1. Introduction
With the continuous reduction of traditional fossil energy and the salient environmental pollution problem, the global energy crisis is becoming more and more serious. From the dual demand of human society for energy and environmental protection, renewable energy is bound to become the direction of future energy due to its advantages of being clean, pollution-free, and recyclable. As a sort of renewable energy, wind energy has the advantages of wide source and convenient development, but it also exhibits strong volatility, intermittent, and non-control characteristics, which pose great challenges to the safety and stability of grid system. Accurate and reliable short-term wind speed prediction not only minimizes the economic losses caused by wind power grid connection, but also reduces the risk of grid dispatch and grid transmission [
1].
Considering the development of the wind speed prediction method, the principle gradually changes from the physical method to the statistical, and the prediction method is developed from linear prediction to nonlinear. In recent years, the intelligent algorithm has been adopted and optimized gradually. Wanting to improve the accuracy of prediction and make up for the shortcomings of separate methods, more and more scholars have explored combined prediction methods. In summary, the wind speed prediction methods can be roughly divided into five categories: (a) Physical methods, (b) spatial correlation, (c) conventional statistical methods, (d) artificial intelligence algorithms, (e) combined methods.
The input indexes of the physical methods are geographical information of the wind farm such as meteorological message, topographical features, surface roughness, obstacles, etc. [
2], then analyzing and calculating the input comprehensively can obtain the wind speed and direction of the fan hub height [
3]. Physical methods regard NWP (numerical weather prediction system) as the chief technology, which has excellent performance in medium- and long-term wind speed prediction [
4], but NWP has some disadvantages including complex calculation, time-consuming, and high accuracy requirements for basic physical quantities [
5]. The position of the spatial correlation methods in the wind speed prediction field has been raised to the same height as physical methods and statistical methods since 2014 [
6]. Spatial correlation believes that the wind speed of a certain place has a high correlation with the wind speed of neighborhood spaces, making it possible to use the weather and other information of the surrounding areas to improve the local wind speed prediction effect [
7]. The key in spatial correlation prediction is establishing mapping relationship through the regression analysis method, so the optimizations of the method mean all of it.
The statistical models predict future wind speed by analyzing historical statistics [
8]. Conventional statistical methods include AR (autoregressive) model [
9], ARMA (autoregressive moving average) model [
10], ARIMA (autoregressive integral moving average) model [
11], and SARIMA (seasonal autoregressive integral moving average) model [
12]. The most notable method is the ARIMA method proposed by Box-Jenkins [
13], which has the advantages of a simple principle and high precision. Because ARIMA can effectively extract linear features of data [
14] and improve the adaptability of time-series models [
15], it performed well in wind speed prediction. Torres et al. [
16] compared the ARIMA with the persistence model and found that the ARIMA always performed better in the prediction. The deformation of the ARIMA model has also been widely used already. Liu et al. [
17] used ARIMA to determine the parameters of the KF (Kalman Filter) to optimize the model and improve the performance. Based on the ARIMA model, Erdem et al. [
18] presented four prediction methods: Component ARMA, link AMRA, VAR (vector autoregressive), and restricted VAR, and applied them to forecast wind speed and direction of two wind farms in North Dakota, USA.
Yuan et al. [
19] confirmed that wind speed has obvious chaotic fractal characteristics by using chaos theory, which means wind speed is nonlinear to some extent. Therefore, using the model with a strong ability to extract the nonlinear information can predict the wind speed accurately; meanwhile, the machine model is generally considered to display complex nonlinear relationships well because of its strong robustness and fault tolerance to noise. According to these, a lot of studies have verified that machine models have good pertinence and adaptability to wind speed prediction. In order to interconnect the chaos theory and machine model, Sun et al. [
20] performed phase space reconstruction on the decomposed wind speed to determine the input and output matrix of BP. Nowadays, artificial intelligence techniques for predicting wind speed are divided into two categories according to different principles: ANN (artificial neural networks) and SVM (support vector machines). ANN mainly covers BP [
21], ELM (extreme learning machines) [
22], RBF (radial basis function neural networks) [
23], RNN (recurrent neural networks) [
24], and so on. As the main representative of ANN, BP has strong nonlinear mapping ability and is used in wind speed prediction widespread research. Qu et al. [
25] optimized BP with FPA (flower-pollination algorithm) to predict the wind speed components and obtain excellent results. Yang et al. [
26] combined Broyden family with wind driven optimization to determine initial weights and thresholds of BP, and the result proved that optimization increase the prediction precision and reliability effectively. The core of SVM is kernel function which avoids selecting the structure of neural network and handles local minimum points of BP. Kernel function and penalty factor are two important parameters of SVM, so many optimization algorithms are combined with the SVN to select the best parameters, such as cuckoo search algorithm [
27] and improved chicken algorithm [
28]. The PSO (particle swarm optimization) combined with LSSVM (least squares support vector machine) was proved have advantages of short training time and high precision according to the research of Zhang et al. [
29].
Intending to extract effective information from wind speed series, the original signal is usually decomposed into stable sequences in the widespread wind speed prediction researche [
30]. Existing decomposition techniques mainly contains WD (wavelet decomposition) and EMD (empirical mode decomposition). Liu et al. [
31] proposed three hybrid models based on WD for wind speed prediction, which regard wavelet and wavelet packet as decomposition algorithms. Hu et al. [
32] applied the data processed by WD to LSSVM for single-step and multi-step wind speed prediction. Additionally, Liu H et al. [
33] used FEEMD (fast ensemble empirical mode decomposition) to process wind speed and established the FEEMD-MEA-MLP model to demonstrate its excellent effect. Wang et al. [
22] put forward a hybrid model that amalgamates EMD with Elman neural network for wind speed prediction and confirmed that the proposed method has the smallest MAE (mean absolute error), RMSE (root mean square error), and MAPE (mean absolute proportional error) among the compared models. However, WD has to set the mother wavelet function artificially, while EMD exists as some intractable problems such as lacking mathematical theory, interpolation selection, and modal aliasing phenomenon [
34]. In contrast, the VMD method proposed by Konstantin Dragomiretskiy [
35] in 2014 not only overcomes the mode mixing, but also decomposes components of different frequencies adaptively. Both Ali Akbar Abdoos [
36] and Ali M [
37] have proved the outstanding performance of VMD in the wind speed data processing.
Correlation study of Bates et al. [
38] evidenced the combined prediction is capable of breaking the limitations of separate prediction models, absorbing the advantages of two or more methods, and reducing the difficulty of model selection, thus, the results of combined prediction tend to be more accurate. According to the combination mode of separate models, it is usually to divide the combined model into series and parallel methods. The series method is making the second prediction of the first results or error correction of first residual by regarding the result or residual as the input of another model, such as [
39] and [
40]. Similarly, the parallel method uses several models to predict original data separately and then weight the results of the separate prediction models by other methods to form the combination prediction results such as [
41] and [
42]. Furthermore, more studies combine different signal decomposition techniques into predictions and various optimization algorithms. For example, Liu et al. [
43] employed WPD (wavelet packet decomposition) and EMD to decompose the wind speed in turn to make the sequences more stable and then use ELM to make the prediction. Jiang et al. [
44] combined BA (bat algorithm), FA (firefly algorithm), and CS (cuckoo search) to optimize the weight coefficients of the three neural networks in order to obtain higher prediction accuracy.
On account of the superiority of the parallel combination and the features of the wind speed being linear accompanied with chaotic, this study put forward a new combined prediction optimization model named VMD-P-(ARIMA, BP)-PSOLSSVM to forecast the wind speed in the short term. The novel model combines the emerging signal decomposition technology, chaos theory, with linear and nonlinear prediction technology to make contributions as follow: (a) Intending to collect the usable information from the original wind speed, a signal processing method based on VMD and phase space reconstruction is invented for the first time. Firstly, the raw data is decomposed into several stable sequences by using VMD, which has been newly proposed in recent years. Then, phase space reconstruction method based on the chaos principle is used to determine the input and output matrix of the prediction model to upgrade the prediction ability. (b) In order to express the strength of the separate models, the research adopts a parallel way to combine the typical linear prediction model and ANN model. Specifically, the processed components and residuals are predicted by ARIMA and BP, respectively, to obtain the predicted values by summing the IMFs. (c) In this study, two results predicted by ARIMA and BP in parallel are used as the input of the LSSVM optimized by PSO for the secondary prediction to obtain the final combined result. PSOLSSVM is a completely different model from the ARIMA and BP from the principle aspect and using this model to make secondary prediction can overcome the limitations of separate models. (d) The excellent performance of the new combined model is evaluated by comparing the prediction results to six other models. Moreover, another set of data was collected to repeat the same experiment and the result confirmed the versatility and application of the proposed model.
The schedule of the paper is showed as follow:
Section 2 presents the rationales of VMD, phase space reconstruction, ARIMA, BP, and PSOLSSVM; the construction process of the combination model is given in
Section 3;
Section 4 uses the proposed model to predict the wind speed in the short term;
Section 5 analyzes and discusses the results of
Section 4;
Section 6 demonstrates the repeatability of the experiment with different cases;
Section 7 draws conclusions from two experiments.
3. Framework of the Combined Model
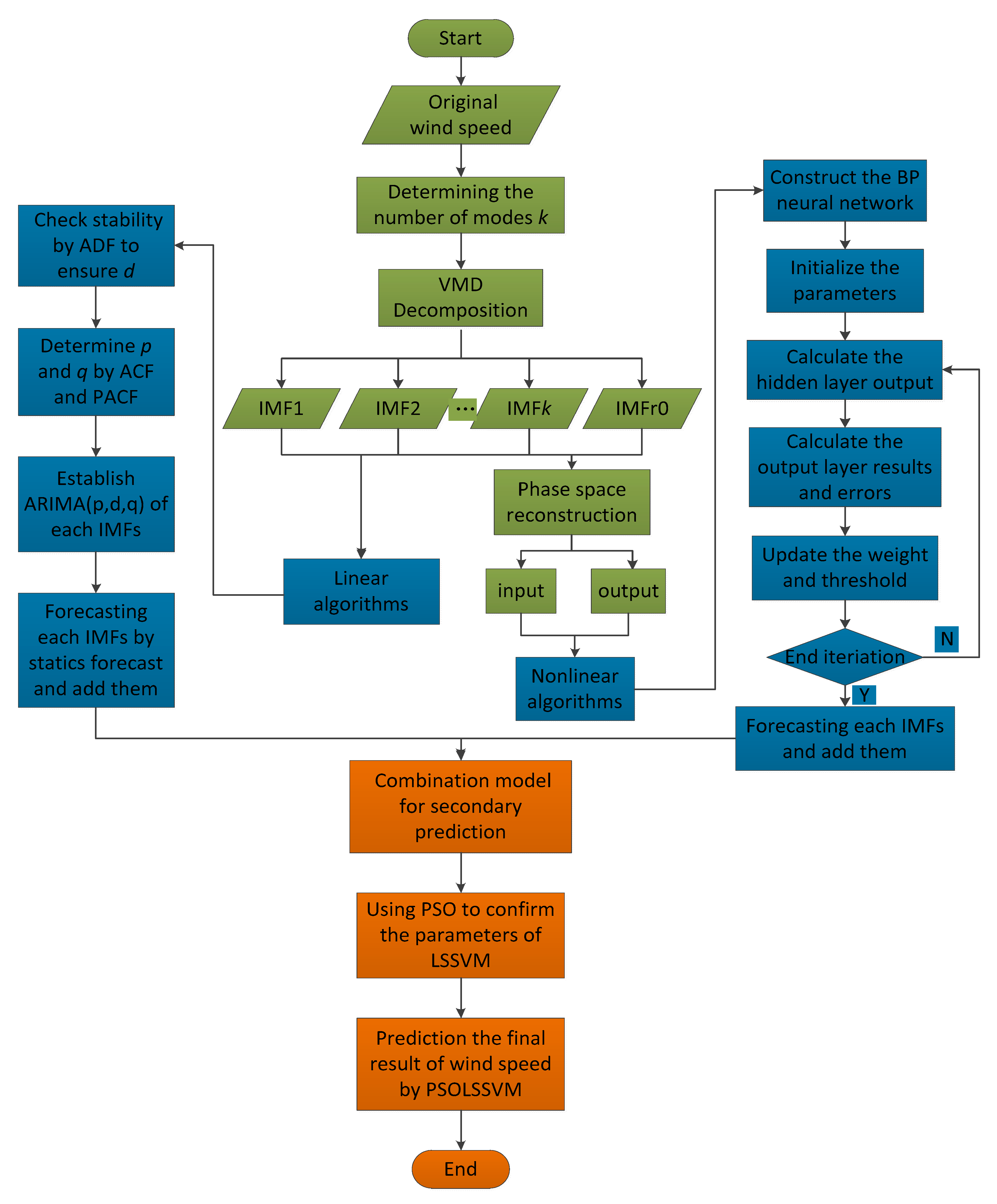
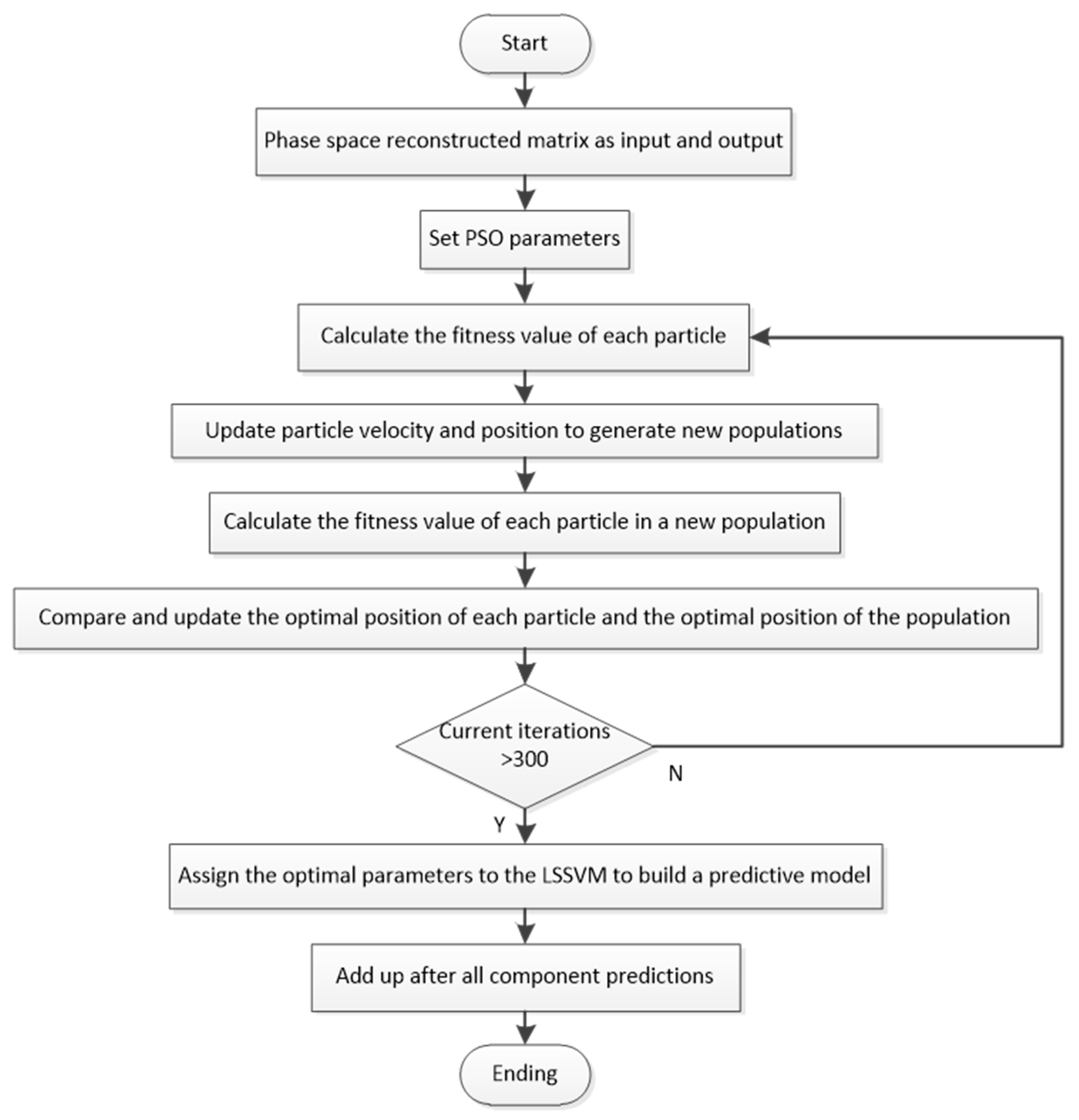
VMD is capable of defining the relevant bands adaptively and balancing the errors between the modes. The solid mathematical foundation that this non-recursive decomposition owns means it could display the local features of the signal effectively. Phase space reconstruction uses delay time to reconstruct the raw time series for maintaining the geometry and dynamic characteristics like the original system. ARIMA is a simple and convenient model that only requires endogenous variables could predict wind speed, but it could not capture nonlinear relationships very well. BP has strong distribution and storage ability to approximate complex nonlinear relationship substantially. However, plenty of parameters need to be fixed to ensure the accuracy of BP, so that the initial values will affect the credibility and acceptability of the results greatly. SVM could avoid the local minimum point and the structure selection of neural network; besides, two vital parameters can be optimized by PSO. Nonetheless, PSOLSSVM also has problems such as unclear directionality and low target during particle searching. According to the merits and demerits summed above, combining all models can give full play to the advantages of each model, and the place where a single model is defective will be compensated by other models. The main steps of the proposed combination model are listed below, and the flowchart is shown in
Figure 2. The green part indicates the data processing process, blue indicates linear–nonlinear single prediction models, and orange represents the combination prediction model of PSOLSSVM.
According to all the analysis above, the combination model VMD-P-(ARIMA, BP)-PSOLSSVM is proposed. Research in this paper is based on three hypotheses: (a) Hypothesis 1—VMD and phase space reconstruction can achieve excellent effects, more so than any other data processing methods. (b) Hypothesis 2—regarding the prediction results of the linear–nonlinear single models as the input of the nonlinear combination prediction can effectively improve the accuracy and reliability of the prediction. (c) Hypothesis 3—the PSOLSSVM method for secondary prediction can make up for the shortcomings of the individual prediction models, and this nonlinear prediction is much more accurate than the linear weighted combination.
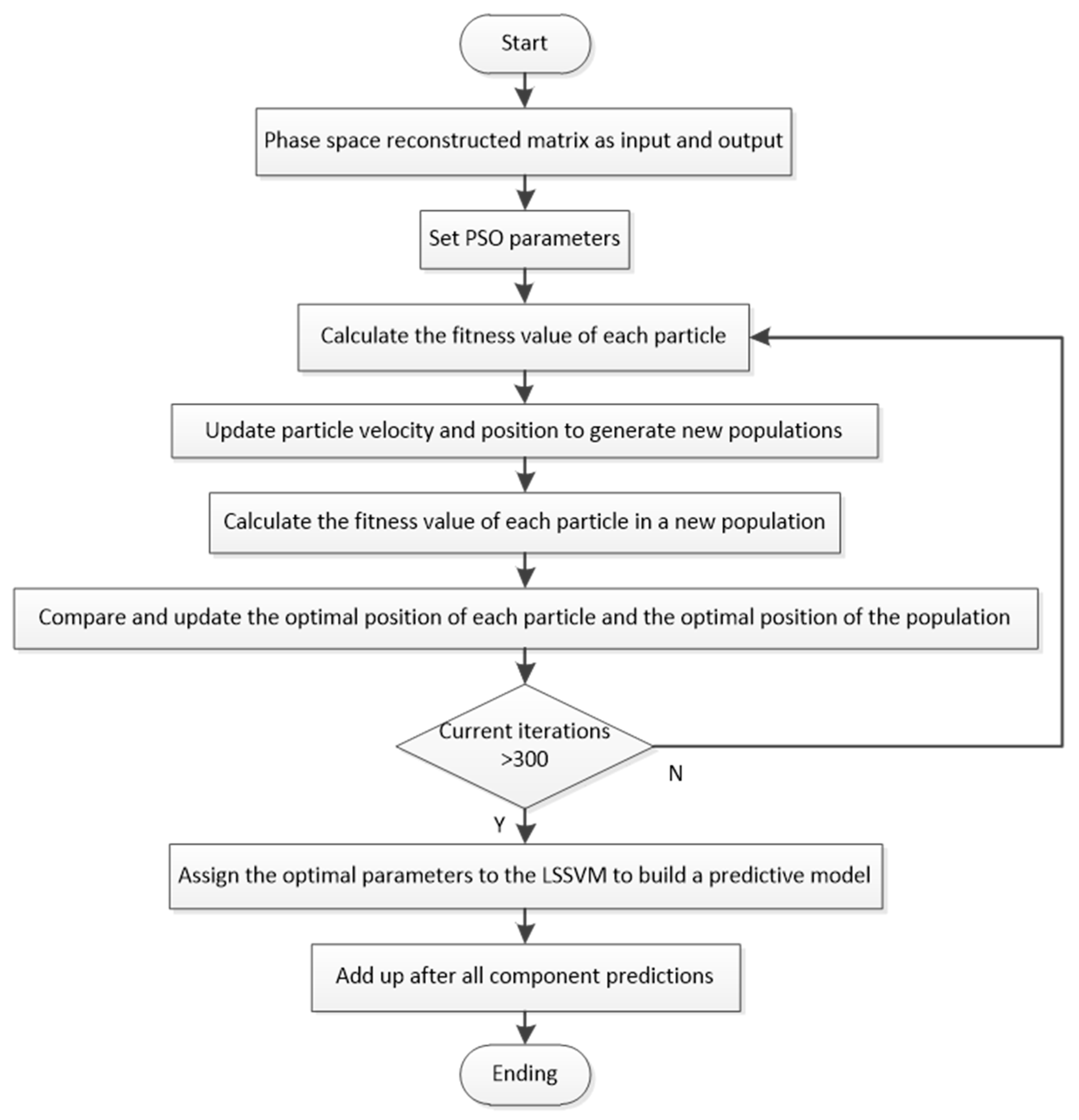
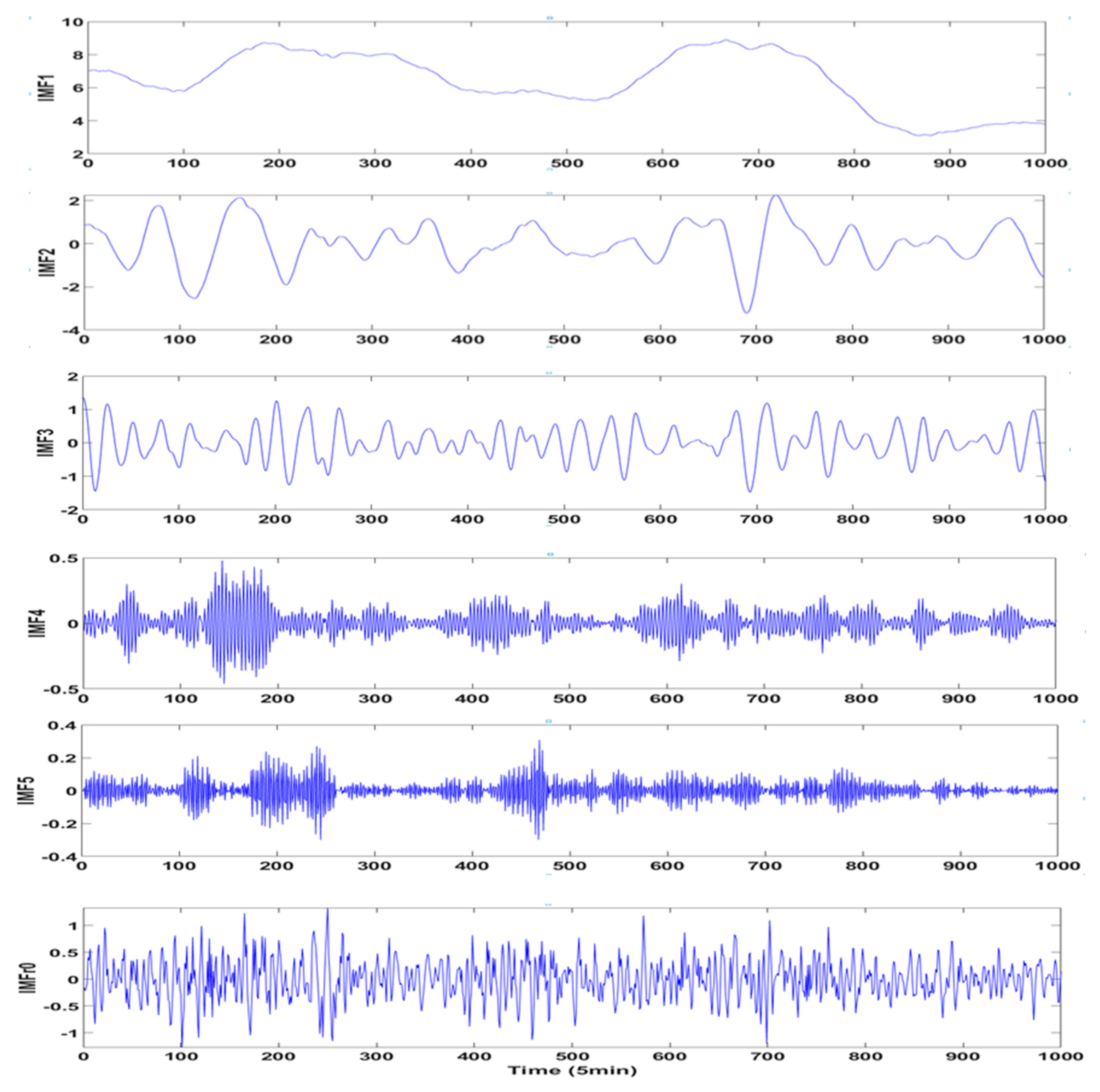
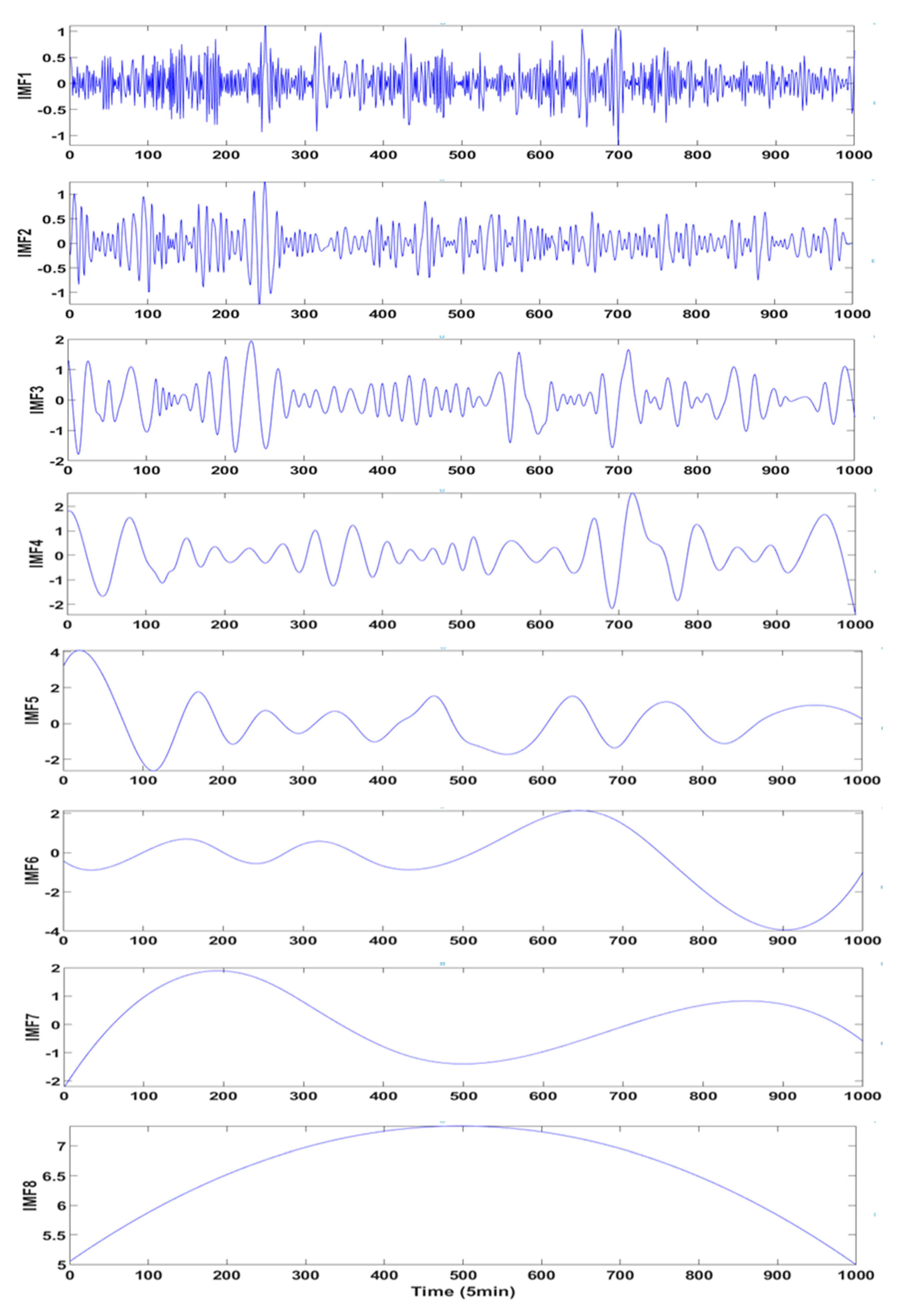
Firstly, VMD is applied to decompose the original wind speed and obtain more stable components. The number of modes k is mainly determined by the difference between the center frequencies of IMF (k) and IMF (k − 1). When the difference tends to stabilize, the value of k can be determined to obtain k patterns and a residual term, and the next step is to reconstruct the phase space for each IMF. The application of C-C method could arrange delay time and embedding dimension simultaneously and thereby define the input–output matrices of the prediction models. Thirdly, predict the k + 1 IMFs separately by paralleling ARIMA and BP methods. The prediction of ARIMA only needs original IMFs so reconstruction is optional. The detailed ARIMA construction is utilizing unit root test to define d, exploiting ACF and PACF to determine q and p partly, and then finishing the model construction and making a static prediction. The most significant parameter of BP neural network is the number of hidden layers. In order to ensure the accuracy of a single model, we conducted multiple BP network training and determined the best quantity according to accuracy of the test set. Adding up the prediction results of every IMF can obtain the prediction results of the individual models. The fourth step is to perform combined prediction with PSOLSSVM, which optimizes the parameters through the PSO and then uses the trained network for data prediction. Different with separate models, the input values of combined prediction are the prediction results of ARIMA and BP.
6. Additional Forecasting Case
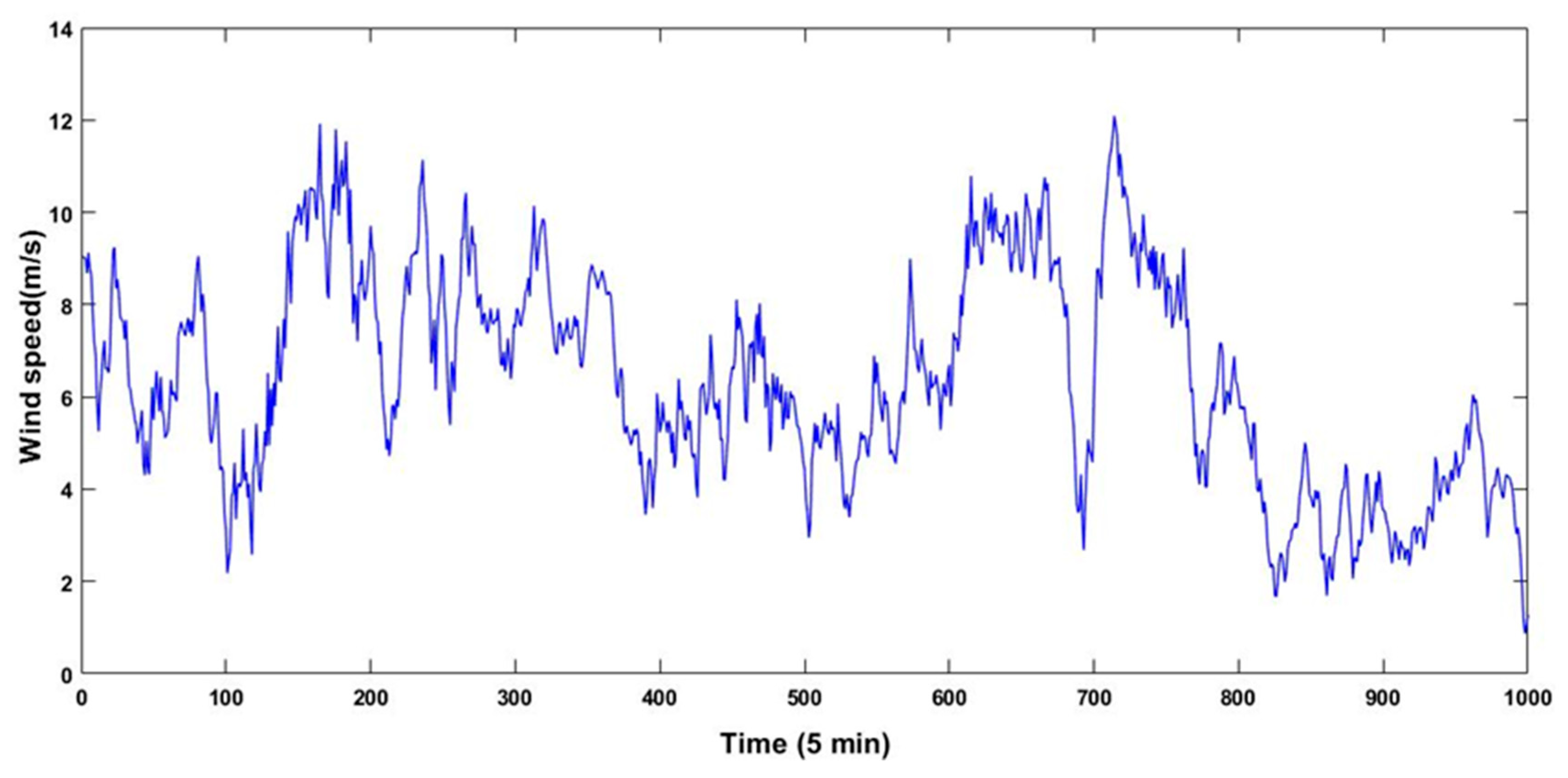
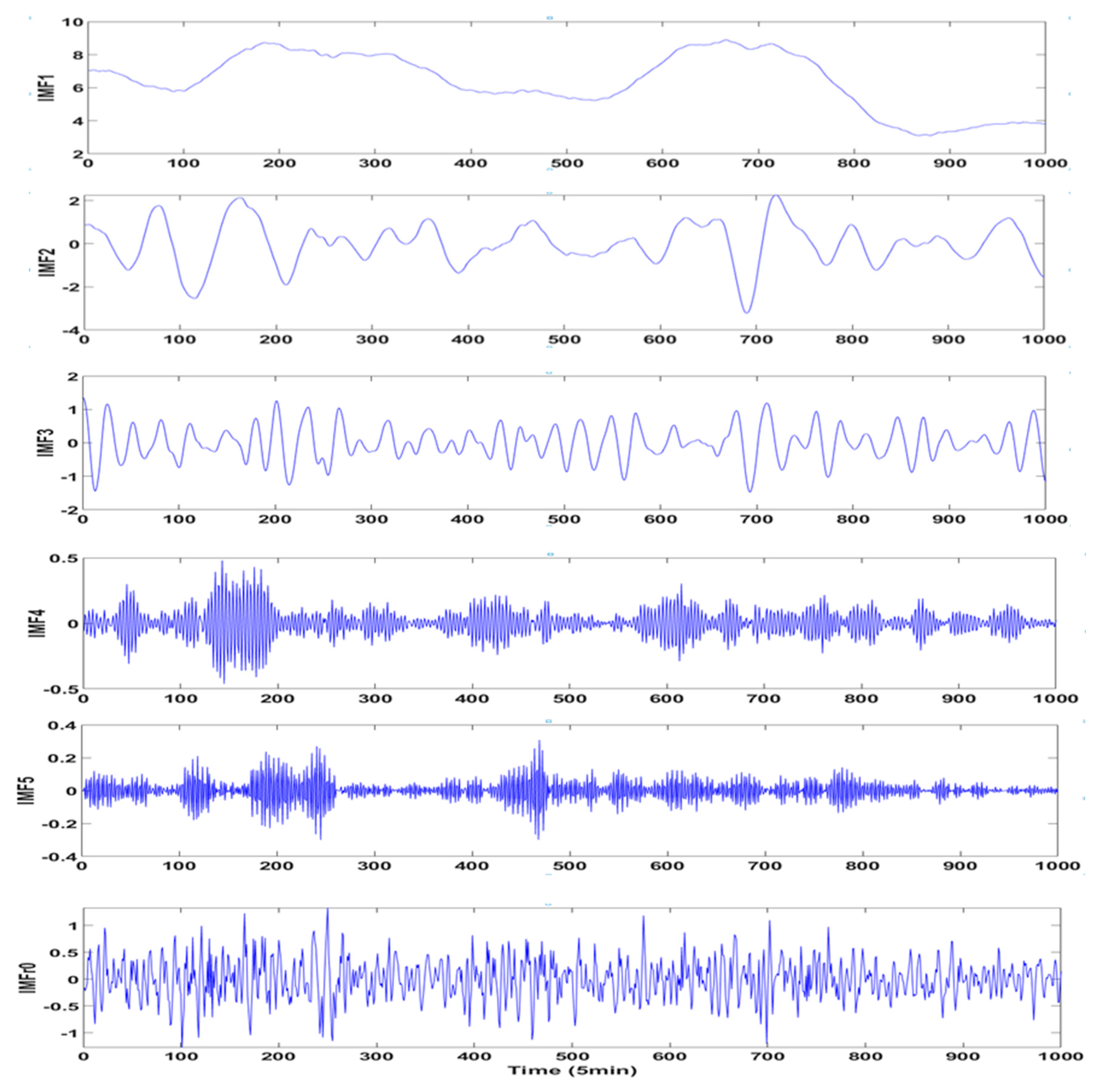
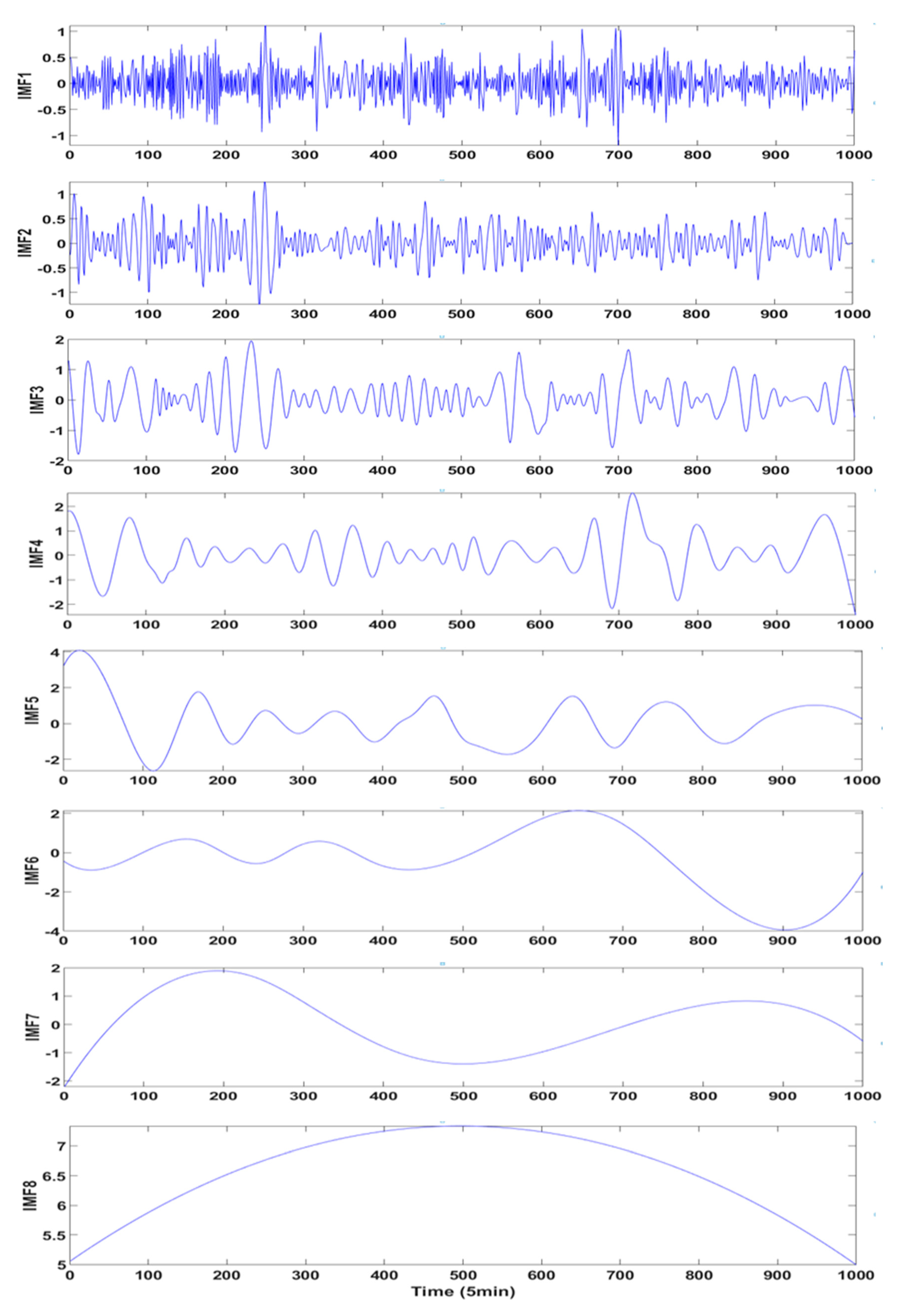
The universality and applicability must be proofed when a novel method proposed, so the spring data from the same district is applied to complete the study. In consideration of the most fluctuating wind speed, 1000 data start from 30 March of 2017 are picked as a supplementary case. After decomposition, six components and one residual term are obtained by VMD and nine components by EMD, and the specific phase space reconstruction and prediction steps are omitted for the sake of avoiding the duplication. The statistical information and the final prediction results are exhibited in
Table 11 and
Table 12, respectively.
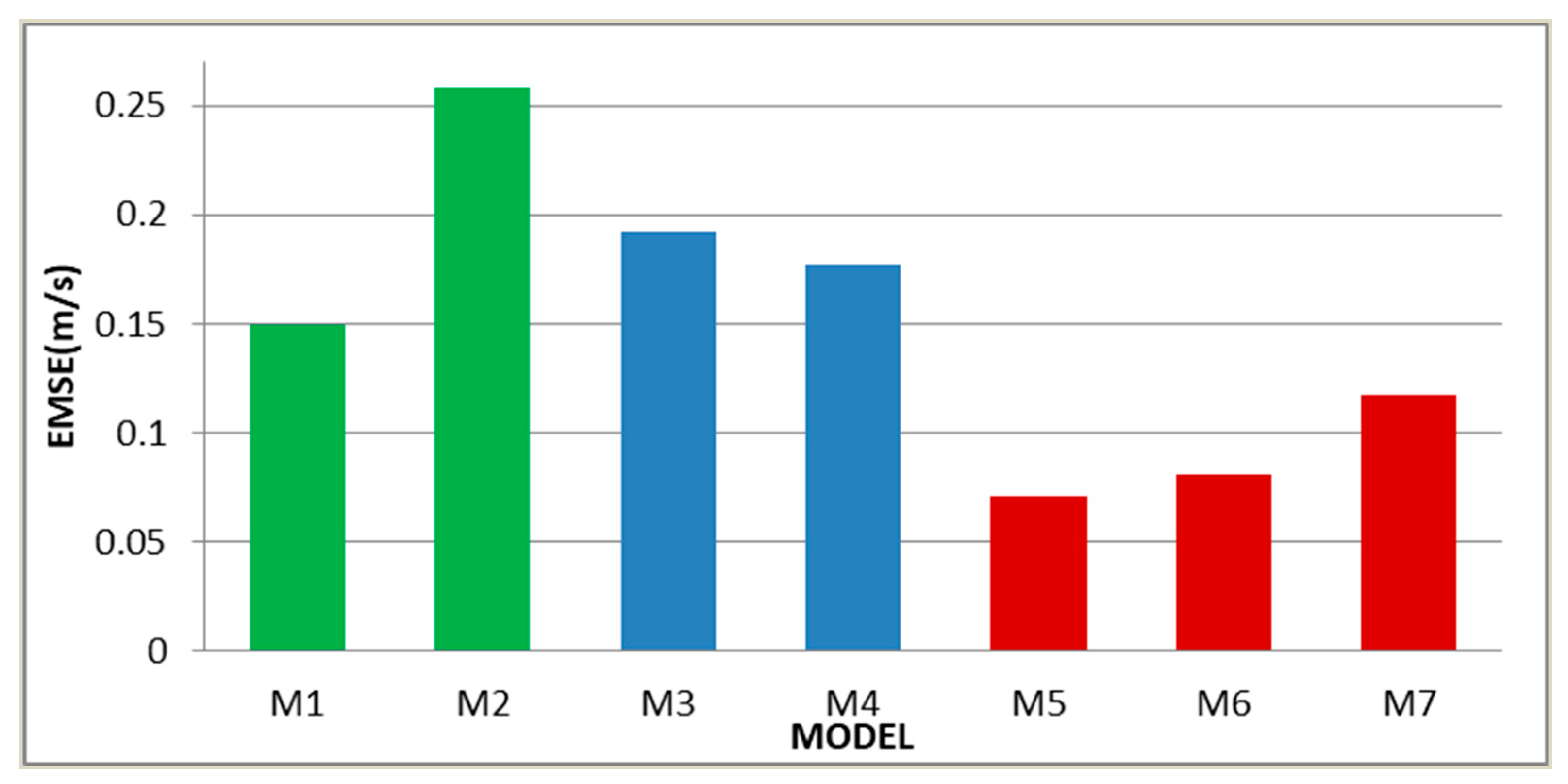
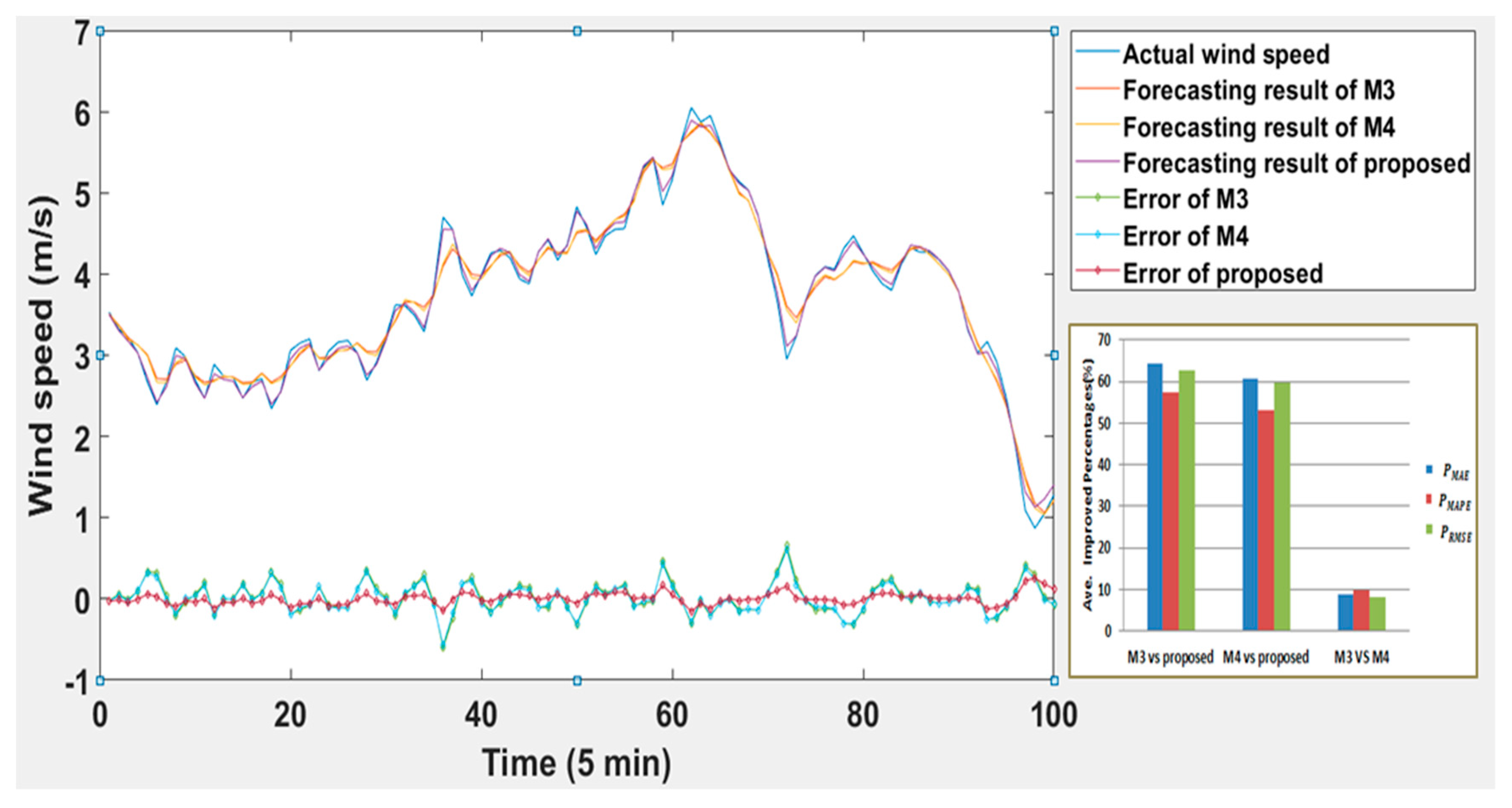
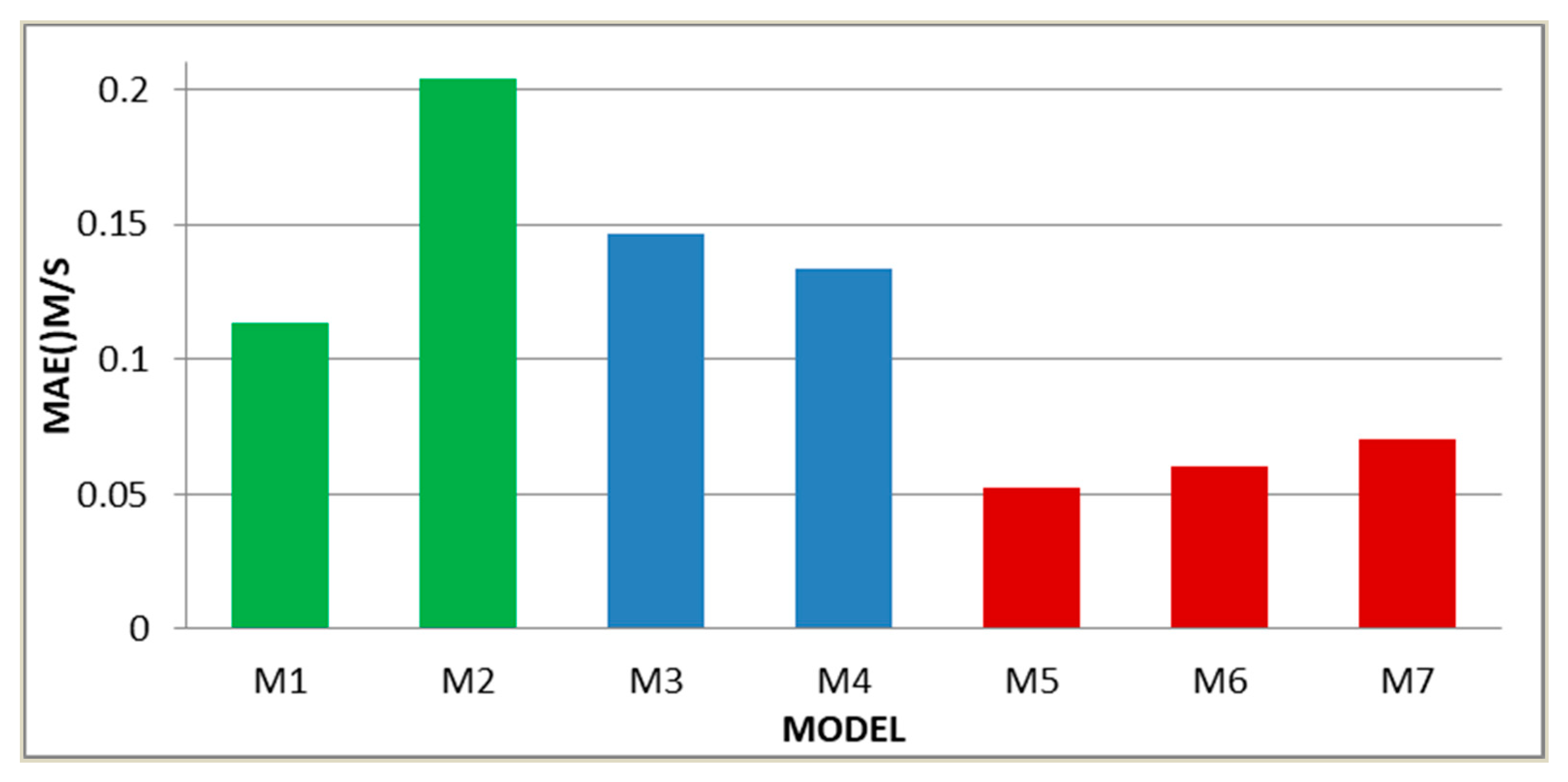
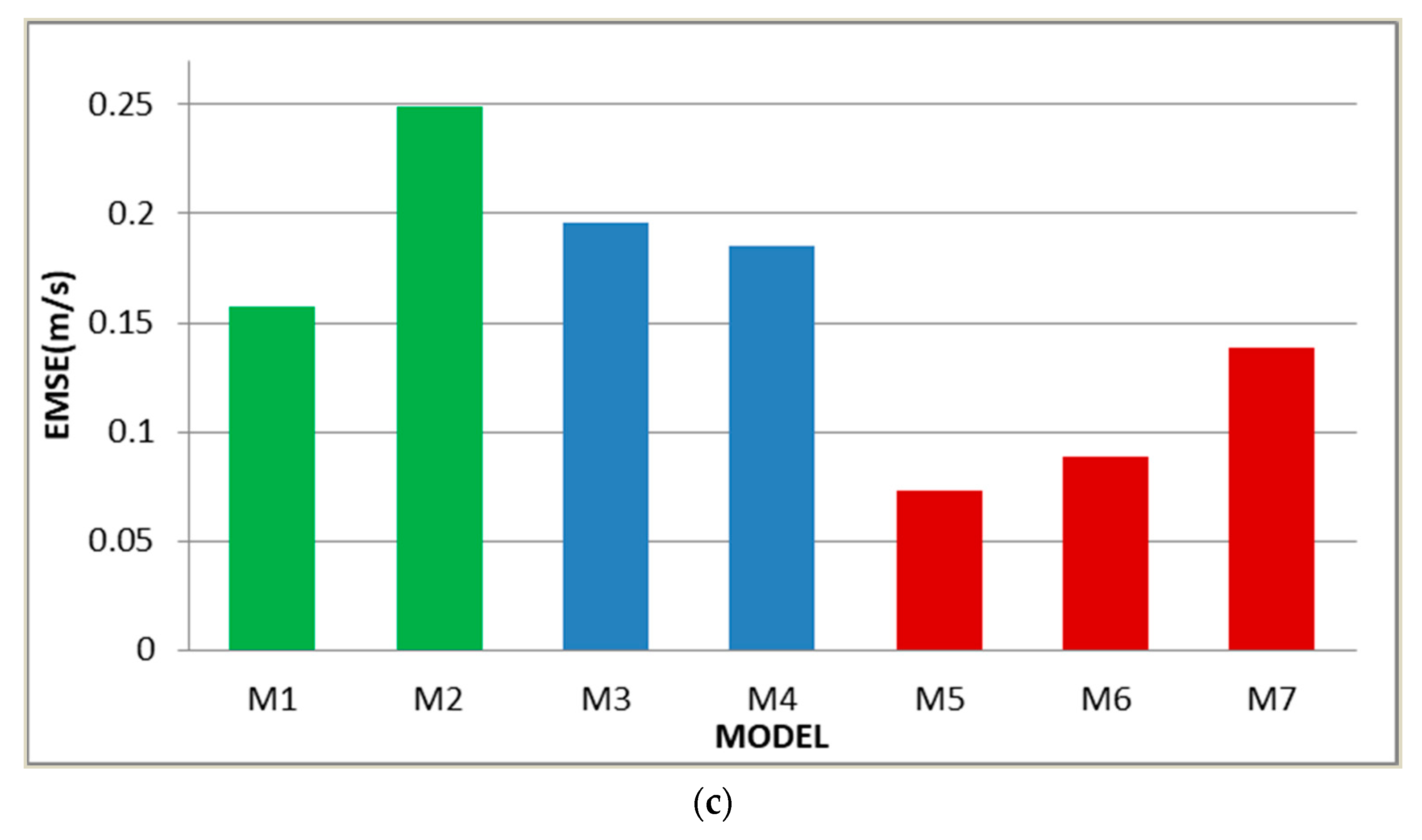
Different resources receive different prediction results is a natural phenomenon, while the error analysis results of the supplementary case are consistent with the main case to some extent. Original data of the supplementary case is more volatile, which makes the prediction precision and reliability of the proposed model lower than the previous case. But the model developed in this paper is still the best in the supplementary case according to the results that the value of MAE, MAPE, and RMSE is 0.0591 m/s, 1.8937%, and 0.0729 m/s, respectively. ARIMA is still the better one in the separate models, and the improved indicators of it compared with BP are 37.4%, 37.2%, and 36.8%. The secondary prediction in this case manifests much better than the linear weighted, which the performance is ranked as M5 > M4 > M3, where > represents better. For instance, the
of the proposed compared with M3 is 62.4%,
is 61.8%, and
is 62.7%. When analyzing the M5, M6, and M7, it can be found that the data processed by VMD and phase space reconstruction is more excellent than unprocessed or processed by EMD. Synthetically speaking, the data have more fluctuation when the proposed model has worse results, but is still optimal compared to other methods.
Figure 12 and
Figure 13 show the specific comparison results and improvement degree of the supplementary case.
On the one hand, the supplementary case proves that the proposed model has universal applicability to short-term wind speed prediction from the aspects of the data processing method, secondary predictive idea, and the final prediction method. By comparing it with other methods, the best results of the proposed method confirm that the requirement of high prediction accuracy and stability has been satisfied. On the other hand, for different data, the performance of the proposed model is different, as well as the degree of improvement. However, though the data with sharp waves will predict poorly, it demonstrates the proposed method is not a completely theoretical application but a practicality one.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}