1. Introduction
With the development of science and technology, the running speed of trains is rapidly increasing, which means that the capacity utilization of existing infrastructure is high [
1]. Undoubtedly, railway safety also faces major challenges. High-speed trains may suffer from various faults during operation, such as human errors, internal equipment faults of the system and adverse external environments, which delays the trains. More seriously, such faults may cause accidents [
2]. Through statistical research on train delays, it was found that the main causes of train faults are line faults, turnout faults, signal faults, car body faults, power supply faults and bad weather effects. Therefore, it is necessary to identify the root cause to help fault diagnosis, security monitoring and guidance for specific routine maintenance measures.
Much research has been proposed to identify the root cause, such as Fault Tree Analysis (FTA) [
3], anticipatory failure determination (AFD) [
4], subversion analysis [
5], root conflicts analysis (RCA+) [
6], etc. FTA is mainly used to construct the tree structure of accident faults and find out the cause of the accident failure. AFD is a method aimed at finding possible unexpected and undesirable events that risk disrupting the normal operation of a technical system, with the use of existing resources. Apart from AFD, subversion analysis is very useful in the identification of causes of given phenomena and events (faults, errors, negative impact), especially in situations where causes cannot be easily determined [
5]. RCA+ is a technique for problem analysis developed for the top-down decomposition of problems to chains of causes and contradictions.
Recently, fault-related problems have attracted increasing attention from researchers in the field of railway transportation. Due to the difficulty in obtaining actual train operation data, studies at home and abroad mainly focus on the determination and prediction of faults, the simulation of faults and the theoretical model of train delay propagation [
7]. For example, as the railway track circuit is the most commonly used component for train detection worldwide, fault diagnosis for railway track circuits has already been addressed [
8,
9,
10,
11]. Moreover, because turnout is very important equipment in railway infrastructure, accounting for approximately 33% of the annual railway maintenance cost, several studies on turnout have been reported in the literature. A failure prediction algorithm of railway turnouts based on a neural network is proposed by Yilboga et al. [
12]. Also, to predict railroad turnout failure, an autoregressive moving average model was developed [
13]. Additionally, a simple state-based prediction method is proposed to detect and predict the fault progression of railway turnout systems [
14].
In addition, various studies regarding methods for diagnosing railway system faults have been carried out in recent years. An artificial neural network (ANN)-based fault diagnosis method for a turning area of jointless track circuits was proposed by Zhao et al. [
15]. Additionally, to detect faults in the railway track circuit, the neuro-fuzzy system and the Dempster–Shafer theory were employed [
8]. Yin and Zhao proposed an automated vehicle onboard equipment (VOBE) diagnosis network for a high-speed train via a deep learning approach, which captures the complexity and uncertainty of the VOBE faults [
16]. VOBE for trains can receive real-time data, including the speed limits, length of the track circuit, gradients and running speed, and then calculate the preferred control strategies [
17]. Verbert et al. proposed such an approach for fault diagnosis in networks, which is knowledge-based and uses temporal, spatial, and spatiotemporal network dependencies as diagnostic features, requiring fault diagnosis methods that can work with a limited set of monitoring signals [
18]. Bruin et al. proposed a long short-term memory (LSTM) recurrent neural network to identify faults based on commonly available measurement signals [
19].
For the reason that most of the existing fault methods are based on state detection, starting from the mechanical properties of the equipment or the failure rate of the equipment, the root cause analysis performed by researchers is often based on structured data when it is necessary to consider unstructured text data, such as fault tracking reports, libraries, fault libraries, causal analysis, and process analysis. In addition to the identification of the causal factors required for risk analysis, past researchers have usually used manual processing or have neglected and then conducted related analysis on structured data. The identification of cause factors, once manual screening and identification are required, is undoubtedly a time-consuming and laborious task, especially when the data are large. Unstructured text data contain a considerable amount of useful information. The text data of railway faults, as an example, usually includes the root cause of the failure, the process, the main causal factors, the underlying factors, the relationship between the factors, and the consequences of the failure, and it requires considerable effort to identify the needed information. However, the content in unstructured data is not detailed.
Therefore, it is meaningful to study how to identify the cause of railway failures from the railway text data and to promote relevant subsequent analysis. Currently, there are many fault records and maintenance data in the maintenance and management of railway equipment. These unstructured data can play a very important role in equipment fault prediction. If we can make full use of these document data and excavate the underlying value of the data, it will greatly improve the reliability and security of railways.
Many researchers use word networks to research natural language processing. Beliga et al. showed that network-based methods have the best performance in extracting keywords [
20]. Considering the similarity between the extraction of railway causal factors and the extraction of keywords, this paper considers whether the extraction of railway fault text data can be extracted by the keyword extraction method, thus effectively improving the extraction efficiency of accident causative factors. It provides a new idea for the analysis of the causes of railway accidents/events, the analysis of railway fault accidents and the risk analysis of railway faults. To reduce the time required and to use the text data correctly, which could be further used in research, we propose extracting the root cause of railway faults from every detail.
This paper is organized as follows. The principles that are employed in our proposed method are presented in
Section 2. A method for identifying root causes is described in detail in
Section 3.
Section 4 shows the experimental analysis and relevant results. Finally, conclusions are summarized in
Section 5.
3. Proposed Method
To use the keyword extraction method to identify the causes, we present a method that employs the following assumptions:
Assumption 1: All fault records can be viewed as a fault report.
Assumption 2: The keyword extraction method can be applied to the text fault report and the assumptions of the method are also established.
Assumption 3: A failure cause is in the form of noun + verb combinations or independent nouns, where the latter noun could form a noun phrase with a default.
We reviewed the previous literature, and the cause of the failure text is in the form of noun + verb combinations or independent noun forms. Additionally, in a failure record, we found the cause is always the combination of a noun and a verb.
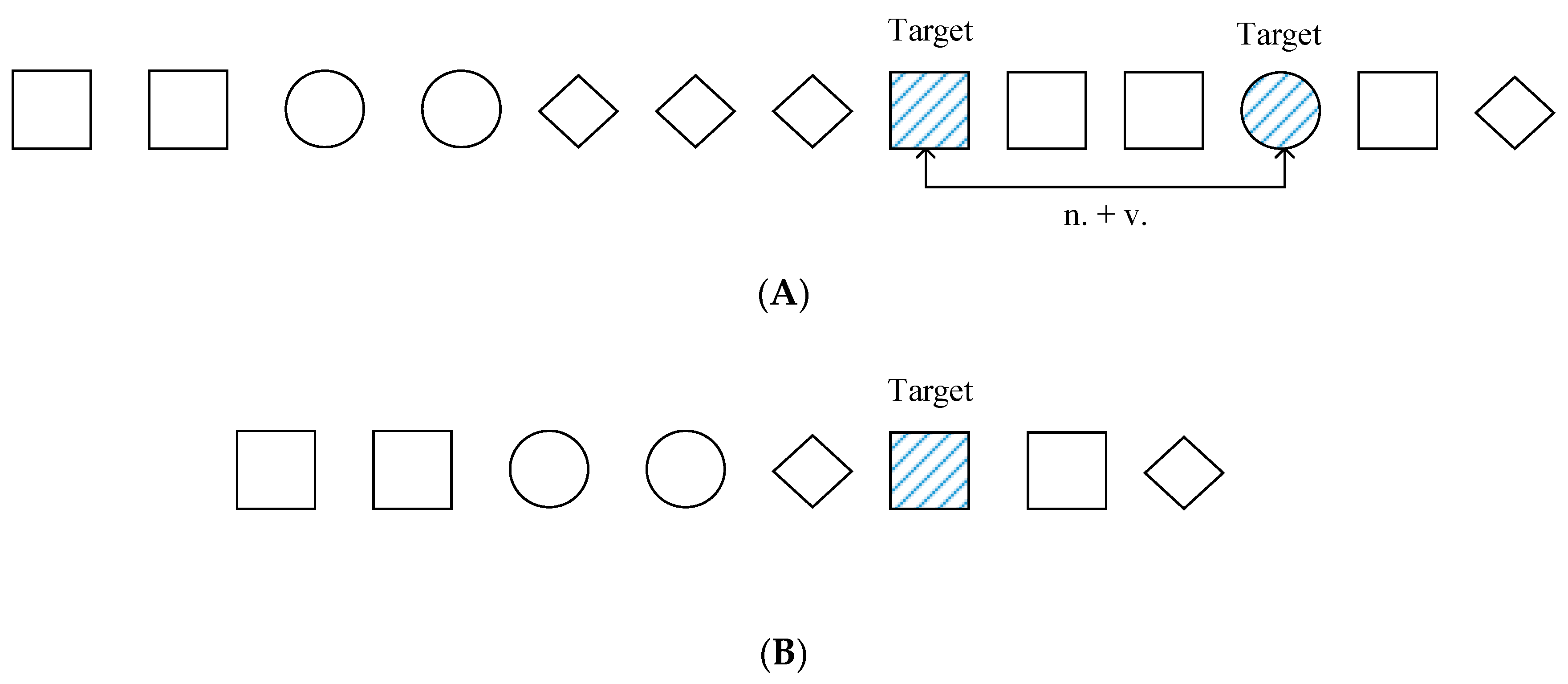
Figure 2 shows a railway fault text record, which can have various parts of speech, such as nouns, verbs, and an uncertain number of them. In
Figure 2, squares represent nouns, circles represent verbs, and other shapes represent the other parts of speech. When a noun (n.) and a verb (v.) can constitute a fault cause in this a record, such as n. + v., there will be shadows in both the square and circle, and they are marked as the “target” we are looking for.
Therefore, we identified the result of the task to find the words in the form of n. + v. or isolate n.
To quickly find the cause noun and the cause verb, a dictionary is necessary. However, a dictionary of railway faults does not exist. To complete the task, we split the tasks of nouns and verbs.
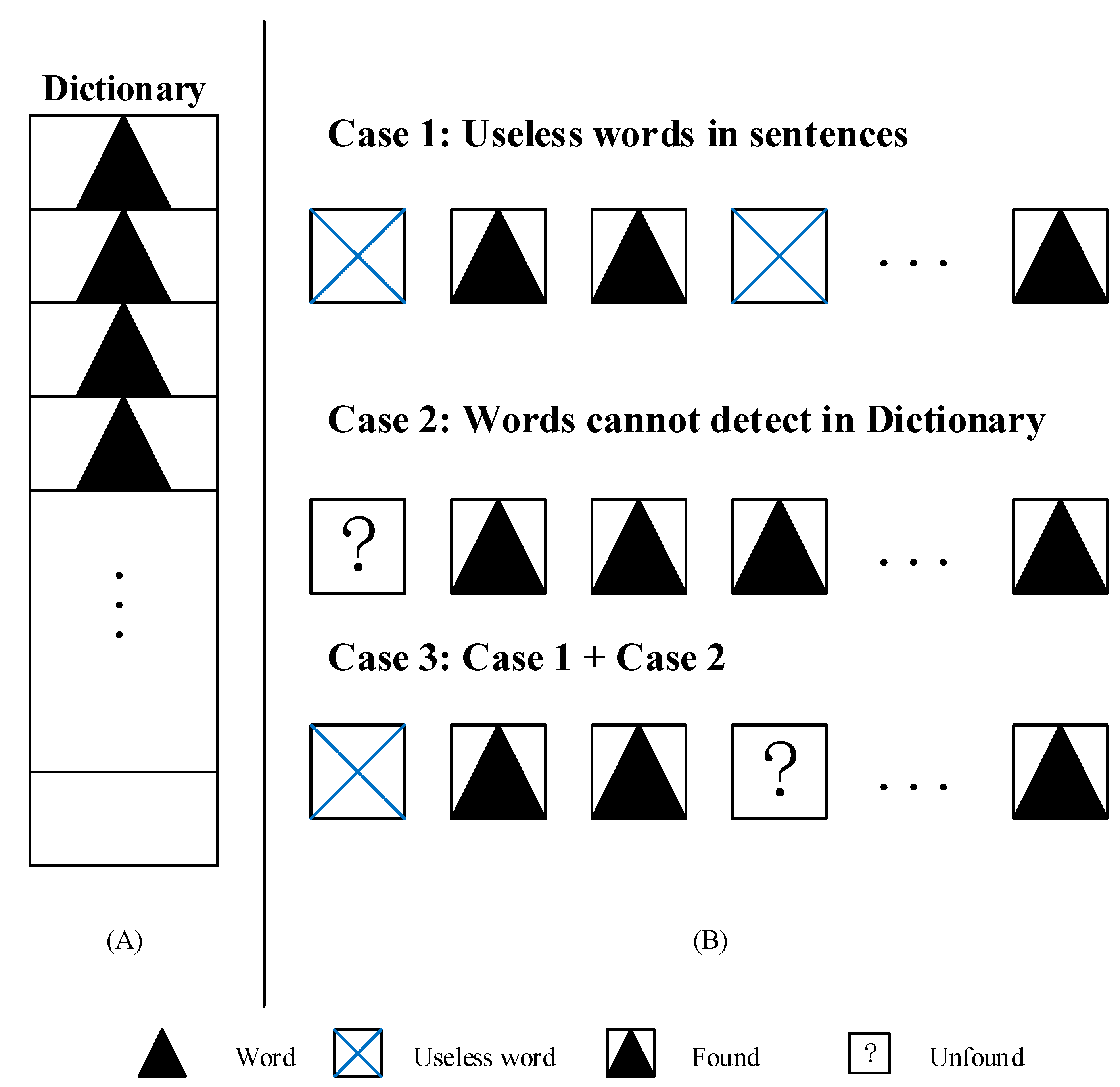
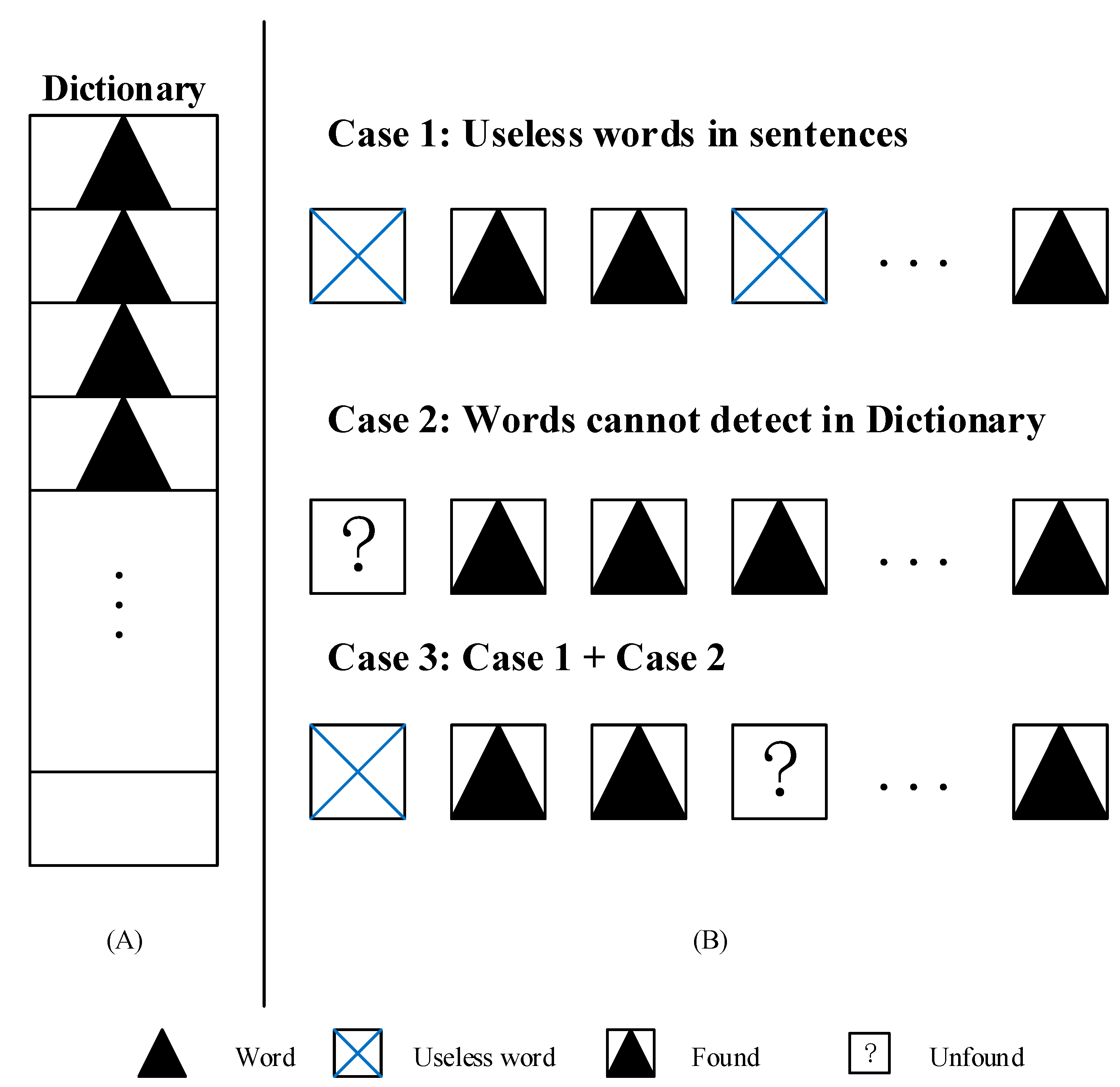
Collecting and establishing a dictionary from previous literature is a good start but is not enough. Since the dictionary has incomplete content, it prevents us from identifying the cause nouns in the sentence (fault record).
Figure 3 shows an incomplete dictionary with three hidden situations. Case 1: A useless word exists in the dictionary, which means this dictionary must filter the useless words. Case 2: A useful word should be detected but is not in the dictionary, which means the dictionary is incomplete. Case 3: Both Case 1 and Case 2 occur. Basically, to solve these problems, we need to continuously expand the dictionary content through the task text and match the text to achieve the match function. Moreover, we also need to establish a text stopword list and filter and eliminate the text to supplement the dictionary. Incomplete words are reserved, and thus, filter functionality with the text is achieved. Therefore, the cause identification object is split into recognition reason nouns and verbs, and the identified tasks are split into establishing a cause dictionary and a deactivation dictionary.
The steps of the proposed method are divided into the following: text preprocessing, noun recognition, and verb recognition. Noun recognition is further divided into establishing a user dictionary and stopword lists.
Briefly, extracting root cause text is divided into the following steps: identify the irrelated nouns; eliminate stopwords; require the suggested useful words; and clear the useful words to obtain the aim of our study. According to these steps, the root cause text should be extracted more precisely.
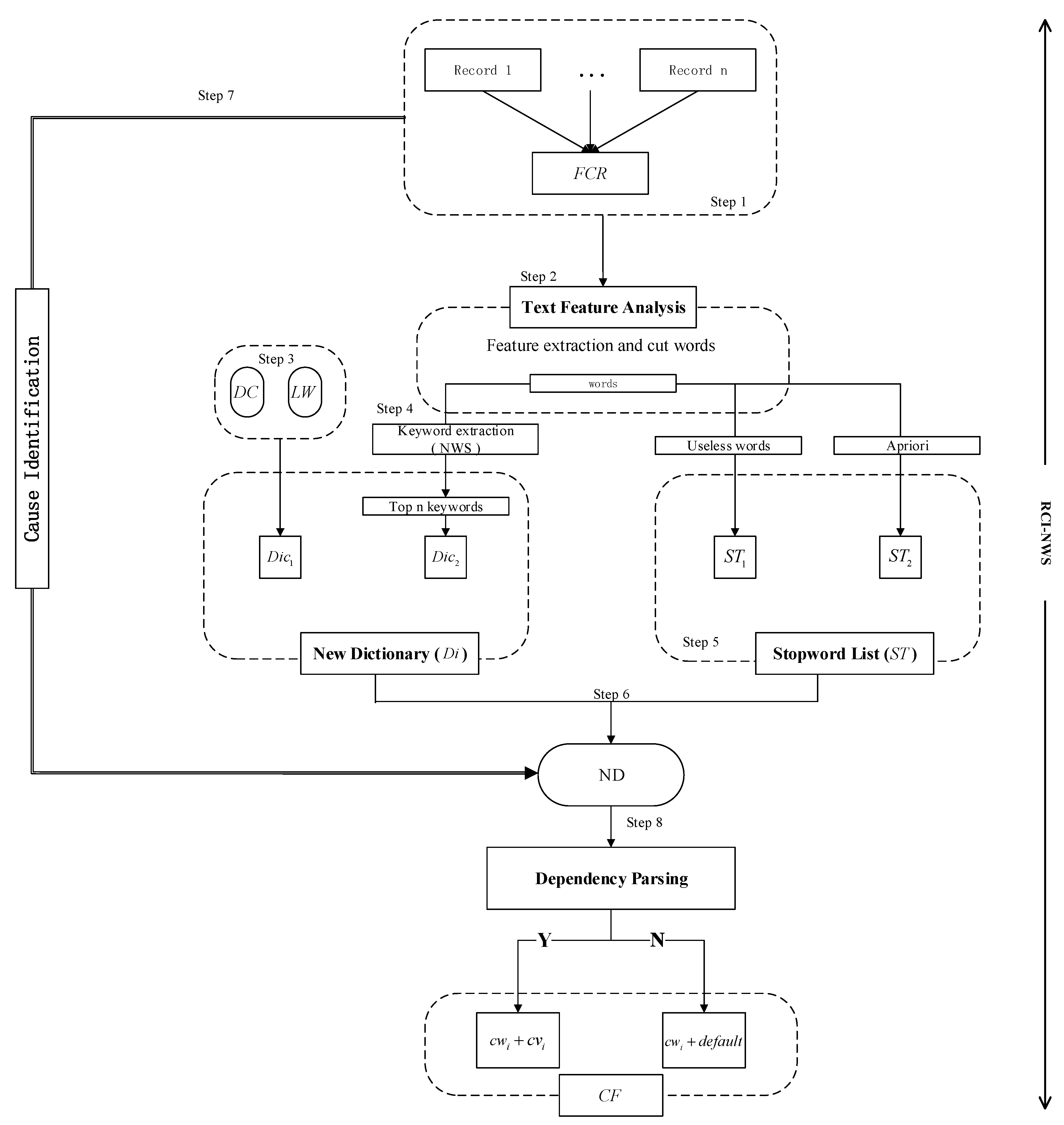
Specifically, the steps are as follows (see
Figure 4):
- Step 1
Pre-process the fault cause records as a fault cause text FCR =
- Step 2
Text feature analysis and feature extraction.
- Step 3
Follow the feature description and split the tasks into several processes. Collect the literature and . Set up the first part dictionary .
- Step 4
Build the second part dictionary . Build a noun list, which selects the nouns from the cut text. Perform text keyword extraction on the fault cause text. Add the cause text from the top n keywords to the noun list.
- Step 5
Build a stopword list . Consider the elemental information, such as train departure time and train station (location) and collect them as stopwords . In addition, use the apriori algorithm to obtain the stopwords which include frequency and meaningless words, to build a necessary stopword list.
- Step 6
Merge the two dictionaries and obtain a new dictionary Di = + , then filter this new dictionary by the stopword list to obtain ND = + − ST = .
- Step 7
Use the dictionary to match the cause noun. For in FCR, if is in ND, the cause word is obtained.
- Step 8
Use a dependency parsing to find the cause verb
if it exists; otherwise, the causal factor is combined with a
default combination failure to obtain causal factor
.
3.1. Feature Description and Selection
(1) Participle symbol feature
When the divided text is sparse, the resulting reason words are sparse; if the word segmentation is relatively close, the result may be composed of multiple nouns. Therefore, when the text is segmented, the characteristics of the word segmentation also affect the identification of the cause.
(2) Part of speech
By analyzing the fault causes manually extracted from previous literature, we find that these reasons are usually caused by a noun and a verb phrase or a single noun. The characteristic of these nouns is that they are all the structure of a train body or the name of a part of the train. Thus, the part-of-speech feature can be used to identify the root cause of railway faults. Thus, through the feature extraction of the text part of speech, we determined that the goal of the task is to find nouns and verbs related to the car body.
(3) Semantic feature
When analyzing the railway fault text data, summarizing the naming rules of the root cause identification is beneficial for improving the accuracy of the root cause. For example, “the traction current transformer charging resistor burns” can be composed of the body structure term “traction converter charging resistance” and the fault occurrence action “burning”.
(4) Term length feature
Combined with Chinese writing habits, from the entire fault record, the description of the root cause of the fault will be in the second half of the sentence; that is, other information unrelated to the root cause identification is usually concentrated in the first half of the sentence. Thus, the word position of the reason word is a general and inconspicuous feature.
(5) Keyword characteristics
When we are extracting keywords from the text fault data, we see the keywords of “so”, “discovery”, “because cause”, “have”, “occur”, “fault”, etc. In conjunction with the sentence description of the fault in the text, many reason words occur after or before these feature words. These words are used to create a new dictionary of prompt words and to consider the use of the inverse maximum matching method for the location and semantic annotation of the reason words. These can be used as a feature in the base of text keyword features.
Therefore, to build a user dictionary, we consider the particularity of the railway fault text data, including the linguistic part of speech, semantics, keyword characteristics and other characteristics of the various levels of representation.
3.2. Identify the Root Cause Body Name
a Fundamental to the body list
We build the dictionary by combining the description of feature extraction in
Section 3.1.
First, according to the characteristics of the reason words in the text, the reason can be divided into noun + verb form. For nouns, the nouns that constitute the reason are usually related to the train body structure. The fundamental method uses a dictionary to depict the desired words. However, most of the time, the records we have are limited and not open data, which means that we have to review the history and former literature for help with performing the extraction. Therefore, we obtained the preliminary version of Dic1 of the body dictionary by finding limited literature.
Second, considering the keyword characteristics of the text, the word segmentation is obtained, and the nouns of the cause are extracted. The nouns after the word segmentation are extracted, and then the word length and sentence features are combined with the terminology of the sentence. According to the characteristics of the keyword, the keyword must contain important reason words. The nouns related to the cause of the failure are found for Dic2. Since the vehicle has been determined for the dictionary of body nouns, we consider the fault text for keyword extraction features. The keyword is extracted from the text describing the reason, and the keyword must contain important reason words. Combined with the feature analysis of the text, the dictionary additions are performed step by step, and all the dictionaries are merged to obtain the initial document Di.
b Stopword list foundation
Because the body list is still not sufficient for matching the target word in each record, to some extent a stopword list would enhance the efficiency of finding the root cause word. In a record, words such as city name, location, numbers and letters are eliminated immediately. To find more valid stopwords, we use the keyword extraction method and then select stopwords from the top 100 keyword list. In addition, we also use apriori to collect more stopwords and update the original stopwords list.
c Merge
The obtained dictionary file and the stopwords document are processed by the merchant, thereby obtaining a dictionary in which we can identify the reason noun.
3.3. Identify the Root Cause Action
When we obtain the reason noun, we start the second stage of identifying the root cause action. We introduce a dependency parsing, find pairs of grammatical verbs through existing nouns, and perform similarity calculations on these verbs with the obtained verb lists to filter out effective verbs and finally obtain the reason, a phrase of nouns and verbs.
4. Experimental Results
In this section, to verify the validity of the proposed method, we manually extracted the reason for the 299 fault texts, which were compared with the fault reason extracted using our method. Moreover, we adopted traditional indicators, including the precision, recall, and F-measure, to evaluate the performance of the algorithms.
4.1. Fault Text Data
The data used were from a seven-month railway record and were collected in China from January to July, 2010. The contents of the database include the dates, the railway system information, the detailed description of the faults, the miles, and the consequences of the faults. The detailed description of the faults contains 299 descriptive text records of faults. Each descriptive record provides almost all the information related to a fault in detail, such as railway name, time and causal factors in a descriptive sentence.
As a short passage consisting of 299 Chinese railway records, the basic process for keyword extraction contains parts of speech, ranking the values and finally, obtaining the required keywords. In this short passage, we selected the top 20 keywords in the experiment while we could easily have the mix text words, which means some useful words and useless words among the top 20 keywords. (see
Table 1).
4.2. Cause Factor Analysis: Characteristics
We randomly selected certain records (sentences) to extract root cause factors, and some common characteristics were as follows:
- (1)
A root cause factor could be divided into two types: one is a noun with a verb, and the other is a noun with a “fault” in Chinese. To better describe and distinguish, we call the noun the root cause word.
- (2)
The part of speech of the root cause word is a noun, and the noun is related to the train structure.
- (3)
The average length of the root cause word is approximately two; in other words, its length is greater than one word.
- (4)
A root cause word is also important when all records are regarded as similar to one in a passage. Therefore, when extracting keywords in such passages, root cause words are more likely in the keyword list.
- (5)
Ninety percent of the root cause words are in the 37% length of a sentence.
In this experiment, we had two types of study references. The first is the train technical terms (TTTs) as a dictionary with more than 6188 terms translated into Chinese as well as English. As a dictionary, it has many Chinese terms, where the length of the Chinese terms ranges from two (door lock) to nine (cyclone-type air filter) in TTTs and contains almost all of the train body. Second, with the help of these studies, we can directly or indirectly apply these causal factors for analysis, which are summarized and divided into five classes: track, roadbed and structures; signal and communication; mechanical and electrical faults; human; and other. These five classes contain 326 factors recorded by the structure with noun and verb in a record, which were generated by workers, machinery, electrical equipment, external environment, etc.
4.3. Identify the Root Cause
To illustrate the role of the keyword extraction method in building a dictionary, we designed Experiment 1 and Experiment 2, and the difference was whether the keyword extraction method was considered. Experiment 2 considered the cause recognition results of different keyword extraction methods. Experiment 3 considered the effect of stopping the vocabulary on the cause identification. Experiment 4 considered the effect of text similarity on the cause of fault cause recognition (see
Figure 4).
To illustrate the role of the keyword extraction method in the proposed method, we used the most frequent (MF) method to take the place of NWS in the part of root cause identification-new word sentence (RCI-NWS).
4.4. The Most Frequent (MF) method
In the MF keyword extraction method [
27,
28], the score of the word
is obtained by counting the number of occurrences of the word in the matrix:
where
represents word
,
represents a sentence
,
denotes a total sentences set and
denotes word
in sentence
.
In addition, we compare the results considering stopwords and word similarity.
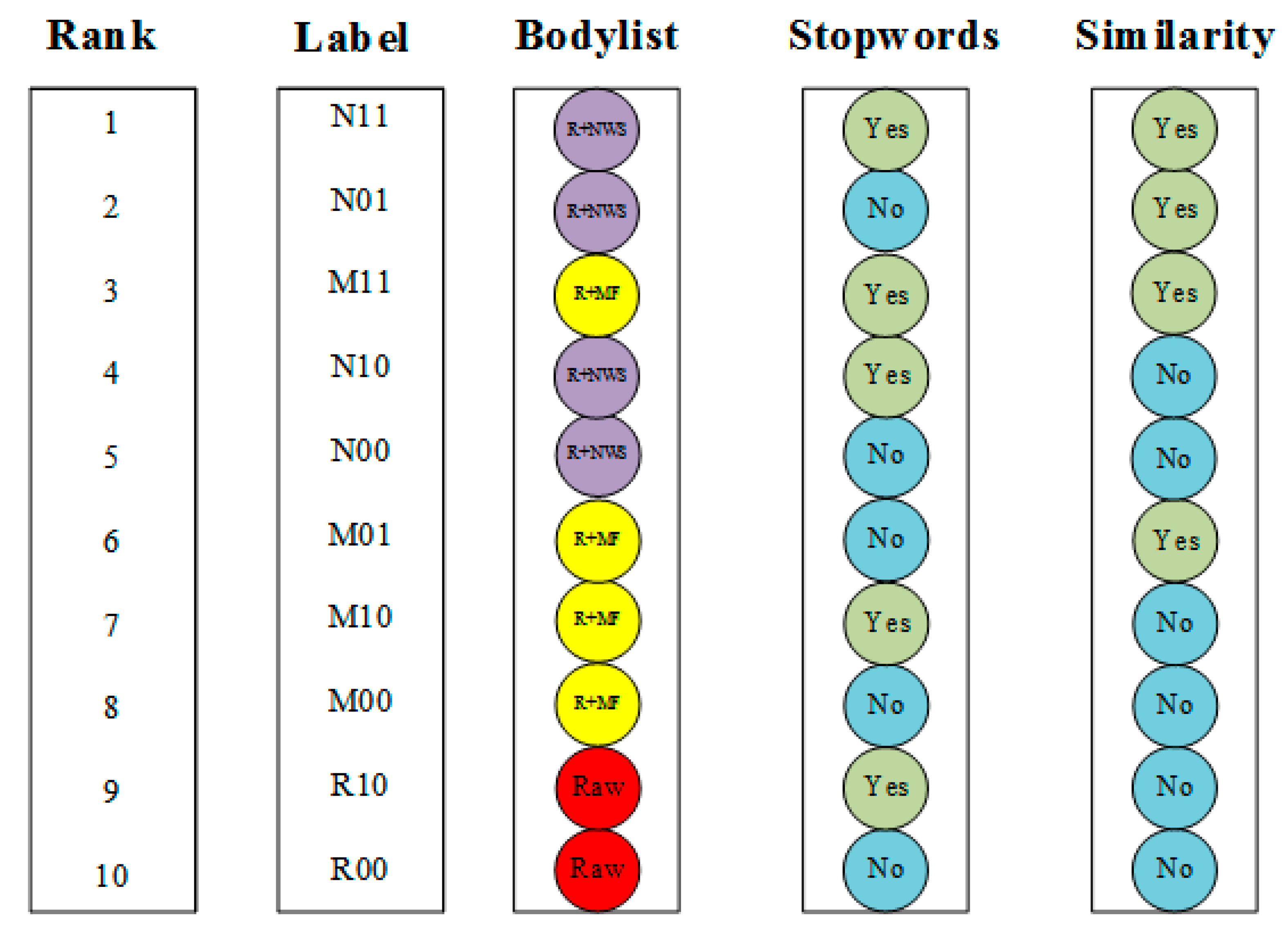
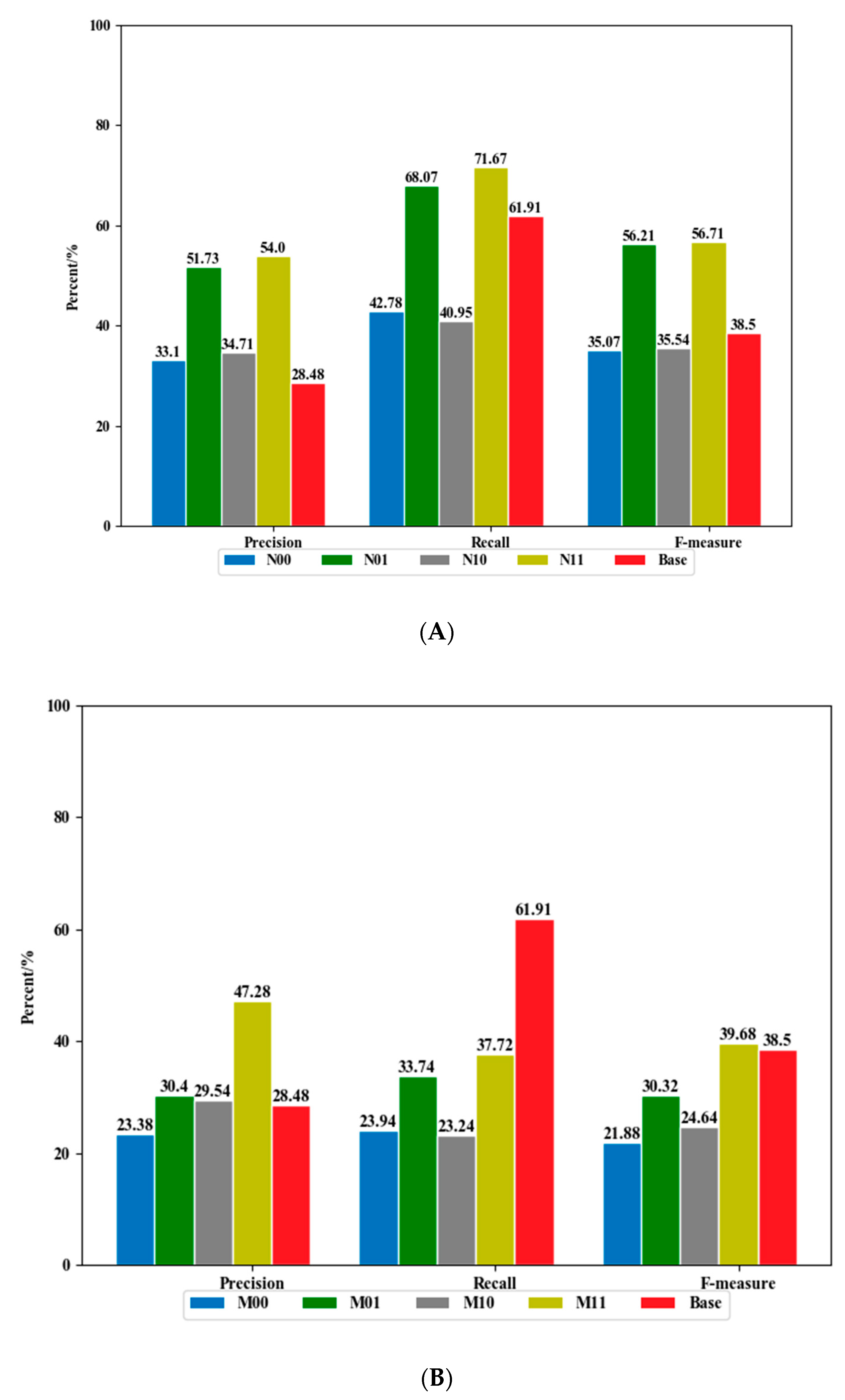
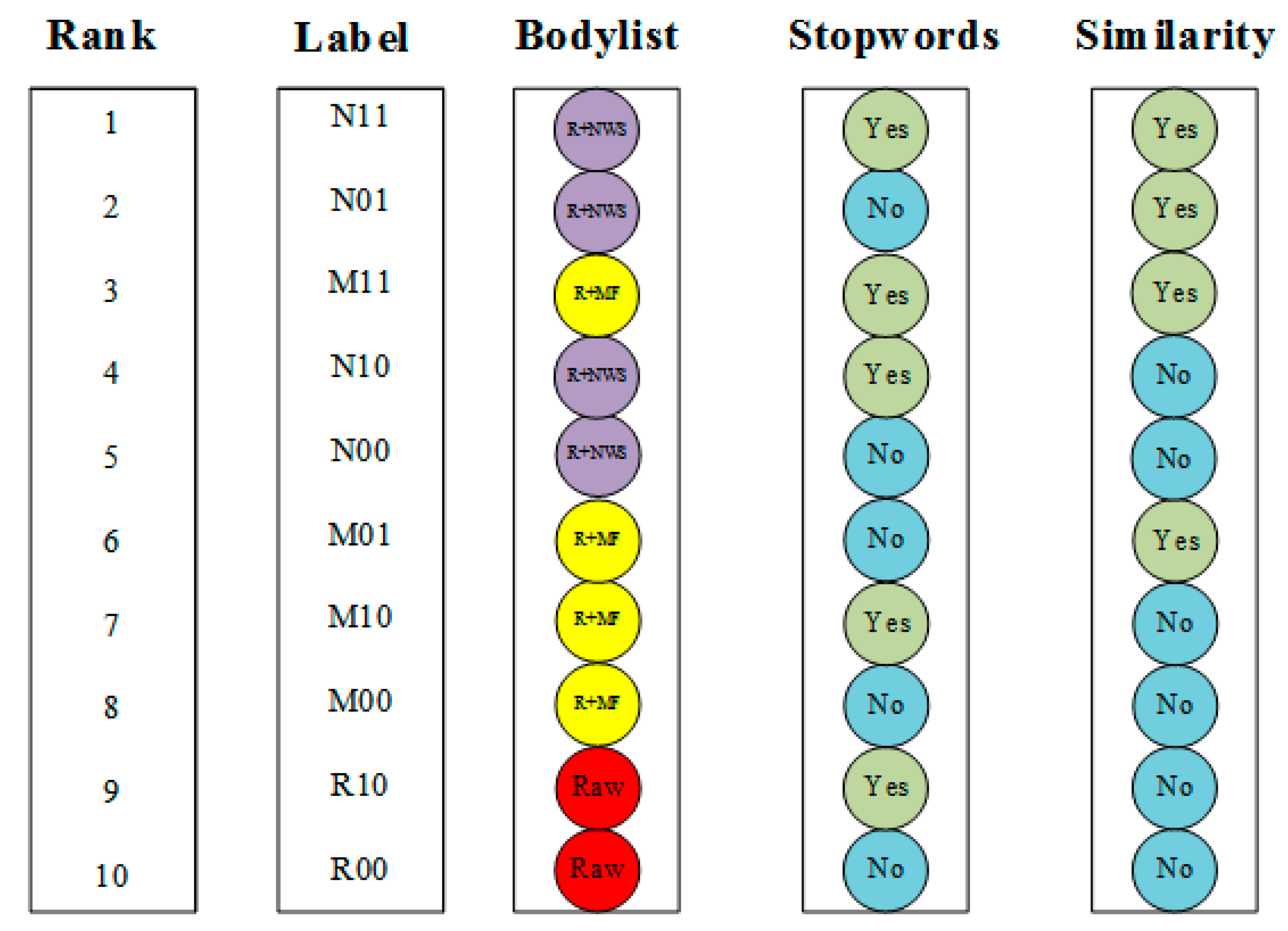
The letters R, N, and M indicate the keyword extraction method used in the dictionary section. R is the abbreviation for raw, which means that the dictionary is not built using any keyword extraction method, and only the first-generation dictionary newly created by the literature is used. N is the NWS keyword extraction method, and M is the MF keyword method. The number after the letter indicates whether the factor is considered in the method, whether one considers the stopword table for the merge operation, and whether the other considers the text similarity. For example, R00 indicates that the fault text reason identification uses only the first-generation dictionary and does not consider the stopword list and similarity; N11 indicates that the NWS keyword extraction method is used in this text failure cause identification to create a new dictionary and the stopword is used. The vocabulary is used to fuse the dictionary, and the text similarity is considered in the experimental calculation.
To illustrate the role of keyword extraction in the new dictionary, we compared Step 2 using only the first-generation dictionary and using NWS as the keyword extraction. The comparison results are shown in
Figure 5 (R00, N00), and it can be seen that NWS is used when the keyword is extracted because its extraction is better than using only the first-generation dictionary. To illustrate the role of the stopword list in the new dictionary, we performed two sets of comparisons ((R10,R00), (N10,N00)), and the results showed whether the keyword extraction NWS method was used during the dictionary process. All of them show that considering the stopword list, the effect of extracting the cause of the fault is better than not considering the stopword list. However, the N10 effect is far superior to R10. This comparison shows that the method of keyword extraction is helpful in identifying the cause words (R10, N10) in the fault text.
To further illustrate the performance of the NWS keyword extraction method in fault cause text recognition, we chose the MF keyword method. The performance of MF in the literature is more prominent. When we compare the performance of NWS and MF, we also carried out three sets of comparison implementations: (1) M00 and N00; (2) M10 and N10; and (3) M11 and N11. As can be observed from
Figure 5, the results of our proposed method are better than those of MF, regardless of whether stopwords and similarities are considered.
To investigate the influence of root cause noun extraction on the performance, we conducted experiments with different methods, stopword lists and similarities. Moreover, we added the base to compare with others. The base is the average level based on the manual performance of root cause noun extraction. It is defined as a sample with the possibility of good performance and is introduced to reflect the better performance if the values of P, R, and F are higher than the base values.
Table 2 shows that the performance of N11 is the best, which represents the performance of our proposed method. The highest values in RCI-NWS are M11, which means that in this situation, the body list was required by the RCI-NWS method, and both considered the two changing differences in stoplist and similarity. Specifically, comparing M11 and N11, the gap in precision increases to 8.72%, the recall increases from 47.28% to 54% and from 37.72% to 71.67%, and the F-measure values increase from 39.68% to 56.71%. All three improvements in N11 are higher than the average performance corresponding to the base.
To better understand the relative performances of the RCI-NWS and RCI-MF methods, the trends in precision, recall, and F-measure values are shown in
Figure 6. From
Figure 6A, we can see that the bars of N01 (green) and N11 (yellow) are both always higher than the bars of base (red), which represents RCI-NWS using the NWS keyword extraction method. If the NWS keyword extraction method combines with a stoplist and similarity, the performance of N11 is the best. Similar results are shown in
Figure 6B, but the performance of M11 demonstrates that its recall performance is not higher than that of the base. Furthermore, it can be observed from
Figure 6C, comparing the best performance in RCI-NWS (M11), RCI-MF (N11), base and original (R00,R01), the highest value of the three is for M11 (red); therefore, our proposed method exhibits the best performance.
5. Conclusions
In this paper, a novel approach for extracting root cause factors was proposed. For this purpose, a detailed procedure was provided to build an effective dictionary by utilizing combination of the keyword extraction method NWS, Apriori and Dependency Parser. To demonstrate the application of the proposed approach in practice, Chinese railway fault records were selected and investigated. By employing the proposed approach, the results demonstrate that applying our approach successfully achieves the goal of extracting the root cause factors, which can further influence future analysis and clustering among these results, and reducing the time required to use the texts correctly, which could be further used in research. The extraction of railway fault text data can be extracted by the keyword extraction method, which provides a new idea for the analysis of the causes of railway accidents/events, the analysis of railway fault accidents and the risk analysis of railway faults.
However, our proposed method can be further improved. The method considers only the root cause identification from railway faults, which are related to the railway file; thus, future work can make full use of different traffic-related fields. In addition, in future research, we intend to apply our proposed method to conduct research on cause chain identification.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}