Research on Short-Term Load Prediction Based on Seq2seq Model



Abstract
1. Introduction
2. Motivation and Problem Statement
3. Seq2seq Codec
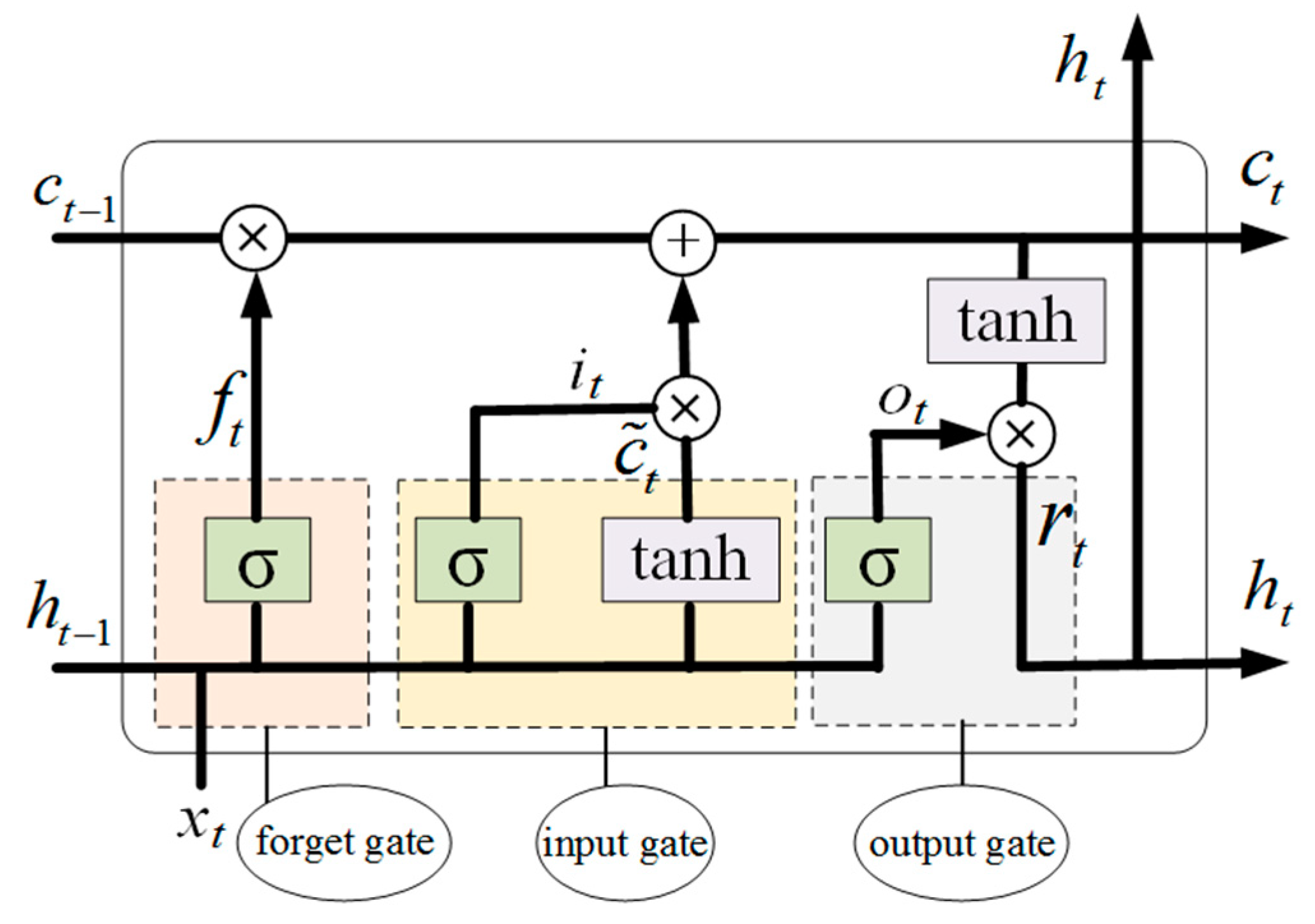
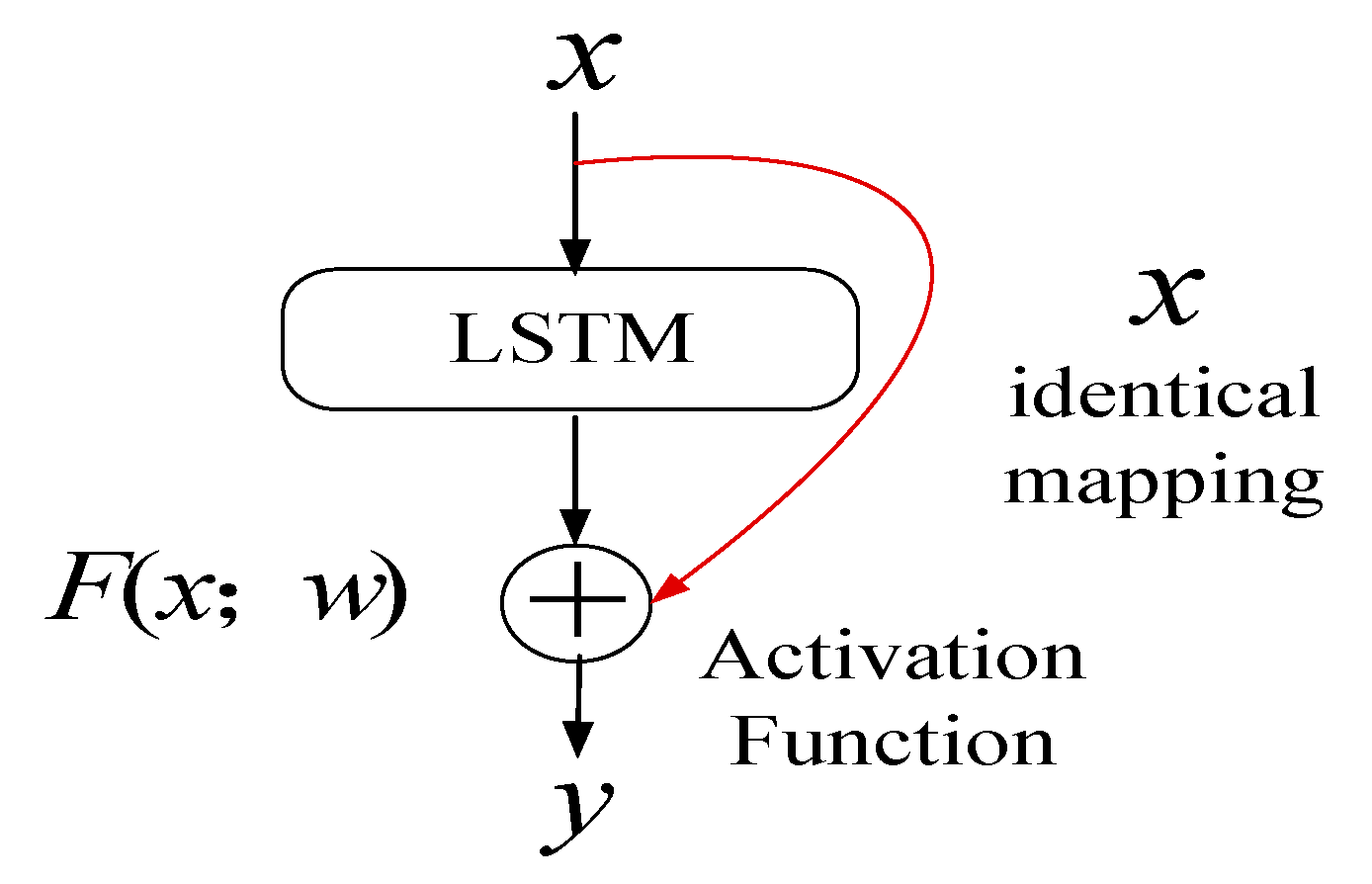
3.1. LSTM
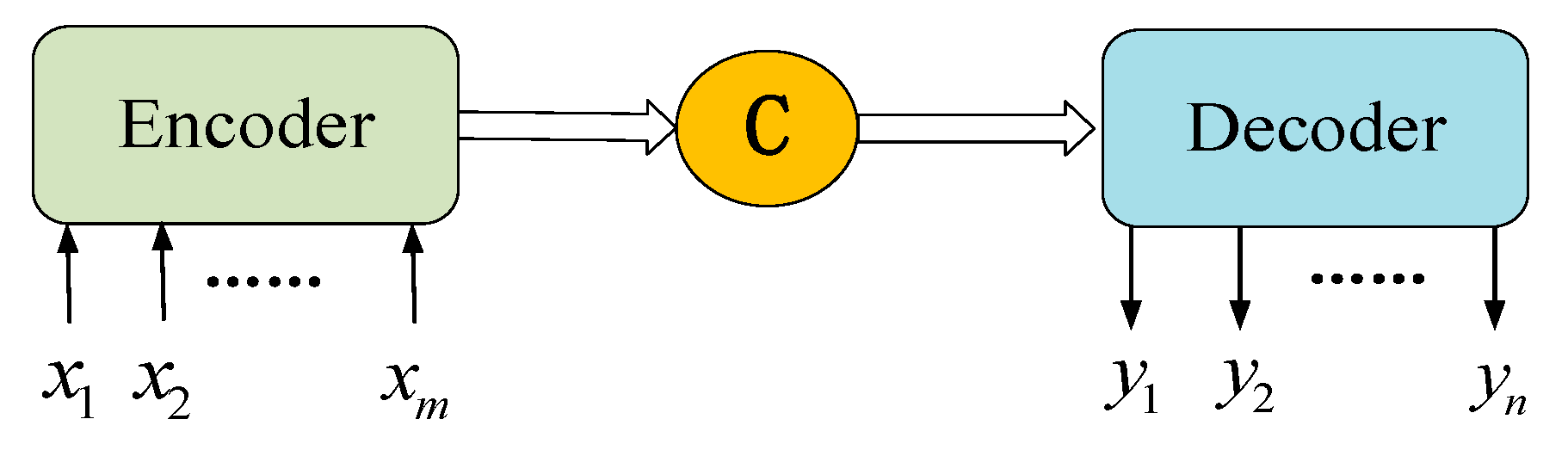
3.2. Seq2seq Codec Principle
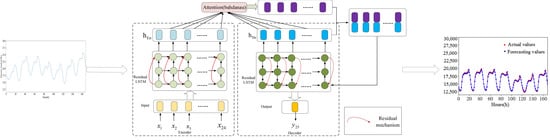
4. A Short-Term Load Prediction Model Based on Seq2seq Codec Structure
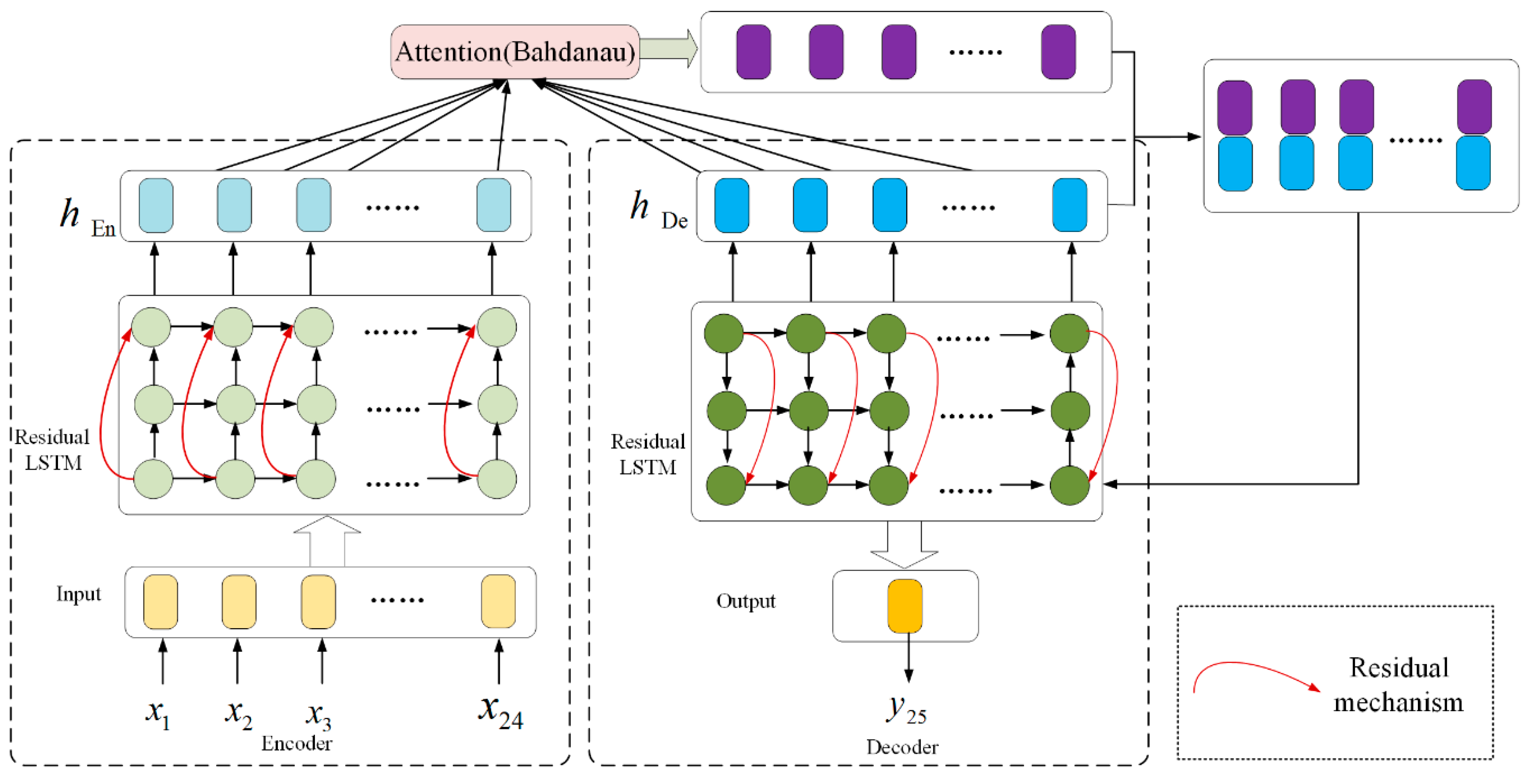
4.1. Attention Mechanism
- (1)
- Bahdanau Attention: During decoding, the first step is to generate the semantic vector for particular time:where is the semantic vector at time t, is the degree of influence of the hidden state of LSTM in the process of encoding, and of the hidden state of LSTM in the process of decoding. is a normalized value given by the softmax function. V and W are the weight parameters of the model.
- (2)
- Luong Attention: During decoding, the first step is to generate the semantic vector for time t:
4.2. Residual Mechanism
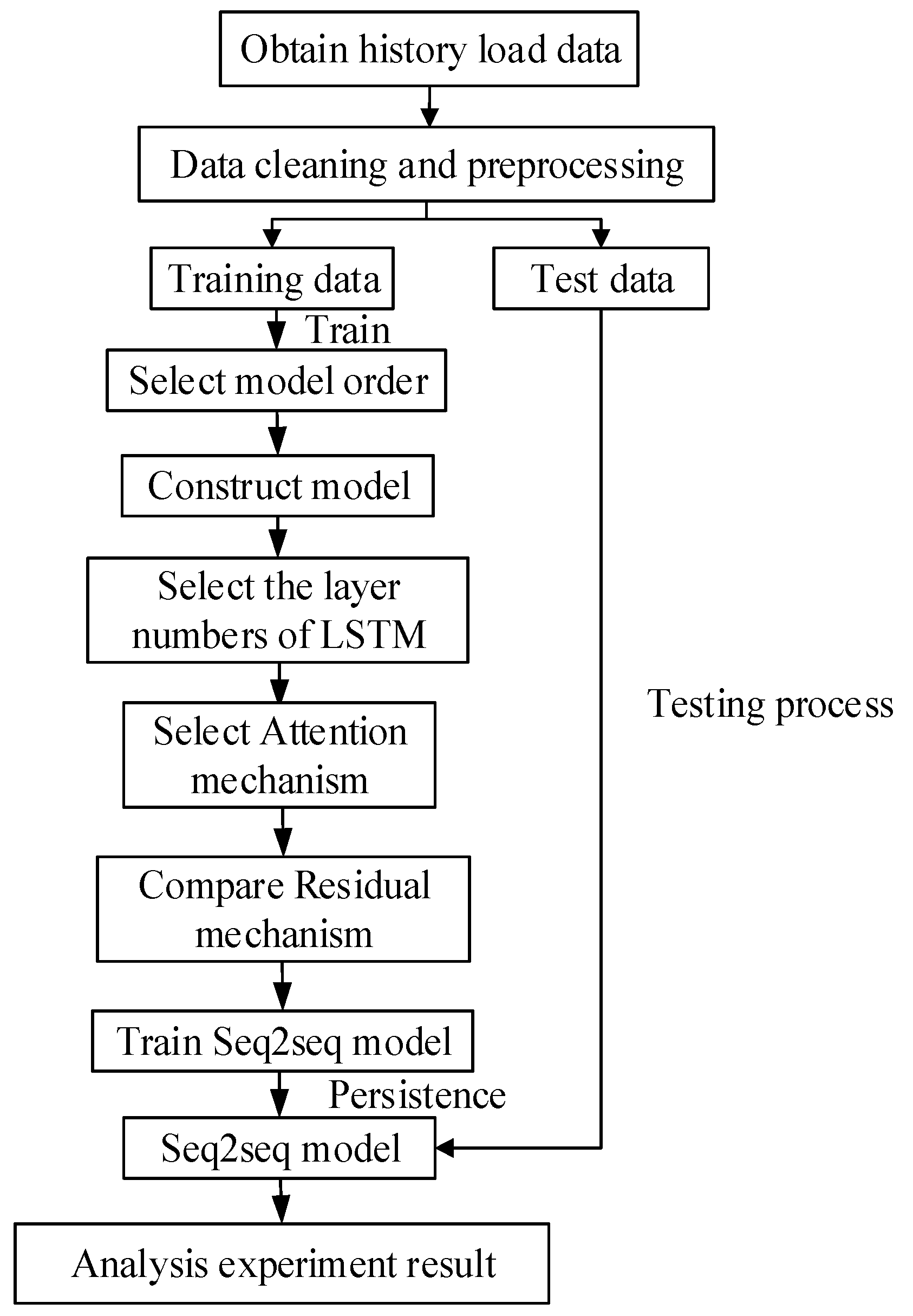
4.3. Short-Term Load Forecasting Model and Flowchart
5. Simulation Experiments
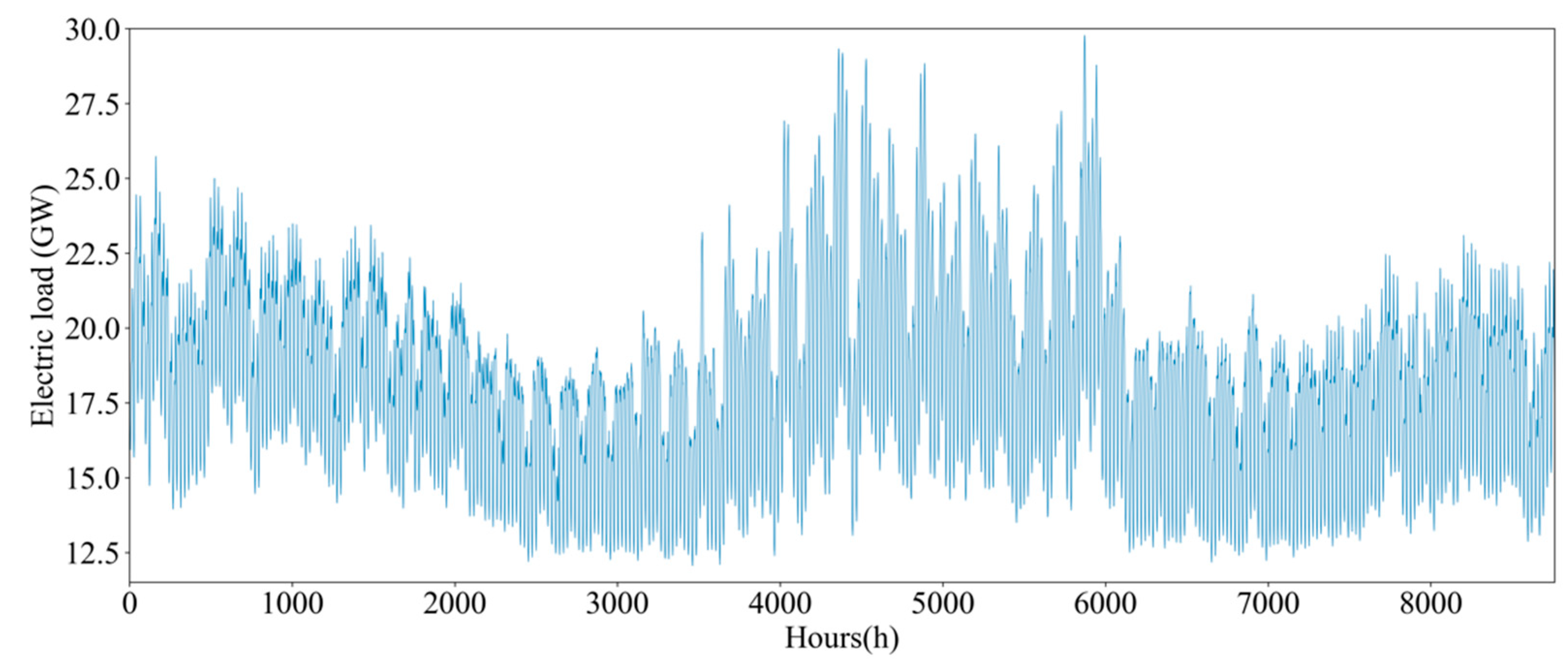
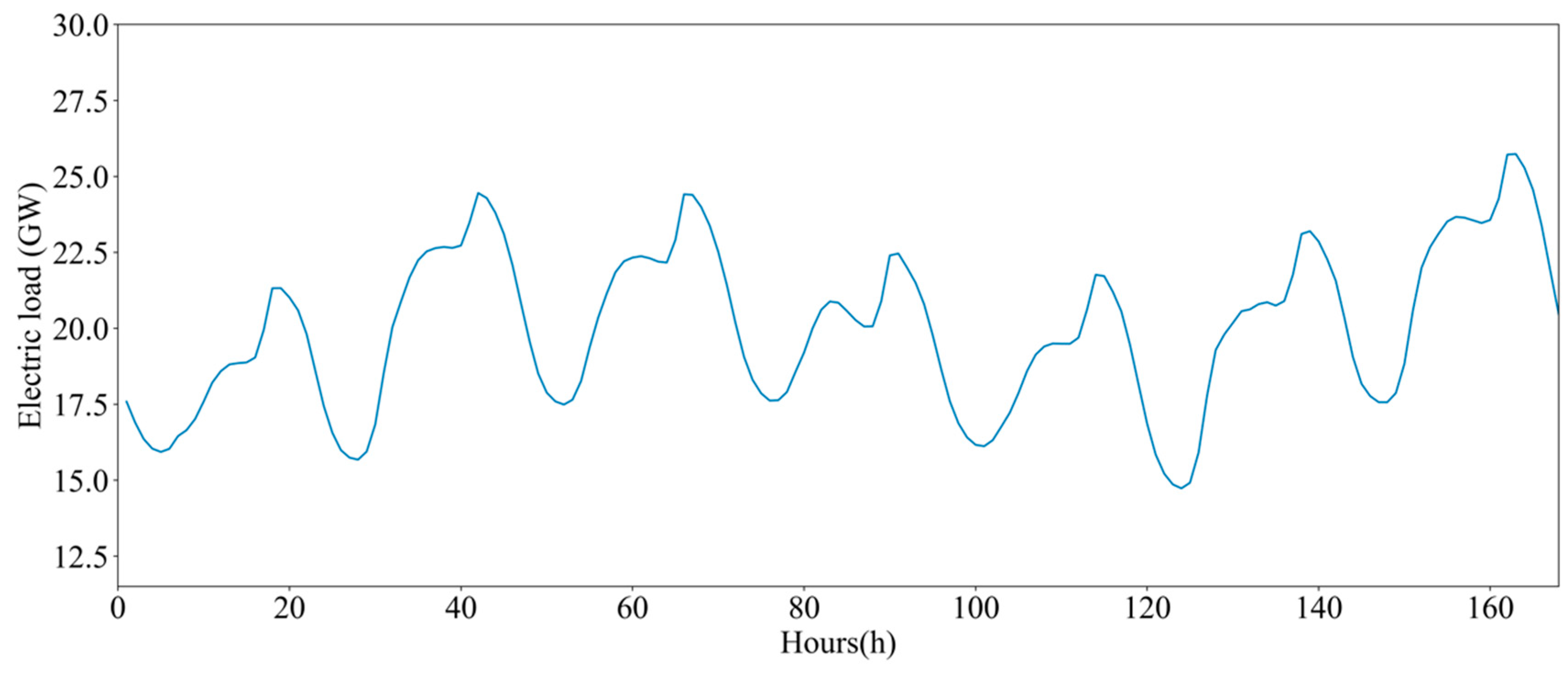
5.1. Introduction to the Dataset
5.2. Performance Indices
5.3. Seq2seq Preferred Model Parameters
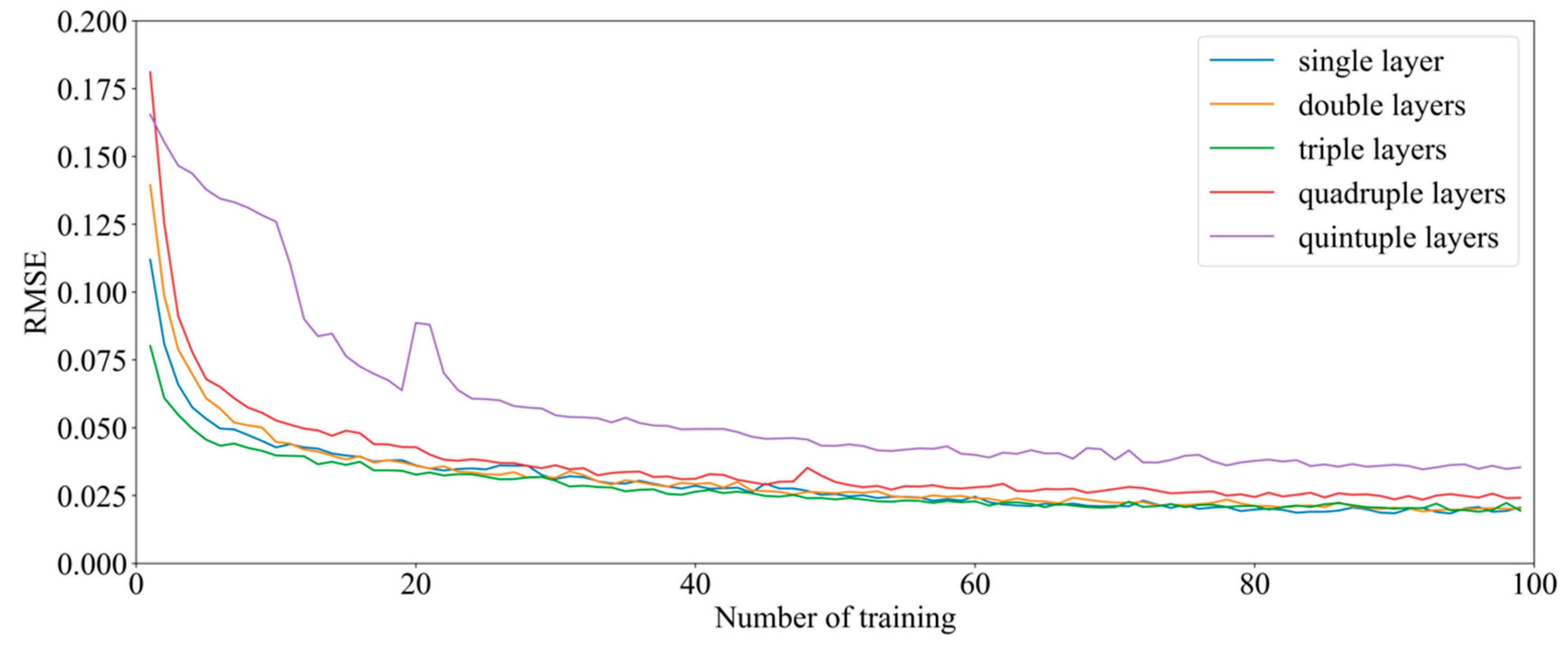
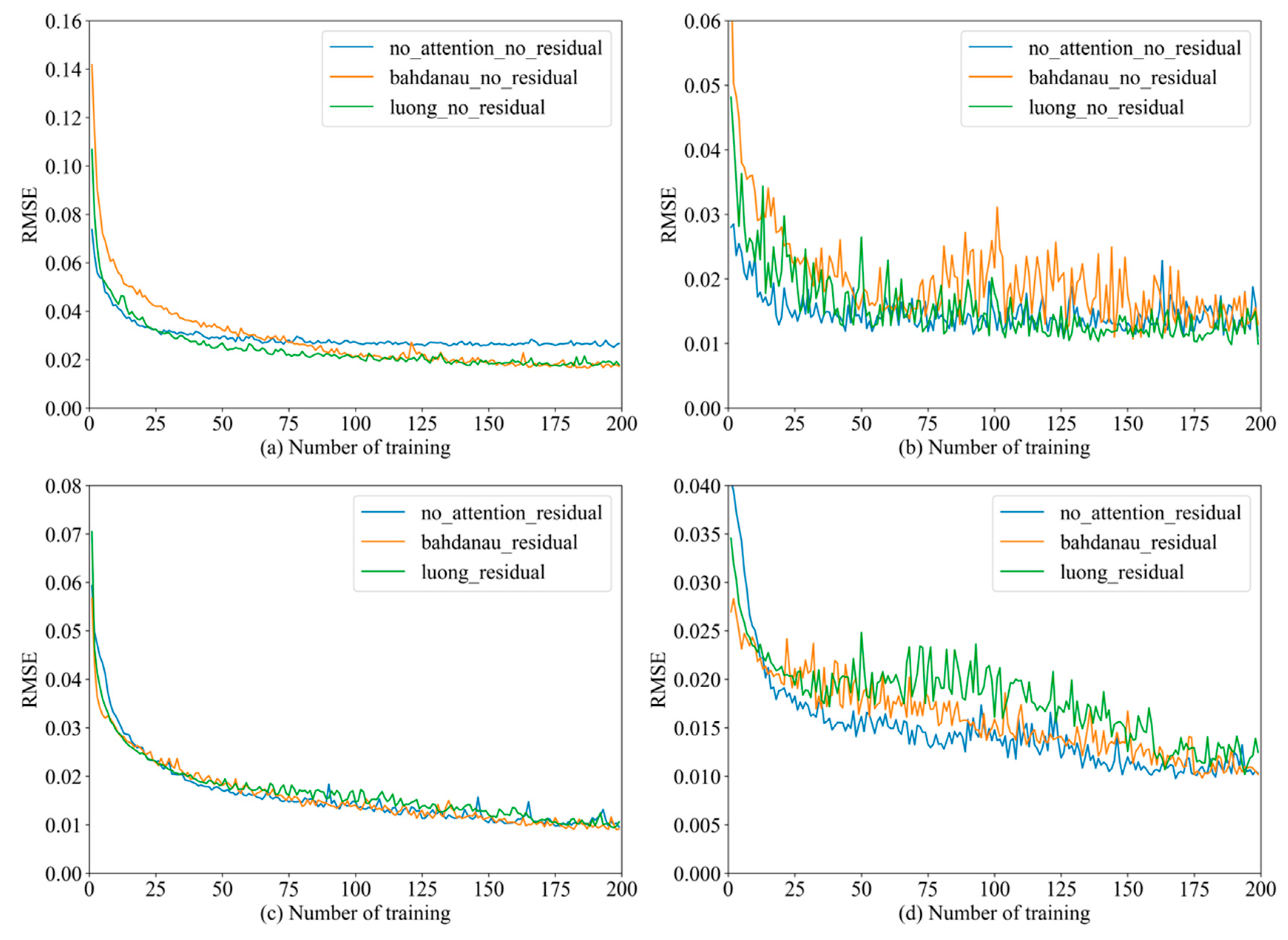
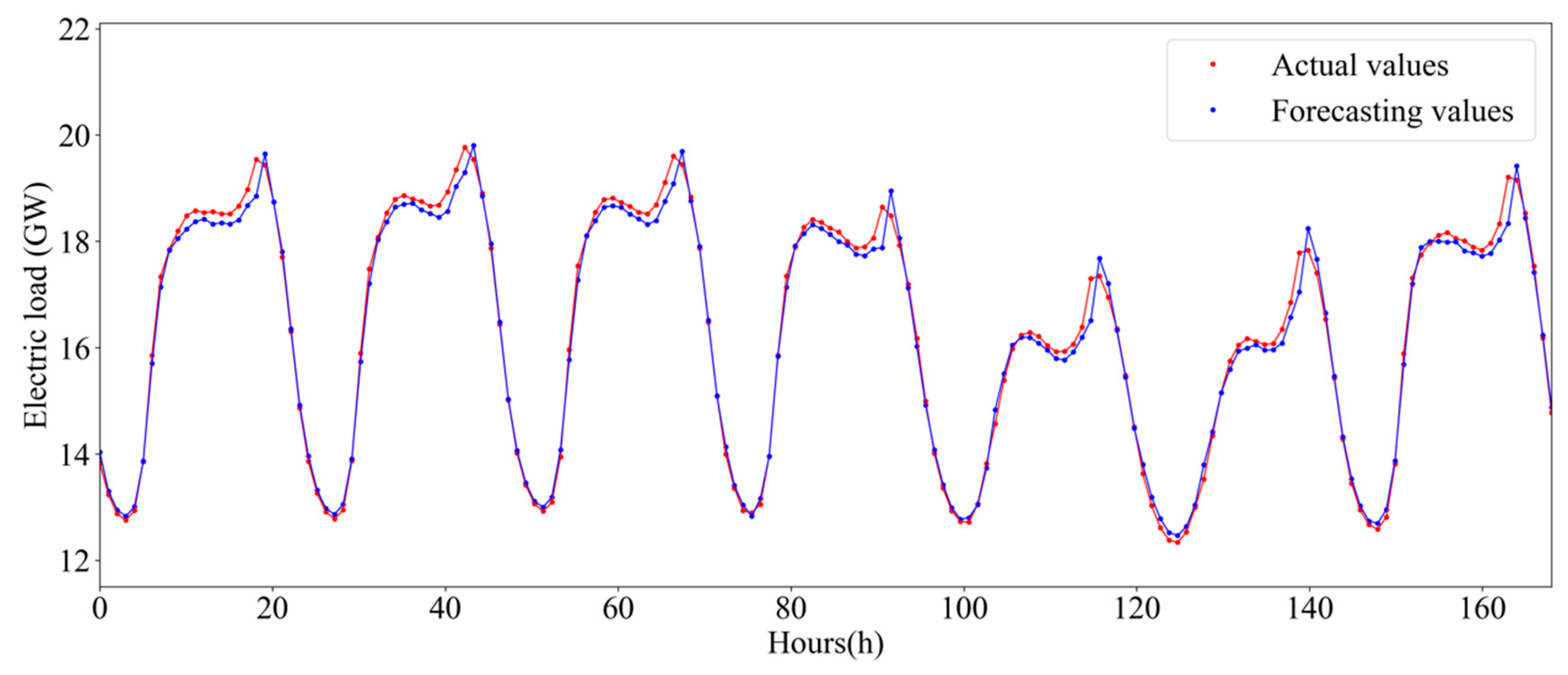
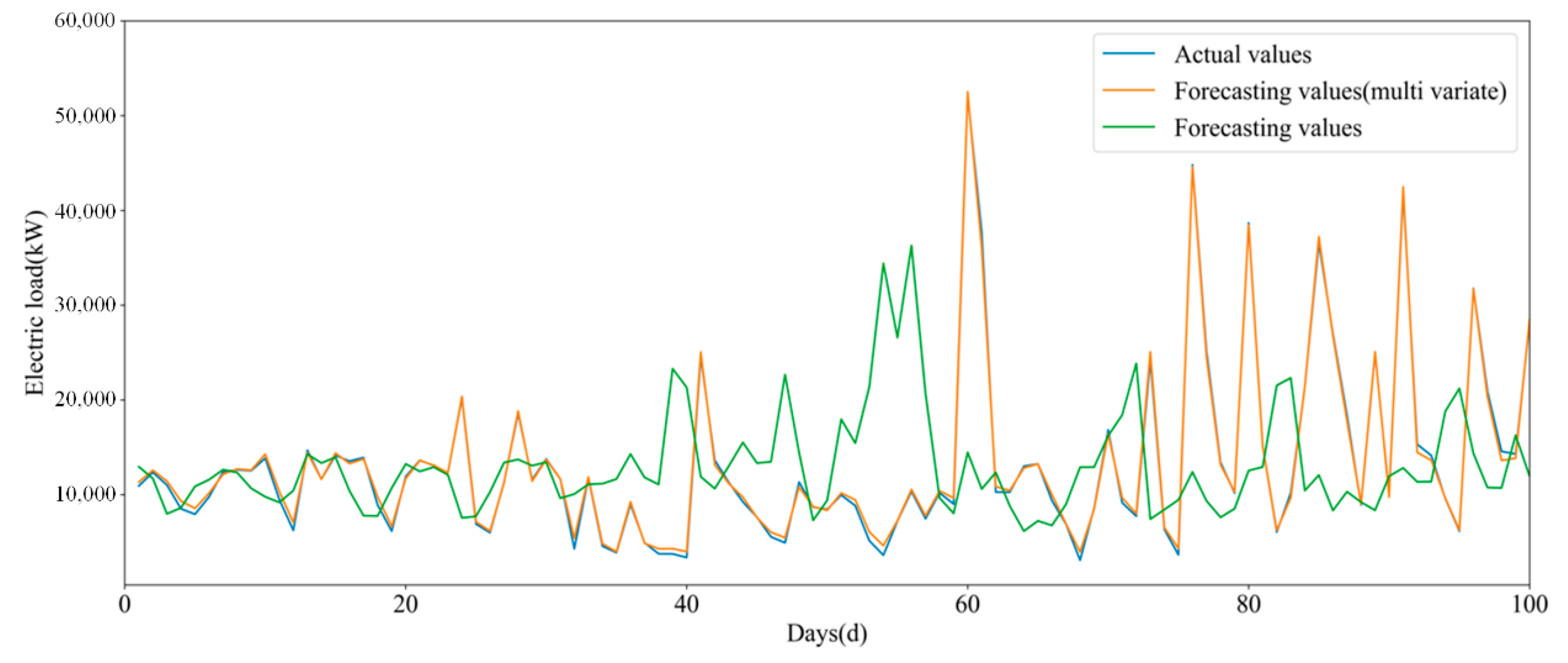
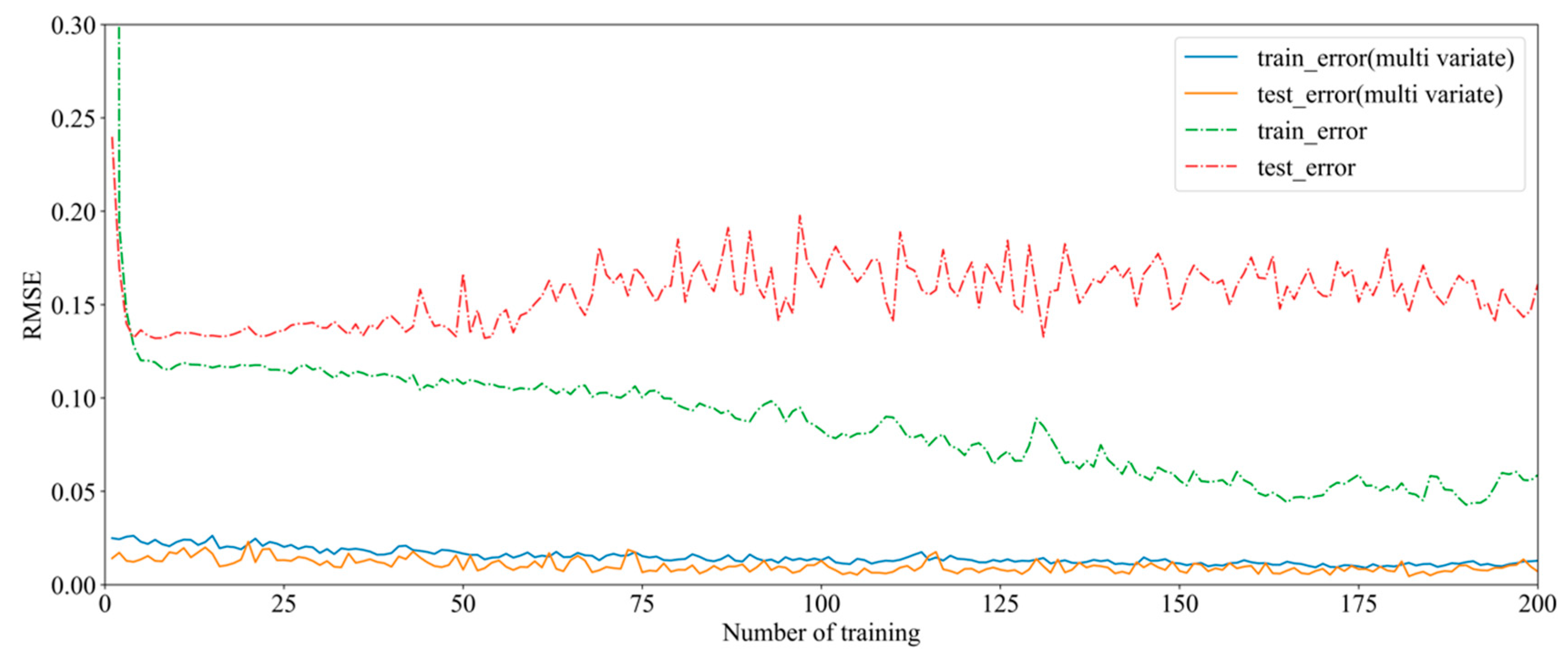
5.4. Experimental Results and Analysis
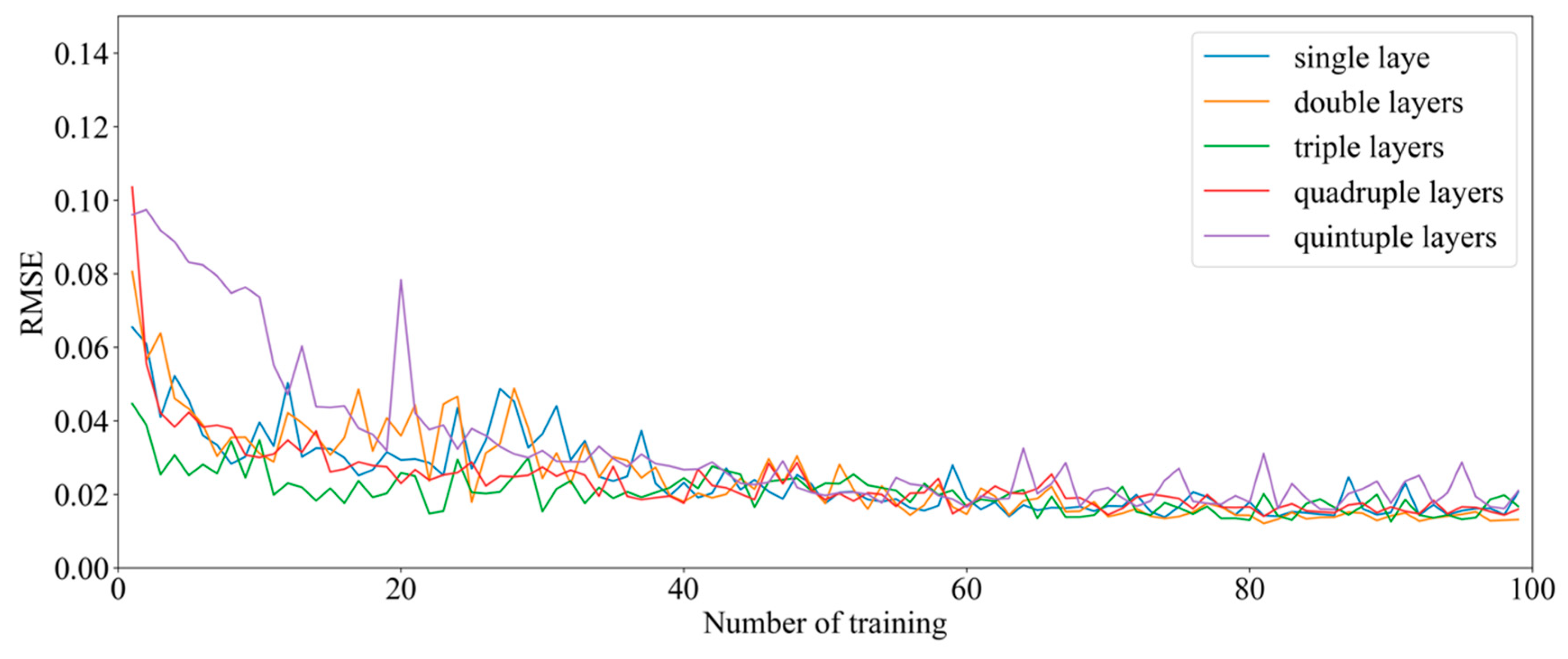
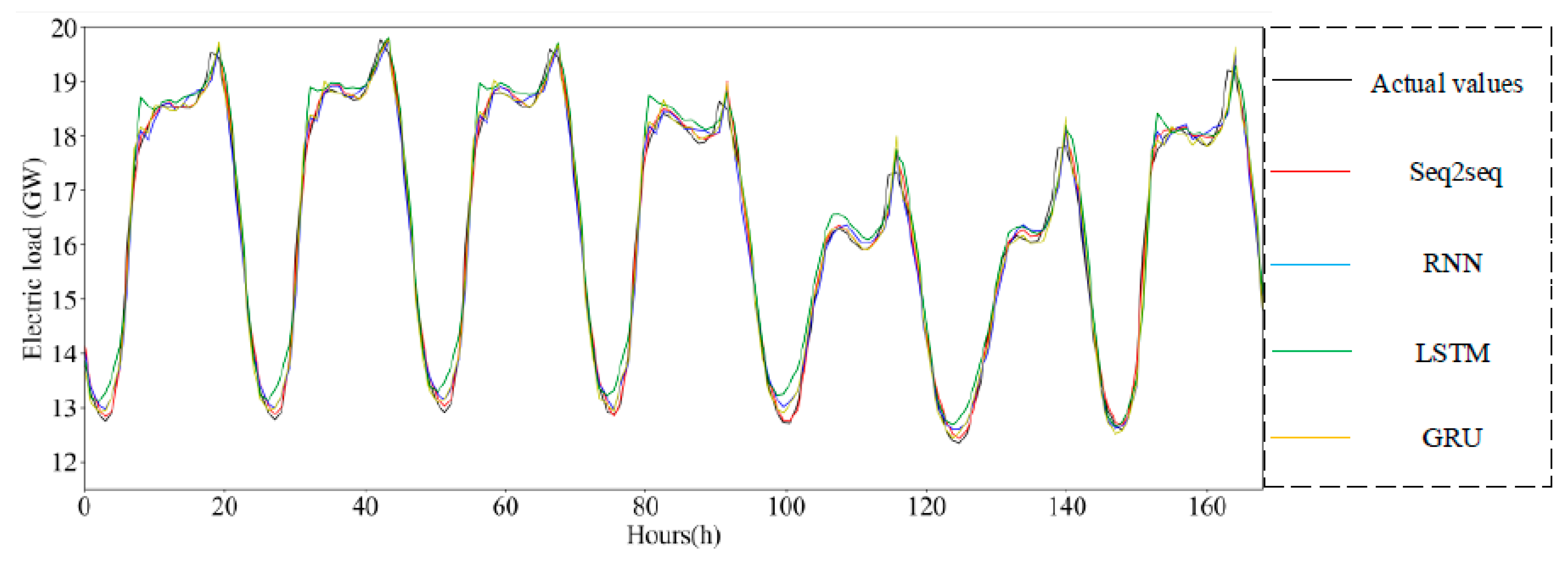
5.5. Supplementary Experiment
6. Conclusions
- (1)
- The progressive application of the Seq2seq model for load forecasting. Initially, the model was widely used in the field of machine translation, and it has been used for load forecasting to obtain better load forecasting results.
- (2)
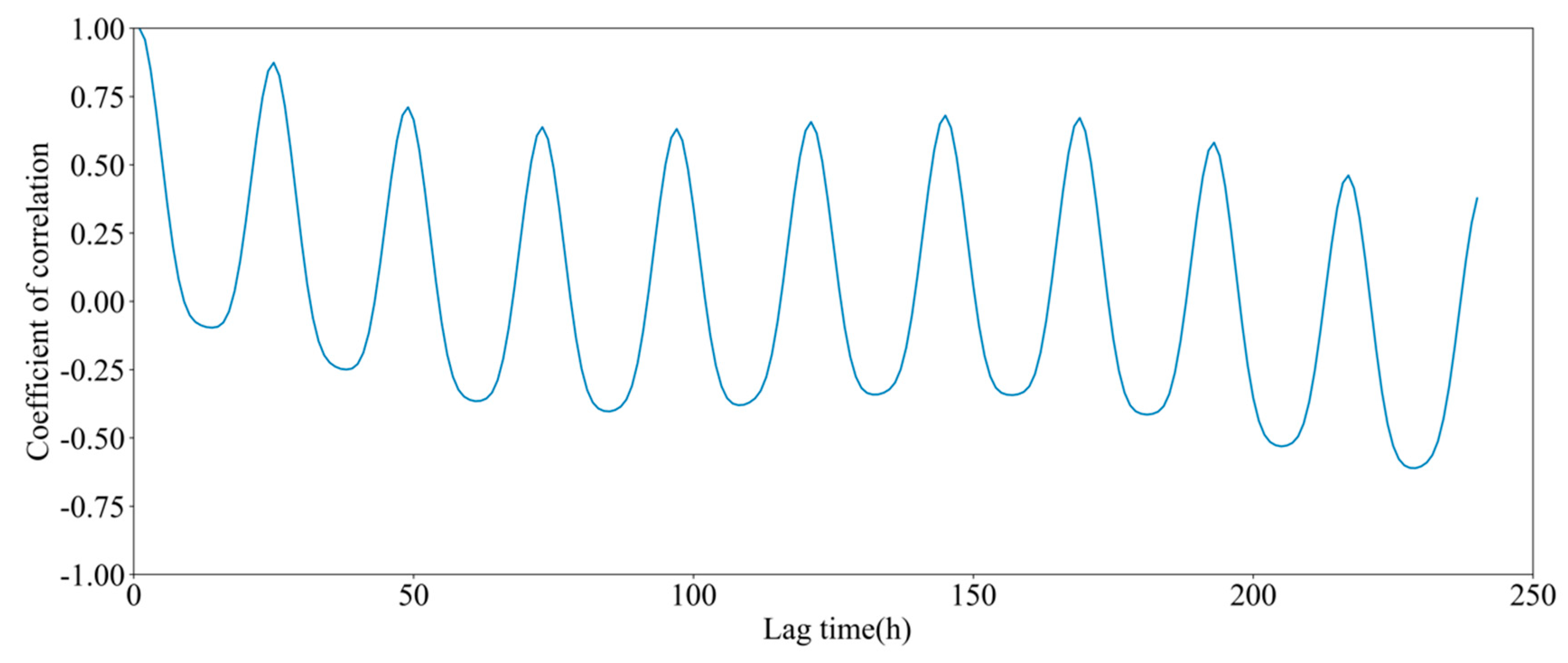
- According to the periodic characteristics of historical load data, the correlation coefficient method is used to determine the order of the input historical load, and the accuracy of data feature extraction is improved.
- (3)
- The coalescence of Residual and Attention mechanisms is used to optimize the Seq2seq model, which overcomes shortcomings, such as model instability and lower precision, ensuring the effectiveness of power load forecasting.
- (4)
- To demonstrate the robustness and the stability of the proposed model, the electricity dataset of the small power grid is used for prediction, also considering different weather conditions and user behaviors.
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| ANN | Artificial neural network |
| GRU | Gated recurrent unit |
| LSTM | Long short-term memory network |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percent Error |
| MSE | Mean squared error |
| RMSE | Root Mean Square Error |
| RNN | Recurrent neural network |
| The output state of the updated forgotten gate | |
| Activation function | |
| W and V | Weight Matrices |
| The hidden state | |
| Bias coefficient | |
| The updated input gate | |
| The output state | |
| Activation function | |
| Input sequences of the model | |
| Output sequences of the model | |
| The degree of influence of the hidden state | |
| The hidden state of the encoder | |
| The dimension of the data | |
| True value | |
| Predicted value |
References
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef]
- Liu, S. Peak value forecasting for district distribution load based on time series. Electr. Power Sci. Eng. 2018, 34, 56–60. [Google Scholar]
- Wei, T. Medium and long-term electric load forecasting based on multiple linear regression model. Electronics World 2017, 23, 31–32. [Google Scholar]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. Int. J. Electr. Power Energy Syst. 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Göb, R.; Lurz, K.; Pievatolo, A. More Accurate Prediction Intervals for Exponential Smoothing with Covariates with Applications in Electrical Load Forecasting and Sales Forecasting: Prediction Intervals for Exponential Smoothing with Covariates. Qual. Reliab. Eng. Int. 2015, 31, 669–682. [Google Scholar] [CrossRef]
- Jiang, P.; Zhou, Q.; Jiang, H.; Dong, Y. An Optimized Forecasting Approach Based on Grey Theory and Cuckoo Search Algorithm: A Case Study for Electricity Consumption in New South Wales. Abstr. Appl. Anal. 2014, 2014, 1–13. [Google Scholar] [CrossRef]
- Wang, H.; Yang, K.; Xue, L.; Liu, S. The Study of Long-term Electricity Load Forecasting Based on Improved Grey Prediction. In Proceedings of the 21st International Conference on Industrial Engineering and Engineering Management 2014 (IEEM 2014), Selangor Darul Ehsan, Malaysia, 9–12 December 2014; Atlantis Press: Paris, France, 2015. [Google Scholar]
- Abreu, T.; Amorim, A.J.; Santos-Junior, C.R.; Lotufo, A.D.P.; Minussi, C.R. Multinodal load forecasting for distribution systems using a fuzzy-artmap neural network. Appl. Soft Comput. 2018, 71, 307–316. [Google Scholar] [CrossRef]
- Ncane, Z.P.; Saha, A.K. Forecasting Solar Power Generation Using Fuzzy Logic and Artificial Neural Network. In Proceedings of the 2019 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), Bloemfontein, South Africa, 28–30 January 2019; IEEE: Bloemfontein, South Africa, 2019; pp. 518–523. [Google Scholar]
- Alamin, Y.I.; Álvarez, J.D.; del Mar Castilla, M.; Ruano, A. An Artificial Neural Network (ANN) model to predict the electric load profile for an HVAC system. IFAC-PapersOnLine 2018, 51, 26–31. [Google Scholar] [CrossRef]
- Sun, Q.; Yang, L. Smart energy—Applications and prospects of artificial intelligence technology in power system. Control Decis. 2018, 33, 938–949. [Google Scholar]
- Dai, Y.; Wang, L. A Brief Survey on Applications of New Generation Artificial Intelligence in Smart Grids. Electr. Power Constr. 2018, 39, 10–20. [Google Scholar]
- Cheng, D.; Xu, J.; Zheng, Z. Analysis of Short-term Load Forecasting Problem of Power System Based on Time Series. Autom. Appl. 2017, 11, 99–101. [Google Scholar]
- Zhang, F.; Zhang, F. Power Load Forecasting in the Time Series Analysis Method Based on Lifting Wavelet. Electr. Autom. 2017, 39, 72–76. [Google Scholar]
- Dehalwar, V.; Kalam, A.; Kolhe, M.L.; Zayegh, A. Electricity load forecasting for Urban area using weather forecast information. In Proceedings of the 2016 IEEE International Conference on Power and Renewable Energy (ICPRE), Shanghai, China, 21–23 October 2016; IEEE: Shanghai, China, 2016; pp. 355–359. [Google Scholar]
- Sun, Y.; Zhang, Z. Short-Term Load Forecasting Based on Recurrent Neural Network Using Ant Colony Optimization Algorithm. Power Syst. Technol. 2005, 29, 59–63. [Google Scholar]
- Li, P.; He, S. Short-Term Load Forecasting of Smart Grid Based on Long-Short-Term Memory Recurrent Neural Networks in Condition of Real-Time Electricity Price. Power Syst. Technol. 2018, 42, 4045–4052. [Google Scholar]
- Wu, R.; Bao, Z. Research on Short-term Load Forecasting Method of Power Grid Based on Deep Learning. Mod. Electr. Power 2018, 35, 43–48. [Google Scholar]
- Lin, Q. Research on Power System Short-term Load Forecasting Based on Neural Network Intelligent Algorithm. Master’s Thesis, Lanzhou University of Technology, Lanzhou, China, 2017. [Google Scholar]
- Khuntia, S.; Rueda, J.; van der Meijden, M. Long-Term Electricity Load Forecasting Considering Volatility Using Multiplicative Error Model. Energies 2018, 11, 3308. [Google Scholar] [CrossRef]
- Mujeeb, S.; Javaid, N.; Ilahi, M.; Wadud, Z.; Ishmanov, F.; Afzal, M. Deep Long Short-Term Memory: A New Price and Load Forecasting Scheme for Big Data in Smart Cities. Sustainability 2019, 11, 987. [Google Scholar] [CrossRef]
- Tian, C.; Ma, J.; Zhang, C.; Zhan, P. A Deep Neural Network Model for Short-Term Load Forecast Based on Long Short-Term Memory Network and Convolutional Neural Network. Energies 2018, 11, 3493. [Google Scholar] [CrossRef]
- Zhang, X.; Shu, Z.; Wang, R.; Zhang, T.; Zha, Y. Short-Term Load Interval Prediction Using a Deep Belief Network. Energies 2018, 11, 2744. [Google Scholar] [CrossRef]
- Ran, X.; Shan, Z.; Fang, Y.; Lin, C. An LSTM-Based Method with Attention Mechanism for Travel Time Prediction. Sensors 2019, 19, 861. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, Z.; Mourshed, M.; Guo, Y.; Zhou, Y.; Chang, Y.; Wei, Y.; Feng, S. Electric Vehicle Charging Load Forecasting: A Comparative Study of Deep Learning Approaches. Energies 2019, 12, 2692. [Google Scholar] [CrossRef]
- Huang, J.; Sun, Y.; Zhang, W.; Wang, H.; Liu, T. Entity Highlight Generation as Statistical and Neural Machine Translation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1860–1872. [Google Scholar] [CrossRef]
- Kim, J.-G.; Lee, B. Appliance Classification by Power Signal Analysis Based on Multi-Feature Combination Multi-Layer LSTM. Energies 2019, 12, 2804. [Google Scholar] [CrossRef]
- He, X.; Haffari, G.; Norouzi, M. Sequence to Sequence Mixture Model for Diverse Machine Translation. arXiv 2018, arXiv:1810.07391. [Google Scholar]
- Jang, M.; Seo, S.; Kang, P. Recurrent neural network-based semantic variational autoencoder for Sequence-to-sequence learning. Inf. Sci. 2019, 490, 59–73. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Kim, J.; El-Khamy, M.; Lee, J. Residual LSTM: Design of a Deep Recurrent Architecture for Distant Speech Recognition. arXiv 2017, arXiv:1701.03360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Niu, M.Y.; Horesh, L.; Chuang, I. Recurrent Neural Networks in the Eye of Differential Equations. arXiv 2019, arXiv:1904.12933. [Google Scholar]
- Haber, E.; Ruthotto, L. Stable architectures for deep neural networks. Inverse Probl. 2017, 34, 014004. [Google Scholar] [CrossRef]
- New York Independent System Operator (NYISO). Available online: http://www.nyiso.com/public/markets_operations/market_data/load_data/index.jsp (accessed on 18 February 2019).
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- López, M.; Sans, C.; Valero, S.; Senabre, C. Classification of Special Days in Short-Term Load Forecasting: The Spanish Case Study. Energies 2019, 12, 1253. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Residual | Attention | Train | Test | ||
|---|---|---|---|---|---|
| MSE | RMSE | MSE | RMSE | ||
| False | False | 0.000711 | 0.027 | 0.000124 | 0.011 |
| Bahdanau | 0.000297 | 0.017 | 0.000169 | 0.013 | |
| Luong | 0.000317 | 0.018 | 0.000198 | 0.014 | |
| True | False | 0.000091 | 0.0095 | 0.000106 | 0.01 |
| Bahdanau | 0.000083 | 0.0091 | 0.000104 | 0.01 | |
| Luong | 0.000112 | 0.0105 | 0.000155 | 0.012 | |
| Parameter | Parameter Setting | Parameter | Parameter Setting |
|---|---|---|---|
| Training data | 7008 | Test data | 1752 |
| Length input | 24 | Length output | 1 |
| Learning rate | 0.01 | Decay rate of learning rate | 0.5 |
| Node in hidden layer | 100 | Decay steps | 200 |
| Number of trainings | 300 | Batch | 200 |
| Optimization algorithm | Adam | Gradient value | 5.0 |
| Different Method | Error of Normalized Data | |||
|---|---|---|---|---|
| MSE | RMSE | MAE | MAPE | |
| Seq2seq | 0.000083 | 0.0091 | 0.0076 | 5.20% |
| RNN | 0.00019 | 0.0138 | 0.01015 | 7.35% |
| LSTM | 0.00039 | 0.01964 | 0.0158 | 14.04% |
| GRU | 0.0002 | 0.01449 | 0.01066 | 8.29% |
| Different Method | Error of Raw Data | |||
|---|---|---|---|---|
| MSE | RMSE | MAE | MAPE | |
| Seq2seq | 0.0319 | 0.1787 | 0.1347 | 0.8262% |
| RNN | 0.0599 | 0.2448 | 0.1799 | 1.1143% |
| LSTM | 0.1212 | 0.3482 | 0.2809 | 1.7847% |
| GRU | 0.0659 | 0.2567 | 0.1890 | 1.1760% |
| Type of Data | Specific Meaning |
|---|---|
| F_day1 | Load value one day before the date to be tested |
| F_week | The load value of the day of the previous week |
| Day of week | Which day of the week |
| Workday | Whether it is working day or not |
| Holiday | Whether it is a holiday or not |
| Tem_max | Maximum temperature |
| Tem_min | Minimum temperature |
| RH_max | Maximum humidity |
| RH_min | Minimum humidity |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, G.; An, X.; Mahato, N.K.; Sun, S.; Chen, S.; Wen, Y. Research on Short-Term Load Prediction Based on Seq2seq Model. Energies 2019, 12, 3199. https://doi.org/10.3390/en12163199
Gong G, An X, Mahato NK, Sun S, Chen S, Wen Y. Research on Short-Term Load Prediction Based on Seq2seq Model. Energies. 2019; 12(16):3199. https://doi.org/10.3390/en12163199
Chicago/Turabian StyleGong, Gangjun, Xiaonan An, Nawaraj Kumar Mahato, Shuyan Sun, Si Chen, and Yafeng Wen. 2019. "Research on Short-Term Load Prediction Based on Seq2seq Model" Energies 12, no. 16: 3199. https://doi.org/10.3390/en12163199
APA StyleGong, G., An, X., Mahato, N. K., Sun, S., Chen, S., & Wen, Y. (2019). Research on Short-Term Load Prediction Based on Seq2seq Model. Energies, 12(16), 3199. https://doi.org/10.3390/en12163199