In this section, we break down the problem into multiple parts. We initially discuss the computation of network reliability for arbitrary topologies, proposing a simple method for estimating reliability with reduced complexity. Subsequently, we propose a novel heuristic for attributing reliability values to individual links, which takes into account power outage indexes of the subjacent power grid. Finally, we elaborate on network cost computation and constraints associated with the link allocation problem.
3.1. Reliability Computation
The value of reliability associated with a communication network is a measure of the probability of transmission failure. In normal operation, networks must provide one or more communication routes for any node pair. Considering the possible occurrence of contingencies in individual links, it is necessary to provide redundancies in the network design [
21]. This procedure enables information flow between nodes during operation with faulted links.
Let us consider the computation of two-terminal reliability, which is the probability of successful transmission between a given node pair [
22]. In other terms, the two-terminal reliability
associated with a node pair
is equal to
, where
indicates successful transmission between nodes
and
.
The general form of the two-terminal reliability is
, where
is the failure probability associated with one of the
existing paths between the nodes. Each path is composed of multiple links, whose individual reliability values are
. We remark that
, since the right-hand side parameter is the global reliability between the nodes, whereas
is the reliability of a single link. It is clear that, for a given path
,
, we have
, where
is the reliability of a link belonging to path
. However, since we are considering all possible failures, the dependence of different paths must be taken into account. Let
be the greatest path such that
and
. Since the failure of
implies that of
, it is clear that we must consider a reliability value
when accounting for the failure of
[
23]. Hence,
can be expressed as:
We note that the above computations assume there is only one link per node pair. However, even if this is not case (that is, at least one node pair possesses series and/or parallel links), Equation (1) may be used if the network is previously reduced to an equivalent topology with one link for each node pair. Reduction can be accomplished by using the following equations:
where
and
are, respectively, the equivalent reliabilities of series and parallel associations of links
,
.
Optimizing a single two-terminal reliability in the network is a method susceptible to the introduction of bias in the solutions obtained, since only one pair of nodes would be considered. In this sense, there would be no guarantee of convergence to an optimal network topology in terms of average reliability. Hence, we shall now consider the global network reliability, which is given by .
In order to compute
C, the probability of each possible transmission attempt
must be known, since the relative frequency of a given attempt weights its contribution to
C. Let
be the probability that transmission
will be attempted. It is clear that its contribution to
C is
. Hence, the network reliability can be computed with the following equation:
where
n is the total number of network nodes, and we define
. Assuming no previous information is available concerning transmission attempt probabilities, it is reasonable to suppose all attempts are equiprobable. Let
denote the number of permutations of two elements chosen from a set of
n objects; our assumption gives
. Substituting in Equation (
4), we have:
where
is the average of two-terminal reliabilities taken over
. Hence,
C can be computed by obtaining each
and computing the average of
over all nodes. We note that
has an important interpretation, namely
, which is the probability of a successful transmission originating in
.
Based on this discussion, we highlight the following reliability values and their properties:
Node transmission reliability
: Associated with a single node
, it is a measure of the average two-terminal reliabilities that involve the given node:
Global transmission reliability
C: Associated with a given network topology, it consists of the average between all
node reliability values:
We propose using C as one of the objective functions for optimizing link allocation, since it represents an average value of reliability associated with the network and takes into account the distribution of reliability throughout the network.
The possibly high values of path numbers may pose a problem in terms of computational complexity. In order to reduce the processing effort for calculating each , we propose an approximation that consists of considering only the K paths with greater reliability that compose each path . If K is such that , computational effort can be saved. The approximate values obtained for are reasonable approximations, given K is not exceedingly small.
We observe that in (1), the smaller a given path’s is, the more negligible its contribution to is, since its corresponding term in the product series tends to one. Hence, the procedure of ignoring paths with smaller reliabilities is justified.
The computation of each presupposes knowledge of values for the link reliabilities . For now, let us assume such values are given and describe the proposed evaluation method. It consists of the following steps:
Use Equations (2) and (3) to reduce all series/parallel link associations in order to obtain a topology with only one link per node pair;
Use an enumeration algorithm to obtain the K paths from to with the highest associated reliability values ;
Use Equation (
1) and the obtained paths to compute
.
Step 1 provides an equivalent graph with independent paths, for which Equation (
1) may be applied for reliability computation, whereas Step 2 implements our proposal of only using the highest reliability paths for computing two-terminal reliabilities. Step 3 consists of applying Equation (
1) to the obtained enumerated paths for computing
.
We propose using Yen’s algorithm [
24] as the enumeration procedure for Step 2. This algorithm outputs the
K paths with the smallest
. However, we want to enumerate paths with higher reliabilities, which are given by products
. To solve this problem, we adapt the algorithm as follows. Consider the function
; it is clear that
and is strictly increasing for
. Since
, the function maps high reliability links to lower values. Furthermore, the property
maps product terms into sums.
Hence, it is enough to supply all as input to Yen’s algorithm. After enumeration, the themselves (and not their transformed values) may be used for computing in Step 3.
The proposed algorithm requires as input the nodes , the possible links to be allocated, and their reliability values . We present this information as a list of links and their respective reliabilities . This representation is adopted in order to account for multiple links in a single connection from to (in series or parallel). The list is then reduced, by means of Equations (2) and (3), to a new list in which there is only one link between each node pair, allowing the computations to be carried out.
Once this reduction is made, an adjacency matrix weighted by the equivalent can be defined for simultaneously handling link reliability and allocation information. Let be the standard adjacency matrix, in which if a given topology contains the link from to and otherwise. Defining , with , this matrix can be used for reliability computations and for defining link presence or absence .
The proposed procedure for computing C is given in pseudocode form in Algorithm 1.
| Algorithm 1: Computation of global reliability. |
Input: , ; ; K.
Output: C.- 1:
, . - 2:
, . - 3:
. - 4:
fordo - 5:
for do - 6:
Use to reduce series/parallel associations. - 7:
return and A. - 8:
Generate by using A and . - 9:
Generate , in which . - 10:
Execute Yen’s algorithm over . - 11:
return Paths , . - 12:
for do - 13:
. - 14:
end for - 15:
. - 16:
. - 17:
end for - 18:
. - 19:
end for - 20:
returnC.
|
3.2. Reliability Attribution Heuristic
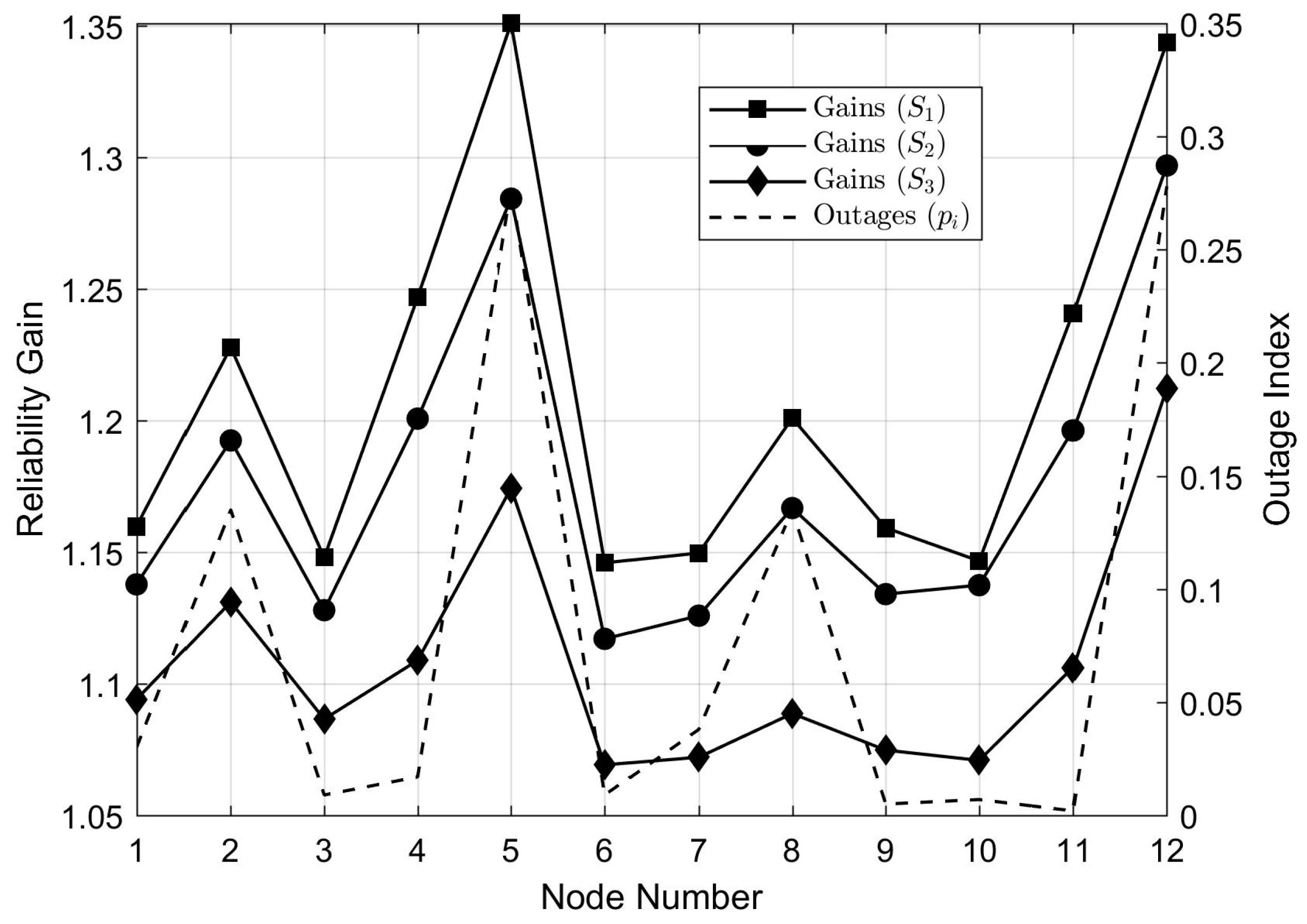
In a communication network, the relative importance of individual nodes for the system determines how critical the maintenance of their connectivity is. This suggests that network redundancies must be implemented towards securing communication between the most critical system nodes. For communications among automated grid breakers, it is clear that node importance is related to power outage indexes. In fact, if a feeder protected by a given breaker has frequent contingencies, it is more important to guarantee the breaker connection to the network than it would be if the associated feeder were not faulty.
Taking this into account, we propose a novel heuristic for prioritizing breakers associated with faulty feeders during optimization of optical link allocation. The procedure works by attributing reliabilities to the network links as functions of grid continuity indexes.
The main index used for evaluating power continuity in Brazil is named
DEC. This parameter represents the monthly average blackout time (in hours) measured in a given consumer group supplied by a feeder and is given by [
1]:
where
is the monthly blackout time for the
ith consumer of the group and
denotes the total number of consumers in the group.
The measurement and storage of values for all consumer groups is a regulatory requirement imposed on Brazilian utilities. Hence, this index is a reliable measurement of power continuity in the grid. Given the breakers and DEC values of their associated feeders, we propose attributing each value as a function of the DEC values associated with feeders protected by breakers and , as follows.
Considering that high values of DEC in a feeder imply frequent outages, it is clear that breakers protecting feeders with high DEC must be prioritized during communication link allocation. In this sense, we propose attributing link failure probabilities equal to the normalized value of the highest DEC associated with feeders protected by nodes and .
We justify this heuristic in the following manner: for a greater value of attributed to a certain link, the optimization algorithm will select solutions that possess redundancies around this link in order to maximize global reliability C. Therefore, redundancy allocation in the communication network will prioritize breakers that protect feeders with higher DEC values. In other words, the selected solutions will be the ones that attain greater communication reliability for breakers operating in faulty feeders.
Before indicating how to attribute the
to the network links, we note that there are two main types of breaker connections in power grids, namely grid and tie breakers [
25]. Their difference resides in the natural state of operation and number of feeders to which they are connected: grid breakers are normally closed and protect one feeder, whereas tie breakers are normally open and connected between two feeders. Due to this difference, we shall propose slightly different heuristics for attributing
values in each case.
Let denote the DEC of a feeder associated with node . Considering that DEC is measured monthly, we have h. Given the network nodes and their associated feeder(s) with respective DEC value(s), we propose the following strategy for attributing reliabilities to the network links:
Normalize all by h. The new values will be such that ;
For every breaker , verify if its type is a grid or tie. In the first case, define . Otherwise, define .
For every link from to , attribute . Hence, .
The parameter associated with is equal to the DEC of the worst performing feeder to which this breaker is connected. Hence, can be interpreted as a measure of grid failure probability associated with . For this attribution heuristic, it is clear that and . Thus, the assigned increase for greater node DEC values. This shows that nodes with unreliable feeders tend to decrease C, which makes the optimization process select network topologies that prioritize link redundancies between high-DEC nodes. The proposed strategy is summarized in Algorithm 2.
| Algorithm 2: Computation of link reliabilities. |
Input: ; , .
Output: , - 1:
, . - 2:
fordo - 3:
if is grid-type then - 4:
. - 5:
else - 6:
. - 7:
end if - 8:
end for - 9:
, . - 10:
, . - 11:
return.
|
Considering that all
are attributed in a heuristic manner, we need a reference network topology against which we may compare
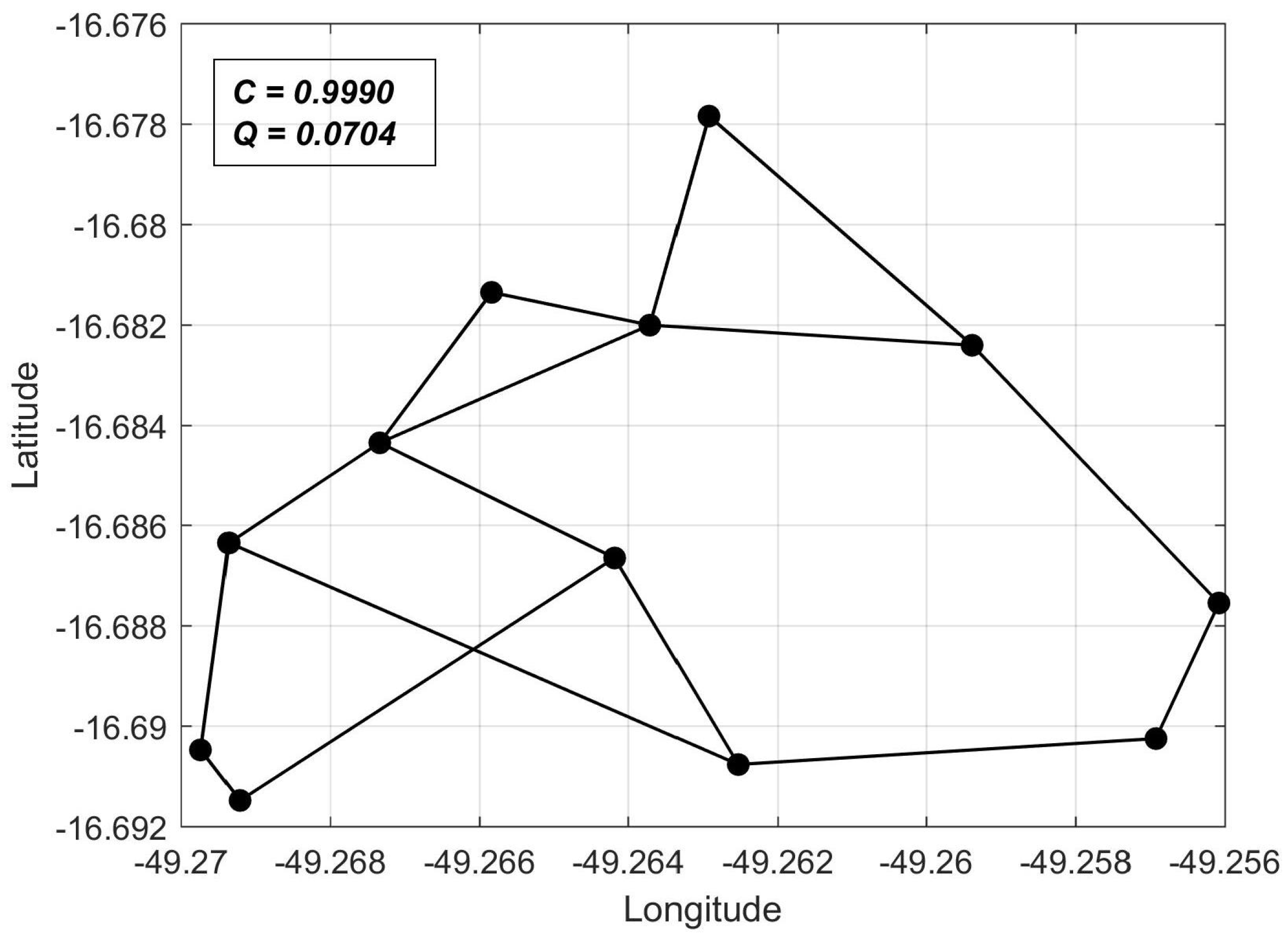
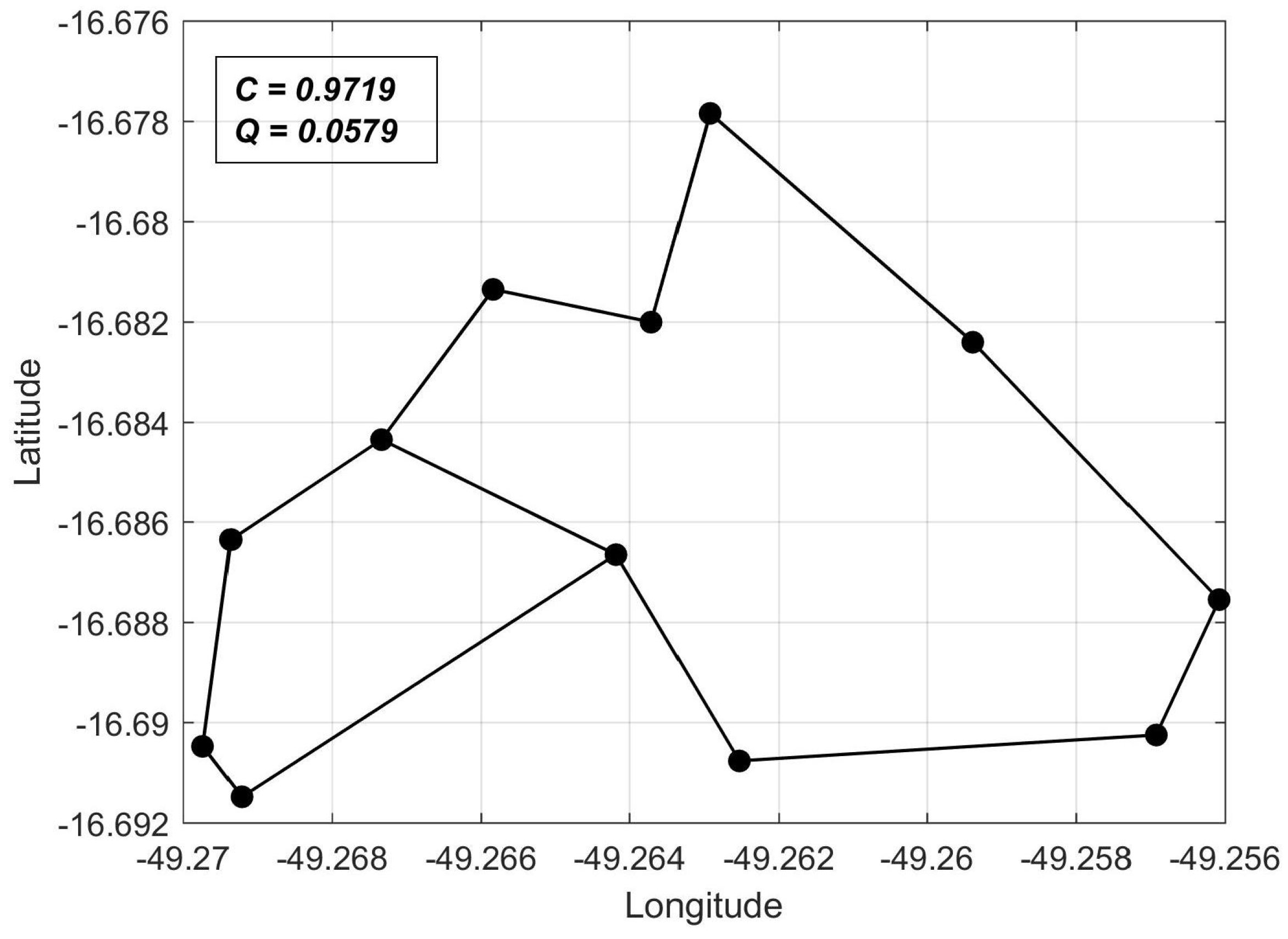
C values computed for arbitrary networks. In this sense, we chose as a reference the shortest-perimeter ring topology, whose reliability we denote as
. Thus, for any network topology, we can compute
as a reliability measure, as will be shown in the computer experiments of
Section 5.
3.3. Network Cost Computation
In the deployment of fiber optics links, cost is mainly associated with the required length of fiber needed. Hence, the network cost is a function of the distances between all node pairs that are connected by links. Let the node positions be identified in an arbitrary coordinate system by means of the set
. Assuming the coordinates are known and denoting the distance between
and
by
, we consider the euclidean distance
. Disregarding multiplicative factors for converting distance into monetary units, we compute the cost
Q of a given topology as the sum of link lengths. Considering that optical links are implemented for bidirectional communication [
26], we have
and
. A factor
must be used to account for the bidirectional links. Hence, given the adjacency matrix
A, the cost can be computed by:
We note that , as the existence of a self-connecting node is meaningless in the problem context. We now address handling of equivalent link costs in case the list contains series or parallel links. If there are series links to be reduced, it is clear that the total distance is equal to the sum of individual link lengths. Hence, costs may simply be summed. For parallel links, the individual connections have approximately the same length. Therefore, the equivalent cost is equal to the individual link length multiplied by the total number of links.
We shall use network cost Q as the second objective function to be optimized, alongside reliability C. Therefore, solutions obtained will represent different levels of compromise between these opposing factors. This approach is necessary in solving practical link allocation problems, since the amount of resources available for network deployment is limited.
3.4. Problem Constraints
Optimization problems usually present constraints in terms of the design variables and objective functions. In the link allocation problem, reasonable constraints would be maximum cost and minimum reliability values for all network solutions. However, this type of constraint disregards the connectivity of individual nodes.
For instance, a minimum value for C would not punish a network that achieves high reliability for all nodes, except for one that is left isolated. Likewise, a maximum Q value may cause links with good reliability that are never chosen due to their higher lengths. Based on these considerations, in what follows, we define alternative constraints that naturally limit cost and reliability, while still accounting for individual nodes.
We consider a physical constraint that can be given in terms of the design variables. Every automated breaker has a maximum number of communication ports. Hence, there is a limit
of links that can be connected to any network node. Supposing equal port limitation for all nodes, we address this constraint by defining a violation index [
27] given by a step-form function:
where
is the number of links connected to node
. Analogously, we consider a minimum connectivity constraint
for all nodes. This can be interpreted as ensuring any given node is supplied with sufficient link redundancies. The associated violation index is defined as:
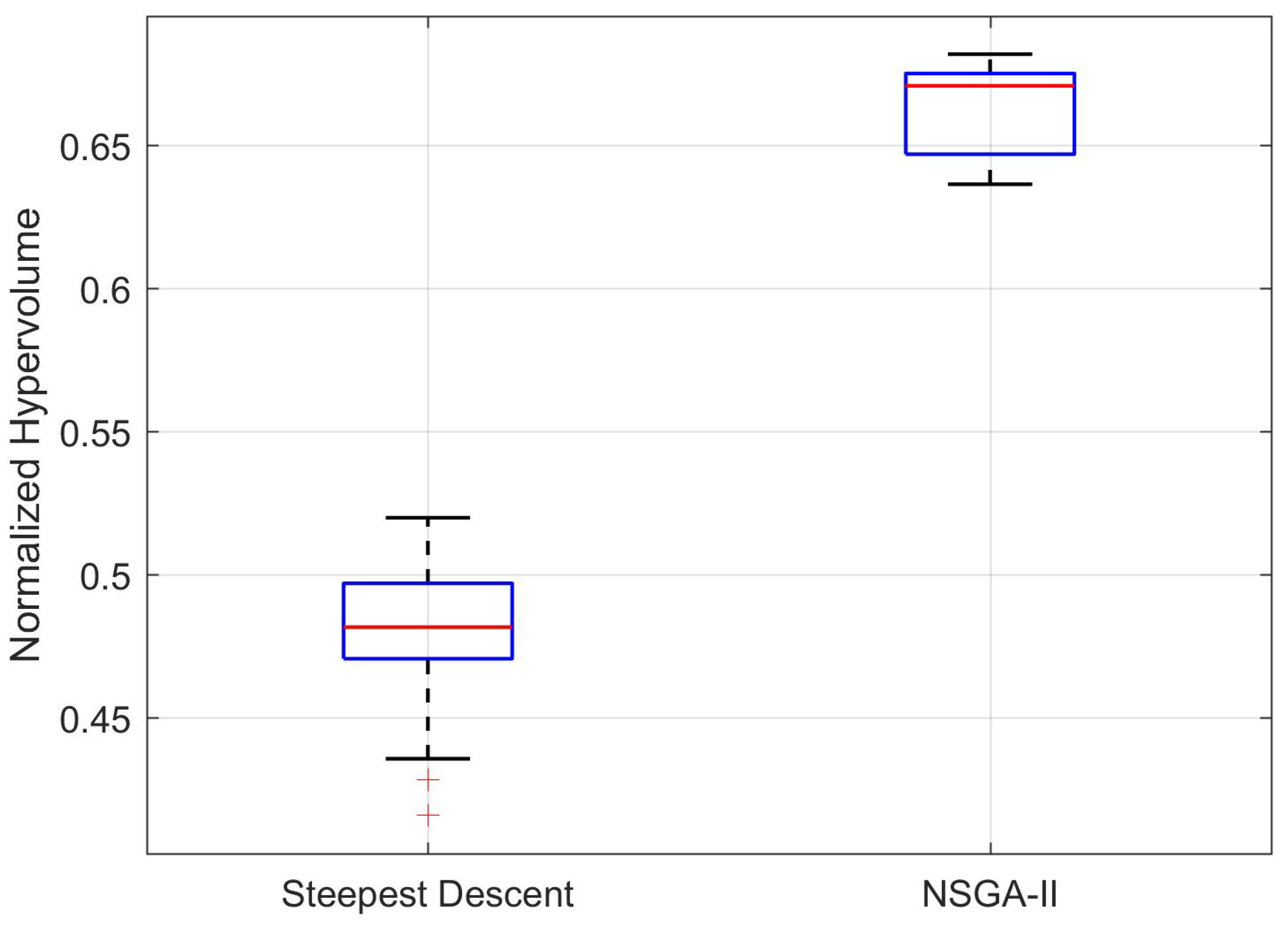
Depending on the type of optimization algorithm used to solve a problem, violation indexes can be implemented differently. For example, in gradient-based methods, they can be implemented as regularization terms in the objective function, whereas in genetic algorithms, they may be processed independently by means of binary tournament methods. The implementation of violation handling will be discussed in
Section 4.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}