1. Introduction
Nowadays, the hybrid energy system has become more popular in the electricity industry. The main reason of this trend is the exponential reduction of energy storage cost and the development of digital connection, enabling real time monitoring and smarter grid establishment. Moreover, the hybrid energy system is considered as one of the best solutions in tackling intermittency experienced by most renewable energy schemes including solar- and wind-based energy. For example, in solar photovoltaic, the energy is only delivered when obtaining sufficient solar irradiance. As a consequence, a lot of research has been conducted in order to provide the best scheme of this hybrid system [
1].
Among provided hybrid energy system schemes, the most possible way to be implemented in the majority of countries is the integration between renewable and fossil energy, because fossil energy has already well established. In case of sustainability, this scheme is very good, because fossil energy is obviously able to supply adequate power to the grid when the alternative sources cannot handle users’ load demand. The major concern of this scheme is the cost to be borne by users once the renewable sources cannot supply adequate power to the grid in which they will pay an expensive fossil-based electric price. Moreover, fossil energy tends to gradually increase leading to economic conflict in society [
2]. Therefore, in order to tackle this issue, an appropriate demand response scheme can be applied.
Demand response is the change of electric usage by users due to change of electric price or maybe an incentive as a reward of lowering their power consumption [
3]. Applying demand response to this hybrid system is very beneficial for shaving peak load demand [
4,
5], leading to the reduction of fossil energy consumption. Moreover, it can provide short-term impact and economic benefit for both consumer and utility.
In order to support this demand response, short-term load forecasting (STLF) is very important for predicting whether the energy storage from renewable sources is able to handle the forthcoming power consumption or not. If the prediction states that the storage is not adequate to support the future load, then the electricity utility can announce this situation to the users, which eventually triggers them to reduce their electric usage, because users do not only want to pay more for conventional energy source but also want to get incentives from the authorities.
Fortunately, with the help of developed infrastructures like smart meters equipped with a lot of sensors and the Internet of Things (IoT), a robust STLF method is feasible to be implemented. Broadly speaking, research in load forecasting can be categorized into two research classes, traditional and advanced model. Traditional model uses simple statistics method for example regression models [
6] and Kalman filtering model [
7]. Nevertheless, among proposed traditional models, autoregressive integrated moving average (ARIMA) and generalized autoregressive conditional heteroscedascity (GARCH) are two of the most popular techniques in regression function that were used in several precedent research studies [
8,
9]. Unfortunately, these traditional models only provide good accuracy if the electrical load and other parameters have a linear relationship. Meanwhile, the advanced model is a data-driven model implementing the machine learning technique for instance support vector machine (SVM) [
10], K-nearest neighbor (KNN) [
11], and others [
12,
13,
14].
However, based on the recent publications [
15,
16,
17,
18], the deep learning-based methods show the most convincing performance by outperforming other machine learning-based solutions. The main reason of the deep learning superiority is first, deep learning does not highly rely on feature engineering and the hyperparameters tuning is relatively easier compared to other data-driven models. The second is the availability of huge datasets, where deep learning can precisely map the inputs to the certain output by making complex relations among layers in the network based on that huge training data. Moreover, since the availability of Graphics Processing Unit (GPU) parallel computation and methods providing weights sharing like convolutional neural network (CNN) [
19], the computational speed of deep learning models become significantly faster.
Because of the superiority of the deep learning, this research proposes a method in load forecasting task, specifically STLF, to predict the hourly power consumption by using deep learning algorithms which is the combination of the advanced version of the convolutional neural network (CNN), dilated causal residual CNN, and long short-term memory (LSTM) [
20].Dilated causal residual CNN is inspired by the Wavenet model [
21], which is very famous for audio generation, and the residual network [
22] with gated activation function. This model will learn the trend based on long sequence input while the LSTM layer works as a model’s output self-correction which relates the output of the wavenet-based model with the recent load demand trend (short sequence).
The main contribution of this research is that we propose a novel model utilizing a combination of dilated causal residual CNN and LSTM utilizing long and short sequential data and fine tuning technique. External feature extraction or feature selection data are not included in this research. Moreover, this research only takes into account time index information as the external factor data, making it easy to be compared as a benchmark model for future research.
In order to prove the generality of our proposed model performance, two different scenarios of model testing are conducted. The first scenario is using the testing dataset having identical distribution with the validation dataset, while the second is using dataset having unknown distribution. As a comparison, our proposed model results are compared with the performance of the model from [
15,
16] and the standard wavenet [
21]. The simulation result shows that our proposed model outperforms other deep learning models in root mean squared error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE).
Therefore, due to the accuracy of our model performance, this model can be used for supporting utilities in applying demand response program since it can help the utilities to obtain accurate prediction about the future load demand that eventually providing precise information to the users whether the future load demand can be supplied by the renewable source or not.
The rest of the paper is organized as follows.
Section 2 describes the dataset used in detail including preliminary data analysis and data preprocessing.
Section 3 explains the model architecture and its parameter, training, and testing stage.
Section 4 provides information about results obtained by using the proposed models compared with other deep learning-based models and clear explanation about the reason why the proposed model can achieve the result. Lastly,
Section 5 summarize the findings discussed in this paper and also possible future works.
2. Dataset
In order to prove the generality of our proposed method, two datasets are used as the model’s input which are the ENTSO-E (European Network of Transmission System Operators for Electricity) [
23] and ISO-NE (Independent System Operator New England) dataset [
24]. The ENTSO-E dataset is the dataset obtained from load demand in every country in Europe. In this research we only take into account data gathered from Switzerland. Meanwhile, the ISO-NE dataset is data of hourly load demand in New England.
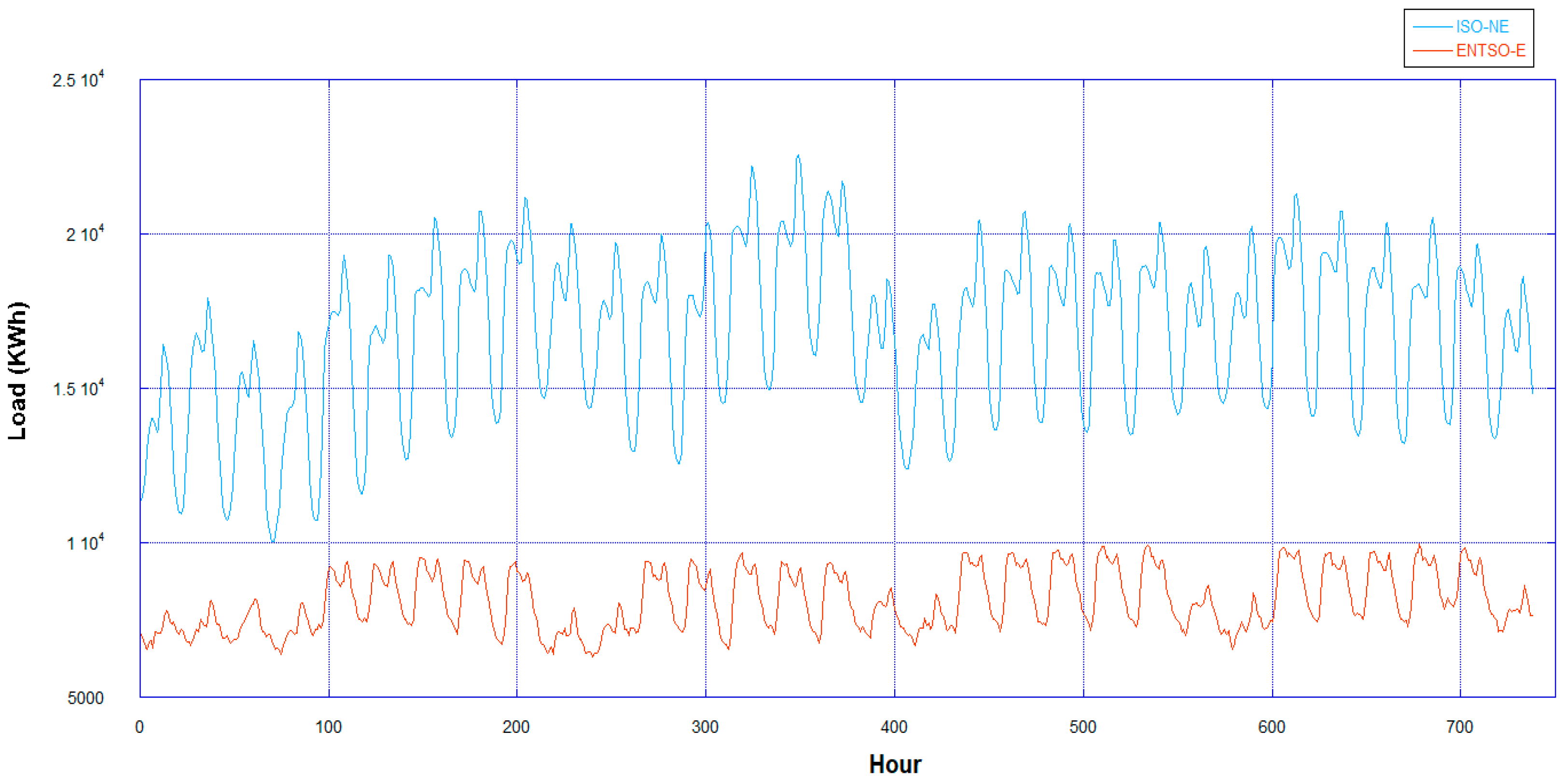
Those datasets have different kinds of characteristics, especially in the case of load demand range and complexity. In the ENTSO-E dataset, the lowest and highest value of load are 1483 KWh and 18,544 KWh, respectively, while in the ISO-NE dataset they are 9018 KWh and 26,416 KWh, respectively. Another different characteristic is the fluctuation trend in a single day load demand. In the ENTSO-E dataset, the load demand is more oscillated compared to the ISO-NE dataset. As proof,
Figure 1 and
Figure 2 show the average daily power consumption and example of load trend in a day based on those datasets and example of demand trend of each dataset.
In building a solution for load forecasting, deep understanding of the load demand trend is very necessary.
Figure 3 shows data in both datasets over a year period. From
Figure 3, broadly speaking, the trend of load demand has a periodicity that will be repeated over the next weeks. However, this trend is highly affected by a lot of external factors causing a fluctuation over a certain period, for example, the economic, weather, and time index. Unfortunately, obtaining those external factors are difficult, the easiest external data that can be gathered is time index data containing information about the date and clock. Therefore, in this research we not only fed the model by load demand trend but also time index data represented by one-hot vector. One-hot vector is a sparse vector that maps a feature with M categories into a vector which has M elements where only the corresponding element is one while the remaining are zero.
Before fed to the model, the datasets must be pre-processed, which consists of checking for null values, splitting dataset into training, validation and testing dataset, and eventually data normalization. The data used for this research is limited only to data taken from 1 January 2015 until 30 May 2017 for the ENTSO-E dataset and from 1 January 2004 until 30 May 2006 for the ISO-NE dataset. The first two years of data are used for the training stage, while the rest of the 3600 data are split into 3000 and 600 data. The first 3000 data are randomly taken for validation and testing data with proportion of nearly 0.65 and 0.35 to be used for validation and the testing stage, respectively. In other words, the total of validation data and first testing data are 1900 and 1100, respectively, while another 600 data are used for the second testing data. We conduct two testing stage, because the first testing data have a nearly identical distribution with the validation data which clearly make the model provide good accuracy in the testing stage. Meanwhile, the second testing data is clearly new data that their distribution is never experienced by the model both in the training and validation stage. This kind of testing process is appropriate for proving the generality of the model.
In the data normalization process, min-max scaling method as expressed in Equation (1) is implemented.
and
is the
ith normalized data. The parameters in the normalization process must come from training dataset only, because we assume that the future data (validation and test set) have different distribution with the training dataset.
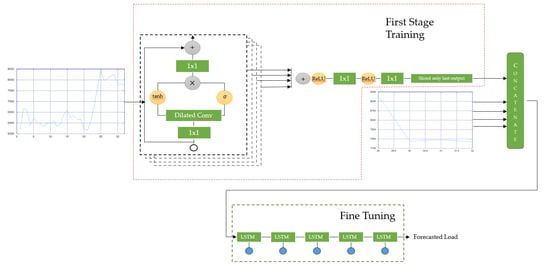
3. Model Design
In this research, the cores of the proposed model are wavenet architecture implementing both of the dilated causal CNN and residual network and LSTM, which have proven very well in time-series data prediction.
Our proposed model consists of two stages that have a function to learn long and short sequence data. Inspired by the success of wavenet architecture and LSTM in handling time series data, the long sequence taken from the 32 time steps before the target is learned using wavenet while the short sequence taken from 4 time steps before target is learned using LSTM.
3.1. Wavenet
Wavenet consists of deep generative models utilizing the dilated causal convolutional neural network of audio waveform. Causal convolution means that the output of the recent time step is only affected by the previous time step. Meanwhile, the dilated convolutional neural network is a modified convolutional neural network where the filter weight alignment is expanded by a dilation factor that eventually results in a broader receptive field that can be expressed as follows:
while the standard convolution is expressed as follows:
The dilated convolution is denoted by notation. The difference between dilated convolution with standard convolution is the notation representing the dilation factor which causes the filter to skip one or several points during the convolution process.
Figure 4 shows the dilated convolution applied in one dimensional data. The blue, white, and orange circle are input data, hidden layer output, and output layer output, respectively. There are 32 input data taken from
t = 1 until
t = 32 that are convoluted with filter with the size of two. The dilation rate is increased by one in every hidden layer that causes a broader receptive field. This dilation rate is repeated twice. In the output layer, only the last value is taken, which we assume represents the feature of load at
t = 33.
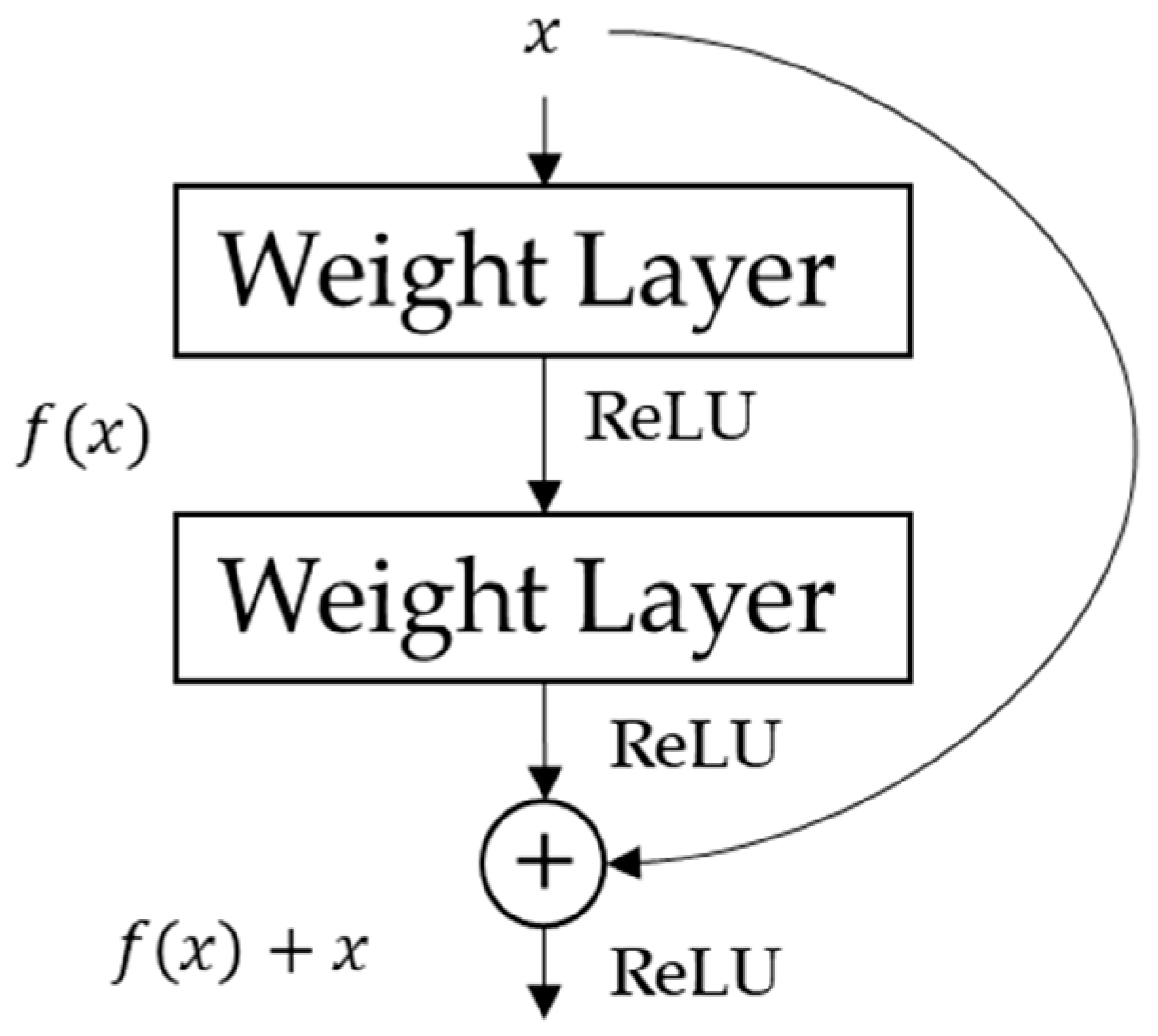
In order to optimize the usage of the dilated convolutional neural network, the residual technique [
22] is applied to the model. The implementation of the residual network will take into account lower levels outputs which have features that will help in predicting the future power demand, especially in the case of a network implementing a sparse filter which has the potential to lose several information from the previous layers.
The residual model is a famous way to build the deep neural network that was firstly proposed for the image recognition task. Using this way, instead of only mapping input data
to a function
that outputs
, the mapping scenario from the previous residual block
where
is the learned weights and biases from the residual block
i is also considered. Therefore, the output of the residual block can be expressed as:
Moreover, since we use the stacked residual block, then the output of the residual block can be represented as:
is the output of residual block
K,
is the input of the residual network and
is the output and associated weight of the previous residual blocks. As a result of several summation between the previous and final residual block, then the back propagation of the network to
can be calculated using the following equation:
is the total loss of the network and constant 1 indicates that the gradient of the network output can be directly back-propagated without considering layers’ parameters (weights and biases). This formulation ensures the layers do not suffer of vanishing gradient, even the weights are small.
Figure 5 shows the basic residual learning process.
Moreover, skip connection and gated activation are applied to the network for speeding up the convergence and avoiding overfitting. The process of residual and skip connection with gated activation is shown in
Figure 6.
The gated activations are inspired by the LSTM layer where tanh and sigmoid
work as learned filter and learned gate, respectively. The use of gated activations has been proved to work better compared to using ReLU activation in time series data [
21]. The output of dilated convolution with gated activations can be expressed as:
where
and
are learned filter and learned gate, respectively.
3.2. LSTM
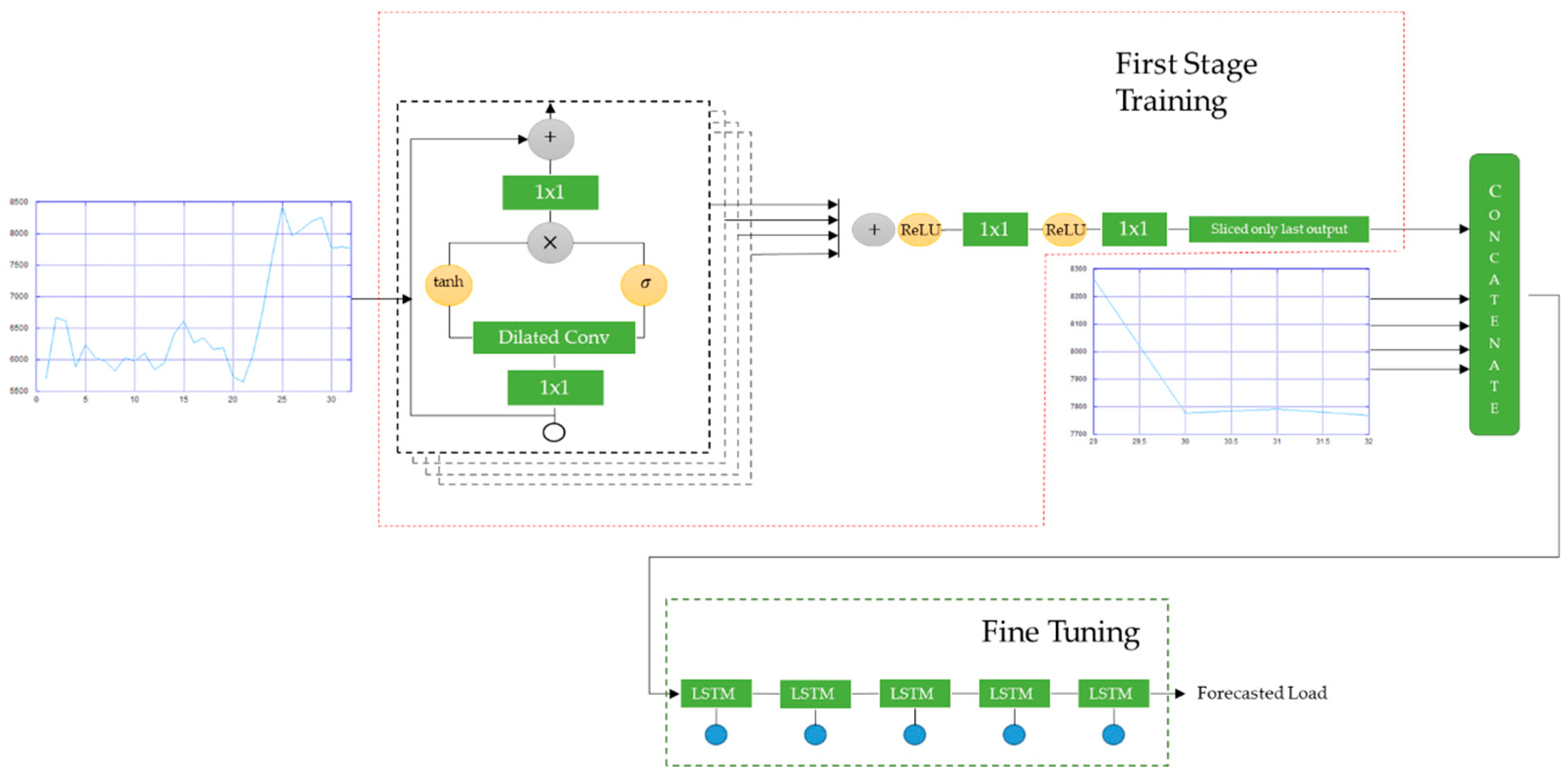
In the case of forecasting future data, the knowledge of the recent trend is very essential. As an illustration, in predicting future data, we mostly start to figure out a long sequence trend. After we have already known the pattern of the trend based on the long sequence of previous data, then in order to provide better forecast, we also try to relate our understanding of long sequence data with the recent trend. The same concept is applied to our proposed method. We fine tune the wavenet-based model with one LSTM layer assigned to help the network to relate the output of dilated CNN with the recent trend. This step can also be considered as a correction step of the dilated CNN output, as we assert a fix input to be concatenated with dilated CNN output which are then fed to the LSTM layer that also work as output layer.
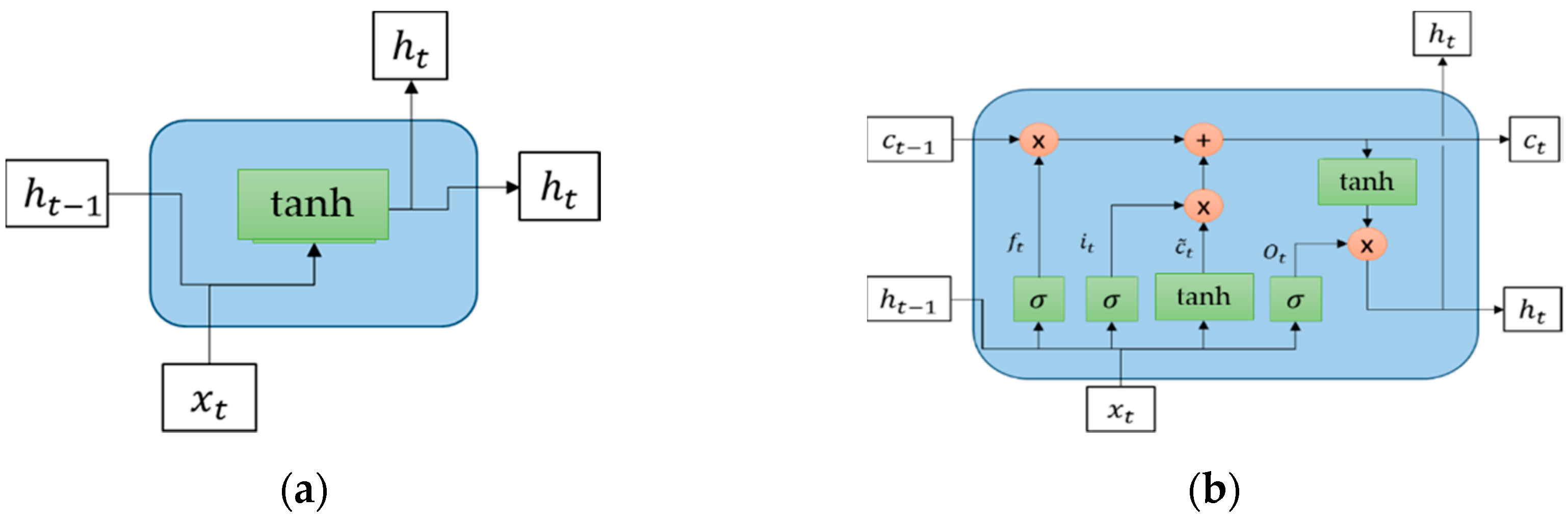
Brief Explanation of LSTM
LSTM is the developed version of the standard recurrent neural network (RNN) where instead of only having a recurrent unit, LSTM has “LSTM cells” that have an internal recurrence consisting of several gating units controlling flow of information [
25]. Comparison between the simple RNN and LSTM layer using tanh as the activation function is depicted in
Figure 7.
From
Figure 7, the difference between the simple RNN and LSTM layer is clear. The LSTM layer is more complex than the simple RNN, because LSTM not only takes into account input (
) and hidden state (
) at a certain time step, but also LSTM cells (
) that will replace the hidden state to prevent older signals from vanishing during the process. Three control gates ruling the LSTM cells, forget gate, input gate, and output gate are represented by
,
, respectively. Those gates use sigmoid activation function having an output range between 0 and 1 represented by
. Meanwhile,
is the input node that works identical to the simple RNN layer.
Mathematically explained, forget gate and input gate, respectively can be expressed as:
is the concatenation between input and hidden state value, while
and
are weight matrices, respectively. On the other hand, the cell state is updated with the formulation:
where
is expressed as:
The last, the output gate
and hidden state
is calculated by using the following equation:
3.3. Detailed Model Setup
Complete representation of our model is depicted in
Figure 8. The wavenet-based model is fed by 32 data sequences containing information of load demand and time index information (clock, day, and month). This wavenet model is used for the initial forecasting algorithm based on long sequence data. Before fed to dilated CNN, long sequence data are prepossessed using standard 1D-CNN with filter size equal to one. Next, the prepossessed data is convoluted by dilated causal CNN with filter size of 2. All of the convolutional layers have ReLU activation function expressed as:
In the case of the residual network, the total residual block in our model is 10 with a dilation rate set to be a repetition of a sequence
dr = [1, 2, 4, 8, 16]. Dilation rate is a hyperparameter that represents how large the gap between the element of the filter is, as shown in
Figure 4 and indicated by the arrows. All of the residual blocks are summed followed by the ReLU activation function. The post-processing is conducted before the last convolutional layer which works similar with time distributed fully connected layer in which it is assigned for normalization of the residual output.
Because the length of input and output in the dilated causal CNN are identical, then the customize layer is built for taking only the last output’s neuron representing load at t = 33. After completing the wavenet-based network training, the output of the last convolutional layer is concatenated with recent data sequences (t = 29 until t = 32) that work as LSTM input. Here, by using the fine tuning technique, LSTM with linear activation function is assigned to make self-correction of convolutional output in order to provide more accurate prediction based on short sequence. This self-correction method is nearly identical to how humans make a prediction based on data sequences. For example, in predicting the environment temperature, humans will relate the understanding between the temperature trend from the previous day with the recent temperature trend in order to make an accurate prediction for the next hour temperature.
Table 1 shows the summary of our model’s parameter where
f,
ks,
s, and
dr are the number of filters, kernel size, stride, and dilation rate, respectively. Loss function and optimizer are mean absolute error and adaptive and momentum (ADAM) [
26], respectively, and batch size is 512. The model was trained using Nvidia GTX 1070, Tensorflow 1.13.1 [
27], CUDA 10, and CuDNN 7.6.2 with 500 epochs and the final model is chosen based on the validation accuracy.
5. Conclusions and Future Works
This paper proposes a novel method for hourly load forecasting case which is very important in the case of demand response for hybrid energy systems, especially for system use of both renewable and fossil energy in order to reduce fossil energy usage. The proposed method is mainly inspired by the wavenet-based model utilizing dilated causal residual CNN and LSTM. In this approach, two different data sequences are fed to the model. The long data sequences are fed to the wavenet-based model while the short data sequences are fed to the LSTM layer assigned for model self-correction using fine-tuning technique.
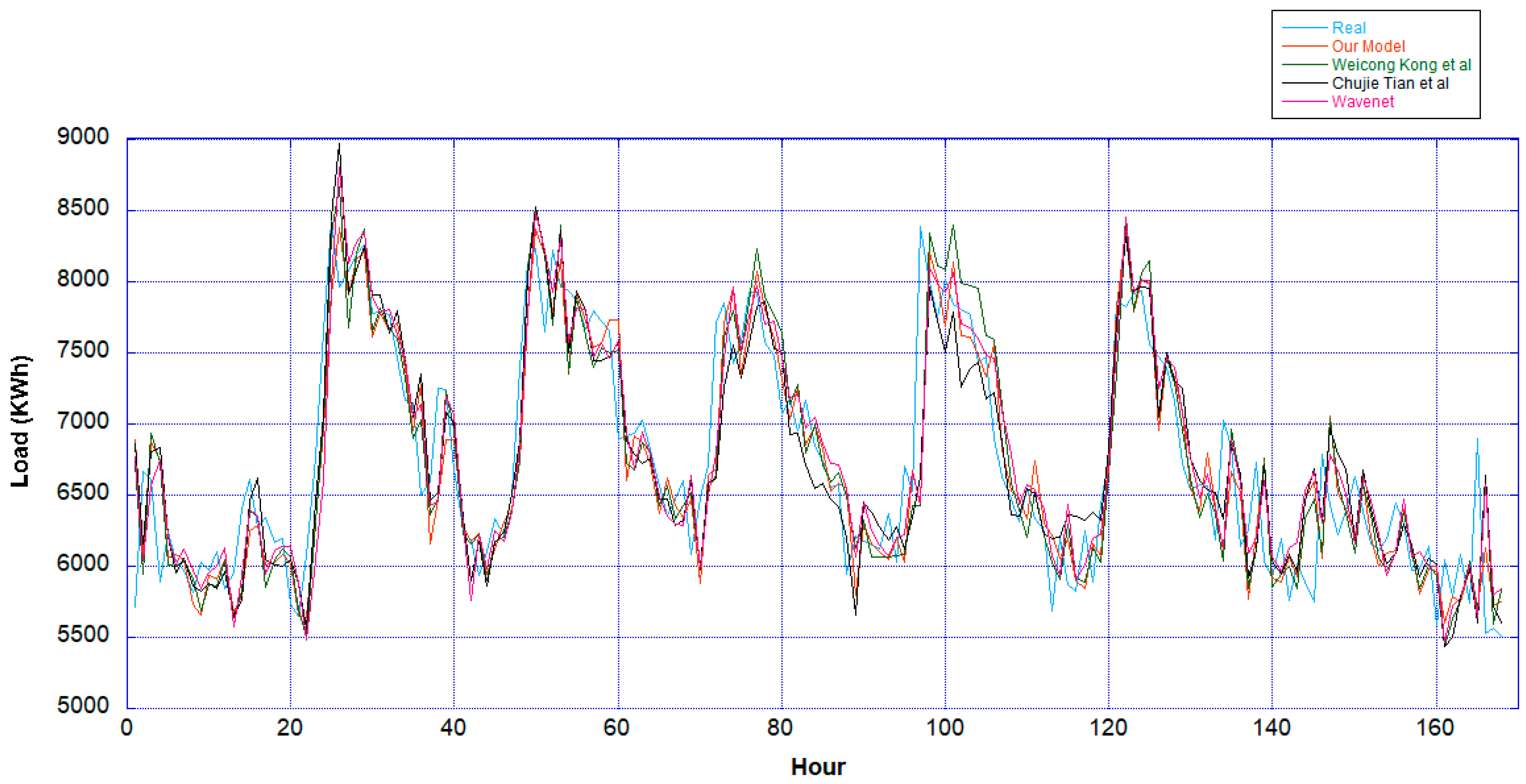
In order to prove the generality of our model, two different datasets, which are the ENTSO-E and ISO-NE dataset, are used with two different testing scenarios. The first testing scheme uses the dataset having nearly identical distribution with the validation dataset, while the second uses a dataset from slightly different data distribution. Based on the obtained result, our proposed model exhibits the best performance compared to other deep learning-based models in terms of RMSE, MAE, and MAPE. In detail, our model achieves RMSE, MAE, and MAPE equal to 203.23, 142.23, and 2.02 for ENTSO-E testing dataset 1 and 292.07, 196.95, and 3.1 for ENTSO-E dataset 2. Meanwhile, in the ISO-NE dataset, the RMSE, MAE, and MAPE equal to 85.12, 58.96, and 0.4 for ISO-NE testing dataset 1 and 85.31, 62.23, and 0.46 for ISO-NE dataset 2. However, there are several findings that can be improved in future work. The first is in the ENTSO-E dataset testing result; all models cannot provide high accuracy forecasting if they are fed using slightly different data distribution. It indicates that all models face difficulties in understanding fluctuated or unpredicted data like the ENTSO-E dataset. The second is although RMSE, MAE, and MAPE show our model exhibits better accuracy compared to the Kong et al. model in the ISO-NE dataset, our model cannot provide a significant improvement.
Therefore, for future work, additional external factors data like information of holidays and weather conditions can be fed as the models’ input in order to improve our findings. In addition, building a new model can also be conducted since this research area and artificial intelligence (AI) algorithms are developed very quickly, making a new idea come up very fast. All of the codes and datasets used in this research are available on Github.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}