A Time-Series Data Analysis Methodology for Effective Monitoring of Partially Shaded Photovoltaic Systems



Abstract
:1. Introduction
1.1. Research Motivation
1.2. Literature Review
1.2.1. PV Monitoring and Malfunction Detection through the Years
1.2.2. Shadow Detection and Its Impacts on PV Performance
1.3. Research Purpose and Paper Organization
1.3.1. Research Purpose
1.3.2. Paper Organization
2. Scope, Limitations and Data Preparation of the Algorithm
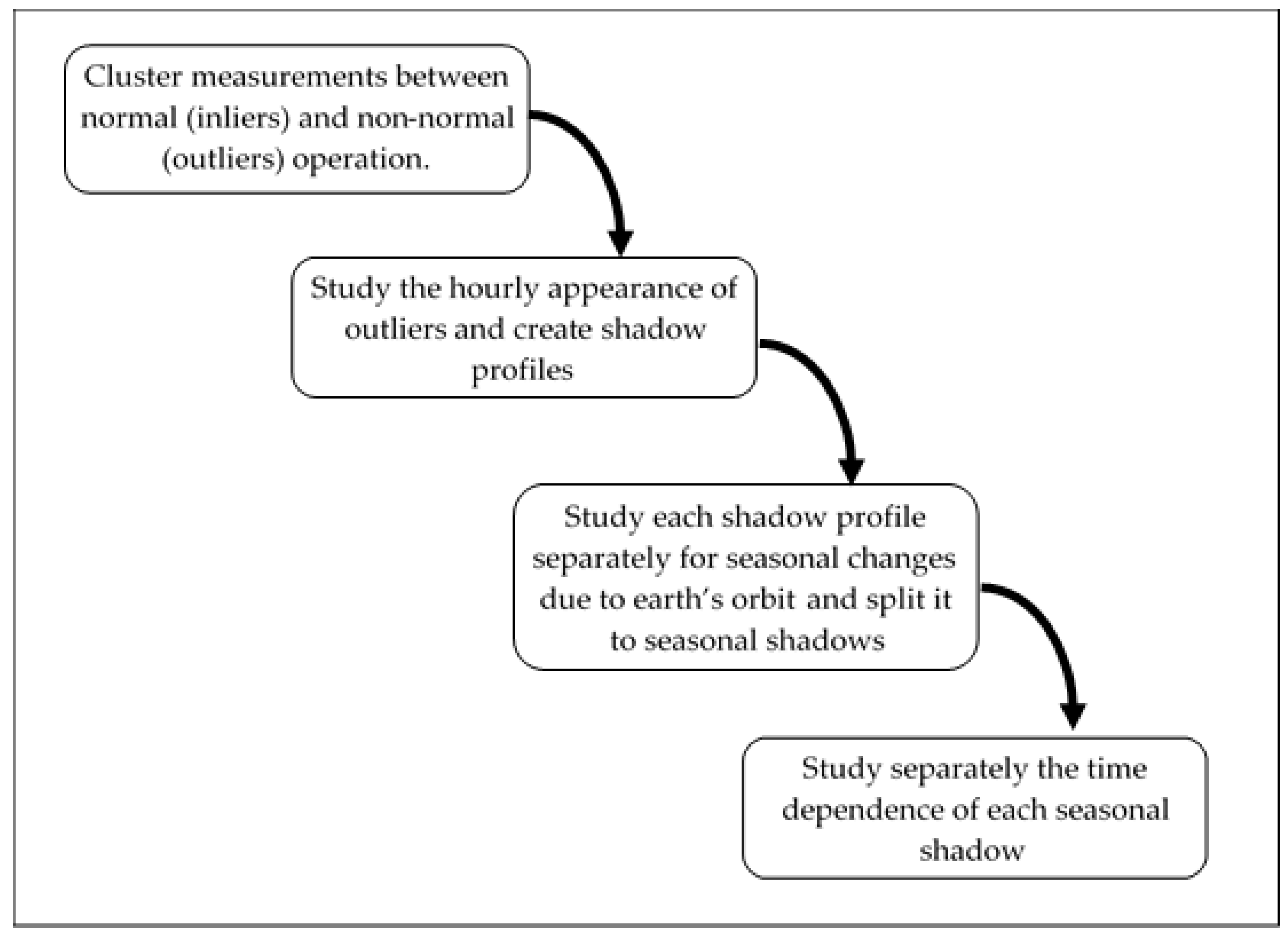
2.1. Scope of the Algorithm
- Define a threshold of the error, to distinguish between normal and non-normal operation.
- Study the hourly appearance of non-acceptable errors.
- Study the shadow profile for seasonal changes in the start-end time of the shadow.
- Study, separately, the time dependence of each shadow profile.
2.2. Limitations of the Algorithm
2.2.1. The Dependence of Shadow on the Irradiance Conditions
2.2.2. Error Outside Shadow Characterized as Potential Malfunction
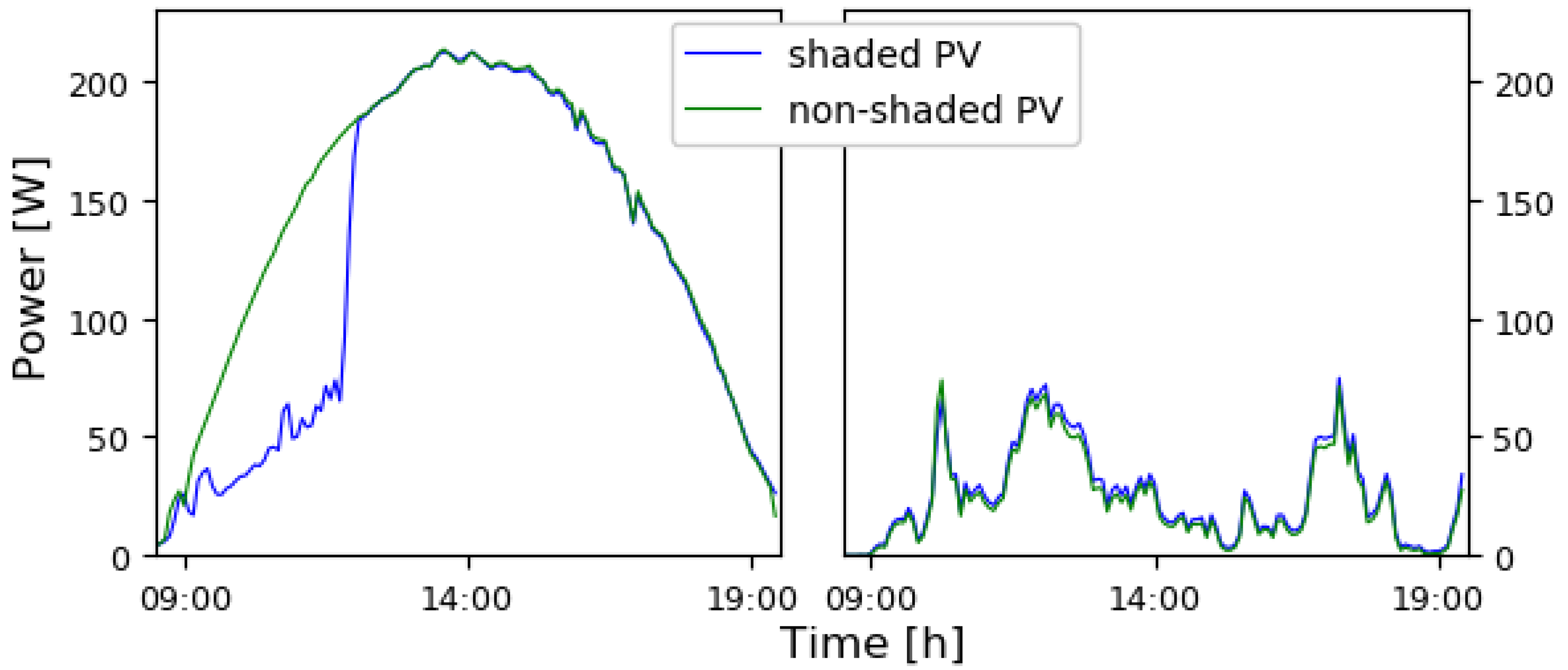
2.3. Data Preparation
2.4. Data Source
3. Description of the Algorithm
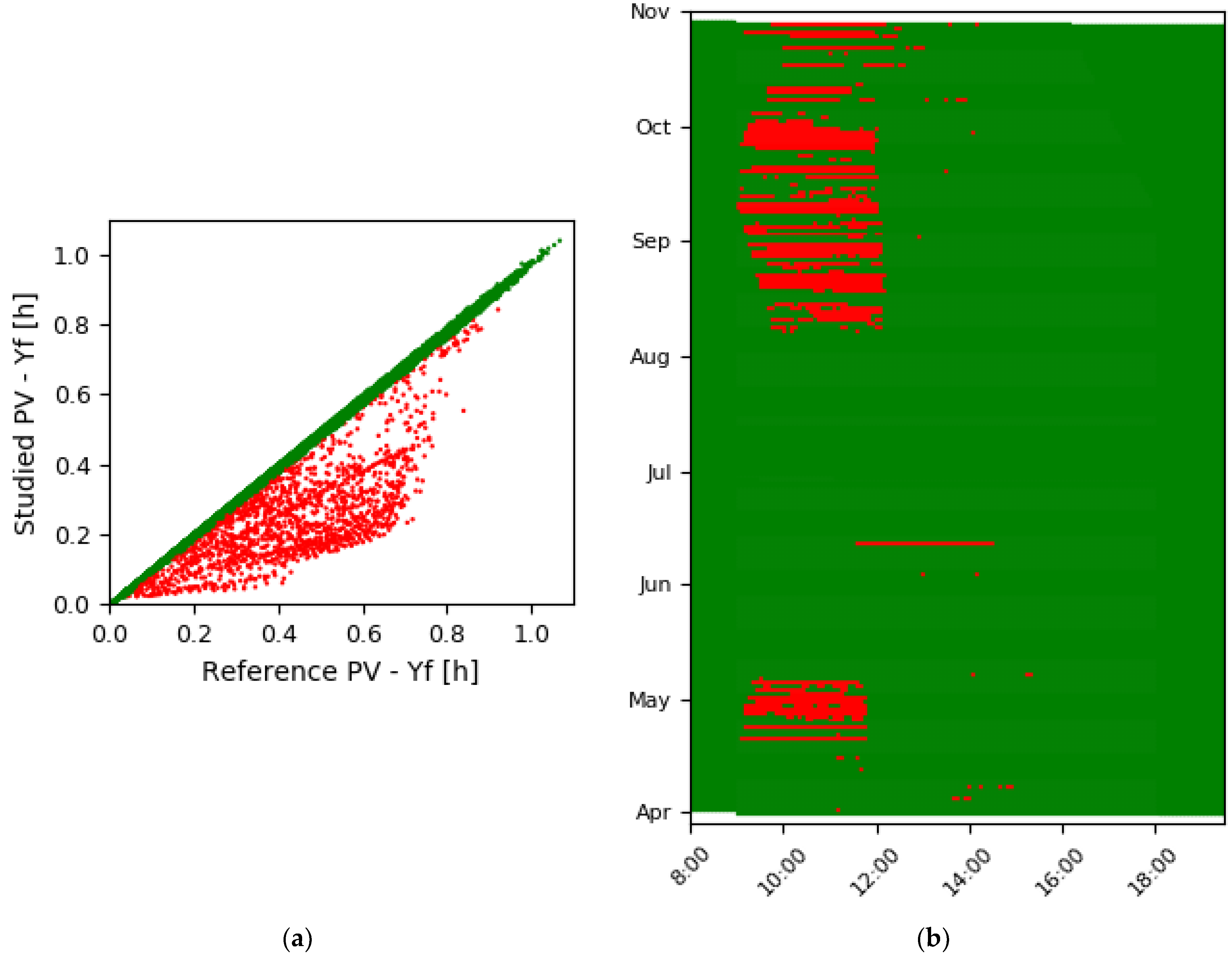
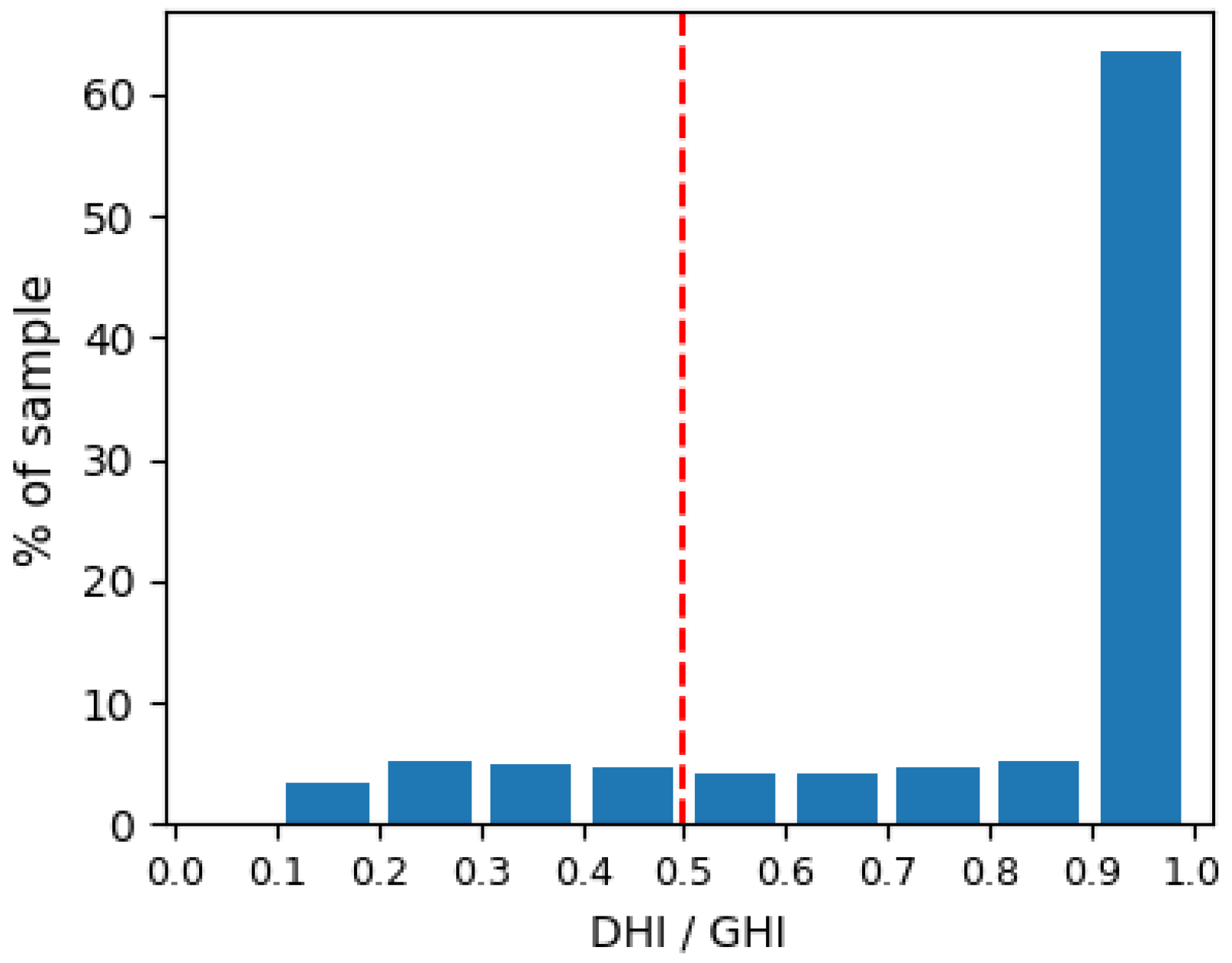
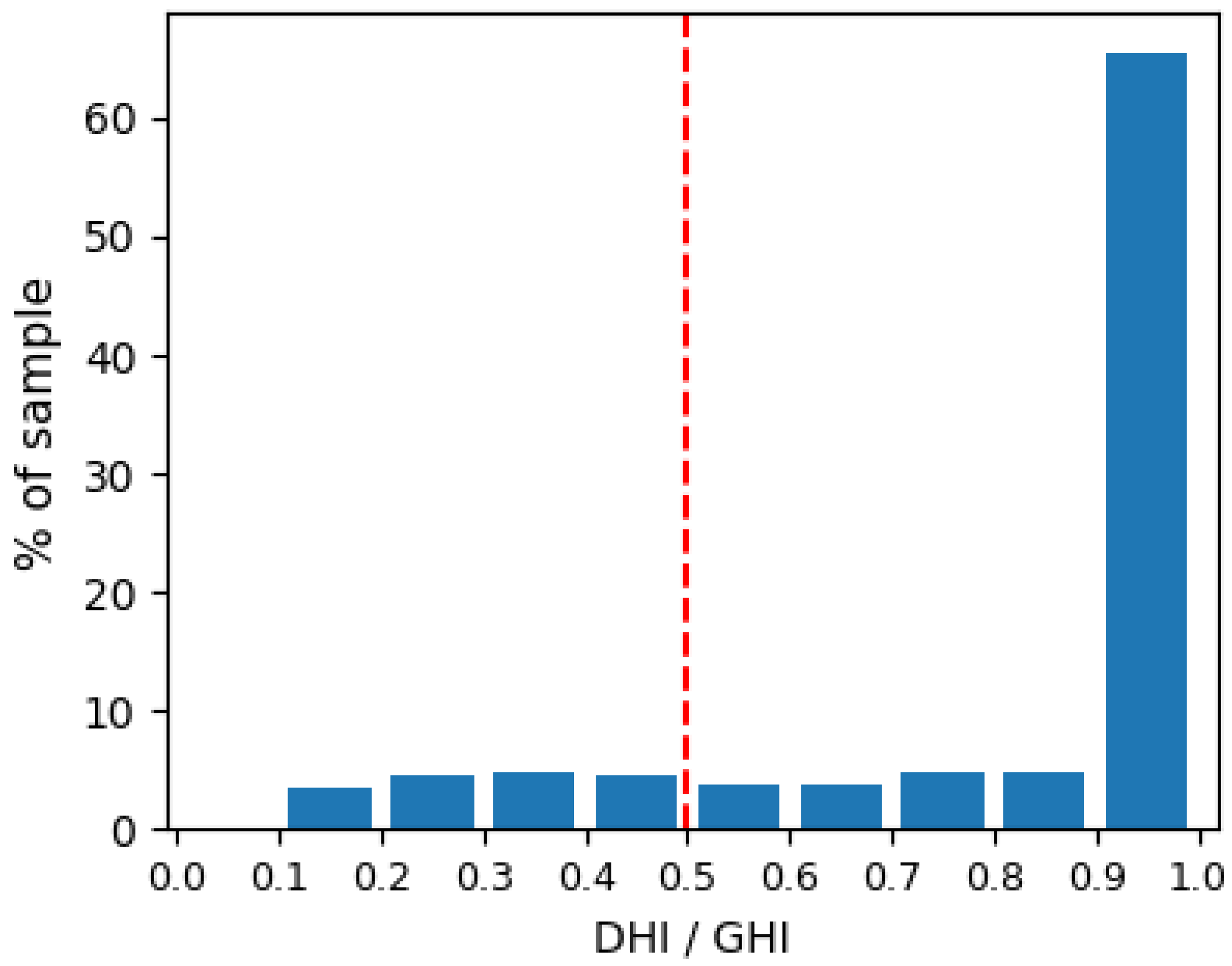
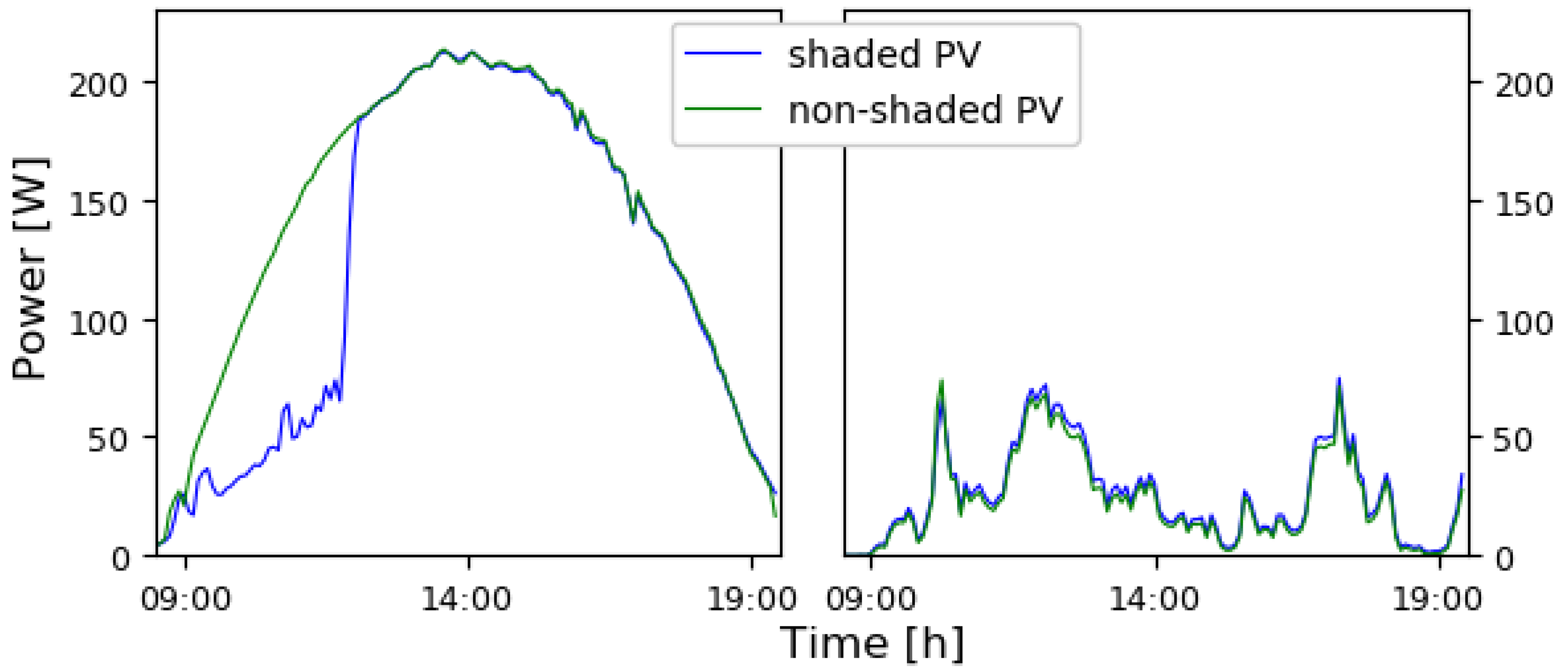
3.1. Step I, Define the Outliers
3.1.1. Explanation of Step I
3.1.2. Application and Visualization of Step I
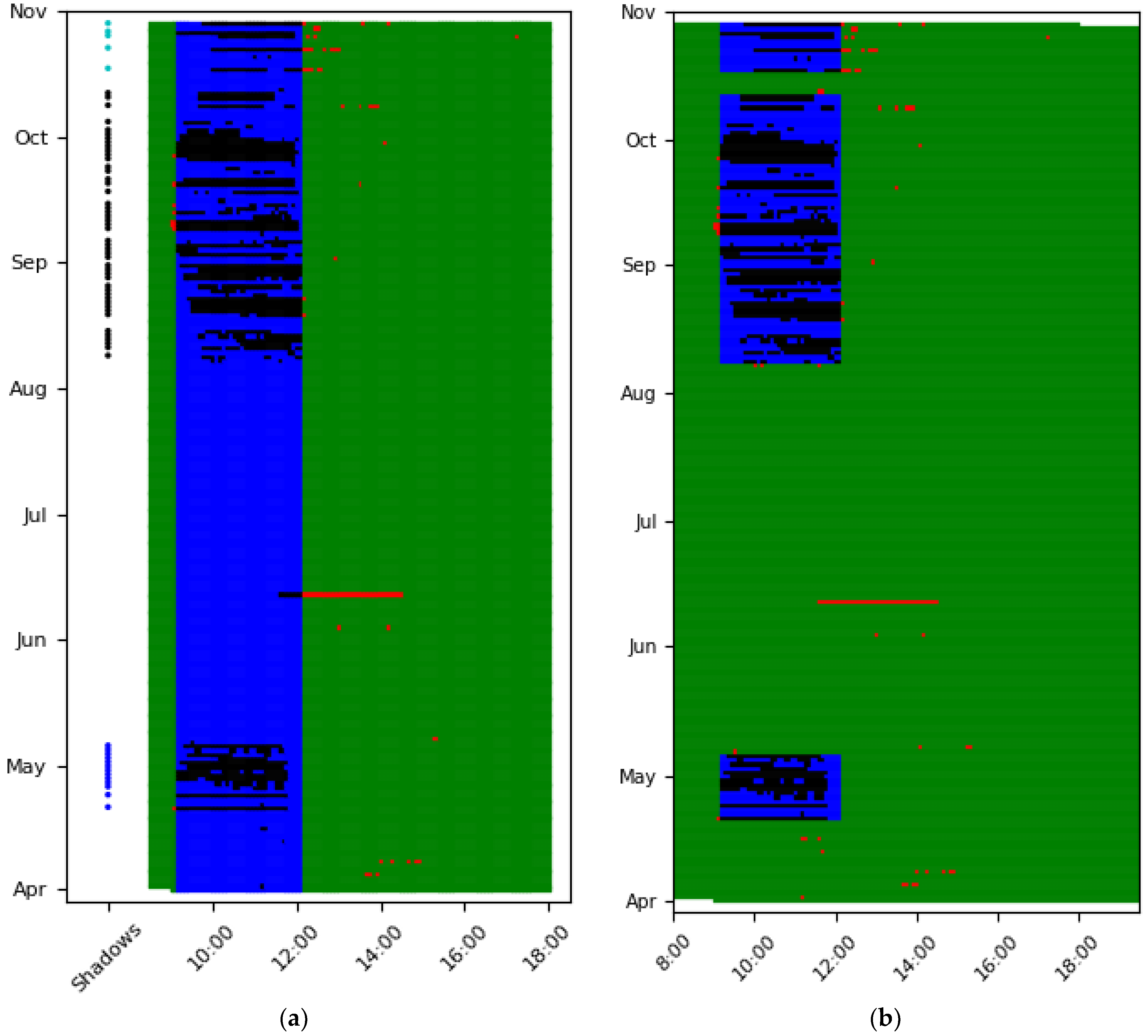
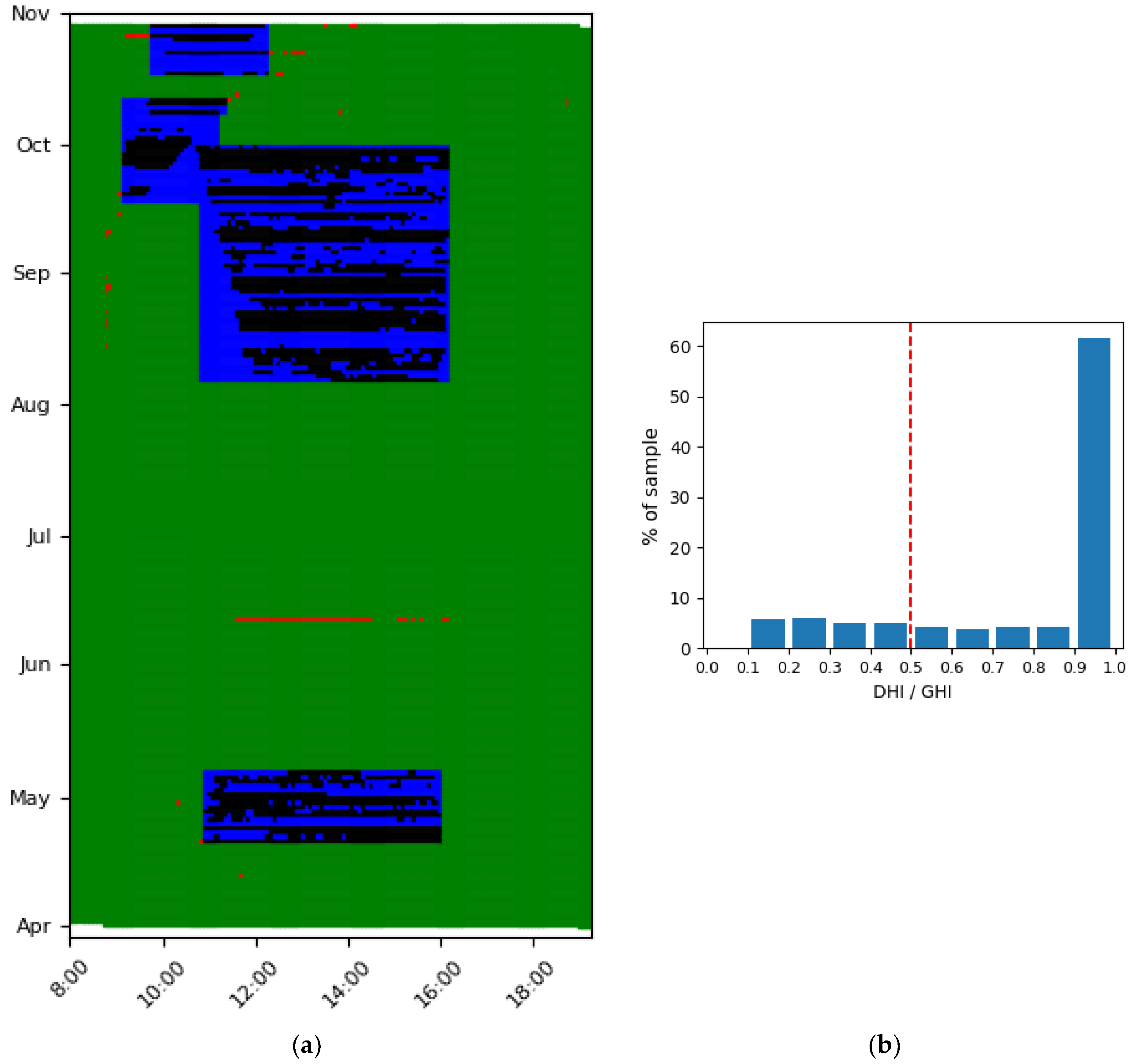
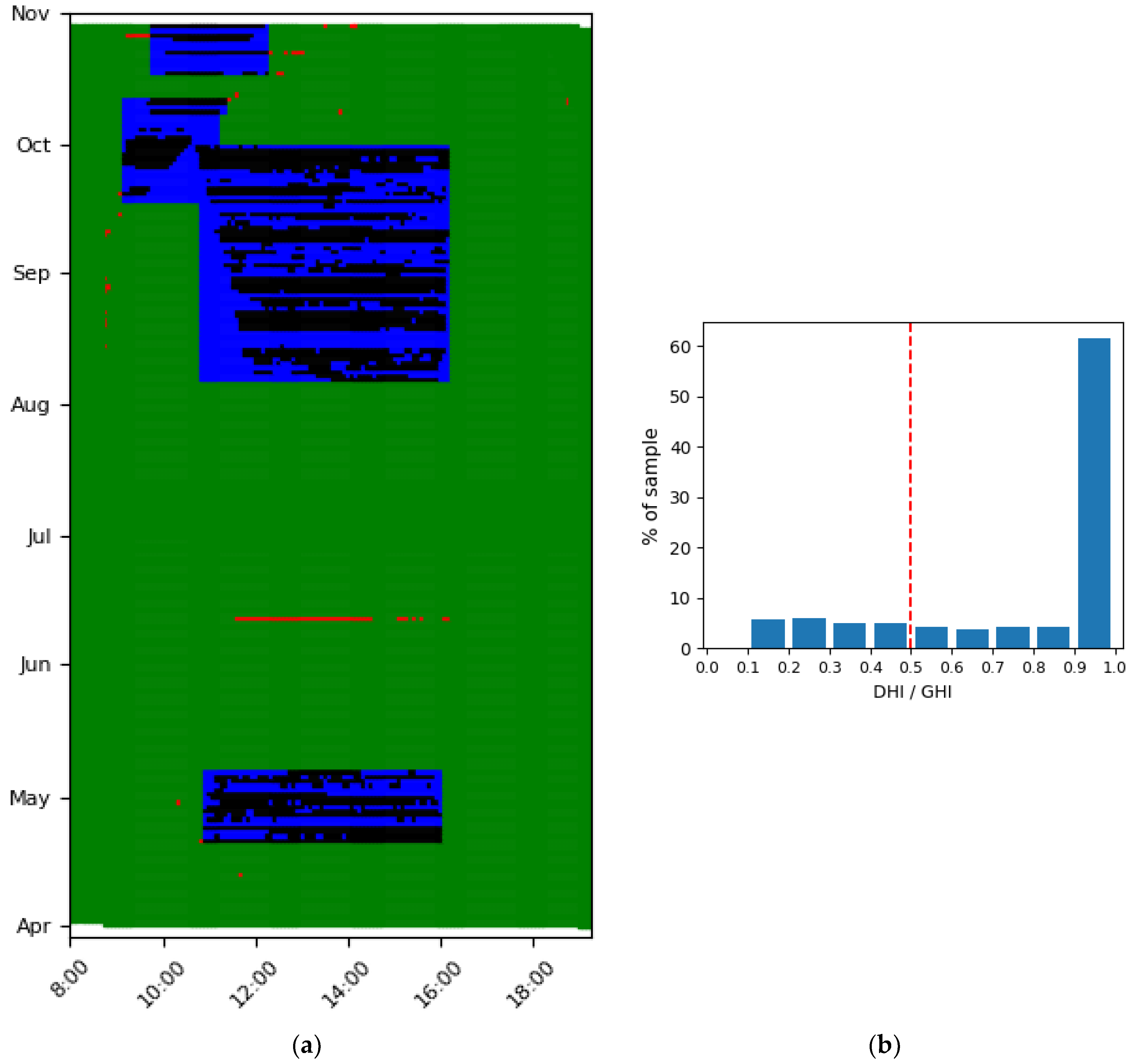
3.2. Step II, Hourly Occurrence of Outliers—Detect Shadows
3.2.1. Explanation of Step II
3.2.2. Application and Visualization of Step II
- Green: Inlier outside of shadow profile
- Blue: Inlier within shadow profile
- Black: Outlier within shadow profile, thus shadow
- Red: Outlier outside shadow profile, thus other malfunction
3.2.3. Discussion of Step II
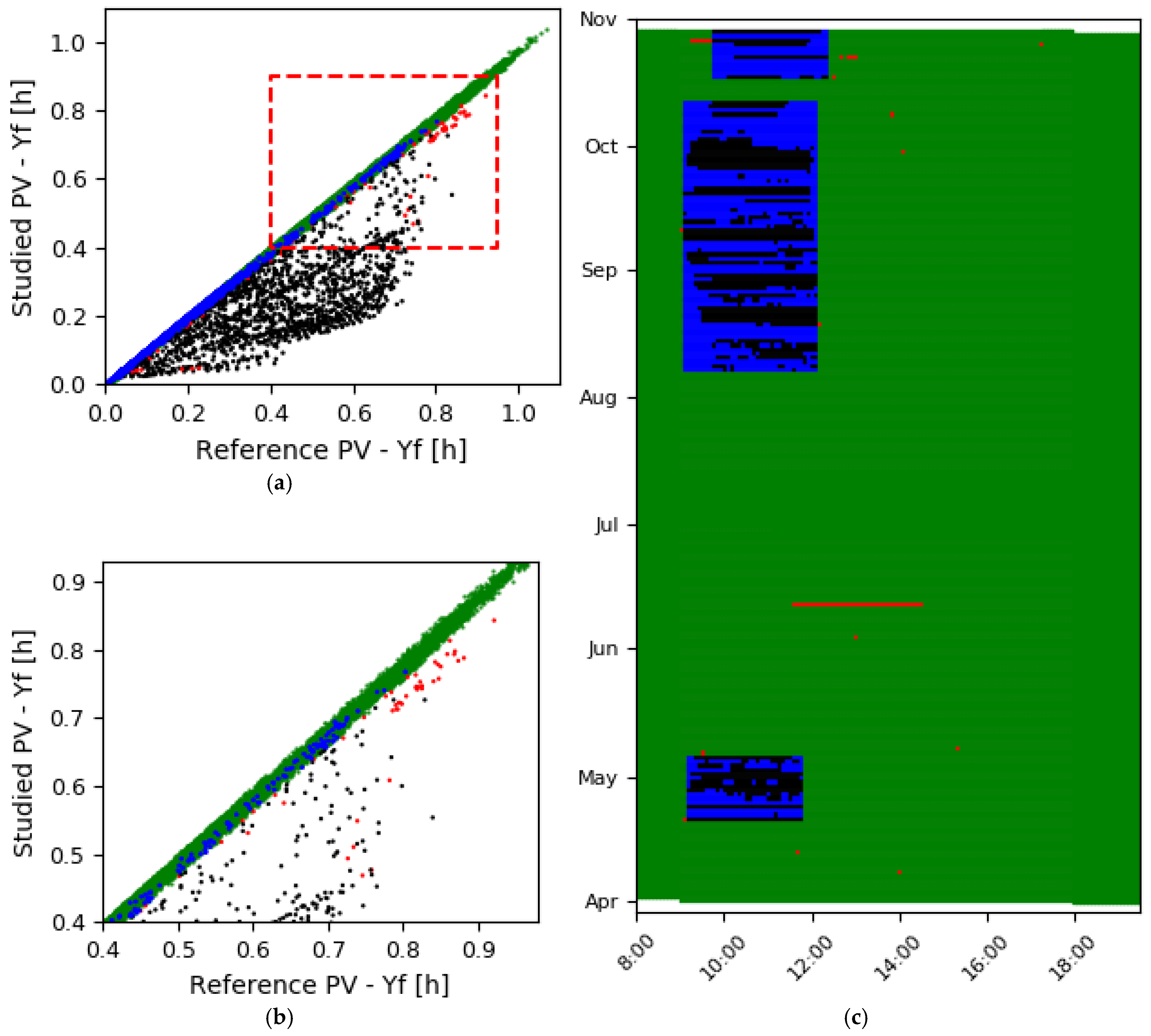
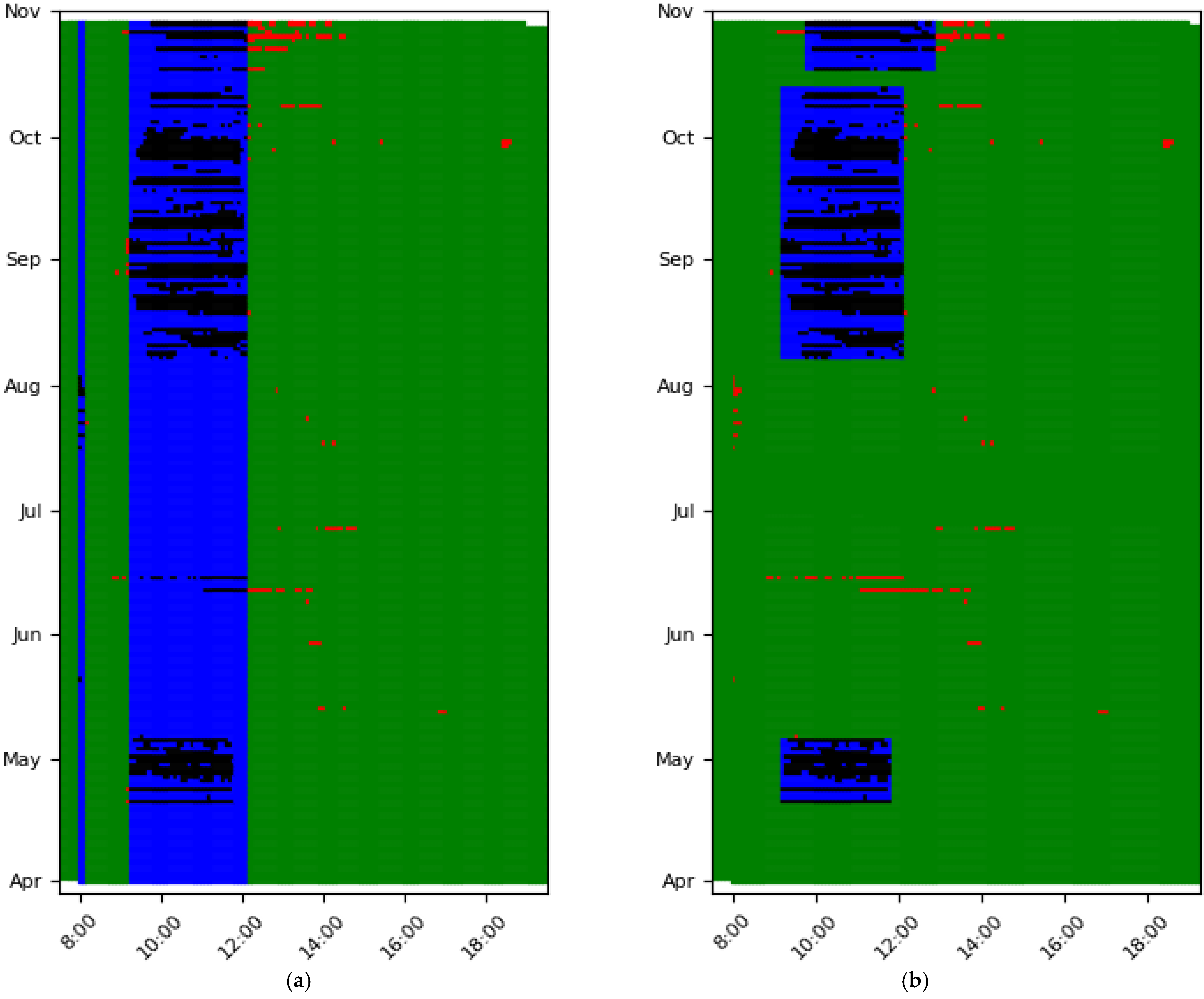
3.3. Step III, Cluster Dates in to Smaller Groups
3.3.1. Explanation of Step III
3.3.2. Application and Visualization of Step III
3.4. Step IV, Second Hourly Distribition
3.4.1. Explanation of Step IV
3.4.2. Application and Visualization of Step IV
3.5. Verification of the Method
4. Results
4.1. Example 1: Different Shadows on a Panel with Power Optimizer
4.2. Example 2: Panel with Micro Inverter and Morning Shadow
5. Conclusions
- Only the power output is used, which is the most common timeseries data for a PV system.
- Static system data is not necessary if the reference and the studied PV system have the same capacity.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- InterSolarEurope. Global Market Outlook For Solar Power/2018–2022; InterSolarEurope: Amsterdam, The Netherlands, 2018; p. 81. [Google Scholar]
- SolarSolutions. Dutch Solar Trend Report 2018. 2018. Available online: http://www.solarsolutions.nl/download/ (accessed on 6 May 2019).
- Centraal Bureau voor de Statistiek (CBS). Bijgeplaatst Vermogen Zonnestroom Bijgesteld n.d. Available online: https://www.cbs.nl/nl-nl/achtergrond/2015/51/bijgeplaatst-vermogen-zonnestroom-bijgesteld (accessed on 23 April 2019).
- Solar Solutions Int. Nationaal Solar Trendrapport 2019; Solar Solutions Int: Amsterdam, The Netherlands, 2019. [Google Scholar]
- EU. Directive 2010/31/ of the European Parliament on the Energy Performance of Buildings; EU: Brussels, Belgium, 2010; Volume 63. [Google Scholar]
- Li, D.; Liu, G.; Liao, S. Solar potential in urban residential buildings. Sol. Energy 2015, 111, 225–235. [Google Scholar] [CrossRef]
- Moraitis, P.; Kausika, B.; Nortier, N.; van Sark, W. Urban Environment and Solar PV Performance: The Case of the Netherlands. Energies 2018, 11, 1333. [Google Scholar] [CrossRef]
- Woyte, A.; Richter, M.; Moser, D.; Green, M.; Mau, S.; Beyer, H.G. Analytical Monitoring of Grid-Connected Photovoltaic Systems; Technical Report IEA-PVPS T13-03:2014; IEA-PVPS: St. Ursen, Switcherland, 2014. [Google Scholar]
- CENELEC IEC 61724. Photovoltaic System Performance Monitoring—Guidelines for Measurement, Data Exchange and Analysis; Edition 1.0, 1998-04; CENELEC IEC: Brussels, Belgium, 1998. [Google Scholar]
- Ransome, S.; Wohlgemuth, J.H.; Poropat, S.; Aguilar, E. Advanced analysis of pv system performance using normalised measurement data. In Proceedings of the 31st IEEE PVSC, Orlando, FL, USA, 3–7 January 2005. [Google Scholar]
- Van Sark, W.; Drews, A.; Heinemann, D.; Heilscher, G. PVSAT-2: Results of Field Test of the Satellite-Based PV System Perfomance. In Proceedings of the 21st European Photovoltaic Solar Energy Conference, Dresden, Germany, 4–8 September 2006; pp. 2–7. [Google Scholar]
- Drews, A.; de Keizer, A.C.; Beyer, H.G.; Lorenz, E.; Betcke, J.; van Sark, W.G.J.H.M.; Heydenreich, W.; Wiemken, E.; Stettler, S.; Toggweiler, P.; et al. Monitoring and remote failure detection of grid-connected PV systems based on satellite observations. Sol. Energy 2007, 81, 548–564. [Google Scholar] [CrossRef] [Green Version]
- Firth, S.K.; Lomas, K.J.; Rees, S.J. A simple model of PV system performance and its use in fault detection. Sol. Energy 2010, 84, 624–635. [Google Scholar] [CrossRef] [Green Version]
- Chouder, A.; Silvestre, S. Automatic supervision and fault detection of PV systems based on power losses analysis. Energy Convers. Manag. 2010, 51, 1929–1937. [Google Scholar] [CrossRef]
- Silvestre, S.; Chouder, A.; Karatepe, E. Automatic fault detection in grid connected PV systems. Sol. Energy 2013, 94, 119–127. [Google Scholar] [CrossRef]
- Chouder, A.; Silvestre, S.; Sadaoui, N.; Rahmani, L. Simulation Modelling Practice and Theory Modeling and simulation of a grid connected PV system based on the evaluation of main PV module parameters. Simul. Model. Pract. Theory 2012, 20, 46–58. [Google Scholar] [CrossRef]
- Eke, R.; Senturk, A. Monitoring the performance of single and triple junction amorphous silicon modules in two building integrated photovoltaic (BIPV) installations. Appl. Energy 2013, 109, 154–162. [Google Scholar] [CrossRef]
- Chine, W.; Mellit, A.; Pavan, A.M.; Kalogirou, S.A. Fault detection method for grid-connected photovoltaic plants. Renew. Energy 2014, 66, 99–110. [Google Scholar] [CrossRef]
- Jahn, U.; Farnung, B. Task 13—Performance and Reliability of PV Systems. Photovolt Power Syst Program Annu Rep 2016. 2017, p. 26. Available online: http://www.iea-pvps.org/index.php?id=57 (accessed on 6 May 2019).
- Akram, M.N.; Lotfifard, S. Modeling and Health Monitoring of DC Side of Photovoltaic Array. IEEE Trans. Sustain. Energy 2015, 6, 1245–1253. [Google Scholar] [CrossRef]
- Platon, R.; Martel, J.; Woodruff, N.; Chau, T.Y. Online Fault Detection in PV Systems. IEEE Trans. Sustain. Energy 2015, 6, 1200–1207. [Google Scholar] [CrossRef]
- Dhimish, M.; Holmes, V. Fault detection algorithm for grid-connected photovoltaic plants. Sol. Energy 2016, 137, 236–245. [Google Scholar] [CrossRef]
- Serrano-Luján, L.; Cadenas, J.M.; Faxas-Guzmán, J.; Urbina, A. Case of study: Photovoltaic faults recognition method based on data mining techniques. J. Renew. Sustain. Energy 2016, 8, 043506. [Google Scholar] [CrossRef]
- Mallor, F.; León, T.; De Boeck, L.; Van Gulck, S.; Meulders, M.; Van Der Meerssche, B. A method for detecting malfunctions in PV solar panels based on electricity production monitoring. Sol. Energy 2017, 153, 51–63. [Google Scholar] [CrossRef]
- Tsafarakis, O.; Sinapis, K.; van Sark, W.G.J.H.M. PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation. Energies 2018, 11, 977. [Google Scholar] [CrossRef]
- Libra, M.; Daneček, M.; Lešetický, J.; Poulek, V.; Sedláček, J.; Beránek, V. Monitoring of Defects of a Photovoltaic Power Plant Using a Drone. Energies 2019, 12, 795. [Google Scholar] [CrossRef]
- Mohammedi, A.; Mezzai, N.; Rekioua, D.; Rekioua, T. Impact of shadow on the performances of a domestic photovoltaic pumping system incorporating an MPPT control: A case study in Bejaia, North Algeria. Energy Convers. Manag. 2014, 84, 20–29. [Google Scholar] [CrossRef]
- Sinapis, K.; Litjens, G.; Van Den Donker, M.; Folkerts, W.; Van Sark, W. Outdoor characterization and comparison of string and MLPE under clear and partially shaded conditions. Energy Sci. Eng. 2015, 3, 510–519. [Google Scholar] [CrossRef] [Green Version]
- Sinapis, K.; Tzikas, C.; Litjens, G.; Van Den Donker, M.; Folkerts, W.; Van Sark, W.G.J.H.M.; Smets, A. A comprehensive study on partial shading response of c-Si modules and yield modeling of string inverter and module level power electronics. Sol. Energy 2016, 135, 731–741. [Google Scholar] [CrossRef]
- Topić, D.; Knežević, G.; Fekete, K. The mathematical model for finding an optimal PV system configuration for the given installation area providing a maximal lifetime profit. Sol. Energy 2017, 144, 750–757. [Google Scholar] [CrossRef]
- Bressan, M.; El Basri, Y.; Galeano, A.G.; Alonso, C. A shadow fault detection method based on the standard error analysis of I-V curves. Renew. Energy 2016, 99, 1181–1190. [Google Scholar] [CrossRef]
- Garoudja, E.; Harrou, F.; Sun, Y.; Kara, K.; Chouder, A.; Silvestre, S. Statistical fault detection in photovoltaic systems. Sol. Energy 2017, 150, 485–499. [Google Scholar] [CrossRef]
- Bognár Loonen, R.C.G.M.; Valckenborg, R.M.E.; Hensen, J.L.M. An unsupervised method for identifying local PV shading based on AC power and regional irradiance data. Sol. Energy 2018, 174, 1068–1077. [Google Scholar] [CrossRef]
- Lingfors, D.; Killinger, S.; Engerer, N.A.; Widén, J.; Bright, J.M. Identification of PV system shading using a LiDAR-based solar resource assessment model: An evaluation and cross-validation. Sol. Energy 2018, 159, 157–172. [Google Scholar] [CrossRef]
- Libra, M.; Beránek, V.; Sedláček, J.; Poulek, V.; Tyukhov, I.I. Roof photovoltaic power plant operation during the solar eclipse. Sol. Energy 2016, 140, 109–112. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Data | GTI | Neighboring PV System | ||
|---|---|---|---|---|
| Data | Same Capacity | Different Capacity | ||
| Studied PV | Yf | Pstudied (DC or AC) | Yf,studied | |
| Reference data | YR | Pref (DC or AC) | Yf,ref | |
| Detected Shadow | ||||
|---|---|---|---|---|
| Shadow Profile | Dates | Hours | ||
| from | to | from | to | |
| 1 | 21 April | 6 May | 9:10 | 11:45 |
| 2 | 8 August | 13 October | 9:05 | 12:05 |
| 3 | 18 October | 29 October | 9:45 | 12:30 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsafarakis, O.; Sinapis, K.; van Sark, W.G.J.H.M. A Time-Series Data Analysis Methodology for Effective Monitoring of Partially Shaded Photovoltaic Systems. Energies 2019, 12, 1722. https://doi.org/10.3390/en12091722
Tsafarakis O, Sinapis K, van Sark WGJHM. A Time-Series Data Analysis Methodology for Effective Monitoring of Partially Shaded Photovoltaic Systems. Energies. 2019; 12(9):1722. https://doi.org/10.3390/en12091722
Chicago/Turabian StyleTsafarakis, Odysseas, Kostas Sinapis, and Wilfried G. J. H. M. van Sark. 2019. "A Time-Series Data Analysis Methodology for Effective Monitoring of Partially Shaded Photovoltaic Systems" Energies 12, no. 9: 1722. https://doi.org/10.3390/en12091722
APA StyleTsafarakis, O., Sinapis, K., & van Sark, W. G. J. H. M. (2019). A Time-Series Data Analysis Methodology for Effective Monitoring of Partially Shaded Photovoltaic Systems. Energies, 12(9), 1722. https://doi.org/10.3390/en12091722