1. Introduction
With the increasing impact of the greenhouse effect on the environment, low-carbon economy has gradually become the key development direction of various energy consumption industries. As the largest CO
2 emitter, the electric power industry will play an important role in low-carbon economic development [
1]. All kinds of energy-consuming enterprises have also commenced on focusing on the control of carbon emissions, especially in the power industry, which makes up approximately 40% of CO
2 emissions in the whole world [
2]. Generally speaking, low-carbon power involves four sectors: generation, transmission, distribution and consumption. Therefore, how to reduce the carbon emissions of transmission and distribution sectors in the power grid industry has turned into an instant issue to be solved [
3,
4].
Up to now, numerous scholars have carried out research on all aspects of low-carbon power, including optimal power flow (OPF) [
5,
6,
7], economic emission dispatching [
8,
9], low-carbon power system dispatch [
10], unit commitment [
11,
12], carbon storage and capture [
13,
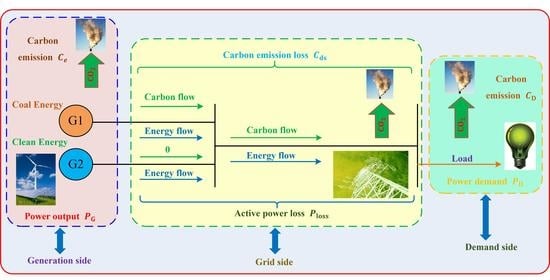
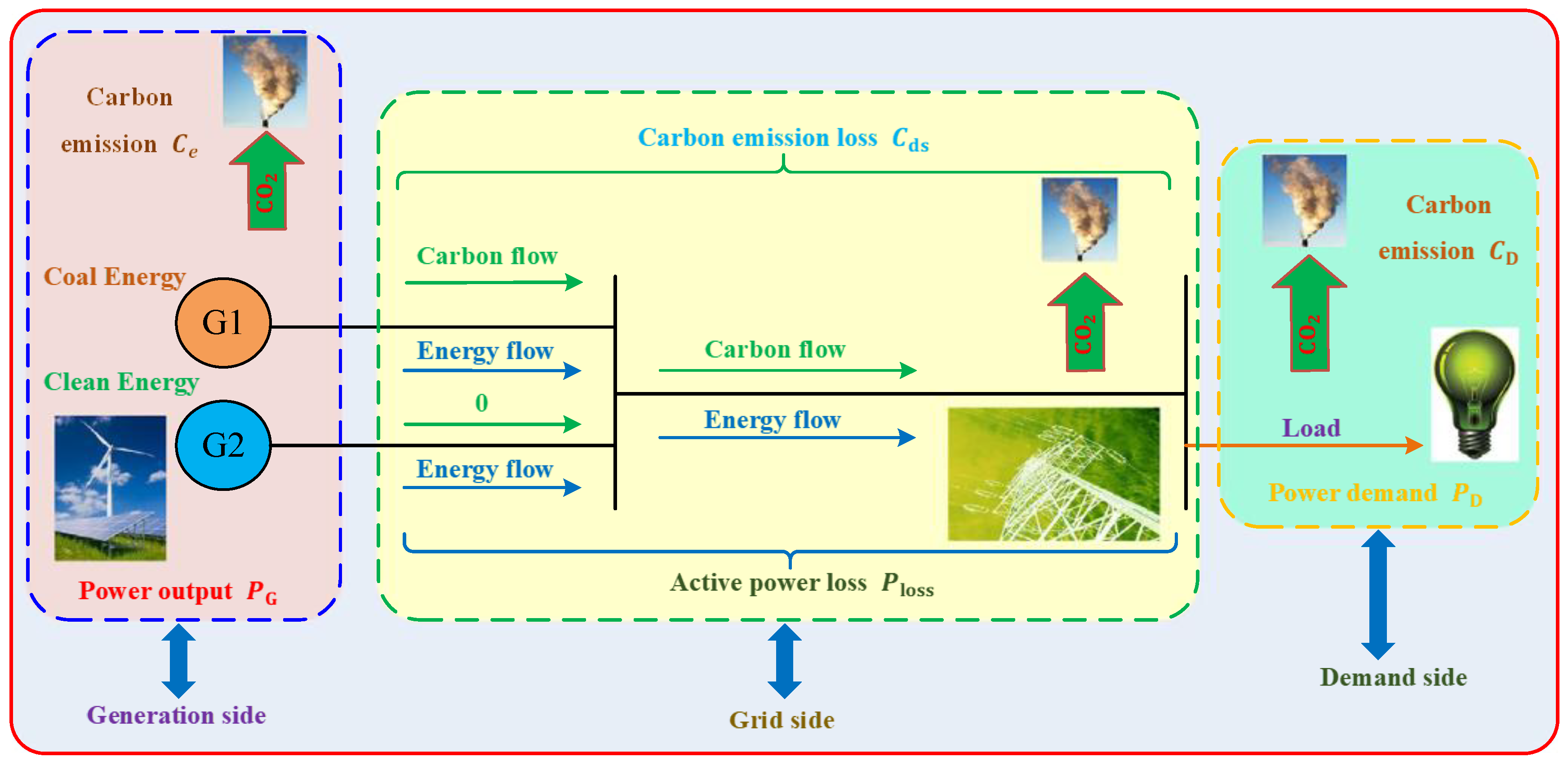
14] and other issues. However, the previous studies mainly focused on the carbon emissions of the generation side, with a lack of research on how to reduce the carbon emissions of the power network (i.e., the transmission and distribution sides). Therefore, the optimal carbon-energy combined-flow (OCECF) model, which can reflect the energy flow and carbon flow distribution of the power grid, is further established in this paper. Basically, the OCECF is on the basis of the conventional reactive power optimization model, which should not only attempt to minimize the power loss and voltage deviation, but also aim to minimize the carbon emission of the power network while satisfying the various operating constraints of power systems.
Obviously, the OCECF is a complicated nonlinear planning problem considering the carbon flow losses of power grids, which can be solved by traditional optimization strategies including nonlinear planning [
15], the Newton method [
16] and the interior point method [
17]. However, due to the strong nonlinearity of power systems, the discontinuity of the objective function and constraint conditions, as well as the existence of multiple local optimal solutions, usually hinder the effectiveness or applications of the classical optimization methods. On the other hand, meta-heuristic algorithms including the genetic algorithm (GA) [
18], particle swarm optimization (PSO) [
19,
20], grouped grey wolf optimizer (GWO) [
21] and the memetic salp swarm algorithm (MSSA) [
22] have relatively low dependence on specific models, and can obtain relatively satisfactory results when solving such problems. However, due to the low convergence stability of the algorithm, these algorithms may only converge to a local optimal solution. Thus, the conventional Q(λ) reinforcement learning algorithm with better convergence robustness and stability is proposed in [
23]. Nevertheless, because of the search ergodicity of the single agent Q(λ) algorithm, its convergence is relatively long for large-scale system optimization due to the low learning efficiency, while the “dimension disaster” problem with the increasing number of variables can also occur. Moreover, the on-line optimization requirement of the OCECF is also difficult to be met.
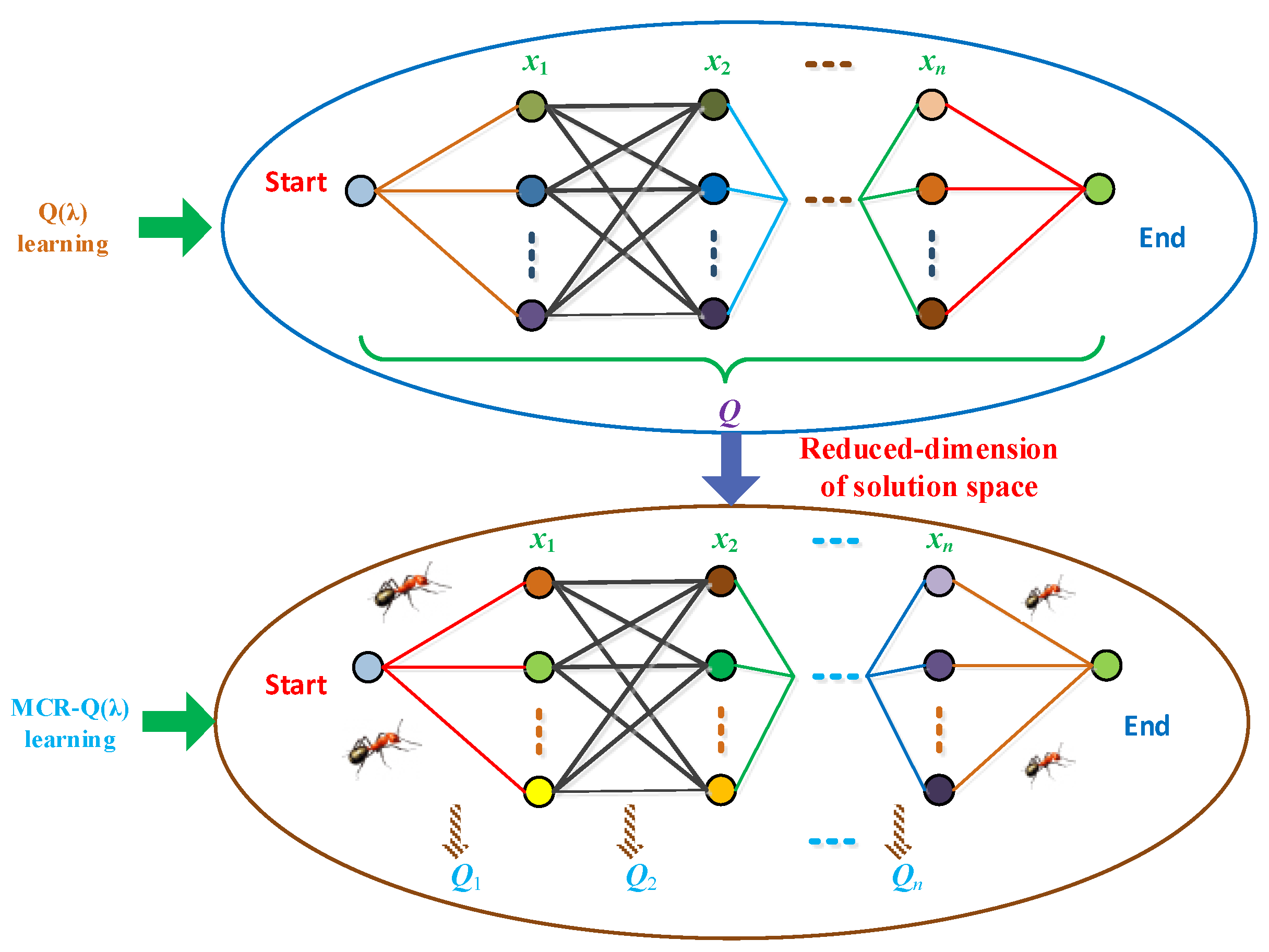
Therefore, the author of ant colony optimization (ACO) introduces the concept of ant colony in the classical Q-learning algorithm and puts forward the multiagent Ant-Q algorithm with a faster optimization speed [
24]. Based on this, a new multi-agent cooperation-based reduced-dimension Q(λ) (MCR-Q(λ)) learning is proposed for OCECE in this paper, which mainly contains the following contributions:
(i) Most of existing low-carbon power studies did not consider the carbon emissions of the power network due to the energy flow and carbon flow from the generation side to the load side, which cannot satisfy the low-carbon requirement from the viewpoint of the power network. In contrast, the presented OCECF can further reduce the carbon emissions of the power network, which can improve the benefit of the power grid company in a carbon trading market.
(ii) The proposed MCR-Q(λ) can effectively shorten the dimension of the solution space of the Q algorithm to solve the OCECF problem by introducing the eligibility trace (λ) returns mechanism [
23]. Besides, it also can accelerate the convergence rate and avoid trapping into a low-quality optimum for OCECE via multi-agent cooperation.
The framework of this paper mainly includes: firstly,
Section 2 which concludes the related work;
Section 3 presents the establishment of the OCECF mathematical model; then, the principle of MCR-Q(λ) learning is described in
Section 4;
Section 5 gives the concrete steps of solving the OCECF problem;
Section 6 undertakes simulation studies on the IEEE 118 node system to verify the convergence and stability of MCR-Q(λ) learning. Finally, the conclusion of the whole paper is presented in
Section 7.
6. Case Studies
For purpose of testing the optimization performance of MCR-Q(λ) learning, the simulation results of Q(λ) learning, Q learning [
41], quantum genetic algorithm (QGA) [
42], GA [
43], PSO [
44], ant colony system (ACS) [
45], group search optimizer (GSO) [
46] and artificial bee colony (ABC) [
47] were also introduced for comparison. Note that the weight coefficient in Equation (5) can be adjusted according to the preference on different components of the objective function. In the simulation analysis, since three components of the objective function in Equation (5) have the same preferences, and the weight coefficient in Equation (5) is set to be 1/3, both the testing IEEE 118-bus system and IEEE 300-bus system are referenced from the tool called MATPOWER [
48], in which the detailed parameters can be found in [
49]. Besides, it assumes that both the wind and solar energy outputs can be accurately acquired by using effective forecasting techniques, e.g., the deep long-short-term memory recurrent neural network [
50]. Among them, the algorithms are simulated and tested in Matlab 2016b by a personal computer with an Intel(R) Core TM i5-4210 CPU at 2.6 GHz with 8 GB of RAM.
6.1. Case Study of IEEE 118-Bus System
6.1.1. Simulation Model
According to different generator types, the carbon emission rate
δsw of each unit in the IEEE 118-bus system is summarized in
Table 2. Besides, this paper adopts the same benchmark model of IEEE 118-bus system in all case studies, related detail parameters can be referenced in [
36].
Moreover, the system load of the IEEE 118-bus system is mainly divided into five scenarios, as shown in
Table 3. Particularly, the scenarios from 1 to 5 represent the system with different load demands, where the load demand gradually increases from scenarios 1 to 5 for all the presented nodes in
Table 3. As mentioned above,
Table 2 and
Table 3 are obtained under the same benchmark model of IEEE 118-bus system [
36].
In fact, reactive power compensation can be designed for the nodes with generators or load demand to provide adequate reactive power, while the OLTC ratio can be selected for the line with two different voltage nodes. According to this rule, the reactive power compensation of nodes 45, 79, and 105, and the OLTC ratio of lines 8–5, 26–25, 30–17, 63–59, and 64–61 are respectively selected as controllable variables, which are defined in sequence as (x1, x2, x3, x4, x5, x6, x7, x8), with
- (1)
The reactive power compensation is divided into five configurations as {−40%, −20%, 0%, 20%, 40%} with its reference value;
- (2)
The OLTC ratio is divided into three grades, which are {0.98, 1.00, 1.02}.
Hence, the optimization variables of the IEEE 118-bus system can be found in
Table 4, where the variables can be divided into two types, i.e., the reactive power compensation and OLTC ratio; the “no. of bus” represents the location of each variable in the power network; the “action space” denotes the set of the alternative control actions for each variable; and the “variable number” is the number of all the optimization variables.
6.1.2. Convergence Analysis
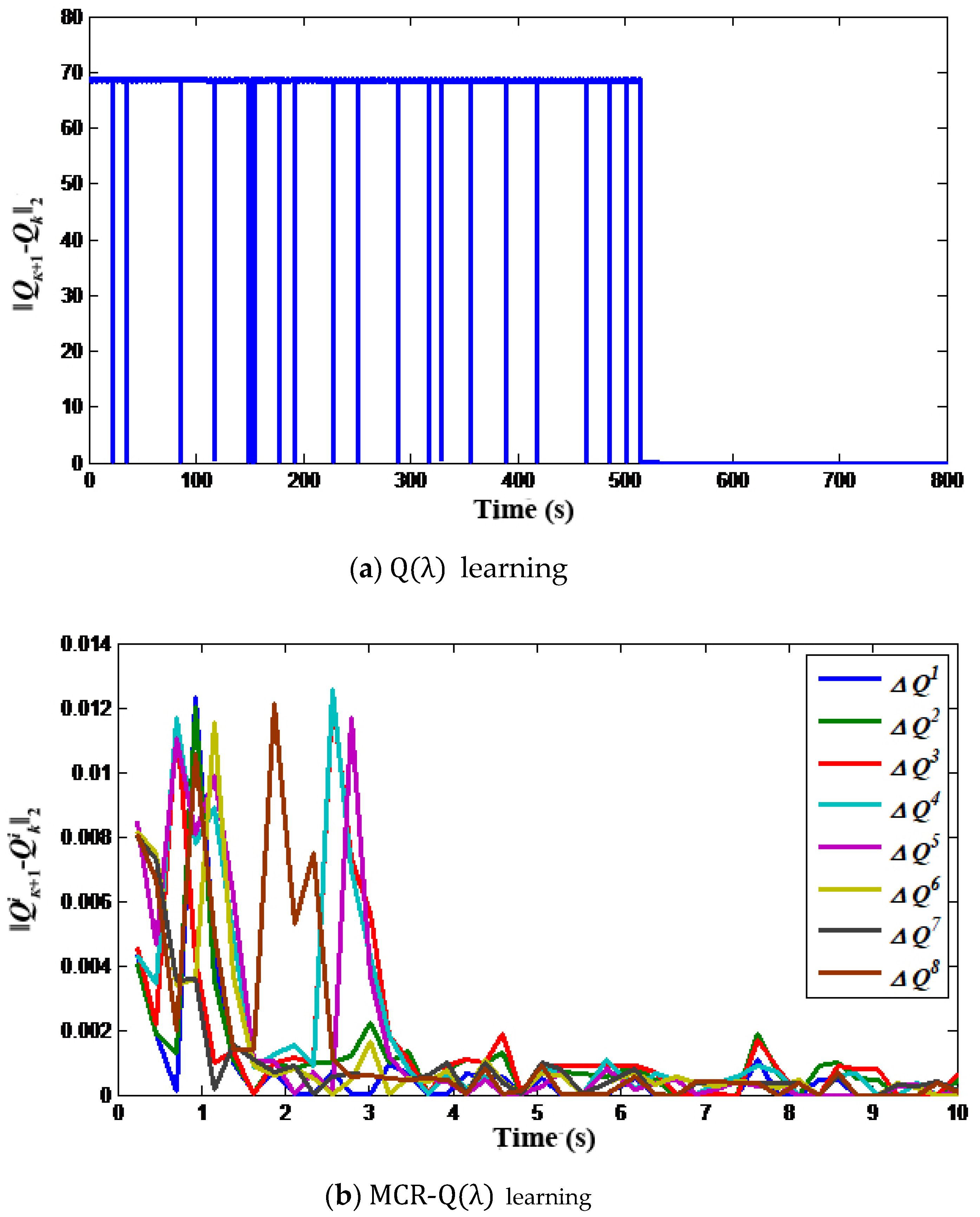
Figure 3 illustrates the convergence process of the
Q-value deviation between Q(λ) learning and MCR-Q(λ) learning under scenario 1, where the
Q-value deviation is defined as the 2-norm of matrix
, that is,
. As obtained from
Figure 3a, since the
Q matrix of single-objective Q(λ) learning is large and the updating speed is slow, the algorithm can converge to the optimal
Q* matrix through a variety of trial-and-error explorations, while the convergence time is about 530s. In contrast, after reducing the dimension of the solution space of MCR-Q(λ) learning, the
Qi matrix corresponding to each variable is very small, and 20 objectives are updated at the same time. The optimization speed is more than 100 times of that of Q(λ) learning, which can converge after about 3.5 s, as shown in
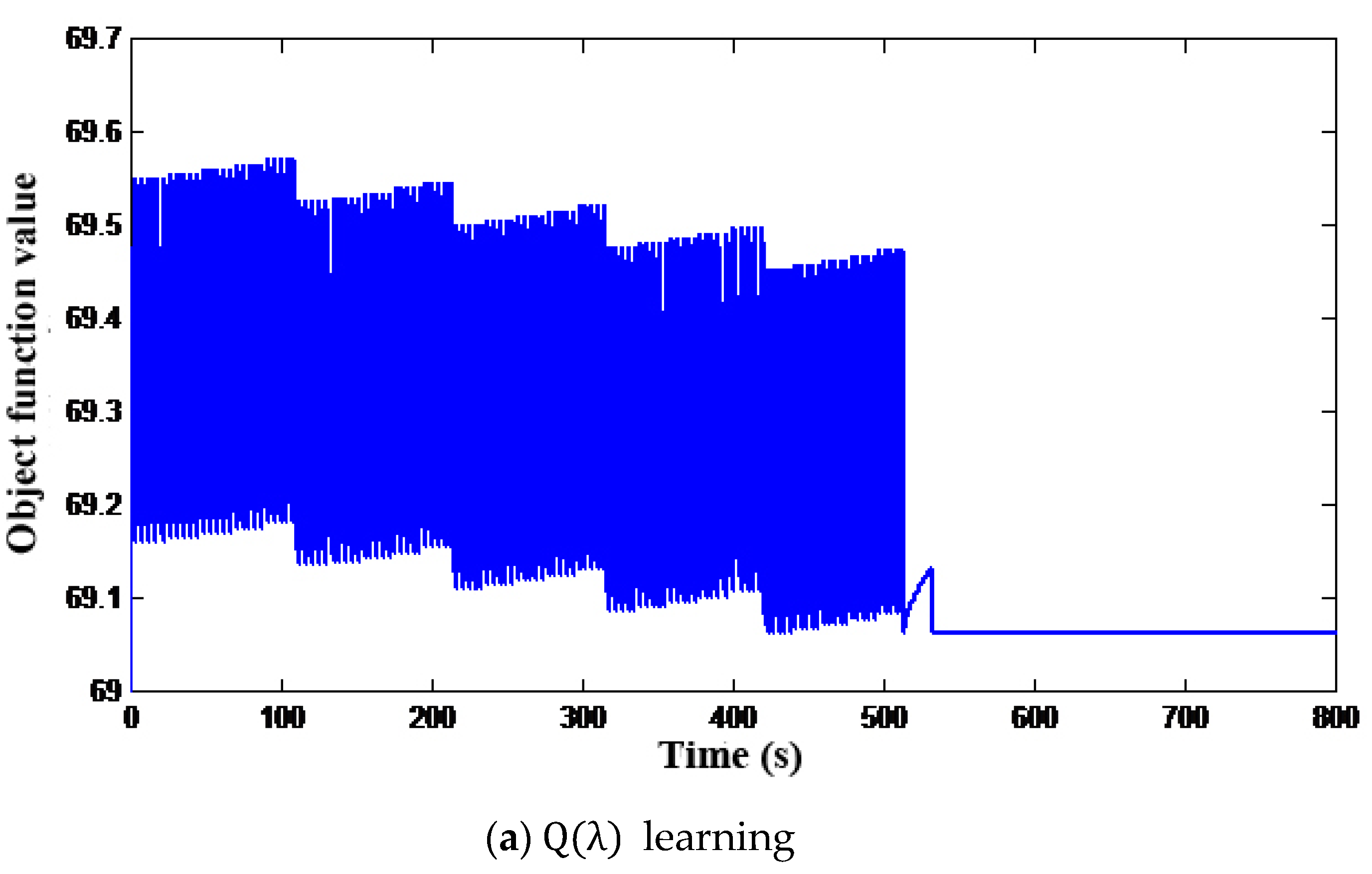
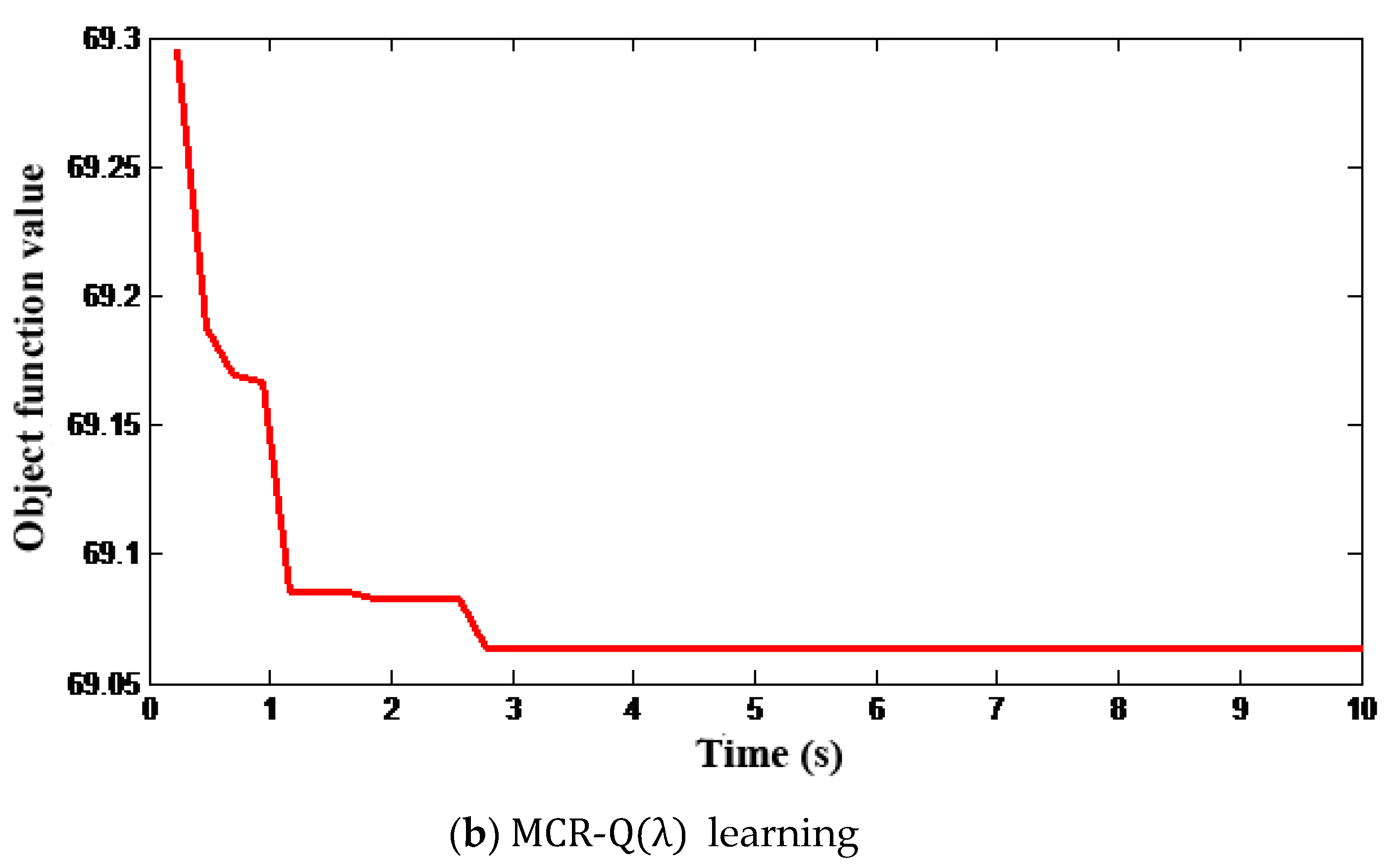
Figure 3b. Moreover, it can be obtained from the convergence of the objective function values in
Figure 4 that the optimization speed of MCR-Q(λ) learning is much faster, and both algorithms can converge to the global optimal solution.
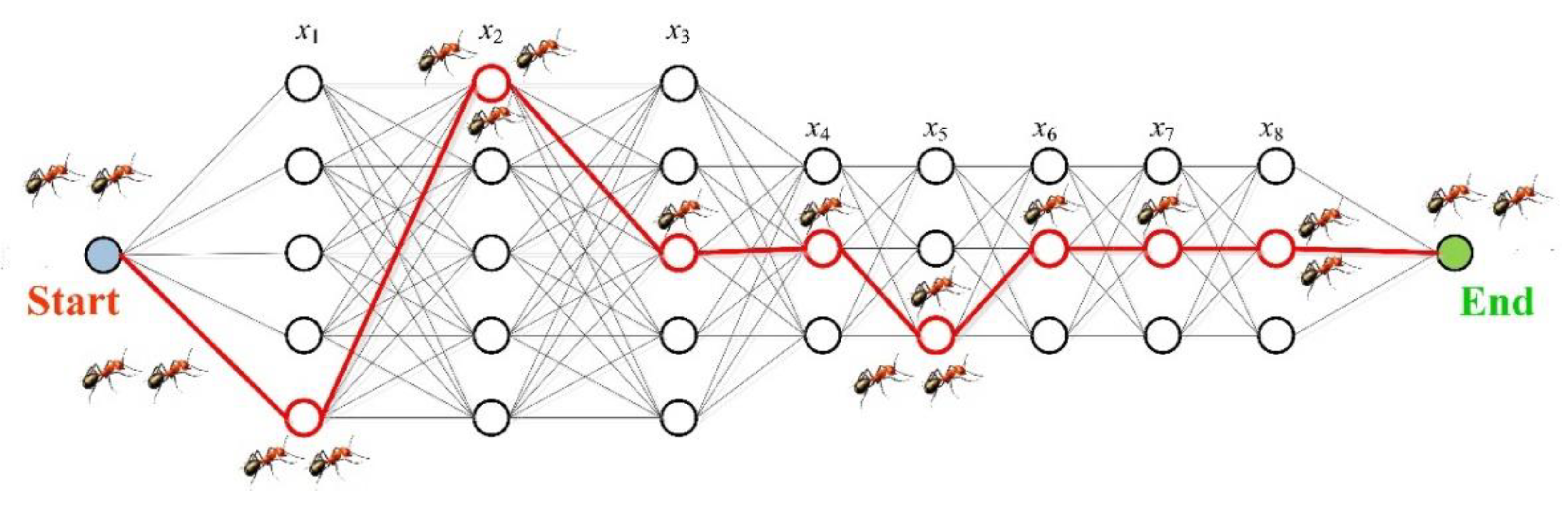
When MCR-Q(λ) learning converges, the value function matrix
Qi and probability matrix
Pi corresponding to all variables will prefer a state-action pair, and all individuals will tend to be consistent in selecting the action, as demonstrated in
Figure 5.
6.1.3. Comparative Analysis of Simulation Results
For the purpose of evaluating the optimization capability of MCR-Q(λ) learning, this section applies all the algorithms to solve the OCECF model for 10 repetitions. For each method, the objective function value is directly taken to evaluate the quality of a solution during the searching process, which is the most crucial index to evaluate the optimization performance.
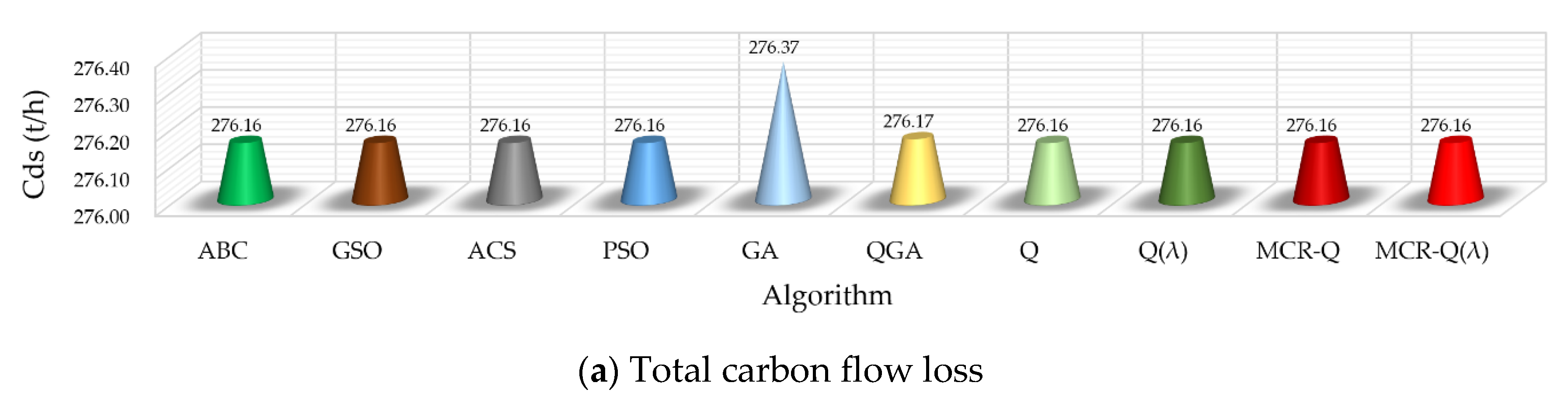
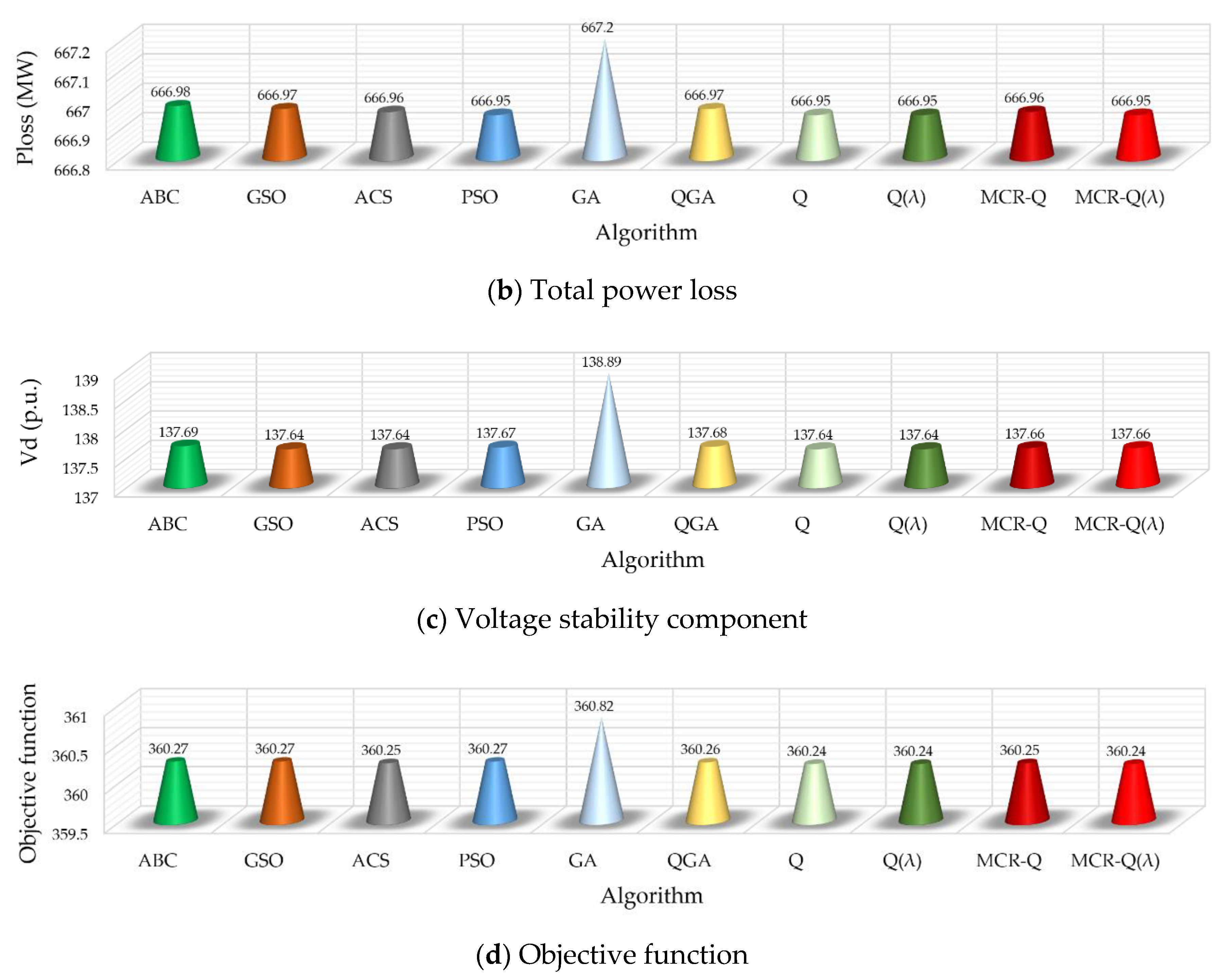
Table 5 indicates the average convergence results of 10 repetitions for the different algorithms, and it can be found that:
- (a)
The optimal solution obtained by Q learning and Q(λ) learning is the best, but the optimization time is also the longest, which also shows the strong ergodicity of RL;
- (b)
The convergence objective value of MCR-Q learning and MCR-Q(λ) learning is the closest to Q learning and Q(λ) learning, and the convergence time is the shortest, while the convergence speed is about 100 times that of single-objective Q learning and Q(λ) learning;
- (c)
RL improves the algorithmic speed by up to 37.13% with the introduction of the eligibility trace (λ) returns mechanism;
- (d)
With the increase in the load scenario, the line losses and carbon losses of the power grid will also increase correspondingly. However, since the power system has a sufficient reactive power supply, its voltage stability component just changes slightly.
Figure 6 gives the results comparison between different methods, where each value is the average of the sum value of five scenarios in 10 runs. It is obvious that the result obtained by GA is the worst among all the methods due to its premature convergence. On the other hand, the proposed MCR-Q(λ) learning only has a slight improvement on each index compared with the other methods, but it also can obtain the lowest total carbon flow loss and objective function. It verifies that the proposed method can effectively satisfy the low-carbon requirement from the viewpoint of power networks.
Lastly,
Table 6 gives the statistic convergence results of 10 repetitions for the different algorithms, and it can be found that:
- (a)
The Q learning and Q(λ) learning have the highest convergence stability and can converge to the global optimal solution every time;
- (b)
The statistical variance and standard deviation of MCR-Q(λ) learning are the closest to Q learning and Q(λ) learning, which have a relatively high convergence stability;
- (c)
Except RL, other algorithms are more likely to trap at a local optimum because of the parameter setting and the lack of learning ability.
6.2. Case Study of the IEEE 300-Bus System
6.2.1. Simulation Model
According to different generator types, the carbon emission rate
δsw of each unit in the IEEE 300-bus system is summarized in
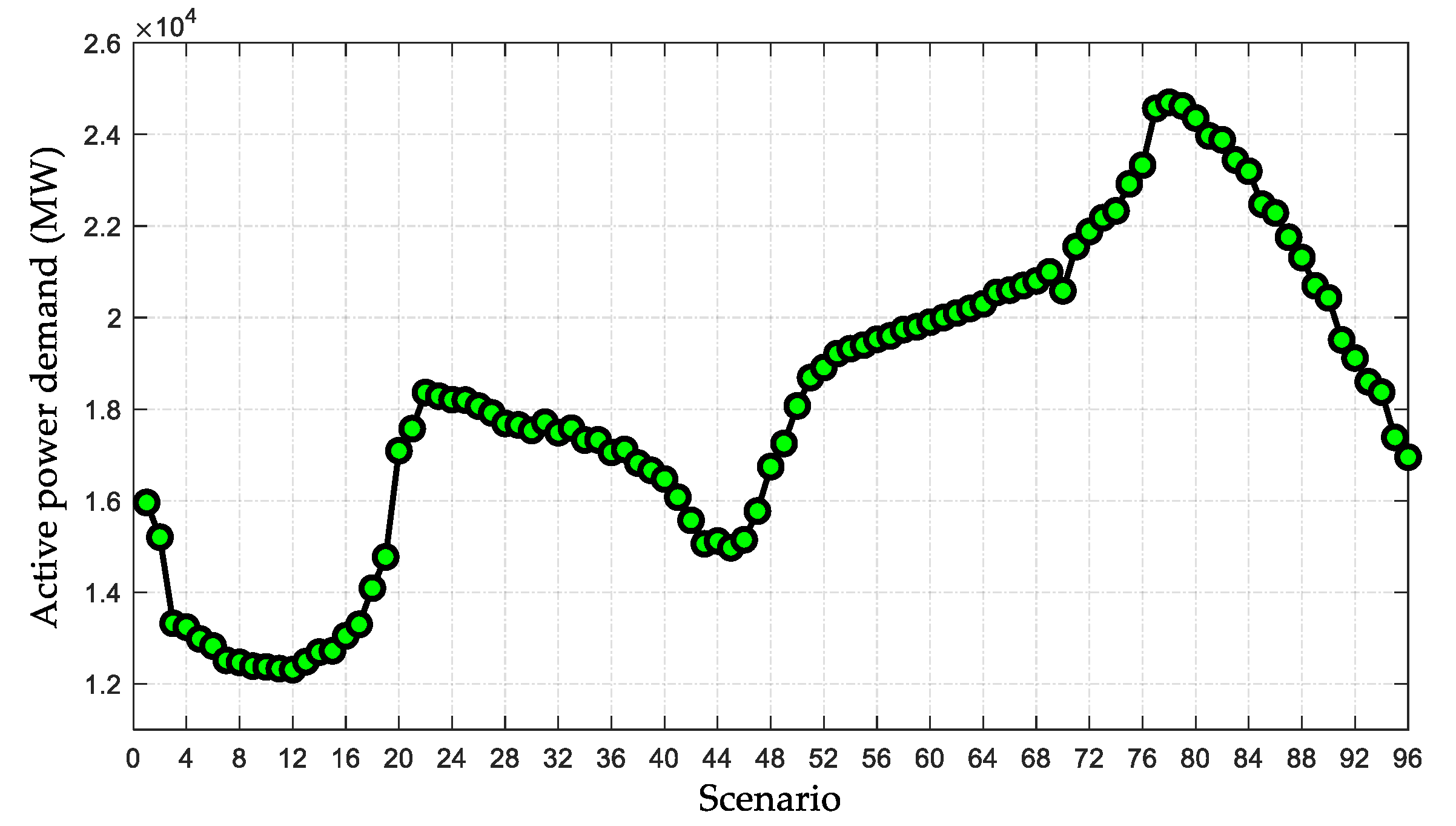
Table 7. Besides, 96 different load scenarios are designed to simulate different optimization tasks in a day for the IEEE 300-bus system, as shown in
Figure 7. Moreover, the optimization variables are given in
Table 8.
6.2.2. Comparative Analysis of Simulation Results
For the purpose of evaluating the optimization capability of MCR-Q(λ) learning, this section applies all the algorithms to solve the OCECF model for 10 runs. Since the number of optimization variables of the IEEE 300-bus system dramatically increases, the conventional Q and Q(λ) algorithms cannot implement an optimization due to the dimension disaster.
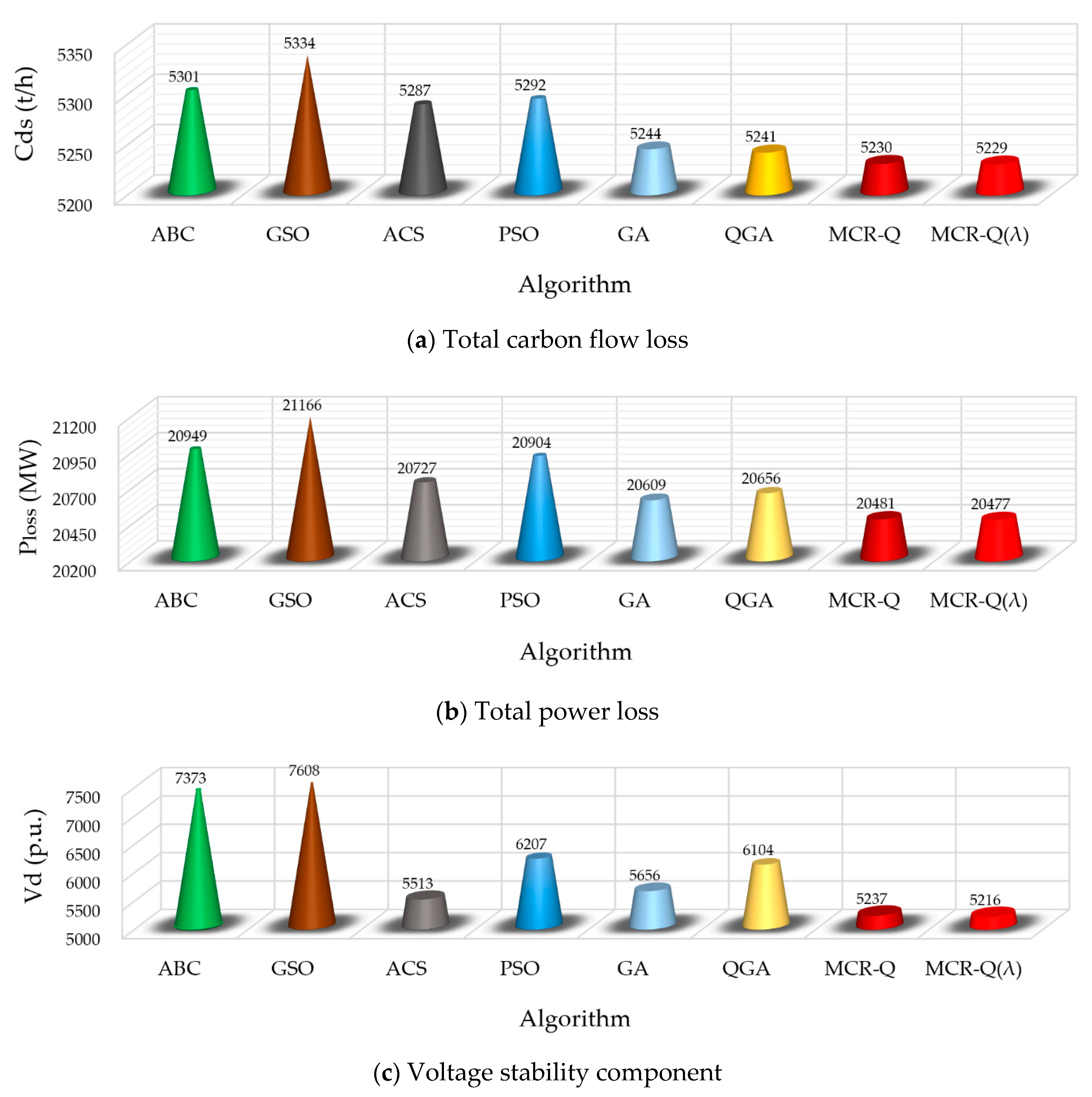
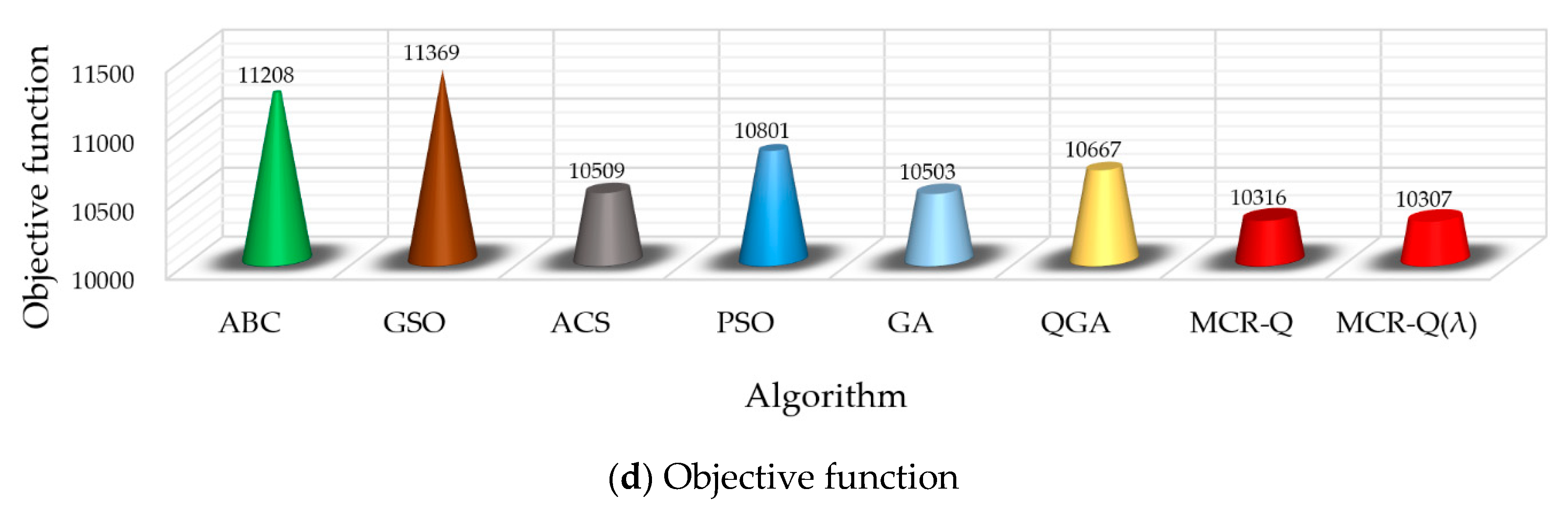
Figure 8 provides the results comparison between different methods, where each value is the average of the sum value of a day in 10 runs. It can be found that the proposed MCR-Q(λ) learning significantly outperforms other methods on the total carbon flow loss, total power loss, voltage stability component and the objective function. Hence, the MCR-Q(λ) learning-based OCECF can achieve a low-carbon operation for the power network. Particularly, these values obtained by MCR-Q(λ) learning are 2.0%, 3.4%, 45.9% and 10.3% lower than that obtained by GSO. It verifies that the optimization performance of MCR-Q(λ) is much better than other conventional meta-heuristic algorithms as the system scale increases.
Besides,
Table 9 gives the distribution statistics of the objective function under different algorithms in the IEEE 300-bus system, where each value is the sum value of the objective function of a day in 10 runs; the best, worst, variance and standard deviation (Std. Dev.) are calculated to evaluate the convergence stability [
51]. It can be seen from
Table 9 that the convergence stability of MCR-Q(λ) learning is the highest among all the methods with the smallest variance and standard deviation of the objective function.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}