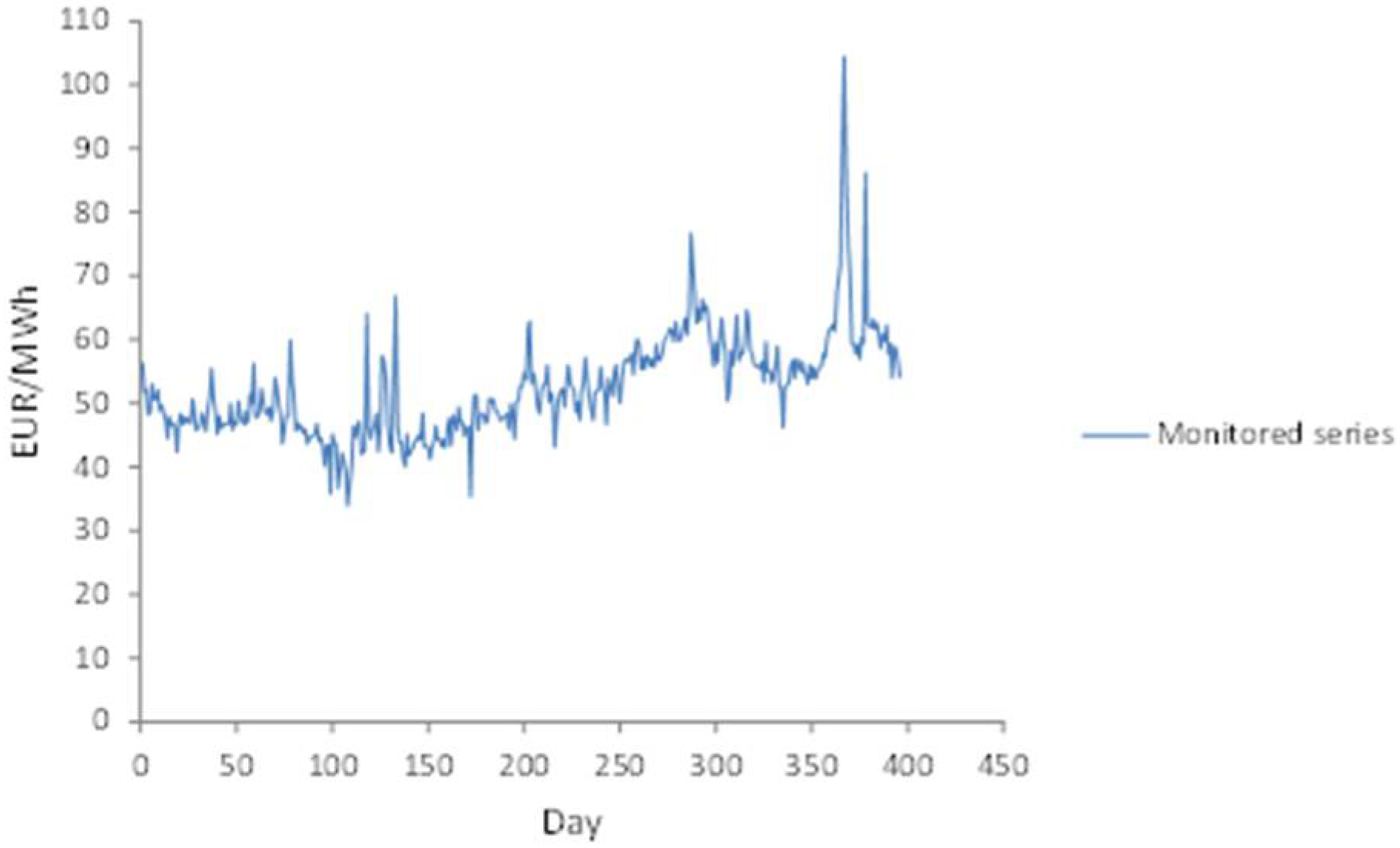
This paper investigates time invariant fuzzy time series of daily electricity prices. The investigation includes two main components. The first component refers to the fuzzification of monitored data using the fuzzy C-mean clustering algorithm, while the second refers to the creation of a forecasting model based on the interval-valued autoregressive process.
2.1. Fuzzification of Monitored Data
The fuzzy time series was originally defined by Song and Chissom [
26,
27]. The basic definitions of the fuzzy time series, and time-variant and time-invariant fuzzy time series, are given as follows.
Suppose that is the universe of monitored data that should be fuzzified by fuzzy sets and let be a set of . Then, is called a fuzzy time series on . If is caused by , this dependency is defined as , where is a fuzzy relation of the first order between and and * is the fuzzy operator. If is caused by and is constant for each t, then is a time-invariant fuzzy series.
The intention of fuzzification is to transform a series of monitored data into a series of fuzzy states. Using this approach, each value within a series is transferred into an adequate fuzzy state and we obtain the order of states instead of the order of discrete values. For that purpose, we apply the fuzzy C-mean clustering algorithm [
28,
29,
30,
31] over the set of daily monitored electricity prices,
.
A fuzzy C-mean algorithm is a method based on the minimization of a generalized least-squared error function within groups. Let be the univariate series of monitored data and be the electricity price vector composed of M cluster centers. Every cluster is a fuzzy set defined by the relative closeness to space .
The membership degree
indicates to what degree the relative closeness
PN belongs to the cluster center vector
Cm, which results in a fuzzy partition matrix
. Let
uim be the membership,
Cm the center of the cluster,
N the number of observed data points, and
M the number of clusters. Then, the objective function, which should be minimized in fuzzy clustering, is defined as follows:
where
dmi is the Euclidean distance between the observation and the center of the cluster;
, and exponent
ω is the fuzzy index (
). In this paper we set up
. The objective function
J is minimized subject to the following constraints:
An iterative algorithm is used to find the minimum of the objective function. In
j-th iteration, the values of
and
are updated as follows:
The iteration process stops when , where represents the minimum amount of improvement or a given threshold value.
The number of clusters represents the number of fuzzy sets or states. According to the obtained fuzzy partition matrix (
) we can define the fuzzy state matrix
S(
i) of the observed data as follows:
If we take into consideration that the fuzzy C-mean algorithm produces a sequence of M cluster centers, then, on the basis of the maximum value of the membership function we can determine the fuzzy state to which the i-th monitored value belongs. Finally, the sequence of fuzzy states represents a fuzzy time series on .
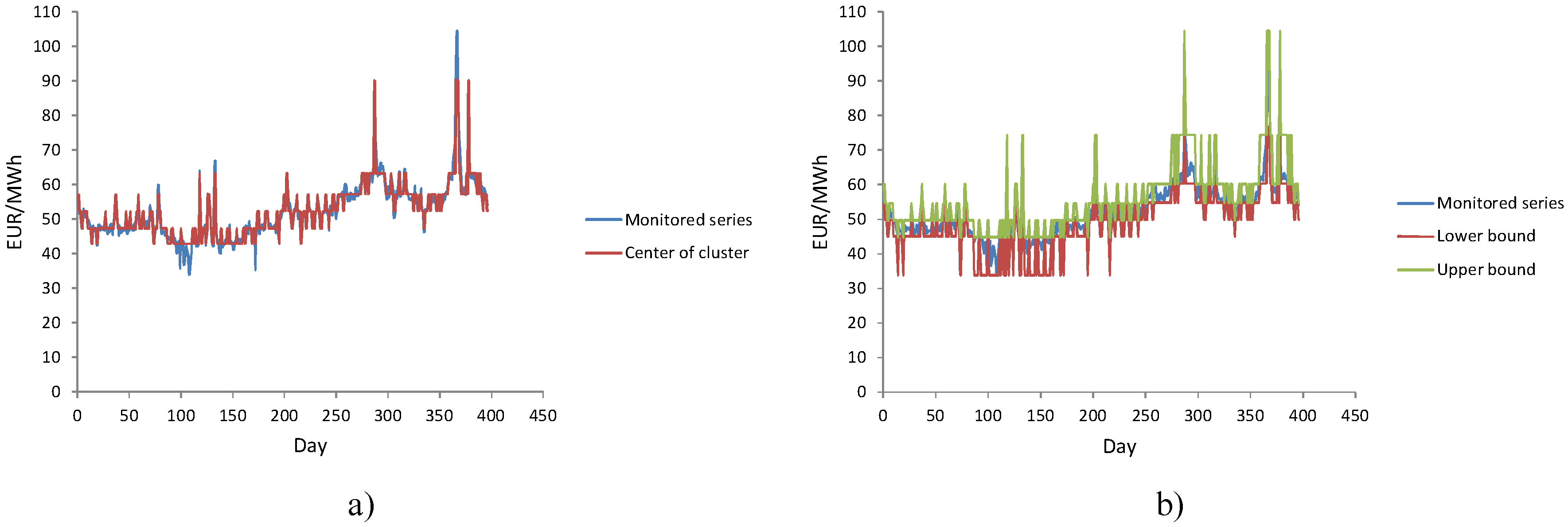
The creation of fuzzy relations among obtained fuzzy states can be very complex. To overcome this problem, we transform the sequence of fuzzy states into an adequate stationary interval series and apply an interval-valued autoregressive process to create a short-term forecasting model.
2.2. Interval-Valued Forecasting Model
The process of transformation of a fuzzy time series into an interval time series is based on the fact that each fuzzy state
can be represented by a triplet;
, where
is equal to the element of the cluster with minimum value,
is equal to the element with the maximum value, and
is the center of the cluster. If we take into consideration that we monitored the daily electricity price then transformation produces the following interval time series:
where,
is the lowest and
is the highest daily electricity price for the
m-th fuzzy state. Accordingly, we can say that we created chronological sequence of interval-valued data, i.e., we have a time series of interval data.
An interval variable
X is defined as a closed, bounded set of real numbers in the form of
, where
is the lower bound,
is the upper bound of interval, and
. An interval time series is a sequence of interval variables monitored in successive time points and expressed as a two-dimensional vector
. In this paper we use the basic interval arithmetic operations introduced by Moore et al. [
32]:
The attraction of interval arithmetic is that it would not be necessary to analyze whether the conventional point-wise floating-point computations are safe. As the interval results contain all possible values, a narrow interval indicates success. A wide interval does not prove that a conventionally computed result is wrong, but it does indicate a risk. Interval arithmetic has the property of correctness; result intervals are guaranteed to contain the real number that is the value of the expression [
33].
Every monitored series contains information about the process that generated it. This process can be realized by modeling the current value as a function of its previous values. An autoregressive process defines the current value of the variable as a weighted linear sum of its previous values and is defined as the following stochastic difference equation:
where,
is a constant,
are coefficients of the model,
is white noise (
), and
k is the order of the autoregressive process (lag). In the context of interval variables, the autoregressive process becomes an interval autoregressive process:
Another representation of the interval can be done in terms of the so-called midpoint and radius, with
and
. The midpoint is the center of an interval (the location), whereas the radius is the half-width of an interval (a measure of imprecision), with
[
34]. Let
be the interval response variable and
be the set of interval explanatory variables monitored on
N units. Accordingly, Equation (11) can now be expressed by the following linear relationships:
where:
, —the center and radius of the i-th interval response variable,
, —the center and radius of the j-th interval explanatory variables,
, —the center and radius of the constant,
, —the center and radius of the regression coefficients of j-th interval explanatory variables,
, —the center and radius of the residual of the i-th interval response variable.
The optimal coefficients are obtained according to the least-squares approach by minimizing the sum of squared residuals of
and
subject to non-negativity of
. The criterion of minimization is defined as:
To define the values of the coefficients we apply the center and range method developed by Neto and de Carvalho [
35]. The values of the coefficients
and
are the solutions of the following system of
normal equations written in matrix form:
where
A is a
matrix and
b is a
vector described as:
.
If the interval time series is stationary, then
; otherwise
, where
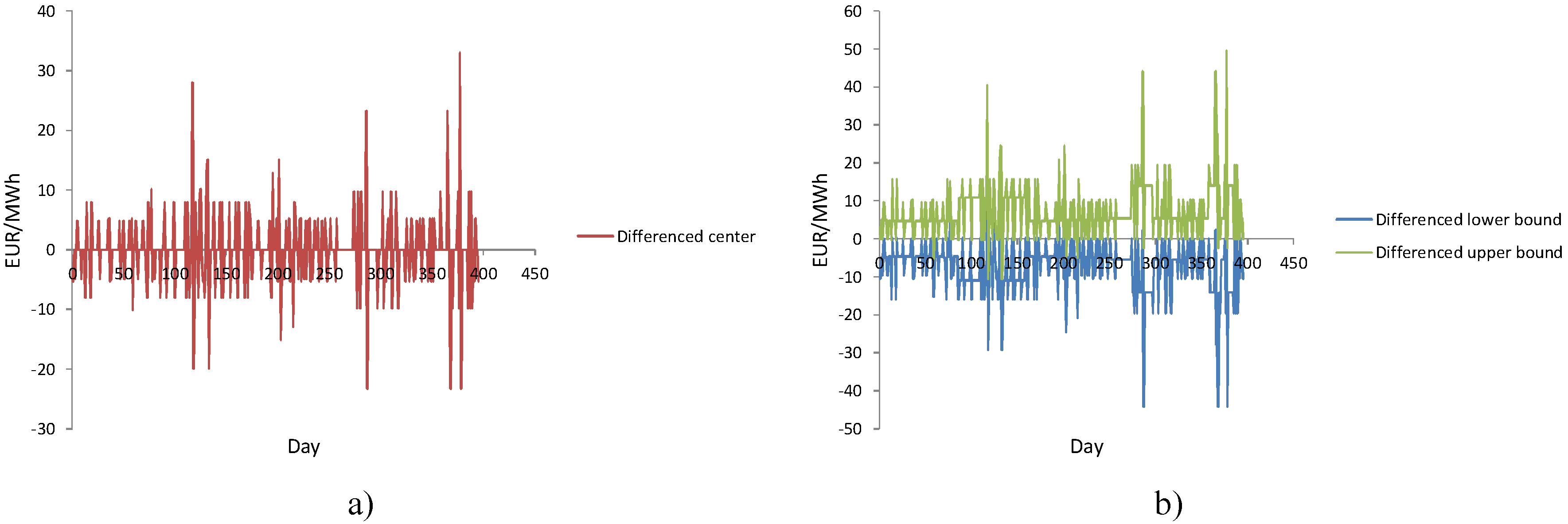
d denotes the order of differencing. If the interval series is non-stationary, then it is necessary to transform it into a stationary series by
d-differencing. First-order differencing is performed in the following manner:
After differencing, the interval time series becomes stationary and we can apply the
k-th interval autoregressive process (Equation (11)) on differenced series. Values of the interval differenced series will be forecasted as follows:
Equation (19) represents values for forecasting the first-order differenced series, but we want to forecast monitored electricity price series. Therefore, we must transform these values into the
form as follows:
If we take into consideration that the monitored series is represented by the series composed of
M fuzzy states, then it is necessary to find out to which fuzzy state of
M values the forecasted state corresponds. We propose the following procedure for expressing the sequence of forecasted fuzzy states by the set of
M fuzzy states (Algorithm 1):
| Algorithm 1: |
| Input: forecasted series by AR(k); |
| Output: forecasted fuzzy states expressed by M fuzzy states |
| Step 1. create series of forecasted centers; |
| Step 2. create a fuzzy partition matrix; |
|
| Step 3. create forecasted fuzzy state matrix; |
|
| Step 4. create the sequence of forecasted fuzzy states; |
| Step 5. according to create interval forecasted series; |
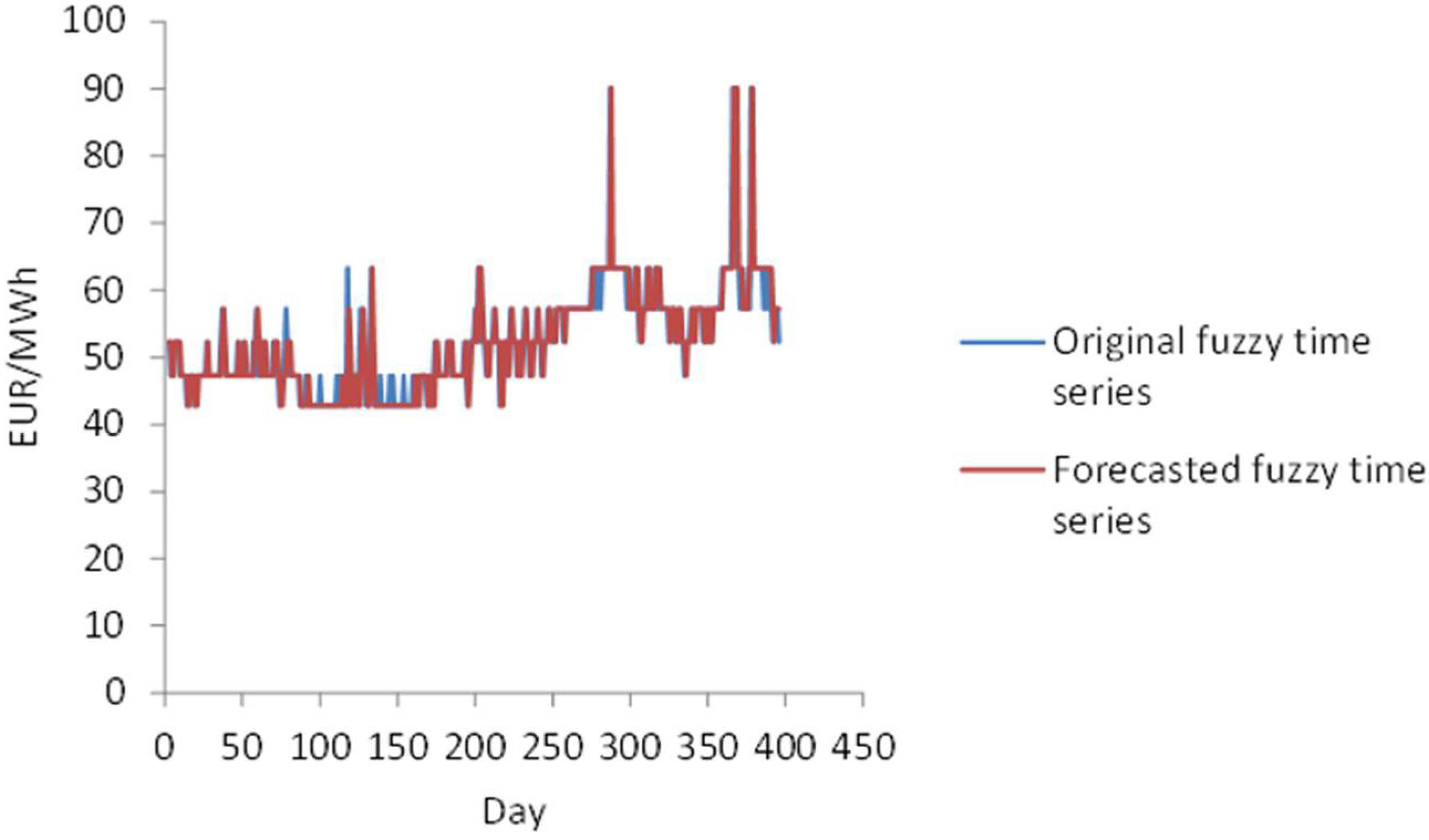
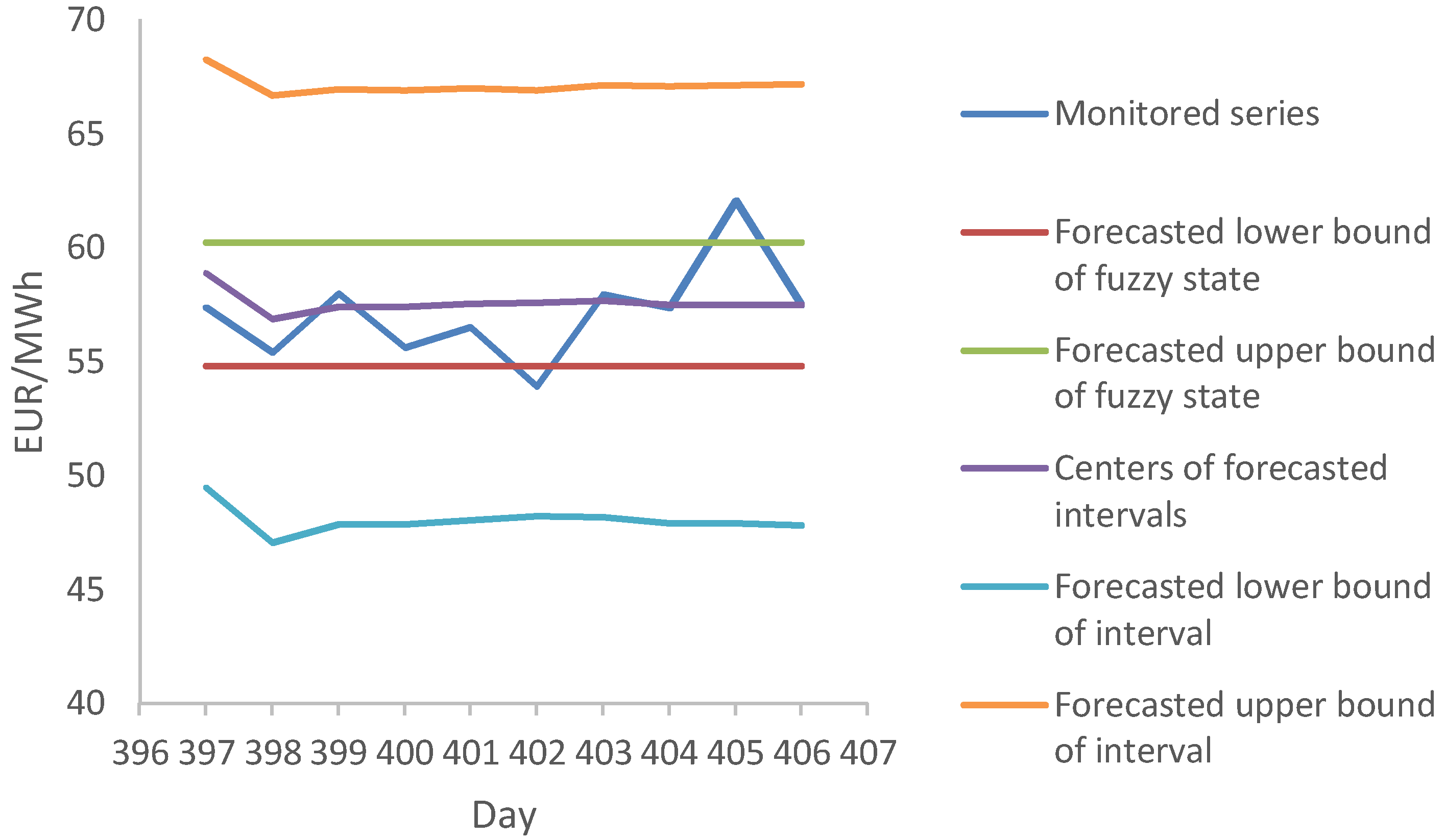
Algorithm 1 represents the forecasting model. This algorithm is applied to forecast the future electricity price for . Note that this is a short-term forecasting model and H should be set to a few days.
Calibration of the forecasting model is related to the determination of two main parameters. The first parameter considers the number of fuzzy states (M-clusters) for a monitored electricity price series, while the second considers the order of the autoregressive process (k).
We developed the following iterative algorithm to define the minimum number of possible fuzzy states (clusters), (Algorithm 2):
| Algorithm 2: |
| Input: monitored series |
| Output: minimum number of clusters mmin |
| Step 1. set up the initial value of M to m = 3 and k = 20 |
| Step 2. do the fuzzy C-mean |
| Step 3. create interval series |
| Step 4. if interval series is non-stationary do d-differencing |
| Step 5. create center series |
| Step 6. do autocorrelation function for 20 lags |
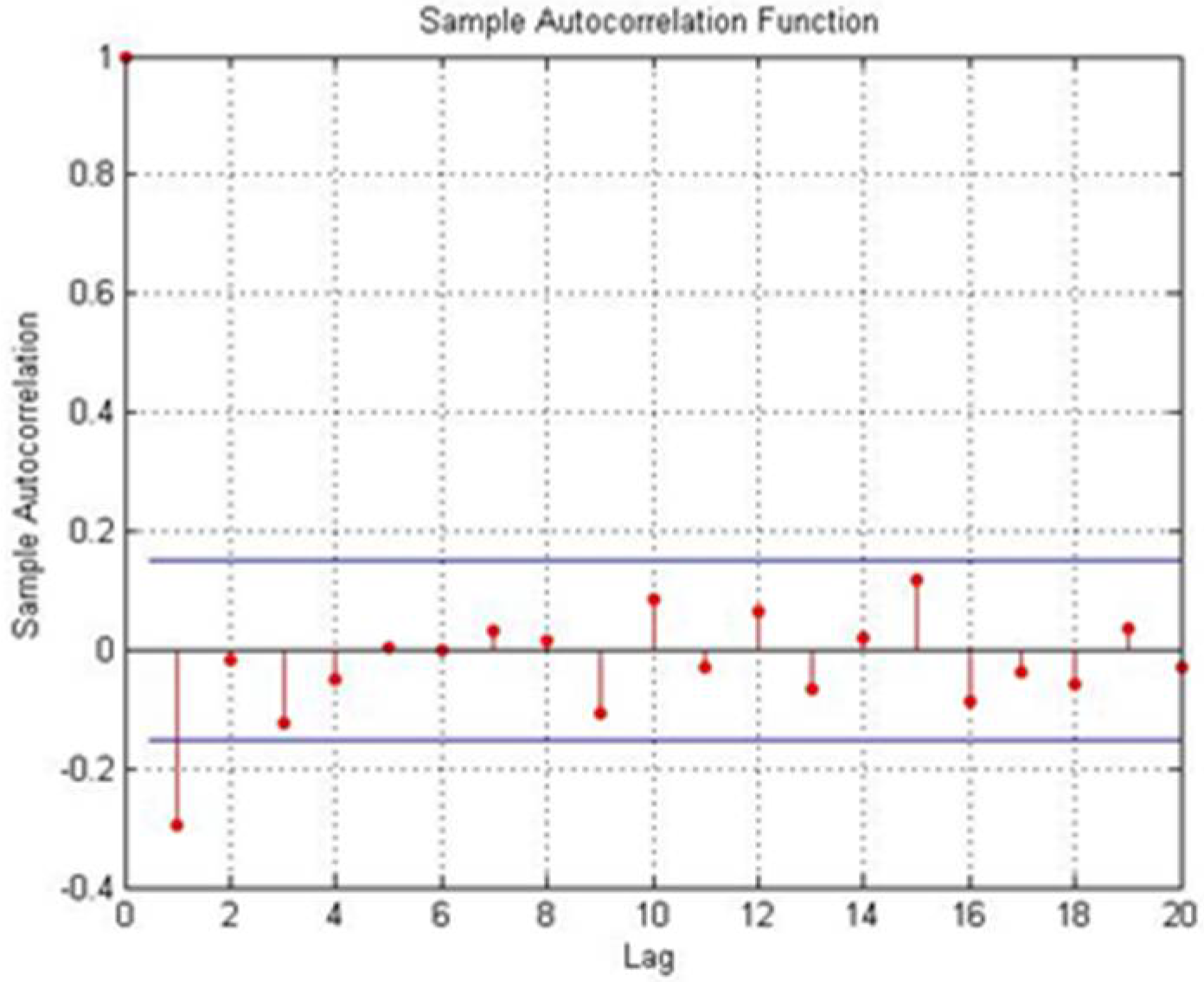
| Step 7. if there is one and only one lag such that , stop. |
| Otherwise set m + 1 and go to Step 2 |
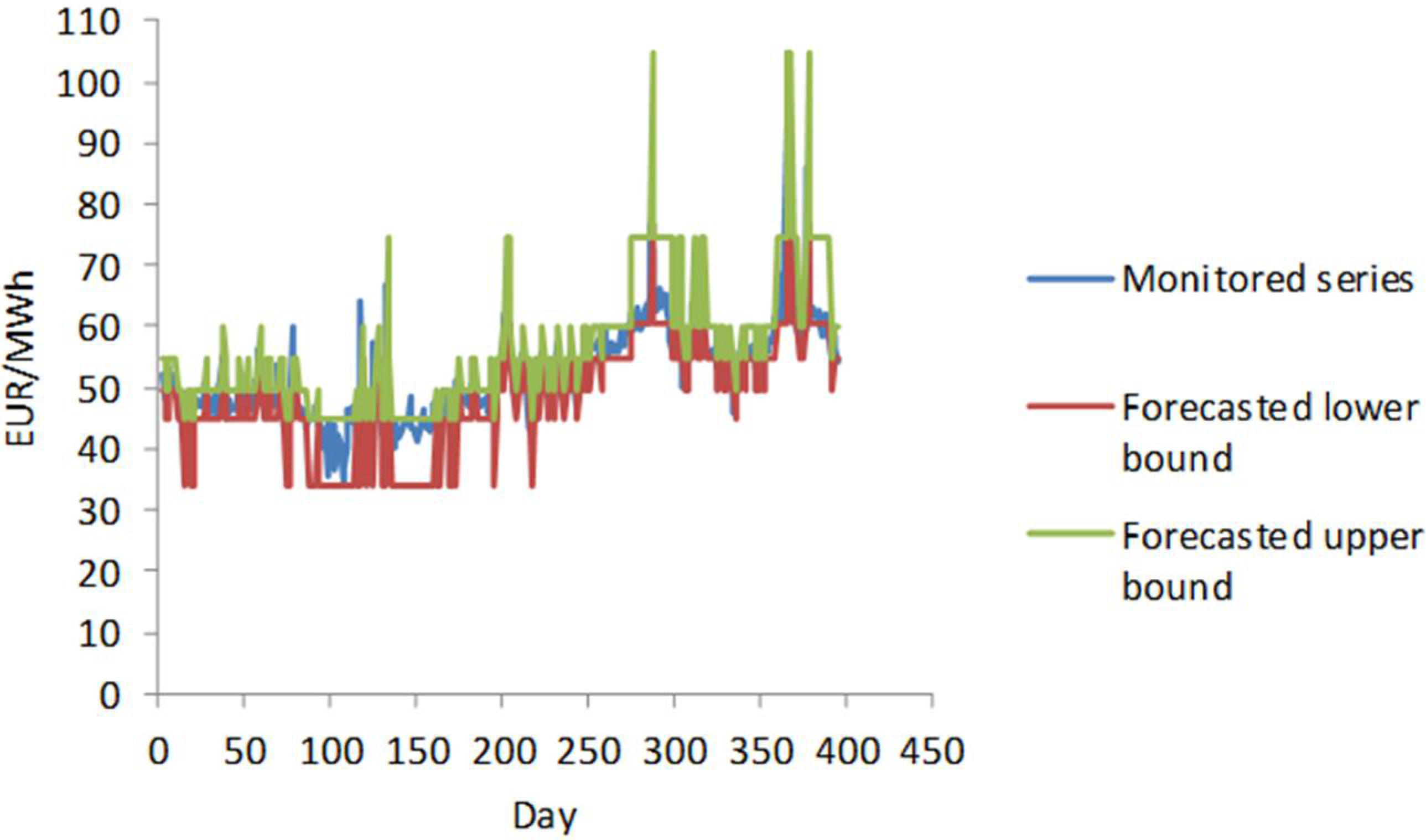
Figure 1 shows a case when the condition defined by Step 7 is met.
The autocorrelation function (
ACF) of any series gives the correlation between
yt and
yt−k for
k = 1, 2, 3, …. Theoretically, the autocorrelation between
yt and
yt−k is calculated as:
Since the minimum number of clusters is defined, we continue the iteration process until the condition (Step 7) is met. Suppose the condition is not met in the
j-th iteration, in that case, we stop the iterative process and take the number of clusters from
j − 1 iteration to be the maximum number of clusters. The algorithm that considers the maximum number of fuzzy states is as follows (Algorithm 3):
| Algorithm 3: |
| Input: monitored series |
| Output: maximum number of clusters mmax |
| Step 1. set up the initial value of M to m = mmin and k = 20 |
| Step 2. do the fuzzy C-mean |
| Step 3. create interval series |
| Step 4. if interval series is non-stationary do d-differencing |
| Step 5. create center series |
| Step 6. do autocorrelation function for 20 lags |
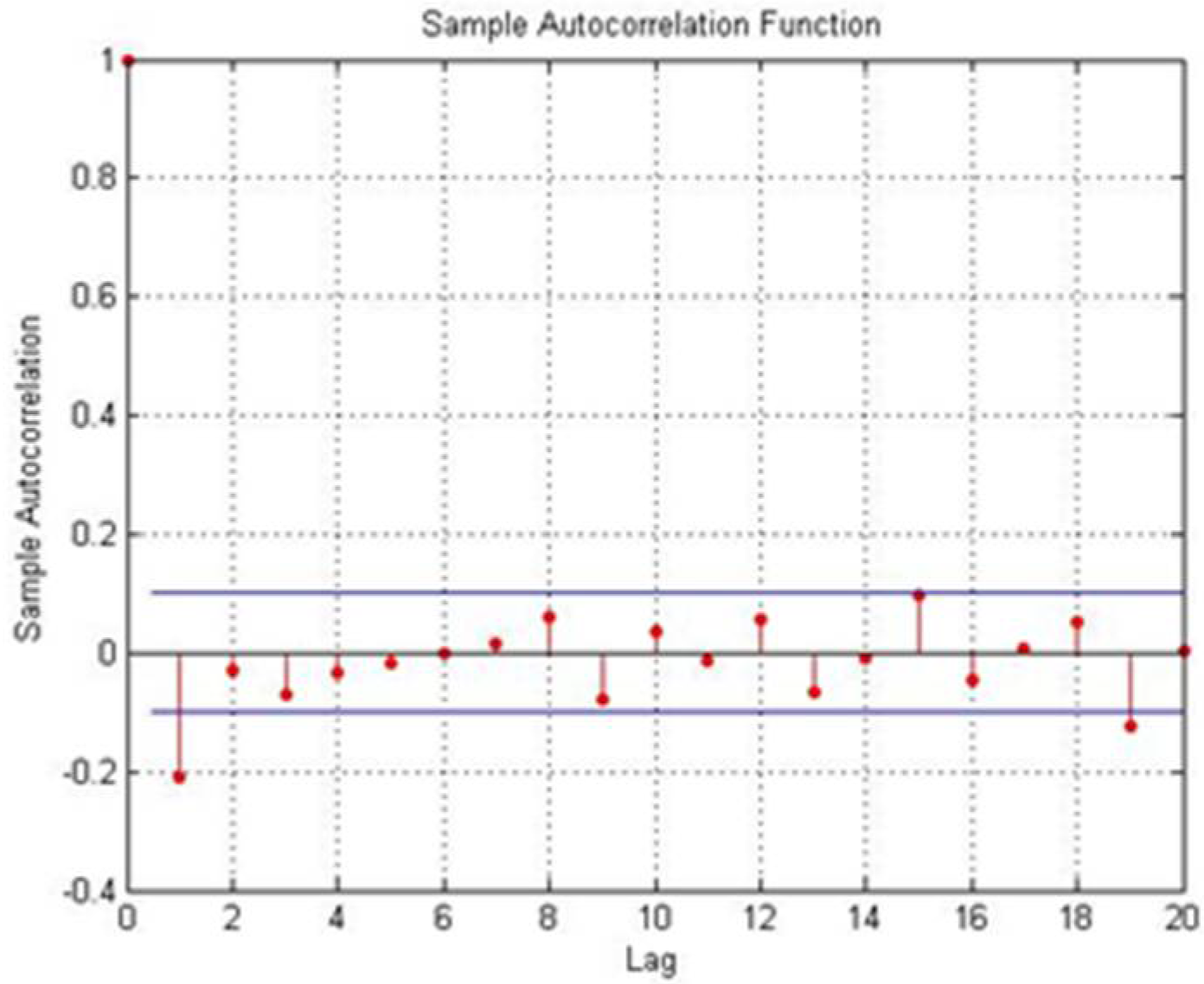
| Step 7. if there is one and only one lag such that , |
| set m+1 and go to Step 2. Otherwise stop and get from the previous iteration |
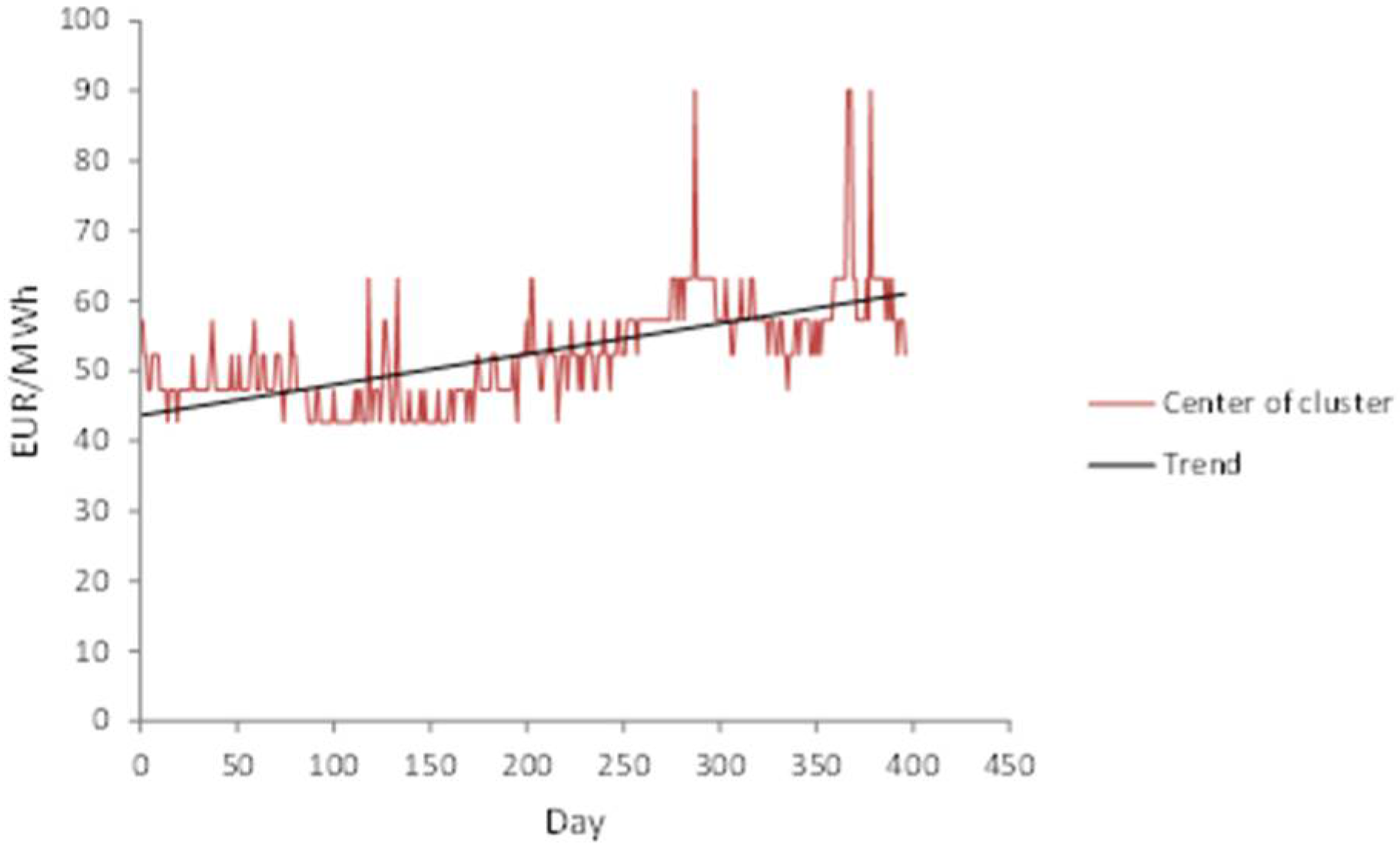
Accordingly, the number of possible fuzzy states is defined as . The expected number of clusters equals the center of the interval; .
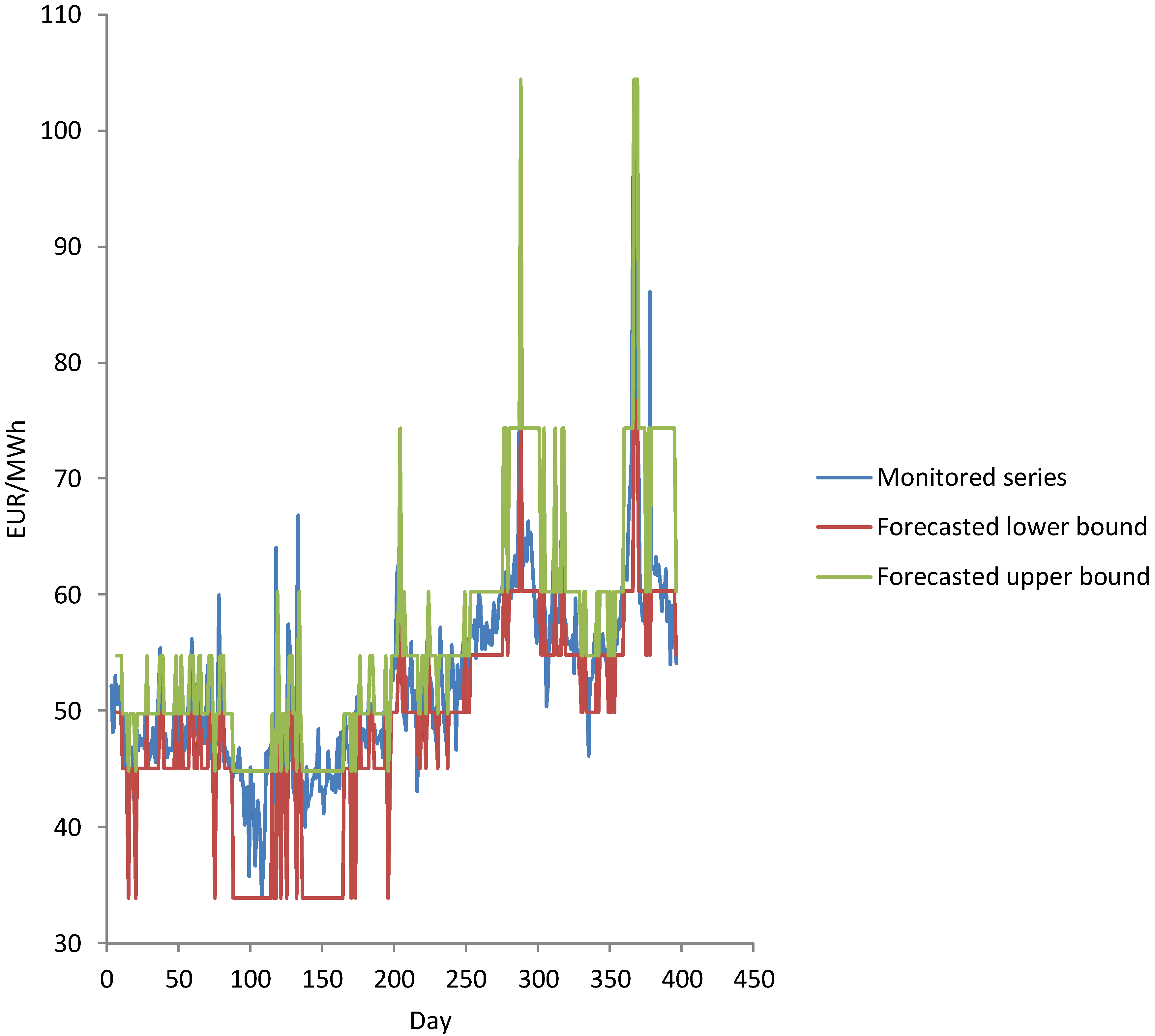
Figure 2 shows a case when the condition defined by Step 7 is not met.
Algorithm 2 produces the minimum number of fuzzy states that can be used to transform a monitored series into an interval one, which can be further forecasted by the interval autoregressive process alone, while Algorithm 3 produces the maximum number of fuzzy states. In this way we can increase the flexibility of the forecasted model because any number of fuzzy states in that range can be taken for the purposes of transformation. Finally, the main aim of the proposed algorithms is to prepare a monitored series to be forecasted by the autoregressive model only.
The order of the autoregressive model (lag length) is defined according to information criteria that measure the quantity of information about the dependent variable contained in a set of regressors. In this paper we will use the Akaike information criterion (
AIC) [
36] and the Schwartz–Bayesian information criterion (
SBIC) [
37]. They are calculated by the following equations:
where
N is the sample length;
k is the total number of estimated coefficients; and
are the residuals.
The sum of the squared residuals represents the main part of both criteria and we want to minimize it. Thus, we select the model with the smallest value of ACI or SBIC.
The absolute percentage error of the model for the
i-th electricity price is calculated as follows:
To demonstrate the effectiveness of the model, the forecasted results are analyzed by the mean absolute percentage error (
MAPE):

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}