1. Introduction
The power transformer is an important equipment in a power system, which directly affects the safety of the power station and the safe operation of the power grid. Among them, the cast-resin transformer provides the products numerous excellent characters such as low no-load loss, oilless, anti-flaming, maintenance-free, good moisture resistance and crazing resistance, etc. The cast-resin transformer is perfectly matched to the requirement on inflammable and explosive site such as commercial center, high-tech factory, hospital, underground, airport, train station, tower building, industrial and mining enterprise, etc. Disturbances of power quality will result in significant financial consequences to network operators and customers. Since many uncertainties are involved, it is difficult to obtain exact financial losses due to poor power quality. Therefore, online monitoring of the cast-resin transformers has been an important challenge for power engineers. Failures of cast-resin transformers not only reduce reliability of power system, but also have great effects on power quality. Power engineers are devoted to intensifying diagnosis on the cast-resin transformer for discovering hidden troubles timely and guaranteeing the normal operation of the cast-resin transformer. Partial discharge (PD) is one of the main causes which leads to internal insulation deterioration of the cast-resin transformer. Online monitoring of PD can reduce the risk of insulation failure of cast-resin transformers [
1]. There are many methods, such as ultrasound, acoustic emission, electrical contact, optical and radio frequency sensing, could be used to detect and locate PD in a cast-resin transformer [
2]. For electrical detection, UHF antenna is widely used in the PD measurements because it is more sensitive than other methods with regard to the noise issue.
PD is a localized electrical discharge that occurs repetitively in a small region. In general, PD can be categorized into six forms from their occurring causes: corona discharge, surface discharge, internal discharge, electrical tree, floating partial discharge and contact noise. Corona discharge takes place at atmospheric pressure in the presence of inhomogeneous fields. Surface discharge appears in arrangements with tangential field distribution along the boundary of two different insulation materials. Internal discharge occurs within cavities or voids inside solid or liquid dielectrics. Electric trees occur at points where gas voids, impurities, mechanical defects or conducting projections cause excessive local electrical field stresses within small regions of the dielectric. Floating PD occurs when there is an ungrounded conductor within the electric field between conductor and ground. Contact noise occurs if the ground connection to a bushing is poor.
PD occurs in high-voltage electrical equipment, such as cables, transformers, motors and generators. It is a kind of very small spark that occurs due to a high electrical field. Since a PD occurring in high-voltage electrical equipment has a specific pattern, pattern recognition of PD is a useful tool for improving the reliability of high-voltage electrical equipment [
3]. With the development of electricity, the PD diagnosis is a useful tool for evaluation of the cast-resin transformer and prevention of the possible failures. It is essential to determine the different types of faults by PD diagnosis to estimate the likely defect type and severity. The use of PD pattern recognition can identify potential faults and inspect insulation defects from the measured data. Then, the potential effects are used to estimate the risk of insulation failure in high-voltage electrical equipment. This information is important to evaluate the risk of discharge in the insulation. PD pattern recognition in the past depended on expert judgments for classification and defect level determination. Such a process is unscientific and needs professional experience from years’ practice.
To date, artificial intelligent techniques were adopted for pattern recognition and classification of PD. Mor et al. used the cross wavelet transform to perform automatic PD recognition [
4]. The wavelet analysis has been regarded as a promising tool to denoising and fault diagnosis, however it is difficult to determine the composition level that yields the best result. Gu et al. proposed a fractional Fourier transform-based approach for gas-insulated switchgear PD recognition [
5]. Ma et al. proposed a fractal theory-based PD recognition technique for medium-voltage motors [
6]. However, some clusters of PD patterns are very close in the fractal map, which may result in incorrect identification.
As a more scientific approach, machine learning technique for PD recognition is utilized to bypass human errors [
7].
There exist numerous machine learning techniques for the pattern recognition of PD such as the artificial neural network [
8], clustering [
9,
10], support vector machine [
11] and deep learning [
12,
13,
14]. The artificial neural network constitutes an information processing model which contains empirical knowledge using a learning process. However, it is computationally expensive and lack of rules for determining the proper network structure. The clustering technique is set up based on the stream density and the clustering theory, however the zero-weight problem exists in the general clustering approach. The support vector machines belong to supervised learning techniques based on statistical learning theory which may be applied for PD pattern recognition, however the classification performance of SVM is conveniently affected by the setting of parameters. Deep learning was successfully applied in pattern recognition and image segmentation, however it is a challenging task due to the limited data availability.
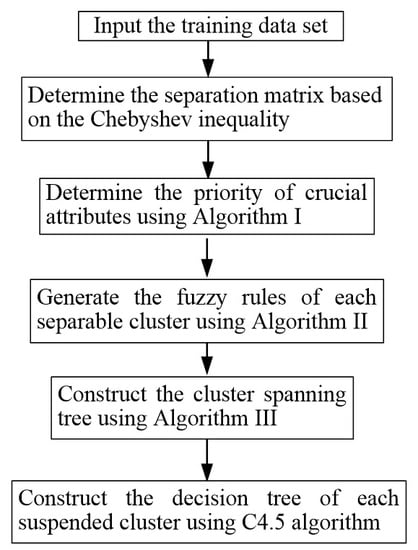
The contribution of this work is to develop a fuzzy logic clustering decision tree (FLCDT) to classify the abnormal defects of cast-resin transformers. Fuzzy logic methods have been successfully applied to many applications in renewable energy. Liu et al. developed an ultra-short-time forecasting method based on the Takagi–Sugeno fuzzy model for wind power and wind speed [
15]. In [
16], an offline time series forecasting approach with an adaptive neuro-fuzzy inference system was conducted for electrical insulator fault forecast. Wang et al. proposed a fuzzy hybrid model to evaluate the energy policies and investments in renewable energy resources [
17]. Thao et al. presented an improved interval fuzzy modeling technique to estimate solar photovoltaic, wind and battery power in a demonstrative renewable energy system under large data changes [
18].
A 60-MVA cast resin transformer with a rated voltage of 22.8 kV is used in this study. The IEC 60,270 standard [
19] is utilized to perform an off-line PD measurement on electrical equipment. The training dataset has three continuous attributes and three abnormal defects. Three continuous attributes are the number of discharge (
n) over the chosen block, discharge magnitude (
q) and the corresponding phase angle (
) where PD pulses occur. Three abnormal defects are failure in S-phase cable termination, failure in R-phase cable and failure in T-phase cable termination. The FLCDT integrates a hierarchical clustering scheme with the decision tree. The hierarchical clustering scheme uses splitting attributes to divide the data set into suspended clusters according to a separation matrix and fuzzy rules. The suspended clusters consist of more than one pattern, which can be further classified by the decision tree [
20].
In the remaining part of the study, the
Section 2 is used to present the fuzzy logic clustering decision tree.
Section 3 introduces the PD measurements of cast-resin transformers and describes the pattern recognition of PD. In
Section 4, the FLCDT is applied to classify the aberrant PD of cast-resin transformers and compared with two software packages, See5 and CART. Finally,
Section 5 makes a conclusion.
4. Experiment Results and Comparison
This work uses data collected by a well-known foundry company in Taiwan. A PD measurement based on the IEC 60,270 standard was performed on a 60-MVA cast resin transformer with a rated voltage of 22.8 kV. Three RF sensors are installed near the surfaces of the power transformer to detect the PD signals. The positions of RF sensors are adjusted to obtain the same performance. Three phase voltages are obtained from voltage output. Phase voltage and three PD signals are connected to a 4-channel oscilloscope to identify where the PD occurs. The R-S-T sensors capture the PD signal and send them to the scope through three wideband RF cables. The phase voltages are adjusted to measure the PD from the power transformer.
Table 1 shows the three attributes used in the PD detection, which are phase angle (
), discharge magnitude (
q) and number of discharges (
n).
Table 2 lists the four classes of PD patterns, which are failure in S-phase cable termination, failure in R-phase cable, failure in T-phase cable termination and normal operation. Three cable defects were created artificially on the cable prior to the cable joints installation. Each PD pattern is experimented on 40 times. In total, this experiment produced 160 sets of PD patterns, 128 of which are for training and 32 of which are for testing. Each class has 32 training patterns and 8 testing patterns. After three steps of data transformation, 84,368 feature vectors were used for training and 21,092 feature vectors were used for testing. After applying Algorithm I, the CA utilized to split the root cluster is the charge pC. Three threshold values
= 0.5, 0.7 and 0.9 were used in Algorithm III. The FLCDT was compared with two software packages, See5 and CART. See5 is a data mining tool to extract informative patterns from data and assemble them into classifiers to make predictions [
36]. See5 is developed based on the C4.5 to operate on large databases and incorporate innovations such as boosting. The classification and regression tree (CART) in the classification toolbox for MATLAB was utilized to compare the accuracy [
37]. CART selects the best decision split that maximizes the improvement in Gini index over all possible splits of all predictors.
Figure 18 shows the cluster spanning tree and the corresponding CA, where a block represents a cluster and the classes are displayed inside the parenthesis in each cluster. The CA is listed above the outgoing branch. There are two SCs in the cluster spanning tree for
= 0.5, where each SC consists of two patterns. There are three SCs in the cluster spanning tree for
= 0.7 and 0.9, where SC
3 consists of two patterns. Finally, the C4.5 algorithm is applied to SC
3 and construct the decision tree.
Figure 19 displays the decision tree of SC
3, which consists of patterns 3 and 4. Two attributes including phase angle and charge pC are utilized in the decision tree of SC
3. Since the attribute values of cycle number has a higher overlapping degree, different classes in a dataset are not easily separable. Thus, attribute of cycle number is never used in the cluster spanning tree and decision tree of SC
3. Figure 20 shows the pattern distributions of the 21,092 testing feature vectors. In
Figure 20, ‘○’ represents the failure in S-phase cable termination (pattern 1), ‘□’ represents the failure in R-phase cable (pattern 2), ‘Δ’ represents the failure in T-phase cable termination (pattern 3), ‘☆’ represents the normal operation of the equipment (pattern 4). From the pattern distributions, it is clear that three SCs can be classified using the charge pC (k
2), and pattern 3 and 4 can be classified using the phase angle (k
1) and the charge pC (k
2).
The classification precision of FLCDT was compared with the existing software CART and See5. The classification precision is defined as the number of correctly classified patterns to the total number of patterns.
Table 3 shows the resulting classification precisions of four patterns, training time and classification time. Consider the three threshold values, we found that case ‘
= 0.5′ resulted in a smaller classification precision, while the results of other two cases are the same. Since a larger threshold value
allows a higher overlapping degree, two classes are more easily separable. The classification precisions, training times and classification times obtained by the software CART and See5 are also shown in
Table 3. Test results show that the FLCDT with
= 0.7 and
= 0.9 performs better than CART and See5 for classification precisions. The reason is that overfitting arises when the decision trees are directly applied to the training data set. Overfitting happens when a decision tree is excessively dependent on irrelevant features of the training data so that its predictive ability for untrained data is reduced. For patterns 1 and 4, See5 has a better performance than CART. Furthermore, the training time required by FLCDT is much shorter than those required by CART and See5. The FLCDT not only performs better than CART and See5 in the aspect of classification precision, but also requires less training time. This also reveals that the hierarchical clustering scheme helps reduce the time complexity of C4.5 algorithm.
Figure 21 shows the confusion matrix of four patterns. The confusion matrix shows that all the measurements belonging to pattern 1 are classified correctly. For pattern 2, 12.5% of the data measurement are misclassified into pattern 3. In addition, 12.5% of the data measurement known to be in pattern 3 are misclassified into pattern 4. For pattern 4, 12.5% of the data measurements are misclassified into pattern 2 and 3, respectively.
Table 4 shows the classification recall, precision, F-score and the average results of four patterns using FLCDT with
= 0.7. The overall accuracy of the FLCDT with
= 0.7 is 87.5%. Currently, there is no way to plot a ROC curve for multi-class classification problems as it is defined only for binary class classification. The ROC-AUC score for considered problem is not provided in this work.

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}