Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation


Abstract
1. Introduction
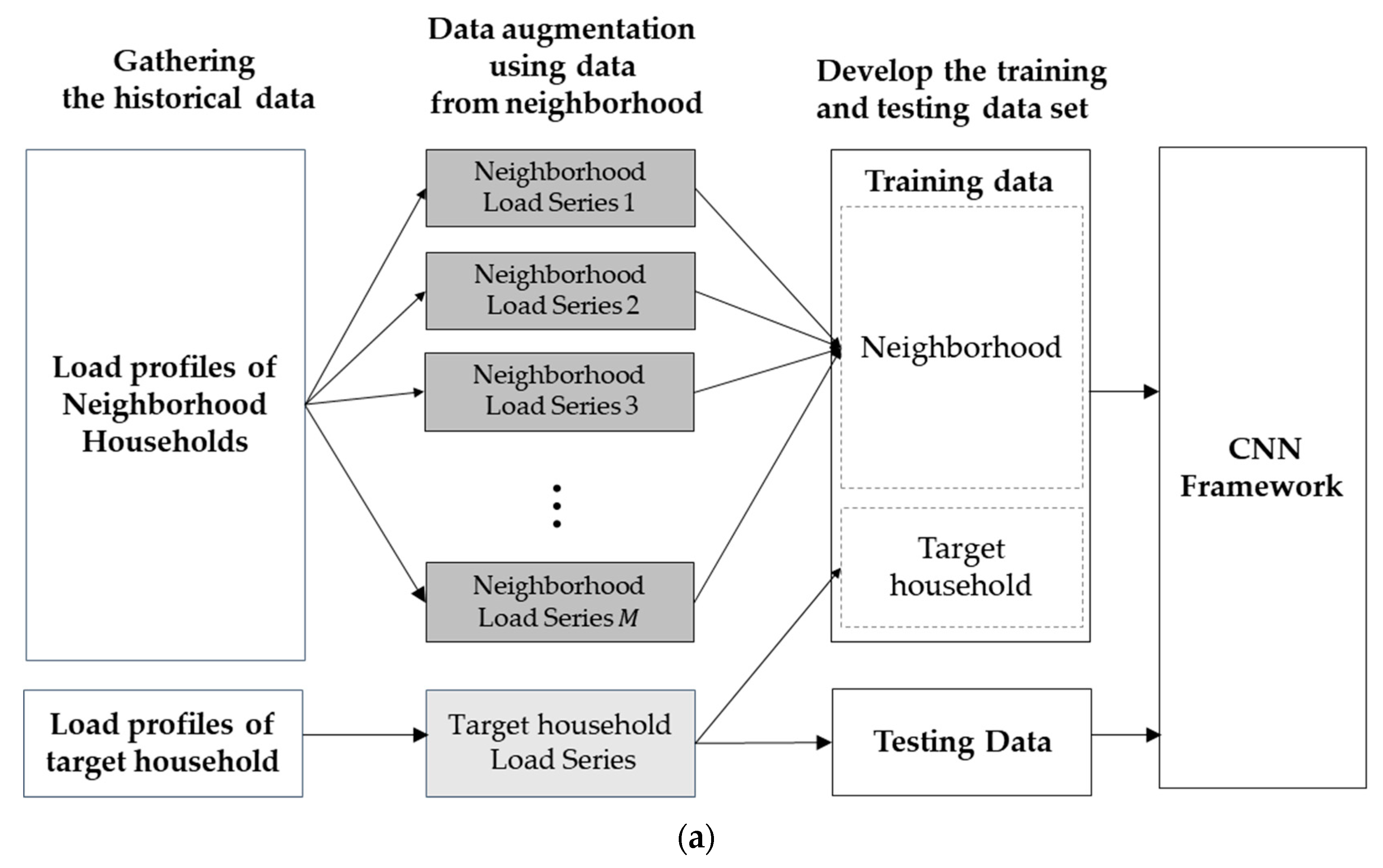
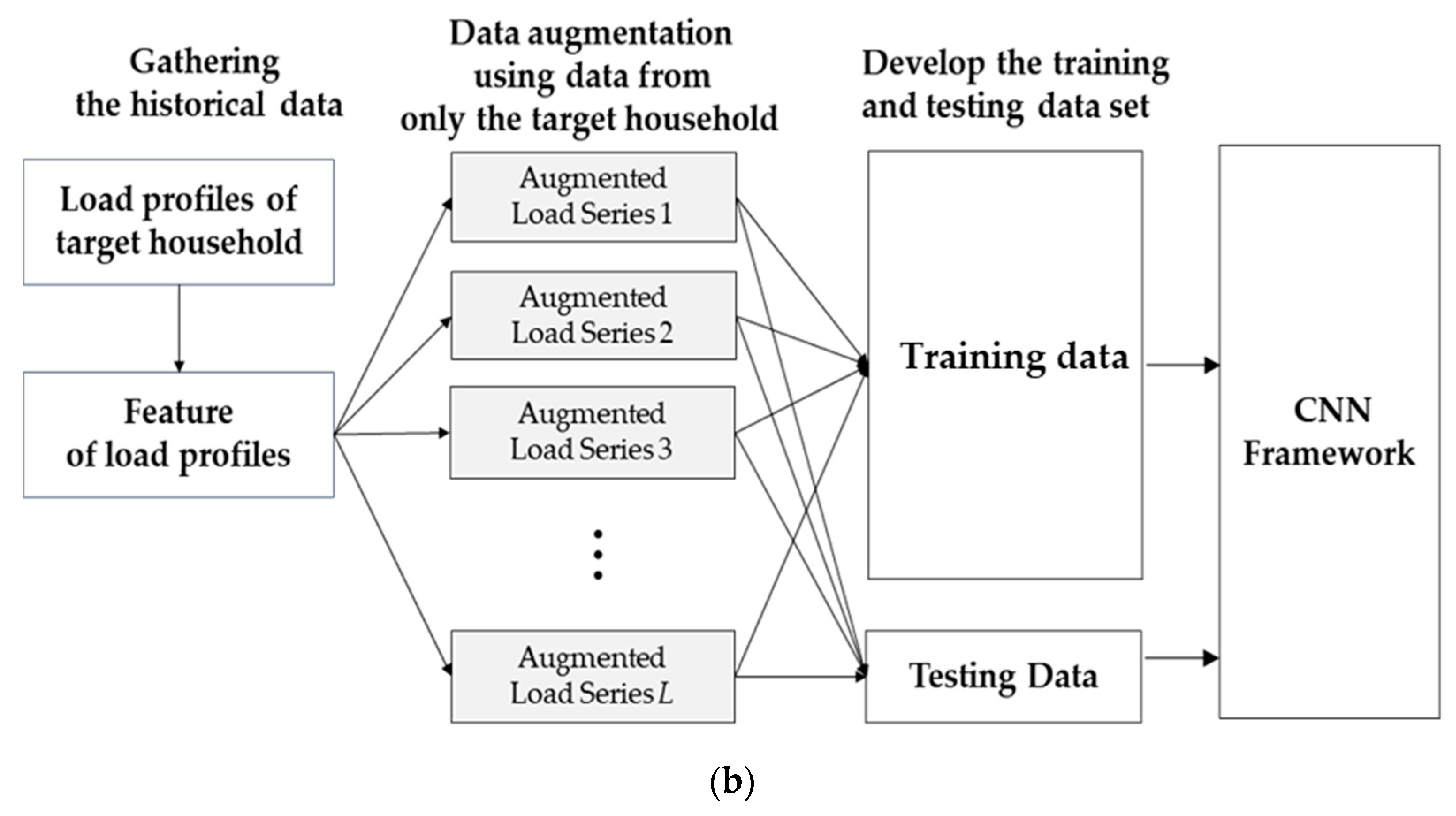
2. Augmentation Implementation
2.1. CNN with Augmentation
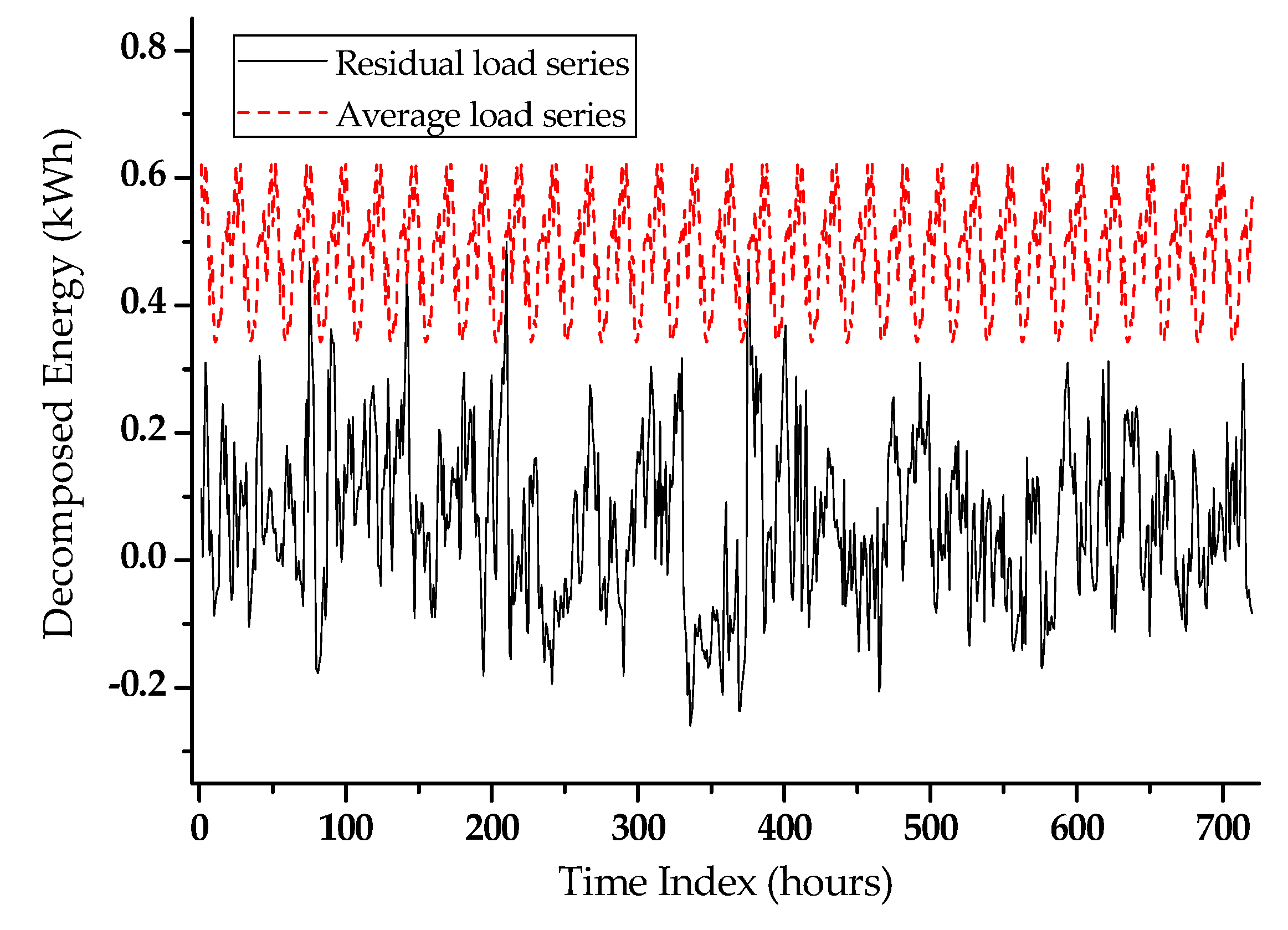
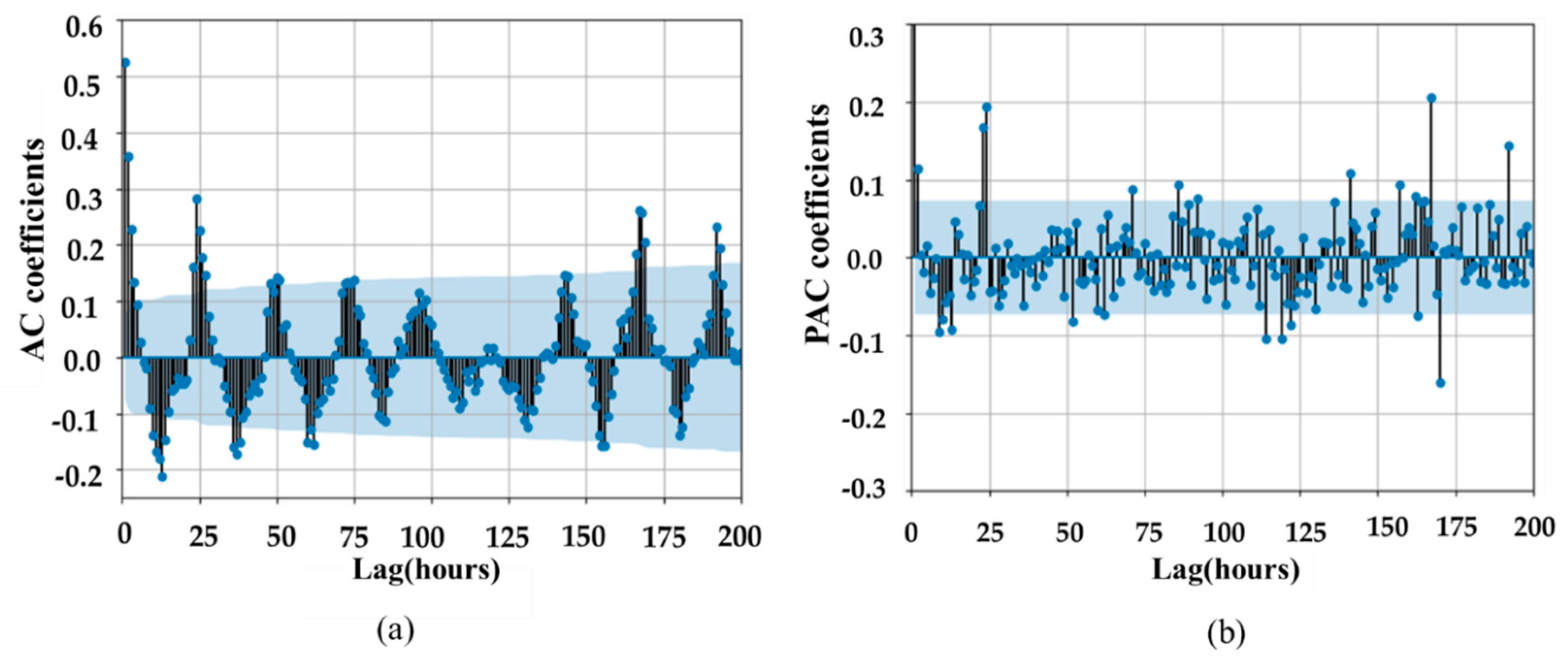
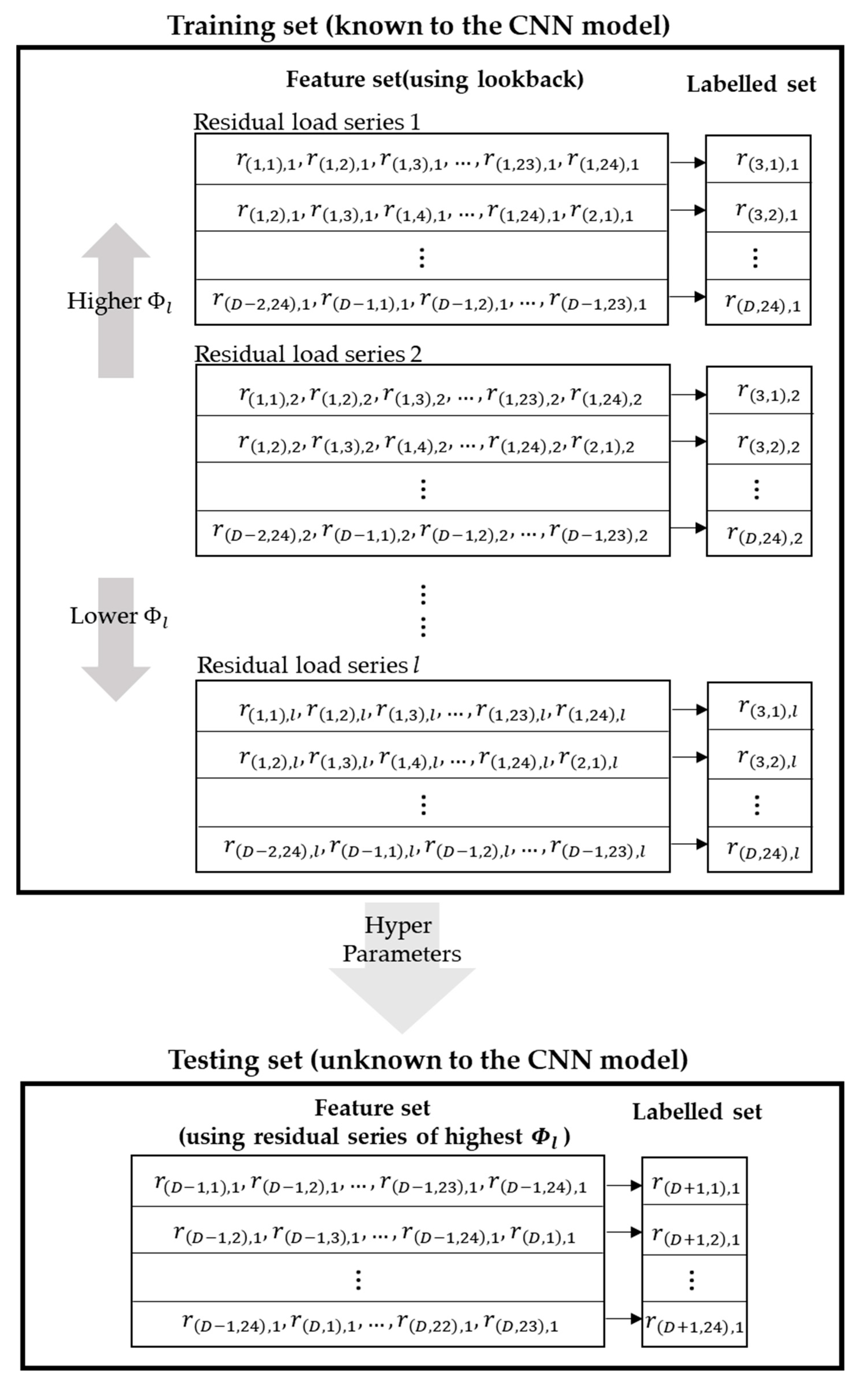
2.2. Extraction of Residual Load Series
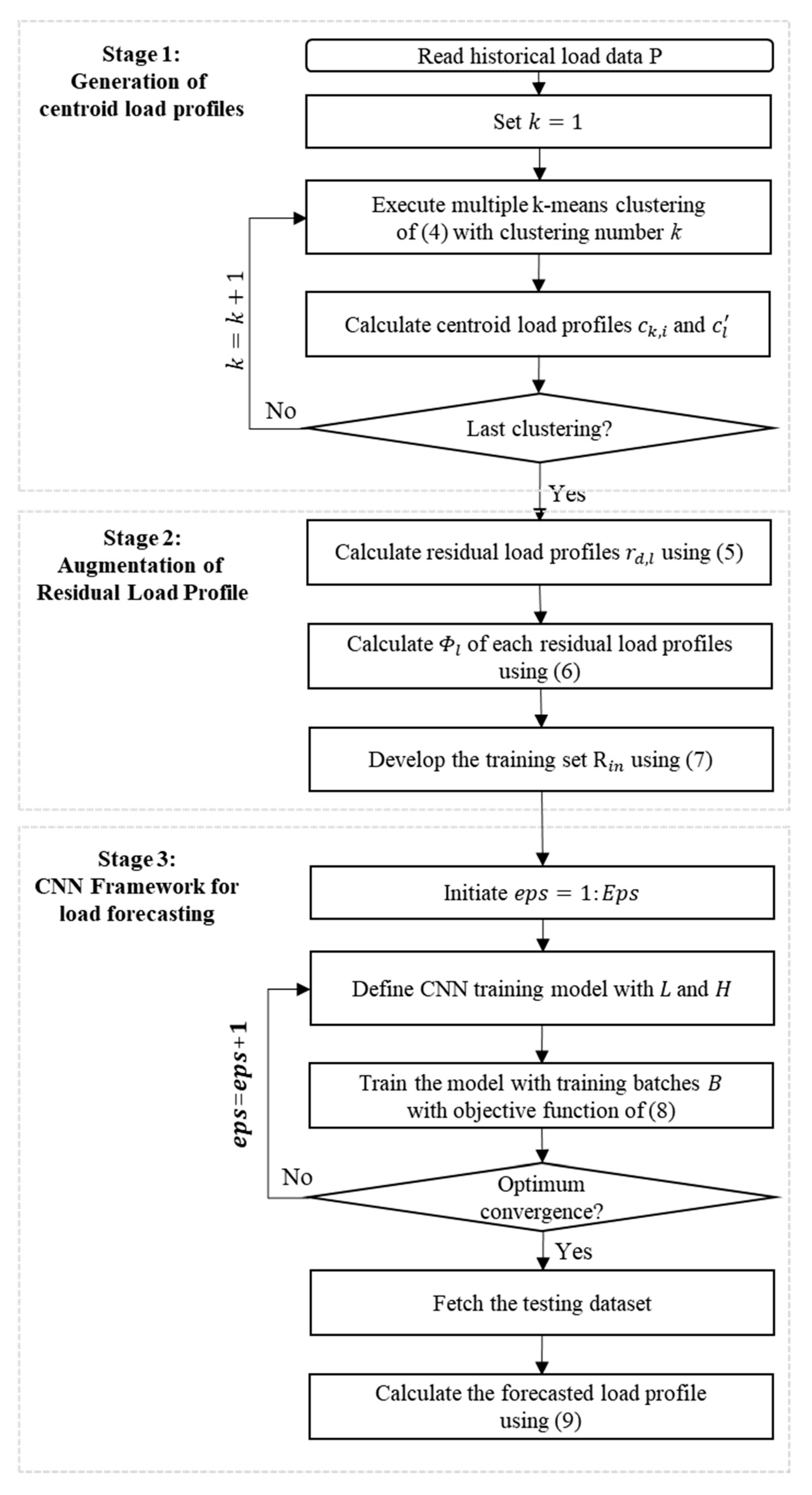
3. Proposed Residential Load Forecasting Method
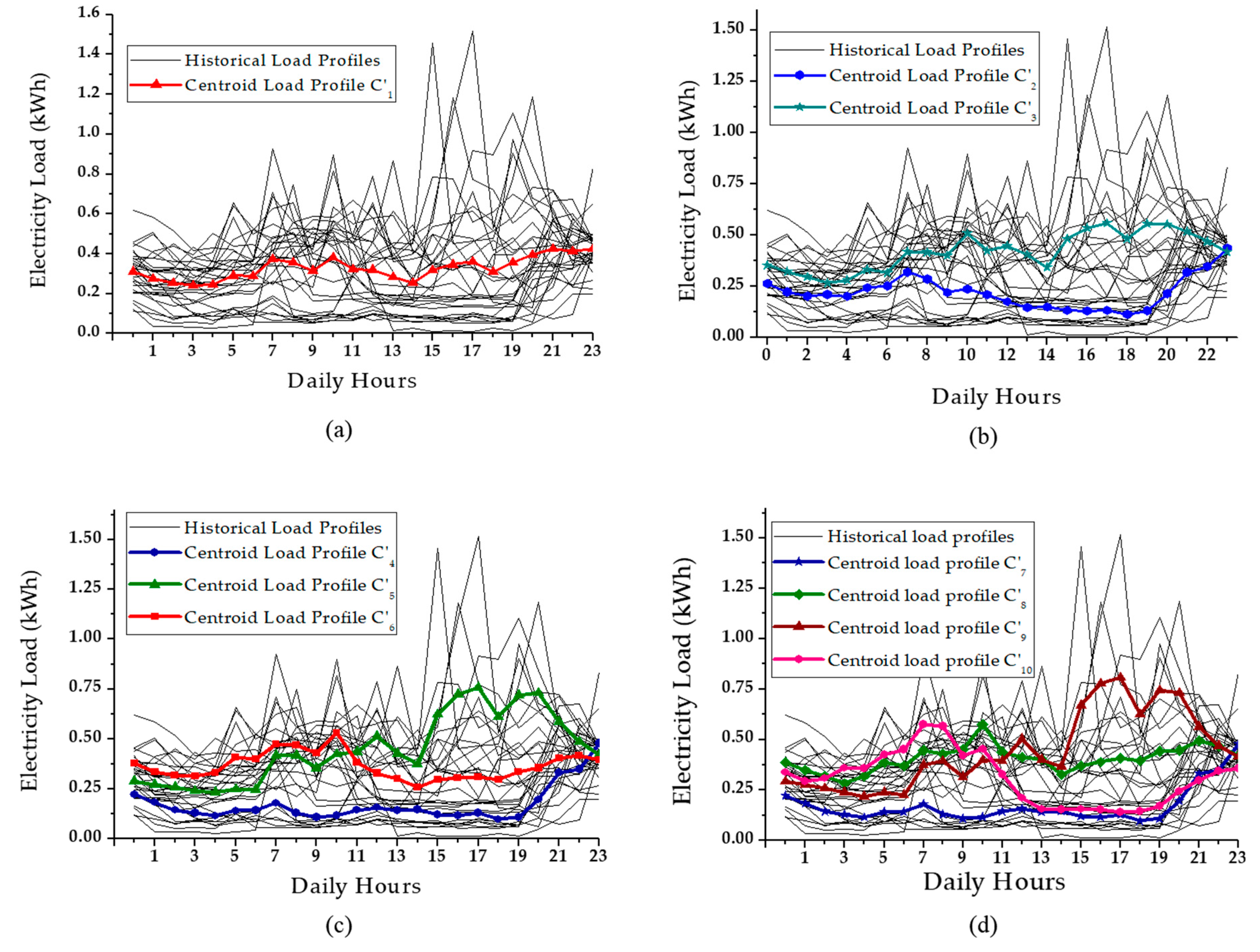
3.1. Generation of Centroid Load Profiles
3.2. Augmentation of Homogeneous Residual Load Profile
3.3. CNN Model for Residential Load Forecasting
4. Simulation Results
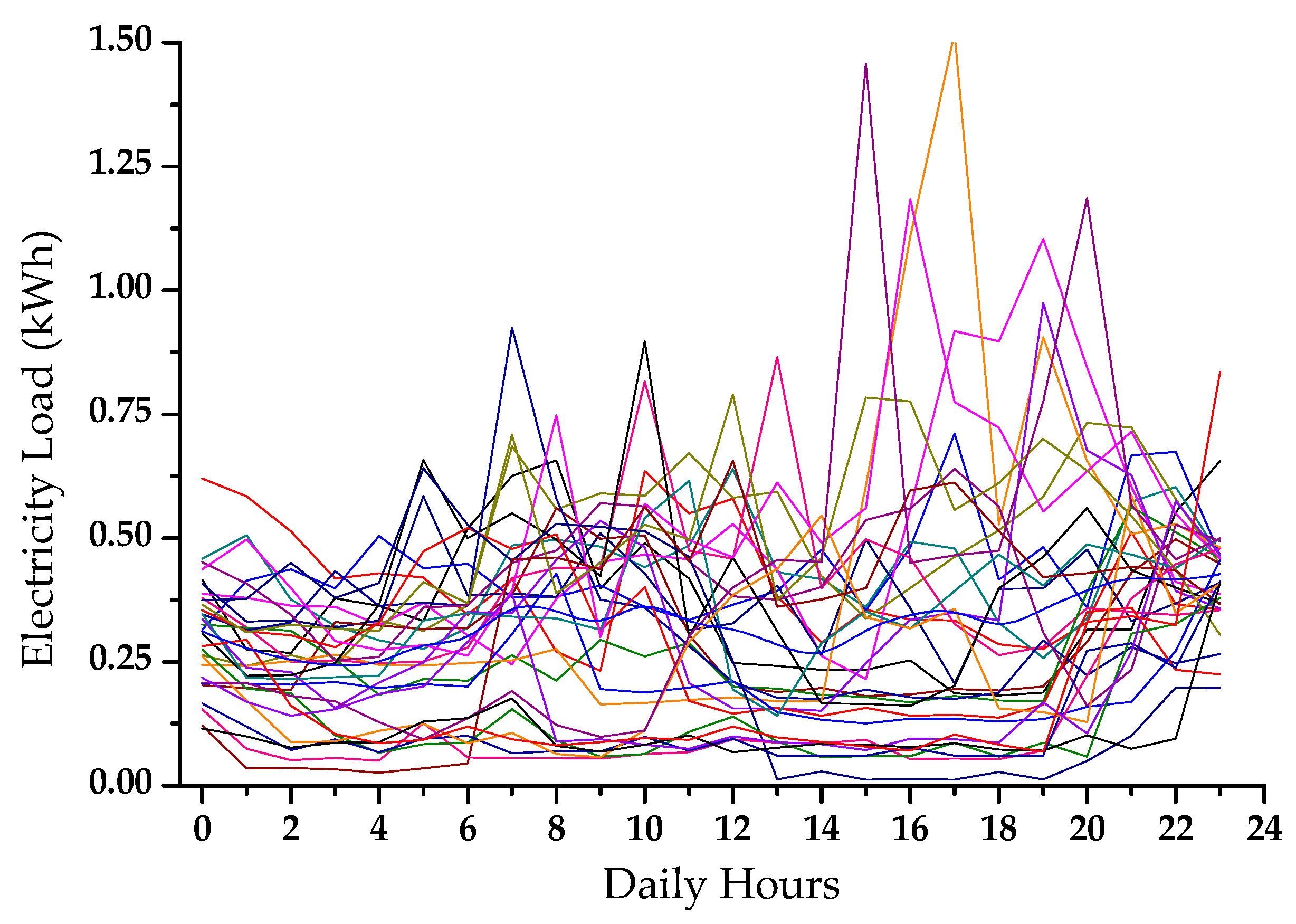
4.1. Data Description and Hyper-Parameter Tuning
4.2. Effects of Proposed Augmentation Method
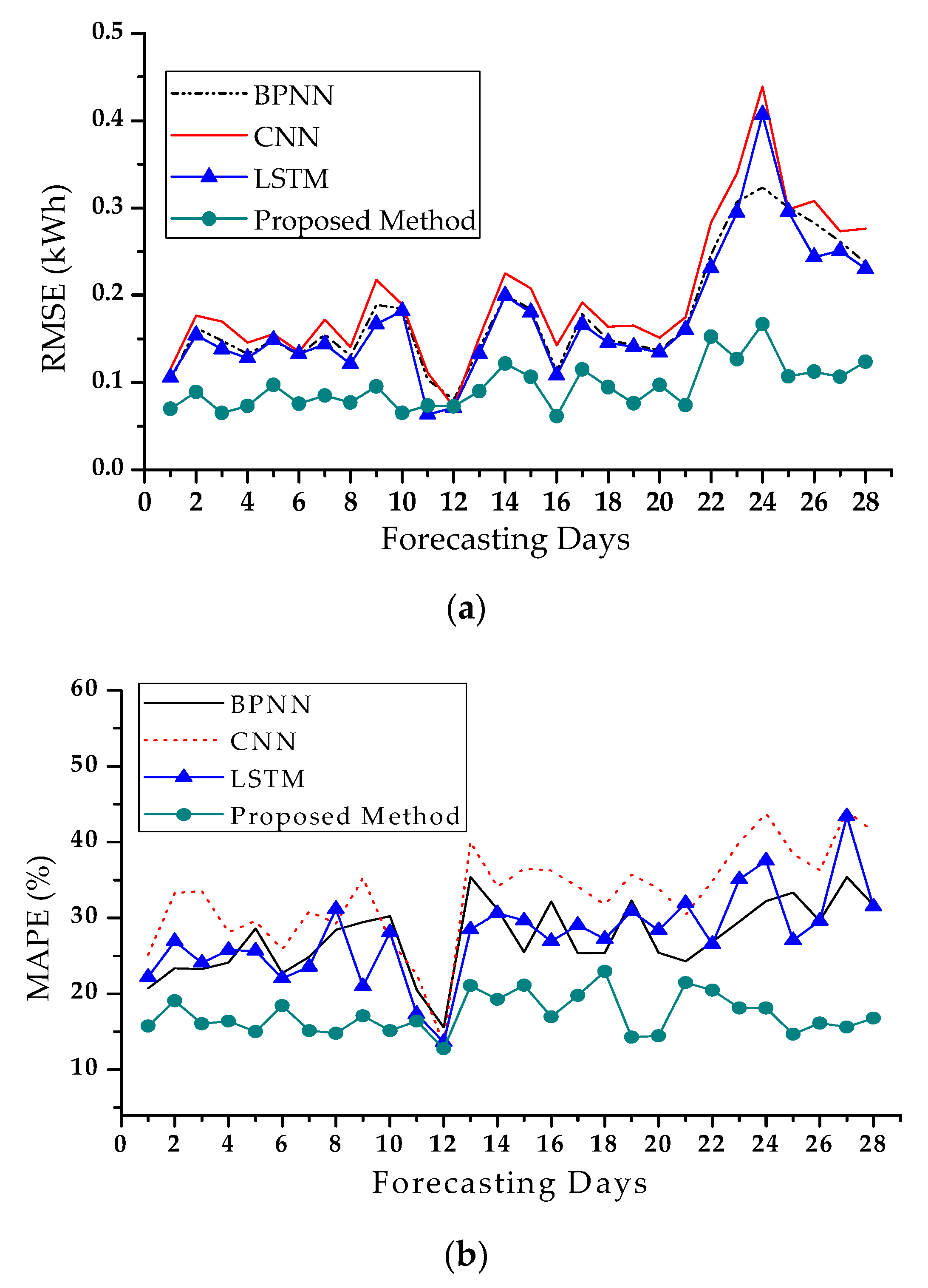
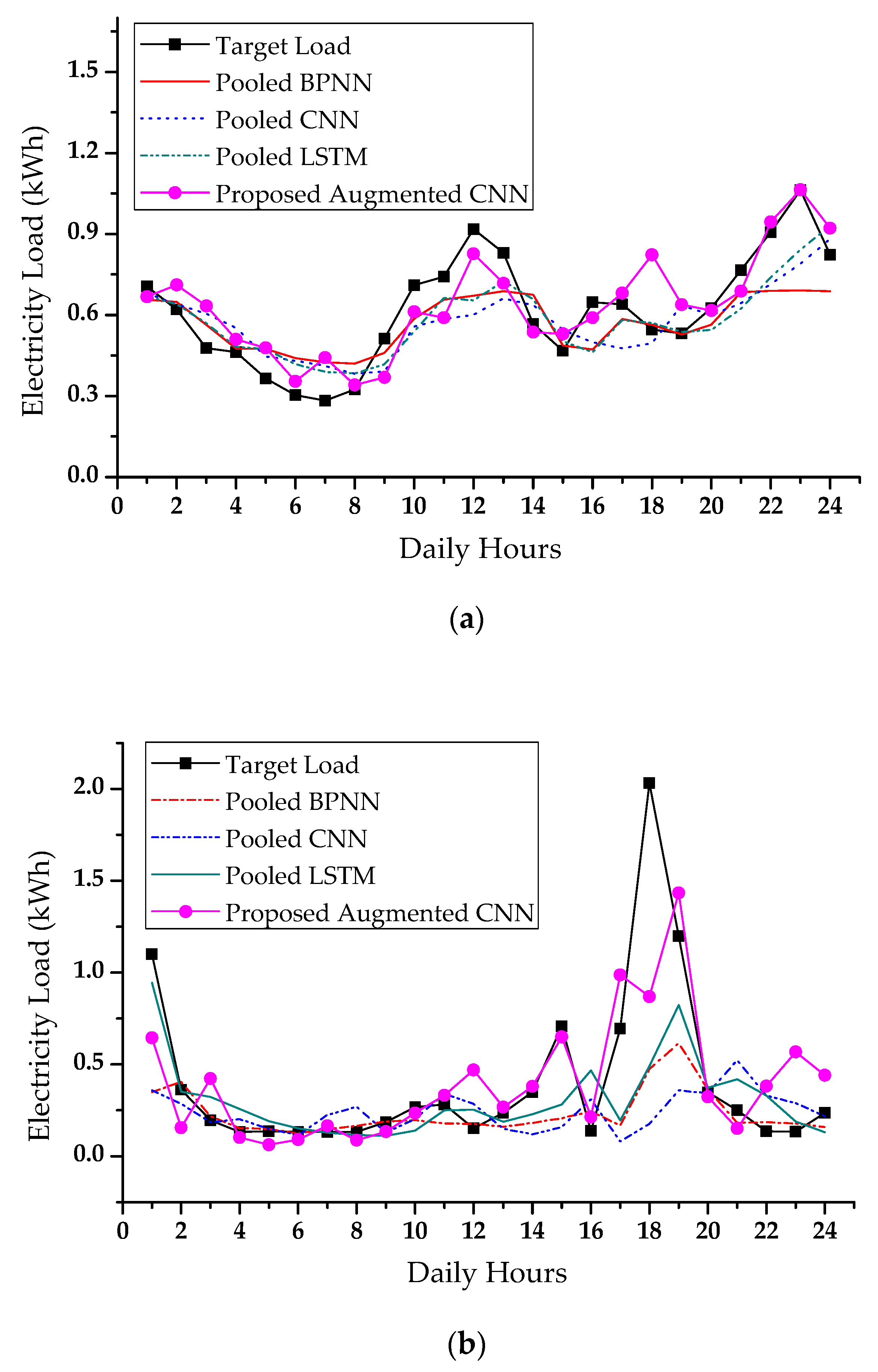
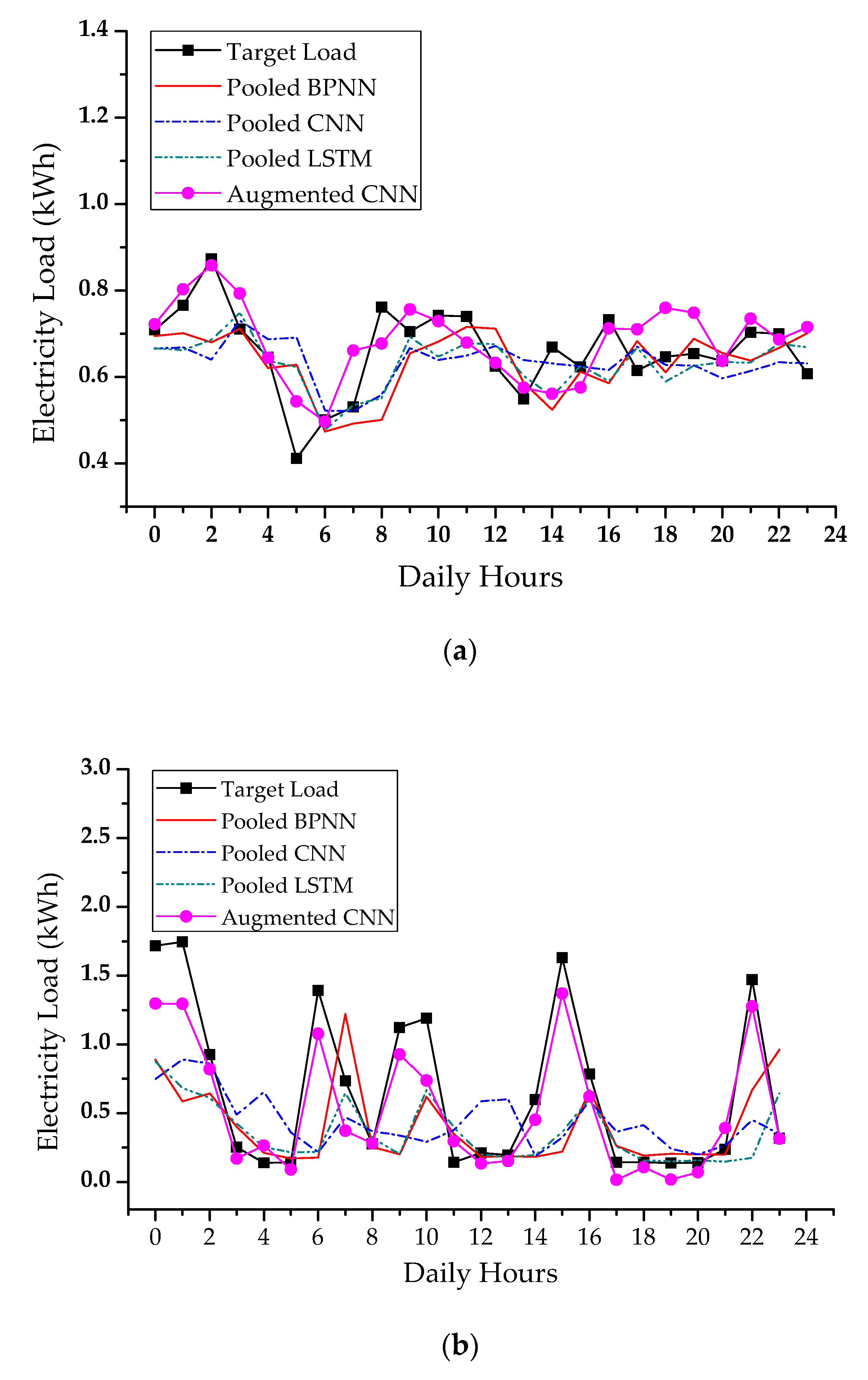
4.3. Forecasting Results in Peak Day
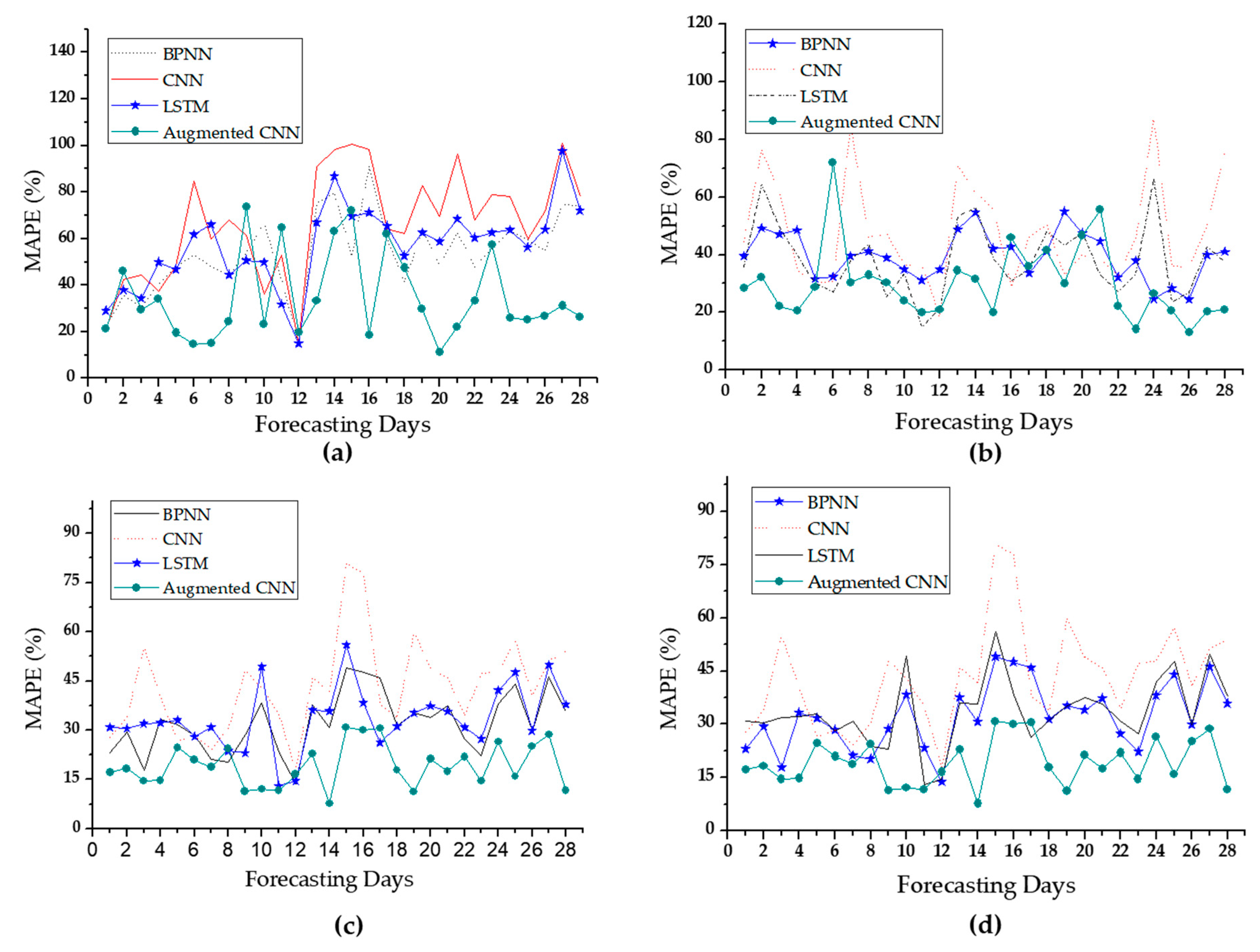
4.4. Monthly Results of Day-Ahead Load Forecasting
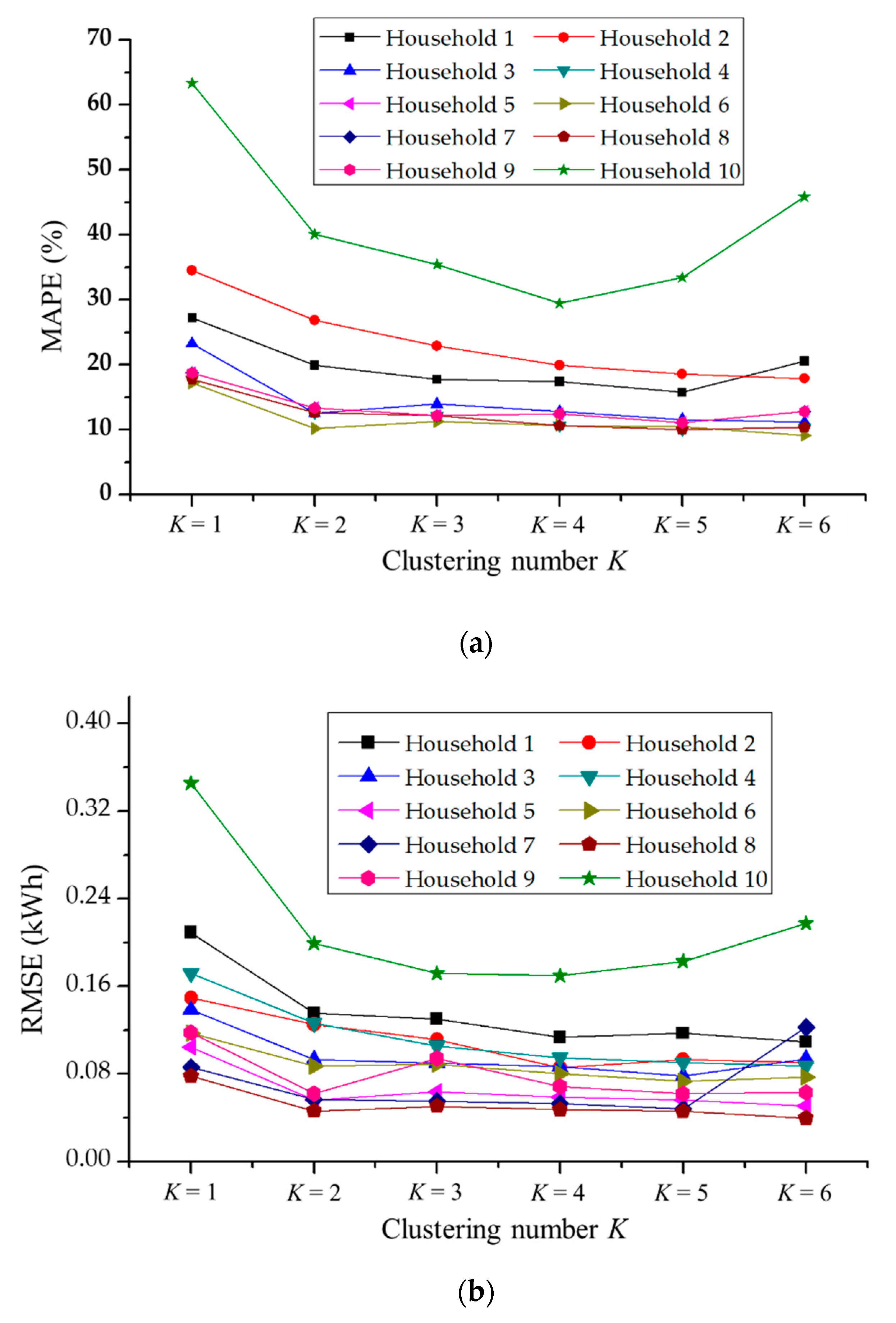
4.5. Impact of Clustering Number
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shahidehpour, M.; Yamin, H.; Li, Z. Market Operations in Electric Power Systems: Forecasting Scheduling and Risk Management, 1st ed.; Wiley-IEEE Press: New York, NY, USA, 2002; pp. 21–55. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Charytoniuk, W.; Chen, M.S.; Van Olinda, P. Nonparametric Regression Based Short-Term Load Forecasting. IEEE Trans. Power Syst. 1998, 13, 725–730. [Google Scholar] [CrossRef]
- Song, K.-B.; Baek, Y.-S.; Hong, D.H.; Jang, G. Short-Term Load Forecasting for The Holidays Using Fuzzy Linear Regression Method. IEEE Trans. Power Syst. 2005, 20, 96–101. [Google Scholar] [CrossRef]
- Christiaanse, W.R. Short-Term Load Forecasting Using General Exponential Smoothing. IEEE Trans. Power Syst. 1971, 2, 900–911. [Google Scholar] [CrossRef]
- Mohamed, N.; Ahmad, M.H.; Ismail, Z. Short Term Load Forecasting Using Double Seasonal ARIMA Model. In Proceedings of the Regional Conference on Statistical Sciences 2010 (RCSS’10), Kota Bharu, Malaysia, 13 June 2010. [Google Scholar]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting-A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2018, 9, 5271–5280. [Google Scholar] [CrossRef]
- Tian, C.; Ma, J.; Zhang, C.; Zhan, P. A Deep Neural Network Model for Short-Term Load Forecast Based on Long Short-Term Memory Network and Convolutional Neural Network. Energies 2018, 11, 3493. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal Deep Learning LSTM Model for Electric Load Forecasting using Feature Selection and Genetic Algorithm: Comparison with Machine Learning Approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef]
- Torres, J.F.; Galicia, A.; Troncoso, A. A Scalable Approach Based on Deep Learning for Big Data Time Series forecasting. In Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation (IWINAC), A Coruña, Spain, 19–23 June 2017. [Google Scholar]
- Guo, Z.; Zhou, K.; Zhang, X.; Yang, S. A Deep Learning Model for Short-Term Power Load and Probability Density Forecasting. Energy 2018, 160, 1186–1200. [Google Scholar] [CrossRef]
- Lin, Y. Time Series Forecasting by Evolving Deep Belief Network with Negative Correlation Search. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018. [Google Scholar]
- Vu, D.H.; Muttaqi, K.M.; Agalagaonkar, A.P. Combinatorial Approach using Wavelet Analysis and Artificial Neural Network for Short-term Load Forecasting. In Proceedings of the 2014 Australasian Universities Power Engineering Conference (AUPEC), Perth, Australia, 28 September–1 October 2014. [Google Scholar]
- Haq, M.R.; Ni, Z. A New Hybrid Model for Short-Term Electricity Load Forecasting. IEEE Access 2019, 7, 125413–125423. [Google Scholar] [CrossRef]
- Gram-Hanseen, G. Standby consumption in households analyzed with a practice theory approach. J. Ind. Ecol. 2010, 14, 150–165. [Google Scholar] [CrossRef]
- Du, S.; Li, T.; Gong, X.; Yang, Y.; Horng, S.J. Traffic Flow Forecasting based on Hybrid Deep Learning Framework. In Proceedings of the 12th International Conference on Intelligent Systems and Knowledge Engineering, Nanjing, China, 24–26 November 2017. [Google Scholar]
- Wang, Y.; Chen, Q.; Gan, D.; Yang, J.; Kirchen, D.S.; Kang, C. Deep Learning-Based Socio-demographic Information Identification from Smart Meter Data. IEEE Trans. Smart Grid 2018, 10, 2593–2602. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolution Neural Networks for Images; Speech and Time Series; MIT Press: Cambridge, MA, USA, 1988. [Google Scholar]
- Pattanayek, S. Pro Deep Learning with TensorFlow: A Mathematical Approach to Advanced Artificial Intelligence in Python, 1st ed.; Apress: New York, NY, USA, 2017; pp. 153–222. [Google Scholar]
- Amarasinghe, K.; Marino, D.L.; Manic, M. Deep Neural Network for Energy Load Forecasting. In Proceedings of the IEEE 26th International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017. [Google Scholar]
- Kwac, J.; Flora, J.; Rajagopal, R. Household Energy Consumption Segmentation Using Hourly Data. IEEE Trans. Smart Grid 2015, 5, 420–430. [Google Scholar] [CrossRef]
- Wang, X.D.; Chen, R.C.; Yan, F.; Zeng, Z.Q.; Hong, C.Q. Fast Adaptive K-means Subspace Clustering for High-Dimensional Data. IEEE Access 2019, 7, 42639–42651. [Google Scholar] [CrossRef]
- Lai, G.; Chang, W.C.; Yang, Y.; Liu, H. Modelling Long-and Short-Term Temporal Patterns with Deep Neural Networks. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018. [Google Scholar]
- Stephen, B.; Tang, X.; Harvey, P.R.; Galloway, S.; Jennett, K.I. Incorporating Practice Theory in Sub-Profile Models for Short term aggregated Residential Load Forecasting. IEEE Trans. Smart Grid 2017, 8, 1591–1598. [Google Scholar] [CrossRef]
- Charalambous, C.C.; Bharath, A.A. A data augmentation methodology for training machine/deep learning gait recognition algorithms. In Proceedings of the British Machine Vision Conference, York, UK, 19–22 September 2016. [Google Scholar]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart Augmentation Learning an Optimal Data Augmentation Strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Goodfellow, I.; Dengio, Y.; Courville, A. Deep Learning, 1st ed.; The MIT Press: Cambridge, MA, USA, 2016; pp. 224–270. [Google Scholar]
- Zhang, Y.; Chen, W.; Xu, R.; Black, J. A Cluster-Based Method for Calculating Baselines for Residential Loads. IEEE Trans. Smart Grid 2015, 7, 1–10. [Google Scholar] [CrossRef]
- Farukh, A.; Feng, D.; Habib, S.; Rahman, U.; Rasool, A.; Yan, Z. Short Term Residential Load Forecasting: An Improved Optimal Nonlinear Auto Regressive (NARX) Method with Exponential Weight Decay Function. Electronics 2018, 7, 432. [Google Scholar]
- Sharma, T.; Shokeen, D.; Mathur, D. Multiple K Means++ Clustering of Satellite Image Using Hadoop Map Reduce and Spark. Int. J. Adv. Stud. Comput. Sci. Eng. 2016, 5, 23–29. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C. Tensor Flow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Pedregosa, F.; Varoquax, G.; Gramfort, A. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Luo, F.; Meng, K. Effect of Automatic Hyper-Parameter Tuning for Residential Load Forecasting via Deep Learning. In Proceedings of the 2017 Australasian Universities Power Engineering Conference (AUPEC), Melbourne, Australia, 9–22 November 2017. [Google Scholar]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building Energy Load Forecasting Using Deep Neural Networks. In Proceedings of the 42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 24–27 October 2016. [Google Scholar]
- Ozaki, Y.; Yano, M.; Onishi, O. Effective Hyperparameter Optimization Using Nelder–Mead Method in Deep Learning. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 20. [Google Scholar] [CrossRef]
- Torres, J.F.; Troncoso, A.; Gutierrez, D.; Martinez-Alvarez, F. Random Hyper-Parameter Search-Based Deep Neural Network for Power Consumption Forecasting. In Proceedings of the International Work-Conference on Artificial Neural Networks Neural Networks, Gran Canaria, Spain, 12–14 June 2019. [Google Scholar]
- Neary, P. Automatic Hyper Parameter Tuning in Deep Convolutional Neural Networks Using Asynchronous Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Cognitive Computing (ICCC), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar]
- Kim, J.Y.; Cho, S.B. Evolutionary Optimization of Hyper-Parameters in Deep Learning Models. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | BPNN | CNN | LSTM |
|---|---|---|---|
| No. of hidden layers | 2 or 3 | 2 or 3 | 2 or 3 |
| No. of nodes per layer | 32 | 24 | 20 |
| Activation functions | ReLU | ReLU | tanh and sigmoid |
| No. of Epochs (iteration) | 150 | 150 | 300 |
| Optimizer | RMS-Prop | RMS-prop | RMS-prop |
| Loss Function | MSE | MSE | MSE |
| Testing samples | 24-h | 24-h | 24-h |
| Household | Hidden | Hidden | Hidden | Hidden | Hidden | Hidden |
|---|---|---|---|---|---|---|
| Layer 0 | Layer 1 | Layer 2 | Layer 3 | Layer 4 | Layer 5 | |
| 1 | 23.75% | 24.44% | 19.26% | 21.77% | 23.43% | 26.77% |
| 2 | 11.96% | 11.25% | 11.17% | 9.63% | 11.51% | 12.98% |
| 3 | 32.10% | 32.05% | 30.08% | 35.87% | 38.09% | 39.73% |
| 4 | 9.86% | 9.53% | 9.65% | 10.30% | 11.05% | 11.47% |
| 5 | 13.13% | 13.59% | 11.72% | 12.44% | 15.47% | 15.54% |
| 6 | 12.88% | 12.44% | 11.77% | 11.43% | 12.32% | 13.82% |
| 7 | 11.76% | 11.34% | 9.77% | 12.15% | 11.68% | 12.82% |
| 8 | 14.78% | 14.97% | 13.53% | 14.60% | 15.12% | 16.32% |
| 9 | 22.19% | 22.30% | 22.06% | 21.41% | 22.46% | 21.69% |
| 10 | 37.24% | 43.59% | 34.72% | 46.80% | 47.12% | 49.25% |
| Household | Without Augmentation | With the Proposed Augmentation | |||
|---|---|---|---|---|---|
| BPNN (%) | LSTM (%) | CNN (%) | LSTM (%) | CNN (%) | |
| 1 | 32.17 | 33.49 | 43.40 | 31.36 | 19.26 |
| 2 | 20.54 | 21.62 | 24.77 | 16.60 | 9.63 |
| 3 | 39.52 | 38.15 | 48.48 | 37.41 | 30.08 |
| 4 | 15.56 | 14.61 | 18.42 | 15.47 | 9.53 |
| 5 | 17.36 | 16.50 | 20.85 | 17.15 | 11.72 |
| 6 | 17.46 | 16.85 | 20.77 | 16.99 | 11.77 |
| 7 | 14.61 | 14.85 | 17.01 | 13.36 | 9.77 |
| 8 | 20.38 | 20.31 | 24.08 | 18.17 | 13.53 |
| 9 | 42.40 | 43.11 | 46.03 | 28.89 | 21.41 |
| 10 | 53.71 | 57.02 | 66.64 | 51.28 | 34.72 |
| Household | Without Augmentation | With the Proposed Augmentation | |||
|---|---|---|---|---|---|
| BPNN (kWh) | LSTM (kWh) | CNN (kWh) | LSTM (kWh) | CNN (kWh) | |
| 1 | 0.3601 | 0.3440 | 0.4092 | 0.3156 | 0.1666 |
| 2 | 0.2614 | 0.2864 | 0.3169 | 0.1253 | 0.1116 |
| 3 | 0.2382 | 0.2242 | 0.2570 | 0.2160 | 0.1313 |
| 4 | 0.0954 | 0.0907 | 0.1114 | 0.1397 | 0.0691 |
| 5 | 0.0790 | 0.0768 | 0.0882 | 0.0744 | 0.0506 |
| 6 | 0.0757 | 0.0728 | 0.0859 | 0.0769 | 0.0488 |
| 7 | 0.0663 | 0.0679 | 0.0743 | 0.0635 | 0.0389 |
| 8 | 0.1083 | 0.1028 | 0.1160 | 0.0960 | 0.0683 |
| 9 | 0.1423 | 0.1321 | 0.1638 | 0.1072 | 0.0661 |
| 10 | 0.3323 | 0.3074 | 0.3421 | 0.2984 | 0.1796 |
| Forecasting Model | Sept. | Oct. | Nov. | Dec. | Jan. | Feb. | Mar. | Apr. | May | Jun. | Jul. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pooled BPNN | MAPE (%) | 16.48 | 16.72 | 19.33 | 16.55 | 18.21 | 17.30 | 20.99 | 20.22 | 20.88 | 26.99 | 15.02 |
| RMSE (kWh) | 0.086 | 0.099 | 0.105 | 0.095 | 0.099 | 0.111 | 0.104 | 0.110 | 0.110 | 0.124 | 0.106 | |
| Pooled CNN | MAPE (%) | 15.97 | 20.66 | 21.11 | 18.04 | 19.80 | 18.71 | 22.38 | 22.12 | 22.74 | 28.62 | 15.89 |
| RMSE (kWh) | 0.085 | 0.111 | 0.116 | 0.104 | 0.110 | 0.121 | 0.112 | 0.119 | 0.120 | 0.132 | 0.112 | |
| Pooled LSTM | MAPE (%) | 14.46 | 16.33 | 18.23 | 15.31 | 17.31 | 16.70 | 23.30 | 18.76 | 19.90 | 26.82 | 14.03 |
| RMSE (kWh) | 0.080 | 0.099 | 0.101 | 0.091 | 0.096 | 0.069 | 0.107 | 0.106 | 0.110 | 0.123 | 0.100 | |
| Proposed Method | MAPE (%) | 9.662 | 11.65 | 10.53 | 9.50 | 9.91 | 10.34 | 11.25 | 10.95 | 12.07 | 12.25 | 9.65 |
| RMSE (kWh) | 0.062 | 0.061 | 0.060 | 0.060 | 0.061 | 0.105 | 0.067 | 0.075 | 0.072 | 0.068 | 0.070 | |
| Forecasting Model | Sept. | Oct. | Nov. | Dec. | Jan. | Feb. | Mar. | Apr. | May | Jun. | Jul. | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pooled BPNN | MAPE (%) | 20.07 | 24.65 | 34.87 | 46.06 | 34.32 | 36.06 | 43.42 | 42.87 | 36.86 | 43.25 | 35.39 |
| RMSE (kWh) | 0.086 | 0.119 | 0.137 | 0.156 | 0.160 | 0.168 | 0.185 | 0.191 | 0.141 | 0.152 | 0.241 | |
| Pooled CNN | MAPE (%) | 18.80 | 28.08 | 34.83 | 55.80 | 39.61 | 37.44 | 48.49 | 53.90 | 40.09 | 50.07 | 41.40 |
| RMSE (kWh) | 0.085 | 0.129 | 0.140 | 0.168 | 0.174 | 0.175 | 0.203 | 0.204 | 0.151 | 0.162 | 0.246 | |
| Pooled LSTM | MAPE (%) | 16.998 | 24.81 | 32.13 | 46.47 | 34.02 | 33.10 | 43.09 | 47.59 | 33.81 | 45.15 | 35.99 |
| RMSE (kWh) | 0.080 | 0.116 | 0.135 | 0.156 | 0.164 | 0.161 | 0.176 | 0.198 | 0.140 | 0.153 | 0.228 | |
| Proposed Method | MAPE (%) | 13.83 | 12.79 | 22.26 | 30.47 | 23.51 | 22.09 | 26.21 | 30.89 | 23.05 | 29.53 | 29.12 |
| RMSE (kWh) | 0.062 | 0.075 | 0.085 | 0.101 | 0.092 | 0.105 | 0.106 | 0.119 | 0.099 | 0.084 | 0.131 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Acharya, S.K.; Wi, Y.-M.; Lee, J. Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation. Energies 2019, 12, 3560. https://doi.org/10.3390/en12183560
Acharya SK, Wi Y-M, Lee J. Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation. Energies. 2019; 12(18):3560. https://doi.org/10.3390/en12183560
Chicago/Turabian StyleAcharya, Shree Krishna, Young-Min Wi, and Jaehee Lee. 2019. "Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation" Energies 12, no. 18: 3560. https://doi.org/10.3390/en12183560
APA StyleAcharya, S. K., Wi, Y.-M., & Lee, J. (2019). Short-Term Load Forecasting for a Single Household Based on Convolution Neural Networks Using Data Augmentation. Energies, 12(18), 3560. https://doi.org/10.3390/en12183560