1. Introduction
The rolling element bearing, an essential component of rotating machinery, is one of the most common fault sources of equipment. Mechanical failure of bearings results in significant property losses. However, the practical application environments of bearings are diverse and complex; thus, systematic identification of fault types and fault degrees without human intervention is still a significant challenge. The traditional engineering approaches include many data-driven methods, among which signal processing methods are widely used [
1]. Because of the periodicity of the fault bearing signal, this method usually contains three parts: data acquisition, feature extraction [
2,
3], and fault location. In feature extraction, the collected bearing signals are analyzed, and the useful features containing fault information are selected according to prior knowledge. Generally, the time domain features that can be extracted manually include kurtosis [
3] and entropy [
4], and the time–frequency domain features that can be extracted manually include the wavelet packet [
5] and Hilbert spectrum [
6]. Classification tasks are involved in fault location, mostly using k-nearest neighbor (k-NN) [
3], support vector machine (SVM) [
7,
8], artificial neural network (ANN) [
4], and other methods. Zhang et al. [
9] optimized support vector machines using the inter-cluster distance (ICD) in the feature space (ICDSVM) to identify the fault types and the fault severity of bearing. The experimental results, taking into consideration various combinations of fault types, fault degrees, and loads, showed that the proposed method has high accuracy in identifying the fault type and fault degree of the bearing. Although these methods can make full use of existing human knowledge, they cannot sufficiently meet the requirements of working conditions and automation. The automatic completion of diagnostic tasks of feature extraction and classification can be overcome by new advanced artificial intelligence technology.
With the rapid improvement of computational operations and the development of machine learning and deep learning, various kinds of deep neural networks were applied to the field of fault diagnosis, such as the convolutional neural network (CNN). Ince et al. [
10] proposed a motor fault diagnosis system based on a one-dimensional (1D) convolution neural network for 1D data. Peng et al. [
11] proposed a new deep 1D CNN to diagnose faults of wheel bearings for high-speed trains. Eren et al. [
12] proposed a system for bearing diagnosis using a compact adaptive 1D CNN classifier. The system directly takes raw sensor data as input; thus, it is suitable for real-time fault diagnosis. However, the accuracy of fault recognition is still limited. Guo et al. [
13] proposed a new intelligent method for fault diagnosis of machines based on transfer learning. The deep convolutional transfer learning network was able to promote the application of fault diagnosis of machines with unlabeled data, based on a complex deep CNN model. Huang et al. [
14] proposed an improved CNN called the multi-scale cascade convolutional neural network (MC-CNN) to enhance the classification information of input. The multi-scale information was obtained by filters with different scales to input the CNN. This method avoided the local optimization of CNN and exhibited high accuracy in bearing fault diagnosis. An [
15] provided a detailed mathematical definition of the feedback mechanism in a deep CNN, and combined sparse expression with the feedback mechanism of CNN (FMCNN) to determine the fault degree when assessing bearing fault location. However, these methods still cannot mine the multi-scale information in the data. Guo et al. [
16] reconstructed a two-dimensional (2D) array using adaptive learning rate calculation and time vibration signals, and then applied the deep learning method to effectively diagnose bearing faults. The remaining service life of the equipment was predicted by Xiang et al. [
17] utilizing a deep CNN. With the discrete Fourier transform of two vibration signals as the input of the CNN in the study of Janssens et al. [
18], the fault states of rotating machinery were successfully diagnosed and classified using the 2D CNN. All of these CNN-based methods identified the vibration data of equipment. However, CNN was originally designed for image processing. Yang et al. [
19] combined wavelet transform with CNN, and a new fault diagnosis method was proposed, including the direct classification of continuous wavelet transform scalograms (CWTSs) using CNN. According to this method, different types of vibration signals from rotating machinery are decomposed into CWTSs after wavelet transform. After that, CWTSs are used as input to train the CNN for fault diagnosis. A number of experiments were carried out on the rotor experimental platform based on this method. The results showed that this method could accurately diagnose faults. However, there are still the same limitations in the CNN. Udmale et al. [
20] introduced a method based on a kurtogram and convolutional neural network for the fault diagnosis of rotating machines. The kurtogram as the input of CNN provided additional frequency information. Lei et al. [
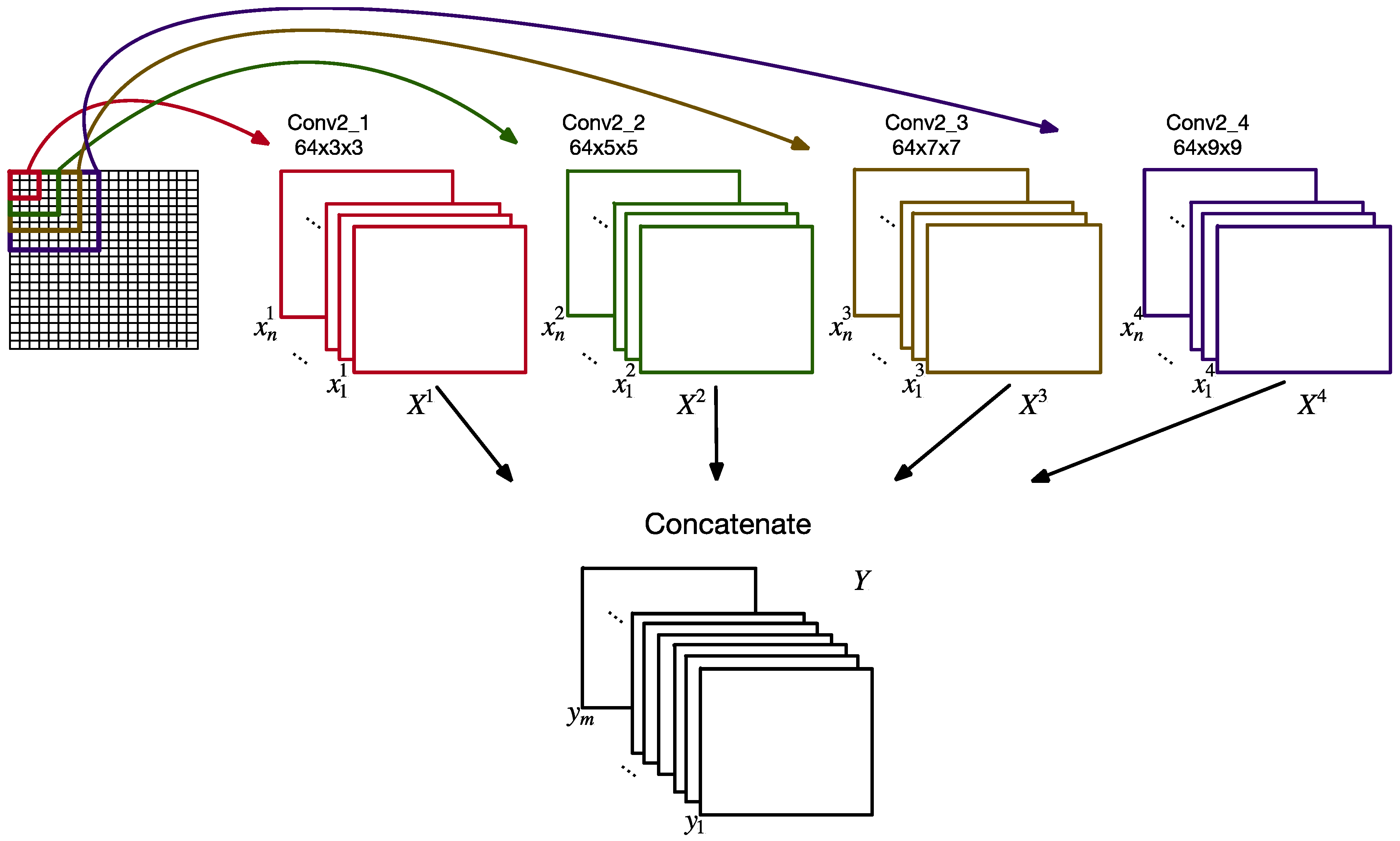
21] proposed an intelligent fault diagnosis method based on unsupervised learning. An unsupervised neural network by sparse filtering was used to learn the features from vibration signals. Compared with other fault diagnosis methods, the high recognition accuracy of CNN relies on the complex deep network structure. Thus, a large number of training samples are needed to improve the generalization ability of the model. However, the data for mechanical fault diagnosis in practical application are limited, the CNN model is too deep and too complex, making it prone to overfitting, and the model with too simple a structure and shallow layers cannot fully learn the effective features of the data. Two aspects need to be improved in the existing CNN-based models for bearing fault diagnosis. Firstly, in the structure of the traditional CNN, only feature maps in the last convolutional layer are provided for classification, and the feature maps are more constant and robust with the loss of pivotal information. Secondly, convolutional filters with fixed window sizes are widely adopted in most existing CNN models, which cannot flexibly select variable pivotal features in bearing fault diagnosis, and the model may be disturbed by redundant information in feature maps during training.
To overcome these limitations, this paper proposes a shallow multi-scale (MS) CNN with a multi-attention mechanism for bearing fault diagnosis. The time–frequency representation (TFR) as the input of the model was generated by original vibration data of the bearing. TFR bearing degradation signals are complex, nonstationary, and more effective. Zhu et al. [
22] proposed an effective deep feature learning approach for remaining useful life prediction of bearings, which relied on the TFR and CNN. The TFR was applied to analyze the transients, including rapid changes in amplitude or phase during an event relative to post-event conditions [
23]. TFR worked better than the vibration image used by Hoang and Kang in CNNs based on bearing fault diagnosis, which retained more comprehensive information in image data [
24]. Wang et al. [
25] compared eight time–frequency analysis methods for creating images, and the results indicated that continuous wavelet transform and fast Stockwell transform were the best methods for bearing diagnosis. Because of the low visual complexity of TFR images, the shallow CNN structure effectively avoids the problem of deep network training, which does not converge or overfit. MS convolutional networks were studied by Sermanet and LeCun [
26], and used for recognizing traffic signs. Their research showed that the multi-scale features combined with precise details were more robust and invariant than the deep features based on the traditional CNN structure. By studying the recent literature, most of the deep learning-based fault diagnosis methods improved the depth of the network structure and the data of the training network, and they neglected the utilization efficiency of the features in the model training process. In the study of Sun et al. [
27], before generating a multi-scale layer, the pooling layer and the last convolutional layer were combined, and favorable performances were obtained in a face identification task. Therefore, it can be predicted that, by keeping the global and local information synchronously, more identifiable features can be obtained between bearing health status and modes. Using the MS layer as the last convolutional layer in this study, the global and local features were sustained to increase the network capacity, allowing more scale features to be extracted for classification. Furthermore, a multi-attention mechanism was proposed to adaptively select vital features to obtain superior recognition results. Attention is an effective mechanism for selecting vital information to achieve excellent results. There are some effective attention mechanisms for image caption and machine translation, such as soft and hard attention [
28], and global and local attention [
29]. In this study, a deep learning model combined with the attention mechanism was adopted. The attention mechanism was used to focus on the more sensitive features of specific labels in the training process for improving the performance of model. Deep neural networks, including CNNs and recurrent neural networks, can achieve better results if they are equipped with an attention mechanism. In this paper, a multi-scale convolutional neural network (MSCNN) was combined with the multi-attention mechanism to propose a novel method for bearing fault diagnosis. The MSCNN is different from the multi-scale information in Reference [
14], which was obtained from the signal before the input of the CNN; here, the multi-scale feature was obtained from the training process, combining it with the multi-attention mechanism. The proposed method achieved excellent results in simultaneously identifying the fault type and fault degree of bearings. Furthermore, the identification of specific bearing conditions was improved using the multi-attention mechanism.
3. Experimental Verification
A series of experiments were carried out to evaluate the effectiveness of the proposed bearing fault diagnosis method. The Bearing Data Center of Case Western Reserve University provided experimental data for multiple faults [
34]. Single point faults of 0.007, 0.014, and 0.021 inches were distributed on the rolling parts, and the inner and outer rings of drive end bearings, respectively. In the experiment, there were four load conditions, including 0, 1, 2, and 3 hp. The vibration generated in the test was measured at 12-kHz sampling frequency. According to the proposed method, fault type and fault degree could be separated simultaneously. The damage degree of the bearing was indicated by the fault sizes of 0.007, 0.014, 0.021, and 0.028 inches. Twelve kinds of bearing health conditions under four kinds of loads were included in the dataset, among which the same health conditions under different loads were divided equally.
Table 2 shows the 12 data labels from different fault types and different fault degrees. Samples were obtained in the vibration data of each health condition by enhanced sampling. Each sample contained 1000 points, and the stride of enhanced sampling was 100. Therefore, each dataset contained 4360 samples. In total, 70% of the 17,440 samples were used as training samples and 30% were used as test samples.
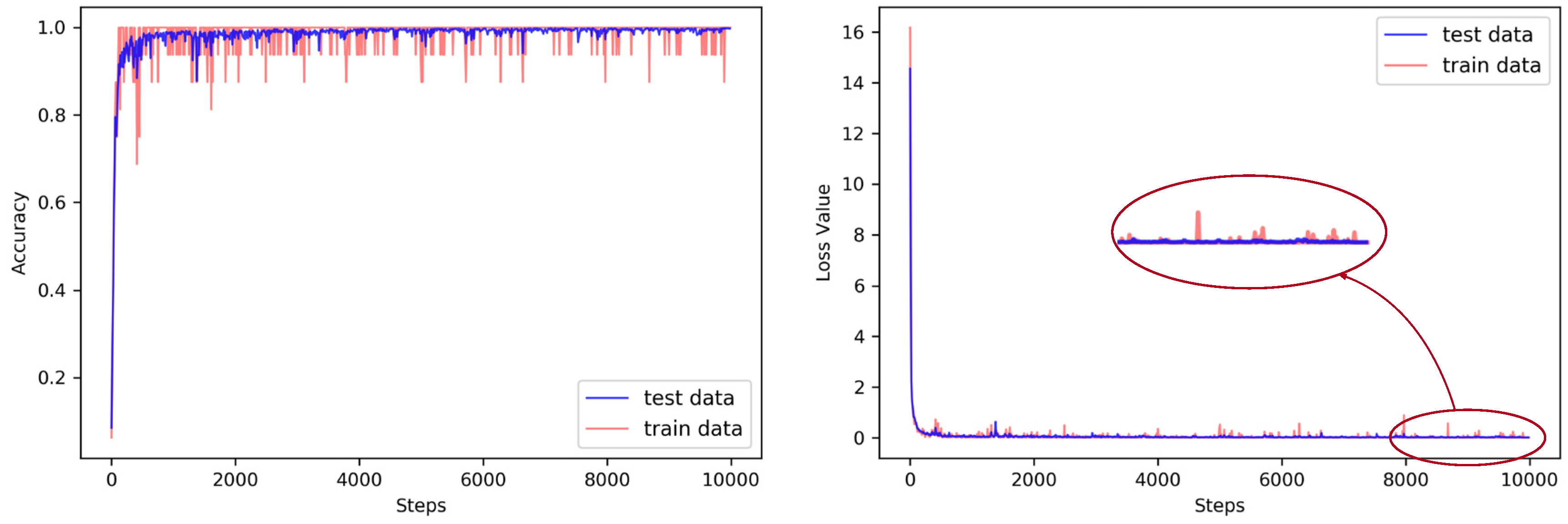
Figure 9 shows that the loss value and accuracy of the proposed MA-MSCNN tended to stabilize during the training steps of 8000 to 10,000. Thus, in the experiment, the number of training steps was determined to be 10,000 steps. The model was built by TensorFlow (1.8.0) and was only completed by central processing unit (CPU) training. The training time was nearly six hours on a laptop computer (64-bit, i7 7700HQ 2.8-GHz CPU, 16 GB random-access memory (RAM)).
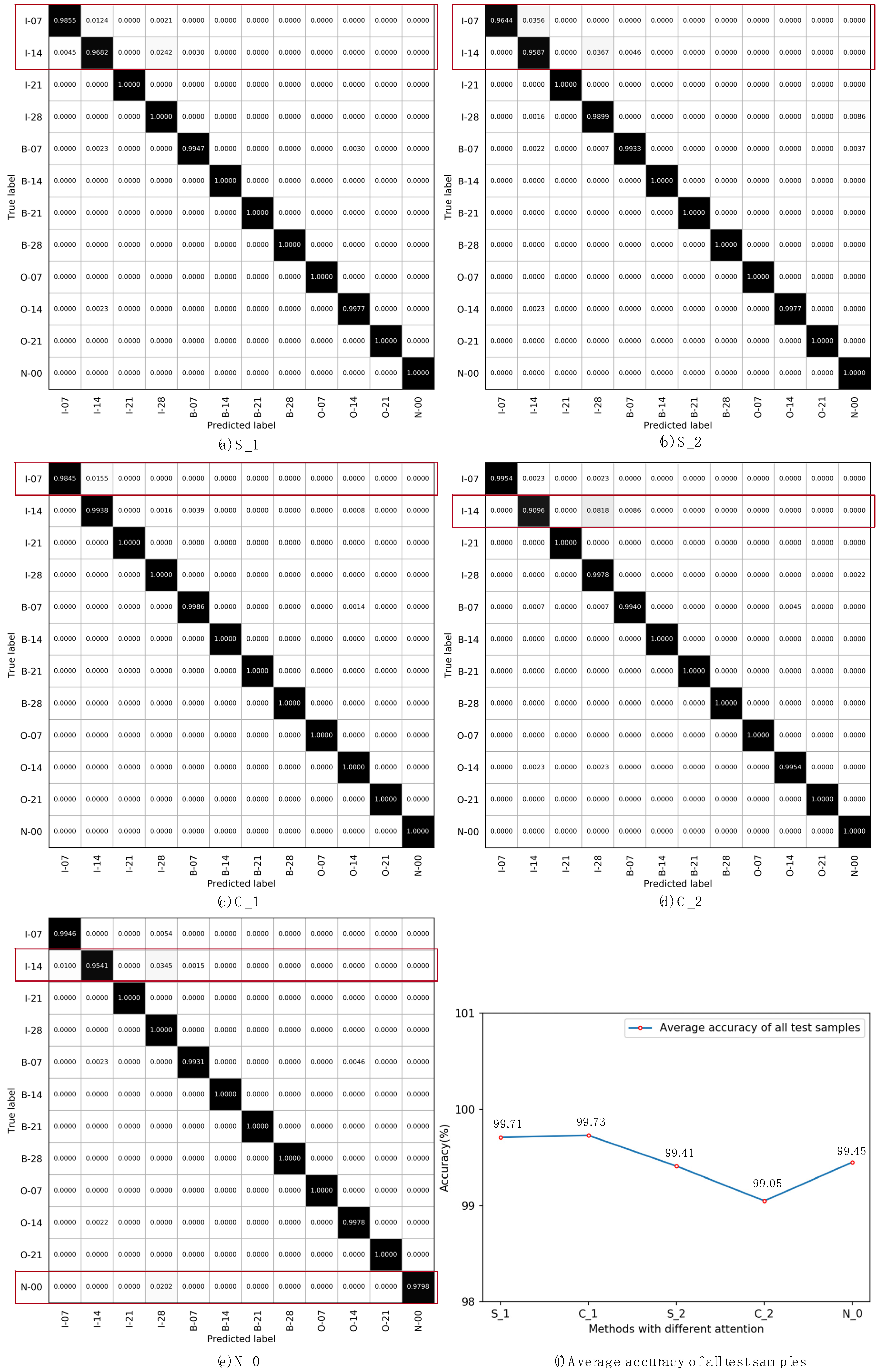
3.1. Evaluations of Single Attention
In this section, the comparison of a single kind of attention mechanism with the multi-scale CNN is evaluated. S_1 was a pure spatial attention mechanism followed by the first convolution layer (C1). After getting the spatial attention weights from the attention mechanism, we combined it with the feature maps of the C1 layer through element multiplication and fed it into the next layer. S_2 was a pure spatial attention mechanism followed by the MS layer. Then, the spatial weighted feature maps were fed into the next layer for classification. C_1 was a pure channel-based attention mechanism followed by the first convolution layer (C1). After getting the channel attention weights from the attention mechanism, we combined it with the feature maps of the C1 layer using Equations (11) and (12) and fed it into the next layer. C_2 was a pure channel-based attention mechanism followed by the MS layer. Then, the channel weighted feature maps were fed into the next layer for classification. N_0 was the MSCNN without an attention mechanism, and the architecture was similar to the multi-attention layer removed in
Figure 7.
According to the statistics during the experiment, there were a total of 51,124 valid samples participating in this section of the validation, of which 35,787 were for training, and 15,337 were for testing. All the results are reported in
Figure 10. The identification of each faulty label in each method is represented in the form of a confusion matrix. According to the results from
Figure 10, we can make a few observations. Firstly, from the average recognition accuracy, shown in
Figure 10f, by identifying all the test samples, we can see that the fault recognition ability of the model was improved by setting the single attention mechanism followed by the first convolution layer (C1). Secondly, from the confusion matrix shown in
Figure 10a–e, we can see that the single attention mechanism had an impact on the recognition of the specific condition of the bearing, and the accuracy of normal condition (N_0) recognition was significantly improved by the model. Thirdly, from the recognition results, the identification of the label I-14 sample using the single attention mechanism was not improved, and the sample identification accuracy of the label I-07 was even reduced.
3.2. Evaluations of Multi-Attention
Depending on the order of implementation of channel-based attention and spatial attention, there were two types of models that combined the two attention mechanisms. The distinction between these two types is shown in
Figure 11. The first type, named the SC-Attention mechanism, applied spatial attention before channel-based attention. Firstly, initial feature map
was given, and the spatial attention weight
was obtained by using the spatial attention
. The spatial weighted feature maps were obtained by the linear combination of
and
. Then, the spatial weighted feature maps were input into the channel-based attention model
to receive the channel attention weight
. Finally, the channel attention weights
and feature maps after spatial attention were multiplied in the channel dimension to get the final feature
. The second type, denoted as the CS-Attention mechanism, was a model with the channel-based attention implemented first. For the CS-Attention mechanism, given the initial feature map
, the channel attention weight
was firstly obtained using the channel-based attention
. Then, the channel weighted feature maps were input into the spatial attention model
to obtain the spatial attention weight
. Finally, feature maps
were obtained by multiplying the spatial weights
and the feature maps after channel attention in the spatial dimension.
In this section, the comparisons of MA-MSCNN with different kinds of multi-attention mechanisms are evaluated. SC_1 was the SC-Attention mechanism followed by the first convolution layer (C1). The feature maps after multi-attention mechanism were fed into the next layer. CS_1 was the SC-Attention mechanism followed by the first convolution layer (C1). SC_2 was the SC-Attention mechanism followed by the MS layer. Then, the attention weighted feature maps were fed into the next layer for classification. CS_2 was the CS-Attention mechanism followed by the MS layer. The results of these four comparisons are shown in
Figure 12. According to the results from
Figure 12, we can make a few observations. Firstly, from the average recognition accuracy, shown in
Figure 12e, by identifying all the test samples, we can see that the multi-attention mechanism after a multi-scale convolutional layer (MS-Layer) is better than a single attention mechanism. This shows that the MA-MSCNN model combined with the multi-scale convolutional layer and the multi-attention mechanism proposed in this paper is more effective in bearing fault diagnosis. Secondly, by using the multi-attention mechanism, the ability of the model to identify individual fault types was also improved. It can be seen from the experimental results that the identification of fault labels I-07 and I-14 was not excellent using the single attention mechanism, and the recognition accuracy of the two fault labels was significantly improved by the multi-attention mechanism.
Table 3 and
Table 4 show the identification results for different situations using the single attention mechanism and the multi-attention mechanism, respectively. Comparing
Table 3 and
Table 4, the results show clearly that the model with the multi-attention mechanism had better diagnosis accuracies for labels I-07 and I-14 than the model with the single attention mechanism.
Table 5 shows the recognition results of the different fault degrees under each fault type. It can be seen that the diagnosis method proposed in this paper can also perform well in the case of a small difference in fault degree.
4. Comparison with Related Works
As a common method in the study of mechanical fault diagnosis, the rolling bearing dataset used in this investigation is very popular. Many excellent classification results were reported in recent years (95%) and higher testing accuracies were achieved in References [
9,
14,
15,
21]. However, when studying the existing methods for this dataset, it was found that the accuracy of the current intelligent diagnosis reached a ceiling. Most studies focused on the input data and the structure of model, whereas very limited work could be found on efficiently mining multi-scale features using the attention mechanism.
In the latter case, a testing accuracy of 97.91% was obtained in Reference [
9] using optimized support vector machines. The model was trained by 880 samples, and the number of test samples was 1320. Then, 1000 test samples were divided into 11 classes with different fault types and degrees. An improved multi-scale cascade CNN (MC-CNN) was proposed in Reference [
14] to mine multi-scale features of input signals. This study focused on the input data of the CNN, and the multi-scale information was obtained in the input layer to improve the performance of the CNN. Only four bearing conditions were classified, and 99.61% testing accuracy was obtained based on 50 experiments. The 800 samples used in the experiment were divided into training sets and testing sets according to three proportions, and the model had the best testing accuracy when the training set had the largest number of samples. Ten bearing conditions were considered in Reference [
15], and 20,000 samples were obtained via data augmentation. As a result, as high as 98.8% classification accuracy was achieved from 2500 testing samples. In Reference [
21], a two-stage machine learning method based on unsupervised feature learning and sparse filtering was proposed. The experimental dataset contained 4000 samples, and a fairly high identification accuracy of 99.66% was obtained when 10% of samples were used for training.
The method proposed in this paper allowed achieving an accuracy of bearing fault diagnosis as high as 99.86%. The MSCNN model with a multi-scale attention mechanism provided higher recognition accuracy, as shown in
Figure 11e. This study carried out a more detailed condition segmentation using the same dataset obtained from Case Western Reserve University. Considering 12 bearing health conditions, the trained model identified 15,337 testing samples. A detailed study on the comparisons of classification accuracy with other researches on the same bearing dataset with diagnosis accuracy higher than 95% is shown in
Table 6.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}