Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach






Abstract
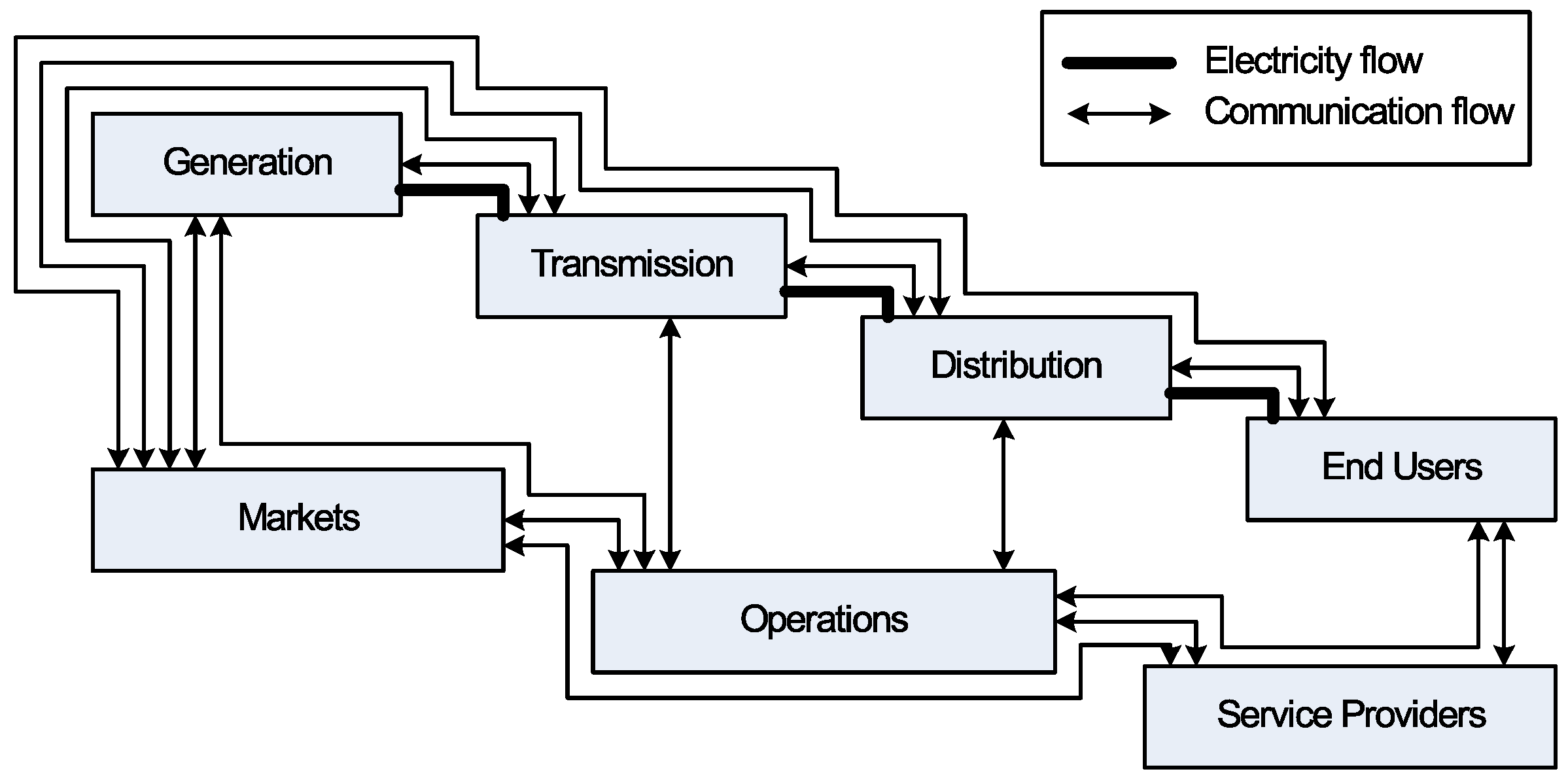
1. Introduction
- The proposed model takes into account external DALF influencing factors such as meteorological and exogenous variables.
- Due to better accuracy and less execution time, we have used MARA for training which none of the existing forecast models has used for training.
- To improve the forecast accuracy and minimize the execution of the forecast model, we have performed local training which none of the existing forecast models has used.
- We have used our modified version of the EDE in the error minimization module. The existing Bi-level strategy [28] has used EDE algorithm in the error minimization module.
- We have tested our proposed model on the datasets of two USA grids: DAYTOWN and EKPC. For evaluation and validation purposes, we have compared our proposed model with two existing forecast models (bi-level forecast and MI+ANN forecast) and provided extensive simulation results.
2. Related Work
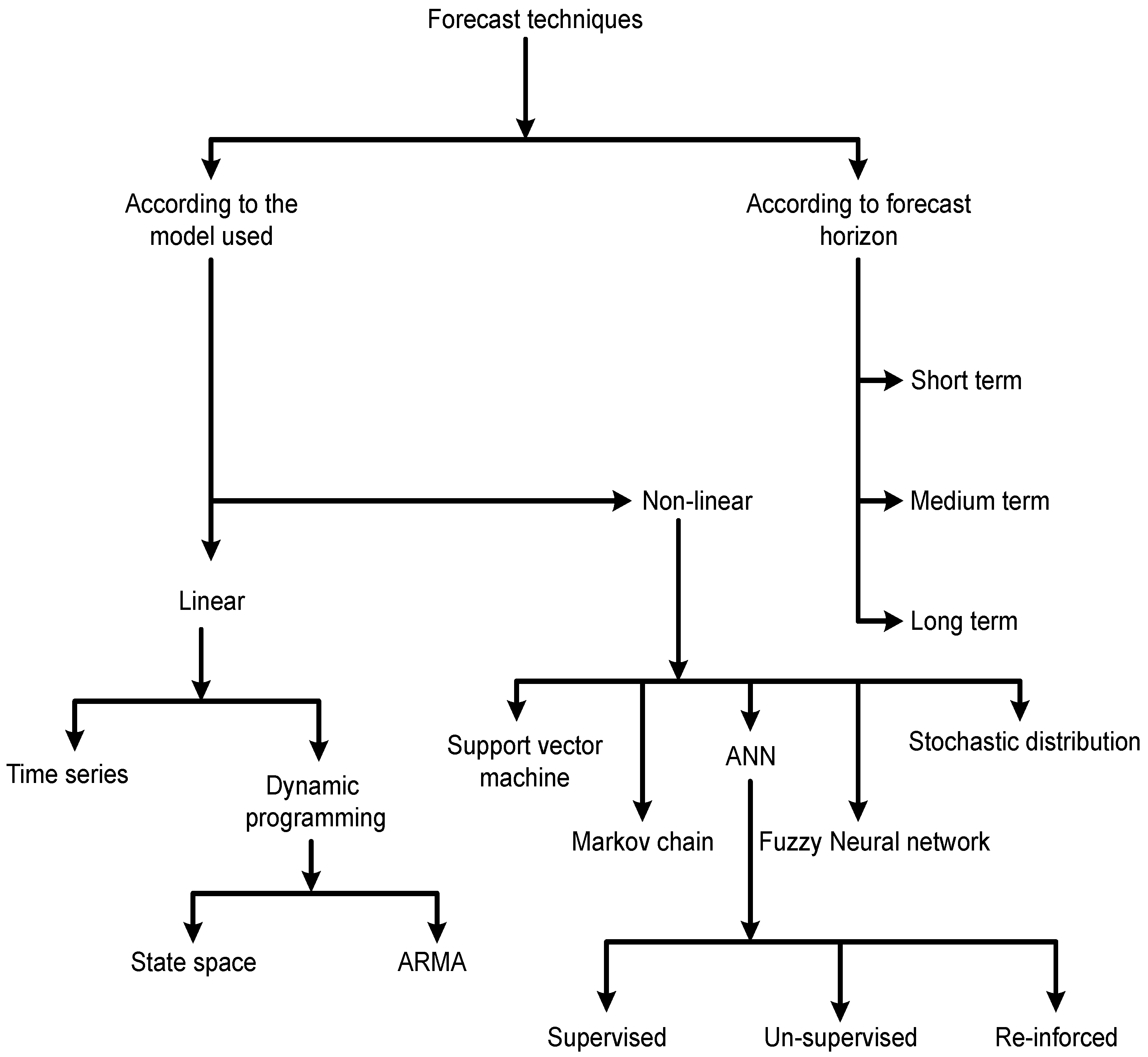
2.1. Linear Models
2.2. Non-Linear Models
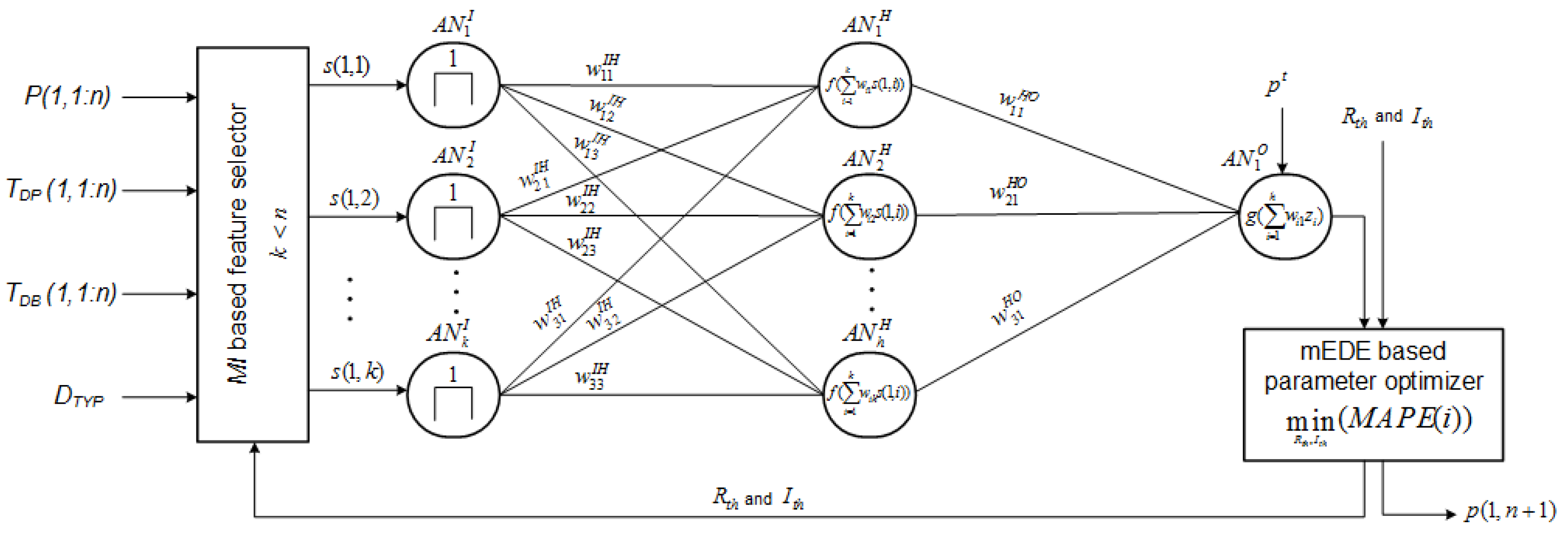
3. The Proposed Forecast Strategy
3.1. Pre-Processing Module
- (a)
- The ANN is trained by all elements of the matrix P except the first row.
- (b)
- The ANN is trained only by the 1st column of the matrix P except .
- (i)
- If the data set size is small (≤1 month), feature selection has no significant impact on the computational complexity of the overall strategy.
- (ii)
- If the data set size is moderate (≥1 month and ≤3 months), feature selection somehow affects the computational complexity of the overall strategy.
- (iii)
- If the data set size is large (≥3 months), feature selection has a significant impact on the computational complexity of the overall strategy.
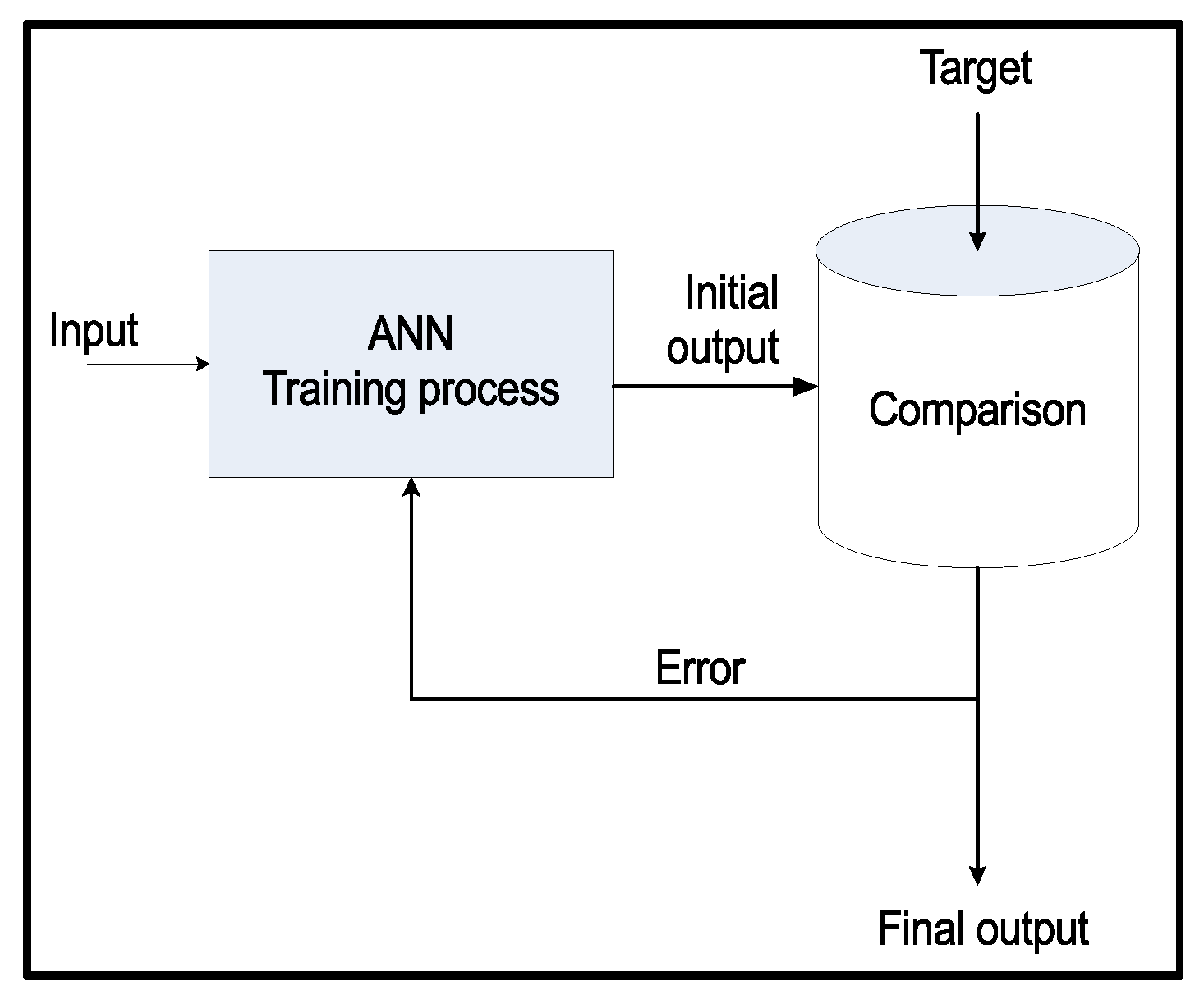
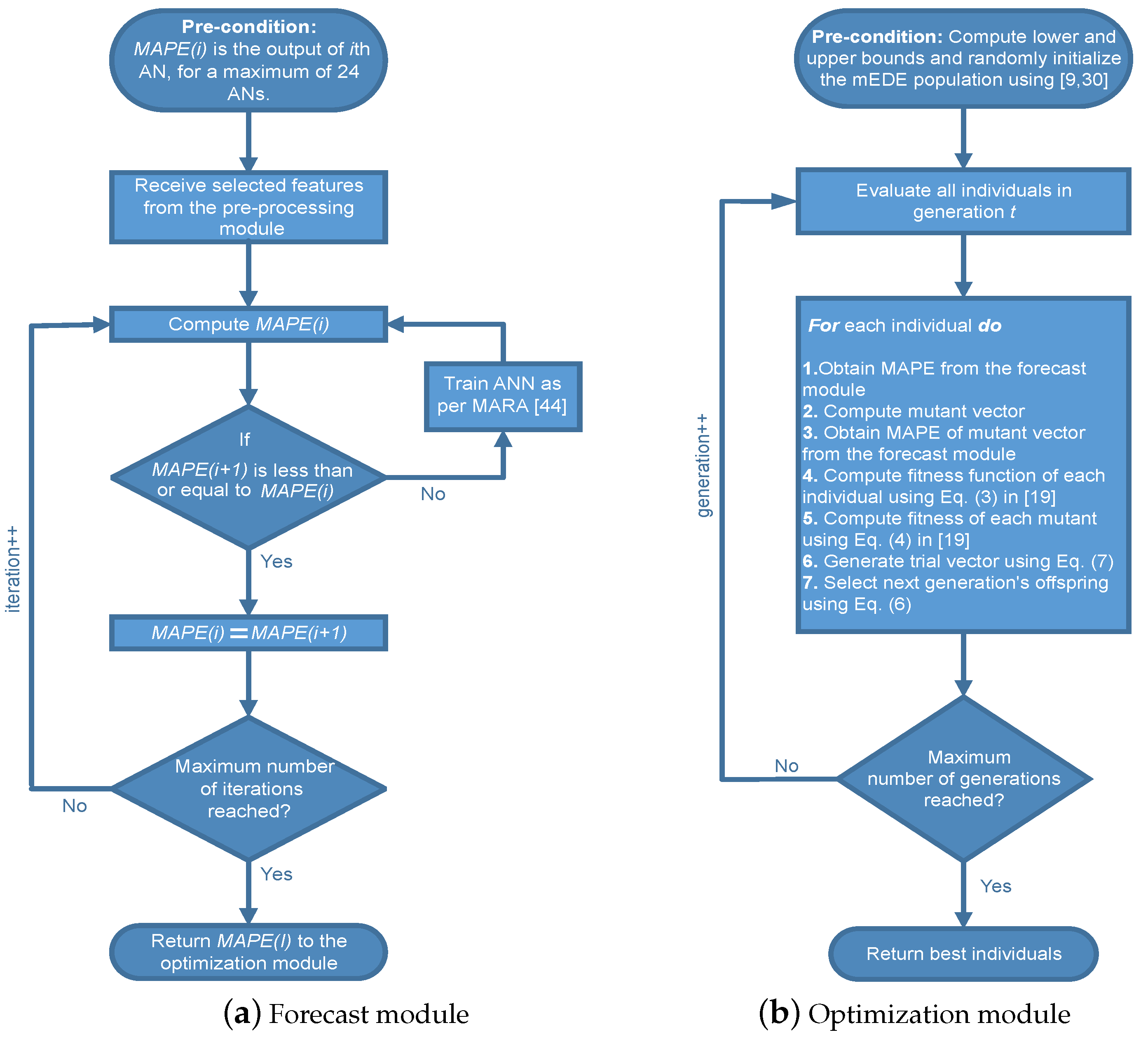
3.2. Forecast Module
3.3. Optimization Module
4. Simulation Results
- Accuracy:. We have measured this metric in %.
- Variance:. Where is the mean value of . Monthly variance is calculated by using the same formula while considering the calculated daily variances.
- Execution time: During simulations, the time taken by the system to completely execute a given forecast strategy. The strategy for which execution time is small converges more quickly and vice versa. In simulations, we have measured execution time in seconds.
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| SG | Smart grid |
| DAL | Day-ahead load |
| DALF | Day-ahead load forecast(ing) |
| AN | Artificial neuron |
| ANN | Artificial neural network |
| MARA | Multivariate auto regressive algorithm |
| ARMA | Auto regressive and moving average |
| EDE | Enhanced differential evolution algorithm |
| mEDE | Modified version of EDE algorithm |
| NIST | National institute of standards and technology |
| MSE | Minimum square error |
| P | Historical load data matrix |
| Historical dew point temperature data matrix | |
| Historical boiling point temperature data matrix | |
| Historical dew point temperature data matrix | |
| Load value at mth hour of the nth day | |
| Local maxima for each column of P | |
| Locally normalized P | |
| Locally normalized | |
| Locally normalized | |
| Relative mutual information between input K and target G | |
| Joint probability between K and G | |
| Individual probability of K | |
| Selected features | |
| Training samples | |
| Validation samples | |
| Mean absolute percentage error | |
| Actual load | |
| Forecasted load | |
| Irrelevancy threshold value | |
| Redundancy threshold value | |
| jth trial vector for ith individual in generation t | |
| jth parent vector x for ith individual in generation t | |
| jth mutant vector u for ith individual in generation t | |
| jth offspring vector y for ith individual in generation t | |
| Random number | |
| Fitness function | |
| Forecast error |
References
- Gelazanskas, L.; Gamage, K.A. Demand side management in smart grid: A review and proposals for future direction. Sustain. Cities Soc. 2014, 11, 22–30. [Google Scholar] [CrossRef]
- Yan, Y.; Qian, Y.; Sharif, H.; Tipper, D. A Survey on Smart Grid Communication Infrastructures: Motivations, Requirements and Challenges. IEEE Commun. Surv. Tutor. 2013, 15, 5–20. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. NIST Framework and Roadmap for Smart Grid Interoperability Standards. Release 1.0.; 2010. Available online: http://www.nist.gov/publicaffairs/releases/upload/smartgridinteroperabilityfinal.pdf (accessed on 10 November 2018 ).
- Leiva, J.; Palacios, A.; Aguado, J.A. Smart metering trends, implications and necessities: A policy review. Renew. Sustain. Energy Rev. 2016, 55, 227–233. [Google Scholar] [CrossRef]
- How Does Forecasting Enhance Smart Grid Benefits? SAS Institute Inc.: Cary, NC, USA, 2015; pp. 1–9.
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A survey on electric power demand forecasting: Future trends in smart grids, microgrids and smart buildings. IEEE Commun. Surv. Tutor. 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- Vardakas, J.S.; Zorba, N.; Verikoukis, C.V. A Survey on Demand Response Programs in Smart Grids: Pricing Methods and Optimization Algorithms. IEEE Commun. Surv. Tutor. 2015, 17, 152–178. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, C.R. Neural Networks for Short-Term Load Forecasting: A review and Evaluation. IEEE Trans. Power Syst. 2001, 16, 44–51. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Hagan, M.T.; Behr, S.M. The Time Series Approach to Short Term Load Forecasting. IEEE Trans. Power Syst. 1987, 2, 785–791. [Google Scholar] [CrossRef]
- Niu, D.; Wang, Y.; Wu, D. Power load forecasting using support vector machine and ant colony optimization. Exp. Syst. Appl. 2010, 37, 2531–2539. [Google Scholar] [CrossRef]
- Li, H.; Guo, S.; Zhao, H.; Su, C.; Wang, B. Annual Electric Load Forecasting by a Least Squares Support Vector Machine with a Fruit Fly Optimization Algorithm. Energies 2012, 5, 4430–4445. [Google Scholar] [CrossRef]
- Aung, Z.; Toukhy, M.; Williams, J.R.; S’anchez, A.; Herrero, S. Towards Accurate Electricity Load Forecasting in Smart Grids. In Proceedings of the Fourth International Conference on Advances in Databases, Knowledge, and Data Applications, Athens, Greece, 2–6 June 2012; pp. 51–57. [Google Scholar]
- Meidani, H.; Ghanem, R. Multiscale Markov models with random transitions for energy demand management. Energy Build. 2013, 61, 267–274. [Google Scholar] [CrossRef]
- Nijhuis, M.; Gibescu, M.; Cobben, J.F. Bottom-up Markov Chain Monte Carlo approach for scenario based residential load modelling with publicly available data. Energy Build. 2016, 112, 121–129. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, Z.J.; Kashani, A. Home appliance load modeling from aggregated smart meter data. IEEE Trans. Power Syst. 2015, 30, 254–262. [Google Scholar] [CrossRef]
- Gruber, J.K.; Prodanovic, M. Residential energy load profile generation using a probabilistic approach. In Proceedings of the IEEE UKSim-AMSS 6th European Modelling Symposium, Valetta, Malta, 14–16 November 2012; pp. 317–322. [Google Scholar]
- Kou, P.; Gao, F. A sparse heteroscedastic model for the probabilistic load forecasting in energy-intensive enterprises. Electr. Power Energy Syst. 2014, 55, 144–154. [Google Scholar] [CrossRef]
- Fan, S.; Hyndman, R.J. Short-Term Load Forecasting Based on a Semi-Parametric Additive Model. IEEE Trans. Power Syst. 2012, 27, 134–141. [Google Scholar] [CrossRef]
- Goude, Y.; Nedellec, R.; Kong, N. Local Short and Middle Term Electricity Load Forecasting with Semi-Parametric Additive Models. IEEE Trans. Power Syst. 2014, 5, 440–446. [Google Scholar] [CrossRef]
- Doveh, E.; Feigin, P.; Greig, D.; Hyams, L. Experience with FNN Models for Medium Term Power Demand Predictions. IEEE Trans. Power Syst. 1999, 14, 538–546. [Google Scholar] [CrossRef]
- Mahmoud, T.S.; Habibi, D.; Hassan, M.Y.; Bass, O. Modelling self-optimised short term load forecasting for medium voltage loads using tunning fuzzy systems and Artificial Neural Networks. Energy Convers. Manag. 2015, 106, 1396–1408. [Google Scholar] [CrossRef]
- Wang, Z.Y. Development Case-based Reasoning System for Shortterm Load Forecasting. In Proceedings of the IEEE Russia Power Engineering Society General Meeting, Montreal, QC, Canada, 18–22 June 2006; pp. 1–6. [Google Scholar]
- Che, J.; Wang, J.; Wang, G. An adaptive fuzzy combination model based on self-organizing map and support vector regression for electric load forecasting. Energy 2012, 37, 657–664. [Google Scholar] [CrossRef]
- Nadimi, V.; Azadeh, A.; Pazhoheshfar, P.; Saberi, M. An Adaptive-Network-Based Fuzzy Inference System for Long-Term Electric Consumption Forecasting (2008–2015): A Case Study of the Group of Seven (G7) Industrialized Nations: USA, Canada, Germany, United Kingdom, Japan, France and Italy. In Proceedings of the Fourth UKSim European Symposium on Computer Modeling and Simulation, Pisa, Italy, 17–19 November 2010; pp. 301–305. [Google Scholar]
- Lou, C.W.; Dong, M.C. Modeling data uncertainty on electric load forecasting based on Type-2 fuzzy logic set theory. Eng. Appl. Artif. Intell. 2012, 25, 1567–1576. [Google Scholar] [CrossRef]
- Amjaday, N.; Keynia, F. Day-Ahead Price Forecasting of Electricity Markets by Mutual Information Technique and Cascaded Neuro-Evolutionary Algorithm. IEEE Trans. Power Syst. 2009, 24, 306–318. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F.; Zareipour, H. Short-Term Load Forecast of Microgrids by a New Bilevel Prediction Strategy. IEEE Trans. Smart Grid 2014, 1, 286–294. [Google Scholar] [CrossRef]
- Liu, N.; Tang, Q.; Zhang, J.; Fan, W.; Liu, J. A Hybrid Forecasting Model with Parameter Optimization for Short-term Load Forecasting of Micro-grids. Appl. Energy 2014, 129, 336–345. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Alrajeh, N.; Khan, Z.A.; Qasim, U.; Khan, A. A modified feature selection and artificial neural network-based day-ahead load forecasting model for a smart grid. Appl. Sci. 2015, 5, 1756–1772. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Guizani, M.; Alrajeh, N.; Khan, Z.A. An accurate and fast converging short-term load forecasting model for industrial applications in a smart grid. IEEE Trans. Ind. Inform. 2017, 13, 2587–2596. [Google Scholar] [CrossRef]
- Bunn, D.W.; Farmer, E.D. Comparative Models for Electrical Load Forecasting; Wiley: New York, NY, USA, 1985; pp. 13–30. [Google Scholar]
- Ahmad, I.; Abdullah, A.B.; Alghamdi, A.S. Application of artificial neural network in detection of probing attacks. IEEE Sympos. Ind. Electron. Appl. 2009, 57–62. [Google Scholar]
- Malki, H.A.; Karayiannis, N.B.; Balasubramanian, M. Short term electric power load forecasting using feedforward neural networks. Exp. Syst. 2004, 21, 157–167. [Google Scholar] [CrossRef]
- Hahn, H.; Meyer-Nieberg, S.; Pickl, S. Electric load forecasting methods: Tools for decision making. Eur. J. Oper. Res. 2009, 199, 902–907. [Google Scholar] [CrossRef]
- Amakali, S. Development of Models for Short-Term Load Forecasting Using Artficial Neural Networks. Master’s Thesis, Cape Peninsula University of Technology, Cape Town, South Africa, 2008. [Google Scholar]
- Valova, I.; Szer, D.; Gueorguieva, N.; Buer, A. A parallel growing architecture for self-organizing maps with unsupervised learning. Neurocomputing 2005, 68, 177–195. [Google Scholar] [CrossRef]
- Anderson, J.; Silverstein, J.; Ritz, S.; Jones, R. Distinctive features, categorical perception and probability learning: Some applications on a neural model. Psychol. Rev. 1977, 84, 413–451. [Google Scholar] [CrossRef]
- Yang, H.T.; Liao, J.T.; Lin, C.I. A Load Forecasting Method for HEMS Applications. In Proceedings of the 2013 IEEE Grenoble Conference, Grenoble, France, 16–20 June 2013; pp. 1–6. [Google Scholar]
- Amjady, N.; Keynia, F. Electricity market price spike analysis by a hybrid data model and feature selection technique. Electr. Power Syst. Res. 2010, 80, 318–327. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Short-term load forecasting of power systems by combination of wavelet transform and neuro-evolutionary algorithm. J. Energy 2009, 34, 46–57. [Google Scholar] [CrossRef]
- Engelbrecht, A.P. Computational Intelligence: An Introduction, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2007. [Google Scholar]
- Anderson, C.W.; Stolz, E.A.; Shamsunder, S. Multivariate autoregressive models for classification of spontaneous electroencephalographic signals during mental tasks. IEEE Trans. Biomed. Eng. 1998, 45, 277–286. [Google Scholar] [CrossRef] [PubMed]
- Lasseter, R.H.; Piagi, P. Microgrid: A conceptual solution. In Proceedings of the IEEE International Conference on Power Electronics Specialists, Aachen, Germany, 20–25 June 2004; pp. 4285–4290. [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 2009, 11, 341–359. [Google Scholar] [CrossRef]
- PJM Electricity Market. Available online: www.pjm.com (accessed on 1 February 2015).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecast Class | Accuracy | Execution Time | Convergence Rate | Remarks |
|---|---|---|---|---|
| Support vector machine-based models [11,12,13] | Moderate | High | Slow | These models achieve relatively moderate accuracy, however, at the cost of high execution time (slow convergence rate) due to high complexity. |
| Markov chain-based models [14,15,16] | Low | Low | Fast | Forecast accuracy of these models needs improvement. |
| ANN-based models [27,28,39,40] | Low to moderate | Low to high | Fast to slow | Hybrid ANN-based models improve the forecast accuracy of ANN-based models, but at the cost of high execution time (slow convergence rate). |
| Fuzzy ANN-based models [21,22,23,24,25,26] | Low to moderate | High | Slow | Execution time (convergence rate) need improvement. |
| Stochastic distribution-based models [17,18,19,20] | Low | High | Slow | Both forecast accuracy, and execution time (convergence rate) need improvement. |
| Parameter | Value |
|---|---|
| Forecasters | 24 |
| Hidden layers | 1 |
| Maximum iterations | 100 |
| Neurons (in the hidden layer) | 5 |
| Bias | 0 |
| Initial weights | |
| Momentum | 0 |
| Load data (historical) | 1 year |
| Maximum generations | 100 |
| Day | Forecast Model | |||||
|---|---|---|---|---|---|---|
| MI+ANN | Bi-Level | MI+ANN+mEDE | ||||
| MAPE | Variance | MAPE | Variance | MAPE | Variance | |
| 1 | 3.99 | 1.89 | 2.40 | 1.50 | 1.04 | 1.12 |
| 2 | 3.42 | 1.78 | 1.97 | 1.46 | 1.32 | 0.97 |
| 3 | 4.10 | 2.08 | 2.61 | 1.26 | 1.15 | 1.09 |
| 4 | 3.67 | 1.91 | 2.13 | 1.41 | 1.44 | 0.96 |
| 5 | 3.79 | 1.70 | 1.97 | 1.37 | 1.16 | 1.05 |
| 6 | 3.62 | 1.88 | 2.43 | 1.48 | 1.29 | 0.97 |
| 7 | 3.93 | 1.73 | 2.62 | 1.39 | 1.40 | 1.11 |
| 8 | 3.97 | 1.94 | 1.92 | 1.28 | 1.19 | 1.03 |
| 9 | 3.54 | 2.04 | 2.18 | 1.42 | 1.39 | 0.90 |
| 10 | 3.46 | 1.79 | 2.21 | 1.36 | 1.10 | 1.03 |
| 11 | 4.05 | 1.72 | 1.85 | 1.39 | 1.25 | 1.05 |
| 12 | 4.21 | 1.84 | 1.97 | 1.29 | 1.29 | 0.90 |
| 13 | 3.89 | 2.00 | 1.94 | 1.33 | 1.07 | 1.03 |
| 14 | 3.62 | 1.75 | 1.84 | 1.46 | 1.36 | 1.10 |
| 15 | 3.79 | 1.99 | 2.11 | 1.26 | 1.14 | 0.93 |
| 16 | 3.47 | 1.81 | 2.44 | 1.38 | 1.36 | 1.07 |
| 17 | 4.24 | 2.10 | 2.26 | 1.26 | 1.20 | 1.04 |
| 18 | 4.20 | 1.74 | 2.61 | 1.41 | 1.23 | 1.08 |
| 19 | 3.86 | 1.97 | 2.44 | 1.46 | 1.07 | 0.96 |
| 20 | 3.61 | 1.80 | 2.52 | 1.42 | 1.18 | 0.98 |
| 21 | 3.82 | 1.95 | 2.29 | 1.48 | 1.36 | 1.12 |
| 22 | 3.77 | 2.03 | 2.62 | 1.45 | 1.42 | 0.99 |
| 23 | 4.23 | 1.86 | 2.53 | 1.51 | 1.34 | 1.01 |
| 24 | 3.94 | 1.77 | 2.38 | 1.29 | 1.11 | 0.92 |
| 25 | 3.44 | 1.73 | 2.20 | 1.47 | 1.32 | 1.14 |
| 26 | 3.56 | 1.94 | 2.23 | 1.34 | 1.10 | 0.97 |
| 27 | 3.81 | 1.78 | 2.29 | 1.40 | 1.24 | 1.11 |
| 28 | 3.39 | 1.82 | 1.94 | 1.29 | 1.39 | 1.03 |
| 29 | 4.19 | 2.05 | 2.43 | 1.32 | 1.08 | 0.98 |
| 30 | 3.52 | 1.77 | 1.98 | 1.42 | 1.12 | 1.06 |
| 31 | 4.01 | 1.99 | 1.82 | 1.42 | 1.33 | 0.99 |
| Average | 3.81 | 1.84 | 2.23 | 1.38 | 1.24 | 1.03 |
| Month | Forecast Model | |||||
|---|---|---|---|---|---|---|
| MI+ANN | Bi-Level | MI+ANN+mEDE | ||||
| MAPE | Variance | MAPE | Variance | MAPE | Variance | |
| January | 3.81 | 1.84 | 2.23 | 1.38 | 1.24 | 1.03 |
| February | 3.85 | 1.75 | 2.15 | 1.44 | 1.20 | 0.99 |
| March | 4.76 | 1.90 | 2.26 | 1.39 | 1.26 | 1.05 |
| April | 3.84 | 1.76 | 2.19 | 1.41 | 1.29 | 1.00 |
| May | 3.80 | 1.71 | 1.20 | 1.47 | 1.23 | 1.02 |
| June | 3.73 | 1.73 | 2.16 | 1.35 | 1.21 | 1.01 |
| July | 3.72 | 1.81 | 2.29 | 1.40 | 1.24 | 1.07 |
| August | 3.84 | 1.70 | 1.28 | 1.40 | 1.25 | 1.03 |
| September | 3.82 | 2.90 | 2.22 | 1.33 | 1.20 | 0.99 |
| October | 3.82 | 1.88 | 2.15 | 1.36 | 1.30 | 1.01 |
| November | 4.77 | 1.75 | 1.17 | 1.48 | 1.22 | 1.06 |
| December | 4.80 | 1.82 | 1.27 | 1.32 | 1.27 | 1.02 |
| Average | 3.79 | 1.80 | 2.13 | 1.39 | 1.24 | 1.01 |
| Day | Forecast Model | |||||
|---|---|---|---|---|---|---|
| MI+ANN | Bi-Level | MI+ANN+mEDE | ||||
| MAPE | Variance | MAPE | Variance | MAPE | Variance | |
| 1 | 3.72 | 1.70 | 2.59 | 1.36 | 1.20 | 1.02 |
| 2 | 3.60 | 1.86 | 2.38 | 1.30 | 1.31 | 1.10 |
| 3 | 3.54 | 1.90 | 2.20 | 1.51 | 1.35 | 0.97 |
| 4 | 3.81 | 1.88 | 1.77 | 1.27 | 1.25 | 0.95 |
| 5 | 3.78 | 1.92 | 2.57 | 1.41 | 1.32 | 1.07 |
| 6 | 4.07 | 1.83 | 2.65 | 1.33 | 1.21 | 0.96 |
| 7 | 3.88 | 1.79 | 2.58 | 1.43 | 1.35 | 1.11 |
| 8 | 3.62 | 1.81 | 2.25 | 1.28 | 1.22 | 1.01 |
| 9 | 4.30 | 1.88 | 2.25 | 1.50 | 1.15 | 0.90 |
| 10 | 3.71 | 1.93 | 2.43 | 1.44 | 1.27 | 1.03 |
| 11 | 3.59 | 1.77 | 2.27 | 1.30 | 1.34 | 1.12 |
| 12 | 3.82 | 1.74 | 2.34 | 1.37 | 1.24 | 0.95 |
| 13 | 3.77 | 1.84 | 2.50 | 1.25 | 1.29 | 1.06 |
| 14 | 4.15 | 1.83 | 2.64 | 1.31 | 1.16 | 1.13 |
| 15 | 3.69 | 1.91 | 1.88 | 1.40 | 1.28 | 0.93 |
| 16 | 3.87 | 1.89 | 2.47 | 1.52 | 1.30 | 1.12 |
| 17 | 4.27 | 2.76 | 2.60 | 1.33 | 1.29 | 1.10 |
| 18 | 3.64 | 1.78 | 2.15 | 1.42 | 1.31 | 1.00 |
| 19 | 4.18 | 1.84 | 1.86 | 1.40 | 1.21 | 1.12 |
| 20 | 3.75 | 1.99 | 2.31 | 1.28 | 1.19 | 0.99 |
| 21 | 3.58 | 1.97 | 2.05 | 1.39 | 1.18 | 1.05 |
| 22 | 3.83 | 2.72 | 2.70 | 1.30 | 1.32 | 0.98 |
| 23 | 4.88 | 1.99 | 2.60 | 1.38 | 1.37 | 1.09 |
| 24 | 3.73 | 1.88 | 2.44 | 1.29 | 1.18 | 1.12 |
| 25 | 4.21 | 2.01 | 1.91 | 1.47 | 1.33 | 0.92 |
| 26 | 3.59 | 1.76 | 1.79 | 1.32 | 1.21 | 1.04 |
| 27 | 3.80 | 1.96 | 2.20 | 1.37 | 1.24 | 1.10 |
| 28 | 3.66 | 1.89 | 1.97 | 1.27 | 1.22 | 1.03 |
| 29 | 4.25 | 1.81 | 2.33 | 1.49 | 1.15 | 0.98 |
| 30 | 3.51 | 1.92 | 1.90 | 1.24 | 1.36 | 1.03 |
| 31 | 4.03 | 1.95 | 1.88 | 1.43 | 1.20 | 1.06 |
| Average | 3.86 | 1.92 | 2.27 | 1.36 | 1.25 | 1.03 |
| Month | Forecast Model | |||||
|---|---|---|---|---|---|---|
| MI+ANN | Bi-Level | MI+ANN+mEDE | ||||
| MAPE | Variance | MAPE | Variance | MAPE | Variance | |
| January | 3.86 | 1.92 | 3.27 | 1.36 | 1.25 | 1.03 |
| February | 3.85 | 1.71 | 2.30 | 1.47 | 1.20 | 0.99 |
| March | 3.80 | 1.75 | 2.20 | 1.44 | 1.22 | 1.05 |
| April | 3.71 | 1.79 | 2.24 | 1.38 | 1.27 | 1.06 |
| May | 3.79 | 1.87 | 2.28 | 1.40 | 1.22 | 1.02 |
| June | 3.72 | 1.85 | 2.13 | 1.30 | 1.24 | 1.07 |
| July | 3.76 | 1.76 | 2.22 | 1.36 | 1.28 | 0.99 |
| August | 3.87 | 1.76 | 2.18 | 1.43 | 1.26 | 1.08 |
| September | 3.70 | 2.70 | 2.29 | 1.38 | 1.23 | 1.02 |
| October | 3.77 | 1.88 | 2.17 | 1.36 | 1.21 | 1.09 |
| November | 3.83 | 1.83 | 2.27 | 1.50 | 1.27 | 1.00 |
| December | 3.80 | 1.81 | 2.25 | 1.33 | 1.21 | 1.01 |
| Average | 3.78 | 1.88 | 2.31 | 1.39 | 1.23 | 1.03 |
| Dataset | Forecast Model | Iterations | Training | Testing | Validation |
|---|---|---|---|---|---|
| DAYTOWN | MI+ANN | 20 | 0.9626 | 0.9619 | 0.9556 |
| Bi-Level | 94 | 0.9787 | 0.9799 | 0.9776 | |
| MI+ANN+mEDE | 95 | 0.9876 | 0.9890 | 0.9872 | |
| EKPC | MI+ANN | 23 | 0.9622 | 0.9617 | 0.9551 |
| Bi-Level | 95 | 0.9769 | 0.9783 | 0.9766 | |
| MI+ANN+mEDE | 96 | 0.9877 | 0.9892 | 0.9878 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies 2019, 12, 164. https://doi.org/10.3390/en12010164
Ahmad A, Javaid N, Mateen A, Awais M, Khan ZA. Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies. 2019; 12(1):164. https://doi.org/10.3390/en12010164
Chicago/Turabian StyleAhmad, Ashfaq, Nadeem Javaid, Abdul Mateen, Muhammad Awais, and Zahoor Ali Khan. 2019. "Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach" Energies 12, no. 1: 164. https://doi.org/10.3390/en12010164
APA StyleAhmad, A., Javaid, N., Mateen, A., Awais, M., & Khan, Z. A. (2019). Short-Term Load Forecasting in Smart Grids: An Intelligent Modular Approach. Energies, 12(1), 164. https://doi.org/10.3390/en12010164