A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN


Abstract
:1. Introduction
- The proposed forecasting strategy takes advantage of individual methods, including two-stage decomposition technique, HBSA, DAWNN, that can enhance forecasting accuracy. The proposal not only thoroughly tackles the nonstationary characteristics of wind speed data, but also remedies the deficiencies of the AI approach.
- To decompose thoroughly, a two-stage decomposition technique combining EEMD with VMD is exploited to deal with wind speed data, eliminating the characteristic of irregularities.
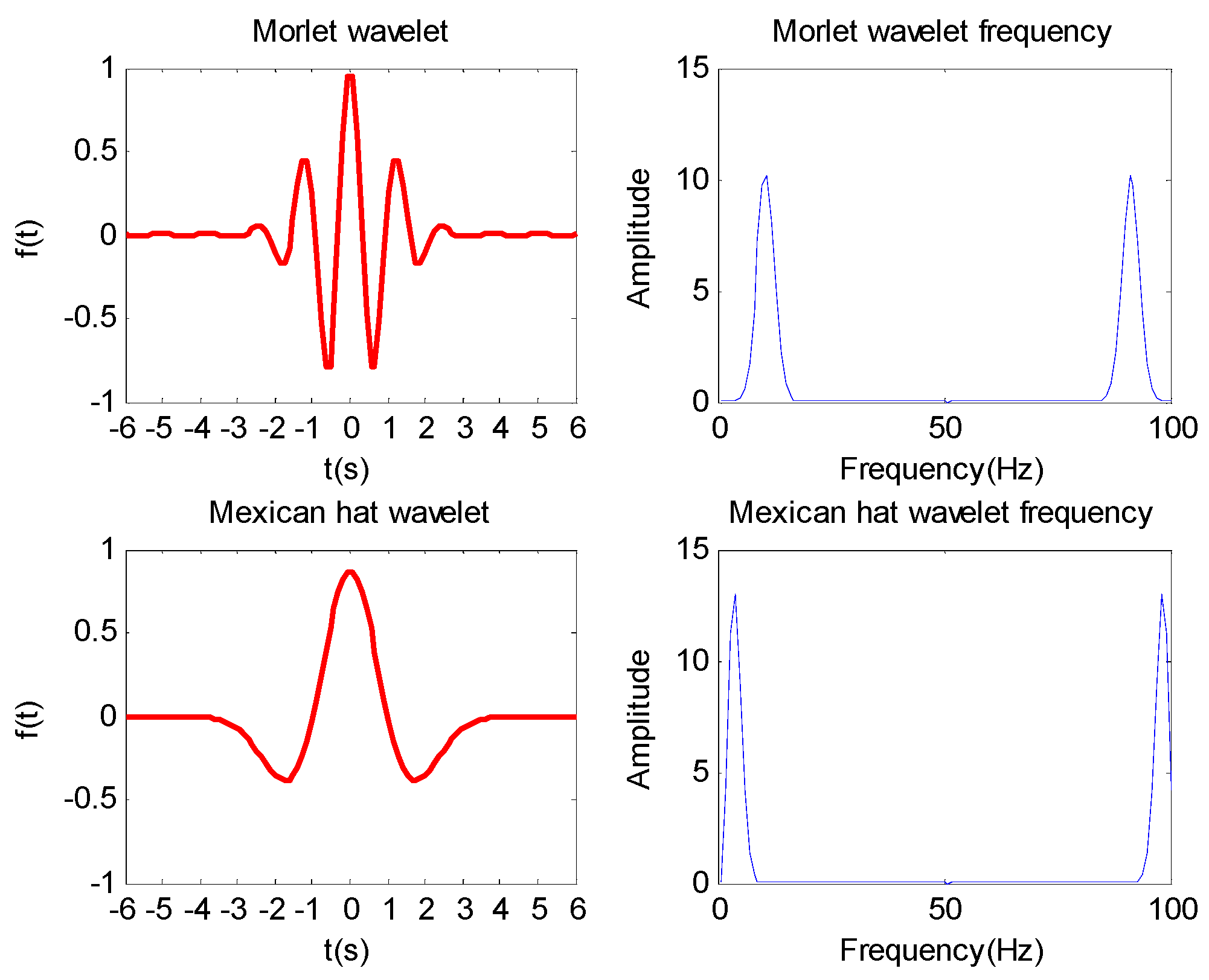
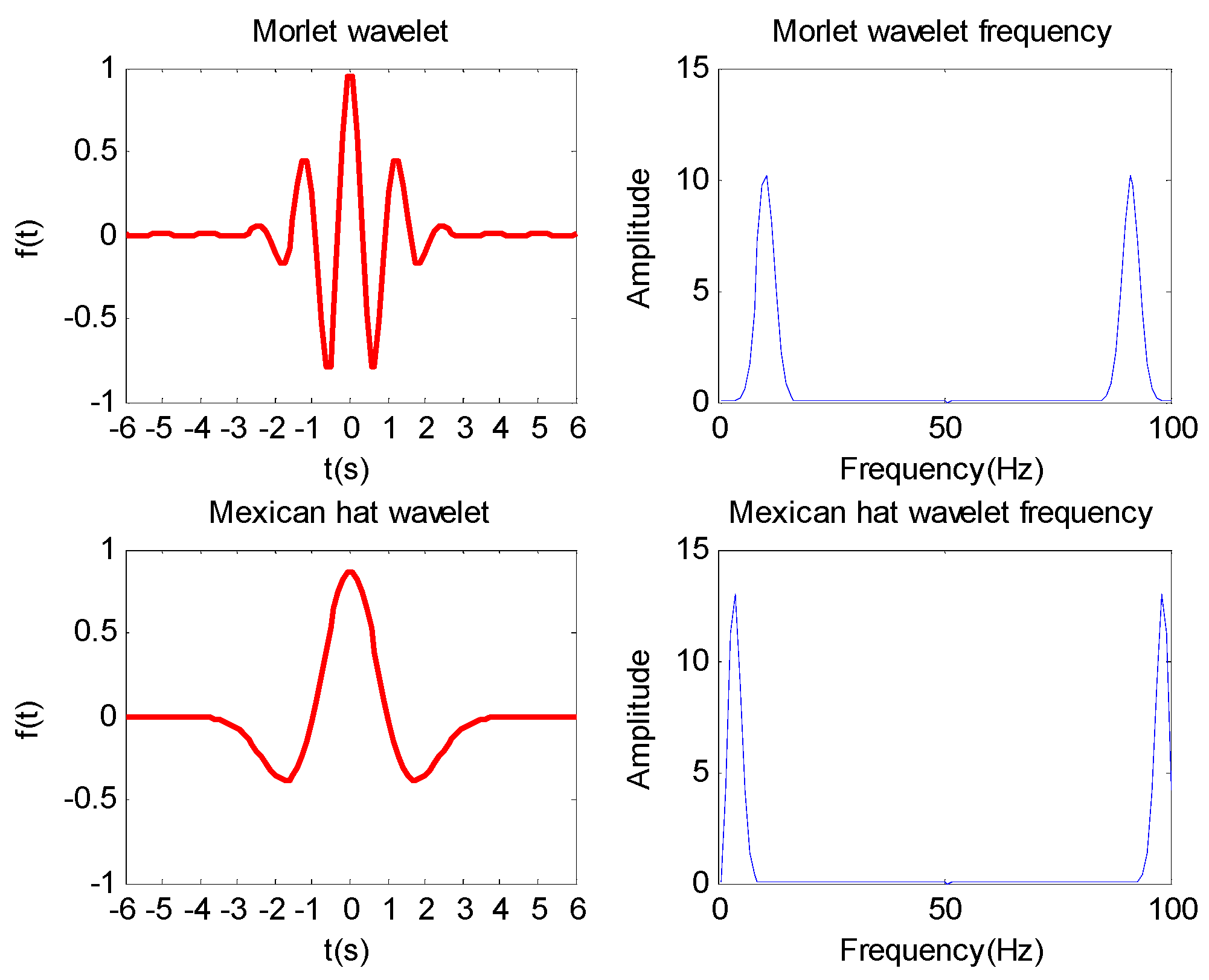
- To better improve the regression performance of WNN, double activation functions combining the Morlet function with the Mexican hat function by weighted coefficients, namely DAWNN, are proposed.
- As stated by Zheng et al. [28], there are ineffective candidate features in wind speed time series that generate negative influence on forecasting results, and WNN with inappropriate parameters tends to get stuck in over-fitting or under-fitting easily. The parameters of WNN should be tuned for the improvement of forecasting accuracy. Thus, the BBSA algorithm is applied to remove ineffective candidate variables, while RBSA is used to tune the input weights, output weights, and weighted coefficients in DAWNN other than random selection for the proposed forecasting engine. The feature selection technique and parameter optimization are realized by HBSA algorithm.
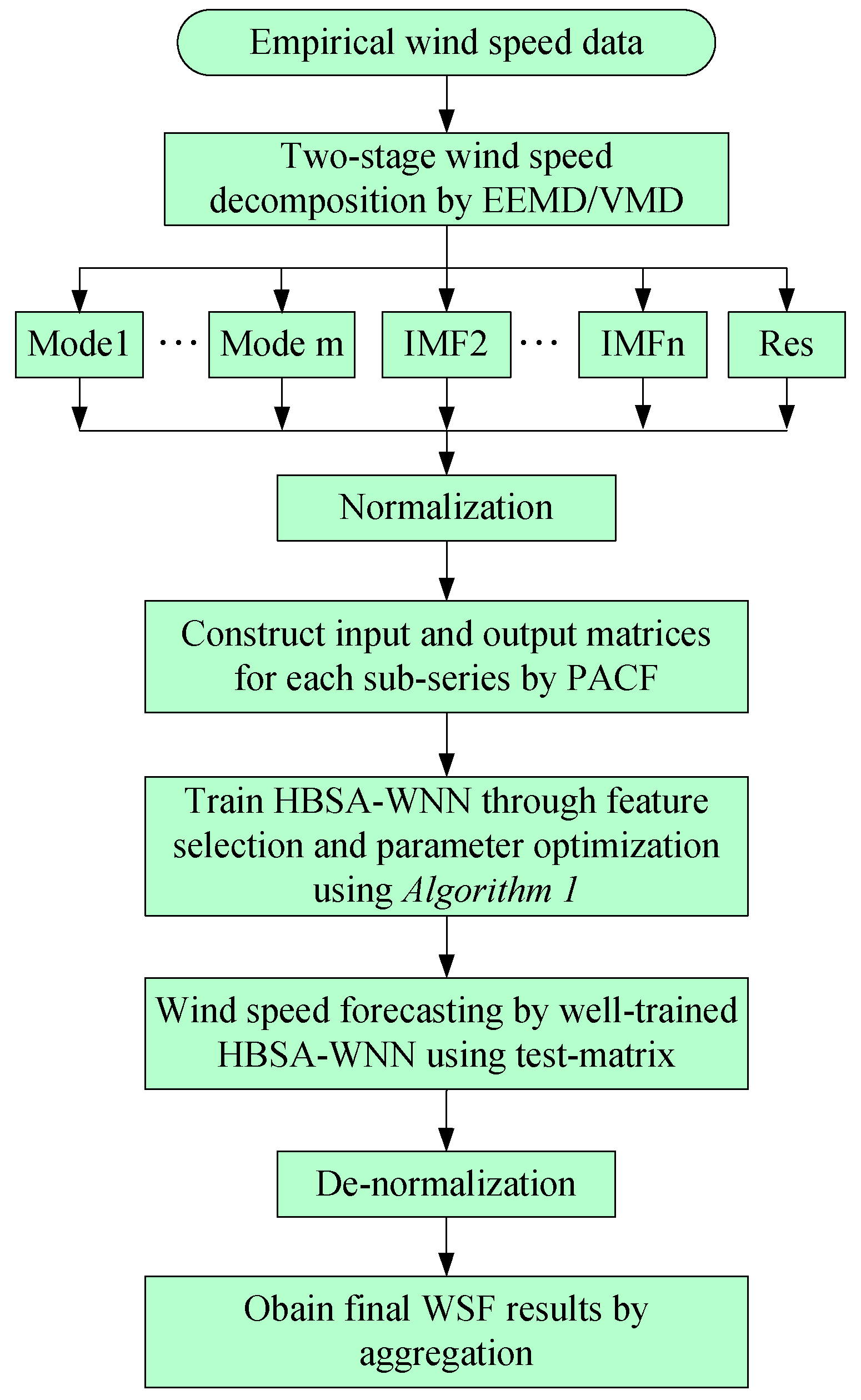
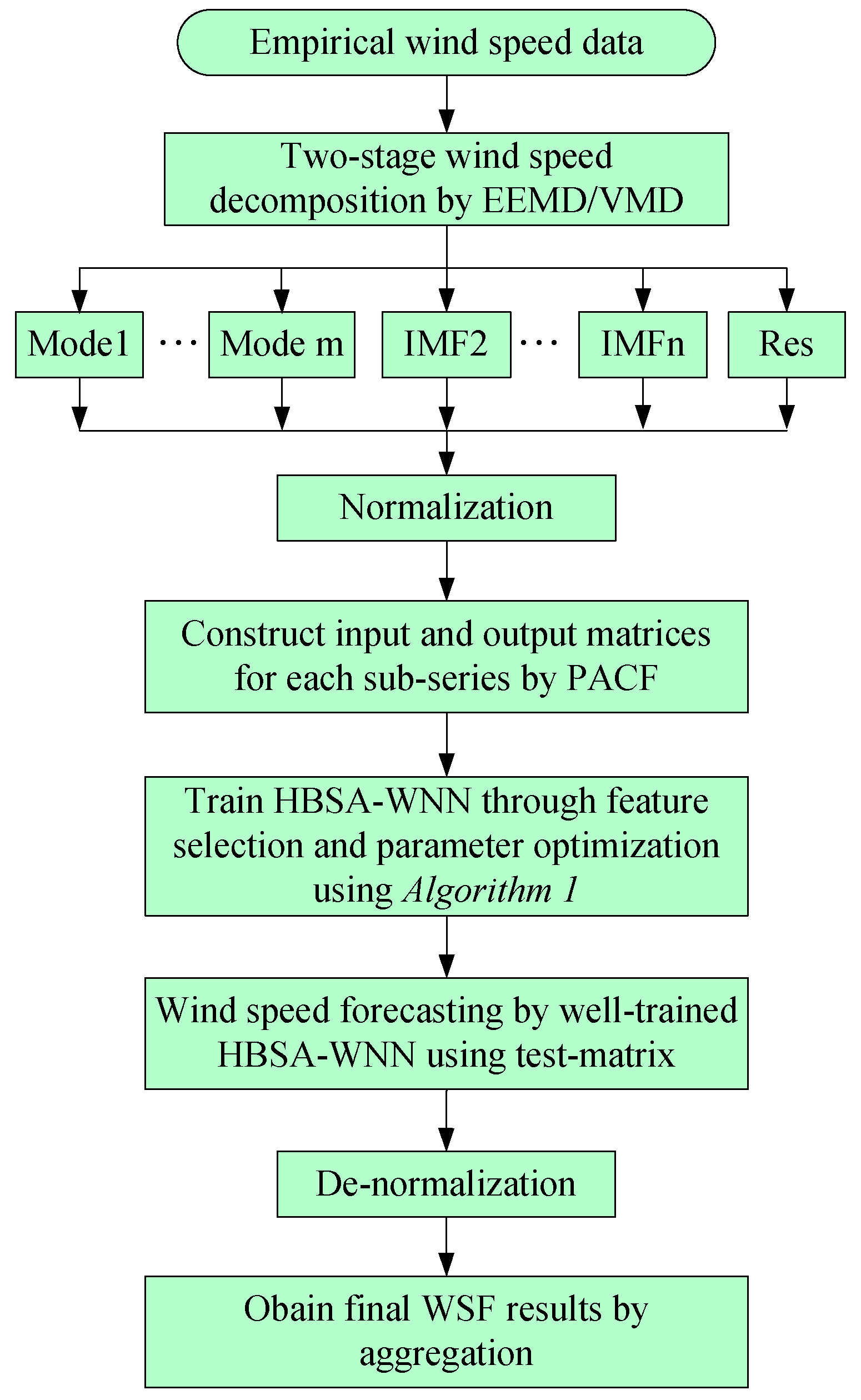
2. The Proposed WSF Strategy
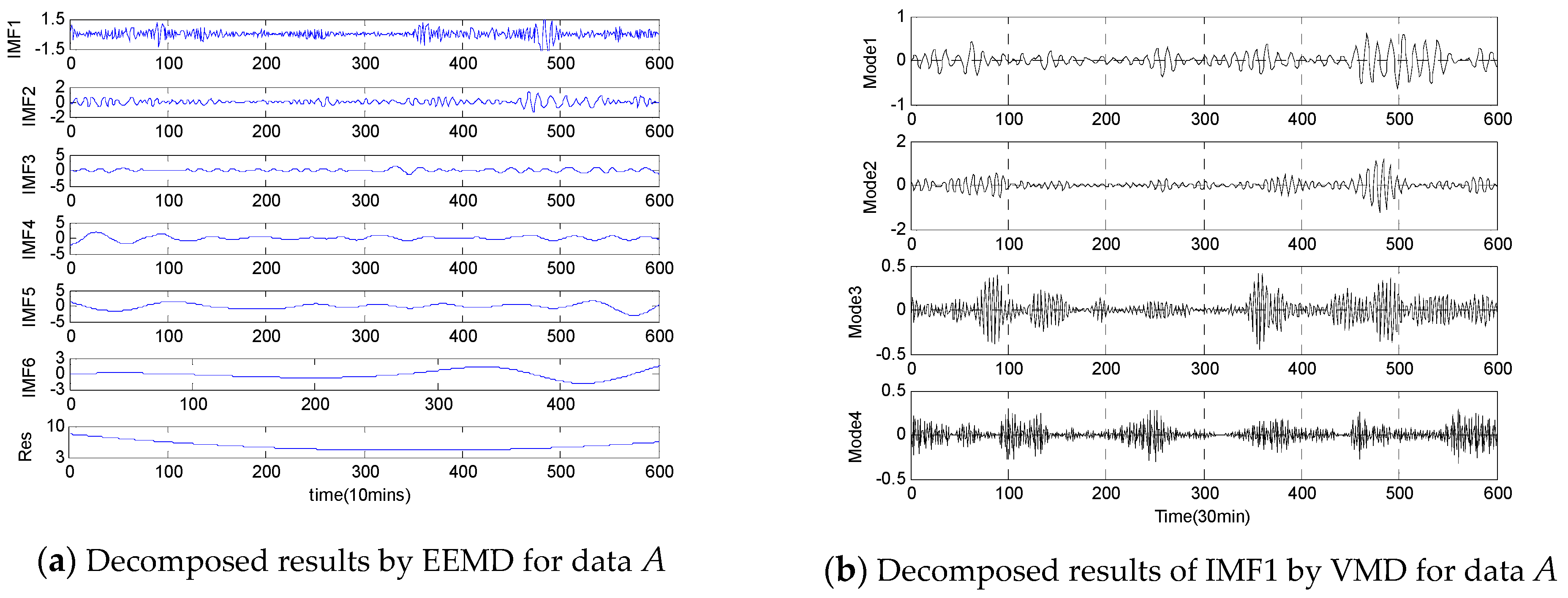
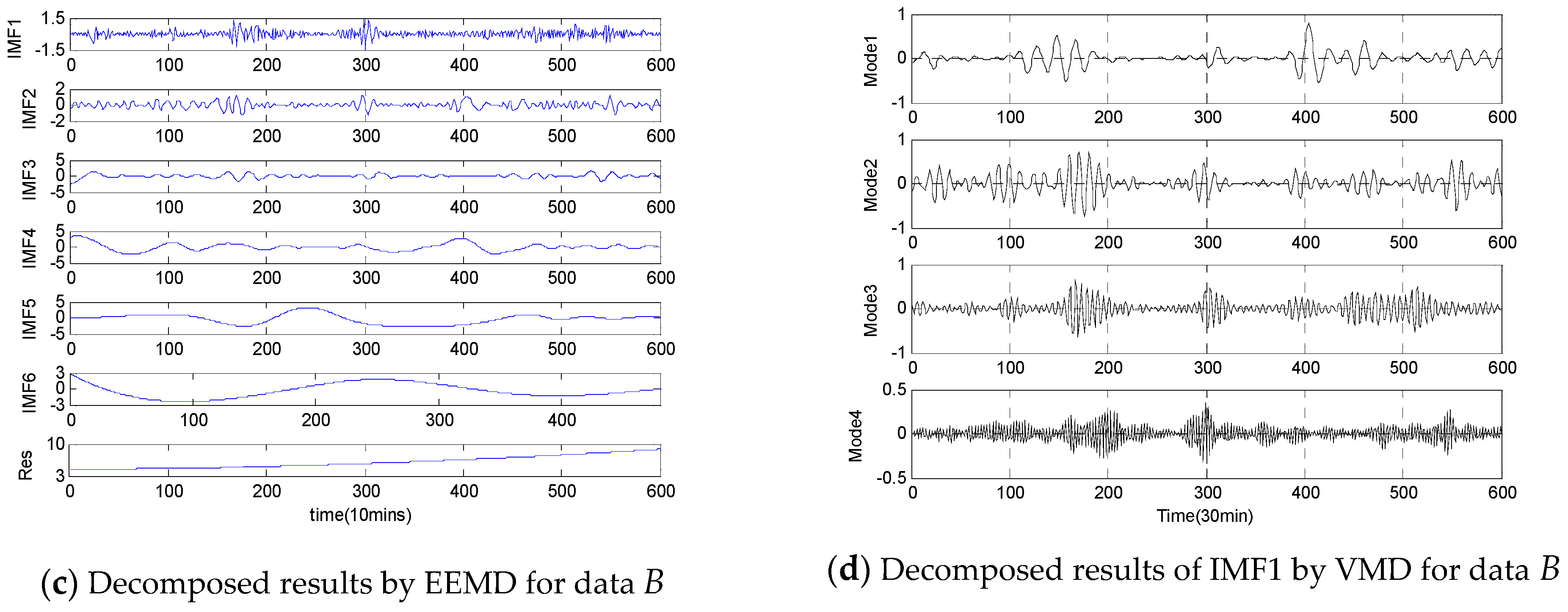
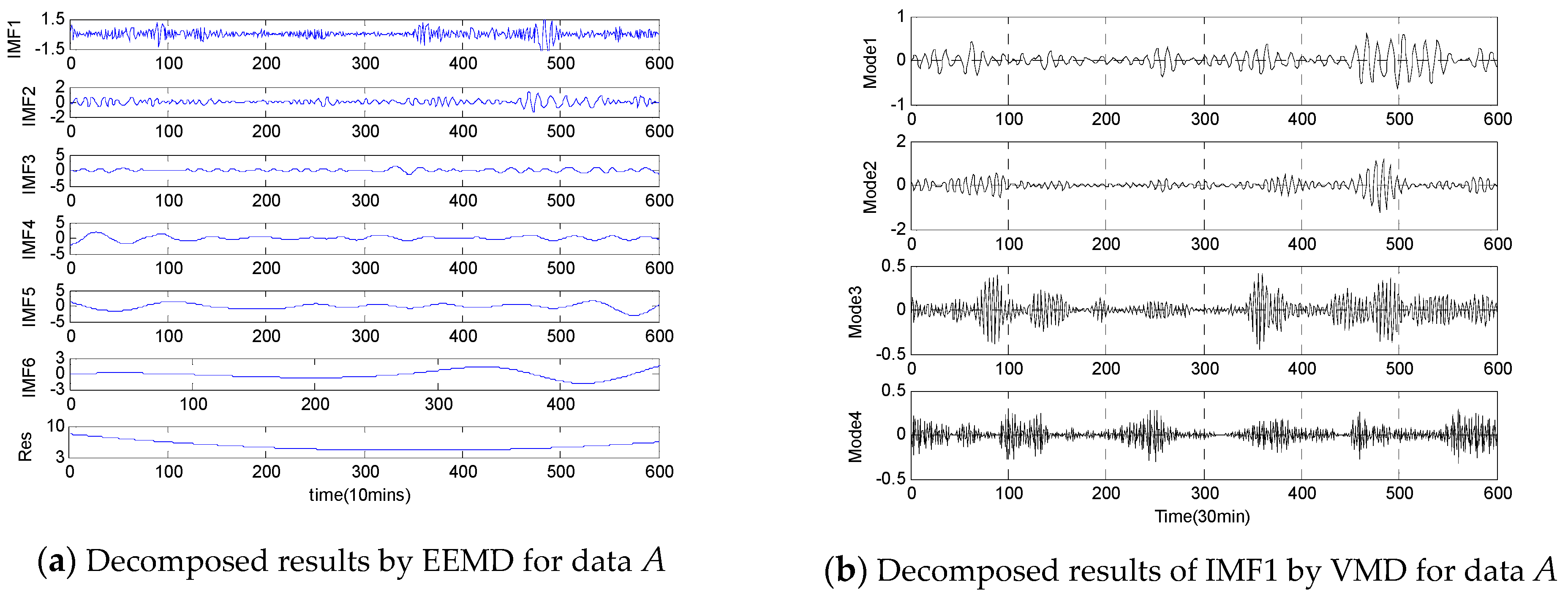
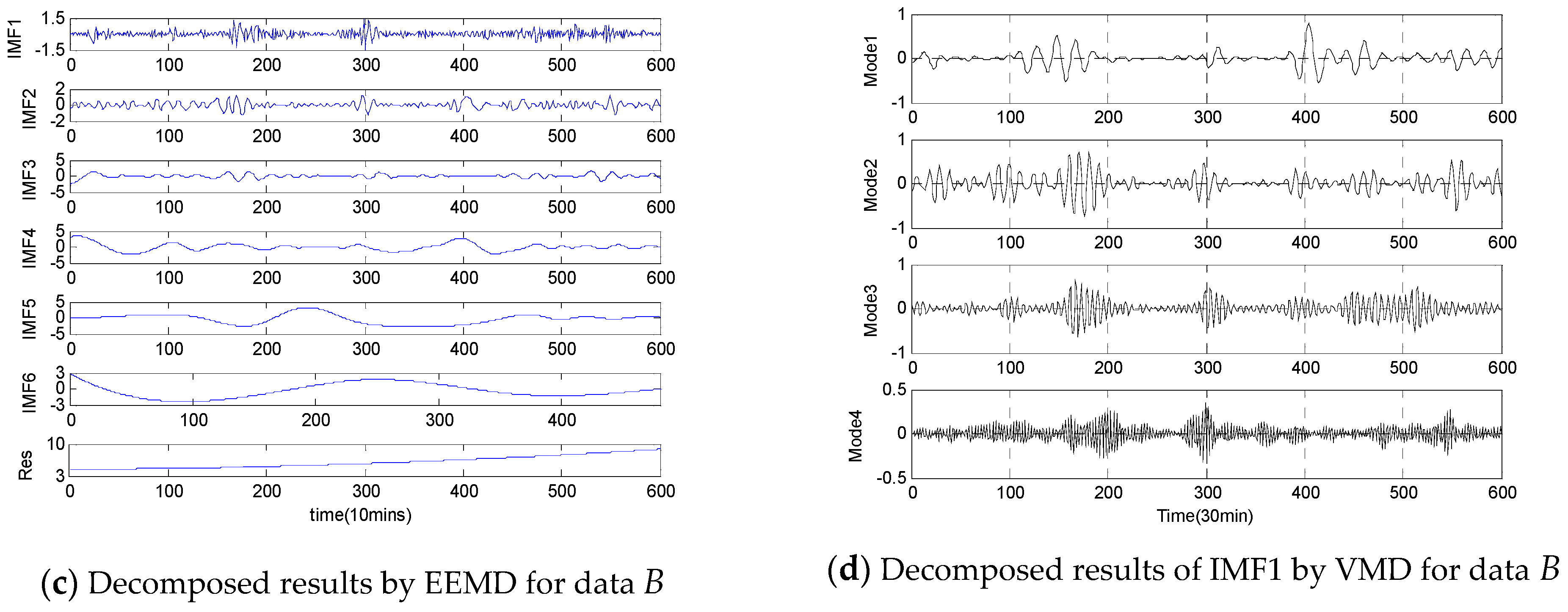
- Step 1: In this step, the original empirical wind speeds are decomposed into several modes, different IMFs and a Res using two-stage decomposition technique EEMD/VMD to eliminate the irregular and fluctuant characteristics of wind speed for better forecasting. Firstly, the original empirical samples are broken into different IMFs and one Res, then, the IMF1 generated by EEMD is further decomposed by VMD approach into several modes.
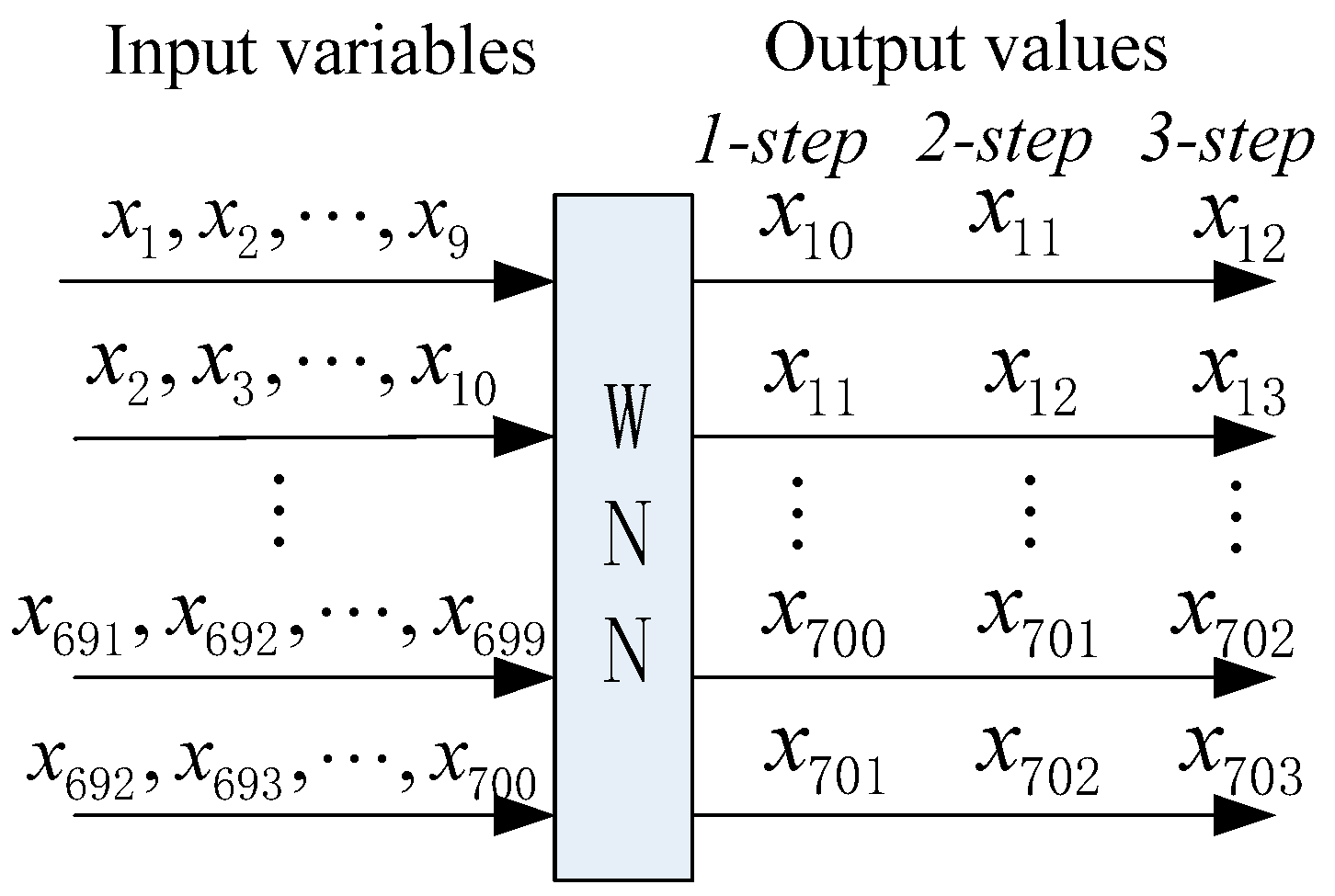
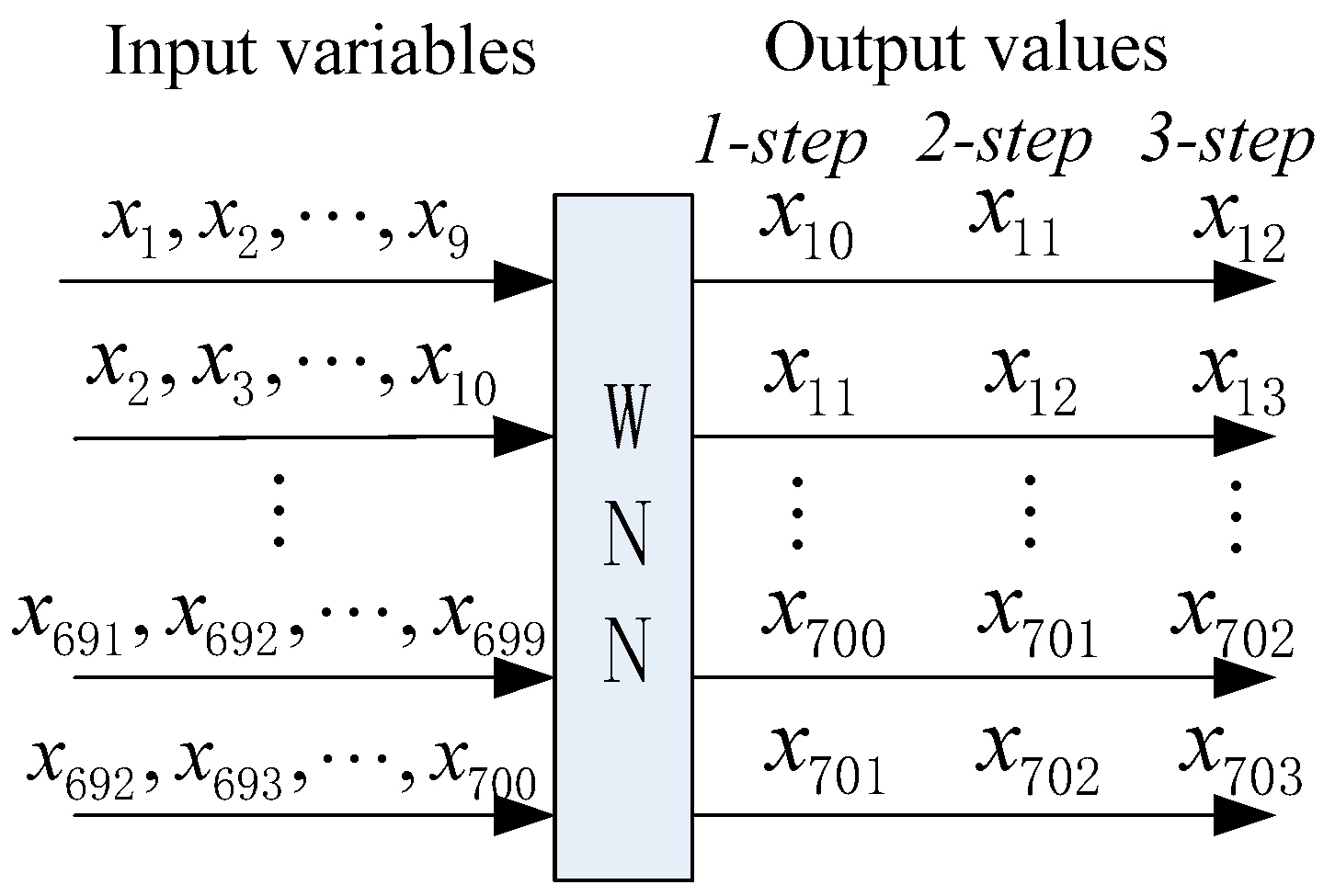
- Step 2: Considering the positive influences of normalization on the performance of WNN, the input variables are linearly normalized into interval [0, 1]. Prior to WSF using the proposed DAWNN method, partial autocorrelation function (PACF) values are applied to determine the correlation coefficients among the input candidates for establishing the training and testing input-matrix.
- Step 3: As illustrated in Algorithm 1, select the effective candidates through feature selection by BBSA technique and optimize the parameters combination of DAWNN model by RBSA algorithm using the decomposed wind speed data, which are realized by HBSA simultaneously.
3. Theoretical Background
3.1. Two-Stage Wind Speed Decomposition Technique
3.1.1. EEMD
- Step 1: A Gaussian white noise is added into the empirical wind speed data, and new signal is generated as Equation (1),where n(t) stands for the Gaussian signal.X(t) = x(t) + n(t),
- Step 2: Disassemble the new signal into N different amplitude-frequency IMFs and a Res by EMD algorithm, then, the X(t) can be expressed as Equation (2),where N stands for the decomposed quantity.
- Step 3: Repeat Step 1 and 2 by adding different Gaussian white noise at each sifting process.
- Step 4: Eliminate the Gaussian white noise and obtain the final IMFs by averaging all the corresponding IMFs in the end.
3.1.2. VMD
3.2. The Working Principle of HBSA
3.2.1. RBSA
- Step 1: Initialization
- Step 2: Selection-I
- Step 3: Mutation
- Step 4: Crossover
- Step 5: Selection-II
3.2.2. BBSA
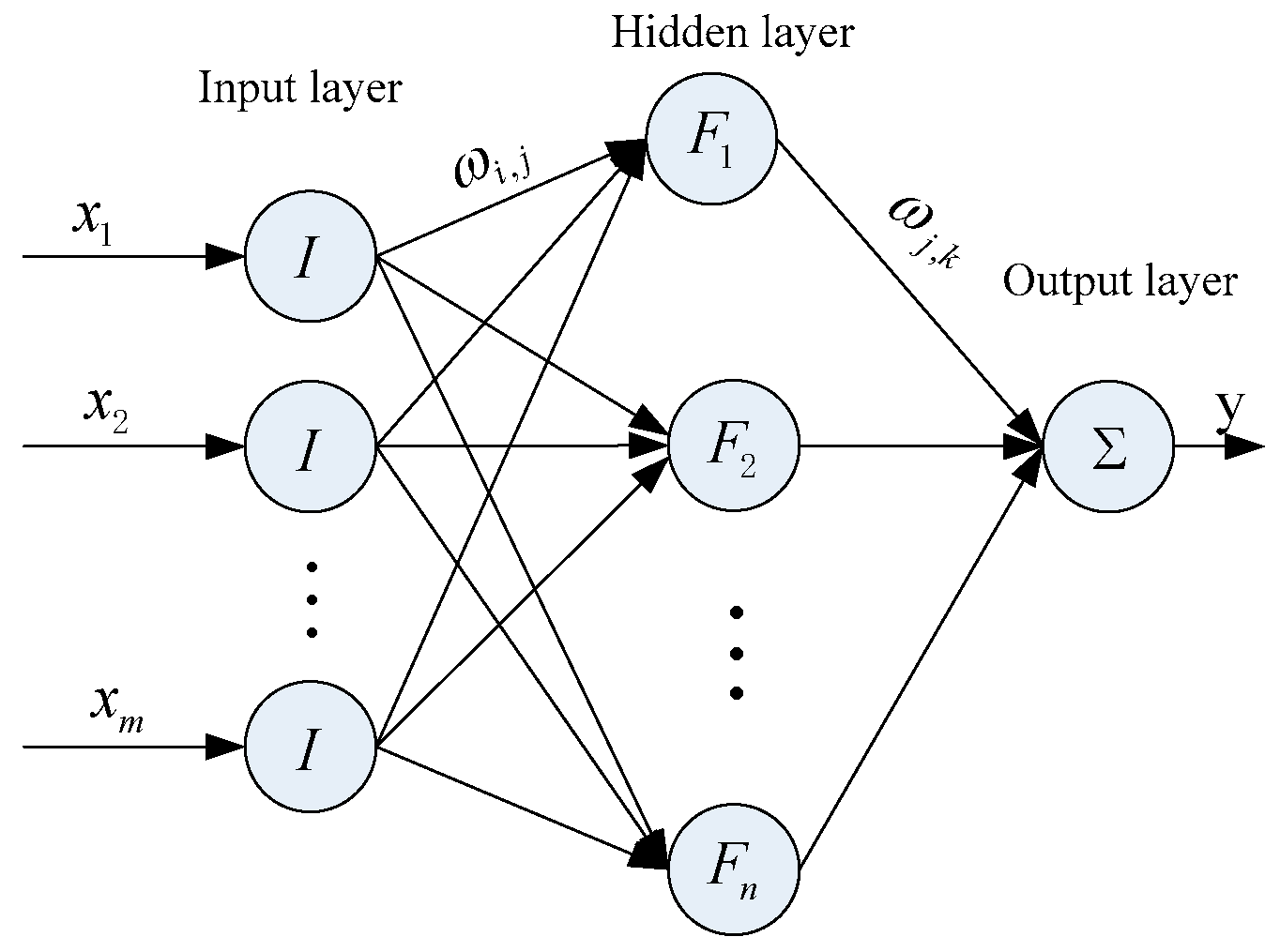
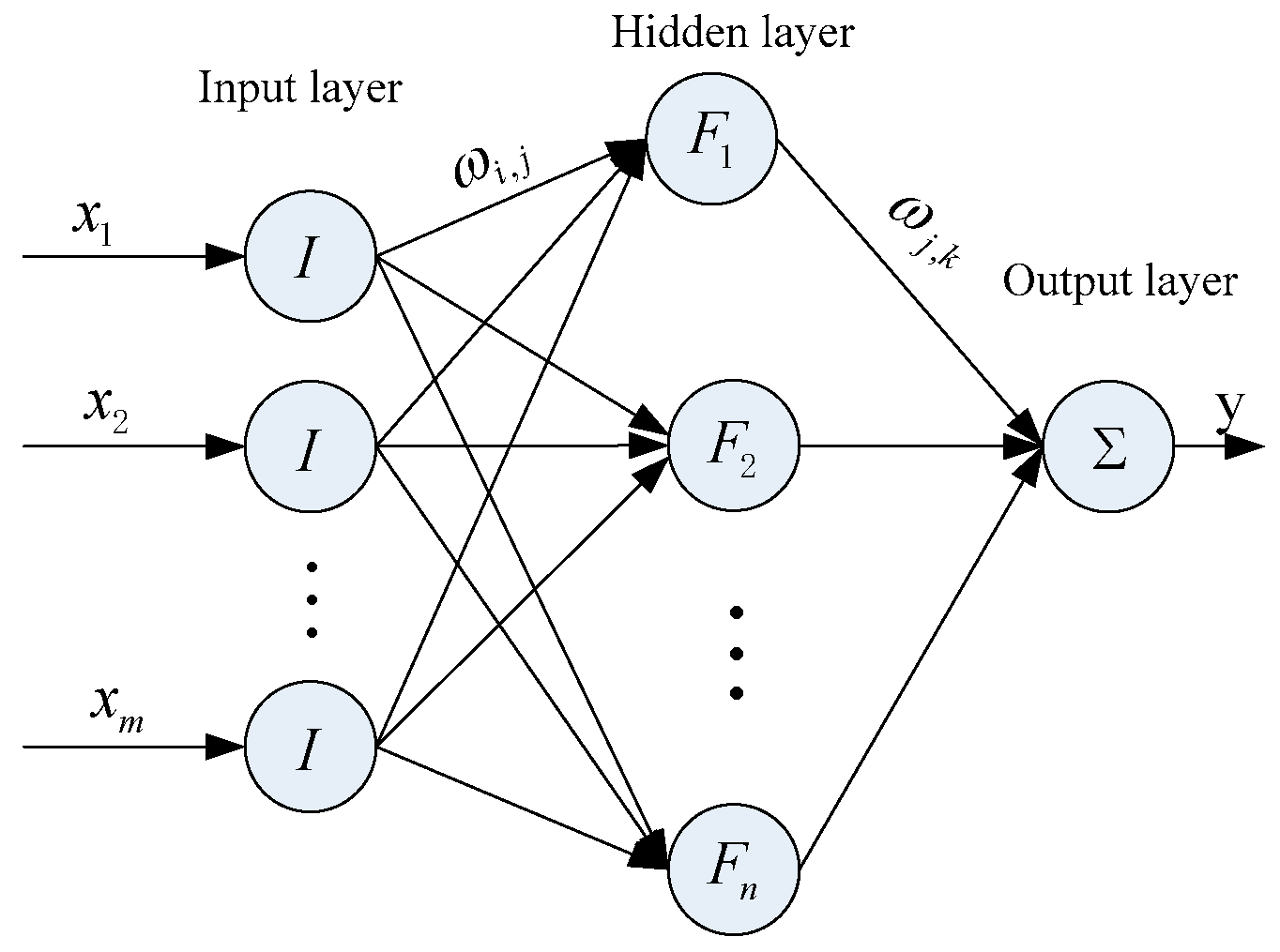
3.3. WNN
3.4. The Proposed HBSA-DAWNN Approach
| Algorithm 1 The pseudo code of HBSA-DAWNN | |
| 1: | Generate the initial parameters in BSA: iteration number (T), dimension number (D), population size (N) and F. |
| 2: | Set the initial population according to Equation 20. |
| 3: | Convert the population values into binary values according to Equations 14 and 15. |
| 4: | for i from 1 to N do |
| 5: | Make WSF by the proposed forecasting engine using each population. |
| 6: | Calculate the fitness function according to Equation 23 for each population. |
| 7: | endfor |
| 8: | Produce initial historical population according to Equation 8. |
| 9: | for i from 1 to T do |
| 10: | Update historical population (oldPi) according to Equations 9 and 10. |
| 11: | Calculate the trial population mutant according to Equation11. |
| 12: | Convert the population values into binary value according to Equations 14 and 15. |
| 13: | Determine the input variable matrix using the binary value. |
| 14: | Calculate the final trial population (Tij). |
| 15: | for i from 1 to N do |
| 16: | Make wind speed forecasting by the proposed forecasting engine. |
| 17: | Calculate the fitness function using Equation 23 for each population. |
| 18: | endfor |
| 19: | Determine the minimal objective function, and find the optimum parameters combination and the effective input variables. |
| 20: | endfor |
| 21: | Obtain the effective input variables matrix and the optimum parameters combination for forecasting. |
4. Model Construction and Development
4.1. The Statistical Error Evaluation Indices
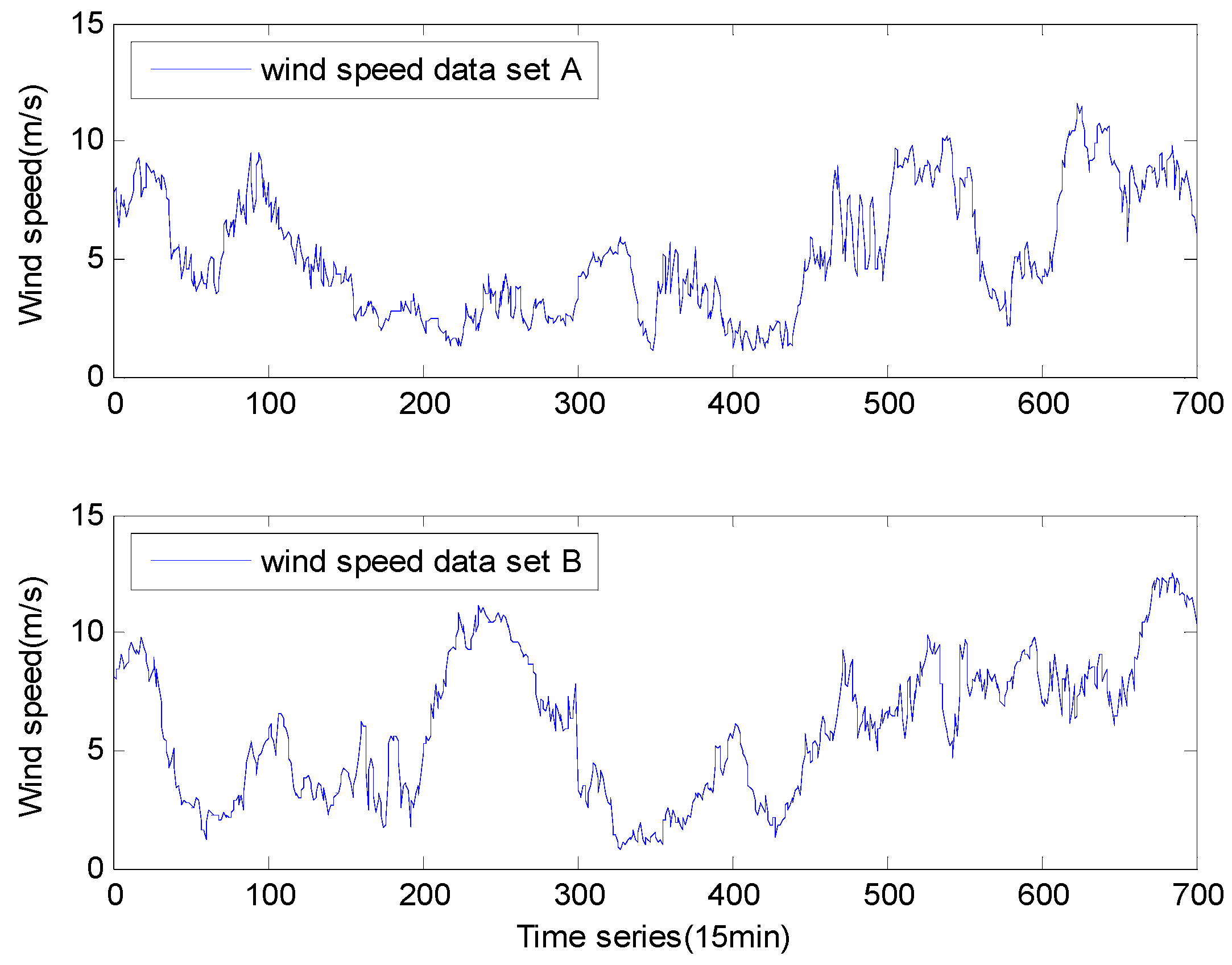
4.2. Empirical Wind Speed Time Series
4.3. Wind Speed Decomposition Using Two-Stage Decomposition Technique
4.4. Construction of Input Feature Matrix for the Forecasting Engine
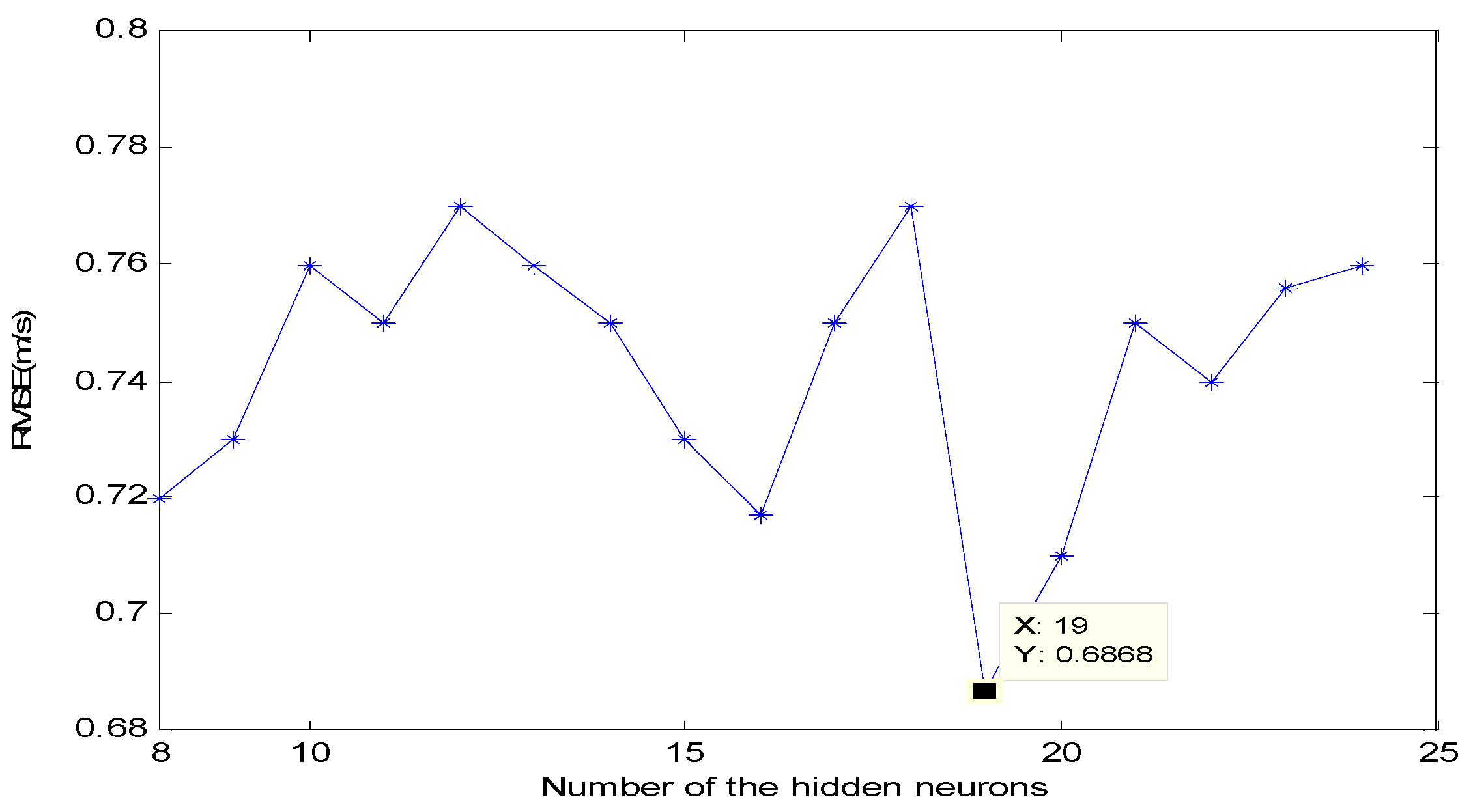
4.5. Construction of the HBSA-DAWNN
5. Numerical Results and Discussion
5.1. Case 1
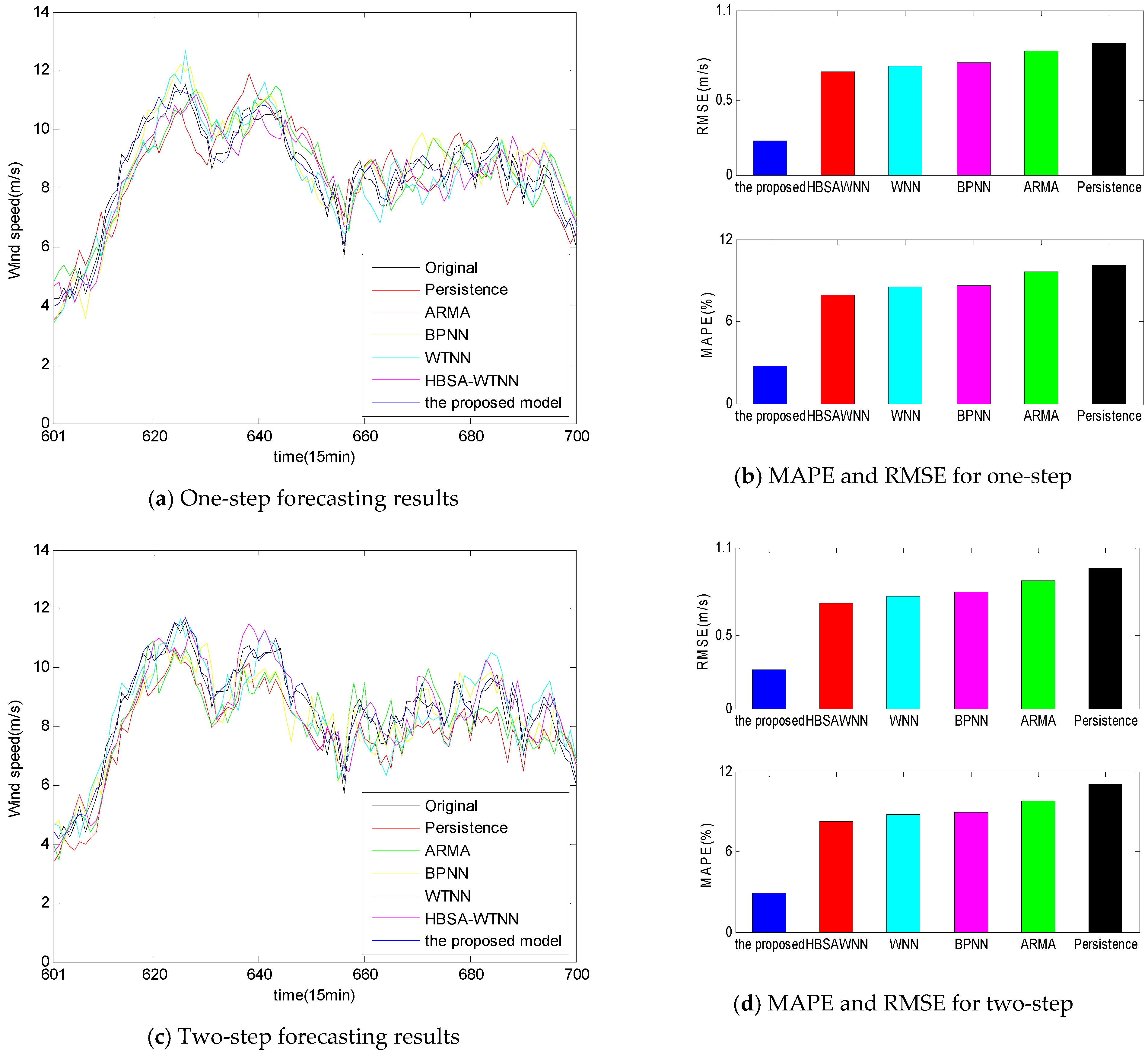
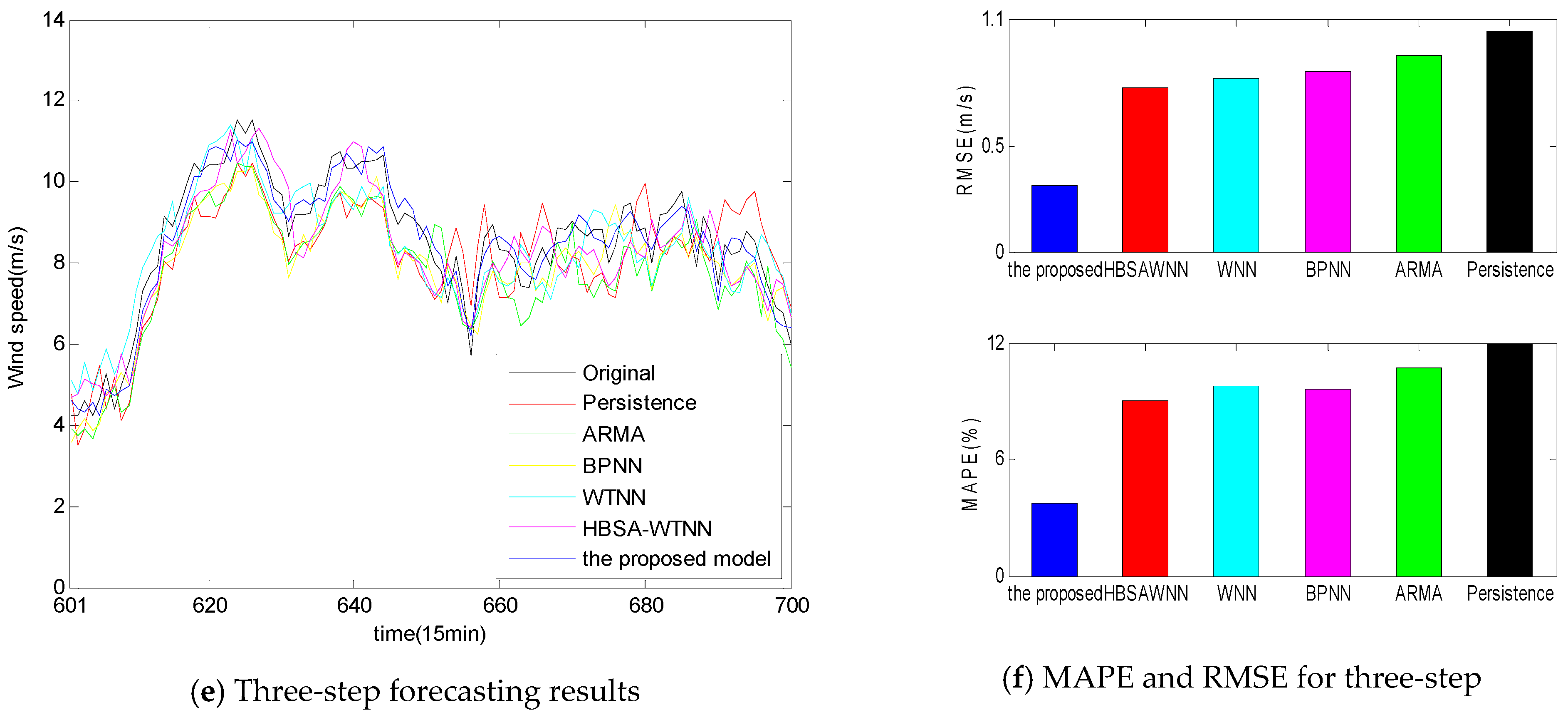
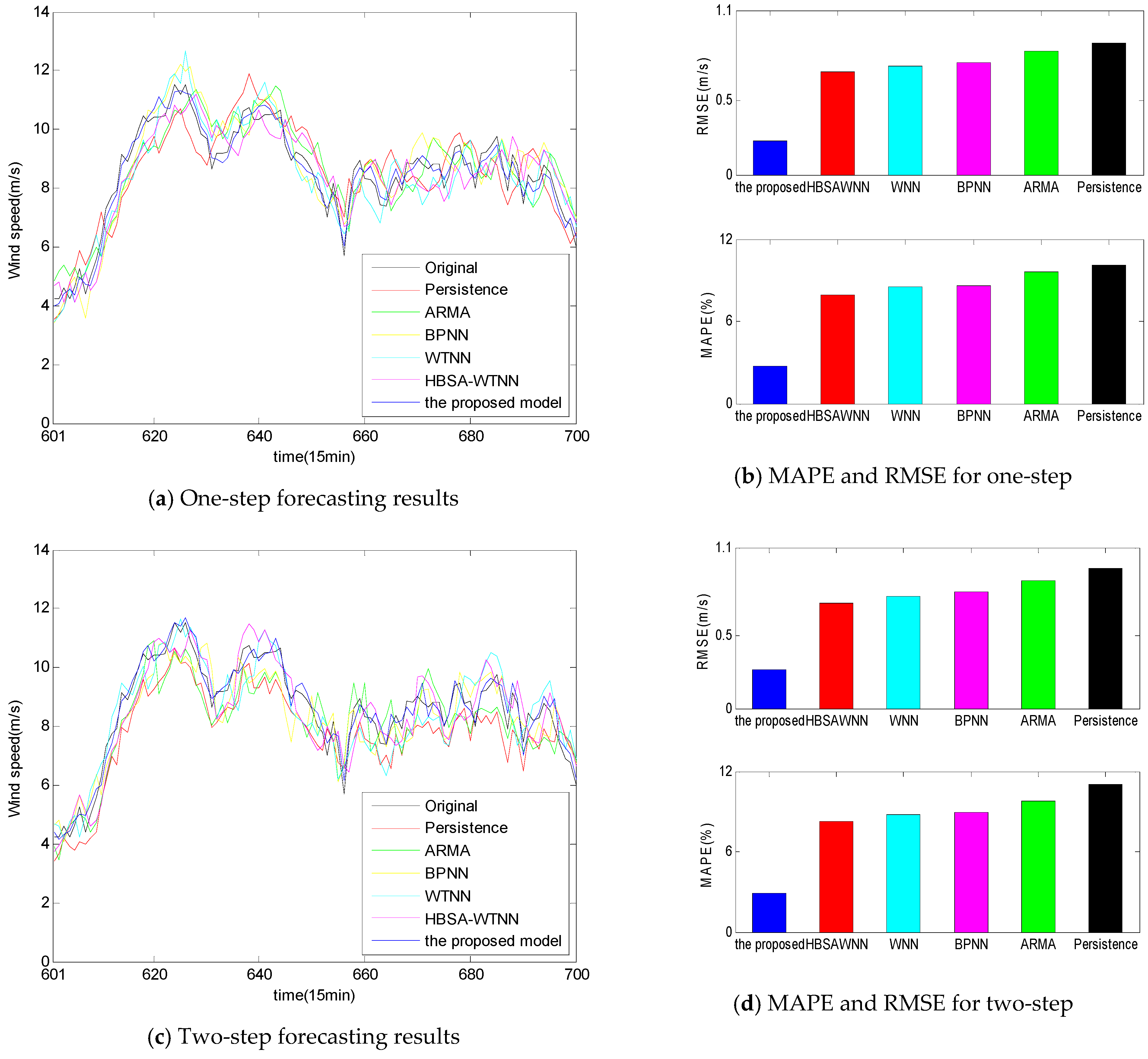
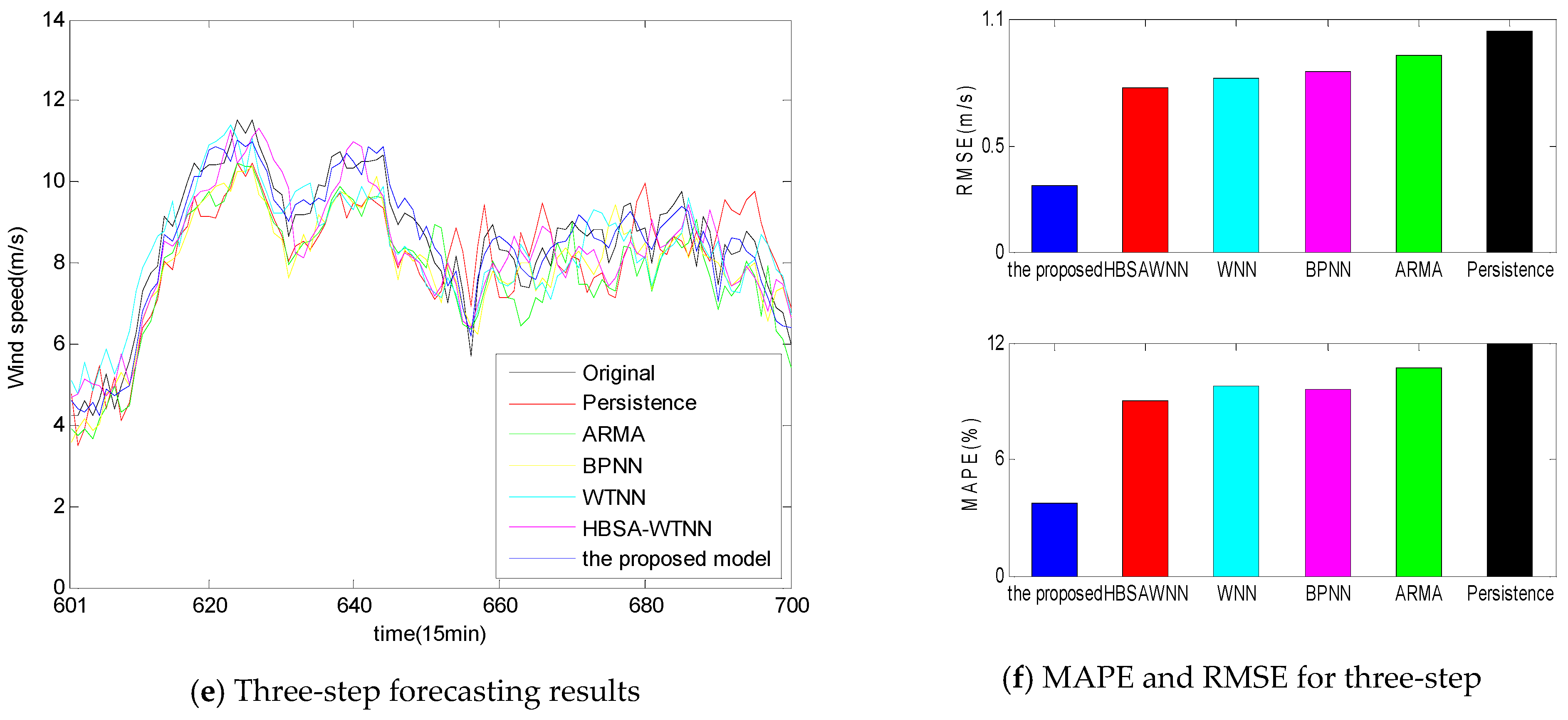
- Persistence presents the highest forecasting statistical indices values with 0.8818 m/s, 0.9543 m/s, and 1.0433 m/s RMSE values for one-, two-, and three-step ahead prediction, respectively.
- From Figure 8b,d,f, the accuracy of the individual models is ranked from low to high as Persistence, ARMA, BPNN, WNN and HBSA-WNN.
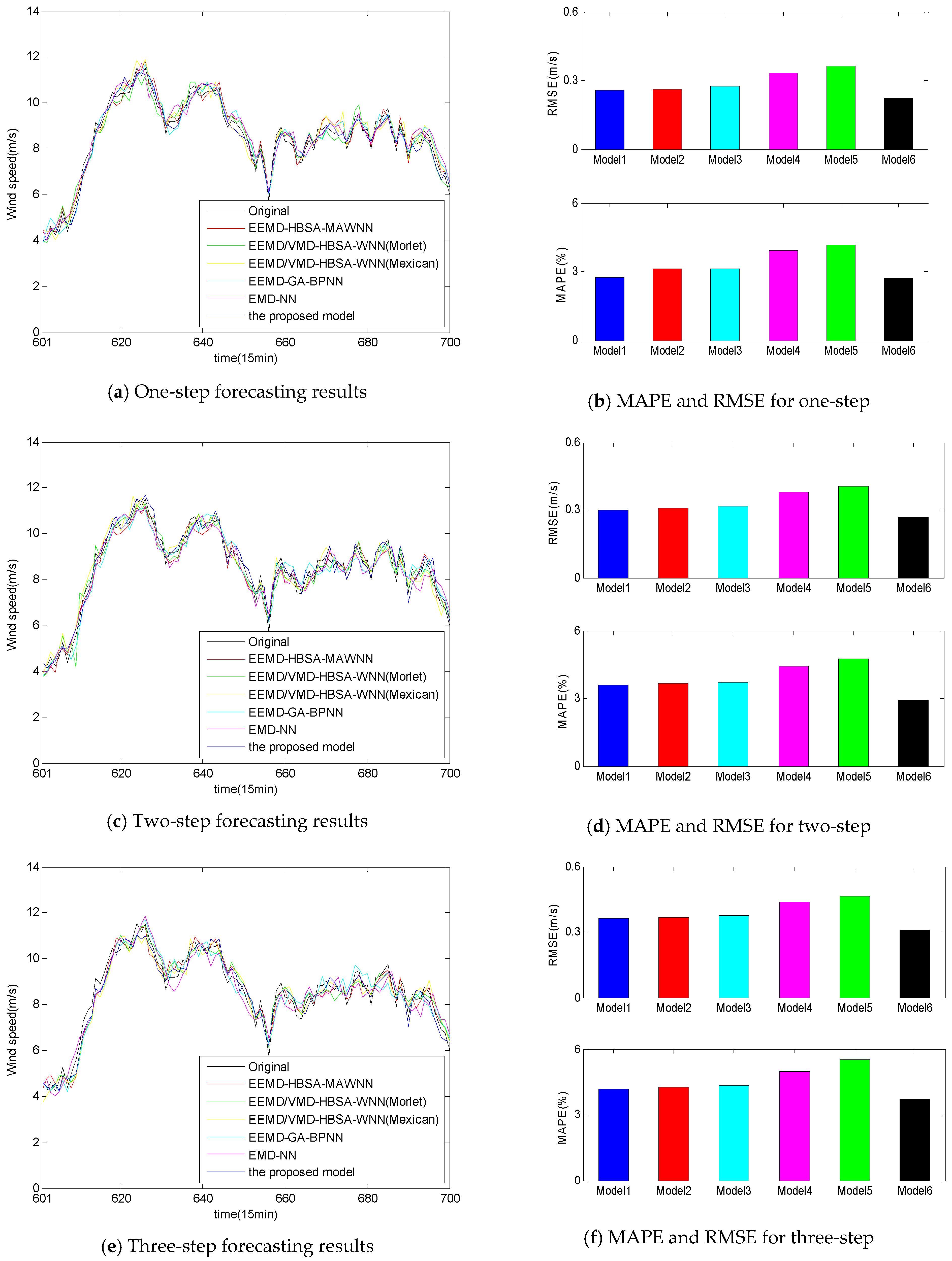
- To illustrate the effectiveness of the double activation functions in WNN, the proposed EEMD/VMD-HBSA-DAWNN is compared with the models with Morlet function and Mexican hat function. Table 5 and Table 6 illustrate the forecasting results. The RMSE values of the proposed EEMD/VMD-HBSA-DAWNN are the smallest. Thus, the proposed strategy outperforms the model with Mexican hat wavelet function or Morlet function.
- Compared with the single statistical approaches ARMA and Persistence, the single AI models BPNN and WNN yield better forecasting performance in that the artificial intelligent models have better capacities in handling non-linear wind speed time series.
- Signal decomposition-based forecasting models obtain remarkable improvements over the individual forecasting models without signal decomposition methods because there exists non-linearity, non-stable, and high fluctuation in the wind speed time series, the signal techniques break wind speed data into different relatively stationary subseries, thus reducing the regression difficulties of the forecasting engine and improving the prediction accuracy.
- Comparisons between the HSBA-WNN model with Morlet function and the individual WNN model with Morlet function using the same wind speed data are made to examine the capacity of HBSA in feature selection and parameter optimization. From Table 5 and Figure 8, HBSA-WNN performs better than WNN for multi-step prediction. The reasons of these results are that feature selection technique by BBSA method eliminates the illusive components and identify the effective components, while RBSA algorithm is utilized as parameter optimization to tune the parameters in WNN, thus enhancing the forecasting performance.
- The HBSA-DAWNN model with two-stage decomposition method EEMD/VMD has higher forecasting accuracy than the HBSA-DAWNN model with EEMD, whose underlying reasons are that the two-stage decomposition can effectively deal with the problems of the irregularity of IMF1 through further decomposition. Thus, the two-stage decomposition approach EEMD/VMD is an efficient data-preprocessing method in improving WSF performance.
- WNN based on Morlet and Mexican hat activation functions with weighted coefficient outperforms that based on Morlet or Mexican hat activation function, because the proposed forecasting engine takes advantages of the combination of the individual mother wavelet functions of Morlet function and Mexican hat function by weighted coefficient.
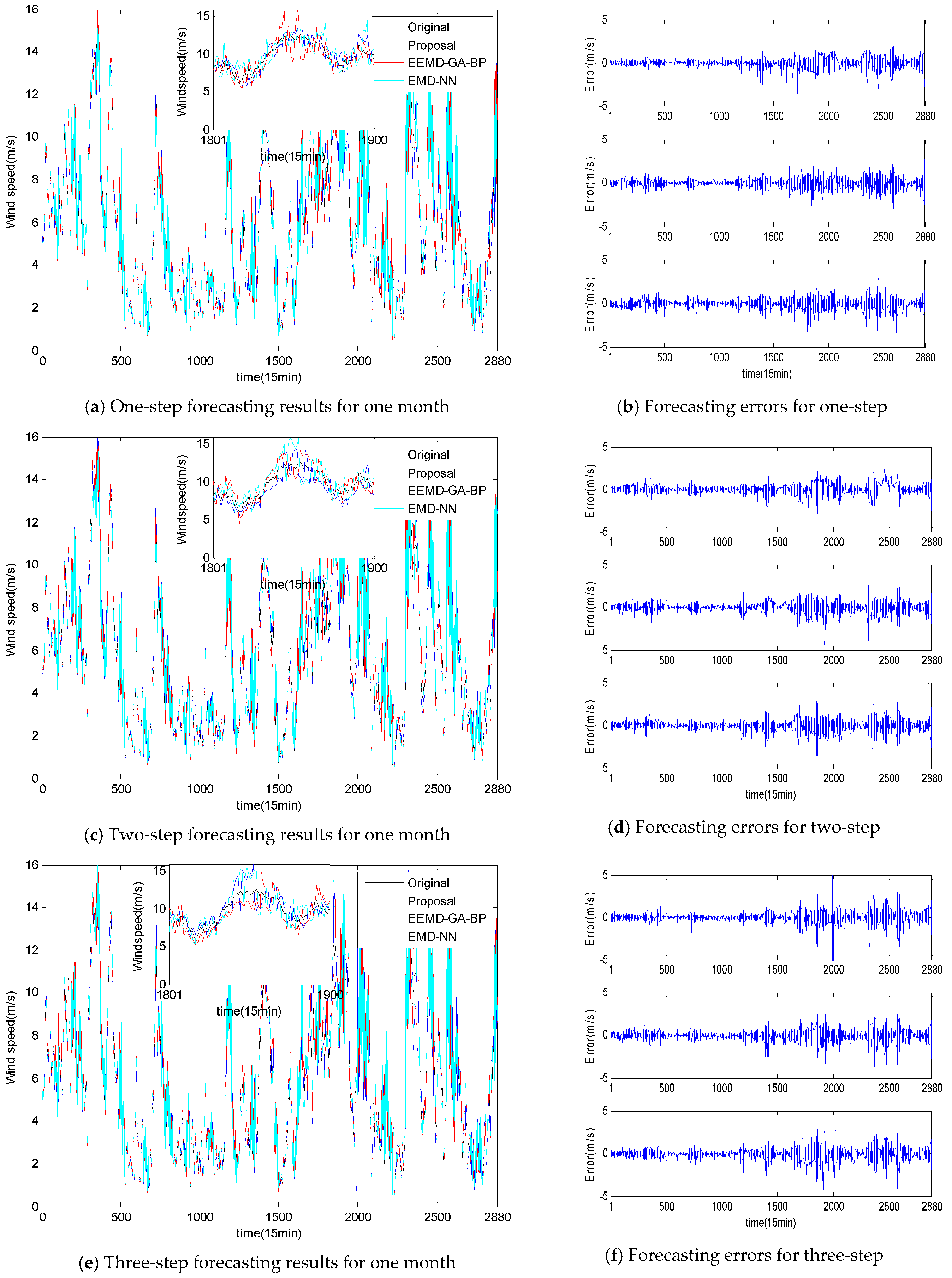
5.2. Case 2
5.3. Case 3
6. Conclusion
Author Contributions
Funding
Conflicts of Interest
Appendix A List of Abbreviations
| AI | Artificial intelligent |
| ARMA | Autoregressive moving average |
| ARIMA | Autoregressive integrated moving average |
| BBSA | Binary-valued backtracking search algorithm |
| BPNN | Back-propagation neural network |
| BSA | Backtracking search algorithm |
| CEEMDAN | Complementary ensemble empirical mode decomposition with adaptive noise |
| CSA | Coupled simulated annealing |
| DAWNN | WNN with double activations through weighted coefficient |
| EEMD | Ensemble empirical mode decomposition |
| ELMNN | Elman neural network |
| EWT | Empirical wavelet transforms |
| HBSA | Hybrid backtracking search algorithm |
| HGSA | Hybrid gravitational search algorithm |
| IMF | Intrinsic mode function |
| KF | Kalman filter |
| MAE | Mean absolute error |
| MAPE | Mean absolute percent error |
| MASE | Mean absolute scale error |
| MLP | Multilayer perceptron |
| PACF | Partial autocorrelation function |
| RBFNN | Radial basis function neural network |
| RBSA | Real-valued backtracking search optimization algorithm |
| Res | Residual |
| RMSE | Root mean square error |
| SSA | Singular spectrum analysis |
| VMD | Variational mode decomposition |
| WNN | Wavelet neural network |
| WPD | Wavelet packet decomposition |
| WSF | Wind speed forecasting |
| WT | Wavelet Transform |
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables in WNN | Values | Variables in WNN | Values |
| Input weighted coefficient ωi,j | [−1, 1] | Scale factor ai,j | [0.5, 2] |
| Output weighted coefficient ωj,k | [−1, 1] | Position factor bi,j | [−3, 3] |
| Weighted coefficient μ | [0, 1] | ||
| Variables in HBSA | Values | Variables in HBSA | Values |
| Iteration number T | 100 | Dimension number D | 218 |
| Population size (N) | 30 | Parameter F | 3*rndn |
References
- Ponta, L.; Raberto, M.; Teglio, A.; Cincotti, S. An agent-based stock-flow consistent model of the sustainable transition in the energy sector. Ecol. Econ. 2018, 145, 274–300. [Google Scholar] [CrossRef]
- Filippo, A.D.; Lombardi, M.; Milano, M. User-aware electricity price optimization for the competitive market. Energies 2017, 10, 1378. [Google Scholar] [CrossRef]
- Fortuna, L.; Nunnari, S.; Guariso, G. Fractal order evidences in wind speed time series. In Proceedings of the 2014 International Conference on Fractional Differentiation and Its Applications, Catania, Italy, 23–25 June 2014. [Google Scholar]
- Wang, J.Z.; Hu, J.M. A robust combination approach for short-term wind speed forecasting and analysis—Combination of the ARIMA (Autoregressive Integrated Moving Average), ELM (Extreme Learning Machine), SVM (Support Vector Machine) and LSSVM (Least Square SVM) forecasts using a GPR (Gaussian Process Regression) model. Energy 2015, 93, 41–56. [Google Scholar]
- Liang, Z.T.; Liang, J.; Wang, C.J.; Dong, X.M.; Miao, X.F. Short-term wind power combined forecasting based on error forecast correction. Energy Convers. Manag. 2016, 119, 215–226. [Google Scholar] [CrossRef]
- Torres, J.L.; García, A.; Blas, M.D.; Francisco, A.D. Forecast of hourly average wind speed with ARMA models in Navarre (Spain). Sol. Energy 2009, 1, 65–77. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Pan, D.F.; Li, Y.F. Forecasting models for wind speed using wavelet, wavelet packet, time series and artificial neural networks. Appl. Energy 2013, 107, 191–208. [Google Scholar] [CrossRef]
- Louka, P.; Galanis, G.; Siebert, N.; Kariniotakis, G.; Katsafados, P.; Pytharoulis, I.; Kallos, G. Wind speed and wind energy forecast through Kalman filtering of numerical weather prediction model output. Appl. Energy 2012, 99, 154–166. [Google Scholar]
- Fortuna, L.; Guariso, G.; Nunnari, S. One day ahead prediction of wind speed class by statistical models. Int. J. Renew. Energy Res. 2016, 6, 1137–1145. [Google Scholar]
- Ren, C.; An, N.; Wang, J.Z.; Li, L.; Hu, B.; Shang, D. Optimal parameters selection for BP neural network based on particle swarm optimization: A case study of wind speed forecasting. Knowl.-Based Syst. 2014, 56, 226–239. [Google Scholar] [CrossRef]
- Yu, C.; Li, Y.; Zhang, M. Comparative study on three new hybrid models using Elman neural network and empirical mode decomposition-based technologies improved by Singular Spectrum Analysis for hour-ahead wind speed forecasting. Energy Convers. Manag. 2017, 147, 75–85. [Google Scholar] [CrossRef]
- Hu, J.M.; Wang, J.Z.; Zeng, G.W. A hybrid forecasting approach applied to wind speed time series. Renew. Energy 2013, 60, 185–194. [Google Scholar] [CrossRef]
- Chitsaz, H.; Amjady, N.; Zareipour, H. Wind power forecast using wavelet neural network trained by improved Clonal selection algorithm. Energy Convers. Manag. 2015, 89, 588–598. [Google Scholar] [CrossRef]
- Sideratos, G.; Hatziargyriou, N.D. Probabilistic wind power forecasting using radial basis function neural networks. IEEE Trans. Power Syst. 2012, 27, 1788–1796. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. A short-term wind speed forecasting model by using artificial neural networks with stochastic optimization for renewable energy systems. Energies 2018, 11, 2777. [Google Scholar] [CrossRef]
- Cincotti, S.; Gallo, G.; Ponta, L.; Raberto, M. Modelling and forecasting of electricity spot-prices: Computational intelligence vs classical econometrics. AI Commun. 2014, 27, 301–314. [Google Scholar]
- Hu, J.M.; Wang, J.Z.; Ma, K.L. A hybrid technique for short-term wind speed prediction. Energy 2015, 81, 563–574. [Google Scholar] [CrossRef]
- Meng, A.B.; Ge, J.F.; Yin, H.; Chen, S.Z. Wind speed forecasting based on wavelet packet decomposition and artificial neural networks trained by crisscross optimization algorithm. Energy Convers. Manag. 2016, 114, 75–88. [Google Scholar] [CrossRef]
- Wang, D.Y.; Luo, H.Y.; Grunder, O.; Lin, Y.B. Multi-step ahead wind speed forecasting using an improved wavelet neural network combining variational mode decomposition and phase space reconstruction. Renew. Energy 2017, 113, 1345–1358. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.; Liang, X. Wind speed forecasting approach using secondary decomposition algorithm and Elman neural networks. Appl. Energy 2015, 157, 183–194. [Google Scholar] [CrossRef]
- Sun, W.; Wang, Y.W. Short-term wind speed forecasting based on fast ensemble empirical mode decomposition, phase space reconstruction, sample entropy and improved back-propagation neural network. Energy Convers. Manag. 2018, 157, 1–12. [Google Scholar] [CrossRef]
- Peng, T.; Zhou, J.Z.; Zhang, C.; Zheng, Y. Multi-step ahead wind speed forecasting using a hybrid model based on two-stage decomposition technique and AdaBoost-extreme learning machine. Energy Convers. Manag. 2017, 153, 589–602. [Google Scholar] [CrossRef]
- Yin, H.; Dong, Z.; Chen, Y.L.; Ge, J.F.; Lai, L.; Vaccaro, A.; Meng, A.B. An effective secondary decomposition approach for wind power forecasting using extreme learning machine trained by crisscross optimization. Energy Convers. Manag. 2017, 150, 108–121. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pastor-Sánchez, A.; Prieto, L.; Blanco-Aguilera, A.; Garcá-Herrera, R. Feature selection in wind speed prediction systems based on a hybrid coral reefs optimization-Extreme learning machine approach. Energy Convers. Manag. 2014, 87, 10–18. [Google Scholar] [CrossRef]
- Zhang, C.; Zhou, J.Z.; Li, C.S.; Fu, W.L.; Peng, T. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Convers. Manag. 2017, 143, 360–376. [Google Scholar] [CrossRef]
- Jiang, Y.; Huang, G.Q. Short-term wind speed prediction: Hybrid of ensemble empirical mode decomposition, feature selection and error correction. Energy Convers. Manag. 2017, 144, 340–350. [Google Scholar] [CrossRef]
- Luo, M.; Li, C.S.; Zhang, X.Y.; Li, R.H.; An, X.L. Compound feature selection and parameter optimization of ELM for fault diagnosis of rolling element bearings. ISA Trans. 2016, 65, 556–566. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.Q.; Peng, X.G.; Lu, D.; Zhang, D.; Liu, Y.; Lin, Z.H.; Lin, L.X. Composite quantile regression extreme learning machine with feature selection for short-term wind speed forecasting: A new approach. Energy Convers. Manag. 2017, 151, 737–752. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. EEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Civicioglu, P. Backtracking search optimization algorithm for numerical optimization problems. Appl. Math. Comput. 2013, 219, 8121–8144. [Google Scholar] [CrossRef]
- Zhang, C.J.; Lin, Q.; Gao, L. Backtracking Search Algorithm with three constraint handling methods for constrained optimization problems. Expert Syst. Appl. 2015, 42, 7831–7845. [Google Scholar] [CrossRef]
- Ahmed, M.S.; Mohamed, A.; Khatib, T.; Shareef, H.; Homod, R.Z. Real time optimal schedule controller for home energy management system using new binary backtracking search algorithm. Energy Build. 2017, 138, 215–227. [Google Scholar] [CrossRef]
- Liu, D.; Niu, D.X.; Wang, H.; Fan, L.L. Short-term wind speed forecasting using wavelet transform and support vector machines optimized by genetic algorithm. Renew. Energy 2014, 62, 592–597. [Google Scholar] [CrossRef]
- Doucoure, B.; Agbossou, K.; Cardenas, A. Time series prediction using artificial wavelet neural network and multi-resolution analysis: Application to wind speed data. Renew. Energy 2016, 92, 202–211. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, W.; Lu, H. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]
- Wang, S.X.; Zhang, N.; Wu, L.; Wang, Y.M. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
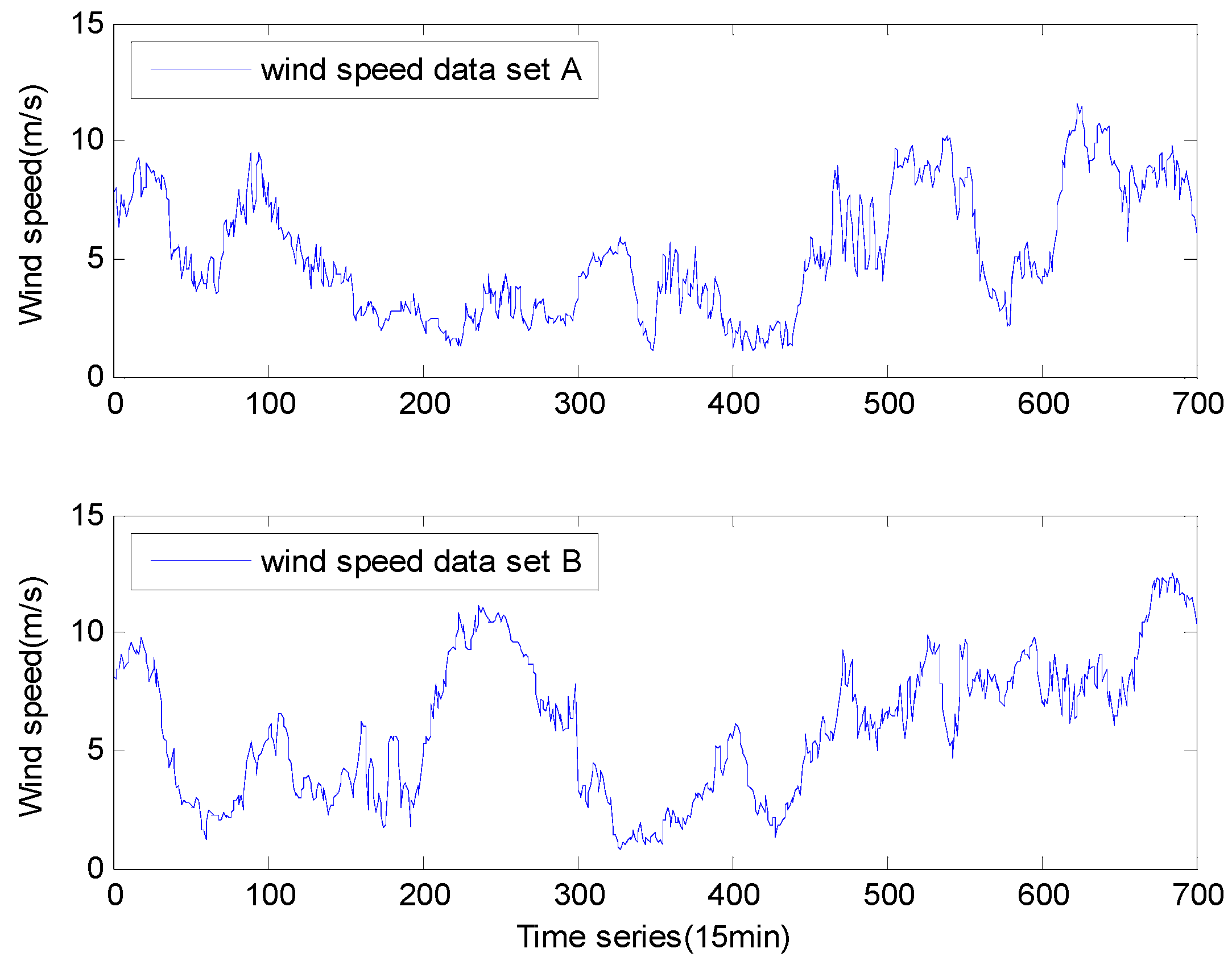



| Data set A | NO. | Max | Median | Min | Mean | St.dev. |
| Empirical samples | 700 | 11.54 | 4.71 | 1.09 | 5.22 | 2.61 |
| Training data | 600 | 10.19 | 1.22 | 1.09 | 4.66 | 2.31 |
| Test data | 100 | 11.54 | 8.81 | 4.24 | 8.54 | 1.69 |
| Data set B | NO. | Max | Median | Min | Mean | St.dev. |
| Empirical samples | 700 | 12.57 | 6.03 | 0.75 | 5.98 | 2.94 |
| Training data | 600 | 11.16 | 0.94 | 0.75 | 5.46 | 2.74 |
| Test data | 100 | 12.57 | 8.45 | 5.99 | 9.14 | 2.01 |
| Data Set | Original | Mode1 | Mode2 | Mode3 | Mode4 | IMF2 | IMF3 | IMF4 | IMF5 | IMF6 | Res |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 9 | 6 | 5 | 4 | 5 | 12 | 9 | 6 | 8 | 5 | 6 |
| B | 11 | 5 | 6 | 8 | 7 | 10 | 6 | 5 | 7 | 7 | 5 |
| Time Series | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Original | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | |||
| Mode1 | 1 | 1 | 0 | 1 | 1 | 1 | ||||||
| Mode2 | 1 | 1 | 1 | 0 | 1 | |||||||
| Mode3 | 1 | 1 | 0 | 1 | ||||||||
| Mode4 | 1 | 1 | 0 | 1 | 1 | |||||||
| IMF2 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| IMF3 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 1 | |||
| IMF4 | 1 | 0 | 1 | 1 | 1 | 1 | ||||||
| IMF5 | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | ||||
| IMF6 | 1 | 1 | 1 | 1 | 0 | |||||||
| Res | 1 | 1 | 1 | 0 | 0 | 1 |
| Time Series | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Original | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 |
| Mode1 | 1 | 1 | 1 | 0 | 1 | ||||||
| Mode2 | 1 | 0 | 1 | 0 | 1 | 1 | |||||
| Mode3 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | |||
| Mode4 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | ||||
| IMF2 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | |
| IMF3 | 1 | 1 | 1 | 0 | 1 | 1 | |||||
| IMF4 | 1 | 0 | 1 | 1 | 1 | ||||||
| IMF5 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | ||||
| IMF6 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | ||||
| Res | 1 | 0 | 1 | 1 | 1 |
| Forecasting Horizon | Index | Persistence | ARMA | BPNN | WNN | HBSA- WNN | The Proposed Model |
|---|---|---|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.8818 | 0.8288 | 0.7513 | 0.7282 | 0.6868 | 0.2249 |
| MAPE (%) | 10.0786 | 9.6457 | 8.5611 | 8.5581 | 7.9595 | 2.6943 | |
| MAE(m/s) | 0.8256 | 0.7789 | 0.6911 | 0.6962 | 0.6473 | 0.2185 | |
| MASE | 1.7097 | 1.6129 | 1.4312 | 1.4417 | 1.3405 | 0.4525 | |
| Two-step | RMSE(m/s) | 0.9543 | 0.8719 | 0.7967 | 0.7672 | 0.7228 | 0.2681 |
| MAPE (%) | 11.0418 | 9.8157 | 8.9655 | 8.7754 | 8.2616 | 2.9087 | |
| MAE(m/s) | 0.9165 | 0.8238 | 0.7487 | 0.7169 | 0.6798 | 0.2311 | |
| MASE | 1.8979 | 1.7061 | 1.5505 | 1.4846 | 1.4078 | 0.4785 | |
| Three-step | RMSE(m/s) | 1.0433 | 0.9273 | 0.8501 | 0.8183 | 0.7709 | 0.3084 |
| MAPE (%) | 12.3091 | 10.7316 | 9.5828 | 9.7785 | 9.0099 | 3.7053 | |
| MAE(m/s) | 1.0178 | 0.8969 | 0.8128 | 0.7935 | 0.7413 | 0.2985 | |
| MASE | 2.1077 | 1.8574 | 1.6833 | 1.6432 | 1.5352 | 0.6182 |
| Forecasting Horizon | Index | Model1 1 | Model2 2 | Model3 3 | Model4 4 | Model5 5 | Model6 6 |
|---|---|---|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.2599 | 0.2631 | 0.2737 | 0.3321 | 0.3631 | 0.2249 |
| MAPE(%) | 2.7453 | 3.1384 | 3.1366 | 3.9048 | 4.1554 | 2.6943 | |
| MAE(m/s) | 0.2328 | 0.2514 | 0.2605 | 0.3119 | 0.3399 | 0.2185 | |
| MASE | 0.4821 | 0.5206 | 0.5394 | 0.6458 | 0.7039 | 0.4525 | |
| Two-step | RMSE(m/s) | 0.3013 | 0.3076 | 0.3168 | 0.3784 | 0.4055 | 0.2681 |
| MAPE(%) | 3.5856 | 3.6612 | 3.7224 | 4.4355 | 4.7689 | 2.9087 | |
| MAE(m/s) | 0.2909 | 0.2861 | 0.3035 | 0.3604 | 0.3883 | 0.2311 | |
| MASE | 0.6023 | 0.5923 | 0.6285 | 0.7463 | 0.8041 | 0.4785 | |
| Three-step | RMSE(m/s) | 0.3615 | 0.3651 | 0.3752 | 0.4379 | 0.4647 | 0.3084 |
| MAPE(%) | 4.1633 | 4.2764 | 4.3314 | 4.9604 | 5.5356 | 3.7053 | |
| MAE(m/s) | 0.3302 | 0.3435 | 0.3537 | 0.4012 | 0.4489 | 0.2985 | |
| MASE | 0.6838 | 0.7113 | 0.7325 | 0.8308 | 0.9296 | 0.6182 |
| Forecasting Horizon | Index | Persistence | ARMA | BPNN | WNN | HBSA-WNN | The Proposed Model |
|---|---|---|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.9074 | 0.8379 | 0.7764 | 0.7393 | 0.7097 | 0.2422 |
| MAPE (%) | 9.8853 | 8.9319 | 8.4734 | 6.8348 | 7.3247 | 2.7088 | |
| MAE(m/s) | 0.8689 | 0.7782 | 0.7349 | 0.6281 | 0.6529 | 0.2355 | |
| MASE | 1.6322 | 1.4618 | 1.3805 | 1.1797 | 1.2265 | 0.4424 | |
| Two-step | RMSE(m/s) | 0.9609 | 0.8871 | 0.8201 | 0.7761 | 0.7408 | 0.2771 |
| MAPE (%) | 10.3226 | 9.7594 | 8.8807 | 8.0361 | 7.0844 | 3.0096 | |
| MAE(m/s) | 0.9151 | 0.8627 | 0.7871 | 0.7213 | 0.6468 | 0.2615 | |
| MASE | 1.7189 | 1.6205 | 1.4783 | 1.3542 | 1.2148 | 0.4913 | |
| Three-step | RMSE(m/s) | 1.0581 | 0.9372 | 0.8733 | 0.8312 | 0.7892 | 0.3197 |
| MAPE (%) | 11.5199 | 9.6726 | 8.7605 | 8.5297 | 8.3009 | 3.2471 | |
| MAE(m/s) | 1.0281 | 0.8717 | 0.7903 | 0.7617 | 0.7406 | 0.2805 | |
| MASE | 1.9311 | 1.6373 | 1.4845 | 1.4307 | 1.3911 | 0.5269 |
| Forecasting Horizon | Index | Model1 1 | Model2 2 | Model3 3 | Model4 4 | Model5 5 | Model6 6 |
|---|---|---|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.2887 | 0.2856 | 0.2941 | 0.3495 | 0.3811 | 0.2422 |
| MAPE (%) | 3.0531 | 3.1792 | 3.2191 | 3.7697 | 4.0994 | 2.7088 | |
| MAE(m/s) | 0.2659 | 0.2742 | 0.2757 | 0.3234 | 0.3581 | 0.2355 | |
| MASE | 0.4996 | 0.5149 | 0.5179 | 0.6074 | 0.6725 | 0.4424 | |
| Two-step | RMSE(m/s) | 0.3266 | 0.3203 | 0.3341 | 0.3744 | 0.4105 | 0.2771 |
| MAPE (%) | 3.3038 | 3.3778 | 3.4375 | 4.0851 | 4.0481 | 3.0096 | |
| MAE(m/s) | 0.2871 | 0.2889 | 0.2967 | 0.3528 | 0.3571 | 0.2615 | |
| MASE | 0.5393 | 0.5426 | 0.5573 | 0.6626 | 0.6706 | 0.4913 | |
| Three-step | RMSE(m/s) | 0.3778 | 0.3733 | 0.3897 | 0.4367 | 0.4741 | 0.3197 |
| MAPE (%) | 3.8426 | 3.7687 | 3.9728 | 4.3296 | 4.7845 | 3.2471 | |
| MAE(m/s) | 0.3321 | 0.3189 | 0.3411 | 0.3864 | 0.4324 | 0.2805 | |
| MASE | 0.6239 | 0.5992 | 0.6405 | 0.7258 | 0.8122 | 0.5269 |
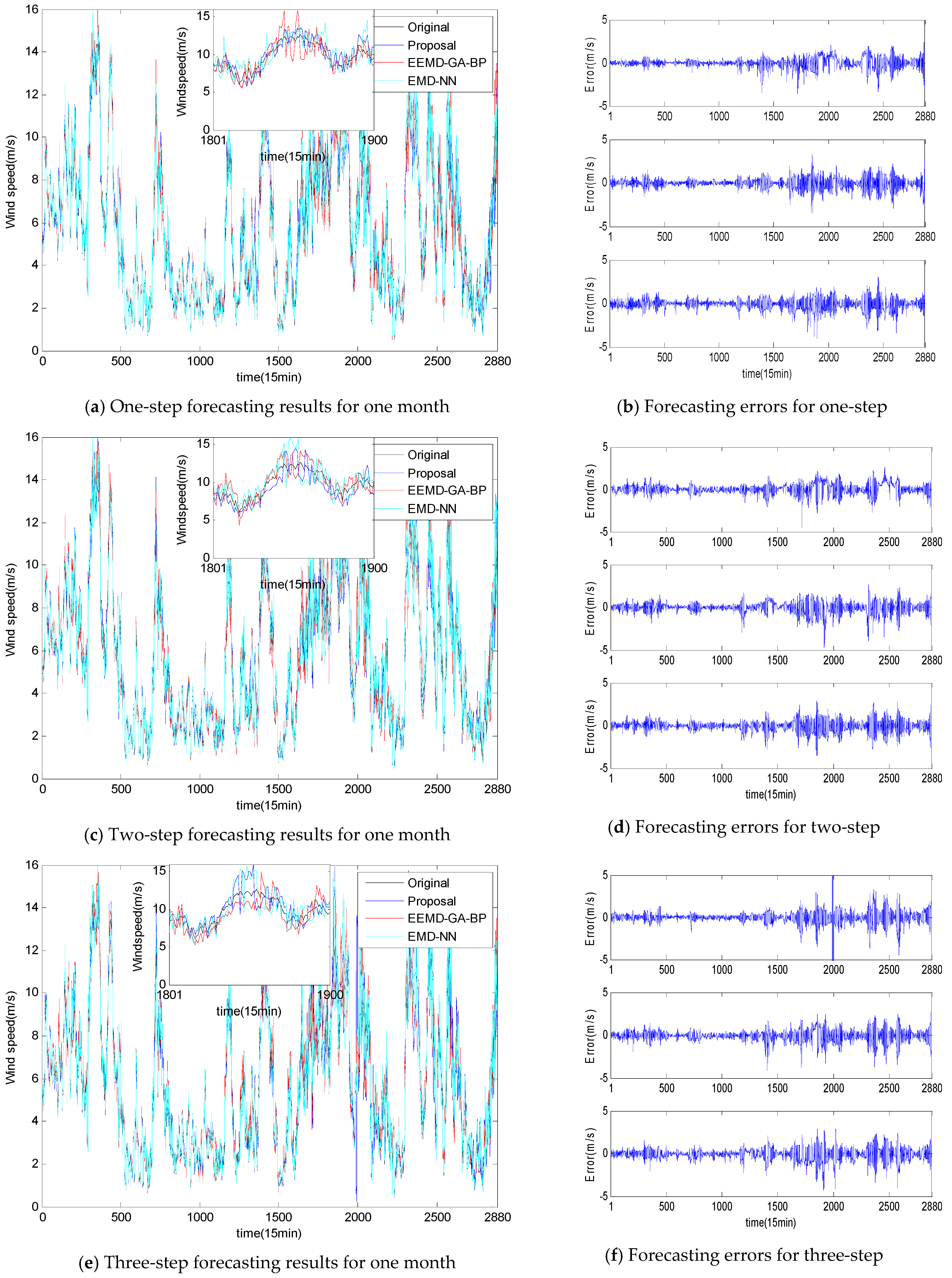
| Horizon | Index | Proposal | EEMD-GA-BPNN | EMD-NN |
|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.6516 | 0.7398 | 0.7634 |
| MAPE (%) | 8.3655 | 9.2497 | 9.4184 | |
| MAE(m/s) | 0.4721 | 0.5691 | 0.5793 | |
| MASE | 1.0642 | 1.2298 | 1.2991 | |
| Two-step | RMSE(m/s) | 0.7234 | 0.7974 | 0.8235 |
| MAPE (%) | 9.5018 | 10.3757 | 10.5942 | |
| MAE(m/s) | 0.5377 | 0.6079 | 0.6496 | |
| MASE | 1.2119 | 1.3585 | 1.4163 | |
| Three-step | RMSE(m/s) | 0.8026 | 0.8685 | 0.8895 |
| MAPE (%) | 10.4591 | 11.0179 | 11.5248 | |
| MAE(m/s) | 0.7187 | 0.7645 | 0.7983 | |
| MASE | 1.5159 | 1.5748 | 1.6150 |
| Horizon | Index | Proposal | EEMD-GA-BPNN | EMD-NN |
|---|---|---|---|---|
| One-step | RMSE(m/s) | 0.4456 | 0.4911 | 0.5235 |
| MAPE (%) | 7.5988 | 8.3497 | 8.6911 | |
| MAE(m/s) | 0.3434 | 0.4131 | 0.4404 | |
| MASE | 0.8786 | 0.9298 | 0.9426 | |
| Two-step | RMSE(m/s) | 0.5018 | 0.5465 | 0.5592 |
| MAPE (%) | 7.9787 | 8.9947 | 9.5173 | |
| MAE(m/s) | 0.3668 | 0.4383 | 0.4690 | |
| MASE | 0.9385 | 0.9886 | 1.1003 | |
| Three-step | RMSE(m/s) | 0.5427 | 0.5928 | 0.6270 |
| MAPE (%) | 8.8626 | 9.8938 | 10.6943 | |
| MAE(m/s) | 0.4178 | 0.4795 | 0.4993 | |
| MASE | 0.9947 | 1.1167 | 1.2975 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.; Wei, L.; Xu, J.; Jin, Z. A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN. Energies 2019, 12, 334. https://doi.org/10.3390/en12030334
Sun S, Wei L, Xu J, Jin Z. A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN. Energies. 2019; 12(3):334. https://doi.org/10.3390/en12030334
Chicago/Turabian StyleSun, Sizhou, Lisheng Wei, Jie Xu, and Zhenni Jin. 2019. "A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN" Energies 12, no. 3: 334. https://doi.org/10.3390/en12030334
APA StyleSun, S., Wei, L., Xu, J., & Jin, Z. (2019). A New Wind Speed Forecasting Modeling Strategy Using Two-Stage Decomposition, Feature Selection and DAWNN. Energies, 12(3), 334. https://doi.org/10.3390/en12030334