Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series

Abstract
:1. Introduction
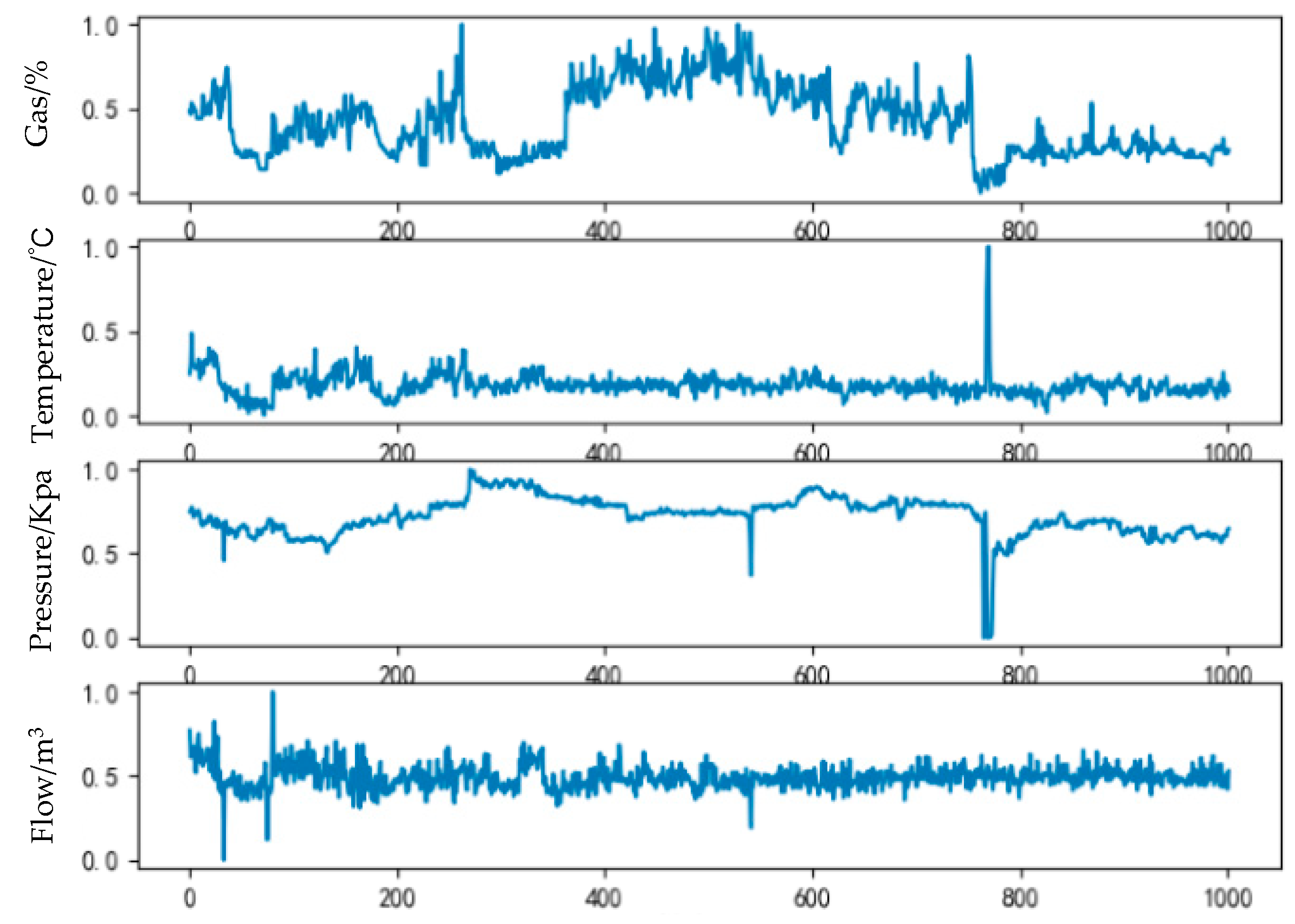
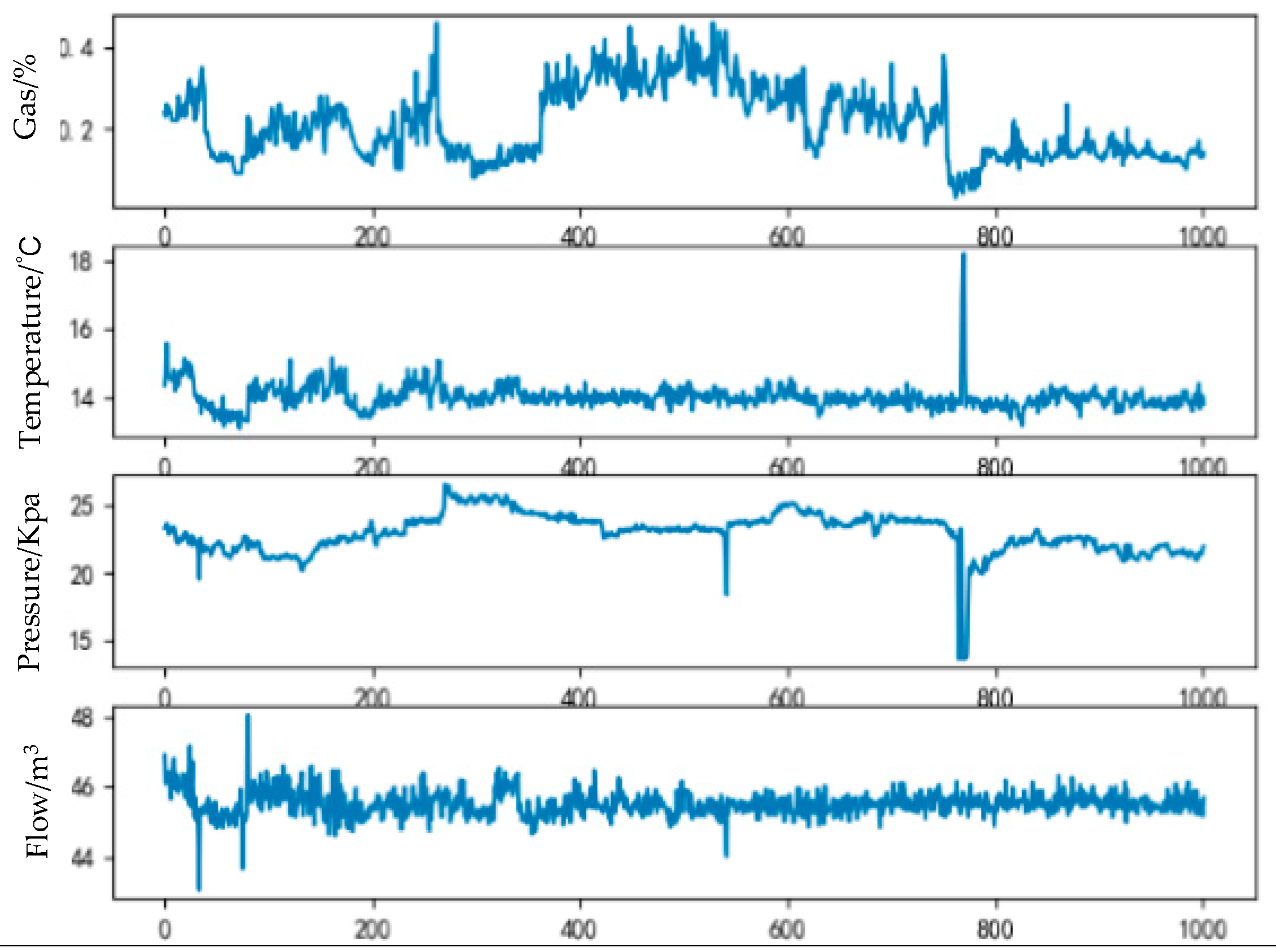
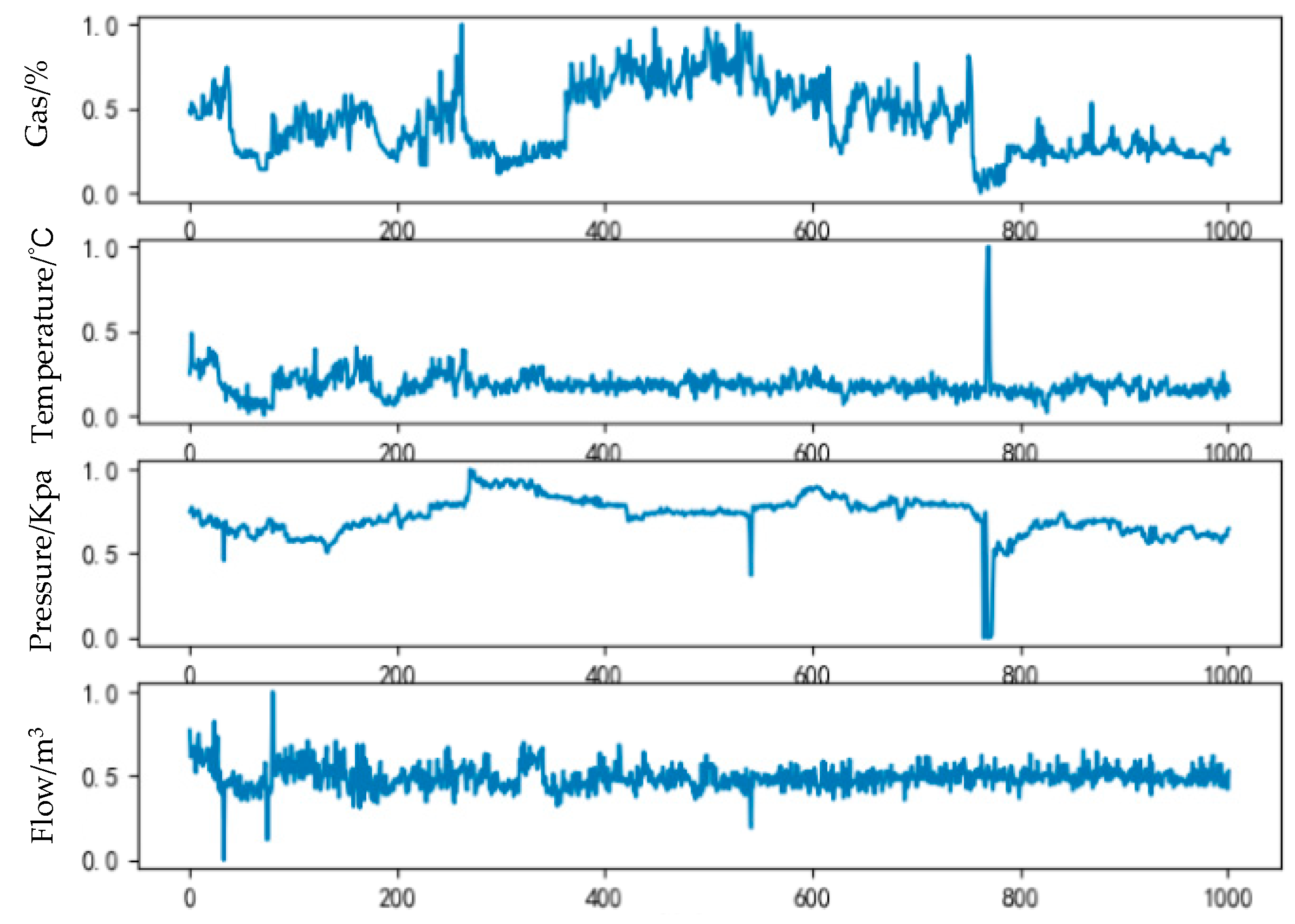
2. Materials and Methods
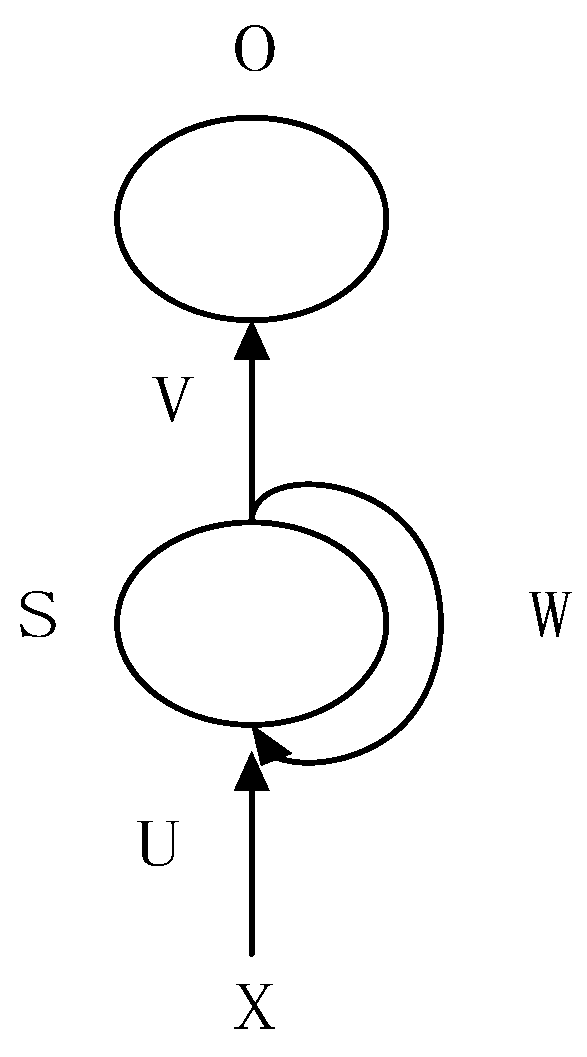
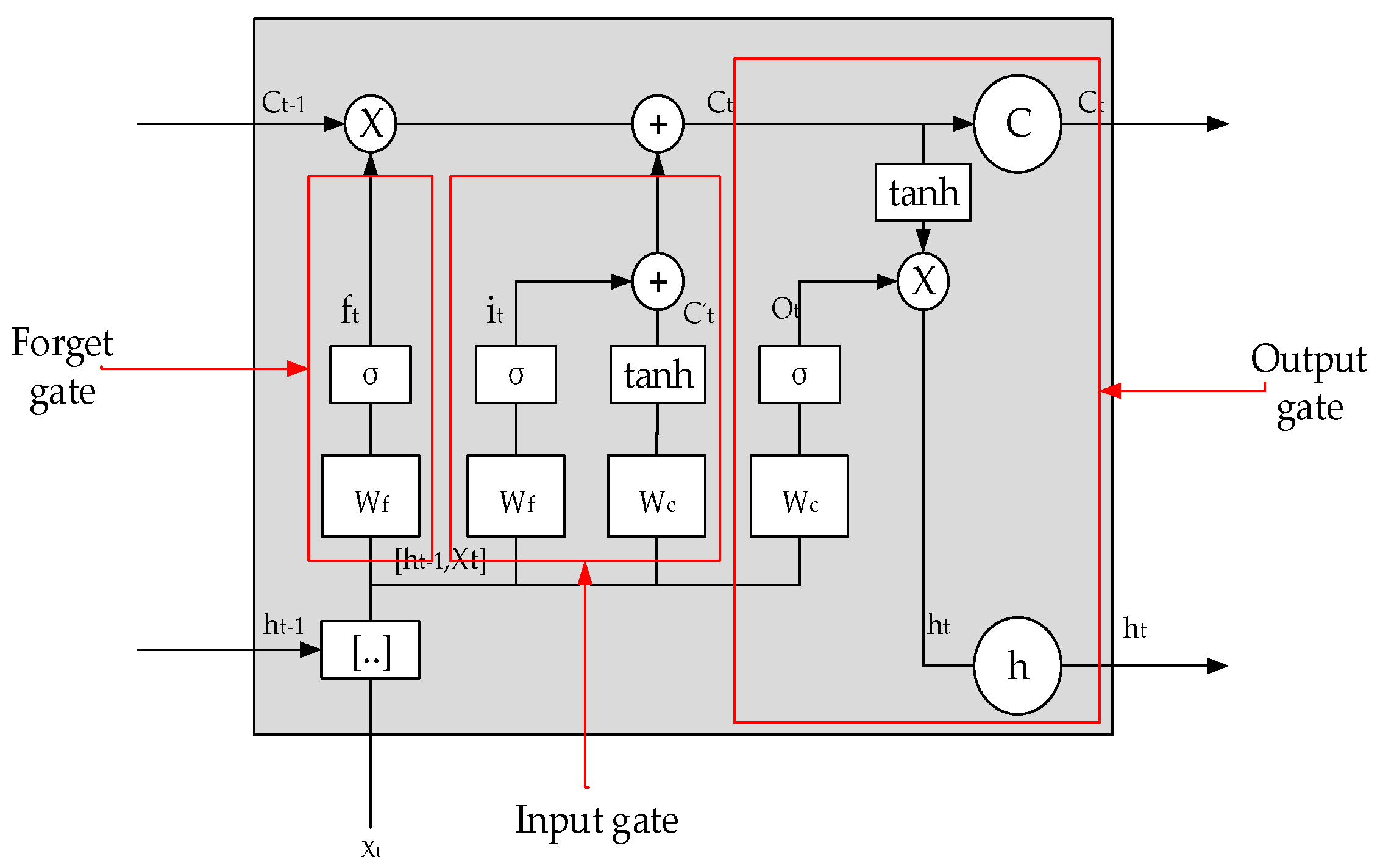
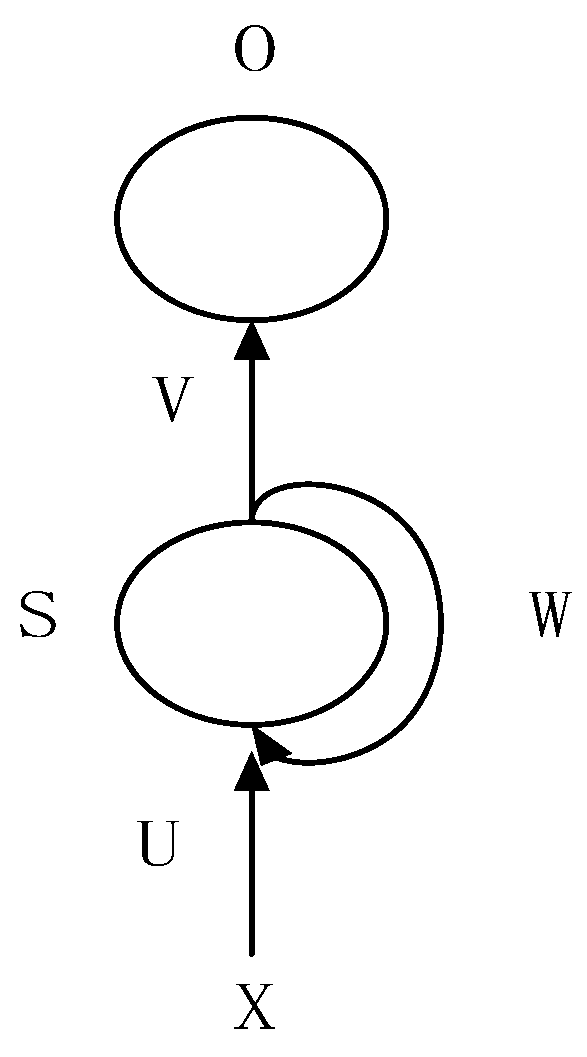
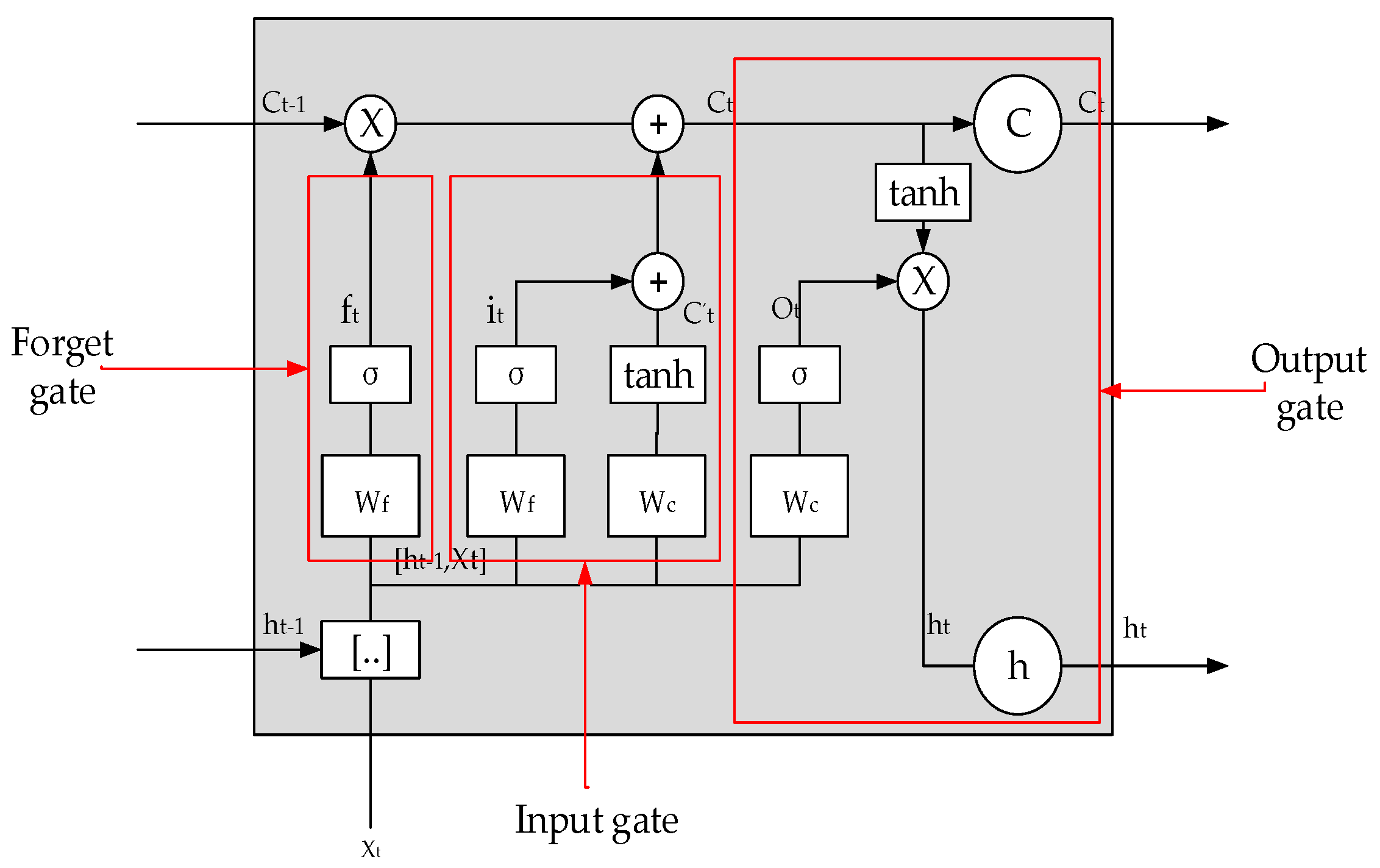
2.1. Deep Learning Model and Parameter Optimization Algorithm
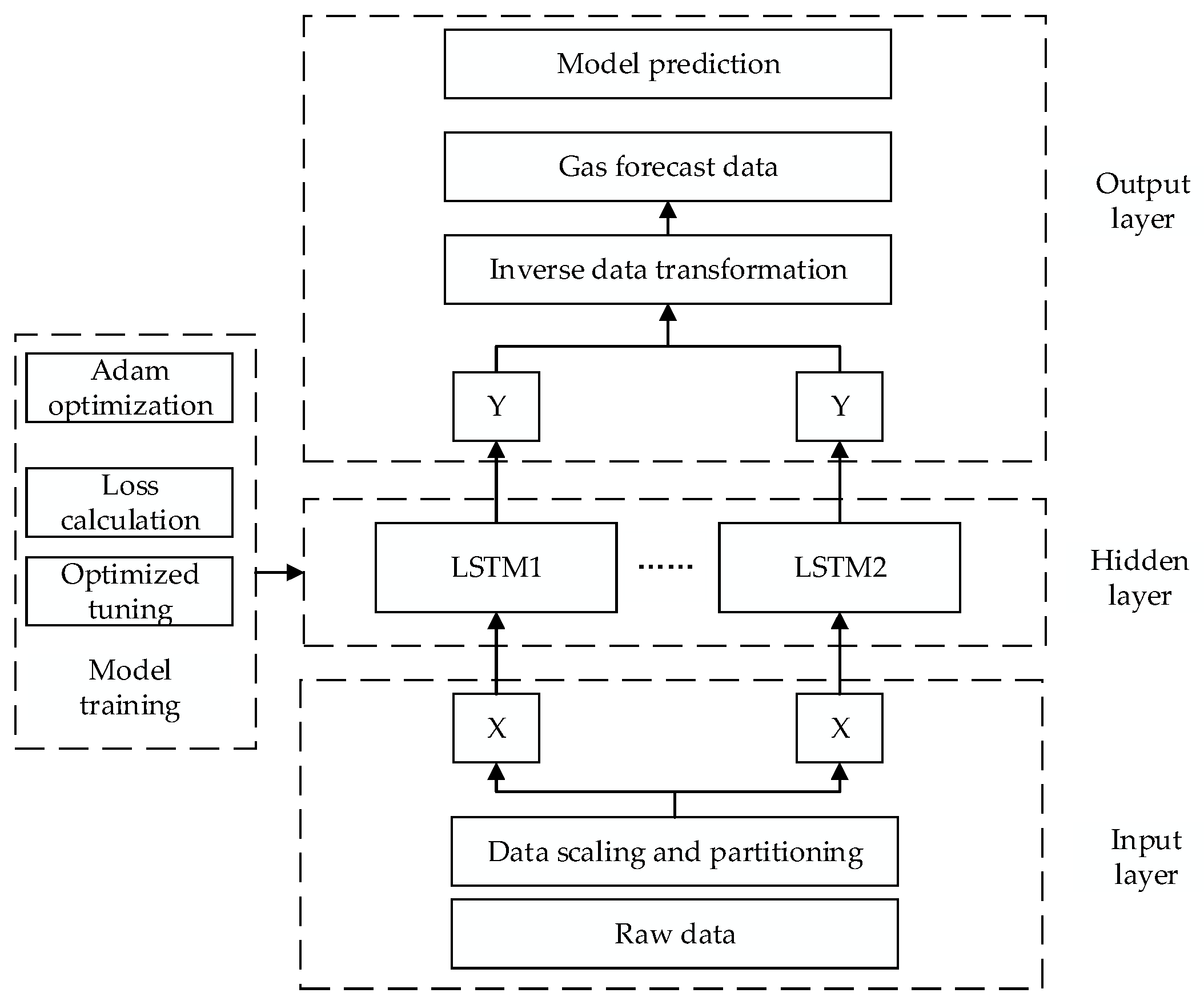
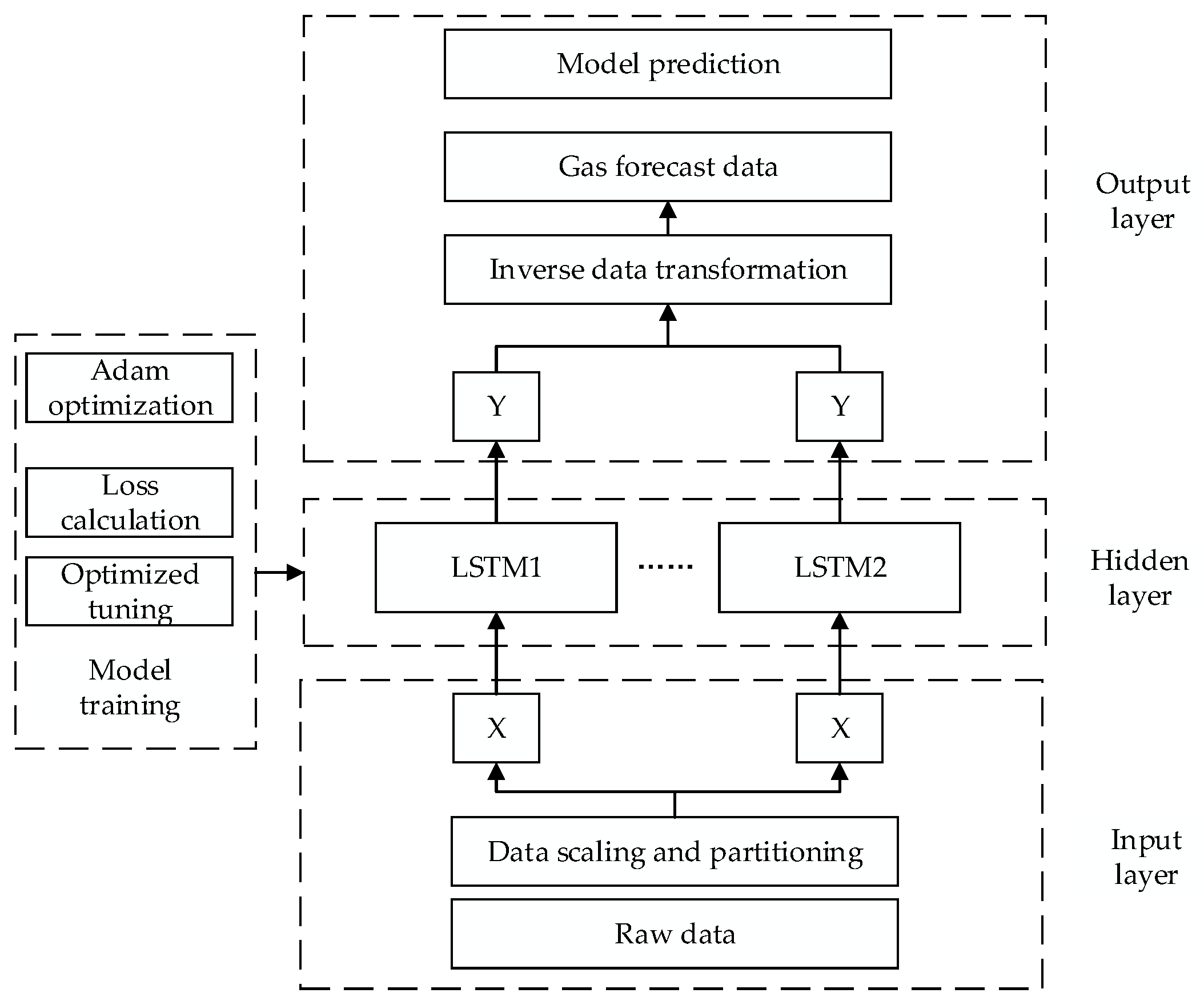
2.2. Construction of Predictive Model
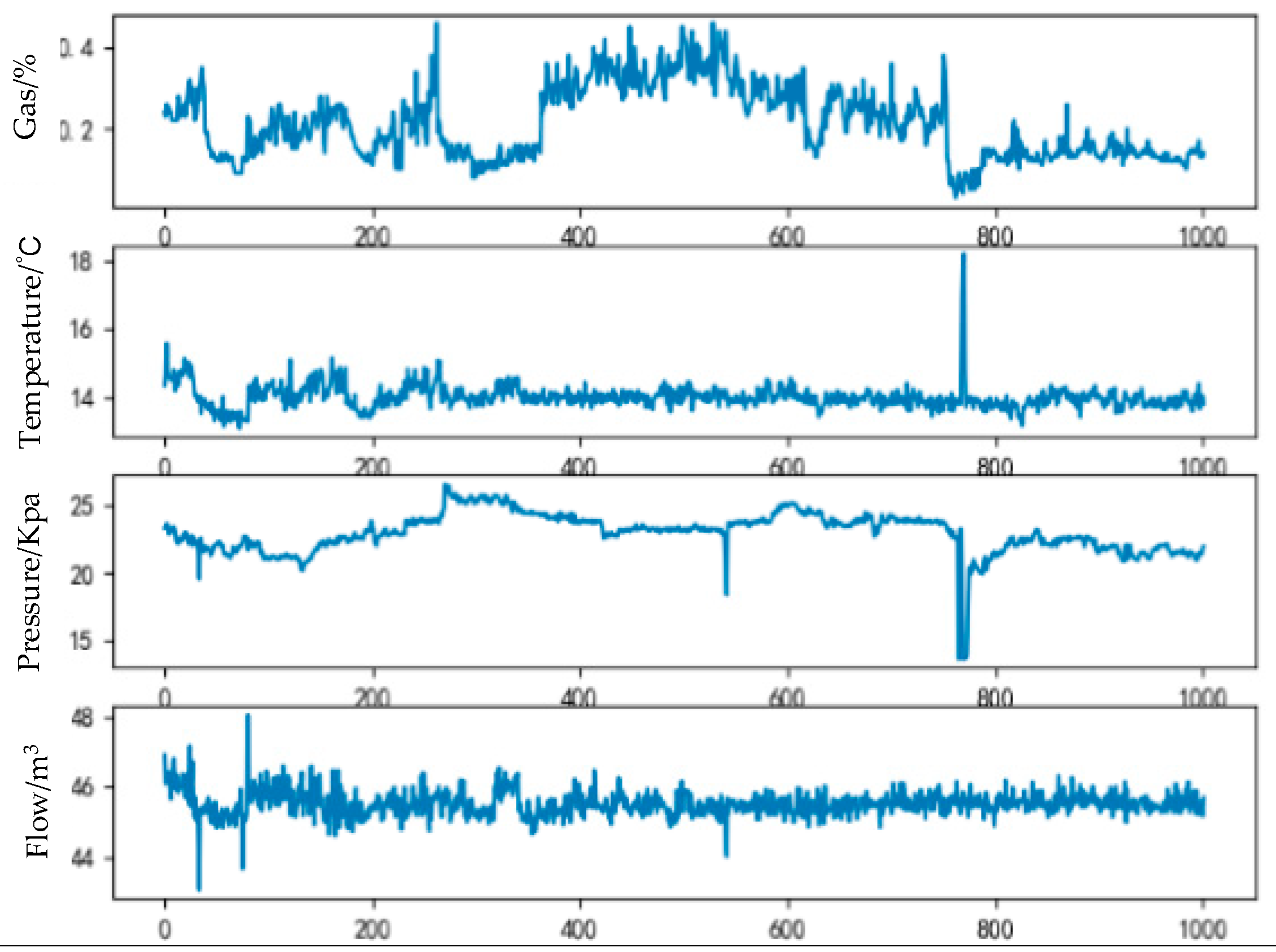
3. Experiment and Results
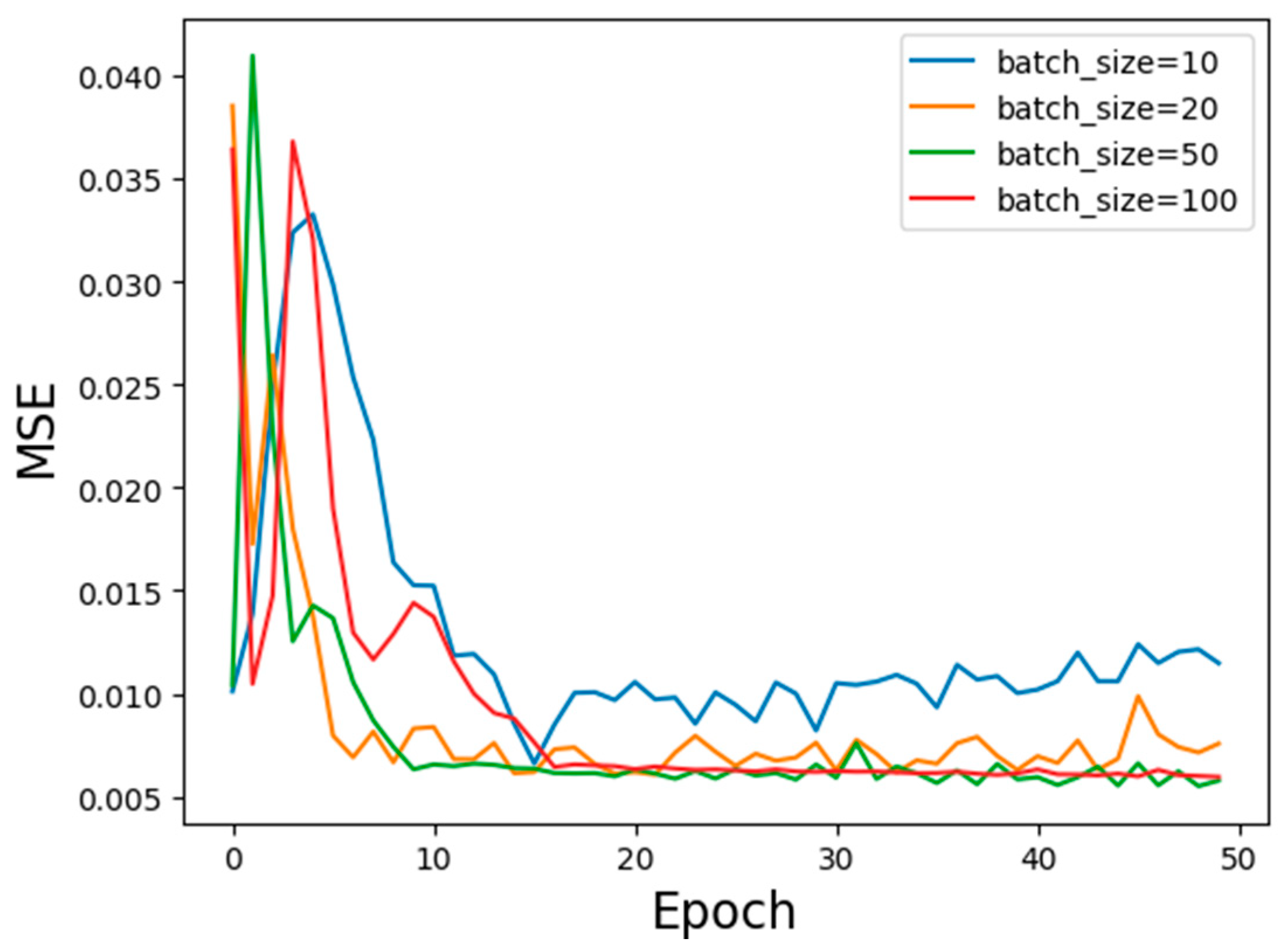
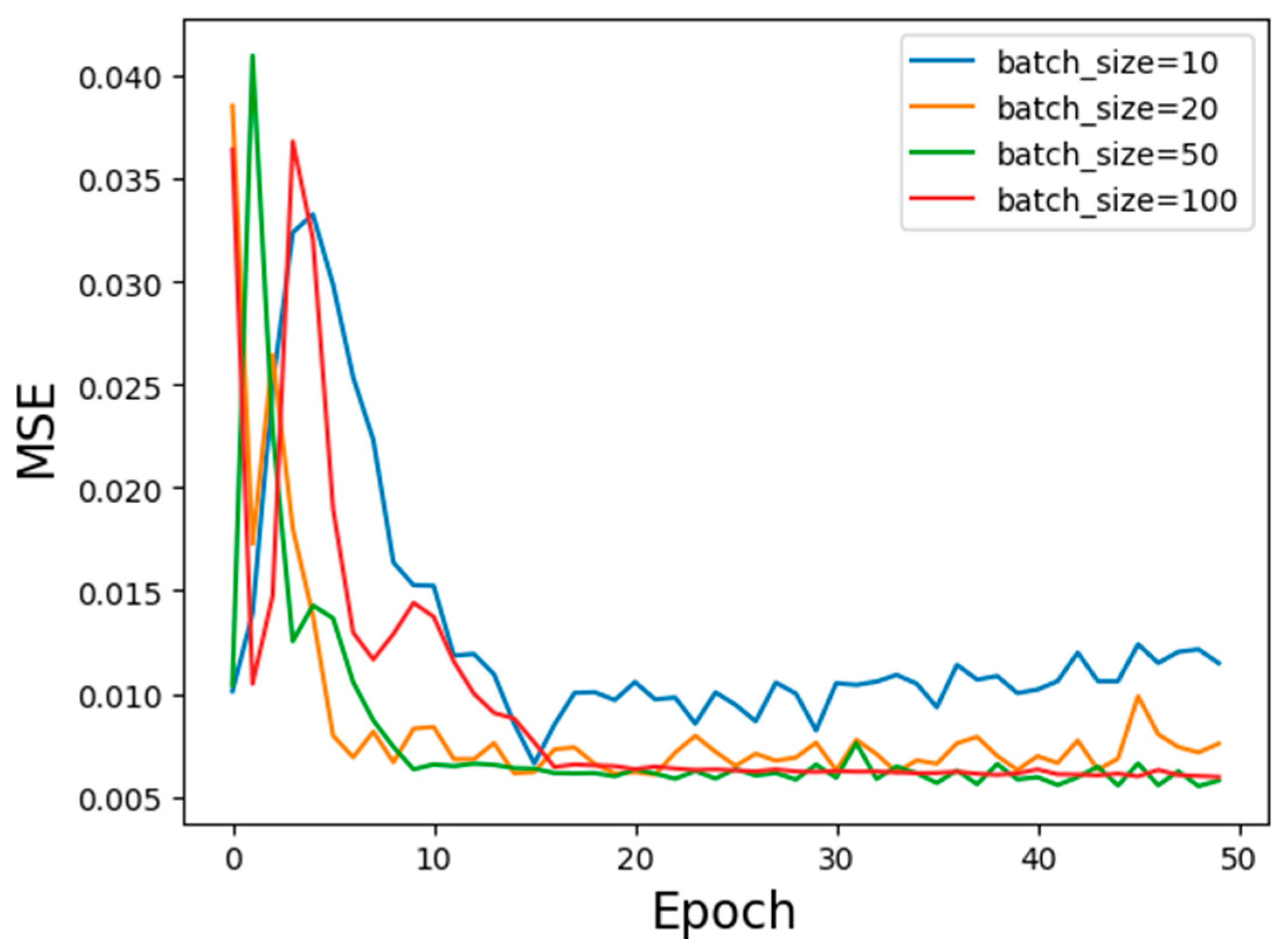
3.1. Optimization of Batch Size
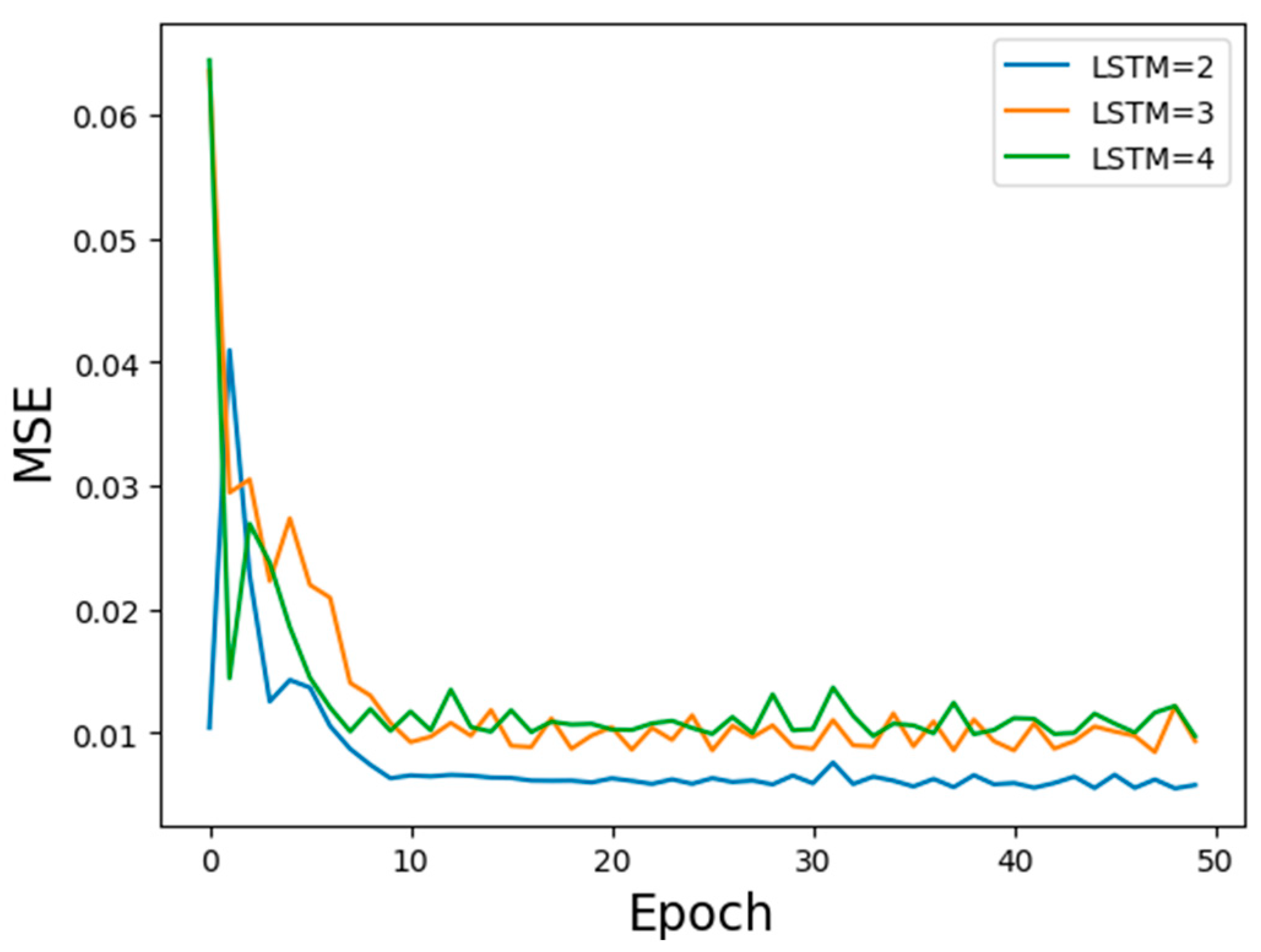
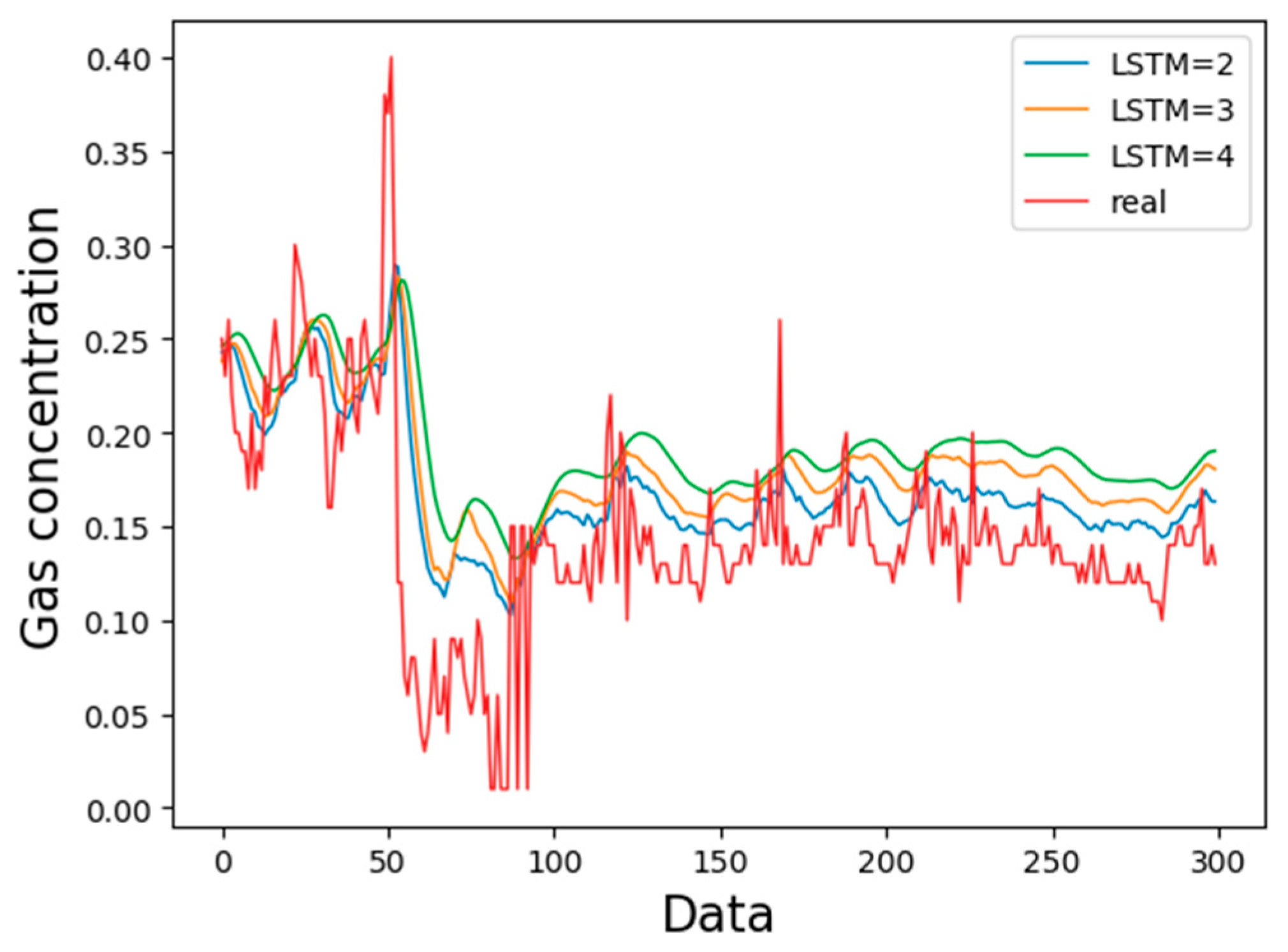
3.2. Optimization of Network Layer Number
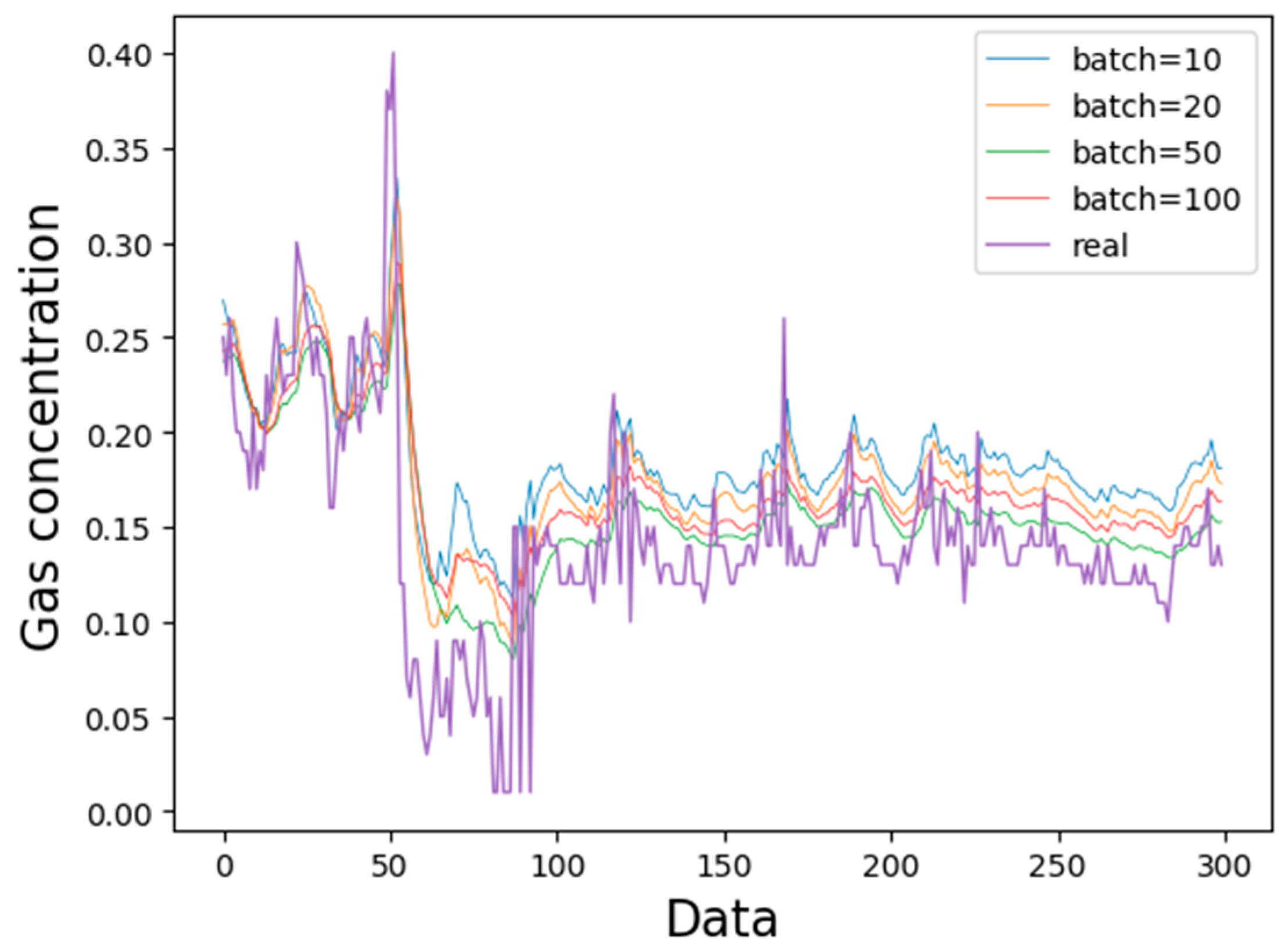
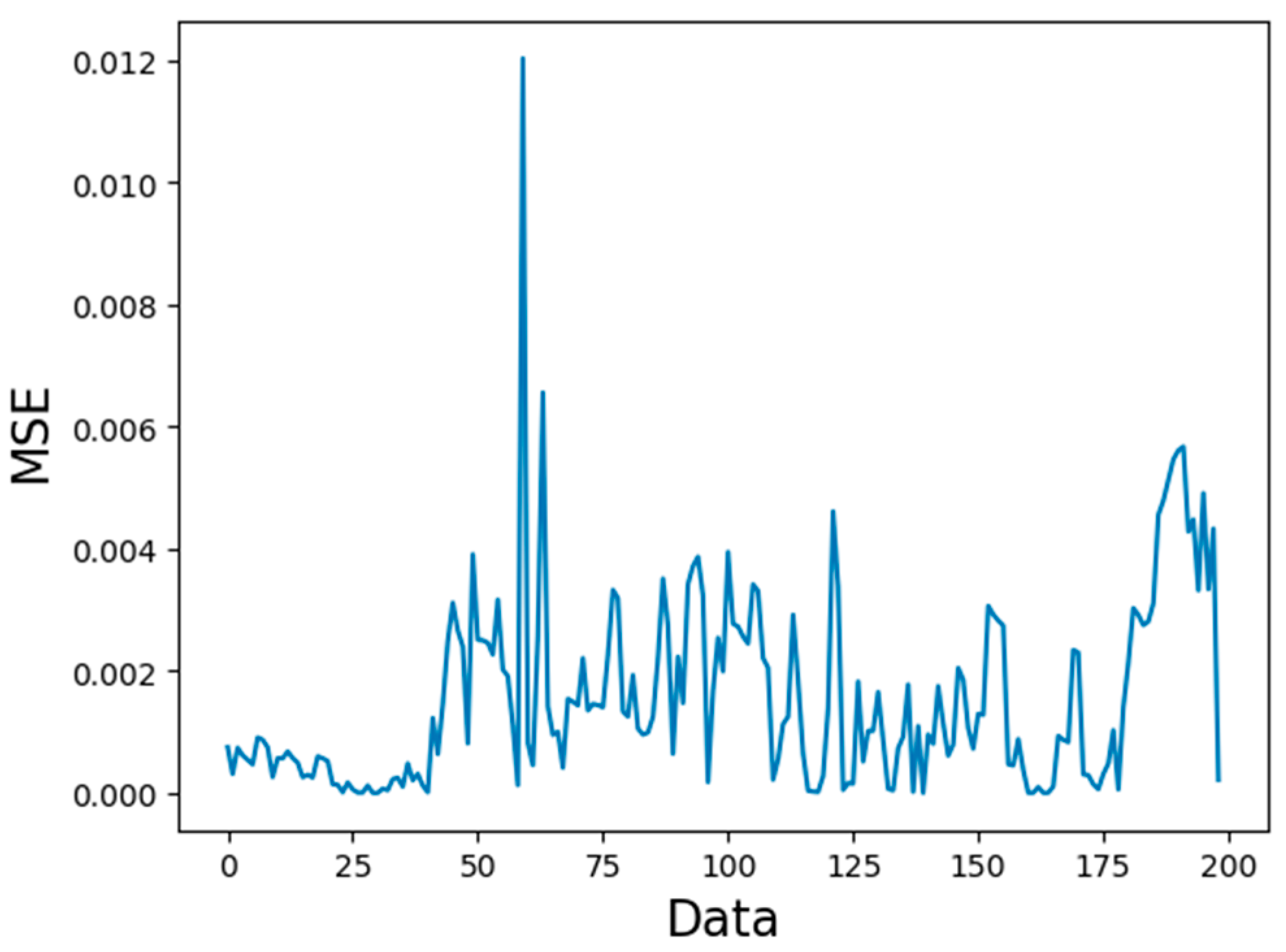
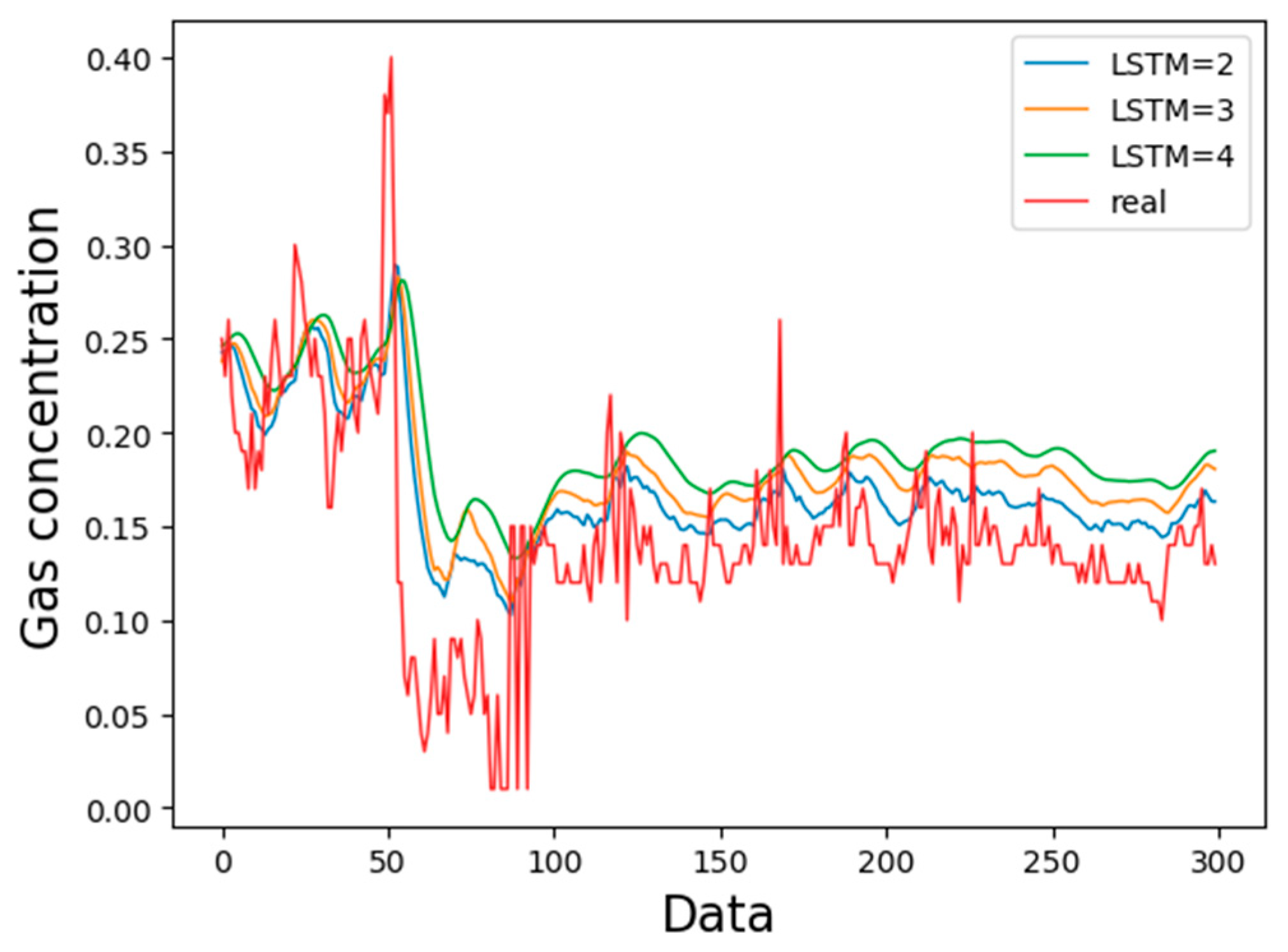
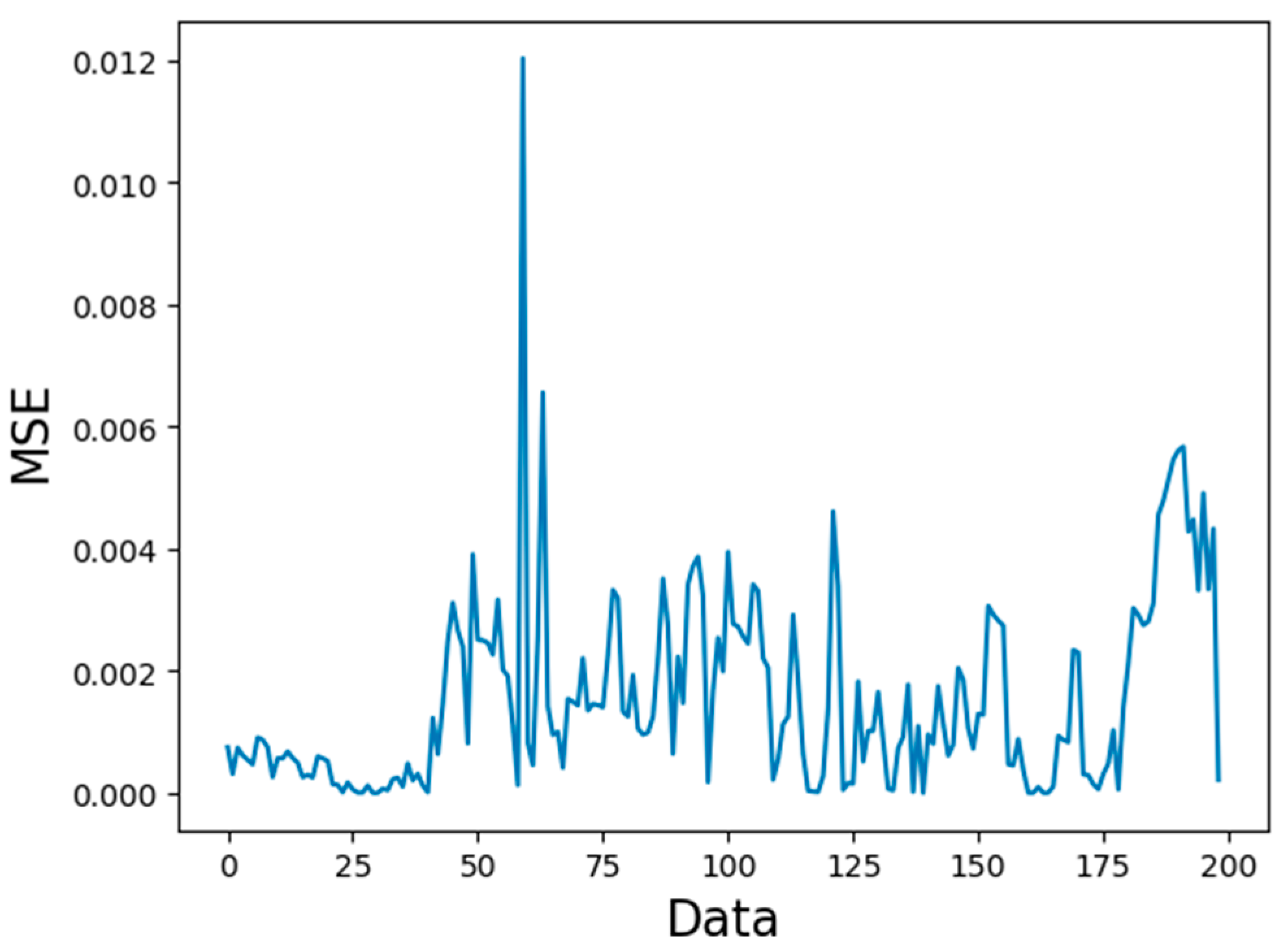
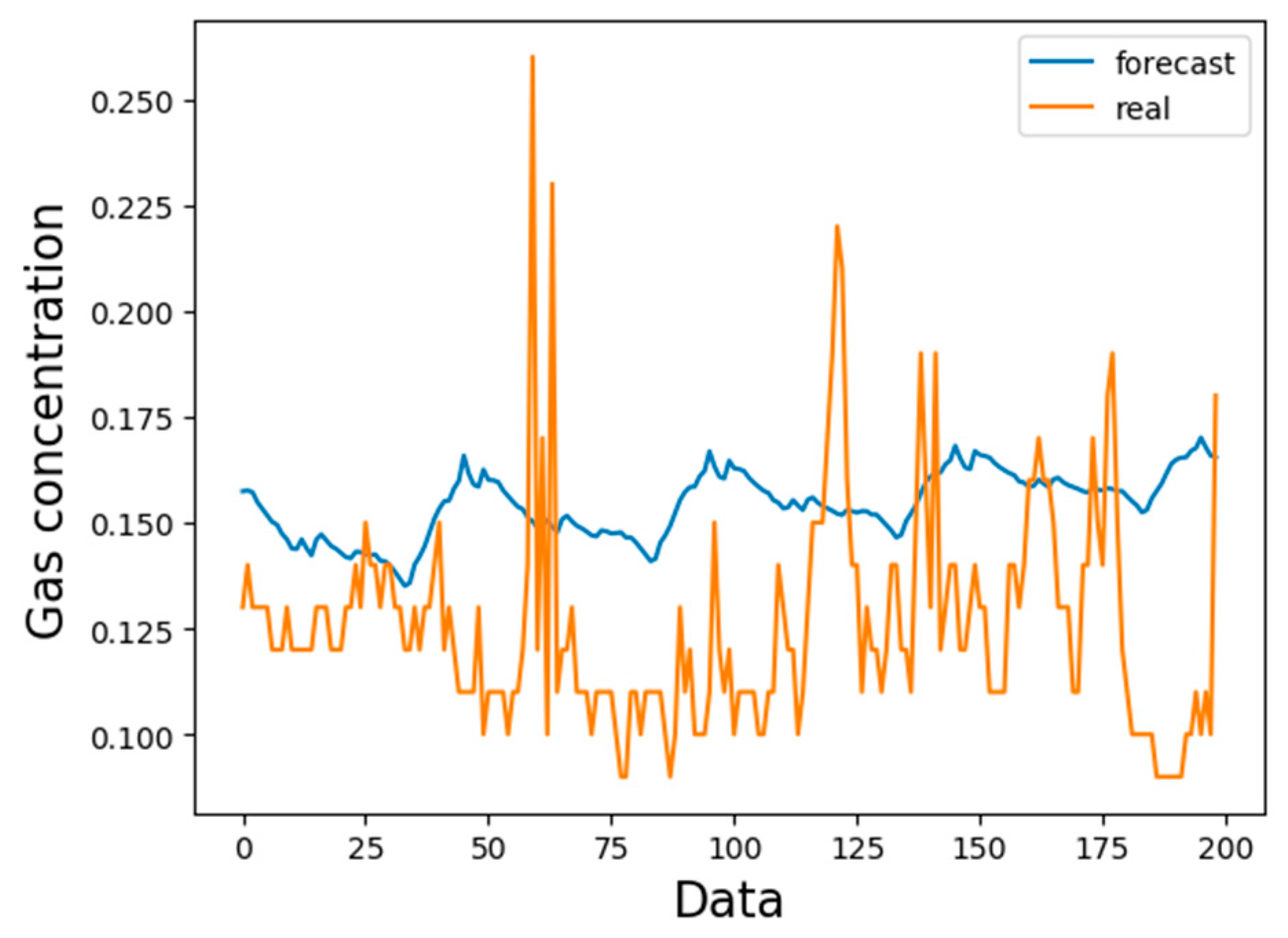
3.3. Comparison of Predicted Length
4. Discussion
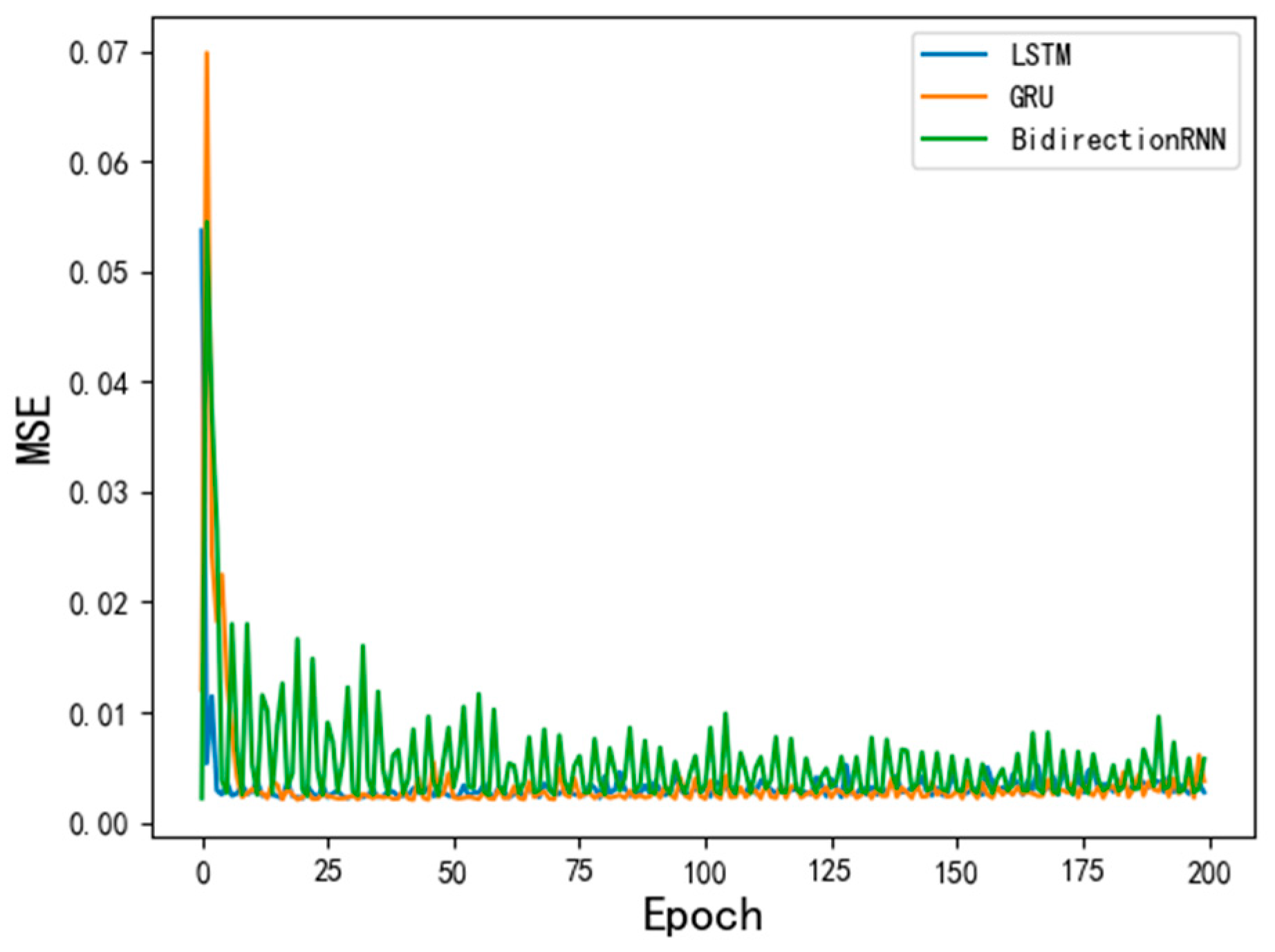
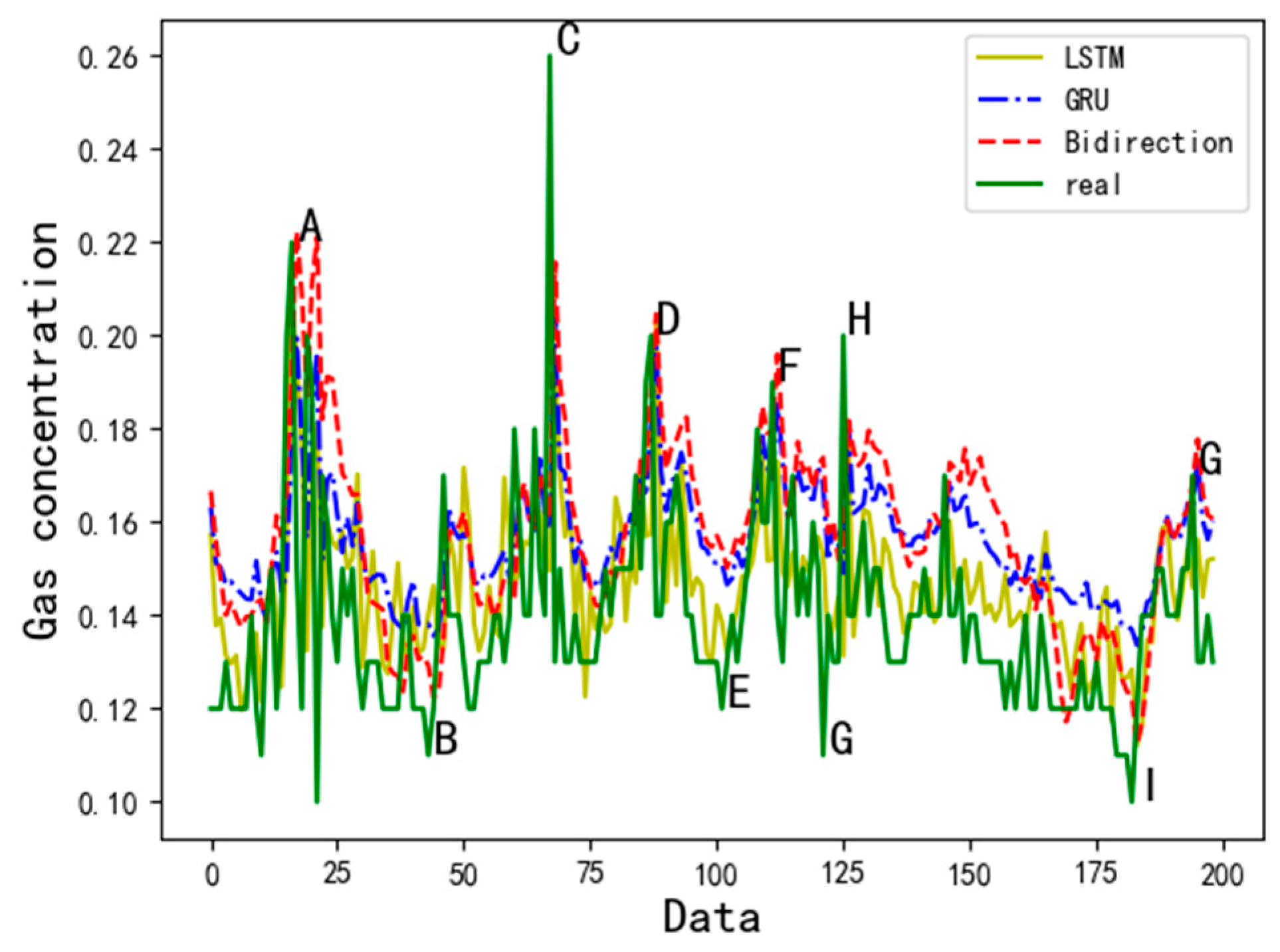
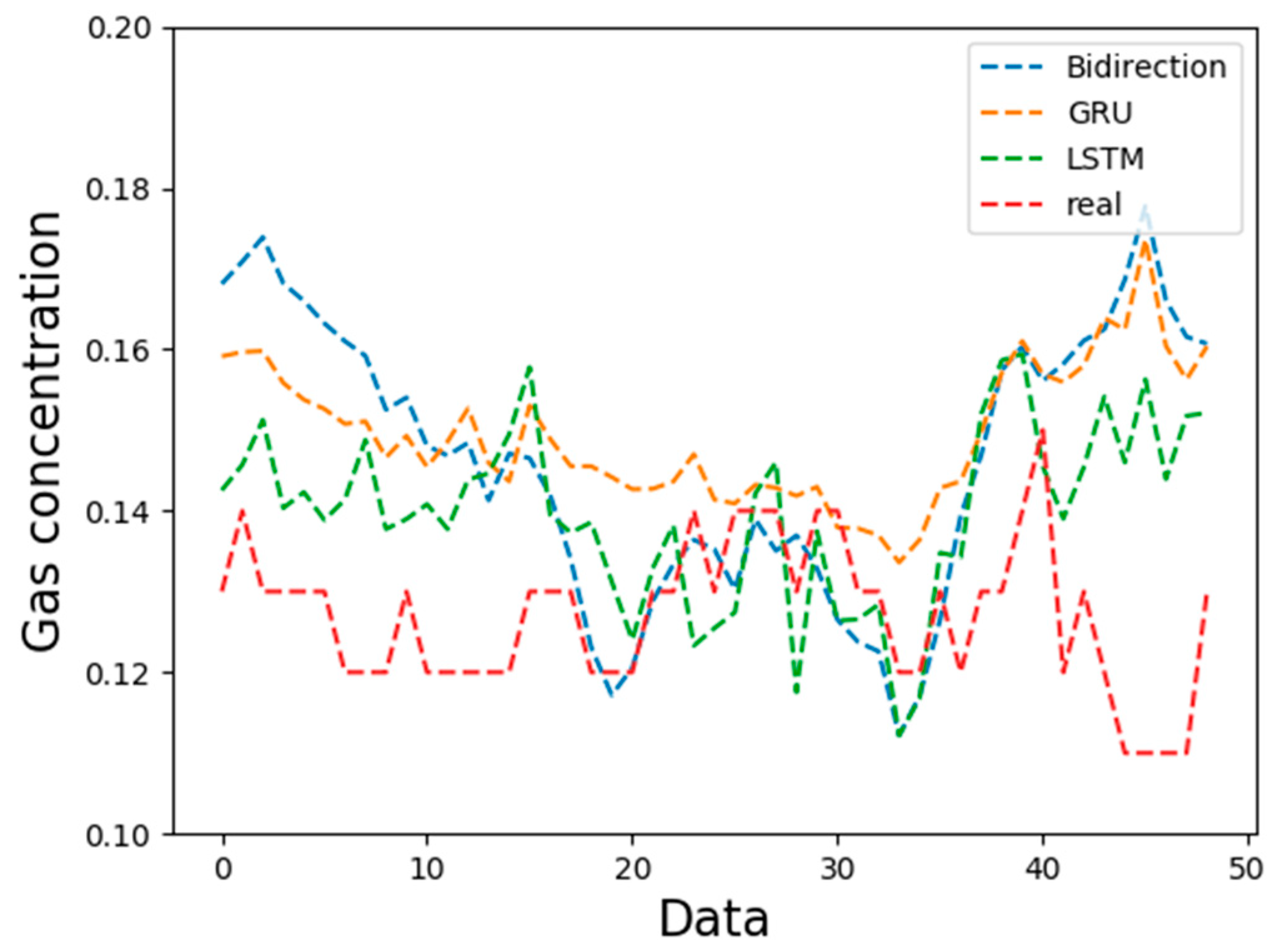
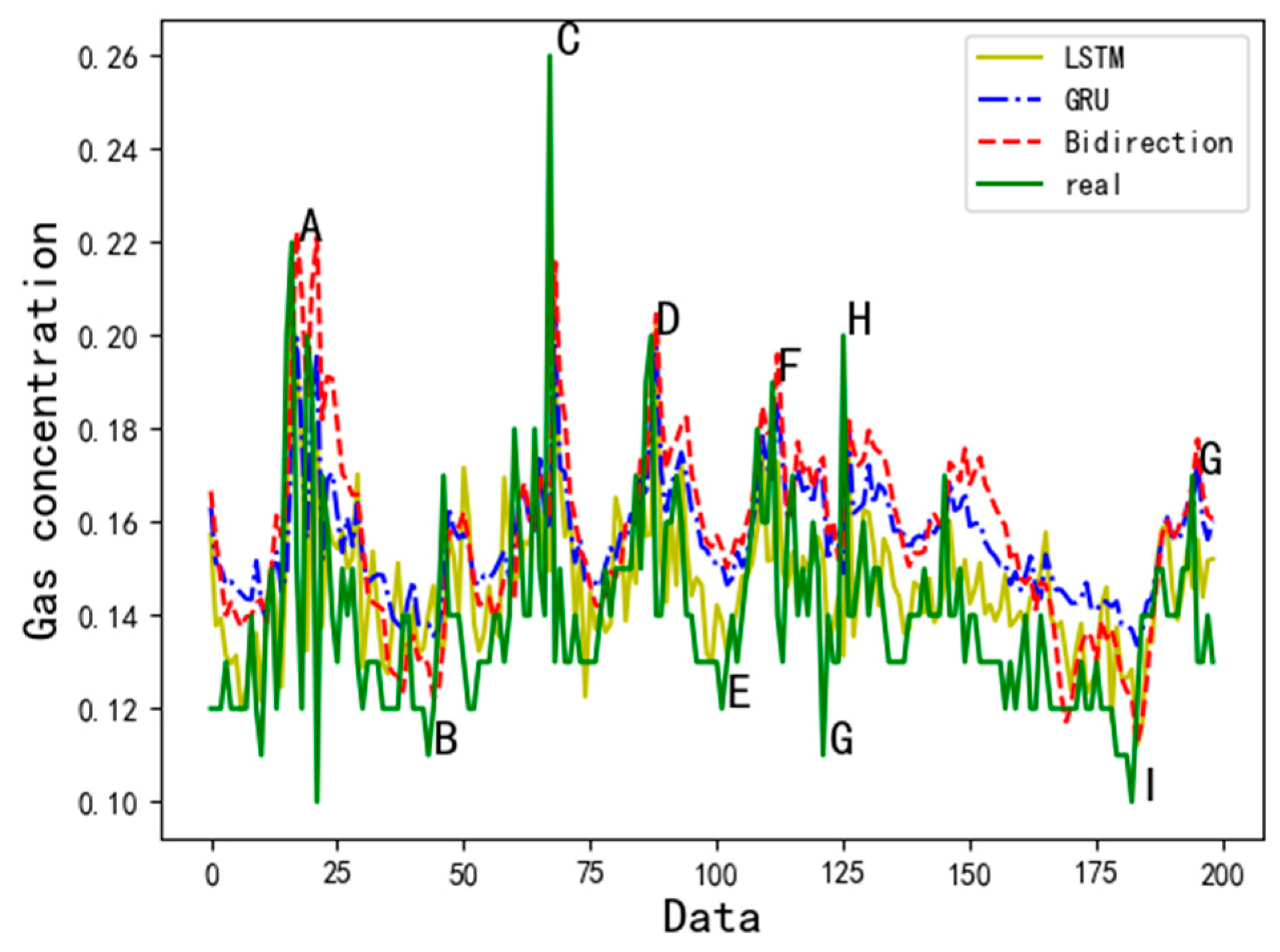
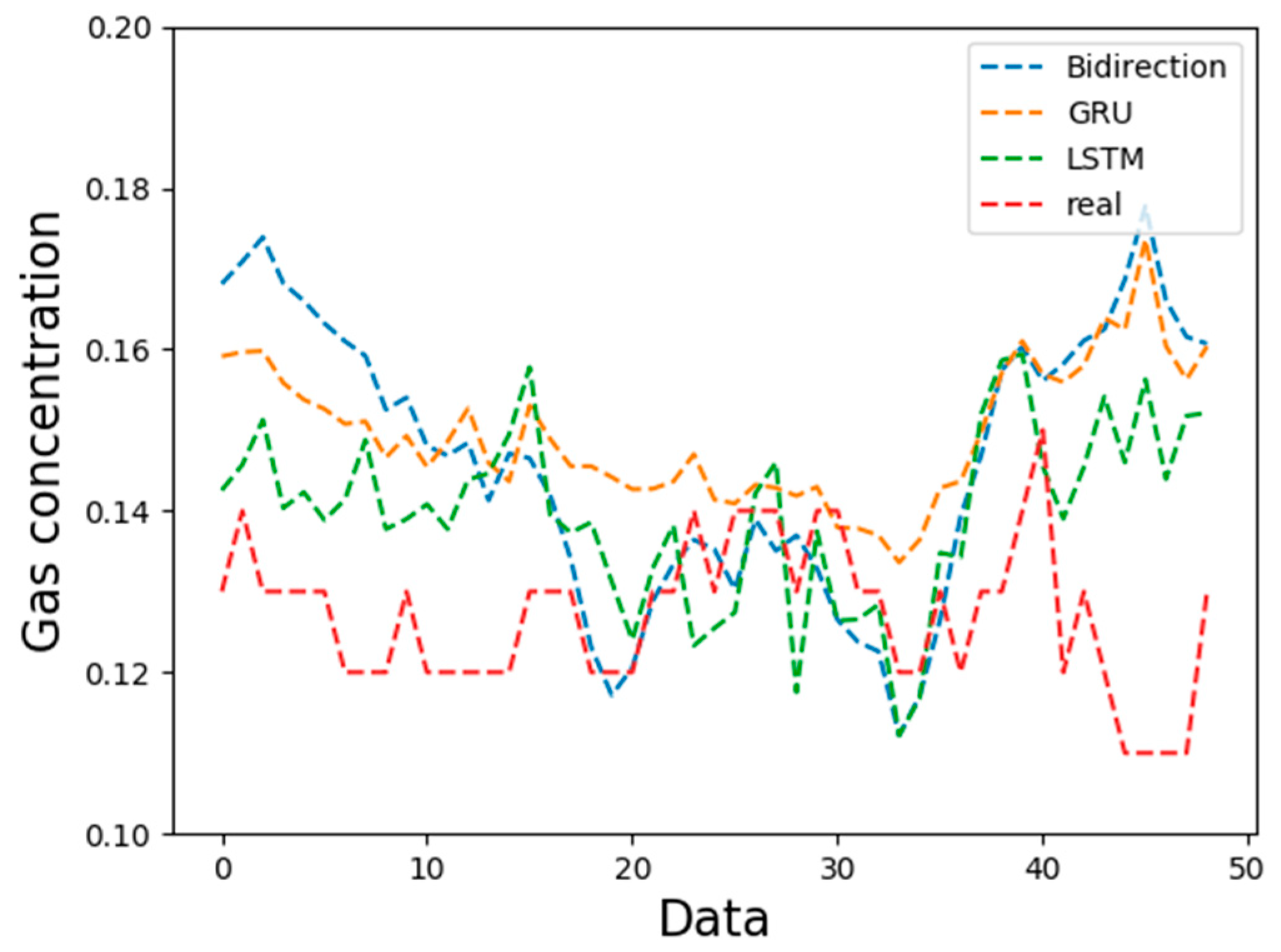
4.1. Model Comparison
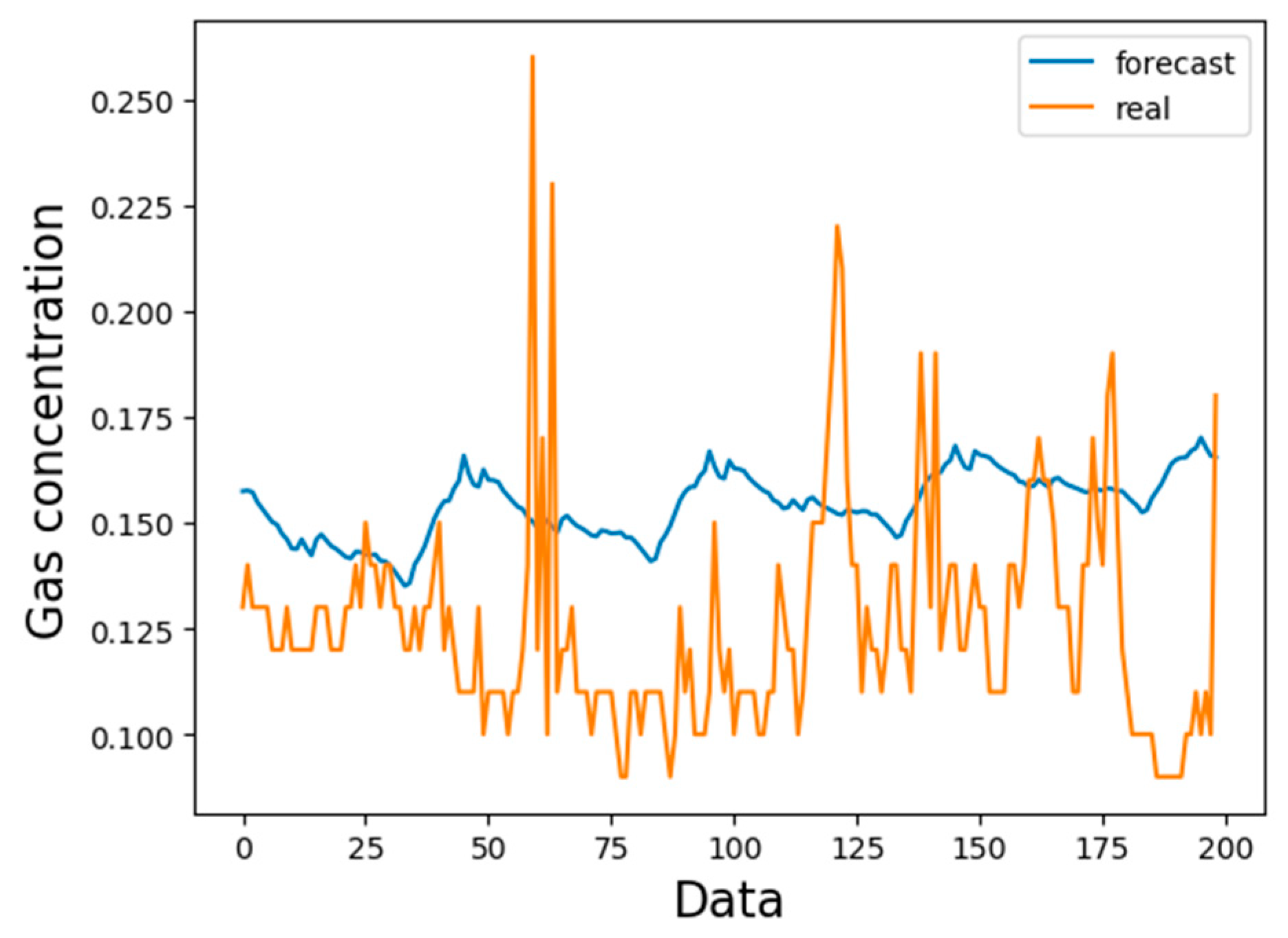
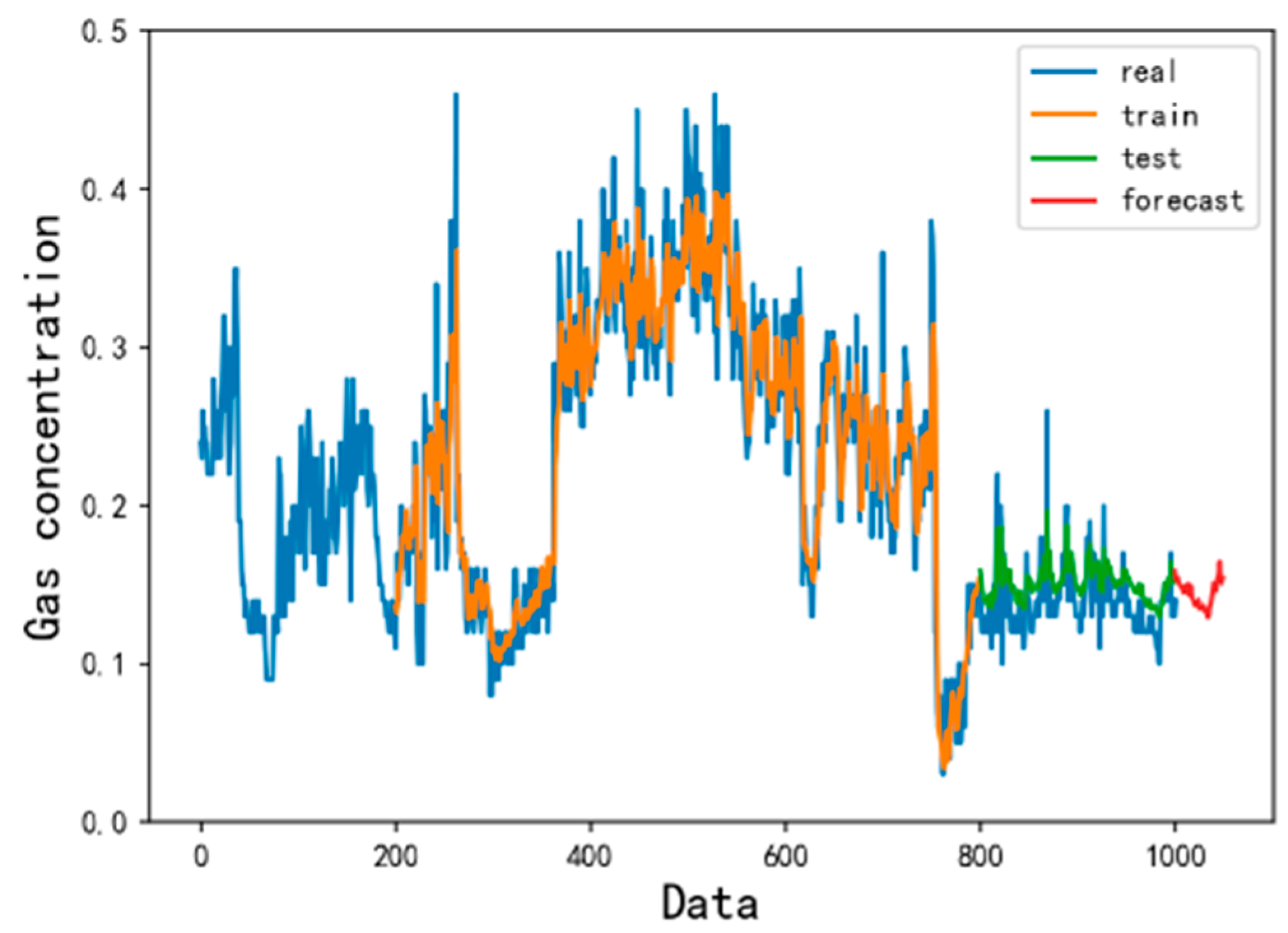
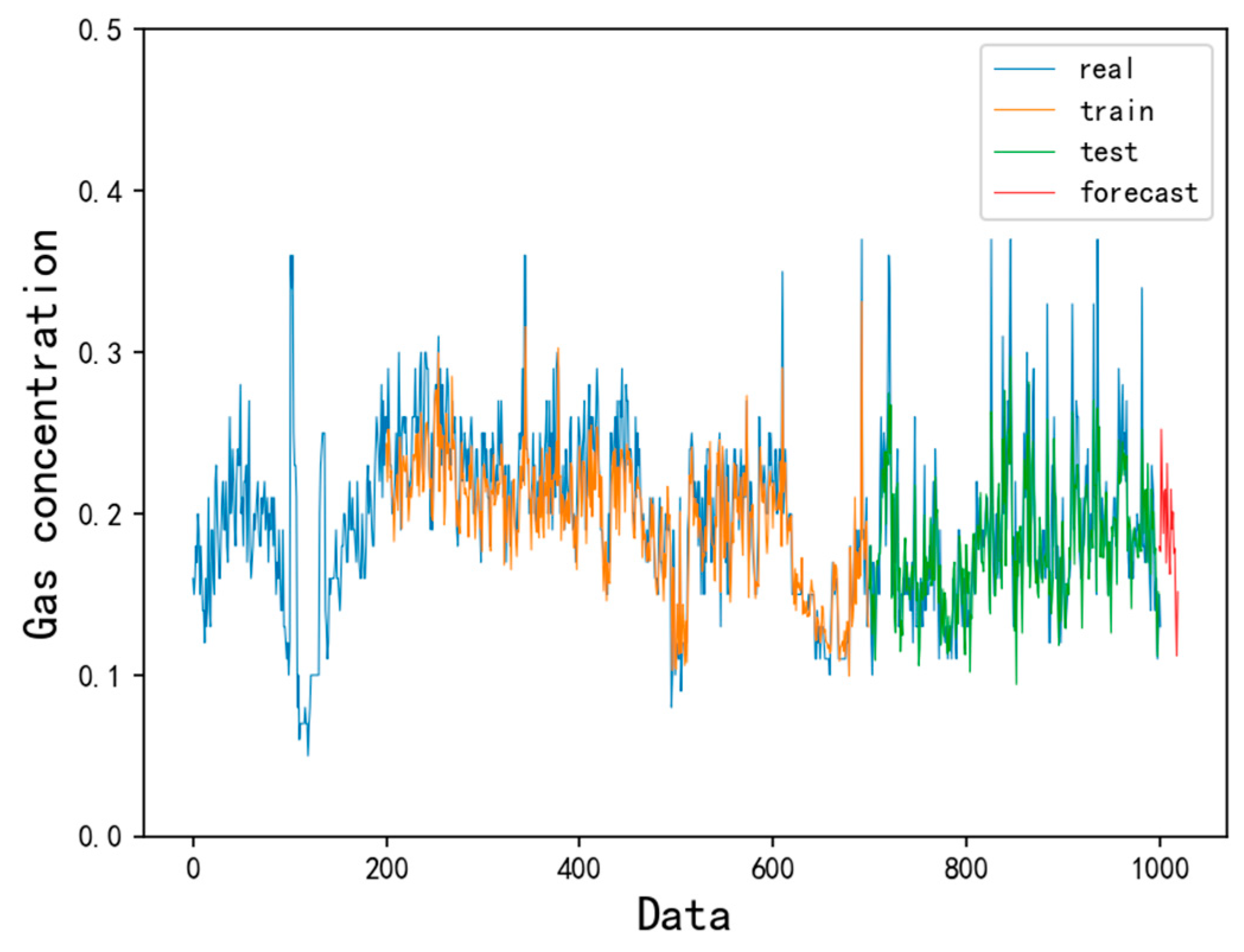
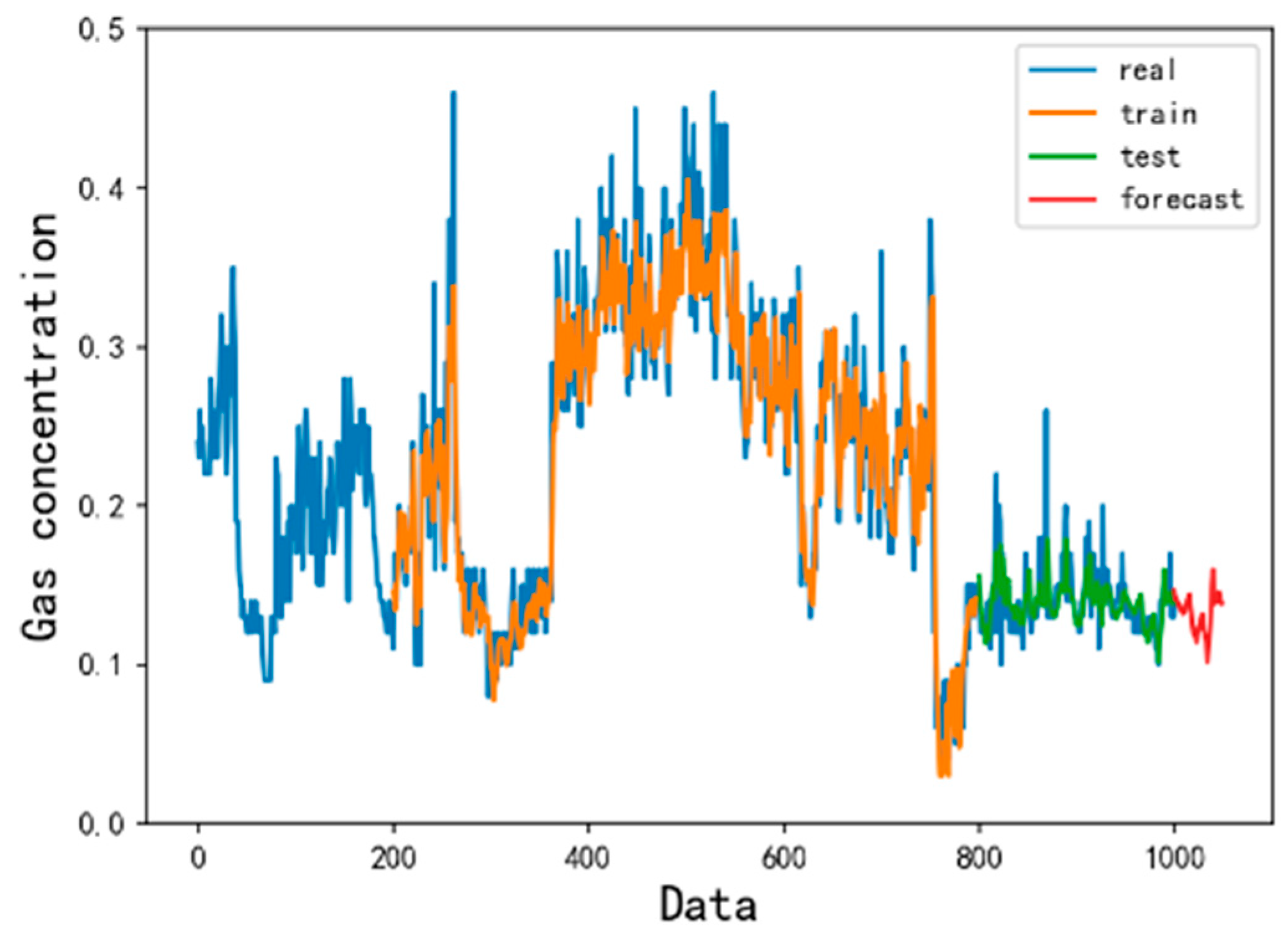
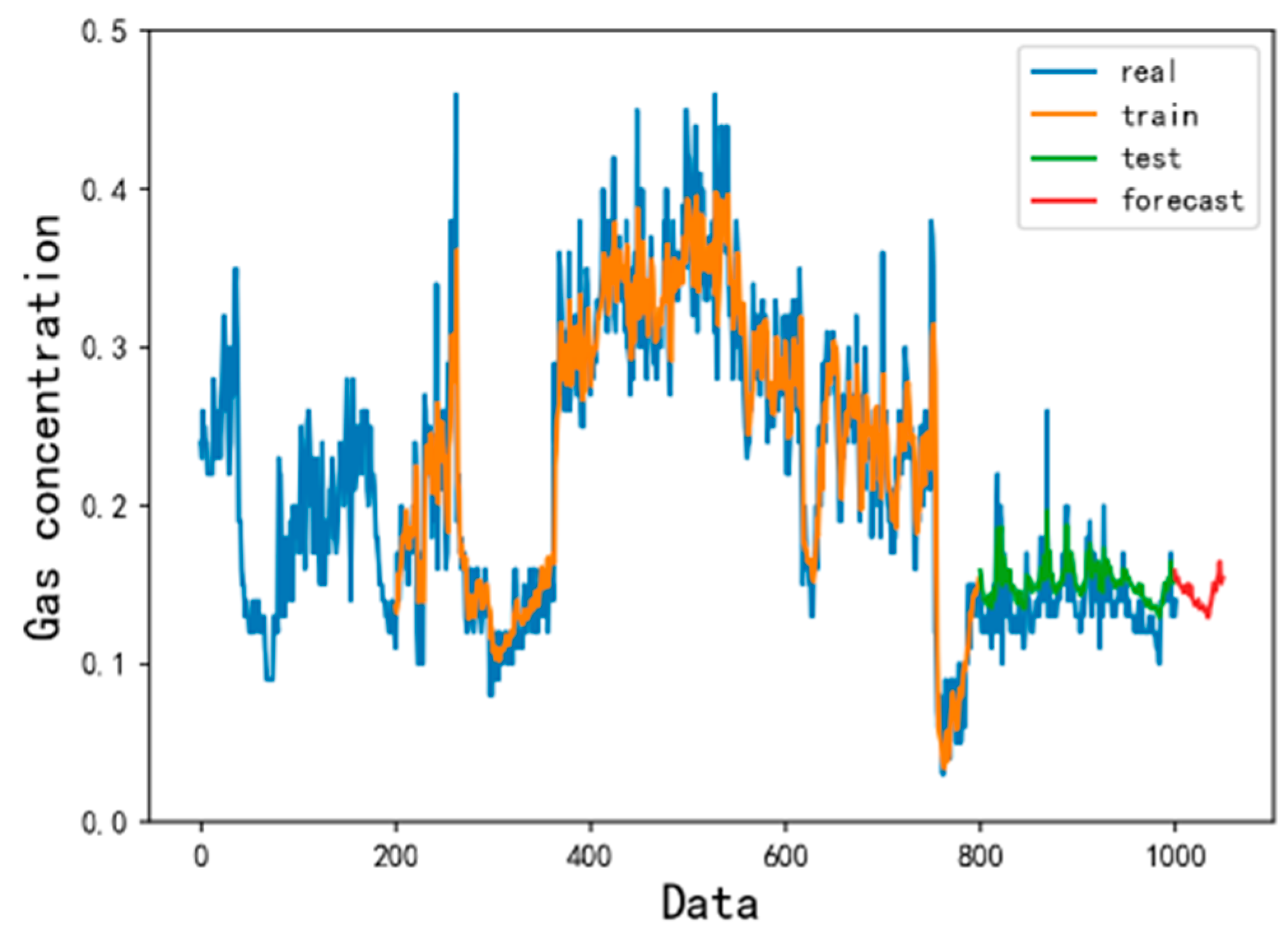
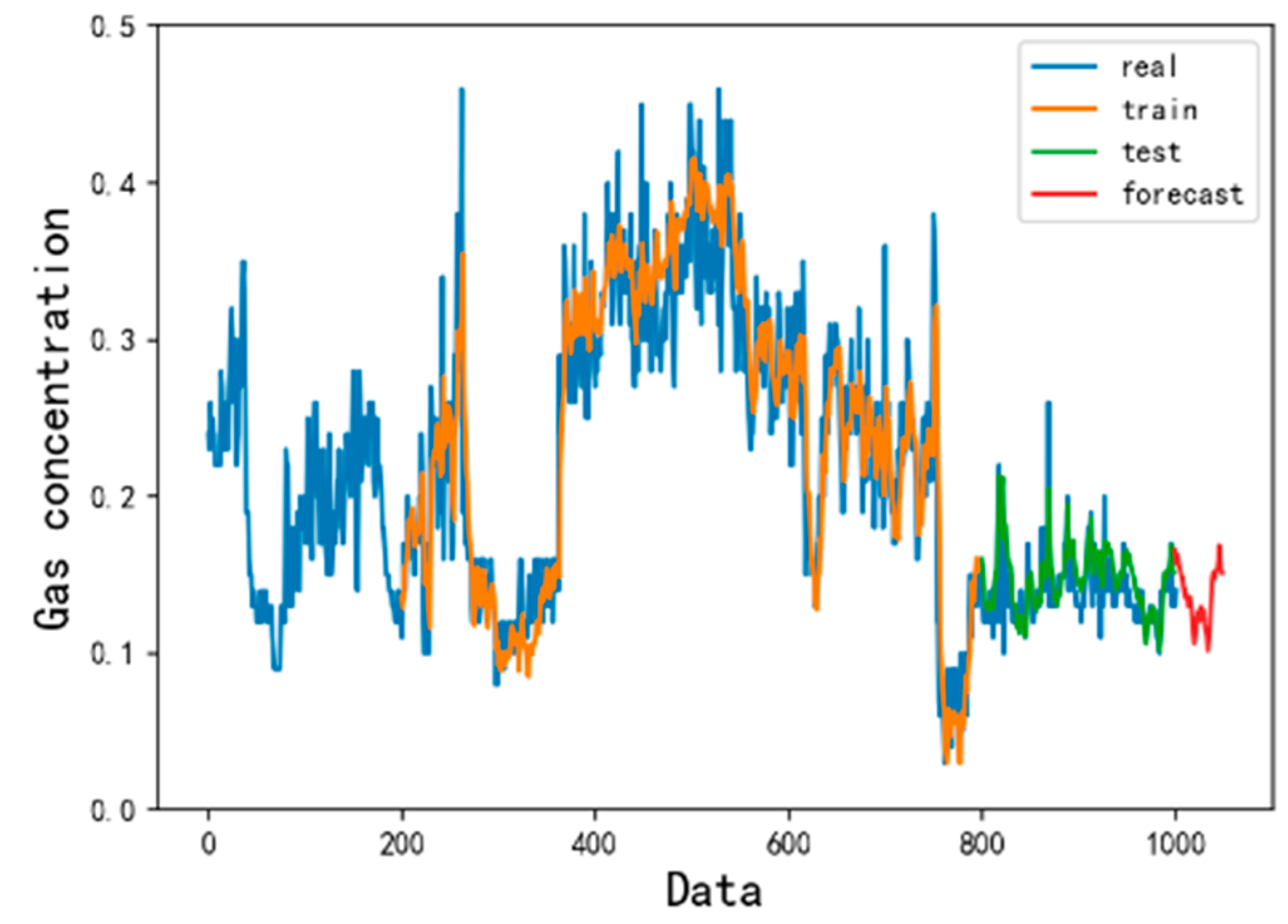
4.2. Forecast Results and Analysis
5. Conclusions
- (1)
- During the training process, the selection of batch size and number of LSTM layers has a great influence on the objective function value, fitting effect, and running time. The appropriate batch size and number of LSTM layers can effectively improve the model. Predicting the accuracy and fitting effect and reducing the training running time, the LSTM gas concentration prediction model in this experiment used a batch size of 50 and two LSTM layers as the optimal model parameters.
- (2)
- Compared with other cyclic neural network variants, BidirectionRNN and GRU prediction models, the effects of LSTM prediction are better, the average mean square error of the model can be reduced to 0.003, the predicted mean square error can be reduced to 0.015, and the predicted mean square error range is 0.0005–0.04, which has higher accuracy, robustness, and applicability.
- (3)
- The cyclic neural network can solve the time series problem, and the LSTM can solve the problem of gradient disappearance and gradient explosion and deal with the time series with long delay. For the gas concentration time series, the LSTM model can predict the concentration of gas in the next time period in a short time range, especially at the time inflection point of the gas concentration change, which can better reflect the LSTM prediction time series data, and the mean square error can be reduced to 0.005.
- (4)
- Compared with the traditional gas concentration prediction method, the model selects more monitoring data with longer samples and time spans as training samples. The LSTM prediction model has higher precision and wider application scenarios. At the same time, after learning the gas concentration time series law, the LSTM model can clearly predict the trend of gas concentration change in the next time period and provide a reference for coal mine safety.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fu, H.; Dai, W. Dynamic Prediction Method of Gas Concentration in PSR-MK-LSSVM Based on ACPSO. J. Transduct. Technol. 2016, 29, 903–908. [Google Scholar]
- Fu, H.; Feng, C.; Liu, J.; Tang, B. Study on Modeling and Simulation of Gas Concentration Prediction Based on DE-EDA-SVM. J. Transduct. Technol. 2016, 29, 285–289. [Google Scholar]
- Wei, L.; Ling, L.; Fu, H.; Yin, Y. Dynamic Prediction Model of Gas Concentration Based on EMD-LSSVM. J. Saf. Environ. 2016, 16, 119–123. [Google Scholar]
- Fu, H.; Zhai, H.; Meng, X.; Sun, W. A New Method for Gas Dynamic Prediction Based on EKF-WLS-SVR and Chaotic Time Series Analysis. J. Transduct. Technol. 2015, 28, 126–131. [Google Scholar]
- Wu, Y.; Qiu, C.; Lü, X. Gas concentration prediction based on fuzzy information granulation and Markov correction. Coal Technol. 2018, 37, 173–175. [Google Scholar]
- Liu, J.; Zhao, Q.; Hao, W. Study on Gas Concentration Prediction Based on Genetic Algorithm Optimized BP Neural Network. Min. Saf. Environ. Prot. 2015, 42, 56–60. [Google Scholar]
- Guo, S.; Tao, Y.; Li, C. Dynamic Prediction of Gas Concentration Based on Time Series. Ind. Min. Autom. 2018, 44, 20–25. [Google Scholar]
- Zhang, Z.; Qiao, J.; Yu, W. Real-time prediction method of gas concentration based on dynamic neural network. Control Eng. 2016, 23, 478–483. [Google Scholar]
- Wang, X.; Wu, J.; Liu, C.; Yang, H.; Du, Y.; Niu, W. Fault Time Series Prediction Based on LSTM Recurrent Neural Network. J. Beijing Univ. Aeronaut. Astronaut. 2018, 44, 772–784. [Google Scholar]
- Ma, X.; Tao, Z.; Wang, Y.; Yu, H.; Wang, Y. Long short-term memory neural network for traffic speed prediction using remote microwave sensor data. Transp. Res. 2015, 54, 187–197. [Google Scholar] [CrossRef]
- Alex, G. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602. [Google Scholar]
- Dai, J.; Song, H.; Sheng, G.; Jiang, X.; Wang, J.; Chen, Y. Study on the operation state prediction method of power transformers using LSTM network. High Volt. Technol. 2018, 44, 1099–1106. [Google Scholar]
- Li, P.; He, S.; Han, P.; Zheng, M.; Huang, M.; Sun, J. Short-term load forecasting of smart grid based on real-time electricity price based on long-term and short-term memory. Power Syst. Technol. 2018, 42, 4045–4052. [Google Scholar]
- Song, K.; Hong, D. Short-term load forecasting for the holidays using fuzzy linear regression method. IEEE Trans. Power Syst. 2005, 20, 96–101. [Google Scholar] [CrossRef]
- Pandey, A.; Singh, D.; Sinha, S. Intelligent hybrid wavelet models for short-term load forecasting. IEEE Trans. Power Syst. 2010, 25, 1266–1273. [Google Scholar] [CrossRef]
- Wang, X.; Xu, L. Research on short-term traffic flow prediction based on deep learning. J. Transp. Syst. Eng. Eng. 2018, 18, 81–88. [Google Scholar]
- Zhang, L.; Huang, S.; Shi, Z.; Rong, G. CAPCTA recognition method based on LSTM type RNN. Pattern Recognit. Artif. Intell. 2011, 24, 40–47. [Google Scholar]
- Shi, W. Time Series Correlation and Information Entropy Analysis; Beijing Jiaotong University: Beijing, China, 2016. [Google Scholar]
- Li, S.; Liu, L.; Yan, M. Improved particle swarm optimization algorithm for short-term traffic flow prediction based on BP neural network. Syst. Eng.—Theory Pract. 2012, 32, 2045–2049. [Google Scholar]
- Yang, B.; Yin, K.; Du, J. Dynamic prediction model of landslide displacement based on time series and long and short time memory networks. Chin. J. Rock Mech. Eng. 2018, 10, 2334–2343. [Google Scholar]
- Xu, C. Research on Multi-Granularity Analysis and Processing Method of Time Series Signal Based on Convolution-Long-Term Memory Neural Network; Harbin Institute of Technology: Harbin, China, 2017. [Google Scholar]
- Xu, F.; Wang, Y.; Du, J.; Ye, J. Study on landslide displacement prediction model based on time series analysis. Chin. J. Rock Mech. Eng. 2011, 30, 746–751. [Google Scholar]
- Zhao, X.; Song, Z. Adam optimized CNN super-resolution reconstruction. Comput. Sci. Explor. 2018, 12, 1–9. [Google Scholar]
- Liu, W.; Liu, S.; Zhou, W. Research on Sub-Batch Learning Method of BP Neural Network. J. Intell. Syst. 2016, 11, 226–232. [Google Scholar]
- Hao, Z.; Huang, H.; Cai, R.; Wen, W. Fine-grained Opinion Analysis Based on Multi-feature Fusion and Bidirectional RNN. Comput. Eng. 2018, 44, 199–204. [Google Scholar]
- Li, X.; Duan, H.; Xu, M. Chinese word segmentation based on GRU neural network. J. Xiamen Univ. (Nat. Sci. Ed.) 2018, 12, 1–9. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LSTM = 2 Layers; Neurons = 64 | ||
|---|---|---|
| Batch | Operation Time | Mean Square Error |
| 10 | 8 min | 0.010897 |
| 20 | 5 min | 0.009293 |
| 50 | 3 min | 0.008331 |
| 100 | 2 min | 0.009689 |
| Batch Size = 50; Neurons = 64 | ||
|---|---|---|
| LSTM Layers | Time | Mean Square Error |
| 2 | 3 min | 0.008331 |
| 3 | 6 min | 0.012725 |
| 4 | 10 min | 0.0155 |
| Timestep | Mean Square Error | Maximum Error |
|---|---|---|
| 1 (50) | 0.000713 | 0.003381 |
| 2 (100) | 0.001551 | 0.011366 |
| 3 (150) | 0.001862 | 0.011355 |
| 4 (200) | 0.001549 | 0.012031 |
| Model | Model Parameter | Operation Time | MSE |
|---|---|---|---|
| LSTM | Batch size = 50 2 nerve layers 128 neurons | 5960 s | 0.003298 |
| GRU | 4543 s | 0.003475 | |
| Bidirection | 19,000 s | 0.00541 |
| Model | Maximum Error | Minimum Error | Average Error |
|---|---|---|---|
| BidirectionRNN | 0.067761 | 0.000572 | 0.022019 |
| GRU | 0.063648 | 0.000916 | 0.02246 |
| LSTM | 0.046283 | 0.000589 | 0.015979 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Song, S.; Li, S.; Ma, L.; Pan, S.; Han, L. Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series. Energies 2019, 12, 161. https://doi.org/10.3390/en12010161
Zhang T, Song S, Li S, Ma L, Pan S, Han L. Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series. Energies. 2019; 12(1):161. https://doi.org/10.3390/en12010161
Chicago/Turabian StyleZhang, Tianjun, Shuang Song, Shugang Li, Li Ma, Shaobo Pan, and Liyun Han. 2019. "Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series" Energies 12, no. 1: 161. https://doi.org/10.3390/en12010161
APA StyleZhang, T., Song, S., Li, S., Ma, L., Pan, S., & Han, L. (2019). Research on Gas Concentration Prediction Models Based on LSTM Multidimensional Time Series. Energies, 12(1), 161. https://doi.org/10.3390/en12010161