3.1. Data-Driven Analysis
Data driven analysis refers to data-driven thinking and control [
21,
22]. Data-driven thinking refers to the use of online and offline data from a controlled system to implement various desired functions of the system, mainly for data-based forecasting, evaluation, scheduling, monitoring, diagnosis, decision making, and optimization. With the data-driven approach, the results of forecasting, control, and evaluation can be tested based on real-time system data [
23,
24].
Traditional power network analysis and optimization problems often establish a complete physical model based on the basic laws of a power system, such as power flow calculation models. Through constraints, such as renewable energy output and network topology parameters, numerical calculation or optimization solution are taken as the means, the network’s power flow distribution is obtained, as well as voltage profile, active loss and other operational data. Therefore, traditional power network analysis and optimization problems—such as power flow calculation, planning and scheduling, voltage control, etc.—are mostly model data calculation problems.
Data-driven power network analysis and optimization problems mostly do not depend on the physical model of the power system. With a certain relationship between data, the process of solving unknown data is based on known values. This is a data-driven computation problem. Notably, the data-driven power flow calculation mentioned in this paper still needs to establish the physical model of the power system. The introduction of the data-driven method reduces the reliance on the physical model of the power system, however, in the process of processing the data, we still needed to establish a mathematical model.
3.2. Kernel Function Extreme Learning Machine
The extreme learning machine (ELM) was developed by Huang et al. in 2004 to introduce machine learning theory [
13]. Based on this theory, various related algorithms, including the extreme learning machine with kernel function (KELM), were derived and widely used by researchers in different fields [
25,
26]. The basic topology of the ELM is shown in
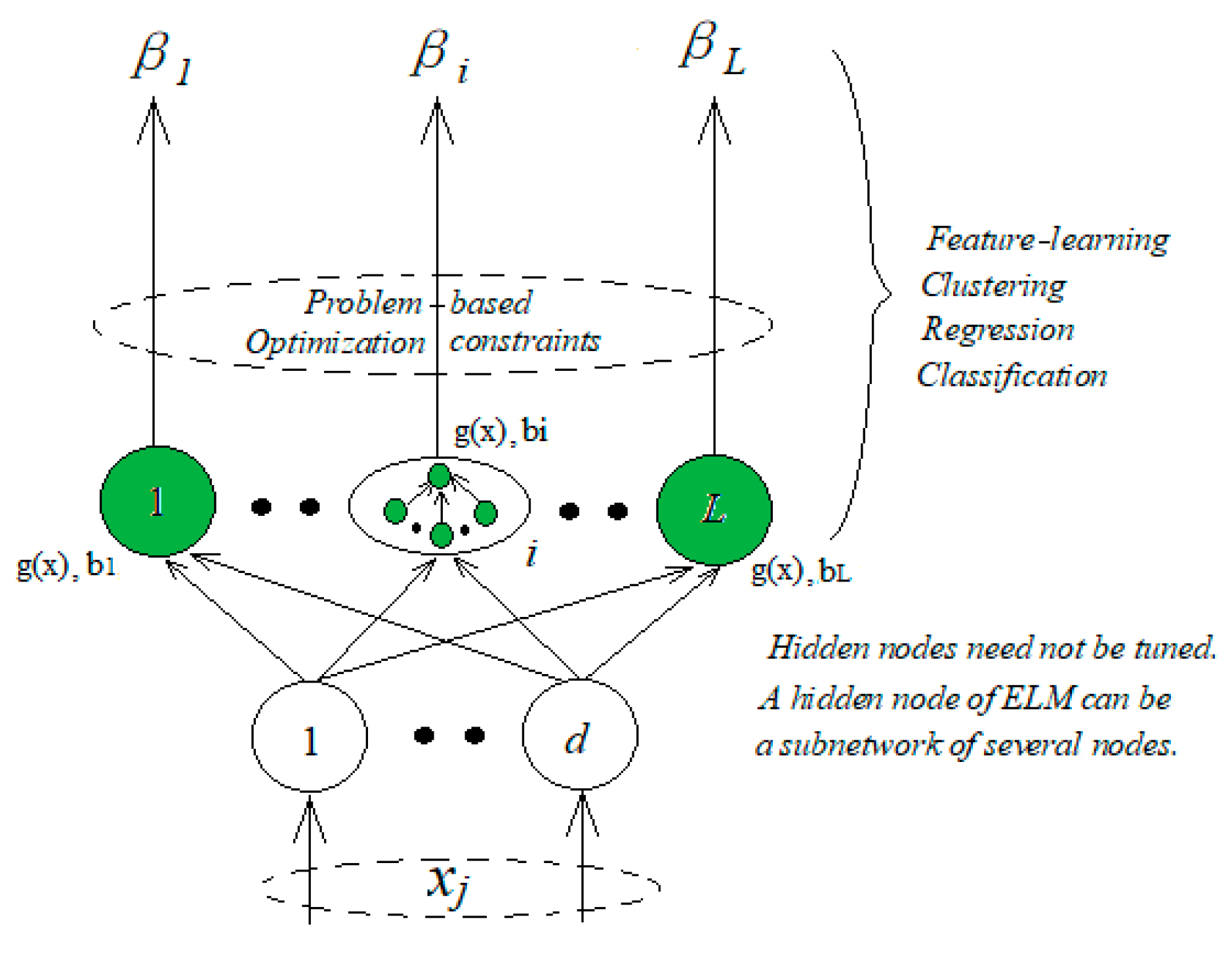
Figure 1.
ELM is a generalized single hidden layer feedforward neural network. After randomly generating input weights and offsets, the output weights are obtained through matrix calculation. Compared with the traditional feedforward post-transmission neural network, extreme learning machine has extremely fast training speed, better generalization performance, and easier implementation.
Suppose a given training set
N = {(xi,
ti)|xi∈Rd,
ti∈Rm,
i = 1,
2, …,
d}, where
xi is training data,
ti is the category label for each sample. The basic ELM training algorithm can be summarized as follows: (1) randomly assign hidden node parameters: input weight
wi and offset
bi,
i = 1, …,
L,
1⁄c for bias constant; (2) calculate the hidden layer output matrix
H; and (3) obtain an output weight
β. Thus,
Then, the corresponding output function of the ELM is
where,
h(x) is the hidden layer feature mapping.
ELM guarantees regression prediction accuracy by minimizing output error, which is
where
fo(
x) is the function to be predicted consisting of the target value.
The basic ELM algorithm has been applied to short-term electric load forecasting [
27], high-voltage circuit breaker mechanical fault diagnosis [
28], and a tunnel foundation pit deformation intelligent prediction model [
29]. ELM demonstrated high quality performance to meet the needs of different applications. ELM is a new algorithm for SLFN, which randomly generates the connection weight between the input layer and the hidden layer, and the threshold of the hidden layer neurons. ELM does not need to be adjusted during the training process; it only needs to set the hidden layer neurons. Therefore, ELM can be used to obtain the only optimal solution. When the number of neurons in the hidden layer is equal to the number of samples in the training set, the ELM can approach all training samples with zero error. However, more neurons in the hidden layer is not necessarily better. From the prediction accuracy of the test set, when the number of neurons in the hidden layer is gradually increased, the prediction rate of the test set gradually decreases. Therefore, it is necessary to comprehensively consider the prediction accuracy of the training set and the test set and make a compromise selection.
Compared to the basic ELM algorithm, the kernel extreme learning machine is more capable of solving regression prediction problems, and faster while obtaining better or similar prediction accuracy [
30]. In the KELM algorithm, the specific form of the feature mapping function
h(
x) of the hidden layer node is not specifically given, but only needs to know the specific form of the kernel function
K(
u,
v) to find the value of the output function. Because the kernel function directly adopts the form of inner product, it is not necessary to set the number of hidden layer nodes when solving the output function, so that the initial weight and offset of the hidden layer do not need to be set.
For the KELM algorithm, a kernel function is introduced to obtain better regression prediction accuracy, as
where Ω
ELM is kernel function matrix,
K(
u,
v) is the kernel function, which usually chooses Gaussian kernel function, and
N is the input layer dimension.
Therefore, through the above analysis, we chose KELM to study the DG location and capacity planning in distribution network.
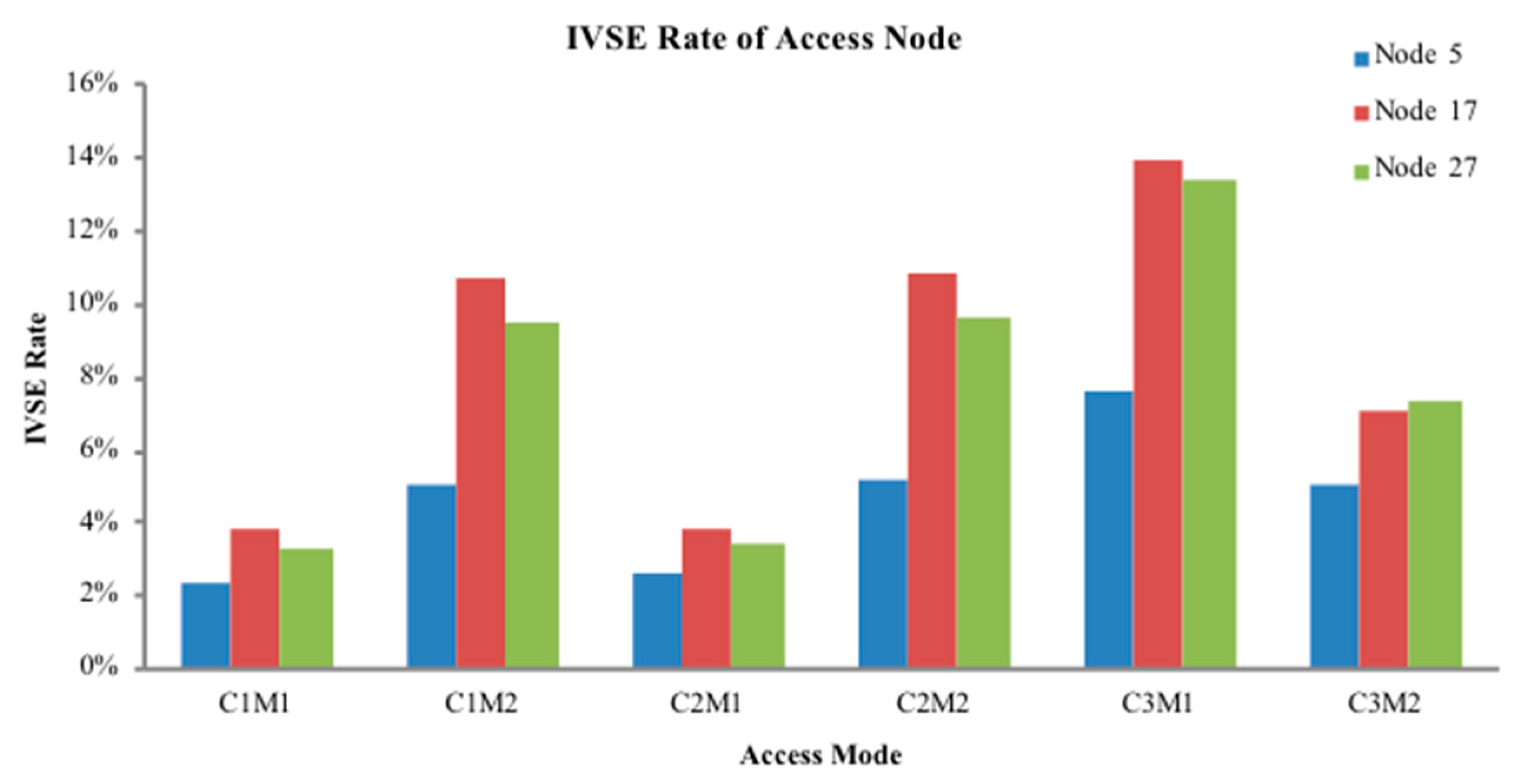
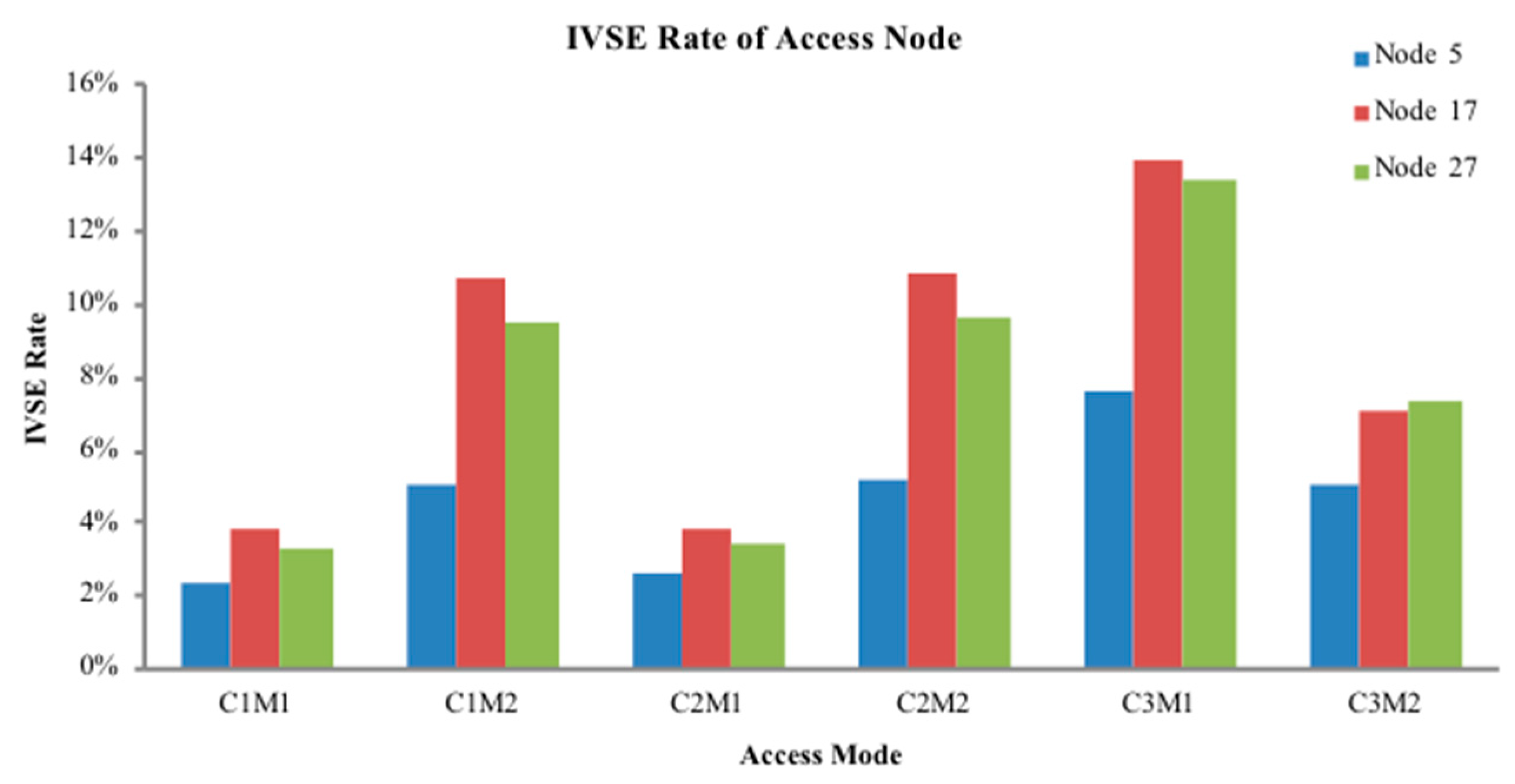
The model mainly uses KELM’s approximation ability of nonlinearity and generalization performance, to approximate the nonlinear relationship expressed with physical model between nodes in power system. In this paper, KELM is used to approximate the relationship between different access points of DG and the change of output power and network node voltage. Through training and testing, the variation of node voltage distribution with the DG access position and output power is given. By judging the root mean square error (RMSE) between the predicted and measured values given by the KELM model, the calculation accuracy of the model is judged. The voltage stability evaluation index is introduced to evaluate the result, so that the DG configuration scheme that satisfies the condition is selected.
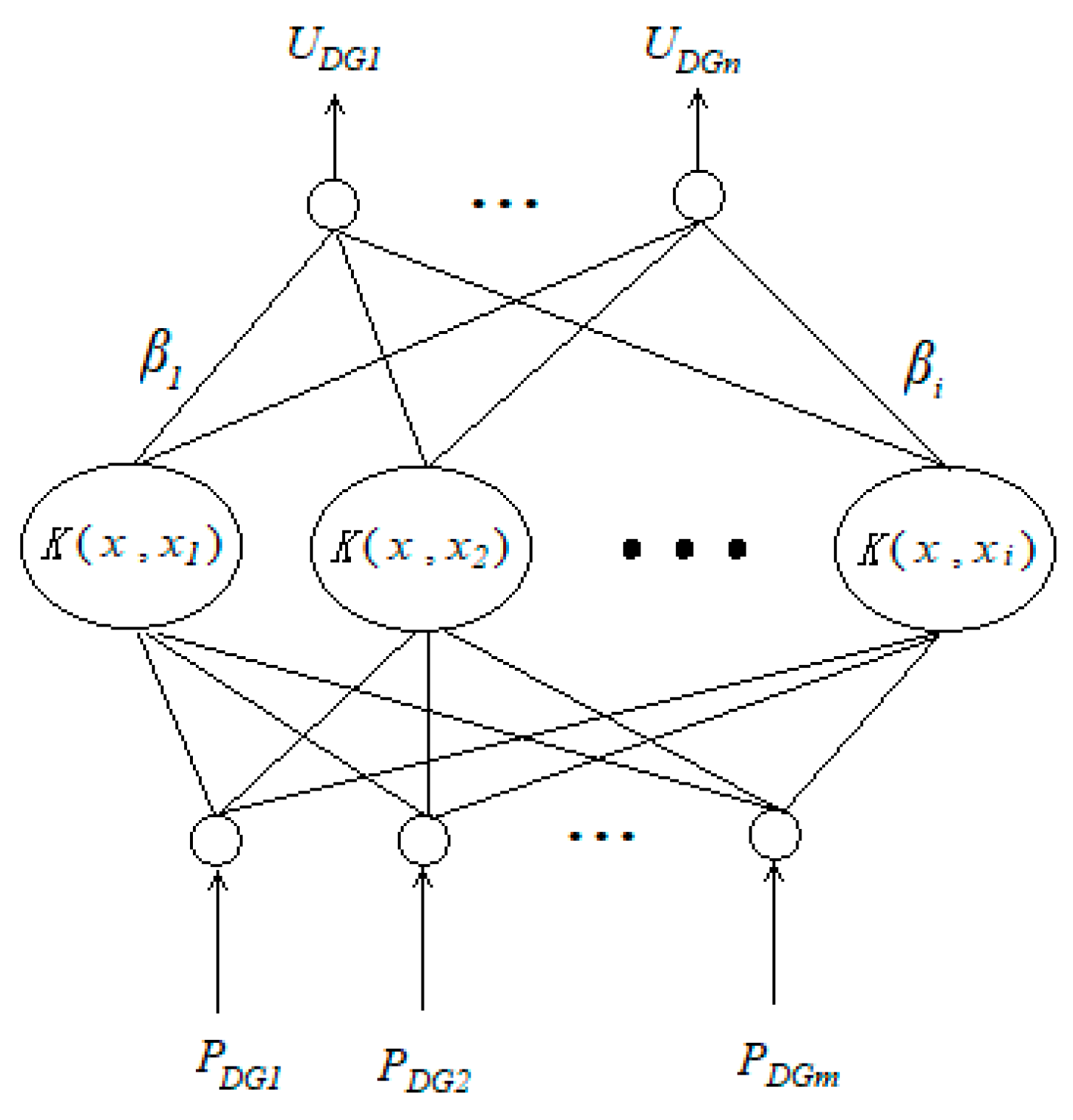
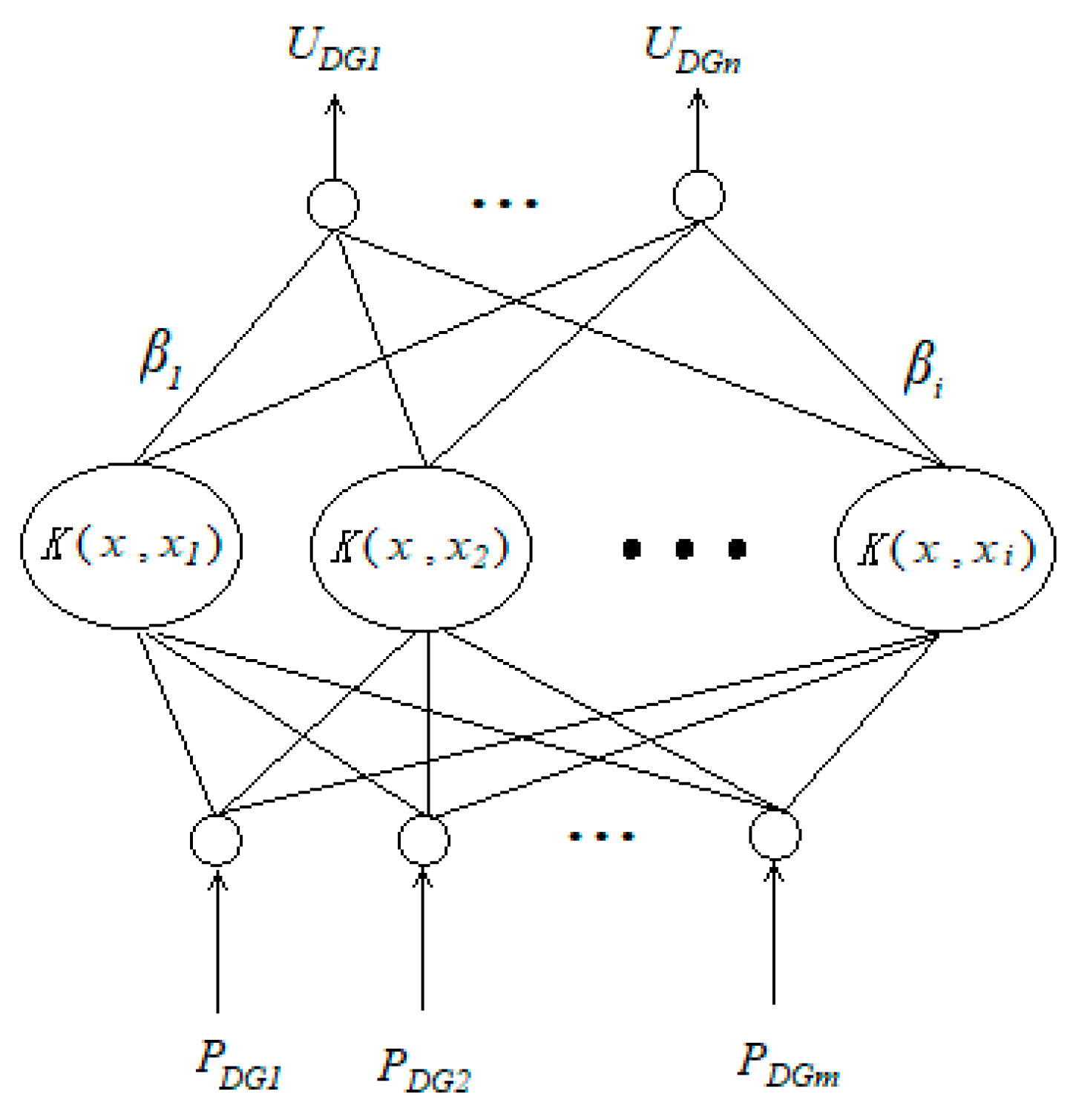
The
Figure 2 above shows the structure of the KELM model.
PDG represents the output power of DG,
UDG represents the voltage of the DG access point, and
K(
u,
v) represents the kernel function.
In the above formula, RMSE represents the root mean square error, y(i) represents the measured value, y*(i) represents the predicted value given by the KELM model, and N is the number of samples. The smaller the RMSE, the closer the prediction effect is to the measured value.
3.3. Solution Steps
The KELM algorithm is based on data-driven idea with the aim calculating data-driven power flow, and using the KELM algorithm to solve the DG location and capacity selection model. The algorithm is divided into two parts. The first is using the data-driven technology to describe the uncertainty of the wind and photovoltaic power generation output, minimizing the loss of the network as the objective function, and computing power flow that satisfies the constraint conditions. The second is using the obtained results to train KELM to map from DG output to voltage distribution. When the set value of mean square error (RMSE) is satisfied, the DG configuration scheme that meets the requirements is obtained. Finally, the results were evaluated using the voltage stability evaluation index, and the obtained configuration scheme was compared with the existing PSO and GA algorithms.
The solution steps are as follows:
Step 1: Initialize the system parameters, set the type of DG, and obtain basic parameters, such as DG output PDG.
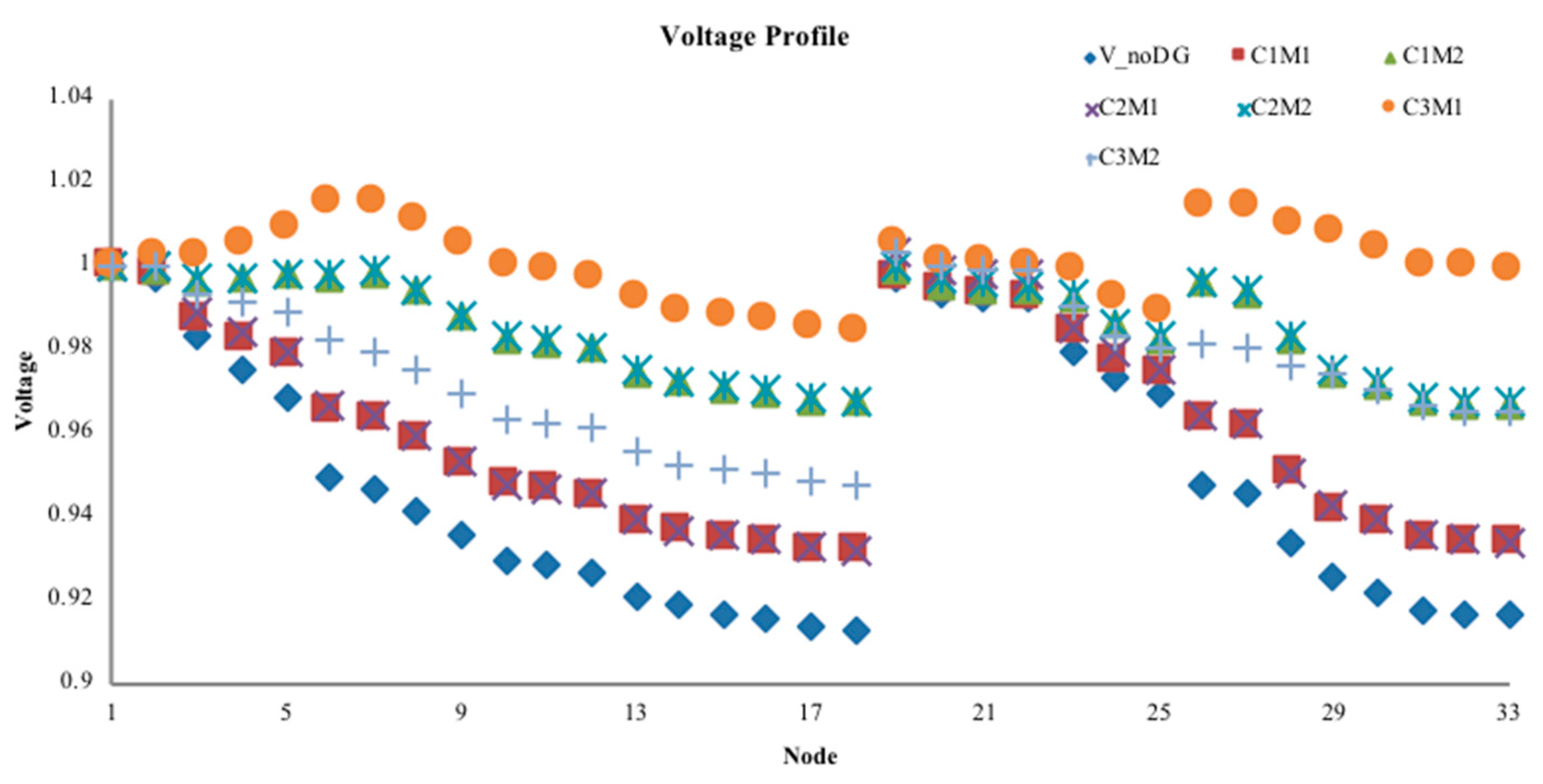
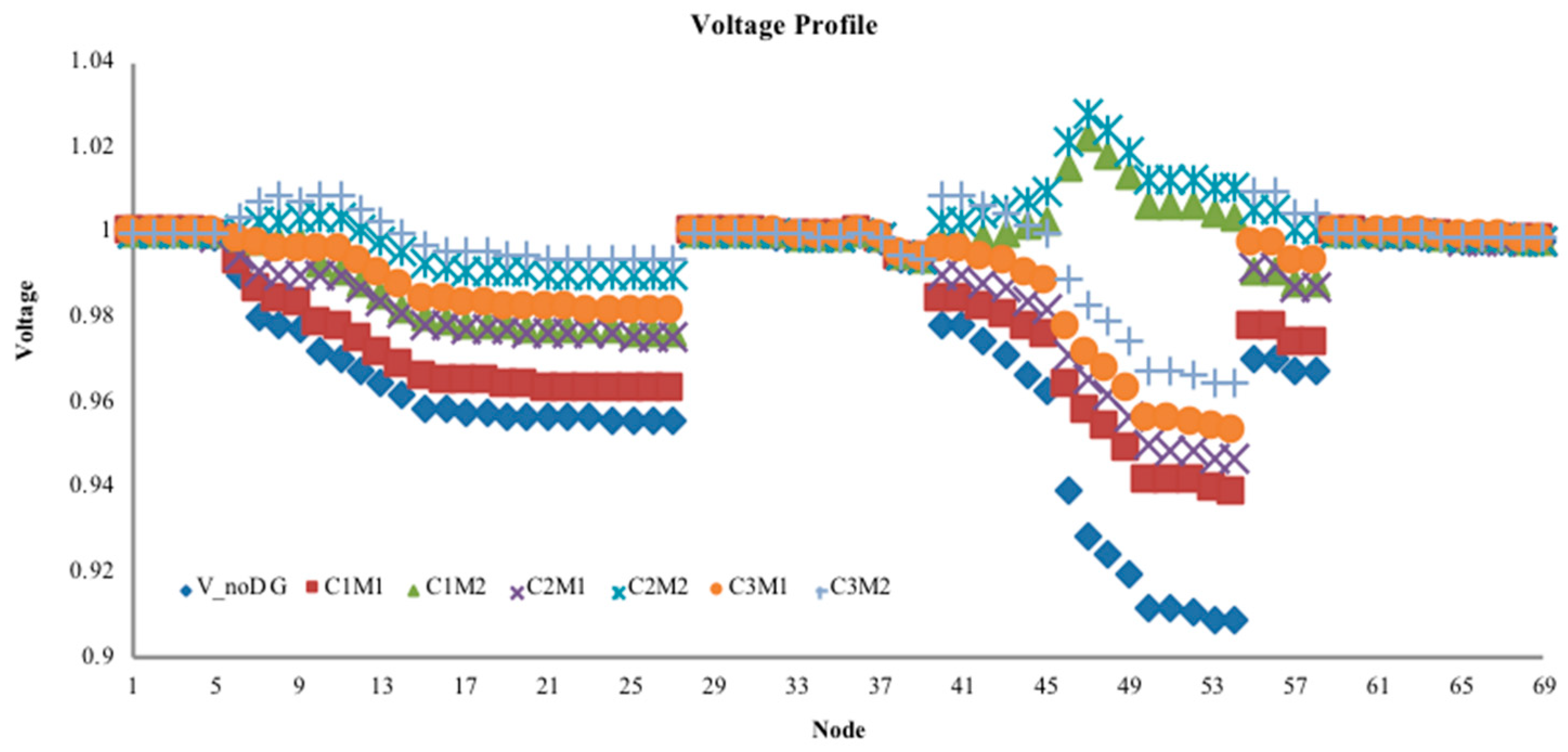
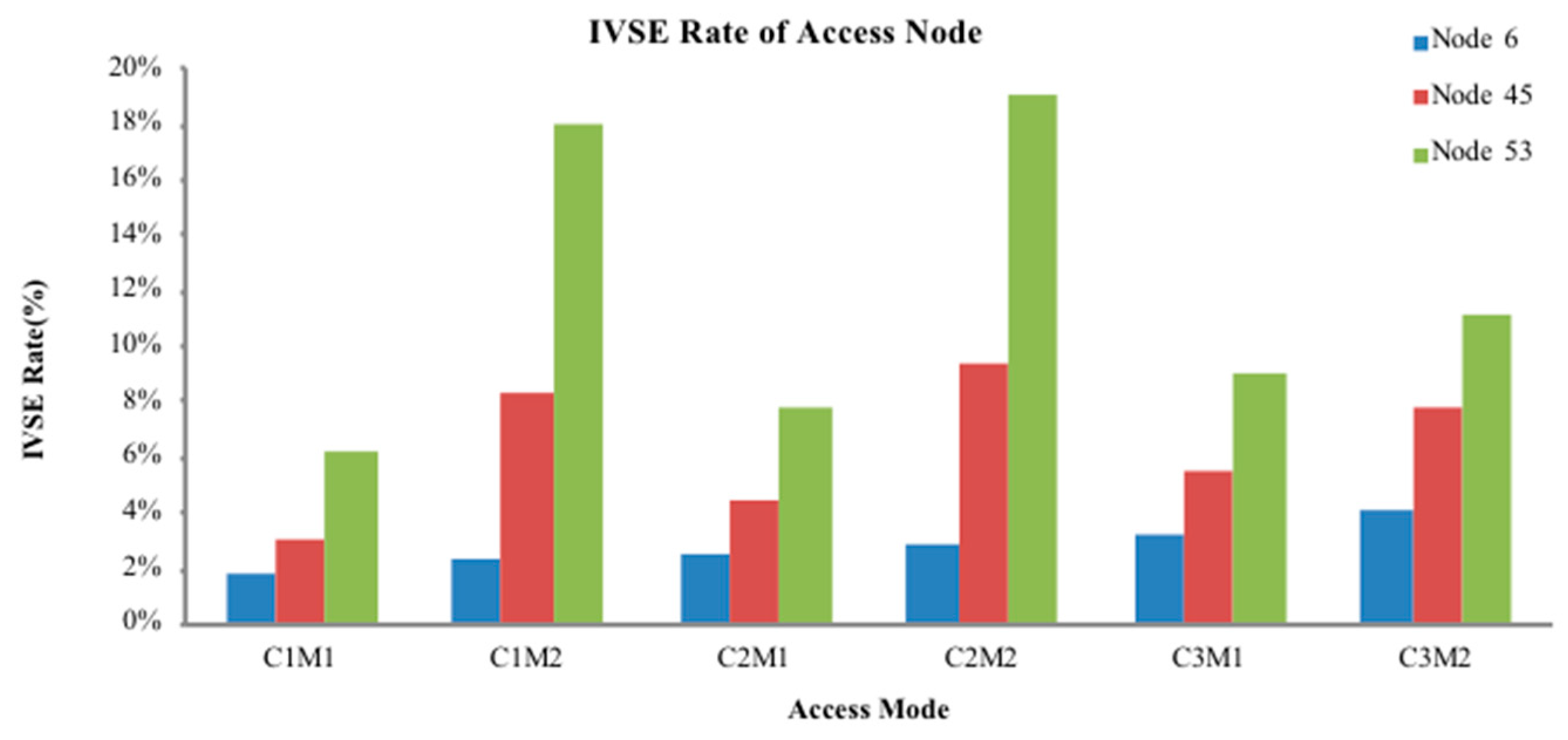
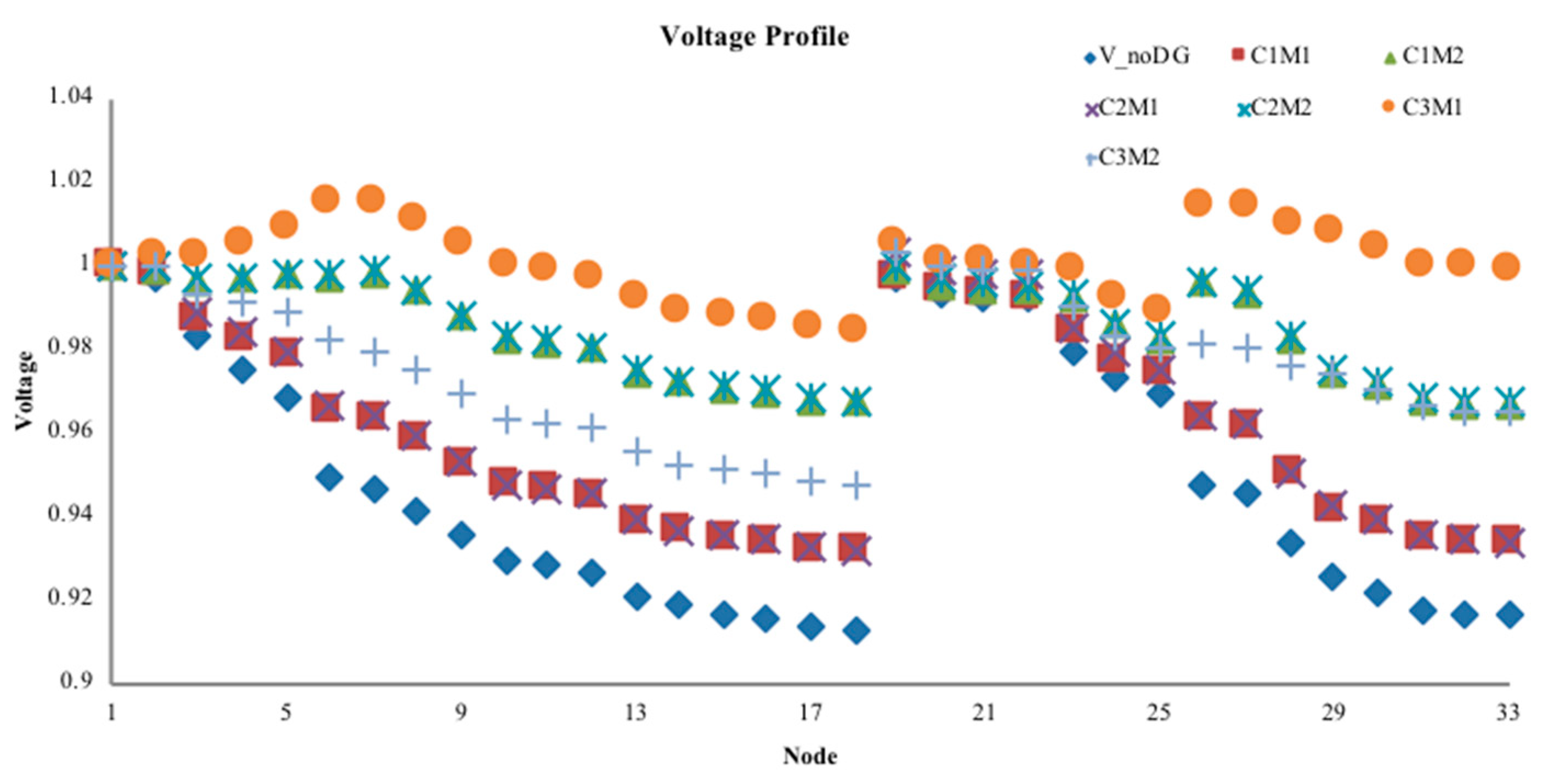
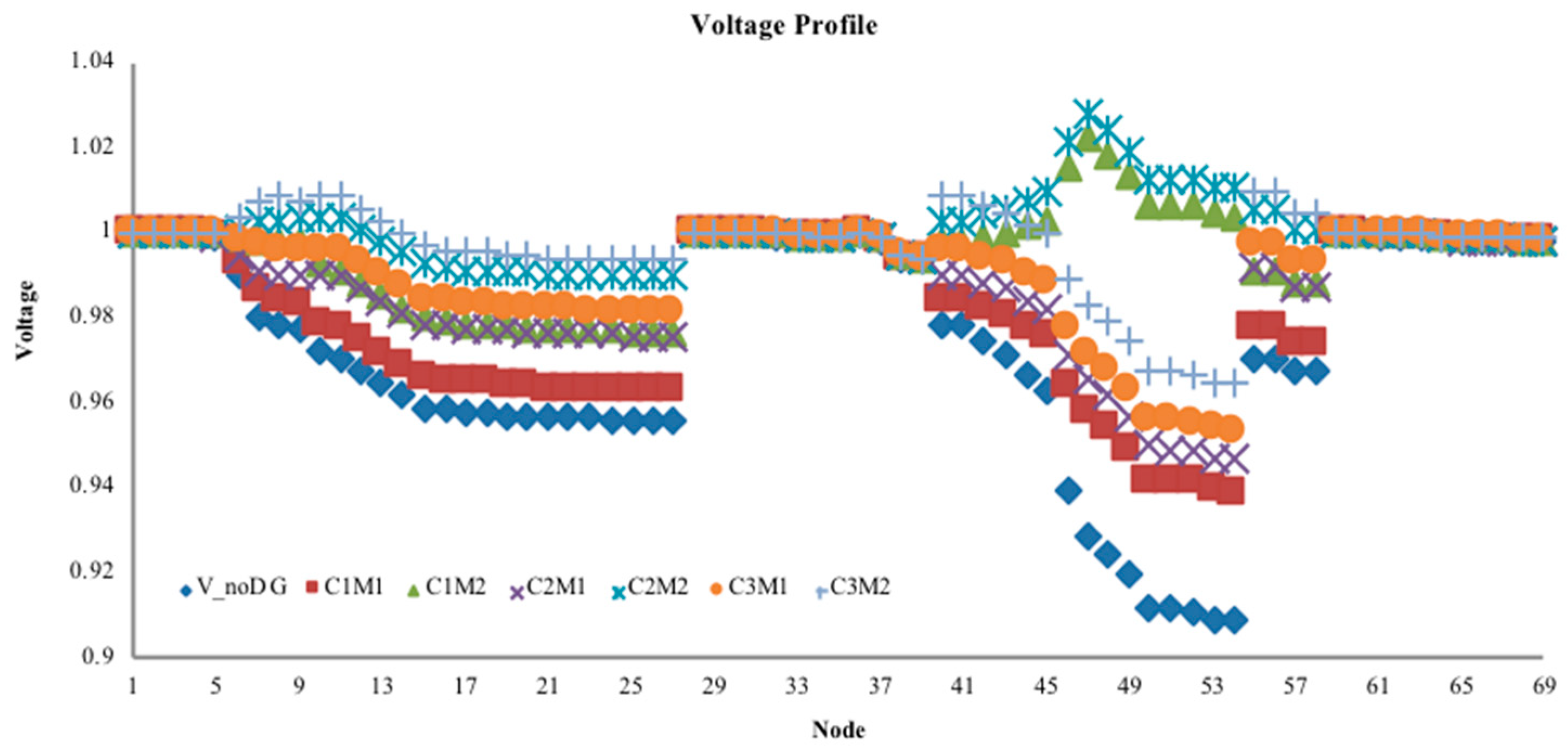
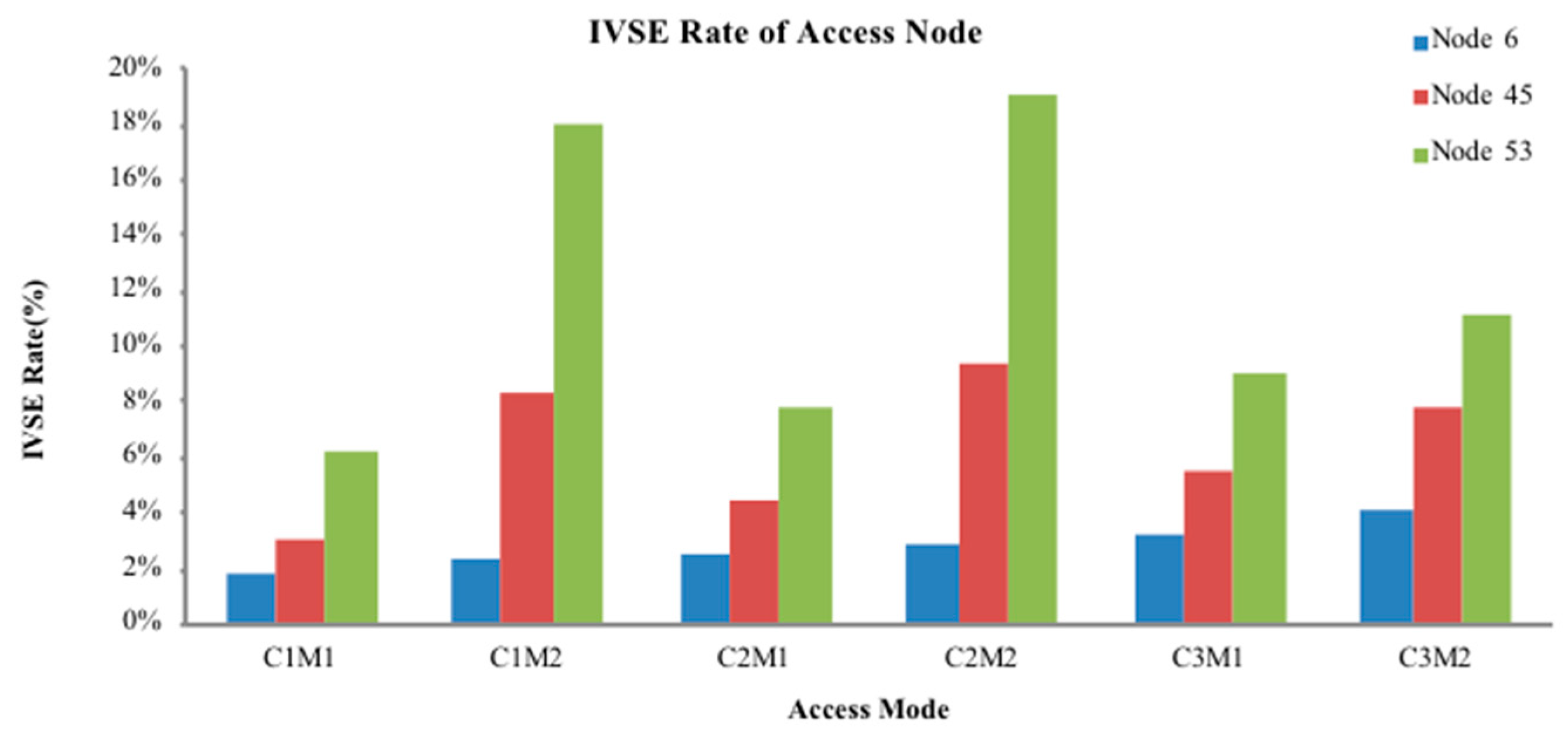
Step 2: Calculate the power flow of the distribution network without DG to obtain the IVSE index, the voltage profile, and active power loss. Select the point with the highest index value as the initial DG access location.
Step 3: Taking the initial access location as the starting point, calculate the power flow of the distribution network with DG, and record the DG output sequence PDG and the corresponding node voltage sequence UDG, as P = {PDG1, …, PDGm; UDG1, …, UDGn}.
Step 4: The KELM model is trained until the value of the root mean square error (RMSE) satisfies the set value, thereby obtaining the initial configuration scheme of DG, which is the access location and capacity of DG under the basic load condition.
Step 5: Based on the DG configuration scheme obtained in Step 4, the output of the DG is set to vary in the range of 10% to 30% of the total load, recorded as ∆SDG1 and ∆SDG2, respectively. Perform the power flow calculation again, and obtain a new data sample, denoted as P’ = {P’DG1, …, P’DGm; U’DG1, …, U’DGn}.
Step 6: P’ is taken as a test sample and input into the trained KELM. Judge if the RMSE satisfies the set value. If yes, the P’ at this time is saved as the new DG configuration scheme. Otherwise, return to Step 5.
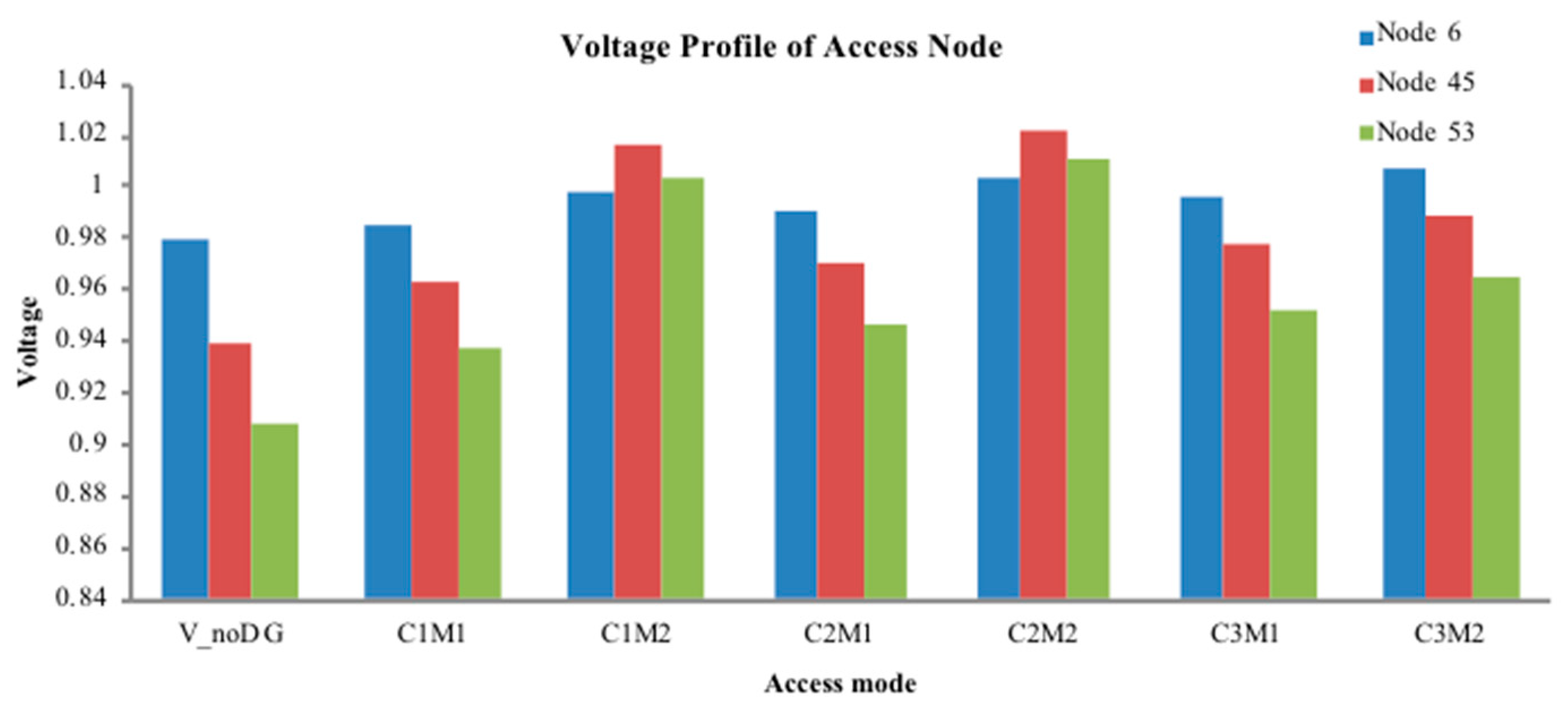
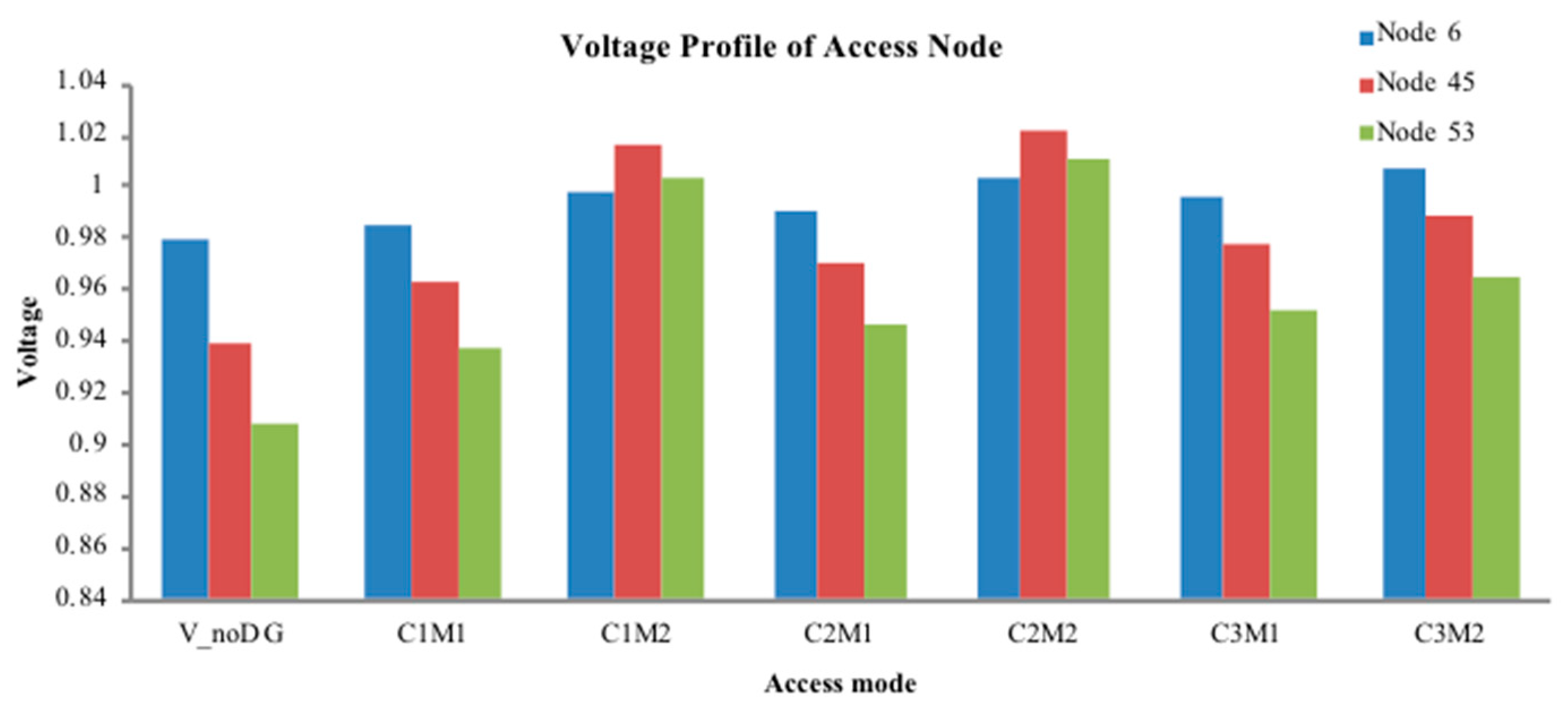
Step 7: From the obtained DG configuration scheme, substitute access capacity and corresponding location information into the pre-return method of distribution network to re-calculate the power flow. Calculate the IVSE index, voltage profile, and active power loss.
Step 8: Select the access capacity and location information of the DG corresponding to the minimum active power loss.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}