1. Introduction
Crude oil is the world’s largest energy commodity and is actively traded internationally. The welfare of oil-importing and oil-producing economies are heavily influenced by fluctuations in oil prices, especially when they are unexpectedly large and persistent. As indicated by Abosedra and Baghestani [
1], “sharp increases in crude oil prices adversely influence economic growth and accelerate inflation for oil importing economies. Large fall in crude oil prices will generate serious budgetary deficit problems for oil exporting countries”. Accurate oil price forecasting is appealing and important. Nevertheless, in modern time series analysis it is a very difficult task owing to its complex dynamics. Many researchers have tried to develop models to maximize forecasting accuracy. However, until now, they have not achieved a satisfactory level of performance from their models. The failure of traditional approaches is derived from their model setting. The model forms adopted are usually linear and parametric (Atsalakis and Valavanis [
2,
3], Fan and Li [
4]), which are not flexible enough to track fast changing price dynamics. This study aims to solve this problem by developing a new strategy that combines the advanced deep learning and multiple kernel methods.
Oil price forecasts are important for related business operations, and they have great influences on many sectors of the economy. For example, these forecasts are used to determine airfares for airline companies, planning capacity for utility companies, shipping fees in the logistics industry, and product prices in the petrochemical industry. Referring to prior research (Bahrammirzaee [
5], Fan and Li [
4], Krollner et al. [
6]), time series forecasting techniques can be divided into the three groups: (1) statistical or econometric models; (2) machine learning, artificial intelligence, and soft computing; (3) hybrid models that combine the above two methods. The typical models include the auto-regressive moving average (ARMA) (or the auto-regressive integrated moving average (ARIMA)) used in statistics, and the generalized auto-regressive conditional heteroscedasticity (GARCH), which is used in econometrics. Among ARMA and GARCH, there are many new ideas and improved models that have been developed recently for oil price forecasting. For example, Gupta and Wohar [
7] forecasted oil and stock returns with a Qual VAR (Qualitative Vector Autoregressive) model. Gavriilidis et al. [
8] examined whether the inclusion of oil price shocks of different origin as exogenous variables in a wide set of GARCH-X models improved their volatility forecasts. Herrera et al. [
9] employed high-frequency intra-day realized volatility data to evaluate the relative forecasting performances of various econometrics models, such as the RiskMetrics, GARCH, asymmetric GARCH, fractional integrated GARCH, and Markov switching GARCH models. Morana [
10] developed a semiparametric approach for short-term oil price forecasting. With respect to machine learning, artificial intelligence, and soft computing, traditional models include neural networks, genetic algorithms, and fuzzy logics. There are also many newly developed methods in this field. For example, Ding [
11] developed a novel decompose-ensemble methodology with the AIC-ANN (Akaike information criterion-artificial neural network) approach for crude oil forecasting. Yu et al. [
12] proposed a neural network ensemble learning paradigm based on empirical mode decomposition (EMD) to forecast crude oil prices.
In the third group, many hybrid models integrate the strengths of both methods to enhance their predictions. For example, Naderi et al. [
13] developed a novel approach by using a meta-heuristic bat algorithm to optimally combine four predictors including the least square support vector machine (LSSVM), genetic programming (GP), ANN, and ARIMA in an integrated equation. Safari and Davallou [
14] proposed a hybrid combination of the exponential smoothing model (ESM), ARIMA, and the nonlinear autoregressive (NAR) model in a state space model framework, in which the time-varying weight of the proposed hybrid model was determined by Kalman-Filter. Li et al. [
15] proposed a method integrating ensemble empirical mode decomposition (EEMD), adaptive particle swarm optimization (APSO), and relevance vector machine (RVM) to predict crude oil prices. Wang et al. [
16] used a linear ARIMA to correct the nonlinear metabolic grey model (NMGM) forecasting residuals to improve forecasting accuracy in China’s foreign oil dependence. Xiao et al. [
17] developed a hybrid model based on a selective ensemble for energy consumption forecasting in China. Drachal [
18] tried to find the time-varying drivers of spot oil price in a dynamic model averaging framework. Iranmanesh et al. [
19] proposed a mid-term energy demand forecasting system by hybrid neuro-fuzzy models.
Recently, support vector machines (SVMs, Vapnik [
20]) have been developed to enhance traditional neural networks. Kernel methods (Schoelkopf et al. [
21]), the core of SVMs, have also received a lot of attention. In general, artificial intelligence and similar approaches are nonlinear, nonparametric, and adaptive in their model forms. They are flexible to track complex price dynamics, and thus usually outperform statistical methods. Another weakness of statistical models is related to their assumption that random variables follow a normal or other kind of distribution, which is limited because real data is not stationary and their dynamics change with time. Time-varying coefficient or distribution models in statistics are also insufficient, because their model settings are parametric. The dimensionality of their function space is finite, limited, and not flexible enough to track fast changing dynamics.
Due to the rapid development of the Internet and information technology, global financial markets are highly correlated. Oil is both an important energy commodity and a financial instrument that is heavily traded in global markets. Upon reviewing the research in oil or financial price predictions (Ding et al. [
22], Iranmanesh et al. [
19], Khashman and Nwulu [
23], Liu et al. [
24], Wang et al. [
25], Xie et al. [
26], Yu et al. [
12]), we can confirm that machine learning or artificial intelligence approaches usually outperform statistical and econometric methods. However, there are still some weaknesses associated with machine learning or artificial intelligence approaches. Previously, kernel methods have been prolific, theoretical, and algorithmic machine learning frameworks. The success of kernel methods depends on good data representation or kernel design, and this has resulted in a lot of research that focuses on kernel design, which is adapted to specific data types. Conversely, there are also several generic kernel-based algorithms for typical learning tasks. The strength of SVMs is that they use structural risk to regularize model complexity, which leads to excellent generalization properties in out-sample forecasting. The mathematical formulation of an SVM is ideal because its objective function is convex with a unique solution. Consequently, the solution searching or parameter optimization algorithms are easier than those in neural network (NN) models. The kernels are typically hand-crafted and fixed in advance, and the roles of the kernel in an SVM can be divided into two parts: (1) it defines the similarity between two examples, and (2) it simultaneously acts as a regularization for the objective function.
Hand-tuning kernel parameters is difficult, as the appropriate sets of features need to be selected and combined. On the other hand, traditional SVMs are based on a single kernel, whereas in real-life applications data comes from multiple sources, and therefore, the representation by a single kernel is not sufficient. The combination of multiple kernels is a good solution; however, determining the process to combine them presents another problem. Lanckriet et al. [
27] sought to address this problem and proposed an idea to learn the multiple kernels from training data. Their solution was to learn the target kernels as a linear combination of given basis or local kernels. Following Lanckriet et al. [
27], various multiple kernel learning (MKL) formulations and modifications have been proposed. The success of MKL stems from the fact that using multiple kernels can enhance the interpretability of the decision function, and thus improve performance (Lanckriet et al. [
27]). However, the number of the basis kernels that we need to consider is exponential in the dimension of the input space. Considering this decomposition for MKL directly is intractable. To address the issue of selecting basis kernels more efficiently, Bach [
28,
29] proposed a useful framework to design the MKL kernels. Owing to the fact that data features of modern time series are complex, compositional, and hierarchical, using the natural hierarchical (or deep) structure of the problem for the kernel design of MKL is a good solution. The suggestion made by Bach [
28,
29] involves embedding the kernels in a directed acyclic graph (DAG). The kernels embedded in a DAG form provide an excellent deep representation of the data features. Another contribution from Bach [
28,
29] is the proposal to perform high-dimensional kernel selection through a graph-adapted sparsity-inducing norm. Using the norm, the selection can be completed in polynomial time in the number of selected kernels.
Recently, deep learning (DL, Bengio et al. [
30], Schmidhuber [
31]) or deep representations (DR) have become very popular. As opposed to task-specific algorithms, DL aims to learn the data representation. Consequently, DL is also known as deep structured learning or hierarchical learning. In machine learning methods, DL has become the new trend in overcoming complex data mining problems. As previously mentioned, kernel methods are usually shallow models that cannot fully represent or capture complex, compositional, and hierarchical data features. This study aimed to combine the strengths of DL (or DR) and MKL. The kernels used in this study were embedded in a hierarchical directed acyclic graph, which is a deep representation form for real data. In the past few years, DL has become very popular in many fields of computer science, and the most recognized applications are in computer vision and natural language processing. With the advancement in storage technology, there are considerable quantities of labeled data available for training a model. This allowed us to learn large numbers of model parameters in DL without having to be concerned about overfitting. Another factor contributing to the success of DL is the rapid development of the Graphics Processing Unit (GPU). The computing power of the GPU grows very fast, whereas traditional complex DL model using CPU (Central Processing Unit) training requires weeks of computations. The training can be completed in a day on a GPU (see, e.g., He et al. [
32], Ioffe and Szegedy [
33], Krizhevsky et al. [
34], Simonyan and Zisserman [
35]). This study sought to bridge kernel methods and deep representations and ideally achieve the best of both worlds.
The remainder of this paper is organized as follows:
Section 2 reviews the weaknesses and strengths of prior research, including the support vector regression (a type of SVMs), feedforward neural network (FFNN), radial basis functions (RBF) neural network, general regression neural network (GRNN), and DLs.
Section 3 describes the proposed model.
Section 4 introduces the real data we used to test the model, and discusses the empirical results. Finally,
Section 5 is the conclusion.
3. Deep (or Hierarchical) Multiple Kernel Learning
Kernel methods are popular learning frameworks and the basis of the approach can be stated as follows: through non-linear transformations, we can transform the input space to a larger and potentially infinite-dimensional feature space. Typically, the feature space is a reproducing kernel Hilbert space (RKHS), which is a space of functions in which point evaluation is a continuous linear functional. The advantage of RKHS is that it is more flexible and rich for feature representations than original input space. Via representer theorems, with the kernel function and appropriate regularization by Hilbertian norms, we can consider larger and potentially infinite-dimensional feature spaces without computing the coordinates of data in that space, but rather by simply computing the inner products between the images of all pairs of data in the feature space. This approach is called the “kernel trick”, which is computationally cheaper than the explicit computation of the coordinates. This has led to several studies on kernel design adapted to specific data types and generic kernel-based algorithms for many learning tasks.
In practical applications, data comes from multiple sources. Classical kernel machines are based on a single kernel, which is not capable of representing complex data sources. Consequently, it is more desirable to construct learning machines based on combinations of multiple kernels. The approach suggested by Bach [
28,
29] proposed a large feature space that is the concatenation of smaller feature spaces, and for real-life application, considered a positive definite kernel that can be expressed as a large sum of positive definite basis or local kernels. After the construction, we can apply multiple kernel learning to select among these kernels. However, directly applying multiple kernel learning in this decomposition is intractable because the number of these smaller kernels increases exponentially in the dimension of the input space. In order to overcome the difficulty in basis kernel selections, Bach [
28,
29] made an arrangement so that these small kernels could be embedded in a DAG, which happens to be a hierarchical structure that is effective at deep representations.
The following description of DMKL follows Bach [
28,
29]. For the problem to consider predicting a random variable
Y from a random variable
X, we defined
and
to be spaces of
X and
Y. Given
n observations
, the empirical risk in the estimation of a function
f from
X to
R can be defined as
, where
l is a loss function.
Graph-Structured Positive Definite Kernels
To construct a larger kernel, , we assumed that this positive definite kernel is the sum, over an index set V, of basis kernels ; namely, for all , we have . For each , let’s denote and as the feature space and feature map of , i.e., , respectively. Consequently, the larger feature map and larger feature space of k can be expressed as the concatenation of the feature maps for each kernel , i.e, and . The learning algorithm of MKL tried to find for a certain to form a predictor function , which is equivalent to find jointly for , and .
The goal of this research was to perform kernel selection among the kernels
. In order to accelerate the searching, we only considered specific subsets of
V. We limited the basis kernels to be embedded in a graph, and as described by Bach [
28], “instead of considering all possible subsets of active (relevant) vertices, we are only interested in estimating correctly the hull of these relevant vertices”.
We assumed that the input space can be factorized into p-components , and that there are p sequences of length of kernels , , such that the larger kernel . Thus we had a sum of kernels, that could be computed efficiently as a product of p sums. In this scenario, the products of kernels was equivalent to interactions between certain variables. The basis kernels embedding in a DAG implies that an interaction will be selected only after all sub-interactions are already selected. The framework of DAGs are particularly suited to deep feature representations and non-linear variable selection, and especially for the polynomial and Gaussian kernels.
In considering the linear kernel,
, where
stands for inner product; the full kernel is then equal to
. Please note that this is not exactly the usual polynomial kernel. Typical polynomial kernels,
, are multivariate polynomials of total degree less than
q. Another example is the product of the Gaussian kernel,
, which is also known as all-subset Gaussian kernel. ANOVA (analysis of variance) kernel is also famous in research. It is shown as follows:
The optimal hierarchical multiple kernel learning could be formulated as the following minimization problem:
where
is the structured block
-norm;
are positive weights and
is the descendant set of
v (Since we are only interested in the hull of the selected elements
, the hull of a set
I is characterized by the set of
v, such that
, i.e., hull(
I) =
. In our context, we are hence looking at selecting vertices
for which
.). Penalizing by such a norm will indeed impose that some of the vectors
are exactly zero, thereby leading to sparse solutions.
4. Experimental Results and Analysis
4.1. Data Sets Used for The Research
In modern society, our economy heavily depends on the energy sector. Investors all over the world pay attention to oil prices, which are one of the most important global economic variables. Energy markets are closely correlated with financial markets and are therefore economically linked. In determining which variables to include in our study, gold and oil are two kinds of commodities to hedge against inflation. In addition, since both gold and oil are globally traded in U.S. dollars, the currency markets should also be considered. Typically, the U.S. dollar is more sensitive to oil than gold. Consequently, this study proposed to consider the possible economic and financial linkages between the oil, gold, and currency markets. The markets for oil and gold have been extensively studied; however, in this analysis, we attempt to bring together these three markets and use recent methodologies to uncover the emerging relationships.
The testing data used in this study include five major crude oil spot prices: West Texas Intermediate (WTI), Brent, Forties, Dubai, and Oman. Brent and Forties are the reference for crude oil in the North Sea, WTI is the reference for the America, and Dubai and Oman are the references for the Middle East. This study aimed to forecast these crude oil spot prices, while taking the economic and financial linkages among oil, gold, currency markets into account. This analysis included the gold prices (New York), and the exchange rate between the U.S. dollar (USD) and the Taiwanese dollar (TWD) to enhance the predictions. In total, we had 5 crude oil spot prices (WTI, Brent, Forties, Dubai, and Oman), 2 financial prices (the gold prices and the U.S. exchange rate), and for every variable we considered 2 time lags. Consequently, there were 14 ((5 + 2) × 2 = 14) input time series in our model. The data covered the period from 1 May 2009 to 31 December 2010, and comprised of 435 daily observations. The descriptive statistics of each variable are provided in
Table 1.
Table 2 shows the p-value of the unit root test on every time series. We tested for a unit root against a trend-stationary alternative, augmenting the model with 0, 1, and 2 lagged difference terms. Under 1%, 5%, and 10% significance level, the results indicated that these tests failed to reject the null hypothesis of a unit root against the autoregressive alternative, regardless of lagged 0, 1, or 2 difference terms; namely, these time series are not stationary.
Market information is generated instantly every day, and therefore considering one-step-ahead forecasting is enough in constructing a forecasting system. We needed to adaptively adjust the model for the following day’s predictions. Moreover, in online applications, one-step-ahead forecasting can also prevent cumulative errors from the previous period, which is important in out-of-sample forecasting. This study used 300 data points before the day of prediction to serve as the training data. The DMKL model was trained in a batch manner, and the window of the training data set slides with the current prediction. Other models are trained in a similar manner, and the remaining 135 daily oil prices served as the testing data to evaluate the performance of all prediction models. Two lagged prices (
, two time lags) of each asset served as the explanatory or input variables for the predictions. The flow diagram of the proposed system is shown in
Figure 1.
4.2. Model Settings and Performance Measurements
Traditionally, researchers use the mean square error (MSE), root mean squared error (RMSE), mean absolute error (MAE), and the mean absolute percent error (MAPE) to measure the performance of a model. Different indices emphasize distinct parts of errors, and are suitable for different applications. This study compared the DMKL model with traditional predictors. These predictors include the auto-regressive integrated moving average (ARIMA), the feed-forward neural network (FFNN), and the generalized regression neural network (GRNN). This study adopted a general ARIMA(1, 1, 1) model for its general good performance; specifically the order of the autoregressive part, the degree of differencing, and the order of the moving-average part were all set to one. The FFNN and GRNN are shallow network models with two layers. There are five sigmoid neurons in the first layer of FFNN, and the initial spread of radial basis functions of GRNN was set to 1. The basis kernels used in the DAG of DMKL were the union of ANOVA kernels with full interaction. Since we had 14 input variables (7 original variables, each with two time lags), from the first order linear part (), second order interaction (), third interaction (),..., to full interaction () and then outputs, there were 15 () layers with hundreds of kernels organized by the DAG. The basis kernels are . If we were to include more input variables and more time lags, the depth of the DAG network would increase in proportion to the input dimension.
4.3. Performance Comparison
Table 3,
Table 4,
Table 5 and
Table 6 list the results of the four models.
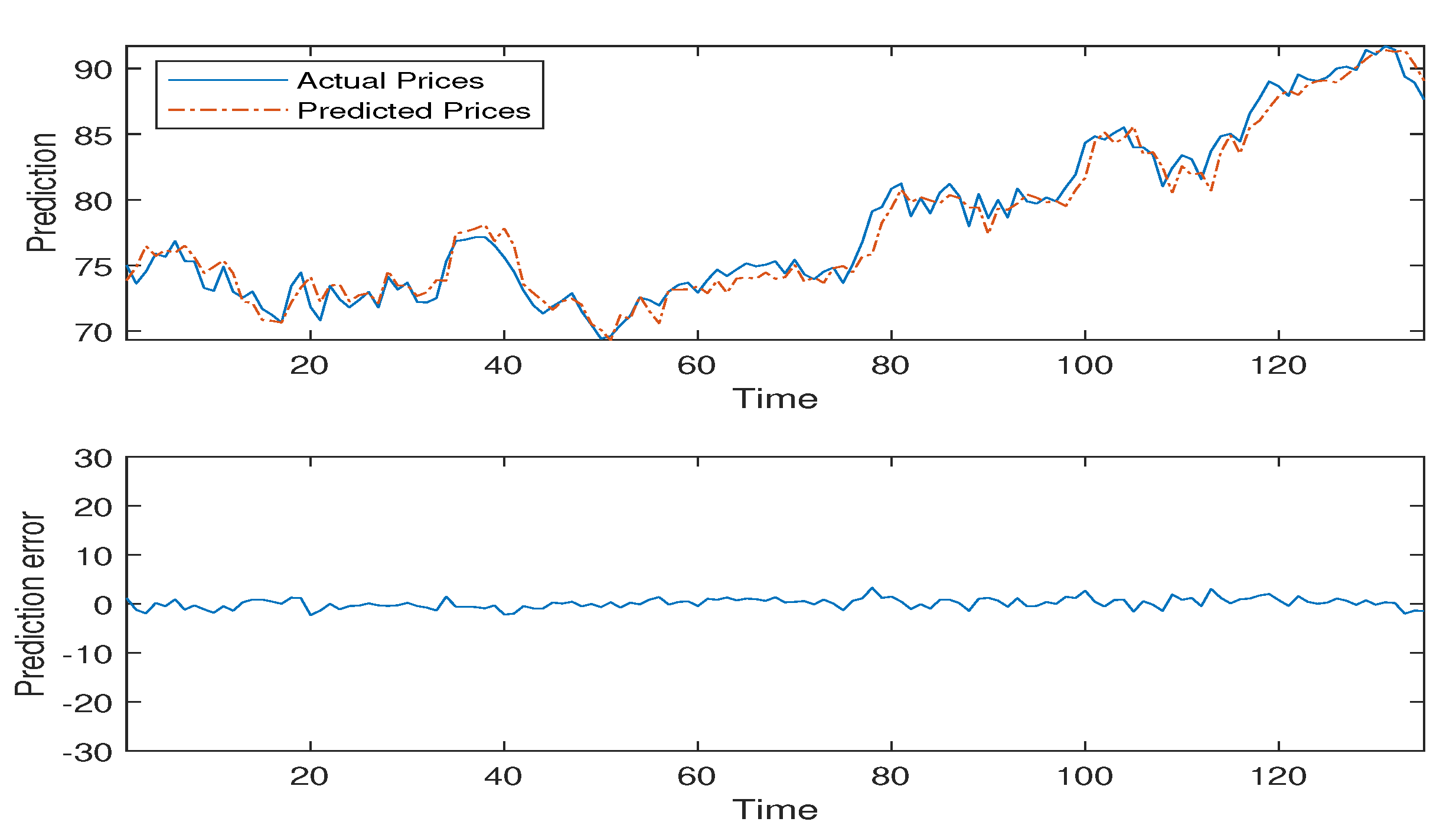
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 detail the empirical results of the proposed model including: the actual oil prices, predicted values, and model residuals. These figures display the forecasting capabilities of the DMKL models and demonstrate that the proposed model can instantaneously track price fluctuations. As shown by the four tables, DMKL performed the best. FFNN was the second, ARIMA the third, and GRNN performed the worst. The DMKL model significantly outperformed the others and it substantially reduced the forecasting errors. The FFNN, ARIMA and GRNN are all shallow models. They cannot compete with DMKL.
Performance Comparison Using Theil’s U
Theil’s U coefficient indicates how well a forecasting model performs compared with naive no-change extrapolation. It is different from the MSE, RMSE, MAE, and MAPE indices that emphasize only the forecasting errors. As indicated in Theil [
40], “Theil’s U will equal 1 if a forecasting technique is essentially no better than using a naive forecast. Theil’s U values less than 1 indicate that a technique is better than using a naive forecast. Hence, a value equal to zero indicates a perfect fit, and consequently, a better model gives a U value close to zero.” The Theil’s U value can be divided into three components including the bias, variance, and covariance. As the names suggest, the bias part accounts for the bias between actual and predicted values, the variance part represents the inequality accounted for by higher/lower variance in the simulated series, and the covariance part is the residual.
Table 7 displays the model performance measured by Theil’s U index.
As shown in
Table 7, DMKL was approximately one order better than FFNN, ARIMA, and GRNN based on the Theil’s U index.
Figure 7 plots the results of
Table 7.
Table 8 provides the average error of each model.
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12 displays the details of
Table 8. As shown in
Table 8, according to the performance ranking measured by average errors, DMKL was the best, followed by FFNN, then by ARIMA, and lastly the GRNN. The average RMSE, MAE, and MAPE errors of DMKL were approximately
than those of the GRNN, and the reduction was even greater for the MSE.
5. Conclusions
This study focused on developing advanced techniques in oil price forecasting, which is one basis for implementing an effecting hedging or trading strategy. The success of the proposed forecasting model was derived from the combination of multiple kernel machines and deep kernel representation. Deep kernel representation provides a solid foundation for extracting the key features of oil price dynamics. The kernels embedded in a directed acyclic graph provides a deep model that is good at representing complex, compositional, and hierarchical data features. This study used a deep multiple kernel learning for oil price forecasting that eliminated the drawbacks of traditional neural network and support vector machine models. DMKL is successful at high-dimensional data representation and performing non-linear variable selection. By using DMKL, we can both select which variables should enter and the corresponding degrees of interaction complexity. This study applied five major crude oil prices for testing. Empirical results showed that our model was robust, and it systematically outperformed traditional neural networks and regression models. The new model significantly reduced the forecasting errors.
This study developed a highly effective framework for energy commodity price forecasting. The proposed model combines the strengths of kernel methods and deep learning. It can achieve better performance easily. The strength of kernel methods is that they can learn a complex decision boundary with only a few parameters by projecting the data onto a potentially infinite-dimensional reproducing kernel Hilbert space. On the basis of kernel methods and deep learning, the proposed model works by combining multiple kernels within each layer to increase the richness of representations, and by stacking many layers to process a signal in an increasingly abstract manner. Oil price dynamics are complex, nonlinear, and non-stationary. Traditional models tends to be linear, parametric, and shallow, which are not suitable for oil price forecasting. Extracting data features in an abstract manner using a directed acyclic graph (as in our study) is a good strategy to handle complex oil price dynamics.
In summary, the effective framework of this study is also suitable for applications in other forecasting problems. With the leverage of cloud computing, or multiple GPUs on the CUDA (Compute Unified Device Architecture) platform, the system can be applied to online forecasting. Energy commodity investors can also apply the proposed system to effectively hedge their risk in global investments.
Implications and Limitations of This Study, and Suggestions for Future Research
Oil is an important energy commodity, and its price is influenced by many factors, which makes capturing its dynamics quite challenging and leads to difficulties in forecasting. However, with the advances in electronic transactions, vast amounts of financial market data can been collected in real time. Owing to the real time information flow, global markets are closely correlated with instant interactions, especially in the oil and financial markets. This study used information from oil, gold, and currency markets to serve as multiple inputs for our forecasting system. Considering more real time information from global markets is not difficult for future research. However, the computational loading is heavy. Implementing the algorithm in an IC (Interrgrated Circuit) chip is a good solution to achieve the real time response.
There are certain limitations in the study, which may in turn provide fruitful avenues for future studies. First, the DMKL model working in time domains may be not very effective at capturing oil price dynamics. Transforming to a good feature space, such as wavelet domain, could enhance the prediction. However, this would have required more computations, and the loading would be heavier for our algorithm. Second, for simplicity and reducing computation loading, this study employed a global model. The weakness of global models is that they cannot fit each dynamic region very well. However, their strength is that they are easy to implement and are suitable for online applications. Third, this study used data sets of oil, gold, and currency markets only. There are other factors that are also influential in oil prices, such as the supply, demand, GDP, consumer price levels, and commodities markets, and future studies may consider these variables. Fourth, trading is also an important issue for future research. There are many strategies to trading, which poses several issues in finance, for example, price trading, volatility trading, paired trading, and hedge trading, which were beyond the scope of this study. Further investigation is required to determine how to effectively use the forecasting power of this study for trading requirements. Finally, market data that can be collected becomes very large. Complex high-dimensional data tends to obscure the essential feature of data. Identifying intrinsic characteristics and structure of high-dimensional data is important for various fields of research, not limited to the oil price forecasting. Due to the curse of dimensionality, considering sparse modeling (coding) or dimensionality reductions (such as manifold learning) for high-dimensional data will be very important in performance improvements.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}