4.1. Improved CLPSO
CLPSO is an improved algorithm of PSO, in which it is easy to jump out of local optimum. For traditional PSO, gbest plays a key role in the evolution. So if the gbest traps in local optimum, the entire population will trap in local optimum too. So CLPSO updates particle velocities mainly by learning pbest rather than gbest, which is shown in
Figure 5. The particle velocity update formula of CLPSO is as follows [
29]:
where
is the template chosen from the population, which has been sorted by the aggregate function based on Tchebycheff decompose;
is the best value of the chosen particle; in the ideal state, by using the decomposition method,
N direction vectors will be generated uniformly in the multi-objective solution space, so as to divide the population into
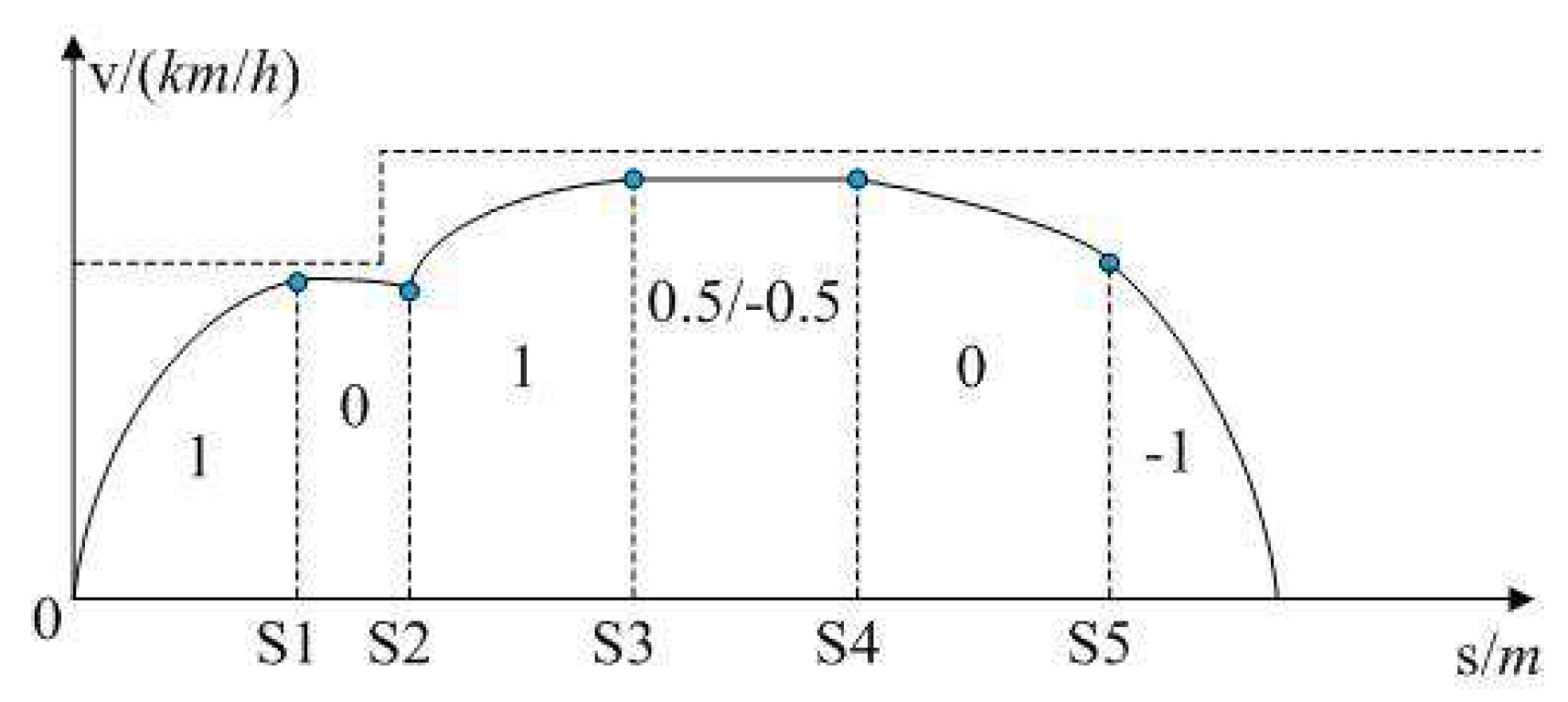
N subproblems, and each particle is upadated based on the direction vectors. As shown in the
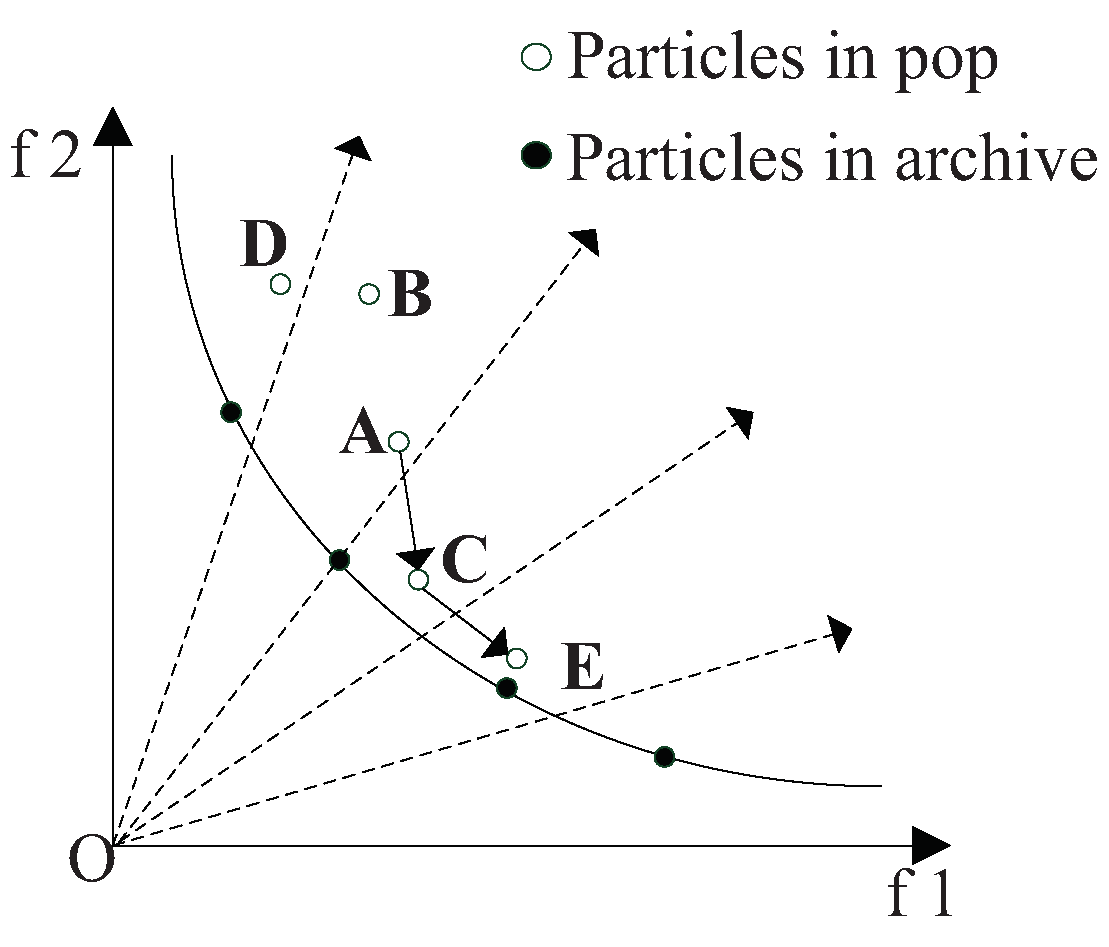
Figure 5 and
Figure 6, the dotted lines represent the direction vectors that partition the objective space. The solid lines represent the true frontier of the function. The solid dots represent the particles of elite archive. The hollow dots represent the particles of the population. In the update process,
A is the position at the previous moment,
B is the position at the current moment, and
C is the position at the next moment. The individual optimal value update mode of CLPSO is shown in
Figure 5, and the optimal particle individual plays a guiding role in the search of the whole population. In order to update
, the decomposition method should be adopted to scale the multi-objective problem. Tchebycheff method is used to construct the aggregation function in this paper. By calculating the aggregate value of each particle, the binary tournament will remain throughout the binary tournament. The global optimal value update method for traditional PSO is shown in
Figure 6. In
Figure 6, the global optimal value of particle swarm is used to guide the development of particles, and the global optimal value of the particles is updated by using the information of the neighborhood particles.
Similar to traditional PSO, CLPSO tends to locally converge to an individual extreme value. In fact, the diversity of the population is obviously destroyed by the single learning optimization model. In this paper, an improved particle swarm optimization algorithm based on comprehensive learning strategy is proposed, which is denoted as ICLPSO. The flow diagram of this paper is shown in
Figure 7.
In
Figure 7,
is the learning probability, which determines whether it is updated based on template particles or not. As the number of iterations increases, the probability of particle swarm falling into local optimum increases gradually. In order to avoid that, the learning probability should also increase gradually. The formula of learning probability
is shown as follows:
If the i-th particle cannot be effectively optimized in continuous iteration (the refresh interval generally is 2), this particle will learn by using formula 29 (CLPSO’s individual optimal value updating method). If > , the corresponding dimension will learn from its own pbest, or it will learn from pbest of template particles. To obtain better diversity when handling complex MOP, the optimal particle among four random particles in template will be chosen as the template pbest.
4.2. Improved CLWOA
Whale optimization algorithm simulating whale foraging is one of the most efficient optimization algorithms, but it also has the disadvantage that it is easy to fall into local convergence in the later iteration [
30]. Therefore, this paper proposes an improved WOA algorithm (ICLWOA) that contains both learning strategies. the specific improved measures are described below.
(1) Parameter adjustment based on chaos mapping
In the whale optimization algorithm, parameters A and C are important parameters, which affect the searching ability of the algorithm to some extent. In the traditional whale optimization algorithm, its parameters are generated in an excessively random manner, which will reduce the convergence speed of the algorithm and invalidate the search area in the later period of operation.
Chaos is a common phenomenon in nonlinear systems. Its change process seems to be chaotic, but, in fact, it has inherently regularity and can iterate over all states according to its own law within a certain range. The behavior of chaotic map is complex, which is similar to random motion. But compared with random motion, it has ergodicity, which can make up for the defect of random motion to achieve global optimization. Therefore, chaos theory is applied to WOA in this paper to improve WOA’s ability to explore and create new individuals [
31].
By using chaos mapping to adjust parameters, the range of random search of parameters reduces and the regularity of parameters increases. In this way, on the basis of avoiding fall into local optimum in the search process, thus, avoiding the problems of slow convergence and invalid search area caused by random blind search.
(2) Boundary processing measures based on reverse learning
In the process of algorithm optimization, it is possible to ‘overflow’ the search scope when the individual updates. The general way to deal with that is to generate new random individuals who cross the boundary. However, if a large number of individuals exceeds the boundary, this results in the waste of search resources. When the updating position of the individual is out of bounds, if the individual position is randomly reset, the beneficial information obtained by the previous iteration of the individual will be lost. A reverse learning strategy can generate a reverse individual far away from the local optimal. Therefore, this paper uses the reverse learning strategy to effectively guide the whale to quickly return to the decision space which needs to be searched.
In the calculation process, if the
i-th individual is over the boundary, then the reverse learning strategy is adopted for the previous individual
. The specific formula is as follows:
where
is the reverse solution of the previous individual
;
and
are respectively the maximum and minimum value of solution;
, as a generalization coefficient, which can prevent individuals from excessive escape.
4.3. Improved Archive Mechanism
In the multi-objective optimization problem, it is impossible to directly compare the advantages and disadvantages of two individuals. In this paper, the Tchebycheff decomposition method is selected to quantify the multi-objective problem, and the aggregation function is used to compare the advantages and disadvantages of individuals. For the multi-objective optimization algorithm based on the decomposition method, the reference point
(elite individual) in the aggregation function plays a significant role in guiding the convergence direction of the population. In order to make better use of the information of each generation, the external elite archive set is used to record the beneficial information of the population after each population’s update. The elite archive set is recorded as Archive. The existing literature adds the updated non-dominant individuals from each generation to the archive mostly, so does this paper. As the number of iterations increases, more and more non-dominanted individuals are obtained. If all of them are kept in archive, it will greatly increase the computational burden of the algorithm [
32]. Therefore, the elite archive set need to be kept within a certain size. In order to maintain the diversity of the whale elite archive set, this paper deletes the denser individuals by calculating the distance among individuals in archive. Traditional optimization algorithms generally adopt Euclidean distance, which is simple in definition and easy to calculate, as the distance measurement index. However, there are two weaknesses in Euclidean distance. First, the calculation of Euclidean distance depends on the dimensionality of variables, so its actual meaning is difficult to be explained. In addition, the distribution of samples is not taken into account when calculating Euclidean distance, so the correlation between variables cannot be measured. It is the straight-line distance between samples, so it is insufficient in solving the multivariate data analysis. Therefore, this paper uses the fusion distance which fuses Mahalanobis distance and Euclidean distance as the distance measurement index to maintain the archive scale. When the archive exceeds the predetermined scale, the fusion distance of each individual is calculated and the individual with small fusion distance is deleted until the scale of the archive is maintained at the predetermined value. The calculation formula of specific fusion distance is as follows:
where
represents fusion distance;
represents Mahalanobis distance;
represents the correlation confficient matrix of sample set
Y;
n represents the number of samples in
Y;
represents the samples in
Y;
represents the correlation confficient. Since the Mahalanobis distance takes into account the correlation between variables, it uses
the weight with relevant information to fuse, while the Euclidean distance uses
to fuse. Therefore, the fusion distance takes into account both the correlation between variables and the independence between variables [
33].
Both PSO and WOA are optimization algorithms that the population mainly learns from the optimal individuals or some elite individuals. This optimization model of directional learning always has a relatively fixed evolutionary direction, which is not conducive to its maintenance of population diversity. Genetic algorithm has obvious advantages over PSO and WOA in maintaining population diversity, because it produces a large number of new solutions with great differences through selection, crossover and variation. Therefore, this paper introduces the genetic evolution mechanism into the optimization algorithm, so as to better maintain the population diversity of the optimization algorithm. However, if the genetic algorithm is introduced blindly and excessively, it will destroy the favorable information obtained by the long-term iterative learning of individuals on a large scale, which is not conducive to optimization. Based on the genetic algorithm and the elite archiving set, this paper proposes the following improvement strategy to prevent the aggregation of individuals in the population to maintain the diversity of the population, which is denoted as the improved elite archiving set mechanism (IESM). The specific steps are as follows:
Step 1: add the updated non-dominanted individuals in each generation to the elite archive set;
Step 2: determine whether the size of the archive exceeds the predetermined value . If the condition is not true, skip step 3 and perform step 4.
Step 3: calculate the fusion distance between each individual to the archive (formula 34), and delete the individual with a smaller fusion distance until the size of the archive is maintained at a predetermined value;
Step 4: calculate the fusion distance radius of the elite individuals. The radius is the maximum distance between each individual in the elite archive set and the archive;
Step 5: test whether the number of individuals in the archive range in the current population is greater than the threshold value . If the condition is not established, it indicates that there is no phenomenon of individuals gathering in the archive range in the population at this time. The fusion distance between the individual and the archive is less than the radius of the archive , which indicates that the individual is within the range of the elite archive set.
Step 6: select, cross recombination and mutation operation of genetic algorithm is used to reset the individuals that gather in the elite archive set, until there is no phenomenon that individuals gather in the archive range in the population.
Obviously, this mechanism has the following advantages:
(1) Keep the scale of archive little than the predetermined value ().
(2) Ensure that elite individuals are evenly distributed in the elite archive set.
(3) Suppress the archive ‘domination’ of the entire population by restricting the concentration of individuals in the archive () to enhance the global convergence performance of the hybrid optimization algorithm.
4.4. Design of Hybrid Optimization Algorithm
PSO and WOA have a fixed optimization mode, and this optimization mode with certain optimization direction will damage the diversity of the population to a certain extent. Therefore, this paper designs a hybrid optimization algorithm which uses the elite archive as the medium of information exchange. The intelligent evolution process of its hybrid optimization algorithm is denoted as IEP, and the specific IEP flow chart is shown in
Figure 8.
As shown in
Figure 8, the step of improved CLHOA IEP is as follows:
Step 1:
(1) Initialize particle swarm (the size is N) and whale swarm (the size is N), including the velocity and position of each particle in the particle swarm, the Tchebycheff aggregation function value, and the individual optimal value, global optimal value of particle swarm, the Tchebycheff aggregation function value of each whale position in the whale group, the optimal whale position of the whale group . The current iteration number is 1, and the number of weight vectors in each neighborhood is T.
(2) To initialize the common elite archive set of particle swarm and whale swarm, let archive = ∅ and initialize the reference point , where , and m is the number of optimization objectives. A uniformly distributed weight vector set is generated and used in the initial iteration calculation of ICLPSO and ICLWOA. let , the elements in each row and column of the matrix are uniformly distributed.
Step 2:
(1) Archive and two populations (particle swarm and whale swarm) are obtained.
(2) If the current iteration number is greater than 1, recalculate the reference points
,
and
. In the
j-th iteration, the weight of the
k-th optimization index of the
i-th individual in the population is
,
,
, and its calculation formula is as follows [
34].
For any Pareto solution target in a continuous Pareto front, the weight vector is obtained according to the formula . The optimal solution of the single objective subproblem corresponding to the weight vector is the Pareto solution target . Because Pareto front is not easily available, it is replaced by the nearest solution target to in the archive. The angles between and the weight vectors of other individuals are calculated (), then take the smallest T weight vectors in to form the neighbor of .
(3) For each particle in the particle swarm, the particle velocity update process (
Section 3.1) of ICLPSO is used to calculate the particle velocity and update the particle position. For each whale in the whale population, the whale location is updated according to the three stages of ICLWOA, and three additional learning strategies are adopted in the update process (
Section 3.2).
(4) Update individual value and global optimal value based on the aggregate function’s value. If ( could be , or ), the and will be replaced by and .
(5) Obtain the Pareto front of the current particle population and the Pareto front of the whale population.
Step 3: information exchange based on the archive
(1) Expand the scale of the archive: extend the Pareto front of the current particle swarm and whale swarm to the elite archive. If there are the same individuals or dominated individuals, delete them until any two individuals in the elite archive are different and there is no dominated relationship.
(2) Maintain the size of the archive: if the size of the elite archive set exceeds the preset value, calculate the crowding distance between the elite solutions and delete the particle with the smallest crowding distance. If the size of the elite archive set still exceeds the preset value, continue to perform that until the size remains at the preset value. Fusion distance is used as the index of distance measurement.
(3) Restrict the concentration of the population in the archive area: if there are individuals within the range of the archive in the population, the individuals within the elite archive set will be partially reset by selection, cross recombination, mutation operation of genetic algorithm until there is no individuals that are clustered within the range of archive. In order to better retain the favorable information obtained by the previous iteration of the individual, the object of the crossover recombination operation of the i-th individual in the j-th iteration needs to be selected from the individuals set corresponding to the neighbor of its weight vector. Same as in step 2, the fusion distance is adopted as the distance measurement index.
Step 4: if the maximum iteration number (or the maximum evaluation number) is reached, then terminate the algorithm and output the archive set, otherwise return Step 2.

































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}