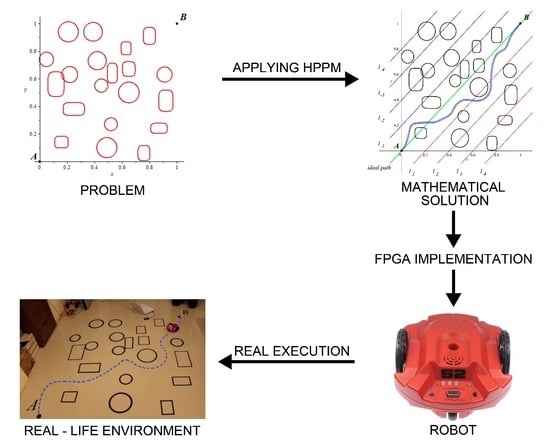
1. Introduction
Robotics has improved the quality of human life by simplifying tasks, especially those that require high precision or imply physical risks [
1]. As a consequence, it has been necessary that the robot could properly move within a particular environment [
2], in order to extend its coverage range. Therefore, the study of free-collision movements in a given environment has become a need to guarantee robot safety and the surrounding objects or persons. Several methods have been developed to obtain feasible paths to avoid collisions, such as low degrees of freedom (DoF) methods or sampling-based techniques [
3]; several of them are optimized [
4,
5,
6] and deterministic algorithms [
7,
8]. The following lines will provide a brief description of these methods.
Among the low DoF methods, the Bug algorithm is a planning method that uses static environment maps and local analysis [
9], by simulating the behavior of insects. This algorithm aims to reach the final position using a straight line; if an obstacle appears, the algorithm tries to surround it. In practice, preventing collisions depends on the information obtained from optical or proximity sensors. In fact, the method performs a
scan to determine the next position based on information provided by the sensors. Whether a change of the sensed distance from infinity to a determined value is detected, or from a certain value to infinity, or between two different values, results in a new point for the motion trajectory. The main disadvantage lies in the need of sensors to recognize the environment, and even so, the method can often fall into closed loops without reaching the end point. In order to solve these issues, the algorithm has been modified and there are recently developed variants that complement the initial idea [
10,
11,
12].
In addition, regarding low DoF algorithms, we can mention the Artificial Potential Fields method (APF) [
13] as an alternative. It is based on the allocation of repulsion forces between the robot and obstacles, as well as attraction forces between the robot and goal position. By superimposing the resultant forces, a resultant vector is generated that determines the next point in the trajectory. For this method, both the gain constant and the influence distance are fixed values defined at the beginning of the algorithm; in addition, a partial derivative vector between the obstacle and robot is generated. Complexity of the method increases when a set of nearby, or adjacent, obstacles are present within the range of influence, thus, for each one the partial derivative vector has to be calculated. Moreover, under certain conditions, it is possible that local minima is generated during the trajectory calculation, which the robot would interpret as having reached the desired final position because attraction and repulsion forces are in equilibrium. An important advantage of this algorithm is the possibility to work in continuous real time domains [
7,
14].
The Expansive-Configuration Space Trees (EST) (The acronym EST to describe Expansive- Configuration Space Trees does not appear in the original papers but is used in many others for convenience.) is an algorithm of random planning that samples a portion of the space that is relevant to the analysis, avoiding the cost of determining the entire environment [
15,
16]. It performs two basic steps, expansion and connection. During expansion, the number of points to be sampled (milestones) is set as well as the distance between new and previous points. These milestones are selected randomly, independently, and uniformly within the free space (environment without obstacles). To improve the response time, two trees (two space expansion configurations) are generated simultaneously, one having the initial point as its root and the other having solution point as the other root, both growing until both expansions are visible to each other. Under a certain proximity condition, a connection of the spaces (through both trees) is established, generating the solution path. This algorithm is executed until the solution path is found or until the maximum number of iterations have been reached. An issue with this method appears when the solution space contains narrow corridors, because the radius of expansion needs to take small values, which causes a notorious increase in execution time. Conversely, another shortcoming occurs when trajectories exhibit numerous vertices, which complicates the selection of an accurate trajectory. Although it is possible to execute a smoothing algorithm, there is the possibility that during its execution the smoothed path could cause collisions with the obstacles. Moreover, in the original EST algorithm, the tree grows in all directions, generating numerous points to evaluate and expand; nevertheless, this can be reduced by guiding the robot through a specific path [
17].
The Kinodynamic Planning by Interior-Exterior Cell Exploration (KPIECE) is a suitable method for real-time path planning that iteratively builds a tree of movements in the solution space [
18,
19]. Motion trees are started with an initial position, and a null control function is applied at time
. Afterwards, continuous segments are generated by using a propagation function with fixed step size. The solution space is discretized by creating cells so small that they allow just a single movement within each one. Cells are classified in two groups, namely Interior and Exterior cells. This classification is important because the algorithm focuses on the exterior group by selecting those cells that allow a more efficient exploration leading to a faster encompassing of the free space. The next breakthrough point is decided by a probabilistic calculation, preferring the displacement on recently added cells. The problem of this method lies in the compromise between cell size and memory space. Consequently, if the free space presents a high degree of complexity, then, results from algorithm progress are relatively slow because memory space must be increased in order to keep a record on importance indicators, cell classification, progress, and penalties.
The Probabilistic RoadMap method (PRM) [
20,
21], consists of two phases: a preprocessing phase and a search phase. The preprocessing phase encompasses three processes, roadmap construction, connectivity checker, and the collision verifier. The first process starts with a single-node graph containing the starting point. Around it, a maximum radius region is defined. Within it a uniform probability distribution of a set
N of possible arrival nodes is generated. These selected nodes in
N must avoid collisions with any obstacles in the region. Connectivity checker establishes valid connections between these nodes and the starting point by generating additional edges to the graph. Collision verifier is aimed to avoid collisions of the edges with obstacles using an iterative halving algorithm of the edge until a minimum segment size is reached. In case that collision verifier does not detect any issue, the edge is considered valid and stored. The search phase is devoted to finding a valid shortest path using any search algorithm such as Dijkstra’s or A*. An important advantage of this method is the roadmap reusability for other pairs of starting-final nodes, for the case of static environments.
Rapidly-exploring Random Tree (RRT) [
22,
23,
24] is a sampling scheme to perform fast searches in large-dimensional spaces. The given spaces may contain geometrical or differential constraints depending on obstacles, type of robot, or dynamics implicit in the problem. This procedure starts by generating a randomly-selected set of sampling points near a specific vertex. The search for a tree continues by resorting to an extension function that is used as a metric to choose the next set of vertices. The method also achieves collision detection to determine if the next step of the search fulfils the original constraints. During each iteration, three situations may arise. First: the goal position has been reached, then the search ends. Second: a new vertex in the tree has been found, but it is not the goal, then continue with the expansion procedure. Finally, third: the vertex is stuck, then it cannot be used for any further expansion procedure.
Several variants of the RRT method have been proposed in order to deal with different optimization parameters. Among them, the RRT_Connect [
4] has been designed with the goal of solving problems that do not consider differential restrictions. It is based on two main ideas: one is to grow trees simultaneously from starting and goal positions and the other is to use heuristics attempting to reach a maximum distance rather than a fixed step size per expansion. During each iteration, both trees try to connect to the nearest vertex of the other one, resulting in a guided exploration. Another variant is the RRT_Star method [
5,
6], which is an optimal version of the RRT with respect to the path length, by removing loops and redundant nodes in the graph during the growing process and operates only with directed trees. Although the algorithm optimizes path length, it exhibits a serious shortcoming because its execution time tends to increase. This means that if search time is exceeded, then the method is not able to find a solution.
There are also several alternative methods, focused on optimizing path planning and obstacle avoidance, like those based on Cellular automata (CA) [
25,
26,
27], whose main characteristic is its time and space handling at a discrete level. Generally speaking, CA needs, at least, a network of regular cells within n-dimensional space, a set of variables that provide the local state of each cell for every discrete time instant, and a rule specifying evolution time of the states related to a central cell neighborhood. For two-dimensional CAs, the 5-cell Von Neumann neighborhood (central, front, rear, left, and right cells), or the 9-cell Moore neighborhood (central, front, rear, left, right, and their four diagonals) are generally considered. In order to simulate such a system, it must be finite and have boundaries. Within this method, the next state result directly depends on the previous state but nevertheless can be expanded considering several previous states, thus creating a memory system. The movement scheme is similar to that of potential fields; nevertheless, different approximation schemes can be used. The model is attracted to the goal point, seeking to move on every step towards the goal complying with the noncollision rule, which prohibits moving to occupied cells within the neighborhood at that specific time analysis. This method maintains the movement and analysis scheme, updating the states on every step, until the goal point is reached. It has several advantages such as the application in static, dynamic, or combined systems and the inclusion or disappearance of obstacles during its execution, the goal point modification through the process, among others.
Otherwise, there are deterministic methods, that is, methods for obtaining trajectories that are executed only once with the certainty that, if the problem has at least one real solution, it will be found; one of these methods is the Homotopic Path Planning Method (HPPM) [
8,
28,
29,
30,
31,
32]. The HPPM makes use of the Homotopic Continuation Method (HCM), which has been initially used to solve systems of Non-linear Algebraic Equations (NAEs) for the case when these systems have multiple solutions. These are found through the conversion of a homotopic map; HPPM includes obstacle representation within the environment through mathematical singularities in the system of equations to be solved. To generate the homotopic conversion, one starts from a system of nonlinear equations with known solution values and ends when solutions of the desired system of equations are reached by integrating on an additional term known as the homotopic parameter (
). During this conversion, a family of
curves is generated and within all of them, the HPPM will take advantage of the one that implicitly contains the collision-free path. In the study cases presented in this article we will only work in two dimensions; nevertheless, the HPPM algorithm can be expanded to
n-dimensions, as shown in [
8]. An advantage of the HPPM is, when applied in environments with a high density of obstacles and narrow corridors as well [
31], memory use and computation time increases at slower rate compared to the methods previously mentioned, especially if it is considered that the solution method could be implemented in an embedded system like a Field Programmable Gate Array (FPGA). This work proposes a methodology that properly assigns the repulsion parameter for terrestrial mobile robots, given that it constitutes a key value for finding an optimized collision-free path. The goal is to obtain a solution path as close to the optimum, in terms of distance, as possible.
This paper is organized as follows:
Section 2 describes HCM and the path planning solution using HPPM. Description of the repulsion parameter and proposed methodology for its assignment is described in
Section 3. The implementation of this in a FPGA is presented in
Section 4. Three study cases are provided in
Section 5. A brief discussion is given in
Section 6. Finally,
Section 7 presents the conclusions of this work.
2. Homotopy Continuation Method as a Collision-Free Path Planning Method
The Homotopy Continuation Method (HCM) is used to solve NAEs applying a procedure that involves transforming the NAEs into a trivial problem simple to solve; then, it transforms gradually the trivial problem into the original NAEs increasing the probability of finding a solution. The NAEs to solve is:
where
n indicates the number of
x variables of the problem. Based on this, a homotopic map is generated, which has the following representation:
where the homotopic parameter
is responsible for carrying out the continuous deformation of the system of NAEs during its sweep from 0 to 1. When
the solution of the system for
is known or can be calculated by numerical methods in a simple way; when
the function
, which implies that the set of solutions for
has been found.
The perturbations that the homotopic system goes through generates a family of
curves; nevertheless, not all of these curves generate the path from
to
, some produce closed curves and others tend to diverge without intersecting at
= 1. The curve that generates the path from
to
is what essentially constitutes the solution for trajectory analysis. A possible representation to generate the homotopic map would be:
where,
is a simple solving system. For this study, the method known as Newton’s homotopy [
33] is used, where through
allows one to find solutions of the system based on an initial point
. Its representation usually looks like the following:
During the process, the value of may increase or decrease as it encounters backward trajectories; therefore, predictor-corrector scheme shall be repeated until exceeds the value of 1, which means that the original system has been solved and the homotopic path that goes from to has been found. For all this to take place, it is important to define the system of non-linear equations appropriately; once this has been defined, a suitable numerical continuity method is proposed, otherwise global convergence of the system cannot be guaranteed.
In order to solve the problem for robotic applications presented in this investigation, it is important to take into account the management of a normalized space, that is, dimensions adjustment. Then, it is considered to reduce HPPM complexity from
n-dimensions to only two of them. Initial position
is set, for this article, at
; then, goal point
will be
, delimited by a unitary length and width map. In addition, it must be aided by a pair of equations whose only solution is found at end point
, so that:
In such a way that
and
. This is how a pair of linear equations can be established:
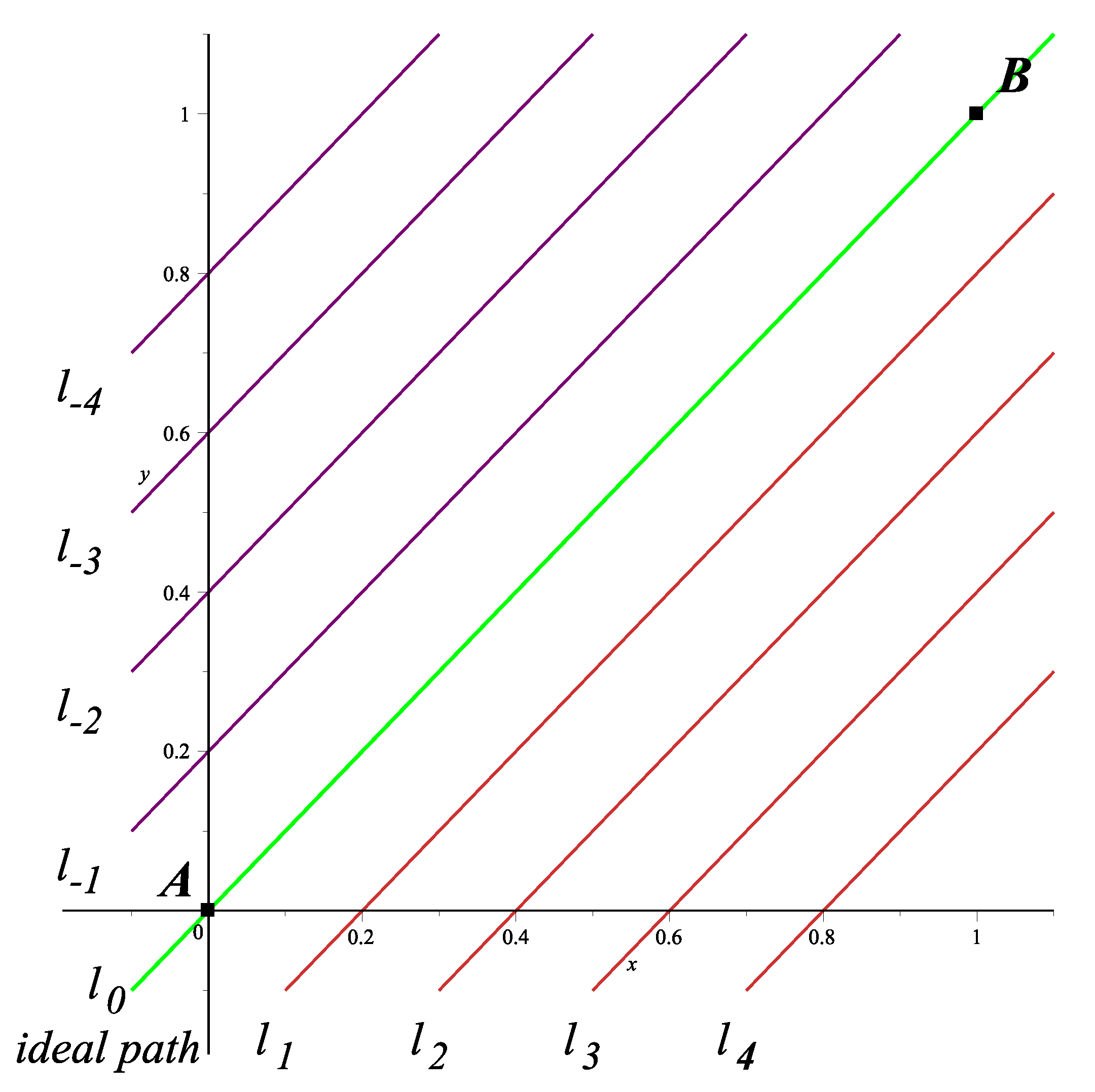
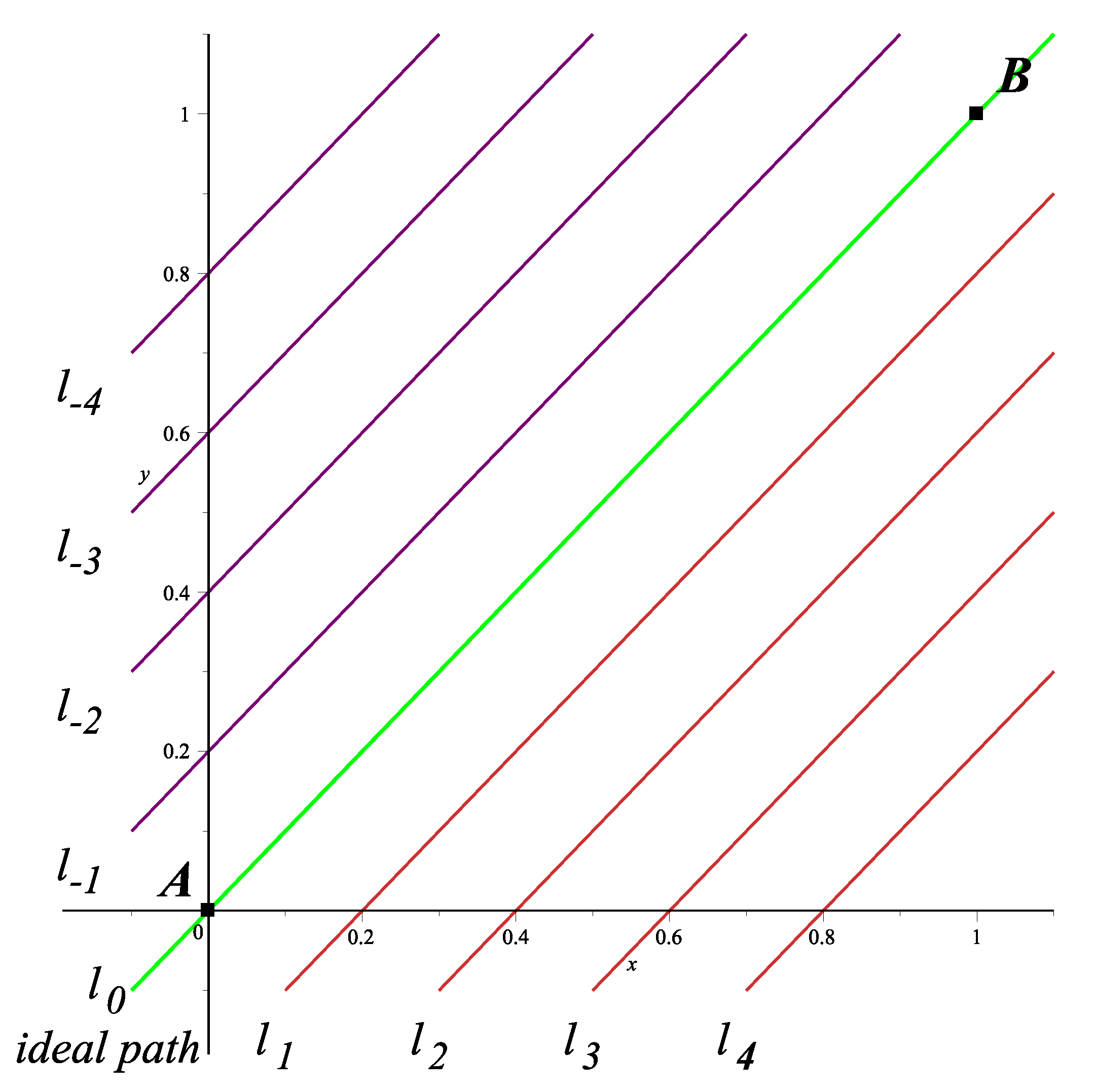
where,
a,
b,
c,
d,
e and
f are constants so that these lines intersect at point
. For this work, we propose
and
, where,
and
represent the respective slopes of each auxiliary line. As already mentioned, homotopy will start from a simple, or known solution; as for this case, the one generated by the crossing of lines
and
.
Values used here are
and
, since they have shown that to accomplish the desired behavior of the resulting trajectory, according to the study carried out in [
31] with various combinations of slopes for the crossing of line
with
.
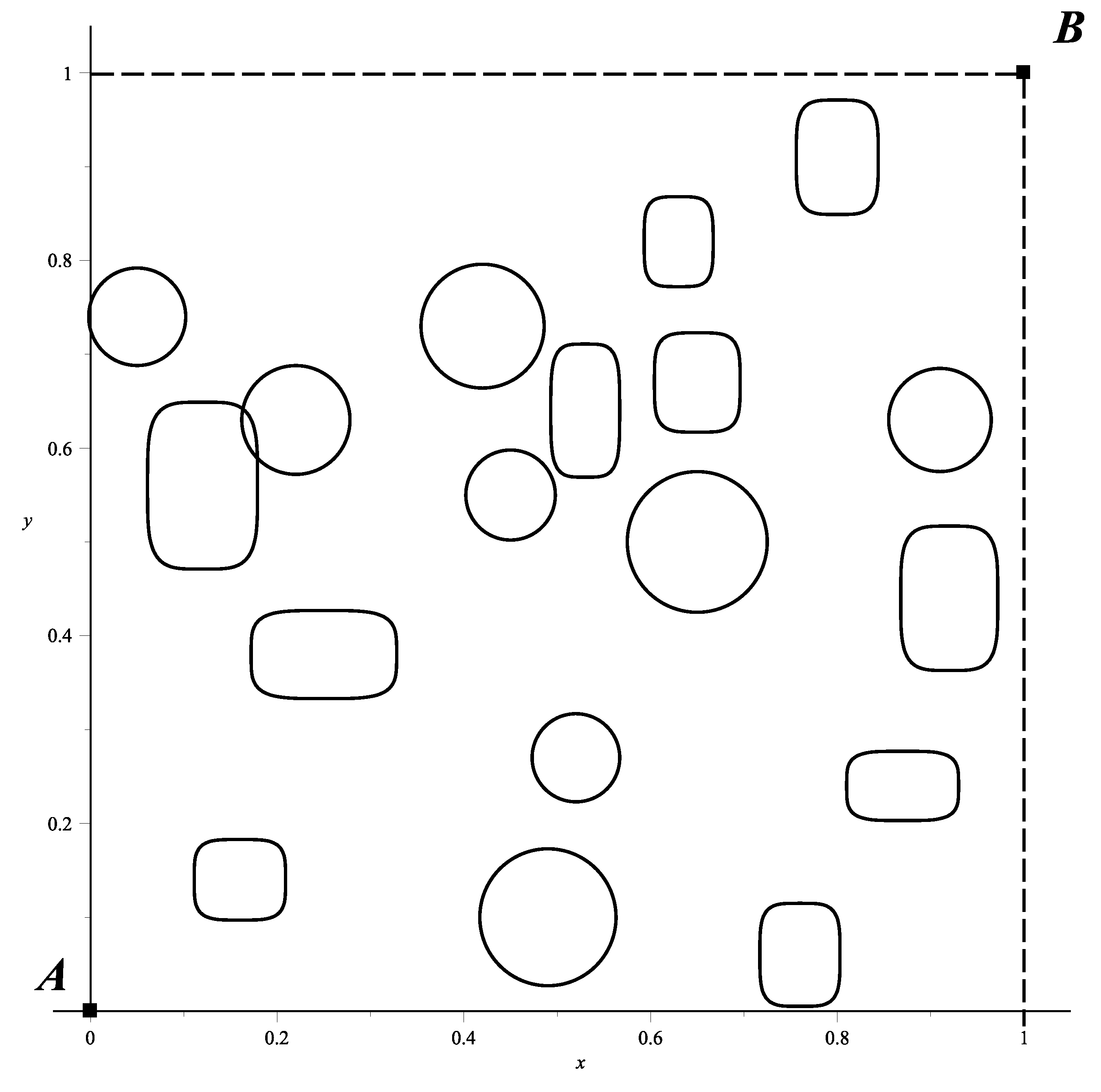
Once the standardized space has been established, obstacles must be included. HPPM can work with all kinds of obstacles represented with closed curves where, for this article, we will use circular and rectangular representations. Circular obstacles are represented as:
where
are the coordinates of the
i-th circular obstacle of radius
. While rectangular obstacles are analytically approximated through the ellipsoidal equation:
where
are the coordinates of the center of the i-th rectangular obstacle, and the base and height approximations approach
and
, respectively, as
tends to infinity; for this study,
defines the vertices of each rectangle. Supported by these descriptions, the set of obstacles in [
31] are expressed through:
where
could be either,
or
;
is known as the repulsion parameter assigned to the
i-th obstacle
. To complete the inclusion of obstacles to the system, a compensation function must be generated:
which evaluates the alterations caused by the obstacles at final point
. With this, the full system of non-linear equations can be established that will describe the problem:
which converts the equation
into the constraint equation. Applying (
11) in (
4) it gets:
where starting point
A has coordinates
. Therefore, the system is established (see
Figure 1).
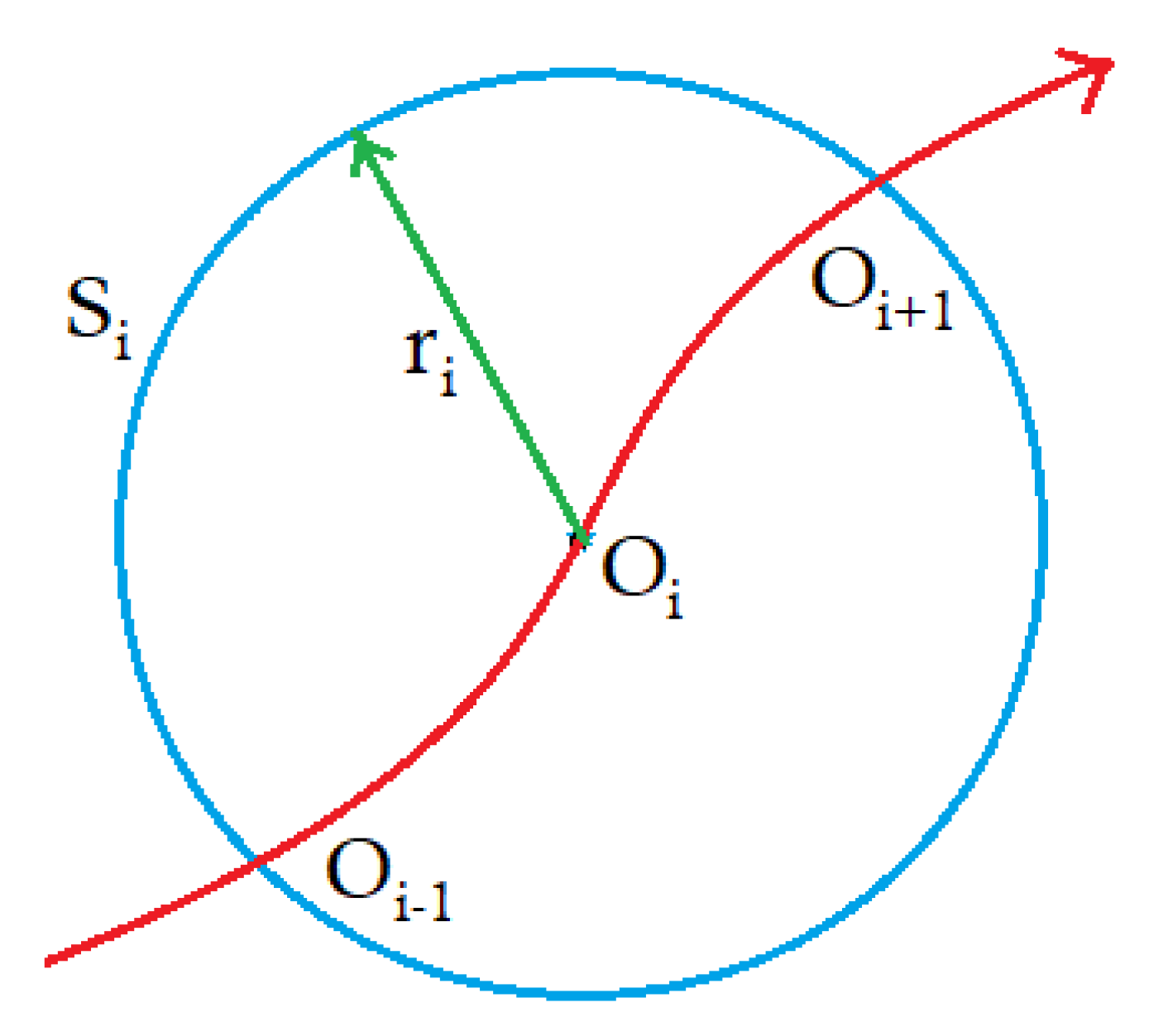
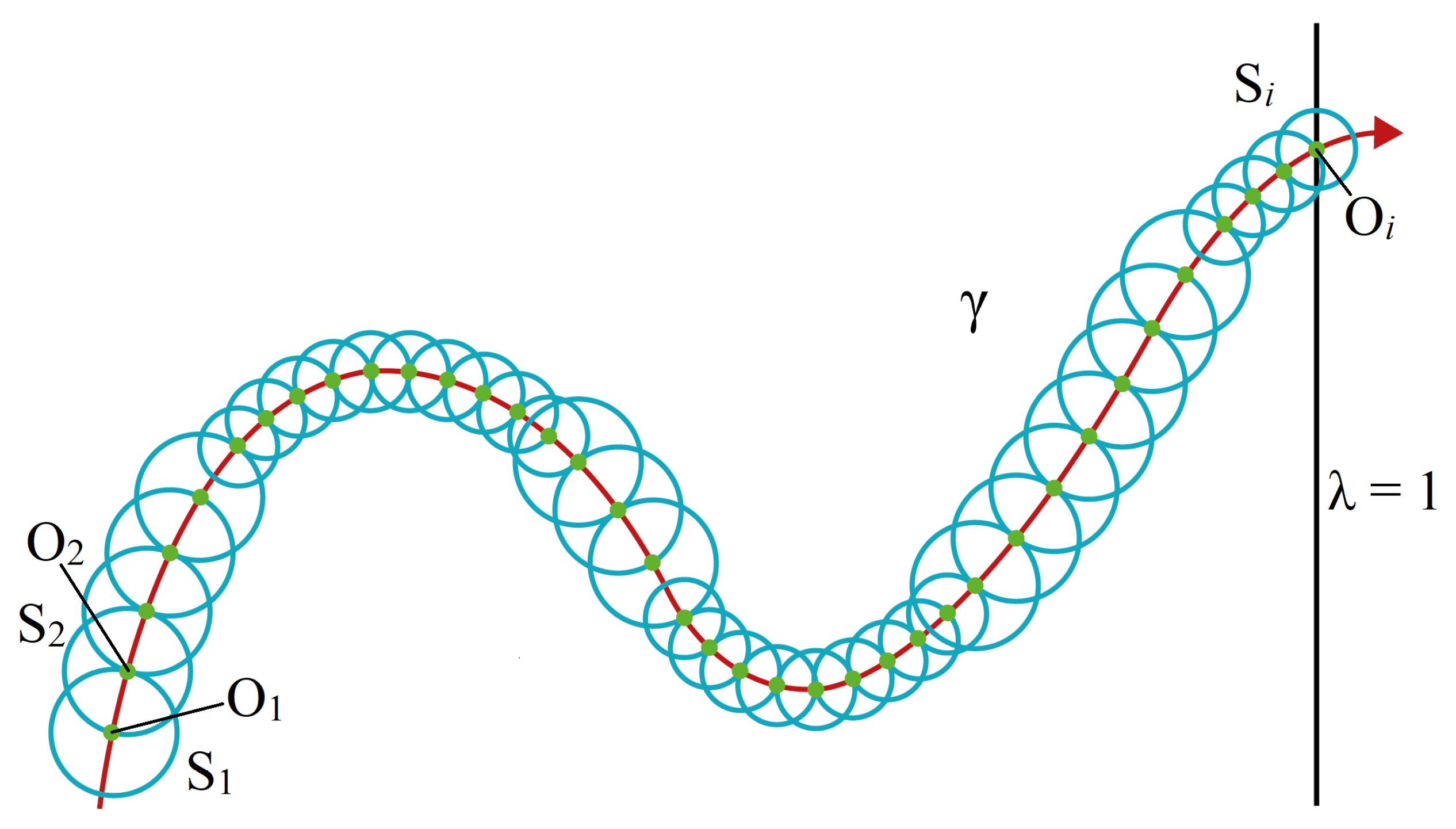
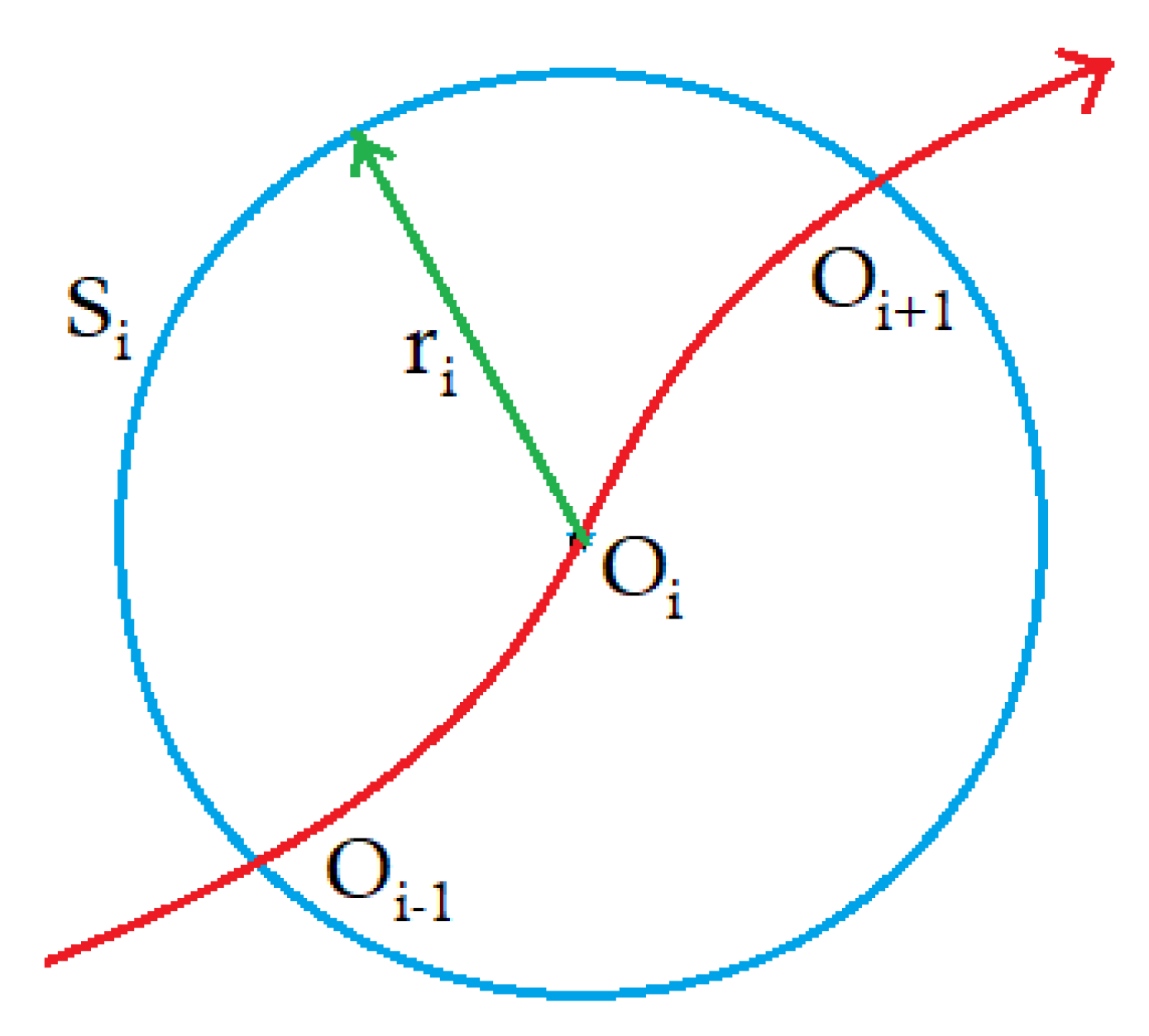
An appropriate path tracking procedure that supports HPPM should be considered. One of them is the Hyperspherical Algorithm [
34,
35,
36] which, as its name implies, is based on the generation of an
n-dimension sphere with radius
r and its center lies on the homotopic curve in
. The contour of this sphere touches at least two points of the same curve,
and
, as can be seen in
Figure 2.
A terrestrial robot has two-dimension variables (
); in addition, there is the need to provide the homotopic parameter
; therefore, the algorithm will use an equation dependent on three variables, represented by:
where
is the center
of each sphere and
its particular radius. Combining this new function with the system (
12), the following system is obtained:
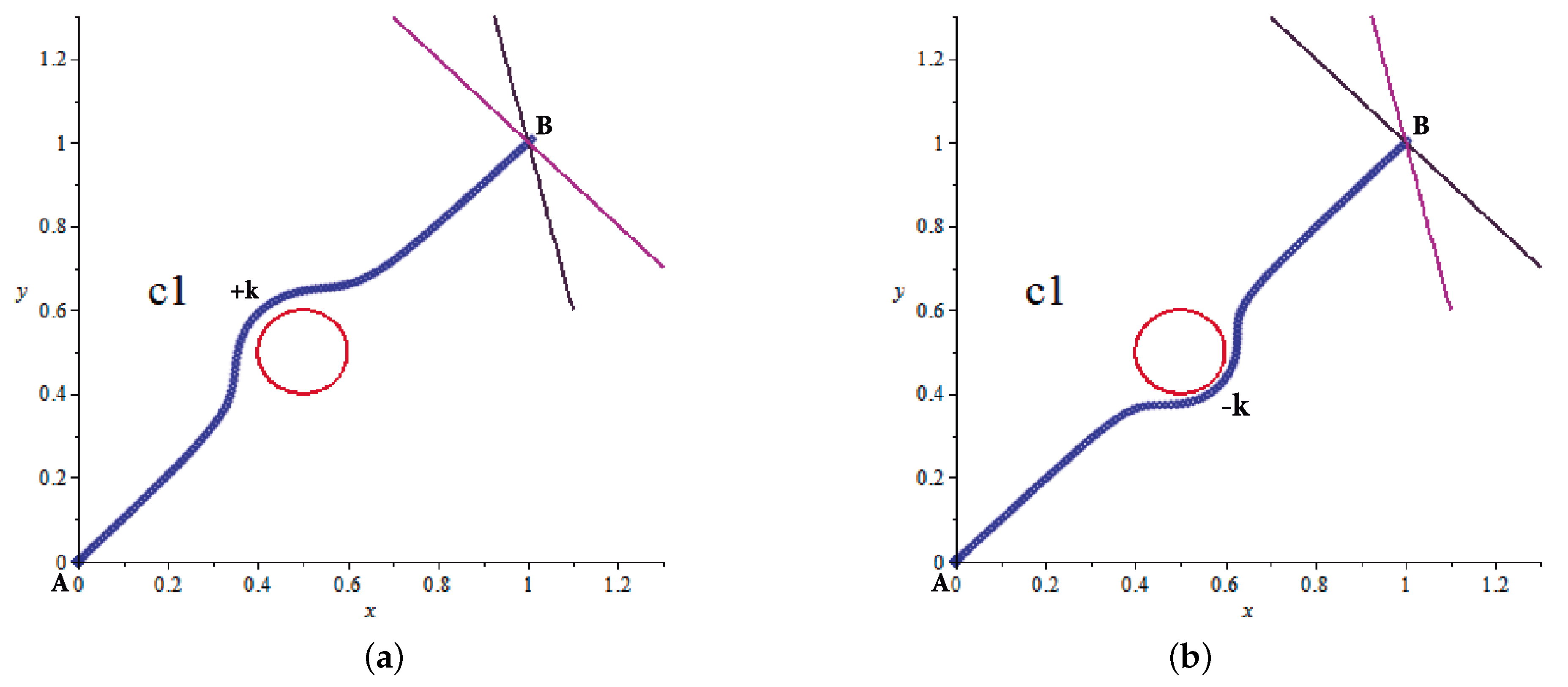
The algorithm changes values after each iteration, that is, updates the center value; in addition, some curve segments may have very closed return points, then, radius values vary to prevent reversal of jump issues between homotopic curves [
35,
37].
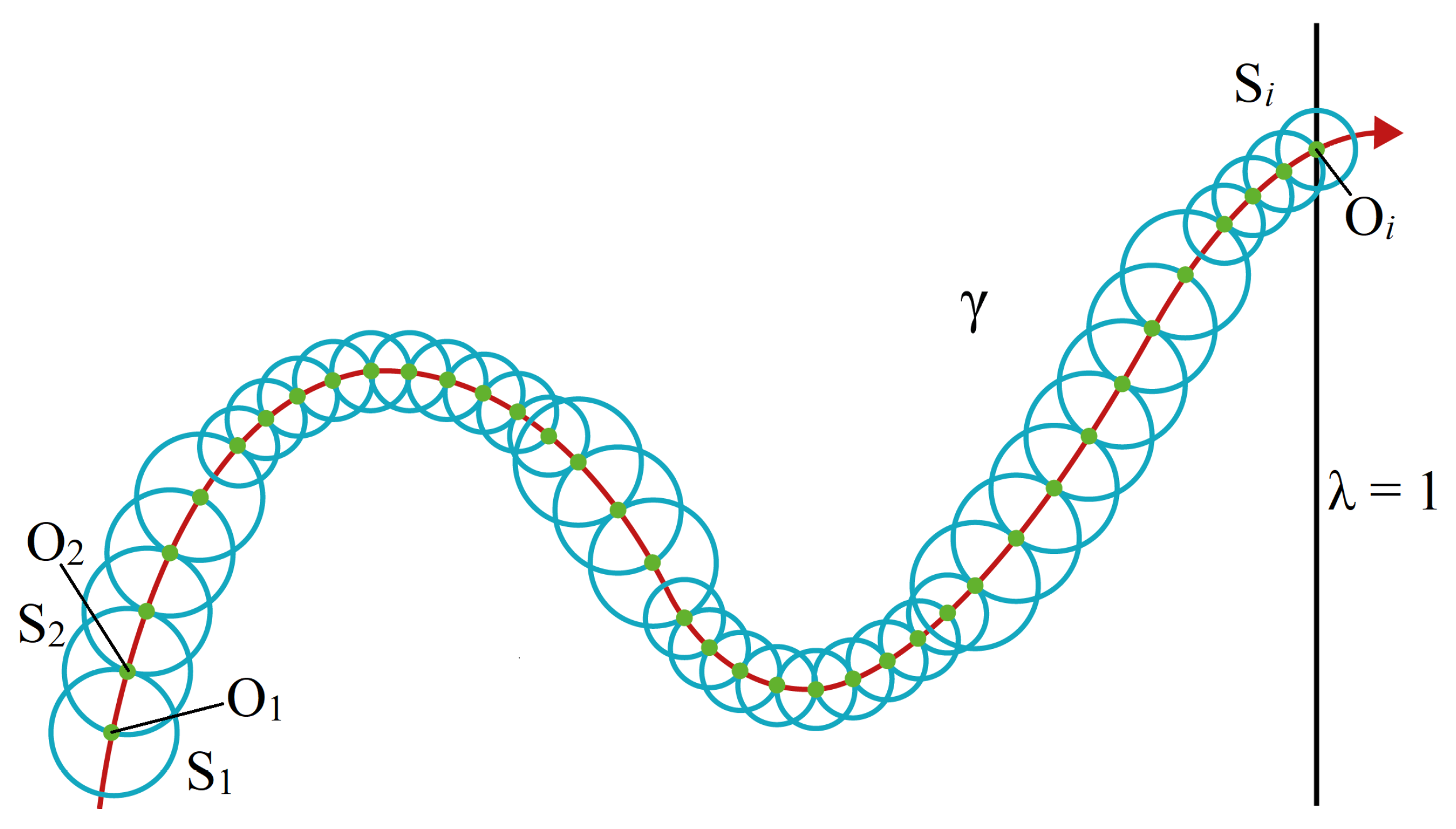
Figure 3 shows this adjustment based on this method. To avoid complications when designing the spheres and maintaining the homotopic trajectory, the method uses a predictor-corrector model complementing the spherical tracking.
To find the next advance position on the path, the Euler predictor algorithm is applied; the reported works [
34,
37,
38] present and verify its effectiveness. It takes advantage of the hypersphere centered at the current position within the homotopic curve
and draws a tangent vector
on its center; when this vector propagates in space, it touches two points of the hypersphere
. From this pair of points, the closest to the advance solution direction
will be selected as the predictor point; this procedure is thoroughly explained in [
39,
40]. According to this, predictor point
formula can be expressed as:
The predicted point is near the solution curve; nevertheless, it is necessary to execute the corrective algorithm so that this approximation is positioned on the homotopic path. For this case, the Newton-Raphson algorithm is used [
35,
37]. Thus, the corrective step can be expressed as:
where
...;
, and
is the inverse Jacobian matrix of
. That is the system representation at current point
. Since it is an iterative method, the obtained value becomes the current value for the next iteration, and so on until any of the following situations is reached: it converges to a point in the homotopic curve, reaches a convergence value with a minimum difference established between one iteration and the next (which for this investigation has a value of
), or consumes the maximum number of iterations (50 for this procedure).
From now on, the predictor-corrector scheme, in conjunction with the hyperspheric advance scheme, will be repeated for every position progressed over the path until
has crossed the 1 value; which implies that there is a path from the start to goal position [
8,
28,
29,
30,
31,
33].
The fundamental difference from the original HPPM is that this proposal adds an automated calculation algorithm for the repulsion parameters, useful for the most complex study cases, where calculations by hand would be time-consuming and cumbersome, as can be noticed in the cases found in [
31].
4. FPGA Implementation
The FPGA implementation in this work, and other implementations on PC or embedded devices [
31], is designed to allow the user to select different initial and goal points within the normalized space (that is, between 0 and 1) and also to modify the quantity and position of obstacles present in this normalized space. Algorithm 1 presents the general algorithm programmed in the FPGA.
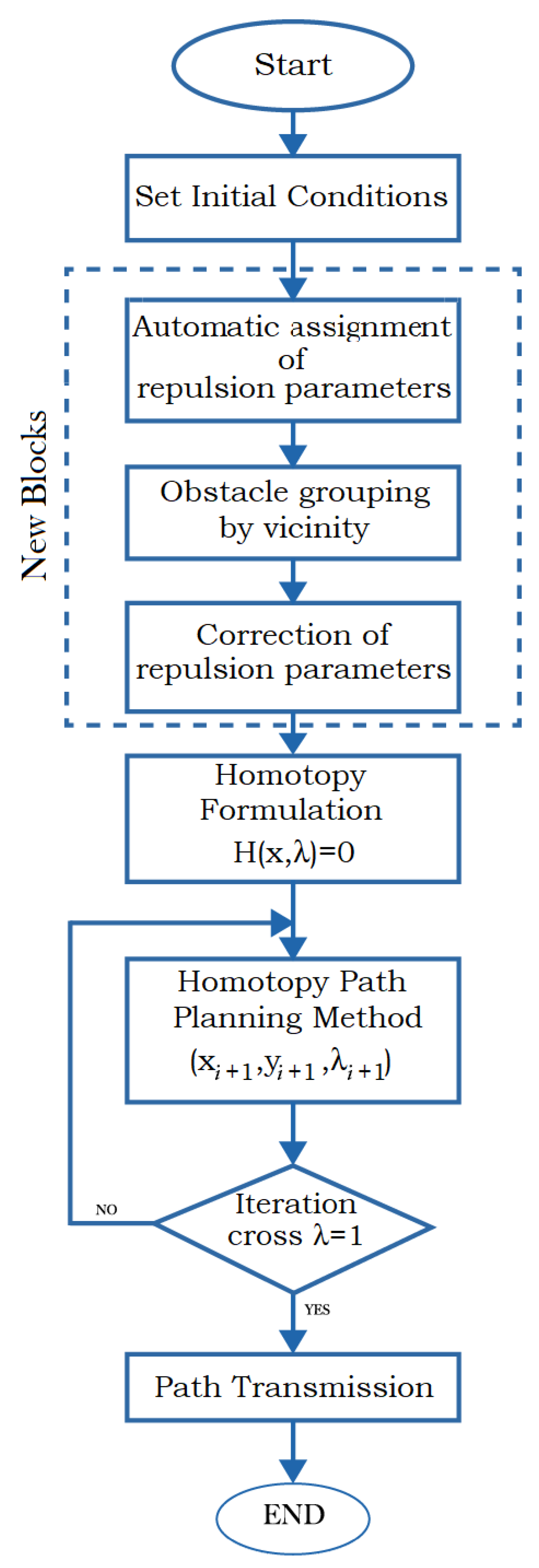
| Algorithm 1 General algorithm |
- 1:
procedureGeneral() - 2:
Set initial conditions - 3:
Automatic assignment of repulsion parameters - 4:
Obstacle grouping by vicinity - 5:
Correction of repulsion parameters - 6:
Homotopy formulation - 7:
Homotopy Path Planning Method - 8:
if then ▹ Stop path tracking condition - 9:
Return to Homotopy Path Planning Method - 10:
end if - 11:
Path transmission - 12:
end procedure
|
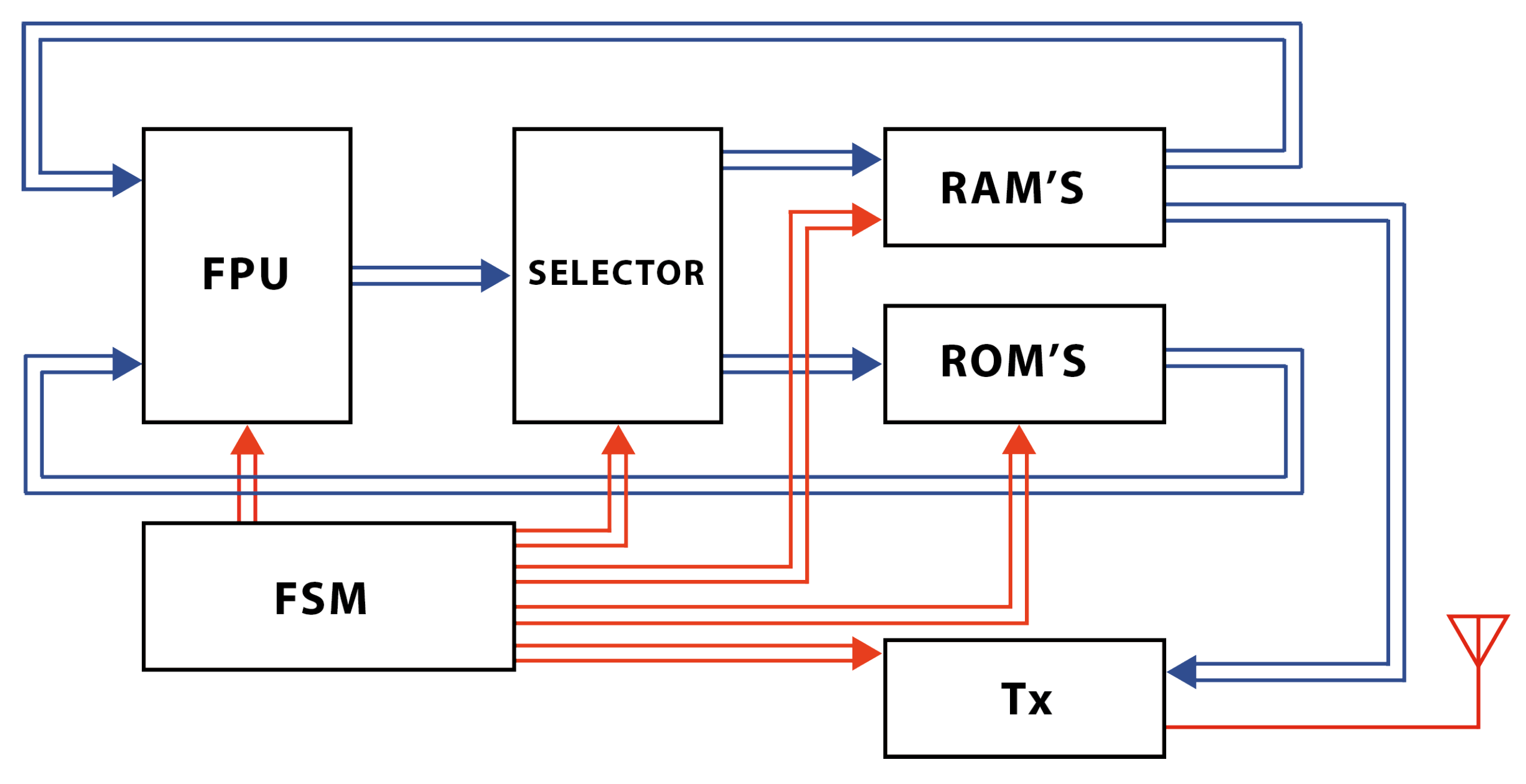
The implemented program in the FPGA consists of an arithmetic floating-point unit (FPU), a set of ROM memories that store obstacle position data, a set of RAM memories to store intermediate results of calculations from the homotopic system, and the
values of the resulting homotopic path; all these elements are controlled using a finite state machine (FSM) that synchronizes the application of every methodology step described in this work (
Figure 9).
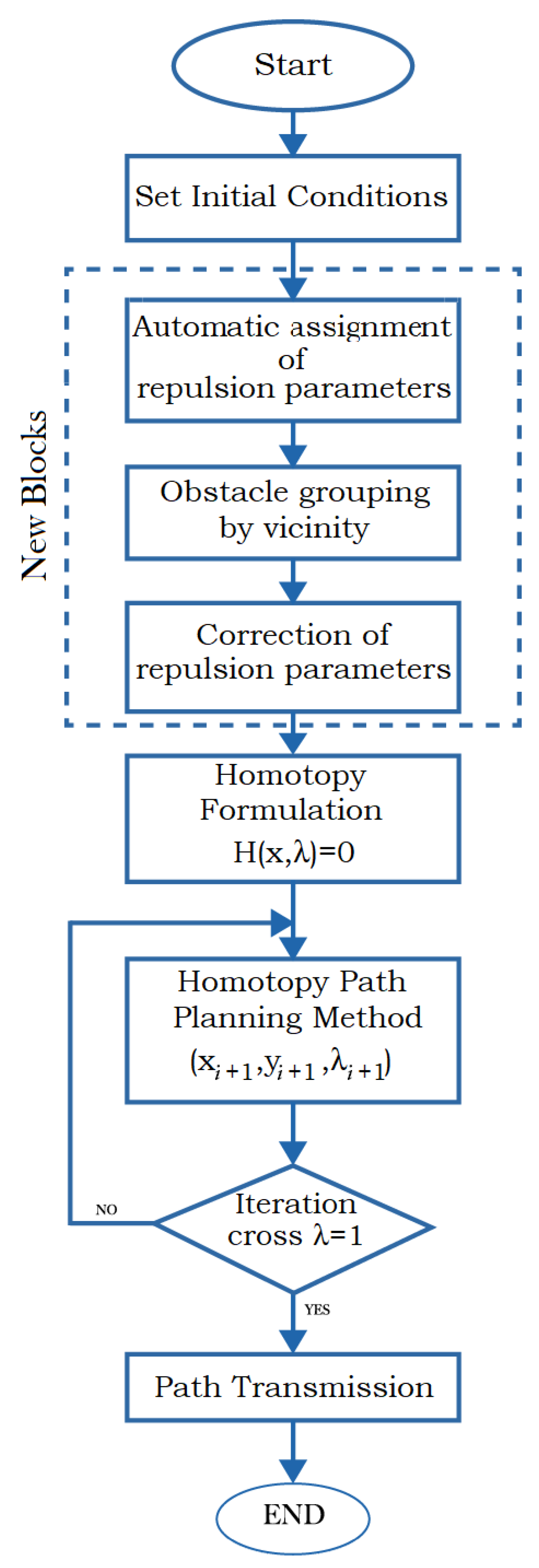
At the first stage of the program (Algorithm 2), obstacles present in the environment have to be declared, as well as some other parameters needed by the homotopic simulation (step size, error criterion, among others). FSM coordinates the sequence in which routines will be executed and provides memory management. It is important to note that the dotted-line box in
Figure 10 encloses the three new blocks (algorithms) proposed in this work. The rest of the diagram belongs to the original HPPM algorithm [
8].
| Algorithm 2 Initial conditions |
- 1:
procedureSet initial conditions() - 2:
RAM ← initial () and final position () - 3:
Set number and position of and obstacles ▹ Stored at ROM - 4:
RAM ← stablish hyperspherical standard size - 5:
end procedure
|
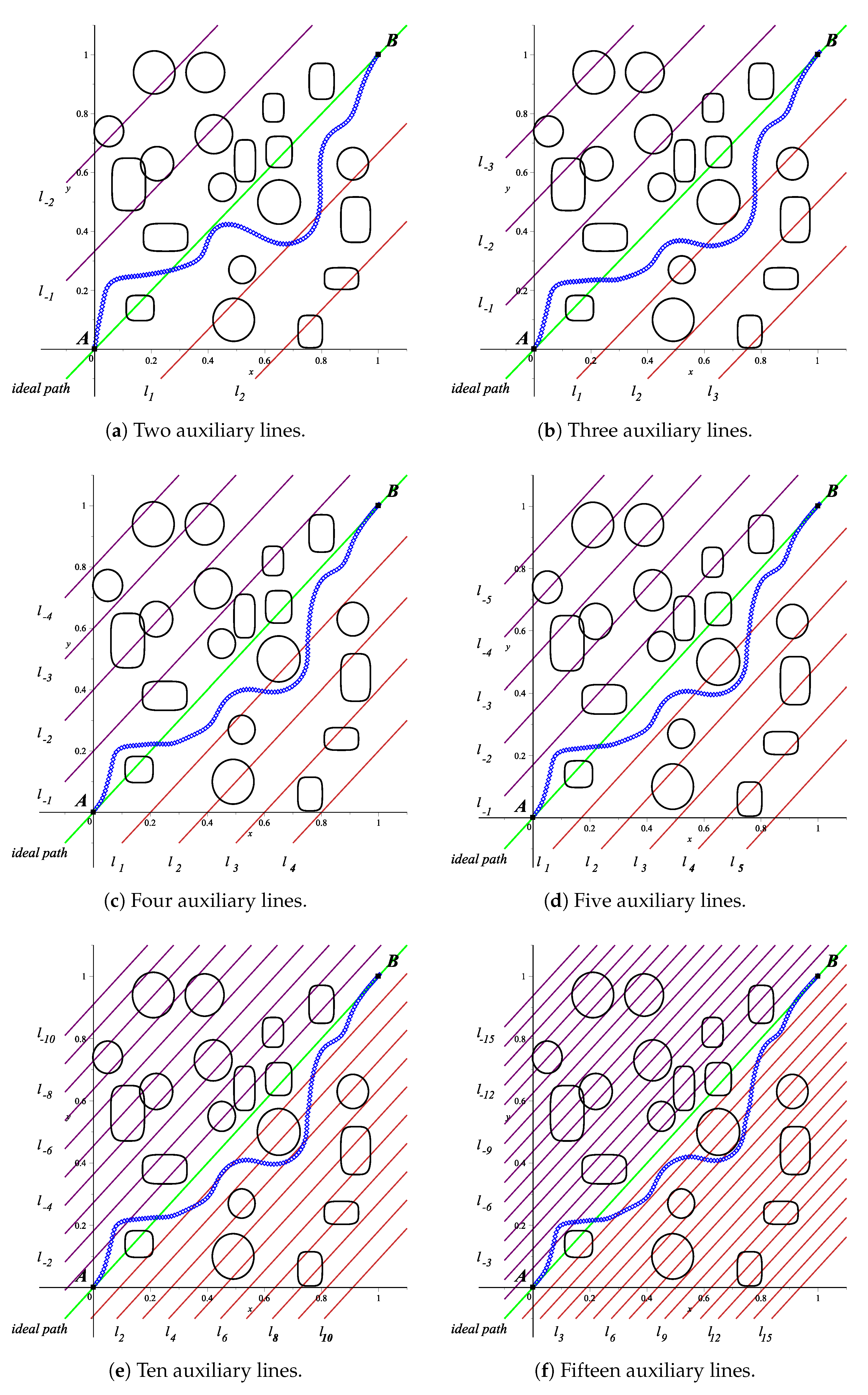
When the automatic assignment of repulsion parameter starts (Algorithm 3), a comparative cycle is established between every obstacle center and the auxiliary straight lines (
). To accomplish this, the state machine sends, one by one, the address corresponding to the center of every obstacle from the ROM memories; the data from these locations are compared to the auxiliary straight lines (
17) and the resulting values are stored in RAM at specific locations addressed from the FSM.
| Algorithm 3 Assignment of repulsion parameters |
- 1:
procedureAutomatic assignment of repulsion parameters(, finish1) - 2:
RAM ← Calculate slope with initial and final position - 3:
RAM ← Set auxiliary lines for assignment of repulsion parameters () - 4:
for i = 1 to number of obstacles do - 5:
RAM ← Calculate distance between i-obstacle and each auxiliary line - 6:
case distance is - 7:
when closer to ▹ is obstacle repulsion parameter - 8:
when closer to - 9:
when closer to - 10:
when closer to - 11:
when closer to - 12:
when closer to - 13:
when closer to - 14:
when others - 15:
end case - 16:
RAM - 17:
end for - 18:
set flag finish1 on - 19:
end procedure
|
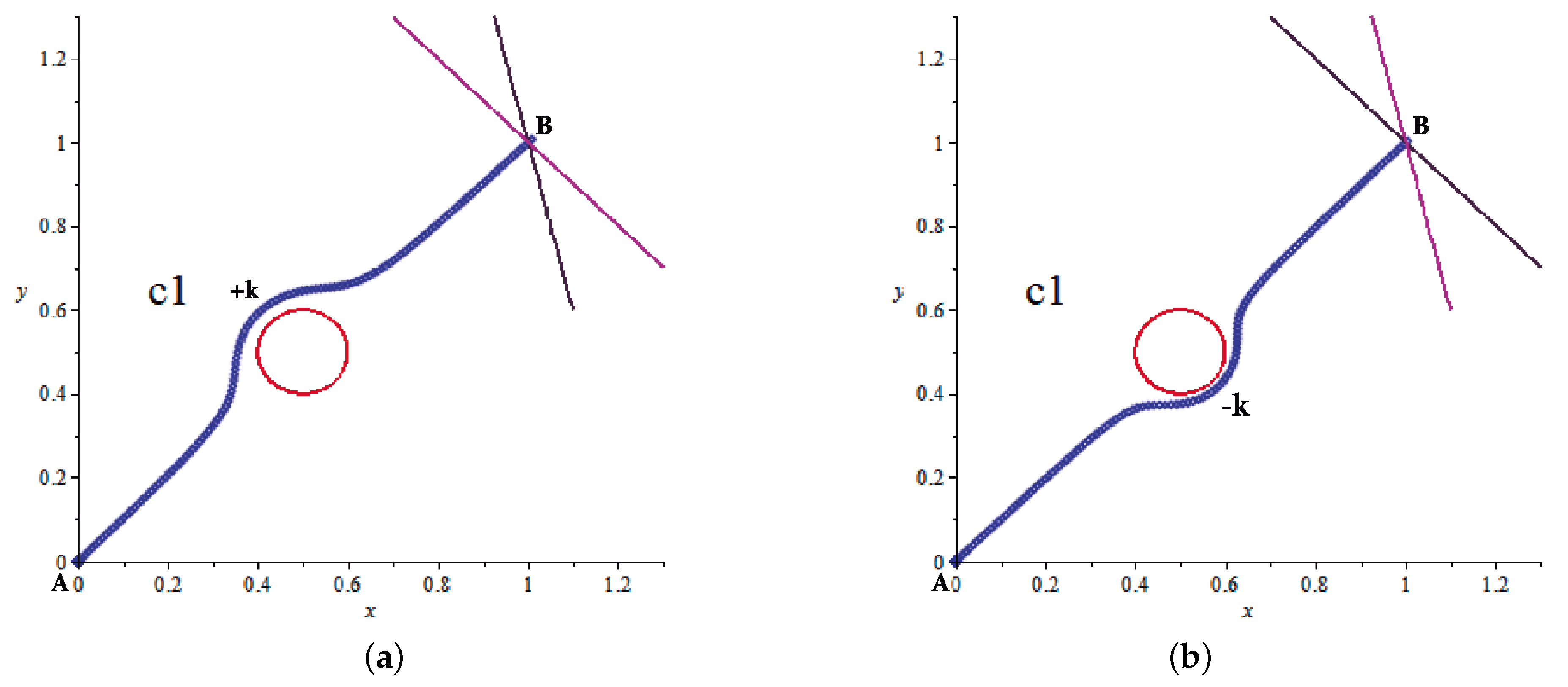
Once the repulsion parameters have been determined for all obstacles, neighbourhoods are analyzed (Algorithm 4) calculating distances between obstacles and generating indicators that find contiguous or overlapping elements that may cause issues when calculating the resulting trajectory. Similarly, the state machine will indicate sequences, addresses, modules, and operations to be employed when grouping obstacles by vicinity. In case of detecting neighboring obstacles, it adjusts the group repulsion parameter with the sign of the largest obstacle prevailing (Algorithm 5).
| Algorithm 4 Obstacle grouping |
- 1:
procedureObstacle grouping by vicinity(finish2) - 2:
Read robot security radius from ROM - 3:
for i = 1 to number of obstacles do - 4:
RAM ← Calculate space between i-obstacle and i+1-obstacle - 5:
if space between obstacles < robot security radius then - 6:
obstacle vicinity marker on - 7:
RAM ← vicinity takes i+1-obstacle number as i-group number - 8:
else - 9:
obstacle vicinity marker off - 10:
end if - 11:
end for - 12:
set flag finish2 on - 13:
end procedure
|
| Algorithm 5 Correction of repulsion parameters |
- 1:
procedureCorrection of repulsion parameters(finish3) - 2:
for i = 1 to number of obstacles do - 3:
if i-obstacle number = i-group number then - 4:
RAM keeps original value ▹ is obstacle repulsion parameter - 5:
else - 6:
sign = i-group number sign - 7:
end if - 8:
end for - 9:
set flag finish3 on - 10:
end procedure
|
The next set of states establishes the system homotopic equations to be solved (Algorithm 6); the representative functions already include the obstacles present in the environment (
14). Once this system is obtained, the hyperspherical path tracking process begins; obtaining the resulting path as a collection of points and storing them in RAM (Algorithm 7). Once the entire path is established, data transmission to the robot begins.
| Algorithm 6 Homotopy formulation |
- 1:
procedureHomotopy formulation(Homotopy equations) - 2:
Set auxiliary goal position lines - 3:
Call repulsion parameter values from RAM - 4:
Set obstacles equations - 5:
Set Newton Homotopy equations - 6:
Set Jacobian equations - 7:
Evaluate previous equations at initial position - 8:
end procedure
|
| Algorithm 7 Homotopy Path Planning Method |
- 1:
procedureHomotopy Path Planning Method() - 2:
for to maximum advance steps number do - 3:
RAM ← Adjust variable radius in hypersphere calculation - 4:
RAM ← Calculate Euler’s predictor position () in FSM - 5:
Call Euler’s predictor position form RAM and evaluate Homotopy System - 6:
Euler’s predictor position () - 7:
for to maximum iterations do - 8:
RAM ← Calculate Newton-Raphson’s corrector position () in FSM - 9:
if satisfies Homotopy System then - 10:
break - 11:
else if approximates Homotopy System below permissible error then - 12:
break - 13:
else - 14:
Call Newton - Raphson’s corrector position form RAM and evaluate Homotopy System - 15:
Newton-Raphson’s corrector position () - 16:
end if - 17:
end for - 18:
- 19:
if then - 20:
break - 21:
end if - 22:
end for - 23:
end procedure
|
The FPU (SoftFloat reported in [
41,
42]) module is a free-code 32-bit floating-point arithmetic unit applied to this design because it requires a reduced number of cycles for the arithmetic operations. In addition, the Selector module is a set of switching units that, according to the options established by the state machine, defines whether the data to be sent to the FPU unit comes from a specific RAM or ROM and indicates the storage location of all data obtained from the FPU unit. RAM memory module allows storing results obtained from assignment of repulsion parameters and homotopic path method operations, resulting points of the homotopic path
, and the data conversion for the transmission of results. Otherwise, the ROM memory module stores the obstacle position data, diameters, height, and width. The transmission module
is an 8-bit serial transmission module that allows the communication with the robot, for this work, the Parallax’s Scribbler 2.
5. Study Cases
To show the performance of the proposed methodology (HPPM), implemented in PC and FPGA, it is compared to the sampling-based path planning algorithms EST, KPIECE, PRM (including its modification PRM Star), and RRT (including its modifications RRT Star and RRT Connect); it is also compared to the low DoF planners: Bug algorithm and the APF method.
In the following cases, all methodologies are implemented in PC attempting a fair comparison between them. The sampling-based methods were executed from an OMPL tool [
43,
44], which allowed us to perform a statistical analysis. The low DoF algorithms were executed using MATLAB Robotics System Toolbox since the OMPL tool does not have the designs of these algorithms.
Table 1 provides technical specifications of the hardware where all processes were run.
Nevertheless, to guarantee the results obtained from these tools are as similar as possible, all are bounded to the same conditions: for sampling-based algorithms, the searching method step size is the same as the HPPM hyperspheres; in addition, the same grid size is used for the low DoF algorithms. In the same way, all algorithms are working under the condition of movement in two dimensions only.
It is known that each methodology has certain advantages and complications according to the type of environment where it is implemented; the intention of this study is to deploy them in environments that have some conditions, both favorable and unfavorable, and thus contrast results to the proposed methodology.
All the methods on PC were implemented with 64-bit word width calculations. FPGA implementation was executed with a 32-bit word width, this due to the use of the Floating Point Unit Core [
41] and certainty that the difference between results obtained in PC and FPGA are insignificant, as demonstrated in [
45].
It is important to note that there is a big difference between the capabilities of a PC against an FPGA; a PC has 26,936 times more memory, its speed is 18.79 times faster, and it also consumes 2.73 times more power than an FPGA. Nevertheless, as it can be appreciated for the presentation of this study, the implementation in FPGA is highly competitive in terms of performance (memory, speed, and distance).
5.1. Case 1
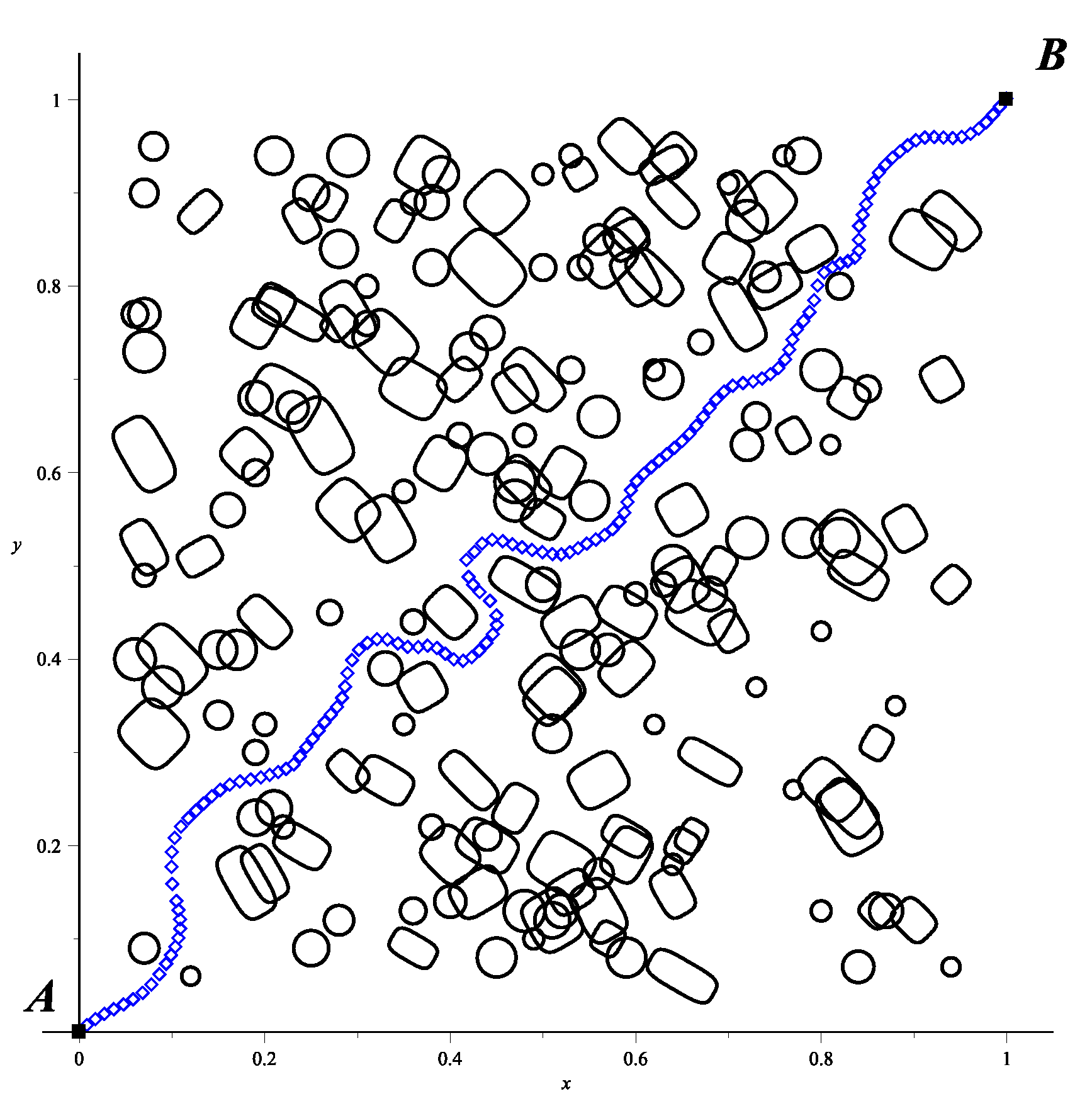
As a didactic example, an environment is generated containing 20 randomly placed obstacles. In the first instance, the development of HPPM algorithm will be presented in detail; later, results will be obtained by its implementation in the FPGA, to finally show results comparison between the HPPM and other path planning methods. It is worth mentioning that all the sampling-based algorithms were run 100 times, while the BUG, APF, and HPPM algorithms were run only once; this is because, like all deterministic methods, they will always provide the same result no matter how many times they are executed.
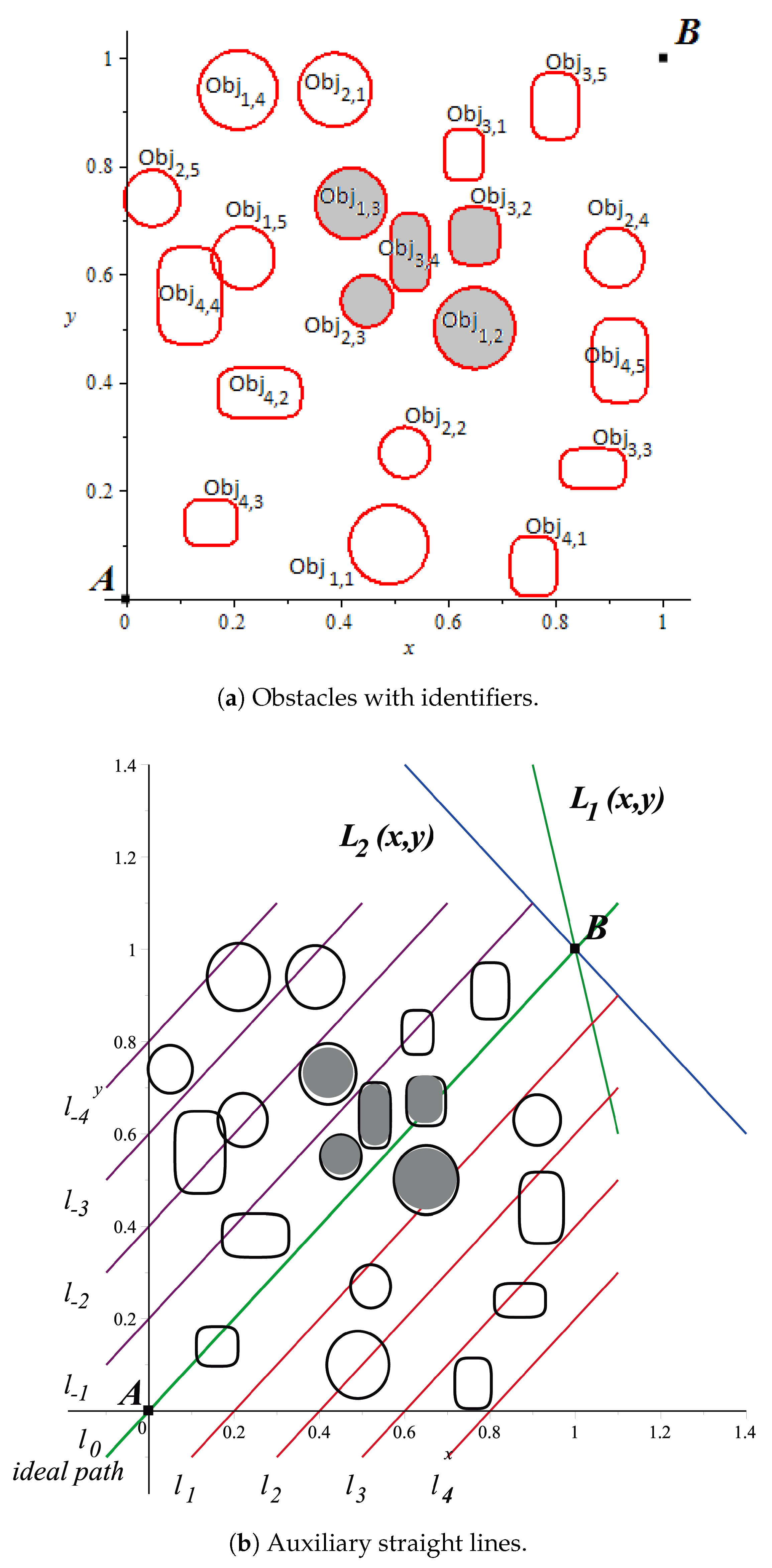
Once initial position
and target position
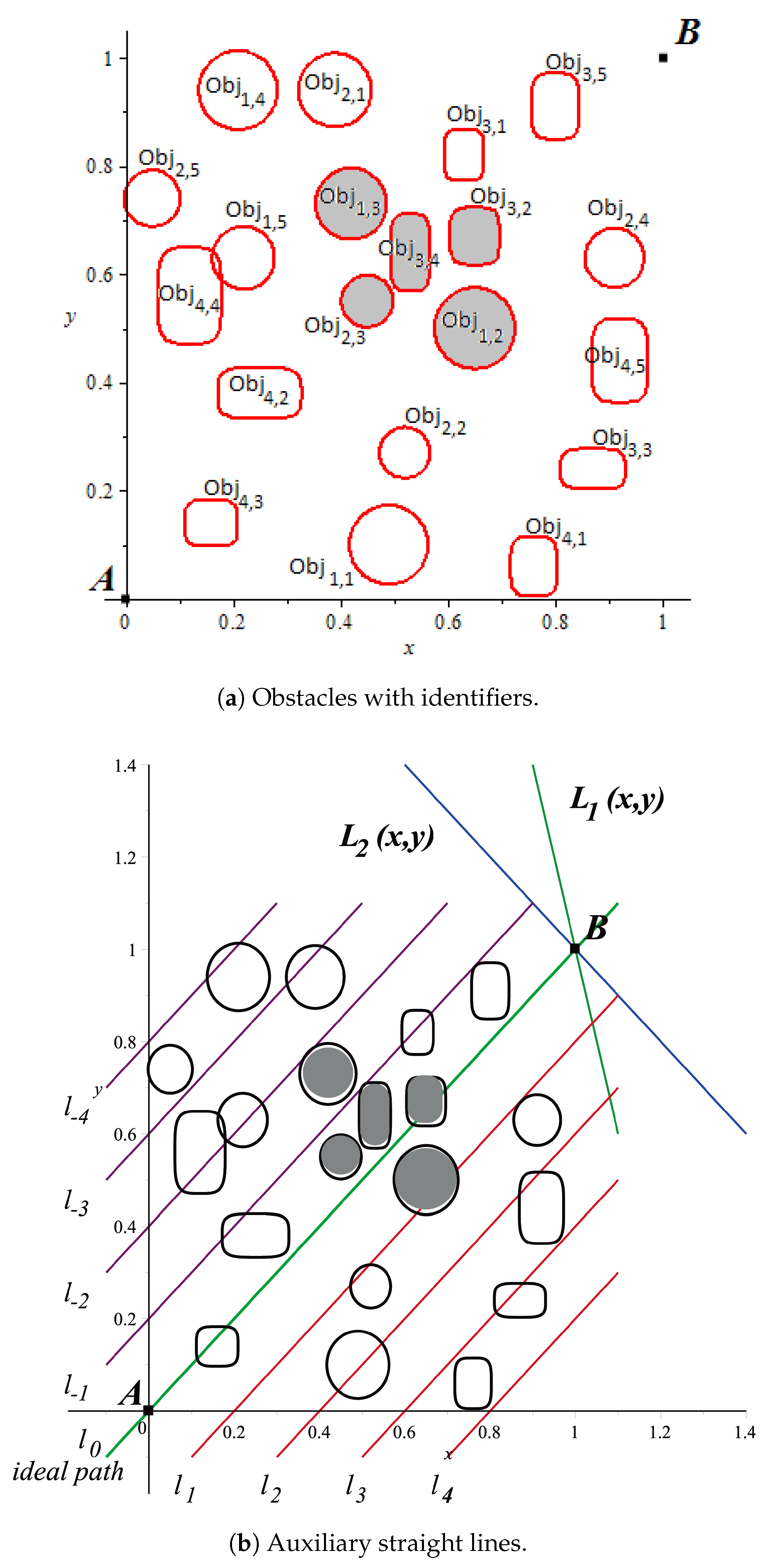
are set, obstacles are enumerated (
Figure 11a). Afterwards, auxiliary straight lines (
17) are generated to define the repulsion parameter (
Figure 11b). As can be seen for this case, circular obstacles
,
, and
along with the rectangular obstacles
and
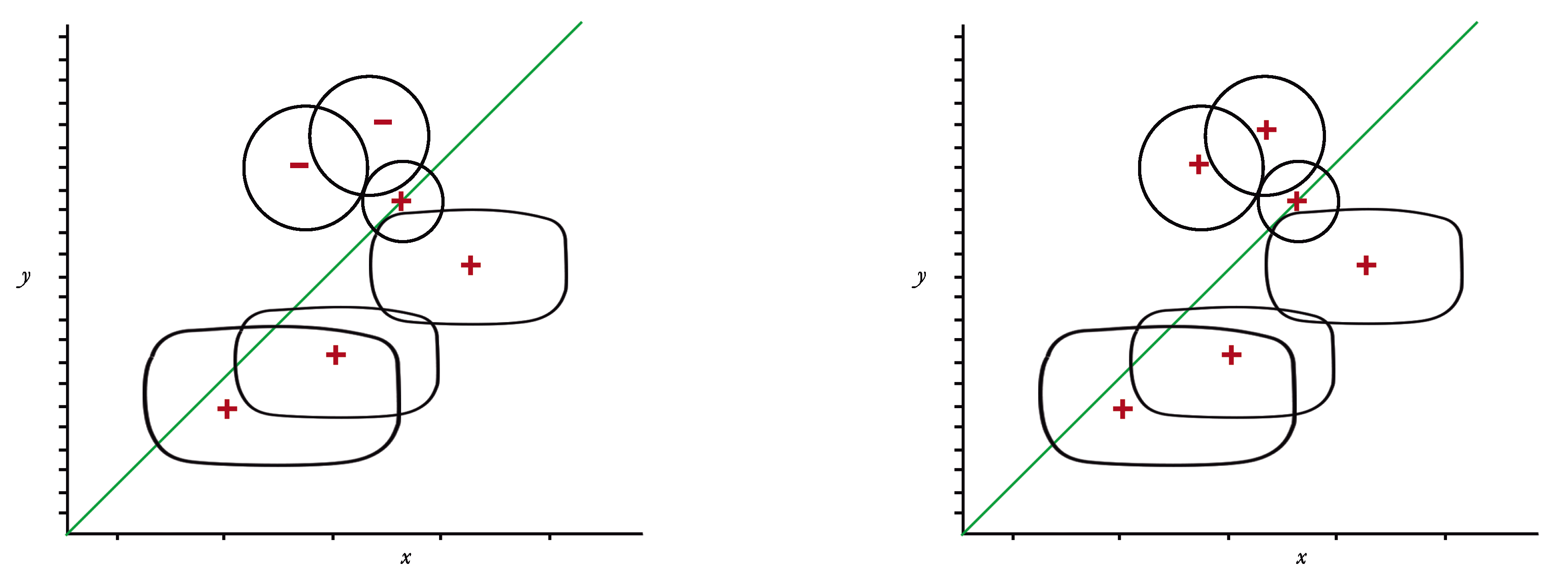
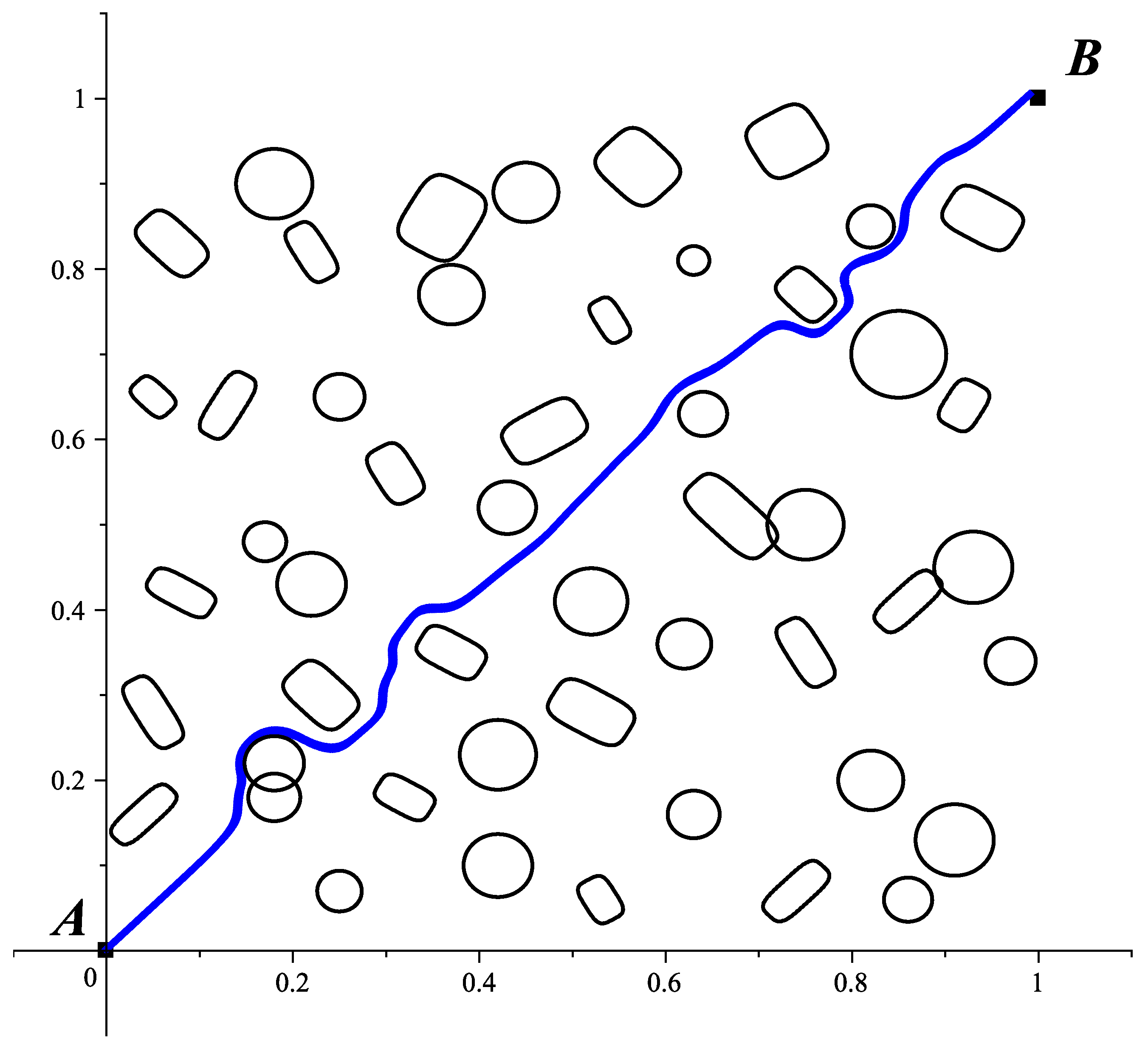
are in a vicinity; this shaded neighbourhood will be surrounded by the resulting path as a consequence of detecting this grouping and correcting the group repulsion parameter.
In
Table 2 the calculated repulsion parameters using (
19) are shown. Next, by applying the algorithm of obstacles grouping by vicinity, some repulsion parameters are updated resulting in
Table 3.
It is important to note that repulsion parameter of obstacle
(marked with an asterisk in
Table 3) has changed because is closer to obstacles
,
,
, and
, definitive parameters used in the HPPM are those obtained in
Table 3. Notice that (
20) and (
21) generate the neighbourhood through signs homogenization within the group, guaranteeing the adequate performance of the system during homotopic path calculation. Continuing the HPPM process execution, as expected, the homotopic path crossed below the group of gray-shaded neighboring obstacles in
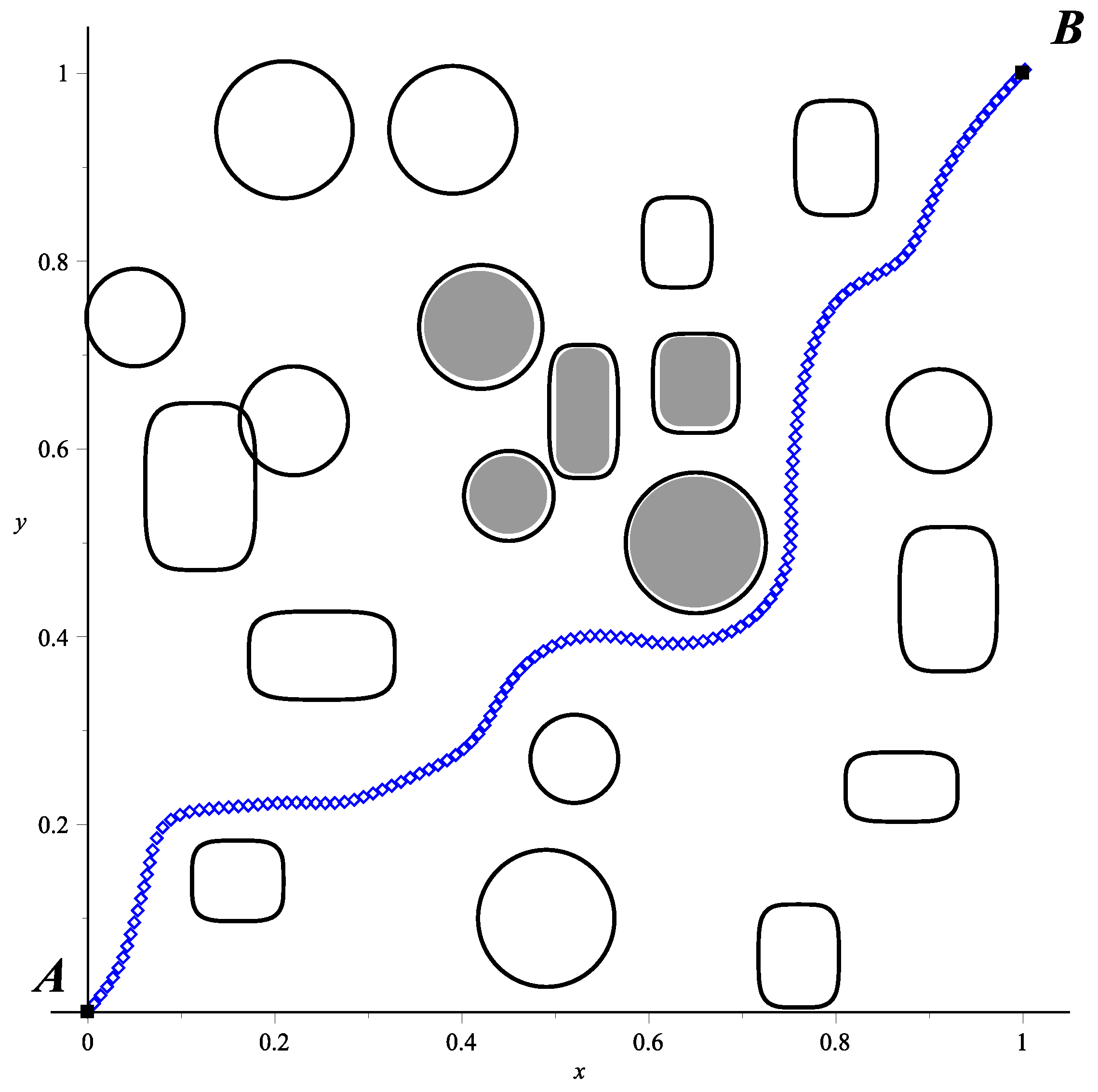
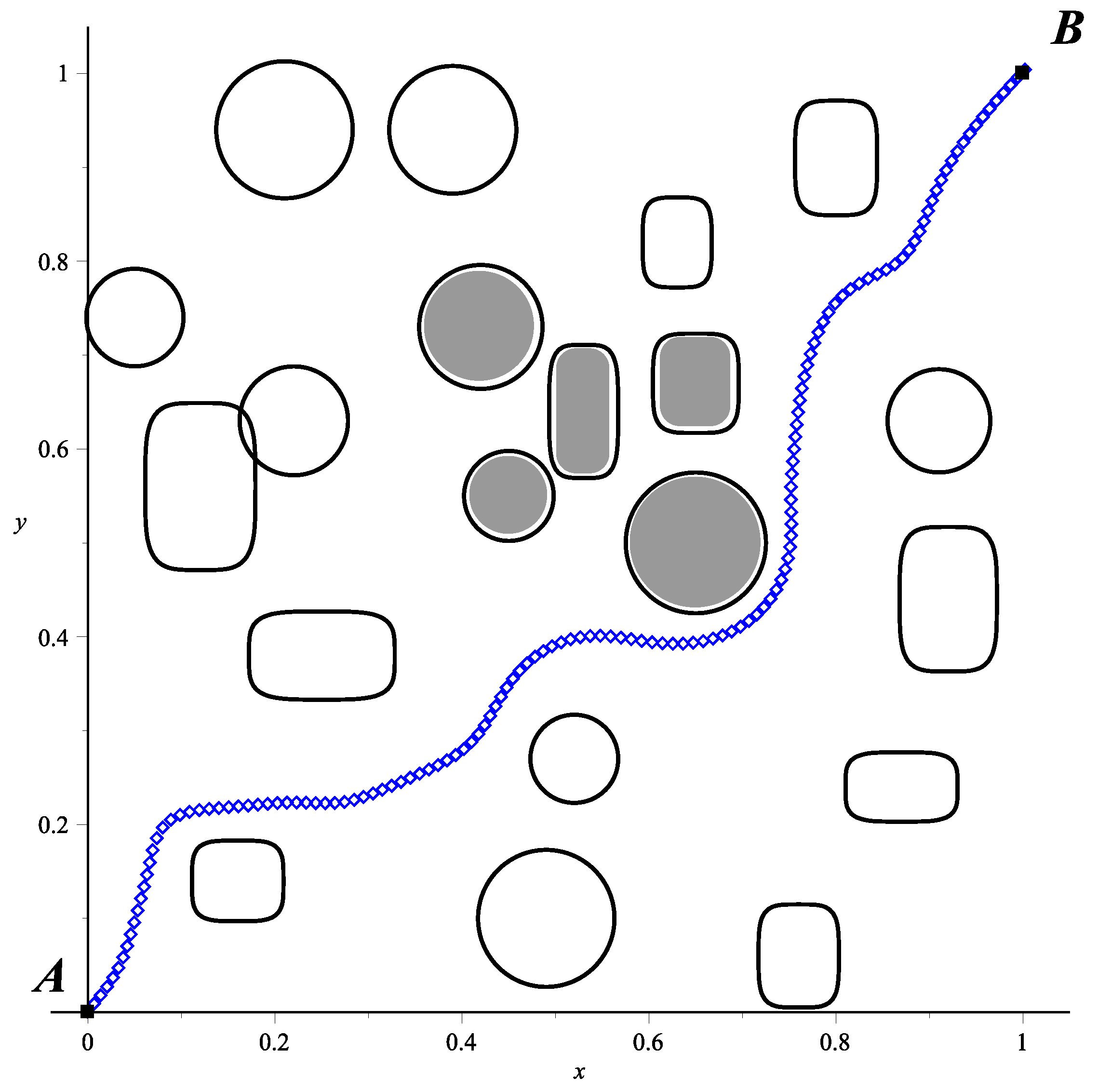
Figure 12.
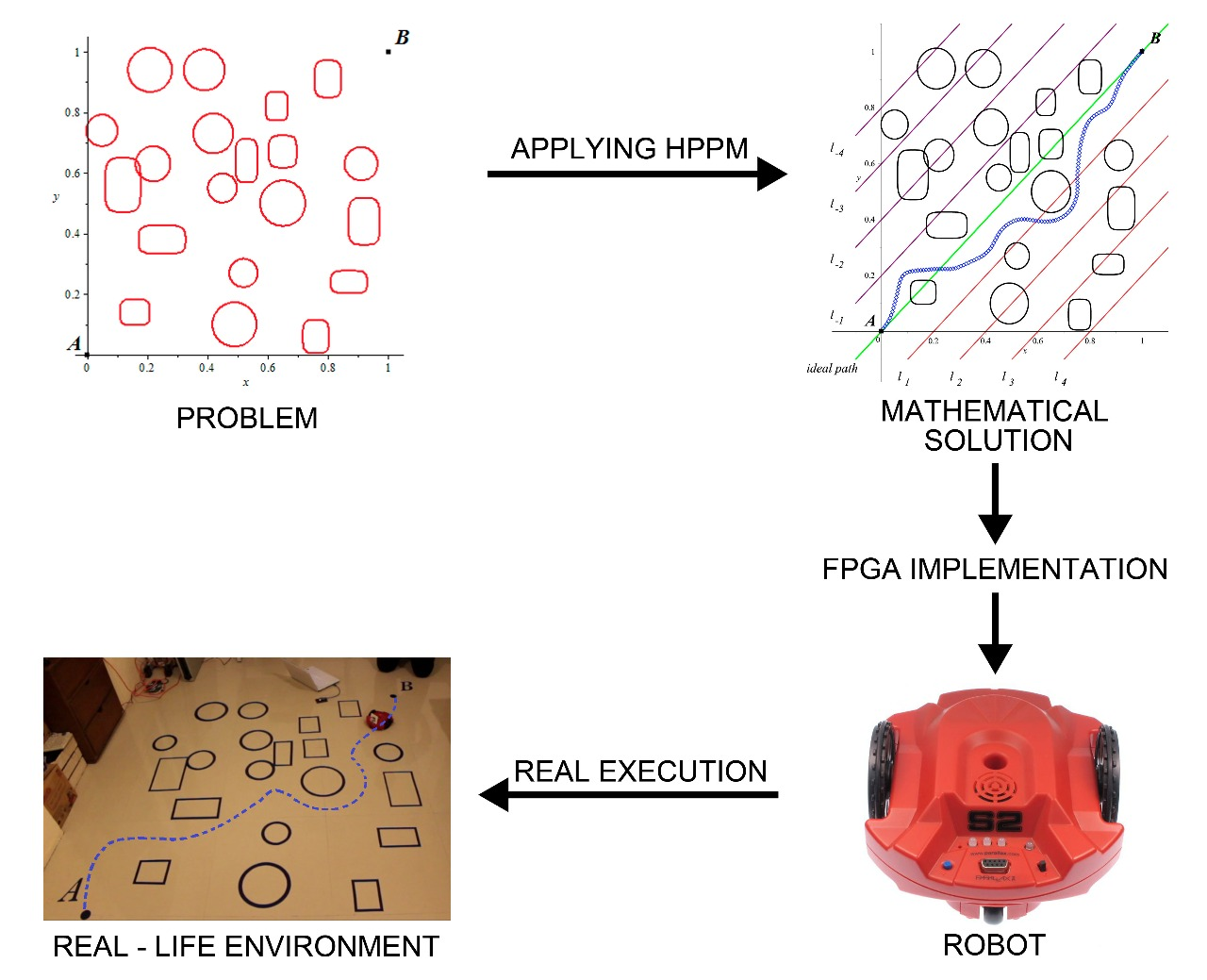
In order to show the use of our implementation in FPGA, the obtained trajectory in
Figure 12 was transferred to a physical experiment (
Figure 13a) testing the path calculated by the HPPM, which is provided to the Scribbler 2 robot (
Figure 13b).
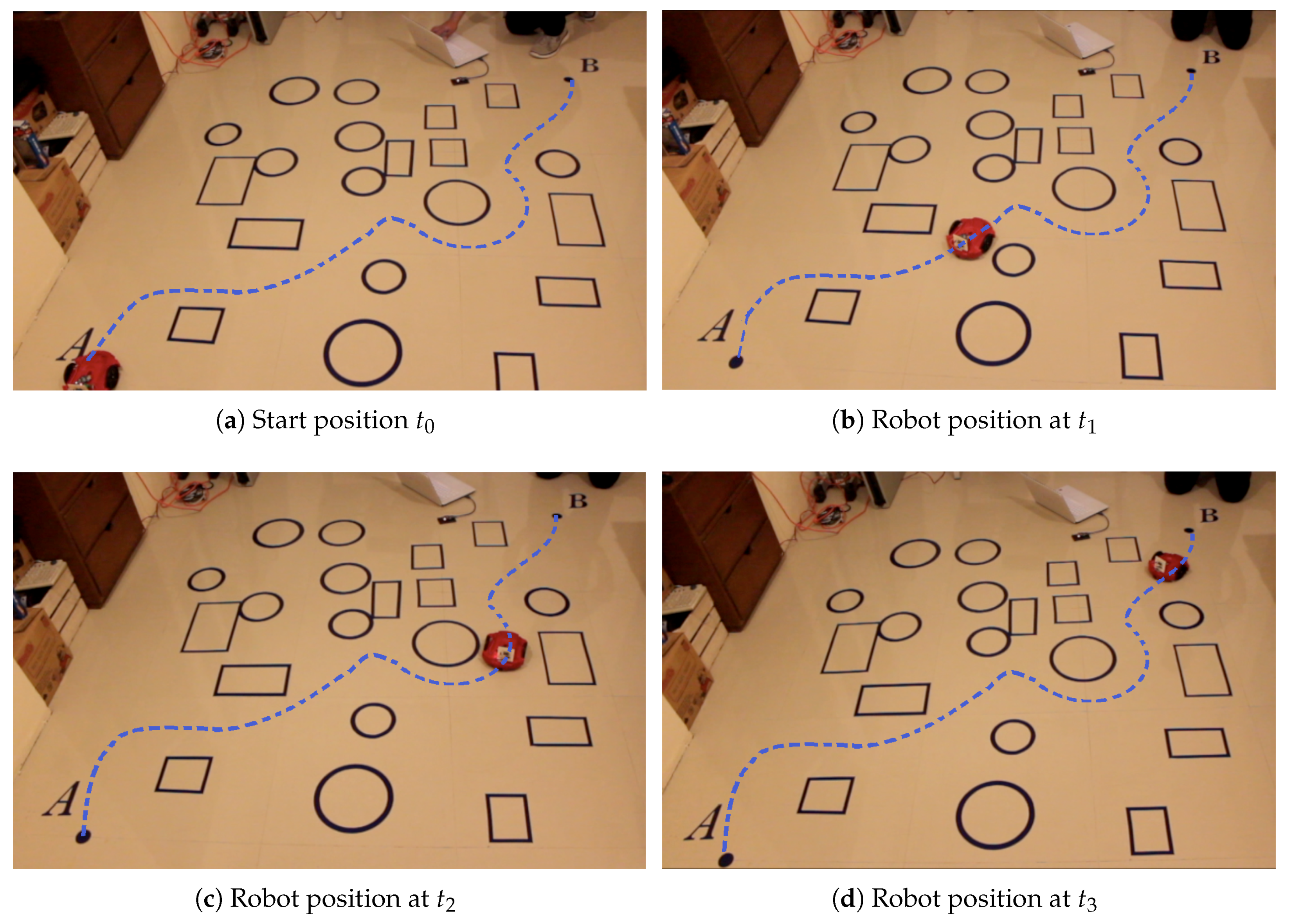
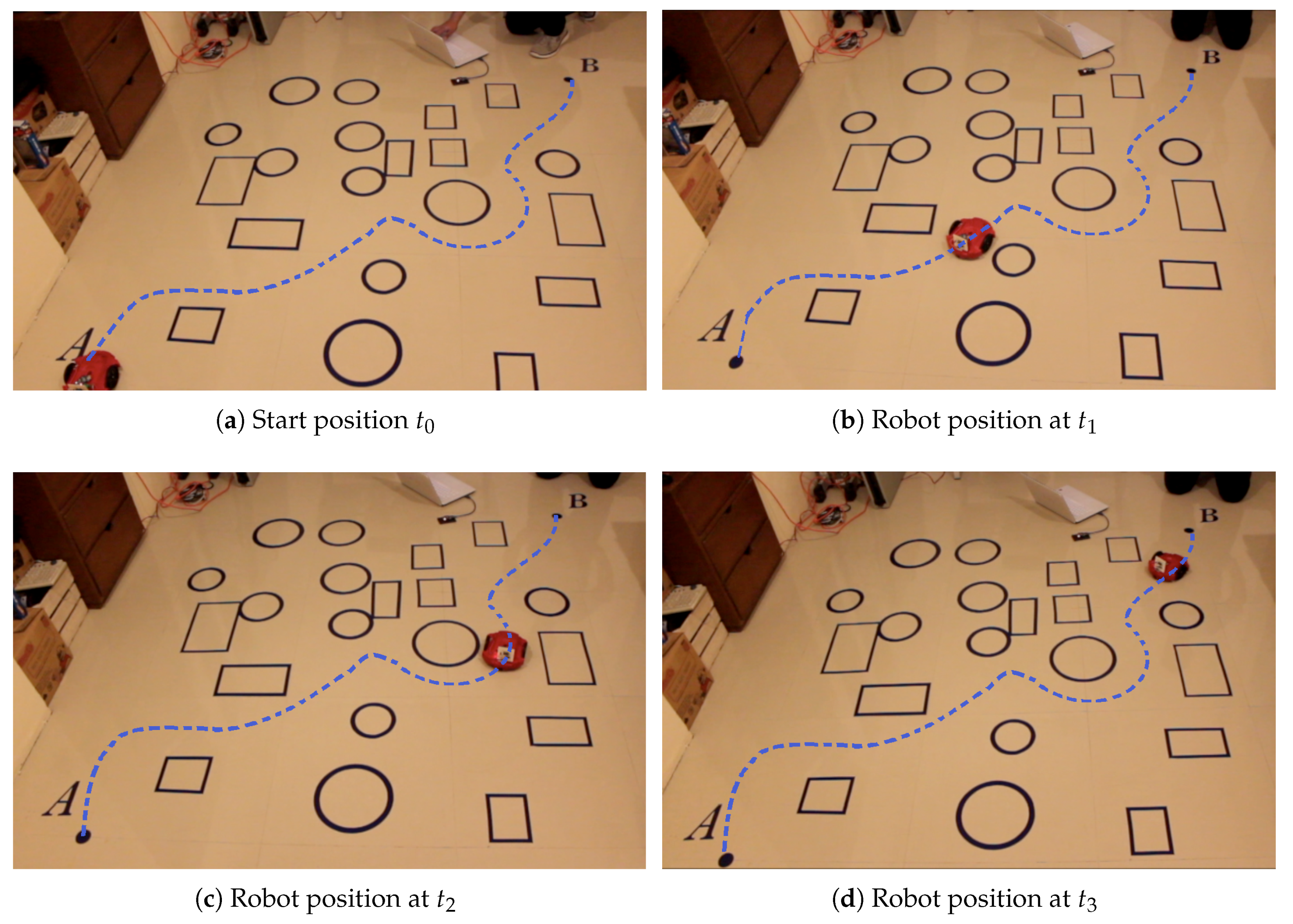
Information transmission to the robot is performed using an XBee 2 mW Wire Antenna device. Data transfer speed and coordinates reception by the robot are set using the Propeller Tool software.
Figure 14 shows the real-life environment execution of the proposed methodology. The simulation was divided into four frames:
,
,
, and
; showing the path followed by the robot.
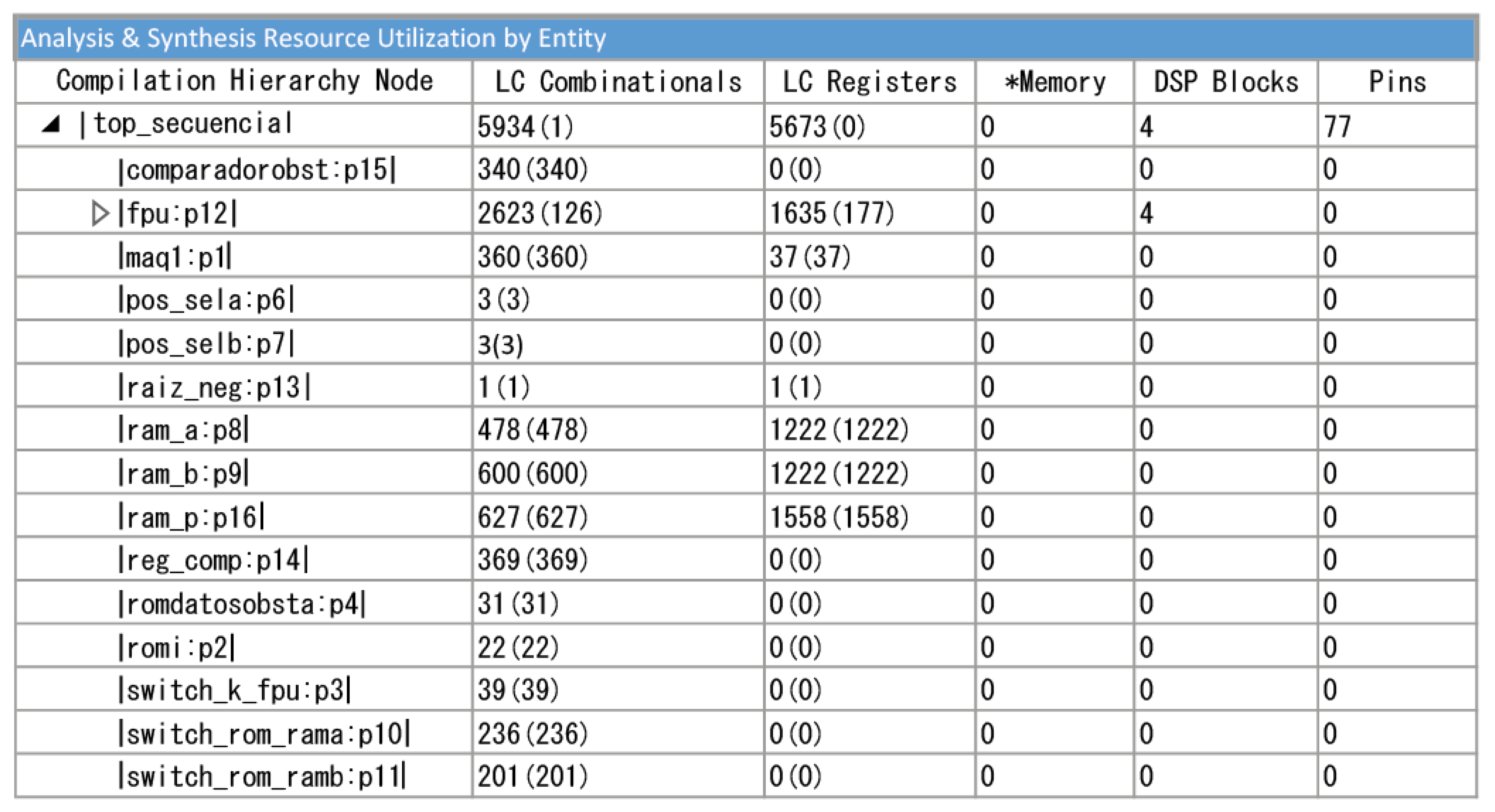
By including the obstacle values present in the environment and executing the algorithms described in
Section 4, the FPGA shows a low resource consumption, as can be seen in
Figure 15.
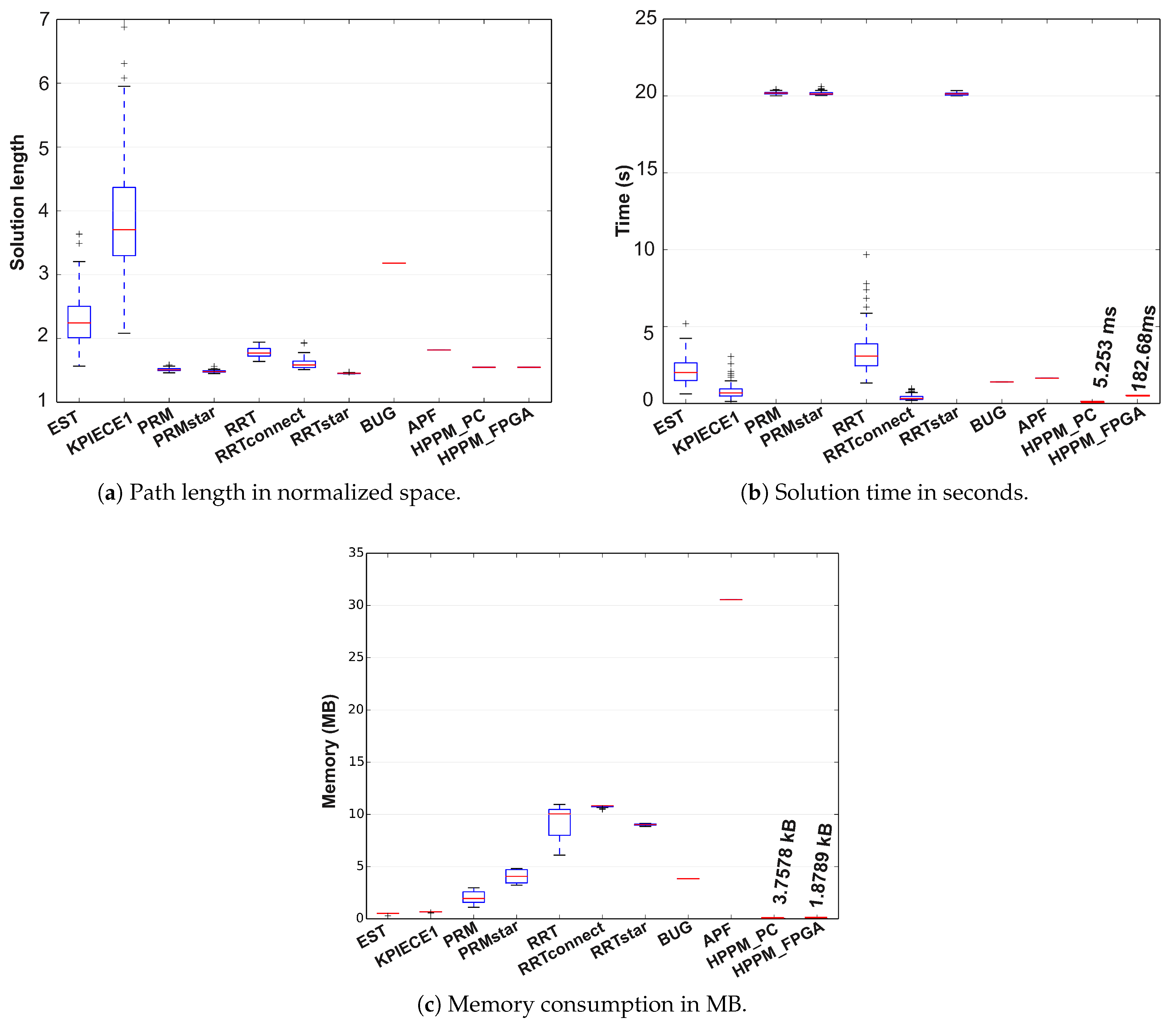
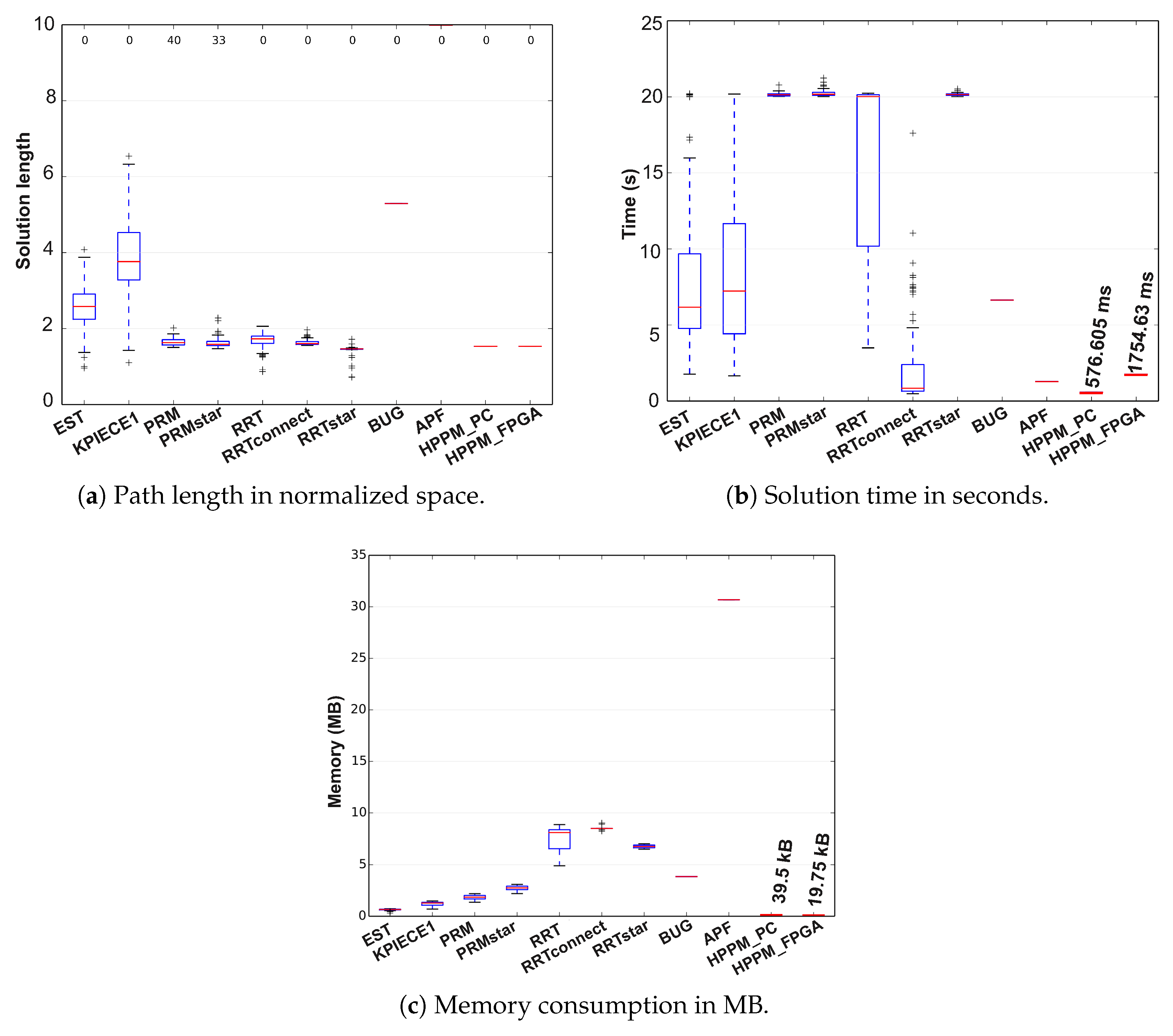
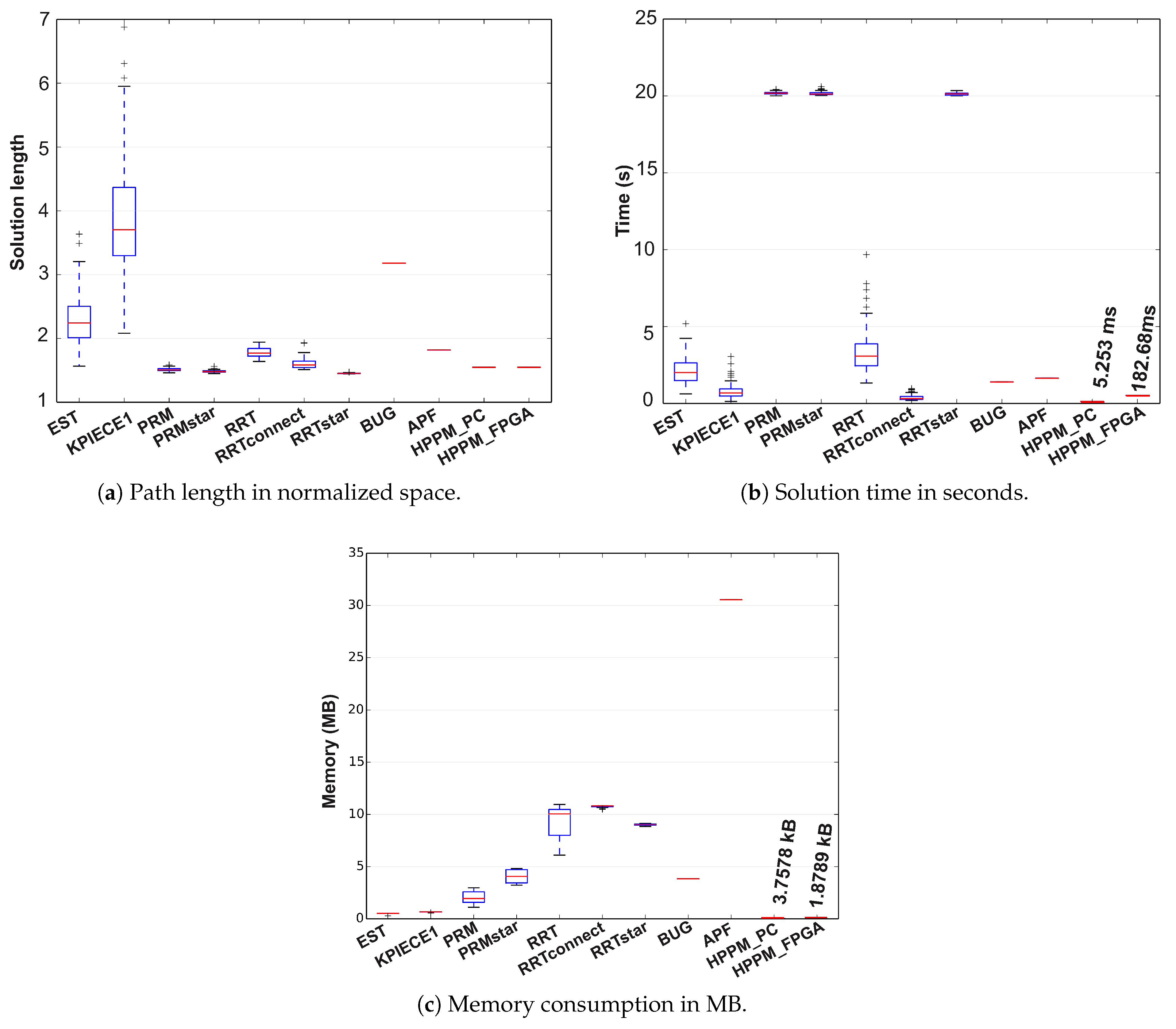
In
Figure 16, results of the descriptive statistical analysis for this case are presented using box plots, where the red line represents the median value obtained by executing each sampling-based method 100 times; it can also be noticed that, for some cases, outliers were obtained which are represented by the + signs.
For the case of deterministic methods, only the red line is represented, which is equivalent to the method median and must be compared to other methods’ medians. The proposed implementations in PC and FPGA were compared in terms of path length, simulation time, and memory consumption. Therefore, from
Figure 16a, we can conclude that the average distance for compared methods, including the HPPM, is almost similar but EST, KPIECE, and the low DoF Bug algorithm provided longer paths; nevertheless, PRM and RRT_Star methods require, on average, ten times more computation time to solve the same problem (
Figure 16b). For this case, the algorithm that provides the best results overall is the HPPM method in both implementations.
As can be seen in
Figure 16c, the difference in memory consumption is considerable, whereas the RRT algorithms (including Star and Connect variants) have high memory consumption (close to 10 MB), the HPPM algorithm occupies about 3.7578 kB in PC and just 1.8789 kB in FPGA, turning it into the best option for embedded systems. It is important to notice that APF algorithm needs plenty of memory (close to 30 MB) to get its job done; it requires 8125 times more memory than the implementation in PC and 16,251 times more in FPGA. In addition, 243 times more computation time in PC and 6.67 times in FPGA is needed, which allows us to conclude that HPPM is more robust, efficient, and suitable for low cost embedded systems.
5.2. Case 2
Noticing the advantage in memory usage and reasonable execution time for our implementation in FPGA, an example containing 50 randomly placed obstacles is generated. This time, the configuration scheme that compares the HPPM method to others found in the literature is provided in
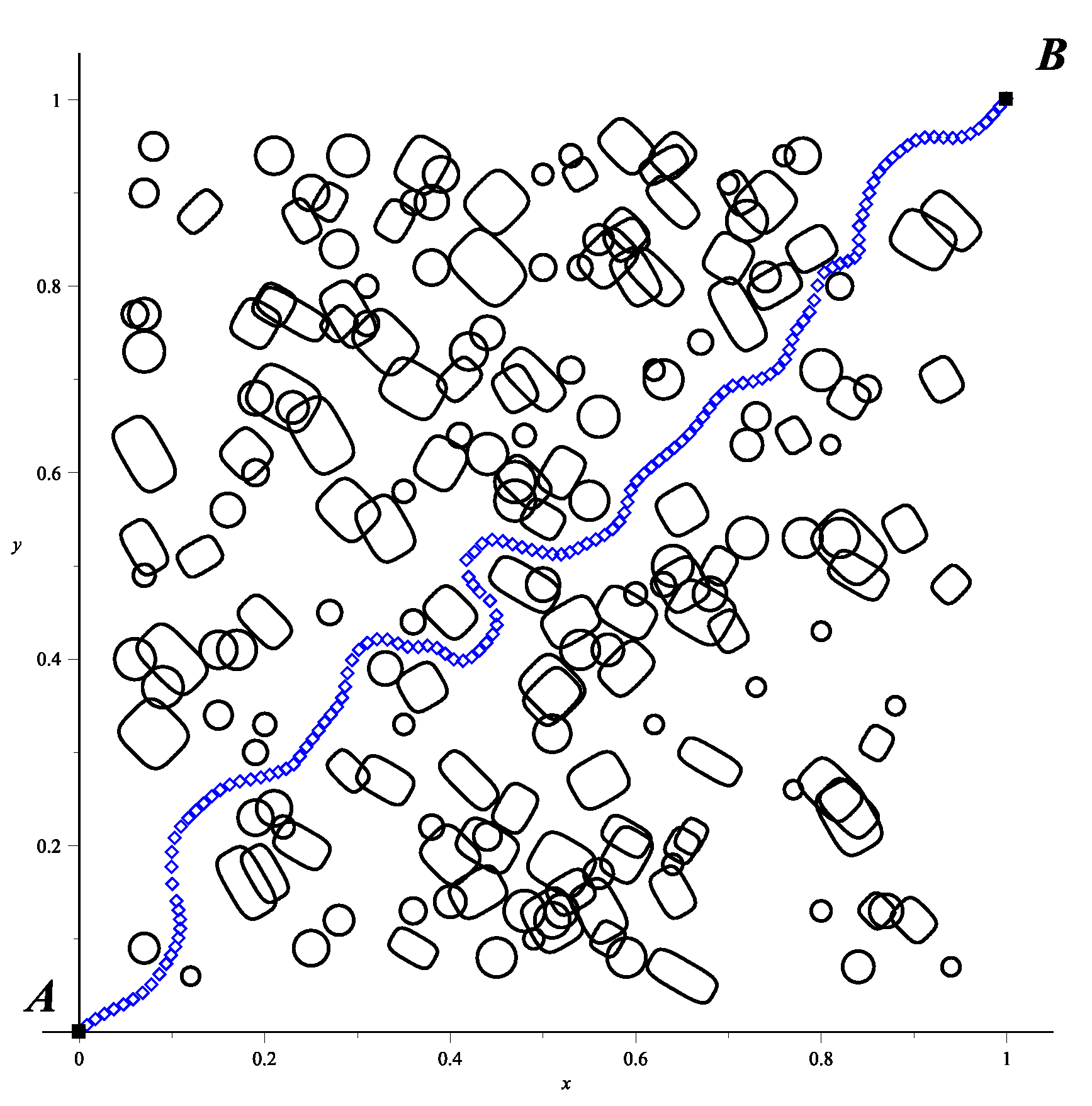
Figure 17, showing a greater concentration of obstacles and the presence of ellipsoidal obstacles with random rotations, as well as the resulting trajectory of the proposed algorithm.
Again, the comparison of results between the HPPM and other path planning methods is presented. It is worth emphasizing that all the sampling-based algorithms were run 100 times, while the BUG, APF, and HPPM algorithms were run only once; this is because, as already mentioned, they are deterministic methods.
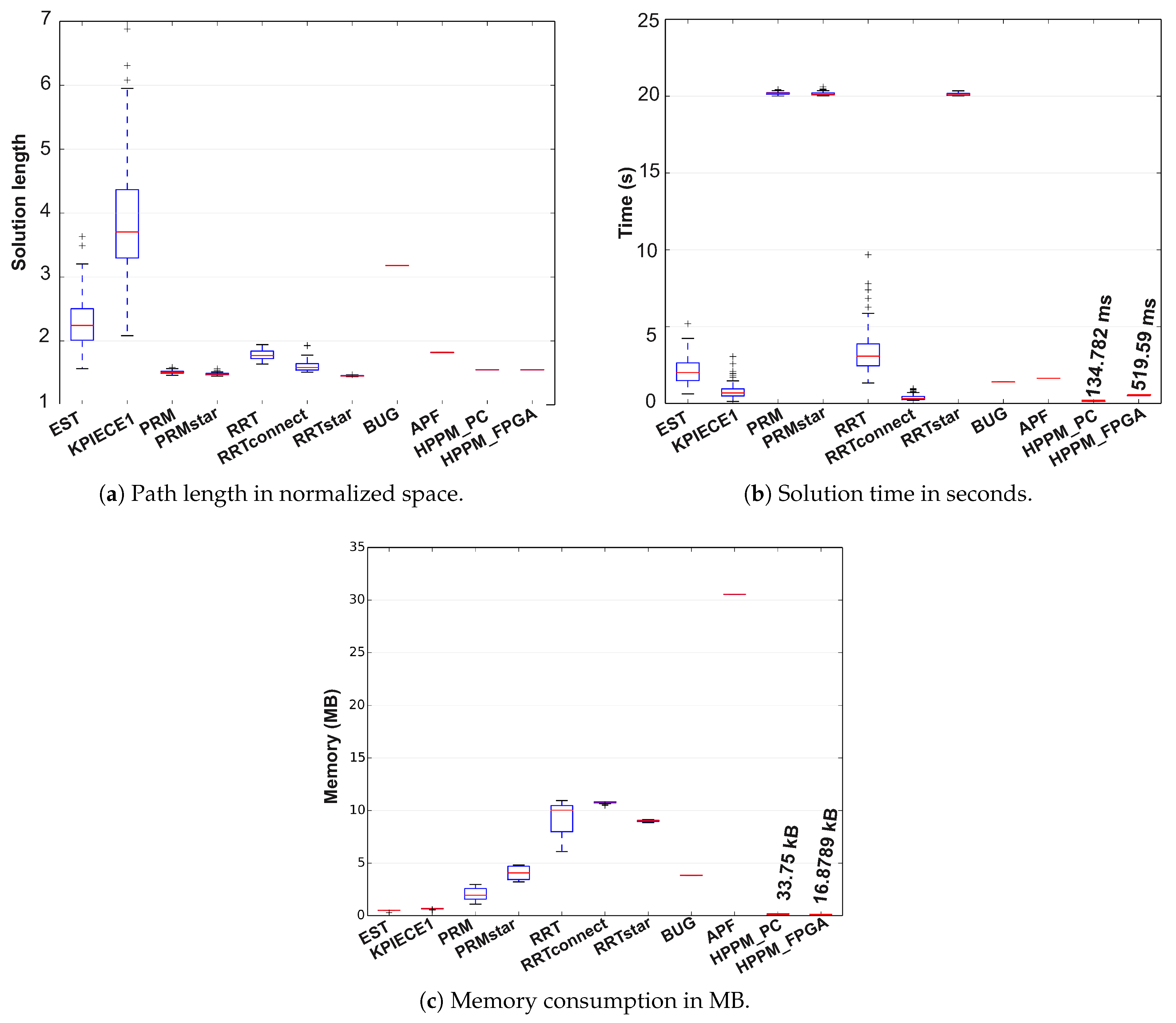
In
Figure 18 the results of descriptive statistical analysis of this case are presented using box plots, where the red line represents the median value obtained by executing each sampling-based method 100 times; it can also be observed that, for some cases, outliers were obtained, which are represented by the + signs. For deterministic methods, only the red line is represented, which is equivalent to the method median and must be compared to other methods’ medians.
For this case, EST and KPIECE1 show a good use of resources in terms of memory; nevertheless, they have an inefficient behavior caused by the high variability of the calculated path distance. Furthermore, PRM, PRM Star, and RRT Star algorithms offer optimal distances and reasonable memory usage; the problem is that, to achieve this, they required high runtime, which is not ideal for a real-time execution robot.
Comparing HPPM to the low DoF algorithms, the APF algorithm has acceptable times and path distances but requires too much memory usage to achieve it, while the Bug algorithm maintains a reasonable use of time and memory but obtained paths are not optimal on distance.
In
Figure 18c, it can be seen that, despite having reduced memory consumption, the RRT algorithms (original, Star, and Connect versions) are around 10 MB, while PRM algorithms (original and Star) are close to 3 or 4 MB. The results of EST and KPIECE1 methods are close to 1 MB, still superior to the HPPM consumption, which for this case are 33.75 kB in PC and 16.8789 kB in FPGA; therefore, the HPPM algorithm is maintained as the best option for embedded systems.
5.3. Case 3
For this case we increase the number of obstacles to 200, aiming to highlight the feasibility of using this methodology in an FPGA given the low memory consumption during the solution process. Obstacles map and the resulting path are depicted in
Figure 19.
For this particular example, all the sampling-based algorithms were run 200 times, because some of the methods could not converge to a solution. It is remarked that the BUG, APF, and HPPM algorithms were executed only once, knowing that their deterministic condition forces them to obtain the same result regardless of the number of times they are executed.
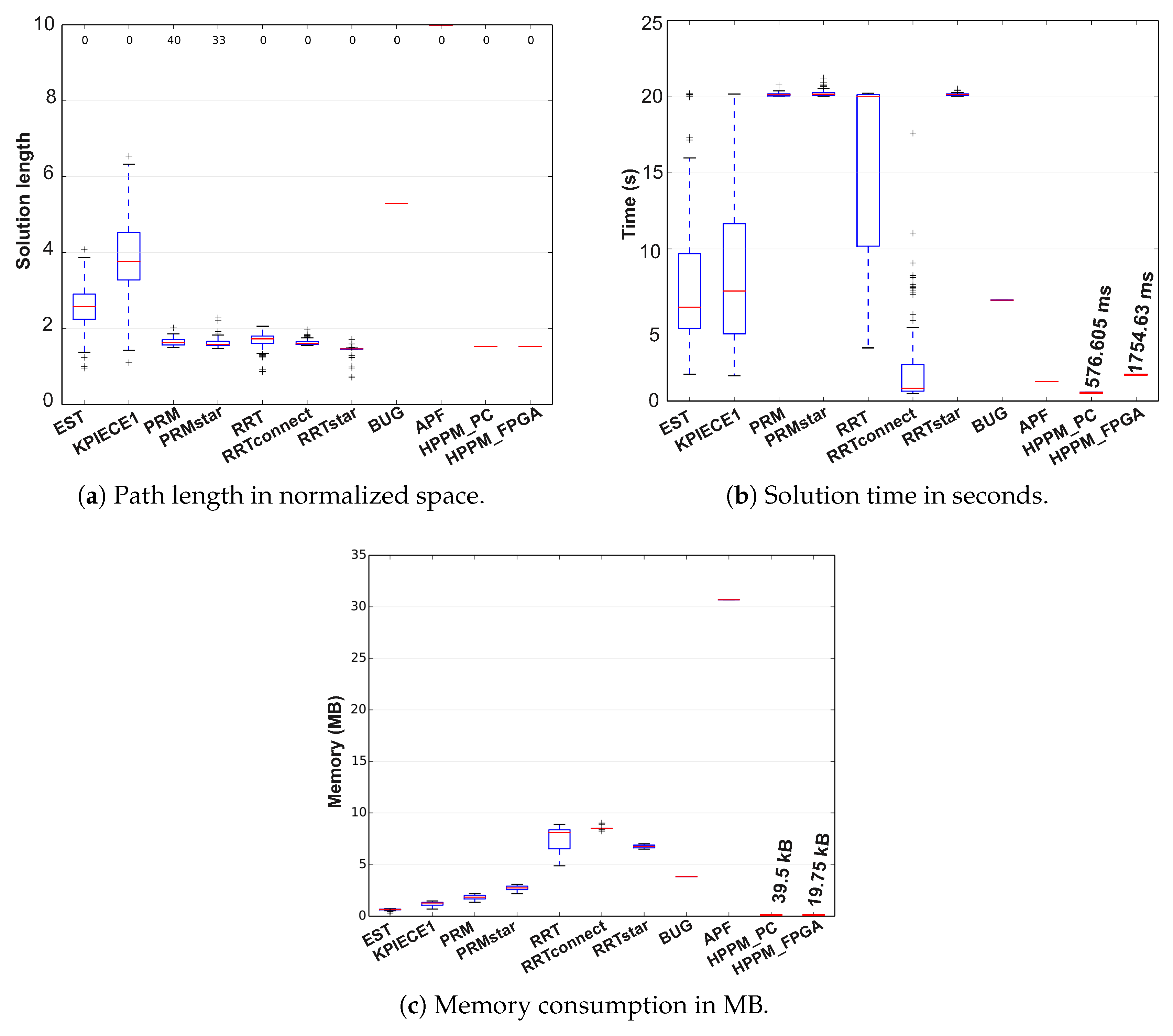
Finally, in
Figure 20 results of the descriptive statistical analysis of this last case are presented using box plots, where the red line represents the median value obtained by executing each sampling-based method 200 times; it can also be observed that, for some cases, outliers were obtained, which are represented by the + signs. For deterministic methods, only the red line is represented, since it is equivalent to the method median and must be compared to other methods’ medians.
As the number of obstacles increase, low DoF algorithms tend to find solutions with paths that are too long (
Figure 20a). Otherwise, the EST and KPIECE1 algorithms practically double the path size with respect to the other algorithms.
Taking into account execution time, most methods need a large amount of time to ensure an adequate response, as can be seen in
Figure 20b; methods with the shortest execution times were the RRT Connect, the APF method, and the HPPM where it can be highlighted that the HPPM algorithm uses less than a second in PC.
Regarding the use of memory, the APF method needed a large amount of memory for its execution, about 30.685 MB (
Figure 20c), the RRT algorithms exceed 5 MB, and the rest required, at least, 1 MB. Therefore, HPPM implementation (PC and FPGA) remains as the best option for embedded systems using 71.6 kB and 408 kB, respectively.
6. Discussion
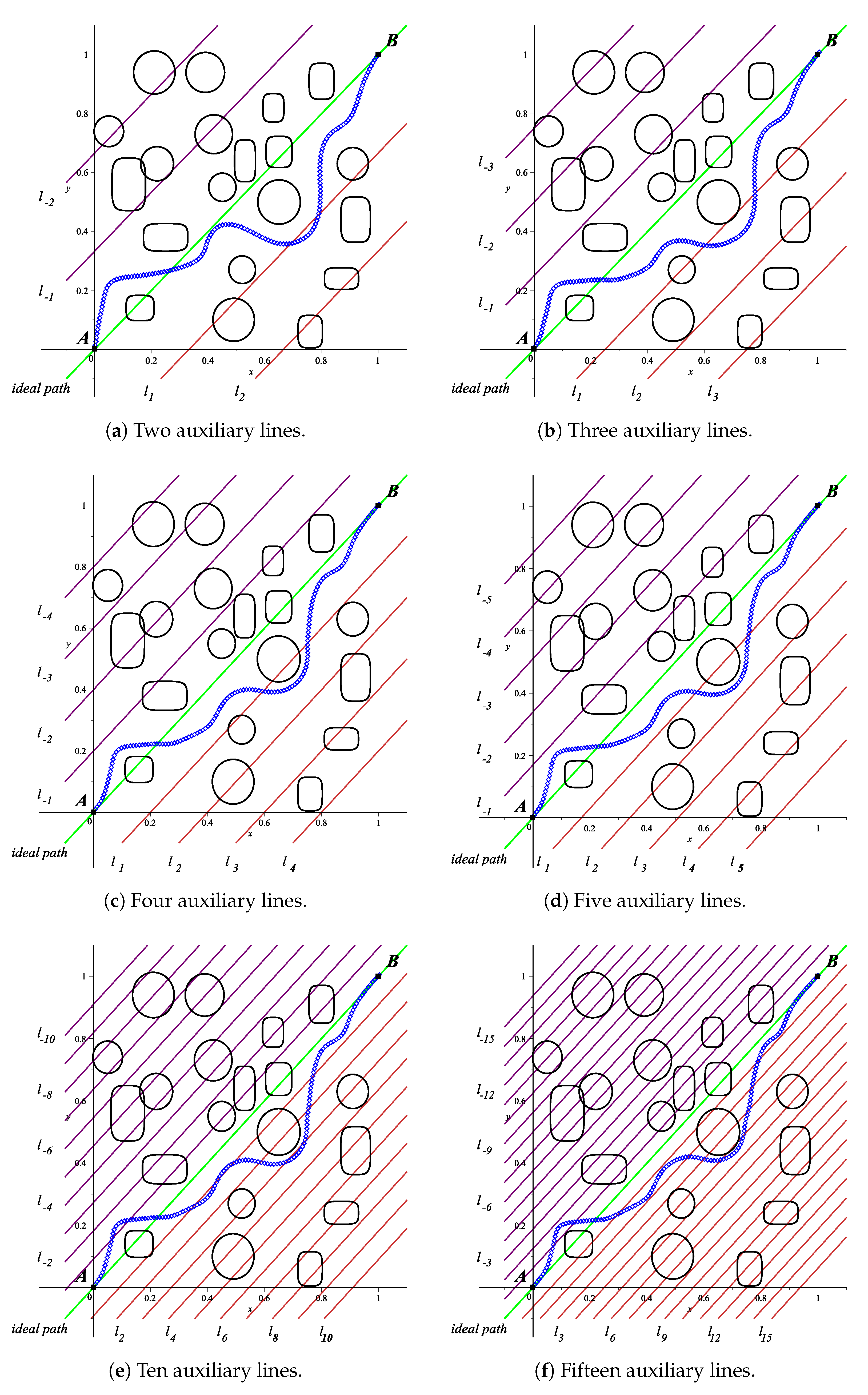
From literature [
31], we know that users should have deep knowledge for the repulsion parameter assignment process. Nevertheless, our proposal aims to circumvent such a cumbersome manual process. What is more, during the repulsion parameter assignment process, there exists a relationship between the number of auxiliary lines and execution time that depends on the available hardware. In fact, we found in
Section 3.1 that four auxiliary lines per side of the ideal path are enough to provide an optimized collision-free path. We found that more than four auxiliary lines increases the computation time and the memory requirements without noticeably improving the collision-free path. Results from the methods described above are summarized in
Table 4.
As can be observed, FPGA implementation of HPPM remains as the best option for a path planning method in terms of memory consumption, while keeping itself as a competitive method in terms of distance and solution time. In general terms, the methods that obtain slightly smaller distances than HPPM face the problem of requiring noticeable higher execution times and memory consumption. Therefore, HPPM is an ideal algorithm for embedded systems.
Low DoF algorithms tend to use simple criteria to achieve their goal, which makes them efficient when the number of obstacles is minimal or there is a wide free space. Nevertheless, if numerous obstacles are found within the environment, having different dimensions, map resolution tends to be increased generating large consumption of memory and time to find the solution. In addition, since they do not have an optimization adjustment, they may find solutions that are too long or complex. In general, APF method requires high memory consumption for its execution and the Bug algorithm maintains a stable consumption, although higher than HPPM.
For some methods, like EST and KPIECE, despite having consumed relatively low memory, they tend to produce longer trajectories. On the other hand, RRT method and its variants provide acceptable trajectories but memory consumption tends to be high during its execution. In contrast, HPPM (which executes only once) generates acceptable trajectories with reasonably low memory consumption. Besides, since the probabilistic methods produce a great variation in the results every time they are executed, it was necessary to run 200 simulations to obtain the median values, thus eliminating the influence generated by atypical values of low performance or failed simulations.
In fact, when free space is limited, a certain percentage of these simulations find no solution; therefore, the use of such algorithms is impractical in embedded systems where low computing resources do not allow their real-time execution, or simply cannot be implemented. Proof of this is the case of 200 obstacles, where PRM methods (original and Star) fail to find the solution at 30% because they run out of time, while RRT methods (original and Star) find an approximate solution 10% of the time, instead of the exact solution.
According to the HPPM algorithm itself, in PC and FPGA, the generated trajectory is almost identical. There is a slight difference in PC because its processor architecture works using 64 bits, while FPGA architecture is 32 bits. Architecture difference is reflected in memory consumption since the PC consumes 3.76 kB for 20 obstacles, 33.75 kB for 50 obstacles, and 39.5 kB for 200 obstacles, while the FPGA consumes 1.88 kB, 16.88 kB, and 19.75 kB, respectively. In addition, while working in PC, calculations can be obtained with higher precision; this means that the number of iterations achieved by the calculations of predictive and corrective values during path generation are greater than the amount reached in calculations with 32 bits.
Another relevant aspect is the execution time; the HPPM developed in the PC shows greater advantage over the other methods. Even more, applying this methodology in an embedded system (FPGA), the execution time of the HPPM is only comparable to KPIECE method in PC; nevertheless, KPIECE obtains, as a recurring result, a longer path.
Although the FPGA computation time in the implementation for 20 obstacles is similar to the different methods, it is important to emphasize that for 50 and 200 obstacles computation times are surprisingly competitive compared to the random tree techniques simulations; besides, it must be considered that the FPGA power consumption is considerably lower (below 50% with respect to the use of PCs, see
Table 1). The importance of this research lies in the fact that other techniques reported in the literature, to the author’s best knowledge, do not have the implementation of these conditions using an FPGA, probably because of the notable high power demand, execution time, and memory consumption required by these methods.
An advantage lies in the fact that obstacle representation in HPPM influences a single equation within the system. If obstacle number increases, the number of equations to be solved remains the same; only one of the terms for this system of equations becomes extensive (with a linear relationship to the number of obstacles). In addition, the equation does not present alterations due to the obstacle size, a circumstance that affects the low DoF algorithms. When small obstacles increase, these algorithms are forced to reduce the cell size, increasing the resolution of the map to be solved.
Another advantage is the fact that it is a deterministic method, reducing the number of calculations because it focuses on a single solution in terms of trajectory, which is contrary to what happens with the sampling-based algorithms. All expansion trees depend on the calculation of a set of possible expansion points, combined with an optimization criterion in the selection of the next trajectory step.
Random tree methods increase their memory and computation time exponentially due to two fundamental aspects: each random point during the process must be stored to be employed later on the path generation phase which implies a notable memory consumption and the collision checking process that consumes most of the CPU time.
On the other hand, memory and computation time of the homotopy continuation methods increase linearly with respect to the number of obstacles as depicted in [
31]. In fact, homotopy continuation method is deterministic, providing a single collision-free path using a numerical continuation process. What is more, the proposed scheme based on homotopy does not require any collision checking stage because it ensures zero-collision probability due to its mathematical formulation.
7. Concluding Remarks and Future Work
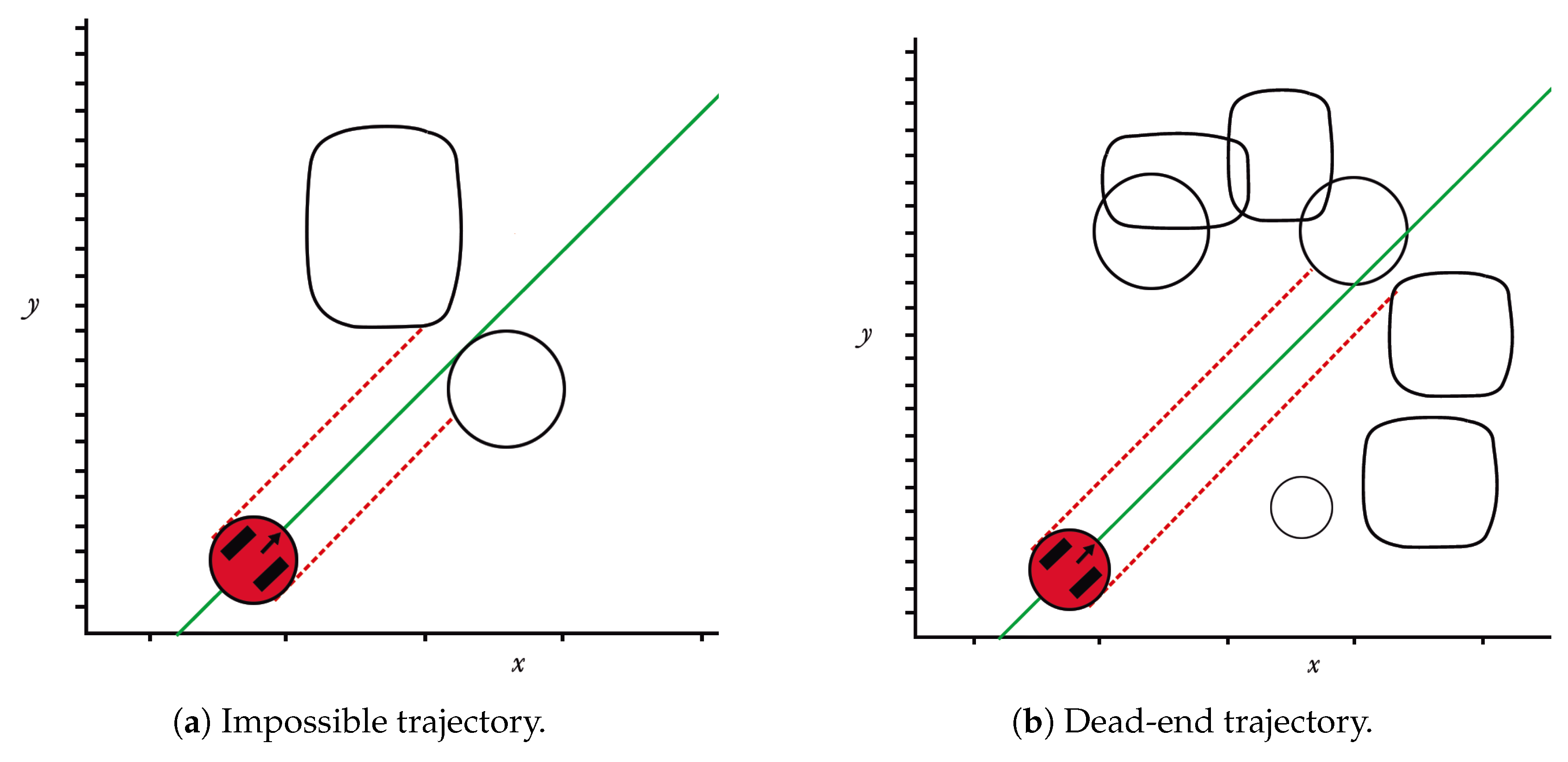
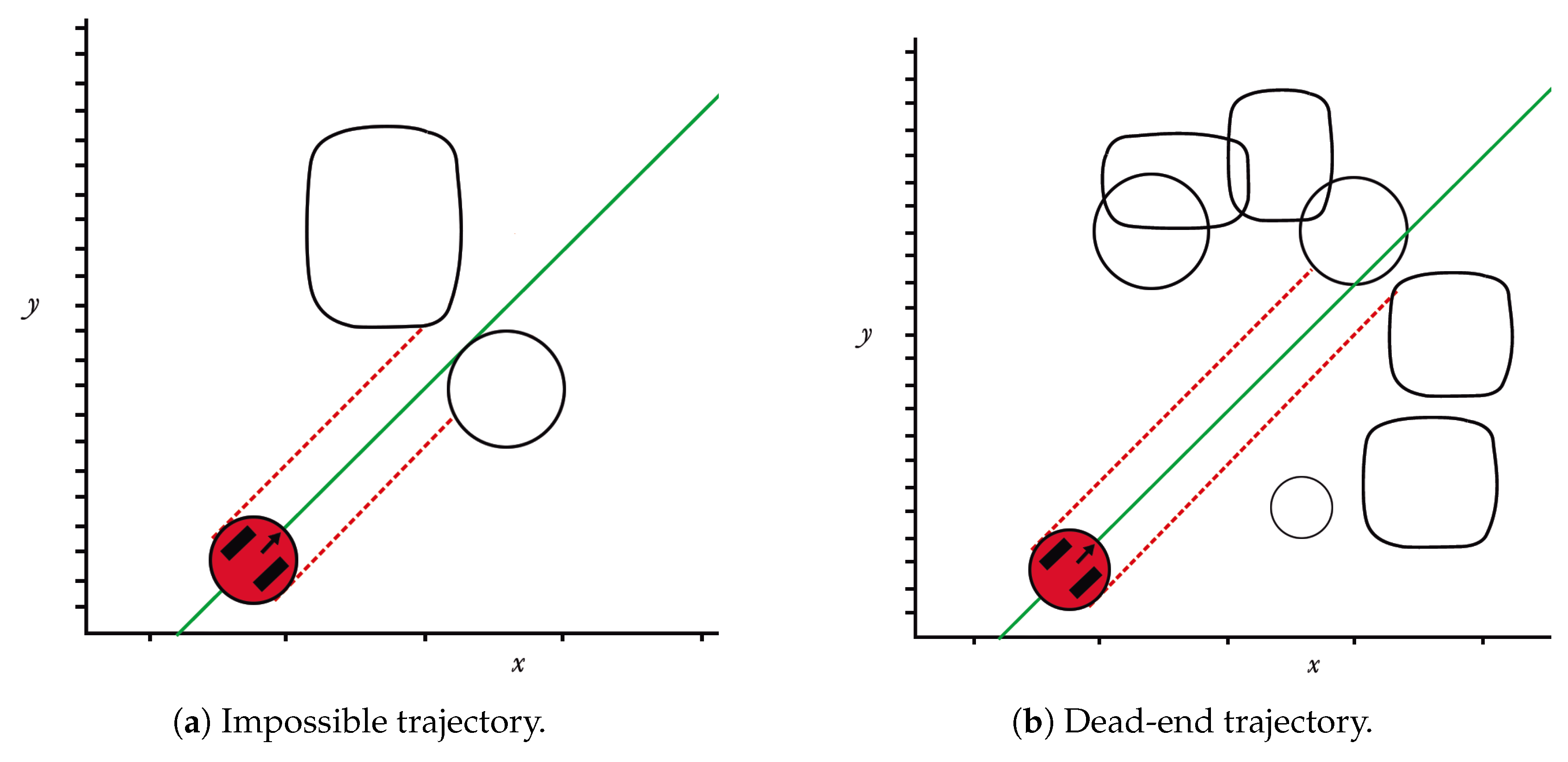
An improvement to the standard HPPM methodology was presented, which consists of a new method for calculating the repulsion parameter, aiming to achieve the shortest distance path. In addition, an analysis of neighbourhoods was included, which ensures that the trajectory moves around spaces that may compromise its continuity, avoiding any dead-end issue.
The implementation was tested in a very low resource FPGA, which demonstrated competitive computing times in relation to implementations of PC sampling techniques, allowing one to conclude that the proposed methodology is viable to solve practical cases in real time on embedded systems, therefore offering the possibility of generating implementations at a very low cost.
Moreover, it will be worthwhile to apply this methodology in closed environments and under the existence of narrow corridors since they are usually the most complicated environments for the methods based on random sampling techniques. In addition, this opens the possibility to perform experimental tests with differential type robots, not holonomic or omnidirectional and with multiple degrees of freedom.
In this investigation, all the calculations were carried out sequentially; nevertheless, we believe that, as future work, we can take advantage of parallel implementation of homotopy methods as those reported in [
46,
47] to reduce computation time. In addition, we can evaluate in parallel the symbolic expressions found during application of the Newton-Raphson algorithm (corrective step) of the numerical continuation.
As future work, the algorithm will be tested in real-time situations with dynamic obstacles. In addition, this methodology will be applied in multiagent schemes, allowing collaborative work without risks of mutual collision. Furthermore, algorithm implementation in applications to real-life problems is desired, like car automatic driving control system. Finally, future work will aim to implement and compare this methodology in three-dimensional environments, as presented in [
6,
19].


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}