Improving Load Forecasting of Electric Vehicle Charging Stations Through Missing Data Imputation


Abstract
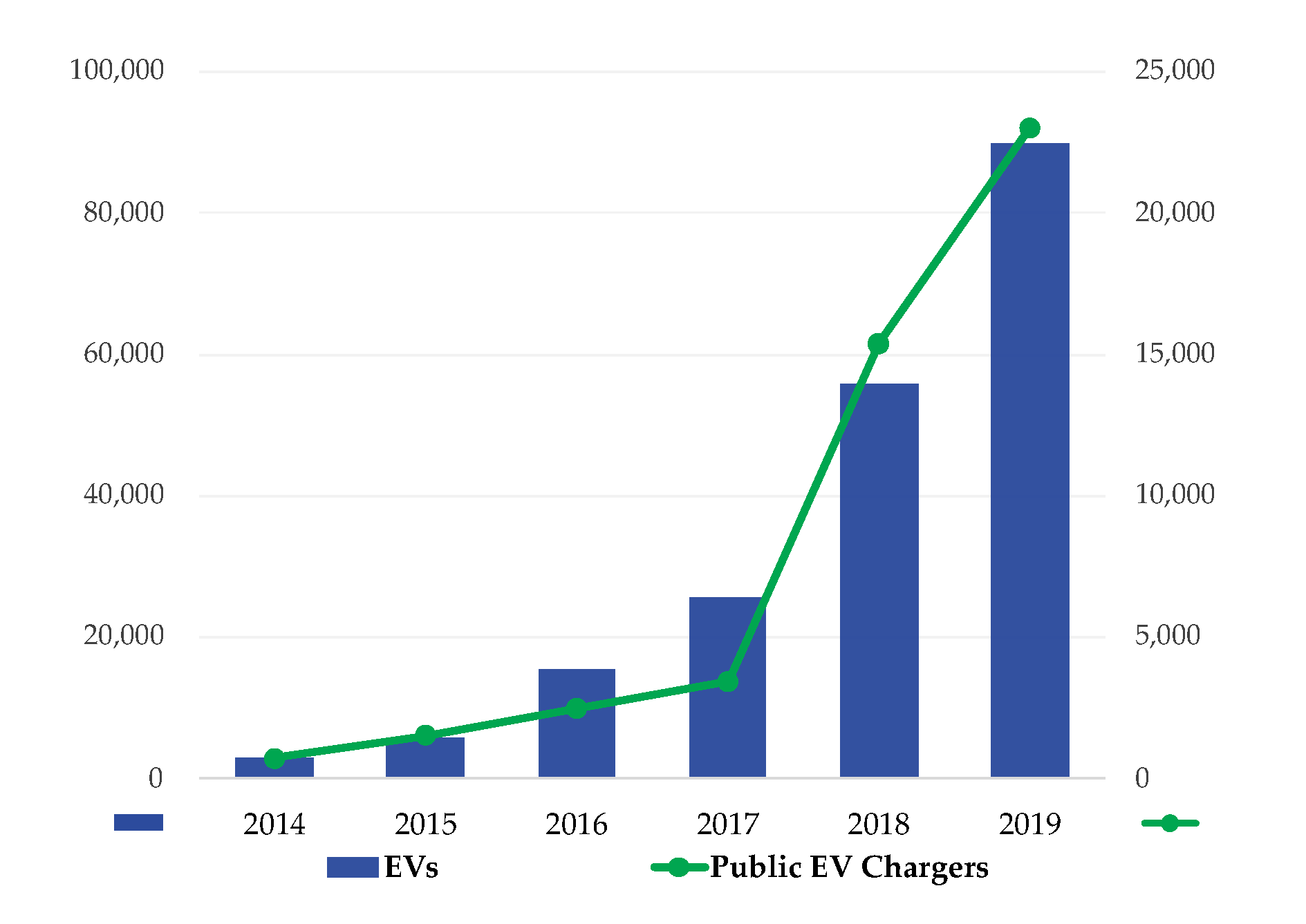
1. Introduction
- This paper presents a load forecasting model for EV charging stations. In particular, we develop the model based on LSTM (Long Short-Term Memory [10]) neural networks, which is compelling in time series forecasting.
- We devise a missing value imputation approach, which exploits both univariate and multivariate imputation techniques. Our approach first estimates the missing values of the target variable through the univariate imputation. Then, the rest of the missing values are replaced with plausible values by multivariate imputations.
- To verify the forecasting model and proposed imputation approach, this paper includes an experiment for comparison with various imputation techniques.
2. EV Charging Data
3. EV Charging Station Load Forecasting
3.1. Forecasting Problem
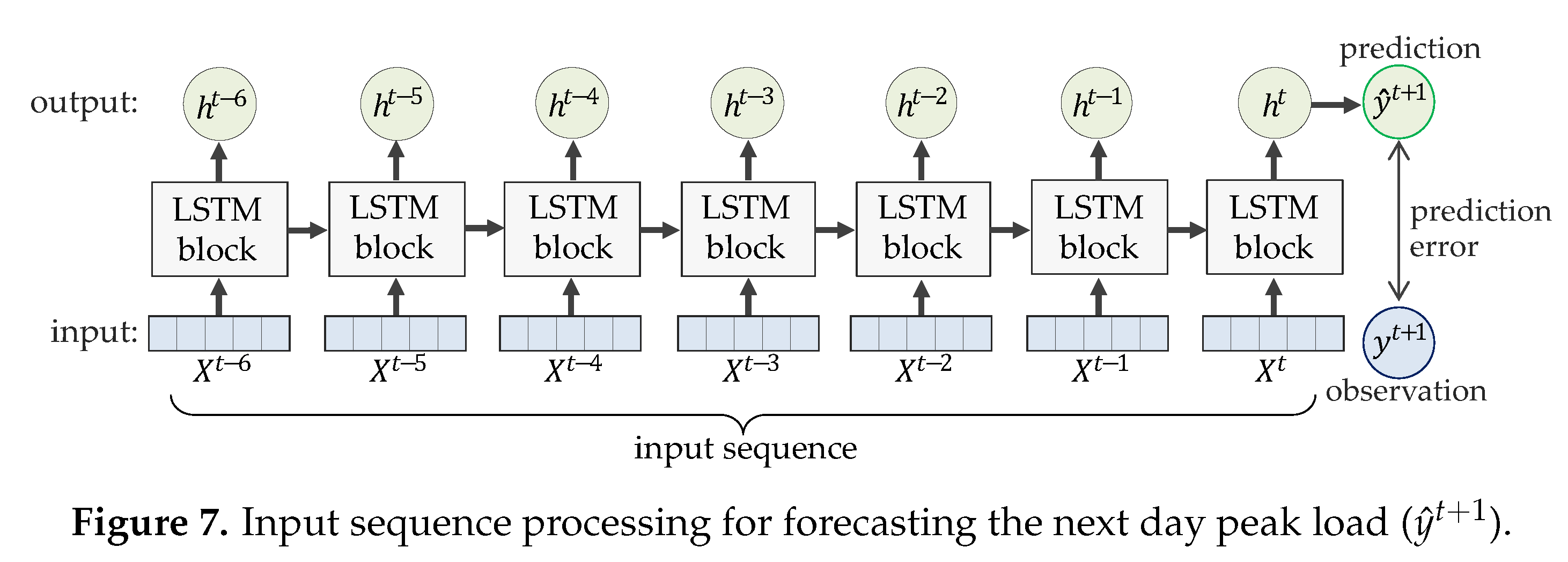
3.2. Development of the Forecasting Model
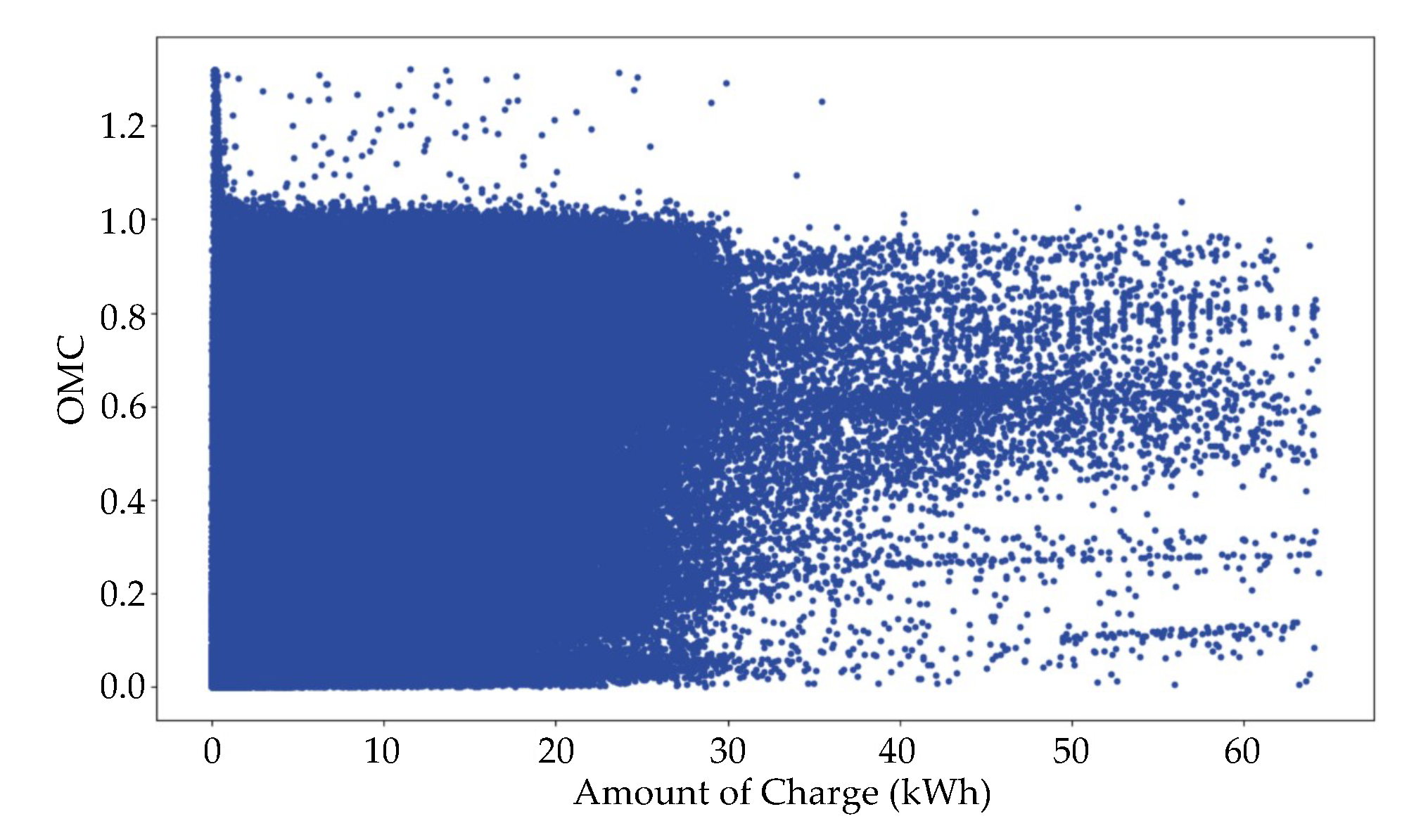
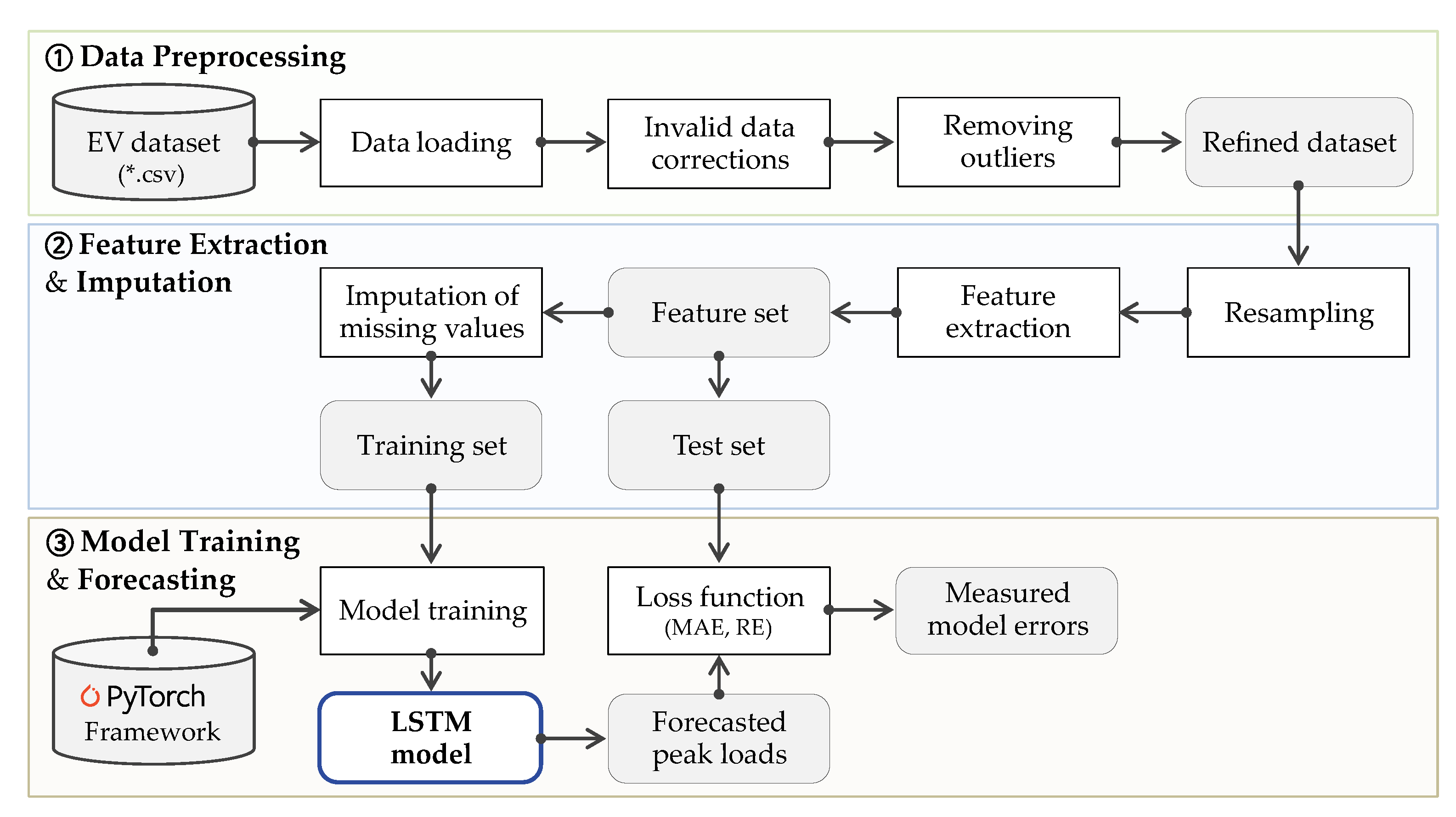
- The given EV dataset is preprocessed (invalid data correction and outlier removal) to obtain a refined dataset. Details on the preprocessing are explained in Section 2 above.
- A feature set is derived from the refined dataset through resampling and feature extraction. Including target values (i.e., daily peak loads), the whole features are extracted from the resampled hourly or daily data. This resampling results in missing values harmful for forecasting accuracy. To this end, several imputation techniques, including our approach are applied to generate new values of replacing the missing values. As a result, different training sets are generated depending on the imputation technique applied.
- A number of LSTM-based forecasting models are built on each training set. Concretely, we exploit the libraries provided by PyTorch to train LSTM neural networks, which is a day-ahead forecast model for charging station peak loads. Finally, we verify the forecasting model and our imputation approach by comparing the forecasting results obtained from models of different imputation techniques.
- Charging station ID is a feature to learn charging patterns unique to individual charging stations. Through one-hot encoding, it is transformed into a binary vector of size N (the number of charging stations).
- Day of the week is a feature for learning different charging patterns for each day of the week. It is also transformed into a binary vector of size 7 by one-hot encoding.
- Numbers of normal/fast charges are the total numbers of charge of each type measured per day.
- Amounts of normal/fast charges are the total energy amounts of charge of each type measured per day.
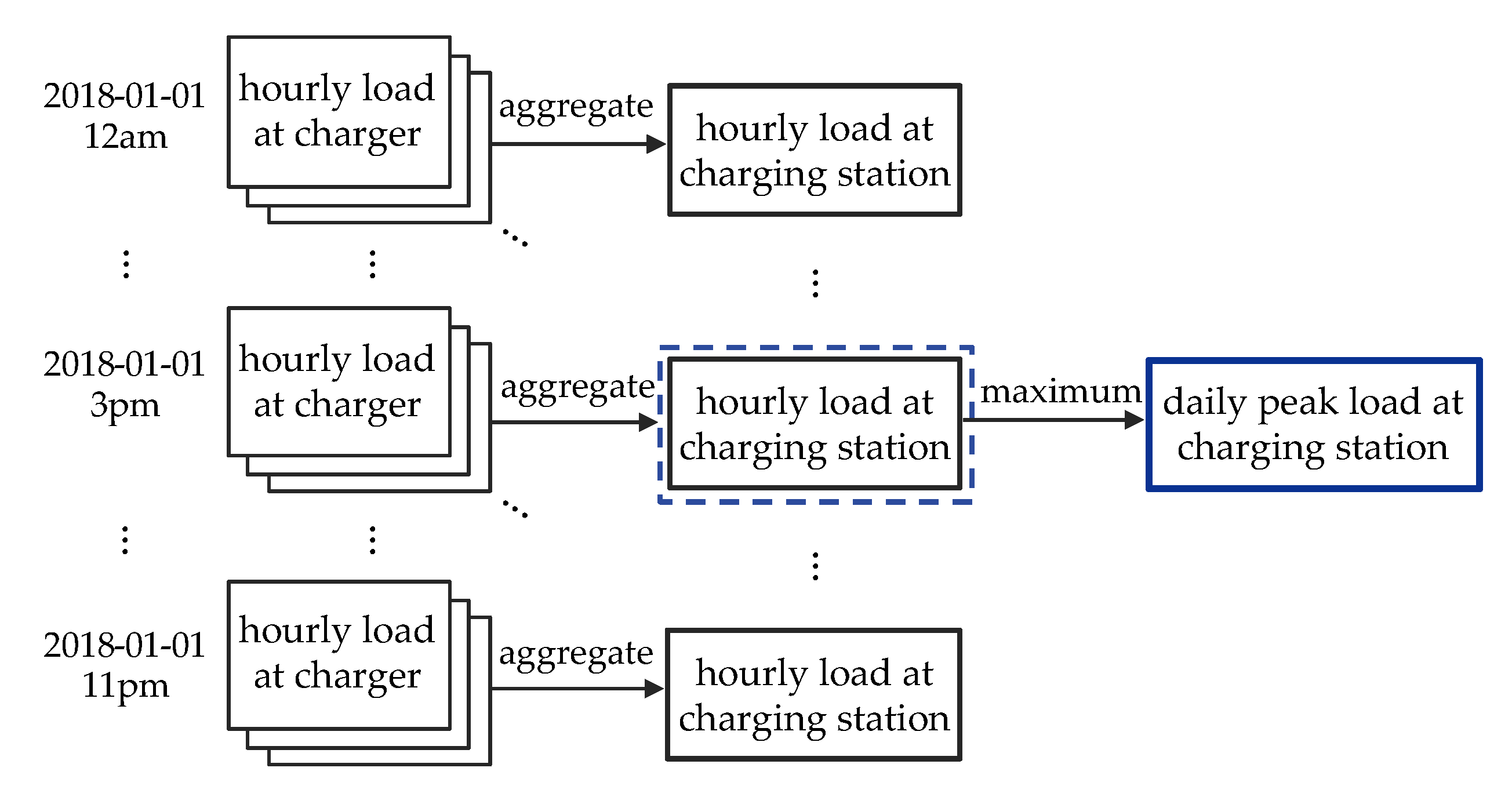
- Daily peak load is the target variable, which the model aims to forecast.
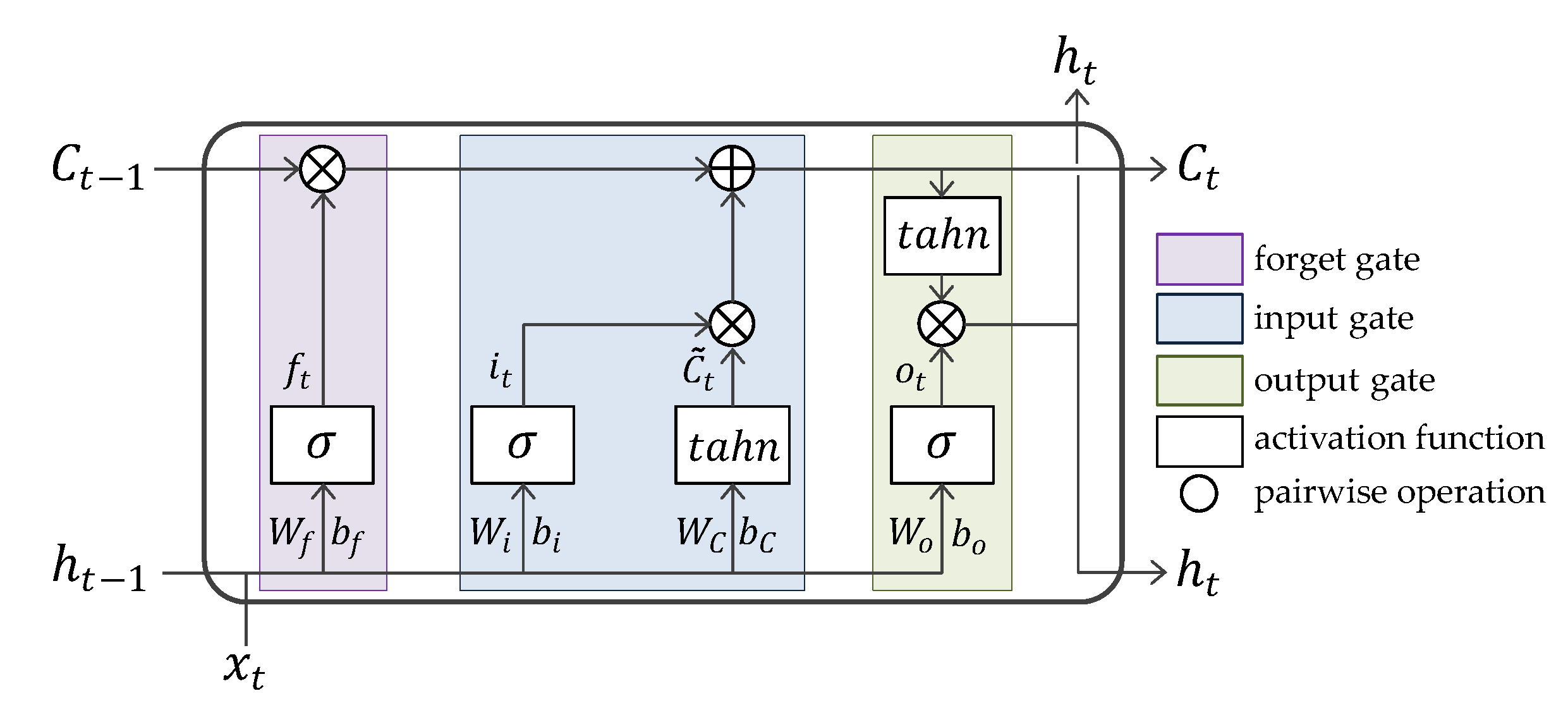
3.3. Long Short-Term Memory
- Forget gate decides what information should be removed from the cell state. Its gating function is implemented by a sigmoid neural net layer, with and as inputs. outputs (between 0 and 1) that indicates a degree of how much this will discard the information. As an LSTM learns data, the weight values in this gate, and will be optimized.
- Input gate decides what new information should be stored in the cell state. This includes two layers. First, a sigmoid layer outputs which means a weight of input information. Next, a hyperbolic tangent (called tahn) layer outputs a set of candidate values, , that could be added to the cell state. Then, the multiple of these two outputs will be added to the cell state.The older cell state, is replaced with the new cell state, through linear operations with the outputs of the two gates mentioned above.
- Output gate is to decide a final output of an LSTM cell. First, a sigmoid layer calculates to scale the significance of output. Then, is put through tahn and multiply it by . This final result is a new hidden state and it is delivered to the next LSTM cell and neighboring hidden layer.
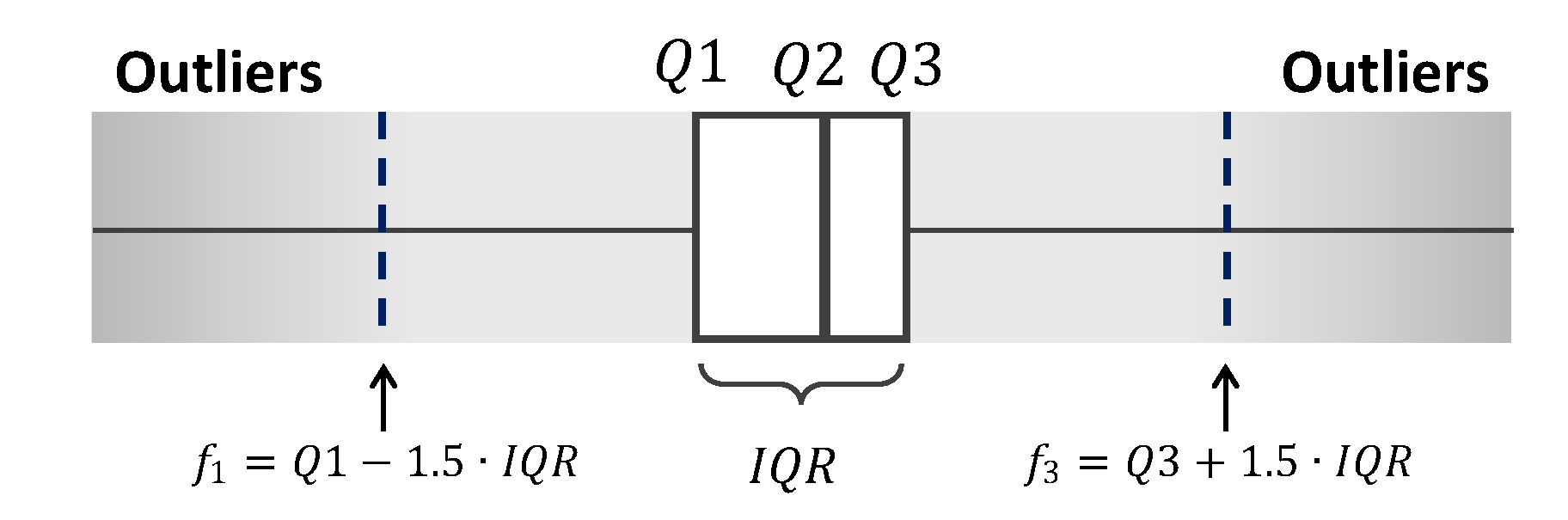
4. Data Imputation
4.1. Existing Data Imputation Techniques
4.2. Proposed Imputation Approach
5. Experimental Results
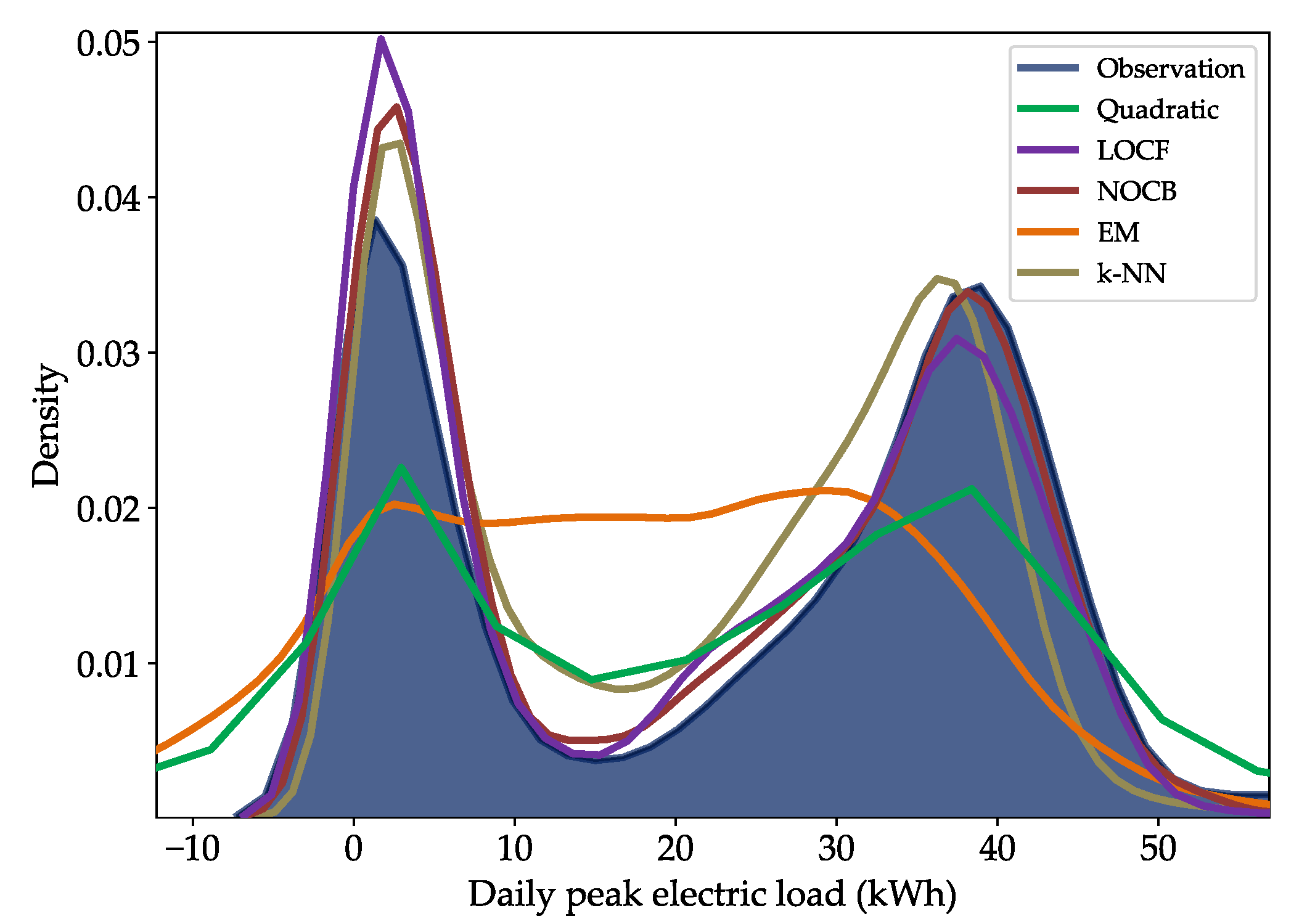
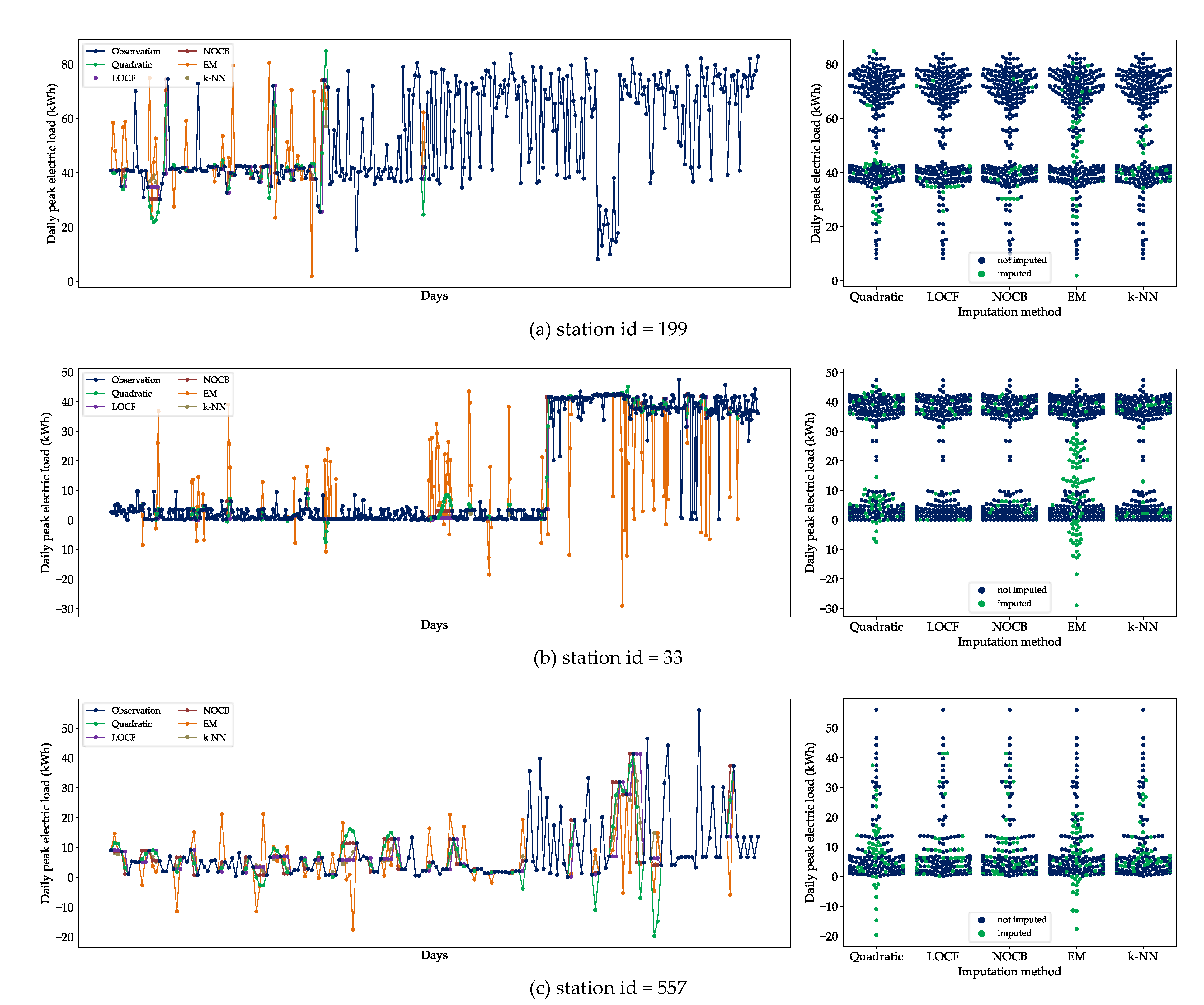
5.1. Missing Data Imputation
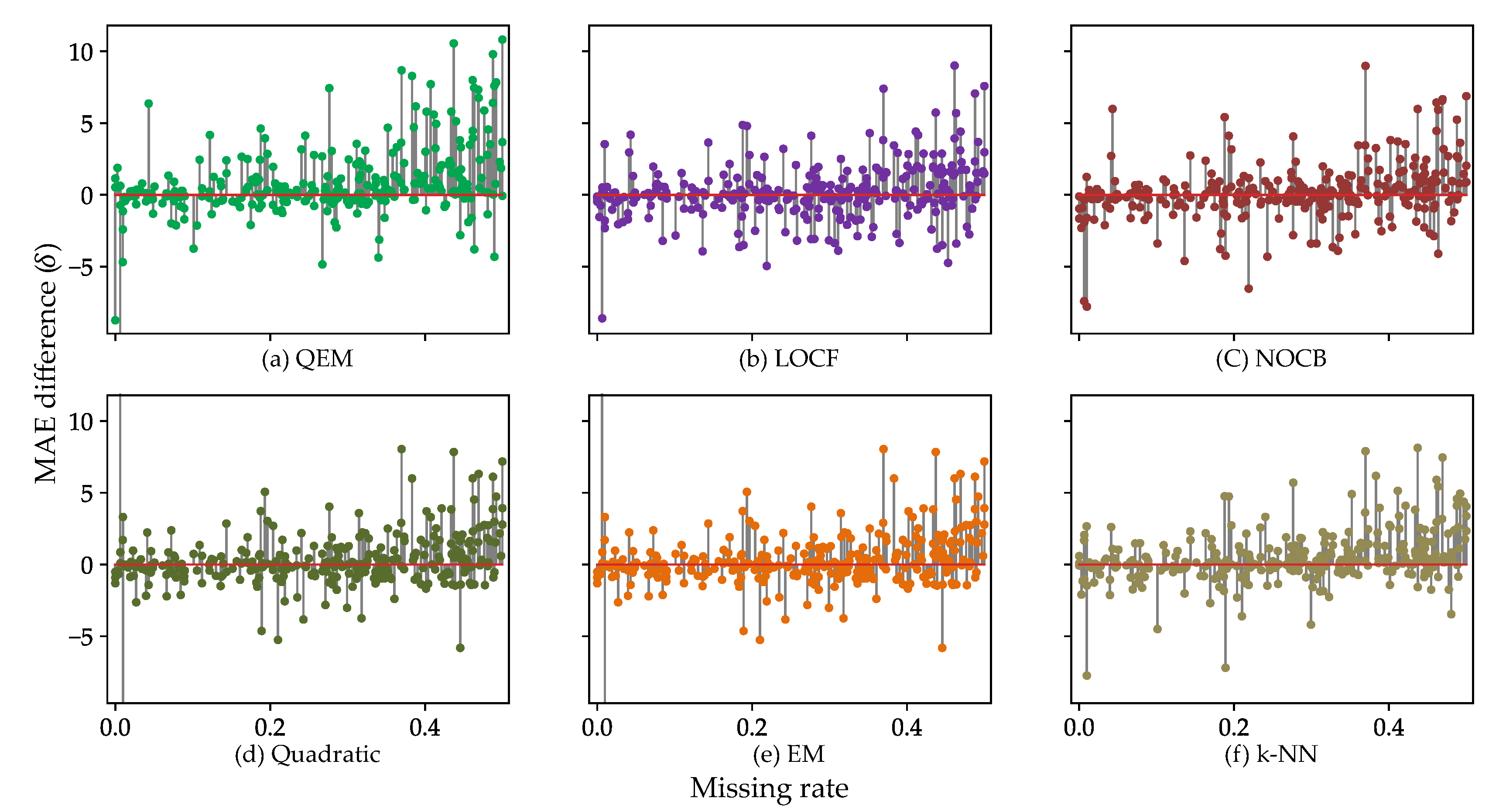
5.2. Performance Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| EM | Expectation-Maximization |
| EV | Electric Vehicle |
| k-NN | k-Nearest Neighbors |
| KEPCO | Korean Electric Power Corporation |
| LOCF | Last Observation Carried Forward |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| NI | No Imputation |
| NLP | Natural Language Processing |
| NOCB | Next Observation Carried Backward |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| STLF | Short-Term Load Forecasting |
| SVR | Support Vector Regression |
References
- Clairand, J.-M.; Álvarez-Bel, C.; Rodríguez-García, J.; Escrivá-Escrivá, G. Impact of electric vehicle charging strategy on the long-term planning of an isolated microgrid. Energies 2020, 13, 3455. [Google Scholar] [CrossRef]
- Lee, J.; Lee, E.; Kim, J. Electric vehicle charging and discharging algorithm based on reinforcement learning with data-driven approach in dynamic pricing scheme. Energies 2020, 13, 1950. [Google Scholar] [CrossRef]
- Jain, A.; Satish, B. Short term load forecasting by clustering technique based on daily average and peak loads. In Proceedings of the 2009 IEEE Power Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–7. [Google Scholar]
- Dong, X.; Qian, L.; Huang, L. Short-term load forecasting in smart grid: A combined CNN and K-means clustering approach. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing, Jeju, Korea, 13–16 February 2017; pp. 119–125. [Google Scholar]
- Arias, M.B.; Kim, M.; Bae, S. Prediction of electric vehicle charging-power demand in realistic urban traffic networks. Appl. Energy 2017, 195, 738–753. [Google Scholar] [CrossRef]
- Majidpour, M.; Qui, C.; Chu, P.; Pota, H.R.; Gadh, R. Forecasting the EV charging load based on customer profile or station measurement? Appl. Energy 2016, 163, 134–141. [Google Scholar] [CrossRef]
- Savari, G.F.; Krishnasamy, V.; Sathik, J.; Ali, Z.M.; Aleem, S.H.E.A. Internet of Things based real-time electric vehicle load forecasting and charging station recommendation. ISA Trans. 2020, 97, 431–447. [Google Scholar] [CrossRef] [PubMed]
- Ryu, S.; Noh, J.; Kim, H. Deep neural network based demand side short term load forecasting. Energies 2017, 10, 3. [Google Scholar] [CrossRef]
- Majidpour, M.; Chu, P.; Gadh, R.; Pota, H.R. Incomplete data in smart grid: Treatment of missing values in electric vehicle charging data. In Proceedings of the 2014 International Conference on Connected Vehicles and Expo, Vienna, Austria, 3–7 November 2014; pp. 1041–1042. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- AlRashidi, M.R.; EL-Naggar, K.M. Long term electric load forecasting based on particle swarm optimization. Appl. Energy 2010, 87, 320–326. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Choi, H.; Ryu, S.; Kim, H. Short-term load forecasting based on ResNet and LSTM. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Ham, S.H.; Ahn, H.; Kim, K.P. LSTM-based business process remaining time prediction model featured in activity-centric normalization techniques. J. Internet Comput. Serv. 2020, 21, 83–92. [Google Scholar]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Proc. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Malarvizhi, M.R.; Thanamani, A.S. K-nearest neighbor in missing data imputation. Int. J. Engineer. Res. Dev. 2012, 5, 5–7. [Google Scholar]
- Pandas. Available online: https://pandas.pydata.org (accessed on 15 August 2020).
- Numpy. Available online: https://numpy.org (accessed on 15 August 2020).
- Autoimpute. Available online: https://kearnz.github.io/autoimpute-tutorials (accessed on 15 August 2020).
- Fancyimpute. Available online: https://github.com/iskandr/fancyimpute (accessed on 15 August 2020).
- Impyute. Available online: https://impyute.readthedocs.io/en/latest (accessed on 15 August 2020).
- Scikit-Learn: Machine Learning in Python. Available online: https://scikit-learn.org/stable (accessed on 15 August 2020).
- Matplotlib: Python Plotting. Available online: https://matplotlib.org (accessed on 15 August 2020).
- Seaborn: Statistical Data Visualization. Available online: https://seaborn.pydata.org (accessed on 15 August 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Data Type | Description |
|---|---|---|
| headquater | string | a total of 17 headquaters (e.g., Seoul HQ) |
| division | string | a total of 193 divisions (e.g., Div. of Mapo-Yongsan) |
| charging station ID | string | a total of 2380 stations |
| address of charging station | string | |
| charger ID | int | a total of 6010 chargers |
| charger type | string | normal or fast |
| maximum capacity of charger | float | unit: kilowatt (kW) |
| amount of charging | float | unit: kilowatt hour (kWh) |
| start time of charging | datetime | |
| end time of charging | datetime | |
| charging time | datetime | format: hh:mm:ss |
| Attribute | Description |
|---|---|
| GPU | NVIDIA GeForce 2080 RTX Super (8GB) |
| CPU | Intel Core i9-9900 |
| RAM | 32GB |
| OS | Windows 10 Pro 64bit |
| Deep learning framework | PyTorch (1.1.0), Cuda (v10.2) |
| Python libraries | pandas [19] (data I/O and manipulation) |
| NumPy [20] (numerical operations) | |
| Autoimpute [21], fancyimpute [22], Impyute [23] (data imputation) | |
| scikit-learn [24] (feature normalization) | |
| Matplotlib [25], seaborn [26] (visualization) |
| Num. of Stations | Data Size | Num. of Missing Values | Missing Rate | 1Q | Med. | 3Q | |||
|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 52 | 19,660 | 853 | 4.34% | 41.221 | 26.160 | 30.219 | 39.815 | 51.302 |
| 0.2 | 96 | 37,820 | 3705 | 9.80% | 35.660 | 24.144 | 22.343 | 37.310 | 43.924 |
| 0.3 | 155 | 65,591 | 10,684 | 16.29% | 31.082 | 23.179 | 6.755 | 35.017 | 41.852 |
| 0.4 | 223 | 96,204 | 21,218 | 22.06% | 29.548 | 21.973 | 6.467 | 34.022 | 41.000 |
| 0.5 | 303 | 135,207 | 38,799 | 28.70% | 28.386 | 21.212 | 6.210 | 33.231 | 40.480 |
| Hidden Layers | Hidden Nodes | Sequence Length | Optimizer | Learning Rate | Drop Rate | Epochs |
|---|---|---|---|---|---|---|
| 3 | 150 | 7 | Adam | 0.001 | 0.5 | 300 |
| NI | QEM | LOCF | NOCB | Quadratic | EM | k-NN | ||
|---|---|---|---|---|---|---|---|---|
| 0.1 | MAE | |||||||
| – | ||||||||
| 0.2 | MAE | |||||||
| – | ||||||||
| 0.3 | MAE | |||||||
| – | ||||||||
| 0.4 | MAE | |||||||
| – | ||||||||
| 0.5 | MAE | |||||||
| – |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, B.; Lee, H.; Ahn, H. Improving Load Forecasting of Electric Vehicle Charging Stations Through Missing Data Imputation. Energies 2020, 13, 4893. https://doi.org/10.3390/en13184893
Lee B, Lee H, Ahn H. Improving Load Forecasting of Electric Vehicle Charging Stations Through Missing Data Imputation. Energies. 2020; 13(18):4893. https://doi.org/10.3390/en13184893
Chicago/Turabian StyleLee, Byungsung, Haesung Lee, and Hyun Ahn. 2020. "Improving Load Forecasting of Electric Vehicle Charging Stations Through Missing Data Imputation" Energies 13, no. 18: 4893. https://doi.org/10.3390/en13184893
APA StyleLee, B., Lee, H., & Ahn, H. (2020). Improving Load Forecasting of Electric Vehicle Charging Stations Through Missing Data Imputation. Energies, 13(18), 4893. https://doi.org/10.3390/en13184893