moreover, also for these cases, there were ranges on the charts, which showed, with 95% probability, where the mean value was placed (according to the 68-95-99.7 rule [40]). The results are presented in Figure 14, Figure 15, Figure 16 and Figure 17.

Figure 14.
Obtained results: estimation quality based on the index for plants with P-type, R-type, and T-type measurements.
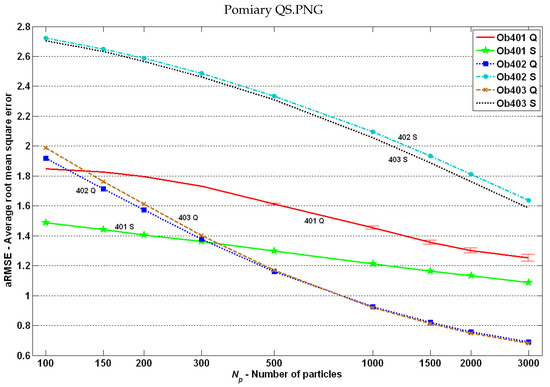
Figure 15.
Obtained results: estimation quality based on the index for plants with Q-type and S-type measurements.
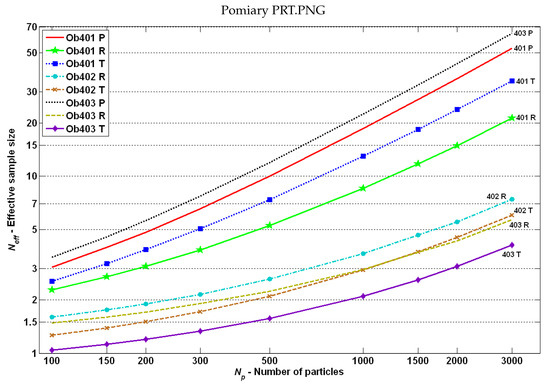
Figure 16.
Obtained results: mean effective sample size (5) for plants with P-type, R-type, and T-type measurements.
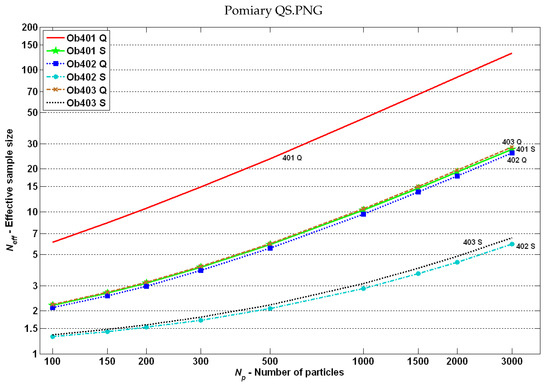
Figure 17.
Obtained results: mean effective sample size (5) for plants with Q-type and S-type measurements.
4. Discussion and Further Work
As one can suppose, the lowest aRMSE values were obtained for the completely linear case -P (except the highest number of particles, where the -R case was the best). However, in general, the complexity level of equations (measurement or transition functions) had no impact on the estimation quality, or this influence was insignificant. In most of the cases, one could see the dependence: the greater the effective sample size, the better the estimation quality.
One could see that the results obtained for objects and in cases with Q-type and S-type measurements were almost the same. This was due to the fact that these systems were very similar (identical transition functions and measurement functions different only in system parameter ). In R-type and T-type measurement functions, the line functions were used, which were very different between these two plants.
Based on the ESS results in Figure 16 and Figure 17, one can conclude that the number of particles impacted the ESS (higher with higher ), but did not impact the order of cases (graphs did not intersect). It was also visible that ESS was relatively high for P-type measurements, which could have an impact on the good estimation quality.
The most interesting was probably the fact that the dependence “the more non-linear transition and measurement functions, the worse the estimation quality” was not always met. This was visible primarily for S-type measurements (see Figure 15): for the system, the estimation quality was definitely better than for the two others. Similarly, in cases with T-type and R-type measurements (see Figure 14), a better estimation quality was obtained for the system than for the plant. Through all the experiments, the internal noise was the same. The following question arises: What was the reason for such results?
For almost all cases, one could see the relationship between the effective sample size and the estimation quality: the higher the , the lower the aRMSE. The -Q case was an exception: very high ESS (in comparison to other cases) resulted from the specificity of measurements (products of two or more state variables) and from the fact that for two state variables, “jumps” to the opposite values were possible (see Equation (47)). Consequently, although there was a relatively high number of significant particles in PF, a part of them was incorrect (with opposite signs).
However, the above-mentioned relationship was not satisfied for T-type and R-type measurements. Why was there the smallest ESS number for systems, but simultaneously the best estimation quality was obtained (in comparison to the two other objects with the same measurements type)?
In these cases, the influence had a range of measurements, which one can see in Table 8. Variances of the subsequent measurements (from exemplary experiments) are presented in this table. A higher variance meant that, during the simulations, the values of that measurement changed more.
Table 8.
Variances of the subsequent measurements during 100 experiments. The yellow background marks higher values in a column.
One should keep in mind that the measurement noises were the same (had the same distribution) during the experiments for all cases. The higher values the measurement had, the lower the impact the measurement noise had on the estimation process. As a result, the small values in these cases were associated with more accurate measurements, and not with difficulties in state vector tracking.
This could be presented in a one-dimensional example with measurement function (). For smaller values of a, a higher value of ESS was obtained, whereas for a higher value of a, lower ESS, but in the latter case, particles with significant weights would be definitely closer to the sought value. An example is presented in Figure 18.
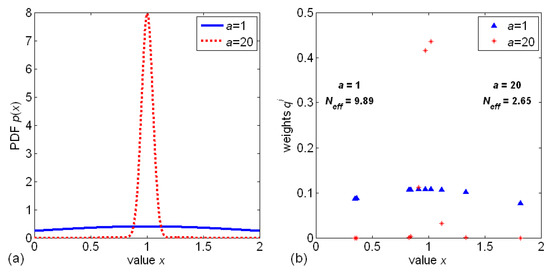
Figure 18.
An example that shows the difference in weight values for measurement (). For , measured value was assumed to be one, and for , the measured value was assumed to be 20 (for better readability). (a) Exemplary probability density functions; (b) exemplary particles (with normalized weights) drawn from PDFs.
However, regardless of the considered case, one could notice a very low number of significant particles; in most cases from two to 30. How precisely will the four-dimensional PDF be modeled using even 30 points? Using 81 points, one would have accuracy similar to modeling a one-dimensional PDF by three points.
Therefore, the authors considered that further studies should be directed at ESS increasing, and the improvement of estimation quality would be only the result of these actions. They would be started with a comparison of different PF methods and resampling algorithms, in terms of state estimation quality and effective sample size in multivariable systems.
One possible solution may be the usage of an adaptive sample size [41]; however, this would only result in the increase of the particle number, as much as ESS would achieve a set threshold. Another method, which should improve the effective sample size, is the Population Monte Carlo (PMC) algorithm [42,43]. In this approach, it is assumed that particles are divided into a few groups and each one is drawn from different PDFs. Every PDF is calculated based on the drawn, up to this moment, particles and their weights. Yet another solution could be a double drawing: the first time locating an interesting area and the second time drawing mainly from this subspace. The authors are already working on a new PF algorithm that will be based on the latter approach.
The network proposed in this article had of course some disadvantages and limitations: the graphical representation of more complex systems with a higher number of nodes would be illegible (a description in the text would also be required). Despite the fact that many different options were proposed, the one was strongly limited in the creation of transition functions, and measurements were mostly non-parametric (only scale factor was available). Furthermore, only additive noises were considered (could be also multiplicative and others).
Despite all these disadvantages, the authors believe that the proposed network was sufficient for a variety of particle filter studies, and not only this one. Additionally, for the main application (simulation of power grid behavior), it was totally suitable.
In the future, the authors will prepare and share the source code, which will allow performing experiments, not only for the networks presented in the article, but also for any other one (based on the external file with a system structure description).
Author Contributions
Conceptualization, P.K. and J.M.; methodology, J.M. and P.K.; software, P.K. and M.R.; validation, P.K.; formal analysis, J.Z. and P.K.; investigation, J.M.; resources, M.R.; writing, original draft preparation, P.K., J.Z., and J.M.; writing, review and editing, W.G., J.Z., and P.K; visualization, M.R.; supervision, W.G.; funding acquisition, W.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was financially supported as a statutory work of Poznan University of Technology (No. 0214/SBAD/0210).
Acknowledgments
Thanks to Talar Sadalla and Szymon Drgas for their help in the preparation of the conference paper, which was the basis for the creation of the current paper. We also thank Dariusz Horla for his help at the very end.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| aRMSE | average root mean squared error |
| DPF | dispersed particle filter |
| EKF | extended Kalman filter |
| ESS | effective sample size |
| KF | Kalman filter |
| MKPF | mixed Kalman particle filter |
| MSE | mean squared error |
| probability density function | |
| PF | particle filter |
| PMC | population Monte Carlo |
| PSSE | power system state estimation |
| RBPF | Rao-Blackwellized particle filter |
| RMSE | root mean squared error |
| SIS | sequential importance sampling |
| SR | systematic resampling |
| UKF | unscented Kalman filter |
| WLS | weighted least squares |
Appendix A. Measurement Equations for Object Ob401
Appendix A.1. Case for P-Type Measurements
Appendix A.2. Case for Q-Type Measurements
Appendix A.3. Case for R-Type Measurements
Appendix A.4. Case for S-Type Measurements
Appendix A.5. Case for T-Type Measurements
Appendix B. Measurement Equations for Object Ob402
The transition functions of this plant are different from ; however, all measurement functions are identical. Hence, to obtain the measurement of object , go to Appendix A.
Appendix C. Measurement Equations for Object Ob403
Appendix C.1. Case for P-Type Measurements
Appendix C.2. Case for Q-Type Measurements
Appendix C.3. Case for R-Type Measurements
Appendix C.4. Case for S-Type Measurements
Appendix C.5. Case for T-Type Measurements
References
- Sutharsan, S.; Kirubarajan, T.; Lang, T.; McDonald, M. An Optimization-Based Parallel Particle Filter for Multitarget Tracking. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 1601–1618. [Google Scholar] [CrossRef]
- Doucet, A.; De Freitas, N.; Murphy, K.; Russell, S. Rao-Blackwellised particle filtering for dynamic Bayesian networks. In Proceedings of the Sixteenth Conference on Uncertainty in Artificial Intelligence; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2000; pp. 176–183. [Google Scholar]
- Hendeby, G.; Karlsson, R.; Gustafsson, F. The Rao-Blackwellized particle filter: A filter bank implementation. EURASIP J. Adv. Signal Process. 2010, 2010, 724087. [Google Scholar] [CrossRef]
- Šmídl, V.; Hofman, R. Marginalized particle filtering framework for tuning of ensemble filters. Mon. Weather Rev. 2011, 139, 3589–3599. [Google Scholar] [CrossRef]
- Djuric, P.M.; Lu, T.; Bugallo, M.F. Multiple particle filtering. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 3, pp. 1181–1184. [Google Scholar]
- Kozierski, P.; Lis, M.; Horla, D. Level of dispersion in dispersed particle filter. In Proceedings of the 20th International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 24–27 August 2015; pp. 418–423. [Google Scholar]
- Schweppe, F.C.; Wildes, J. Power system static-state estimation, Part I: Exact model. IEEE Trans. Power Appar. Syst. 1970, 89, 120–125. [Google Scholar] [CrossRef]
- Schweppe, F.C.; Rom, D.B. Power system static-state estimation, Part II: Approximate model. IEEE Trans. Power Appar. Syst. 1970, 89, 125–130. [Google Scholar] [CrossRef]
- Schweppe, F.C. Power system static-state estimation, Part III: Implementation. IEEE Trans. Power Appar. Syst. 1970, 89, 130–135. [Google Scholar] [CrossRef]
- Monticelli, A. Electric power system state estimation. Proc. IEEE 2000, 88, 262–282. [Google Scholar] [CrossRef]
- Wang, S.; Gao, W.; Meliopoulos, A.S. An alternative method for power system dynamic state estimation based on unscented transform. IEEE Trans. Power Syst. 2011, 27, 942–950. [Google Scholar] [CrossRef]
- Pandey, J.; Singh, D. Application of radial basis neural network for state estimation of power system networks. Int. J. Eng. Sci. Technol. 2010, 2, 19–28. [Google Scholar] [CrossRef]
- Udupa, H.N.; Minal, M.; Mishra, M.T. Node Level ANN Technique for Real Time Power System State Estimation. Int. J. Sci. Eng. Res. 2004, 5, 1500–1505. [Google Scholar]
- Chen, H.; Liu, X.; She, C.; Yao, C. Power System Dynamic State Estimation based on a New Particle Filter. Procedia Environ. Sci. 2011, 11, 655–661. [Google Scholar]
- Zhu, H.; Giannakis, G.B. Multi-area state estimation using distributed SDP for nonlinear power systems. In Proceedings of the 2012 IEEE Third International Conference on Smart Grid Communications (SmartGridComm), Tainan, Taiwan, 5–8 November 2012; pp. 623–628. [Google Scholar]
- Sharma, A.; Srivastava, S.; Chakrabarti, S. Multi area state estimation for smart grid application utilizing all SCADA and PMU measurements. In Proceedings of the 2014 IEEE Innovative Smart Grid Technologies-Asia (ISGT ASIA), Kuala Lumpur, Malaysia, 20–23 May 2014; pp. 525–530. [Google Scholar]
- Xie, L.; Choi, D.H.; Kar, S. Cooperative distributed state estimation: Local observability relaxed. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, Detroit, MI, USA, 24–28 July 2011; pp. 1–11. [Google Scholar]
- Guo, Y.; Wu, W.; Wang, Z.; Zhang, B.; Sun, H. A distributed power system state estimator incorporating linear and nonlinear areas. In Proceedings of the 2014 IEEE PES General Meeting Conference & Exposition, National Harbor, MD, USA, 27–31 July 2014; pp. 1–5. [Google Scholar]
- Kozierski, P.; Sadalla, T.; Owczarkowski, A.; Drgas, S. Particle filter in multidimensional systems. In Proceedings of the 21st International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 29 August–1 September 2016; pp. 806–810. [Google Scholar]
- Kozierski, P.; Michalski, J.; Sadalla, T.; Giernacki, W.; Zietkiewicz, J.; Drgas, S. New Grid for Particle Filtering of Multivariable Nonlinear Objects. In Proceedings of the 2018 Federated Conference on Computer Science and Information Systems (FedCSIS), Poznan, Poland, 9–12 September 2018; pp. 1073–1077. [Google Scholar]
- Candy, J.V. Bayesian Signal Processing; Wiley: Hoboken, NJ, USA, 2009; pp. 237–298. [Google Scholar]
- Gordon, J.N.; Salmond, D.J.; Smith, A.F.M. Novel Approach to Nonlinear/non-Gaussian Bayesian State Estimation. IEE Proc.-F 1993, 140, 107–113. [Google Scholar] [CrossRef]
- Li, F.; Wu, L.; Shi, P.; Lim, C.C. State Estimation and Sliding Mode Control for Semi-Markovian Jump Systems with Mismatched Uncertainties. Automatica 2015, 51, 385–393. [Google Scholar] [CrossRef]
- Kozierski, P.; Lis, M.; Zietkiewicz, J. Resampling in Particle Filtering–Comparison. Stud. Z Autom. I Inform. 2013, 38, 35–64. [Google Scholar]
- Brzozowska-Rup, K.; Dawidowicz, A.L. Particle filter method. Mat. Stosow. Mat. Dla Spoleczenstwa 2009, 10, 69–107. (In Polish) [Google Scholar]
- Yu, J.X.; Liu, W.J.; Tang, Y.L. Adaptive resampling in particle filter based on diversity measures. In Proceedings of the 2010 5th International Conference on Computer Science & Education, Hefei, China, 24–27 August 2010; pp. 1474–1478. [Google Scholar]
- Martino, L.; Elvira, V.; Louzada, F. Effective sample size for importance sampling based on discrepancy measures. Signal Process. 2017, 131, 386–401. [Google Scholar] [CrossRef]
- Arulampalam, S.; Maskell, S.; Gordon, N.; Clapp, T. A Tutorial on Particle Filters for On-line non-Linear/ non-Gaussian Bayesian Tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Doucet, A.; Johansen, A.M. A Tutorial on Particle Filtering and Smoothing: Fifteen years later. Handb. Nonlinear Filter. 2009, 12, 3. [Google Scholar]
- Imtiaz, S.A.; Roy, K.; Huang, B.; Shah, S.L.; Jampana, P. Estimation of states of nonlinear systems using a particle filter. In Proceedings of the 2006 IEEE International Conference on Industrial Technology, Mumbai, India, 15–17 December 2006; pp. 2432–2437. [Google Scholar]
- Doucet, A.; De Freitas, N.; Gordon, N. An introduction to sequential Monte Carlo methods. In Sequential Monte Carlo Methods in Practice; Springer: New York, NY, USA, 2001; pp. 3–14. [Google Scholar]
- Abur, A.; Exposito, A.G. Power System State Estimation: Theory and Implementation; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Andersson, G. Modelling and Analysis of Electric Power Systems; EEH-Power Systems Laboratory, Swiss Federal Institute of Technology (ETH): Zürich, Switzerland, 2008. [Google Scholar]
- Kitagawa, G. Monte Carlo filter and smoother for non-Gaussian nonlinear state space models. J. Comput. Graph. Stat. 1996, 5, 1–25. [Google Scholar]
- Michalski, J.; Kozierski, P.; Zietkiewicz, J. Comparison of Particle Filter and Extended Kalman Particle Filter. Stud. Z. Autom. I Inform. 2017, 42, 43–51. [Google Scholar]
- Liu, X.; Wang, Y. The improved unscented Kalman particle filter based on MCMC and consensus strategy. In Proceedings of the 31st Chinese Control Conference, Hefei, China, 25–27 July 2012; pp. 6655–6658. [Google Scholar]
- Li, Q.; Sun, F. Adaptive cubature particle filter algorithm. In Proceedings of the 2013 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 4–7 Augusat 2013; pp. 1356–1360. [Google Scholar]
- Ha, S.V.U.; Jeon, J.W. Combine Kalman filter and particle filter to improve color tracking algorithm. In Proceedings of the 2007 International Conference on Control, Automation and Systems, Seoul, Korea, 17–20 October 2007; pp. 558–561. [Google Scholar]
- Plucinska, A.; Plucinski, E. Probabilistics Tasks; Panstwowe Wydawnictwo Naukowe: Warsaw, Poland, 1983. (In Polish) [Google Scholar]
- Florek, A.; Mazurkiewicz, P. Signals and Dynamic Systems; Wydawnictwo Politechniki Poznanskiej: Warsaw, Poznan, 2015. (In Polish) [Google Scholar]
- Straka, O.; Šimandl, M. Particle filter with adaptive sample size. Kybernetika 2011, 47, 385–400. [Google Scholar]
- Cappé, O.; Guillin, A.; Marin, J.M.; Robert, C.P. Population monte carlo. J. Comput. Graph. Stat. 2004, 13, 907–929. [Google Scholar] [CrossRef]
- Kozierski, P. Population Monte Carlo and Adaptive Importance Sampling in Particle Filter. Stud. Z Autom. I Inform. 2014, 39, 33–41. [Google Scholar]






















© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).