Comparison of New Anomaly Detection Technique for Wind Turbine Condition Monitoring Using Gearbox SCADA Data

 , ,
, ,
Abstract
1. Introduction
- The use of only two months of data for turbine health classification.
- Isolation Forest and Elliptical Envelope have not previously been used for wind turbine fault detection.
- One Class Support Vector Machine has not been used for wind turbine SCADA fault detection
- Comparing training techniques, generic and specific, for wind turbines.
2. Literature Review
2.1. Previous Examples of the Models Examined in this Paper
2.2. Literature Review Summary
3. Anomaly Detection Method
3.1. Data
3.2. Pre-Processing
3.2.1. Feature Selection
3.2.2. Data Normalisation
3.3. Model Description
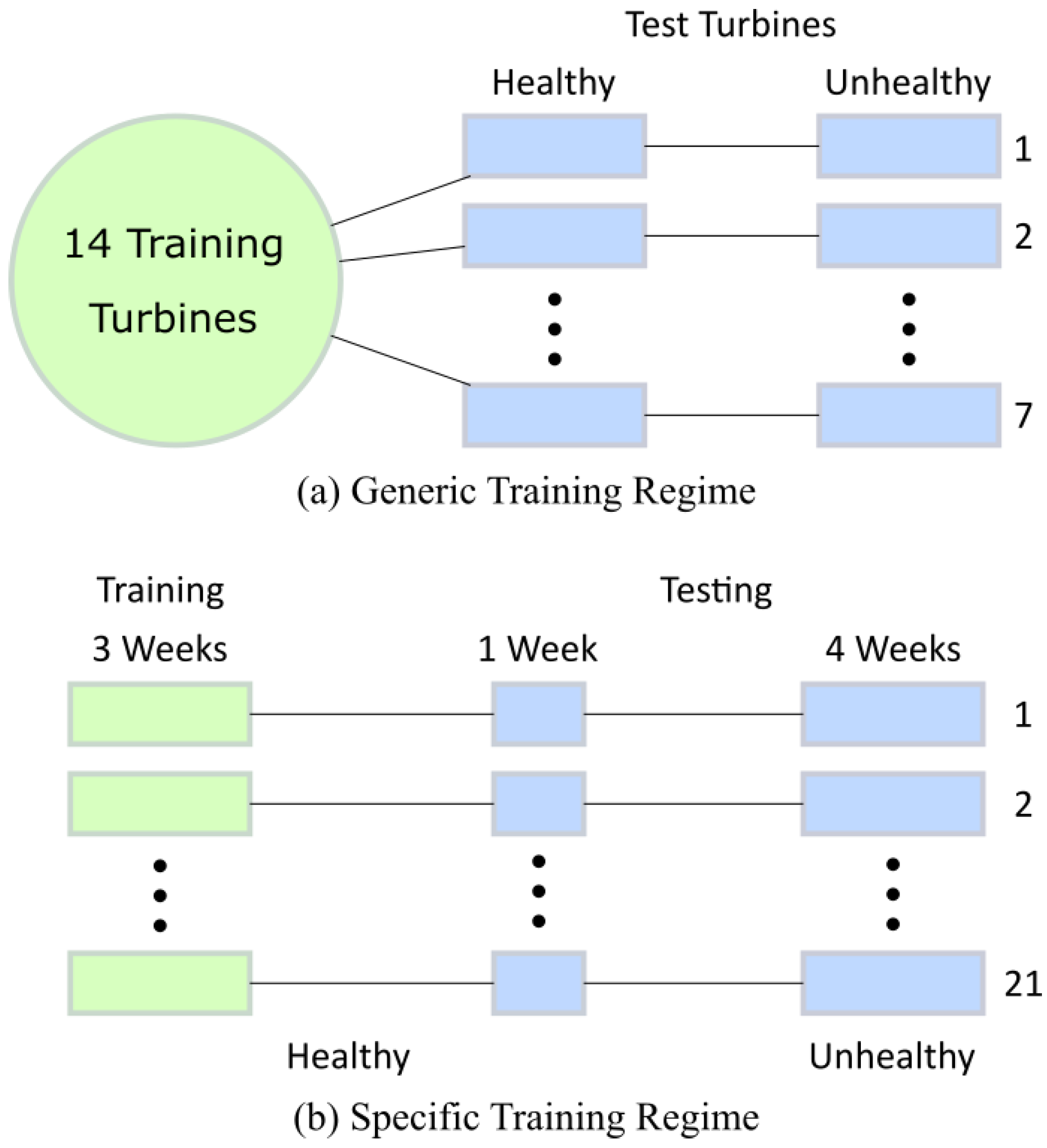
3.4. Test Description
4. Results
4.1. Table of Accuracies
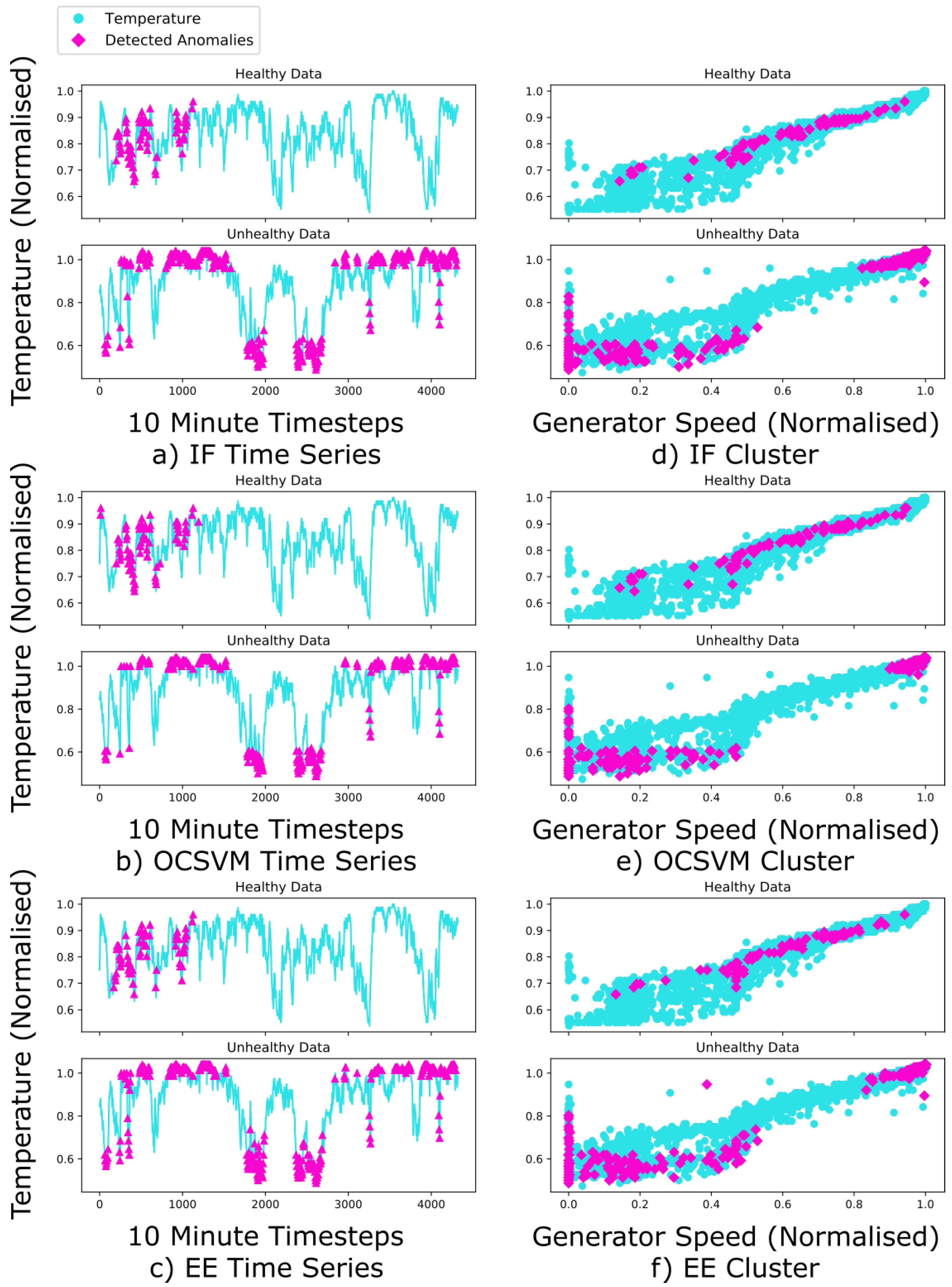
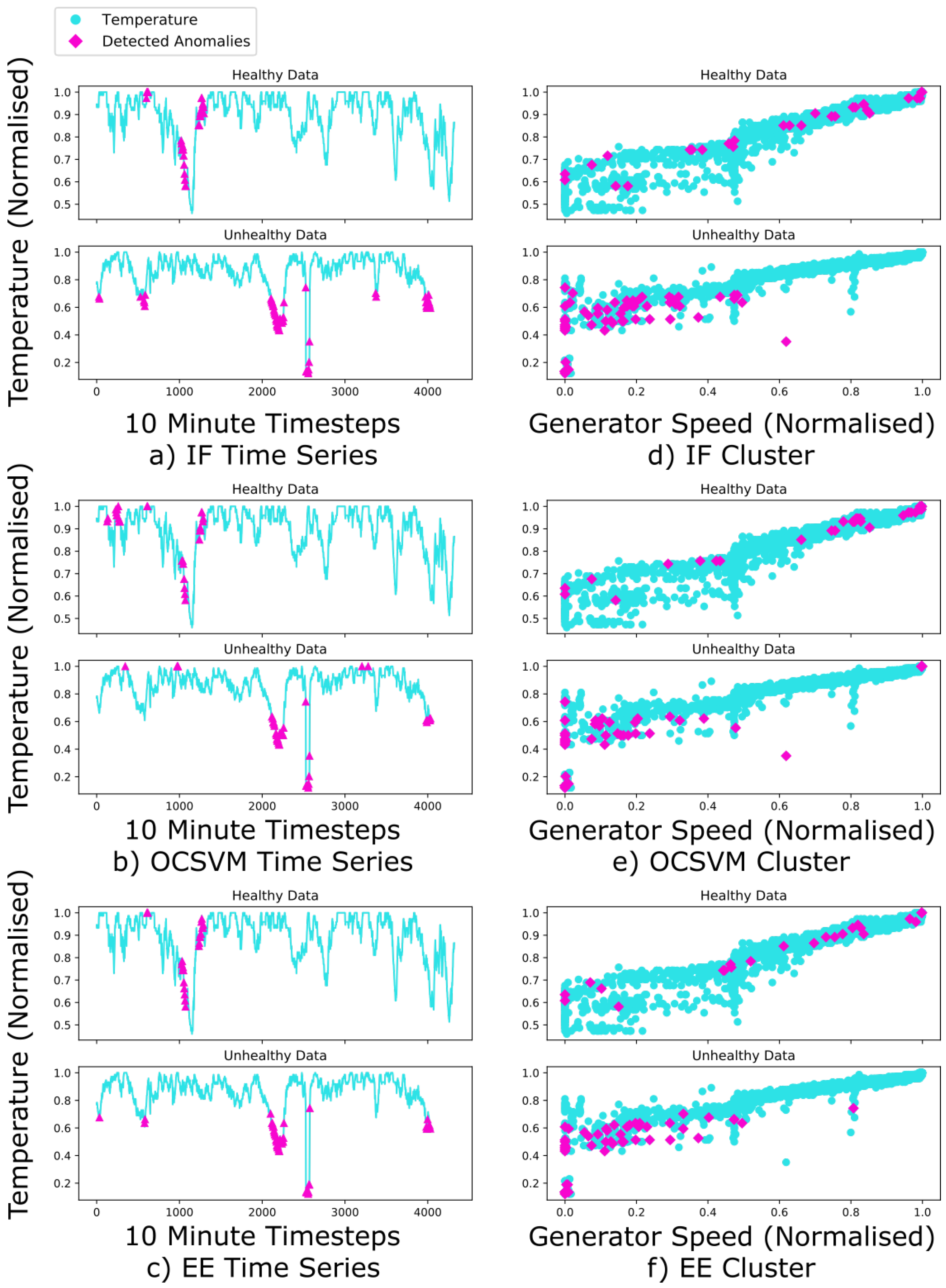
4.2. Selected Results
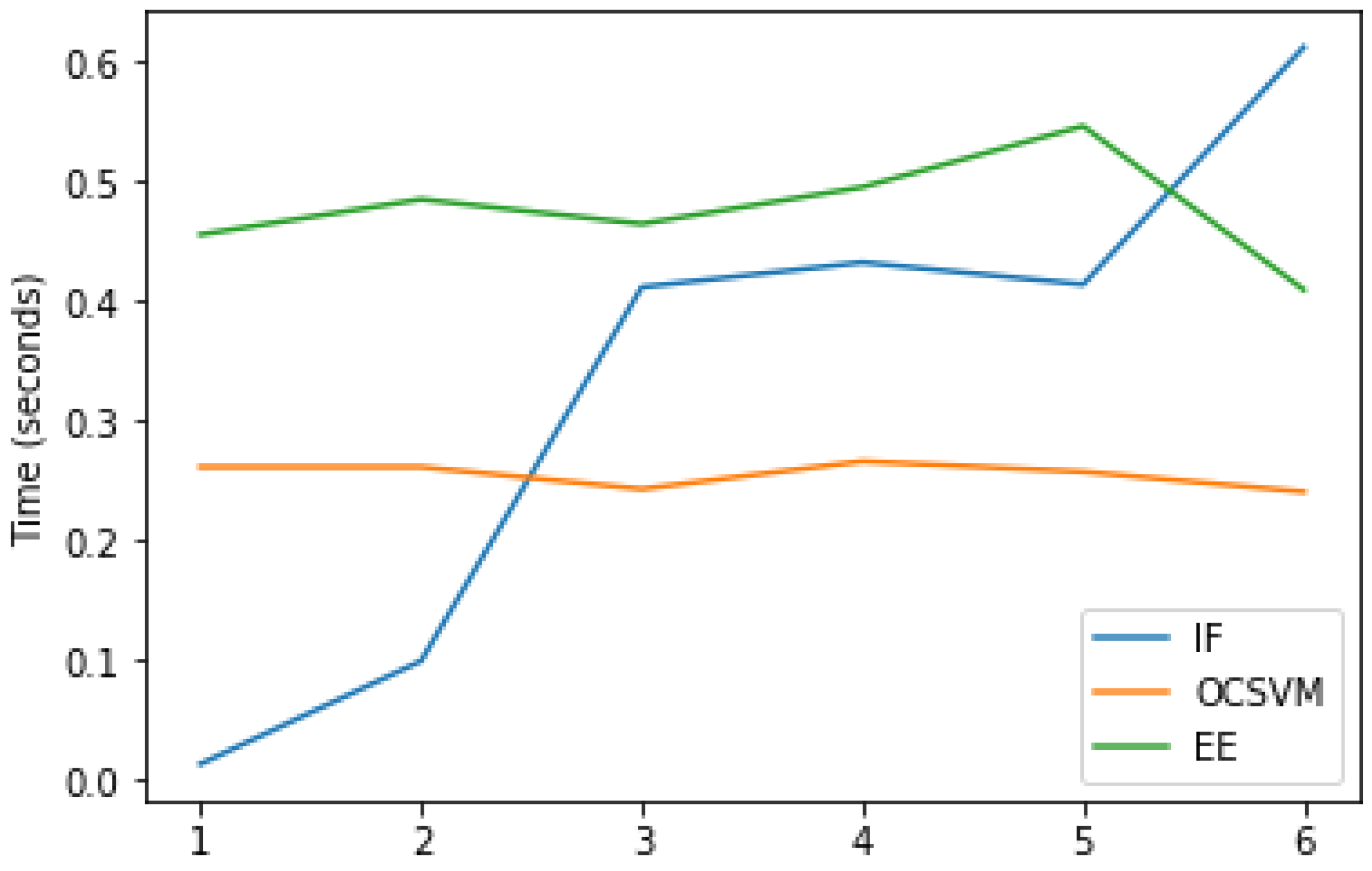
4.3. Analysis of Condition Monitoring Method
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Stehly, T.; Heimiller, D.; Scott, G. 2016 Cost of Wind Energy Review; Technical Report; NREL: Golden, CO, USA, 2016.
- Du, M.; Ma, S.; He, Q. A SCADA data based anomaly detection method for wind turbines. In Proceedings of the China International Conference on Electricity Distribution, CICED, Xi’an, China, 10–13 August 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Carroll, J.; McDonald, A.; McMillan, D. Failure rate, repair time and unscheduled O & M cost analysis of offshore wind turbines. WIND Energy 2016, 19, 1107–1119. [Google Scholar] [CrossRef]
- Faulstich, S.; Hahn, B.; Tavner, P. Wind Turbine Downtime and its Importance for Offshore Deployment. Wind Energy 2011, 14, 327–337. [Google Scholar] [CrossRef]
- Nielsen, J.J.; Sørensen, J.D. On risk-based operation and maintenance of offshore wind turbine components. Reliab. Eng. Syst. Saf. 2011, 96, 218–229. [Google Scholar] [CrossRef]
- Purarjomandlangrudi, A.; Nourbakhsh, G.; Ghaemmaghami, H.; Tan, A. Application of anomaly technique in wind turbine bearing fault detection. In Proceedings of the IECON Proceedings (Industrial Electronics Conference), Dallas, TX, USA, 29 October–1 November 2014; pp. 1984–1988. [Google Scholar] [CrossRef]
- Xu, X.; Lei, Y.; Zhou, X. A LOF-based method for abnormal segment detection in machinery condition monitoring. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018; pp. 125–128. [Google Scholar] [CrossRef]
- Ogata, J.; Murakawa, M. Vibration - Based Anomaly Detection Using FLAC Features for Wind Turbine Condition Monitoring. In Proceedings of the 8th European Workshop On Structural Health Monitoring, Bilbao, Spain, 5–8 July 2016; pp. 5–8. [Google Scholar]
- Abouel-seoud, S.A. Fault detection enhancement in wind turbine planetary gearbox via stationary vibration waveform data. J. Low Freq. Noise Vib. Act. Control 2018, 37, 477–494. [Google Scholar] [CrossRef]
- Huitao, C.; Shuangxi, J.; Xianhui, W.; Zhiyang, W. Fault diagnosis of wind turbine gearbox based on wavelet neural network. JJ. Low Freq. Noise Vib. Act. Control 2018, 37, 977–986. [Google Scholar] [CrossRef]
- Yu, D.; Chen, Z.M.; Xiahou, K.S.; Li, M.S.; Ji, T.Y.; Wu, Q.H. A radically data-driven method for fault detection and diagnosis in wind turbines. Int. J. Electr. Power Energy Syst. 2018, 99, 577–584. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, H.; Hu, W.; Yan, X. Anomaly detection and fault analysis of wind turbine components based on deep learning network. Renew. Energy 2018, 127, 825–834. [Google Scholar] [CrossRef]
- Rezamand, M.; Kordestani, M.; Carriveau, R.; Ting, D.S.; Saif, M. A New Hybrid Fault Detection Method for Wind Turbine Blades Using Recursive PCA and Wavelet-Based PDF. IEEE Sens. J. 2020, 20, 2023–2033. [Google Scholar] [CrossRef]
- Qu, F.; Liu, J.; Zhu, H.; Zhou, B. Wind turbine fault detection based on expanded linguistic terms and rules using non-singleton fuzzy logic. Appl. Energy 2020, 262, 114469. [Google Scholar] [CrossRef]
- Pei, Y.; Qian, Z.; Tao, S.; Yu, H. Wind Turbine Condition Monitoring Using SCADA Data and Data Mining Method. In Proceedings of the 2018 International Conference on Power System Technology (POWERCON), Guangzhou, China, 6–8 November 2018; pp. 3760–3764. [Google Scholar]
- Sun, Z.; Sun, H. Stacked Denoising Autoencoder With Density-Grid Based Clustering Method for Detecting Outlier of Wind Turbine Components. IEEE Access 2019, 7, 13078–13091. [Google Scholar] [CrossRef]
- Yan, Y.; Li, J.; Gao, D.W. Condition Parameter Modeling for Anomaly Detection in Wind Turbines. Energies 2014, 7, 3104–3120. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, D.; Dong, A.; Lin, J.; Kang, D.; Shang, L. Fault prognosis of wind turbine generator using SCADA data. In Proceedings of the NAPS 2016—48th North American Power Symposium, Denver, CO, USA, 18–20 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Bangalore, P.; Letzgus, S.; Karlsson, D.; Patriksson, M. An artificial neural network-based condition monitoring method for wind turbines, with application to the monitoring of the gearbox. Wind Energy 2017, 20, 1421–1438. [Google Scholar] [CrossRef]
- Cui, Y.; Bangalore, P.; Tjernberg, L.B. An anomaly detection approach based on machine learning and scada data for condition monitoring of wind turbines. In Proceedings of the 2018 International Conference on Probabilistic Methods Applied to Power Systems, PMAPS 2018, Boise, ID, USA, 24–28 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Cui, Y.; Bangalore, P.; Tjernberg, L.B. An Anomaly Detection Approach Using Wavelet Transform and Artificial Neural Networks for Condition Monitoring of Wind Turbines ’ Gearboxes. In Proceedings of the 2018 Power Systems Computation Conference (PSCC). Power Systems Computation Conference, Dublin, Ireland, 11–15 June 2018; pp. 1–7. [Google Scholar]
- Hubert, M.; Debruyne, M.; Rousseeuw, P.J. Minimum covariance determinant and extensions. Wiley Interdiscip. Rev. Comput. Stat. 2018, 10, 1–11. [Google Scholar] [CrossRef]
- Guo, K.; Liu, D.; Peng, Y.; Peng, X. Data-Driven Anomaly Detection Using OCSVM with Boundary Optimzation. In Proceedings of the 2018 Prognostics and System Health Management Conference, PHM-Chongqing 2018, Chongqing, China, 26–28 October 2008; pp. 244–248. [Google Scholar] [CrossRef]
- Scholkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Saari, J.; Strömbergsson, D.; Lundberg, J.; Thomson, A. Detection and identification of windmill bearing faults using a one-class support vector machine (SVM). Meas. J. Int. Meas. Confed. 2019, 137, 287–301. [Google Scholar] [CrossRef]
- Wang, Y.; Yoshihashi, R.; Kawakami, R.; You, S.; Harano, T.; Ito, M.; Komagome, K.; Iida, M.; Naemura, T. Unsupervised anomaly detection with compact deep features for wind turbine blade images taken by a drone. IPSJ Trans. Comput. Vis. Appl. 2019, 11. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M. Isolation Forest. In Proceedings of the Eighth IEE International Confrence on Data Mining, Singapore, 17–20 December 2018. [Google Scholar] [CrossRef]
- Lin, Z.; Liu, X.; Collu, M. Wind power prediction based on high-frequency SCADA data along with isolation forest and deep learning neural networks. Int. J. Electr. Power Energy Syst. 2020, 118, 105835. [Google Scholar] [CrossRef]
- Muller, A.C.; Guido, S. Introduction to Machine Learning with Python, 1st ed.; O’Reilly: Springfield, MO, USA, 2016. [Google Scholar]
- Gil, A.; Sanz-Bobi, M.A.; Rodríguez-López, M.A. Behavior anomaly indicators based on reference patterns - Application to the gearbox and electrical generator of a wind turbine. Energies 2018, 11, 87. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | ||
|---|---|---|
| Turbine Variables | Gearbox Temperature Variables | Gearbox Pressure Variables |
| Generator Speed (RPM) | Bearing A Temperature | Filter After Inline Oil Pressure |
| Nacelle Temperature | Bearing B Temperature | Filter After Offline Oil Pressure |
| Rotor Speed (RPM) | Bearing C Temperature | Filter Before Inline Oil Pressure |
| Ambient Wind Speed | Intermediate Stage Bearing Temperature | Gravity Tank Oil Pressure |
| Ambient Temperature | Main Bearing Temperature | Main Tank Oil Pressure |
| Power Production | Main Tank Oil Temperature | Oil Inlet Pressure |
| Oil Inlet Temperature | ||
| Feature | Target | Input 1 | Input 2 | Input 3 |
|---|---|---|---|---|
| Temperature | Gear Main Bearing Temperature | Gear Bearing B Temperature | Gear Main Tank Oil Temperature | Average Power |
| Pressure | After Inline Pressure | After Offline Pressure | Oil Inlet Temperature | Intermediate Stage Bearing Temperature |
| All | Isolation Forest | OCSVM | Elliptical Envelope | |
|---|---|---|---|---|
| Contamination (%) | No. of Estimators | Gamma | Support Fraction | Case Number |
| 0.1 | 1 | 0.001 | 0.35 | 1 |
| 1 | 10 | 0.01 | 0.4 | 2 |
| 5 | 50 | 0.1 | 0.45 | 3 |
| 10 | 100 | 1 | 0.5 | 4 |
| 20 | 250 | 10 | 0.75 | 5 |
| 500 | 100 | 1 | 6 |
| Training Regime | Normalised? | Feature | Numbers | IF | OCSVM | EE |
|---|---|---|---|---|---|---|
| Generic | No | Temp | 2 | 0.000 | 0.905 | 0.905 |
| 3 | 0.857 | 0.857 | 0.571 | |||
| 4 | 0.857 | 0.714 | 0.571 | |||
| Pres | 2 | 0.857 | 0.571 | 0.714 | ||
| 3 | 0.714 | 0.714 | 0.857 | |||
| 4 | 0.857 | 0.857 | 0.714 | |||
| Yes | Temp | 2 | 0.857 | 0.857 | 0.714 | |
| 3 | 0.857 | 1.000 | 0.714 | |||
| 4 | 1.000 | 1.000 | 1.000 | |||
| Pres | 2 | 1.000 | 1.000 | 0.857 | ||
| 3 | 0.714 | 1.000 | 0.571 | |||
| 4 | 0.714 | 0.714 | 0.571 | |||
| Specific | No | Temp | 2 | 1.000 | 0.571 | 0.857 |
| 3 | 0.667 | 0.667 | 0.571 | |||
| 4 | 0.905 | 0.714 | 0.714 | |||
| Pres | 2 | 0.762 | 0.857 | 0.810 | ||
| 3 | 0.952 | 0.952 | 0.905 | |||
| 4 | 0.905 | 0.810 | 0.905 | |||
| Yes | Temp | 2 | 0.952 | 0.810 | 0.905 | |
| 3 | 0.667 | 0.667 | 0.571 | |||
| 4 | 0.905 | 0.810 | 0.762 | |||
| Pres | 2 | 0.810 | 0.810 | 0.810 | ||
| 3 | 0.952 | 0.905 | 0.905 | |||
| 4 | 0.905 | 0.952 | 0.905 |
| Aggregate | IF | OCSVM | EE |
|---|---|---|---|
| All | 0.819 | 0.821 | 0.766 |
| Generic | 0.774 | 0.849 | 0.730 |
| Specific | 0.865 | 0.794 | 0.802 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
McKinnon, C.; Carroll, J.; McDonald, A.; Koukoura, S.; Infield, D.; Soraghan, C. Comparison of New Anomaly Detection Technique for Wind Turbine Condition Monitoring Using Gearbox SCADA Data. Energies 2020, 13, 5152. https://doi.org/10.3390/en13195152
McKinnon C, Carroll J, McDonald A, Koukoura S, Infield D, Soraghan C. Comparison of New Anomaly Detection Technique for Wind Turbine Condition Monitoring Using Gearbox SCADA Data. Energies. 2020; 13(19):5152. https://doi.org/10.3390/en13195152
Chicago/Turabian StyleMcKinnon, Conor, James Carroll, Alasdair McDonald, Sofia Koukoura, David Infield, and Conaill Soraghan. 2020. "Comparison of New Anomaly Detection Technique for Wind Turbine Condition Monitoring Using Gearbox SCADA Data" Energies 13, no. 19: 5152. https://doi.org/10.3390/en13195152
APA StyleMcKinnon, C., Carroll, J., McDonald, A., Koukoura, S., Infield, D., & Soraghan, C. (2020). Comparison of New Anomaly Detection Technique for Wind Turbine Condition Monitoring Using Gearbox SCADA Data. Energies, 13(19), 5152. https://doi.org/10.3390/en13195152