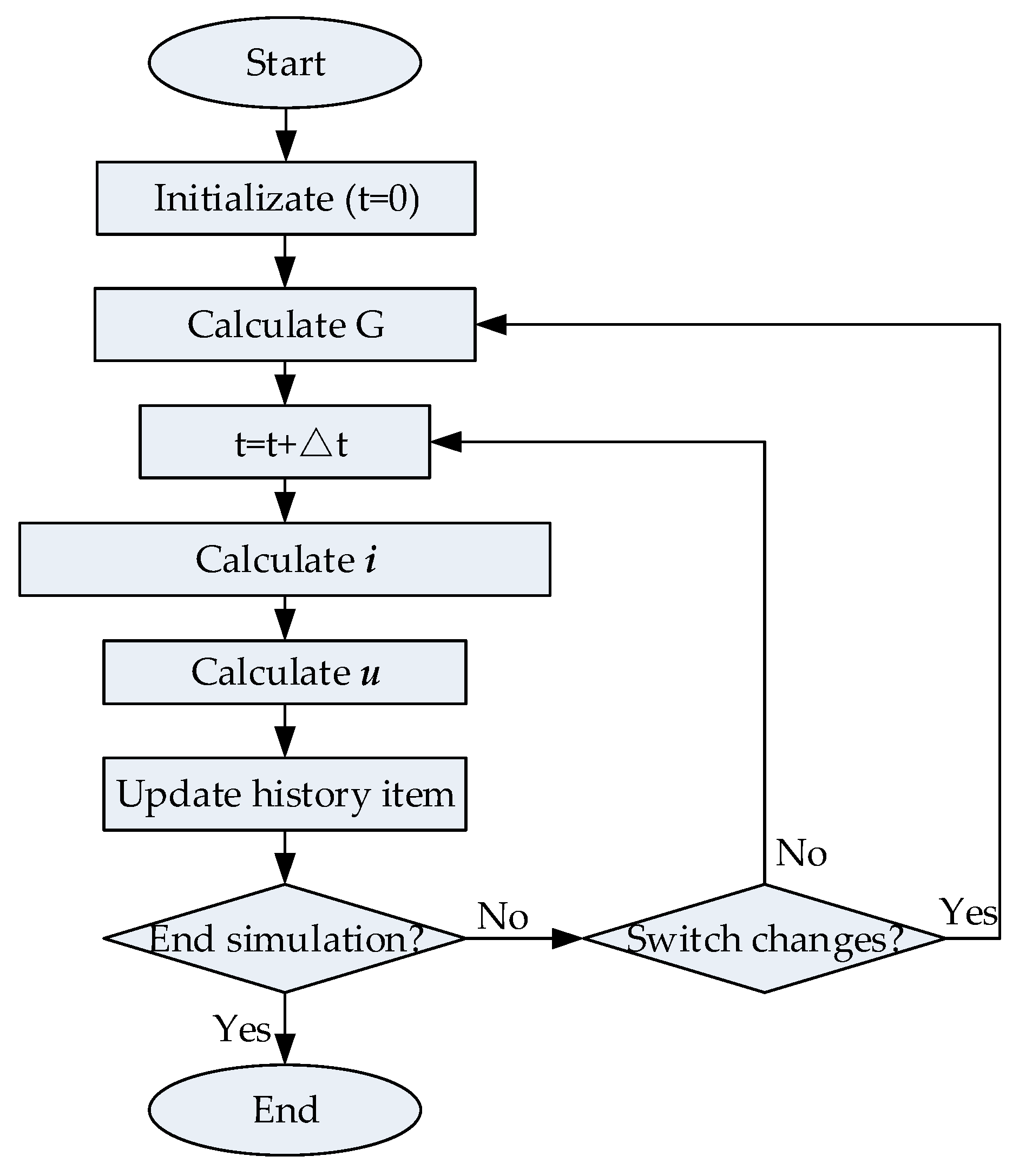
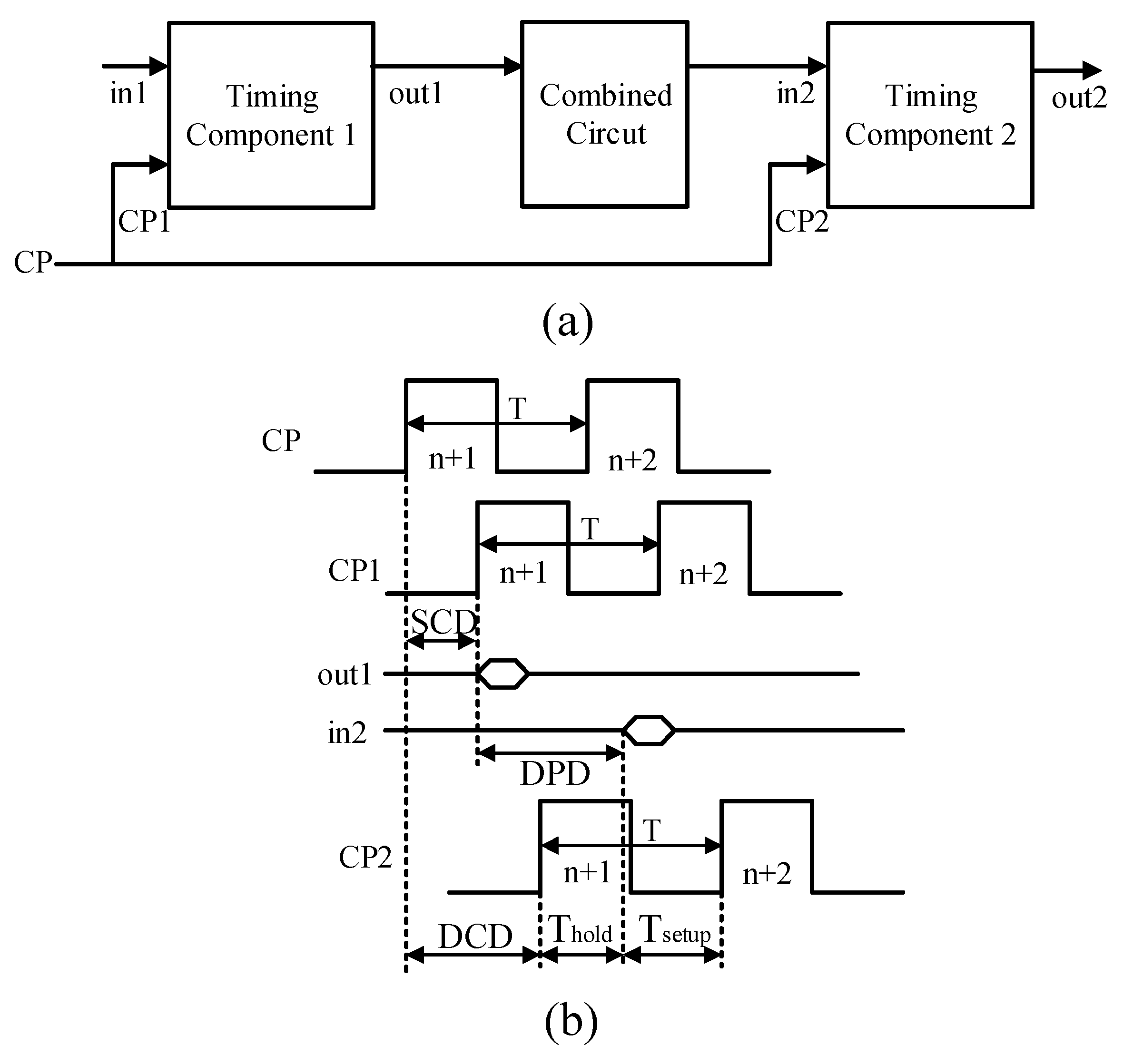
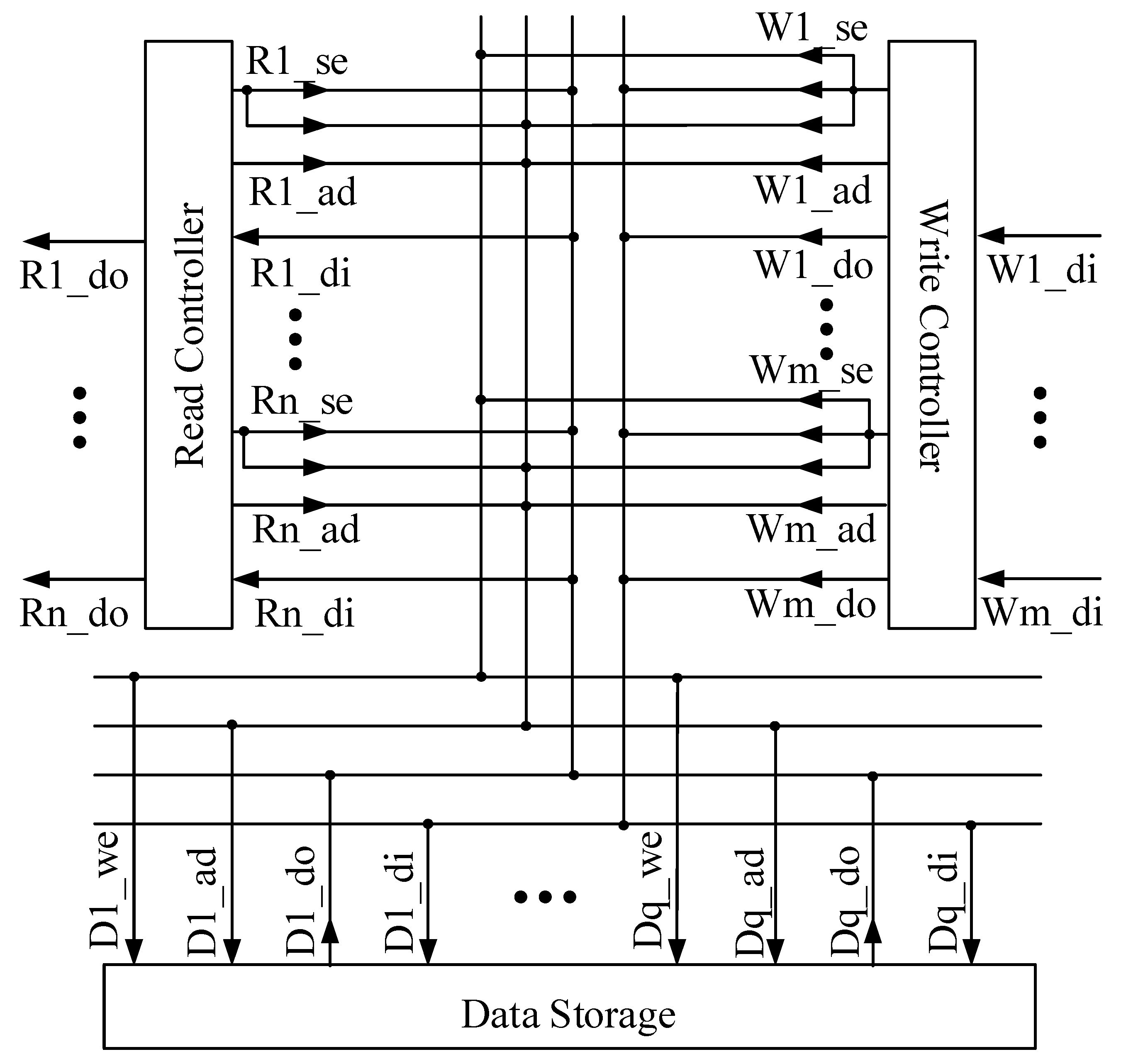
6.1. Computing Capability Test
The computing capability of the solver is mainly reflected in its seriality and parallelism. The seriality is defined as the number of associated computing formulas that can be computed in one second. When performing a seriality test, the metric is , where is the average pipeline length of the formulas, which is equal to the sum of the product of the shortest pipeline length of each computing formula and its weight.
The parallelism is defined as the number of independent computing formulas that can be computed in one second. A computing component can perform m computing formulas at the same time. When performing a parallelism test, the metric is . As , the metric is simplified to .
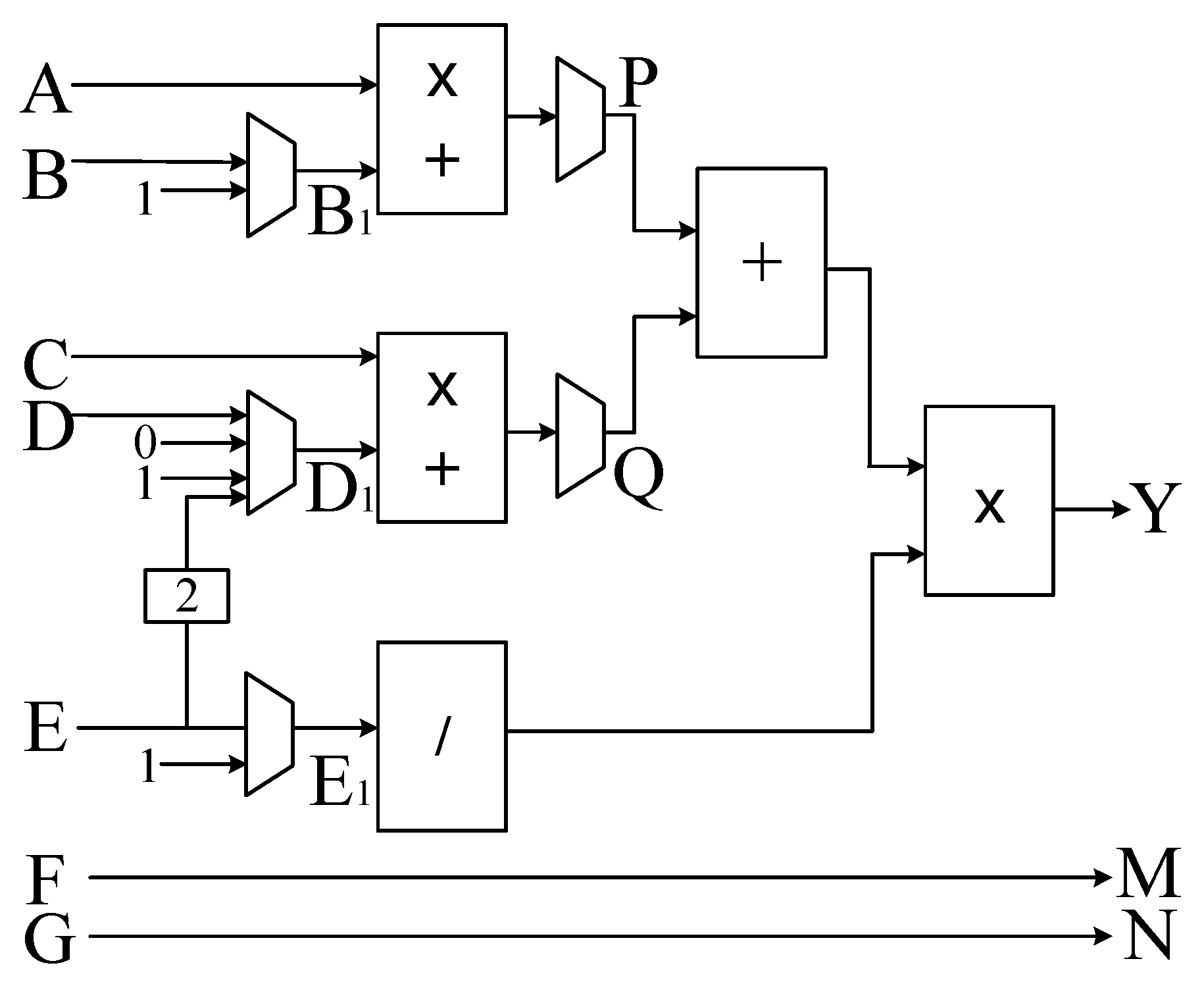
For the original FRTDS, the various types of computing formulas and their proportions are shown in
Table 2, the shortest pipeline lengths are shown in
Table 3. The average pipeline length
of the original FRTDS is calculated to be
. The seriality and parallelism tests were performed on the original FRTDS. The results are shown in
Table 6.
An original computing component can compute two computing formulas at the same time. When performing parallelism test, the metric is
, and the test results are shown in
Table 7.
According to the generation method of
Table 3, the new FRTDS is analyzed, and the relationship between the number of computing components that can be accommodated, the operating frequency, and the shortest pipeline length are as shown in
Table 8.
The average pipeline length
of the new FRTDS is calculated to be
. The seriality and parallelism tests were performed on the new FRTDS. The results are shown in
Table 9.
A new computing component can compute one computing formula at the same time. When performing parallelism test, the metric is
, and the test results are shown in
Table 10.
As shown in
Table 3 and
Table 8, the shortest pipeline length of the new computing component is shorter than the original computing component; as shown in
Table 6 and
Table 9, the new FRTDS has a greater seriality than the original FRTDS; as shown in
Table 7 and
Table 10, the new FRTDS has a higher degree of parallelism than the original FRTDS.
6.2. Example Analysis
On the FRTDS-based power system real-time simulation platform, the simulation of the 110 kV substation shown in
Figure 14 was performed, with a simulation step size of 50 μs. In this substation, 110 kV and 10 kV were connected by a single bus section, two inlets were connected to 110 kV bus, 12 outlets were connected to the 10 kV bus, and the No. 1 main transformer and the No. 2 main transformer were used to connect the 110 kV bus and 10 kV bus. The 12 outlets were connected to the resistive load. The system contained a total of 532 simulation nodes.
To verify the accuracy of the new FRTDS, the simulation system was also simulated with Power Systems Computer Aided Design (PSCAD).
After the simulation started, at time-point t = 0.15 s, the A and B phase-to-phase short-circuit faults were set at 110 kV I bus, the voltage waveform of the fault point is shown in
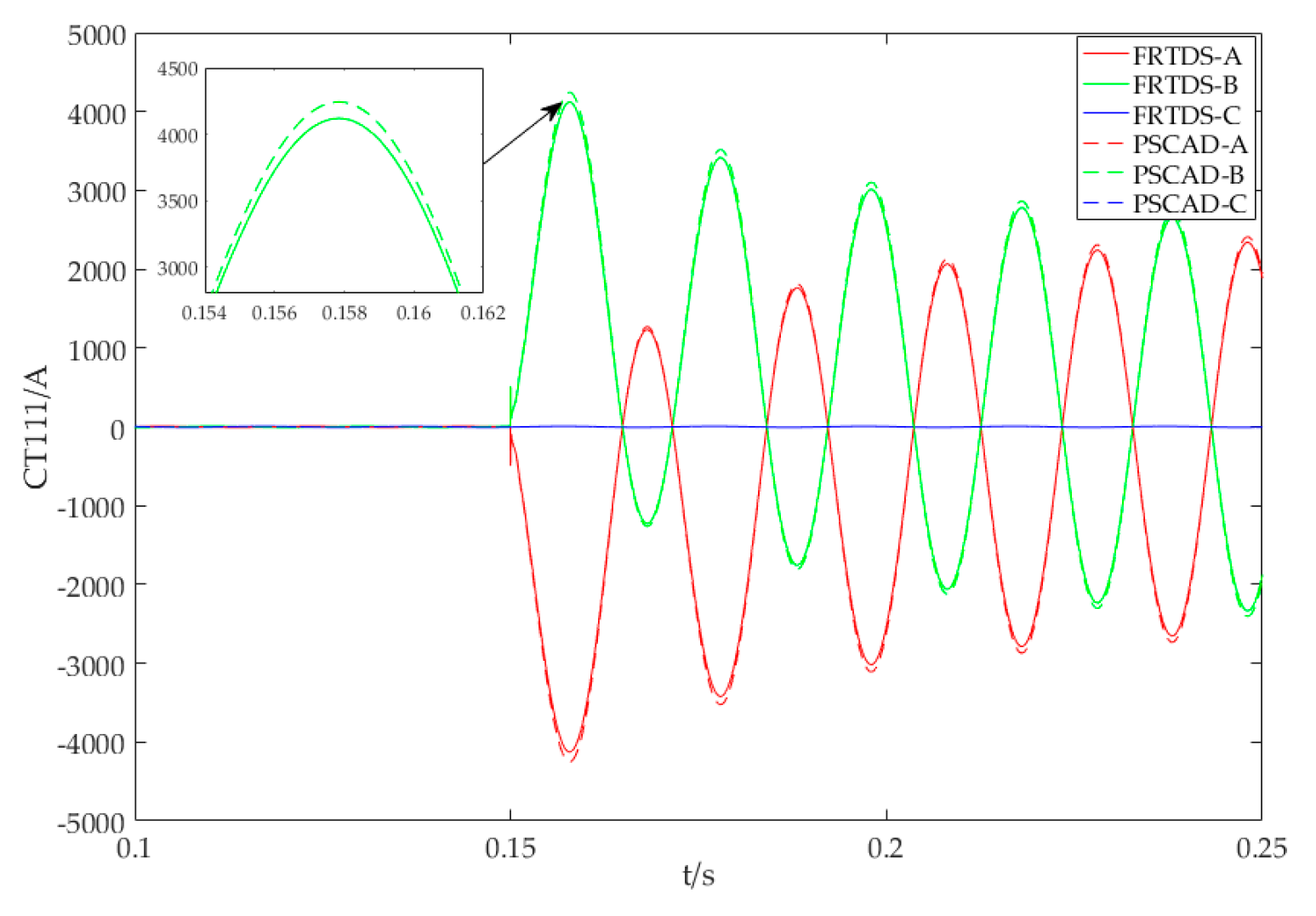
Figure 15 and the current waveform of 111-input line is shown in
Figure 16.
Figure 15 shows after the two-phase fault occurs, both A and B phase voltage of the fault point is reduced, with the same amplitude and phase.
Figure 16 shows that after the two-phase fault occurs the currents of fault phases increase sharply relative to the opposite phase. The non-fault phase current is much lower, as compared to the other two phases.
According to
Figure 15 and
Figure 16, the simulation results of FRTDS and PSCAD are consistent, which proves the accuracy of new FRTDS.
To verify the efficiency of the new FRTDS, it simulates five kinds of systems using the minimum degree method. A is the left half system, with the 10 kV bus connected to the two resistive load outlets 711, 712; B is the left half system, with the 10 kV bus connected to the four resistive load outlets 711, 712, 713, 714; C is all systems, with the two 10 kV buses connected to four resistive load outlets 711, 712, 721, 722; D for all systems, with the two 10 kV buses connected to eight resistive load outlets 711, 712, 713, 714, 721, 722, 723, 724; E is the whole system, with the two 10 kV buses connected to twelve outlets.
It was simulated with six FRTDSes of different performance—FRTDS1 (large seriality, 175MHz, 3 computing components, the original version); FRTDS2 (high parallelism, 195MHz, 4 computing components, the original version); FRTDS3 (max computing capability, 175MHz, 4 computing components, the original version); FRTDS4 (large seriality, 175MHz, 11 computing components, the new version); FRTDS5 (high parallelism, 195MHz, 12 computing components, the new version); and FRTDS6 (max computing capability, 175MHz, 12 computing components, the new version). The results are shown in
Table 11.
The test proved that when the simulation scale was small, the parallelism required by the system was not high, and the actual execution time mainly depended on the seriality of the FRTDS; when the simulation scale was large, the actual execution time mainly depended on the parallelism of the FRTDS. The new FRTDS serial computing capability and parallel computing capability were greatly improved. When using the new FRTDS, the requirements for the simulation scripts were lower and it was much easier for developers to operate. With a more balanced resource usage, shorter ideal execution time and higher parallel computing capability, the new FRTDS was ideal for real-time digital simulation of power systems.


















{kind=link}
{kind=link}
{kind=link}
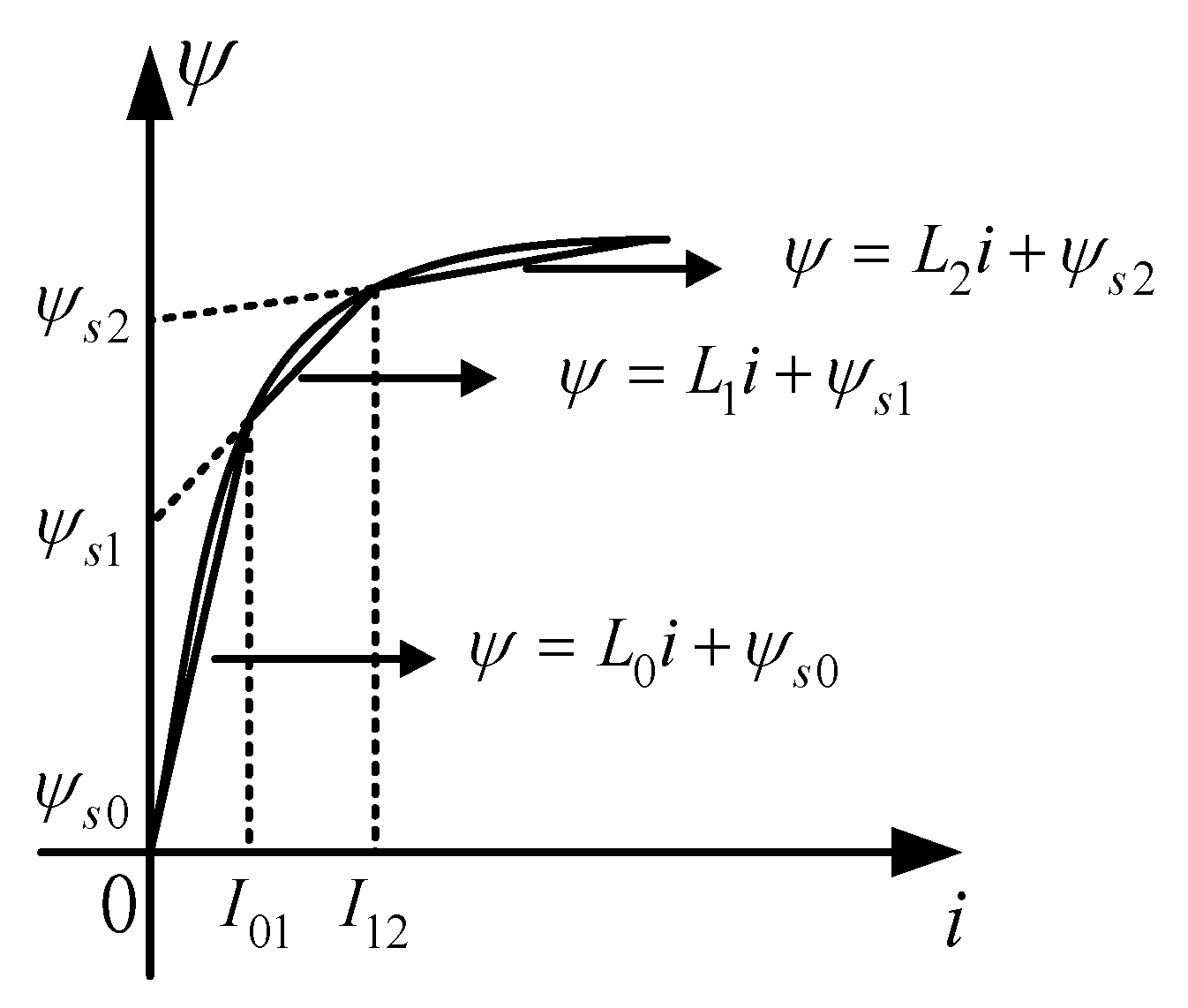{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}