Developing and Comparing Different Strategies for Combining Probabilistic Photovoltaic Power Forecasts in an Ensemble Method




Abstract
1. Introduction
- the development of a new competitive ensemble method that combines the outcomes of three probabilistic models, selected among the ones which have proved consistency in probabilistic PV power forecasting;
- a critical analysis of different strategies and architectures to estimate the weights of the predictive quantile combination;
- a comparison of the results of the numerical experiments, based on the data published in the framework of the GEFCOM2014, with state-of-the-art probabilistic benchmarks.
2. Overview of the Proposed Competitive Ensemble Method for Forecasting PV Power
3. Probabilistic Underlying Models
3.1. Quantile K-Nearest Neighbors
3.2. Quantile Regression Forests
3.3. Quantile Regression
4. The Competitive Ensemble Model for Forecast Combination
- the Pure Quantile Weighted Sum (PQWS);
- the Hourly Quantile Weighted Sum (HQWS);
- the Pure Constrained Quantile Weighted Sum (PCQWS);
- the Hourly Constrained Quantile Weighted Sum (HCQWS);
- the Pure Quantile Weighted Sum with Least Absolute Shrinkage and Selection Operator (LASSO) Regularization (PQWSLR);
- the Hourly Quantile Weighted Sum with LASSO Regularization (HQWSLR);
- the Pure Quantile Weighted Sum with Ridge Regularization (PQWSRR);
- the Hourly Quantile Weighted Sum with Ridge Regularization (HQWSRR).
4.1. Pure Quantile Weighted Sum
4.2. Hourly Quantile Weighted Sum
4.3. Pure and Hourly Constrained Quantile Weighted Sum
4.4. Quantile Weighted Sum with LASSO Regularization
4.5. Quantile Weighted Sum with RIDGE Regularization
5. Benchmarks
5.1. Naïve Benchmark
5.2. Quantile Artificial Neural Network
5.3. Gradient Boosting Regression Trees
5.4. Bayesian Method
6. Numerical Application
6.1. Characteristics of the Data
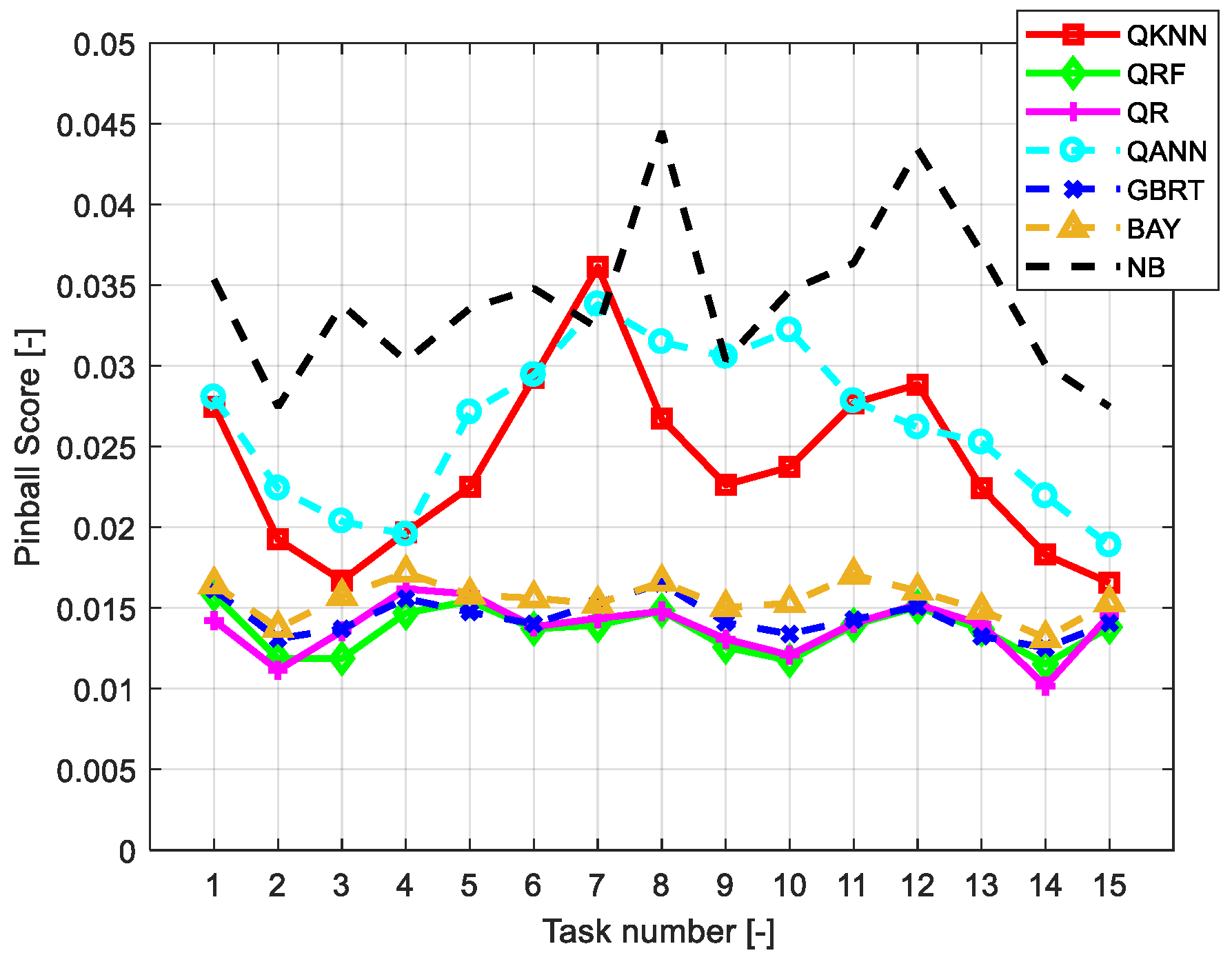
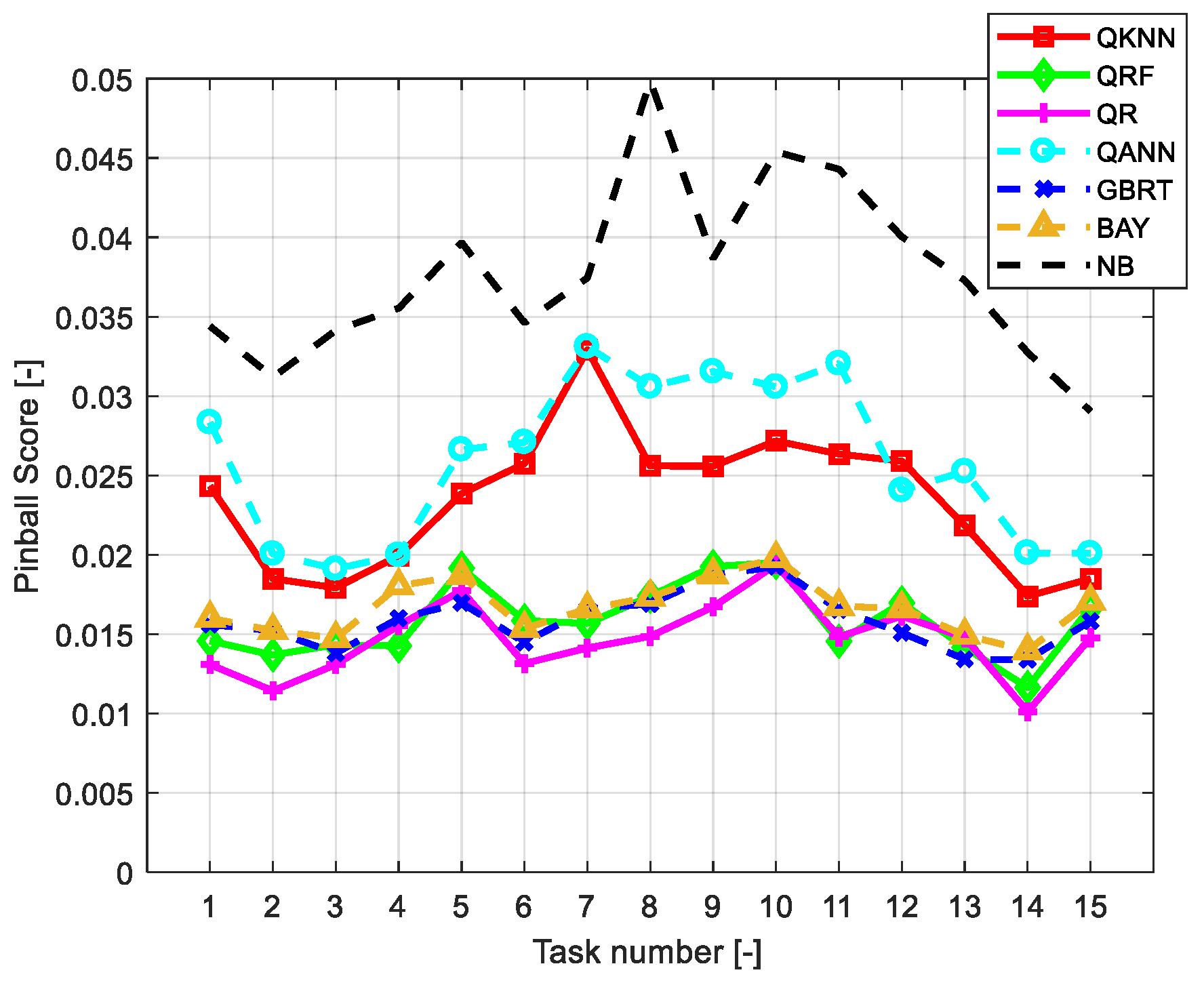
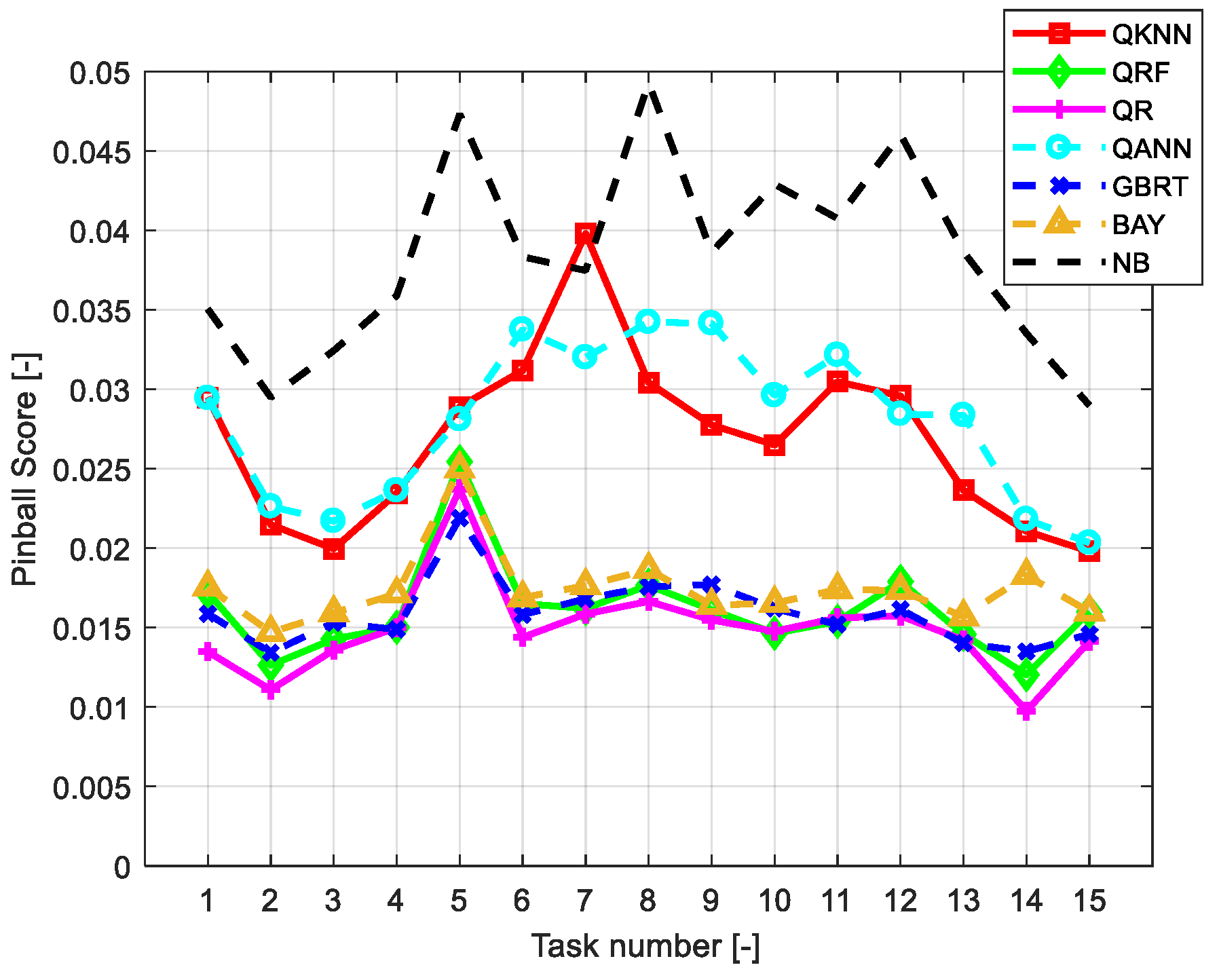
6.2. Assessment of the Accuracy of Individual Forecasts
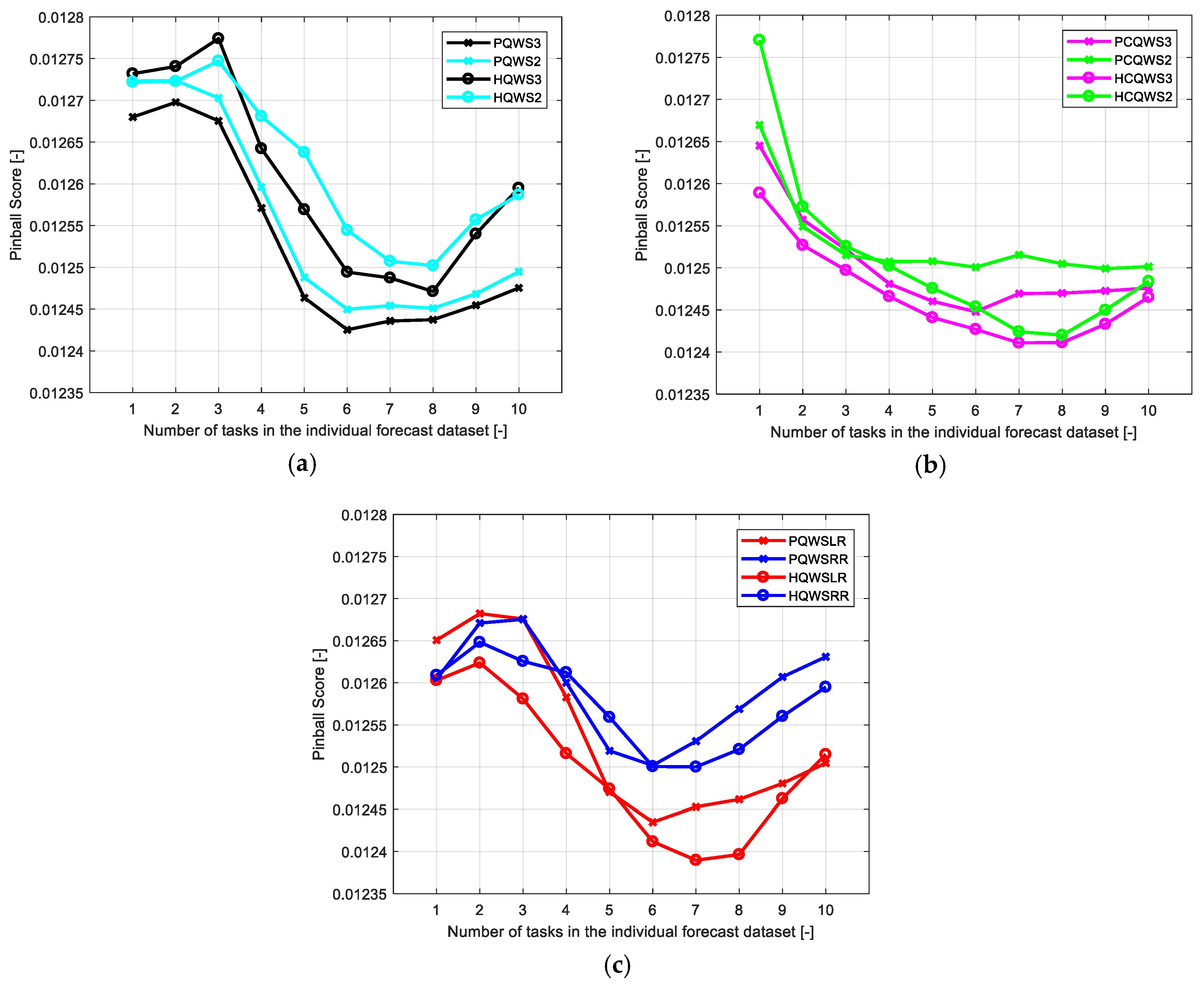
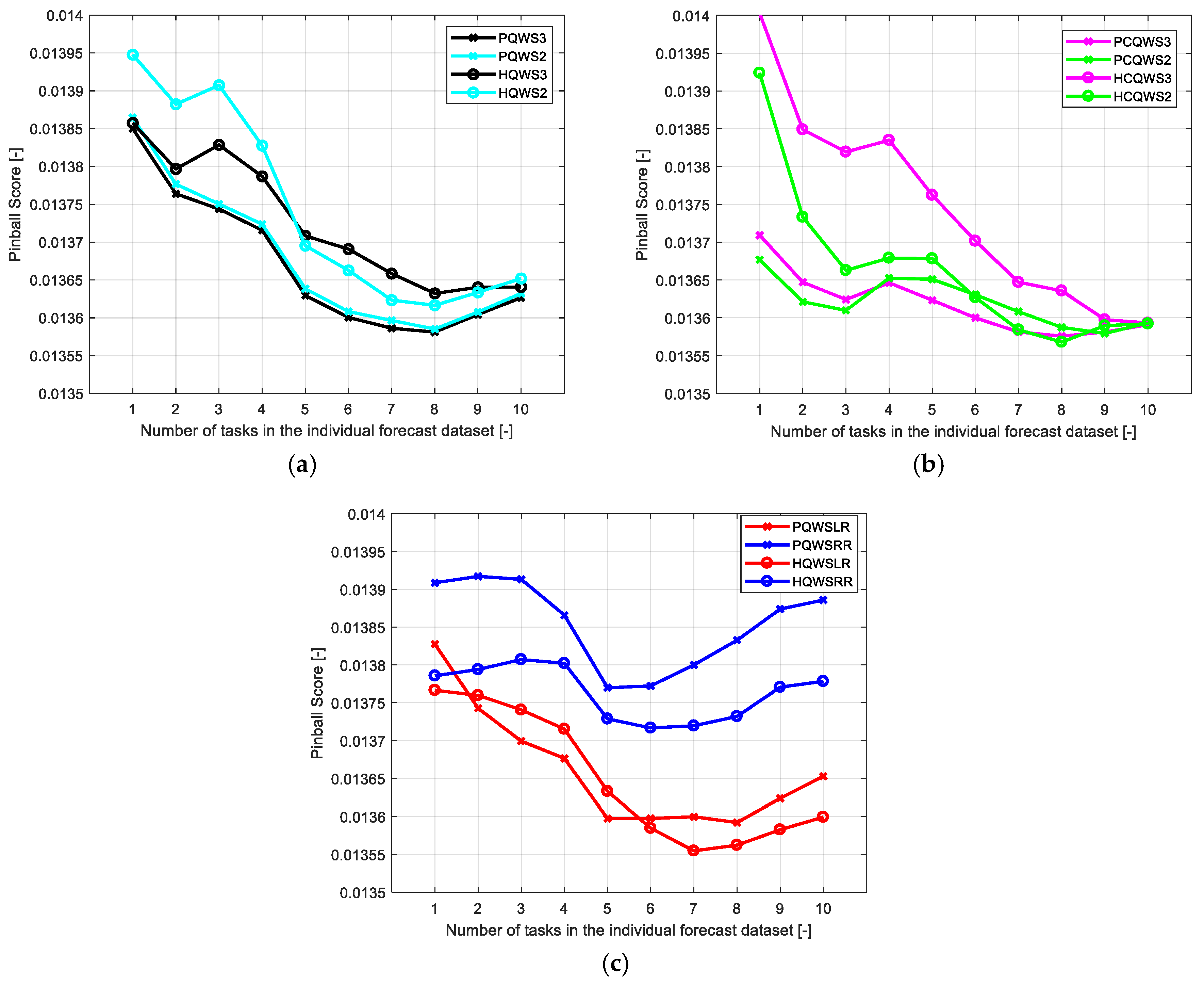
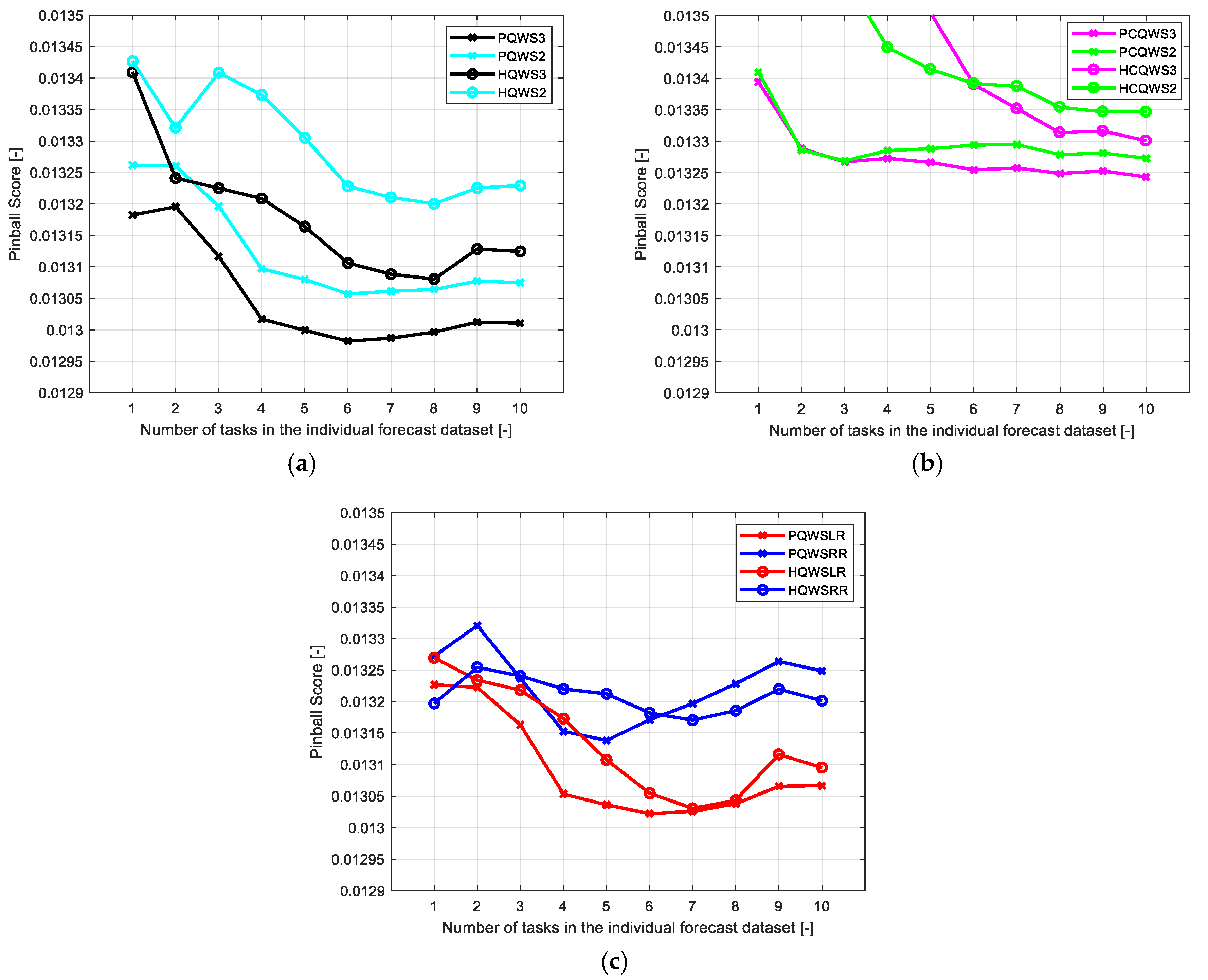
6.3. Assessment of the Accuracy of Combined Forecasts
7. Conclusions
- the weighted quantile combination was effective in improving the accuracy of forecasts; it is able to outperform the accuracy of individual probabilistic forecasts, which is the main aim of competitive ensemble methods.
- The forecast combination improved the skill of the forecasts in all of the scenarios considered, with a reduction in terms of PS that is up to 9%.
- On average, the best results were obtained using the HQWSLR combination strategy for zones 1 and 2, and the PQWS3 combination strategy for the zone 3; the optimal length of the dataset used to train the weights of the combination models always ranges between 6 and 8 tasks.
- Adding the forecasts of an individual model which has worse performances than the other individual models appears to provide useful diversity in the ensemble approach; this appears to be valid both for unconstrained, non-regularized strategies and for constrained strategies.
- Adding too much dispersion to the forecast combination by estimating weights for each hour of the day does not improve the quality of the results for unconstrained, non-regularized regression; vice versa, constraints and/or regularization allow taking benefit from this hourly differentiation.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Toubeau, J.F.; Bottieau, J.; Vallee, F.; De Greve, Z. Deep learning-based multivariate probabilistic forecasting for short-term scheduling in power markets. IEEE Trans. Power Syst. 2018, 34, 1203–1215. [Google Scholar] [CrossRef]
- Javadi, M.; Marzband, M.; Funsho Akorede, M.; Godina, R.; Saad Al-Sumaiti, A.; Pouresmaeil, E. A centralized smart decision-making hierarchical interactive architecture for multiple home microgrids in retail electricity market. Energies 2018, 11, 3144. [Google Scholar] [CrossRef]
- Marzband, M.; Azarinejadian, F.; Savaghebi, M.; Pouresmaeil, E.; Guerrero, J.M.; Lightbody, G. Smart transactive energy framework in grid-connected multiple home microgrids under independent and coalition operations. Renew. Energy 2018, 126, 95–106. [Google Scholar] [CrossRef]
- Capizzi, G.; Lo Sciuto, G.; Napoli, C.; Tramontana, E. Advanced and adaptive dispatch for smart grids by means of predictive models. IEEE Trans. Smart Grid 2018, 9, 6684–6691. [Google Scholar] [CrossRef]
- Matos, M.; Bessa, R.J.; Botterud, A.; Zhou, Z. Forecasting and setting power system operating reserves. In Renewable Energy Forecasting: From Models to Applications, 1st ed.; Kariniotakis, G., Ed.; Woodhead Publishing: Duxford, UK, 2017; pp. 279–308. [Google Scholar]
- Camal, S.; Michiorri, A.; Kariniotakis, G. Optimal offer of automatic frequency restoration reserve from a combined PV/wind virtual power plant. IEEE Trans. Power Syst. 2018, 33, 6155–6170. [Google Scholar] [CrossRef]
- Carpinelli, G.; Mottola, F.; Proto, D. Probabilistic sizing of battery energy storage when time-of-use pricing is applied. Electr. Power Syst. Res. 2016, 141, 73–83. [Google Scholar] [CrossRef]
- Van der Meer, D.W.; Widén, J.; Munkhammar, J. Review on probabilistic forecasting of photovoltaic power production and electricity consumption. Renew. Sustain. Energy Rev. 2018, 81, 1484–1512. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.N.; Srikanth, N. Ensemble methods for wind and solar power forecasting—A state-of-the-art review. Renew. Sustain. Energy Rev. 2015, 50, 82–91. [Google Scholar] [CrossRef]
- Muralitharan, K.; Sakthivel, R.; Vishnuvarthan, R. Neural network based optimization approach for energy demand prediction in smart grid. Neurocomputing 2018, 273, 199–208. [Google Scholar] [CrossRef]
- Alobaidi, M.H.; Chebana, F.; Meguid, M.A. Robust ensemble learning framework for day-ahead forecasting of household based energy consumption. Appl. Energy 2018, 212, 997–1012. [Google Scholar] [CrossRef]
- Mangalova, E.; Agafonov, E. Wind power forecasting using the k-nearest neighbors algorithm. Int. J. Forecast. 2014, 30, 402–406. [Google Scholar] [CrossRef]
- Shang, C.; Wei, P. Enhanced support vector regression based forecast engine to predict solar power output. Renew. Energy 2018, 127, 269–283. [Google Scholar] [CrossRef]
- Tato, J.H.; Brito, M.C. Using smart persistence and random forests to predict photovoltaic energy production. Energies 2018, 12, 100. [Google Scholar] [CrossRef]
- Bracale, A.; Carpinelli, G.; De Falco, P.; Hong, T. Short-term industrial reactive power forecasting. Int. J. Electr. Power Energy Syst. 2019, 107, 177–185. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Fan, S.; Zareipour, H.; Troccoli, A.; Hyndman, R.J. Probabilistic energy forecasting: Global energy forecasting competition 2014 and beyond. Int. J. Forecast. 2016, 32, 896–913. [Google Scholar] [CrossRef]
- Hong, T. Energy forecasting: Past, present, and future. Foresight 2014, 32, 43–48. [Google Scholar]
- Huang, J.; Perry, M. A semi-empirical approach using gradient boosting and k-nearest neighbors regression for GEFCom2014 probabilistic solar power forecasting. Int. J. Forecast. 2016, 32, 1081–1086. [Google Scholar] [CrossRef]
- Almeida, M.P.; Perpiñán, O.; Narvarte, L. PV power forecast using a nonparametric PV model. Sola. Energy 2015, 115, 354–368. [Google Scholar] [CrossRef]
- Bracale, A.; Carpinelli, G.; De Falco, P. A probabilistic competitive ensemble method for short-term photovoltaic power forecasting. IEEE Trans. Sustain. Energy 2017, 8, 551–560. [Google Scholar] [CrossRef]
- Juban, R.; Ohlsson, H.; Maasoumy, M.; Poirier, L.; Kolter, J.Z. A multiple quantile regression approach to the wind, solar, and price tracks of GEFCom2014. Int. J. Forecast. 2016, 32, 1094–1102. [Google Scholar] [CrossRef]
- Hong, T.; Pinson, P.; Fan, S. Global Energy Forecasting Competition 2012. Int. J. Forecast. 2014, 39, 357–363. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, N.; Tan, Y.; Hong, T.; Kirschen, D.S.; Kang, C. Combining probabilistic load forecasts. IEEE Trans. Smart Grid 2018, in press. [Google Scholar] [CrossRef]
- Golestaneh, F.; Pinson, P.; Gooi, H.B. Very short-term nonparametric probabilistic forecasting of renewable energy generation—With application to solar energy. IEEE Trans. Power Syst. 2016, 31, 3850–3863. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Møller, J.K.; Nielsen, H.A.; Madsen, H. Time-adaptive quantile regression. Comput. Stat. Data Anal. 2008, 52, 1292–1303. [Google Scholar] [CrossRef]
- Ziel, F.; Liu, B. Lasso estimation for GEFCom2014 probabilistic electric load forecasting. Int. J. Forecast. 2016, 32, 1029–1037. [Google Scholar] [CrossRef]
- Gaillard, P.; Goude, Y.; Nedellec, R. Additive models and robust aggregation for GEFCom2014 probabilistic electric load and electricity price forecasting. Int. J. Forecast. 2016, 32, 1038–1050. [Google Scholar] [CrossRef]
- R Gbm Package: Generalized Boosted Regression Models. Available online: https://CRAN.R-project.org/package=gbm (accessed on 4 March 2019).
- Bracale, A.; Carpinelli, G.; De Falco, P.; Rizzo, R.; Russo, A. New advanced method and cost-based indices applied to probabilistic forecasting of photovoltaic generation. J. Renew. Sustain. Energy 2016, 8, 023505. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zone | Statistical Parameter [-] | ||
|---|---|---|---|
| Mean | Median | Standard Deviation | |
| 1 | 0.1693 | 0.0026 | 0.2588 |
| 2 | 0.1879 | 0.0022 | 0.2756 |
| 3 | 0.1939 | 0.0028 | 0.2821 |
| Method | Pinball Score [-] | ||
|---|---|---|---|
| Zone 1 | Zone 2 | Zone 3 | |
| QKNN | 0.0228 | 0.0220 | 0.0249 |
| QRF | 0.0136 | 0.0148 | 0.0152 |
| QR | 0.0136 | 0.0141 | 0.0139 |
| QANN | 0.0240 | 0.0243 | 0.0262 |
| GBRT | 0.0138 | 0.0149 | 0.0147 |
| BAY | 0.0153 | 0.0159 | 0.0169 |
| NB | 0.0349 | 0.0367 | 0.0376 |
| Method | Pinball Score [-] | ||
|---|---|---|---|
| Zone 1 | Zone 2 | Zone 3 | |
| QKNN | 0.0228 | 0.0220 | 0.0249 |
| QRF | 0.0136 | 0.0148 | 0.0152 |
| QR | 0.0136 | 0.0141 | 0.0139 |
| QANN | 0.0240 | 0.0243 | 0.0262 |
| GBRT | 0.0138 | 0.0149 | 0.0147 |
| BAY | 0.0153 | 0.0159 | 0.0169 |
| NB | 0.0349 | 0.0367 | 0.0376 |
| Best PQWS3 | 0.0124 | 0.0136 | 0.0130 |
| Worst PQWS3 | 0.0127 | 0.0138 | 0.0132 |
| Best HQWSLR | 0.0124 | 0.0135 | 0.0130 |
| Worst HQWSLR | 0.0126 | 0.0138 | 0.0133 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bracale, A.; Carpinelli, G.; De Falco, P. Developing and Comparing Different Strategies for Combining Probabilistic Photovoltaic Power Forecasts in an Ensemble Method. Energies 2019, 12, 1011. https://doi.org/10.3390/en12061011
Bracale A, Carpinelli G, De Falco P. Developing and Comparing Different Strategies for Combining Probabilistic Photovoltaic Power Forecasts in an Ensemble Method. Energies. 2019; 12(6):1011. https://doi.org/10.3390/en12061011
Chicago/Turabian StyleBracale, Antonio, Guido Carpinelli, and Pasquale De Falco. 2019. "Developing and Comparing Different Strategies for Combining Probabilistic Photovoltaic Power Forecasts in an Ensemble Method" Energies 12, no. 6: 1011. https://doi.org/10.3390/en12061011
APA StyleBracale, A., Carpinelli, G., & De Falco, P. (2019). Developing and Comparing Different Strategies for Combining Probabilistic Photovoltaic Power Forecasts in an Ensemble Method. Energies, 12(6), 1011. https://doi.org/10.3390/en12061011