Energy Efficiency Solutions for Buildings: Automated Fault Diagnosis of Air Handling Units Using Generative Adversarial Networks



Abstract
:1. Introduction
Contributions
- One novel method applying WGAN to AHU fault diagnosis. To our knowledge, this is the first work that applies WGAN to the field of AHU fault diagnosis. The WGAN is employed to generate close-to-real artificial faulty training samples to solve the traditional data-imbalance problem in AHU fault diagnosis.
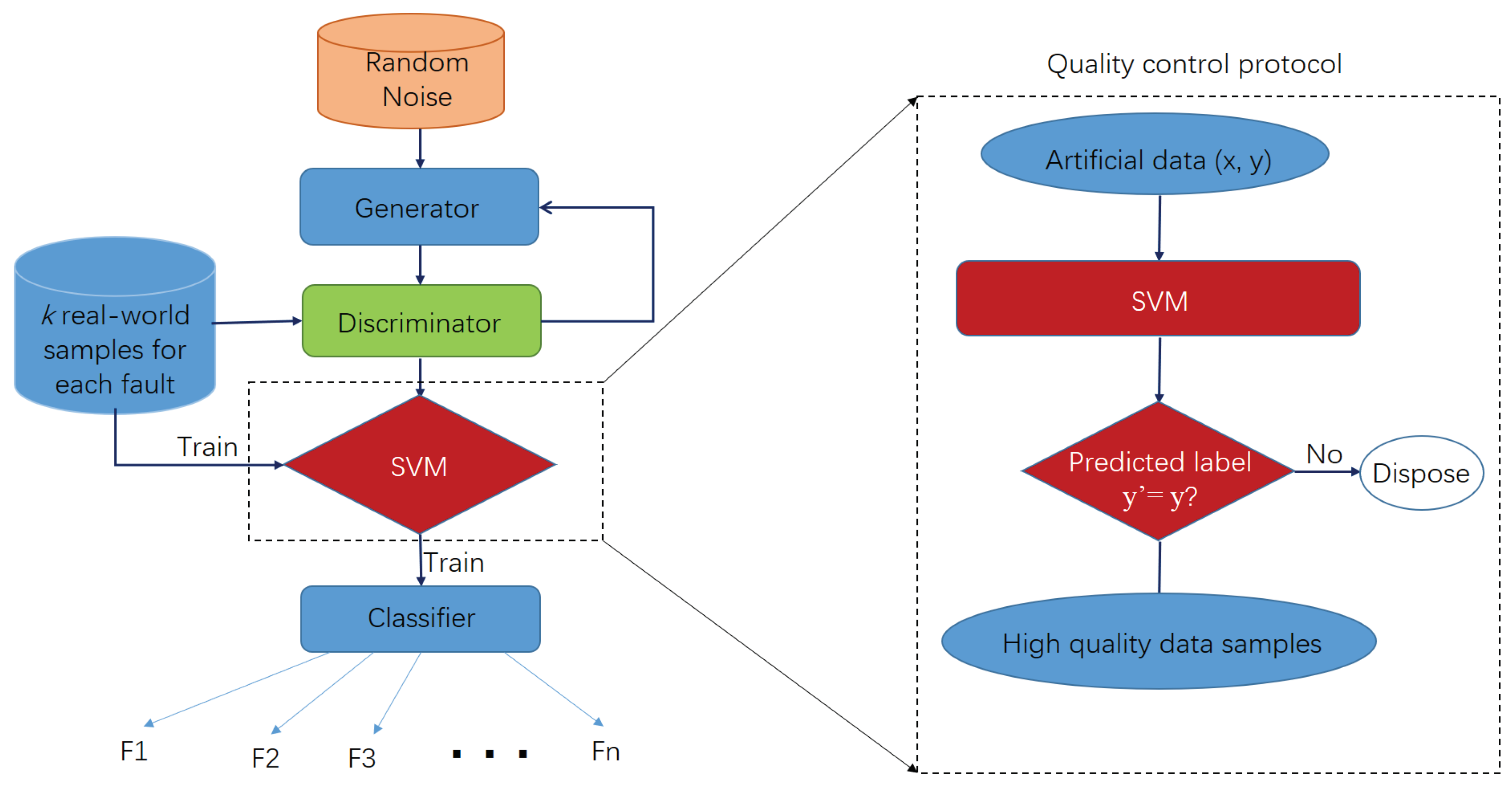
- A framework evaluating the artificial sample generation quality of WGAN. We utilize traditional classifiers, such as SVM, to evaluate the artificial sample generation quality of WGAN in the application field of AHU fault diagnosis.
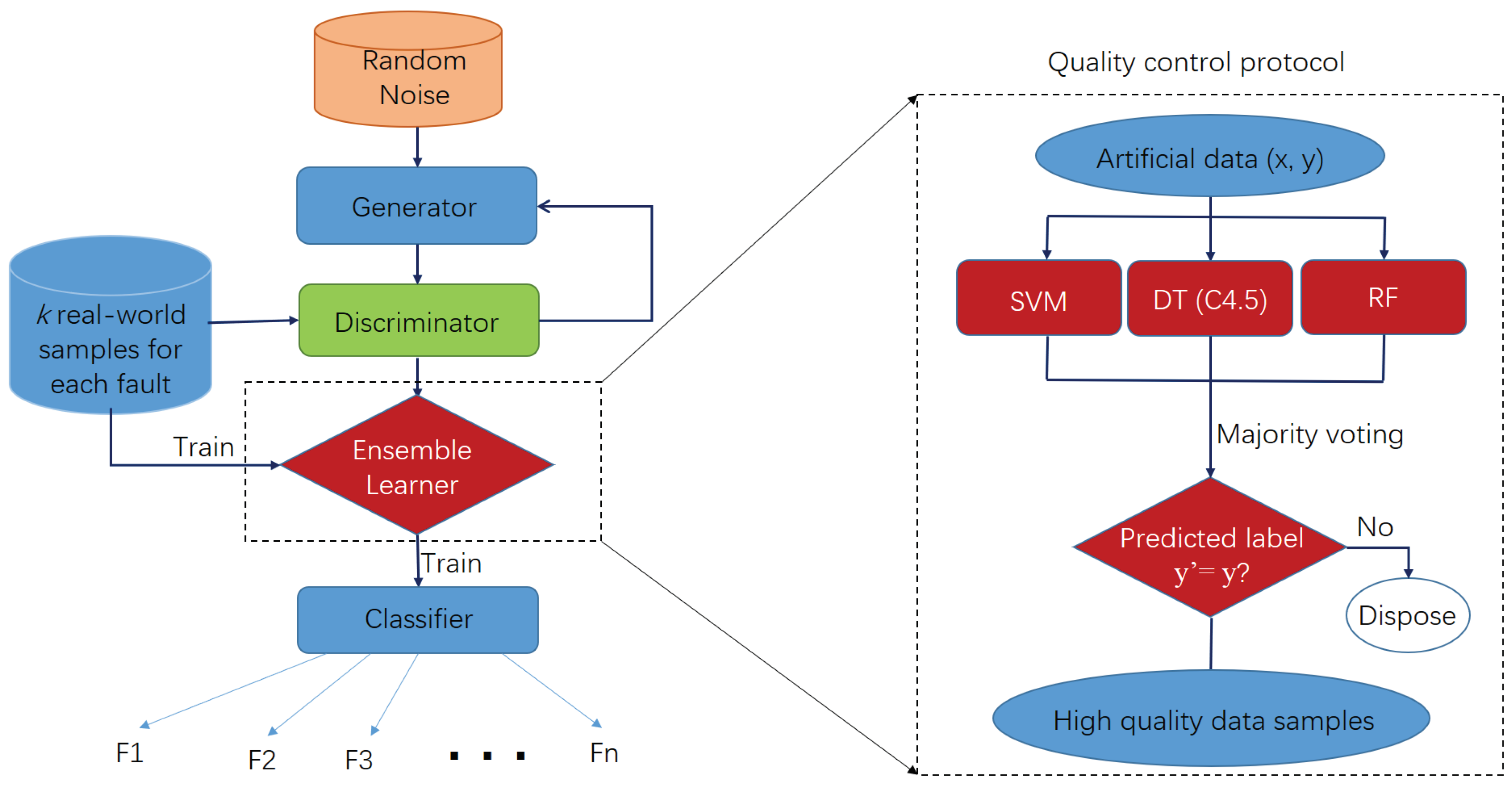
- A comparative study with various classifiers. We perform a comparative study with various classifiers to evaluate the WGAN performance for AHU fault diagnosis. As a result, the combination of WGAN and SVM generally produces the highest classification accuracy with a few real-world (numbers ranging from five to 40 for each fault type) faulty training samples available.
2. Materials and Methods
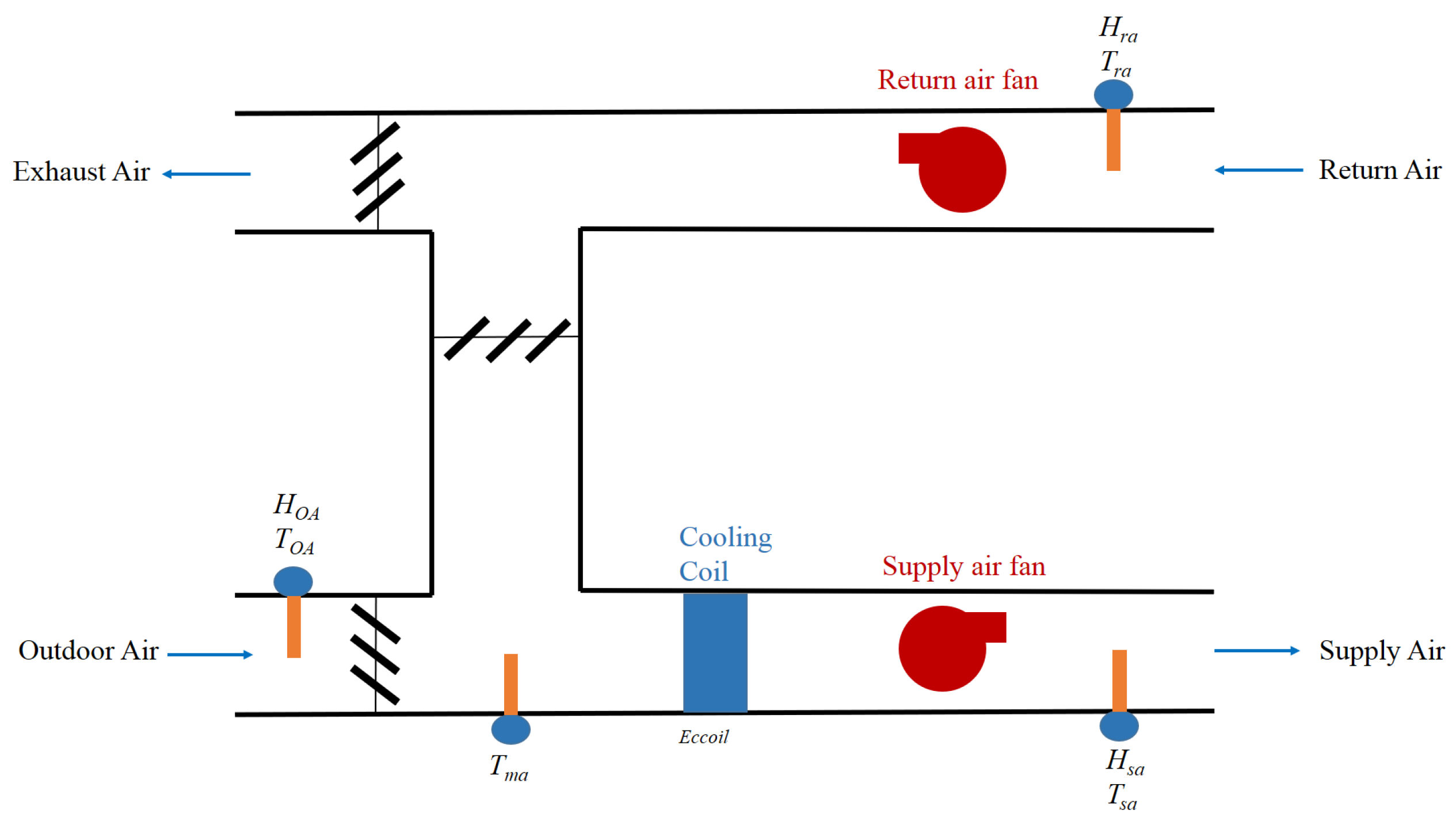
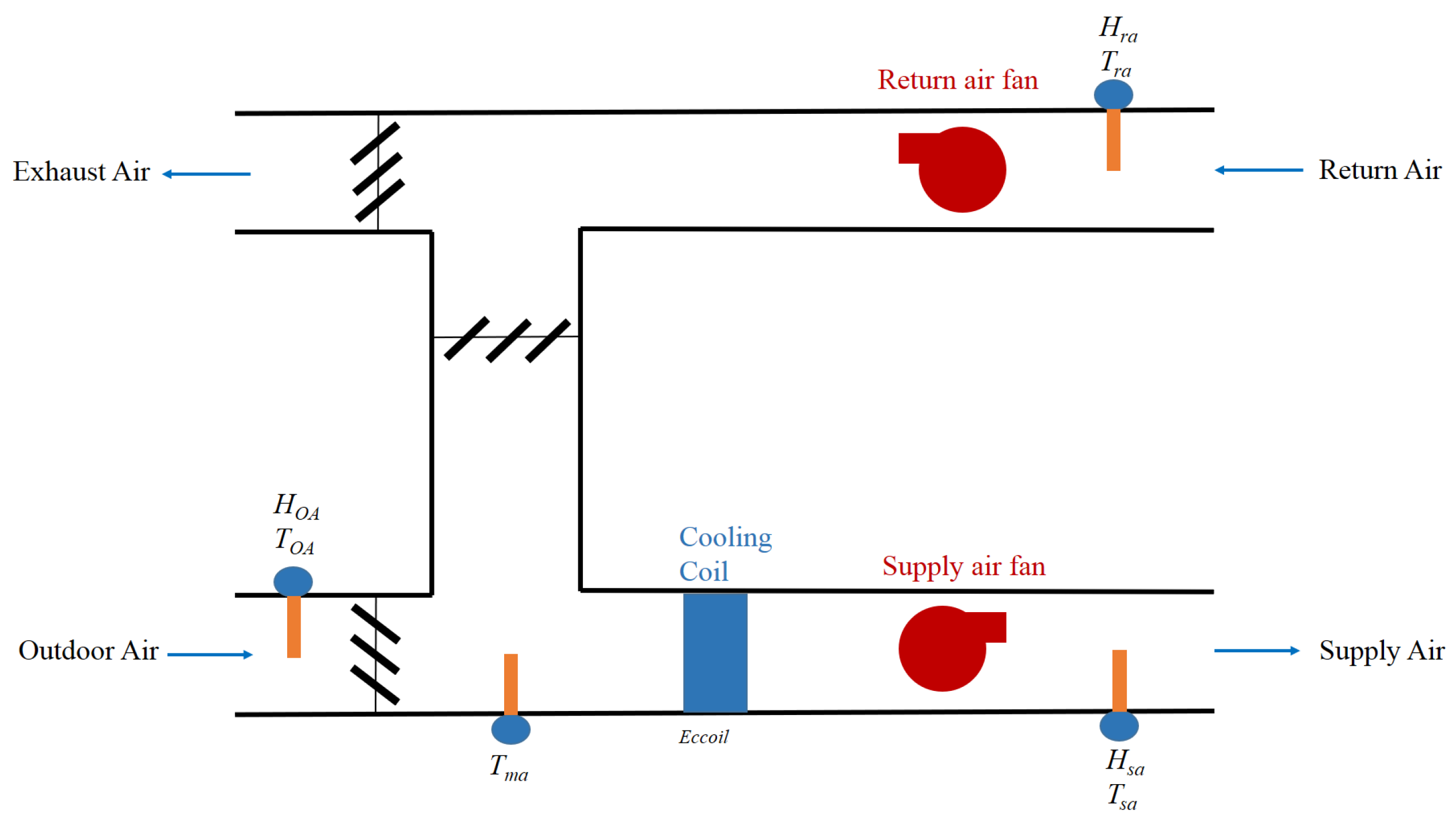
2.1. Data Description
- F1: Exhausted air (EA) damper stuck (fully open);
- F2: Return fan at fixed speed;
- F3: Cooling coil valve control unstable;
- F4: Cooling coil valve partially closed (15% open);
- F5: Outdoor air damper leak;
- F6: AHU duct leaking (after supply fan (SF)).
2.2. Feature Selection for the Proposed AHU Fault Diagnosis Framework
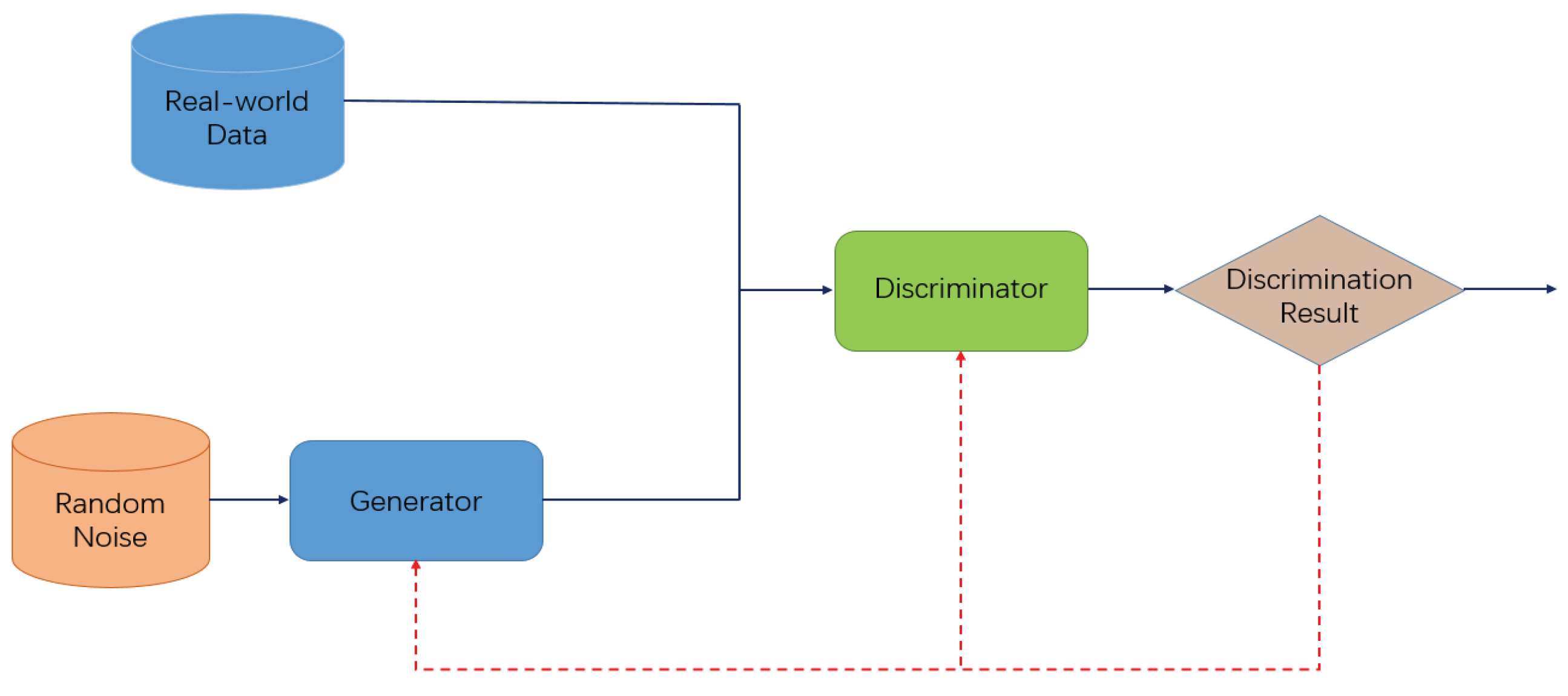
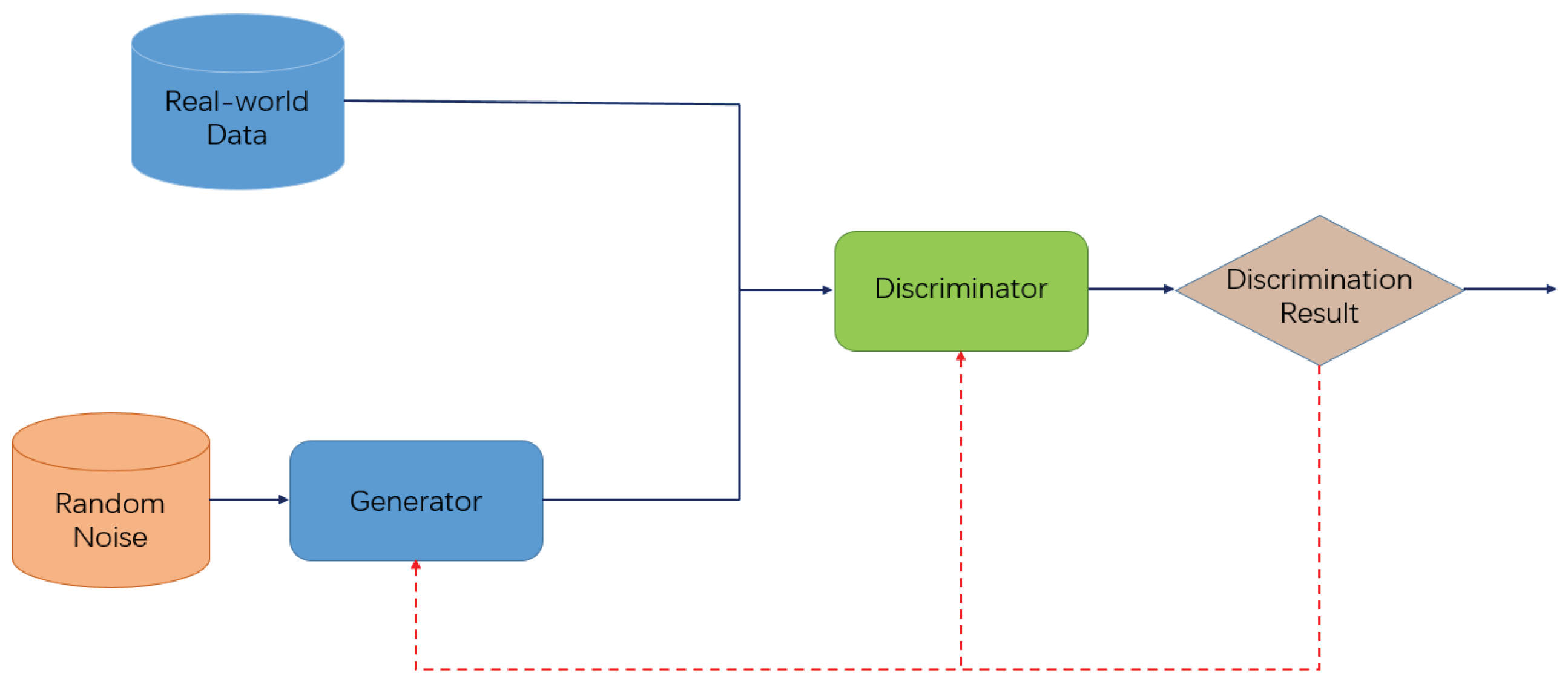
2.3. Generative Adversarial Network and Wasserstein Generative Adversarial Network
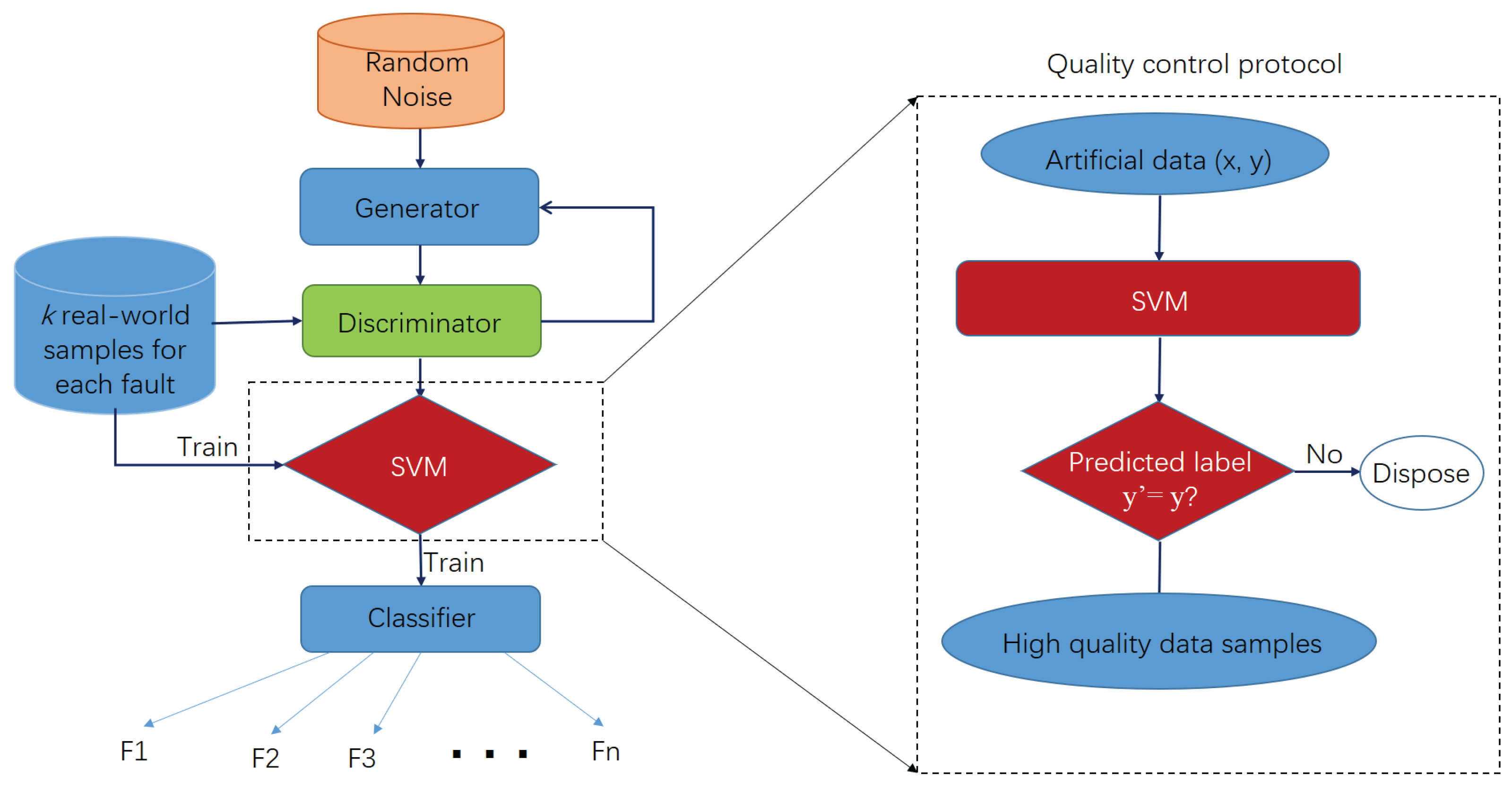
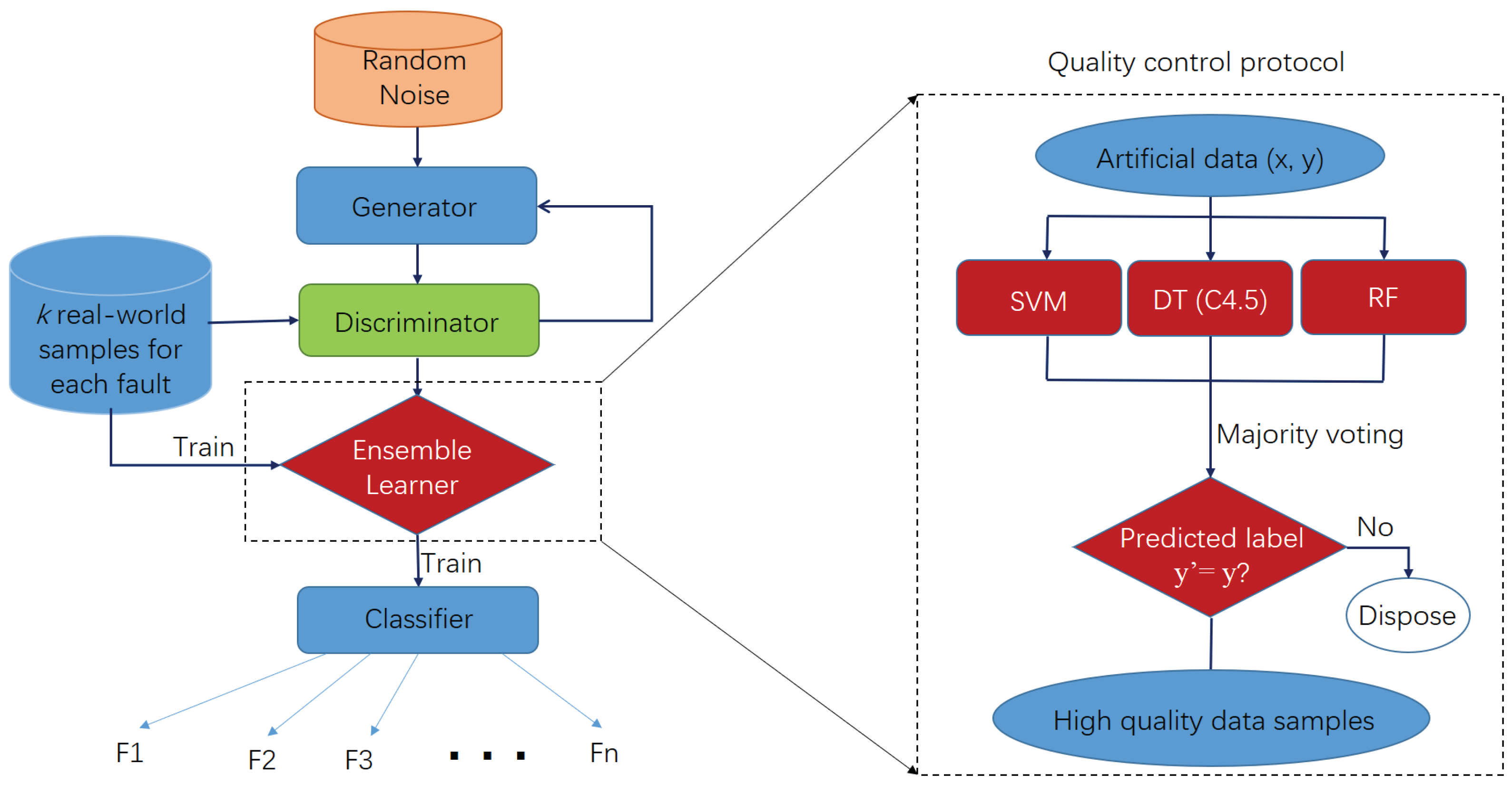
2.4. Proposed Framework for AHU Fault Diagnosis Based on WGAN
3. Results
4. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Doman, L.; Smith, K.; Lindstrom, P.; Mayne, L.; Staub, J.; Yucel, E.; Barden, J.; Fawzi, A.; Martin, P.; Mellish, M.; et al. International Energy Outlook 2006; Energy Information Administration No. DOE/EIA-0484; U.S. Energy Information Administration: Washington, DC, USA, 2006.
- Heiple, S.; Sailor, D.J. Using building energy simulation and geospatial modeling techniques to determine high resolution building sector energy consumption profiles. Energy Build. 2008, 40, 1426–1436. [Google Scholar] [CrossRef]
- Zhao, H.X.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, Z.; Kusiak, A. Predictive modeling and optimization of a multi-zone HVAC system with data mining and firefly algorithms. Energy 2015, 86, 393–402. [Google Scholar] [CrossRef]
- Katipamula, S.; Brambley, M.R. Methods for fault detection, diagnostics, and prognostics for building systems—A review, part I. Hvac&R Res. 2005, 11, 3–25. [Google Scholar]
- Pérez-Lombard, L.; Ortiz, J.; Pout, C. A review on buildings energy consumption information. Energy Build. 2008, 40, 394–398. [Google Scholar] [CrossRef]
- Du, Z.; Fan, B.; Chi, J.; Jin, X. Sensor fault detection and its efficiency analysis in air handling unit using the combined neural networks. Energy Build. 2014, 72, 157–166. [Google Scholar] [CrossRef]
- Mulumba, T.; Afshari, A.; Yan, K.; Shen, W.; Norford, L.K. Robust model-based fault diagnosis for air handling units. Energy Build. 2015, 86, 698–707. [Google Scholar] [CrossRef]
- Yan, R.; Ma, Z.; Zhao, Y.; Kokogiannakis, G. A decision tree based data-driven diagnostic strategy for air handling units. Energy Build. 2016, 133, 37–45. [Google Scholar] [CrossRef]
- Zhao, Y.; Wen, J.; Xiao, F.; Yang, X.; Wang, S. Diagnostic Bayesian networks for diagnosing air handling units faults—Part I: Faults in dampers, fans, filters and sensors. Appl. Therm. Eng. 2017, 111, 1272–1286. [Google Scholar] [CrossRef]
- Yan, K.; Zhong, C.; Ji, Z.; Huang, J. Semi-supervised learning for early detection and diagnosis of various air handling unit faults. Energy Build. 2018, 181, 75–83. [Google Scholar] [CrossRef]
- Zhu, X. Semi-supervised learning literature survey. Comput. Sci. Univ. Wis. Madison 2006, 2, 4. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Yan, K.; Ji, Z.; Lu, H.; Huang, J.; Shen, W.; Xue, Y. Fast and Accurate Classification of Time Series Data Using Extended ELM: Application in Fault Diagnosis of Air Handling Units. IEEE Trans. Syst. Man Cybern. Syst. 2017, PP(99), 1–8. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Yan, K.; Ma, L.; Dai, Y.; Shen, W.; Ji, Z.; Xie, D. Cost-sensitive and sequential feature selection for chiller fault detection and diagnosis. Int. J. Refrig. 2018, 86, 401–409. [Google Scholar] [CrossRef]
- Li, S.; Wen, J. Development and validation of a dynamic air handling unit model—Part I. ASHRAE Trans. 2010, 116, 45–56. [Google Scholar]
- Li, S.; Wen, J.; Zhou, X.; Klaassen, C.J. Development and validation of a dynamic air fandling unit model—Part II. ASHRAE Trans. 2010, 116, 57–73. [Google Scholar]
- Wen, J.; Li, S. Tools for Evaluating Fault Detection and Diagnostic Methods for Air-Handling Units; ASHRAE 1312-RP; ASHRAE: Atlanta, GA, USA, 2011; pp. 1–173. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Huang, X.; Wang, X.; Metaxas, D. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. arXiv, 2017; arXiv:1612.03242. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. Adv. Neural Inf. Process. Syst. 2016, 29, 658–666. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29, 82–90. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Morgan Kaufmann Publishers: San Mateo, CA, USA, 2014. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Variable | Description |
|---|---|---|
| 1 | Cooling coil energy consumption | |
| 2 | Supply air temperature | |
| 3 | Return air temperature | |
| 4 | Outside air temperature | |
| 5 | Mixed air temperature | |
| 6 | Supply air humidity | |
| 7 | Return air humidity | |
| 8 | Chilled Water Coil Discharge Air Temperature | |
| 9 | Supply fan energy consumption | |
| 10 | Supply air flow rate | |
| 11 | Return air flow rate |
| Init. Samp. # | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
| GAN-SVM-KNN | 16.67 | 36.34 | 56.04 | 55.19 | 60.15 | 73.81 | 77.32 | 82.71 |
| GAN-SVM-DT | 17.59 | 35.31 | 55.71 | 53.87 | 52.71 | 67.79 | 75.98 | 75.27 |
| GAN-SVM-MLP | 16.54 | 31.68 | 52.81 | 56.77 | 51.94 | 59.4 | 67.83 | 64.32 |
| GAN-SVM-RF | 17.04 | 39.12 | 56.59 | 58.31 | 59.17 | 74.01 | 79.26 | 81.19 |
| GAN-SVM-SVM | 16.71 | 38.36 | 57.09 | 59.05 | 63.54 | 72.33 | 77.42 | 80.82 |
| Init. Samp. # | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
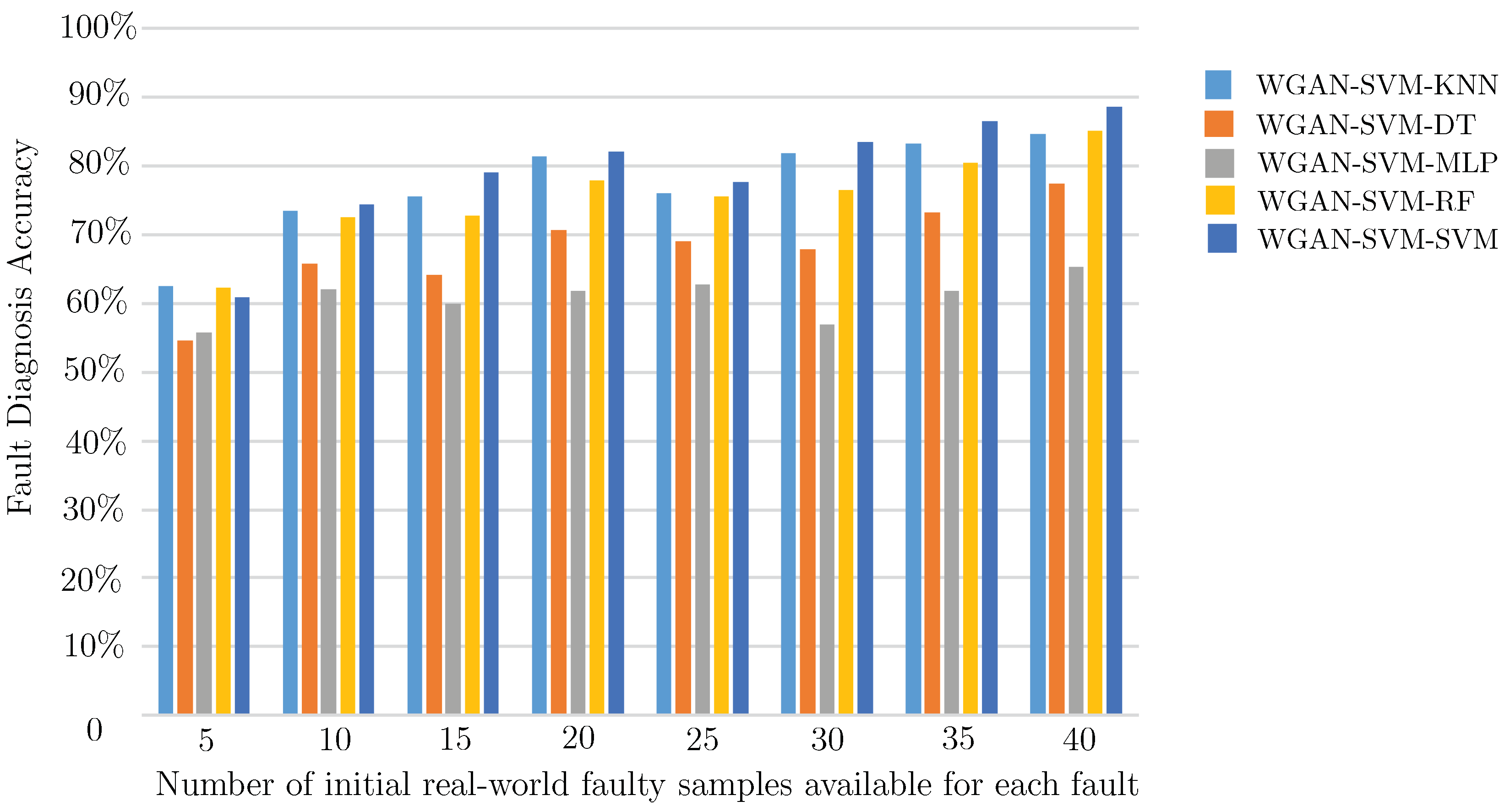
| WGAN-SVM-KNN | 62.59 | 73.53 | 75.60 | 81.45 | 75.94 | 81.83 | 83.24 | 84.52 |
| WGAN-SVM-DT | 54.58 | 65.81 | 64.17 | 70.61 | 69.08 | 67.76 | 73.30 | 77.41 |
| WGAN-SVM-MLP | 55.65 | 62.00 | 60.00 | 61.73 | 62.65 | 56.97 | 61.69 | 65.25 |
| WGAN-SVM-RF | 62.33 | 72.47 | 72.70 | 77.77 | 75.49 | 76.56 | 80.33 | 85.06 |
| WGAN-SVM-SVM | 60.85 | 74.41 | 79.03 | 82.15 | 77.68 | 83.43 | 86.52 | 88.57 |
| Init. Samp. # | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
| GAN-Ensem-KNN | 36.62 | 54.72 | 62.92 | 63.68 | 68.73 | 77.17 | 79.5 | 85.85 |
| GAN-Ensem-DT | 22.98 | 45.47 | 56.17 | 56.61 | 58.31 | 71.02 | 78.89 | 79.74 |
| GAN-Ensem-MLP | 28.91 | 39.57 | 55.69 | 58.49 | 59.25 | 59.56 | 65.48 | 64.41 |
| GAN-Ensem-RF | 36.42 | 57.52 | 64.11 | 67.01 | 70.91 | 77.16 | 83.84 | 87.21 |
| GAN-Ensem-SVM | 32.16 | 52.56 | 65.85 | 66.58 | 63.58 | 77.31 | 80.64 | 86.56 |
| Init. Samp. # | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
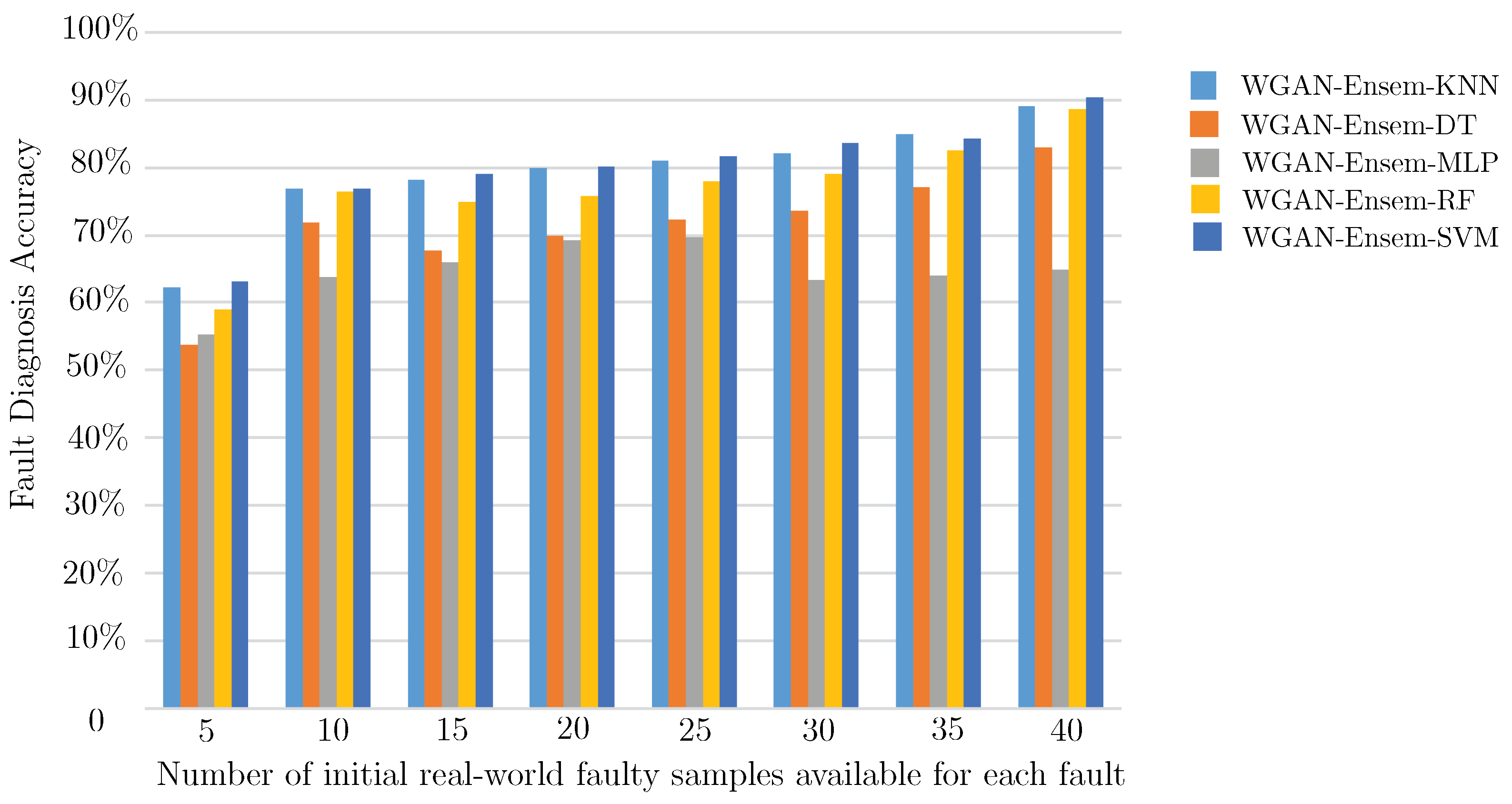
| WGAN-Ensem-KNN | 62.19 | 76.85 | 78.21 | 80.04 | 81.03 | 82.1 | 84.86 | 89.14 |
| WGAN-Ensem-DT | 53.82 | 71.91 | 67.82 | 69.95 | 72.39 | 73.68 | 77.19 | 83.01 |
| WGAN-Ensem-MLP | 55.32 | 63.92 | 65.99 | 69.19 | 69.63 | 63.36 | 64.01 | 65.00 |
| WGAN-Ensem-RF | 58.97 | 76.44 | 75.03 | 75.74 | 77.95 | 79.13 | 82.58 | 88.62 |
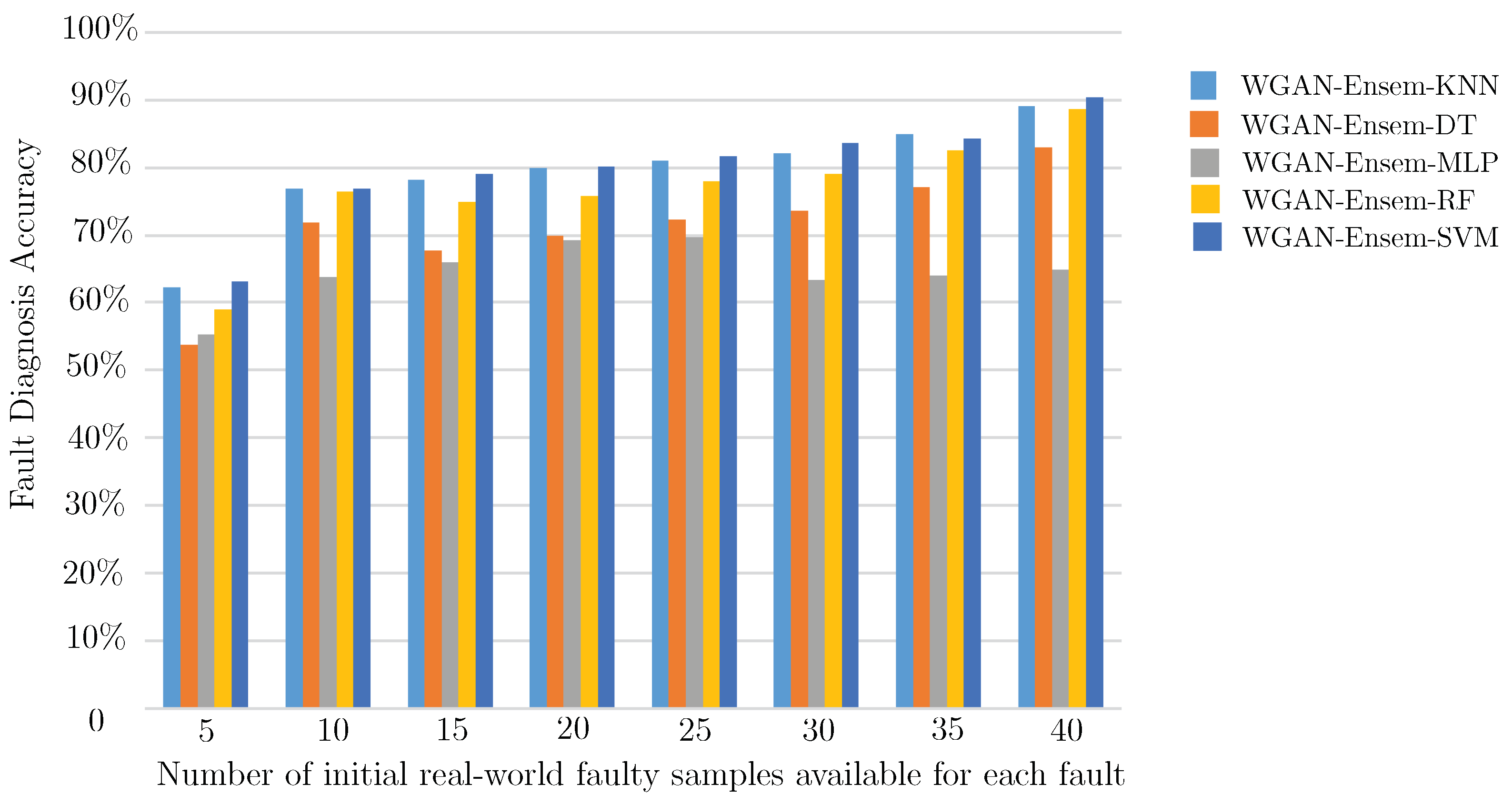
| WGAN-Ensem-SVM | 63.17 | 76.98 | 79.02 | 80.17 | 81.58 | 83.7 | 84.35 | 90.44 |
| Init. Samp. # | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|
| Semi-Sup-SVM | 62.59 | 73.53 | 75.6 | 81.45 | 75.94 | 81.83 | 83.24 | 84.52 |
| WGAN-SVM-SVM | 60.85 | 74.41 | 79.03 | 82.15 | 77.68 | 83.43 | 86.52 | 88.57 |
| WGAN-Ensem-SVM | 63.17 | 76.98 | 79.02 | 80.17 | 81.58 | 83.7 | 84.35 | 90.44 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, C.; Yan, K.; Dai, Y.; Jin, N.; Lou, B. Energy Efficiency Solutions for Buildings: Automated Fault Diagnosis of Air Handling Units Using Generative Adversarial Networks. Energies 2019, 12, 527. https://doi.org/10.3390/en12030527
Zhong C, Yan K, Dai Y, Jin N, Lou B. Energy Efficiency Solutions for Buildings: Automated Fault Diagnosis of Air Handling Units Using Generative Adversarial Networks. Energies. 2019; 12(3):527. https://doi.org/10.3390/en12030527
Chicago/Turabian StyleZhong, Chaowen, Ke Yan, Yuting Dai, Ning Jin, and Bing Lou. 2019. "Energy Efficiency Solutions for Buildings: Automated Fault Diagnosis of Air Handling Units Using Generative Adversarial Networks" Energies 12, no. 3: 527. https://doi.org/10.3390/en12030527
APA StyleZhong, C., Yan, K., Dai, Y., Jin, N., & Lou, B. (2019). Energy Efficiency Solutions for Buildings: Automated Fault Diagnosis of Air Handling Units Using Generative Adversarial Networks. Energies, 12(3), 527. https://doi.org/10.3390/en12030527