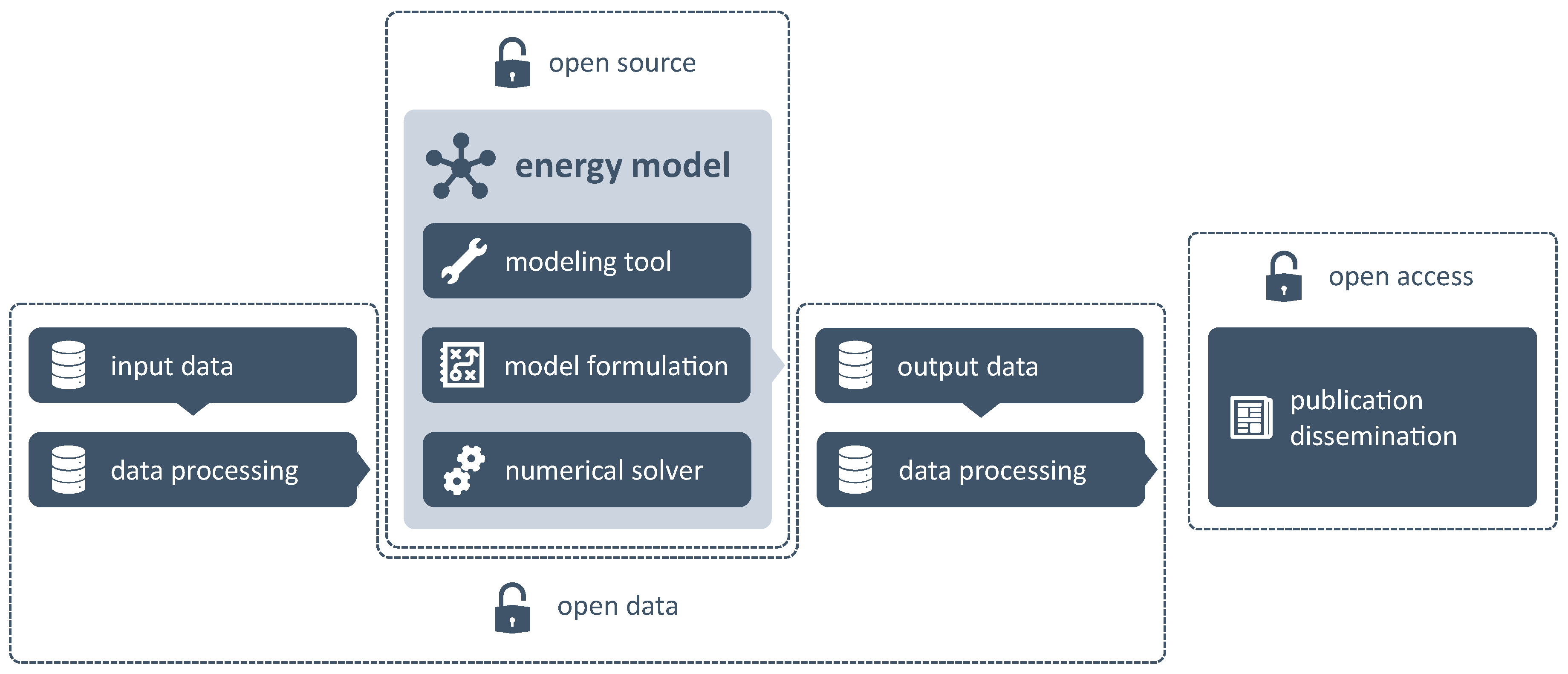
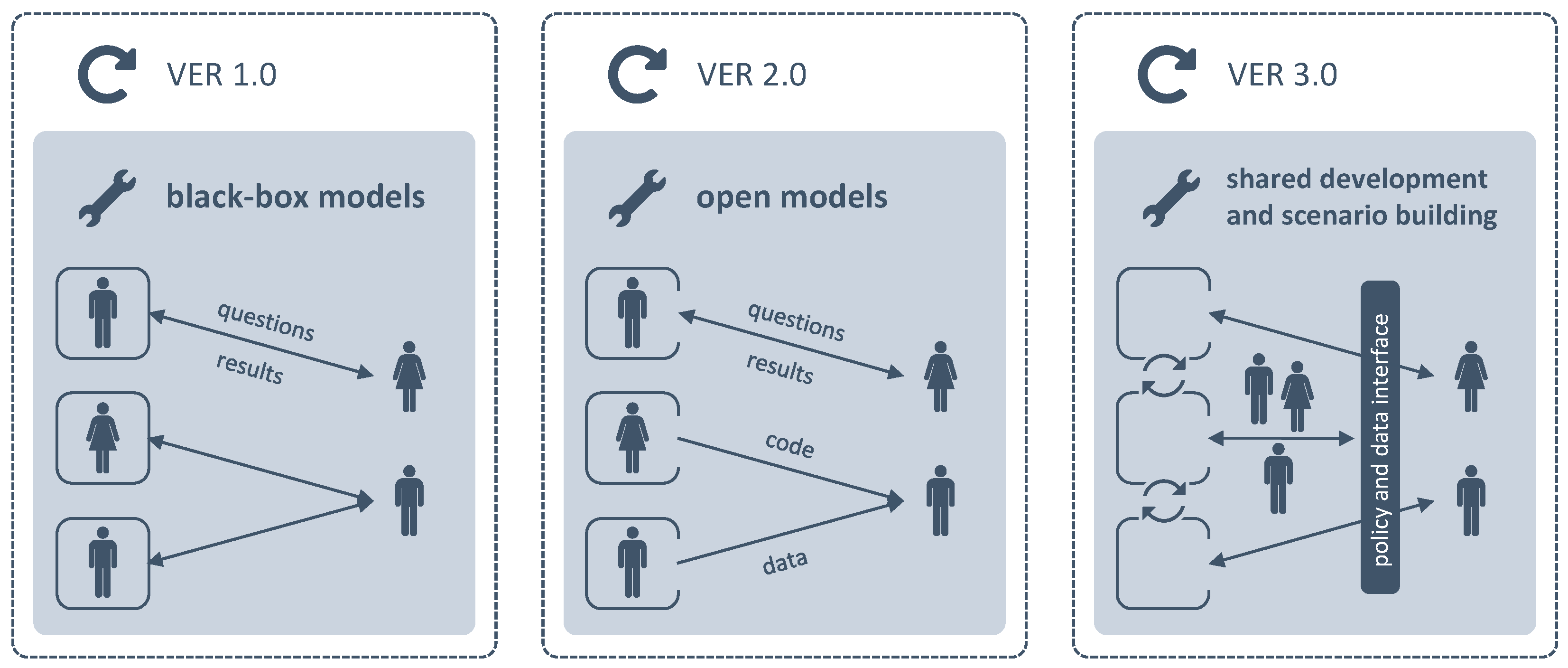
5.1. Joulia.jl
An overview of existing proprietary electricity sector models can be found in Foley et al. [
26] and Carramolino et al. [
27]. With GenX, the MIT Energy Initiative contributed an extensive model written in Julia [
28], but the source code is not publicly available. With
Joulia.jl we want to contribute to the community an energy sector model fulfilling the criteria of all five dimensions of openness according to
Section 2. It should be easily usable for everyone, the first one written in the cutting-edge Julia language, providing all the tools for the entire modeling pipeline and coming with open data ready to be used.
Joulia.jl is a package provided within the JuliaEnergy organization on GitHub (
www.github.com/JuliaEnergy/Joulia.jl), easily to be imported to the Julia environment. It uses the library JuMP as an algebraic modeling tool or language. The package provides the user with generic functions that together constitute the electricity market model described in
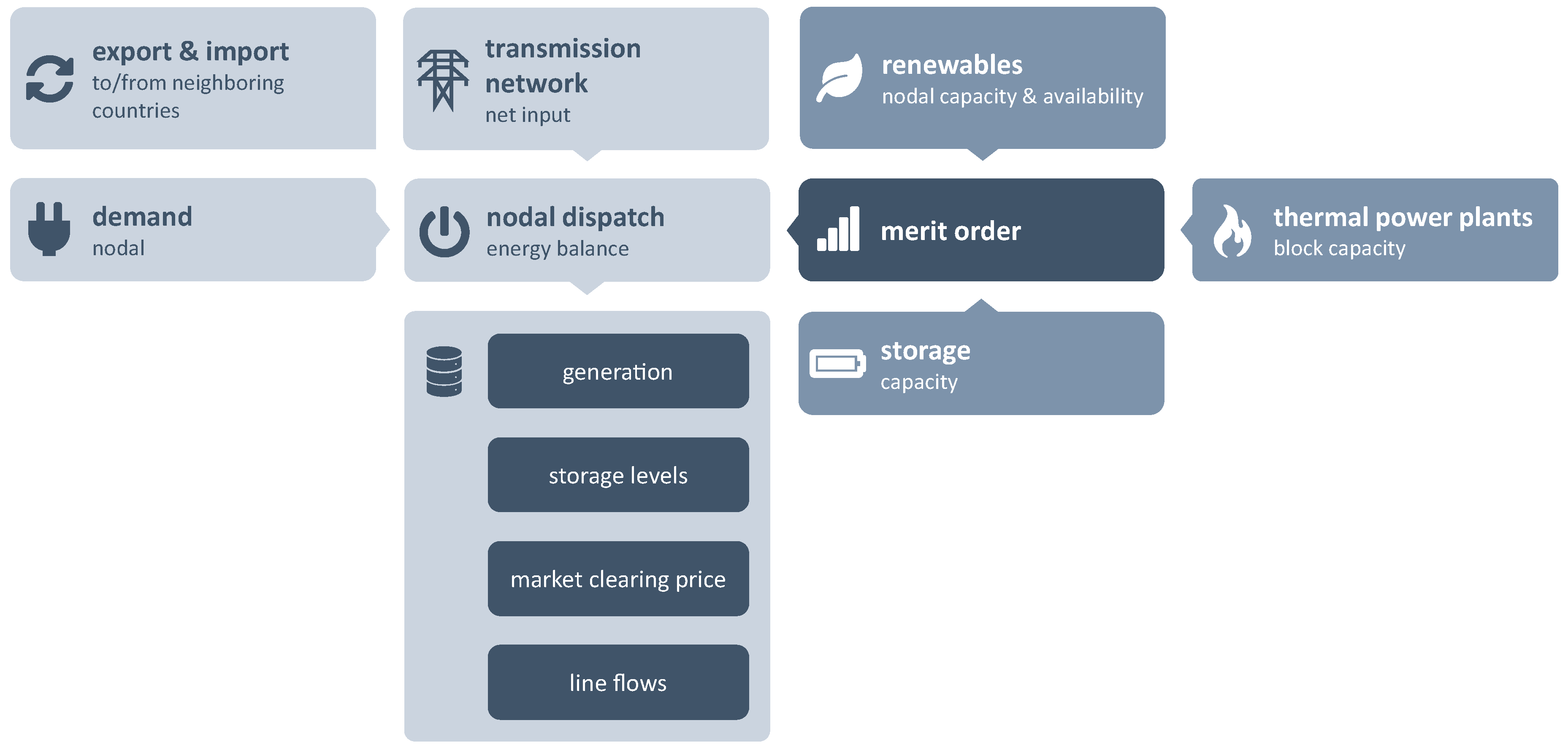
Section 4.
Depending on further packages, any desired data set can be read in from .csv files or binary files. Joulia.jl hereby uses a generic, technology-neutral and extendable data framework in order to be able to extend the future functionality. The model functions can then be called with the data set, generating the actual full model code thereof and passing it on to a desired solver. Results from the solver are being collected and used to produce visualizations, profiting from the plot packages of Julia. Even dynamic plots are possible.
Joulia.jl can be used for a number of research questions, for example the impact of nodal prices and of different configuration of price zones (see [
29] for a possible application). It can be used to analyze the impact of investment decisions into generation or transmission capacities on generation levels by technology, line flow patterns, as well as price levels. Using different data sets, the geographic scope of the model can be extended for example to the whole of Europe or to any other region like developing countries in order to assess policy changes in their markets.
Listing 1 shows a code example representing Equation (
2) (In order to capture possible lost generation or load, a dummy variable is introduced into the equation.). JuMP’s
@constraint macro adds an equality constraint called
market_clearing to the model named
m for each
and
. Listing 2 juxtaposes the same equation in its GAMS implementation. Here, the equation has to be declared and defined first, using the
EQUATION keyword before it can be initialized in a second step following the
.. operator. Using the
sum operator, the set over which the summation should be executed can be limited by the
$ operator. The same effect can be generated in Julia using in-line for loops. Another difference is the assignment of equations to models. In GAMS the model can be defined at the very end of the code and initialized with a list of equations. In JuMP, a variable or an equation is directly linked to a model initialized in the beginning. Nevertheless different models are possible, consisting of the same variables and equations only written out once if the model is generated using functions. It can be stated that in general models in JuMP are more compact then their counterparts in GAMS, as illustrated by an example in [
18].
| Listing 1. Example code for market clearing/energy balance constraint in Julia/JuMP. |
 |
| Listing 2. Example code for market clearing/energy balance constraint in GAMS. |
 |
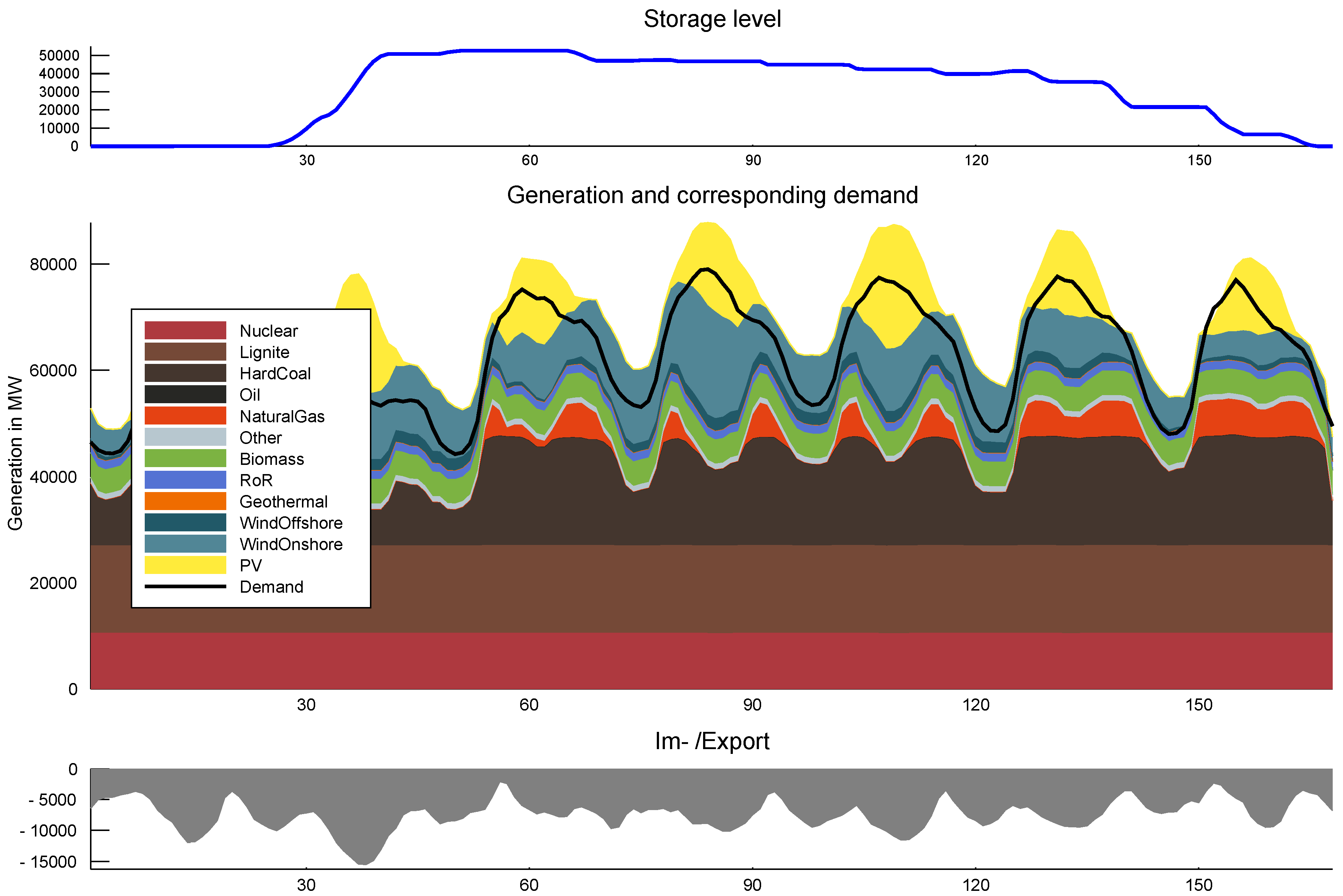
Figure 3 shows an example of the resulting cumulative dispatch for each hour in one week in summer, broken down by fuel and renewable source, respectively. The black line shows electricity demand while imports and exports are represented by the gray area in the bottom subplot and the filling level of pumped hydroelectric storages is mapped in the top subplot in dark blue.
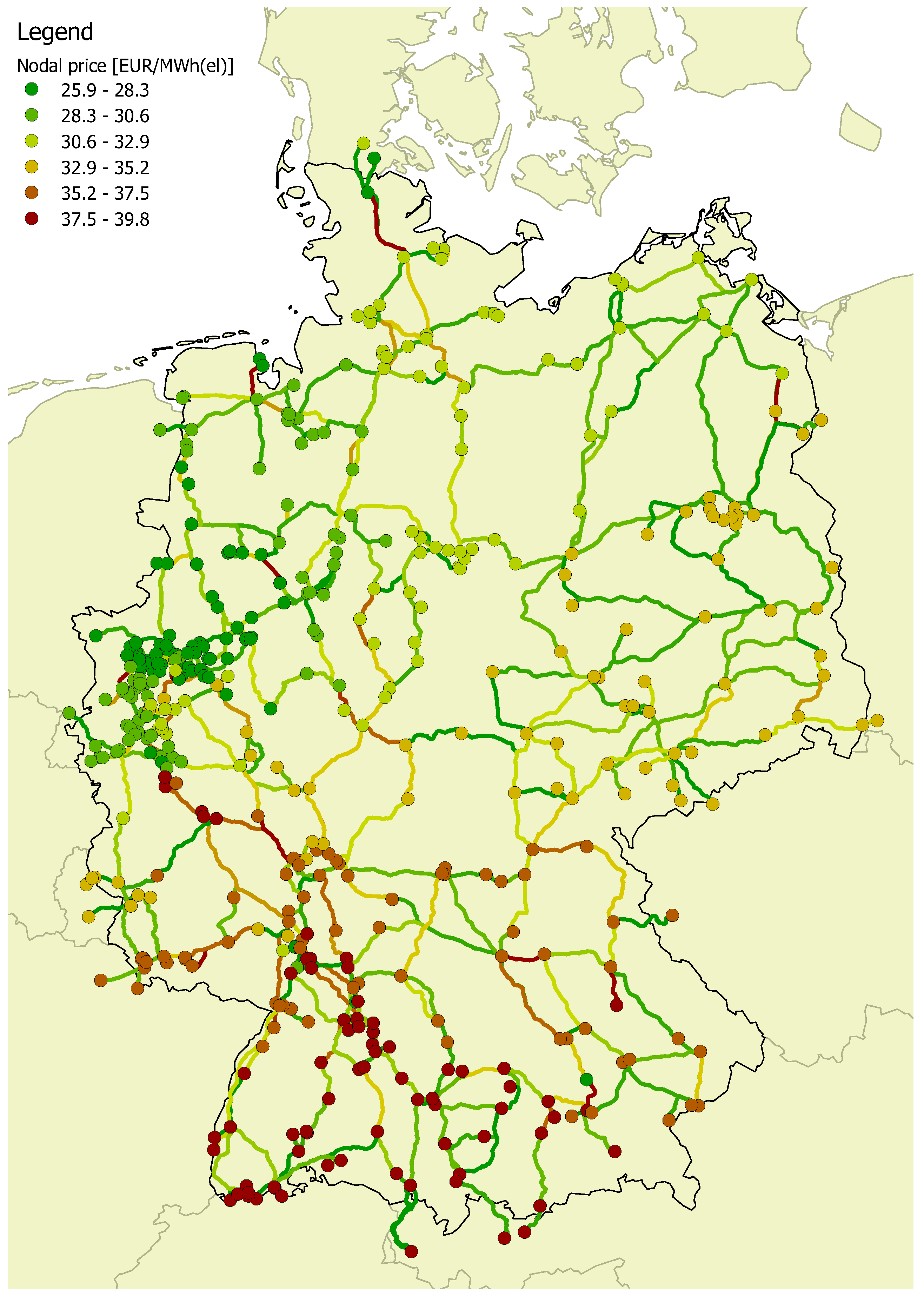
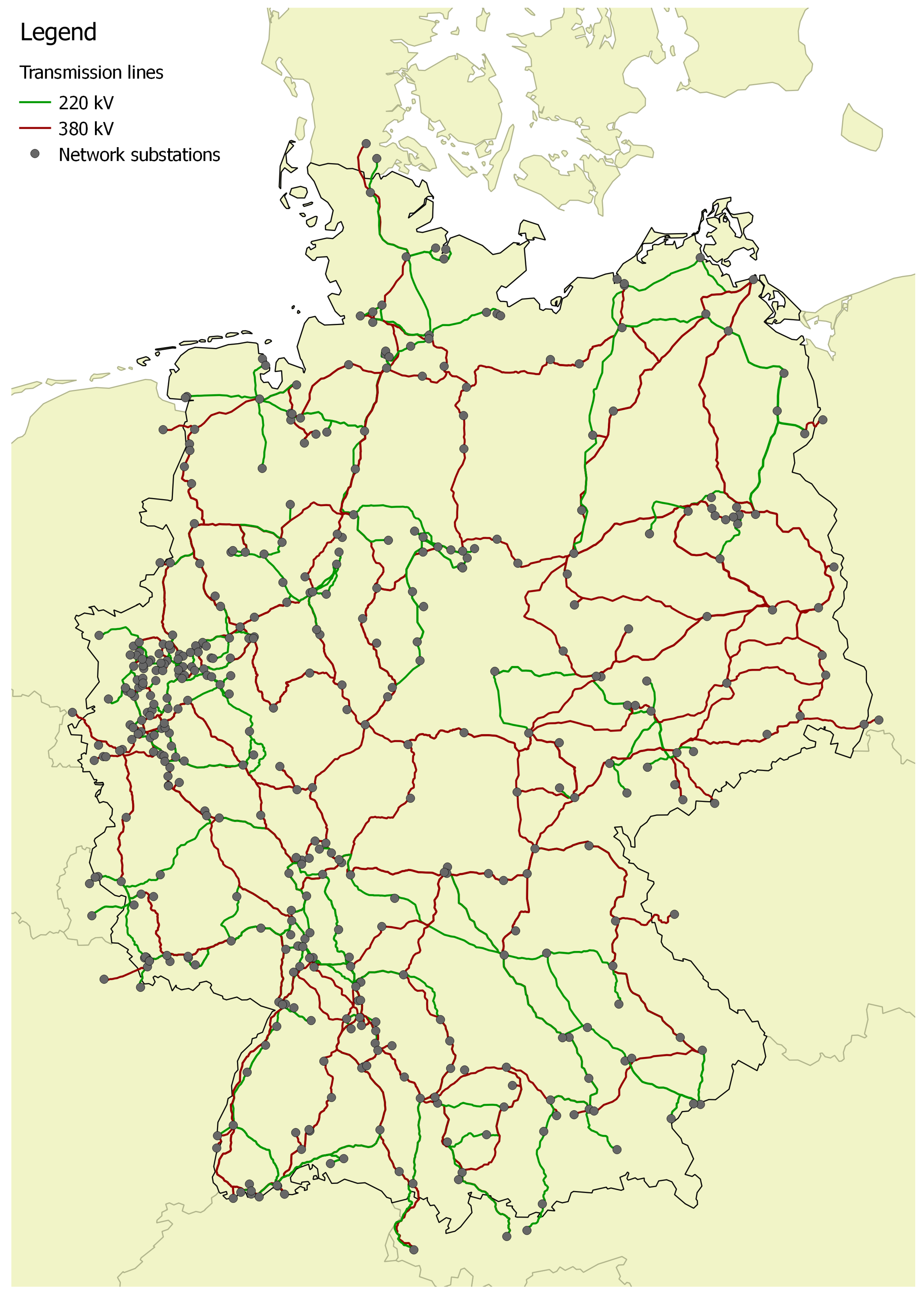
Since the transmission system is also available with its geographical information, the utilization of the lines and the calculated nodal prices in the model can be visualized as in
Figure 4.
5.2. Benchmark Test
In a benchmark test we are comparing the implementation of the model in GAMS (
ELMOD-DE), solved with the three commercial solvers CPLEX, Gurobi, and Mosek with the implementation in Julia/JuMP (
Joulia.jl), solved with the same three solvers plus the additional two open-source solvers ECOS and CLP not available in GAMS. In order to visualize the impact of the complexity of the problem on the runtimes we distinguished three cases: (i) a simple case for dispatch without storage (and hence no intertemporal constraints) and no transmission grid (only Equations (
1)–(3)), (ii) a medium case, adding storage (Equation (4)), and (iii) a hard case, adding the transmission grid (Equation (5)).
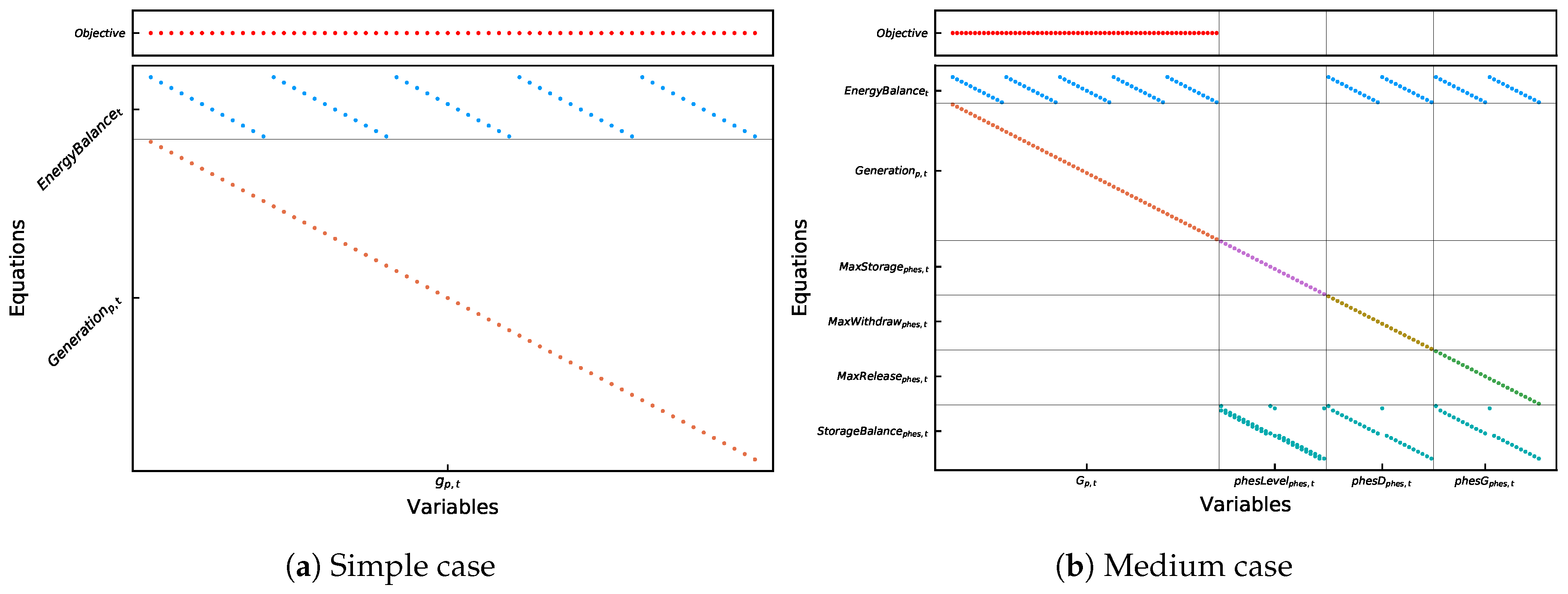
In order to illustrate the difference of these three cases, the constraint coefficient matrix of the problems can be analyzed. Since the original problem is too expansive to be plotted, we generated a sample problem consisting of only five power plant blocks, four network nodes, six network lines, and three storage units. This problem only calculates the dispatch for twelve time slices.
Figure 5a shows the resulting matrix of the simple case. Each dot in the graph represents the occurrence of the variable
in one of the equations, that is, a non-zero element of the matrix. Each increase in
t or
p expands the matrix accordingly. In
Figure 5b the resulting matrix for the medium case is shown. The top left corner contains the matrix of the simple problem. The additional variables and constraints for the storages expand the matrix to the right and downwards, quadrupling the size of the matrix. Again, each increase in
t or
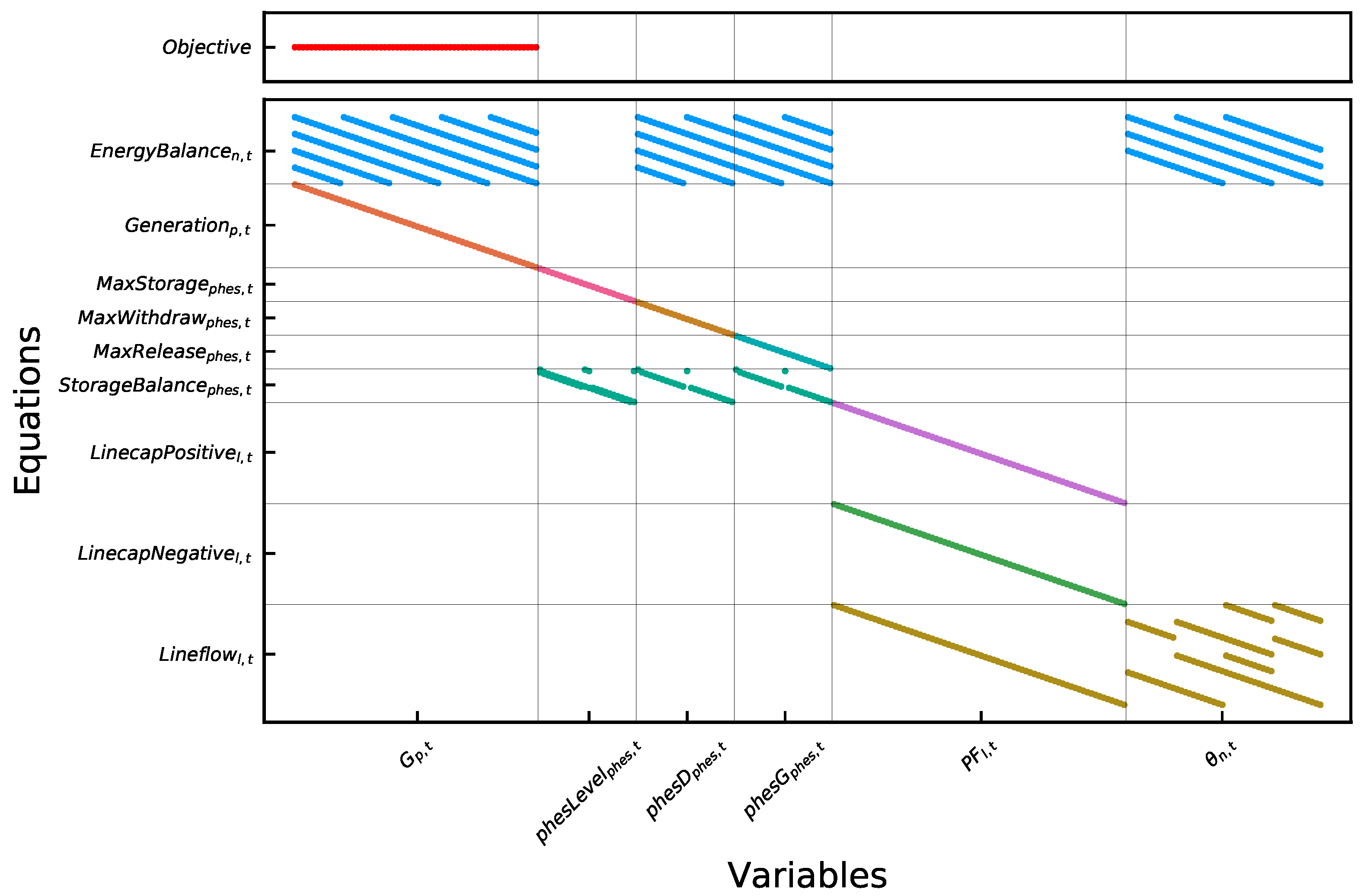
expands the matrix additionally. Adding the power flow constraints of the transmission network, the matrix results in
Figure 6. The matrix of the medium case is included in the top left corner again, representing only one quarter of the full matrix. Now, an increase in
n or
l would expand the matrix additionally. This simple example shows how the hard problem is already 16 times larger than the simple problem.
Now, taking into account the actual sizes of the used sets according to
Section 4.1, the numbers are put into perspective: The
Joulia.jl simple problem consists of 308,112 rows, 308,280 columns, and 616,224 non-zeros, the medium problem of 329,616 rows, 324,408 columns, and 664,608 non-zeros, and the hard problem of 770,112 rows, 673,008 columns, and 1,729,056 non-zeros. The GAMS problem structure is almost—but not perfectly—identical due to minor differences in building the LP files. This has no significant influence on the benchmarking test, though.
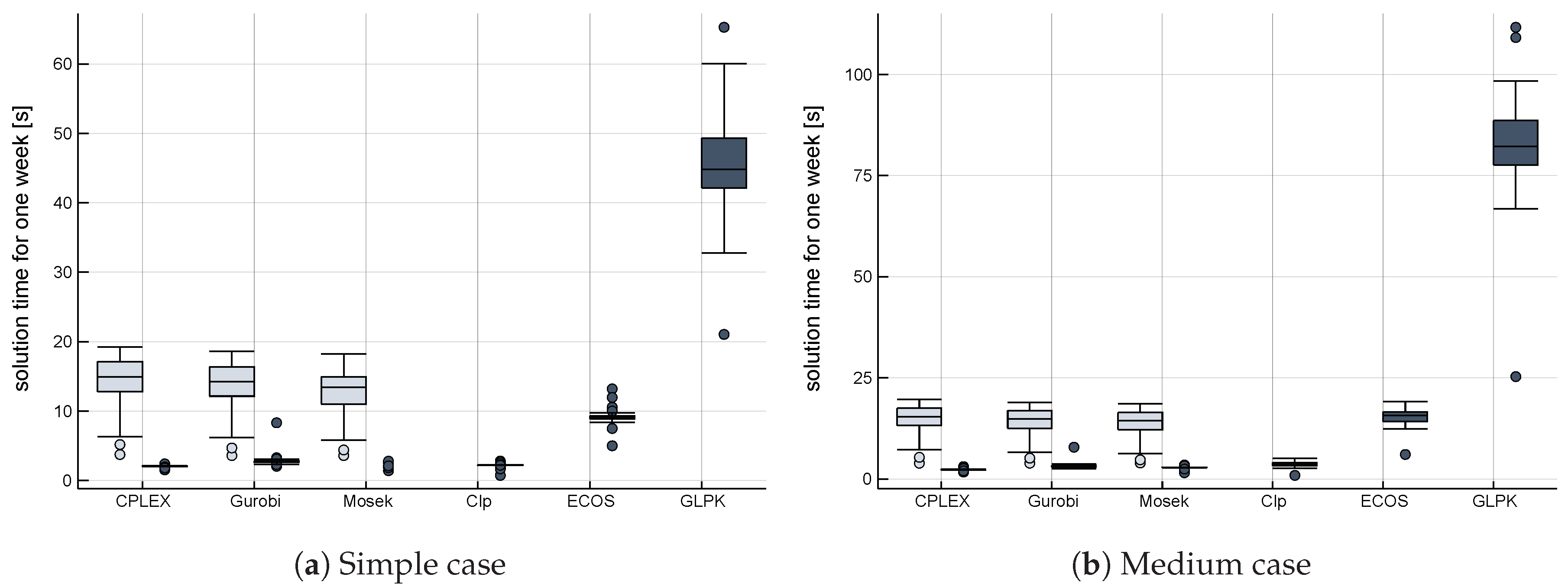
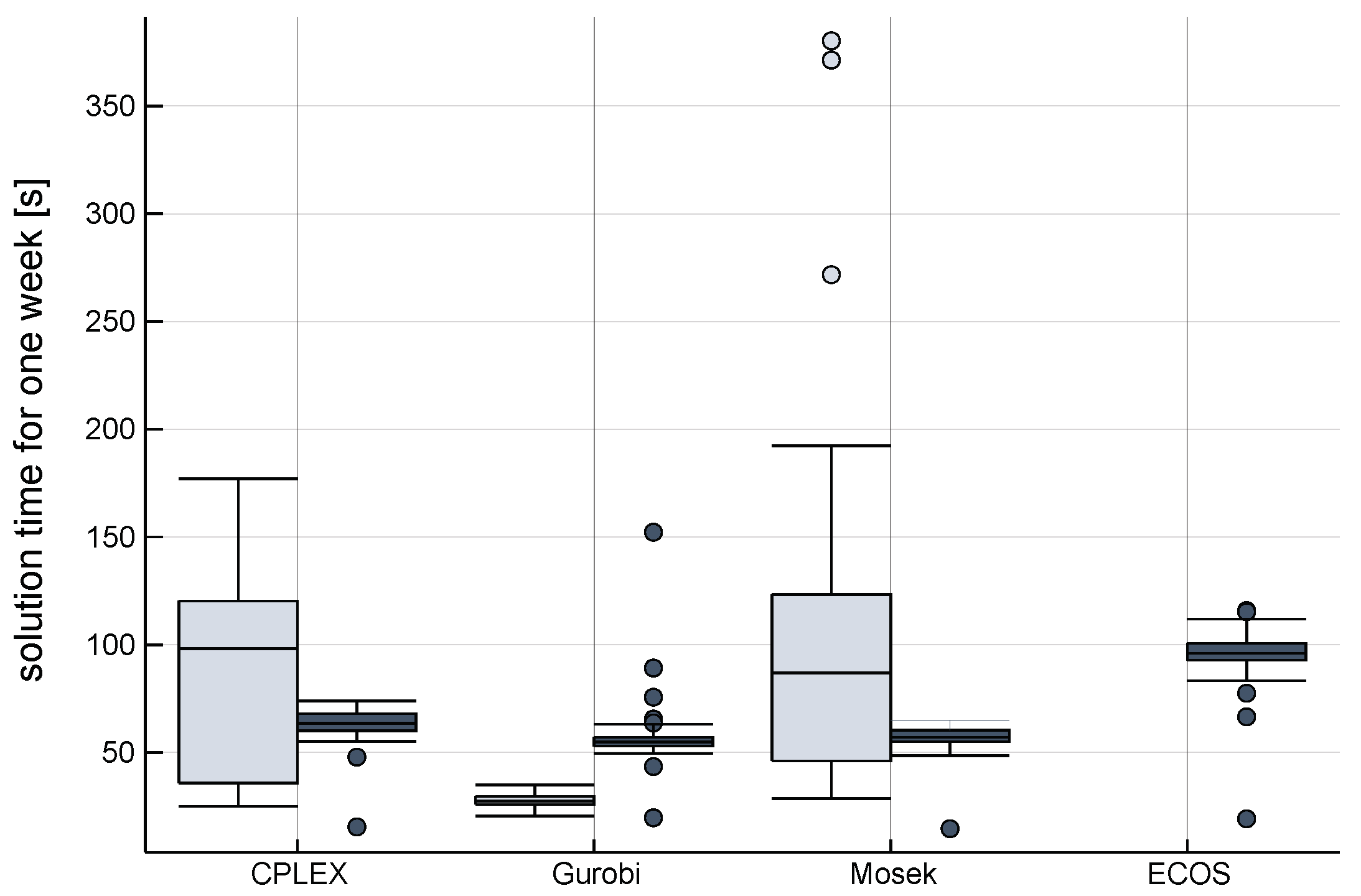
Figure 7 and
Figure 8 show box plots of the total run time of solutions for all the weeks of one year with the named combinations and the three cases.
Table 2 summarizes the solve statistics for the hard case. For reasons of comparability, the total time for building the model and solving it is being used since GAMS and Julia are using different metrics in that regard. The calculations were made with Julia version 1.0.2, JuMP version 0.18.5, GAMS version 25.1.3, CPLEX version 12.8, Gurobi version 8.1, and Mosek version 8.1.
Obviously, the size and complexity of the model to be solved totally depends on the extent of the data used. Therefore, benchmarking tests on optimization problems can only give an indication on the proportions and magnitudes but cannot easily be generalized. Yet, the literature for similar benchmarking tests involving commercial and open-source solvers shows that commercial solvers are always the faster alternative, while open-source solvers cannot match their performance but—depending on the problems tested—capable ones are available if the commercial alternatives are not a viable option.
Meindl and Templ [
30] give an overview of existing open-source as well as commercial solvers for linear problems. They conduct a case study solving 200 instances of the secondary cell suppression problem. These instances can be divided into an easier and a harder group. Generally, they find that both tested commercial solvers CPLEX and Gurobi perform better than the open-source solvers CLP, GLPK, and LP_solve. However, when solving the group of easier instances, GLPK and CLP were only nine and 13 times slower than the fastest solver (CPLEX). The gap widened between the solvers as CLP took 2823 times the run time of CPLEX in the harder cases. Also, Gurobi performed much worse, only being a bit faster than GLPK.
Jablonsky [
31] benchmarks the three commercial solver CPLEX, Gurobi, and FICO XPRESS on a set of 361 mixed integer problems. The results vary between the different instances of problems but overall Gurobi performed best in most cases.
Gearhart et al. [
32] test the four open-source linear programming solver CLP, GLPK, LP_solve, and MINOS against the commercial solver CPLEX. Firstly, they use a set of 180 linear problems which is considered as “easy”. In this run CLP was almost as fast as CPLEX. GLPK also showed a good performance with only being about nine times slower compared to CPLEX. The other two had considerably worse solution times. In the second test they benchmark only the CLP solver against CPLEX with a set of 21 “hard” problems. With CPLEX generally being better, CLP was faster in some of these instances.
In an ongoing benchmarking project by Mittelmann [
33,
34], several open-source and commercial solvers are tested using the Simplex and the Barrier algorithm for linear problems. Results indicate that Gurobi is the fastest and most reliable solver in both cases closely followed by XPRESS. Also, CLP is almost as fast as CPLEX in the Simplex algorithm comparison.
CLP is especially named in the literature as a very fast open-source solution, with GLPK coming in second. While we found that CLP can solve our problem, it did so in a more than 50-fold increase in average time compared to Gurobi as the fastest commercial solver and a more than 40-fold increase compared to CPLEX for the hard case. GLPK was not able to produce a solution in an acceptable amount of time for this case and showed significant shortfalls also for the simple and medium cases. The open-source solver that was able to keep pace with its competitors is ECOS with only a less than twofold increase in average time compared to the fast commercial solutions. This solver is not covered by any of the common benchmark tests.
Comparing across platforms, Julia produces on average faster results than GAMS using CPLEX and Mosek, but is a little slower for Gurobi. What is interesting is the difference for the minimum runtime for one week and the minimum runtime for full weeks only, since weeks 1 and 53 are trunk weeks with less hours. Julia is significantly faster here than GAMS. This is illustrated by the lower outliers in the box plot for Julia. Another interesting observation is the higher variability between weeks for solution times for Mosek and CPLEX with GAMS compared to Julia. Since GAMS is proprietary software, the differences cannot easily be explained (Since this paper focuses on an application in the electricity sector modeling, it is out of the scope of the paper to explain the differences in efficiency based on the low-level differences between GAMS and JuMP.). Julia/JuMP seems to have a more efficient model generation and, in part, faster links to the solvers. Since the underlying MathProgBase.jl as low-level interface will be replaced by the novel MathOptInterface.jl starting from version 0.19 of JuMP, further increases in performance can be expected.
We also tested other non-commercial solvers that are compatible with JuMP—Bonmin, Couenne, Ipopt, and SCS—but none of those were able to either solve the problem at all or to solve it in a runtime close to the solvers shown in
Table 2.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









