Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe



Abstract
1. Introduction
2. Constraint Interaction
3. Methodology
3.1. Criteria Identification
3.2. GLAES and Prior Overview
3.3. Evaluating Constraint Measures
4. Results
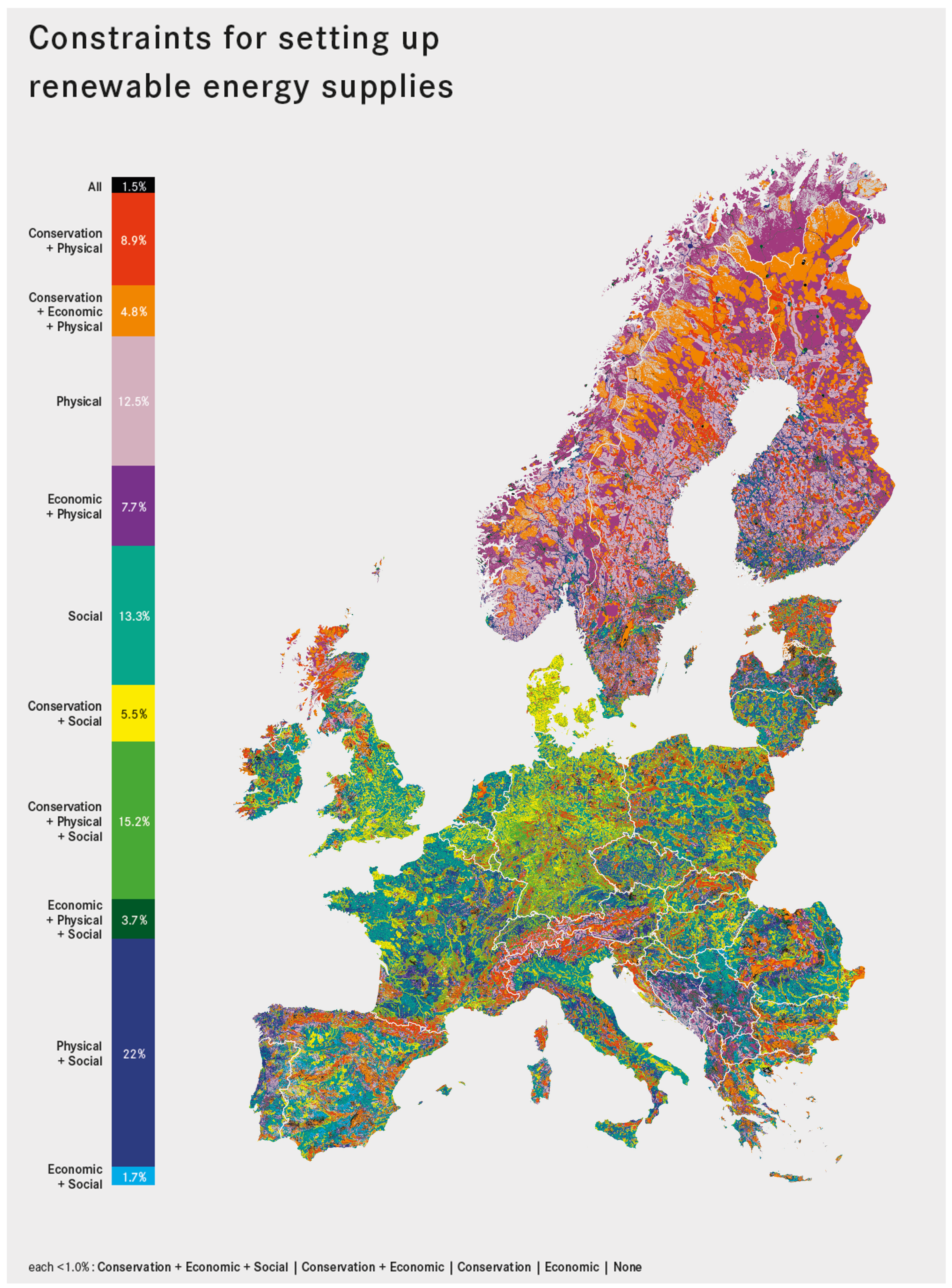
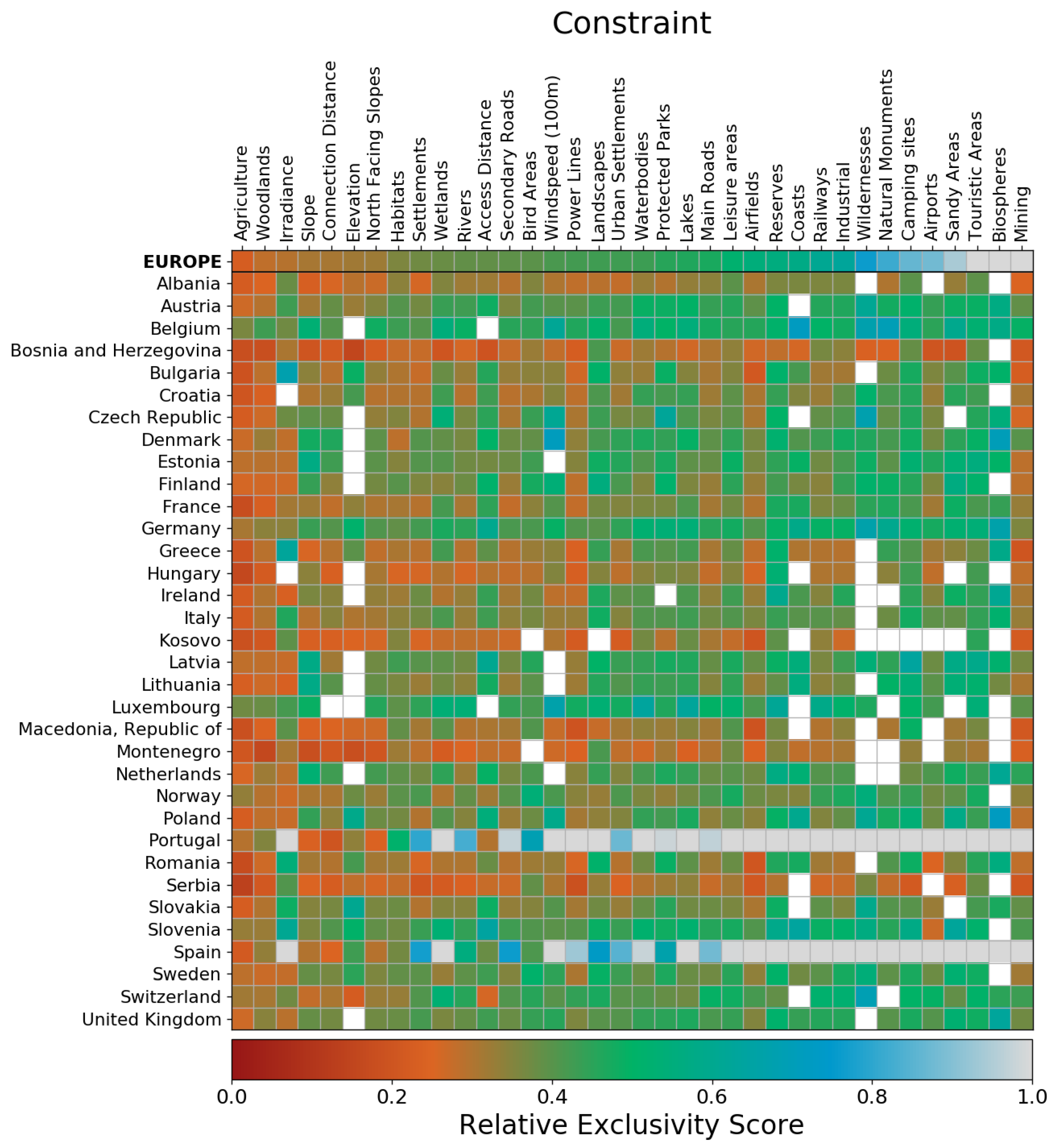
4.1. Constraint Mapping
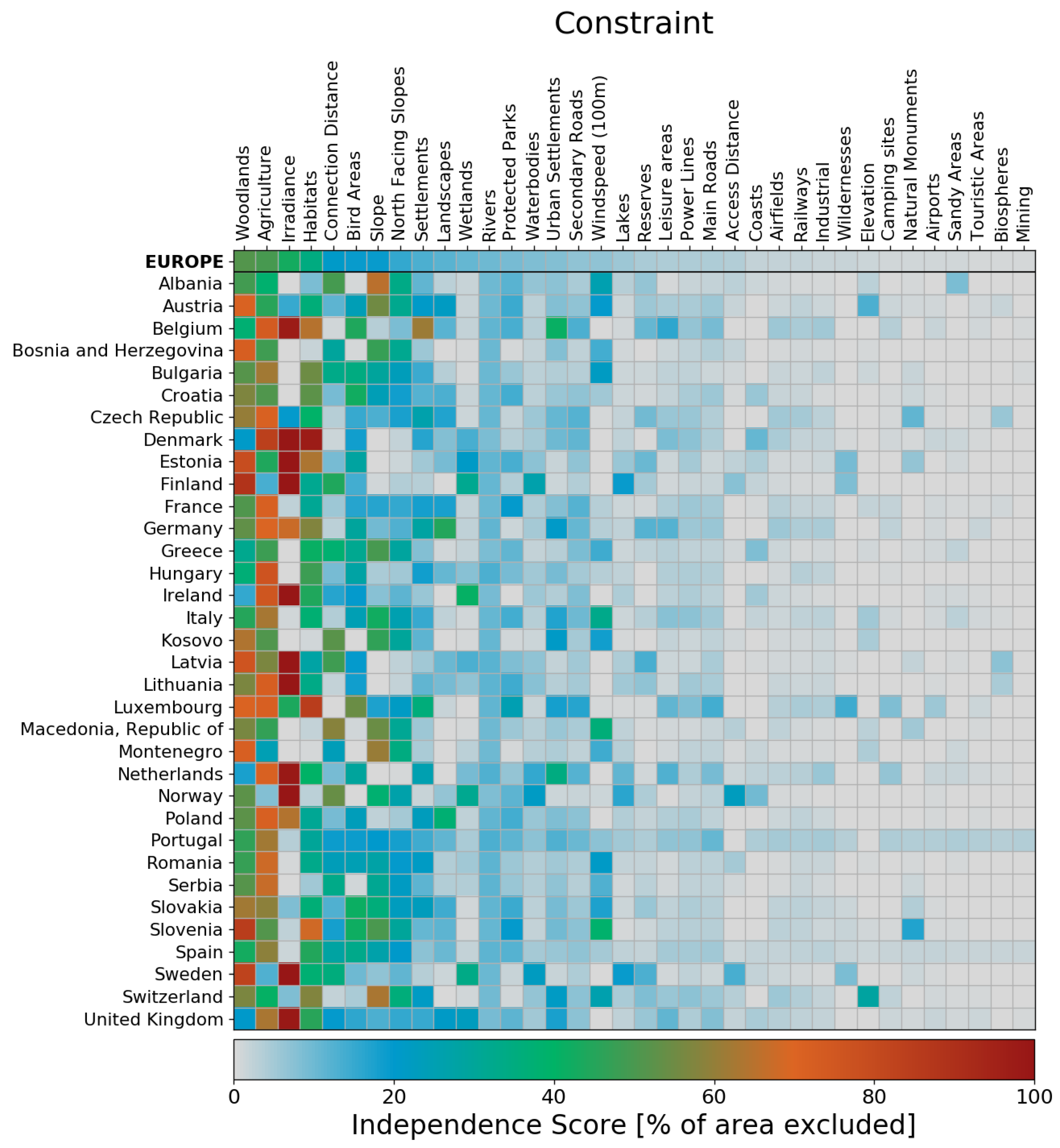
4.2. Independence
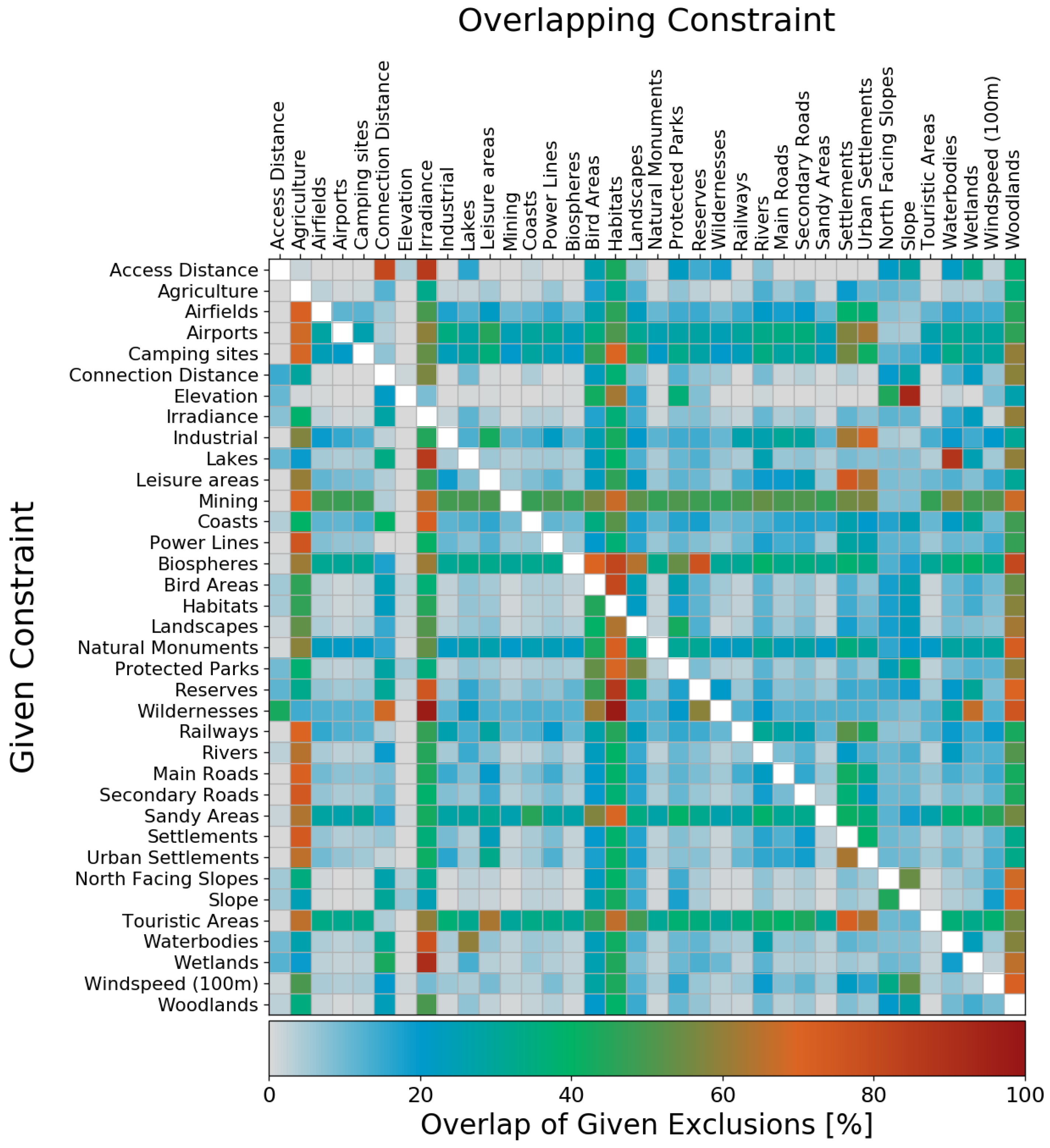
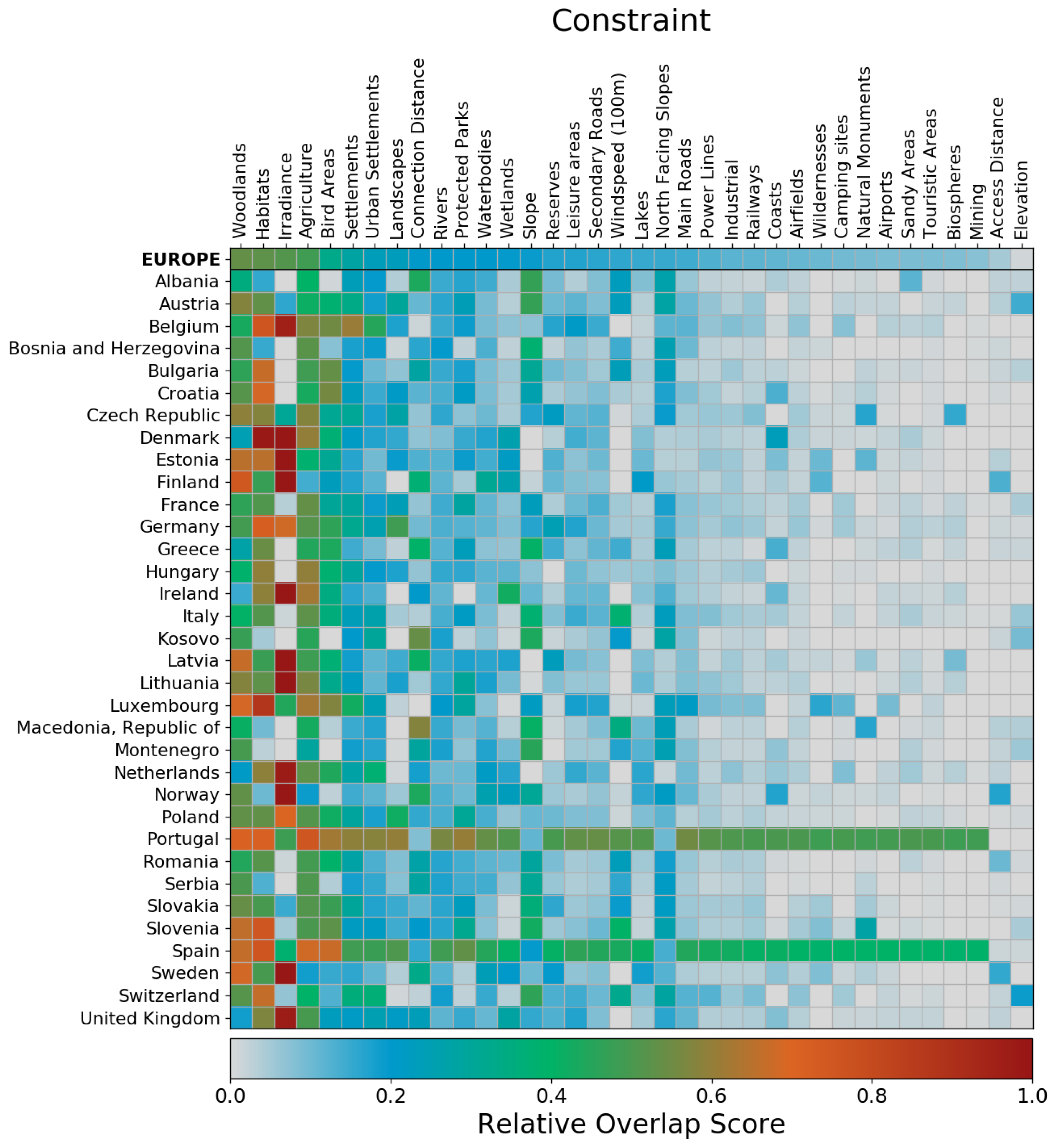
4.3. Overlap and Exclusivity
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Baños, R.; Manzano-Agugliaro, F.; Montoya, F.G.; Gil, C.; Alcayde, A.; Gómez, J. Optimization methods applied to renewable and sustainable energy: A review. Renew. Sustain. Energy Rev. 2011, 15, 1753–1766. [Google Scholar] [CrossRef]
- Iqbal, M.; Azam, M.; Naeem, M.; Khwaja, A.S.; Anpalagan, A. Optimization classification, algorithms and tools for renewable energy: A review. Renew. Sustain. Energy Rev. 2014, 39, 640–654. [Google Scholar] [CrossRef]
- Wang, J.J.; Jing, Y.Y.; Zhang, C.F.; Zhao, J.H. Review on multi-criteria decision analysis aid in sustainable energy decision-making. Renew. Sustain. Energy Rev. 2009, 13, 2263–2278. [Google Scholar] [CrossRef]
- Ellabban, O.; Abu-Rub, H.; Blaabjerg, F. Renewable energy resources: Current status, future prospects and their enabling technology. Renew. Sustain. Energy Rev. 2014, 39, 748–764. [Google Scholar] [CrossRef]
- Spiecker, S.; Weber, C. The future of the European electricity system and the impact of fluctuating renewable energy—A scenario analysis. Energy Policy 2014, 65, 185–197. [Google Scholar] [CrossRef]
- Albadi, M.; El-Saadany, E. Overview of wind power intermittency impacts on power systems. Electr. Power Syst. Res. 2010, 80, 627–632. [Google Scholar] [CrossRef]
- Boyle, G. Renewable Electricity and the Grid: The Challenge of Variability; Earthscan: London, UK, 2012; ISBN 1849772339. [Google Scholar]
- Hoogwijk, M.M.; Turkenburg, W.C.; de Vries, H.J.M. On the Global and Regional Potential of Renewable Energy Sources. Ph.D. Thesis, Utrecht University, Utrecht, The Netherlands, 2004. [Google Scholar]
- Huber, M.; Dimkova, D.; Hamacher, T. Integration of wind and solar power in Europe: Assessment of flexibility requirements. Energy 2014, 69, 236–246. [Google Scholar] [CrossRef]
- Klessmann, C.; Held, A.; Rathmann, M.; Ragwitz, M. Status and perspectives of renewable energy policy and deployment in the European Union—What is needed to reach the 2020 targets? Energy Policy 2011, 39, 7637–7657. [Google Scholar] [CrossRef]
- Möller, B. Spatial analyses of emerging and fading wind energy landscapes in Denmark. Land Use Policy 2010, 27, 233–241. [Google Scholar] [CrossRef]
- Loken, E. Use of multicriteria decision analysis methods for energy planning problems. Renew. Sustain. Energy Rev. 2007, 11, 1584–1595. [Google Scholar] [CrossRef]
- Pohekar, S.D.; Ramachandran, M. Application of multi-criteria decision making to sustainable energy planning—A review. Renew. Sustain. Energy Rev. 2004, 8, 365–381. [Google Scholar] [CrossRef]
- Resch, B.; Sagl, G.; Tornros, T.; Bachmaier, A.; Eggers, J.B.; Herkel, S.; Narmsara, S.; Gundra, H. GIS-Based Planning and Modeling for Renewable Energy: Challenges and Future Research Avenues. ISPRS Int. J. Geoinf. 2014, 3, 662–692. [Google Scholar] [CrossRef]
- Holtinger, S.; Salak, B.; Schauppenlehner, T.; Scherhaufer, P.; Schmidt, J. Austria’s wind energy potential—A participatory modeling approach to assess socio-political and market acceptance. Energy Policy 2016, 98, 49–61. [Google Scholar] [CrossRef]
- McKenna, R.; Hollnaicher, S.; Fichtner, W. Cost-potential curves for onshore wind energy: A high-resolution analysis for Germany. Appl. Energy 2014, 115, 103–115. [Google Scholar] [CrossRef]
- Robinius, M.; Otto, A.; Syranidis, K.; Ryberg, D.S.; Heuser, P.; Welder, L.; Grube, T.; Markewitz, P.; Tietze, V.; Stolten, D. Linking the power and transport sectors—Part 2: Modelling a sector coupling scenario for Germany. Energies 2017, 10, 957. [Google Scholar] [CrossRef]
- Samsatli, S.; Staffell, I.; Samsatli, N.J. Optimal design and operation of integrated wind-hydrogen-electricity networks for decarbonising the domestic transport sector in Great Britain. Int. J. Hydrog. Energy 2016, 41, 447–475. [Google Scholar] [CrossRef]
- Sliz-Szkliniarz, B. Assessment of the renewable energy-mix and land use trade-off at a regional level: A case study for the Kujawsko-Pomorskie Voivodship. Land Use Policy 2013, 35, 257–270. [Google Scholar] [CrossRef]
- Tegou, L.I.; Polatidis, H.; Haralambopoulos, D.A. Environmental management framework for wind farm siting: Methodology and case study. J. Environ. Manag. 2010, 91, 2134–2147. [Google Scholar] [CrossRef] [PubMed]
- Ryberg, D.S.; Tulemat, Z.; Robinius, M.; Stolten, D. Geospatial Land Availability for Energy Systems (GLAES). Available online: https://github.com/FZJ-IEK3-VSA/glaes/releases/tag/v1.0.0 (accessed on 14 May 2018).
- Watson, J.J.W.; Hudson, M.D. Regional Scale wind farm and solar farm suitability assessment using GIS-assisted multi-criteria evaluation. Landsc. Urban Plan. 2015, 138, 20–31. [Google Scholar] [CrossRef]
- European Environmental Agency (EEA). Corine Land Cover (CLC) 2012, Version 18.5.1; EEA: Copenhagen, Denmark, 2012. Available online: https://land.copernicus.eu/pan-european/corine-land-cover/clc/2012/view (accessed on 1 April 2017).
- Ryberg, D.S.; Robinius, M.; Stolten, D. Methodological Framework for Determining the Land Eligibility of Renewable Energy Sources. ArXiv, 2017; arXiv:1712.07840. [Google Scholar]
- European Environmental Agency. Europe’s Onshore and Offshore Wind Energy Potential: An Assessment of Environmental and Economic Constraints; EEA: Copenhagen, Denmark, 2009. [Google Scholar]
- Clifton, J.; Boruff, B. Site Options for Concentrated Solar Power Generation in the Wheatbelt; Technical report; Institute for Regional Development, University of Western Australia: Perth, Australia, 2010. [Google Scholar]
- Lanuv, N. Potenzialstudie Erneuerbare Energien NRW; Teil 1-Windenergie; Das Landesamt für Natur, Umwelt und Verbraucherschutz Nordrhein-Westfalen: Recklinghausen, Germany, 2013. [Google Scholar]
- Lütkehus, I.; Adlunger, K.; Salecker, H. Potenzial der Windenergie an Land: Studie zur Ermittlung des Bundesweiten Flächen-und Leistungspotenzials der Windenergienutzung an Land; Umweltbundesamt: Dessau-Roßlau, Germany, 2013. [Google Scholar]
- Vandenbergh, M.; Neirac, F.P.; Turki, H. A GIS approach for the siting of solar thermal power plants application to Tunisia. J. Phys. IV 1999, 9, Pr3-223–Pr3-228. [Google Scholar] [CrossRef]
- Baban, S.M.J.; Parry, T. Developing and applying a GIS-assisted approach to locating wind farms in the UK. Renew. Energy 2001, 24, 59–71. [Google Scholar] [CrossRef]
- Krewitt, W.; Nitsch, J. The potential for electricity generation from on-shore wind energy under the constraints of nature conservation: A case study for two regions in Germany. Renew. Energy 2003, 28, 1645–1655. [Google Scholar] [CrossRef]
- Hansen, H.S. GIS-based Multi-Criteria Analysis of Wind Farm Development. In Proceedings of the 10th Scandinavian Research Conference on Geographical Information Science, Stockholm, Sweden, 13–15 June 2005. [Google Scholar]
- Ma, J.G.; Scott, N.R.; DeGloria, S.D.; Lembo, A.J. Siting analysis of farm-based centralized anaerobic digester systems for distributed generation using GIS. Biomass Bioenergy 2005, 28, 591–600. [Google Scholar] [CrossRef]
- Rodman, L.C.; Meentemeyer, R.K. A geographic analysis of wind turbine placement in Northern California. Energy Policy 2006, 34, 2137–2149. [Google Scholar] [CrossRef]
- Bennui, A.; Rattanamanee, P.; Puetpaiboon, U.; Phukpattaranont, P.; Chetpattananondh, K. Site selection for large wind turbine using GIS. In Proceedings of the PSU-UNS International Conference on Engineering and Environment, Phuket, Thailand, 10–11 May 2007; pp. 561–566. [Google Scholar]
- Tegou, L.I.; Polatidis, H.; Haralambopoulos, D.A. Distributed generation with renewable energy systems: the spatial dimension for an autonomous Grid. In Proceedings of the 47th Conference of the European Regional Science Association, Paris, France, 29 August–2 September 2007; pp. 1731–1744. [Google Scholar]
- Ummel, K.; Wheeler, D. Desert Power: The Economics of Solar Thermal Electricity for Europe; North Africa, and the Middle East Center for Global Development: Washington, DC, USA, 2008. [Google Scholar]
- Lejeune, P.; Feltz, C. Development of a decision support system for setting up a wind energy policy across the Walloon Region (southern Belgium). Renew. Energy 2008, 33, 2416–2422. [Google Scholar] [CrossRef]
- Ramirez-Rosado, I.J.; Garcia-Garridoa, E.; Fernandez-Jimenez, L.A.; Zorzano-Santamaria, P.J.; Monteiro, C.; Miranda, V. Promotion of new wind farms based on a decision support system. Renew. Energy 2008, 33, 558–566. [Google Scholar] [CrossRef]
- Gastli, A.; Charabi, Y.; Zekri, S. GIS-based assessment of combined CSP electric power and seawater desalination plant for Duqum—Oman. Renew. Sustain. Energy Rev. 2010, 14, 821–827. [Google Scholar] [CrossRef]
- Janke, J.R. Multicriteria GIS modeling of wind and solar farms in Colorado. Renew. Energy 2010, 35, 2228–2234. [Google Scholar] [CrossRef]
- Funabashi, T. A GIS Approach for Estimating Optimal Sites for Grid-Connected Photovoltaic (PV) Cells in Nebraska. Master’s Thesis, University of Nebraska-Lincoln, Lincoln, NE, USA, 2011. [Google Scholar]
- Phuangpornpitak, N.; Tia, S. Feasibility study of wind farms under the Thai very small scale renewable energy power producer (VSPP) program. Energy Procedia 2011, 9, 159–170. [Google Scholar] [CrossRef][Green Version]
- van Haaren, R.; Fthenakis, V. GIS-based wind farm site selection using spatial multi-criteria analysis (SMCA): Evaluating the case for New York State. Renew. Sustain. Energy Rev. 2011, 15, 3332–3340. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, W.X.; Liu, G.X. Assessment of Onshore Wind Energy Resource and Wind-Generated Electricity Potential in Jiangsu, China. Energy Procedia 2011, 5, 418–422. [Google Scholar] [CrossRef]
- Al-Yahyai, S.; Charabi, Y.; Gastli, A.; Al-Badi, A. Wind farm land suitability indexing using multi-criteria analysis. Renew. Energy 2012, 44, 80–87. [Google Scholar] [CrossRef]
- Grassi, S.; Chokani, N.; Abhari, R.S. Large scale technical and economical assessment of wind energy potential with a GIS tool: Case study Iowa. Energy Policy 2012, 45, 73–85. [Google Scholar] [CrossRef]
- Ouammi, A.; Ghigliotti, V.; Robba, M.; Mimet, A.; Sacile, R. A decision support system for the optimal exploitation of wind energy on regional scale. Renew. Energy 2012, 37, 299–309. [Google Scholar] [CrossRef]
- Sultana, A.; Kumar, A. Optimal siting and size of bioenergy facilities using geographic information system. Appl. Energy 2012, 94, 192–201. [Google Scholar] [CrossRef]
- Aydin, N.Y.; Kentel, E.; Duzgun, H.S. GIS-based site selection methodology for hybrid renewable energy systems: A case study from western Turkey. Energy Convers. Manag. 2013, 70, 90–106. [Google Scholar] [CrossRef]
- Gass, V.; Schmidt, J.; Strauss, F.; Schmid, E. Assessing the economic wind power potential in Austria. Energy Policy 2013, 53, 323–330. [Google Scholar] [CrossRef]
- Gorsevski, P.V.; Cathcart, S.C.; Mirzaei, G.; Jamali, M.M.; Ye, X.Y.; Gomezdelcampo, E. A group-based spatial decision support system for wind farm site selection in Northwest Ohio. Energy Policy 2013, 55, 374–385. [Google Scholar] [CrossRef]
- Effat, H.A. Spatial Modeling of Optimum Zones for Wind Farms Using Remote Sensing and Geographic Information System, Application in the Red Sea, Egypt. J. Geogr. Inf. Syst. 2014, 6, 358–374. [Google Scholar] [CrossRef]
- Szurek, M.; Blachowski, J.; Nowacka, A. Gis-Based Method for Wind Farm Location Multi-Criteria Analysis. Min. Sci. 2014, 21, 65–81. [Google Scholar] [CrossRef]
- Sanchez-Lozano, J.M.; Garcia-Cascales, M.S.; Lamata, M.T. Identification and selection of potential sites for onshore wind farms development in Region of Murcia, Spain. Energy 2014, 73, 311–324. [Google Scholar] [CrossRef]
- Schallenberg-Rodriguez, J.; Pino, J.N.D. Evaluation of on-shore wind techno-economical potential in regions and islands. Appl. Energy 2014, 124, 117–129. [Google Scholar] [CrossRef]
- Latinopoulos, D.; Kechagia, K. A GIS-based multi-criteria evaluation for wind farm site selection. A regional scale application in Greece. Renew. Energy 2015, 78, 550–560. [Google Scholar] [CrossRef]
- Tsoutsos, T.; Tsitoura, I.; Kokologos, D.; Kalaitzakis, K. Sustainable siting process in large wind farms case study in Crete. Renew. Energy 2015, 75, 474–480. [Google Scholar] [CrossRef]
- Höfer, T.; Sunak, Y.; Siddique, H.; Madlener, R. Wind farm siting using a spatial Analytic Hierarchy Process approach: A case study of the Städteregion Aachen. Appl. Energy 2016, 163, 222–243. [Google Scholar] [CrossRef]
- Atici, K.B.; Simsek, A.B.; Ulucan, A.; Tosun, M.U. A GIS-based Multiple Criteria Decision Analysis approach for wind power plant site selection. Util. Policy 2015, 37, 86–96. [Google Scholar] [CrossRef]
- Hernandez, R.R.; Hoffacker, M.K.; Field, C.B. Efficient use of land to meet sustainable energy needs. Nat. Clim. Chang. 2015, 5, 353–358. [Google Scholar] [CrossRef]
- Trieb, F. Expert System for Solar Thermal Power Stations; Institute of Technical Thermodynamics (DLR): London, UK, 2001. [Google Scholar]
- European Environmental Agency. Digital Elevation Model over Europe (EU-DEM). Available online: https://www.eea.europa.eu/data-and-maps/data/eu-dem (accessed on 1 April 2017).
- UNEP-WCMC and IUCN. Cambridge, UK. Protected Planet: The World Database on Protected Areas (WDPA). Available online: www.protectedplanet.net (accessed on 1 April 2017).
- GEODATA, GISCO, Eurostat. Clusters: Urban 2011. Available online: http://ec.europa.eu/eurostat/web/gisco/geodata/reference-data/population-distribution-demography/clusters (accessed on 1 April 2017).
- OpenStreetMap Contributors. OpenStreetMap. Available online: https://www.openstreetmap.org (accessed on 1 April 2017).
- GEODATA, GISCO, Eurostat. Transport Networks: Airports 2013. Available online: http://ec.europa.eu/eurostat/web/gisco/geodata/reference-data/transport-networks (accessed on 1 April 2017).
- Messager, M.L.; Lehner, B.; Grill, G.; Nedeva, I.; Schmitt, O. Estimating the volume and age of water stored in global lakes using a geo-statistical approach. Nat. Commun. 2016, 7, 13603. [Google Scholar] [CrossRef] [PubMed]
- GEODATA, GISCO, Eurostat. Hydrography (LAEA). Available online: http://ec.europa.eu/eurostat/web/gisco/geodata/reference-data/elevation/hydrography-laea (accessed on 1 April 2017).
- Technical University of Denmark. DTU Global Wind Atlas 1 km Resolution. Available online: https://irena.masdar.ac.ae/gallery/#map/103 (accessed on 1 April 2017).
- World Bank Group. Global Solar Atlas. Available online: http://globalsolaratlas.info/ (accessed on 1 April 2017).
- GDAL Development Team. GDAL—Geospatial Data Abstraction Library; Version 2.1.1; Open Source Geospatial Foundation: Chicago, IL, USA, 2017. [Google Scholar]
- Jones, E.; Oliphant, T.; Peterson, P. SciPy: Open Source scientific tools for Python. Comput. Sci. Eng. 2017, 9, 10–20. [Google Scholar]
- Dudley, N. Guidelines for Applying Protected Area Management Categories; International Union for Conservation of Nature (IUCN): Gland, Switzerland, 2008. [Google Scholar]
- Directive, E.B. Directive 2009/147/EC of the European parliament and of the Council of 30 November 2009 on the conservation of wild birds (codified version). Off. J. L 2009, 20, 7–25. [Google Scholar]
- Directive, H. Council Directive 92/43/EEC of 21 May 1992 on the conservation of natural habitats and of wild fauna and flora. Off. J. Eur. Union 1992, 206, 7–50. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Constraint | Samsatli [18] | Watson [22] |
|---|---|---|
| Average Wind Speed | ≥5 m/s | Not considered |
| Slope | ≥15% | ≥17.6% |
| Distance from roads | ≤500 m | Not considered |
| Distance from power lines | ≥200 m and ≤1500 m | Not considered |
| Distance from protected areas | Some excluded | ≥1000 m |
| Distance from settlements | ≥500 m | ≥500 m |
| Distance from water | ≥200 m | Not considered |
| Distance from woodlands | ≥250 m | Not considered |
| Distance from airports | ≥5 km | Not considered |
| Distance from other turbines | ≥500 m | Not considered |
| Agriculture | Not considered | Excluded |
| Constraint | Freq. % | Excludes | Data Source | |||
|---|---|---|---|---|---|---|
| Social and Political | ||||||
| Settlements | 87 | below | 500 m | CLC [23] | ||
| Urban Settlements | 43 | below | 1000 m | EuroStat [65] | ||
| Roadways | 55 | |||||
| Main | 23 | below | 200 m | OpenStreetMap [66] | ||
| Secondary | 13 | below | 100 m | OpenStreetMap [66] | ||
| Airports | 53 | |||||
| Large and Commercial | 6 | below | 5000 m | CLC [23], EuroStat [67] | ||
| Airfields | 4 | below | 3000 m | CLC [23], EuroStat [67] | ||
| Agricultural Areas | 45 | below | 50 m | CLC [23] | ||
| Railways | 34 | below | 150 m | OpenStreetMap [66] | ||
| Power Lines | 32 | below | 200 m | OpenStreetMap [66] | ||
| Industrial Areas | 19 | below | 300 m | CLC [23] | ||
| Recreational Areas | 17 | |||||
| Tourism | 8 | below | 800 m | OpenStreetMap [66] | ||
| Camping sites | 4 | below | 1000 m | OpenStreetMap [66] | ||
| Leisure areas | 4 | below | 1000 m | OpenStreetMap [66] | ||
| Mining Sites | 15 | below | 100 m | CLC [23] | ||
| Physical | ||||||
| Slope | 68 | above | 10° | EU-DEM [63] | ||
| Water Bodies | 62 | below | 300 m | CLC [23] | ||
| Lakes | 28 | below | 400 m | HydroLAKES [68] | ||
| Rivers | 25 | below | 200 m | EuroStat [69] | ||
| Coast | 9 | below | 1000 m | CLC [23] | ||
| Woodlands | 40 | below | 300 m | CLC [23] | ||
| Wetlands | 30 | below | 1000 m | CLC [23] | ||
| Elevation | 19 | above | 1800 m | EU-DEM [63] | ||
| Ground Composition | 15 | |||||
| Sandy Areas | 6 | below | 1000 m | CLC [23] | ||
| Aspect | 7 | above | 3 °N | EU-DEM [63] | ||
| Conservation | ||||||
| Protected FFH | 79 | |||||
| Habitats | 42 | below | 1500 m | WDPA [64] | ||
| Birds Areas | 33 | below | 1500 m | WDPA [64] | ||
| Biospheres | 13 | below | 300 m | WDPA [64] | ||
| Wildernesses | 6 | below | 1000 m | WDPA [64] | ||
| Protected Areas | 64 | |||||
| Landscapes | 21 | below | 500 m | WDPA [64] | ||
| Reserves | 17 | below | 500 m | WDPA [64] | ||
| Parks | 28 | below | 1000 m | WDPA [64] | ||
| Monuments | 9 | below | 1000 m | WDPA [64] | ||
| Technical Economic | ||||||
| Resource | 62 | |||||
| Windspeed | 45 | below | 4.5 m/s | Global Wind Atlas [70] | ||
| Irradiance | 17 | below | 3.0 kWh/m day | Global Solar Atlas [71] | ||
| Connection Distance | 47 | above | 10 km | OpenStreetMap [66] | ||
| Access Distance | 45 | above | 5 km | OpenStreetMap [66] | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryberg, D.S.; Robinius, M.; Stolten, D. Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe. Energies 2018, 11, 1246. https://doi.org/10.3390/en11051246
Ryberg DS, Robinius M, Stolten D. Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe. Energies. 2018; 11(5):1246. https://doi.org/10.3390/en11051246
Chicago/Turabian StyleRyberg, David Severin, Martin Robinius, and Detlef Stolten. 2018. "Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe" Energies 11, no. 5: 1246. https://doi.org/10.3390/en11051246
APA StyleRyberg, D. S., Robinius, M., & Stolten, D. (2018). Evaluating Land Eligibility Constraints of Renewable Energy Sources in Europe. Energies, 11(5), 1246. https://doi.org/10.3390/en11051246