1. Introduction
Energy is an essential material basis for human survival and development. Along with economic development and social progress in China, large amounts of investments are required in the energy sector to meet the increasing needs of energy. According to the estimation of the International Energy Agency, China will be the world’s largest consumer of energy by 2040, accounting for 22% [
1]. This means that one trillion dollars should be invested in the energy sector in China. Meanwhile, the Chinese energy sector is experiencing challenges due to the geopolitical uncertainty [
2]. To address concerns of climate changes, the Chinese energy sector is also working for national energy policies and actions of strengthening energy security and sustainability. Hence, it is of great significance to keep investing in the Chinese energy sector. However, it suffers high risks.
As main operators and investment targets, the financial performance of energy corporates has attracted tremendous interest from both practitioners and academic researchers recently [
3,
4], for the financial and the social damage inflicted by energy corporate failure cannot be overstated [
2]. More specifically, energy corporate failure, in which the firm is legally bankrupt or cannot pay for bills, etc. [
5], not only makes investors and energy firms suffer huge economic losses but also brings strong negative impacts on both national economies and society stability.
Fortunately, it is generally believed that symptoms of corporate failure can be detected before a firm encounters a failure [
6]. Through the accurate corporate failure forecasting, which is an excellent tool to distinguish firms in failure from normal ones, investors and creditors can obtain timely warnings of energy corporate failure risks. Since the early research in the 1960s [
7], there has been a great deal of literature researching corporate failure forecasting [
8]. Prior studies routinely adopt accounting data from the financial statements to forecast corporate failure. For example, Xu et al. [
9], Hosaka [
10], Li et al. [
11], etc., have demonstrated that accounting based financial ratios can offer signals to forecast corporate failure effectively. At the same time, given the high cost of corporate failure events, many forecasting methods have been proposed for corporate failure forecasting, including discriminant analysis [
7], logistic regression [
12], neural networks [
10], genetic algorithm [
13], decision tree [
14], support vector machine [
15], rough set [
16], and deep learning [
17], to name a few. To improve the forecasting performance, various integrated methods developed based on the basis classifiers above have also been proposed for corporate failure forecasting [
18]. Past studies above have established the foundation for corporate failure forecasting.
A common element of most of the above research is adopting firms from different sectors as samples simultaneously [
19]. It is well known that the character of corporates in different sectors is quite different [
20]. Recently, researchers have paid more attention to the corporate failure forecasting in a specific sector, such as commercial banks distress prediction [
21], bankruptcy forecasting in the agribusiness sector [
22], manufacturing firms financial distress forecasting [
23], hospitality firm failure prediction [
11,
24], etc. Up to date, to the best of our knowledge, only Doumpos et al. [
2] has explored corporate failure forecasting in the energy sector. While their samples were collected from developed European countries, little attention has been paid to corporate failure forecasting in the Chinese energy sector. This motivates us to explore this work.
Another common element of most studies above is that they adopt financial ratios to forecast corporate failure. Recent studies have demonstrated that textual data, such as national policies, news, reports, etc., have high discriminating power in forecasting business failure [
17], for textual data may contain some valuable risk information [
25]. These data can play a key role in corporate failure forecasting in the Chinese energy sector as the complement of financial ratios. For example, in China, energy firms are seriously impacted by national policies [
26]. Chinese listed energy firms always present the impact and related actions in the annual report. However, textual data are qualitative data. Financial ratios are quantitative data. It is a big challenge to effectively integrate textual data with financial ratios for energy corporate failure forecasting due to different formats and qualifying the textual data. Here, we tackle this challenge.
In this framework, the aim of this paper is to propose a novel integrated model (NIM) for corporate failure forecasting in the Chinese energy sector by considering numerical data and textual data simultaneously. It integrates convolutional neural network oriented deep learning (CNN-DL) and support vector machine (SVM) based on the soft set theory (SS). CNN-DL has theoretically proven to be an excellent tool for textual data mining [
27]. It is employed as a basis classifier to forecast with textual data. SVM is a widely accepted machine learning method in the field of corporate failure forecasting [
28]. It is applied to forecast with numerical data as a basis classifier. SS, which is an advanced nonparametric method for dealing with high dimensions [
29], is used to integrate outputs of CNN-DLs and SVMs. Therefore, the model NIM inherits advantages and avoids disadvantages of CNN-DL, SVM, and SS. This algorithm enables it to take full advantage of textual information and financial ratios to forecast corporate failure in the Chinese energy sector. We hope NIM produces a good performance.
To verify the performance of NIM, it is applied to real data of Chinese listed corporates in the energy sector. For comparison, the individual CNN-DL trained using textual data (CNN-DLT), the individual SVM trained using numerical data, the individual CNN-DL trained using textual data and numerical data (CNN-DLM), the integrated model with CNN-DLT and SVM based on the unanimous voting method (IMUV) [
30], and the Dempster–Shafer evidence theory [
31] (IMET) are included as benchmarks.
The important contributions of this study can be summarized as follows.
Compared to developed economies, energy investment in emerging economies climbs faster. Due to immature business environments, it is easier for energy firms in emerging economies to fail. It is significant to identify the failure as early as possible, though it is complex. To date, little attention has been paid to firm failure forecasting in the energy sector of emerging economies. This paper complements prior literature with new empirical evidence from China.
A novel integrated model is proposed for corporate failure forecasting in the Chinese energy sector. It integrates CNN-DL and SVM into SS. More specifically, CNN-DL is employed to forecast with textual data, SVM is applied to forecast with numerical data, and results of CNN-DL and SVM are integrated by SS. The algorithm enables NIM to effectively improve performance by taking full use of textual data and numerical data.
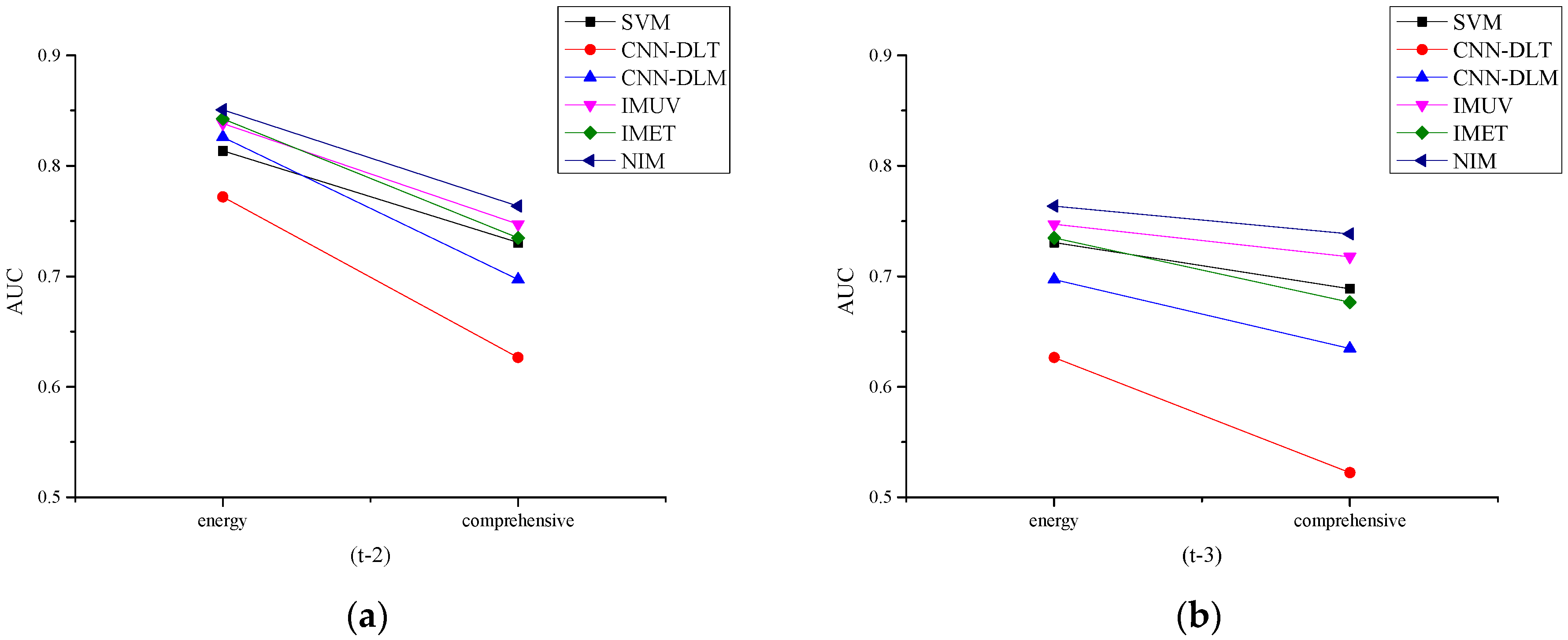
Empirical results demonstrate that textual data can play an important role in corporate failure forecasting in the Chinese energy sector as the complement of numerical data, but the validity is decreasing with a longer forecasting horizon.
The rest of this paper is organized as follows.
Section 2 reviews the pertinent literature on corporate failure forecasting. In
Section 3, we introduce the proposed NIM in detail.
Section 4 presents the application of NIM to real data.
Section 5 reports and compares empirical results. We conclude and discuss the future work in
Section 6.
2. Literature Review
During past decades, some literature has reviewed corporate failure forecasting in detail, such as Sun et al. [
5], Alaka et al. [
20], Prusak [
32], etc. Here, we briefly review more recent literature of corporate failure forecasting (shown as
Table A1) and summarize the recent development as follows.
First, more and more studies have started to forecast corporate failure in a specific sector to improve forecasting performance in recent years because each sector has its characters, such as financial characters, organizational characters, environment characters, etc. [
33]. However, past studies as those above mainly focus on a specific sector such as manufacture, bank, hotel, agribusiness, etc. [
22,
23,
24,
34]. Until now, to the best of our knowledge, only Doumpos et al. [
2] has explored corporate failure forecasting in the energy sector. While their samples were collected from developed European, little attention has been paid to forecast corporate failure in the energy sector of developing economics.
Second, non-financial variables are being more widely applied for corporate failure forecasting recently, though financial ratios are still the most popular variables [
9,
20], such as market information, macroeconomic, industry information, and so on [
2,
24,
34]. With the development of artificial intelligence, some literature has started to adopt textual data to forecast corporate failure [
5,
27,
28]. It can be applied to forecast corporate failure as the complement of financial ratios.
Third, forecasting methods proposed by recent literature can be divided into two categories—individual models and integrated models. Individual statistic methods are widely employed to forecast corporate failure, such as discriminant analysis and its expansions [
35], logistic regression and its expansions [
21], a proportional hazards model and its expansions [
36], etc. It is easy to analyze and explain the impact of each variable on corporate failure using individual statistic models. However, we have to meet some stringent model assumptions about sample data to apply those models [
9]. To overcome the limitations above, more and more individual machine learning methods have been proposed for corporate failure prediction, such as neural networks [
10], genetic algorithm [
13], decision tree [
14], support vector machine [
15], rough set [
16], deep learning [
17], etc. The main advantage of a machine learning algorithm is that it is able to consider multiple features simultaneously and capture the hidden relationship between them, which enables it to perform better when compared to the statistical models [
37,
38,
39,
40]. This enables machine learning methods to have better flexibility in corporate failure forecasting. It is significant for both academic research and real practices.
To achieve a better forecasting performance, integrated models, which employ individual models as basis classifiers, have become a new exploring trend. A great deal of literature has demonstrated how to integrate basis classifiers for corporate failure forecasting [
5,
32]. To date, integrated models can be divided into two groups. One includes horizontal integrated models, such as a UV ensemble model [
30], a spline-rule ensemble model [
41], etc. Horizontal integrated models are used to employ a combination technique to integrate basis classifiers. The other group includes vertical integrated models. Vertical integrated models are mainly employed to improve another method. For example, Chen [
42] adopts particle swarm optimization (PSO) techniques to obtain appropriate parameter settings for subtractive clustering. Integrated models can capture more information and result in much more accurate and stable forecasting performance.
Based on the review above, the main contribution of this paper to corporate failure forecasting can be summarized as follows. First, this study is the pioneering work of corporate failure forecasting in the Chinese energy sector. To date, little attention has been paid to the corporate failure forecasting in the energy sector of emerging economies. China is one of the largest energy consuming countries, and it is also the largest developing state. This paper complements prior literature by providing new empirical evidence from China. Second, given the role of textual data in discriminating failure corporates from normal ones [
17] and the characters of the Chinese energy sector [
26], we propose a novel integrated model with CNN-DL and SVM based on SS to make full use of textual data and numerical data. Until now, there has been no literature reporting the novel integrated model. This paper complements prior literature by proposing a novel integrated model for corporate failure forecasting.
3. The Proposed NIM
Deep learning models, which can obtain better identification performance than conventional methods in text analysis [
17], have been applied to forecast corporate failure with textual data and numerical data simultaneously and have achieved excellent performance [
10,
17]. However, past studies have also demonstrated that deep learning models seem to be more suitable for identifying images and less suitable for numerical data analyses [
10]. Furthermore, considering the big challenge in forecasting textual data and numerical data simultaneously (due to their widely different features), we believe that an effective way to get a better forecasting performance is by adopting a model to forecast with textual data and numerical data respectively, as shown as
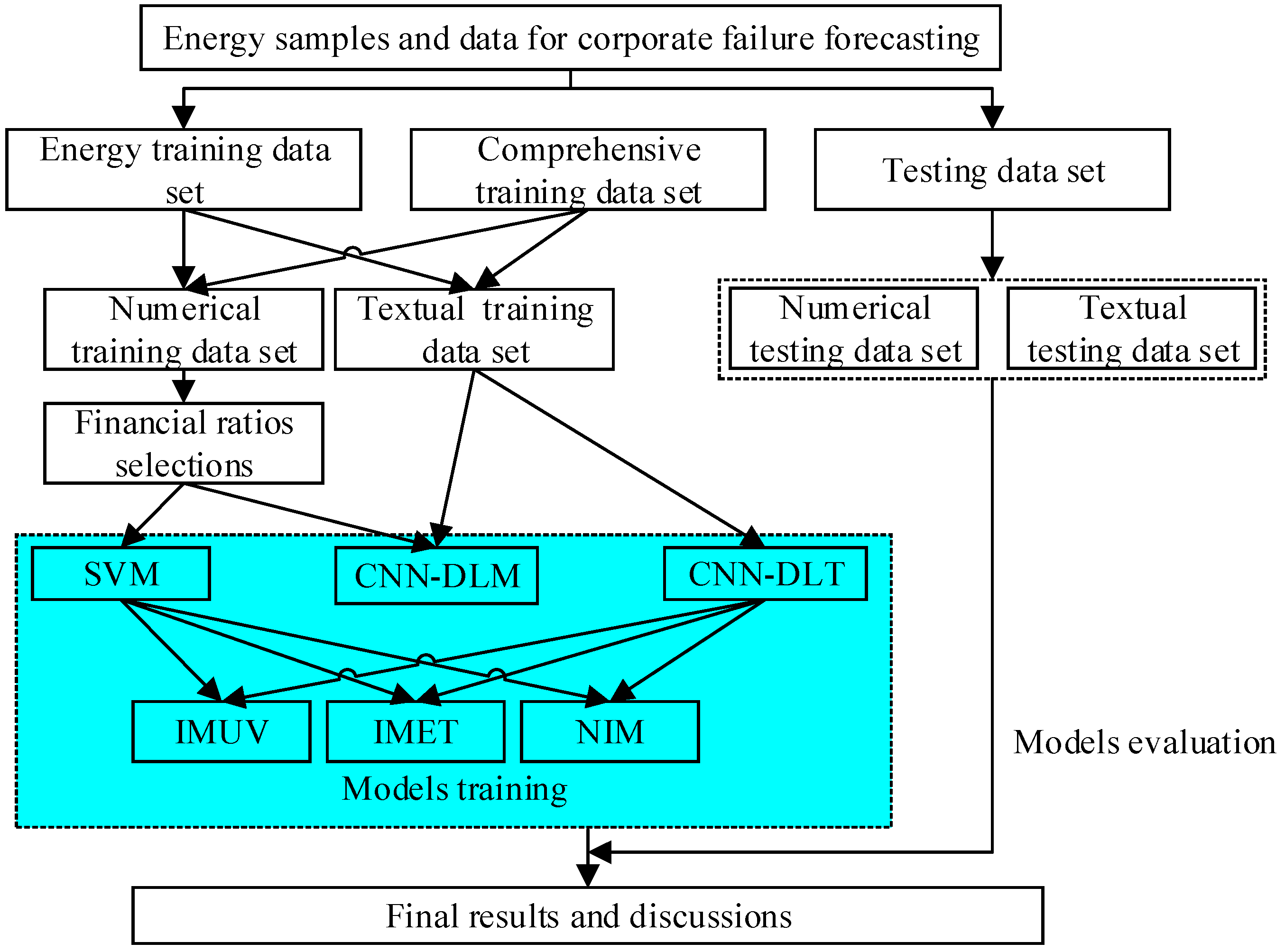
Figure 1.
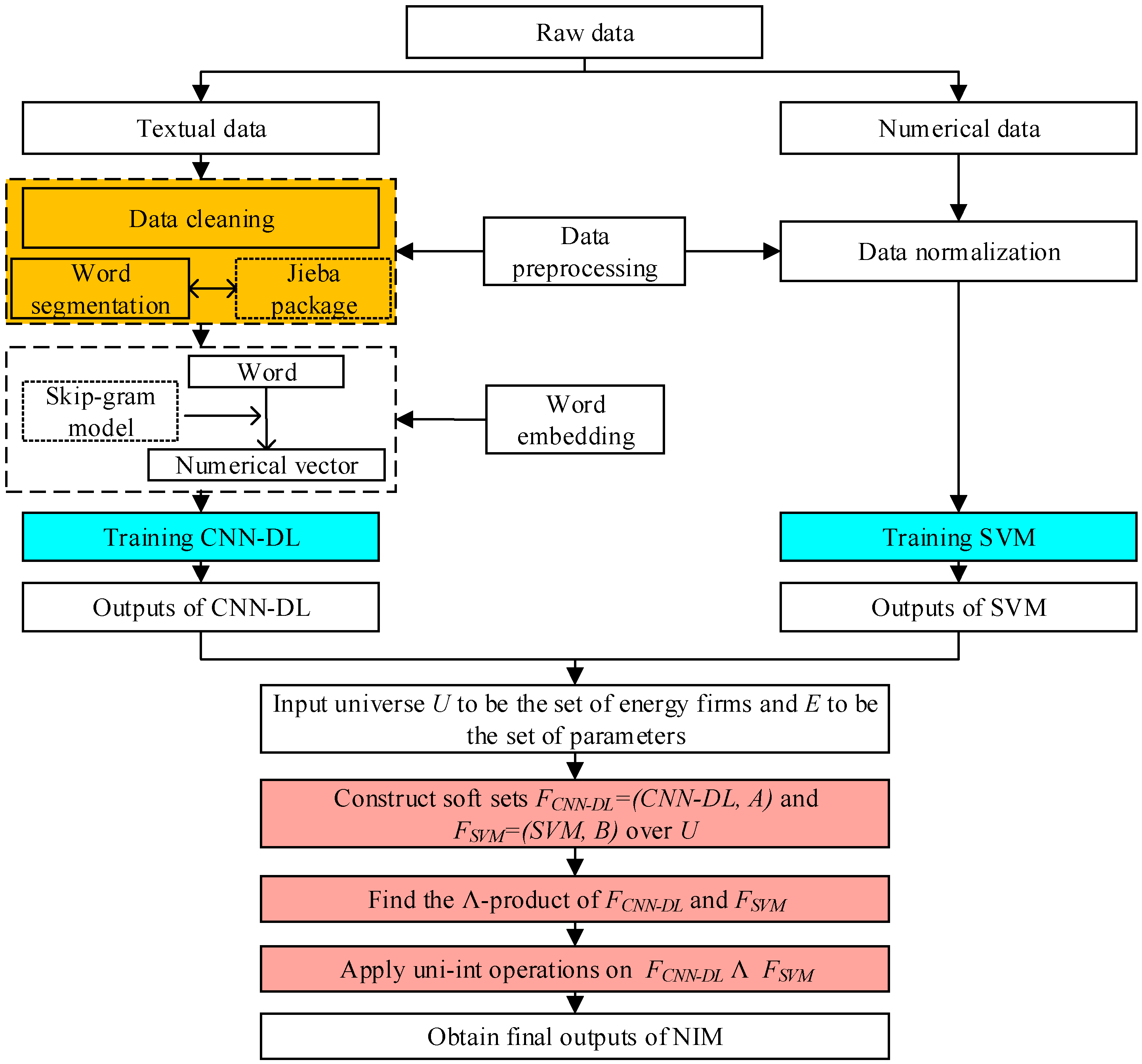
In the framework, we propose an NIM to improve the performance of corporate failure forecasting in the Chinese energy sector by making full use of textual data and numerical data. Specifically, we divide the row samples and data into two groups—textual data and numerical data. CNN-DL is applied to textual data, and SVM is used for numerical data. Subsequently, SS is employed to integrate outputs of CNN-DL and SVM. Details of NIM are demonstrated as follows.
3.1. Corporate Failure Forecasting with Textual Data
CNN-DL is employed for corporate failure forecasting in the Chinese energy sector with textual data. There are three key points of CNN-DL: data preprocessing, word embedding, and convolutional neural network (CNN).
3.1.1. Data Preprocessing and Word Embedding
Textual data is a natural language [
17]. It cannot be directly employed as inputs in many conventional forecasting models. Textual data have to be transformed into numerical data so that mathematic models can be adopted. Therefore, raw data have to be cleaned to reduce noise at first. Numbers and Hypertext Markup Language (HTML) tags included in the textual data are removed. Second, given the difference between Chinese and English, the Jieba package of Python is employed to segment the textual document into words [
43]. To reduce the number of dimensionality, words with low frequency are deleted.
After the preprocessing of textual data, words need to be converted to numerical representations. Many techniques have been proposed for this purpose, such as one-hot representation, distributed representation, word embedding, FastText, embedding from language, etc. [
44]. One can refer to the review literature [
45] for details. Here, given that understanding the semantics of textual data is much more important for corporate failure forecasting, we employ the skip-gram model to convert textual words to numerical word vectors. The skip-gram model, one of the most famous word embedding models, has proved to be an excellent tool for understanding the meaning of textual documents and converting them to word vectors [
46]. Assuming that there are
training words,
, the object of the skip-gram model is to maximize the log probability, as shown as in Formula (1).
where
is the size of the context. Past studies have demonstrated that the skip-gram model is useful to represent a word
using a numerical vector
with
dimensions. However, the time cost of the skip-gram model is higher, thus we adopt a negative sampling technique to address this issue. For more details about the skip-gram model, please refer to the literature [
46].
3.1.2. Convolutional Neural Network (CNN)
Each document can be converted to an
numerical metric by the vectorized presentation of words. The metric can be used as an input of the CNN to forecast corporate failure in the Chinese energy sector. CNN is widely used for mining textual data and has been successfully applied in some financial forecasting fields recently [
10,
17]. The most important point of CNN is that it can detect local features of documents by adopting
convolving filters. For more information about CNN, please refer to literature [
47].
Assume there are some convolutional filters, denoted as
. Then,
is a function mapping
to
. Given an input word vector of a document
, the
i-th entry of the output
that transformed
to a phrase of length
by the filter
can be calculated using Formula (2):
where
is the bias parameter of CNN, and
is the activation function, including sigmoid function, tanh function, ReLu function, etc. [
11]. Here, we employ the ReLu function as
to expedite the convergent speed of CNN, shown as Formula (3):
By conducting the method above to the textual document, a full version of features
is obtained. To forecast corporate failure in the Chinese energy sector, the document including a key phrase (features) or not is the discriminate criteria. Therefore, the pooling operation is employed to maximize the value of each feature map vector,
. At last, a sigmoid output unit and two layers of hidden filters can be added to obtain the forecasting outputs [
17].
3.2. Corporate Failure Forecasting with Nemuerical Data
Various statistical models and machine learning models have been proposed for corporate failure forecasting with numerical data [
32]. SVM has been widely used in various fields [
48,
49,
50,
51,
52], including corporate failure forecasting [
44], and has received great attention in recent years. By mapping original data into the high dimensional space using different kernel functions, SVM not only has advantages in forecasting with linear and non-linear financial data but also performs well in forecasting with high dimensional data and small sample sizes. Hence, given the character of Chinese energy firms, SVM is adopted to forecast with numerical data. Here, we present a brief review; for more information, please refer to the literature.
Given the training data set
,
presents a vector in the M dimensional feature space, and
,
means that
belongs to one category, and
means that
belongs to the other category. The calculation of SVM can be presented as Formula (4), and constraint conditions are shown as Formula (5):
where
C,
is the key parameter. Generally, there are four widely applied kernel functions for mapping original data into high dimensional space, including Gaussian kernel, polynomial kernel, radial basis function (RBF) kernel, and sigmoid kernel.
3.3. Integration of Individual Outputs
An important innovation of this paper is that we introduce the SS as the integration method to integrate outputs of CNN-DL and SVM. To date, unanimous voting algorithm, equal weighted method, Borda count, Bayesian, neural network, evidence theory, rough set theory, etc., are well-known integration methods [
20]. However, it is a big challenge to determine the weight of each individual model. To overcome the limitations above and make full use of individual outputs effectively, SS is employed as the integration method of NIM. SS, initiated by Molodtsov [
29], has advantages in decision making and information discovering [
9,
53]. Details of applying SS to integrate individual outputs are demonstrated as follows.
Let
be a non-empty universe of objects, let
be a non-empty set of parameters related to objects in
, and the power set of
is
. A soft set over
is a pair
, where
is the approximate function of
and
. In others words,
is a parameterized family of subsets of
. With the definition of SS, a binary operation, named uni-int decision making method, is proposed to improve the performance of decision making by taking full information of SSs [
9].
Let
and
be two SSs over the universe
, and the
-product (and product) of
and
equals to
, where
for
. The uni-int operators for
are defined as follows and denoted as
and
.
Then, the uni-int decision set is the union of two uni-int operators, shown as Formula (8).
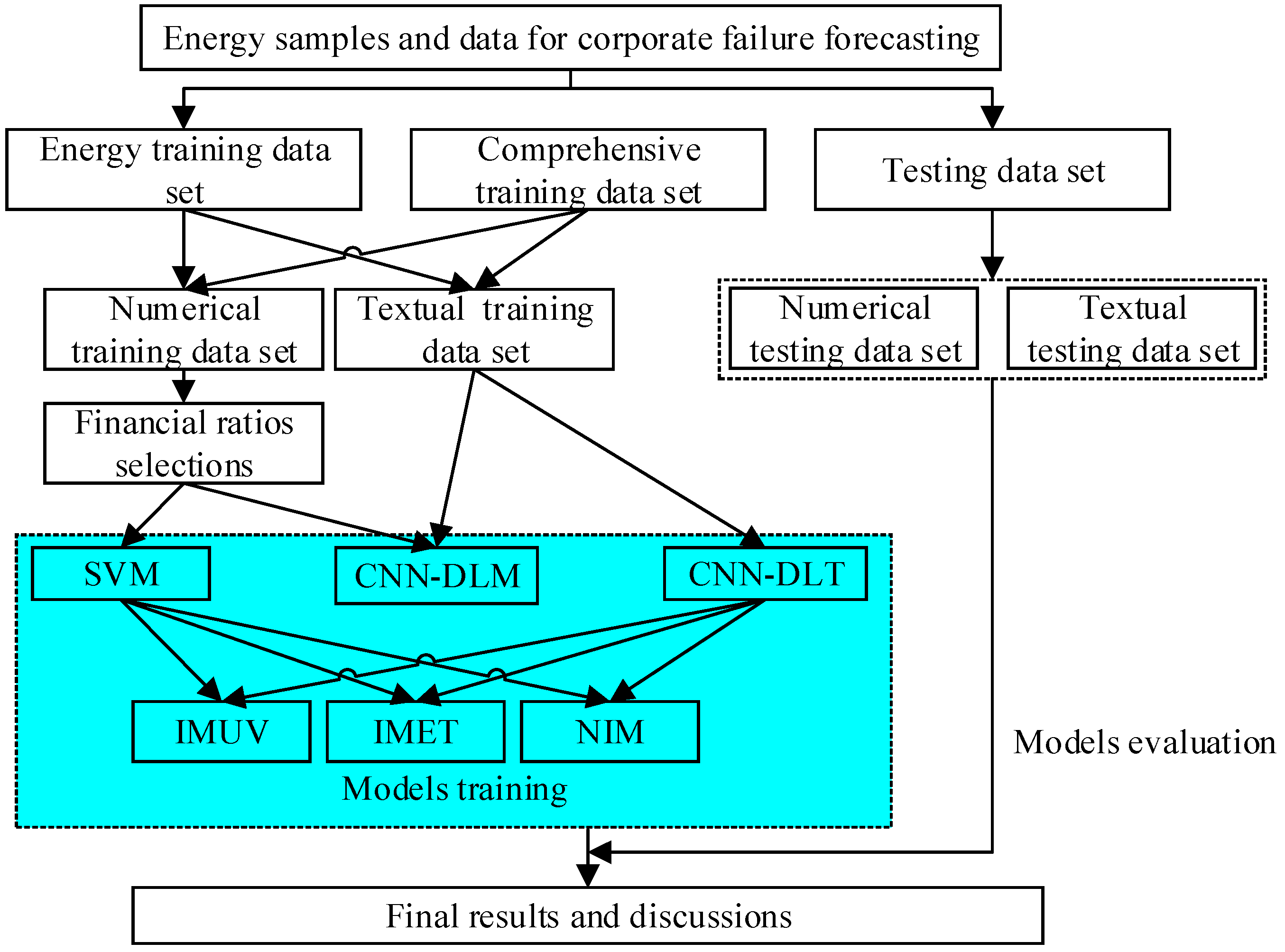
3.4. Algorithm
Based on the analysis above, the algorithm of NIM, which is the key innovation of this paper, is illustrated in
Figure 2.
The collected raw data are divided into two groups—textual data and numerical data. Textual data are text documents. Numerical data are financial ratios.
Textual data are cleaned by removing numbers and HTML tags and are segmented using the Jieba package of Python. At the same time, numerical data are normalized using Formula (9).
Apply the skip-gram model to convert each word of the textual document to a numerical vector.
Train CNN-DL with transformed textual data and train SVM with normalized financial ratios.
Obtain individual outputs of CNN-DL and SVM.
Input a universe to be the set of energy firms and to be the set of parameters. In particular, is the set of selected textual variables and financial ratios for corporate failure forecasting in the Chinese energy sector.
Construct two soft sets and over . For soft set , the approximate function is CNN-DL, and parameter set A is the set of textual variables, . For soft set , the approximate function is SVM, and parameter set B is the set of selected financial ratios, .
Find the -product (and product) of SSs and .
Apply the uni-int operations on .
Obtain the final integrated outputs of NIM.
In such a way, the proposed NIM integrates CNN-DL and SVM into SS and hence inherits advantages of three methods. We hope for an excellent performance of NIM on corporate failure forecasting in the Chinese energy sector with textual data and numerical data.
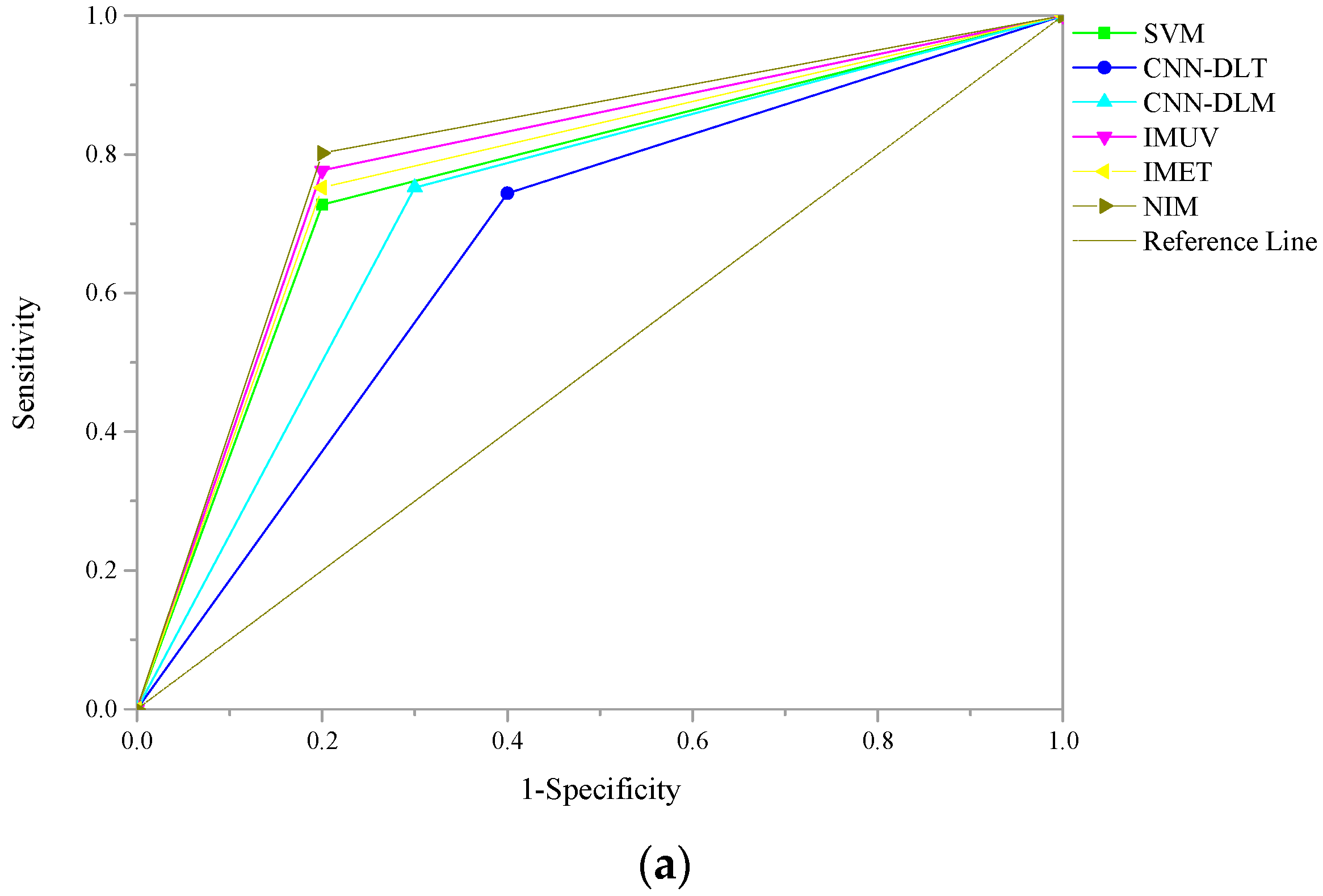
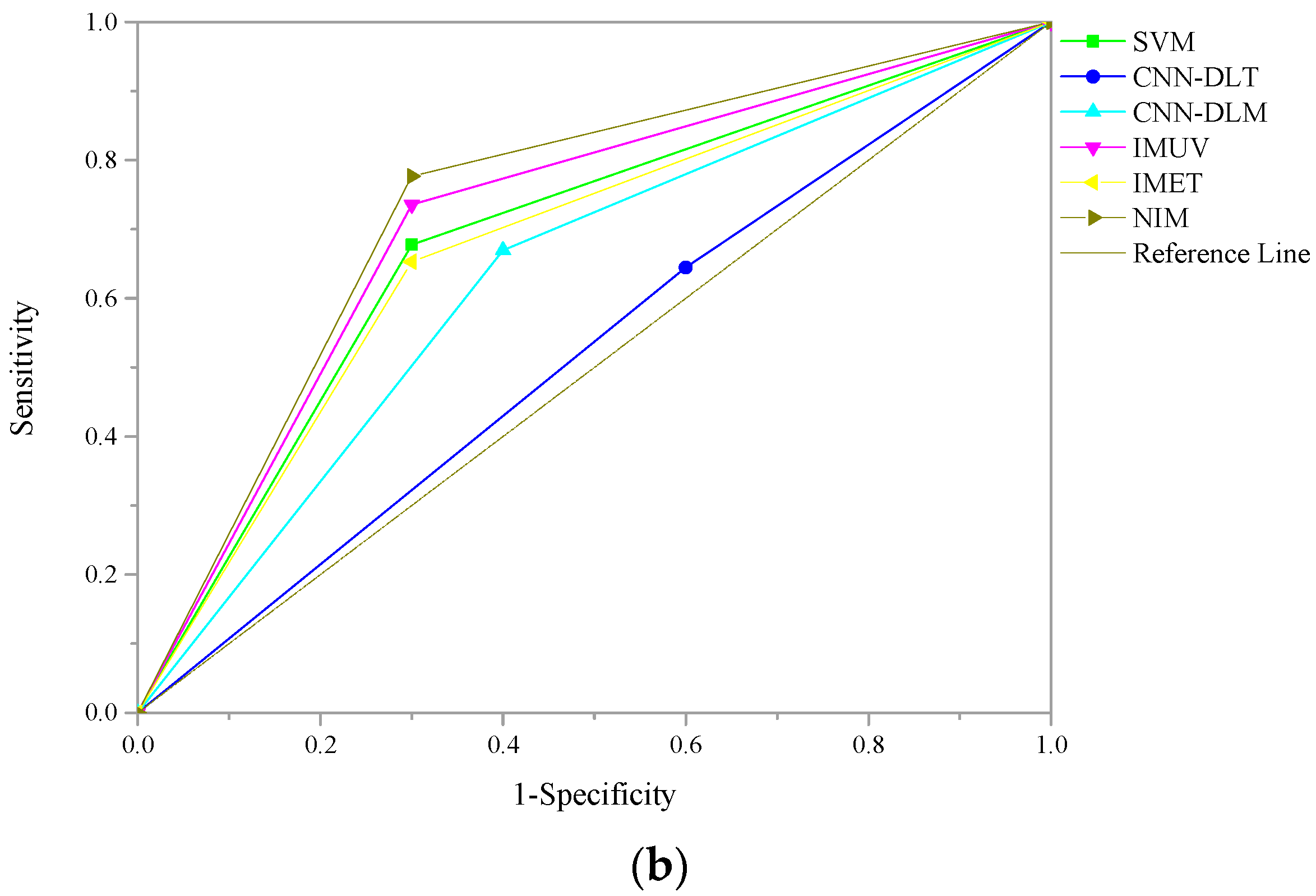
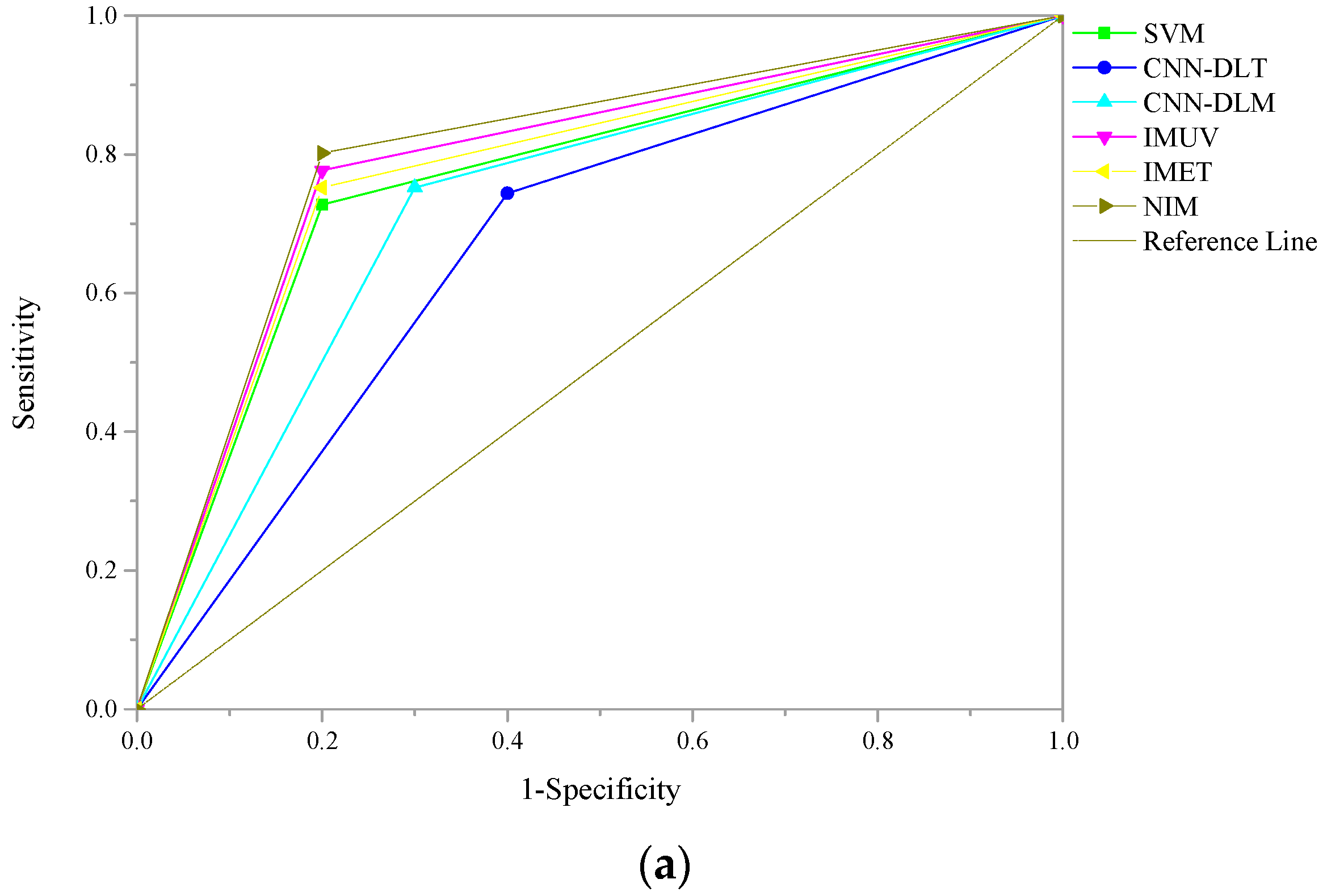
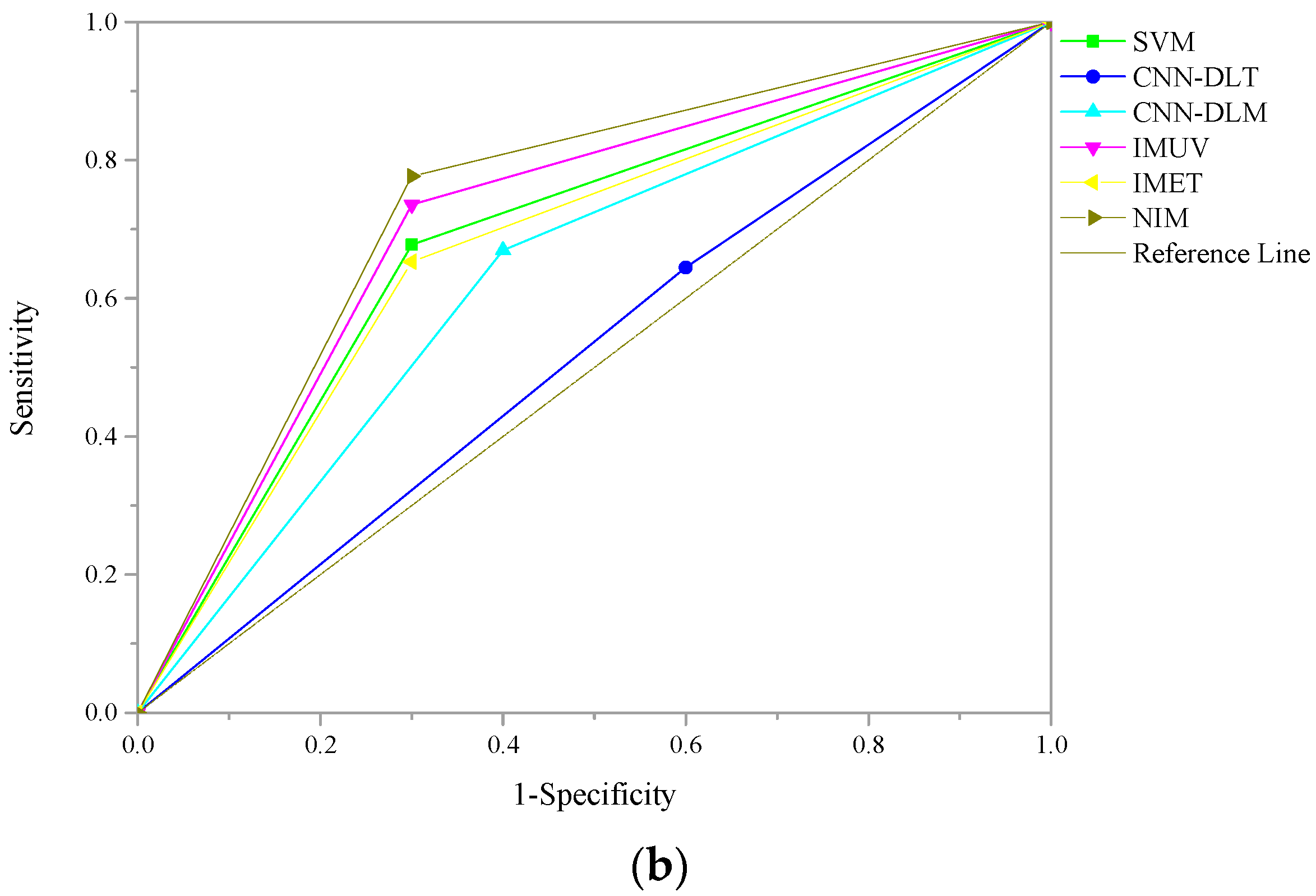
3.5. Model Evaluation Metrics
Many metrics have been proposed to evaluate the performance of forecasting models, such as accuracy (ACC), Matthews correlation coefficient (MCC), F1-score (F1), the area under curve (AUC) of receiver operating characteristic (ROC), etc. In this paper, due to the imbalanced testing sample set, AUC is employed as the evaluation metric [
54]. AUC is widely used to measure the overall discriminatory power of models for flexibility and comprehensiveness [
17]. Commonly, AUC scores range from zero to one, which means that the classification performance is the worst. One indicates the best classification performance. The bigger the AUC score is, the better the classification performance is.
6. Conclusions
In this study, we extend the research of corporate failure forecasting by proposing a novel integrated model with convolutional neural network oriented deep learning and support vector machine based on soft set theory for corporate failure forecasting in the Chinese energy sector. Given characters of energy firms in China, both numerical data and textual data are considered as inputs here. Due to different features of numerical data and textual data, CNN-DL is employed to forecast corporate failure based on the textual data, and SVM is used to forecast based on the numerical data. Then, outputs of CNN-DL and SVM are integrated using SS. Hence, NIM inherits advantages and simultaneously avoids disadvantages of CNN-DL, SVM, and SS. This algorithm enables NIM to make full use of numerical data and textual data. Compared with benchmarks, NIM shows superior performance for corporate failure forecasting in the Chinese energy sector. Empirical results also demonstrate that it is an effective way to improve the performance of corporate failure forecasting in the Chinese energy sector by focusing on this sector.
Though empirical results are satisfactory, there is some work needed to be done in the future to improve the forecasting performance. First, as the key component for the success of NIM, the word segmentation technique with high computing efficiency should be studied more with consideration to the features of Chinese. Second, the management discussion and analysis section is used as textual data for corporate failure forecasting in the Chinese energy sector. Some related national polices and news should be investigated as textual data in future research. Third, financial ratios are employed as numerical variables in this study. More numerical variables should be included for corporate failure forecasting in the Chinese energy sector, such as market data, governance data, national economic data, etc.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}