Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China


 ,
,
Abstract
1. Introduction
- The Word2vec model is used to realize the semantic expression of monitoring alarm information text, instead of the semantic expression based on character retrieval matching or word frequency statistical probability. The text-based power grid monitoring alarm event identification is realized;
- We analyze a large amount of historical warning information and summarize the differences between them and ordinary Chinese text. Combining the excellent performance of LSTM in dealing with the time-series problem and CNN in mining local features of short text, a hybrid deep-learning model is built to realize the rapid identification of alarm events. Compared with the single deep-learning model, the accuracy shows great improvement.
2. Monitoring Alarm Event Identification Process and Characteristics of Monitoring Alarm Information
- Pre-processing the original monitoring alarm information, including word segmentation and filtering of stop words;
- Using the Word2vec model to represent distributed vector of pre-processed monitoring alarm information;
- Extracting various types of alarm event samples from historical monitoring alarm information in a semi-automatic manner and labeling the event types. In the specific implementation, taking the monitoring alarm information with the key-word of “opening” as the sign and the discrete monitoring alarm information of the same substation or line in the 15 s before and after the information is extracted to form an alarm information set. Then, the information set is judged by the experience rules of regulators. The alarm information in the set is divided into position signal, protection signal, and accompanying signal. The rules of each type of alarm event contain the necessary and unnecessary conditions for event determination. After each alarm event is handled, the regulator writes a scheduling log to record the occurrence time, the cause of the event, the processing flow, and the type of event. The set of alarm information determined by rules is checked against the dispatch log to form nine types of monitoring alarm event samples;
- Inputting the alarm event sample into the trained identification model based on LSTM-CNN to obtain the identification result;
- Comparing the model-identifying result with the actual type of the alarm event. If the result is wrong, it can be corrected by manual supervision and added to the sample library of historical alarm events for self-learning.
- Monitoring alarm information relates to the neighborhood content of power engineering, which contains a large number of professional vocabularies for power system operation. The vocabularies contain between two and five words, such as “busbar differential”, “reclosing”, “control loop”, and “fault recorder”;
- The monitoring alarm information contains a detailed description of the power device name and device action, and there is no fixed number of words and structure, which is unstructured text. At the same time, the Chinese words are arranged in a row next to the English text, and there is no space between them;
- A large number of monitoring alarms contain text, numbers, and quantization units. Most of the numbers are line names or switch numbers. These fields play an important role in extracting discrete monitoring alarm information for a period of time before and after a certain piece of information is received;
- Due to the complexity of different types of alarm events and the difference in recording accuracy caused by the version of the on-site information collection system, the number of monitoring alarms contained in various event samples is also different. According to the statistics of the extracted alarm event samples, the shortest contains only five pieces of information, and the longest can contain 137 pieces of information;
- The monitoring alarm information in each alarm event sample occurs continuously over a short period of time and is arranged according to the time of occurrence with a strict timing relationship.
3. Monitoring Alarm Event Identification Based on NLP and LSTM-CNN
3.1. Monitoring Alarm Information Preprocessing
- Word segmentation. Collecting professional electric vocabulary through data review and importing the substation name and line name derived from the historical monitoring alarm information into the vocabulary as a power dictionary for word segmentation. Using the accurate model of the Jieba [29] word segmentation tool to initiate the word segmentation and to generate time-ordered monitoring alarm information consisting of a series of Chinese phrases;
- Filtering of the stop words. Noise such as irregular characters and punctuation in the monitoring alarm information may interfere with the mining of subsequent text information. Therefore, this paper establishes a stop-words list, eliminates the meaningless words in the alarm information, and achieves data cleaning to improve the post-training effect.
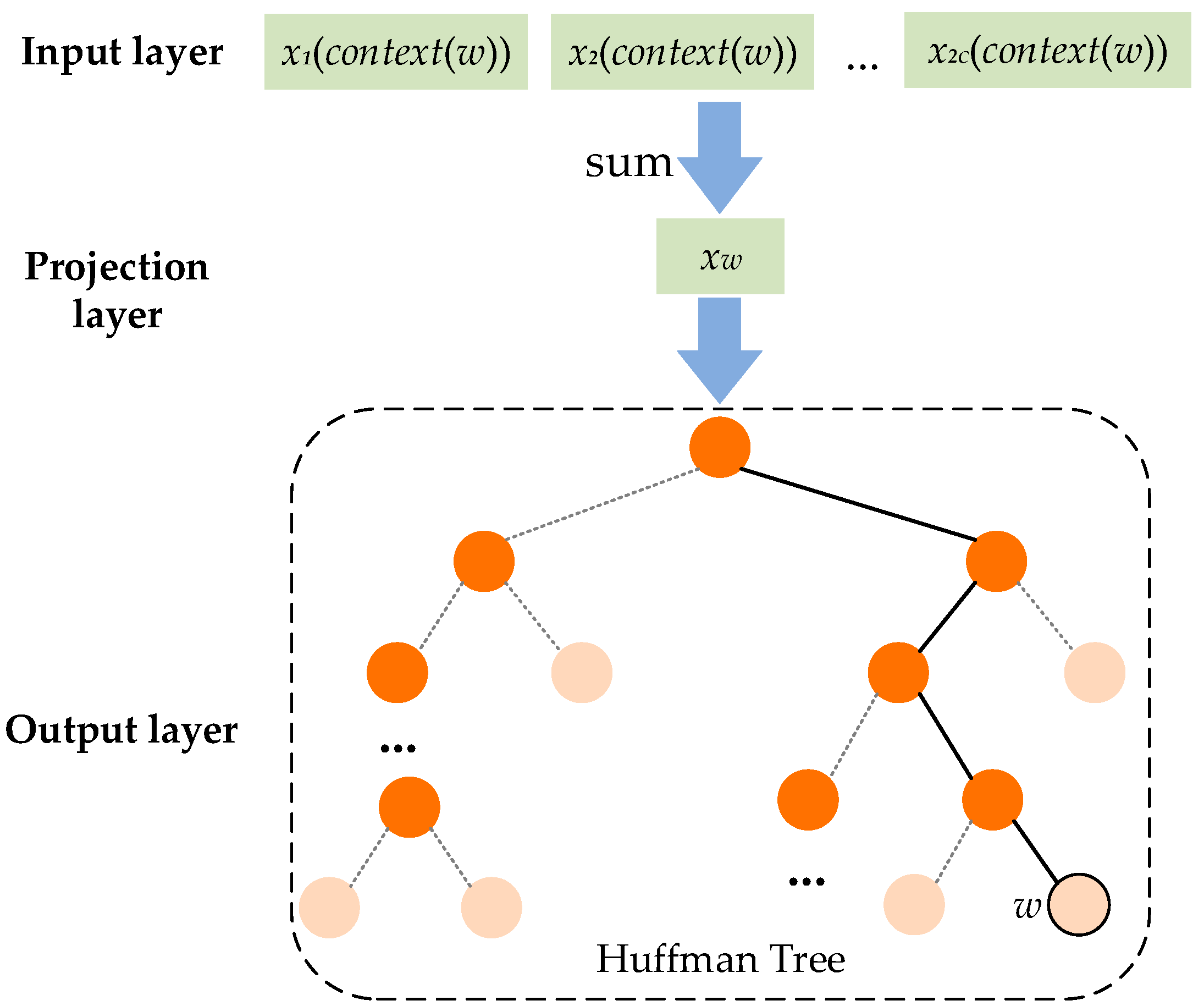
3.2. Vectorization Model of Monitoring Alarm Information Based on Word2vec
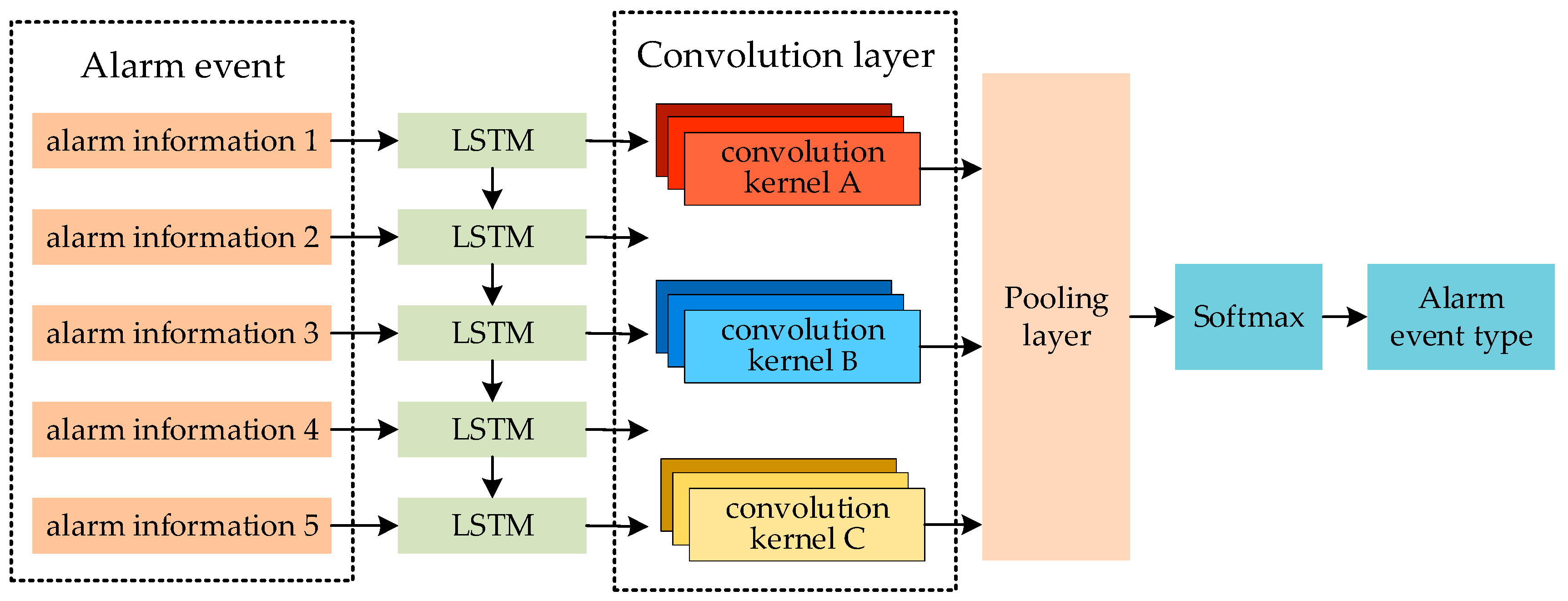
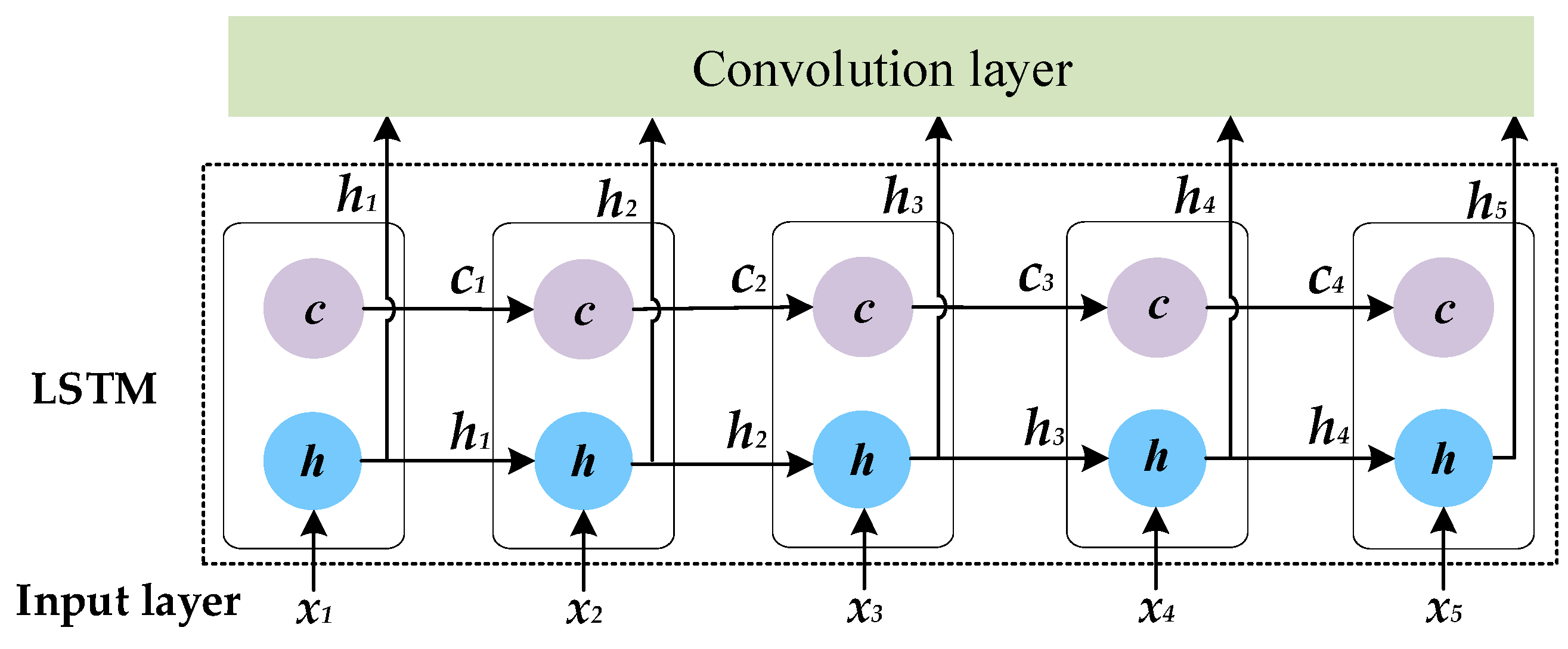
3.3. Monitoring Alarm Event Identification Model Based on LSTM-CNN
3.3.1. Model Structure
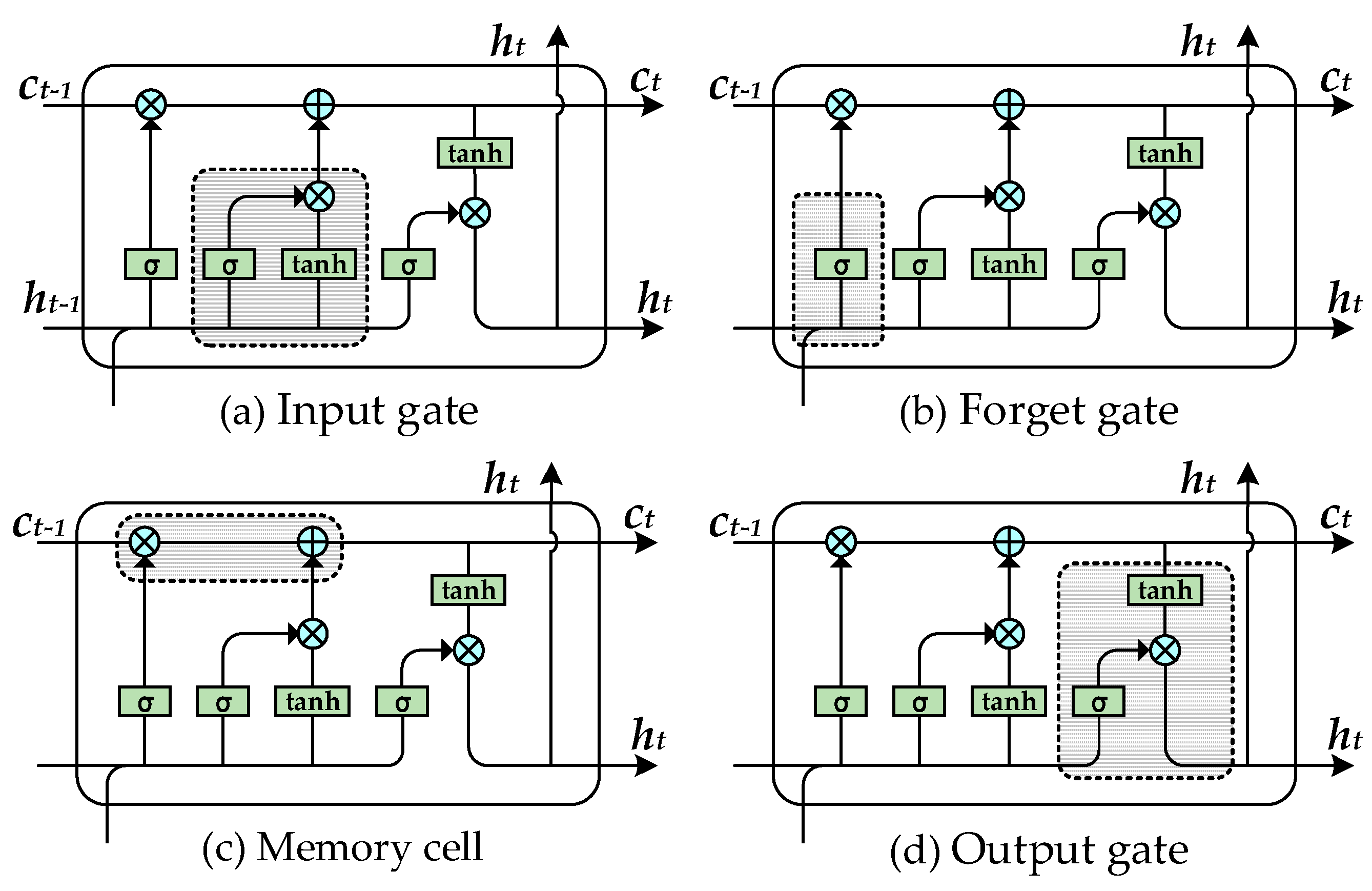
3.3.2. Long Short-Term Memory Network
3.3.3. Convolutional Neural Network
4. Results
4.1. Data Selection and Processing
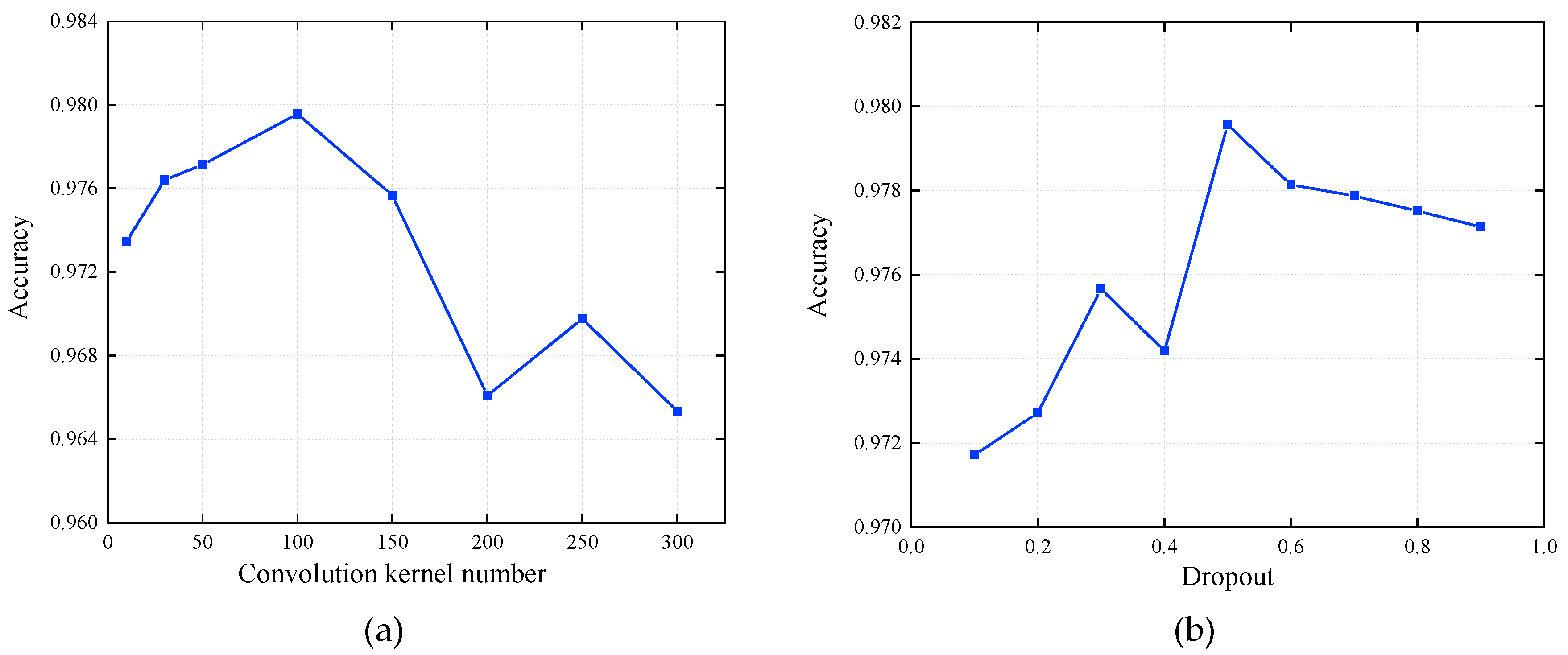
4.2. Model Parameter Setting
4.3. Criteria for Identification Result
4.4. Discussion of Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hor, C.L.; Crossley, P.A.; Watson, S.J. Building knowledge for substation-based decision support using rough sets. IEEE Trans. Power Deliv. 2007, 22, 1372–1379. [Google Scholar] [CrossRef]
- Rawat, S.; Patel, A.; Celestino, J.; Dos Santos, A.L.M. A dominance based rough set classification system for fault diagnosis in electrical smart grid environments. Artif. Intell. Rev. 2016, 46, 389–411. [Google Scholar] [CrossRef]
- Luo, X.; Kezunovic, M. Implementing fuzzy reasoning Petri-nets for fault section estimation. IEEE Trans. Power Deliv. 2008, 23, 676–685. [Google Scholar] [CrossRef]
- Liu, S.H.; Chen, Q.; Gao, Z.J. Power system fault diagnosis based on protection coordination and Petri net theory. In Proceedings of the 2010 Asia-Pacific Power and Energy Engineering Conference (APPEEC), Chengdu, China, 28–31 March 2010. [Google Scholar]
- Zhang, X.; Yue, S.; Zha, X.B. Method of power grid fault diagnosis using intuitionistic fuzzy Petri nets. IET Gener. Transm. Distrib. 2018, 12, 295–302. [Google Scholar] [CrossRef]
- Zhu, Y.L.; Huo, L.M.; Lu, J.L. Bayesian networks-based approach for power systems fault diagnosis. IEEE Trans. Power Deliv. 2006, 21, 634–639. [Google Scholar]
- Li, G.; Wu, H.H.; Wang, F. Bayesian network approach based on fault isolation for power system fault diagnosis. In Proceedings of the 2014 International Conference on Power System Technology (POWERCON), Chengdu, China, 20–22 October 2014; pp. 601–606. [Google Scholar]
- Lin, S.; Chen, X.Y.; Wang, Q. Fault diagnosis model based on Bayesian network considering information uncertainty and its application in traction power supply system. IEEJ Trans. Electr. Electron. Eng. 2018, 13, 671–680. [Google Scholar] [CrossRef]
- Min, S.-W.; Sohn, J.M.; Park, J.K.; Kim, K.H. Adaptive fault section estimation using matrix representation with fuzzy relations. IEEE Trans. Power Syst. 2004, 19, 842–848. [Google Scholar] [CrossRef]
- Chen, W.H. Online Fault Diagnosis for Power Transmission Networks Using Fuzzy Digraph Models. IEEE Trans. Power Deliv. 2012, 27, 688–698. [Google Scholar] [CrossRef]
- Zang, H.X.; Cheng, L.L.; Ding, T.; Cheung, K.W.; Wang, M.M.; Wei, Z.N.; Sun, G.Q. Estimation and validation of daily global solar radiation by day of the year-based models for different climates in China. Renew. Energy 2019, 135, 984–1003. [Google Scholar] [CrossRef]
- Lee, H.J.; Park, D.Y.; Ahn, B.S.; Park, Y.M.; Park, J.K.; Venkata, S.S. A fuzzy expert system for the integrated fault diagnosis. IEEE Trans. Power Deliv. 2000, 15, 833–838. [Google Scholar]
- Watada, J.; Tan, S.C.; Matsumoto, Y.; Vasant, P. Rough set-based text mining from a large data repository of experts diagnoses for power systems. In Proceedings of the 9th KES International Conference on Intelligent Decision Technologies (KES-IDT), Vilamoura, Portugal, 21–23 June 2017; pp. 136–144. [Google Scholar]
- Lee, H.J.; Ahn, B.S.; Park, Y.M. A fault diagnosis expert system for distribution substations. IEEE Trans. Power Deliv. 2000, 15, 92–97. [Google Scholar]
- Song, H.Z.; Dong, M.; Han, R.J.; Wen, F.S.; Salam, M.A.; Chen, X.G.; Fan, H.; Ye, J. Stochastic programming-based fault diagnosis in power systems under imperfect and incomplete information. Energies 2018, 11, 2565. [Google Scholar] [CrossRef]
- Xu, B.; Yin, X.G.; Wu, D.L.; Pang, S.; Wang, Y.K. An analytic method for power system fault diagnosis employing topology description. Energies 2019, 12, 1770. [Google Scholar] [CrossRef]
- Guo, W.X.; Wen, F.S.; Ledwich, G. An analytic model for fault diagnosis in power systems considering malfunctions of protective relays and circuit breakers. IEEE Trans. Power Deliv. 2010, 25, 1393–1401. [Google Scholar] [CrossRef]
- Korkali, M.; Abur, A. Optimal deployment of wide-area synchronized measurements for fault-location observability. IEEE Trans. Power Syst. 2013, 28, 482–489. [Google Scholar] [CrossRef]
- Pradhan, K.; Kundu, P. Online identification of protection element failure using wide area measurements. IET Gener. Transm. Distrib. 2015, 9, 115–123. [Google Scholar]
- Fan, W.; Liao, Y. Wide area measurements based fault detection and location method for transmission lines. Prot. Control Mod. Power Syst. 2019, 4, 53–64. [Google Scholar] [CrossRef]
- Cardoso, G., Jr.; Rolim, J.G.; Zürn, H.H. Application of neural-network modules to electric power system fault section estimation. IEEE Trans. Power Deliv. 2004, 19, 1034–1041. [Google Scholar] [CrossRef]
- Novelo, A.F.; Cucarella, E.Q.; Moreno, E.G.; Anglada, F.M. Fault diagnosis of electric transmission lines using modular neural networks. IEEE Lat. Am. Trans. 2016, 14, 3663–3668. [Google Scholar] [CrossRef]
- Souza, J.C.; Filho, M.B.; Freund, R.S. A Hybrid Intelligent System for Alarm Processing in Power Distribution Substations. Int. J. Hybrid Intell. Syst. 2010, 7, 125–136. [Google Scholar] [CrossRef]
- Julia, H.; Christopher, D.M. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar]
- Qiu, J.; Wang, H.F.; Ying, G.L.; Zhang, B.; Zou, G.P.; He, B.T. Text mining technique and application of lifecycle condition assessment for circuit breaker. Autom. Electr. Power Syst. 2016, 40, 107–112. [Google Scholar]
- Zheng, J.; Dagnino, A. An initial study of predictive machine learning analytics on large volumes of historical data for power system applications. In Proceedings of the 2014 IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 952–959. [Google Scholar]
- Sun, H.F.; Wang, Z.Y.; Wang, J.H.; Huang, Z.; Carrington, N.; Liao, J.X. Data-driven power outage detection by social sensors. IEEE Trans. Smart Grid 2016, 7, 2516–2524. [Google Scholar] [CrossRef]
- Liu, Z.Q.; Wang, H.F.; Cao, J.; Qiu, J. A classification model of power equipment defect texts based on convolutional neural network. Power Syst. Technol. 2018, 42, 644–650. [Google Scholar]
- Lin, B.S.; Wang, C.M.; Yu, C.N. The establishment of human-computer interaction based on Word2Vec. In Proceedings of the 2017 IEEE International Conference on Mechatronics and Automation, Takamatsu, Japan, 6–9 August 2017; pp. 1698–1703. [Google Scholar]
- Hinton, G.E. Learning distributed representations of concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society, Amherst, MA, USA, 15–17 August 1986; pp. 1–12. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Chemali, E.; Kollmeyer, P.J.; Preindl, M.; Ahmed, R.; Emadi, A. Long Short-Term Memory Networks for Accurate State-of-Charge Estimation of Li-ion Batteries. IEEE Trans. Ind. Electron. 2018, 65, 6730–6739. [Google Scholar] [CrossRef]
- Guo, D.S.; Zhang, Y.N. Novel recurrent neural network for time-varying problems solving. IEEE Comput. Intell. Mag. 2012, 7, 61–65. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Ney, H.; Schluter, R. From feedforward to recurrent LSTM neural networks for language modeling. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Kong, W.C.; Dong, Z.Y.; Jia, Y.W.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Zhu, Q.M.; Chen, J.F.; Zhu, L.; Duan, X.Z.; Liu, Y.L. Wind speed prediction with spatio—Temporal correlation: A deep learning approach. Energies 2018, 11, 705. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cheng, L.L.; Zang, H.X.; Ding, T.; Sun, R.; Wang, M.M.; Wei, Z.N.; Sun, G.Q. Ensemble recurrent neural network based probabilistic wind speed forecasting approach. Energies 2018, 11, 1958. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhang, C.Y.; Chen, C.L.P.; Gan, M.; Chen, L. Predictive Deep Boltzmann Machine for Multiperiod Wind Speed Forecasting. IEEE Trans. Sustain. Energy 2015, 6, 1416–1425. [Google Scholar] [CrossRef]
- Zang, H.X.; Cheng, L.L.; Ding, T.; Cheung, K.W.; Liang, Z.; Wei, Z.N.; Sun, G.Q. Hybrid method for short-term photovoltaic power forecasting based on deep convolutional neural network. IET Gener. Transm. Distrib. 2018, 12, 4557–4567. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Volume 15, pp. 315–323. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Wongsuphasawat, K.; Smilkov, D.; Wexler, J.; Wilson, J.; Mané, D.; Fritz, D.; Krishnan, D.; Viégas, F.B.; Wattenberg, M. Visualizing dataflow graphs of deep learning models in Tensorflow. IEEE Trans. Vis. Comput. Graph. 2018, 24, 1–12. [Google Scholar] [CrossRef]
- Aguiam, D.E.; Silva, A.; Guimarais, L.; Carvalho, P.J.; Conway, G.D.; Goncalves, B.; Meneses, L.; Noterdaeme, J.M.; Santos, J.M.; Tuccillo, A.A.; et al. Estimation of X-mode reflectometry first fringe frequency using neural networks. IEEE Trans. Plasma Sci. 2018, 46, 1323–1330. [Google Scholar] [CrossRef]
- Hou, K.Y.; Shao, G.H.; Wang, H.M.; Zheng, L.; Zhang, Q.; Wu, S.; Hu, W. Research on practical power system stability analysis algorithm based on modified SVM. Prot. Control Mod. Power Syst. 2018, 3, 119–125. [Google Scholar] [CrossRef]
- Kiranmai, S.A.; Laxmi, A.J. Data mining for classification of power quality problems using WEKA and the effect of attributes on classification accuracy. Prot. Control Mod. Power Syst. 2018, 3, 303–314. [Google Scholar] [CrossRef]
- Jing, L.P.; Huang, H.K.; Shi, H.B. Improved feature selection approach TFIDF in text mining. In Proceedings of the 2002 International Conference on Machine Learning and Cybernetics, Beijing, China, 4–5 November 2002; pp. 944–946. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Alarm Event Type | Related Alarm Information |
|---|---|
| Instantaneous fault (successful reclosure) | XX City XX substation 124 over-current protection II section action |
| XX City XX substation 124 switch control loop disconnection action | |
| XX City XX substation 124 over-current protection II section return | |
| XX City XX substation 124 switch control loop disconnection reset | |
| XX City XX substation 10 kV XX line 124 switch opening | |
| XX City XX substation 124 accident total action | |
| XX City XX substation 124 protection reclosing action | |
| XX City XX change 10 kV XX line 124 switch closing | |
| XX City XX substation 124 protection reclosing return | |
| XX City XX substation 124 switch spring does not store energy | |
| XX City XX substation 124 switch motor pressure action |
| Alarm Event Type | Training Set | Test Set | Total |
|---|---|---|---|
| Bus fault | 71 | 9 | 80 |
| Instantaneous fault (successful reclosure) | 4284 | 501 | 4785 |
| Permanent fault (unsuccessful reclosure) | 2959 | 296 | 3255 |
| Permanent fault (reclosure failure) | 2413 | 285 | 2698 |
| Main transformer electrical fault | 313 | 29 | 342 |
| Main transformer grave gas fault | 238 | 26 | 264 |
| Main transformer gas fault in voltage regulation | 140 | 13 | 153 |
| Capacitor fault | 1440 | 166 | 1606 |
| Station/grounding transformer fault | 340 | 31 | 371 |
| Total | 12,198 | 1356 | 13,554 |
| Model Parameter | Parameter Meaning | Parameter Value |
|---|---|---|
| Training algorithm | 0: CBOW algorithm | 0 |
| 1: Skip-gram algorithm | ||
| Window size | The maximum distance between the current word and the predicted word in a piece of information | 5 |
| Minimum word frequency | Words whose word frequency is less than the number of parameter values will be discarded | 0 |
| Training acceleration strategy | 0: negative sampling | 1 |
| 1: hierarchical softmax | ||
| Word vector dimension | Vector dimension of each word | 300 |
| Network Layer | Parameter Name | Parameter Value |
|---|---|---|
| LSTM | Alarm information vector dimension | 300 |
| Unit number | 128 | |
| CNN | Convolution kernel size 1 | 3 |
| Convolution kernel size 2 | 4 | |
| Convolution kernel size 3 | 5 | |
| Convolution kernel number | 100 | |
| Activation function | ReLU | |
| Dense | Dropout | 0.5 |
| Activation function | softmax | |
| Output dimension | 9 |
| Model Parameter | Model of This Paper | Contrast Model A | Contrast Model B |
|---|---|---|---|
| If the input alarm info vector is randomly generated | No | Yes | No |
| If the input alarm info vector is iteratively updated | Yes | No | No |
| Event | Recognized as This Type of Event | Recognized as Other Type of Event |
|---|---|---|
| Actually for this type of event | TP (true positive) | FN (false negative) |
| Actually for other type of event | FP (false positive) | TN (true negative) |
| Model | Accuracy (%) | Training Time (s) | Test Time (s) |
|---|---|---|---|
| Model of this paper | 98.30 | 1042.57 | 6.52 |
| Contrast model A | 76.84 | 1054.76 | 6.49 |
| Contrast model B | 97.08 | 806.62 | 6.30 |
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | Training Time (s) | Test Time (s) |
|---|---|---|---|---|---|---|
| LSTM-CNN | 98.30 | 98.32 | 98.30 | 98.66 | 1042.57 | 6.52 |
| Bi-LSTM | 96.75 | 96.79 | 96.76 | 96.75 | 582.47 | 2.66 |
| LSTM | 96.61 | 96.64 | 96.61 | 96.61 | 516.19 | 3.28 |
| CNN | 92.69 | 92.74 | 92.63 | 92.66 | 539.08 | 2.74 |
| SVM | 88.20 | 88.17 | 88.20 | 88.15 | 220.82 | 21.78 |
| RF | 91.18 | 91.52 | 91.08 | 91.18 | 21.88 | 0.064 |
| LR | 86.21 | 86.33 | 86.21 | 86.25 | 3.62 | 0.001 |
| Event Type | LSTM-CNN | Bi-LSTM | LSTM | CNN | RF | SVM | LR |
|---|---|---|---|---|---|---|---|
| Bus fault | 100.00 | 88.89 | 88.89 | 100.00 | 85.71 | 87.50 | 77.78 |
| Instantaneous fault (successful reclosure) | 97.85 | 96.09 | 96.60 | 92.48 | 93.14 | 89.82 | 86.87 |
| Permanent fault (unsuccessful reclosure) | 98.97 | 96.21 | 93.33 | 83.82 | 84.06 | 78.08 | 74.01 |
| Permanent fault (reclosure failure) | 97.90 | 98.92 | 98.64 | 97.53 | 95.62 | 90.17 | 94.20 |
| Main transformer electrical fault | 96.67 | 87.50 | 96.55 | 90.32 | 65.85 | 86.67 | 77.42 |
| Main transformer grave gas fault | 96.30 | 95.83 | 92.86 | 96.00 | 95.65 | 95.83 | 84.62 |
| Main transformer gas fault in voltage regulation | 100.00 | 92.31 | 100.00 | 100.00 | 71.43 | 90.91 | 85.71 |
| Capacitor fault | 99.40 | 98.81 | 97.65 | 99.39 | 97.01 | 94.32 | 94.12 |
| Station/grounding transformer fault | 100.00 | 96.88 | 100.00 | 96.88 | 100.00 | 100.00 | 93.55 |
| Event Type | LSTM-CNN | Bi-LSTM | LSTM | CNN | RF | SVM | LR |
|---|---|---|---|---|---|---|---|
| Bus fault | 88.89 | 88.89 | 88.89 | 77.78 | 87.50 | 77.78 | 77.78 |
| Instantaneous fault (successful reclosure) | 98.80 | 98.00 | 96.41 | 90.82 | 89.82 | 88.02 | 85.83 |
| Permanent fault (unsuccessful reclosure) | 97.30 | 94.26 | 94.60 | 87.50 | 78.08 | 77.03 | 76.01 |
| Permanent fault (reclosure failure) | 97.90 | 96.14 | 97.19 | 96.84 | 89.86 | 93.33 | 91.23 |
| Main transformer electrical fault | 100.00 | 96.55 | 96.55 | 96.55 | 86.67 | 89.66 | 82.76 |
| Main transformer grave gas fault | 100.00 | 88.46 | 100.00 | 92.31 | 100.00 | 88.46 | 84.62 |
| Main transformer gas fault in voltage regulation | 100.00 | 92.31 | 84.62 | 92.31 | 90.91 | 76.92 | 92.31 |
| Capacitor fault | 99.40 | 100.00 | 100.00 | 98.80 | 94.32 | 100.00 | 96.39 |
| Station/grounding transformer fault | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 93.55 | 93.55 |
| Event Type | LSTM-CNN | Bi-LSTM | LSTM | CNN | RF | SVM | LR |
|---|---|---|---|---|---|---|---|
| Bus fault | 94.12 | 88.89 | 88.89 | 87.50 | 75.00 | 82.35 | 77.78 |
| Instantaneous fault (successful reclosure) | 98.81 | 97.04 | 96.50 | 91.64 | 91.24 | 88.91 | 86.35 |
| Permanent fault (unsuccessful reclosure) | 98.13 | 95.22 | 93.96 | 85.62 | 87.34 | 77.55 | 75.00 |
| Permanent fault (reclosure failure) | 98.76 | 97.51 | 98.40 | 97.18 | 93.74 | 91.72 | 92.69 |
| Main transformer electrical fault | 98.31 | 91.80 | 96.55 | 93.33 | 77.14 | 88.14 | 80.00 |
| Main transformer grave gas fault | 98.11 | 92.00 | 96.30 | 94.12 | 89.80 | 92.00 | 84.62 |
| Main transformer gas fault in voltage regulation | 100.00 | 92.31 | 91.67 | 96.00 | 74.07 | 83.33 | 88.89 |
| Capacitor fault | 99.40 | 99.40 | 98.81 | 99.09 | 97.30 | 97.08 | 95.24 |
| Station/grounding transformer fault | 100.00 | 98.41 | 100.00 | 98.41 | 96.67 | 96.67 | 93.55 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, Z.; Sun, G.; Zang, H.; Zhang, M.; Shen, P.; Liu, Y.; Wei, Z. Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China. Energies 2019, 12, 3258. https://doi.org/10.3390/en12173258
Bai Z, Sun G, Zang H, Zhang M, Shen P, Liu Y, Wei Z. Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China. Energies. 2019; 12(17):3258. https://doi.org/10.3390/en12173258
Chicago/Turabian StyleBai, Ziyu, Guoqiang Sun, Haixiang Zang, Ming Zhang, Peifeng Shen, Yi Liu, and Zhinong Wei. 2019. "Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China" Energies 12, no. 17: 3258. https://doi.org/10.3390/en12173258
APA StyleBai, Z., Sun, G., Zang, H., Zhang, M., Shen, P., Liu, Y., & Wei, Z. (2019). Identification Technology of Grid Monitoring Alarm Event Based on Natural Language Processing and Deep Learning in China. Energies, 12(17), 3258. https://doi.org/10.3390/en12173258